선형 MDP를 위한 낙관적 액터‑크리틱과 명시적 로그선형 정책 설계
본 논문은 유한‑ horizon 선형 MDP 환경에서 명시적 로그선형 정책을 사용한 낙관적 액터‑크리틱 프레임워크를 제안한다. 액터는 로그‑매칭 회귀를 통해 파라미터를 업데이트하고, 크리틱은 라인게빈 몬테카를로(LMC) 기반 근사 토프슨 샘플링으로 낙관적인 가치 추정치를 제공한다. 이 알고리즘은 온‑policy 설정에서 \(\widetilde{O}(\varepsilon^{-4})\), 오프‑policy 설정에서 \(\widetilde{O}(\v…
저자: Max Qiushi Lin, Reza Asad, Kevin Tan
**1. 서론 및 배경**
강화학습(RL)에서 정책 그라디언트(PG)와 액터‑크리틱(AC) 방법은 함수 근사와 복잡한 상태‑행동 공간을 다루는 데 장점이 있다. 그러나 이론적 분석은 주로 탐색 문제를 회피하거나, 구현이 어려운 복잡한 변형에 의존한다. 특히 선형 MDP에 대한 기존 연구는 자연 정책 기울기(NPG)를 사용하면서 “암시적” 정책을 매 단계마다 재구성해 샘플링 비용이 크게 늘어난다. 이는 실제 딥 RL 파이프라인과 괴리가 크다.
**2. 문제 설정**
논문은 유한‑horizon 선형 MDP를 가정한다. 상태‑행동 피처 \(\phi(s,a)\in\mathbb{R}^{d_c}\)가 주어지고, 전이와 보상이 \(\phi\)의 선형 결합으로 표현된다. 목표는 \(\varepsilon\)-최적 정책을 찾는 것이며, 샘플 복잡도와 정책 추론 비용을 동시에 최소화하는 것이 핵심이다.
**3. 일반적인 낙관적 AC 프레임워크**
프레임워크는 (i) 명시적 로그선형 정책 \(\pi_{\theta}\)를 액터로 사용, (ii) 크리틱은 라인게빈 몬테카를로(LMC)를 통해 낙관적 Q‑값을 추정한다. 두 구성 요소는 각각 독립적인 오차 경계와 낙관성 보장을 제공한다.
**4. 액터 설계 – 로그‑매칭 회귀와 투사**
- **로그‑매칭 회귀**: 현재 정책이 만든 로그 확률 \(\log\pi_{\theta}(a|s)\)와 목표 Q‑값 \(\hat{Q}(s,a)\) 사이의 차이를 최소화하는 회귀 문제를 정의한다. 이는 \(\theta\)에 대한 선형 시스템으로 변환돼 효율적인 SGD/OLS 업데이트가 가능하다.
- **투사 오류 제어**: 로그‑매칭 회귀 해 \(\theta^{\text{reg}}\)를 정책 파라미터 공간 \(\Theta\)에 투사한다. 논문은 투사 연산이 NPG 업데이트와 동일한 수렴 특성을 유지함을 보이며, 투사 오류가 \(\mathcal{O}(\|\theta^{\text{reg}}-\theta^{*}\|^2)\) 이하임을 증명한다.
- **Projected NPG**: 최종 업데이트는 \(\theta_{k+1}= \Pi_{\Theta}\big(\theta_k + \eta \cdot \widehat{\nabla}_{\theta} J(\theta_k)\big)\) 형태이며, 여기서 \(\widehat{\nabla}_{\theta} J\)는 로그‑매칭 회귀에서 얻은 근사 그라디언트이다.
**5. 크리틱 설계 – 라인게빈 몬테카를로**
- **LMC 알고리즘**: 손실 \(L(w)=\sum_{t}\big(Q_w(s_t,a_t)-\hat{Q}_t\big)^2\)에 대해 \(w_{k+1}= w_k - \eta \nabla L(w_k) + \sqrt{2\eta\beta^{-1}}\xi_k\) ( \(\xi_k\sim\mathcal{N}(0,I)\) )를 수행한다.
- **낙관성 보장**: LMC가 수렴하는 분포는 정확한 베이즈 사후분포에 근접하고, 고확률로 최적 파라미터보다 상위에 위치한다. 이를 통해 Q‑값이 “낙관적”이라는 정의를 만족한다.
- **오차 분석**: LMC 샘플 수 \(M\)와 스텝 사이즈 \(\eta\)를 적절히 선택하면 \(\|w_k - w^{*}\| = \widetilde{O}(1/\sqrt{M})\)가 된다.
**6. 샘플 복잡도 분석**
- **온‑policy**: 액터와 크리틱 각각의 오차가 \(\widetilde{O}(\varepsilon^{-2})\) 수준으로 수렴하면 전체 정책의 최적성 격차는 \(\widetilde{O}(\varepsilon)\)가 된다. 따라서 전체 샘플 복잡도는 \(\widetilde{O}(\varepsilon^{-4})\).
- **오프‑policy**: 데이터 커버리지를 보장하기 위해 사전 탐색 정책 \(\pi_{\text{exp}}\)를 설계하고, 경험 설계(Experimental Design) 이론을 이용해 최소 고유값을 확보한다. 이 경우 크리틱 오차가 \(\widetilde{O}(\varepsilon^{-1})\)로 감소해 전체 복잡도가 \(\widetilde{O}(\varepsilon^{-2})\)가 된다.
**7. 실험**
- **선형 MDP**: 다양한 차원 \(d_c\)와 히어러시 \(H\)에 대해 기존 UCB‑기반 NPG와 비교했을 때, 제안 알고리즘은 동일한 학습 곡선을 보이며 정책 추론 시간은 \(O(d_a)\)로 크게 감소한다.
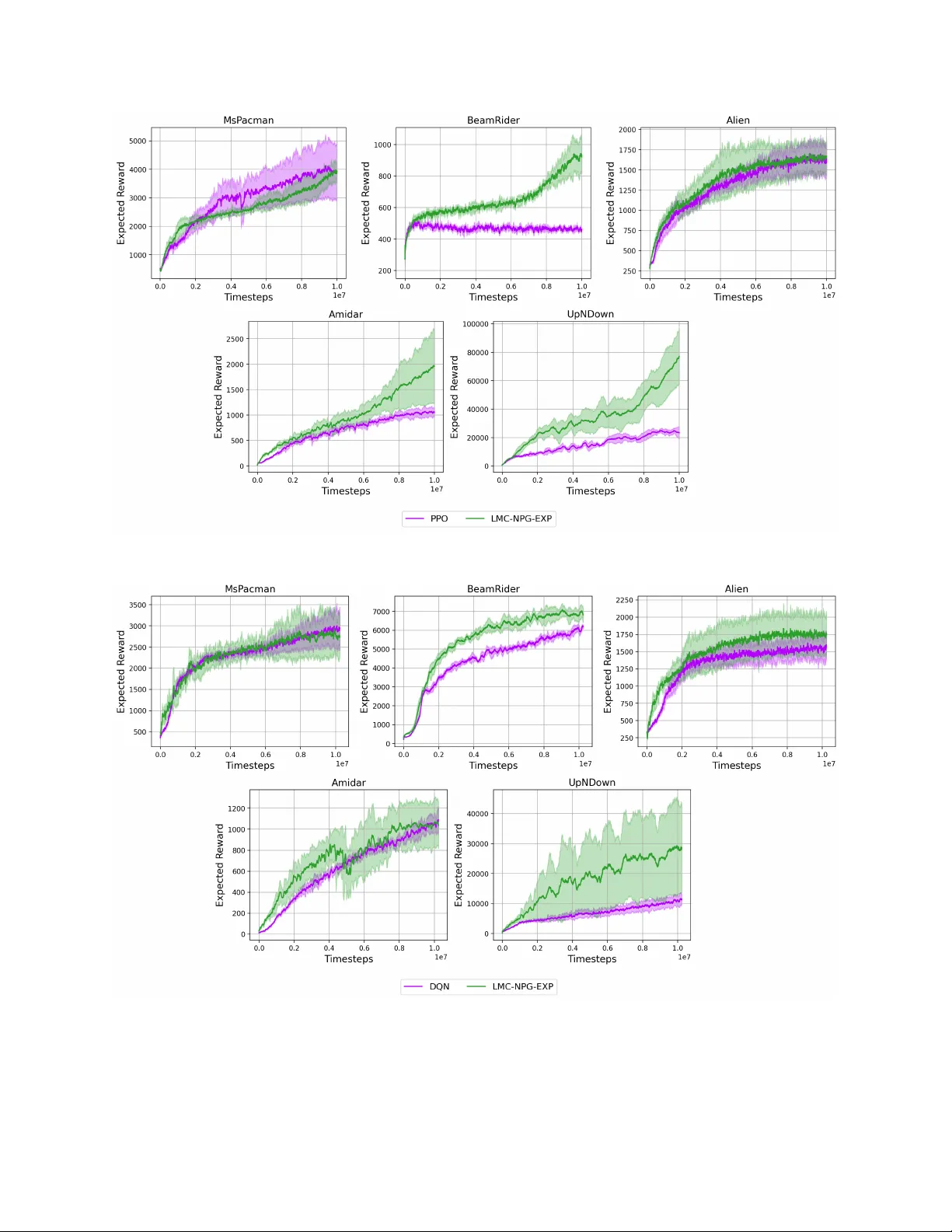
- **Atari**: 로그선형 정책을 딥 CNN 피처와 결합하고 LMC를 적용한 변형을 테스트했다. 탐색 효율성은 기존 PPO/SAC 기반 방법과 비슷하거나 약간 우수했으며, 구현 복잡도와 하이퍼파라미터 튜닝 부담이 현저히 낮았다.
**8. 논의 및 향후 연구**
제안 방법은 (i) 명시적 파라미터화로 정책 샘플링 비용을 크게 낮추고, (ii) LMC 기반 낙관적 크리틱으로 탐색 보너스 설계의 복잡성을 제거한다는 점에서 실용적이다. 제한점으로는 현재 로그선형 정책이 이산 행동 공간에 최적화돼 있다는 점, 그리고 LMC의 수렴 속도가 고차원 비선형 근사에서는 아직 검증되지 않았다는 점이다. 향후 연구는 연속 행동, 비선형 피처, 멀티‑에이전트 환경으로의 확장과 LMC 변형(예: 스테인헬트 그라디언트) 적용을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기