DySTAN: Joint Modeling of Sedentary Activity and Social Context from Smartphone Sensors
📝 Original Info
- Title: DySTAN: Joint Modeling of Sedentary Activity and Social Context from Smartphone Sensors
- ArXiv ID: 2512.02025
- Date: 2025-11-18
- Authors: Aditya Sneh, Nilesh Kumar Sahu, Snehil Gupta, Haroon R. Lone
📝 Abstract
Accurately recognizing human context from smartphone sensor data remains a significant challenge, especially in sedentary settings where activities such as studying, attending lectures, relaxing, and eating exhibit highly similar inertial patterns. Furthermore, social context-whether a person is alone or with someone-plays a critical role in understanding user behavior, yet is often overlooked in mobile sensing research. To address these gaps, we introduce LogMe, a mobile sensing application that passively collects smartphone sensor data (accelerometer, gyroscope, magnetometer, and rotation vector) and prompts users for hourly self-reports capturing both sedentary activity and social context. Using this dual-label dataset, we propose DySTAN (Dynamic Cross-Stitch with Task Attention Network), a multi-task learning framework that jointly classifies both context dimensions from shared sensor inputs. It integrates task-specific layers with cross-task attention to model subtle distinctions effectively. DySTAN improves sedentary activity macro F1 scores by 21.8% over a single-task CNN-BiLSTM-GRU (CBG) model and by 8.2% over the strongest multi-task baseline, Sluice Network (SN). These results demonstrate the importance of modeling multiple, co-occurring context dimensions to improve the accuracy and robustness of mobile context recognition. CCS Concepts • Human-centered computing → Ubiquitous and mobile computing systems and tools; • Computing methodologies → Neural networks; • Applied computing → Health care information systems.📄 Full Content
The widespread use and acceptance of smartphones among students has led to increasing interest in mobile health (mHealth) solutions tailored to the student population. However, delivering contextually appropriate interventions remains challenging. Many sedentary activities-such as attending lectures, studying, relaxing, or eating-exhibit similar patterns in inertial sensor data, making it difficult to distinguish among them solely from movement signals [13,53]. Moreover, interventions that are helpful in one social context (e.g., relaxing alone) may be disruptive in others (e.g., studying or dining socially), highlighting the need for accurate detection of both activity type and social context [32]. In particular, social context-whether a person is alone or with someone-plays a key role in shaping intervention acceptance [36,40]. For example, prompting someone during solitary relaxation may be appropriate, but interrupting during a group meal or conversation may reduce receptivity or even cause annoyance.
Despite its importance, social context remains underexplored in current mobile sensing models. Most existing approaches either ignore overlapping and co-occurring contexts (e.g., eating while conversing), or lack multi-label annotations, which hinders comprehensive recognition [3]. As a result, many models struggle to generalize to real-world scenarios where contexts blend fluidly. These limitations underscore the need for richer, multi-context recognition models that can jointly infer sedentary activities and social settings from passive smartphone sensing.
To address these gaps, we developed LogMe, a mobile sensing app that collects passive Inertial Measurement Unit (IMU) sensor data along with active self-reports of sedentary activity-Attending Lecture (AL), Relaxing (R), Studying (S), Eating (E)-and social context-Alone (A), With Someone (Engaged in Conversation) [WSEIC], With Someone (Not Engaged in Conversation) [WSNEIC]. Using this dataset, we introduce DySTAN, a multi-task learning model that jointly predicts both contexts from shared sensor inputs. DyS-TAN effectively captures task-specific distinctions and consistently outperforms existing methods. Following are our key contributions:
Early research on smartphone-based inertial sensing achieved high accuracy for basic activities such as running, walking, and stair climbing. However, classification performance drops significantly for fine-grained sedentary contexts such as sitting and standing, even with advanced deep learning models. For example, Haghi et al. [17] showed that while a hybrid CNN-LSTM model achieved up to 98% accuracy for gross activities, performance for static postures like sitting and standing was notably lower, with F1 scores around 75-94%. Similarly, Salice et al. [50] reviewed that even state-ofthe-art non-intrusive sensing systems often struggle to robustly differentiate subtle postures, with accuracy frequently dropping below 85% for fine-grained sedentary states.
