Purpose -This work addresses the question of how generative artificial intelligence can be used to reduce the time required to set up electromagnetic simulation models. A chatbot based on a large language model is presented, enabling the automated generation of simulation models with various functional enhancements. Design/methodology/approach -A chatbot-driven workflow based on the large language model Google Gemini 2.0 Flash automatically generates and solves two-dimensional finite element eddy current models using Gmsh and GetDP. Python is used to coordinate and automate interactions between the workflow components. The study considers conductor geometries with circular cross-sections of variable position and number. Additionally, users can define custom post-processing routines and receive a concise summary of model information and simulation results. Each functional enhancement includes the corresponding architectural modifications and illustrative case studies. Findings -With a defined set of functionalities, the chatbot successfully sets up and solves electromagnetic simulation models. Notably, it automatically infers not only Python code but also the domain-specific language code for GetDP. The case studies conducted revealed open research challenges, particularly with regard to the question of how to ensure that results are both syntactically and semantically valid. Originality/value -Currently, the application of machine learning methods to solve electromagnetic boundary value problems is an active area of research (see, e.g., physicsinformed neural networks or neural operators). However, to the best of our knowledge, little research has examined the potential of artificial-intelligence-assisted generation of simulation models that prioritizes code generation and execution rather than the enhancement of numerical solution schemes. We leverage a large language model and design tailored workflows that contextualize it through carefully constructed system prompts.
The application of machine learning (ML) methods, a subfield of artificial intelligence (AI), to the solution of electromagnetic boundary value problems (BVPs) is currently a highly active area of research. Deep neural networks such as neural operators (Kovachki et al. 2023) and physics-informed neural networks, in which information about the BVP (and possibly measurement data) is integrated into the loss function of the network, often aim to replace traditional numerical methods such as the finite element (FE) method, compare, for example, with (Guo et al. 2025;Rezende and Schuhmann 2025).
This work addresses an orthogonal problem: How can AI methods be used to reduce the time required to set up electromagnetic simulation models, rather than solving the numerical models themselves? The focus is thus on the assisted generation of simulation models, whereby the numerical scheme itself remains unaffected. A conceptually related direction has recently emerged in the computational fluid dynamics (CFD) community. In (Yue et al. 2025), a multi-agent framework called Foam-Agent is introduced that supports users in performing simulations based on the open source CFD software OpenFOAM (OpenFOAM Ltd 2025). To the best of the authors’ knowledge, no analogous framework currently exists for electromagnetic simulations.
Motivated by this research gap, the present work introduces a chatbot-driven workflow based on the large language model (LLM) Google Gemini 2.0 Flash (Google DeepMind 2025) that facilitates the automated generation of two-dimensional eddy current simulation models using the open source FE tools Gmsh (Geuzaine and Remacle 2009) and GetDP (Dular et al. 1998). The study focuses on geometries consisting of conductors with circular cross-sections, whose positioning and number can be controlled by the user via natural language prompts. Further, users can define custom post-processing routines, such as a visualization of the ohmic power loss density for a selected subset of conductors. In addition, the user is automatically provided with a textual summary of the model information and simulation results.
The remainder of this paper is organized as follows: Section 2 introduces the model problem, the main software tools, and the basic workflow of the proposed chatbot prototype. Section 3 discusses architectural extensions of the workflow and case studies that demonstrate domain-specific language (DSL) code inference and automatic textual summarization. In addition, we introduce a possible encoding scheme describing what qualifies as an acceptable result from the user’s point of view. Finally, Section 4 summarizes the main findings and outlines future research directions.
This section introduces the two-dimensional eddy current model problem and briefly discusses the open source finite element tools Gmsh and GetDP, focusing on their interfacing capabilities. These tools are subsequently integrated into a chatbot-driven workflow, which is presented here in its basic form.
As an application example, we consider the translationally symmetric eddy current problem shown in Figure 1. Since the electromagnetic fields do not change with respect to the z-direction, the problem can be treated in two spatial dimensions.
