Rethinking Language Model Scaling under Transferable Hypersphere Optimization
Scaling laws for large language models depend critically on the optimizer and parameterization. Existing hyperparameter transfer laws are mainly developed for first-order optimizers, and they do not structurally prevent training instability at scale.…
Authors: Liliang Ren, Yang Liu, Yelong Shen
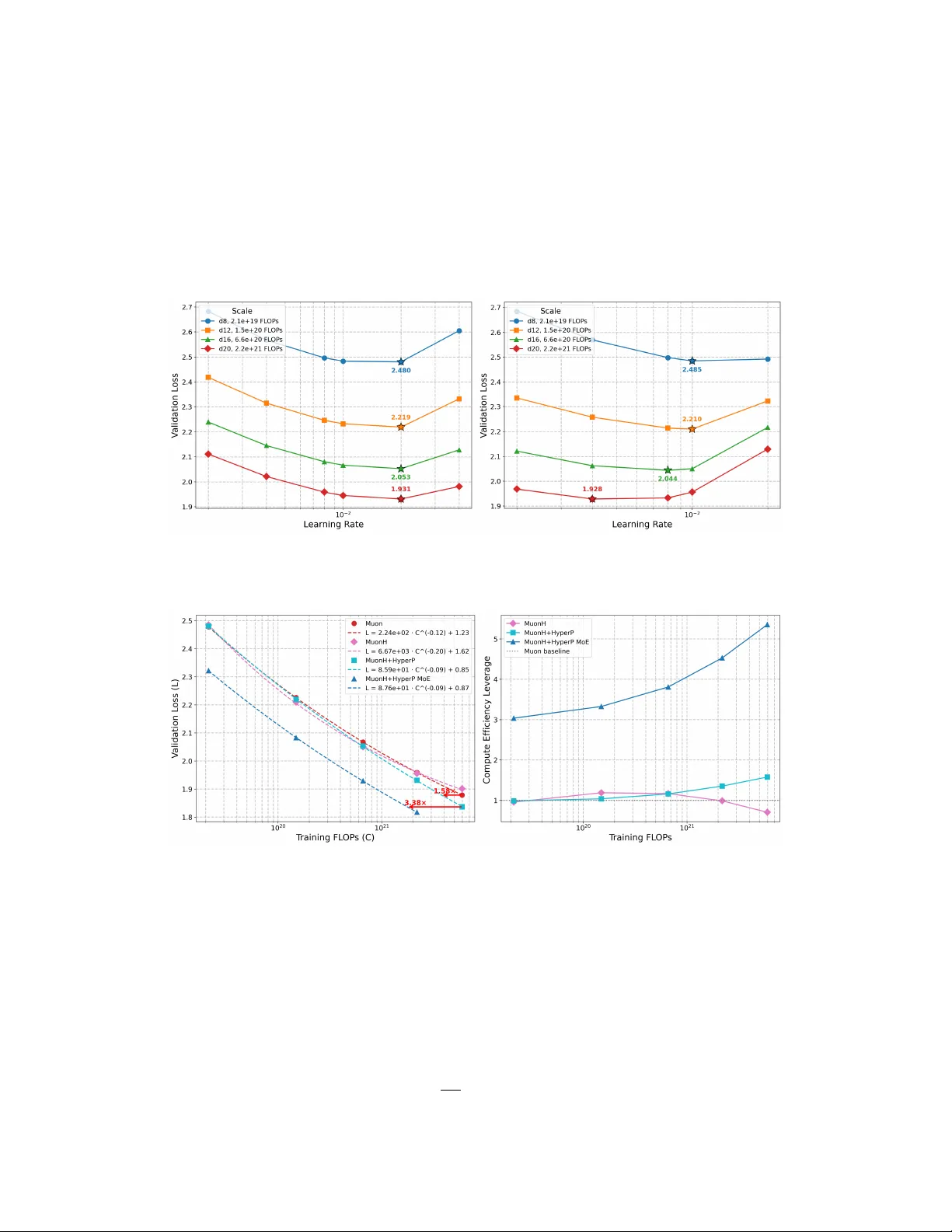
Rethinking Language Model Scaling under T ransferable Hyperspher e Optimization Liliang Ren 1 Y ang Liu 1 Y elong Shen 1 W eizhu Chen 1 1 Microsoft renll1402@gmail.com wzchen@microsoft.com Abstract Scaling laws for lar ge language models depend critically on the optimizer and parameterization. Existing hyperparameter transfer laws are mainly de veloped for first-order optimizers, and they do not structurally pre vent training instability at scale. Recent hypersphere optimization methods constrain weight matrices to a fixed-norm hypersphere, of fering a promising alternativ e for more stable scaling. W e introduce HyperP (Hypersphere Parameterization), the first frame work for transferring optimal learning rates across model width, depth, training tokens, and Mixture-of-Experts (MoE) granularity under the Frobenius-sphere constraint with the Muon optimizer . W e prove that weight decay is a first-order no-op on the Frobenius sphere, show that Depth- µ P remains necessary , and find that the optimal learning rate follo ws the same data-scaling po wer law with the “magic exponent” 0.32 previously observed for AdamW . A single base learning rate tuned at the smallest scale transfers across all compute b udgets under HyperP , yielding 1 . 58 × compute ef ficiency ov er a strong Muon baseline at 6 × 10 21 FLOPs. Moreover , Hy- perP deliv ers transferable stability: all monitored instability indicators, including Z -v alues, output RMS, and acti v ation outliers, remain bounded and non-increasing under training FLOPs scaling. W e also propose SqrtGate, an MoE gating mecha- nism deriv ed from the hypersphere constraint that preserves output RMS across MoE granularities for improv ed granularity scaling, and sho w that hypersphere optimization enables substantially lar ger auxiliary load-balancing weights, yielding both strong performance and good e xpert balance. W e release our training codebase at https://github.com/microsoft/ArchScale . 1 Introduction Neural scaling laws [ KMH + 20 , HBM + 22 , T ea25b ] are central to the compute-efficient dev elop- ment of Large Language Models (LLMs) [ R WC + 19 , BMR + 20 , Ope23 , Goo25 , D A24b , T ea25a , YL Y + 25 ]. In practice, architectural designs and data recipes are explored at small scales for cost- savings, hoping that the improvements will persist when scaled up to prohibiti v ely e xpensiv e compute budgets. Ho wev er , identifying the true scaling beha vior requires each model along the curve to be trained with near-optimal hyperparameters for its o wn scale. Even with well-tuned hyperparameters, scaling up training FLOPs routinely triggers logit explosion, acti vation outliers, and loss spikes [ ZBK + 22 , DLBZ22 , CND + 23 , QWZ + 25 , QHW + 26 ] that push training off the optimal trajectory or ev en lead to training failures [ ZRG + 22 , RCX + 25 ]. Existing hyperparameter transfer frame works [ YHB + 22 , YYZH23 , BBC + 25 , LZH + 25 , CQP + 25 ] primarily focus on transferring optimal Learn- ing Rate (LR), weight decay , and batch size across width and depth, while largely overlooking how learning rate should scale with training tokens for transfer across training FLOPs. Moreover , they do not provide structural guarantees on training stability at larger scales. In practice, miti- gations such as z-loss regularization [ ZBK + 22 ] and careful weight decay scheduling [ Def25 ] are Preprint. applied as ad hoc patches rather than principled solutions. Recent work on hypersphere optimization [ Ber25 , WDL + 25 , XL T + 26 ] offers a fundamentally different approach. By constraining weight matrices to a fixed-norm sphere, hypersphere optimization provides structural stability guarantees: the weight-norm constraint naturally bounds output logit magnitudes for each linear projection. It also has the potential to eliminate weight decay , a notorious hyperparameter whose optimal value depends intricately on learning rate, training duration [ W A24 , BDG + 25 ], and model width [ CQP + 25 ]. In this work, we derive the first learning rate transfer laws across training FLOPs for hypersphere optimization, cov ering width, depth, training duration, and MoE granularity , under a typical second- order hypersphere optimizer MuonH [ WDL + 25 ]. W e summarize our transfer laws as HyperP (Hypersphere Parameterization), a framework under which a single base learning rate tuned at the smallest scale transfers optimally to all compute budgets. Our theoretical and empirical results rev eal that hypersphere optimization, when equipped with proper transfer laws, achie ves not only optimal scaling efficienc y but also transferable stability : the same hyperparameters that work at small scale produce equally or more stable training dynamics at large scale. W ith these results, fair comparisons of architectural scaling become possible: ev ery model at ev ery scale is trained at its transferred optimal learning rates, so the resulting scaling curves reflect each architecture’ s near-optimal performance. Our contributions are as follo ws: • First transfer laws across FLOPs f or h ypersphere optimization. W e derive HyperP , which achiev es optimal LR transfer across training FLOPs, spanning width, depth, training tokens, and MoE granularity . W e prove that weight decay is a first-order no-op under Frobenius-sphere optimization, and empirically show that removing weight decay does not harm model quality . W e also deriv e that Depth- µ P [ YYZH23 ] is still required, disproving the claim that MuonH is inherently depth-transferable [ WDL + 25 ], and discover the “magic exponent” 0.32 for data scaling, matching the pre vious result on AdamW [ BBC + 25 ] and suggesting uni versality across optimizers. • T ransferable stability . Empirically , we show that HyperP yields stability transfer : all six monitored instability indicators ( Z -values, output RMS, activ ation outlier percentages for both attention and MoE sub-layers) are bounded and non-increasing as we scale training FLOPs for MoE models from 913M to 13.3B total parameters. • Robust MoE scaling and load balancing . W e deriv e SqrtGate, a square-root gating mechanism that preserves output RMS across MoE granularities, reducing router Z -value peaks by 5 × compared to standard gating. HyperP’ s optimal LR transfers robustly across MoE sparsity ( S ∈ { 1 , . . . , 32 } ) and granularity ( k ∈ { 2 , . . . , 64 } ). It also allows for much larger auxiliary load balancing weights, achieving the best v alidation loss and e xpert balance simultaneously , in contrast to prior findings that a large load balancing weight hurts model quality [ WGZ + 24 ]. • Scalable compute efficiency leverage. A single base LR tuned at the smallest scale with 208M activ e parameters transfers effecti vely to all compute b udgets explored. At the largest 6 × 10 21 FLOPs, HyperP achie ves 1 . 58 × Compute Ef ficiency Le verage (CEL) [ KMH + 20 , T ea25b ] ov er a strong Muon baseline with µ P++ and weight decay scaling for dense models, and our MoE model with S = 8 , k = 8 further achiev es 3 . 38 × CEL ov er the dense models. The advantage of HyperP ov er the baseline grows monotonically with scale, implying ev en larger gains at frontier compute. • Architectur e comparison under optimal scaling. W ith HyperP , we systematically examine dense (QK-Norm, Gated Attention) and MoE (SqrtGate, shared expert) architectures at their optimal performance, re vealing that while the performance gains of SqrtGate and Gated Attention shrink as the training FLOPs increase, they pro vide significant stability gains that can remove the RMS spikes and control the exploding Z-v alues. 2 Background Hypersphere optimization. Hypersphere optimization constrains weight matrices to lie on a unit sphere under a chosen matrix norm. After each gradient update, the weight matrix W is re-projected as follows, W ← C W − η G ∥ W − η G ∥ , (1) where η is learning rate, C is a constant, G denotes the weight update and ∥ · ∥ is the chosen matrix norm. Sev eral choices of the matrix norm have been proposed recently: MuonH [ WDL + 25 ] uses 2 the Frobenius norm with the Muon optimizer [ JJB + 24 ]; Both MuonSphere [ XL T + 26 ] and SSO [ XL T + 26 ] use the spectral norm, while SSO further applies the steepest descent on the spectral sphere. Previous w orks hav e explored column- and row-wise weight normalization [ SK16 , KAL + 23 , FDD + 25 ], while in this work we focus primarily on matrix-wise normalization for theoretical simplicity . MuonH optimizer . MuonH (Muon-Hyperball) [ WDL + 25 ] instantiates hypersphere optimization with the Muon optimizer [ JJB + 24 ] and Frobenius norm, normalizing both the weight and the update: b G = c G G ∥ G ∥ F , W + = c W W − η b G ∥ W − η b G ∥ F , (2) where c W = ∥ W 0 ∥ F is the initial weight norm, c G = c W , and G is the standard Muon update. MuonH is applied to each hidden weight matrix, while AdamW [ LH18 ] with the same weight and up- date normalization schemes (denoted as AdamH) is used for the weight matrix of the language-model head, and the remaining vector parameters and embeddings are optimized with the original AdamW . The update normalization further ensures that the relative update magnitude ∥ ∆ W ∥ F / ∥ W ∥ F is constant for a gi ven layer , enabling the same learning-rate scale to be used for both MuonH and AdamH. 