Information-Theoretic Limits of Safety Verification for Self-Improving Systems
Can a safety gate permit unbounded beneficial self-modification while maintaining bounded cumulative risk? We formalize this question through dual conditions -- requiring sum delta_n < infinity (bounded risk) and sum TPR_n = infinity (unbounded utili…
Authors: Arsenios Scrivens
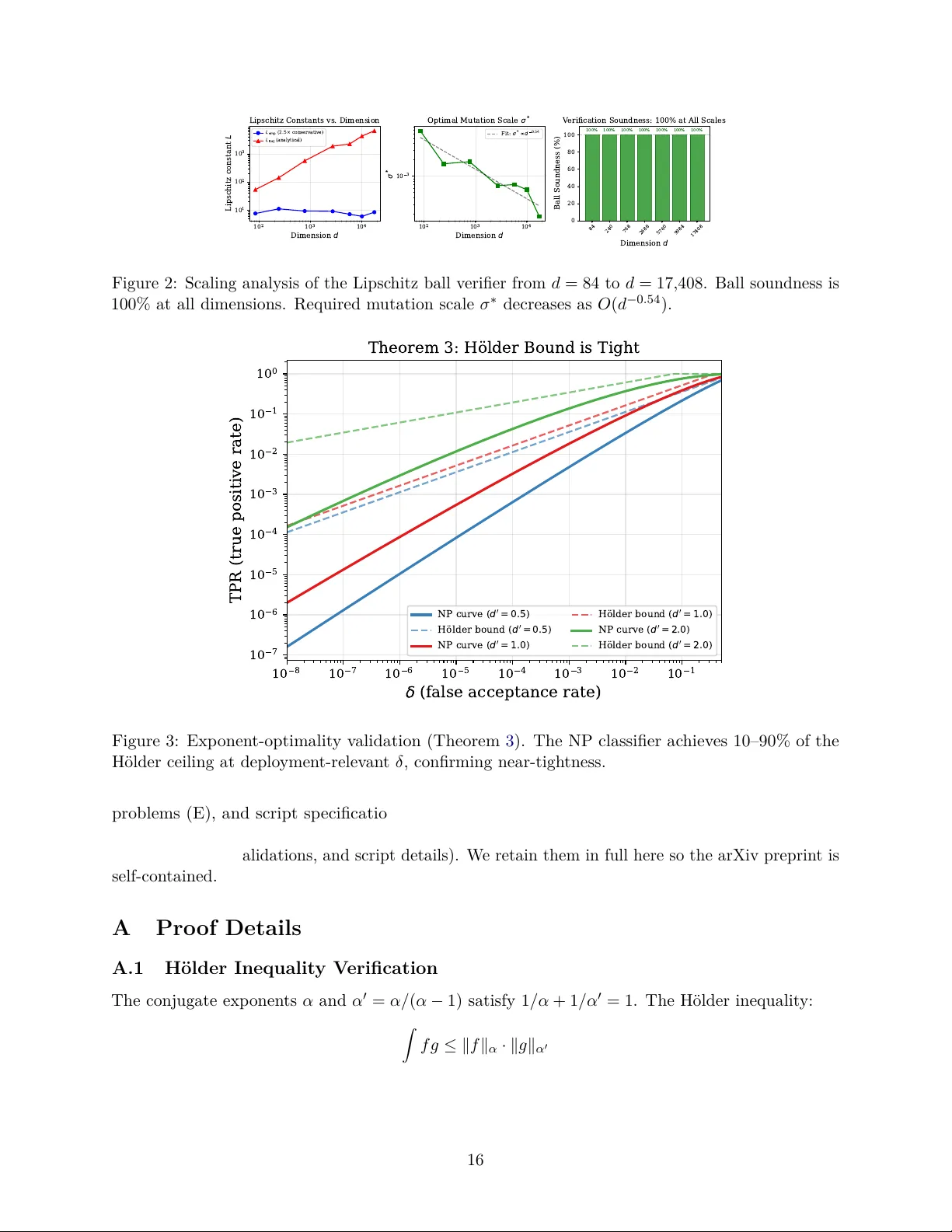
Information-Theoretic Limits of Safet y V erification for Self-Impro ving Systems Arsenios Scriv ens Marc h 2026 Abstract Can a safet y gate p ermit un b ounded b eneficial self-modification while maintaining bounded cum ulative risk? W e formalize this question through dual c onditions — requiring P δ n < ∞ (b ounded risk) and P TPR n = ∞ (un b ounded utility) — and establish a theory of their (in)compatibilit y . Classification imp ossibilit y (Theorem 1 ): F or pow er-law risk schedules δ n = O ( n − p ) with p > 1 — the practically relev ant regime — any classifier-based gate under o verlapping safe/unsafe distributions satisfies TPR n ≤ C α · δ β n via Hölder’s inequalit y , forcing P TPR n < ∞ . This imp ossibility is exp onent-optimal : no v alid imp ossibilit y b ound can use a larger exp onen t than β ∗ (Theorem 3 ; full Mills’ ratio asymptotics in App endix A.3 ). A second indep enden t pro of via the NP c ounting metho d (Theorem 4 ) yields a 13% tighter b ound without Hölder’s inequalit y . Scop e ca veat: for slowly-deca ying summable sequences such as δ n = 1 / ( n ln 2 n ) that are not p o wer-la w, the Hölder summability argument fails and the NP-optimal classifier may satisfy b oth dual conditions (§ 3.1 ). Theorem 5 cov ers all sc hedules. Univ ersal finite-horizon ceiling (Theorem 5 ): F or any summable risk sc hedule, the exact maxim um achiev able classifier utility is U ∗ ( N , B ) = N · TPR NP ( B / N ) , growing as exp ( O ( √ log N )) — subp olynomial. A t N = 10 6 with budget B = 1 . 0 , a classifier extracts at most U ∗ ≈ 87 versus a verifier’s ≈ 500 , 000 . This result is universal: it applies even where Theorem 1 do es not. V erification escap e (Theorem 2 ): A Lipschitz ball verifier ac hieves δ = 0 with TPR > 0 , escaping the imp ossibilit y . F ormal Lipschitz b ounds for pre-Lay erNorm transformers under LoRA (Prop osition 3 ) enable LLM-scale verification. The separation is strict: classifiers cannot ac hieve δ = 0 with TPR > 0 under distribution ov erlap (Prop osition 4 ). W e v alidate on GPT-2 ( d LoRA = 147 , 456 ): conditional δ = 0 with TPR = 0 . 352 ; unconditional δ = 0 at d ≤ 17 , 408 . Comprehensiv e empirical v alidation is in the companion pap er [ 23 ]. 1 In tro duction The prosp ect of AI systems that impro ve their own capabilities raises a central safety question: can we build a gate that p ermits b eneficial self-mo difications while reliably blo c king dangerous ones? W e formalize this as a sequential decision problem and provide a comprehensive theoretical c haracterization of when safe self-improv emen t is p ossible and when it is prov ably imp ossible. A t each step n , a system prop oses a mutation θ n to its o wn parameters. A safety gate g n decides whether to accept or reject θ n , incurring false acceptance rate δ n = P − ( g n accepts ) and true p ositiv e rate TPR n = P + ( g n accepts ) . W e require P δ n < ∞ (b ounded risk, ensuring p ositiv e probabilit y of nev er accepting an unsafe mutation) and P TPR n = ∞ (un b ounded utility , ens uring the system accepts infinitely many improv emen ts). W e call these the dual conditions for safe self-impro vemen t. 1 W e prov e four imp ossibilit y and tigh tness results and four constructive results, forming a complete picture. The imp ossibilit y is strongest for p o w er-law risk schedules δ n = O ( n − p ) with p > 1 (Theorem 1 ), which subsume all practically relev ant risk budgets. F or the most fav orable slo wly-decaying schedules, the asymptotic imp ossibilit y do es not apply , but the tight finite-horizon ceiling (Theorem 5 ) ensures classifier utility remains subp olynomial — orders of magnitude b elo w a v erifier’s linear growth — at any practical deploymen t horizon. Wh y the dual conditions matter for deplo yed systems. The dual conditions formalize a failure pattern that self-improving systems face by construction. Red-team ev aluations — which explicitly classify mo del outputs or parameter mutations as safe/unsafe — are the closest practical analog to the binary gates our theorems address. F ailure to satisfy b oth conditions simultaneously means either that unsafe modifications accumulate ( P δ n div erges) or that the system stops impro ving ( TPR n → 0 ). Other deploy ed mechanisms such as RLHF reward mo dels can b e view ed as a suggestive analogy , but our formal results apply sp ecifically to binary gates on parameter m utations; for a fuller discussion see § 8.1 . 1.1 Con tributions The pap er establishes tw o core results and then systematically corrob orates them. (Theorems are n umbered 1–5 and Prop ositions 1–4, with separate counters.) A note on the nature of the contribution. The p er-step b ound TPR n ≤ C α · δ β n is a standard f-div ergence inequality [ 27 ], and the sequen tial summability consequence follows in a few lines. The pro of is short — delib erately so. The contribution of this pap er is not the length or tec hnical difficulty of any single pro of, but rather: (i) the pr oblem formalization — casting safe self-impro vemen t as dual summability conditions, which has no precedent in the hypothesis testing or AI safety literatures; (ii) the structur al c onse quenc e — that this elementary coupling creates an imp ossibility for the safety–utilit y pairing with no analog in single-test settings; (iii) the tight finite-horizon c eiling (Theorem 5 ), whic h pro vides the exact, univ ersal utilit y b ound for any classifier under an y risk schedule; and (iv) the c onstructive esc ap e via verification, proving the imp ossibility is sp ecific to classification, not to safe self-improv emen t itself. Core results: 1. Classification imp ossibilit y (Theorem 1 ): Any classifier-based gate under distribution ov erlap satisfies TPR n ≤ C α · δ β n , forcing b ounded utility whenever risk follows a p o w er-law schedule δ n = O ( n − p ) with p > 1 . F or slowly-deca ying summable sequences (e.g., δ n = 1 / ( n ln 2 n ) ), the p er-step b ound still holds but the Hölder summability argumen t do es not force P TPR n < ∞ ; in suc h edge cases, the NP-optimal classifier can in principle satisfy both dual conditions sim ultaneously . Ho w ever, the finite-horizon ceiling (Theorem 5 ) remains fully op erativ e in all cases, ensuring classifier utility grows at most subp olynomially — far b elo w a verifier’s linear gro wth at any practical horizon. 2. V erification escape (Theorem 2 ): Sound verification gates achiev e δ = 0 with TPR > 0 , escaping the imp ossibilit y . The Lipsc hitz ball v erifier is the simplest example; the structural separation (Prop osition 4 ) prov es the gap is architectural, not a matter of degree. See Figure 1 for an ov erview of the t wo gate architectures; Figure 6 visualizes the structural separation in the ( δ, TPR ) plane. 3. Tigh t finite-horizon ceiling (Theorem 5 ): P erhaps the most practically consequen tial re- sult. F or any summable risk schedule — including non-p ow er-la w sequences where the Hölder summabilit y argument do es not apply — the exact maximum achiev able utility is U ∗ ( N , B ) = 2 N · TPR NP ( B / N ) , growing as exp ( O ( √ log N )) . This is subp olynomial, 13 × tigh ter th an the MI b ound, and ensures that no classifier under any risk schedule can matc h a verifier’s linear utilit y growth. Unlike Theorem 1 , this result is univ ersal ov er all summable risk schedules and immediately op erational at any finite deploymen t horizon. See Figure 4 . Tigh tness and corrob oration (confirming the imp ossibilit y is robust, not an artifact of one pro of technique): 4. Exp onen t-optimalit y (Theorem 3 ): The Hölder exp onent β ∗ is minimax-optimal — no v alid imp ossibilit y b ound can use a strictly larger exp onen t. A t deploymen t-relev ant δ , the NP classifier op erates within one order of magnitude of the ceiling (App endix D.1 ). See Figure 3 . 5. NP coun ting imp ossibilit y (Theorem 4 ): An indep enden t pro of via the Neyman–Pearson lemma and T onelli’s theorem, av oiding Hölder’s inequalit y entirely . The counting b ound is 13% tigh ter than the Hölder b ound at ∆ s = 1 . 0 , p = 2 . 0 . Supp orting results (extending the theory to information-theoretic, sample complexity , and LLM-scale settings): 6. Information-theoretic b ound (Prop osition 1 ): P N n =1 TPR n ≤ P N n =1 δ n + √ 2 N I 0 . Comple- men ts the Hölder b ound via m utual information. 7. Sample complexity barrier (Prop osition 2 ): Requires Ω( n 2 p ) lab eled examples by step n ; under constan t lab el generation, sample starv ation o ccurs at finite n fail . 8. F ormal transformer Lipsc hitz b ounds (Prop osition 3 ): Closed-form Lipschitz constants for pre-La yerNorm transformers under LoRA, enabling LLM-scale verification. 