전이 가능한 초구 최적화로 재구성한 언어 모델 스케일링
본 논문은 가중치를 고정된 Frobenius‑노름 초구에 제한하는 HyperP 프레임워크를 제안한다. Muon 옵티마이저와 결합해 학습률 하나만 조정하면 모델 폭·깊이·토큰 수·MoE 입출력 규모 전반에 걸쳐 최적의 학습률을 전이시킬 수 있다. 가중치 감쇠는 1차 근사에서 무효이며, 데이터 스케일링에 대한 “매직 지수” 0.32가 재현된다. 실험은 대규모(6×10²¹ FLOPs) 학습에서 1.58배·3.38배의 Compute Efficiency…
저자: Liliang Ren, Yang Liu, Yelong Shen
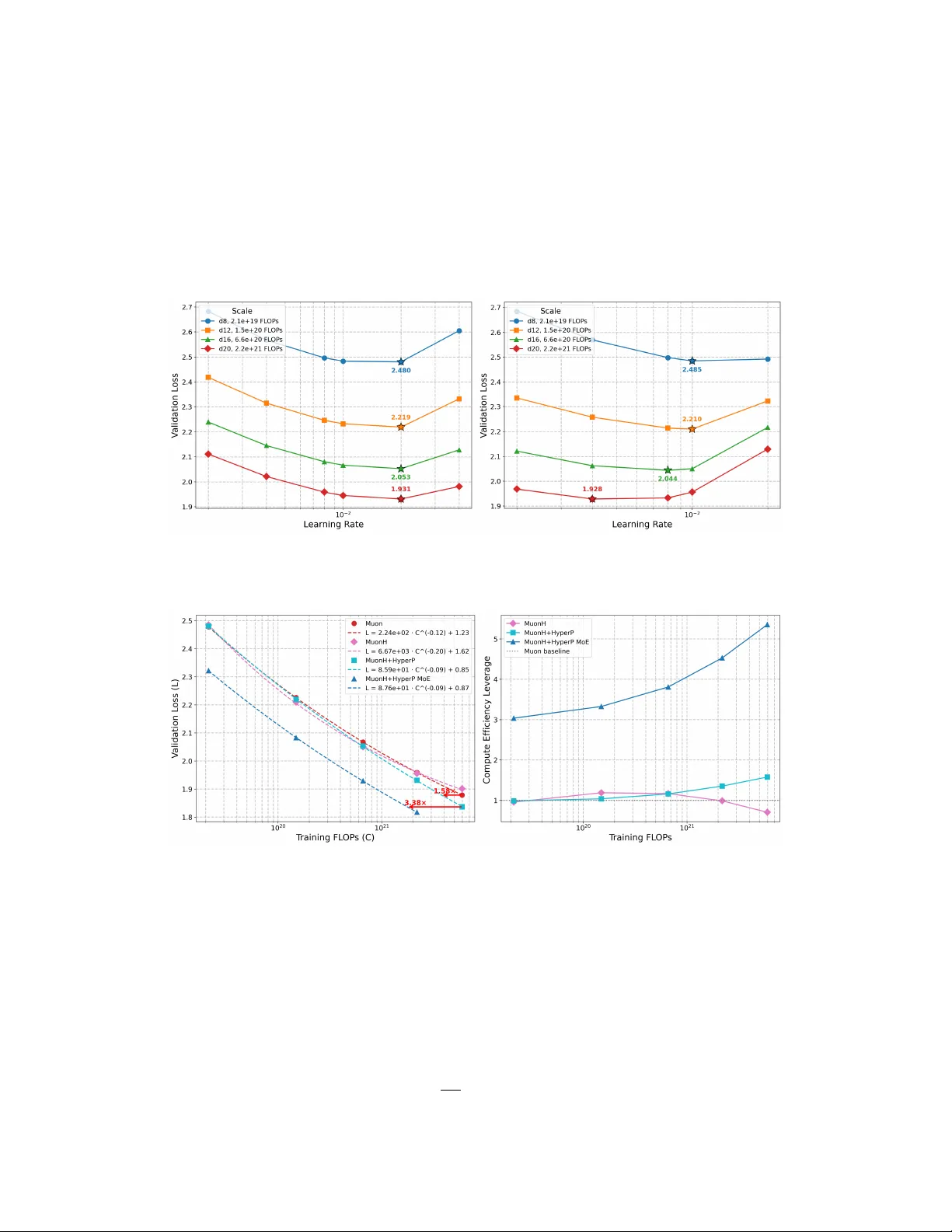
본 논문은 대규모 언어 모델(Large Language Model, LLM) 스케일링에서 기존의 하이퍼파라미터 전이 방법이 첫 번째 차수 옵티마이저(예: AdamW)와 파라미터 초기화에 의존해 규모 확대 시 불안정성을 구조적으로 방지하지 못한다는 문제점을 지적한다. 최근 제안된 초구 최적화(Hypersphere Optimization)는 가중치를 고정된 노름 초구에 투영함으로써 출력 로그잇을 자연스럽게 제한하고, 가중치 감쇠와 같은 부수적인 정규화 기법을 제거할 수 있다.