3 Scaling Hypersphere Optimization W e first moti vate our choice of the Frobenius hypersphere by sho wing that it can eliminate the need for weight decay under the first-order approximation. W e then deri ve the hyperparameter transfer laws for width and depth scaling by examining the theoretical implications of hypersphere optimization. The learning rate transfer law is further established for the data scaling scenario through empirical studies. W e present our Hypersphere Parameterization, HyperP , for training FLOPs scaling by summarizing our transfer laws o ver width, depth, and data scaling in T able 1 . Finally , we illustrate the theoretical stability benefits of hypersphere optimization in Section 3.6 and propose our SqrtGate mechanism for the granularity scaling of Mixture-of-Experts (MoE) in Section 3.7 . 3.1 Elimination of W eight Decay Among v arious choices of norms in hypersphere optimization, the Frobenius norm admits a simple geometric interpretation: after projection back to a fixed Frobenius sphere, only the tangent component of an update surviv es to first order . Theorem 1 (First-order form of Frobenius-sphere updates) . Let W ∈ R d out × d in satisfy ∥ W ∥ F = c W , and define f W = W + ∆ , W + = c W f W ∥ f W ∥ F . (3) Then, for sufficiently small ∥ ∆ ∥ F , W + − W = Π T (∆) + O ( ∥ ∆ ∥ 2 F ) , (4) wher e Π T (∆) = ∆ − ⟨ ∆ ,W ⟩ F ∥ W ∥ 2 F W is the tangent-space pr ojection at W . A direct corollary is that radial shrinkage is remov ed to first order . Corollary 1.1 (W eight decay is a first-order no-op) . If ∆ = − η G − η λW, then W + − W = − η Π T ( G ) + O ( η 2 ) . Hence, the weight decay term has no first-or der effect under F r obenius r enor- malization. The detailed proof is included in Appendix B . Therefore, in this work, we only study the MuonH optimizer , which is based on the Frobenius norm, and we leave the formal uniqueness characterization as a future work. Our theorem eliminates weight decay as a hyperparameter entirely , reducing the search space from the joint ( η , λ ) plane to a single dimension η . In contrast, standard optimizers (e.g. AdamW , Muon) require careful co-tuning of the learning rate and weight decay , and the optimal weight decay interacts with the learning rate, training duration [ W A24 , BDG + 25 ], and e ven model width [ CQP + 25 ], which further complicates hyperparameter transfer laws. 3 3.2 Width Scaling Our deriv ation of the width transfer laws is based on the following observ ation: For W ∈ R d out × d in , the spectral and Frobenius norms satisfy ∥ W ∥ 2 ≤ ∥ W ∥ F ≤ √ r ∥ W ∥ 2 , r := rank( W ) ≤ min( d in , d out ) . The upper bound is attained if and only if W has full rank and all its nonzero singular v alues are equal. When the update ∆ W is orthogonalized, as in Muon, the resulting dynamics tend to av oid highly anisotropic spectra and instead fav or a relatively flat singular-v alue profile. In that regime, ∥ W ∥ F / √ r becomes a good proxy of ∥ W ∥ 2 , which leads to the same width-transfer property as in µ P [ YHB + 22 ]. Theorem 2 (W idth transfer under Frobenius sphere) . Let Y = W X , W ∈ R d out × d in , and assume ∥ W ∥ rms = C / √ d in , equivalently ∥ W ∥ F = C √ d out , for a width-independent constant C = O (1) . Assume further that W is appr oximately isotropic on its input space, in the sense that its nonzer o singular values ar e sufficiently uniform. Equivalently , for typical inputs X , ∥ W X ∥ 2 ≈ ∥ W ∥ F p min( d in , d out ) ∥ X ∥ 2 . Since p d in / min( d in , d out ) = O (1) , then ∥ Y ∥ rms ≈ C ∥ X ∥ rms . The proof is included in Appendix A . Therefore, hypersphere optimization with ∥ W ∥ F = C √ d out preserves width transfer without e xplicit 1 /w learning rate scaling as in standard µ P . 3.3 Depth Scaling W e analyze how the learning rate and residual scaler depend on depth when optimization is performed on a Frobenius sphere. Consider a depth- L residual network x l +1 = x l + α L f l ( x l ; W l ) , l = 1 , . . . , L, (5) where α L denotes the depth-dependent residual scaler . Each matrix parameter is constrained to satisfy ∥ W l ∥ F = c W . W e first study the hypersphere optimization with only weight normalization as in Equation ( 1 ) and then consider the v ariant in which the raw update is normalized to have a fixed Frobenius norm as in Equation ( 2 ), where c W is not necessarily equal to c G . Theorem 3 (Depth scaling under Frobenius-sphere optimization) . Under r esidual networks, assume that local J acobians ar e O (1) under the chosen width parameterization, and that the update step size is sufficiently small for fir st-or der linearization to hold. 1. W eight renormalization under scale-dependent optimizers. If only the weights ar e renormal- ized as in ( 1 ) , and the layerwise update satisfies ∥ G l ∥ F = O ( α L ) , then the total first-or der function perturbation is O ( Lα 2 L η l ) . In particular , for the standar d depth-stabilizing scaling α L = L − 1 / 2 , a depth-independent learning rate η l = O (1) yields an O (1) function-space update. 2. Normalizing both weight and update. If the weight update is normalized so that ∥ U l ∥ F = c G , then the total first-or der function perturbation is O ( Lα L η l ) . Hence, the learning rate must scale as η l = O 1 Lα L (6) to maintain an O (1) function-space update. In particular , when α L = L − 1 / 2 , η l = O ( L − 1 / 2 ) . 3. P ost-norm Architecture. The same exponent holds for post-norm r esidual blocks x l +1 = La yerNorm( x l + α L f l ( x l ; W l )) , (7) since the standar d deviation of the input of LayerNorm [ BKH16 ] is O (1) with depth. 4 The proofs are included in Appendix C . Our theorem shows that the original forms of Depth- µ P [ YYZH23 ] for both scale-dependent and scale-in variant optimizers are preserved under hypersphere optimization, and the post-norm residual does not remov e the dependence on model depth for accumulated weight perturbations. Importantly , our result does not rely on any independence assumptions across layers. Under the small-step condition η ∥ G l ∥ F ≪ ∥ W l ∥ F , we use a first-order T aylor expansion to express the total perturbation as a sum of layerwise contributions and then apply the triangle inequality to obtain a deterministic worst-case bound. Our theorem shows that, contrary to the original claim of the authors in MuonH [ WDL + 25 ], the optimizer is not inherently transferable across model depth because they neglect the cumulati ve angular drift introduced by the summation of residual connections. W e further provide empirical verification of our theoretical result in Section 4.2 . 3.4 Data Scaling Since there is no clear theory on how the learning rate should scale with the training to- kens, we study the transfer law with empirical studies. W e fix model depth d =8 (208M parameters) and v ary training tokens from 10.4B to 166.4B, sweeping LR on a fine grid { 0 . 004 , 0 . 006 , 0 . 008 , 0 . 010 , 0 . 012 , 0 . 014 , 0 . 016 , 0 . 018 } with quadratic fitting in log( η ) space. The detailed setup is provided in be ginning of Section 4 . Figure 1: Left: Loss vs. LR at different token b udgets. Right: Fitted optimal LR vs. training tokens on log-log scale, sho wing a clean power -law relationship with e xponent 0 . 32 . The exact values are reported in T able 4 . As shown in Figure 1 , the optimal LR follo ws a clean power la w: η ∗ = 24 . 27 · T − 0 . 320 (8) where T is the total number of training tokens. W e also conduct leav e-one-out cross-validation, which giv es a mean absolute prediction error of only 1.50% for optimal LR. The exponent 0 . 32 is remarkably consistent with the finding of Bjorck et al. [ BBC + 25 ], who report the same exponent for AdamW on different architectures and datasets. This “magic exponent” may be a uni versal property of gradient-based optimization in neural networks, independent of the specific optimizer . W e leav e a more rigorous empirical verification and the theoretical analysis of this coincidence as intriguing future work. 3.5 Hypersphere Parametrization W e summarize the complete HyperP framework in T able 1 , contrasting it with µ P and µ P++ [ RCX + 25 ]. HyperP eliminates the weight decay entirely as in Section 3.1 , inherits native width transfer from the Frobenius-sphere constraint in Section 3.2 , applies the depth scaling derived in Section 3.3 , and incorporates the data scaling η ∝ T − 0 . 32 established in Section 3.4 . 5 T able 1: Differences between µ P , µ P++ [ RCX + 25 ] and HyperP under Muon-based optimizers [ JJB + 24 ]. LR mult. denotes the per-parameter multiplier applied on top of the global learning-rate ( η ), Init. std. means the standard deviation of the initialization, Res. mult. is the multiplier applied to the output of residual branches and WD denotes the weight decay . w is the model width, d means model depth and T is the training tokens. µ P and µ P++ applies Muon for matix-like parameters with adjustments of LR and WD follo wing [ CQP + 25 ] and AdamW for vector-lik e parameters, while HyperP adopts MuonH [ WDL + 25 ] for matrix-like and AdamH for vector -like parameters. Parameter Scheme LR mult. Init. std. Res. mult. W eight mult. WD Embedding/V ector µ P ∝ 1 ∝ 1 — ∝ 1 ∝ 1 µ P++ ∝ 1 / √ d ∝ 1 — ∝ 1 0 HyperP ∝ 1 / √ d ∝ 1 — ∝ 1 0 Unembedding µ P ∝ 1 ∝ 1 — ∝ 1 /w ∝ 1 µ P++ ∝ 1 / √ d ∝ 1 — ∝ 1 /w 0 HyperP ∝ 1 / √ d ∝ 1 — ∝ 1 0 Hidden W eights µ P ∝ p d out /d in ∝ 1 / √ d in 1 ∝ 1 ∝ 1 /w µ P++ ∝ p d out / ( d in d ) ∝ 1 / √ d in 1 / √ 2 d ∝ 1 ∝ 1 /w HyperP ∝ 1 / ( T 0 . 