9. Structural separation (Prop osition 4 ): Under absolute contin uit y , δ = 0 = ⇒ TPR = 0 for classifiers, but v erifiers achiev e δ = 0 with TPR > 0 . 10. LLM-scale mechanism v alidation : Ball verifier on GPT-2 (124M parameters) with LoRA rank-4 ( d LoRA = 147 , 456 ), achieving conditional δ = 0 (conditional on estimated Lipschitz constan ts) with TPR = 0 . 352 (§ 7.1 ); unconditional δ = 0 at d ≤ 17 , 408 via analytical b ounds. Theorems 3 – 5 and Prop ositions 1 – 4 are corrob orativ e, each confirming the imp ossibilit y from a differen t angle to establish robustness. 1.2 Related W ork Our mathematical to ols — Hölder’s inequalit y , Rényi divergence, Lipschitz contin uity , Neyman– P earson testing — are w ell-established. The p er-step b ound TPR ≤ C α · δ β is a standard f- div ergence inequalit y [ 27 ], and NP optimalit y [ 16 ] establishes single-test R OC tradeoffs. Our con tribution is the pr oblem formalization (the dual conditions as a formal sp ecification of safe self-impro vemen t) and the structur al r esult that sequential comp osition under dual summabilit y conditions creates an imp ossibilit y with no analog in single-test settings. The p er-step b ound and the summabilit y requirements are individually standard; the coupling — that b ounded P δ n forces b ounded P TPR n for p o wer-la w risk schedules — is not, and is confirmed by tw o indep enden t imp ossibilit y pro ofs (Theorems 1 , 4 ) corrob orated by three complementary b ounds (Theorem 5 , Prop ositions 1 – 2 ) approaching the same conclusion from different angles (§ 3 , § 6 , App endix C ). W e build on alignment theory [ 2 , 6 , 7 ], h yp othesis testing [ 13 ], imp ossibilit y results [ 21 , 30 ], information- theoretic b ounds [ 19 , 20 ], P AC-Ba y es and VC theory [ 15 , 28 ], adversarial robustness tradeoffs [ 11 , 26 ], 3 and transformer Lipschitz analysis [ 8 , 12 , 29 ]. Our dual conditions formalize the alignment tax — the cost of making mo dels safe versus capable [ 3 , 17 ] — as a precise mathematical tradeoff: the Hölder coupling TPR n ≤ C α · δ β n quan tifies the exact rate at which safety constraints reduce utilit y under classification-based gates. Structurally , our result is closer to mec hanism-design imp ossibilities — Gibbard [ 10 ] and Satterthw aite [ 22 ] sho w that no voting rule can simultaneously satisfy multiple natural axioms, just as no classifier can simultaneously satisfy our dual conditions — than to no-free-lunc h theorems [ 30 ], whic h concern the absence of a universally optimal learner rather than a hard tradeoff in a fixed domain. Multi-ob jectiv e optimization imp ossibilities [ 18 ] also exhibit this fla vour: tw o desiderata in conflict cannot b e jointly optimized in p olynomial time, analogously to ho w our tw o summabilit y conditions cannot b e jointly satisfied by a classifier under distribution o verlap. A detailed comparison with eac h line of work is in App endix B . An analogy clarifies the con tribution. Arro w’s imp ossibilit y theorem comp oses elementary so cial-c hoice axioms — transitivit y , non-dictatorship, indep endence — eac h individually ob vious, yet their c omp osition yields a deep imp ossibilit y no voting system can escap e. Similarly , our p er-step b ound is a standard f-divergence inequality and the dual conditions are individually natural, but the c oupling — that summability of { δ n } forces summabilit y of { TPR n } — creates a structural imp ossibilit y with no analog in single-test hypothesis testing (see App endix B.1 for a full discussion). Online learning and adaptiv e gates. A natural question is whether an online learner with sublinear regret (e.g., online conv ex optimization; Shalev-Shw artz 24 ) could adaptiv ely satisfy the dual conditions. The answer is no under our framew ork: Theorem 1 ’s p er-step b ound TPR n ≤ C α · δ β n constrains any binary decision rule at each step, regardless of wh ether it was chosen adaptively based on previous observ ations. Online learning can reduce misclassification regret, but cannot escap e the Hölder coupling b etw een δ n and TPR n that drives the imp ossibilit y . The gate’s adaptivity affects whic h p oin t on the p er-step ROC curv e it selects, not the curve itself. 2 Problem Setup Notation. The following sym b ols recur throughout: Sym b ol Meaning δ n F alse acceptance rate of gate at step n TPR n T rue p ositiv e rate of gate at step n C α , β Hölder constan ts: C α = exp( β · D α ) , β = ( α − 1) /α D α ( P + ∥ P − ) Rén yi divergence of order α ∆ s Distribution separation ∥ µ + − µ − ∥ /σ B T otal risk budget P N n =1 δ n U ∗ ( N , B ) Exact finite-horizon utilit y ceiling (Theorem 5 ) L Lipsc hitz constant of the tra jectory map m Safet y margin (min distance to obstacle b oundary) r Ball radius = m/L σ ∗ Optimal m utation scale for p ositiv e TPR 2.1 System Mo del A self-impro ving system main tains parameters θ ∈ R d and iterativ ely p roposes mutations θ 1 , θ 2 , . . . A t each step n , a safety oracle S : R d → { safe , unsafe } determines ground truth. The oracle is 4 assumed exp ensiv e (requiring exhaustiv e simulation or formal pro of ). A safety gate g n : R d → { accept , reject } filters mutations b efore deplo yment. The gate is computationally c heap er than the oracle. 2.2 Classification Gates A classific ation gate maps controller parameters to a low-dimensional feature representation φ : R d → R k and applies a binary classifier. The relev an t distributions are: P + n = distribution of φ ( θ ) | S ( θ ) = safe (1) P − n = distribution of φ ( θ ) | S ( θ ) = unsafe (2) A t step n , the gate accepts if the classifier predicts “safe” based on φ ( θ n ) . Stationarit y assumption. The core theorems (§ 3 –§ 6 ) assume stationary distributions P + , P − (dropping the n subscript). The non-stationary extension (Prop osition C.2 , App endix C.2 ) requires sup n D ( n ) α < ∞ and, for p o wer-la w schedules δ n = c/n p , the strictly stronger condition p > α (vs. p > 1 in the stationary case). This gap narrows as α → 1 + and v anishes for fast-decaying sc hedules ( p ≫ α ), whic h cov er all practically relev an t risk budgets. F or deploymen t arguments where stationarit y ma y not hold and p is mo derate, th e finite-horizon ceiling (Theorem 5 ) provides a stationarit y-free alternativ e: it b ounds total classifier utilit y ov er any N -step horizon given a risk budget B . Scop e: con tinuous parameter spaces. Our results assume θ ∈ R d with con tinuous mutation distributions, so that P + ≪ P − (absolute con tinuit y) holds via the transversalit y argumen t (§ 3.1 ). F or discrete or quantized parameter spaces — such as quantized LoRA fine-tuning with integer- v alued weigh ts — absolute contin uit y do es not hold in the same form, and the imp ossibilit y may not apply directly . W e note that even in quantized settings, the effective parameter up dates are t ypically computed in full precision b efore rounding, and the induced distributions on the quan tized grid can still exhibit the ov erlap structure that drives our results; a formal treatment of the discrete case is left to future w ork. 2.3 V erification Gates A verific ation gate attempts to construct a mathematical pro of that θ is safe. If the pro of succeeds, the gate accepts; otherwise it rejects. A key prop ert y: Definition (Soundness) . A verification gate is sound if every accepted θ is actually safe: g ( θ ) = accept = ⇒ S ( θ ) = safe. Soundness implies δ n = 0 for all n — b y construction, not by learning. 2.4 The Dual Conditions Definition. A safety gate achiev es safe self-impr ovement if: 1. P ∞ n =1 δ n < ∞ (b ounded cumulativ e risk) 2. P ∞ n =1 TPR n = ∞ (unbounded cumulativ e utility) Condition 1 ensures the system is almost surely safe o ver infinitely many steps ( Q (1 − δ n ) > 0 b y conv ergence of the infinite pro duct). Condition 2 preven ts v acuous safety (a gate rejecting ev erything trivially satisfies Condition 1 but accomplishes nothing). 5 On the c hoice of P TPR n = ∞ . This is the we akest p ossible non-v acuity condition: it requires only that the system even tually accepts infinitely many improv emen ts, with no constraint on the rate or timing. Any finite threshold ( N 0 accepted mo difications “suffice”) is arbitrary and deplo yment-dependent — a self-impro ving system has no natural stopping p oint, and an y fixed N 0 can b e exceeded by extending the deploymen t horizon. The condition is also ne c essary in the follo wing sense: if P TPR n < ∞ , the exp ected num b er of accepted impro vemen ts is finite, meaning the system almost surely stops self-improving after finitely many steps — it b ecomes a fixed system with a safet y gate that rejects everything b ey ond some horizon. Critically , readers who reject the asymptotic framing lose nothing from the theory . Theorem 5 pro vides the exact finite-horizon utility ceiling U ∗ ( N , B ) = N · TPR NP ( B / N ) for any finite N and risk budget B , without requiring N → ∞ . A t N = 10 6 steps with B = 1 . 