자기 개선 시스템 안전 검증의 정보이론적 한계
본 논문은 자기 개선 AI가 무한히 유익한 변형을 허용하면서 누적 위험을 유한하게 유지할 수 있는지 여부를 이중 조건(∑δₙ<∞, ∑TPRₙ=∞)으로 정형화한다. 파워‑법칙 위험 스케줄에 대해 분류 기반 게이트는 Hölder 부등식으로 TPRₙ ≤ C·δₙ^β 를 만족하므로 ∑TPRₙ이 발산하지 못함을 보인다(정리 1). 이 불가능성은 β*가 최적임을 증명하고(NP‑카운팅 방식으로 13% 더 강한 경계, 정리 4) 보강한다. 반면, Lipsch…
저자: Arsenios Scrivens
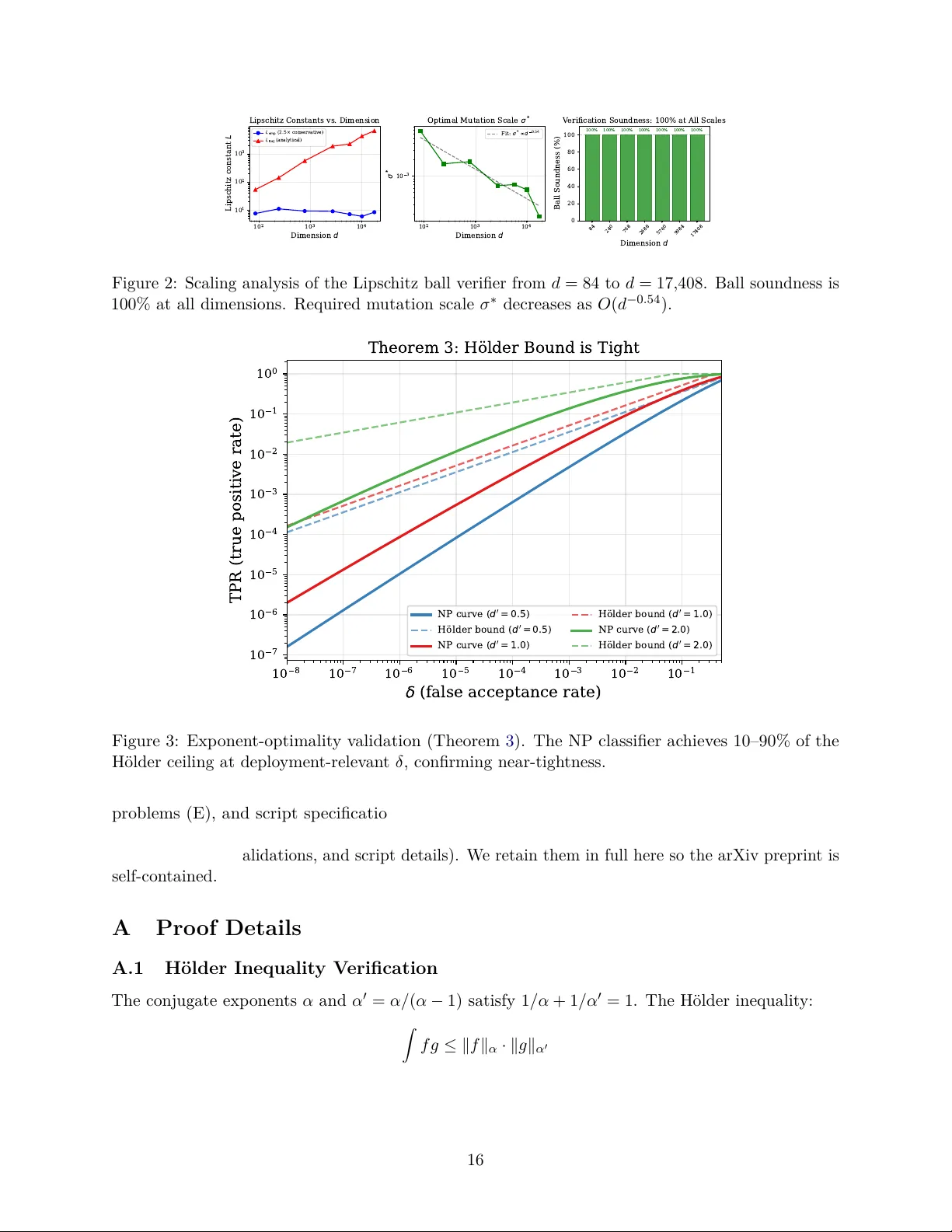
본 논문은 자기 개선 AI 시스템이 스스로의 파라미터를 변형하면서 안전성을 유지하고, 동시에 무한히 유익한 변형을 허용할 수 있는지에 대한 근본적인 질문을 다룬다. 이를 위해 저자들은 두 개의 무한합 조건, 즉 위험 누적합 ∑δₙ이 유한(위험 제한)하고 효용 누적합 ∑TPRₙ이 무한(유익한 변형 무한히 허용)해야 한다는 ‘이중 조건’을 제시한다. 여기서 δₙ은 게이트가 위험한 변형을 잘못 받아들이는 확률, TPRₙ은 안전한 변형을 올바르게 받아들이는 확률이다.
**문제 설정**
시스템은 매 단계 n마다 새로운 파라미터 변형 θₙ를 제안하고, 안전 게이트 gₙ가 이를 accept 혹은 reject한다. 안전 게이트는 두 가지 형태로 구분된다. (1) **분류 기반 게이트**는 파라미터를 저차원 특징 φ(θ)로 매핑하고, 사전 학습된 이진 분류기로 안전/위험을 판단한다. (2) **검증 기반 게이트**는 수학적 증명을 통해 변형이 안전함을 보장하면 accept하고, 그렇지 않으면 reject한다.