32 √ d ) ∝ 1 / √ d in 1 / √ 2 d ∝ 1 0 3.6 Bounded Logit Magnitudes In standard training, the weight norms can gro w unbounded due to the translation-in variance property of Softmax, causing attention, router or LM head logits z to explode. The z-loss penalty λ z log 2 Z (where Z = P i exp( z i ) ) is a common practice [ ZBK + 22 ] introduced to constrain the growth of the log-sum-exponential of the logits. A key practical benefit of hypersphere optimization is that it naturally bounds the logit magnitudes in both attention and MoE routing, alle viating the need for z-loss regularization. W e state the proposition below and pro vide empirical verification in Section 5.1 . Proposition 4 (Bounded Logits under Hypersphere Constraint) . F or any weight matrix W with ∥ W ∥ F = C and input x with ∥ x ∥ rms = O (1) : ∥ W x ∥ 2 ≤ ∥ W ∥ F ∥ x ∥ 2 = C ∥ x ∥ 2 = C ∥ x ∥ rms p d in . (9) The per-element logit magnitude is bounded as | [ W x ] j | ≤ C ∥ x ∥ 2 , and the RMS of the logit vector satisfies: ∥ W x ∥ rms ≤ C r d in d out ∥ x ∥ rms . (10) The pr oposition similarly applies to the spectral spher e scenario where ∥ W ∥ 2 = C . 3.7 MoE Granularity Scaling In a Mixture-of-Experts (MoE) [ SMM + 17 ] layer, the output y is formed by combining the T op- k routed experts selected from a larger expert pool. Let k denote the number of acti ve routed experts (the granularity) and let S denote the sparsity ratio, so the layer contains k S routed experts in total. Formally , y = k X i =1 g i E i ( x ) + E shared ( x ) , k X i =1 g i = 1 , (11) where g i are the routing weights ov er the selected k experts, following the design of [ SMM + 17 , Ope25 ], and E shared is an optional shared expert [ D A24a ]. Proposition 5 (Classical gating is k -dependent) . Let y route = P k i =1 g i E i ( x ) . Assume the active expert outputs satisfy ∥ E i ( x ) ∥ rms = r for all i, and ar e appr oximately pairwise uncorr elated: ⟨ E i ( x ) , E j ( x ) ⟩ ≈ 0 for i = j. Then ∥ y route ∥ rms ≈ r v u u t k X i =1 g 2 i . (12) 6 In particular , if the r outing weights ar e near-uniform on the selected experts, i.e . g i ≈ 1 /k , then ∥ y route ∥ rms ≈ r √ k . (13) By contr ast, ∥ y route ∥ rms ≈ r is r ecover ed only in the de generate case wher e r outing is nearly one-hot, i.e. one g i ≈ 1 and the others ar e close to zer o. This shows that classical softmax gating preserves RMS only in the worst-case collapsed-routing regime. In the more typical case where multiple selected experts contrib ute non-trivially , the routed signal shrinks with k . In our setting, hypersphere optimization makes the equal-RMS assumption natural by explicitly controlling the output scale of each expert with weight normalization. Moreover , Muon optimizer can indirectly reduce co-adaptation across experts by reducing anisotropy in each expert’ s matrix updates, which makes the pairwise-uncorrelated approximation more realistic. This motiv ates us to analyze the routed branch under the equal-RMS, weak-correlation regime rather than under the worst-case scenario. W e propose to replace g i with √ g i , and denote our approach as SqrtGate (Square-root Gate). Proposition 6 (SqrtGate is approximately k -in variant) . Define the r outed branch by y ′ route = P k i =1 √ g i E i ( x ) , P k i =1 g i = 1 . Under the same assumptions as in Pr oposition 5 , ∥ y ′ route ∥ rms ≈ r v u u t k X i =1 ( √ g i ) 2 = r . (14) Hence the r outed-branch RMS is appr oximately invariant to the gr anularity k . W e can see that classical gating is RMS-preserving only when T op- k routing effecti vely collapses to T op-1, whereas SqrtGate is RMS-preserving for any gating distrib utions in the equal-RMS, weak- correlation regime induced by hypersphere optimization. When the shared expert is presented, we also multiply 1 / √ 2 to the final output y to preserve the o verall output RMS after summation. 4 Experiments & Results Architectur e. Throughout this work, we use the Transformer-Next architecture family , inspired by the attention module design in Qwen3-Next [ Qwe25 ]: dense Transformers with GQA (4 KV heads) [ AL TdJ + 23 ], head dimension 128, aspect ratio α = 128 ( i.e. model width w = 128 d ), QK-Norm [ DDM + 23 ], and headwise gated attention [ QWZ + 25 ]. The number of attention heads is set to n head = 2 d , where d is the model depth, so that n head is always a multiple of 8 during scaling. W e use SwiGLU [ Sha20 ] with 4 w intermediate size [ RCX + 25 , Ope25 ] for MLP , and apply Pre-Norm [ XYH + 20 ] for residual connections. The MoE module follows the same design as in Section 3.7 with SqrtGate and a shared expert, where the Softmax operator is after T op-k selection [ Ope25 ], and we denote this architecture as Transformer-Next-MoE . W e sweep depths d ∈ { 8 , 12 , 16 , 20 , 24 } , corresponding to 208M–3.8B parameters for the dense model and 913M–22.9B total parameters for MoE models with a sparsity of 8. T o match the activ e parameters to the dense model, we (1) choose T op-( k − 1 ) experts from an e xpert pool of k S − 1 experts and ha ve 1 shared expert alw ays activ ated, and (2) shrink the intermediate dimension of the experts as we scale up the granularity . T raining setup. By def ault, all models are trained on the SlimPajama dataset [ SAKM + 23 ] with a context length of 4K and a batch size of 2M tokens. The learning rate schedule uses a linear decay to 10% of peak without warm-up, following [ JBR + 24 ]. A momentum of 0.95 is adopted for both Muon and MuonH. For FLOPs scaling, the number of training tokens is scaled proportionally to number of parameters according to Chinchilla Law [ HBM + 22 ] with a measure of T okens Per Parameter (TPP) = T / N , where T is the total training tokens and N is the parameter count. The PyT orch [ PGM + 19 ] default initialization from Kaiming uniform distribution [ HZRS16 ] is adopted. The independent weight decay [ WLX + 24 ] is applied for the Muon optimizer . Scaling comparison and compute efficiency leverage. W e follow the Chinchilla la w [ HBM + 22 ] for fine-grained FLOPs computation, which accounts for embedding and language-model head FLOPs, as well as an accurate self-attention FLOPs calculation. T o compare scaling beha viors, we 7 follo w [ KMH + 20 , T ea25b ] to fit each method’ s final validation loss as a po wer la w in training FLOPs, C , then define the compute efficiency lev erage ρ = C base /C ∗ , where C ∗ is the method’ s actual FLOPs and C base is the FLOPs the baseline would need to reach the same loss L ∗ of the method according to its fitted scaling law; ρ > 1 indicates better compute ef ficiency than the baseline. 4.1 Empirical Optimality of MuonH A natural concern of hypersphere optimization is whether remo ving weight decay trades of f perfor- mance. W e compare MuonH against standard Muon at d =8 dense model with 10.4B tokens. For Muon, we jointly sweep learning rate η ∈ { 4 × 10 − 3 , 8 × 10 − 3 , 10 − 2 , 2 × 10 − 2 , 4 × 10 − 2 } , and weight decay λ ∈ { 4 × 10 − 4 , 8 × 10 − 4 , 10 − 3 , 2 × 10 − 3 , 4 × 10 − 3 } ; for MuonH, weight decay is set to 0. Figure 2: V alidation loss vs. learning rate for Muon (sweeping weight decay λ ) and MuonH ( λ =0 ). MuonH achiev es comparable optimality with a simpler hyperparameter space. As shown in Figure 2 and T able 2 , MuonH achie ves a slightly better validation loss while entirely removing weight decay as a hyperparameter . The optimal LR for MuonH is ∼ 1 . 4 × smaller than for Muon. Muon’ s performance is sensitive to weight decay: the best λ = 10 − 3 giv es a loss of 2.479, while λ = 4 × 10 − 3 giv es 2.500 ( +0 . 021 nats). These empirical results mean that MuonH does not trade-off quality for a simpler hyperparameter space and support our theory on the weight decay elimination effect of Frobenius-sphere optimization in Theorem 1 . T able 2: Fitted optimal learning rate η ∗ and validation loss between MuonH and Muon. MuonH matches Muon while eliminating weight decay . Method Fitted η ∗ Best V al Loss W eight Decay Muon (best λ =10 − 3 ) 0.0222 2.479 10 − 3 MuonH ( λ =0 ) 0.0155 2.475 0 4.2 Parameter Scaling W e empirically verify the depth scaling predictions of Section 3.3 by co-scaling width and depth at a fixed aspect ratio ( w = 128 d , α = 128 ), so that the model is well-shaped across scales. W e run all depth experiments at 10.4B tokens and sweep learning rates on a fine grid { 0 . 002 , 0 . 004 , . . . , 0 . 020 } . Figure 3 compares MuonH with and without Depth- µ P at 50 TPP across d ∈ { 8 , 12 , 16 , 20 , 24 } on the same LR grid, while full LR-loss sweeps are reported in T ables 5 and 6 and a summary of optimal values is pro vided in T able 7 . 8 Figure 3: Loss vs. LR curves across model sizes with Depth- µ P (left) and without Depth- µ P (right). Depth- µ P keeps the optimal LR stable at η ∗ ≈ 0 . 014 – 0 . 016 across all depths, while the optimum drifts from η ∗ = 0 . 