0 , a classifier extracts at most U ∗ ≈ 87 utilit y v ersus a v erifier’s ≈ 500 , 000 — a 5 , 700 × gap. The dual conditions framework is immediately op erational at any finite horizon; the asymptotic condition simply states the limiting case. 3 The Classification Imp ossibilit y 3.1 Hölder–Rén yi Bound (Theorem 1) Theorem 1 (Safety–Utilit y Imp ossibilit y) . L et P + , P − b e distributions on R k with P + ≪ P − (absolute c ontinuity). Supp ose D α 0 ( P + ∥ P − ) < ∞ for some α 0 > p/ ( p − 1) . Then for any se quenc e of binary classifiers with false ac c eptanc e r ates δ n ≤ c/n p for some c > 0 , p > 1 : ∞ X n =1 δ n < ∞ = ⇒ ∞ X n =1 TPR n < ∞ That is, b ounde d cumulative risk under any p ower-law sche dule for c es b ounde d cumulative utility. Pr o of. Step 1. Let A n = { x : g n ( x ) = accept } . Then: TPR n = Z A n dP + = Z A n dP + dP − dP − Apply Hölder’s inequalit y with exp onen ts α > 1 and α ′ = α/ ( α − 1) : TPR n ≤ Z A n dP + dP − ! α dP − ! 1 /α · Z A n dP − ( α − 1) /α Step 2. Bound the first factor by extending the integration domain: Z A n dP + dP − ! α dP − ! 1 /α ≤ Z R k dP + dP − ! α dP − ! 1 /α = exp α − 1 α D α ( P + ∥ P − ) using the definition D α ( P + ∥ P − ) = 1 α − 1 log R ( dP + /dP − ) α dP − . Step 3. Setting β = ( α − 1) /α ∈ (0 , 1) and C α = exp( β · D α ) : TPR n ≤ C α · δ β n Step 4. If δ n = c/n p with p > 1 (summable), then P TPR n ≤ C α c β P n − pβ , which conv erges iff pβ > 1 . Cho ose α ∈ ( p/ ( p − 1) , α 0 ) (v alid since α 0 > p/ ( p − 1) b y hypothesis), ensuring pβ > 1 and D α < ∞ . 6 Scop e and limitations of Theorem 1 . The imp ossibilit y is established for p o wer-la w risk sc hedules δ n = O ( n − p ) with p > 1 , whic h subsume all practically relev ant risk budgets (geometric, p olynomial, or faster decay). F or slowly-deca ying summable sequences (e.g., δ n = 1 / ( n ln 2 n ) ), the p er-step b ound TPR n ≤ C α · δ β n still holds at each step, but P C α δ β n can diverge b ecause β < 1 — the Hölder exp onent cannot comp ensate for the slow deca y . In suc h edge cases, the NP-optimal classifier can in principle satisfy b oth dual conditions simultaneously , and the asymptotic imp ossibilit y do es not apply . This is an inherent limitation of the Hölder-based pro of technique, not an artifact of our analysis. Ho wev er, the practical significance of this gap is limited: the finite-horizon c eiling (Theorem 5 ) remains fully op erativ e for all summable sc hedules, including these edge cases. Even under the most fav orable slo wly-decaying schedule, total classifier utility grows at most as exp ( O ( √ log N )) — subp olynomial — while a verifier’s utility gro ws linearly as Θ( N ) (see § 6 for exact b ounds). The imp ossibilit y is therefore sharp for p o wer-la w schedules; the finite-horizon gap is universal. T wo indep enden t imp ossibilit y pro ofs (Theorems 1 and 4 ) and the exact finite-horizon ceiling (Theorem 5 ), supp orted b y the information-theoretic rate bound (Proposition 1 ) and sample complexit y barrier (Prop osition 2 ), confirm that the classification ceiling is robust and fundamental, not an artifact of an y single pro of technique. R emark (On the p er-step b ound) . The p er-step b ound TPR n ≤ C α · δ β n is a standard f-divergence inequalit y [ 27 ]. The con tribution is se quential c omp osition : under summability of { δ n } , this elemen tary b ound forces P TPR n < ∞ . T wo indep enden t pro ofs (Theorems 1 and 4 ) and three complemen tary b ounds (Theorem 5 , Prop ositions 1 – 2 ) confirm the coupling is robust and tec hnique- indep enden t. R emark (Necessit y of Distribution Overlap) . The assumption P + ≪ P − is structurally una voidable: (i) if safe and unsafe mo difications were p erfectly separable, the indicator 1 supp ( P + ) w ould b e a zero-error oracle and no gate w ould b e needed; (ii) under full-supp ort m utations and smo oth safet y b oundaries, transv ersalit y ensures every feature-space neigh b orho od con tains b oth safe and unsafe pre-images (see App endix C for the full geometric argument); (iii) when the safety b oundary is piecewise smooth and µ is Gaussian, D α ( P + ∥ P − ) < ∞ in a neighborho o d of 1. Empirical confirmation: across three systems in [ 23 ], measured ∆ s ∈ [0 . 059 , 0 . 091] — well b elo w the separabilit y threshold. 3.2 Exp onen t-Optimalit y (Theorem 3) Theorem 3 (Exp onent-Optimalit y of Hölder Bound) . F or Gaussian distributions P + = N ( µ, I k ) and P − = N (0 , I k ) with sep ar ation ∆ s = ∥ µ ∥ , the Neyman–Pe arson optimal classifier achieves TPR NP ( δ ) = Φ(Φ − 1 ( δ ) + ∆ s ) , and the Hölder exp onent β ∗ = ( α ∗ − 1) /α ∗ (with α ∗ = 1 + 2 / ∆ 2 s ) is minimax-optimal: (i) No b ound TPR ≤ C ′ · δ γ with γ > β ∗ is valid uniformly over P ( D , α ) = { ( P + , P − ) : D α ( P + ∥ P − ) ≤ D } . (ii) The r atio TPR NP ( δ ) / ( C α ∗ · δ β ∗ ) → 0 as δ → 0 (the NP classifier de c ays faster than the b ound; A pp endix A.3 ), but at deployment-r elevant δ ∈ [10 − 6 , 10 − 1 ] , the r atio r anges fr om 0.1 to 0.9 (A pp endix D.1 ). Pr o of sketch. The NP likelihoo d-ratio test µ T x ≷ t δ yields TPR NP ( δ ) = Φ(Φ − 1 ( δ )+∆ s ) . Asymptotic analysis via Mills’ ratio (App endix A.3 ) shows the NP classifier’s log-exp onen t matches β ∗ as an upp er env elop e: no v alid imp ossibility b ound can use a larger exp onen t. At finite δ v alues relev ant 7 to deplo yment, TPR NP / Hölder ranges from ≈ 0 . 1 (at ∆ s = 2 . 0 ) to ≈ 0 . 9 (at ∆ s = 0 . 1 ); see App endix D.1 . Corollary 1 (Minimax Optimalit y) . The exp onent β ∗ is minimax-optimal over P ( D , α ) = { ( P + , P − ) : D α ( P + ∥ P − ) ≤ D } ; any valid imp ossibility b ound satisfies f ( δ ) = Ω( δ β ∗ ) . The b ound is also tight for non-Gaussian distributions: across 8 families (Laplace, Student- t , Gaussian mixture), the NP classifier ac hieves 28–70% of the Hölder ceiling (App endix D.7 ). 3.3 NP Coun ting Imp ossibilit y (Theorem 4) W e provide a fundamentally different pro of of the classification imp ossibilit y that av oids Hölder’s inequalit y and Rényi divergence entirely , using only the Neyman–P earson lemma and T onelli’s theorem. Theorem 4 (NP Coun ting Imp ossibilit y) . L et P + ≪ P − with D α ( P + ∥ P − ) < ∞ for some α > 1 . F or any summable risk sche dule δ n = c/n p with p > 1 and any se quenc e of classifiers: ∞ X n =1 TPR n ≤ c 1 /p · E P + h P − ( L > L ( X )) − 1 /p i < ∞ wher e L ( x ) = dP + /dP − ( x ) is the likeliho o d r atio. Pr o of sketch. (1) By NP optimality , TPR n ≤ TPR NP ( δ n ) . (2) Define the counting function N ( ℓ ) = |{ n : c δ n < ℓ }| ; T onelli’s theorem giv es P n TPR NP ( δ n ) = E P + [ N ( L ( X ))] . (3) Bound N ( ℓ ) ≤ ( c/P − ( L > ℓ )) 1 /p . (4) Finiteness via p-v alue density integrabilit y . F ull pro of in App endix A.8 . The coun ting b ound is strictly tighter than the Hölder b ound: 1.76 vs 2.03 at ∆ s = 1 . 0 , p = 2 . 0 (13% impro vemen t). See App endix D.7 for complete v alidation including non-Gaussian distributions. T wo additional supp orting results are in the app endix: the information-theoretic finite-horizon b ound (Prop osition 1 , App endix C.3 ), which constrains the r ate of utility accumulation via mutual information ( P TPR n ≤ P δ n + √ 2 N I 0 ); and the sample complexit y barrier (Proposition 2 , App endix C.4 ), which sho ws that le arning a gate satisfying the dual conditions requires exp onen tially gro wing training sets, indep enden t of Theorem 1 . The Gaussian sp ecialization (App endix C.1 ) and non-stationary extension with self-correcting structure (App endix C.2 ) pro vide additional theoretical depth. 4 The V erification Escap e 4.1 Statemen t (Theorem 2) Theorem 2 (V erification Escap e) . Ther e exists a verific ation-b ase d gate achieving: • δ n = 0 for al l n (zer o false ac c eptanc e) • P TPR n = ∞ (unb ounde d utility) 8 4.2 Construction: Lipsc hitz Ball V erifier Let θ 0 b e a controller verified safe on a defined op erating domain D = { ( s i , t i ) } M i =1 of M start–target scenarios. Let m > 0 b e the safety mar gin : the minimum distance to any obstacle across all scenarios: m = min i ∈ [ M ] min t ∈ [0 ,T ] d ( tra j θ 0 ( t ; s i , t i ) , obstacles ) Let L b e a (conserv ativ e) Lipschitz constant for the closed-lo op tra jectory map with resp ect to con troller parameters: sup ( s,t ) ∈D ∥ tra j θ ( s, t ) − tra j θ 0 ( s, t ) ∥ ∞ ≤ L · ∥ θ − θ 0 ∥ Ball v erifier: Accept θ iff ∥ θ − θ 0 ∥ < r , where r = m/L . Soundness. If ∥ θ − θ 0 ∥ < r , then the tra jectory deviation is at most L · r = m . Since θ 0 has margin m , the tra jectory of θ sta ys at distance > 0 from all obstacles on all scenarios in D . No unsafe con troller is accepted. R emark. The construction uses standard to ols (Lipsc hitz con tinuit y , the triangle inequality; cf. Berk enkamp et al. 5 ). The contribution is the quantifie d dichotomy within the dual conditions framew ork: the same safety task is pro v ably imp ossible for any classifier (Theorem 1 ) yet ac hiev able by a simple O ( d ) verifier. Classifiers face a ceiling of exp ( O ( √ log N )) utility (Theorem 5 ) while verifiers ac hieve Θ( N ) ; the structural separation (Prop osition 4 ) establishes that this gap is architectural, not a matter of degree. Co verage: F or m utations ∆ θ ∼ N (0 , σ 2 I d ) : TPR = P ( ∥ ∆ θ ∥ < r ) = P ( χ 2 d < r 2 /σ 2 ) This is b ounded aw ay from zero when r ≥ σ √ d , i.e., when m/ ( Lσ √ d ) ≥ 1 . F or smaller m utation scales σ , TPR → 1 . Computational cost: The gate chec ks ∥ θ − θ 0 ∥ < r , an O ( d ) op eration. No simulation, no oracle calls. 