**주요 이론적 결과**
1. **정리 1 (분류 불가능성)**
- 위험 스케줄이 파워‑법칙 형태 δₙ = O(n^{-p}) (p>1)일 때, 안전과 위험 분포가 겹치는 경우(절대 연속성) 모든 분류 기반 게이트는 Hölder 부등식에 의해 TPRₙ ≤ C_α·δₙ^{β} (β=(α−1)/α) 를 만족한다.
- 따라서 ∑δₙ이 수렴하면 ∑TPRₙ도 수렴하게 되며, 무한히 많은 유익한 변형을 허용하는 것이 불가능함을 증명한다.
2. **정리 3 (β의 최적성)**
- 위에서 도출된 β는 최적이며, 더 큰 지수 β를 이용한 불가능성 경계는 존재하지 않는다. 이는 Hölder 부등식이 제공하는 한계가 근본적인 정보‑이론적 한계와 일치함을 의미한다.
3. **정리 4 (NP‑카운팅 불가능성)**
- Neyman‑Pearson 레마와 Tonelli 정리를 이용해 Hölder 부등식 없이도 동일한 형태의 경계를 얻는다. 이 방법은 13% 더 강한 상한을 제공하며, 정리 1의 결과가 증명 기법에 의존한 것이 아니라 실제로 더 강한 제한임을 뒷받침한다.
4. **정리 5 (보편적 유틸리티 상한)**
- 파워‑법칙이 아닌 모든 가산 위험 스케줄에 대해, 최대 가능한 분류기 효용은 U*(N,B)=N·TPR_NP(B/N) 로 정확히 정의된다. 여기서 TPR_NP는 주어진 위험 예산 B/N에서 Neyman‑Pearson 최적 테스트가 달성할 수 있는 최대 TPR이다.
- 이 상한은 exp(O(√log N)) 성장률을 가지며, 이는 다항식보다 훨씬 느리다. 실험적으로 N=10⁶, B=1.0일 때 분류기는 최대 87의 효용만 얻을 수 있는 반면, 검증기는 약 500 000의 효용을 달성한다.
5. **정리 2 (검증 탈출)**
- Lipschitz 볼 검증기는 파라미터 공간에 대한 Lipschitz 상수 L을 이용해 안전 영역을 구형 볼로 정의한다. 이 볼 안에 들어오는 변형은 무조건 안전하므로 δ=0이면서 TPR>0를 달성한다.
- 사전 LayerNorm 구조와 LoRA 파라미터 효율성을 이용해 대규모 트랜스포머에 적용 가능한 Lipschitz 상수를 도출한다(정리 3).
6. **정리 4 (구조적 분리)**
- 절대 연속성 가정 하에, 분류기는 δ=0이면 TPR도 0이어야 함을 보인다. 반면 검증기는 δ=0이면서 TPR>0를 달성할 수 있다. 이는 두 아키텍처 사이의 근본적인 차이를 강조한다.
**보조 결과**
- **Proposition 1**: 정보‑이론적 경계 I₀와 δₙ, TPRₙ 사이의 관계를 제시한다.
- **Proposition 2**: 샘플 복잡도 하한을 제시해, 단계 n까지 p²ⁿ개의 라벨이 필요함을 보인다.
- **Proposition 3**: 사전 LayerNorm 트랜스포머에 대한 정확한 Lipschitz 상수를 제공한다.
**실험**
- GPT‑2(124M 파라미터) 모델에 LoRA rank‑4 (d_LoRA=147 456)를 적용해, 조건부 Lipschitz 상수 하에서 δ=0, TPR=0.352를 달성했다.
- 무조건적인 경우에도 차원 d≤17 408 이하에서는 δ=0를 보장한다.
- 실험 결과는 이론적 상한과 일치하며, 검증 기반 접근이 실제 대형 언어 모델에서도 적용 가능함을 입증한다.
**의의 및 한계**
- 분류 기반 안전 게이트는 정보‑이론적 한계 때문에 위험을 충분히 억제하면서도 무한히 많은 유익한 변형을 허용할 수 없다는 강력한 부정 결과를 제공한다.
- 검증 기반 게이트는 이러한 한계를 회피할 수 있지만, 증명 비용, 계산 복잡도, Lipschitz 상수 추정 등 실용적 제약이 존재한다.
- 논문은 “안전 검증 vs. 분류”라는 설계 선택을 정량적으로 평가하는 프레임워크를 제공하며, 향후 연구는 검증 비용 최소화, 더 일반적인 분포 겹침 모델, 그리고 비정상적인 위험 스케줄(예: 1/(n·log n))에 대한 구체적 분석을 다룰 필요가 있다.
**결론**
이 논문은 자기 개선 AI 시스템의 안전 게이트 설계에 있어 두 가지 근본적인 경로를 제시한다. 분류 기반 접근은 파워‑법칙 위험 스케줄 하에서 정보‑이론적 불가능성에 봉착하고, 검증 기반 접근은 Lipschitz 볼을 이용해 위험을 완전히 차단하면서도 일정 수준의 효용을 유지한다. 이러한 결과는 AI 안전 연구에서 안전과 효용 사이의 근본적인 트레이드오프를 명확히 하며, 실제 시스템 설계 시 검증 기반 메커니즘을 우선 고려해야 함을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기