In parallel, researchers have explored social context inference. Classical classifiers distinguishing “alone” versus “with others” often exceed 90% AUC [32]; for example, Mäder et al. report >90% AUC for companionship status, while Kammoun et al. achieve approximately 75% AUC for eating companionship using gradient boosting [22]. However, these models typically ignore co-occurring contexts-such as eating while conversing-and struggle with poor classification performance on complex social situations. Moreover, both classical machine learning and deep learning models generally treat activity and social inference as separate tasks, highlighting the need for unified modeling approaches [2,30].
To overcome these limitations, multi-task learning (MTL) has been increasingly applied to smartphone sensing. MTL approaches leverage shared feature layers to model related tasks, improving classification accuracy jointly. For example, Azadi et al. [4] used a multi-channel asymmetric autoencoder to reconstruct IMU signals and classify activities simultaneously. Peng et al. [44] developed the AROMA model, combining a shared CNN backbone and LSTM to recognize complex activities jointly. Mekruksavanich et al. [34] applied a CNN-BiLSTM network for joint prediction of user activity and identity, while Nisar et al. [42] proposed a hierarchical MTL framework using multi-branch network for activity recognition. Most of these HAR models use hard parameter sharing (shared CNN/LSTM layers with task-specific heads), which allows leveraging relatedness between tasks for better joint modeling of multiple.
Despite progress in modeling, existing university smartphonesensing datasets are limited in their ability to capture both detailed activity and social context concurrently. Some datasets offer rich activity labels but lack social annotations; others include only coarse social categories or lack detailed, temporally aligned annotations. For example, Bouton-Bessac et al. [8] collected over 216,000 activity reports from 600+ students across five countries, but did not include social context labels. Aurel et al. [33] surveyed 581 undergraduates using a simple survey but lacked fine-grained activity data. Nathan et al. [23] focused on eating episodes among 678 students, distinguishing only “eating alone” versus “eating with others. " The DiversityOne dataset [22] spans 782 students in eight countries with 350,000+ half-hour activity and social context diaries, but primarily supports cross-country comparisons and lacks temporally precise, detailed joint annotations.
Our Sedentary and Social Context Dataset (SSCD) addresses these limitations by providing fine-grained, temporally aligned labels for sedentary activities and nuanced social context states. This enables more accurate and integrated modeling of real-world sedentary activity and social context in university environments.
We developed a custom Android application (LogMe) to collect inthe-wild data using both passive sensors and active self-reports. We process raw IMU sensor data comprising 13 channels: accelerometer (X, Y, Z), gyroscope (X, Y, Z), magnetometer (X, Y, Z), and rotation quaternion (X, Y, Z, W) signals. The app continuously recorded motion and orientation data from these sensors at 50 Hz. Participants received hourly notifications at the 55th minute from 7:00 AM to Following institutional ethics approval, participants were recruited via campus email. Sixty students attended a briefing session that outlined the two-week study, explained app usage, and demonstrated notification timing and the app interface. Three students opted out due to privacy concerns, resulting in 57 participants (out of 57 participants, 39 were male and 18 were female, mean age = 20.16 ± 1.92 years ). The study collected 67.2 hours of passive sensor and self-report data focused on fine-grained sedentary activity labels and nuanced social context states, with background data collection minimizing user disruption. Refreshments were provided as an incentive.
IMU sensor data were preprocessed to reduce noise and improve signal quality. We explicitly use only raw sensor signals in our analysis [15,56]. Accelerometer readings were converted to linear acceleration by removing the gravitational component, then filtered sequentially using a 3rd-order Butterworth high-pass filter (0.3 Hz cutoff) [41] and a low-pass filter (20 Hz cutoff) [46] to reduce drift and high-frequency noise. Gyroscope signals were smoothed with a 3rd-order Butterworth low-pass filter at 20 Hz [46], while magnetometer data were denoised using a 2nd-order Chebyshev Type-I low-pass filter with a 0.001 dB passband ripple [1]. Rotation vector signals [14,18] (quaternions) were used without additional filtering due to their inherent stability reported in prior studies [39]. After preprocessing, we extracted 1-minute IMU segments aligned with each self-reported response, representing the participant’s activity during that period. The original 50 Hz data were downsampled to 40 Hz to balance computational efficiency and accuracy [12]. These segments were further divided into overlapping 2.5-second windows with 50% overlap [55], a setup shown effective for activity and context recognition.