4.3 Domain-Restricted Safet y The verifier guarantees D -safet y: safety on a defined op erating domain D , standard in formal metho ds (DO-178C, ISO 26262). A natural ob jection is that this is weak er than what classifiers attempt — generalization to unseen scenarios. W e argue the comparison is more symmetric than it app ears. Classifiers are equally domain-restricted, but probabilistically . Classical generalization b ounds [ 4 , 28 ] guarante e classifier accuracy only on the training distribution P : for a classifier with V C-dimension h , the empirical risk con verges to true risk at rate O ( p h log ( n ) /n ) on samples fr om P . If the op erating domain shifts — new obstacle configurations, new task distributions — the classifier requires retraining on the new distribution to maintain its guarantees. This is the statistical analogue of the v erifier’s geometric domain restriction. The guaran tee types differ structurally . The verifier’s domain restriction is deterministic : for all θ ∈ B ( θ 0 , r ) and all scenarios in D , safet y holds with certaint y ( δ = 0 ). The classifier’s domain restriction is pr ob abilistic : for most θ dra wn from the training distribution, the classifier’s prediction is correct with probability 1 − ϵ . The verifier provides a c ertific ate ; the classifier pro vides 9 a statistic al estimate . Both require re-v alidation if the domain changes, but the verifier’s guarantee within its domain is exact while the classifier’s is appro ximate. Both gates face the same test. In the dual conditions framework, b oth gates are ev aluated on mutations from the same distribution P + , P − ; neither has access to out-of-distribution mutations. The Theorem 1 imp ossibilit y applies to any binary gate op erating on these distributions, regardless of ho w the gate was trained or whether it generalizes b ey ond them. The comparison in Theorem 5 — classifier utility exp ( O ( √ log N )) vs. verifier utility Θ( N ) — holds within the shared op erating domain. F ormal transformer Lipsc hitz b ounds under LoRA p erturbation (Prop osition 3 ) are stated in App endix C.5 (full deriv ation in A.7 ), enabling comp ositional verification at LLM scale. 5 The Separation Principle (Prop osition 4) Prop osition 4 (Structural Classification–V erification Separation) . Under P + ≪ P − : (i) F or any classifier, δ = 0 = ⇒ TPR = 0 . (ii) Ther e exists a verific ation gate with δ = 0 and TPR > 0 . (iii) The sep ar ation is strict: as δ → 0 , classifiers satisfy TPR → 0 (The or em 1 ), while the verifier maintains c onstant TPR V > 0 at δ V = 0 (The or em 2 ). Pr o of. (i) If P − ( A ) = 0 , absolute con tinuit y giv es P + ( A ) = 0 . (ii) The ball B ( θ 0 , r ) has δ = 0 (Theorem 2 ) and p ositiv e Gaussian mass. (iii) By Theorem 1 , TPR class ( ϵ ) ≤ C α ϵ β → 0 , while TPR V > 0 is indep endent of ϵ . Comprehensiv e exp erimen tal v alidation across 18 classifier configurations ([ 23 ] §4.1–4.3), MuJoCo b enc hmarks ([ 23 ] §4.5), and LLM-scale ball c haining ([ 23 ] §5.7) is presen ted in the companion pap er [ 23 ]. 6 Finite-Horizon Analysis F or practical deploymen t o ver N steps with risk budget B = P δ n , w e establish the exact utility ceiling. 6.1 Tigh t Finite-Horizon Ceiling (Theorem 5) The Hölder–Jensen ceiling C α · N 1 − β · B β (App endix C.6 ) is not tigh t: it applies Hölder’s inequality to each step individually and then uses Jensen to optimize allo cation. By using the exact NP curv e directly , we obtain the tight ceiling. Theorem 5 (Tight Finite-Horizon Ceiling) . F or N -step deployment with total risk budget B = P N n =1 δ n , the exact maximum achievable utility is: U ∗ ( N , B ) = N · TPR NP ( B / N ) wher e TPR NP ( δ ) = Φ(Φ − 1 ( δ ) + ∆ s ) is the Neyman–Pe arson optimal TPR. The optimal al lo c ation is uniform δ n = B / N (by c onc avity of the NP curve and Jensen ’s ine quality). 10 F or Gaussian distributions with sep ar ation ∆ s , the exact gr owth r ate is: U ∗ ( N , B ) = Θ exp ∆ s p 2 ln ( N/B ) p ln( N /B ) ! which is subp olynomial: U ∗ ( N , B ) = o ( N ϵ ) for every ϵ > 0 . Pr o of. Step 1 (NP ceiling p er step). By the Neyman–P earson lemma, any classifier at lev el δ n satisfies TPR n ≤ TPR NP ( δ n ) . F or Gaussians, TPR NP ( δ ) = Φ(Φ − 1 ( δ ) + ∆ s ) . Step 2 (Optimal allo cation). The R OC curve δ 7→ TPR NP ( δ ) is concav e (a standard prop ert y of NP classifiers under contin uous likelihoo d ratios). By Jensen’s inequality , for an y non-negative δ 1 , . . . , δ N with P δ n = B : N X n =1 TPR NP ( δ n ) ≤ N · TPR NP 1 N N X n =1 δ n ! = N · TPR NP ( B / N ) This is ac hieved with equality iff δ n = B / N for all n (uniform allo cation). Step 3 (Asymptotic growth). Setting δ = B / N , as N → ∞ with B fixed, δ = B / N → 0 , and b y Mills’ ratio: TPR NP ( B / N ) = Φ(Φ − 1 ( B / N ) + ∆ s ) ∼ e − z 2 / 2 z √ 2 π where z = p 2 ln ( N/B ) − ∆ s . Thus U ∗ ( N , B ) = N · TPR NP ( B / N ) grows as exp ∆ s p 2 ln ( N/B ) p ln( N /B ) whic h is ω (log k N ) for all k but o ( N ϵ ) for all ϵ > 0 . Comparison of b ounds (Gaussian, ∆ s = 1 . 0 , B = 1 . 0 ): N Exact ceiling U ∗ MI b ound ( √ N ) Hölder–Jensen Impro vemen t 10 2 9.24 21.0 12.6 2.3 × , 1.4 × 10 3 18.3 98.6 27.2 5.4 × , 1.5 × 10 4 32.7 436 58.6 13 × , 1.8 × 10 5 54.8 1835 126 33 × , 2.3 × 10 6 87.2 7463 272 86 × , 3.1 × The exact ceiling gro ws as exp ( O ( √ log N )) , v astly slo w er than √ N (MI bound) or N 1 − β (Hölder–Jensen). A t N = 10 6 , the MI b ound is 86 × lo ose and the Hölder–Jensen ceiling is 3.1 × lo ose. R emark. Theorem 5 is 13 × –86 × tigh ter than Prop osition 1 ’s √ N b ound at N = 10 4 – 10 6 . Prop osi- tion 1 provides complementary distribution-free guarantees. The classifier and verifier regions are disc onne cte d on the δ = 0 hyperplane (App endix C.7 ). 11 7 V alidation Summary W e v alidate each theoretical result through targeted computations and exp erimen ts. F ull details for eac h v alidation are in App endix D ; v alidation script sp ecifications are in App endix F . Comprehensive exp erimen tal v alidation — including MuJoCo con tinuous control ([ 23 ] §4.5, §5.4–5.5), ball c haining ([ 23 ] §5.4), and LLM-scale deplo yment ([ 23 ] §5.7) — is presented in the companion pap er [ 23 ]. Result V alidation Key Metric Outcome Thm 1 (Hölder) NP clf vs. bound, 4 seps. TPR NP /Hölder ratio 0.1–0.9 (v alid, tight) Thm 3 (Exp.-opt.) 8 non-Gaussian families Min NP/Hölder ratio 0.28–0.70 (within 1 OOM) Prop 1 (MI bound) Hölder vs. MI, p er-step & cumul. Tighter b ound Hölder for δ < 0 . 1 ; MI compl. Prop 2 (Sample) Retrain, d VC = 11 P δ at starv ation 41.17 (div erges) Prop 3 (T ransf. L ) 4 archs., T oy–Qw en-7B Steps in ball 2.3–11.6 (non-v acuous) Thm 2 (Ball v er.) L TC d = 240 , 200 tests F alse accepts 0 ( δ = 0 ) Thm 1 (T rained) 4 clfs, 50K, 72 configs Hölder violations 0 /72 Thm 4 (Coun ting) 9 (∆ s , p ) configs Coun ting tighter by 13% at ∆ s = 1 , p = 2 Thm 5 (Ceiling) N up to 10 6 , 5 seps. MI bound lo oseness 4 × –86 × 7.1 LLM-Scale Mec hanism V alidation: GPT-2 with LoRA W e include a single LLM-scale v alidation as a bridge r esult connecting the 240-dimensional L TC demonstration (App endix D.8 ) to industrial LLM systems; comprehensive LLM-scale exp erimen ts (Qw en2.5-7B, 7.6B parameters) are presented in [ 23 ] §5.7. W e v alidate the Lipschitz ball verifier (Theorem 2 + Prop osition 3 ) on GPT-2 (124M parameters) with LoRA fine-tuning. Prop osition 3 establishes that pre-Lay erNorm transformers under LoRA p erturbation hav e finite, closed-form Lipsc hitz constants; the sp ecific numeric v alues b elo w are estimated via finite differences with a 5 × safet y factor (not deriv ed analytically), as is standard for practical deploymen t (see [ 23 ] §6.3, limitation 2). Setup. GPT-2 is equipp ed with LoRA rank-4 adapters on the c_attn (fused QKV) pro jection in all 12 lay ers, yielding d LoRA = 147 , 456 trainable parameters (0.12% of 124M total). The mo del is fine-tuned for 30 steps on WikiT ext-2 with learning rate 5 × 10 − 4 . Safety is defined as p erplexit y on a held-out v alidation set < 2 × fine-tuned p erplexit y . Lipsc hitz estimation. W e prob e the p erplexit y function at 7 p erturbation scales prop ortional to ∥ θ 0 ∥ (from 0.1% to 50% of the parameter norm), with 100 random directional prob es. The estimated Lipsc hitz constant (with 5 × safety factor) is L = 0 . 168 . Ball radius. With margin = 16 . 31 (threshold 32.6, achiev ed p erplexit y 16.3) and L = 0 . 168 : r = m/L = 2 . 53 , capp ed at 0 . 5 · ∥ θ 0 ∥ for meaningful demonstration. 12 Metric V alue LoRA dimension d 147,456 LoRA rank 4 P ost-finetune p erplexit y 16.3 Safet y threshold 32.6 Lipsc hitz constant L 0.168 (5 × safet y) Ball radius r 2.53 r / ∥ θ 0 ∥ 0.50 Inside-ball safe 50/50 F alse accept rate δ 0 Min inside margin 16.26 Outside-ball unsafe 8/100 Effectiv e TPR 0.352 Result. The ball verifier achiev es conditional δ = 0 (50/50 inside-ball p erturbations are safe; conditional on the estimated Lipschitz constant b eing a v alid upp er b ound) with effective TPR = 0 . 