We consider N ∈ N separated massive conductors with circular cross-sections of radius r c and electrical conductivity σ > 0. The position of the i-th conductor is defined by its center point p i ∈ R 2 , with i ∈ N . We denote the conducting domain as Ω c = ∪ i∈N Ω c i , which is surrounded by the insulating domain Ω i with σ = 0. The total domain Ω = Ω c ∪ Ω i has a circular boundary ∂Ω. Since the positions of the conductors are considered variable, it must be ensured that the boundary ∂Ω fully encloses all of them, including a minimal distance d bnd to reduce the influence of the boundary on the solution. To ensure this, the centroid of all conductors is computed, which defines the center of the circular boundary ∂Ω. The radius of the boundary ∂Ω is determined by the distance from the centroid to the outermost conductor center p i , plus the constant d bnd , see again Figure 1. We model the boundary ∂Ω as perfectly electrically conductive, i.e., σ → ∞. Furthermore, magnetic materials are excluded from this application example, so the magnetic reluctivity is ν = 1/µ 0 in the entire domain.
The model is excited by imposed currents, which define the global conditions of the associated eddy current BVP: Each conductor carries a time-harmonic current of amplitude I with frequency f , respectively, angular frequency ω = 2πf . For the sake of clarity, all parameters of the model problem are summarized in Table 1. The physical phenomena are governed by the time-harmonic Maxwell’s equations in the magnetoquasistatic limit:
in which B is the magnetic flux density, E is the electric field, H is the magnetic field, J is the current density, and j = √ -1 is the imaginary unit. As we consider linear materials, the following constitutive laws hold:
(2)
The perfectly electrically conductive boundary ∂Ω leads to vanishing tangential components of the electric field E:
in which n is the unit external normal vector of the boundary ∂Ω.
Equations ( 1), ( 2), ( 3), together with the global conditions for the conductor currents, define an eddy current BVP that can be solved numerically using the finite element method. A commonly used finite element formulation for this type of problem is the modified A -v magnetic vector potential formulation, see, e.g., (Dular 2023).
Here, the magnetic vector potential A satisfying B = curl A is introduced in Ω, while an electric scalar potential v is defined only in Ω c . The electric field E can be expressed in terms of the scalar and vector potentials as E = -jωAgrad v. To ensure the uniqueness of the magnetic vector potential A, a gauge condition must be imposed. For the translationally symmetric model the current density J is assumed to be purely z-directed, such that the magnetic flux density B only has in-plane components, i.e., B = e x B x + e y B y . This is ensured by choosing A = e z A z , which implicitly fulfills the Coulomb gauge div A = ∂A z /∂z = 0, as the component A z solely depends on the coordinates x and y.
Concisely, the A -v formulation, expressed in its weak (variational) form, can be stated follows: Seek A ∈ A(Ω) and grad v ∈ V(Ω c ), such that for all test functions
The discrete counterpart of the function space A(Ω) is spanned by z-directed nodal basis functions that vanish on the boundary, i.e., A z | ∂Ω = 0. The function space V(Ω c ) is represented by N z-directed constants, one associated with each conductor. The term V ′ i denotes the voltage that can be associated to the i-th conductor. As the current I i∈N = I is fixed for each conductor, the voltages are resulting from the finite element solution. For additional information, the reader is referred to (Dular 2023).
The computational domain Ω shown in Figure 1 is discretized using the open source finite element mesh generator Gmsh. Here, the coupling with our later chatbot-driven workflow is achieved via its Python (Python Software Foundation 2025) application programming interface (API). This interface enables the implementation of a Python function that accepts as input a list of tuples of length 2, each specifying the coordinates of a conductor’s center p i , with i ∈ N . The number of conductors N is directly determined by the length of the input list. This procedure enables mesh generation independently of the specific number and spatial arrangement of the individual conductors. The minimal and maximal mesh characteristic sizes are defined based on the radius of the boundary ∂Ω and the radius of the conductors r c (see Table 1), in order to obtain a manageable number of triangles (for fast prototyping) independently of the number and spatial arrangement of the conductors. Prior to meshing, a check is performed to ensure that the conducting domains do not overlap. Furthermore, for the discretized counterparts of the conductive subdomains Ω c i∈N and the boundary ∂Ω, so-called physical groups need to be defined and stored in the resulting mesh file (".msh" file extension), so that common material properties and boundary conditions can be assigned for the subsequent FE solver.
The A-v formulation, see Equations ( 4), ( 5), is implemented in the open source finite element solver GetDP. Unlike Gmsh, GetDP cannot be interfaced directly from Python, as no dedicated API is available. Instead, solver files must be written in GetDP’s domainspecific language and stored as ASCII files with the “.pro” file extension. These solver files can then be executed via the command-line interface (CLI). After computation, the resulting field plots, e.g., for the magnetic flux density B (".pos" file extension) can be visualized using the post-processing facilities provided by Gmsh. It should be emphasized that the CLI commands are executed from Python through the subprocess module.
Both open source FE tools are now integrated into a chatbot-driven workflow, as illustrated in Figure 2. The chatbot is based on the free tier version of the LLM Google Gemini 2.0 Flash. The user interface is implemented as an interactive web application using the open source framework Streamlit (Streamlit 2025), see Figure 3. Python serves as the coordinating and automation layer, managing the interaction between workflow components.
The program workflow can be summarized as follows: The user’s prompt is incorporated into a system prompt containing a task description, rules and examples (see Appendix A.1), which is given to the LLM to generate a string of (ideally 1 ) syntactically correct Python code. Then, a cleaned version of the LLM’s output string serves as the input for a function that executes the dynamically generated Python code. The Gmsh and GetDP code is static and accessed via a predefined Python wrapper function (see Section 2.2), which takes a list of coordinate tuples as input and runs the finite element simulation as a side effect. It is important to emphasize that the LLM’s weights are not updated or re-trained (that is, there is no fine-tuning); rather, the pre-trained model is contextualized at runtime via the system prompt. More precisely, the system prompt supplies task-specific instructions and context regarding the model’s input, however, it does not alter the model’s parameters. Moreover, this workflow does not employ retrieval-augmented generation (RAG) or any persistent memory mechanism: no exter-nal knowledge store is queried during generation and no state is retained beyond the immediate prompt.
This Section presents functional enhancements to the basic AI workflow described in Section 2.3. The architectural modifications are detailed, and case studies are conducted and discussed for each autonomy level of the chatbot.
The workflow of Section 2.3 is used without further modifications to generate the exemplary results shown in Figure 4 It can be observed that the workflow successfully infers Python code capable of generating conductor arrangements across multiple levels of complexity. The risk of conductor overlap can be significantly reduced if the user’s prompt includes the specific value of the conductor radius r c , a parameter that is not known a priori to the LLM. The simulation models shown in Figure 5, based on identical user prompts (e) and (f), illustrate the stochastic nature of the underlying LLM. Both generated geometries are correct; however, the Python code for (e) assumes α = 1, whereas the code for (f) uses α = 100. The resulting simulation model for the user prompt (g) can be interpreted as hallucination of the LLM, that is, an output inconsistent with reality. However, such hallucinations were observed only rarely in this use case; in this instance, the effect was triggered by the inconsistent user prompt, as a square obviously has only four vertices. From the standpoint of automated model validation, a notable challenge occurs when the inferred Python code is syntactically valid, yet the resulting model exhibits an incorrect geometric interpretation (see the generated model for the user prompt (h) in Figure 5).
The workflow described in Section 2.3 is extended to allow the user to define custom post-processing routines; see Figure 6. As an application example, the visualization of the ohmic power loss density p Ω is considered, which is defined as a time-averaged quantity as follows:
An extended system prompt is provided to the LLM, that contains GetDP code examples for a post-processing routine, that computes and plots the ohmic power loss density p Ω only for a selected subset of conductors, see Appendix A.2. Internally, GetDP uses PostProcessing objects to define quantities based on the primary variables of the finite element formulation -here, the vector potential A and the gradient of the electric scalar potential grad v. Their visualization and output are controlled via PostOperation objects, which specify formats such as line evaluations, surface plots, or data tables. The dynamically generated GetDP code is written into dedicated “.pro” files, which are then included in the main solver file. It should be emphasized that the LLM now infers code in the domain-specific language of GetDP, a language on which, most likely, Google Gemini 2.0 Flash has been trained considerably less such that the LLM’s internal knowledge (cf. (Huyen 2025, p. 301)) about GetDP is most likely quite low. Plot of the ohmic power loss density p Ω for the subset of conductors specified in user prompt (i), i.e., the corresponding GetDP code was correctly dynamically generated and executed. generated domain-specific language code. It was observed that including an adequate number of representative code examples significantly reduces syntax errors related to the GetDP language. In their absence, numerous syntax errors occurred, primarily due to missing or superfluous curly brackets.
In Figure 8, the main difference to the previous architecture presented in Figure 6 is that (ideally) syntactically and semantically correct domain-specific language code is generated without having any relevant examples in the system prompt. The goal of this architectural modification is to enable valid responses to user prompts such as “Using nine conductors that are positioned along a rectangle such that one point is at the center (intersection of the diagonals) and the other eight are distributed along the edges of the rectangle, evaluate the plot of the magnetic energy density in terms of the magnetic vector potential vector field within the frequency domain only for the central conductor and the conductors on the first and third bisectors of the rectangle.”
An exemplary system prompt can be found in the Appendix A.3. The distinctive property of this kind of user prompts is that, at the same time, (I) these user prompts build upon examples within the system prompt discussed in previous posts such as “only for the central conductor” (cf. Section 3.2) and “along a rectangle” (cf. Section 3.1), and
(II) these user prompts refer to examples that are not within the system prompt such as “the magnetic energy density”.
Considering the visualization of the magnetic energy density w m , recall its definition as a time-averaged quantity as follows:
A meaningful user prompt provides the LLM-based chatbot with sufficient knowledge regarding (II) such that syntactically and semantically correct DSL code can be inferred. For example, the above-mentioned user prompt has to be extended in such a way such that a contextual answer is received that conforms with the user’s expectation. More precisely, the following sentence has to be added to the above-mentioned user prompt: “Mind that the following three constraints regarding the magnetic energy density formula should be satisfied: (1) the correct factor 0.25 is present; (2) the material relation between the magnetic flux density vector field and the magnetic vector field holds to be true w.r.t. the reciprocal permeability, i.e., nu; (3) the expression is simplified by using norms.” Some observations concerning the inferring of domain-specific language code without using meaningful examples in the system prompt within the chatbot-driven workflow are:
• The lack of the extension for the above-mentioned user prompt may result in:
-syntactically incorrect code within the context of the DSL; -syntactically correct code that is semantically incorrect within the context of the underlying physics (e.g., using a factor of 0.5 vs. 0.25);
-syntactically correct code that behaves semantically correct within the context of the underlying physics, though, semantically incorrect within the context of the DSL (e.g., using the magnetic flux density instead of the magnetic vector potential as primary numerical solution quantity).
• Given the system design at hand, there are still many optimization paths regarding the overall prompt engineering in order to, e.g., balance the provision of knowledge by user prompts and system prompts. An interesting approach could be the use of a curated prompt store in a similar manner to a feature store (see, e.g., (Huyen pp. 325ff)) in other machine learning systems.
The main extension of the previous section’s workflow is the following: A function is added that executes a second LLM API-call. Its input is the output of the function that executes the first LLM API-call; and its output is a textual summary, see Figure 9.
Note that there is a system prompt that contains meaningful examples and rules for structuring the output format of the textual summary, see Appendix A.4. In other words, the dynamically generated syntactically and semantically (ideally) correct code is translated into a textual summary that expresses the physical meaning of the code in a natural language. A couple of observations and conceptual challenges regarding the textual summary within the chatbot-driven workflow are:
• Specifically, the description regarding the skin-and the proximity-effect is reasonable to a certain degree. Since a well-defined metric for quantifying potential improvements in the quality of a textual summary is currently lacking, it remains unclear whether incorporating the skin depth as an additional physical entity in the code would yield a more nuanced textual summary.
• Generally, the translation of code into natural language seems to work well to a reasonable extent, see Figure 10. Due to the above-mentioned lack of a quality metric for a textual summary, though, it remains unclear whether translating numerical simulation plots (i.e., images) into text or translating numerical simulation numbers (i.e., tabular data) into text could lead to a more nuanced textual summary.
Notice that the conceptual challenge with regard to a quality metric for a textual summary is linked to the fundamental conceptual challenge of how to enable an automated LLMworkflow evaluation.
(j) Run an MQS simulation using 10 conductors that follow the pattern of a circle. Plot the ohmic loss density only at every second conductor. Provide a summary of the output.
The plot shows a 2D simulation of 10 conductors arranged in a circle. The ohmic loss density, representing power dissipation due to current flow, is displayed for every second conductor (conductors 1, 3, 5, 7, and 9). The positions of the conductors’ center points are determined by a circle of radius 0.02, with coordinates calculated using sine and cosine functions, reflecting their circular arrangement. Due to the alternating current, both skin and proximity effects are present, leading to nonuniform current density distributions within the conductors and influencing the ohmic loss density.
The skin effect causes current to concentrate near the surface of each conductor, while the proximity effect modifies the current distribution due to the presence of neighboring conductors.
The workflows presented in Sections 3.1-3.4 introduce different levels of capabilities in the generated code. Here, we introduce a possible encoding scheme that describes what qualifies as an acceptable result from the user’s point of view.
Considering the workflow described in Section 3.1, the dynamically generated Python code must first satisfy the syntax and semantics of the Python programming language. Theoretically, all combinations of the truth values listed in Table 2 could occur. Syntax errors can arise, for instance, if brackets are left unclosed, as in “(a + 1”, or if reserved keywords are used as variable names. Semantic errors can occur, for example, when a variable is used before it is defined, or when operations are incompatible with the types of their inputs, as in “‘a’ + 3”. While syntactic errors are detected during parsing, both syntax and semantic errors are ultimately revealed when the generated code is executed.
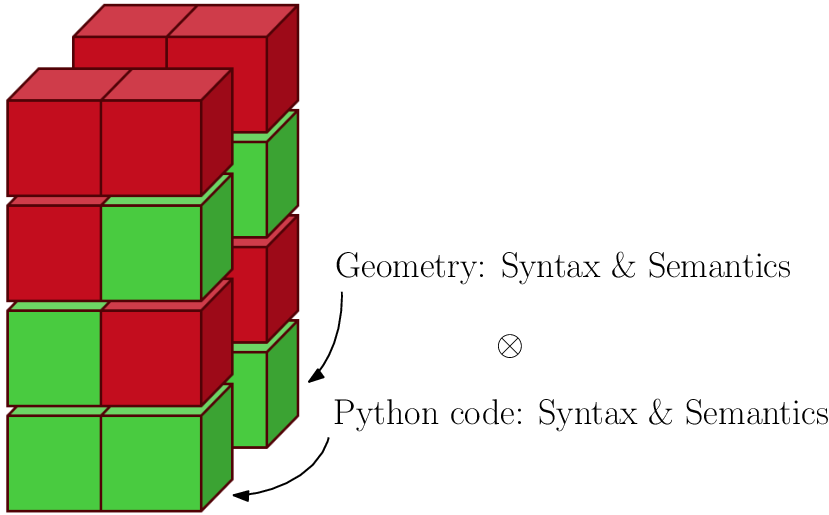
More subtle errors occur when the generated Python code is both syntactically and semantically correct, but the resulting geometry does not match the user’s expectations, consider, e.g., the resulting model for the user prompt (h) in Figure 5. Consistent with the concepts of syntax and semantics, an additional layer can be introduced to capture geometric information, which gives rise to the tensorial structure depicted in Figure 11. This structure can be understood as follows: an output is considered acceptable to the user only if it is valid on both the syntax and semantic levels; applied to both the Python code and the corresponding geometry. Conceptually, for the workflow presented in Sections 3.2 and 3.3, two additional layers are introduced (see Figure 12). Here, also the inferred GetDP code might contain syntax errors, such as improperly matched curly brackets. Semantic errors arise when a field variable is accessed that does not correspond to a primary variable in the FE formulation. Again, these errors are not difficult to detect, as GetDP’s parser will produce an error message. Again more subtle, the inferred formula for the magnetic energy density w m must be physically consistent. In this context, syntactical errors can be interpreted as operations that violate mathematical syntax, such as the addition of scalar and vector fields, consider, e.g., the expression “v + A”. Semantic errors, on the other hand, refer to operations that are mathematically valid but physically meaningless, for example, the addition of different vector field quantities such as “E + H”.
The dynamically generated textual summary (see Section 3.4) introduces yet another layer. In this context, syntactical errors can be interpreted as grammatical or spelling errors in the generated text. Semantic errors, on the other hand, occur when there is a mismatch between the actual generated model and its corresponding textual summary.
This work has investigated an LLM-based chatbot for electromagnetic simulations as a minimum viable setup within the context of AI-assisted code generations and executions for numerical experiments.
More precisely, we have presented a workflow that is composed by open source FE tools (Gmsh and GetDP) and a large language model (Google Gemini 2.0 Flash) embedded within a common Python-based interface (cf. Section 2). The basic AI workflow presented in Section 3.1 infers Python code to generate a list of coordinate tuples. However, architectural extensions also enabled the inference of domain-specific language code, with and without meaningful examples in the system prompt (see Sections 3.2 and 3.3), and the inference of a textual summary of the AI workflow’s output (see Section 3.4). Finally, we have examined the semantic and syntactic sources of potential failure within the AI workflow (see Section 3.5).
One key insight is that the provided setup can already enable a useful level of automation of a numerical simulation workflow which can significantly reduce the time required to generate a well-posed numerical simulation model. Mind that this time-toexperimentation is a critical metric and lowering it facilitates the accelerated exploration of, for instance, various physical scenarios and corresponding numerical simulation model configurations.
Another key insight is that relying merely on the internal knowledge of an LLM (that is, its training data) as a memory mechanism leads to insufficient outcomes of the AI workflow based on human evaluation. For example, physically relevant factors are not taken into account properly. However, by additionally using the LLM’s context (via the user prompt and the system prompt) as a further memory mechanism satisfactory outcomes of the AI workflow can be achieved.
A third key insight is that the systematic consideration of both the semantic and syntactic aspects of an AI workflow’s essential elements can offer a valuable conceptual guidance for analyzing potential failure modes. The proposed visual representation of a stack of syntaxes and semantics for the workflow’s essential elements illustrates the many combinations in which the workflow can fail. Note that this proposed visual representation is highly scalable with respect to the increasing complexity of the underlying setup, thus offering a way to conceptually manage the increased complexity.
A fourth key insight is that the shown AI workflow facilitates a declarative development style where the focus is on describing what the desired outcome is, rather than explicitly specifying how to achieve the outcome step-by-step. In many scenarios, the desired outcome is a correct numerical solution, regardless of the exact method used to achieve it. However, for validating the solution’s correctness, domain knowledge is needed -which leads to the last key insight.
The final key insight is that, due to the probabilistic nature of an LLM, it is unclear how to construct a reliable automated evaluation method for the AI workflow. The evaluation of the discussed AI workflow’s outcomes relied on human evaluation. Human evaluation defines one end of the spectrum of evaluation methods, formal verification defines the other end of the spectrum. Since most likely no formal guarantees regarding the AI workflow’s outcomes can be given, it seems at least conceivable to design semi-automated evaluation methods where human evaluation is potentially reduced to a minimum. An in-depth analysis of these ideas is left for future investigations.
Future research and development efforts can build on the presented results in several directions. One of the most challenging and crucial efforts is the investigation of reliable (semi-)automated evaluation methods for the AI workflow. For evaluating the quality of textual summaries, for instance, one promising approach could be the usage of an additional LLM that is adapted for evaluation purposes. Another promising approach involves the use of embeddings, or vector representations (Weller et al. 2025), along with similarity metrics that enable a textual summary to be quantitatively compared to human-curated or AI-generated benchmarks.
Addressing (semi-)automated evaluation methods is also important for systematically examining the space spanned by system prompts and LLMs in order to find the optimal configuration for the given AI workflow.
Furthermore, examining (semi-)automated evaluation methods is also critical in the investigation of more complex AI workflows. Notice that, from a control-flow graph point of view, the discussed AI workflow can be mathematically represented as a directed acyclic graph. However, more intricate graphs are conceivable that include both sequential and parallel paths as well as iterations and selections. Moreover, if more tools (i.e., if more callable functions) are available and the planning (i.e., the construction of a control-flow graph) to complete a user-defined task is undertaken by an LLM, then the resulting system is more appropriately characterized as an AI agent rather than a predefined AI workflow. It should be noted that the research field of AI agents currently lacks a well-defined theoretical foundation (see, e.g., (Huyen 2025, pp. 276)). Therefore, there are many open research questions on AI agents in the context of electromagnetic simulations that deserve a thorough investigation.
Another potential architectural extension to further enhance the developed chatbot’s functionalities is the use of retrieval-augmented generation (RAG) techniques (see, e.g., (Huyen 2025, pp. 253-275)). These techniques would enable the underlying LLM to access and integrate information that the model was not, or only partially, trained on. Additionally, this information is more relevant to a given user prompt than a predefined and user-prompt-agnostic system prompt. In particular, with the FE software tools (Gmsh and GetDP) integrated in the chatbot, it would be beneficial to provide to the LLM only those portions of code repositories or manuals of the FE software tools that are most relevant to a user prompt.
Lastly, a valuable opportunity for future work involves expanding the set of open source numerical tools beyond Gmsh and GetDP to include additional frameworks such as openCFS (Schoder and Roppert 2025) and DeepXDE (Lu et al. 2021). Such an extension would enable a unified platform of diverse numerical simulation software that can be accessed by user prompts in natural language.
This appendix includes representative code examples from the system prompts of the workflows discussed in Section 3. Each code snippet is part of a Python multi-line string that is passed to the LLM. Mind that the full system prompt that is containing a task description, some rules and examples as well as the user input placeholder is only provided for the first system prompt A.1. For the other system prompts, only some examples are shown and, for the sake of brevity, the rest is omitted.
Note that in the system prompts, curly braces “{” and “}” serve a special function, as they are used to denote placeholders for dynamic content. Therefore, when literal braces are required in the string (i.e., not as placeholders), they must be escaped by doubling them -written as “{{” and “}}”. This ensures that the braces are interpreted as characters rather than as variable placeholders during template rendering. This is particularly necessary for the GetDP syntax code. The output of Example 4 shows a 2D -plot of three electric conductors whose center points are at (0.02 , 0.0) , (0.0 , 0.02) , and ( -0.02 , 0.0) and all radii are 5 mm . Thus , two conductors lie on the x -axis with respect to a Cartesian coordinate frame and one lies on the y -axis . Current density vector fields are observed only within the conductors , in the surrounding non -conducting computational domain , there current density vector fields are zero . All three current density vector fields possess solely a non -zero z -component and are oriented in positive zdirection . Since there are more than one conductor , in addition to the skin effect , the so -call proximity physical effect can be observed . This leads to nonuniformly spatially distributed current density vector fields . The given spatial configuration of the conductors and the spatial direction of the currents results in shift of the current density distribution towards the outer regions of crosssections of the outer conductors . Due the given spatial configuration of the conductors and the spatial direction of the currents results , the magnetic flux densities associtated with each individual conductor are exhibiting different directions within the computational domain between both conductors , and are exhibiting same directions within the computational domain outside of the inbetween area of both conductors . Hence , the total magnetix flux density ’s magnitude is lower within the computational domain between both conductors , and higher elsewhere . Finally , a shift of the current density distribution towards the outer regions of cross -sections of the conductors can be observed .
This appendix includes representative code examples generated by the LLM. Note that the LLM’s output is originally a multi-line string. Here, we show its cleaned version, i.e., the version that is actually executed by Python (B.1) and GetDP (B.2 and B.3).
The Python code below generates the conductor arrangement shown in Figure 4 (as a consequence of user prompt (c)).
1 import numpy as np 2 from typing import List , Tuple 3 import matplotlib . pyplot as plt
The GetDP code below generates the custom post-processing routine for the ohmic power loss density p Ω shown in Figure 7 (as a consequence of user prompt (i)).
0 , with 4π × 10 -7 Vs/Am σ electrical conductivity 0 in Ω i , σ Cu = 58.1 MS/m in Ω c I amplitude of the imposed current 1 A f = 2π/ω frequency of the imposed current 50 Hz
18 {{ Name MagDyn_c ; N a m e O f P o s t P r o c e s s i n g MagDyn_c ; 19 Operation {{ 20 Print [ h_vector_field , OnElementsOf Omega , 21 File " Results / h_vec tor_fiel d . pos " , 22 Name " H ( xyz ) [ A / m ] " , Format Gmsh
Mind that the LLM is a probabilistic model where, even though, input and output guardrails are used, there is no complete guarantee that the expected correct structured output is generated and that this output is fully reproducible in a deterministic sense. Thus, even when given the same input, a degree of uncertainty regarding the resulting output remains.
This content is AI-processed based on open access ArXiv data.