016 at d =8 to η ∗ = 0 . 008 at d =24 without Depth- µ P . W ithout Depth- µ P , the optimal learning rate decreases from η ∗ = 0 . 016 at d =8 to η ∗ = 0 . 008 at d =24 , consistent with the depth-dependent LR trend predicted in Section 3.3 ; the loss landscape also sharpens with depth, as increasing LR from the optimum to η = 0 . 020 incurs a +0 . 023 nats penalty at d =8 (2.492 vs. 2.469) but a +0 . 098 nats penalty at d =20 (2.264 vs. 2.166). In contrast, with Depth- µ P the optimal LR remains nearly constant at η ∗ ≈ 0 . 014 – 0 . 016 from d =8 to d =24 . Crucially , both configurations achiev e comparable best losses at each depth (T able 7 ), confirming that Depth- µ P preserves model quality while enabling hyperparameter transfer . These results empirically validate our theory in Section 3.3 and refute the claim that MuonH is inherently depth-transferable [ WDL + 25 ]. 4.3 Critical Batch Size W e fix d =8 with 10.4B tokens and sweep LR across batch sizes B ∈ { 256 K , 512 K , 1 M , 2 M } tokens to identify the critical batch size, the threshold abov e which increasing batch size significantly degrades the achie vable loss [ MKA T18 ]. Figure 4: Left: Loss vs. LR at dif ferent batch sizes. Right: Optimal LR vs. batch size on log-log scale. The exact values are reported in T able 8 . The optimal LR scales as η ∗ = 4 . 66 × 10 − 6 · B 0 . 558 , with exponent ≈ 0 . 56 sitting between the linear scaling rule (exponent 1.0) and the square-root rule (e xponent 0.5, predicted by SDE analysis [ MLP A22 ]). The minimum achiev able loss is remarkably stable across batch sizes (within a 0.001 difference across batch sizes from 256K to 1M and within 0.004 for 2M), indicating that all tested batch sizes are belo w the critical batch size for this configuration. Since the optimal loss is mostly in variant under the tested batch size, we fix the batch size to 2M tokens for all subsequent experiments 9 so that the batch size does not confound the scaling behavior . W e leave the study of the relationship between critical batch size and training tokens to future work, as it requires a straightforward but costly scaling of the same suite of experiments explored in this section across multiple token budgets. 4.4 MoE Scaling W e extend our empirical verification of HyperP to our Transformer-Next-MoE architecture, in ves- tigating when scaling sparsity and granularity plateaus under optimal learning rates. A uxiliary Balance Loss. W e apply the Switch-T ransformer load balancing loss [ FZS22 ], computed ov er the global batch across all data-parallel ranks: L aux = γ · N · N X i =1 f i · P i , (15) where N is the number of experts, f i = c i / P N j =1 c j is the fraction of tokens dispatched to e xpert i (with c i the hard count), and P i = P T t =1 p t,i / P N j =1 P T t =1 p t,j is the normalized total router probability for expert i , with p t,i the post-softmax routing weight for token t . Both f i and P i are aggregated across all ranks via all-reduce before computing the loss. Under 10.4B training token budgets with d = 8 model size, we sweep the auxiliary balance loss weight γ ∈ { 10 − 3 , 10 − 2 , 10 − 1 } for the S = 8 , k = 4 MoE configuration,as sho wn in Figure 5 . Note that in this setting, we train without SqrtGate or shared experts to remo ve architectural confounders, allo wing us to better isolate the effect of h ypersphere optimization on load balancing. Figure 5: Loss vs. LR curves for three auxiliary loss weights. The curves nearly ov erlap, indicating robustness on γ under hypersphere optimization. The exact v alues across all LR and γ combinations are reported in T able 9 . T o quantify load imbalance, we use the MaxV io (maximal violation) metric [ WGZ + 24 ], which measures how much the most loaded e xpert exceeds the balanced baseline: MaxVio = max i c i − ¯ c ¯ c , ¯ c = 1 N N X i =1 c i , (16) where c i is the number of tokens dispatched to expert i within a batch and ¯ c is the expected load under perfect balance. A value of zero indicates perfectly uniform routing. W e compute MaxV io per layer and report the mean across layers (Mean MaxV io). Surprisingly , as sho wn in T able 3 , the largest weight γ = 10 − 1 achiev es the best loss (2.332) with the lo west Mean MaxV io. This contrasts with prior work suggesting that the auxiliary loss harms language modeling quality and thereby motiv ates auxiliary-loss-free load balancing [ WGZ + 24 ]. Under hypersphere optimization, the bounded logits (Theorem 4 ) likely pre vent the auxiliary loss from interfering with the language modeling objecti ve, and we leav e the theoretical study to future work. Motiv ated by these results, we adopt γ = 0 . 1 for all experiments in the remainder of the paper . 10 T able 3: Effect of γ on global load balancing. Mean max violation measures worst-case load imbalance across experts at η ∗ = 0 . 012 from the global batch. γ Best V al Loss Mean MaxV io 10 − 3 2.334 0.848 10 − 2 2.336 0.132 10 − 1 2.332 0.086 Sparsity Scaling. W e sweep sparsity S ∈ { 1 , 2 , 4 , 8 , 16 , 32 } for Transformer-Next-MoE with granularity k = 4 . The model has a constant 208M acti ve parameters, with a range of 208M–3.33B total parameters depending on the sparsity . As shown in Figure 6 , the optimal LR varies only mildly (0.012–0.016) across a 32 × sparsity range, indicating strong LR transferability o ver MoE sparsity . Increasing sparsity consistently improv es validation loss: moving from S =1 to S =32 reduces the optimal loss by 0.224. This means that it would require approximately 5 . 2 × more dense training FLOP to achiev e the same loss reduction under the MuonH+HyperP scaling curve in Figure 9 . Figure 6: Left: Loss vs. LR across sparsity le vels. Right: Optimal loss follows a po wer law in the MoE sparsity . The exact v alues are reported in T able 10 . Granularity Scaling. W e sweep k ∈ { 2 , 4 , 8 , 16 , 32 , 64 } with and without SqrtGate to verify that our granularity scaling theory in Section 3.7 holds in practice. As shown in Figure 7 , the optimal LR varies only between 0.012–0.014 across a 32 × range of k , enabling direct LR transfer across MoE granularity configurations. SqrtGate consistently improves v al loss at e very k , with the largest gain at k = 2 ( − 0 . 018 nats) and k = 32 ( − 0 . 009 nats). With SqrtGate, performance continues to improv e up to k = 32 , which achiev es the best loss of 2.310, whereas the baseline saturates at k = 16 . These results show that SqrtGate impro ves both the model quality and the granularity scalability compared to the baseline. Figure 7: Loss vs. LR across top- k values with and without SqrtGate. The exact optimal learning rates and losses are provided in T able 11 . 11 4.5 T raining FLOPs Scaling Empirical optimality of HyperP acr oss FLOPs. Before comparing scaling behaviors between different hyperparameter transfer la ws, we first verify that HyperP preserves the empirical optimality of a single small-scale LR choice as training FLOPs increase. As sho wn in Figure 8 , the loss-vs-LR curves under HyperP remain well aligned from d =8 through d =20 , and the same base optimum η 0 = 0 . 02 is preserved across scales. This confirms the central premise of HyperP: one LR sweep at small scale is suf ficient to determine the learning rates used along the full scaling trajectory . In contrast, without HyperP the optimal learning rate drifts with depth, so directly reusing the small-scale learning rate becomes increasingly miscalibrated and leads to substantially worse performance. Figure 8: Loss vs. LR across depths with HyperP (left) and without HyperP (right). HyperP keeps the curves aligned and preserv es a common base optimum at η 0 = 0 . 02 from d =8 through d =20 . Figure 9: Left: Loss vs. FLOPs with po wer-la w fits for all four methods. Right: Compute Efficiency Lev erage (CEL) relativ e to the Muon baseline. MuonH+HyperP achie ves 1.58 × CEL than the MuonH baseline, while the MuonH+HyperP MoE models achie ve 3.38 × CEL ov er the dense model baselines. The exact values are reported in T able 12 . Compute scaling comparisons. In Figure 9 , we compare the end-to-end compute scaling behaviors of various h yperparameter transfer laws. Each method is tuned once at the smallest model size d =8 using a coarse-grained LR sweep η ∈ { 2 × 10 − 3 , 4 × 10 − 3 , 8 × 10 − 3 , 1 × 10 − 2 , 2 × 10 − 2 , 4 × 10 − 2 } and then scaled with the observed optimal learning rate across model sizes d ∈ { 8 , 12 , 16 , 20 , 24 } with 50 TPP . Specifically , we compare four configurations: • Muon : µ P++ [ RCX + 25 ] with ∝ 1 /w weight decay scaling [ CQP + 25 ], using optimal base LR η ∗ = 0 . 02 with base weight decay λ ∗ = 10 − 3 . • MuonH : v anilla MuonH with ∝ 1 / √ d in initialization [ WDL + 25 ], using optimal base LR η ∗ = 0 . 01 . 12 • MuonH+HyperP : MuonH with HyperP , using optimal base LR η ∗ = 0 . 02 . • MuonH+HyperP MoE : HyperP applied to the Transformer-Next-MoE model with S =8 and k =8 , using the optimal base LR η ∗ = 0 . 01 . Gi ven the empirical results, we fit each Loss–FLOPs trajectory with L = A · C − b + C 0 (Figure 9 , left). Among dense models, MuonH+HyperP e xhibits the strongest scaling trends, achie ving the lowest irreducible floor ( C 0 = 0 . 85 ), compared with 1 . 23 for Muon and 1 . 62 for MuonH without HyperP . At the largest budget ( 5 . 96 × 10 21 FLOPs), MuonH+HyperP attains 1 . 