LLM-Powered Text-Attributed Graph Anomaly Detection via Retrieval-Augmented Reasoning
📝 Original Info
- Title: LLM-Powered Text-Attributed Graph Anomaly Detection via Retrieval-Augmented Reasoning
- ArXiv ID: 2511.17584
- Date: 2025-11-16
- Authors: Haoyan Xu, Ruizhi Qian, Zhengtao Yao, Ziyi Liu, Li Li, Yuqi Li, Yanshu Li, Wenqing Zheng, Daniele Rosa, Daniel Barcklow, Senthil Kumar, Jieyu Zhao, Yue Zhao
📝 Abstract
Anomaly detection on attributed graphs plays an essential role in applications such as fraud detection, intrusion monitoring, and misinformation analysis. However, text-attributed graphs (TAGs), in which node information is expressed in natural language, remain underexplored, largely due to the absence of standardized benchmark datasets. In this work, we introduce TAG-AD, a comprehensive benchmark for anomaly node detection on TAGs. TAG-AD leverages large language models (LLMs) to generate realistic anomalous node texts directly in the raw text space, producing anomalies that are semantically coherent yet contextually inconsistent and thus more reflective of real-world irregularities. In addition, TAG-AD incorporates multiple other anomaly types, enabling thorough and reproducible evaluation of graph anomaly detection (GAD) methods. With these datasets, we further benchmark existing unsupervised GNN-based GAD methods as well as zero-shot LLMs for GAD. As part of our zero-shot detection setup, we propose a retrieval-augmented generation (RAG)assisted, LLM-based zero-shot anomaly detection framework. The framework mitigates reliance on brittle, hand-crafted prompts by constructing a global anomaly knowledge base and distilling it into reusable analysis frameworks. Our experimental results reveal a clear division of strengths: LLMs are particularly effective at detecting contextual anomalies, whereas GNNbased methods remain superior for structural anomaly detection. Moreover, RAG-assisted prompting achieves performance comparable to human-designed prompts while eliminating manual prompt engineering, underscoring the practical value of our RAG-assisted zero-shot LLM anomaly detection framework. * Equal contribution.📄 Full Content
In this work, we address this gap by constructing the first comprehensive text-attributed graph anomaly detection (TAG-AD) benchmark dataset. Our key idea is to leverage large language models (LLMs) to directly generate realistic anomalous node texts in the raw text space. Compared with previous methods that inject anomalies by perturbing node features in the embedding or feature space, generating anomalies in the raw text space is more flexible, offers better interpretability, and preserves the fluency and semantic coherence of node attributes. Beyond LLM-generated anomalies, our framework also incorporates multiple additional types of contextual and structural anomalies. We instantiate this pipeline on several widely used realworld graph datasets (e.g., Cora, CiteSeer, etc.), producing a curated benchmark that reflects both structural and contextual anomaly patterns.
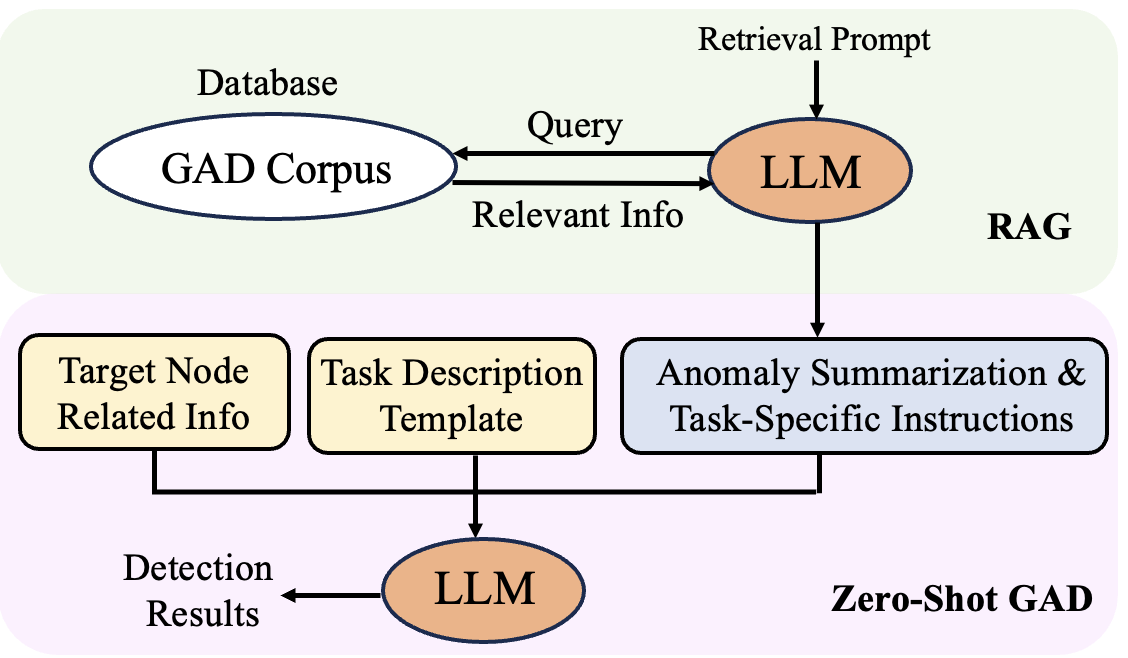
To evaluate the utility of this benchmark, we conduct a comprehensive assessment of state-ofthe-art unsupervised GNN-based GAD methods on Figure 1: Our method introduces a RAG framework for zero-shot GAD, in which a globally retrieved anomaly knowledge base is distilled by an LLM into unified detection guidelines. During inference, each prompt integrates this analysis framework, the task description, and node-specific graph context to enable consistent and interpretable anomaly reasoning.
the proposed TAG-AD dataset. Furthermore, we explore the zero-shot anomaly detection capabilities of modern LLMs (e.g., Qwen3-14B (Yang et al., 2025), GPT-4o-mini (Hurst et al., 2024), Deepseek-V3 (Liu et al., 2024a), Gemma-3-27b-it (Team et al., 2025)) by prompting them directly with node texts and local graph structure information, offering a new perspective on how LLMs can serve as anomaly detectors without task-specific training. In total, our benchmark includes four datasets, each containing five types of anomalies, and we evaluate six unsupervised GNN-based methods and four LLMs across all settings.
A practical limitation we observe is that zeroshot GAD with LLMs often relies on hand-crafted prompts that must encode detailed knowledge about the specific types of anomalies present in a graph. Moreover, LLMs require explicit instructions to accurately detect diverse types of anomalies across graphs from different domains. Such prompt engineering is brittle, time-consuming, and poorly scalable across datasets and anomaly categories in TAGs. To address this limitation, we introduce a retrieval-augmented generation (RAG) (Lewis et al., 2020;Gao et al., 2023) scheme tailored for zero-shot GAD. In our design, the retrieval process is performed once at the global level, independent of any specific node or dataset, and provides a shared knowledge base summarizing canonical definitions and taxonomies of anomaly types (e.g., contextual, structural, textual-semantic). The retrieved content is distilled by the LLM into concise detection guidelines, which form a unified analysis framework.
As shown in Fig. 1, during inference, each prompt combines three components: (i) the RAG-generated analysis framework that provides anomaly definitions and reasoning criteria; (ii) a task description specifying the detection task and scoring rubric (e.g., assigning a 0-10 anomaly score); and (iii) node-specific information, including the target node’s text and its neighborhood or structural context. This structured prompt ensures that each decision is grounded in retrieved anomaly knowledge, guided by consistent evaluation rules, and informed by the target node’s local graph context. The RAG-assisted prompting design decreases the reliance on manual prompt engineering and substantially improves robustness and consistency across datasets and anomaly categories. In summary, our contributions are threefold:
• We construct the first comprehensive TAG anomaly detection dataset, using LLMs to generate realistic node-level anomalies in the raw text space and incorporating additional contextual and structural anomaly types.
• We propose a RAG-assisted prompting framework for zero-shot GAD that retrieves and summarizes anomaly knowledge and detection instructions from the literature, replacing manually designed prompts with a structured combination of the Analysis Framework, the Task Description and Scoring Rubric, and the Node-specific Information.
• We systematically benchmark a variety of unsupervised GAD methods under the TAG setting and investigate the zero-shot anomaly detection ability of LLMs, highlighting their strengths and limitations relative to graph-based methods. We release the testbed, corresponding code, and the proposed pipelines at: https://github.com/ Flanders1914/TAG_AD.
We hope this work provides a foundation for advancing GAD research on TAGs and opens new directions for integrating graph learning with foundation language models.
TAG datasets have become a cornerstone for advancing research at the intersection of graph learning and LLMs. The recent surge in interest has led to the development of a diverse array of benchmarks. (Yan et al., 2023) introduces CS-TAG, a diverse and large-scale suite of benchmark datasets for TAGs, and establishes standardized evaluation protocols. Recognizing the importance of temporal dynamics, (Zhang et al., 2024) introduced DTGB, a dynamic TAG dataset. (Li et al., 2025) further proposed TEG-DB, which incorporates both node and edge textual attributes. Despite these advances, there is no comprehensive TAG dataset for anomaly detection due to a lack of anomalies.
Anomaly detection on graphs has been studied extensively in the context of attributed graphs, where node features are represented as fixeddimensional vectors. Representative approaches include reconstruction-based methods such as DOM-INANT (Ding et al., 2019), Autoencoder-based detectors like AnomalyDAE (Fan et al., 2020), contrastive methods such as CoLA (Liu et al., 2021). These methods demonstrate strong performance on standard attributed graph benchmarks, but they are not directly applicable to TAGs where node attributes are texts. Existing methods typically rely on pre-computed embeddings, which may fail to capture fine-grained textual inconsistencies characteristic of contextual anomalies in TAGs. Recently, a few studies have explored AD on TAGs (Xu et al., 2025d,e), but the datasets they used are quite limited. They rely on perturbing original textual attributes, which often produces unnatural or incoherent semantics, and their evaluation methods are restricted in scope.
A fast-growing body of work studies how LLMs can assist or replace graph models across node classification, link prediction, graph classification, and reasoning. For TAG-oriented GNN-based anomaly detection, we adopt the LLMs-as-Prefix pipeline (Ren et al., 2024), where an LLM first processes text-enriched graph data and then provides either node embeddings or pseudo-labels to enhance subsequent GNN training. Representative approaches that use LLM-generated embeddings to support GNNs include G-Prompt (Huang et al., 2023), TAPE (He et al., 2023), and LLMRec (Wei et al., 2024). For LLM-based zero-shot GAD, we follow a tuning-free, LLMs-only pipeline that designs graph-understandable prompts to directly leverage pretrained LLMs for graph-related reasoning without further training. Notable works in this line include NLGraph (Wang et al., 2023), GPT4Graph (Guo et al., 2023), Graph-LLM (Chen et al., 2024), GraphText (Zhao et al., 2023), and Talk Like a Graph (Fatemi et al., 2023).
Let G = (V, E, T, X) denote a text-attributed graph, where V is the set of nodes, E ⊆ V × V is the set of edges, and T = {t v | v ∈ V } is the collection of node attributes with each t v represented as free-form text (e.g., titles, abstracts, or user-generated content). These text attributes can be transformed into embeddings X = x v | v ∈ V } using a pretrained model (Reimers, 2019). The goal of anomaly node detection is to identify a subset of nodes V ano ⊂ V whose textual or structural characteristics deviate significantly from the majority. Formally, we define an anomalous node as one that violates expected consistency across either:
• Contextual consistency: the semantic content of the target node v diverges from that of its neighborhood N (v) or global domain patterns. • Structural consistency: the connectivity pattern of node v deviates from community-level norms, potentially forming irregular subgraphs.
In TAG-AD, contextual anomalies are generated directly in the text space to ensure realism and semantic diversity. Given a normal node (v, t v ) and its neighborhood context, our objective is to produce a modified text tv such that (v, tv ) is indistinguishable in style and fluency from authentic nodes but contextually anomalous with respect to G. The anomaly detection task is then to learn a scoring function f : V → R that assigns higher scores to nodes in V ano than to normal nodes, without access to anomaly labels during training.
We propose an LLM-based approach to generate realistic contextual anomalies directly in the text space of TAGs. Unlike prior perturbation-based approaches (Xu et al., 2025e), which modify existing textual attributes through insertion or replacement, our method leverages the generative capabilities of LLMs to produce fluent and coherent yet contextually inappropriate text that is semantically inconsistent with its neighbors or original context. In addition, our TAG-AD framework incorporates other established techniques for injecting contextual and structural anomalies, ensuring a comprehensive and versatile benchmark for evaluation.
Our approach consists of two stages: Target Label Selection and Text Generation. Given a node for anomaly injection, the framework first determines an appropriate target label for the anomalous text, and then generates a corresponding text attribute conditioned on this label. This design ensures that the generated anomalies remain indistribution while still deviating from the original semantics and the semantics of neighboring nodes.
We employ a label elimination strategy to identify a suitable anomalous target label. Starting from the full set of candidate labels, the node’s original label is first removed. Then, labels frequently appearing in the node’s k-hop neighborhood are iteratively eliminated, beginning with the most frequent labels among the closest neighbors. This process continues until a single label remains, which is selected as the target label. This strategy ensures that the chosen label maximally diverges from both the node’s original textual attributes and the predominant semantics in its local neighborhood.
Text Generation Given the selected anomalous target label, we design dataset-specific prompts to guide the LLM in rewriting the original node text. The prompts are carefully crafted so that the generated text (1) aligns topically with the target label, (2) departs significantly from the original semantics, (3) maintains the writing style and structural characteristics of the dataset, and (4) preserves the approximate length distribution of the original text.
Another type of anomaly we generate is the global anomaly, for which our framework adopts a textattribute replacement strategy. Within a dataset centered on a specific theme, we replace the target node’s text with another text of the same format and high-level topic domain, but originating from a class not present in the original dataset. In this way, the anomalous node appears topically consistent with the graph, yet remains out-of-distribution from the perspective of class semantics.
Our framework adopts the text perturbation strategy of (Xu et al., 2025e) to generate text perturbation anomalies. For each target node, a set of K candidiate candidate nodes is randomly sampled, and the semantic distances between the target node and each candidate are computed using cosine similarity on their text attribute vectors. The candidate node with the lowest similarity is then selected as the source of anomalous information. A sequence of l tokens is then sampled from the source text and replaces an equal-length segment of the target text, introducing semantically inconsistent content.
To generate structural anomalies, our framework leverages PyGOD (Liu et al., 2024b). Specifically, m nodes are randomly sampled and fully connected to form a clique. This procedure is repeated n times to construct n such cliques, thereby injecting anomalous structural patterns into the graph.
For GNN-based unsupervised GAD methods, we first transform the raw text of all nodes into embeddings X using Sentence-BERT (Reimers, 2019). Then, we use the adjacency information with the transformed node embeddings to train GAD models. After training, we directly derive the anomaly scores from the well-trained GAD models.
For LLM-based zero-shot GAD methods, we input each target node into the LLM along with its textual description, neighborhood information, and task instructions that prompt the model to determine whether the node is anomalous. The model’s output is then converted into numerical anomaly scores, from which we compute the final GAD performance. More details are in Section 4.1.4.
A key challenge in applying LLMs to zero-shot GAD is the reliance on hand-crafted prompts. These prompts must explicitly encode knowledge about how different types of anomalies should be defined for a given graph (e.g., “what is structural anomaly in a financial network”), which makes them costly to construct and difficult to scale across datasets and anomaly categories in TAGs.
To address this limitation, we propose a RAG scheme specifically tailored for zero-shot GAD on TAGs. The pipeline is illustrated in Fig. 1 and consists of three stages: corpus construction, retrieval and summarization, and grounded prompting.
We construct a domain-specific corpus consisting of research papers, survey articles, and dataset doc-umentation related to anomaly detection, with emphasis on attributed graph and text-attributed graph anomaly detection. This corpus serves as the source of background knowledge for anomaly definitions and detection principles.
Rather than performing node-level or datasetspecific retrieval, our method conducts a single global retrieval step that is shared across all experiments. The LLM is prompted to read the corpus and summarize key information about anomaly categories, their definitions, and common indicators. The resulting summary is distilled into a compact set of structured instructions S, which include:
• Anomaly knowledge: concise descriptions of anomaly types such as contextual, structural, and textual-semantic anomalies; • Detection guidelines: high-level criteria for identifying inconsistencies in text or structure.
These instructions remain fixed across all nodes and datasets, providing consistent background knowledge for zero-shot evaluation.
Our final prompting design unifies the retrieved anomaly knowledge, the user-defined task description, and node-specific information into a single structured prompt for zero-shot detection. Each prompt fed to the LLM contains three components:
(1) RAG-generated instructions (S): these are globally shared definitions and detection guidelines obtained from the retrieval and summarization stage, forming an Analysis Framework that describes what constitutes an anomaly (e.g., textual inconsistency, semantic deviation, or structural irregularity). ( 2) Task description and scoring rubric: the LLM is instructed to analyze the given node using the analysis framework and assign an integer anomaly score between 0 and 10, where higher values indicate stronger anomaly evidence, and the rubric defines the interpretation of each score range to ensure a consistent evaluation scale across datasets. (3) Target node information: this part provides node-specific content. For contextual anomaly detection, the LLM receives the target node’s text attribute and the textual descriptions of its direct neighbors. For structural anomaly detection, the LLM receives a textualized subgraph representation that encodes relational or local edge information. Formally, the complete input to the LLM is:
where S denotes the analysis framework, UserPrompt encodes the scoring rubric and the task description, and NodeInfo contains textualized node and neighborhood information. The LLM produces both a natural language rationale and a final integer score in the format: Analysis: …
This structured design ensures that reasoning is grounded in retrieved knowledge, guided by explicit evaluation criteria, and informed by local graph semantics. Importantly, no node labels are provided; zero-shot anomaly scores depend solely on the retrieved framework, the task rubric, and the node’s textual or structural context. Moreover, RAG-assisted prompting reduces reliance on manually engineered prompts and applies a unified analysis framework across all nodes, datasets, and anomaly types, improving robustness and consistency while remaining fully zero-shot.
We evaluate on four widely used TAG datasets: Cora (McCallum et al., 2000), Citeseer (Giles et al., 1998), PubMed (Sen et al., 2008), and Wi-kiCS (Mernyei and Cangea, 2020). Each dataset consists of scientific publications represented as nodes, citation links as edges, and textual metadata (titles or abstracts) as node attributes. Detailed information about these datasets is in Appendix A. To construct TAG-AD, we inject synthetic anomalies into the graphs using the methods described in Section 3.2. In addition, we combine LLMgenerated anomalies with structural anomalies to form a mixed anomaly type in our experiments. For each dataset, we sample a fixed proportion of nodes (5%) as anomaly candidates. In the case of mixed anomalies, approximately (2.5%) of the nodes are sampled for LLM-generated anomalies and another (2.5%) for structural anomalies. Details about the different types of anomaly generation processes are provided in Appendix D and Appendix E.
We benchmark two categories of methods: GNN-based Anomaly Detectors. We benchmark representative unsupervised GAD methods, including DOMINANT (Ding et al., 2019), Anomaly-DAE (Fan et al., 2020), CoLA (Liu et al., 2021), CONAD (Chen et al., 2020), DONE (Bandyopadhyay et al., 2020) and AdONE (Bandyopadhyay et al., 2020). Zero-shot LLMs. We evaluate four modern LLMs (Gemma-3-27b-it, GPT-4o-mini, DeepSeek-V3, Qwen3-14B) in a zero-shot setting. Each model is provided with the textual or structural information of the target node and its neighbors, and is asked to determine whether the target node is anomalous. The prompt design is model-agnostic, ensuring fair and consistent evaluation across all LLMs.
We adopt two widely used metrics for evaluating anomaly detection performance: Area Under the Receiver Operating Characteristic Curve (ROC-AUC) and Average Precision (AP). ROC-AUC measures the probability that an anomalous node is ranked higher than a normal node, while AP summarizes the precision-recall tradeoff across different thresholds. Higher ROC-AUC and AP values indicate better detection performance.
For GNN-based methods, we follow the default implementations in PyGOD (Liu et al., 2024b) and retrain each model using the default hyperparameter configurations. For zero-shot LLMs, we design two distinct encoding strategies-one designed to capture contextual information and the other to capture structural information-to formulate the model inputs. Additionally, we design three prompt templates that enable the LLMs to detect contextual, structural, or mixed anomalies. The two encoding strategies are defined as follows: Contextual encoding. The contextual encoding strategy provides the textual context surrounding the target node. For each target node, we concatenate its text attribute followed by the text attributes of its 1-hop neighbors. If a node’s text exceeds m token tokens, we truncate it to the first m token tokens. If the target node has more than k first-hop neighbors, we randomly sample k neighbors. In our experiments we set m token = 1000 and k = 20 for the contextual prompt template and m token = 1000 and k = 10 for the mixed prompt template. Structural Encoding. The structural encoding strategy converts the topological information of the subgraph centered on the target node into a natural language description interpretable by LLMs. For each target node, we extract its 2-hop subgraph and apply the incident encoding method recommended by Talk Like a Graph (Fatemi et al., 2023) to translate the subgraph structure into textual form. In our experiments, we limit the encoding to at most m node = 100 nodes, and up to m incident = 100 incident relations per node for the structural prompt template, and to at most m node = 50 nodes with up to m incident = 50 incident relations per node for the mixed prompt template. Prompt Templates. We design three types of prompt templates: contextual, structural and mixed, each tailored for detecting contextual anomalies, structural anomalies, and mixed anomalies, respectively. Each prompt template comprises three components: the task description with a scoring rubric, the analysis framework, and the node-specific information. For the node-specific information, at the test time, the contextual prompt template is supplied with contextually encoded text, the structural prompt template with structurally encoded text, and the mixed prompt template with both. Analysis framework. For most of our experiments, the RAG-generated analysis framework is employed. Concretely, we construct the corpus from (Ding et al., 2019), (Gutiérrez-Gómez et al., 2020), (Xu et al., 2025e), and (Liu et al., 2022), which serves as the knowledge base for the RAG module to synthesize analysis frameworks tailored to different prompt templates. The RAG system is implemented on top of PaperQA2 (Skarlinski et al., 2024). To assess the effectiveness of RAG in the context of LLM-based GAD, we additionally conduct an ablation experiment on both LLM-generated anomalies and structural anomalies, where we replace the RAG-derived analysis framework with either (i) a plain prompt (a minimal placeholder) or (ii) an manual prompt (manually crafted by a human with relevant knowledge of GAD). All the prompts used for zero-shot anomaly detection are provided in Appendix F and Appendix G, respectively.
Results for detecting LLM-generated contextual anomalies and structural anomalies are shown in Tables 1 and2, respectively. More results for the Injecting anomalies in the feature space vs. the raw text space. Although GNN-based GAD methods can detect synthetic anomalies injected in the embedding space fairly well, as demonstrated in prior works (Ding et al., 2019;Liu et al., 2022), we find that many GNNs struggle to detect realistic LLM-generated contextual anomalies, even when they are semantically obvious. This suggests that applying pretrained language models only to obtain node embeddings and then training GNNbased detectors on top of these embeddings does not guarantee semantic awareness. The resulting models still fail to capture subtle textual inconsistencies, because the GNNs operate primarily on smoothed feature propagation rather than explicit reasoning about node semantics. In contrast, zeroshot LLM-based approaches reason directly over natural language descriptions and can flexibly interpret diverse anomaly patterns without task-specific training. Nevertheless, their weakness in structural reasoning suggests an opportunity for hybrid methods-combining GNNs’ structural inductive biases with LLMs’ contextual understanding-to achieve a unified, generalizable graph anomaly detector.
Table 3 reports the performance of unsupervised GNN-based anomaly detectors and zero-shot LLMs on the mixed-anomaly setting, where both contextual and structural anomalies are introduced. This task is more challenging than detecting a single anomaly type, since models must capture inconsistencies in both textual attributes and graph structure at the same time.
Among GNN-based approaches, AdONE achieves the strongest overall performance, obtaining the highest ROC-AUC on Cora and PubMed and the highest AP on Citeseer. CoLA also performs well, especially on WikiCS. These results show that methods that jointly consider structure and node attributes remain effective in settings where multiple anomaly sources coexist. In contrast, reconstruction-only methods such as Anoma-lyDAE perform poorly, indicating that mixed anomalies are not well detected by feature reconstruction alone.
Zero-shot LLMs show mixed results. Although they can detect some anomalies without any taskspecific training, their overall performance is lower than that of GNN-based detectors. DeepSeek-V3 achieves the best LLM performance on Cora and WikiCS but performs poorly on PubMed. In contrast, GPT-4o-mini performs the best among LLMs on PubMed, showing that LLMs can still detect a subset of mixed anomalies. However, across most datasets, zero-shot LLMs remain behind the strongest GNN baselines.
These results indicate that mixed anomalies continue to require strong structural modeling, and current zero-shot LLMs do not consistently capture both semantic and structural signals at the same time. GNN-based detectors therefore remain more reliable in this setting. A potential future direction is to combine graph neural encoders with LLMbased reasoning so that semantic understanding and topology-aware modeling can be integrated within a single framework.
Fig. 2 compares the performance of zero-shot LLM-based anomaly detection between the plain prompt, the RAG prompt, and the manual prompt.
For structural anomaly detection, both the manual prompt and the RAG prompt yield a substantial performance gain. This improvement arises because both prompts incorporate background knowledge drawn from the GAD literature, such as canonical definitions and diagnostic cues for structural irregularities, and explicitly integrate these insights into the detection prompt. Such prior knowledge enables the LLM to reason more effectively about what constitutes abnormal structural behavior, leading to more accurate judgments even in the absence of task-specific training. While the manual prompt delivers the strongest performance, the RAG prompt offers the clear practical advantage of avoiding manually engineered, expert-crafted instructions. Empirically, DeepSeek-V3, the most capable model in our experimental setup, exhibits the most significant improvement, with both ROC-AUC and AP increasing sharply over the plain prompt when either enhanced prompt is used. This finding suggests that more powerful LLMs are better able to exploit the background knowledge encoded in the prompts, and that the benefits of incorporating such prior knowledge become more pronounced as model capacity increases.
In contrast, for contextual anomalies, the performance gain of RAG over the plain prompt is less pronounced. This result is expected, as detecting contextual anomalies typically depends on commonsense and semantic reasoning, capabilities that modern LLMs already acquire through large-scale pretraining. As a result, the additional retrieved information yields only marginal benefits in this setting. Notably, human-designed prompts do not achieve the strongest overall performance, suggesting that manually crafted, domain-specific reasoning templates may be constrained by human bias and cognitive limitations. Overall, RAG-assisted prompting attains the best performance, albeit with a modest margin, indicating that our RAG design is both effective and practically advantageous. In particular, RAG prompting requires minimal manual prompt engineering, which enhances its practicality and adaptability in real-world scenarios.
In summary, RAG is particularly effective when detecting anomaly types that depend on explicit prior knowledge-such as structural or domainspecific irregularities-where background definitions play a crucial role. For more general contextual anomalies, where commonsense suffices, its contribution is smaller. These results suggest that retrieval-augmented prompting can greatly im-prove zero-shot GAD performance in knowledgeintensive settings while reducing dependence on hand-crafted manual prompts.
In this paper, we introduce TAG-AD, the first comprehensive benchmark for anomaly node detection on TAGs. Our framework leverages LLMs to generate realistic contextual anomalies directly in the raw text space, overcoming the limitations of featurelevel perturbations that often degrade semantic coherence. TAG-AD also integrates text perturbation contextual and structural anomaly injection strategies, providing a unified and flexible platform for evaluating GAD methods under diverse conditions.
We benchmark both unsupervised GNN-based anomaly detectors and zero-shot LLMs. The results highlight that while conventional graph models capture structural irregularities effectively, modern LLMs-especially with RAG prompting-demonstrate strong zero-shot capabilities in detecting text-driven anomalies without any taskspecific training. These findings reveal the emerging potential of foundation models as versatile anomaly detectors on graph-structured data.
In future work, we plan to extend TAG-AD to multi-modal graph settings (e.g., graphs with textual, visual, and temporal attributes) and to explore instruction-tuned graph-language models that can jointly reason over structure and semantics. We hope that the release of TAG-AD will catalyze further research on integrating graph learning and large language models for robust, interpretable, and label-efficient anomaly detection.
Cora The Cora dataset (McCallum et al., 2000) contains 2,708 scientific publications categorized into seven research topics: Case-Based Reasoning, Genetic Algorithms, Neural Networks, Probabilistic Methods, Reinforcement Learning, Rule Learning, and Theory. Each node represents a paper, and edges denote citation links between papers, forming a graph with 5,429 edges.
CiteSeer The CiteSeer dataset (Giles et al., 1998) consists of 3,186 scientific publications grouped into six research domains: Agents, Machine Learning, Information Retrieval, Databases, Human-Computer Interaction, and Artificial Intelligence. Each node corresponds to a paper, with textual features extracted from its title and abstract. The graph is constructed based on citation relationships among the publications.
PubMed The PubMed dataset (Sen et al., 2008) comprises scientific articles related to diabetes research, divided into three categories: experimental studies on mechanisms and treatments, research on Type 1 Diabetes focusing on autoimmune factors, and Type 2 Diabetes studies emphasizing insulin resistance and management. Nodes represent papers, edges denote citation links, and node features are derived from the medical abstracts.
WikiCS The WikiCS dataset (Mernyei and Cangea, 2020) is a Wikipedia-based citation graph built for benchmarking graph neural networks. Nodes correspond to computer science articles categorized into ten subfields serving as class labels, while edges represent hyperlinks between articles. Node features are extracted from the textual content of the corresponding Wikipedia entries.
DOMINANT (Ding et al., 2019) DOMINANT is among the first approaches to combine GCNs with autoencoders for GAD. It employs a two-layer GCN encoder and two decoders: one reconstructs node attributes using a GCN, and the other reconstructs the adjacency matrix via a dot-product layer.
The final anomaly score is the combination of reconstruction errors from both decoders.
DONE (Bandyopadhyay et al., 2020) DONE uses separate autoencoders for structural and attribute reconstruction, both implemented with multilayer perceptrons. The method jointly optimizes node embeddings and anomaly scores through a unified loss that balances reconstruction consistency.
AdONE (Bandyopadhyay et al., 2020) AdONE extends DONE by introducing an adversarial discriminator to align structure and attribute embeddings in the latent space. The discriminator encourages consistency between the two representations, leading to more robust detection performance.
CoLA (Liu et al., 2021) CoLA employs a contrastive learning framework that captures informative representations by contrasting node-subgraph pairs. The learned representations enable the model to assign discriminative anomaly scores, allowing effective ranking of abnormal nodes.
AnomalyDAE (Fan et al., 2020) AnomalyDAE leverages dual autoencoders for structure and attributes. Its structural encoder jointly processes the adjacency matrix and node features, while the attribute decoder reconstructs the node attributes using both structural and attribute embeddings. The reconstruction error serves as the node’s anomaly score.
CONAD (Chen et al., 2020) CONAD belongs to the family of BOND-based methods that integrate graph augmentation with contrastive learning. It introduces prior knowledge about potential outlier nodes by generating augmented graph views. These augmented graphs are encoded using Siamese GNN encoders, and the model is optimized via a contrastive loss to enhance representation consistency. Similar to DOMINANT, the final anomaly score for each node is obtained through two separate decoders that reconstruct structural and attribute information.
We further present anomaly detection results for both global contextual and text perturbation anomalies. As shown in Tables 4 and5, in the case of contextual anomaly detection, the zero-shot LLMbased methods generally outperform the best unsupervised GNN baselines across most datasets. This demonstrates that LLMs, leveraging their strong semantic understanding and reasoning capabilities,
The detailed procedure for constructing the LLMgenerated contextual anomalies is described in Section 4.1.4. For text perturbation anomalies, we set K candidate = 50 in our experiments. The replaced sequence length l is computed as:
where l t and l s denote the numbers of tokens in the target and source node text attributes, respectively. Regarding global contextual anomalies, we employ text attributes from WikiCS as the outlier source for Cora and Citeseer, and use Citeseer as the outlier source for WikiCS. The outlier text source for PubMed is built by combining four PubMed datasets 2 from HuggingFace. For structural anomalies, we utilize PyGOD (Liu et al., 2024b) with the parameter m = 10.
2 Datasets used for constructing global contextual anomalies for Pubmed Datasets: 3) Graph Context: Judge whether the node fits naturally within its local graph neighborhood.""" ANALYSIS_FRAMEWORK_STRUCTURAL_HUMAN_DESIGNED = “““A structural anomaly node exhibits one or more of the following characteristics: 1) Clique-like density spike: The node sits inside an unusually dense (near-)clique; its immediate neighbors are also heavily interconnected.
-
Egonet surplus vs. expectation: The node’s egonet (the node and its immediate neighbors, plus all edges among them) contains far more edges or triangles than would be expected for a node of its degree or position in the graph.
-
Boundary sparsity: The dense core around the node has relatively few edges that cross to the outside, creating a sharp contrast between internal density and external connectivity.
You should analyze each of the above characteristics from the following aspects: 1) Local Structural Intensity: Measure the internal connectivity around the target node (e.g., number of edges, triangles, or density within the egonet). Compare these values to local baselines, such as the egonets of neighbors with similar degree or position.
-
Boundary & Cut Properties: Assess the number of edges that connect the egonet (the node and its immediate neighbors) to the rest of the graph. Determine whether there is a sharp drop in connectivity at the boundary, indicating a well-separated dense core.
-
Community & Positional Consistency: Evaluate whether the node’s structural position and its local community structure are consistent with the broader graph. Consider if the node is embedded in a community in a way that is unusual or inconsistent with typical nodes in the graph.””” ANALYSIS_FRAMEWORK_PLACEHOLDER = """ You should design an analysis framework by yourself. Then follow your analysis framework to analyze the target node. """ G RAG Prompts ANALYSIS_FRAMEWORK_EXAMPLE = “““An <type_of_anomaly> anomaly node exhibits one or more of the following characteristics: 1) <characteristic_1>: 1 sentences 2) <characteristic_2>: 1 sentences … You should analyze each of the above characteristics from the following aspects: 1) <aspect_1>: 1 sentences 2) <aspect_2>: 1 sentences …””” CONTEXTUAL_ANOMALY_PROMPT_RAG = """ You task is to generate the Analysis Framework Section of a prompt used to detect contextual anomaly. The Analysis Framework should be concise, practical, and directly usable within an LLM prompt for anomaly detection. Do not include any instructions that go beyond the scope of the inputs. Do not include any instructions that cannot be executed by the large language model(e.g., compare embeddings).
The ONLY inputs available to the model at inference time: the target node’s text and the texts of its direct neighbors. The prompt has already contained the following Rubric Section: Rubric: The score should be an integer from 0 to 10 (higher = stronger anomaly evidence) Score 0: definitely normal Score 1-4: more likely normal (minor issues) Score 5: equally likely normal and anomalous Score 6-9: more likely anomalous (increasing evidence) Score 10: definitely anomalous You should generate the Analysis Framework Section for the contextual anomaly without any other information such as titles, citations, references, summaries, conclusions, etc.
Here is an example: {example} """ STRUCTURAL_ANOMALY_PROMPT_RAG = """ You task is to generate the Analysis Framework Section of a prompt used to detect structural anomaly. The Analysis Framework should be concise, practical, and directly usable within an LLM prompt for anomaly detection. Do not include any instructions that go beyond the scope of the inputs. Do not include any instructions that cannot be executed by the large language model(e.g., compare embeddings). The ONLY inputs available to the model at inference time: the structure of a 2-hop subgraph centered at the target node. The text attribute of the target node is not available. The prompt has already contained the following Rubric Section: Rubric: The score should be an integer from 0 to 10 (higher = stronger anomaly evidence) Score 0: definitely normal Score 1-4: more likely normal (minor issues) Score 5: equally likely normal and anomalous Score 6-9: more likely anomalous (increasing evidence) Score 10: definitely anomalous You should generate the Analysis Framework Section for the contextual anomaly without any other information such as titles, citations, references, summaries, conclusions, etc.
Here is an example: {example} """ MIXED_ANOMALY_PROMPT_RAG = """ You task is to generate the Analysis Framework Section of a prompt used to detect both contextual and structural anomaly. The Analysis Framework should be concise, practical, and directly usable within an LLM prompt for anomaly detection. Do not include any instructions that go beyond the scope of the inputs. Do not include any instructions that cannot be executed by the large language model(e.g., compare embeddings). The ONLY inputs available to the model at inference time: 1) The text attributes of the target node and its direct neighbors.
- The structure of a 2-hop subgraph centered at the target node. The prompt has already contained the following Rubric Section: Rubric: The score should be an integer from 0 to 10 (higher = stronger anomaly evidence) Score 0: definitely normal Score 1-4: more likely normal (minor issues) Score 5: equally likely normal and anomalous Score 6-9: more likely anomalous (increasing evidence) Score 10: definitely anomalous You should generate the Analysis Framework Section for the mixed anomaly without any other information such as titles, citations, references, summaries, conclusions, etc.
Here is an example: {example} """
ROC-AUC↑ AP ↑ ROC-AUC ↑ AP ↑ ROC-AUC ↑ AP ↑ ROC-AUC ↑ AP ↑
ROC-AUC
ROC-AUC↑ AP ↑ ROC-AUC ↑ AP ↑ ROC-AUC ↑ AP ↑ ROC-AUC ↑ AP ↑
ROC-AUC
The context window of Qwen-3-14B is limited to 32k tokens, which makes it incompatible with the WikiCS dataset under the same experimental settings as the other models. All remaining models use a 128k-token context window.
📸 Image Gallery