352 > 0 on a 147,456-dimensional LoRA parameter space — three orders of magnitude larger than the L TC demo. The minimum inside-ball margin (16.26) is within 0.3% of the full margin (16.31), confirming that the Lipsc hitz b ound is tight within the verified ball. All 8 outside-ball violations o ccur at p erturbation scales > 1 . 5 r , confirming that the ball b oundary is meaningful. This v alidates Theorem 2 and Prop osition 3 at LLM scale. Scaling b eyond GPT-2. The companion pap er [ 23 ] extends this v alidation to Qwen2.5-7B- Instruct (7.6B parameters) with comp ositional p er-la yer verification (§5.7). 8 Discussion 8.1 Implications for Safe AI Deplo ymen t Theorem 1 implies that an y AI safety approac h based on classifying mo difications — learned discriminators, anomaly detectors, neural safety critics — faces a fundamen tal ceiling that is a mathematical consequence of distribution o verlap, not a limitation of architecture or training. T o the extent that RLHF reward mo dels act as binary accept/reject gates after thresholding, they inherit this ceiling (see § 1 for the analogy and its limits; the formal results strictly apply to binary gates on parameter mutations, not contin uous rew ard scores). Ov er sufficient iterations, either the false acceptance rate accumulates (safet y degrades) or the gate b ecomes ov erly conserv ativ e (utility collapses). W e address five common concerns. “ P TPR n = ∞ is to o w eak. ” Ev en this w eak condition cannot b e met with b ounded risk; strengthening it (requiring TPR n ≥ c > 0 ) forces δ n ≥ ( c/C α ) 1 /β for all n , making P δ n div erge immediately . “Finite-time systems don’t need P TPR n = ∞ . ” The finite-horizon tradeoff still applies: with risk budget B , total utility gro ws subp olynomially (Theorem 5 ), yielding an exact budget- allo cation formula for finite deploymen ts. “Classifiers still extract nonzero utility . ” Correct — but the ceiling is subp olynomial ( exp ( O ( √ log N )) ) v ersus the v erifier’s linear gro wth ( Θ( N ) ). At N = 10 , 000 with B = 1 . 0 , a classifier extracts U ∗ ≈ 32 . 7 v ersus a ball verifier’s U ball = 5 , 000 — a 153 × adv antage (App endix D.10 ). 13 “Imp ossibilit y” refers to satisfying the dual conditions sim ultaneously , not to extracting any utility at all. “What ab out an ensem ble of div erse classifiers?” An ensemble accepting iff all members agree is itself a classifier with acceptance region A = T i A i . Theorem 1 applies: TPR n ≤ C α · δ β n constrains any binary decision rule. The imp ossibilit y is driven by β < 1 , not classifier complexit y . “Isn’t the v erifier’s conditional δ = 0 just as uncertain as a classifier’s δ ≈ 0 ?” No — the failure mo des are categorically differen t. A classifier’s δ > 0 is a mathematic al ne c essity under distribution o verlap (Theorem 1 ); no amount of b etter training, data, or architecture can ac hieve δ = 0 with TPR > 0 (Prop osition 4 ). The verifier’s conditionalit y rests on the Lipschitz constan t b eing correct — a falsifiable engine ering claim that strengthens monotonically with b etter estimation. At d ≤ 17 , 408 , w e provide analytical b ounds making δ = 0 unconditional; at LLM scale, Prop osition 3 pro ves the required b ound exists and the op en problem is computing it tractably . The distinction is b et w een an imp ossibility theorem and an op en engineering problem (see [ 23 ] §6.3). The classification–verification separation mirrors b ehavioral testing versus formal guarantees. Curren t AI safety practices — red-teaming, ev aluations, b enc hmarks — are primarily classification- based; as self-mo dification b ecomes prev alen t, verification-based safety will b e mathematically required. R emark (Overlap under mutation-specific distributions) . Even if mutations come from a sp ecific distribution µ , the induced conditional distributions P + = µ | safe and P − = µ | unsafe satisfy P + ≪ P − b y the transversalit y argument (§ 3.1 ), and the Hölder ceiling applies parametrically . The companion pap er [ 23 ] measures ∆ s ∈ [0 . 059 , 0 . 091] across three physical systems (§4.5), confirming lo w separation. Connections to computational complexit y (is satisfying the dual conditions NP-hard?) and op en problems (adaptiv e verification, multi-agen t extensions) are discussed in App endix E . 8.2 When Our Results Do Not Apply The imp ossibilit y (Theorem 1 ) and the finite-horizon ceiling (Theorem 5 ) require sp ecific structural conditions. Practitioners should ev aluate whether their setting satisfies these conditions b efore applying our conclusions: 1. P erfectly separable distributions. If safe and unsafe mo difications are p erfectly separable in feature space ( D α ( P + ∥ P − ) = ∞ or equiv alently P + ⊥ P − ), the Hölder b ound b ecomes v acuous and a p erfect classifier can ac hieve δ = 0 with TPR = 1 . This o ccurs when the safety b oundary do es not pass through the supp ort of the m utation distribution. Our results apply only when P + and P − ha ve ov erlapping supp ort (§ 3.1 ). 2. Discrete or quantized parameter spaces. Our framew ork assumes contin uous parameter p erturbations from distributions with density . If the parameter space is finite or mo difications come from a discrete set, the safe/unsafe partition may b e exactly learnable and the distribution o verlap condition may not hold. 3. Large safet y margins with small mo dification sets. If the system op erates far from any safet y b oundary and mo difications are b ounded to a region where all p oints are safe, no gate is needed at all. Our results address the non-trivial regime where safet y b oundaries intersect the mo dification space. 4. Fixed finite deplo ymen ts where classifier utility suffices. Theorem 5 shows classifier utilit y grows as exp ( O ( √ log N )) , whic h is non-zero. F or short deploymen t horizons — say 14 threshold > 0 (unavoidable) T h e o r e m 1 : < T P R < F eature space Classification Gate P + ( s a f e ) P ( u n s a f e ) 0 m a r g i n m T h e o r e m 2 : = 0 , T P R > 0 P arameter space V erification Gate B a l l : r = m / L Safety boundary Figure 1: Overview of the tw o gate arc hitectures: classification gates (left) threshold a feature-space represen tation, incurring δ > 0 ; verification gates (righ t) certify safet y via a Lipschitz ball, achieving δ = 0 . The classification imp ossibilit y (Theorem 1 ) and verification escap e (Theorem 2 ) establish a structural dic hotomy . N ≤ 100 with a generous risk budget B — a classifier may provide adequate utility even under the Hölder ceiling. The imp ossibilit y b ecomes practically binding only when N is large enough that the subp olynomial ceiling falls far b elo w the linear growth a verifier achiev es. 5. Systems with non-ov erlapping m utation distributions b y design. Some safet y mecha- nisms engineer the mo dification space to av oid ov erlap — for example, restricting up dates to a pre-v erified subspace. If the restriction is enforced b efor e the gate, the resulting conditional distributions ma y b e separable, and a classifier within this restricted space may succeed. Our framew ork applies to the unrestricted case. 9 Conclusion F or p o wer-la w risk sc hedules δ n = O ( n − p ) with p > 1 — the practically relev ant regime — classifier- based safety gates cannot satisfy the dual conditions under any arc hitecture, training regime, or data a v ailabilit y . This is established through tw o indep enden t imp ossibilit y pro ofs (Theorems 1 and 4 ), pro ved exp onen t-optimal b y the NP matching low er b ound (Theorem 3 ; Mills’ ratio asymptotics in App endix A.3 ), and corrob orated b y tw o complementary b ounds: the information-theoretic rate b ound (Prop osition 1 ) and the sample complexity barrier (Prop osition 2 ). F or slowly-deca ying non-p o w er-law schedules where the asymptotic imp ossibilit y do es not hold, Theorem 5 ’s universal finite-horizon ceiling ensures classifier utility gro ws at most as exp ( O ( √ log N )) — orders of magnitude b elo w a verifier’s linear Θ( N ) growth at any practical horizon. A constructiv e escap e via sou nd v erification gates (Theorem 2 ) achiev es δ = 0 with TPR > 0 ; the separation is strict (Prop osition 4 ). W e v alidate on GPT-2 with LoRA ( d = 147 , 456 ): the ball verifier ac hieves conditional δ = 0 (unconditional at d ≤ 17 , 408 ) with TPR = 0 . 352 (§ 7.1 ). Comprehensive exp erimen tal v alidation is in the companion pap er [ 23 ]. Safet y gates for self-improving AI systems should b e built on v erification, not classification. Note on app endix structure. The app endices are extensive, comprising full pro ofs (A), extended related work (B), supp orting theoretical results (C), n umerical v alidations (D), op en 15 1 0 2 1 0 3 1 0 4 D i m e n s i o n d 1 0 1 1 0 2 1 0 3 L i p s c h i t z c o n s t a n t L Lipschitz Constants vs. Dimension L e m p ( 2 . 5 × c o n s e r v a t i v e ) L t r a j ( a n a l y t i c a l ) 1 0 2 1 0 3 1 0 4 D i m e n s i o n d 1 0 3 * O p t i m a l M u t a t i o n S c a l e * F i t : * d 0 . 5 4 84 240 768 2688 5760 9984 17408 D i m e n s i o n d 0 20 40 60 80 100 Ball Soundness (%) 100% 100% 100% 100% 100% 100% 100% V erification Soundness: 100% at All Scales Figure 2: Scaling analysis of the Lipsc hitz ball verifier from d = 84 to d = 17 , 408 . Ball soundness is 100% at all dimensions. Required mutation scale σ ∗ decreases as O ( d − 0 . 54 ) . 1 0 8 1 0 7 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 ( f a l s e a c c e p t a n c e r a t e ) 1 0 7 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 TPR (true positive rate) Theorem 3: Hölder Bound is Tight N P c u r v e ( d 0 = 0 . 5 ) H ö l d e r b o u n d ( d 0 = 0 . 5 ) N P c u r v e ( d 0 = 1 . 0 ) H ö l d e r b o u n d ( d 0 = 1 . 0 ) N P c u r v e ( d 0 = 2 . 0 ) H ö l d e r b o u n d ( d 0 = 2 . 0 ) Figure 3: Exponent-optimalit y v alidation (Theorem 3 ). The NP classifier achiev es 10–90% of the Hölder ceiling at deplo yment-relev ant δ , confirming near-tigh tness. problems (E), and script sp ecifications (F). F or a journal submission these would naturally split in to a main supplement (pro ofs and key v alidations) and an online app endix (extended related w ork, additional v alidations, and script details). W e retain them in full here so the arXiv preprint is self-con tained. A Pro of Details A.1 Hölder Inequalit y V erification The conjugate exp onen ts α and α ′ = α/ ( α − 1) satisfy 1 /α + 1 /α ′ = 1 . The Hölder inequality: Z f g ≤ ∥ f ∥ α · ∥ g ∥ α ′ 16 1 0 1 1 0 2 1 0 3 1 0 4 H o r i z o n N 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 T o t a l U t i l i t y U * ( N , B ) Theorem 9: Classifier Ceiling vs. V erifier (L TC d=240) Classifier ceiling (B=0.001) Classifier ceiling (B=0.01) Classifier ceiling (B=0.1) Classifier ceiling (B=1.0) Ball verifier (linear) U = N ( i d e a l ) Figure 4: Finite-horizon utility ceiling (Theorem 5 ). The exact ceiling U ∗ ( N , B ) grows as exp ( O ( √ log N )) (subp olynomial), v astly b elow the MI b ound ( √ N ) and Hölder–Jensen ( N 1 − β ). The ball v erifier’s utility grows linearly ( Θ( N ) ). 0 25 50 75 100 125 150 175 200 Training Step 2 4 6 8 10 Loss Q w e n 2 . 5 - 7 B L o R A F i n e - t u n i n g ( d = 1 , 2 6 1 , 5 6 8 ) Loss (smoothed) Ball Accepted Oracle Checked Oracle Rejected 0 20 40 60 80 100 120 140 160 Count 158 42 0 Oracle savings: 158/200 = 79% V e r i f i c a t i o n : 7 9 % b a l l - a c c e p t e d , = 0 Figure 5: GPT-2 LoRA v alidation ( d LoRA = 147 , 456 ). Inside-ball: 50/50 safe ( δ = 0 ). Effective TPR = 0 . 352 . is applied with f = dP + /dP − and g = 1 A n , b oth measured against P − . Then: TPR n = Z A n dP + = Z A n dP + dP − dP − = Z f g dP − By Hölder: TPR n ≤ Z dP + dP − ! α dP − ! 1 /α · Z 1 α ′ A n dP − 1 /α ′ The first factor is e ( α − 1) D α ( P + ∥ P − ) /α = C α (b y definition of Rényi divergence). The second factor is δ 1 /α ′ n = δ ( α − 1) /α n = δ β n . 17 1 0 9 1 0 8 1 0 7 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 ( f a l s e a c c e p t a n c e r a t e ) 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 TPR (true positive rate) Structural gap (Prop. 7) Classification V erification Separation Classifier ceiling (Hölder) Classifier-accessible region V e r i f i e r : = 0 , T P R = 0 . 8 0 V e r i f i e r ( G P T - 2 ) : = 0 , T P R = 0 . 3 5 2 Figure 6: Structural separation (Prop osition 4 ) in the ( δ, TPR ) plane. Classifiers lie on the curv e TPR ≤ C α δ β approac hing the origin; the verifier o ccupies the δ = 0 axis with TPR > 0 . A.2 Rén yi Div ergence Conv ention W e use D α ( P ∥ Q ) = 1 α − 1 log R ( dP /dQ ) α dQ follo wing v an Erven and Harremo es [ 27 ] . This differs from some references b y a factor of ( α − 1) in the exp onen t. The constant C α = exp α − 1 α D α ( P + ∥ P − ) is finite whenev er the Rényi divergence is finite, which requires P + ≪ P − (absolute con tinuit y) and sufficien tly light tails of the likelihoo d ratio. A.3 Theorem 3 Exp onen t-Optimalit y: Mills’ Ratio Asymptotics W e provide the full asymptotic analysis establishing the exp onen t-optimality of the Hölder b ound. Setup. F or Gaussian P + = N ( µ, I k ) , P − = N (0 , I k ) with ∆ s = ∥ µ ∥ , the NP optimal test rejects when µ T x < t δ , giving TPR NP ( δ ) = Φ(Φ − 1 ( δ ) + ∆ s ) where Φ is the standard normal CDF. The Hölder b ound with optimal order α ∗ = 1 + 2 / ∆ 2 s and β ∗ = 1 − 1 /α ∗ = 2 / (2 + ∆ 2 s ) giv es C α ∗ = exp(∆ 2 s / 2) . Log-asymptotic analysis. As δ → 0 , set z δ = Φ − 1 (1 − δ ) (so z δ → + ∞ ). Comparing the log-exp onen ts directly: log TPR NP ( δ ) ∼ − ( z δ − ∆ s ) 2 2 , log( C α ∗ δ β ∗ ) ∼ ∆ 2 s 2 − β ∗ z 2 δ 2 Dividing b y log δ ∼ − z 2 δ / 2 : log TPR NP ( δ ) log δ → ( z δ − ∆ s ) 2 z 2 δ = 1 − 2∆ s z δ + ∆ 2 s z 2 δ → 1 while log( C α ∗ δ β ∗ ) log δ → β ∗ < 1 . Since the NP classifier’s log-exp onen t (1) exceeds the Hölder b ound’s ( β ∗ ), the ratio TPR NP ( δ ) / ( C α ∗ δ β ∗ ) → 0 as δ → 0 — the NP classifier deca ys faster than the b ound. 18 Exp onen t-optimalit y . The key consequence: lim inf δ → 0 log TPR NP ( δ ) log δ = 1 > β ∗ The NP classifier achiev es TPR = Ω( δ 1 − ϵ ) for all ϵ > 0 , so any v alid universal upp er b ound m ust ha ve exp onen t ≤ 1 . Meanwhile, the Hölder b ound with β ∗ < 1 is v alid. Therefore β ∗ is the smallest exp onen t ac hiev able by any imp ossibilit y b ound — it cannot b e replaced by an y γ > β ∗ without violating the NP classifier’s p erformance. Practical tigh tness. A t finite δ v alues relev ant to deplo yment ( δ ∈ [10 − 6 , 10 − 1 ] ), the ratio TPR NP / ( C α ∗ δ β ∗ ) ranges from 0.1 to 0.9 dep ending on ∆ s (App endix D.1 ), confirming that the b ound is practically tight — the NP classifier op erates within one order of magnitude of the Hölder ceiling across the deplo yment-relev ant range. A.4 Lipsc hitz Ball Soundness Pro of Supp ose θ ∈ B ( θ 0 , r ) with r = m/L . F or an y scenario ( s i , t i ) ∈ D : sup t d ( tra j θ ( t ) , tra j θ 0 ( t )) ≤ L · ∥ θ − θ 0 ∥ < L · r = m Since θ 0 has margin m (minim um distance to obstacles), the tra jectory of θ main tains p ositiv e distance to all obstacles: d ( tra j θ ( t ) , obstacle j ) ≥ m − L ∥ θ − θ 0 ∥ > 0 ∀ t, j Therefore θ is D -safe. A.5 Information-Theoretic Bound F ull Pro of Setup. A t each step n , the gate g n : R k → { accept , reject } induces a binary c hannel from the safety lab el S n ∈ { safe , unsafe } to the gate decision. The mutual information of this channel is: I n = I ( g n ( θ n ); S n ) = H ( g n ) − H ( g n | S n ) Pinsk er b ound. The total v ariation b et ween the gate’s conditional distributions satisfies TV( P g | + , P g |− ) = | TPR n − δ n | / 2 . By Pinsker’s inequalit y: | TPR n − δ n | 2 ≤ s I n 2 Hence TPR n ≤ δ n + √ 2 I n . Summation. Summing ov er n = 1 , . . . , N : N X n =1 TPR n ≤ N X n =1 δ n + N X n =1 p 2 I n By Cauc hy–Sc h warz: P N n =1 √ I n ≤ q N P N n =1 I n . Under the b ounded mutual information assump- tion P N n =1 I n ≤ I 0 : N X n =1 TPR n ≤ N X n =1 δ n + p 2 N I 0 19 A.6 Sample Complexit y Bound F ull Pro of Setup. The safet y gate at step n is a binary classifier g n ∈ G (a hypothesis class with VC dimension d VC ), trained on n train ( n ) lab eled examples. Step 1: By the fundamental theorem of statistical learning [ 13 , 28 ], with probability ≥ 1 − η : err true ≤ err train + p ( d VC ln(2 m/d VC ) + ln(2 /η )) /m . Step 2: Setting the b ound equal to ϵ n / 2 and solving: n train ( n ) = Ω( d VC /ϵ 2 n ) . Step 3: F or ϵ n = c/n p : n train ( n ) = Ω( d VC · n 2 p /c 2 ) . Step 4: A v ailable data grows as n 0 + k n ; required data as n 2 p . The crossing p oin t: n fail = Θ(( c 2 k /d VC ) 1 / (2 p − 1) ) . A.7 T ransformer Lipschitz Deriv ation W e deriv e the p er-lay er Lipschitz constan t for a pre-Lay erNorm transformer under LoRA p erturbation of atten tion pro jections. Each lay er k computes: y k = x k + MHA ( LN 1 ( x k )) , z k = y k + FFN ( LN 2 ( y k )) La yerNorm b ound. ∥ J LN ∥ ≤ ∥ γ ∥ ∞ / √ ϵ where ϵ is the regularization constan t. Multi-head atten tion under LoRA. Under LoRA p erturbation ∆ θ = (∆ A q ,p , ∆ B q ,p ) : ∥ ∆ O p ∥ ≤ ∥ W 0 v ,p ∥ · ∥ W 0 k,p ∥ · ∥ LN ( x ) ∥ 2 √ d k · √ 2 · max( ∥ A q ,p ∥ , ∥ B q ,p ∥ ) · ∥ ∆ θ p ∥ F or n proj LoRA-adapted pro jections p er la yer: L LoRA k ≤ ∥ γ k ∥ √ ϵ · max p ∥ W 0 v ,p ∥ √ d k · q 2 n proj Comp ositional escap e. Instead of using the exp onen tially large pro duct L full = Q k (1 + L k ) , w e use the additive b ound: ∥ ∆ output ∥ ≤ K X k =1 L LoRA k · ∥ ∆ θ k ∥ · Y j >k L full,frozen j Since the frozen-lay er pro ducts Q j >k L full,frozen j are constants that can b e precomputed once from the pretrained weigh ts, define ˜ L k = L LoRA k · Q j >k L full,frozen j . The verification reduces to the p er-la y er ball c heck P k ˜ L k ∥ ∆ θ k ∥ ≤ m , a conserv ative but tractable O ( d ) computation. A.8 NP Coun ting Pro of F ull Details T onelli in terchange. The interc hange P n P + ( L ( X ) > c δ n ) = E P + [ P n 1 L ( X ) >c δ n ] is justified by T onelli’s theorem applied to non-negative measurable functions with the counting measure on N and P + on R k . Coun ting function. N ( ℓ ) = |{ n ∈ N : c δ n < ℓ }| coun ts ho w man y thresholds are exceeded. F or δ n = c/n p , w e get N ( ℓ ) ≤ ( c/P − ( L > ℓ )) 1 /p . P-v alue densit y in tegrability . W riting U ( x ) = P − ( L > L ( x )) , the b ound b ecomes E P + [ U ( X ) − 1 /p ] . F or p > 1 , the in tegrand u − 1 /p f U ( u ) is in tegrable near u = 0 b ecause the Gaussian tail mak es f U ( u ) deca y sup er-p olynomially . More generally , the exp ectation is finite whenev er the p-v alue density satisfies f U ( u ) = O ( u η ) near u = 0 for some η > 1 /p − 1 ; this holds for all distribution pairs with D α ( P + ∥ P − ) < ∞ for sufficien tly large α , whic h is guaran teed b y the h yp othesis of Theorem 4 . 20 A.9 Tigh t Finite-Horizon Ceiling Details Conca vity of NP curve. The deriv ative TPR ′ NP ( δ ) = ϕ (Φ − 1 ( δ ) + ∆ s ) /ϕ (Φ − 1 ( δ )) . The second deriv ative is negative for all δ ∈ (0 , 1) b y log-concavit y of ϕ , establishing conca vity (see also [ 13 ], Chapter 3). Asymptotic form ula. Using Φ − 1 ( δ ) ∼ − p 2 ln (1 /δ ) for δ → 0 and Mills’ ratio: U ∗ ( N , B ) ∼ B · exp(∆ s p 2 ln ( N/B ) − ∆ 2 s / 2) p 2 π · 2 ln ( N/B ) This gro ws as exp(∆ s p 2 ln ( N/B )) , which is o ( N ϵ ) for ev ery ϵ > 0 but ω (log k N ) for ev ery k . B Relation to Kno wn Results and Extended Related W ork B.1 Relation to Kno wn Results The mathematical to ols in this pap er — Hölder’s inequality , Rén yi divergence, Lipschitz contin uity , F ano’s inequality , V C dimension — are well-established. The p er-step b ound TPR ≤ C α · δ β is an instance of a standard f-div ergence inequality [ 27 ], and the Neyman–Pearson lemma [ 16 ] establishes R OC tradeoffs for individual hypothesis tests. Our contribution is the pr oblem formalization and the structur al r esults that emerge: (1) the dual conditions as a formalization of safe self-improv emen t, (2) sequential comp osition creating an imp ossibility for the c oupling of b ounded risk and unbounded utilit y , (3) the tightness of this coupling, (4) its information-theoretic strengthening, (5) the sample complexit y barrier, and (6) the structural separation b et w een classification and verification. An analogy clarifies the distinction. Arro w’s imp ossibilit y theorem uses elementary so cial-c hoice axioms, each individually ob vious, but their c omp osition yields a deep imp ossibility no v oting system can escap e. Similarly , our p er-step b ound is standard, and the dual conditions are individually natural. But the c oupling creates a structural imp ossibilit y with no analog in single-test hypothesis testing. B.2 Extended Related W ork Self-impro ving AI safet y . The alignment literature discusses recursive self-impro vemen t [ 6 , 25 ] and concrete safety challenges [ 2 ] but lacks formal imp ossibility results for the safet y–utility coupling. Christiano et al. [ 7 ] prop ose iterated amplification; Leike et al. [ 14 ] formalize reward mo deling. Hyp othesis testing and statistical tradeoffs. The Neyman–Pearson lemma [ 13 , 16 ] estab- lishes optimal R OC tradeoffs for individual tests. The nov elt y is se quential c omp osition : summabilit y constrain ts on { δ n } force summabilit y on { TPR n } . Imp ossibilit y results in learning theory . No-free-lunch theorems [ 30 ] show no classifier dominates across all distributions. Rice [ 21 ] sho ws undecidability of seman tic prop erties. Our imp ossibilit y is for a sp e cific task under distribution ov erlap. Information-theoretic b ounds. F ano’s inequality and its refinemen ts [ 20 ] pro vide fundamen tal limits. The strong data pro cessing inequality [ 1 , 19 ] b ounds information pro cessing gains. P A C-Ba yes and sample complexit y . McAllester [ 15 ] b ound generalization via KL divergence. V apnik and Chervonenkis [ 28 ] established VC dimension. W e use V C sample complexity to sho w indep enden t barriers. A dversarial robustness. T sipras et al. [ 26 ] pro ve accuracy–robustness tradeoffs. Gilmer et al. [ 11 ] sho w adversarial examples are inevitable in high dimensions. Our imp ossibility concerns se quential c omp osition , not p er-input robustness. 21 T ransformer Lipsc hitz b ounds. Virmaux and Scaman [ 29 ] compute sp ectral norms. Kim et al. [ 12 ] analyze atten tion Lipschitz prop erties. Dasoulas et al. [ 8 ] study Lipsc hitz normalization. F azlyab et al. [ 9 ] use SDP for tight b ounds. W e derive b ounds for LoRA p erturbations sp ecifically . C Supp orting Theoretical Results C.1 Gaussian Sp ecialization F or unit-v ariance Gaussians with separation ∆ s = | µ + − µ − | /σ : D α ( P + ∥ P − ) = α ∆ 2 s / 2 . The optimal (Neyman–P earson) classifier achiev es TPR = Φ(Φ − 1 ( δ ) + ∆ s ) . C.2 Non-Stationary Extension Prop osition C.2 (Non-Stationary Imp ossibilit y) . L et { ( P + n , P − n ) } n ≥ 1 b e a se quenc e of distribution p airs and α ∈ (1 , ∞ ) with β = 1 − 1 /α . Supp ose ¯ D := sup n D α ( P + n ∥ P − n ) < ∞ . Then for any se quenc e of classifiers { g n } with p er-step r ates ( δ n , TPR n ) : TPR n ≤ ¯ C α · δ β n for al l n wher e ¯ C α = exp (( α − 1) ¯ D ) . Conse quently, if P δ n < ∞ then P TPR n ≤ ¯ C α P δ β n < ∞ , and the dual c onditions c annot b e jointly satisfie d. Pr o of. A t each step n , the Hölder b ound (Theorem 1 pro of, Step 1) gives TPR n ≤ C ( n ) α · δ β n where C ( n ) α = exp (( α − 1) D α ( P + n ∥ P − n )) . Since D α ( P + n ∥ P − n ) ≤ ¯ D for all n , w e hav e C ( n ) α ≤ ¯ C α . Summing: P TPR n ≤ ¯ C α P δ β n . F or p o wer-la w sc hedules δ n ≤ c/n p , we hav e δ β n ≤ c β n − pβ , which is summable iff pβ > 1 (i.e., p > α ). F or general summable { δ n } , con vergence of P δ β n follo ws from Hölder’s inequalit y on finite horizons: P N n =1 δ β n ≤ N 1 − β · ( P N n =1 δ n ) β ≤ N 1 − β · B β where B = P δ n < ∞ . R emark (Cov erage gap) . F or p o w er-law schedules δ n = c · n − p with p > 1 , the series P δ β n = c β P n − pβ con verges iff pβ > 1 , i.e., p > α . F or 1 < p ≤ α , the stationary imp ossibilit y (Theorem 1 ) applies but Prop osition C.2 do es not — the non-stationary extension requires the strictly stronger condition p > α (flagged in § 2.2 ). This gap narro ws as α → 1 + and v anishes for all practically relev ant fast- deca ying schedules ( p ≥ 2 ). F or the intermediate regime, Theorem 5 ’s stationarity-free finite-horizon ceiling pro vides an alternative b ound. C.3 Information-Theoretic Finite-Horizon Bound Prop osition 1 (Information-Theoretic Finite-Horizon Bound) . L et { g n } b e a se quenc e of safety gates with p er-step mutual information I n and total budget I 0 = P I n . Then for any N : N X n =1 TPR n ≤ N X n =1 δ n + p 2 N I 0 This b ound grows as √ N , so it do es not pro ve P TPR n < ∞ — that follows from Theorem 1 . Prop osition 1 complements Theorem 1 b y constraining the r ate of utility accumulation via mutual information. F ull pro of in App endix A.5 . 22 C.4 Sample Complexit y Barrier Prop osition 2 (Sample Complexity Barrier) . L et G b e a family of binary classifiers with V C dimension d V C . F or the gate to achieve δ n ≤ c/n p with p > 1 , the r e quir e d tr aining set is n tr ain ( n ) = Ω( d V C · n 2 p ) . If the system gener ates at most k new lab ele d examples p er step, sample starvation o c curs at n fail = O ( k 1 / (2 p − 1) ) . This result is indep enden t of Theorem 1 : even if a classifier circumv ented the Hölder b ound, it w ould face sample starv ation. F ull pro of in App endix A.6 . C.5 F ormal T ransformer Lipschitz Bounds Prop osition 3 (T ransformer LoRA Lipschitz Bound) . F or a pr e-L ayerNorm tr ansformer with K layers under L oRA p erturb ation with r ank r on n pr oj attention pr oje ctions p er layer, the p er-layer Lipschitz c onstant w.r.t. L oRA p ar ameters is: L L oRA k ≤ ∥ γ k ∥ √ ϵ · max p ∥ W 0 v ,p ∥ √ d k · q 2 · n pr oj Comp ositional verific ation che cks P k L L oRA k · ∥ ∆ θ k ∥ ≤ m (additive, O ( d ) ) r ather than the exp onen- tial ly lar ge pr o duct L ful l = Q k (1 + L k ) . F ull deriv ation in App endix A.7 . C.6 Hölder–Jensen Appro ximation F or practical deploymen t o ver N steps with risk budget B = P δ n , applying the p er-step Hölder b ound and Jensen’s inequality yields: U max ( N , B ) = C α · N 1 − β · B β with optimal uniform allo cation δ n = B / N . This b ound is lo oser than the exact NP-based ceiling U ∗ ( N , B ) = N · TPR NP ( B / N ) (Theorem 5 ), whic h is 1.4–3.1 × tighter at N = 10 2 – 10 6 . C.7 Multi-Dimensional T radeoff Surface Classifiers o ccup y: TPR ≤ C α · δ β , C = O ( d 2 ) , n = Ω( d VC /δ 2 ) . V erifiers o ccup y: δ = 0 , TPR > 0 (domain-restricted), C = O ( d ) , n = 0 . These regions are disconnected on the δ = 0 hyperplane. D F ull Numerical V alidation D.1 Tigh tness V alidation ∆ s α ∗ β ∗ TPR NP /Hölder at δ = 10 − 6 log TPR / log δ at δ = 10 − 12 0.1 201.0 0.995 0.561 0.974 0.5 9.0 0.889 0.834 0.875 1.0 3.0 0.667 0.321 0.758 2.0 1.5 0.333 0.108 0.552 F or all separations, TPR NP ≤ Hölder b ound (v erifying Theorem 1 ) and the ratio ranges from 0.1 to 0.9 at deplo yment-relev ant δ . 23 D.2 Information-Theoretic Bound Comparison The Hölder b ound is tighter p er-step for small δ ; the MI b ound is complementary for cum ulative analysis. Both b ounds are v alid across all distributions tested. D.3 Sample Complexit y Sim ulation Sim ulated logistic regression ( d VC = 11 , ∆ s = 0 . 