DySTAN (Dynamic Cross-Stitch with Task Attention Network) shown in Figure 2 is a cross-stitch-based architecture with an integrated attention module for multi-task learning. It is designed to jointly classify sedentary activity and social context using smartphone IMU sensors data. Its design allows the model to capture both shared and task-specific temporal features, which is crucial for distinguishing activities with similar sensor signatures while leveraging their underlying commonalities [4,37,42,44,51]. We process raw IMU sensor data comprising 13 channels for each data window of 100 time steps, capturing rich information on user movement and orientation for classification.
The architecture begins with a shared convolutional feature extractor (1D CNN) consisting of two sequential one-dimensional convolutional layers, each followed by batch normalization and ReLU activation [6,7,43]. The first convolutional layer (64 filters, kernel size 7) captures broad temporal dependencies across all sensor channels, while the second layer (64 filters, kernel size 5) further refines these features. By sharing this feature extractor, DySTAN efficiently learns temporal patterns common to both tasks, enhancing both data efficiency and model robustness [16]. To ensure the model captures distinctions unique to each task, DySTAN branches into two task-specific convolutional streams (Sedentary 1D CNN and Social 1D CNN) following the shared layers. Each stream applies a 1D convolution (128 filters, kernel size 3) with batch normalization and ReLU activation. This design enables each task head to specialize its features, allowing the network to focus on subtle patterns that might be overlooked if all representations were shared [24,37,48,51].
A central innovation of DySTAN is the Dynamic Cross-Stitch Unit (DCSU). Unlike traditional cross-stitch networks that use fixed, static mixing weights [37], the DCSU dynamically generates mixing weights conditioned on the input. After the task-specific convolutional layers, each feature map is summarized using average pooling and fed into a lightweight controller network. This controller consists of a two-layer multilayer perceptron (MLP): the first layer reduces the pooled feature vector to a compact hidden representation, followed by a second layer that outputs per-channel, per-instance adaptive weights, which are then reshaped to form dynamic mixing matrices. These adaptive weights determine in real time how much information should be exchanged between the two tasks. By enabling input-dependent feature sharing [31,51], the DCSU provides DySTAN with greater flexibility to adapt to diverse sensor contexts and activity patterns, leading to improved performance in complex, real-world classification settings. Following dynamic fusion, a Cross-Task Attention module is applied. This module uses multi-head attention to let each task focus on important time steps in the feature sequence of the other task [26,29]. This mechanism enables DySTAN to capture complex, bidirectional dependencies between sedentary activity and social context, which often influence each other in practice. The use of residual connections ensures that the original task features are preserved, while the attention layer enriches them with additional context [11,21,25]. To further model temporal dependencies, DyS-TAN applies bidirectional LSTM layers after the attention blocks for each task. These LSTMs (128 units per direction) process the attended features to capture long-range patterns in both forward and backward directions [27,54]. Temporal mean-pooling of the bidirectional LSTM outputs yields fixed-length embeddings that summarize the sequence information for each task.
Finally, DySTAN passes the resulting embeddings through taskspecific classification heads. Each head consists of a fully connected layer with ReLU activation, followed by a dropout layer (dropout rate 0.4) for regularization, and then outputs the logits for its respective task. The entire network is trained end-to-end using a combined cross-entropy loss for both tasks and optimized with Adam, ensuring balanced updates to both shared and task-specific parameters for robust multi-task classification. Overall, DySTAN’s architecture-combining shared and task-specific convolutions, dynamic cross-stitch fusion, cross-task attention, and bidirectional LSTMs-is carefully designed to capture complex, overlapping, and distinct temporal patterns required for accurate, joint context classification from raw sensor data.
We compare DySTAN against recent state-of-the-art baselines highly relevant to our task. These include single-task CNN-BiLSTM-GRU (CBG) [20], which integrates convolutional, bidirectional LSTM, and gated recurrent layers, and multi-task models such as AROMA [45], DMTLN (Deep Multi-Task Learning Network) [35], and METIER [10]. Additionally, we evaluate advanced architectures like Cross-Stitch Networks (CN) [38] and Sluice Networks (SN) [49] that enable adaptive and dynamic parameter sharing across tasks. All baselines are trained and tested with the same data processing and validation protocols to ensure a fair and rigorous comparison.
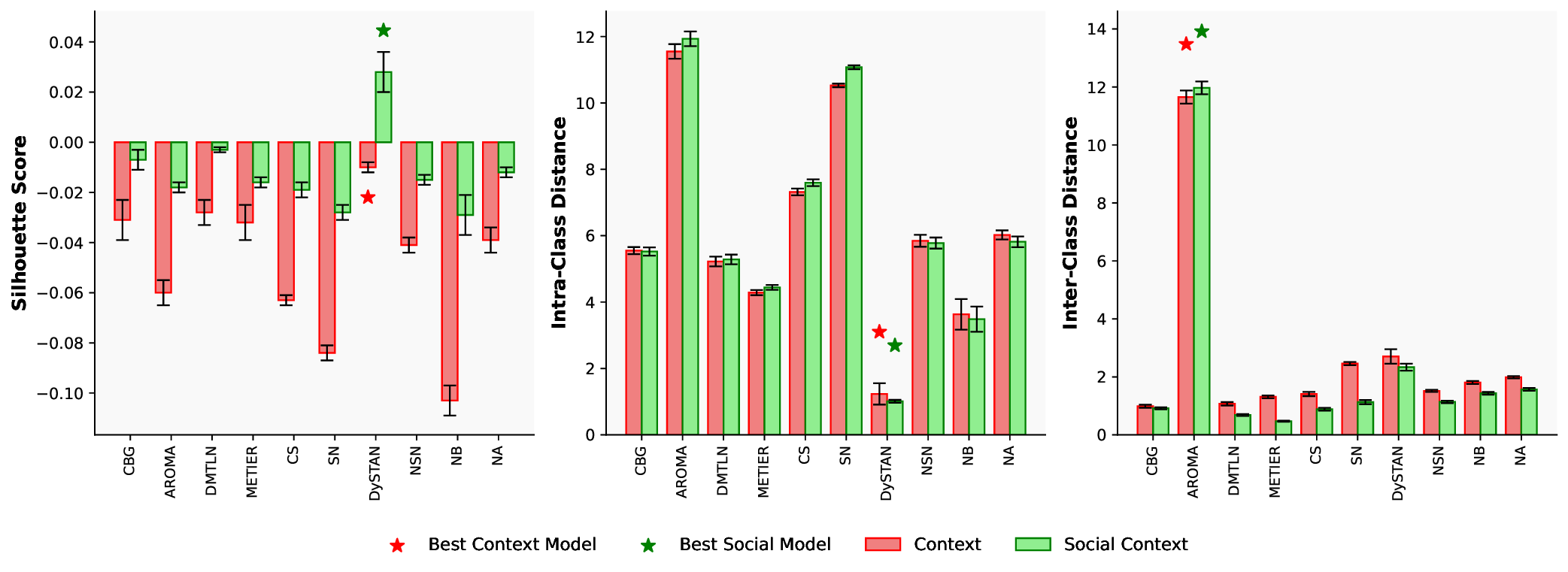
IMU data were segmented into windows of 2.5 seconds with 50% overlap. All sensor channels were standardized prior to model training, and the labels were appropriately encoded. We employed fivefold stratified cross-validation for evaluation [47]. In each fold, 64% of the data was used for training, 16% for validation (taken as 20% of the training set), and 20% for testing. Models were trained with the Adam optimizer (learning rate = 1e-3), a batch size of 64, and a maximum of 50 epochs per fold [43]. Cross-entropy loss was used for both tasks, with class weights calculated from the training data to address class imbalance. Model performance was assessed using accuracy, macro-F1 score, silhouette score (measuring cluster separation and cohesion), intra-class distance (how close samples are within the same class), inter-class distance (how far apart different class centers are), and normalized confusion matrices (visualizing class-wise prediction performance) for both sedentary activity and social context tasks.
DySTAN outperforms (see Table 1) all baselines across every major metric, achieving a mean accuracy of 0.882±0.003 for Sedentary Activity and 0.902±0.003 for Social Context. This represents a relative improvement of 10.5% in Sedentary Activity accuracy and 9.5% in Social Context accuracy compared to the strongest multi-task baseline, Sluice Network (0.798 and 0.824, respectively). Macro F1 scores exhibit similar trends: DySTAN achieves 0.852±0.004 for Sedentary Activity and 0.876±0.003 for Social Context, surpassing all baseline models. The joint accuracy metric, reflecting the The single-task CBG baseline performs notably worse than all multi-task frameworks, with only 0.666±0.007 accuracy on Sedentary Activity and 0.701±0.012 on Social Context. DySTAN outperforms CBG by 32.5% in Sedentary Activity accuracy and 28.7% in Social Context accuracy, illustrating the clear advantage of multitask learning and shared representation. Cross-Stitch and Sluice Network models, which use cross-stitch-based parameter sharing, generally surpass conventional multi-task models (AROMA, DMTLN, METIER), but still fall short of DySTAN. Sluice Network, the strongest of these, achieves 0.798±0.008 (Sedentary Activity), 0.824±0.015 (Social Context), and 0.700±0.012 (joint accuracy).
Macro F1 results closely mirror the accuracy metrics, confirming that DySTAN not only achieves high overall accuracy but also maintains balanced performance across all classes, including underrepresented categories. For example, DySTAN’s macro F1 for Sedentary Activity is 10.6% higher than Sluice Network (0.852±0.004 vs. 0.770±0.008), and 29.1% higher than the best conventional multitask baseline, AROMA (0.660±0.007).
Another important observation is the low standard deviation achieved by DySTAN across all metrics (typically ±0.003-0.005), indicating highly consistent performance across cross-validation folds. This stability contrasts with higher variance observed in baselines such as Cross-Stitch (Sedentary Activity accuracy SD = 0.032), highlighting that DySTAN not only achieves superior accuracy but is also more robust and reliable across different participant splits and real-world data variations.
The ablation results in
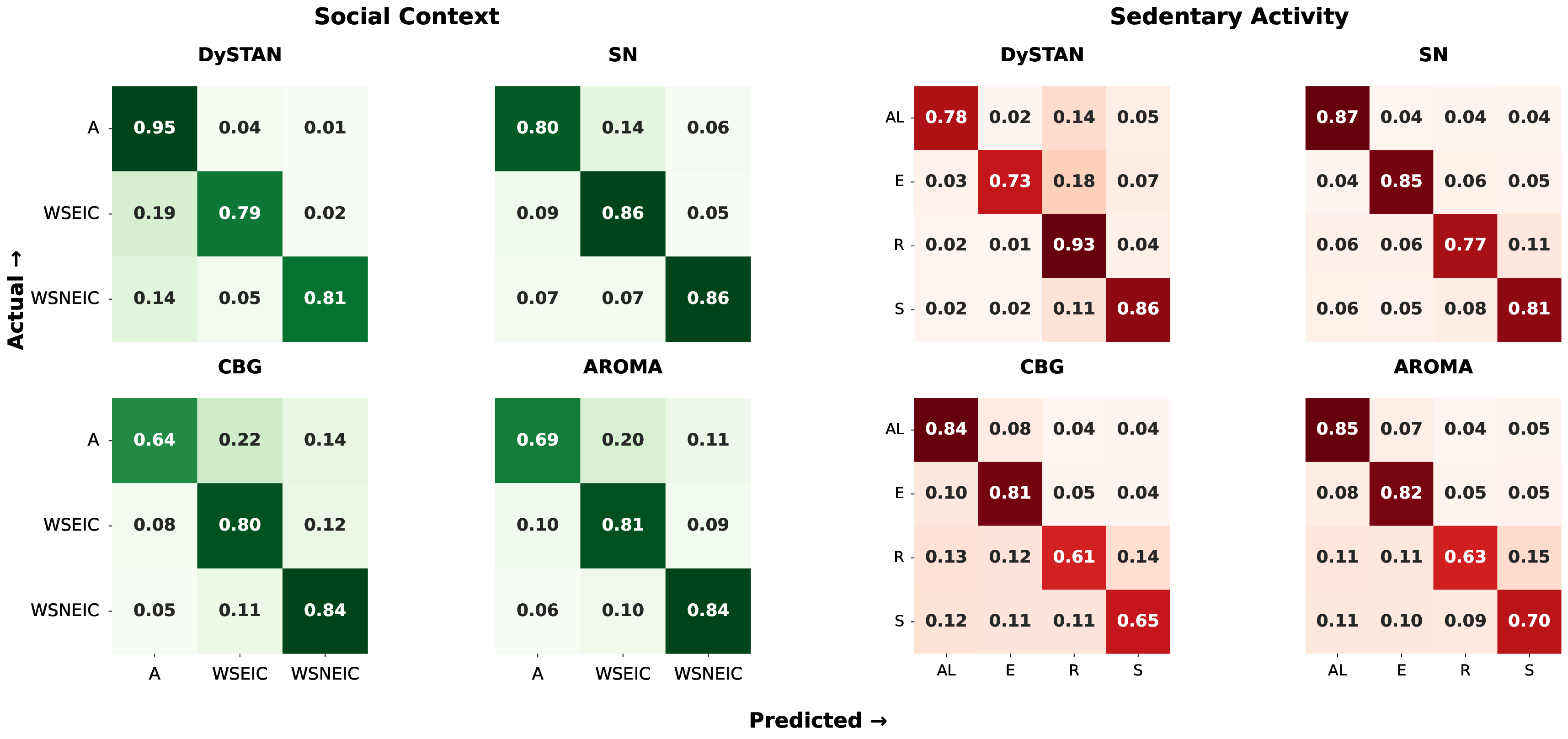
The confusion matrices shown in Fig. 4 demonstrate that DyS-TAN achieves the highest true positive rates for all classes in both Social Context and Sedentary Activity, with minimal confusion between similar classes. For example, DySTAN correctly classifies the ‘Alone’ (A) class 95% of the time and ‘With Someone (Engaged In Conversation)’ [WSEIC] 79% of the time, outperforming Sluice Network (SN), CNN-BiLSTM-GRU (CBG), and AROMA, which all display more off-diagonal errors. For Sedentary Activity, DySTAN also demonstrates strong diagonal dominance, with ‘Relaxing’ (R) and ‘Studying’ (S) recognized at 93% and 86% respectively, while ‘Attending Lecture’ (AL) and ‘Eating’ (E) are recognized at 78% and 73%. In contrast, baseline models like CBG and AROMA show more substantial misclassification between activities such as ‘Relaxing’ and ‘Studying’. Overall, DySTAN’s confusion matrices indicate more precise, consistent predictions with fewer confusions between closely related contexts, validating its effectiveness for fine-grained context recognition.
This paper presented DySTAN, a neural model that combines dynamic cross-stitch units and cross-task attention for joint recognition of sedentary activities and social contexts from smartphone IMU data. Unlike standard Cross-Stitch Networks, DySTAN dynamically adapts feature sharing per instance and leverages cross-task temporal attention, leading to consistently higher accuracy and macro-F1 scores across all classes on student data. Ablation results confirm that these components drive DySTAN’s improvements over strong multi-task baselines, demonstrating the value of adaptive feature fusion and task interaction for context recognition in naturalistic settings.
A key limitation of this study is the demographic scope of the dataset, which was drawn exclusively from a university student population. Future work will explore expanding data collection to more diverse populations and settings.
📸 Image Gallery