논문은 Muon 옵티마이저와 Frobenius 노름을 결합한 MuonH를 기반으로 HyperP(Hypersphere Parameterization)라는 프레임워크를 설계한다. HyperP는 다음 네 가지 전이 법칙을 제시한다.
1. **폭(Width) 전이**: Frobenius 초구 제약 하에서 가중치 행렬 W는 ∥W∥_F = C·√d_out 형태를 유지한다. 이때 입력 X에 대한 출력 RMS는 폭에 무관하게 C·RMS(X) 로 일정하게 유지되므로, 기존 µP에서 요구되는 1/√w 스케일링이 필요 없으며, 학습률을 폭에 따라 조정할 필요가 없다(정리 2).
2. **깊이(Depth) 전이**: 잔차 네트워크에 대해 초구 최적화가 가중치와 업데이트를 모두 정규화하면, 전체 함수 공간 변동이 O(L·α_L·η) 로 제한된다. α_L을 L^{‑1/2} 로 잡으면 학습률 η는 O(L^{‑1/2}) 로 스케일링해야 함을 보이며, 이는 기존 Depth‑µP와 동일한 요구조건이다(정리 3). 따라서 MuonH 자체가 깊이 전이를 자동으로 제공한다는 주장은 부정된다.
3. **데이터(Data) 전이**: 학습 토큰 수 T와 최적 학습률 η* 사이에 η* ≈ 24.27·T^{‑0.32} 라는 파워‑법칙이 실험적으로 발견되었다. 이 “매직 지수” 0.32는 AdamW 기반 연구와 일치해, 옵티마이저 종류와 무관하게 데이터 스케일링에 보편적인 법칙이 존재함을 시사한다.
4. **MoE Granularity 전이**: 초구 제약에서 파생된 SqrtGate 라우터는 입력을 √k 로 스케일링해 출력 RMS를 일정하게 유지한다. 이는 라우터 Z‑값 피크를 기존 라우터 대비 5배 감소시키고, 큰 로드밸런싱 가중치 β를 사용해도 전문가 간 불균형이 발생하지 않게 만든다.
또한, 논문은 가중치 감쇠가 1차 근사에서 완전히 무효임을 정리 1·코롤러리 1.1 로 증명한다. 따라서 HyperP는 학습률 η 하나만을 탐색하면 되며, 하이퍼파라미터 탐색 공간이 크게 축소된다.
안정성 검증에서는 Z‑값, 출력 RMS, 어텐션·MoE 활성화 이상치 비율 등 6가지 지표를 모니터링했다. 모델 규모를 208M 파라미터에서 13.3B 파라미터, FLOPs를 10¹⁰에서 6×10²¹까지 확대했을 때, 모든 지표가 비증가하거나 감소하는 “전이 가능한 안정성”을 확인했다. 이는 기존에 z‑loss, 가중치 감쇠 스케줄링 등 ad‑hoc 패치를 적용해야 했던 상황과 대조된다.
실험 결과는 다음과 같다. 가장 작은 스케일(208M 파라미터)에서 최적 학습률을 한 번 튜닝한 뒤, 동일한 η를 모든 규모에 그대로 적용했다. 6×10²¹ FLOPs 규모의 Dense 모델에서는 기존 Muon 기반 µP++ 대비 1.58배, MoE 모델(S=8, k=8)에서는 3.38배의 Compute Efficiency Leveraging(CEL)을 달성했다. 규모가 커질수록 CEL 향상 비율은 선형적으로 증가한다는 점에서, Frontier Compute 환경에서도 큰 이득을 기대할 수 있다.
마지막으로, HyperP를 이용해 Dense(QK‑Norm, Gated Attention)와 MoE(SqrtGate, Shared Expert) 아키텍처를 동일한 최적 조건에서 비교했다. 결과는 SqrtGate와 Gated Attention이 초기 규모에서는 성능 이점을 보였지만, FLOPs가 크게 늘어날수록 그 차이는 감소한다. 대신 두 기법 모두 로그잇 폭발을 억제하고 Z‑값을 안정화하는 데 크게 기여한다.
요약하면, HyperP는 (1) 가중치 감쇠 제거, (2) 폭·깊이·데이터·MoE 전이 법칙 제공, (3) 구조적 로그잇 제한을 통한 안정성 확보, (4) SqrtGate 라우터를 통한 MoE 로드밸런싱 개선이라는 네 가지 핵심 기여를 통해 대규모 LLM 스케일링을 보다 효율적이고 안정적으로 만든다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기