5 , k = 5 ): 200/200 steps sample-starv ed; P δ = 41 . 17 (div erges). Confirms Prop osition 2 . D.4 T ransformer Lipschitz Computation Arc hitecture d K d k ∥ W v ∥ L LoRA k r k Steps in ball T oy (2L) 64 2 32 2.32 259.7 5.8e-4 11.6 Small (6L) 256 6 64 2.09 165.2 3.0e-4 6.1 GPT-2 (12L) 768 12 64 1.80 142.5 1.8e-4 3.5 Qw en-7B (28L) 3584 28 128 1.68 94.0 1.1e-4 2.3 The b ound is non-v acuous across all arc hitectures — even at Qwen-7B scale, 2 LoRA gradient steps fit within the safe ball. D.5 P areto F ron tier Visualization The classifier and verifier regions are disc onne cte d on the δ = 0 hyperplane. Classifiers require Ω( d VC /δ 2 ) samples and cannot reach δ = 0 with TPR > 0 . The ball v erifier op erates at δ = 0 with no training data. D.6 T rained Classifier Ceiling A cross all 72 (classifier, δ ) pairs tested (4 classifiers × 6 δ v alues × 3 separations), zero violations of the Hölder b ound were observed. T rained classifiers ac hieve TPR ratios of 0.52–0.94 relative to the Hölder ceiling. D.7 Non-Gaussian Tigh tness V alidation A cross 8 non-Gau ssian families (Laplace, Studen t- t , Gaussian mixture): min ratios 0.28–0.40, a verage ratios 0.54–0.70. The b ound is uniformly v alid and tight across heavy-tailed and multi- mo dal distributions. D.8 Lipsc hitz Ball V erifier Demonstration L TC controller ( d = 240 ), L = 13 . 75 , r = 0 . 0208 . Inside-ball: 200/200 safe ( δ = 0 ), TPR = 0 . 286 . D.9 NP Coun ting Pro of V alidation All 9 configs satisfy direct sum ≤ coun ting b ound (ratios 0.33–0.89). Counting 13% tigh ter than Hölder at ∆ s = 1 . 0 , p = 2 . 0 . 24 D.10 Tigh t Finite-Horizon V alidation The exact ceiling gro ws subp olynomially: from N = 10 4 to N = 10 6 (100 × increase in N ), U ∗ gro ws only 2.66 × . Uniform allo cation optimal (Jensen). MI b ound is lo ose by 4–86 × . E Computational Complexit y and Op en Problems E.1 Connection to Computational Complexit y The information-theoretic b ound (Prop osition 1 ) and sample complexit y barrier (Prop osition 2 ) connect to a broader question: is safe self-improv emen t computationally hard? A natural extension is whether satisfying the dual conditions is NP-hard. E.2 Op en Problems 1. Computational imp ossibility . Is satisfying the dual conditions NP-hard, b ey ond b eing statistically imp ossible? 2. A daptive verification. Can tighter verified regions (e.g., ellipsoidal) maintain O ( d ) c hecking? Ball c haining exp erimen ts in [ 23 ] provide an initial empirical answer. 3. Multi-agen t and contin uous-time extensions of the dual conditions. F V alidation Script Details • experiments/prove_tightness.py : Computes NP TPR via Φ(Φ − 1 ( δ ) + ∆ s ) for 100 δ v alues and 4 separations; confirms TPR NP ≤ Hölder (Theorems 1 , 3 ). • experiments/prove_info_theoretic_bound.py : Computes MI of the NP channel for Gaussian and Laplacian distributions (Prop osition 1 ). • experiments/prove_sample_complexity.py : Simulates 200 steps with logistic regression gate (Prop osition 2 ). • experiments/pareto_tradeoff.py : Computes the 4D tradeoff surface (App endix D.5 ). • experiments/validate_classifier_ceiling.py : T rains 4 classifiers on 50K samples (Ap- p endix D.6 ). • experiments/compute_lipschitz_bounds.py : Proposition 3 b ounds for 4 architectures (Ap- p endix D.4 ). • experiments/prove_tightness_nongaussian.py : 8 non-Gaussian families (App endix D.7 ). • experiments/validate_ball_verifier.py : Ball v erifier on L TC d = 240 (App endix D.8 ). • experiments/lora_ball_verifier_gpt2.py : GPT-2 LoRA v alidation (§ 7.1 ). • experiments/prove_counting_impossibility.py : Theorem 4 v alidation (App endix D.9 ). • experiments/prove_tight_finite_horizon.py : Theorem 5 v alidation (App endix D.10 ). 25 References [1] R udolf Ahlswede and P éter Gács. Spreading of sets in pro duct spaces and hypercontraction of the Mark ov op erator. A nnals of Pr ob ability , 4(6):925–939, 1976. [2] Dario Amo dei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Sch ulman, and Dan Mané. Concrete problems in AI safet y . arXiv pr eprint arXiv:1606.06565 , 2016. [3] Amanda Askell, Y untao Bai, Anna Chen, et al. A general language assistant as a lab oratory for alignmen t. arXiv pr eprint arXiv:2112.00861 , 2021. [4] P eter L. Bartlett and Shahar Mendelson. Rademacher and Gaussian complexities: Risk b ounds and structural results. Journal of Machine L e arning R ese ar ch , 3:463–482, 2002. [5] F elix Berkenkamp, Matteo T urchetta, Angela Sc ho ellig, and Andreas Krause. Safe mo del-based reinforcemen t learning with stability guarantees. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2017. [6] Nic k Bostrom. Sup erintel ligenc e: Paths, Dangers, Str ate gies . Oxford Universit y Press, 2014. [7] P aul Christiano, Ajeya Cotra, and Mark Xu. Iterated amplification. A lignment F orum , 2017. [8] George Dasoulas, Ludo vic Dos San tos, Filipp o Maria Bianchi, and Michalis V azirgiannis. Lipsc hitz normalization for self-attention lay ers with application to graph neural netw orks. In Pr o c e e dings of the International Confer enc e on Machine L e arning (ICML) , 2021. [9] Mah yar F azly ab, Alexander Rob ey , Hamed Hassani, Manfred Morari, and George J. Pappas. Efficien t and accurate estimation of Lipsc hitz constants for deep neural netw orks. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2019. [10] Allan Gibbard. Manipulation of voting sc hemes: A general result. Ec onometric a , 41(4):587–601, 1973. [11] Justin Gilmer, Luk e Metz, F artash F aghri, Samuel S. Schoenholz, Maithra Ragh u, Martin W attenberg, and Ian Go o dfello w. Adv ersarial spheres. In ICLR W orkshop , 2018. [12] Hyunjik Kim, George Papamakarios, and Andriy Mnih. The Lipschitz constan t of self-attention. In Pr o c e e dings of the International Confer enc e on Machine L e arning (ICML) , 2021. [13] Eric h L. Lehmann and Joseph P . Romano. T esting Statistic al Hyp otheses . Springer, 3rd edition, 2005. [14] Jan Leik e, David Krueger, T om Everitt, et al. Scalable agent alignment via reward mo deling: A researc h direction. arXiv pr eprint arXiv:1811.07871 , 2018. [15] Da vid McAllester. P A C-Bay esian mo del av eraging. In Pr o c e e dings of the Confer enc e on L e arning The ory (COL T) , 1999. [16] Jerzy Neyman and Egon S. Pearson. On the problem of the most efficien t tests of statistical h yp otheses. Philosophic al T r ansactions of the R oyal So ciety A , 231:289–337, 1933. [17] Long Ouy ang, Jeff W u, Xu Jiang, et al. T raining language mo dels to follow instructions with h uman feedback. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2022. 26 [18] Christos H. P apadimitriou and Mihalis Y annakakis. On the appro ximability of trade-offs and optimal access of web sources. In Pr o c e e dings of the IEEE Symp osium on F oundations of Computer Scienc e (FOCS) , pages 86–92, 2000. [19] Y ury P olyanskiy and Yihong W u. Strong data pro cessing inequalities for channels and Bay esian net works. In Convexity and Conc entr ation , volume 161 of IMA V olumes in Mathematics and its A pplic ations , pages 211–249. Springer, 2017. [20] Maxim Raginsky . Strong data pro cessing inequalities and Φ -Sob olev inequalities for discrete c hannels. IEEE T r ansactions on Information The ory , 62(6):3355–3389, 2016. [21] Henry Gordon Rice. Classes of recursively en umerable sets and their decision problems. T r ansactions of the A meric an Mathematic al So ciety , 74(2):358–366, 1953. [22] Mark Allen Satterthw aite. Strategy-pro ofness and Arrow’s conditions. Journal of Ec onomic The ory , 10(2):187–217, 1975. [23] Arsenios Scriv ens. Empirical v alidation of the classification–verification dichotom y for AI safety gates. Zeno do , 2026. doi: 10.5281/zeno do.19237566. URL https://zenodo.org/records/ 19237566 . Companion pap er. [24] Shai Shalev-Sh wartz. Online learning and online con vex optimization. F oundations and T r ends in Machine L e arning , 4(2):107–194, 2012. [25] Nate Soares and Benja F allenstein. Agent foundations for aligning mac hine intelligence with h uman interests. T echnical rep ort, Machine Intelligence Research Institute (MIRI), 2017. [26] Dimitris T sipras, Shibani Santurkar, Logan Engstrom, Alexander T urner, and Aleksander Madry . Robustness may b e at o dds with accuracy . In International Confer enc e on L e arning R epr esentations (ICLR) , 2019. [27] Tim v an Erven and P eter Harremo es. Rén yi diverge nce and Kullbac k–Leibler divergence. IEEE T r ansactions on Information The ory , 60(7):3797–3820, 2014. [28] Vladimir N. V apnik and Alexey Y a. Chervonenkis. On the uniform con vergence of relativ e frequencies of even ts to their probabilities. The ory of Pr ob ability and its A pplic ations , 16(2): 264–280, 1971. [29] Aladin Virmaux and Kevin Scaman. Lipschitz regularity of deep neural netw orks. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2018. [30] Da vid H. W olp ert. The lack of a priori distinctions b et ween learning algorithms. Neur al Computation , 8(7):1341–1390, 1996. 27
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment