AI-assisted gait analysis holds promise for improving Parkinson's Disease (PD) care, but current clinical dashboards lack transparency and offer no meaningful way for clinicians to interrogate or contest AI decisions. To address this issue, we present Motion2Meaning, a cliniciancentered framework that advances Contestable AI through a tightly integrated interface designed for interpretability, oversight, and procedural recourse. Our approach leverages vertical Ground Reaction Force (vGRF) time-series data from wearable sensors as an objective biomarker of PD motor states. The system comprises three key components: a Gait Data Visualization Interface (GDVI), a one-dimensional Convolutional Neural Network (1D-CNN) that predicts Hoehn & Yahr severity stages, and a Contestable Interpretation Interface (CII) that combines our novel Cross-Modal Explanation Discrepancy (XMED) safeguard with a contestable Large Language Model (LLM). Our 1D-CNN achieves 89.0% F1-score on the public PhysioNet gait dataset. XMED successfully identifies model unreliability by detecting a five-fold increase in explanation discrepancies in incorrect predictions (7.45%) compared to correct ones (1.56%), while our LLM-powered interface enables clinicians to validate correct predictions and successfully contest a portion of the model's errors. A human-centered evaluation of this contestable interface reveals a crucial trade-off between the LLM's factual grounding and its readability and responsiveness to clinical feedback. This work demonstrates the feasibility of combining wearable sensor analysis with Explainable AI (XAI) and contestable LLMs to create a transparent, auditable system for PD gait interpretation that maintains clinical oversight while leveraging advanced AI capabilities. Our implementation is publicly available at: https://github.com/hungdothanh/motion2meaning.
The management of chronic neurodegenerative diseases is shifting from episodic evaluations to continuous monitoring with wearable sensors, which provide ob-jective digital biomarkers for earlier intervention and individualized therapy [25,5,26]. Parkinson's Disease (PD), a condition marked by progressive motor impairments [16], exemplifies this need. Standard clinical tools like the Unified Parkinson's Disease Rating Scale (UPDRS) [27] are applied too intermittently and are vulnerable to observer and patient bias [6,2]. Consequently, they fail to capture daily motor fluctuations, leading to imprecise treatment, heightened fall risk, and reduced quality of life [26,17].
Although AI models can accurately quantify gait and predict disease severity [52,29], their clinical translation is stalled by a critical “last-mile problem.” Current dashboards present outputs like Hoehn & Yahr stages [12] as opaque, static scores, preventing clinicians from scrutinizing or overriding predictions that conflict with their expertise. This opacity undermines trust and the principles of evidencebased medicine. While Explainable AI (XAI) offers partial solutions like saliency maps [20,32,30], these are typically one-way communications that fail to support the dialogic nature of clinical reasoning [34,31]. The crucial gap is not merely a lack of transparency but the absence of mechanisms for procedural recourse, enabling clinicians to actively contest and amend AI-driven decisions.
To address this gap, we draw on the principles of Contestable AI (CAI). CAI extends beyond explanation by embedding structures for dialogue, challenge, and justification within system design [34,31]. This approach aligns with regulatory demands for human oversight (GDPR [48], EU AI Act [8]). A contestable system allows users not only to understand a decision but also to dispute it with domain expertise, ensuring that such challenges are recorded, processed, and capable of influencing the final outcome. This study seeks to apply these principles in a clinician-centered interface for PD care. The key contributions are as follows:
-We design and implement Motion2Meaning, a novel clinician-centered framework that unifies three core components: a deep learning (DL) diagnostic model, a dual-modality explainability module, and an LLM-driven interaction layer within a single human-in-the-loop interface. -We implement a 1D-CNN architecture that performs end-to-end classification of Hoehn & Yahr severity from raw vGRF time-series data. This model outputs a probability distribution over the four discrete severity stages. -We introduce Cross-Modal Explanation Discrepancy (XMED), a novel XAI technique to automatically flag unreliable predictions. XMED operates on the principle that trustworthy predictions should have stable explanations across different methods. It quantifies the divergence between a gradientbased explanation (Grad-CAM [45]) and a backpropagation-based one (LRP [20]). A high divergence score signifies inconsistent model reasoning, which automatically flags the prediction for mandatory clinical review. -We develop a contestable interaction system powered by a Large Language Model (LLM) that uses a structured “Contest & Justify” workflow. The LLM synthesizes the CNN’s prediction, XAI-identified salient features, and the clinician’s specific challenge to generate clinically-grounded textual justifications. These justifications form the basis for a transparent, evidence-based dialogue between the clinician and the AI.
This work is situated at the confluence of two research domains. We first review advances in AI for sensor-based PD gait analysis, where progress in predictive accuracy has often come at the cost of clinical interpretability. We then connect this gap to the broader evolution of human-centered AI in healthcare, which argues for moving beyond passive Explainable AI (XAI) toward the more interactive and legally robust principles of Contestable AI (CAI).
For decades, gait analysis has been central to movement disorder research, but it was traditionally limited to specialized motion capture laboratories. Wearable Inertial Measurement Units (IMUs) have transformed this field by enabling continuous, high-resolution data collection in natural environments [43,24,40,38]. This is vital for PD care, where gait serves as a rich digital biomarker. Neurodegeneration of dopaminergic pathways in the basal ganglia disrupts movement automaticity, producing measurable deficits in stride length, speed, cadence, turning velocity, and asymmetry. IMUs are also well-suited to detect episodic phenomena such as Freezing of Gait (FOG) and medication-related fluctuations that are difficult to capture in clinic visits [43,35]. Early computational methods relied on handcrafted biomechanical features derived from statistical, spectral, and non-linear analyses, which were classified using models such as Support Vector Machines and Random Forests [37]. Although interpretable, these approaches were constrained by their dependence on expert-driven feature design and limited ability to capture complex pathological patterns. More recently, end-to-end DL has emerged, with one-dimensional Convolutional Neural Networks effective for local spatio-temporal motifs, and Recurrent Neural Networks or Transformers capturing long-range dependencies [7,28,39]. Despite SOTA performance, their opacity poses a major barrier to clinical adoption. This accuracy-interpretability trade-off erodes trust, as clinicians are reluctant to rely on opaque predictions that cannot be examined against their expertise [34,31]. The problem is compounded by dashboards that act only as data presenters, showing parameters or outputs without revealing model reasoning or enabling clinician input or correction [13,34].
Bridging the gap between high-performance AI and clinical use requires humancentered socio-technical systems that are transparent, interpretable, and trustworthy. This effort began with XAI and is now advancing toward CAI, as illustrated in Figure 1 [31]. XAI seeks to make black-box predictions understandable, supporting trust and error detection [33,30,32]. In clinical gait analysis, XAI remains early, though methods from other medical domains provide guidance. Backpropagation-based approaches, such as Saliency Maps and LRP [20], highlight critical temporal regions of the input. CAM-based techniques, including Grad-CAM [45] and Grad-CAM++ [4], localize discriminative regions linked to predictions. Perturbation-based methods [41,36,49] identify influential regions by altering inputs and monitoring changes in output probabilities. More recent work emphasizes interactive explanations, allowing users to test counterfactuals or adjust inputs, and cognitively aligned formats, such as contrastive reasoning or natural language dialogue [34,31]. These developments recognize explanation as a social process aimed at shared understanding between humans and AI.
A central challenge in human-AI collaboration is achieving appropriate trust calibration [42,21], the process by which a user develops an accurate mental model of an AI’s capabilities to avoid both blind over-trust (automation bias) and reflexive dismissal (algorithm aversion). Conventional XAI, while providing transparency, may not suffice for this task. A compelling but incorrect explanation can actively impair calibration by creating a false sense of security [53]. A system designed for effective calibration must therefore go beyond one-way explanations and provide a mechanism for procedural recourse [11]. This is the principle of CAI: to create an essential feedback loop where clinicians can act on their calibrated judgments, transforming them from passive observers into active supervisors, enabling expert-driven recourse that forms the foundation of our Motion2Meaning framework, which aims to operationalize contestability in a real-world clinical setting.
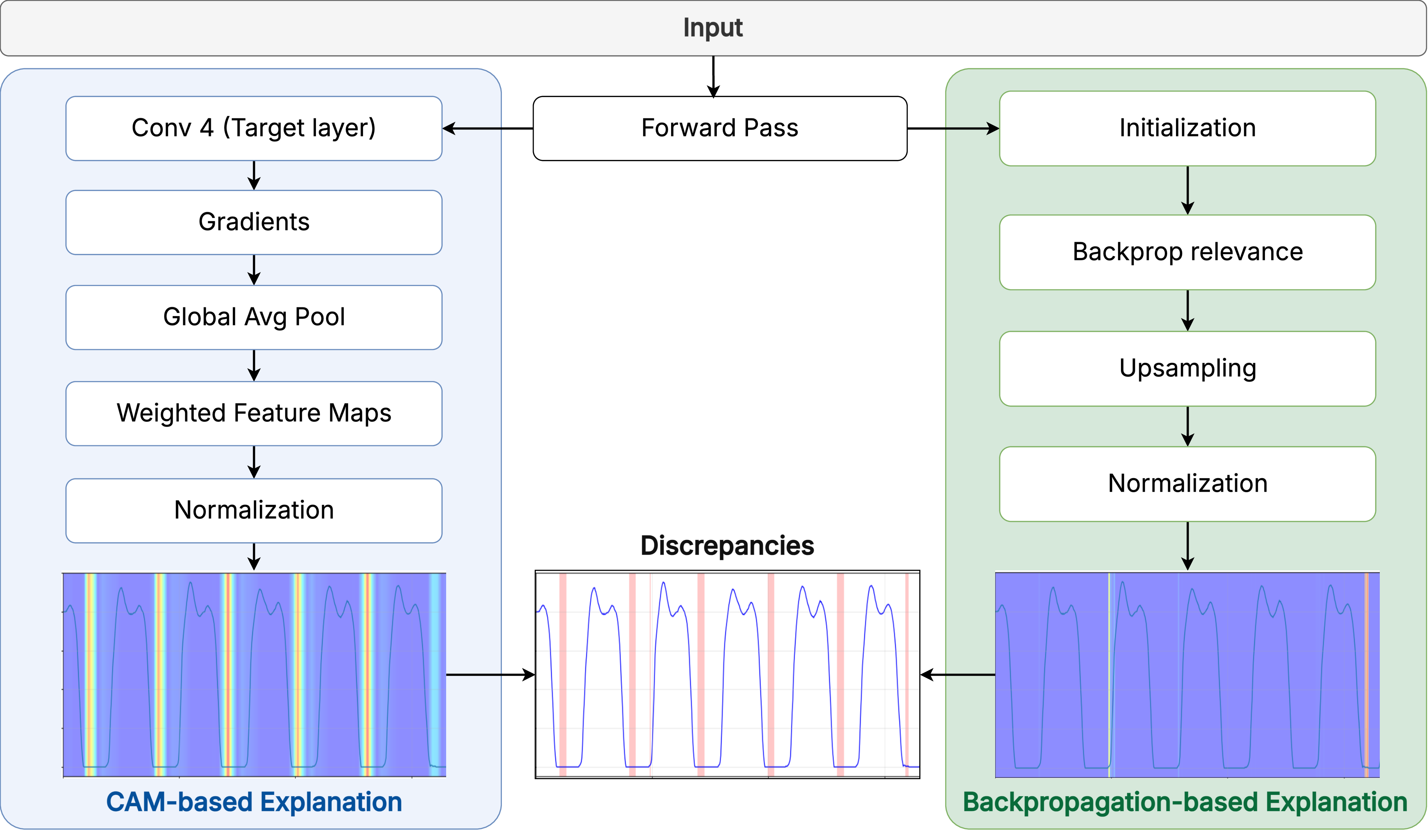
Figure 2 presents an overview of the Motion2Meaning framework, which integrates two core interfaces into an end-to-end system for gait interpretation.
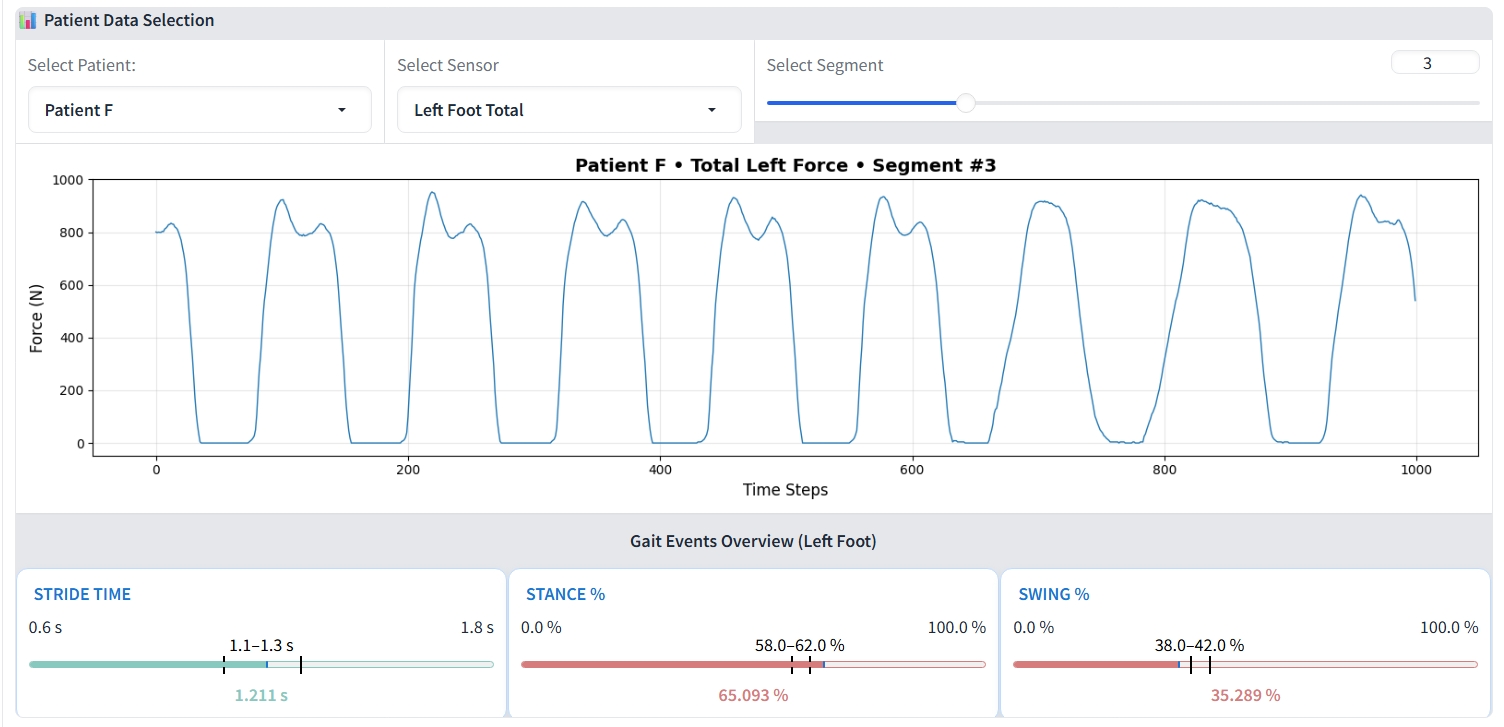
The first component is the Gait Data Visualization Interface (GDVI). It is an interactive web-based tool for exploring gait data from the PhysioNet dataset [10], as depicted in Figure 3. The interface presents raw vGRF signals in 10-second windows, with controls to toggle sensor channels and select time segments for detailed inspection. A complementary summary panel uses color- The second and also core component of the framework is the Contestable Interpretation Interface (CII), the dashboard where the human-AI dialogue occurs. Its workflow is operationalized through three integrated technical pillars:
- The workflow begins with the 1D-CNN, our predictive engine designed following [1], which analyzes a patient’s gait data to generate an initial classification of the Hoehn & Yahr severity. This prediction is presented not as a final answer, but as a testable hypothesis for clinical review. 2. To audit the reliability of this hypothesis, the Cross-Modal Explanation Discrepancy (XMED) module performs an automated consistency check on the model’s reasoning. It leverages the fundamental differences between Grad-CAM [45], which identifies where in the signal the model focuses, and LRP [20], which attributes what specific data points were most influential. A significant divergence between these two reveals a critical failure mode where the model may correctly identify a clinically relevant temporal region but base its decision on a spurious artifact within it. This quantified “attentionattribution” gap provides a targeted alert for a structurally flawed reasoning process that a single explanation method would miss. 3. Finally, the LLM-powered “Contest & Justify” workflow enables procedural recourse. When a prediction is challenged, either due to an XMED alert or independent clinical judgment, the clinician registers dissent through a structured typology: Factual Error (contesting input data integrity), Normative Conflict (flagging contradiction with clinical knowledge), or Reasoning Flaw (challenging the XAI’s visual evidence). This formal contestation triggers the LLM to synthesize all available evidence and generate a new, contextualized justification. This exchange creates a transparent, collaborative negotiation that culminates in either acceptance or a clinician-driven override, with every step logged in an immutable record to ensure accountability.
To evaluate the effectiveness of our Motion2Meaning framework, we conducted a comprehensive, multi-stage investigation. Our evaluation was designed to answer three central questions: (1) What is the baseline predictive performance of our core 1D-CNN model on PD severity classification? ; (2) Can the XMED method effectively distinguish between reliable and unreliable model predictions? ; (3) How effectively can LLMs leverage these discrepancy signals to validate correct predictions and contest erroneous ones in a simulated clinical workflow?
Our experiments were conducted using the public PhysioNet Gait in PD dataset, which contains vertical Ground Reaction Force (vGRF) signals from 93 individuals with PD and 73 healthy controls [10]. For our deep learning model, we preprocessed the data by segmenting the variable-length recordings into fixed, non-overlapping 1000-frame windows. To create a focused and interpretable attribution space for our XMED safeguard, we used a single, highly informative feature for our analysis: the “Total left force” signal.
The dataset was partitioned into training (70%), validation (15%), and test (15%) sets, using multiple random seeds to ensure robustness. We trained our model using a nested cross-validation strategy on the training data. A 5-fold outer loop assessed model generalization, while a 3-fold inner loop within each fold conducted a grid search to optimize hyperparameters. The final optimal configuration derived from this process is presented in Table 1.
To align with CAI and foreground the framework’s human-centered design, we evaluate Motion2Meaning using human-oriented metrics. We concentrate on LLMgenerated textual explanations, which constitute the most direct interface between the AI component and clinicians. Our first two metrics are the Flesch readability tests [18,9], which estimate readability via sentence length and lexical complexity. Flesch Reading Ease (FRE) ranges from 1 to 100, with higher values indicating greater accessibility. The Flesch-Kincaid Grade Level (FKGL) estimates the U.S. school grade needed to comprehend a text. For clinician-oriented medical materials (e.g., clinical documentation used in diagnostic and care workflows), typical FRE scores are 50 to 70. These correspond to FKGL 8 to 12 and are appropriate for readers aged approximately 13 to 18 [51,3] Clinical Grounding (CG) evaluates LLM hallucination by quantifying the verifiability of its explanations against available evidence. We compute it by first isolating all numerical values in the model’s generated text, and then determining the percentage of those numbers that match the figures provided in the input prompt and data. Given the multiset of numerical values extracted from the LLM’s generated explanation, V E , and the multiset of all numerical values provided in the input prompt and data, V I , CG is defined as:
where I(•) is the indicator function and the score is defined as 100 if |V E |= 0 (i.e., no numerical claims are made). A high score indicates the framework’s ability to reduce a clinician’s cognitive load and mitigate clinical risk.
Self-Correction Accuracy (SCA), measures the direct impact of our contestation system on fixing the baseline model’s mistakes. We compute it by first isolating the set of instances D err that the baseline model initially misclassified, and then calculating the percentage of these specific errors that the contestable LLMs system successfully overturns to the correct label. Given the final system’s prediction ŷfinal (x i ) and the true label y i for an instance x i ∈ D err , SCA is formally defined as:
where I(•) is the indicator function. A high score confirms the framework’s self-remediation capacity, enhancing user trust and clinician-AI collaboration.
Upon evaluation on the unseen test set, our model achieved a robust overall accuracy and weighted F1-score of 0.89, with a detailed breakdown of per-class performance provided in Table 2. The model demonstrates excellent performance in identifying the Healthy control group, achieving an F1-score of 0.91. Furthermore, it shows reliable discrimination between the clinically adjacent intermediate severity levels, with balanced F1-scores of 0.87 for Stage 2 and 0.89 for Stage 2.5. The primary challenge was observed in the most advanced category, Stage 3, which recorded a slightly lower recall of 0.84. This reduced sensitivity is likely attributable to the significant class imbalance, as this category contains only 83 samples, which may limit the model’s ability to learn its full intra-class variability. These results confirm the model’s overall robustness but also highlight a clear direction for future refinement; techniques such as targeted data augmentation or class-balancing loss functions could further improve sensitivity for the more advanced disease stages.
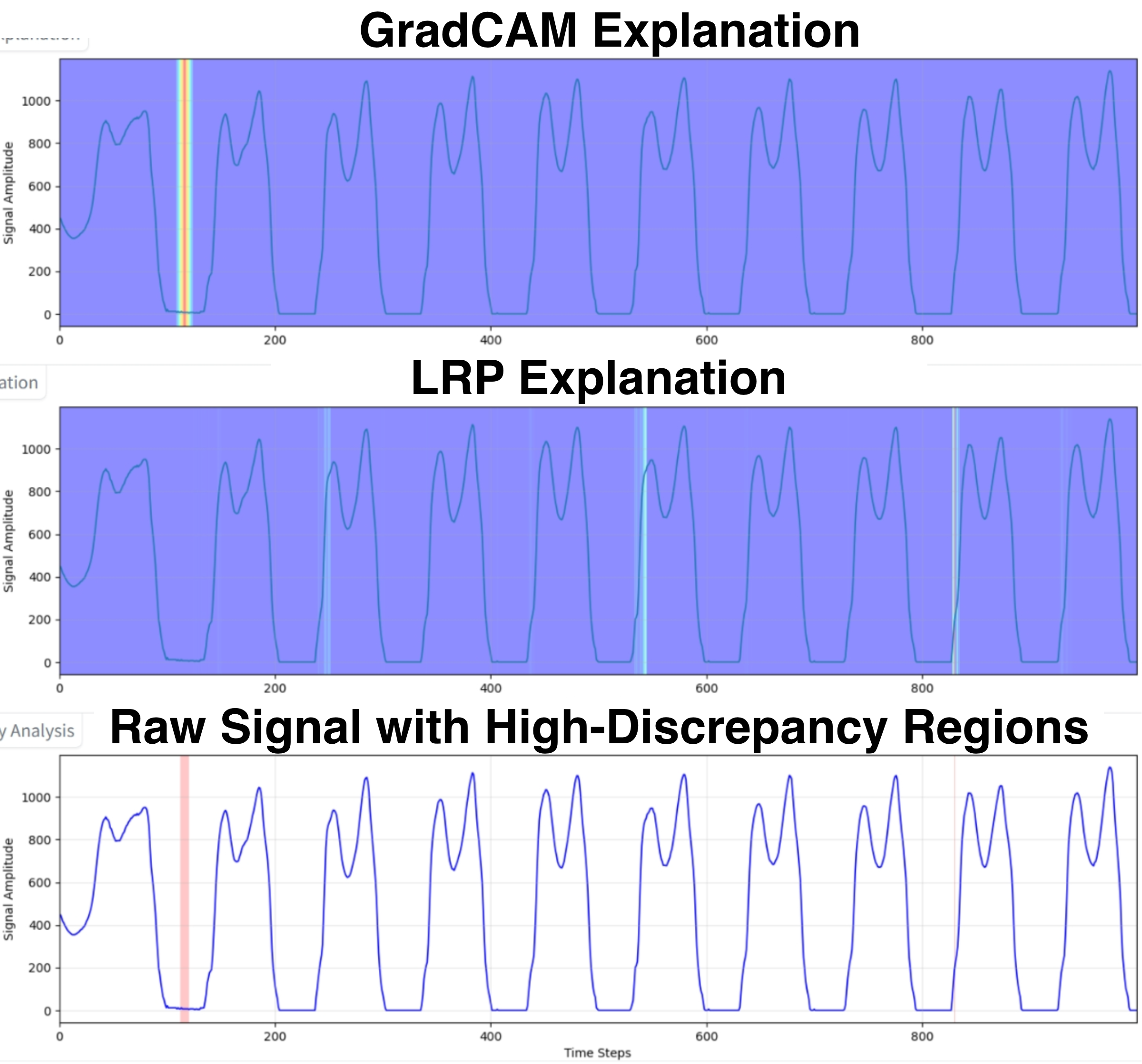
The model’s fallibility, particularly in intermediate and advanced disease stages, highlights the need for a human-in-the-loop system to identify and correct errors. We first evaluated our XMED safeguard, which is based on the hypothesis that discrepancies between explanation methods can serve as a proxy for model uncertainty. To test this, we quantified the “high-discrepancy percentage” for a set of 30 test cases. The results confirm our hypothesis: misclassified cases exhibited a five-fold higher average discrepancy rate (7.56%) compared to correct predictions (1.45%). This demonstrates that attributional inconsistency is a reliable signal of model unreliability.
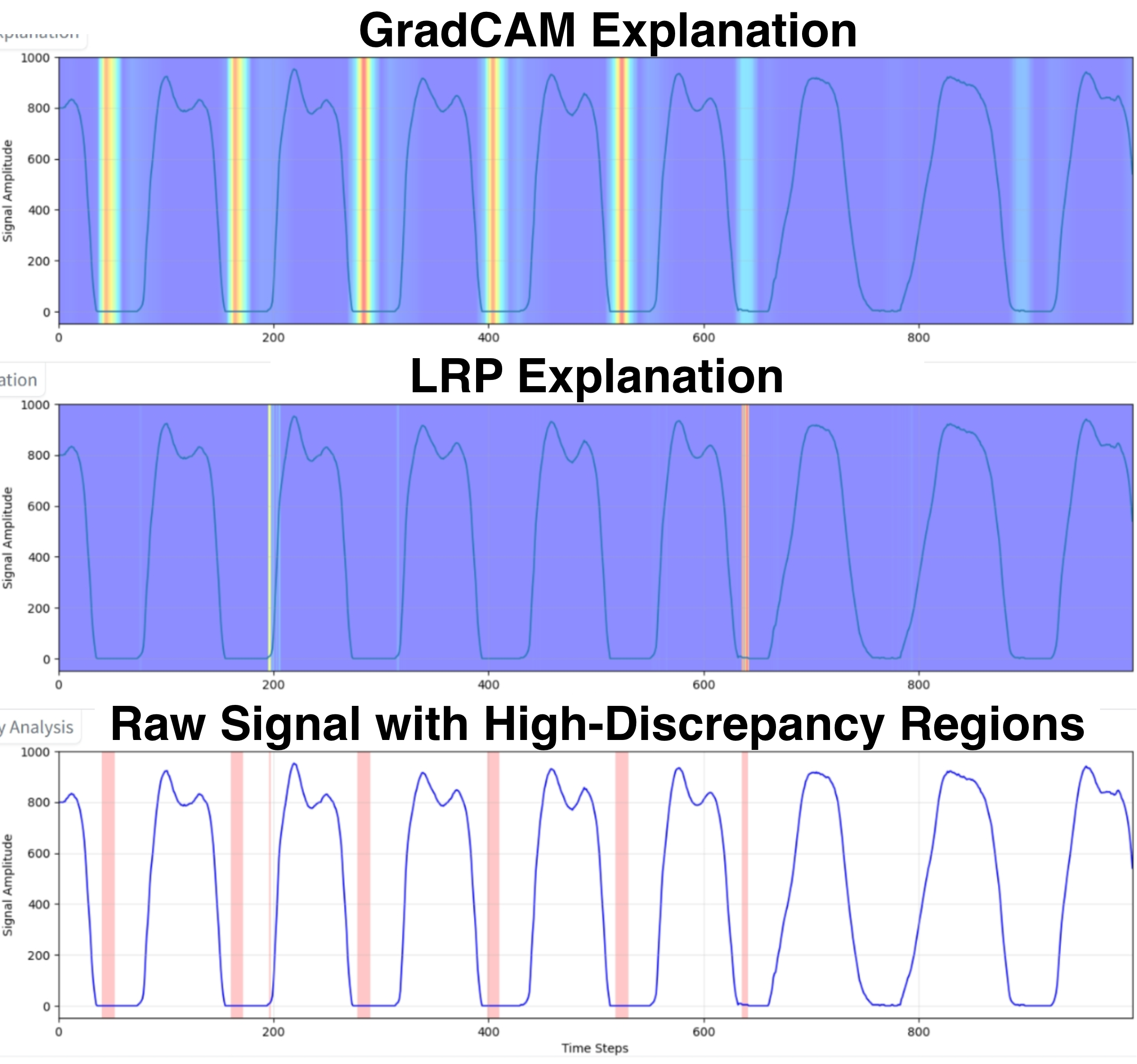
To calculate this metric, we generated two normalized explanation maps for each test sample: one using Grad-CAM [45] and another using LRP [20], as illustrated in Figure 4. We calculated the absolute difference at each timestep, flagging points where it exceeded a threshold of 0.5. These points were then merged into coherent high-discrepancy regions, and the final metric was the fraction of total timesteps falling within these regions.
With the safeguard validated, we investigated whether LLMs could use these signals for adjudication. We tested Llama 4 Scout (17B) [23] and GPT-4o (200B) [15] with identical prompts (Template 1) and settings. As summarized in Table 3, their performance profiles differed significantly. GPT-4o adopted a more conservative and reliable approach, correctly retaining all 24 correct predictions it reviewed. In contrast, Llama 4 was more interventionist; it successfully overturned two of the six incorrect predictions but also incorrectly overturned one correct case, suggesting different underlying reasoning processes that warrant further case-level analysis. Correct Prediction Case In a representative case of a correct classification (Figure 5a), the 1D-CNN identified a patient as Stage 0 (Healthy) with high confidence (0.821) and a correspondingly low XMED discrepancy of 0.8%. Both LLMs correctly upheld this initial prediction. As detailed in Figure 6, their justifications were grounded in clinical gait data, with both models observing that gait metrics were “within normal ranges.” Llama 4 further specified the “absence of Parkinsonian gait markers,” while GPT-4o correctly interpreted the minor discrepancy regions as not clinically significant, demonstrating a nuanced understanding of the XMED signal.
Incorrect Prediction Case A more revealing case involved a low-confidence (0.462) misclassification by the 1D-CNN, which was correctly flagged by a high XMED score of 6.5% (Figure 5b). In this instance, the LLMs diverged, as shown in Figure 7. Llama 4 successfully overturned the prediction, downgrading it from Stage 2.5 to Stage 2. It correctly reasoned that while the prolonged stance phase (65.1%) indicated impairment, the abnormality was insufficient to justify the higher severity rating. In contrast, GPT-4o retained the incorrect Stage 2.5 label, focusing on the clinical plausibility of the observed gait changes as compensatory mechanisms. It failed to differentiate the degree of this deviation, highlighting a more risk-averse adjudicative style that avoids overturning a prediction without overwhelming contradictory evidence. In terms of computational efficiency, we observed a clear trade-off. Llama 4 was consistently faster, with a response time (RT) between 7 and 9 seconds, while GPT-4o was slower, taking between 11 and 15 seconds. However, GPT-4o produced more concise and direct justifications, with an output token (OT) count of approximately 499-562, compared to Llama 4’s more verbose outputs of 709-818 tokens. This suggests that while the smaller model offers lower latency, the larger model provides superior adjudication quality and more clinically-grounded reasoning.
To assess the framework’s human-centered design in line with CAI principles, we evaluated Motion2Meaning on four key metrics. For a consistent and robust evaluation, these metrics were computed and averaged across the 30 test cases from the previous experiment, with the results summarized in Table 4.
Flesch Reading Ease (FRE) Llama 4 produced substantially more accessible justifications, achieving an FRE score of 51.6, which falls within the typical range for clinical documentation (50-70 [51,3]). In contrast, GPT-4o’s score of 34.73 places its output in the “difficult” range, reflecting a clear prioritization • Stance (L): 0.660 ± 0.023 s (≈64.7% of stride, 9 cycles): The given stance time of approximately 64.7% of the stride is slightly higher but still within a relatively normal range, suggesting a slightly altered gait pattern but not drastically abnormal.
• Swing (L): 0.366 ± 0.020 s (≈35.8% of stride, 9 cycles): The provided swing time of approximately 35.8% is slightly lower than expected, which could indicate a mild gait asymmetry or alteration.
Considering these factors, the initial AI output predicting a “Healthy” status seems justified given the stride, stance, and swing times are relatively within normal ranges. The slight variations could be due to individual differences or minor gait asymmetries that do not drastically deviate from healthy patterns.
• The stride, stance, and swing times are within or very close to normal ranges. The slight variations could be due to individual differences or minor gait asymmetries that do not drastically deviate from healthy patterns.
• There are no significant indicators of Parkinson’s disease gait abnormalities, such as marked bradykinesia (slowness), rigidity, or postural instability, which are typically associated with stages 2, 2.5, or 3.
• Stride time of 1.020 ± 0.026 seconds is within the normal range for healthy individuals, suggesting a regular gait pattern without significant delays.
• Stance Phase: 64.7% of the stride time is typical for healthy gait, where the stance phase usually occupies about 60-65% of the gait cycle.
• Swing Phase: 35.8% of the stride time aligns with the expected range for healthy individuals, complementing the stance phase.
High confidence level of 0.821, low discrepancy percentage (0.8%) indicates minimal deviation from expected patterns. The continuous discrepancy regions are isolated and may not significantly impact the overall gait assessment.
The stride, stance, and swing times are all within normal ranges for a healthy gait cycle. The minimal discrepancy percentage and isolated discrepancy regions do not suggest any significant gait abnormalities.
There is no evidence of asymmetry or variability that would indicate a progression to Parkinson’s disease stages. of technical precision over linguistic simplicity. This highlights that readability is not an inherent model limitation but a highly tunable parameter. A simple directive within the prompt to target a specific readability level could readily align a model’s output with the practical demands of a clinical workflow, making this a key consideration for system design.
Flesch-Kincaid Grade Level (FKGL) Both models produced outputs with an FKGL appropriate for clinical documentation, which typically targets a Grade 8-12 standard [51,3]. Llama 4 scored an 8.5, equivalent to a mid-8th-grade reading level, while GPT-4o scored a 10.52, corresponding to an early high school complexity. These results confirm that both models can generate explanations that are linguistically accessible to their intended clinical audience, with Llama 4 producing slightly more straightforward text. This finding is crucial, as it demonstrates that the complexity of the underlying AI reasoning does not have to result in an equally complex explanation for the end-user.
Clinical Grounding (CG) GPT-4o demonstrated superior factual grounding with a CG of 0.75, slightly outperforming Llama 4 at 0.72. Both models reliably • Stance (L): 0.789 ± 0.093 s (≈65.1% of stride, 7 cycles): The stance phase of ≈65.1% of the stride is slightly higher than the typical value, which might indicate a mild gait disturbance.
• Swing (L): 0.427 ± 0.046 s (≈35.3% of stride, 8 cycles): The swing phase of ≈35.3% is slightly lower than expected, which could be related to the slightly prolonged stance phase. Given these observations:
• Stage 2.5 suggests a moderate level of disease progression, where patients have difficulty with walking and balance but are still able to live independently.
• The slightly prolonged stance phase and reduced swing phase could indicate a mild to moderate level of gait impairment.
• The relatively normal stride time suggests that overall gait cycle duration is preserved.
The adjustment is based on the observed gait abnormalities (slightly prolonged stance phase and reduced swing phase), these might not be sufficient to conclusively classify the patient at Stage 2.5. The relatively preserved stride time and the slight deviations in stance and swing phases suggest an early to moderate stage of gait impairment, aligning more closely with Stage 2.
• Stride Time: A stride time of approximately 1.211 seconds is within a typical range for adults, but the variability (±0.097 s) suggests some inconsistency, which is common in Parkinson’s disease, especially in mid-stages due to bradykinesia and gait disturbances
• Stance Time: A stance time of 65.1% is slightly higher than the typical 60% seen in healthy individuals, indicating a potential compensatory mechanism for balance issues. Increased stance time is often observed in Parkinson’s disease as patients may have difficulty with balance and stability, leading to prolonged ground contact.
• Swing Time: A swing time of 35.3% is slightly reduced compared to the typical 40% seen in healthy individuals. Reduced swing time can indicate difficulty in initiating movement and reduced foot clearance, both of which are characteristic of Parkinson’s disease. reproduced most quantitative details from the input data, a critical capability in clinical domains where numerical precision is paramount. However, neither model achieved perfect accuracy. The persistence of minor hallucinations, even in state-of-the-art models, is a crucial finding that directly validates the necessity of a contestable framework. It underscores that human expertise is not merely beneficial but indispensable for verifying AI-generated claims before they can inform clinical decisions.
Self-Correction Accuracy (SCA) Llama 4 demonstrated superior responsiveness to contestation, achieving a higher SCA score of 0.33 compared to GPT-4o’s 0.17. This suggests the smaller model is more adaptive and willing to revise its initial assessment in light of contradictory evidence. In contrast, GPT-4o’s lower score reflects a more conservative, risk-averse behavior, where it tends to default to the baseline model’s prediction. This finding reveals a crucial trade-off: while larger models may offer greater factual grounding, smaller models might be more amenable to the corrective feedback that is central to a truly collaborative human-AI system.
Our results indicate that Llama 4 produced more readable and adaptive explanations, whereas GPT-4o demonstrated superior factual grounding at the cost of higher linguistic complexity. This reveals a critical design trade-off between factual veracity and adaptive reasoning. The selection of an LLM is therefore not a simple technical optimization but a decision that fundamentally shapes the nature of the human-AI partnership, balancing the need for a reliable adjudicator against that of a collaborative and correctable partner.
Our work demonstrates the feasibility of Motion2Meaning, a framework that successfully integrates AI-powered gait analysis with a contestable, human-inthe-loop interface. The findings confirm that it is possible to build systems that provide objective insights into motor symptoms while preserving essential clinical oversight through a structured and auditable workflow. We structure our discussion around two key themes. First, we reflect on the potential of AIpowered wearable gait analysis to transform PD care, considering our predictive model’s performance and limitations. Second, we analyze the challenges and future directions for developing truly human-centered CAI, drawing specific insights from the performance of our XMED safeguard and LLM-based interaction components.
Our results, showing that a 1D-CNN can effectively classify disease severity from raw gait signals, reinforce the potential of wearable sensors to shift patient assessment from episodic clinical snapshots to continuous, longitudinal monitoring. This objective data stream offers a powerful complement to subjective tools like the UPDRS, enabling clinicians to more precisely track therapy response, detect subtle motor fluctuations, and quantify changes in fall risk. The ultimate promise of this technology is a move toward more personalized and proactive treatment adjustments that can tangibly improve patients’ quality of life.
However, a purely gait-focused approach has inherent limitations. The nuances of intermediate disease stages and the multi-system nature of PD, which includes significant non-motor symptoms like cognitive impairment and sleep disturbances, underscore that gait is only one piece of a complex clinical picture. Therefore, the true value of this technology lies in augmenting, not replacing, holistic clinical judgment. The critical next step is to move beyond a unimodal biomarker toward a comprehensive digital phenotype of PD. Future work should focus on multi-modal fusion, integrating gait data with other streams like speech analysis and sleep tracking. This approach is essential not only for improving predictive accuracy but for capturing the true syndromic nature of the disease, leading to more robust and clinically relevant AI models.
The fallibility of our predictive model, despite its reasonable performance, underscores the critical need for robust human-in-the-loop systems. Our work addresses this by creating a multi-layered verification framework where the XMED module acts as an automated safeguard and the LLM serves as an interactive adjudicator. This design directly confronts the fundamental challenge of balancing automation’s efficiency with the necessity of human oversight. However, our findings also illuminate several key challenges that must be addressed to advance the development of truly effective and collaborative CAI.
Technical and Methodological Limitations Our evaluation confirms that explanation discrepancies can effectively signal prediction errors, validating XMED’s potential as an automated safeguard. The scope of this validation, however, has two key considerations. First, the XMED flagging mechanism relied on an empirically derived discrepancy threshold. While effective for this study, its optimal calibration for broader clinical use is a natural next step for future work. Second, our framework was developed and validated exclusively within the context of PD, which served as a motivating use case. Its applicability and potential modifications for other diagnostic domains remain an important area for further exploration.
Furthermore, our experiments with LLMs highlight an interesting performance trade-off between the more adaptive reasoning of Llama 4 and the more factually grounded but conservative style of GPT-4o. This suggests that the selection of a model for adjudication involves balancing different priorities. A crucial open question, therefore, is whether this trade-off is inherent to LLM-based adjudication or is an artifact of using general-purpose models. The next logical step is to systematically evaluate models specifically fine-tuned on medical corpora, such as the Med-PaLM [46,47] and BioMistral [19] families, and to explore the capabilities of next-generation generalist models like GPT-5 [50], to determine if they can resolve the tension between adaptability and reliability. The modular design of our framework is a key strength in this regard, as it readily allows for the substitution of the predictive model, the LLM adjudicator, or the underlying dataset. This flexibility ensures that the core principles of our contestable system can be adapted and refined as new models and new clinical use cases emerge.
A primary challenge arising from our study is the need for a comprehensive clinical evaluation. While our technical validation provides encouraging proof-of-concept results, the true measure of our framework’s success lies in its real-world utility. This necessitates a formal clinician-in-the-loop pilot study to move beyond automated metrics and assess the system’s impact on actual clinical practice. Such a study would involve close collaboration with neurologists to evaluate the correctness, clarity, and actionability of the LLM’s outputs and to measure key workflow metrics like review time and contest rates. Gathering this contextual, human-centered evidence through detailed case studies is the essential next step for responsibly translating this research prototype into a validated clinical tool.
Future Direction on Evaluation Metrics A truly human-centered approach requires a paradigm shift in evaluation. This involves conducting formal pilot studies with expert clinicians to move beyond accuracy to a suite of utility metrics. These can be divided into automated assessments of the AI’s output and observational measures of user interaction. For instance, an automated metric like Clinical Terminology Grounding (CTG) could assess if an explanation is grounded in professional language by calculating the percentage of sentences containing terms from a predefined clinical lexicon. A high score would indicate reasoning more plausible to an expert. Observational metrics could quantify interaction efficiency through measures like Time to Decision (TTD), the duration until a user validates or contests a finding, and Interaction Length (IL), the number of conversational turns needed to reach that decision. Beyond these, our evaluation could be extended by adapting established metrics of user reliance, such as the Relative AI Reliance (RAIR), Relative Self-Reliance (RSR), and Appropriateness of Reliance (AoR) proposed in [44], as well as the broader range of measures collected in [22,14].
This work demonstrates that Motion2Meaning unites SOTA AI gait analysis with a contestable, human-centered framework to deliver objective, accountable, and clinically viable interpretations of Parkinsonian motor symptoms. By combining accurate 1D-CNN classification with the XMED safeguard for uncertainty detection and the LLM-driven “contest and justify” workflow, the system ensures that clinical expertise remains central to decision making. Beyond advancing PD care, our results highlight a broader design principle: high-stakes medical AI must not only explain but also enable contestation, creating systems that are transparent, auditable, and aligned with regulatory requirements. Looking forward, integrating multimodal data, expanding to diverse populations, and tailoring domain-specific LLMs will further strengthen this approach. As global frameworks increasingly mandate explainability and contestability, Motion2Meaning provides a concrete step toward trustworthy AI that augments rather than replaces human judgment, setting a foundation for safer and more responsible deployment of AI in healthcare.
-Continuous high-discrepancy regions: {[region_1], [region_2],…,[region_n]}. *Note that the numerical input values (in green) have been pre-calculated by the baseline model and XMED.
This content is AI-processed based on open access ArXiv data.