58 × Compute Efficienc y Lev erage (CEL) over the Muon baseline. The MuonH+HyperP MoE model achieves a similarly lo w floor ( C 0 = 0 . 87 ) while outperforming all dense models across the full FLOPs range, reaching up to 3 . 38 × CEL ov er the dense baselines at the largest b udget. The CEL of MuonH+HyperP increases monotonically with scale (Figure 9 , right), rising from near parity at d =8 to 1 . 58 × lev erage at d =24 . In contrast, MuonH without HyperP is briefly competiti ve at intermediate scales b ut ultimately declines to 0 . 70 × , showing that even a modest learning-rate transfer mismatch compounds into a substantial compute efficienc y penalty at large scale. 5 Analysis 5.1 T ransferable Stability Figure 10: Stability metrics across training for MoE models at depths d ∈ { 8 , 12 , 16 , 20 } under the same transferred LR. All metrics are bounded and non-increasing with scales. A practical concern with hyperparameter transfer is whether training stability degrades at lar ger scales when the hyperparameters are configured using a small proxy . W e track six metrics of the training configuration MuonH+HyperP MoE conducted in Section 4.5 for the Transformer-Next-MoE model across depths d ∈ { 8 , 12 , 16 , 20 } : • Z -values ( LSE 2 ): For both attention and MoE routing, we compute Z = 1 B T P LSE( z ) 2 , where LSE( z ) = log P i exp( z i ) is the log-sum-exp of the pre-softmax logits. This is the quantity penalized by Z-loss [ ZBK + 22 ]; large Z indicates logit explosion. • Output RMS : The root-mean-square magnitude of the attention and MoE residual-branch outputs, av eraged across layers. Growing output norms signal representational instability . • Outlier % : The fraction of hidden-state elements of the attention and MoE residual-branch outputs exceeding 5 σ from the per-token mean, a veraged across layers. This detects the emergence of activ ation outliers that degrade quantization. 13 Figure 10 shows that all six metrics are well-behaved as scale increases. The attention Z -values plateau at comparable magnitudes across depths ( ≈ 200–220). The router Z -values are even better behav ed: their peaks decrease monotonically with depth (from 56 at d =8 to 33 at d =20 ) and continue to decline during training at the largest scale. The output RMS norms decrease with depth for both attention and MoE residual branches. The outlier percentages similarly decrease with depth, indicating that lar ger models under HyperP do not develop more acti vation outliers commonly observed in standard training [ DLBZ22 ]. These results show that HyperP provides not only optimal LR transfer but also stability transfer : the same hyperparameters that work well at small scales produce equally or more stable training dynamics at large scales. 5.2 Sensitivity of Optimal Learning Rate Estimation Since we heavily use quadratic fitting to find optimal Learning Rates (LRs), we want to understand how many LR sweep points are needed for reliable estimates. W e take the e xperimental data from our data scaling experiments in Section 3.4 as a case study . W e enumerate all 8 k combinations of k points from 8 av ailable LRs, fit the parabola in log( η ) space, and measure the mean relativ e error compared to the full 8-point fit. Figure 11: Relativ e error in optimal LR (Left) and optimal loss (Right) estimates vs. number of sweep points. The exact values are reported in T able 14 . Optimal loss is far mor e stable than optimal LR. The loss estimate is consistently 50 – 140 × less sensitiv e than the LR estimate (T able 14 ). W ith only n =3 points, the loss error is 0.03–0.14% while the LR error is 3.7–8.1%. This asymmetry is expected: the loss minimum is a second-order quantity that is insensitiv e to perturbations in the sweep points, whereas the minimizing LR is first-order . Five points suffice. Because loss is second-order in LR, even moderate LR errors translate to negligible loss errors. W ith n =5 , the worst-case LR error is 4.1% (at 10.4B tokens), yet the corresponding loss error is only 0.04%, or ∼ 0 . 001 nats in absolute terms. Throughout this paper, we report losses up-to four decimal places and the smallest architecture dif ferences we act on are ∼ 0 . 006 nats (e.g., SqrtGate vs. SharedExp+SqrtGate in T able 16 ). A ∼ 0 . 001 -nat fitting uncertainty is thus well below the resolution needed to distinguish any comparison in our experiments. Note that our analysis assumes a well-fitting quadratic ( R 2 > 0 . 99 ) and when the fit is poor , we base our conclusions on the observed optimal LR instead. 5.3 Rethinking Architecture After establishing the scaling laws on the pre-defined Transformer-Next architecture, we can now re visit and compare the architecture choices under their respectiv e optimal scaling curves with hypersphere optimization. W ith HyperP enabling fair comparisons under scalable, near-optimal hyperparameter settings, we study sev eral architectural variants by first identifying the optimal learning rate at the d = 8 scale, and then scaling to larger models using the fitted optima. Small-scale ablation study . W e first compare architectural variants at the smallest scale ( d =8 , 10.4B tokens) before scaling up. On the dense model side, we ablate three attention normalization 14 v ariants: GA QK-Norm (Gated Attention with QK normalization), QK-Norm , and Baseline (no QK- Norm or GA). On the MoE side, we ablate SqrtGate (Section 3.7 ) and the shared expert (SharedExp) on a sparsity of 8 and a granularity of 8 configuration ( S = 8 , k = 8 ), comparing SqrtGate , SharedExp , and Shar edExp + SqrtGate . Figure 12: Small-scale LR sweeps at d =8 , 10.4B tokens. Left: Dense attention normalization variants. GA QK-Norm achiev es the lowest loss with a slightly shifted optimal LR. W e exclude the LR =0 . 02 data points for dense models because the large learning rate leads to phase changes that harm fitting goodness. Right: MoE architecture variants. SharedExp + SqrtGate achieves the best loss while all v ariants maintain similar optimal LRs ( η ∗ ≈ 0 . 0135 – 0 . 0137 ). The exact values are reported in T able 15 and T able 16 . As shown in Figure 12 , GA QK-Norm outperforms QK-Norm by − 0 . 010 nats and Baseline by − 0 . 023 nats. All three methods ha ve similar optimal LRs ( 0 . 015 – 0 . 016 ), confirming that gated attention with QK normalization directly improves optimization quality without drastically change the LR landscape. All three MoE variants share nearly identical optimal LRs ( η ∗ = 0 . 0135 – 0 . 0137 ), indicating that neither SqrtGate nor the shared expert distorts the LR landscape under hypersphere optimization. SqrtGate and the shared expert alone provide nearly identical impro vements. Combining both yields the best performance, suggesting that the two mechanisms address orthogonal aspects: SqrtGate stabilizes the forward signal magnitude across routing granularity (Theorem 6 ), while the shared expert pro vides a consistently activ ated capacity pathway . Figure 13: Dense architecture scaling. Left: Loss vs. FLOPs with po wer-law fits L = A · C − b . Right: Compute Efficienc y Leverage (CEL) o ver the baseline. Scaling comparisons. In Figure 13 , we compare Baseline (LR =0 . 015 ), QKNorm (LR =0 . 015 ), and GatedAttn+QKNorm (LR =0 . 016 ) across depths d ∈ { 8 , 12 , 16 , 20 } . Since there are fe wer than 5 data points for the fitting, we apply power -law fits without irreducible loss for robust estimates. 15 GatedAttn+QKNorm achie ves the best scaling behaviors overall, translating its − 0 . 023 nats small- scale advantage into gro wing compute efficiency le verage that peaks at ∼ 1 . 15 × at intermediate scale. Howe ver , the advantages of both QKNorm and GatedAttn+QKNorm further shrink as the training scale increases, indicating the diminishing performance returns of these architectural choices. Figure 14: MoE architecture scaling. Left: Loss vs. FLOPs with power -law fits. All properly-tuned v ariants (LR =0 . 014 ) outperform the lower -LR baseline. Right: Compute efficiency le verage ov er the SharedExp+SqrtGate (LR =0 . 01 ) baseline. In Figure 14 , we compare SharedExp, SqrtGate, and SharedExp+SqrtGate across depths d ∈ { 8 , 12 , 16 , 24 } with their fitted optimal LR =0 . 014 . W e also hav e an observed optimal LR base- line for SharedExp+SqrtGate with LR =0 . 01 to understand how using the fitted optimum affects the CEL when compared to the observed optimum. All three variants at the properly tuned LR ( 0 . 014 ) outperform the SharedExp+SqrtGate baseline at the suboptimal LR ( 0 . 01 ), demonstrating that ev en a modest LR mismatch ( 1 . 4 × ) compounds into meaningful ef ficiency losses at scale. Among the properly tuned v ariants, SharedExp+SqrtGate achiev es the best ov erall scaling, confirming that the complementary benefits observed at small scale (Figure 12 ) persist with increasing compute. These results underscore that fine-grained LR tuning at small scale, enabled by HyperP’ s transferable optimal LR, propagates nontri vial compute savings across the entire scaling trajectory . Figure 15: Stability comparison of architecture ablations. Left: Router Z -values for MoE v ariants at d =16 . Router logits are exploding without SqrtGate. Right: MLP output RMS for dense variants at d =20 . QKNorm and Baseline exhibit a large spike at around 110B training tokens, while Gate- dAttn+QKNorm maintains the most stable RMS throughout training. Stability benefits of ar chitecture choices. While the loss improvements from architectural choices narrow with increasing computes, the y present significant stability benefits at lar ger scales. Figure 15 tracks two instability indicators during long training runs at the largest scale in ablation study . For MoE routing (Figure 15 , left), the effect of SqrtGate is dramatic: without SqrtGate (SharedExp only), router Z -v alues gro w continuously from ∼ 25 to ov er 190 with frequent spik es, indicating progressi ve 16 logit explosion. Adding SqrtGate suppresses this entirely: the Z -values remain bounded below 40 throughout training, around 5 × reduction in peak magnitude. For dense architectures (Figure 15 , right), QKNorm alone produces the highest MLP output RMS, while GatedAttn+QKNorm achiev es the most stable trend without an y spikes. The vanilla Baseline sho ws lower final RMS b ut exhibits late-training instability spikes absent from the GatedAttn+QKNorm variant. These results reveal a complementary role for architecture design under HyperP: e ven when loss dif ferences shrink at scale, the stability margin provided by SqrtGate and GatedAttn becomes increasingly important for reliable large-scale training. 6 Conclusion W e introduce HyperP (Hypersphere Parameterization), the first frame work for transferring a sin- gle optimal learning rate across model width, depth, training tokens, and MoE granularity under Frobenius-sphere optimization. W e prove that weight decay is a first-order no-op on the Frobenius sphere and that Depth- µ P remains necessary , and empirically identify a data-scaling exponent of 0 . 32 matching previous studies on AdamW , suggesting universality across optimizers. For MoE, we propose SqrtGate, a gating mechanism that preserves output RMS across granularities, reducing router Z -value peaks by 5 × . A single base learning rate tuned at d =8 (208M activ e parameters) transfers to d =24 (3.8B active parameters), achieving 1 . 58 × compute efficiency le verage over a strong Muon baseline at 6 × 10 21 FLOPs, with MoE models of 13.3B total parameters reaching 3 . 38 × . The advantage gro ws monotonically , suggesting even lar ger gains than the Muon baseline at frontier scales. HyperP also enables substantially larger auxiliary load-balancing weights and allows models to achieve the best loss and expert balance simultaneously . HyperP further deli vers transfer able stability : all monitored instability indicators are non-increasing with scale under the same transferred hyperparameters, and systematic architecture comparisons re veal that while loss improv ements from QK-Norm, Gated Attention, and SqrtGate diminish with scale, their stability benefits become increasingly important for long-horizon training. Limitations. W e assume the Chinchilla law is compute-optimal for our training setup, which in practice needs to be re-fitted per training dataset. The magic data scaling exponent 0 . 32 is an empirical observation that lacks a theoretical deriv ation for a universal ity guarantee. Extending these scaling laws to other architectures (e.g., hybrid models [ RCX + 25 ], linear recurrent models [ LLC + 26 , YKH25 ]) and verifying them at larger scale remains an important future direction. The batch size scaling exponent 0 . 56 deviates from the SDE-predicted 0 . 5 , warranting further theoretical in vestigation. Acknowledgement W e want to thank Kaiyue W en, Cheng Lu, Songlin Y ang and Jingyuan Liu for helpful discussions. References [AL TdJ + 23] J. Ainslie, J. Lee-Thorp, Michiel de Jong, Y ury Zemlyanskiy , Federico Lebr’on, and Sumit K. Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. Confer ence on Empirical Methods in Natural Language Pr ocessing , 2023. [BBC + 25] Johan Bjorck, Alon Benhaim, V ishrav Chaudhary , Furu W ei, and Xia Song. Scaling optimal LR across token horizons. In The Thirteenth International Confer ence on Learning Representations , 2025. [BDG + 25] Shane Bergsma, Nolan Dey , Gurpreet Gosal, Gavia Gray , Daria Sobolev a, and Joel Hestness. Power lines: Scaling laws for weight decay and batch size in llm pre-training. arXiv preprint arXiv: 2505.13738 , 2025. [Ber25] Jeremy Bernstein. Modular manifolds. Thinking Machines Lab: Connectionism , 2025. https://thinkingmachines.ai/blog/modular-manifolds/. [BKH16] Jimmy Lei Ba, Jamie Ryan Kiros, and Geof frey E. Hinton. Layer normalization. arXiv pr eprint arXiv: 1607.06450 , 2016. [BMR + 20] T om Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry , Amanda Askell, et al. Language models are few-shot learners. Advances in neural information pr ocessing systems , 33:1877–1901, 2020. 17 [CND + 23] Aakanksha Chowdhery , Sharan Narang, Jacob Devlin, Maarten Bosma, Gaura v Mishra, Adam Roberts, Paul Barham, Hyung W on Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of machine learning r esearc h , 24(240):1–113, 2023. [CQP + 25] Zixi Chen, Shikai Qiu, Hoang Phan, Qi Lei, and Andre w Gordon W ilson. How to scale second- order optimization. In The Thirty-ninth Annual Conference on Neural Information Processing Systems , 2025. [D A24a] DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv pr eprint arXiv: 2405.04434 , 2024. [D A24b] DeepSeek-AI. Deepseek-v3 technical report. arXiv preprint arXiv: 2412.19437 , 2024. [DDM + 23] Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padle wski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner , Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenat- ton, Lucas Be yer , Michael Tschannen, Anurag Arnab, Xiao W ang, Carlos Riquelme Ruiz, Matthias Minderer , Joan Puigcerver , Utku Evci, Manoj Kumar , Sjoerd V an Steenkiste, Gamaleldin F athy Elsayed, Aravindh Mahendran, Fisher Y u, A vital Oliv er, F antine Huot, Jasmijn Bastings, Mark Collier , Alexey A. Gritsenko, V ighnesh Birodkar , Cristina Nader V asconcelos, Y i T ay , Thomas Mensink, Alexander K olesnikov , Filip Pavetic, Dustin T ran, Thomas Kipf, Mario Lucic, Xiaohua Zhai, Daniel Ke ysers, Jeremiah J. Harmsen, and Neil Houlsby . Scaling vision transformers to 22 billion parameters. In Andreas Krause, Emma Brunskill, K yunghyun Cho, Barbara Engelhardt, Siv an Sabato, and Jonathan Scarlett, editors, Pr oceedings of the 40th International Conference on Machine Learning , v olume 202 of Pr oceedings of Machine Learning Resear ch , pages 7480–7512. PMLR, 23-29 Jul 2023. [Def25] Aaron Defazio. Why gradients rapidly increase near the end of training. arXiv preprint arXiv: 2506.02285 , 2025. [DLBZ22] T im Dettmers, Mike Lewis, Y ounes Belkada, and Luke Zettlemoyer . Llm.int8(): 8-bit matrix multiplication for transformers at scale. arXiv pr eprint arXiv: 2208.07339 , 2022. [FDD + 25] Y onggan Fu, Xin Dong, Shizhe Diao, Matthijs V an keirsbilck, Hanrong Y e, W onmin Byeon, Y ashaswi Karnati, Lucas Liebenwein, Hannah Zhang, Nikolaus Binder , Maksim Khadke vich, Alexander Keller , Jan Kautz, Y ingyan Celine Lin, and Pa vlo Molchano v . Nemotron-flash: T ow ards latency-optimal hybrid small language models. arXiv preprint arXiv: 2511.18890 , 2025. [FZS22] W illiam Fedus, Barret Zoph, and Noam Shazeer . Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity . The J ournal of Machine Learning Resear ch , 23(1):5232– 5270, 2022. [Goo25] Google. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality , long context, and next generation agentic capabilities. arXiv preprint arXiv: 2507.06261 , 2025. [HBM + 22] Jordan Hoffmann, Sebastian Bor geaud, A. Mensch, Elena Buchatskaya, Tre vor Cai, Eliza Ruther- ford, Diego de Las Casas, Lisa Anne Hendricks, Johannes W elbl, Aidan Clark, T om Hennigan, Eric Noland, Katie Millican, Geor ge van den Driessche, Bogdan Damoc, Aurelia Guy , Simon Osindero, K. Simonyan, Erich Elsen, Jack W . Rae, Oriol V inyals, and L. Sifre. T raining compute-optimal large language models. ARXIV .ORG , 2022. [HZRS16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CVPR , 2016. [JBR + 24] Keller Jordan, Jeremy Bernstein, Brendan Rappazzo, @fernbear .bsky .social, Boza Vlado, Y ou Ji- acheng, Franz Cesista, Braden Koszarsky , and @Grad62304977. modded-nanogpt: Speedrunning the nanogpt baseline, 2024. [JJB + 24] Keller Jordan, Y uchen Jin, Vlado Boza, Jiacheng Y ou, Franz Cesista, Laker Ne whouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. [KAL + 23] T ero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. arXiv pr eprint arXiv: 2312.02696 , 2023. [KMH + 20] Jared Kaplan, Sam McCandlish, T om Henighan, T om B. Brown, Benjamin Chess, Re won Child, Scott Gray , Alec Radford, Jeffre y Wu, and Dario Amodei. Scaling laws for neural language models. arXiv pr eprint arXiv: 2001.08361 , 2020. [LH18] Ilya Loshchilov and Frank Hutter . Decoupled weight decay regularization. In International Confer ence on Learning Representations , 2018. [LLC + 26] Aakash Lahoti, K evin Y . Li, Berlin Chen, Caitlin W ang, A viv Bick, J. Zico K olter, T ri Dao, and Albert Gu. Mamba-3: Improv ed sequence modeling using state space principles. arXiv preprint arXiv: 2603.15569 , 2026. 18 [LZH + 25] Houyi Li, W enzhen Zheng, Jingcheng Hu, Qiufeng W ang, Hanshan Zhang, Zili W ang, Shijie Xuyang, Y uantao Fan, Shuigeng Zhou, Xiangyu Zhang, and Daxin Jiang. Predictable scale: Part i - optimal hyperparameter scaling law in lar ge language model pretraining. arXiv preprint arXiv: 2503.04715 , 2025. [MKA T18] Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota T eam. An empirical model of large-batch training. arXiv preprint arXiv: 1812.06162 , 2018. [MLP A22] Sadhika Malladi, Kaifeng L yu, Abhishek Panigrahi, and Sanjeev Arora. On the SDEs and scaling rules for adapti ve gradient algorithms. In Alice H. Oh, Alekh Agarwal, Danielle Belgra ve, and Kyungh yun Cho, editors, Advances in Neural Information Pr ocessing Systems , 2022. [Ope23] OpenAI. Gpt-4 technical report. PREPRINT , 2023. [Ope25] OpenAI. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv: 2508.10925 , 2025. [PGM + 19] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury , Gregory Chanan, T rev or Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library . Advances in neural information pr ocessing systems , 32, 2019. [QHW + 26] Zihan Qiu, Zeyu Huang, Kaiyue W en, Peng Jin, Bo Zheng, Y uxin Zhou, Haofeng Huang, Zekun W ang, Xiao Li, Huaqing Zhang, Y ang Xu, Haoran Lian, Siqi Zhang, Rui Men, Jianwei Zhang, Ivan T itov , Dayiheng Liu, Jingren Zhou, and Junyang Lin. A unified view of attention and residual sinks: Outlier-dri ven rescaling is essential for transformer training. arXiv pr eprint arXiv: 2601.22966 , 2026. [Qwe25] Qwen T eam. Qwen3-next-80b-a3b, September 2025. Qwen Blog. Accessed: 2026-03-22. [QWZ + 25] Zihan Qiu, Zekun W ang, Bo Zheng, Zeyu Huang, Kaiyue W en, Songlin Y ang, Rui Men, Le Y u, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Gated attention for large language models: Non-linearity , sparsity , and attention-sink-free. In The Thirty-ninth Annual Confer ence on Neural Information Pr ocessing Systems , 2025. [RCX + 25] Liliang Ren, Congcong Chen, Haoran Xu, Y oung Jin Kim, Adam Atkinson, Zheng Zhan, Jiankai Sun, Baolin Peng, Liyuan Liu, Shuohang W ang, Hao Cheng, Jianfeng Gao, W eizhu Chen, and yelong shen. Decoder-hybrid-decoder architecture for efficient reasoning with long generation. In The Thirty-ninth Annual Confer ence on Neural Information Pr ocessing Systems , 2025. [R WC + 19] Alec Radford, Jeff W u, Rewon Child, Da vid Luan, Dario Amodei, and Ilya Sutske ver . Language models are unsupervised multitask learners. arXiv pr eprint , 2019. [SAKM + 23] Daria Sobolev a, Faisal Al-Khateeb, Robert Myers, Jacob R Steeves, Joel Hes- tness, and Nolan De y . Slimpajama: A 627b token cleaned and dedupli- cated version of redpajama, 2023. URL: https://www.cerebras.net/blog/ slimpajama- a- 627b- token- cleaned- and- deduplicated- version- of- redpajama . [Sha20] Noam Shazeer . Glu variants improv e transformer . arXiv preprint arXiv: 2002.05202 , 2020. [SK16] T im Salimans and Durk P Kingma. W eight normalization: A simple reparameterization to accelerate training of deep neural networks. Advances in neural information pr ocessing systems , 29, 2016. [SMM + 17] Noam Shazeer , Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffre y E. Hinton, and Jef f Dean. Outrageously lar ge neural networks: The sparsely-gated mixture-of-experts layer . In 5th International Conference on Learning Repr esentations, ICLR 2017, T oulon, F rance, April 24-26, 2017, Confer ence Tr ack Pr oceedings . OpenRevie w .net, 2017. [T ea25a] Kimi T eam. Kimi k2: Open agentic intelligence. arXiv pr eprint arXiv: 2507.20534 , 2025. [T ea25b] Ling T eam. Every activ ation boosted: Scaling general reasoner to 1 trillion open language foundation. arXiv pr eprint arXiv: 2510.22115 , 2025. [W A24] Xi W ang and Laurence Aitchison. Ho w to set adamw’ s weight decay as you scale model and dataset size. arXiv pr eprint arXiv: 2405.13698 , 2024. [WDL + 25] Kaiyue W en, Xingyu Dang, Kaifeng L yu, T engyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them ii: From weight decay to hyperball optimization, 12 2025. [WGZ + 24] Lean W ang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-e xperts. arXiv preprint arXiv: 2408.15664 , 2024. [WLX + 24] Mitchell W ortsman, Peter J Liu, Lechao Xiao, Katie E Everett, Alexander A Alemi, Ben Adlam, John D Co-Reyes, Izzeddin Gur , Abhishek Kumar , Roman Novak, Jeffrey Pennington, Jascha Sohl-Dickstein, K elvin Xu, Jaehoon Lee, Justin Gilmer , and Simon K ornblith. Small-scale proxies for large-scale transformer training instabilities. In The T welfth International Confer ence on Learning Repr esentations , 2024. 19 [XL T + 26] T ian Xie, Haoming Luo, Haoyu T ang, Y iwen Hu, Jason Klein Liu, Qingnan Ren, Y ang W ang, W ayne Xin Zhao, Rui Y an, Bing Su, Chong Luo, and Baining Guo. Controlled llm training on spectral sphere. arXiv pr eprint arXiv: 2601.08393 , 2026. [XYH + 20] Ruibin Xiong, Y unchang Y ang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Y anyan Lan, Liwei W ang, and T ie-Y an Liu. On layer normalization in the transformer architecture. In Pr oceedings of the 37th International Conference on Mac hine Learning, ICML 2020, 13-18 J uly 2020, V irtual Event , volume 119 of Proceedings of Machine Learning Resear ch , pages 10524–10533. PMLR, 2020. [YHB + 22] Greg Y ang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder , Jakub Pachocki, W eizhu Chen, and Jianfeng Gao. T ensor programs v: Tuning lar ge neural networks via zero-shot hyperparameter transfer . arXiv pr eprint arXiv: 2203.03466 , 2022. [YKH25] Songlin Y ang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. In The Thirteenth International Confer ence on Learning Repr esentations , 2025. [YL Y + 25] An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran W ei, Huan Lin, Jialong T ang, Jian Y ang, Jianhong T u, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, K eqin Bao, Kexin Y ang, Le Y u, Lianghao Deng, Mei Li, Mingfeng Xue, Mingze Li, Pei Zhang, Peng W ang, Qin Zhu, Rui Men, Ruize Gao, Shixuan Liu, Shuang Luo, T ianhao Li, T ianyi T ang, W enbiao Y in, Xingzhang Ren, Xinyu W ang, Xin yu Zhang, Xuancheng Ren, Y ang Fan, Y ang Su, Y ichang Zhang, Y inger Zhang, Y u W an, Y uqiong Liu, Zekun W ang, Zeyu Cui, Zhenru Zhang, Zhipeng Zhou, and Zihan Qiu. Qwen3 technical report. arXiv preprint arXiv: 2505.09388 , 2025. [YYZH23] Greg Y ang, Dingli Y u, Chen Zhu, and Soufiane Hayou. T ensor programs vi: Feature learning in infinite-depth neural networks. International Confer ence on Learning Representations , 2023. [ZBK + 22] Barret Zoph, Irwan Bello, Sameer K umar , Nan Du, Y anping Huang, Jef f Dean, Noam Shazeer , and W illiam Fedus. St-moe: Designing stable and transferable sparse expert models. arXiv preprint arXiv: 2202.08906 , 2022. [ZRG + 22] Susan Zhang, Stephen Roller , Naman Goyal, Mikel Artetxe, Mo ya Chen, Shuohui Chen, Christo- pher Dew an, Mona Diab, Xian Li, Xi V ictoria Lin, T odor Mihaylov , Myle Ott, Sam Shleifer, K urt Shuster , Daniel Simig, Punit Singh K oura, Anjali Sridhar , Tianlu W ang, and Luk e Zettlemoyer . Opt: Open pre-trained transformer language models. arXiv pr eprint arXiv: 2205.01068 , 2022. A Proof of W idth T ransfer under Frobenius Spher e Lemma 7 (Spectral–Frobenius sandwich) . F or any matrix W ∈ R d out × d in , ∥ W ∥ 2 ≤ ∥ W ∥ F ≤ √ r ∥ W ∥ 2 , r := rank( W ) . Hence, ∥ W ∥ 2 ≤ ∥ W ∥ F ≤ p min( d in , d out ) ∥ W ∥ 2 . Mor eover , the upper bound is attained if and only if r = min( d in , d out ) and all nonzero singular values of W ar e equal. Pr oof. Let σ 1 , . . . , σ r be the nonzero singular values of W . Then ∥ W ∥ 2 = max 1 ≤ i ≤ r σ i , ∥ W ∥ F = r X i =1 σ 2 i 1 / 2 . The lower bound ∥ W ∥ 2 ≤ ∥ W ∥ F is immediate. For the upper bound, r X i =1 σ 2 i ≤ r max i σ 2 i = r ∥ W ∥ 2 2 , hence ∥ W ∥ F ≤ √ r ∥ W ∥ 2 . Equality holds if and only if all nonzero singular values are equal. T o also reach ∥ W ∥ F = p min( d in , d out ) ∥ W ∥ 2 , one additionally needs r = min( d in , d out ) , i.e., full rank. 20 W e now pro ve the width-transfer theorem. Pr oof of Theorem 2 . By assumption, ∥ W ∥ rms = ∥ W ∥ F √ d out d in = C √ d in , which is equiv alent to ∥ W ∥ F = C p d out . Now assume W is approximately isotropic on its input space, so that for typical inputs X , ∥ W X ∥ 2 ≤ ∥ W ∥ 2 ∥ X ∥ 2 ≈ ∥ W ∥ F p min( d in , d out ) ∥ X ∥ 2 . Since p d in / min( d in , d out ) = O (1) , then ∥ Y ∥ rms = ∥ Y ∥ 2 √ d out = ∥ W X ∥ 2 √ d out ≈ ∥ W ∥ F √ d in √ d out ∥ X ∥ 2 . Substituting ∥ W ∥ F = C √ d out giv es ∥ Y ∥ rms ≈ C √ d in ∥ X ∥ 2 . Finally , using ∥ X ∥ rms = ∥ X ∥ 2 / √ d in , we obtain ∥ Y ∥ rms ≈ C ∥ X ∥ rms . Thus the output rms scale is width-stable, which is exactly the desired µ P-style width transfer . B First-Order F orm of Frobenius-Spher e Updates W e prov e that Frobenius renormalization preserves only the tangent component of an update to first order . Pr oof of Theorem 1 . V ectorize W and ∆ as w = vec( W ) and δ = v ec(∆) . Since ∥ w ∥ 2 = c W , ( 3 ) becomes w + = c W w + δ ∥ w + δ ∥ 2 . (17) Now e xpand the denominator: ∥ w + δ ∥ 2 = ∥ w ∥ 2 2 + 2 ⟨ w , δ ⟩ + ∥ δ ∥ 2 2 1 / 2 (18) = c W 1 + 2 ⟨ w , δ ⟩ c 2 W + ∥ δ ∥ 2 2 c 2 W 1 / 2 (19) = c W 1 + ⟨ w , δ ⟩ c 2 W + O ( ∥ δ ∥ 2 2 ) , (20) where we use (1 + z ) 1 / 2 = 1 + 1 2 z + O ( z 2 ) . Therefore, w + = ( w + δ ) 1 + ⟨ w , δ ⟩ c 2 W − 1 + O ( ∥ δ ∥ 2 2 ) (21) = ( w + δ ) 1 − ⟨ w , δ ⟩ c 2 W + O ( ∥ δ ∥ 2 2 ) (22) = w + δ − ⟨ w , δ ⟩ c 2 W w + O ( ∥ δ ∥ 2 2 ) . (23) 21 Hence w + − w = δ − ⟨ w , δ ⟩ c 2 W w + O ( ∥ δ ∥ 2 2 ) . (24) Returning to matrix form giv es W + − W = ∆ − ⟨ ∆ , W ⟩ F ∥ W ∥ 2 F W + O ( ∥ ∆ ∥ 2 F ) = Π T (∆) + O ( ∥ ∆ ∥ 2 F ) , (25) which prov es ( 4 ). Pr oof of Cor ollary 1.1 . By linearity of Π T , Π T ( G + λW ) = Π T ( G ) + λ Π T ( W ) . (26) But Π T ( W ) = W − ⟨ W , W ⟩ F ∥ W ∥ 2 F W = W − W = 0 . (27) Applying Theorem 1 with ∆ = − η ( G + λW ) gives the result. C Depth Scaling under Frobenius-Spher e Optimization W e first deriv e the first-order decomposition of the network perturbation, then analyze residual networks with and without update normalization, and finally extend the argument to post-norm blocks by computing the LayerNorm Jacobian explicitly . C.1 First-order decomposition of the network perturbation Let F ( x ; W 1 , . . . , W L ) denote the network output as a function of all layer parameters. For perturba- tions ∆ W 1 , . . . , ∆ W L , first-order multiv ariate T aylor expansion yields F ( x ; W + ∆ W ) − F ( x ; W ) = L X l =1 ∂ F ∂ W l ∆ W l + O X i,j ∥ ∆ W i ∥ F ∥ ∆ W j ∥ F . (28) Thus the first-order total perturbation is additiv e over layers. C.2 Residual network without update normalization Consider x l +1 = x l + α L f l ( x l ; W l ) . (29) Perturbing both the hidden state and the weights giv es, to first order, ∆ x l +1 = ∆ x l + α L ∂ f l ∂ x l ∆ x l + α L ∂ f l ∂ W l ∆ W l . (30) Define A l = I + α L J ( l ) f ,x and b l = α L J ( l ) f ,W ∆ W l . Then ∆ x l +1 = A l ∆ x l + b l . Unrolling this recursion yields ∆ x L = L X l =1 L − 1 Y k = l +1 A k ! b l . (31) Since ∥ J ( l ) f ,x ∥ F = O (1) with depth, for suf ficiently small α L , each A l has an operator norm O (1) . Hence the do wnstream transport factors in ( 31 ) contribute only constant-order f actors at the le vel of depth exponents, and it suf fices to track the scaling of b l . If only the weights are normalized and the weight updates scale with the magnitude of gradients, then by Theorem 1 , ∥ ∆ W l ∥ F = O ( η l ∥ G l ∥ F ) . Under the stable-depth assumption for residual networks, the layerwise gradient satisfies ∥ G l ∥ F = O ( α L ) , since differentiating ( 29 ) with respect to W l introduces exactly one factor of α L , while the upstream signal is O (1) by assumption. Therefore ∥ ∆ W l ∥ F = O ( η l α L ) . Since ∥ J ( l ) f ,W ∥ F = O (1) , ∥ b l ∥ F = O ( α L ∥ ∆ W l ∥ F ) = O ( η l α 2 L ) . (32) 22 By the T riangle Inequality , summing ov er L layers gi ves ∥ ∆ x L ∥ F = O ( Lη l α 2 L ) . W e consider two cases where alpha is suf ficiently small to satisfy our assumptions: If α L = L − 1 / 2 , this reduces to ∥ ∆ x L ∥ F = O ( η l ) , so a depth-independent learning rate η l = O (1) yields an O (1) first-order function perturbation; If α L = L − 1 , one obtains ∥ ∆ x L ∥ F = O ( L − 1 η l ) , which requires η l = O ( L ) . C.3 Residual network with update normalization Assume the raw update is normalized before the Frobenius-sphere projection: b G l = c G G l ∥ G l ∥ F , f W l = W l − η l b G l , W + l = c W f W l ∥ f W l ∥ F . (33) By Theorem 1 , ∆ W l = W + l − W l = − η l Π T ( b G l ) + O ( η 2 l ) . (34) Because ∥ b G l ∥ F = c G = O (1) , we have ∥ ∆ W l ∥ F = O ( η l ) . Thus the linearized residual contrib ution at layer l scales as ∥ b l ∥ F = O ( α L ∥ ∆ W l ∥ F ) = O ( α L η l ) , (35) and summing ov er depth giv es ∥ ∆ x L ∥ F = O ( Lα L η l ) . (36) Therefore, preserving an O (1) first-order function perturbation requires η l = O 1 Lα L . (37) In particular , if α L = L − 1 / 2 , this giv es η l = O ( L − 1 / 2 ) , while if α L = L − 1 , it giv es η l = O (1) . C.4 Post-norm residual block W e now consider x l +1 = LN( x l + α L f l ( x l ; W l )) . (38) Let u = x + α L f ( x ; W ) , µ = 1 d 1 ⊤ u , v = u − µ 1 , σ = q 1 d ∥ v ∥ 2 + ε . Ignoring learned gain and bias, LayerNorm is LN( u ) = v /σ . Let P = I − 1 d 11 ⊤ . Since v = P u , we have dv = P du . Moreov er , dσ = 1 2 σ d 1 d ∥ v ∥ 2 + ε = 1 σ d v ⊤ dv = 1 σ d v ⊤ du, (39) where we use P v = v . Now d LN( u ) = d v σ = 1 σ dv − v σ 2 dσ = 1 σ P du − 1 σ 3 d v v ⊤ du. (40) Hence the LayerNorm Jacobian is J LN ( u ) = 1 σ P − 1 σ 3 d v v ⊤ = 1 σ P − 1 dσ 2 v v ⊤ . (41) Now dif ferentiate ( 38 ). By the chain rule, ∂ x l +1 ∂ W l = J LN ( u l ) α L ∂ f l ∂ W l , (42) and similarly ∂ x l +1 ∂ x l = J LN ( u l ) I + α L ∂ f l ∂ x l . Since σ l is O (1) with depth under post-norm, then by ( 41 ) , ∥ J LN ( u l ) ∥ op = O (1) . Therefore, the local weight sensitivity has the same depth scaler α L as in the pre-norm residual block. Consequently , the same scaling argument as abo ve applies: with update normalization, one obtains ∥ ∆ x L ∥ = O ( Lα L η l ) , and hence η l = O 1 Lα L . 23 D Detailed Experimental Results This section provides the exact numerical values for the figures presented in Section 3.4 , Section 4 and Section 5 . T able 4: Optimal LR vs. training token b udget under fine-grid sweeping with quadratic fitting. T raining T okens Fitted η ∗ Fitted Min Loss 10.4B 0.01515 2.4741 20.8B 0.01208 2.4189 41.6B 0.00958 2.3773 83.2B 0.00772 2.3456 166.4B 0.00635 2.3214 T able 5: V alidation loss vs. LR across model depth at a fixed token b udget of 10.4B without Depth- µ P . Depth ( d ) Params η =0 . 002 η =0 . 004 η =0 . 006 η =0 . 008 η =0 . 010 η =0 . 012 η =0 . 014 η =0 . 016 η =0 . 018 η =0 . 020 Optimal η 8 208M 2.684 2.569 2.521 2.498 2.485 2.474 2.470 2.469 2.473 2.492 0.016 12 570M 2.523 2.405 2.355 2.328 2.315 2.308 2.309 2.319 2.351 2.386 0.012 16 1.24B 2.426 2.307 2.256 2.230 2.220 2.225 2.251 2.288 2.299 2.315 0.010 20 2.31B 2.354 2.235 2.189 2.166 2.169 2.191 2.218 2.235 2.246 2.264 0.008 24 3.90B 2.300 2.183 2.140 2.126 2.142 2.165 2.184 2.196 2.212 2.221 0.008 T able 6: V alidation loss vs. LR across model depth at a fixed token b udget of 10.4B with Depth- µ P . Depth ( d ) Params η =0 . 002 η =0 . 004 η =0 . 006 η =0 . 008 η =0 . 010 η =0 . 012 η =0 . 014 η =0 . 016 η =0 . 018 η =0 . 020 Optimal η 8 208M 2.682 2.568 2.520 2.496 2.484 2.476 2.473 2.474 2.477 2.479 0.014 12 570M 2.568 2.437 2.377 2.347 2.331 2.319 2.316 2.315 2.317 2.321 0.016 16 1.24B 2.495 2.359 2.297 2.264 2.245 2.235 2.229 2.225 2.225 2.234 0.016 20 2.31B 2.445 2.309 2.246 2.211 2.188 2.177 2.171 2.169 2.172 2.188 0.016 24 3.90B 2.413 2.272 2.208 2.172 2.150 2.137 2.132 2.132 2.137 2.152 0.014 T able 7: Optimal LR and loss vs. model depth at a fixed training token of 10.4B, comparing with and without Depth- µ P . Depth- µ P transfers the optimal LR across parameter size. Depth ( d ) w/ Depth- µ P η ∗ w/ Depth- µ P Loss w/o Depth- µ P η ∗ w/o Depth- µ P Loss 8 0.014 2.4734 0.016 2.4693 12 0.016 2.3150 0.012 2.3079 16 0.016 2.2250 0.010 2.2196 20 0.016 2.1690 0.008 2.1656 24 0.014 2.1320 0.008 2.1263 T able 8: Optimal LR vs. batch size for dense models. The minimum loss is remarkably stable (within 0.004 nats), indicating all tested batch sizes are below the critical batch size. Batch Size Fitted η ∗ Fitted Min Loss 256K 0.00504 2.4711 512K 0.00706 2.4697 1M 0.01056 2.4700 2M 0.01562 2.4741 24 T able 9: V alidation loss vs. LR across auxiliary loss weights. The optimal LR ( η ∗ = 0 . 012 ) and achiev able loss are stable across a 100 × range of γ . γ η =0 . 004 η =0 . 008 η =0 . 01 η =0 . 012 η =0 . 02 Best Loss 10 − 3 2.427 2.350 2.340 2.334 2.349 2.334 10 − 2 2.431 2.354 2.340 2.336 2.346 2.336 10 − 1 2.427 2.350 2.337 2.332 2.346 2.332 T able 10: Optimal LR and loss vs. MoE sparsity . The LR varies mildly (0.012–0.016) across a 32 × range. Sparsity ( S ) Fitted η ∗ Fitted Min Loss 1 0.0163 2.4766 2 0.0162 2.4236 4 0.0145 2.3705 8 0.0139 2.3262 16 0.0124 2.2861 32 0.0115 2.2529 T able 11: Optimal LR and loss across top- k v alues, with and without SqrtGate. T op- k w/o SqrtGate η ∗ w/o SqrtGate Loss w/ SqrtGate η ∗ w/ SqrtGate Loss 2 0.0140 2.4306 0.0139 2.4131 4 0.0132 2.3263 0.0139 2.3262 8 0.0137 2.3220 0.0135 2.3156 16 0.0126 2.3178 0.0129 2.3111 32 0.0127 2.3186 0.0131 2.3096 64 0.0122 2.3244 0.0128 2.3154 T able 12: V alidation loss vs. FLOPs. MuonH + HyperP increasingly outperforms both alternati ves at larger scale. Depth FLOPs Muon MuonH+HyperP MuonH 8 2 . 14 × 10 19 2.4777 2.4804 2.4845 12 1 . 49 × 10 20 2.2257 2.2192 2.2099 16 6 . 59 × 10 20 2.0671 2.0526 2.0500 20 2 . 19 × 10 21 1.9591 1.9311 1.9558 24 5 . 96 × 10 21 1.8785 1.8365 1.9015 T able 13: Compute ef ficiency le verage ov er Muon. MuonH + HyperP’ s adv antage grows monotoni- cally with scale. Depth FLOPs MuonH+HyperP MuonH 8 2 . 14 × 10 19 0 . 99 × 0 . 96 × 12 1 . 49 × 10 20 1 . 04 × 1 . 19 × 16 6 . 59 × 10 20 1 . 16 × 1 . 17 × 20 2 . 19 × 10 21 1 . 35 × 0 . 99 × 24 5 . 96 × 10 21 1 . 58 × 0 . 70 × 25 T able 14: Mean relati ve error (%) of optimal LR and optimal loss estimates as a function of the number of sweep points n . LR Relative Err or (%) Loss Relative Err or (%) T okens n =3 n =4 n =5 n =6 n =7 n =3 n =4 n =5 n =6 n =7 10.4B 5.87 5.08 4.09 2.88 1.55 0.07 0.05 0.04 0.03 0.01 20.8B 3.68 2.01 1.46 1.00 0.53 0.04 0.02 0.01 0.01 0.01 41.6B 4.27 2.55 1.58 0.95 0.46 0.03 0.02 0.01 0.01 0.01 83.2B 5.43 3.06 1.88 1.12 0.54 0.05 0.02 0.02 0.01 0.01 166.4B 8.07 1.97 0.88 0.48 0.28 0.14 0.02 0.01 0.01 0.00 T able 15: QK-Norm ablation at d =8 . GA QK-Norm achiev es the best loss while maintaining a similar optimal LR. Method Fitted η ∗ Min Loss GA QK-Norm 0.0158 2.4727 QK-Norm 0.0151 2.4823 Baseline 0.0149 2.4960 T able 16: MoE architecture ablation at d =8 , S =8 , k =8 , 10.4B tokens. SqrtGate and the shared expert pro vide complementary gains. Method Fitted η ∗ Min Loss ∆ vs. Best SharedExp + SqrtGate 0.0135 2.3154 — SqrtGate 0.0135 2.3210 +0 . 006 SharedExp 0.0137 2.3215 +0 . 006 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment