Optimistic Actor-Critic with Parametric Policies for Linear Markov Decision Processes
Although actor-critic methods have been successful in practice, their theoretical analyses have several limitations. Specifically, existing theoretical work either sidesteps the exploration problem by making strong assumptions or analyzes impractical…
Authors: Max Qiushi Lin, Reza Asad, Kevin Tan
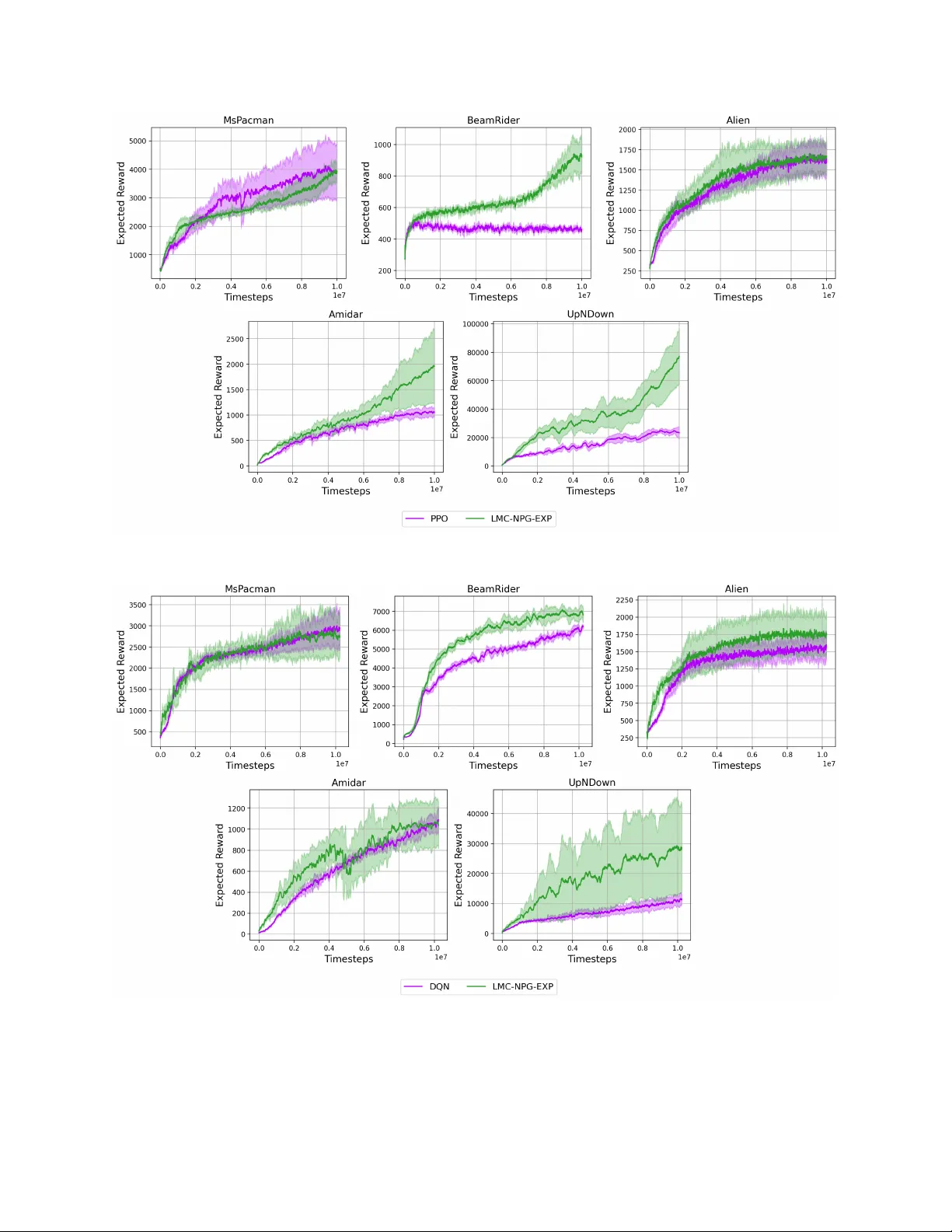
Optimistic Actor -Critic with Parametric Policies for Linear Markov Decision Processes Max Qiushi Lin Simon Fraser University Reza Asad Simon Fraser University Kevin T an University of Pennsylvania Haque Ishfaq Mila, McGill University Csaba Szepesvári Google DeepMind, University of Alberta Sharan V aswani Simon Fraser University Abstract Although actor-critic methods have been successful in practice, their theor etical analyses have several limitations. Specifically , existing theoretical work either sidesteps the exploration problem by making strong assumptions or analyzes impractical methods with complicated algorithmic modifications. Moreover , the actor-critic methods analyzed for linear MDPs often employ natural policy gradi- ent (NPG) and construct “implicit” policies without explicit parameterization. Such policies ar e computationally expensive to sample from, making the environ- ment interactions inef ficient. T o that end, we focus on the finite-horizon linear MDPs and propose an optimistic actor-critic framework that uses parametric log-linear policies. In particular , we introduce a tractable logit-matching regr ession objective for the actor . For the critic, we use appr oximate Thompson sampling via Langevin Monte Carlo to obtain optimistic value estimates. W e prove that the r esulting algorithm achieves e O ( ϵ − 4 ) and e O ( ϵ − 2 ) sample complexity in the on-policy and off-policy setting, r espectively . Our r esults match prior theoretical works in achieving the state-of-the-art sample complexity , while our algorithm is more aligned with practice. Keywords: Actor-Critic, Linear MDP , Log-Linear Policy , Natural Policy Gradient, Strategic Exploration, Langevin Monte Carlo, Sample Complexity 1 Contents 1 Introduction 4 2 Preliminaries 6 3 A General Actor-Critic Framework with Parametric Policies 7 4 Instantiating the Actor: Projected Natural Policy Gradient 7 4.1 Projected Natural Policy Gradient . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 4.2 Controlling the Pr ojection Error for Log-Linear Policies . . . . . . . . . . . . . . . . . . . . . . 9 4.3 Putting Everything T ogether: Projected NPG with Log-Linear Policies . . . . . . . . . . . . . 10 5 Instantiating the Critic: Langevin Monte Carlo 10 5.1 LMC for Linear MDPs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 5.2 Optimism Guarantee and Error Bound . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 6 Sample Complexity Analysis 12 6.1 On-Policy Setting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 6.2 Off-Policy Setting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 7 Experiments 15 7.1 Experiments in Linear MDPs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 7.2 Experiments Beyond Linear MDPs: Atari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 8 Discussion 16 A Notation 21 B Analyses for the Actor 21 B.1 Generalized OMD Regr et (Pr oof of Theorem 4.1) . . . . . . . . . . . . . . . . . . . . . . . . . . 21 B.2 Pr ojection Err or (Proof of Lemma 4.1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 B.3 Instantiating the Actor with SPMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 B.4 T echnical T ools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 C Constructing D exp and ρ exp via Experimental Design 27 C.1 Kiefer–W olfowitz Theorem and G-Experimental Design . . . . . . . . . . . . . . . . . . . . . . 28 C.2 Exploratory Policy and Minimum Eigenvalue . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 D Analyses for the Critic 29 D.1 Proof of Lemma 5.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 D.1.1 Preliminary Pr operties . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 D.1.2 Main Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 D.2 Proofs of Pr eliminary Pr operties . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 D.2.1 Proof of Lemma D.3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 D.2.2 Proof of Lemma D.4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 D.2.3 Proof of Lemma D.5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36 D.2.4 Proof of Lemma D.6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 D.2.5 Proof of Lemma D.7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 D.2.6 Proof of Lemma D.8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41 D.2.7 Proof of Lemma D.9 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 D.3 T echnical T ools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44 E Sample Complexity in the On-Policy Setting 46 2 E.1 Proof of Good Event . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46 E.2 Proof of Theorem 6.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46 E.3 T echnical T ools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 F Sample Complexity in the Off-Policy Setting 50 F .1 Covering Number (Proof of Lemma 6.1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 F .2 Proof of Good Event . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 F .3 Proof of Theor em 6.2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 F .4 T echnical T ools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 G Experiments 55 G.1 Experiments in Linear MDPs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55 G.1.1 Environment Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55 G.1.2 Coreset Construction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56 G.1.3 Algorithms and Hyperparameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56 G.1.4 Experimental Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56 G.2 Ablation Studies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 G.2.1 Ablation on Exploration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 G.2.2 Ablation on Feature Dimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 G.2.3 Sensitivity to Inverse T emperature ( ζ − 1 ) . . . . . . . . . . . . . . . . . . . . . . . . . . . 58 G.2.4 Sensitivity to the Number of Critic Samples ( M ) . . . . . . . . . . . . . . . . . . . . . . 58 G.3 Experiments Beyond Linear MDPs: Atari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 G.3.1 Extension to Deep RL Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 G.3.2 Environment Setups and Hyperparameters . . . . . . . . . . . . . . . . . . . . . . . . . 59 G.3.3 Experimental Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 3 1 Introduction Reinforcement learning (RL) is a general framework for sequential decision making under uncertainty and has been successful in various r eal-world applications, such as r obotics ( Kober et al. , 2013 ) and lar ge language models ( Uc-Cetina et al. , 2023 ). Policy Gradient (PG) methods ( W illiams , 1992 ; Sutton et al. , 1999 ; Kakade , 2001 ; Schulman et al. , 2017a ) are an important class of algorithms that assume a differentiable parameterization of the policy , and directly optimize the policy parameters using the return from interacting with the envir onment. PG methods are widely used in practice as they can easily handle function approxima- tion or structured state-action spaces. However , since the environment is typically stochastic in practice, the estimated returns usually have high variance, resulting in poor sample efficiency ( Dulac-Arnold et al. , 2019 ). Actor-critic (AC) methods ( Konda and T sitsiklis , 1999 ; Peters et al. , 2005 ; Bhatnagar et al. , 2009 ) alleviate this issue by using value-based appr oaches in conjunction with PG methods. In particular , they utilize a critic that estimates the policy’s value and an actor that performs PG to improve the policy towar ds obtaining higher returns. These AC methods have been proven to be empirically successful in both on-policy ( Schulman et al. , 2015 , 2017b ) and off-policy ( Lillicrap et al. , 2015 ; Fujimoto et al. , 2018 ; Haarnoja et al. , 2018 ) settings. Subsequently , there have been many attempts to provide a theoretical understanding of actor-critic methods, especially in the presence of function approximation ( Cai et al. , 2020 ; Zhong and Zhang , 2023 ; Liu et al. , 2023 ). However , there are two prevalent issues that result in mismatches between theory and practice: the studied methods either (i) do not consider strategic exploration in a systematic manner or (ii) analyze complicated and impractical variants of the algorithm. In particular , much of the literature makes unrealistic assumptions to avoid dealing with exploration, a central challenge in RL. For instance, existing works on PG methods ( Agarwal et al. , 2021a ; Y uan et al. , 2023 ; Alfano and Rebeschini , 2022 ; Asad et al. , 2025 ) obtain convergence rates that involve a mismatch ratio between the optimal policy and the initial state distribution. These results ar e only meaningful if the mismatch ratio is bounded. However , a bounded mismatch ratio indicates that the initial state distribution already pr ovides a good coverage over the state space, thereby sidestepping the exploration problem. W ithin actor -critic methods, some early analyses make assumptions on the reachability of the state-action space or the coverage of collected data ( Abbasi-Y adkori et al. , 2019 ; Neu et al. , 2017 ; Bhandari and Russo , 2024 ; Agarwal et al. , 2021a ; Cen et al. , 2022 ; Gaur et al. , 2024 ), which again imply that the state-action space is already relatively easy to explore. Follow-up works ( Hong et al. , 2023 ; Fu et al. , 2021 ; Xu et al. , 2020 ; Cayci et al. , 2024 ) assume a bounded mismatch ratio, while others ( Khodadadian et al. , 2022 ; Gaur et al. , 2023 ) requir e mixing assumptions on the induced Markov chain. Algorithm Sample Complexity (On-Policy) Sample Complexity (Off-Policy) Policy Param. Clipping Q-Function Computational Cost for Policy Inference Liu et al. ( 2023 ) e O ( 1 ϵ 4 ) ✗ implicit yes O ( d 2 c H |A | ϵ − 2 ) Sherman et al. ( 2023 ) ✗ e O ( 1 ϵ 2 ) implicit no O ( d 2 c H |A | ϵ − 2 ) Cassel and Rosenberg ( 2024 ) Ours e O ( 1 ϵ 4 ) e O ( 1 ϵ 2 ) explicit yes O ( d 2 a H |A | ) T able 1: Comparison with the state-of-the-art algorithms for episodic finite-horizon linear MDPs (with feature dimension d c and horizon H ). The sample complexity refers to the number of interactions r equired for outputting an ϵ -optimal policy , whereas the cost of policy inference refers to the per-episode cost for interacting with the environment for H steps. Our pr oposed algorithm matches the optimal sample efficiency in both the on- and off-policy settings. Furthermore, in contrast to existing works, our algorithm employs an explicit policy parameterization (log-linear policies with dimension d a ), resulting in lower computational cost for policy inference. On the other hand, recent works ( Cai et al. , 2020 ; Jin et al. , 2021 ; Zanette et al. , 2021 ; Zhong and Zhang , 2023 ; Agarwal et al. , 2023 ; He et al. , 2023 ; Liu et al. , 2023 ; Sherman et al. , 2023 ; Cassel and Rosenber g , 2024 ; T an 4 et al. , 2025 ) tackle the exploration issue directly . However , the algorithms analyzed are significantly differ ent from those implemented in practice. Much of this body of work studies AC methods that use the natural policy gradient ( NPG ) update for policy optimization. However , the canonical implementation of the NPG update does not consider an explicit policy parameterization. Instead, the update involves constructing “implicit” policies on the fly using all pr eviously stor ed Q -functions. This makes it computationally expensive to sample from these policies and use them to interact with the envir onment. In contrast, the algorithms used in practice typically employ explicitly parameterized complex models as learnable policies and optimize them with gradient descent-based methods. Therefor e, we aim to address the following question: Can we design a provably efficient actor–critic algorithm with parametric policies for linear MDPs in both on- and off-policy settings? Contributions. W e answer the above question affirmatively and make the following contributions. 1. General framework with an explicitly parameterized actor . In Section 3 , we propose a general optimistic actor-critic framework that utilizes an explicitly parameterized policy . W e apply this framework in the setting of linear function approximation for both the environment (i.e., linear MDP ( Jin et al. , 2020 )) and the policy (i.e., log-linear policy class). In Section 4 , we propose an actor algorithm that learns a log-linear policy by solving a specific regr ession pr oblem at each iteration. This allows us to directly contr ol the error between the explicitly parametrized policy and the implicit policy induced by NPG . Using this error bound in conjunction with the well-established theoretical results of NPG ( Hazan et al. , 2016 ; Szepesvári , 2022 ) enables us to analyze the performance of the parameterized actor . W e show that the proposed algorithm benefits from a substantially impr oved memory complexity , while retaining similar theor etical guarantees. 2. LMC critic for practical strategic exploration. In Section 5 , instead of constructing UCB bonuses ( Jin et al. , 2020 ), which are ubiquitous within prior works ( Zhong and Zhang , 2023 ; Liu et al. , 2023 ; Sherman et al. , 2023 ; Cassel and Rosenberg , 2024 ), we adopt a more practical appr oach. W e employ Langevin Monte Carlo ( LMC ) ( W elling and T eh , 2011 ) to update the critic parameters at each episode. Unlike UCB -based approaches that require computing confidence sets at every episode, LMC simply perturbs (by Gaussian noise) the gradient descent update on the critic loss. This gradient descent-based approach is both easier to implement ( Ishfaq et al. , 2025 ) and to extend to general function approximation ( Ishfaq et al. , 2024b ). Furthermore, the LMC algorithm directly leads to an optimistic estimate of the Q -function that has similar guarantees as UCB bonuses. Nevertheless, previous works have only successfully designed provably ef ficient algorithms for solving multi-armed bandits ( Mazumdar et al. , 2020 ), contextual bandits ( Xu et al. , 2022 ), and linear MDPs via value-based methods ( Ishfaq et al. , 2024a ). Our paper is the first to analyze an LMC -based approach in the context of policy optimization. 3. End-to-end theoretical guarantees for actor-critic. In Section 6 , we analyze the proposed actor-critic framework in both the on-policy and off-policy settings without making any assumptions on the mismatch ratio or data coverage. In particular , in the on-policy setting, we prove that our method requir es e O ( ϵ − 4 ) samples to learn an ϵ -optimal policy . This matches the result in ( Liu et al. , 2023 ) that uses an implicit NPG policy in conjunction with UCB bonuses. On the other hand, we also prove that our framework can attain a sample complexity of e O ( ϵ − 2 ) in the off-policy setting. This matches the results of Sherman et al. ( 2023 ); Cassel and Rosenberg ( 2024 ), but with a far less complicated algorithm design. W e thus demonstrate that our proposed algorithm is both sample-efficient and aligned with practice. 5 2 Preliminaries In this section, we introduce the finite-horizon linear MDP setting and the log-linear policy class. Finite-Horizon Linear MDP . A finite-horizon MDP is a tuple M = ( S , A , P , r , H ) where S denotes the state space, A is the action set, and H ∈ Z + is the length of the horizon. P = { P h } h ∈ [ H ] is a set of time- dependent transition kernels, and r = { r h } h ∈ [ H ] denotes a sequence of r eward functions. W e assume that the state space S is a (possibly infinite) measurable space, whereas A is a finite set with cardinality |A | . P h ( · | s , a ) ∈ ∆ ( S ) is the distribution over states when taking action a ∈ A in state s ∈ S at step h ∈ [ H ] , and r h ( s , a ) ∈ [ 0, 1 ] is the corresponding r eward. Additionally , for any given function V : S → R , we define that [ P h V h + 1 ]( s , a ) : = E s ′ ∼ P h ( · | s , a ) V h + 1 ( s ′ ) . The agent interacts with the environment by starting at an initial state (w .l.o.g., fixed to be s 1 ∈ S ). At step h , the agent first observes the current state s h ∈ S , then takes an action a h ∈ A and receives the rewar d r h ( s h , a h ) . After that, the agent transitions to s h + 1 ∼ P h ( · | s h , a h ) . The agent follows a given policy π : [ H ] × S 7 → ∆ ( A ) in which π h ( · | s ) ∈ ∆ ( A ) is the probability distribution over A in state s at step h . T o quantify the performance of any policy π , we define the value function as V π h ( s ) : = E π , P [ ∑ H τ = h r τ ( s τ , a τ ) | s h = s ] , and the corresponding state-action value function is defined as Q π h ( s , a ) : = E π , P [ ∑ H τ = h r τ ( s τ , a τ ) | s h = s , a h = a ] , where the expectation is with respect to the randomness in the stochastic policy and the transition dynamics. The value function (r esp. Q -function) corr esponds to the expected cumulative rewar ds when starting in state s (resp. state-action ( s , a ) ) at step h , and subsequently following the policy π until reaching step H . W e assume that both P and r are unknown to the agent. In order to efficiently learn these quantities, we consider the linear MDP assumption ( Jin et al. , 2020 ) where both the transition kernel and the rewar d function are assumed to be linear functions of given featur es. Definition 2.1 (Linear MDP) . A finite-horizon MDP M = ( S , A , P , r , H ) is a linear MDP with a feature map ϕ : S × A 7 → R d c if the following holds. There exist H signed measures ψ h : S → R d c and υ h : R d c such that P h ( s ′ | s , a ) = ⟨ ϕ ( s , a ) , ψ h ( s ′ ) ⟩ and r h ( s , a ) = ⟨ ϕ ( s , a ) , υ h ⟩ for all h , s , and a . It should also satisfy the following constraints: ∥ ϕ ( s , a ) ∥ 2 ≤ 1 and ∥ υ h ∥ 2 ≤ √ d c for all h , s , and a . Additionally , for any measurable function V : S → [ 0, 1 ] , R s ∈ S V ( s ) ψ h ( s ) d s 2 ≤ √ d c . According to Jin et al. ( 2020 , Proposition 2.3), for a linear MDP and any policy π , Q π h is a linear function of the features: for all ( h , s , a ) , there exists a w h ∈ R d c such that Q π h ( s , a ) = ⟨ ϕ ( s , a ) , w h ⟩ . Learning Objective. For this linear MDP setting, we assume that only ϕ is given to the learner whereas ψ and υ are not. The agent sequentially interacts with the environment for T episodes and aims to minimize the cumulative regret defined as Reg ( T ) : = ∑ T t = 1 V ⋆ 1 ( s 1 ) − V π t 1 ( s 1 ) , where V ⋆ 1 : = V π ⋆ 1 : = sup π V π 1 is the value function of the optimal policy π ⋆ : = arg sup π V π 1 ( s 1 ) . Equivalently , if π T denotes the mixture policy that picks a policy among { π 1 , . . . , π T } uniformly randomly , we aim to learn an ϵ -optimal π T , i.e., its optimality gap ( OG ) is bounded such that OG ( T ) : = E h V ⋆ 1 ( s 1 ) − V π T 1 ( s 1 ) i = Reg ( T ) T ≤ e O ( ϵ ) , where the expectation is taken with r espect to the randomness of the mixture policy . Log-Linear Policy . W e consider a restricted policy class Π lin consisting of log-linear policies . Log-linear policies are repr esented using the softmax function with linear function approximation. In particular , a log-linear policy is defined as follows: for all h ∈ [ H ] , π h ( a | s , θ ) = exp ( z h ( s , a | θ h )) ∑ a ′ ∈A exp ( z h ( s , a ′ | θ h )) , (1) 6 Algorithm 1 Actor-Critic with Parametric Policies 1: Input : number of update steps T , data collection batch size N (only for on-policy) 2: set D 0 ← ∅ , w 1 h ← 0 , π 1 h ( · | s ) ← Unif ( A ) ∀ ( h , s ) 3: for t = 1, . . . , T − 1 do 4: D t ← ( On-Policy: n N fresh traj. i.i.d. ∼ π t o Off-Policy: D t − 1 ∪ 1 traj. ∼ π t 5: w t + 1 ← CRITIC_UPDATE ( D t , π t , w t ) 6: θ t + 1 ← ACTOR_UPDATE ( w t + 1 , θ t ) 7: π t + 1 = π ( θ t + 1 ) 8: Return : mixture policy π T where z h ( s , a | θ h ) = ⟨ φ ( s , a ) , θ h ⟩ repr esents the logits parameterized by θ h , and φ : S × A 7 → R d a are policy features given to the learner . W .l.o.g, we assume that ∥ φ ( s , a ) ∥ ≤ 1 for all s and a . For convenience, we use the shorthand π ( θ ) : [ H ] × S → ∆ ( A ) to refer to the log-linear policy corresponding to the parameters θ . 3 A General Actor -Critic Framework with Parametric Policies In this section, we start by introducing our general optimistic actor-critic framework as shown in Algorithm 1 . Starting with a uniform policy π 1 , at the beginning of every learning episode t ∈ [ T ] , the agent interacts with the environment using policy π t (Line 4). Our framework allows for collecting data fr om the environment in either an on-policy or off-policy fashion. In the on-policy setting, at episode t , the agent collects N fresh trajectories D t by interacting with the environment using the current policy π t . On the other hand, in the off-policy setting, at episode t , the agent collects only 1 trajectory from the environment using π t . However , the agent stores all the historical data collected by the previous policies, and hence, D t consists of t trajectories, each collected by π 1 , . . . , π t respectively . The critic uses the collected data and estimates an (optimistic) Q -function via learning the critic parameters w t + 1 ∈ [ H ] × R d c (Line 5). The actor then uses the estimated Q -function, and updates the parameters of θ t ∈ [ H ] × R d a of the log-linear policy (Line 6). The updated log-linear policy is denoted by π t + 1 (Line 7), and is used to collect data in the next episode. Given this general framework, we will next instantiate the actor in Section 4 and the critic in Section 5 . 4 Instantiating the Actor: Projected Natural Policy Gradient In this section, we instantiate the actor using natural policy gradient ( NPG ) with parametric policies and analyze its behavior . In particular , in Section 4.1 , we devise an algorithm that projects the standard NPG update onto the class of r ealizable policies. In Section 4.2 , we analyze and control the errors induced by the projection step. Finally , in Section 4.3 , we put everything together and instantiate the complete actor algorithm for the log-linear policy class. 4.1 Projected Natural Policy Gradient At episode t ∈ [ T ] , given b Q t h , the estimated Q -function, NPG updates the policy as: for every ( h , s ) ∈ [ H ] × S , π t + 1 h ( · | s ) ∝ π t h ( · | s ) exp ( η b Q t h ( s , · )) (2) with the corresponding normalization acr oss A . Existing work on policy optimization in linear MDPs ( Liu et al. , 2023 ; Sherman et al. , 2023 ; Cassel and Rosenberg , 2024 ) uses NPG to update the actor because of its 7 favorable theoretical pr operties. Importantly , these results do not consider any explicit parameterization for the actor . Directly implementing the update in Eq. (2) requir es O ( | S | | A| ) memory , and is therefor e impractical with large state-action spaces. Consequently , existing work uses the following equivalent form of the NPG update: for every ( h , s ) ∈ [ H ] × S , π t + 1 h ( · | s ) ∝ π 1 h ( · | s ) exp η ∑ t i = 1 b Q i h ( s , · ) , which characterizes the policy implicitly . In particular , at episode t , for any ( h , s , a ) , we can compute the policy on the fly if we have access to the sum of all the parameterized Q -functions up to episode t . However , in existing works ( Liu et al. , 2023 ; Sherman et al. , 2023 ; Cassel and Rosenberg , 2024 ), the sum of parameterized Q functions cannot be stored in a succinct manner , and they r equire storing all the parameterized Q functions. Consequently , when interacting with the environment using such an implicit policy , these works suffer from an extensive per-episode computational cost of O ( d 2 c H | A | T ) . Therefor e, the resulting algorithm is far from practice that typically uses an explicit (and often sophisticated) actor parameterization. T o alleviate these issues, we aim to compute a policy that is (i) realizable by the explicit actor parameterization and (ii) provably approximates the policy induced by the NPG update in Eq. (2) (referred to as the implicit policy ). T o this end, we use a projected NPG update: π t + 1 h ( · | s ) = Proj Π " π t h ( · | s ) exp ( η b Q t h ( s , · )) ∑ a ′ π t h ( a ′ | s ) exp ( η b Q t h ( s , a ′ )) # , where Pr oj is the projection operator , which will be instantiated subsequently in Section 4.2 . When theoretically analyzing policy optimization methods, an important intermediate result is the bound on the regr et for a specific online linear optimization problem. For the standard NPG update in Eq. (2) , this regr et can be bounded by e O ( √ T ) ( Hazan et al. , 2016 ; Szepesvári , 2022 ). In the following lemma, we analyze the effect of the pr ojection operator and bound the regr et for the pr ojected NPG . Theorem 4.1. Given a sequence of linear functions { p t , g t } t ∈ [ T ] for a sequence of vectors { g t } t ∈ [ T ] where for any t ∈ [ T ] , p t ∈ ∆ ( A ) , g t ∈ R |A | , and g t ∞ ≤ H . Consider p t ∈ [ T ] where p 1 is the uniform distribution, and for all t ∈ [ T ] , p t + 1/2 = arg min p ∈ ∆ A p , − η g t + KL ( p ∥ p t ) , (3) p t + 1 = Proj Π ( p t + 1/2 ) . (4) Let ϵ t : = KL ( u ∥ p t + 1 ) − KL ( u ∥ p t + 1/2 ) be the pr ojection error induced by Eq. (4) . Then, for any comparator u ∈ ∆ ( A ) , it holds that T ∑ t = 1 u − p t , g t ≤ log | A | + ∑ T t = 1 ϵ t η + η H 2 T 2 . The update in Eq. (3) with p t = π t h ( · | s ) is equivalent to the standard NPG update in Eq. (2) ( Xiao , 2022 ). Using this lemma for each state s and step h , with g t = b Q t h ( s , · ) and an appropriate choice of η gives the following regr et bound 1 for the projected NPG : ∑ T t = 1 ∑ H h = 1 max s ∈ S ⟨ π ⋆ h ( · | s ) − π t h ( · | s ) , b Q t h ( s , · ) ⟩ 1 This generalized regr et bound holds for any other mirror descent-based policy optimization method (e.g., SPMA ( Asad et al. , 2025 ) in Section B.3 ), but we discuss NPG within the main text for the ease of exposition. 8 ≤ O H 2 p log | A | √ T + H 2 √ ϵ T , (5) where ϵ : = max t , s , h ϵ t h ( s ) is the largest error across all t , s , and h . For the NPG in Eq. (2) without projection, ϵ = 0 and the above r esult r ecovers the standard regret bound for NPG . The above lemma suggests that by choosing the projection operator car efully and controlling the pr ojection err ors, we can bound the regr et. 4.2 Controlling the Projection Error for Log-Linear Policies T o bound the projection error in Theorem 4.1 , one could choose that Proj Π ( p ) = arg min p KL ( u ∥ p ) − KL ( u ∥ p t + 1/2 ) , and hence directly control ϵ t h . However , this results in a non-convex optimization prob- lem. Consequently , we instead choose Proj to minimize the following regr ession loss in the logit space: 1 2 z − ( z t + η g t ) where z t is the logit corresponding to p t such that p t ∝ exp ( z t ) . For the projected NPG with log-linear policies, we aim to minimize the sum of such r egression losses (acr oss all ( s , a ) ∈ S × A ) at episode t and step h , and obtain the loss function: ℓ t h ( θ ) = 1 2 ∑ ( s , a ) ∈S ×A hD φ ( s , a ) , θ − b θ t h E − η b Q t h ( s , a ) i 2 , where b Q t h ( s , a ) is the estimated Q -function from the critic. As a regression pr oblem, this actor loss can be easily optimized via gradient descent-based methods. However , note that the above actor loss requir es a minimization over the entire state-action space, which may be impractical. Therefor e, we propose to construct a good and preferably small subset D exp ⊂ S × A along with a corresponding distribution ρ exp ∈ ∆ ( D exp ) that offers good coverage of the feature space. Given D exp and ρ exp (the construction of which will be detailed subsequently), we instantiate the actor loss, e ℓ t h ( θ ) , in terms of a logit-matching regr ession: e ℓ t h ( θ ) = 1 2 ∑ ( s , a ) ∈D exp ρ exp ( s , a ) hD φ ( s , a ) , θ − b θ t h E − b Q t h ( s , a ) i 2 , (6) In order to show that optimizing the above actor loss can indeed bound the projection err or , we require the following assumptions. W e assume that the given policy features φ are expr essive enough to control the bias when minimizing ℓ t h ( θ ) . Assumption 4.1 (Bias) . min θ sup t , h e ℓ t h ( θ ) ≤ ϵ bias In practice, ϵ bias can be controlled by choosing high-dimensional features (e.g., d a ≫ d c ) or a sufficiently expressive policy class (e.g., neural network). Next, we assume the loss e ℓ t h ( θ ) is sufficiently minimized. Assumption 4.2 (Optimization Error) . Suppose θ t h is obtained by minimizing e ℓ t h ( θ ) in the critic update, then sup t , h e ℓ t h ( θ t h ) − min θ e ℓ t h ( θ ) ≤ ϵ opt . In practice, minimizing e ℓ t h ( θ ) by K t steps of gradient descent ensures that ϵ opt ≤ O ( exp ( − K t )) . Given these two mild assumptions, we can then proceed to bound the pr ojection err or . Using Theorem 4.1 for the projected NPG update at state s , step h , and setting u = π ⋆ ( · | s ) , the projection error ϵ t h ( s ) can be bounded as follows. Lemma 4.1. Suppose φ G : = sup ( s , a ) ∈S ×A ∥ φ ( s , a ) ∥ G − 1 where G : = ∑ ( s , a ) ∈D exp ρ exp ( s , a ) φ ( s , a ) φ ( s , a ) ⊤ . Un- der Assumptions 4.1 and 4.2 , it holds that for all ( t , h , s ) , ϵ t h ( s ) ≤ ϵ : = 2 ( φ G + 1 ) √ ϵ bias + 2 √ ϵ opt . 9 The above lemma is true for any choice of D exp and ρ exp , and suggests that if we can contr ol φ G , the projection error can be bounded. Constructing D exp and ρ exp . Therefore, we would like to construct a suitable D exp and ρ exp to bound ∥ φ ( s , a ) ∥ G − 1 for any ( s , a ) ∈ S × A and solve the following optimization problem: inf D exp ∈S ×A ρ exp ∈ ∆ ( D exp ) sup ( s , a ) ∈S ×A ∥ φ ( s , a ) ∥ G − 1 s.t. G = ∑ ( s , a ) ∈D exp ρ exp ( s , a ) φ ( s , a ) φ ( s , a ) ⊤ , which fits the form of experimental design. Ideally , we would also like D exp to be relatively small so that the actor parameters can be updated efficiently . There ar e standar d techniques to solve this pr oblem. The most common approach is the G -optimal design, which involves constructing a coreset (i.e., D exp and ρ exp ) and bounds ∥ φ ( s , a ) ∥ G − 1 . In particular , the Kiefer–W olfowitz theorem ( Kiefer and W olfowitz , 1960 ) guarantees that there exists a coreset such that ∥ φ ( s , a ) ∥ G − 1 ≤ O ( d a ) and D exp ≤ e O ( d a ) . Constructing such a coreset can be achieved using various methods, such as the Frank-W olfe algorithm ( Frank et al. , 1956 ; Szepesvári , 2022 ). W e remark that this method only uses the given policy features φ , and does not involve the linear MDP features ϕ . Furthermore, the r equir ed cor eset can be constructed offline, even befor e the learning procedur e or without any knowledge of the envir onment (see Section C.1 for details). Giving access to such a coreset guarantees that ϵ ≤ O ( d a √ ϵ bias + √ ϵ opt ) , and optimizing the actor loss upon that only requires O ( d a ) computation. Rather than forming a coreset, alternative approaches assume φ = ϕ , and use some limited interaction with the environment to construct D exp . In particular , under some standard assumptions (e.g., W agenmaker and Jamieson , 2022 , Assumption 1), we can apply methods such as CoverTraj ( W agenmaker et al. , 2022 ) and OptCov ( W agenmaker et al. , 2022 ) that construct D exp and ρ exp and can subsequently ensure that ∥ φ ( s , a ) ∥ G − 1 is bounded. The sample complexity for such procedures is e O ( d 4 c H 3 ϵ − 1 M ) where ϵ M is a problem-dependent constant. W e defer all the details to Section C . Remark 4.1. Having access to D exp and ρ exp does not obviate the necessity of exploration. Specifically, we do not assume random access, i.e., the agent cannot visit all the state-actions in D exp . Hence, we cannot effectively calculate Q π ( s , a ) for any ( s , a ) ∈ D exp . 4.3 Putting Everything T ogether: Projected NPG with Log-Linear Policies In Algorithm 2 , we instantiate the complete actor algorithm, which uses the pr ojected NPG update for log-linear policies. Unlike the standard NPG update, Algorithm 2 alleviates the necessity of storing past Q -functions, improving the memory complexity to O ( d a ) , while enjoying similar theoretical guarantees. Furthermore, the actor parameters are updated by using gradient descent on a properly defined surr ogate loss, rendering it closer to the practical implementation of common algorithms (e.g., PPO ( Schulman et al. , 2017b )). W e remark that although we focused on the log-linear policies, our theoretical guarantees readily extend to general function approximation when Assumptions 4.1 and 4.2 are satisfied, and one has access to an exploratory policy ( Hao et al. , 2021 , Definition 1). In the next section, we instantiate the critic in Algorithm 1 . 5 Instantiating the Critic: Langevin Monte Carlo In this section, we use Langevin Monte Carlo ( LMC ) to instantiate the critic. W e describe the resulting algorithm in Section 5.1 , and analyze it in Section 5.2 2 min { x , a } + : = max { min { x , a } , 0 } is the clipping function that bounds the given value x to the range [ 0, a ] . 10 Algorithm 2 Actor: Projected NPG 1: Input : critic parameters w t , policy optimization learning rate η , number of actor updates K t , actor learning rate α t a , subset and distribution of the state-action space D exp and ρ exp 2: for h = 1, 2, . . . , H do 3: b Q t h ( · , · ) = min { ϕ ( · , · ) , w t h , H − h + 1 } + 2 4: Define the actor loss e ℓ t h ( θ ) using Eq. (6) 5: for k = 1, . . . , K t do 6: θ t , k h ← θ t , k − 1 h − α t a ∇ θ e ℓ t h ( θ t , k − 1 h ) 7: Return : actor parameters for the policy θ t The LMC approaches allow for sampling from a posterior distribution and have recently been used in sequential decision-making problems. For example, Mazumdar et al. ( 2020 ) achieves optimal instance- dependent regr et bounds for multi-armed bandits using Langevin dynamics for appr oximate Thompson sampling. On the other hand, Xu et al. ( 2022 ) uses LMC for contextual bandits, achieving comparable theoretical r esults to Thompson sampling. More recently , Ishfaq et al. ( 2024a ) leverages LMC for linear MDPs by using it to sample the Q -function from its posterior distribution, achieving the optimal e O ( √ T ) regr et. Nevertheless, all existing LMC -based approaches for MDPs, including those for general function approxi- mation ( Ishfaq et al. , 2024b ; Jorge et al. , 2024 ) use value-based algorithms. T o the best of our knowledge, such approaches have never been theoretically analyzed in the context of policy optimization. Next, we incorporate the LMC algorithm into our actor-critic framework and pr ovide the first provable r esult. 5.1 LMC for Linear MDPs At episode t , the critic uses the collected dataset D t to obtain an optimistic estimate of the Q function. In order to instantiate the critic loss, we consider the dataset D t as split into H disjoint subsets D t h h ∈ [ H ] , where D t h consists of ( s h , a h , s h + 1 ) tuples indexed as n ( s i h , a i h , s i h + 1 ) o |D t | i = 1 3 . The critic loss at episode t and step h uses the estimated value function at step h + 1, and forms the following ridge regr ession problem: L t h ( w ) = 1 2 ∑ | D t | i = 1 h χ t , h i = r h ( s i h , a i h ) + b V t h + 1 ( s i h + 1 ) − ϕ ( s i h , a i h ) , w i 2 + λ 2 ∥ w ∥ 2 . (7) For each step h , the LMC algorithm iteratively adds Gaussian noise to the gradient descent updates on L t h ( w ) , and aims to produce approximate samples of the critic parameters from its underlying posterior distribution (Line 6-8). In particular , for an arbitrary loss ℓ , the LMC update can be written as: w t + 1 = w t − α t ∇ w ℓ ( w t ) + p α t / ζ ν t , where α t is the learning rate, ζ is the inverse temperature parameter , and ν t is sampled from an isotropic Gaussian distribution. After J t steps of the LMC update on the critic loss (Lines 6-8 in Algorithm 3 ), the resulting critic parameters are used to produce an optimistic sample of the Q -function (Line 9). From a theoretical perspective, we note that it is important to clip Q t h appropriately . In order to improve the optimism guarantees of the LMC algorithm, we follow the idea in Ishfaq et al. ( 2021 ), and repeat the LMC update M times, taking the maximum over these samples (Line 9). Iterating this procedure backwar ds from h = H to 1, we can obtain the desired critic parameters. Note that compared to UCB -based approaches, LMC does not require computing confidence sets at every episode. Instead, it simply perturbs gradient descent by injecting Gaussian noise, allowing for a natural extension beyond the linear function approximation setting and rendering it easier to implement in practice. 3 |D t | repr esents the number of trajectories in D t or the number of ( s h , a h , s h + 1 ) tuples in D t h 11 Algorithm 3 Critic: LMC 1: Input : collected data D t , policy π t − 1 , number of critic updates J t , critic learning rate α h , t c , inverse temperature ζ , number of critic samples M 2: b V t H + 1 ( · ) ← 0 3: for h = H , H − 1, . . . , 1 do 4: Define the critic loss L t h ( w ) using Eq. (7) 5: w t , m ,0 h ← w t − 1, m , J t − 1 h ∀ m ∈ [ M ] 6: for j = 1, . . . , J t do 7: ν t , m , j h ← N ( 0, I ) ∀ m ∈ [ M ] 8: w t , m , j h ← w t , m , j − 1 h − α h , t c ∇ w L t h ( w t , m , j − 1 h ) + q α h , t c / ζ ν t , m , j h ∀ m ∈ [ M ] 9: b Q t h ( · , · ) = min max m ∈ [ M ] D ϕ ( · , · ) , w t , m , J t h E , H + 10: b V t h ( · ) = E a ∼ π t − 1 ( · | s ) b Q t h ( · , a ) 11: Return : critic parameters for the estimated Q -function { w t , m , J t h } ( m , h ) ∈ [ M ] × [ H ] 5.2 Optimism Guarantee and Error Bound In order to theor etically analyze Algorithm 3 , we first define the following model prediction err or . Definition 5.1. Given an estimated Q -function b Q t and the corresponding estimated value function b V t , for all ( t , h , s , a ) , the model prediction error is defined as: ι t h ( s , a ) : = r h ( s , a ) + P h b V t h + 1 ( s , a ) − b Q t h ( s , a ) . The theoretical analyses in existing work ( Jin et al. , 2020 ; Zhong and Zhang , 2023 ; Liu et al. , 2023 ) that use UCB bonuses typically proceed by pr oving an upper bound of 0 on ι t h ( optimism ) and a lower bound of e O ( √ T ) . The following lemma shows that LMC can offer similar guarantees. Lemma 5.1. Let Λ t h : = ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) ϕ ( s , a ) ⊤ + λ I . With appropriate choices of λ , ζ , J t , α t c , M and for any δ ∈ ( 0, 1 ) , Algorithm 1 with the LMC critic in Algorithm 3 ensur es that in both the on-policy and off-policy settings, for all t, h , s , a and some constant Γ LMC = e O ( H d c ) , with probability at least 1 − δ , − Γ LMC × ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ ι t h ( s , a ) ≤ 0 . The exact definition of Γ LMC varies between the on-policy and off-policy settings, although they are both bounded by e O ( H d c ) (see Section D for the full version of this lemma). In order to prove this r esult in the on-policy setting, we use the fact that all the data points in D t h are collected via independent trajectories from the same policy π t , and are therefore independent and identically distributed. Hence, we can use the self-normalized bounds in Abbasi-Y adkori et al. ( 2011 ) to analyze the dependence in h , and prove the corresponding result. In the off-policy setting, since the data points in D t h are collected by differ ent data- dependent policies, these samples are corr elated in a complicated manner . Hence, we use the value-aware uniform concentration result from Jin et al. ( 2020 ). W e remark that this result requir es control over the covering number of the value function class, which is deferred to Section 6 . Therefor e, we conclude that, compared to UCB bonuses, LMC offers significant practical advantages while still providing similar theor etical guarantees. 6 Sample Complexity Analysis In this section, we analyze the sample complexity of Algorithm 1 with the projected NPG actor from Algo- rithm 2 and the LMC critic from Algorithm 3 . Section 6.1 focuses on the on-policy setting, while Section 6.2 12 addresses the of f-policy setting. 6.1 On-Policy Setting W e now present the following theorem that shows that our pr oposed algorithm achieves a sample complexity of e O ( ϵ − 4 ) in the on-policy setting. Theorem 6.1. Under Assumptions 4.1 and 4.2 , consider Algorithm 1 in the on-policy setting with the projected NPG actor ( Algorithm 2 ) and the LMC critic ( Algorithm 3 ). Suppose ϵ is the projection err or in the actor . For an appropriate choice of the actor and critic parameters, including N = H 4 / ϵ 2 , and any δ ∈ ( 0, 1 ) , it holds that with probability at least 1 − δ , OG ( T ) ≤ e O H 2 p d 3 c log | A | √ T + H 2 √ ϵ ! . Hence, for any ϵ > 0 , Algorithm 1 with T = d 3 c H 4 log | A | ϵ − 2 yields a ( ϵ + H 2 √ ϵ ) -optimal mixture policy , and therefor e requir es T × N = e O ( ϵ − 4 ) samples. Proof Sketch. W e decompose the difference between V π T 1 ( s 1 ) and V ⋆ 1 ( s 1 ) into two terms that only depend on either the actor or the critic. E h V π ⋆ 1 − V π T 1 ( s 1 ) i = 1 T T ∑ t = 1 H ∑ h = 1 E π ⋆ hD π ⋆ h ( · | s h ) − π t h ( · | s h ) , b Q t h ( s h , · ) Ei | {z } policy optimization (actor) error + 1 T T ∑ t = 1 H ∑ h = 1 E π ⋆ [ ι t h ( s h , a h )] − E π t [ ι t h ( s h , a h )] | {z } policy evaluation (critic) error . The policy optimization (actor) error can be bounded using Eq. (5) , and the policy evaluation (critic) error is bounded using Lemma D.2 . In particular , in the on-policy setting, the lower-bound in Lemma D.2 can be instantiated as: T ∑ t = 1 H ∑ h = 1 E π t − ι t h ( s , a ) ≤ O q d 3 c H 4 T log 2 ( N / δ ) / N . Putting everything together with the chosen value of N leads to the stated sample complexity . Comparison to Liu et al. ( 2023 ). The on-policy sample-complexity in Theorem 6.1 matches the bound in Liu et al. ( 2023 , Theorem 1). However , unlike the proposed algorithm, Liu et al. ( 2023 ) uses NPG with implicit policies for the actor . Consequently , sampling from the current policy (to interact with the environment) requir es calculating ∑ t − 1 τ = 1 b Q τ h ( · , · ) for each encountered state-action pair . Since they use clipped Q functions with UCB bonuses for the critic, the above sum of Q functions cannot be stor ed succinctly . Hence, sampling from the policy r equires instantiating each pr evious Q function for each step h and episode t , resulting in a computational cost of O ( d 2 c H ϵ − 2 ) . 6.2 Off-Policy Setting Next, we show that, in the off-policy setting, Algorithm 1 can achieve e O ( ϵ − 2 ) sample complexity . 13 Theorem 6.2. Under Assumptions 4.1 and 4.2 , consider Algorithm 1 in the off-policy setting with the projected NPG actor ( Algorithm 2 ) and the LMC critic ( Algorithm 3 ). Suppose ϵ is the projection err or in the actor . For an appropriate choice of the acto r and critic parameters and any δ ∈ ( 0, 1 ) , it holds that with pr obability at least 1 − δ , OG ( T ) ≤ e O H 2 p d 3 c max { d a , d c } log | A | √ T + H 2 √ ϵ ! . Hence, for any ϵ > 0 , Algorithm 1 with T = d 3 c max { d a , d c } H 4 log | A | ϵ − 2 yields a ( ϵ + H 2 √ ϵ ) -optimal mixture policy , and ther efor e requir es T × 1 = e O ( ϵ − 2 ) samples. Proof Sketch. The proof uses a similar regret decomposition to Theorem 6.1 . Compar ed to the on- policy setting, the most significant difference is the bound on the policy evaluation (critic) errors. First, using Lemma 5.1 , we have that T ∑ t = 1 H ∑ h = 1 E π t − ι t h ( s , a ) ≤ Γ T ∑ t = 1 H ∑ h = 1 E π t ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . The term, ∑ T t = 1 ∑ H h = 1 E π t ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 , can be bounded using the standard elliptical potential lemma. However , since we ar e in the off-policy setting, bounding Γ > 0 r equir es the uniform concentration ar gument from Jin et al. ( 2020 ), which yields that Γ ≤ O H s d c log T + log N ∆ ( V ) δ + T ∆ ! . This involves obtaining a bound on log ( N ∆ ( V ) ) , the logarithm of the covering number of the value function class. The covering number is a measure of the complexity of the space of value functions. In particular , we show that for an actor with log-linear policies, we can bound the logarithm of the covering number using the following lemma. Lemma 6.1. Let Π lin be the policy class induced by Eq. (1) such that sup θ , h , s , a ∥ z h ( s , a | θ ) ∥ ≤ Z . Let Q = n min {⟨ ϕ ( · , · ) , w ⟩ ) , H } + | ∥ w ∥ ≤ W o be the Q -function class and V = { ⟨ Q ( · , · ) , π ( · | · , θ ) ⟩ A | Q ∈ Q , π ∈ Π lin } be the corresponding value function class. Then, it holds that log N ∆ ( V ) ≤ V : = d c log 1 + 4 W + 4 H √ 2 Z ∆ ! + d a log 1 + 4 H √ 2 Z ∆ ! . In particular , we can show that W ≤ O ( √ T ) ( Lemma D.7 ), and Z ≤ O ( ϵ T ) ( Lemma F .1 ). Putting everything together and setting ∆ = 1 / T yields that T ∑ t = 1 H ∑ h = 1 E π t − ι t h ( s , a ) ≤ e O q d 3 c max { d a , d c } H 4 T . Following a proof similar to Theor em 6.1 leads to the desired sample complexity . Remark 6.1. In order to effectively bound the logarithm of the covering number , previous work ( Sherman et al. , 2023 ; Cassel and Rosenberg , 2024 ; T an et al. , 2025 ) has incorporated various algorithmic tweaks, including reward-free warm-ups, feature contractions, and rar e-switching. On the contrary , since our algorithm projects the implicit policy onto the log-linear policy class at each iteration, the logarithm of the covering number can be bounded in a more dir ect manner . 14 Comparison to Sherman et al. ( 2023 ); Cassel and Rosenberg ( 2024 ). The off-policy sample-complexity in Theorem 6.2 matches the bound in Sherman et al. ( 2023 ); Cassel and Rosenberg ( 2024 ). Similar to Liu et al. ( 2023 ), both works use NPG with implicit policies for the actor and UCB bonuses for the critic. Consequently , the r esulting methods suf fer fr om a high cost of policy infer ence. Finally , we note that similar to the proposed algorithm (see Section 4.2 ), Sherman et al. ( 2023 ) also uses a rewar d-free warm-up phase ( W agenmaker et al. , 2022 ). However , while we require the warm-up phase to identify a cor eset to ef ficiently minimize the actor loss (a computational reason), Sherman et al. ( 2023 ) requir es the warm-up procedur e to r estrict the subsequent r egr et minimization procedur e to high occupancy r egions of the state-action space and effectively control the capacity of the policy class (a statistical r eason). 7 Experiments In this section, we first evaluate our proposed algorithm in linear MDPs, consistent with our theoretical analyses. T o further demonstrate its versatility , we extend the proposed algorithm to large-scale deep RL applications, evaluating its performance across several Atari games. 7.1 Experiments in Linear MDPs Figure 1: Comparison of LMC-NPG-EXP (our proposed algorithm), LMC-NPG-IMP (memory-intensive variant), and LMC (value-based baseline) in the Random MDP . T o demonstrate the practical value of our proposed algorithm, we evaluate it over various benchmarks. W e first test our proposed algorithm in the randomly generated linear MDPs (Random MDP). W e compare our proposed algorithm, LMC-NPG-EXP , with the memory-intensive variant with implicit policy parameterization, LMC-NPG-IMP , and the value-based baseline, LMC ( Ishfaq et al. , 2024a ). As shown in Figure 1 , our pr oposed algorithm can achieve comparable performance with the memory-intensive variant and better performance than LMC . In Section G.1 , we also do the same experiment in the linear MDP version of the Deep Sea environment ( Osband et al. , 2019 ). In Section G.2 , we further conduct some ablation studies in these two environments of linear MDPs. 7.2 Experiments Beyond Linear MDPs: Atari In Section G.3 , we extend our proposed algorithm to large-scale deep RL applications. W e then conduct experiments in Atari ( Mnih et al. , 2013 ) using Stable Baselines3 ( Raffin et al. , 2021 ) and compare our pr oposed algorithm to PPO ( Schulman et al. , 2017b ) in the on-policy setting and DQN ( Mnih et al. , 2015 ) in the off-policy setting. W e demonstrate that our algorithm can achieve similar or even better performance. 15 8 Discussion W e proposed an optimistic actor–critic algorithm with explicitly parameterized policies and a systematic exploration mechanism. In particular , for the actor , we demonstrated that using projected NPG with parametric policies is not only practical, but also equipped with theoretical guarantees. For the critic, we demonstrated that LMC is a principled and easy-to-implement exploration scheme for policy optimization methods. W e derived theoretical guarantees in both the on-policy and off-policy settings, showcasing that the pr oposed actor-critic algorithm can simultaneously achieve sample ef ficiency and practicality . For future work, eliminating the dependence on D exp and ρ exp will result in a mor e practical algorithm. W e also aim to investigate the actor -critic algorithms in more r ealistic setups (e.g., infinite-horizon discounted MDPs) with more general function approximation schemes beyond linear models for both the environment and the policy . It would also be fruitful to further evaluate their empirical performance in more challenging large-scale deep RL applications. Acknowledgments W e would like to thank Xingtu Liu, Y unxiang Li, and the anonymous reviewers for their helpful feedback. This work was partially supported by the Natural Sciences and Engineering Resear ch Council of Canada (NSERC) Discovery Grant RGPIN-2022-04816, and enabled in part by support provided by the Digital Research Alliance of Canada (alliancecan.ca). References Abbasi-Y adkori, Y ., Bartlett, P ., Bhatia, K., Lazic, N., Szepesvari, C., and W eisz, G. (2019). Politex: Regret bounds for policy iteration using expert prediction. In International Conference on Machine Learning , pages 3692–3702. PMLR. Abbasi-Y adkori, Y ., Pál, D., and Szepesvári, C. (2011). Improved algorithms for linear stochastic bandits. Advances in Neural Information Processing Systems, 24. Abramowitz, M. and Stegun, I. A. (1948). Handbook of mathematical functions with formulas, graphs, and mathematical tables, volume 55. US Government Printing Office. Agarwal, A., Jin, Y ., and Zhang, T . (2023). VO Q L: T owards optimal regr et in model-free RL with nonlinear function approximation. In The Thirty Sixth Annual Conference on Learning Theory , pages 987–1063. PMLR. Agarwal, A., Kakade, S. M., Lee, J. D., and Mahajan, G. (2021a). On the theory of policy gradient methods: Optimality , approximation, and distribution shift. Journal of Machine Learning Research, 22(98):1–76. Agarwal, N., Chaudhuri, S., Jain, P ., Nagaraj, D., and Netrapalli, P . (2021b). Online target q-learning with reverse experience replay: Efficiently finding the optimal policy for linear mdps. arXiv preprint Alfano, C. and Rebeschini, P . (2022). Linear convergence for natural policy gradient with log-linear policy parametrization. arXiv preprint Asad, R., Harikandeh, R. B., Laradji, I. H., Le Roux, N., and V aswani, S. (2025). Fast convergence of softmax policy mirr or ascent. In International Confer ence on Artificial Intelligence and Statistics , pages 3943–3951. PMLR. Bhandari, J. and Russo, D. (2024). Global optimality guarantees for policy gradient methods. Operations Research, 72(5):1906–1927. 16 Bhatnagar , S., Sutton, R. S., Ghavamzadeh, M., and Lee, M. (2009). Natural actor–critic algorithms. Automatica, 45(11):2471–2482. Cai, Q., Y ang, Z., Jin, C., and W ang, Z. (2020). Pr ovably efficient exploration in policy optimization. In International Conference on Machine Learning, pages 1283–1294. PMLR. Cassel, A. and Rosenberg, A. (2024). W arm-up free policy optimization: Improved regret in linear Markov decision processes. Advances in Neural Information Processing Systems, 37:3275–3303. Cayci, S., He, N., and Srikant, R. (2024). Finite-time analysis of entr opy-regularized neural natural actor-critic algorithm. T ransactions on Machine Learning Research. Cen, S., Cheng, C., Chen, Y ., W ei, Y ., and Chi, Y . (2022). Fast global convergence of natural policy gradient methods with entropy r egularization. Operations Research, 70(4):2563–2578. Dulac-Arnold, G., Mankowitz, D., and Hester , T . (2019). Challenges of real-world reinfor cement learning. arXiv preprint Frank, M., W olfe, P ., et al. (1956). An algorithm for quadratic programming. Naval resear ch logistics quarterly, 3(1-2):95–110. Fu, Z., Y ang, Z., and W ang, Z. (2021). Single-timescale actor-critic pr ovably finds globally optimal policy . In International Conference on Learning Repr esentations. Fujimoto, S., Hoof, H., and Meger , D. (2018). Addressing function approximation error in actor -critic methods. In International conference on machine learning, pages 1587–1596. PMLR. Gaur , M., Bedi, A., W ang, D., and Aggarwal, V . (2024). Closing the gap: Achieving global convergence (last iterate) of actor-critic under Markovian sampling with neural network parametrization. In International Conference on Machine Learning, pages 15153–15179. PMLR. Gaur , M., Bedi, A. S., W ang, D., and Aggarwal, V . (2023). On the global convergence of natural actor -critic with two-layer neural network parametrization. arXiv preprint Haarnoja, T ., Zhou, A., Abbeel, P ., and Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinfor cement learning with a stochastic actor . In International conference on machine learning , pages 1861–1870. Pmlr . Hao, B., Lattimore, T ., Szepesvári, C., and W ang, M. (2021). Online sparse reinforcement learning. In International Conference on Artificial Intelligence and Statistics, pages 316–324. PMLR. Hazan, E. et al. (2016). Intr oduction to online convex optimization. Foundations and T rends® in Optimization, 2(3-4):157–325. He, J., Zhao, H., Zhou, D., and Gu, Q. (2023). Nearly minimax optimal reinforcement learning for linear markov decision processes. In International Conference on Machine Learning , pages 12790–12822. PMLR. Hong, M., W ai, H.-T ., W ang, Z., and Y ang, Z. (2023). A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor-critic. SIAM Journal on Optimization , 33(1):147–180. Ishfaq, H., Cui, Q., Nguyen, V ., A youb, A., Y ang, Z., W ang, Z., Precup, D., and Y ang, L. (2021). Random- ized exploration in r einforcement learning with general value function approximation. In International Conference on Machine Learning, pages 4607–4616. PMLR. Ishfaq, H., Lan, Q., Xu, P ., Mahmood, A. R., Precup, D., Anandkumar , A., and Azizzadenesheli, K. (2024a). Provable and practical: Efficient exploration in r einforcement learning via langevin monte carlo. In The T welfth International Conference on Learning Representations. 17 Ishfaq, H., T an, Y ., Y ang, Y ., Lan, Q., Lu, J., Mahmood, A. R., Precup, D., and Xu, P . (2024b). More ef ficient randomized exploration for reinfor cement learning via approximate sampling. In Reinforcement Learning Conference. Ishfaq, H., W ang, G., Islam, S. N., and Precup, D. (2025). Langevin soft actor-critic: Efficient exploration through uncertainty-driven critic learning. In The Thirteenth International Conference on Learning Representations. Jin, C., Liu, Q., and Miryoosefi, S. (2021). Bellman eluder dimension: New rich classes of rl problems, and sample-efficient algorithms. Advances in Neural Information Processing Systems, 34:13406–13418. Jin, C., Y ang, Z., W ang, Z., and Jordan, M. I. (2020). Provably efficient r einforcement learning with linear function approximation. In Conference on learning theory, pages 2137–2143. PMLR. Jorge, E., Dimitrakakis, C., and Basu, D. (2024). Isoperimetry is all we need: Langevin posterior sampling for rl with sublinear regr et. arXiv preprint Kakade, S. M. (2001). A natural policy gradient. Advances in Neural Information Processing Systems, 14. Khodadadian, S., Doan, T . T ., Romber g, J., and Maguluri, S. T . (2022). Finite-sample analysis of two-time-scale natural actor–critic algorithm. IEEE T ransactions on Automatic Control, 68(6):3273–3284. Kiefer , J. and W olfowitz, J. (1960). The equivalence of two extremum problems. Canadian Journal of Mathematics, 12:363–366. Kober , J., Bagnell, J. A., and Peters, J. (2013). Reinforcement learning in robotics: A survey . The International Journal of Robotics Research, 32(11):1238–1274. Konda, V . and T sitsiklis, J. (1999). Actor-critic algorithms. Advances in Neural Information Processing Systems, 12. Lattimore, T . and Szepesvári, C. (2020). Bandit algorithms. Cambridge University Press. Lillicrap, T . P ., Hunt, J. J., Pritzel, A., Heess, N., Erez, T ., T assa, Y ., Silver , D., and W ierstra, D. (2015). Continuous control with deep r einforcement learning. arXiv preprint Liu, Q., W eisz, G., György , A., Jin, C., and Szepesvári, C. (2023). Optimistic natural policy gradient: a simple efficient policy optimization framework for online rl. Advances in Neural Information Processing Systems, 36:3560–3577. Mazumdar , E., Pacchiano, A., Ma, Y ., Jordan, M., and Bartlett, P . (2020). On approximate thompson sampling with langevin algorithms. In international conference on machine learning, pages 6797–6807. PMLR. Mnih, V ., Kavukcuoglu, K., Silver , D., Graves, A., Antonoglou, I., W ierstra, D., and Riedmiller , M. (2013). Playing atari with deep reinfor cement learning. arXiv preprint Mnih, V ., Kavukcuoglu, K., Silver , D., Rusu, A. A., V eness, J., Bellemare, M. G., Graves, A., Riedmiller , M., Fidjeland, A. K., Ostr ovski, G., et al. (2015). Human-level control thr ough deep r einforcement learning. nature, 518(7540):529–533. Neu, G., Jonsson, A., and Gómez, V . (2017). A unified view of entropy-r egularized markov decision processes. arXiv preprint Osband, I., Doron, Y ., Hessel, M., Aslanides, J., Sezener , E., Saraiva, A., McKinney , K., Lattimore, T ., Szepes- vari, C., Singh, S., et al. (2019). Behaviour suite for reinfor cement learning. arXiv preprint . Peters, J., V ijayakumar , S., and Schaal, S. (2005). Natural actor-critic. In European Confer ence on Machine Learning, pages 280–291. Springer . 18 Raffin, A. (2020). Rl baselines3 zoo. https://github.com/DLR- RM/rl- baselines3- zoo . Raffin, A., Hill, A., Gleave, A., Kanervisto, A., Ernestus, M., and Dormann, N. (2021). Stable-baselines3: Reliable reinfor cement learning implementations. Journal of Machine Learning Research, 22(268):1–8. Schulman, J., Chen, X., and Abbeel, P . (2017a). Equivalence between policy gradients and soft q-learning. arXiv preprint Schulman, J., Levine, S., Abbeel, P ., Jor dan, M., and Moritz, P . (2015). T rust region policy optimization. In International conference on machine learning, pages 1889–1897. PMLR. Schulman, J., W olski, F ., Dhariwal, P ., Radford, A., and Klimov , O. (2017b). Pr oximal policy optimization algorithms. arXiv preprint Sherman, U., Cohen, A., Koren, T ., and Mansour , Y . (2023). Rate-optimal policy optimization for linear markov decision processes. arXiv preprint Sutton, R. S., McAllester , D., Singh, S., and Mansour , Y . (1999). Policy gradient methods for reinfor cement learning with function approximation. Advances in Neural Information Processing Systems, 12. Szepesvári, C. (2022). Algorithms for reinfor cement learning. Springer nature. T an, K., Fan, W ., and W ei, Y . (2025). Actor-critics can achieve optimal sample efficiency . arXiv preprint T odd, M. J. (2016). Minimum-volume ellipsoids: Theory and algorithms. SIAM. T omar , M., Shani, L., Efroni, Y ., and Ghavamzadeh, M. (2020). Mirror descent policy optimization. arXiv preprint Uc-Cetina, V ., Navarro-Guerr ero, N., Martin-Gonzalez, A., W eber , C., and W ermter , S. (2023). Survey on reinfor cement learning for language processing. Artificial Intelligence Review, 56(2):1543–1575. W agenmaker , A. and Jamieson, K. G. (2022). Instance-dependent near-optimal policy identification in linear mdps via online experiment design. Advances in Neural Information Processing Systems, 35:5968–5981. W agenmaker , A. J., Chen, Y ., Simchowitz, M., Du, S., and Jamieson, K. (2022). Reward-free rl is no harder than rewar d-aware rl in linear markov decision pr ocesses. In International Conference on Machine Learning , pages 22430–22456. PMLR. W elling, M. and T eh, Y . W . (2011). Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the 28th international confer ence on machine learning (ICML-11), pages 681–688. W illiams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinfor cement learning. Machine learning, 8(3):229–256. Xiao, L. (2022). On the conver gence rates of policy gradient methods. Journal of Machine Learning Research , 23(282):1–36. Xu, P ., Zheng, H., Mazumdar , E. V ., Azizzadenesheli, K., and Anandkumar , A. (2022). Langevin monte carlo for contextual bandits. In International Conference on Machine Learning, pages 24830–24850. PMLR. Xu, T ., W ang, Z., and Liang, Y . (2020). Improving sample complexity bounds for (natural) actor-critic algorithms. Advances in Neural Information Processing Systems, 33:4358–4369. Y uan, R., Du, S. S., Gower , R. M., Lazaric, A., and Xiao, L. (2023). Linear convergence of natural policy gradient methods with log-linear policies. In International Conference on Learning Repr esentations. 19 Zanette, A., Cheng, C.-A., and Agarwal, A. (2021). Cautiously optimistic policy optimization and exploration with linear function approximation. In Conference on Learning Theory, pages 4473–4525. PMLR. Zhong, H. and Zhang, T . (2023). A theoretical analysis of optimistic pr oximal policy optimization in linear markov decision processes. Advances in Neural Information Processing Systems, 36:73666–73690. 20 A Notation Notation Meaning Problem Definition S , A state space and action space H , h horizon length (total number of steps), current index of step r ∈ R |S |×| A | rewar d function P ∈ R |S |×| A |× | S | transition kernel ϕ : S × A 7 → R d c features for the linear MDP envir onment φ : S × A 7 → R d a features for the learnable policy Algorithm Design T , t total number of learning episodes, index of current episode D t , D t h collected data of at episode t , split data at h -th step (subset of D t ) N number of samples collected for on-policy learning w ∈ R d c learnable critic parameters J number of critic updates α c critic learning rate ν noise vector for LMC sampled from the standar d normal distribution ζ inverse temperature for the LMC critic loss M number of samples for the critic parameters D exp , ρ exp subset of S × A , distribution over the subset θ ∈ R d a learnable actor parameters K number of actor updates α a actor learning rate η policy optimization learning rate T able 2: Notations for Problem Definition and Algorithm Design Additional Notations. Throughout this paper , we use subscripts to represent the index of the step within the horizon of the episodic MDP and superscripts to denote the index of the episode for learning. For example, V t h means the value function for the h -th step derived at the learning episode t . In some cases, where the subscripts are omitted, it represents a set of H functions for all steps h ∈ [ H ] (e.g., V t : = { V t h } h ∈ [ H ] ). |D t | repr esents the number of trajectories in D t or the number of ( s h , a h , s h + 1 ) tuples in D t h . Additionally , for any vector v ∈ R d and any matrix M ∈ R d × d , we denote ∥ v ∥ M = √ v ⊤ M v . B Analyses for the Actor B.1 Generalized OMD Regret (Proof of Theorem 4.1 ) Proof of Theorem 4.1 . Given the update of p t + 1/2 and the fact that ∆ ( A ) is a convex set, we have the following optimality condition: D u − p t + 1/2 , − η g t + log ( p t + 1/2 ) − log ( p t ) E ≥ 0 . (8) Then, for each t ∈ [ T ] , we have that u − p t , η g t = D u − p t + 1/2 , η g t E + D p t + 1/2 − p t , η g t E 21 = D u − p t + 1/2 , η g t − log ( p t + 1/2 ) + log ( p t ) E + D u − p t + 1/2 , log ( p t + 1/2 ) − log ( p t ) E + D p t + 1/2 − p t , η g t E (i) ≤ D u − p t + 1/2 , log ( p t + 1/2 ) − log ( p t ) E + D p t + 1/2 − p t , η g t E (ii) = KL ( u ∥ p t ) − KL ( u ∥ p t + 1/2 ) − KL ( p t + 1/2 ∥ p t ) + D p t + 1/2 − p t , η g t E (iii) ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1/2 ) − KL ( p t + 1/2 ∥ p t ) + 1 2 p t + 1/2 − p t 2 1 + 1 2 η g t 2 ∞ (iv) ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1/2 ) − KL ( p t + 1/2 ∥ p t ) + KL ( p t + 1/2 ∥ p t ) + η 2 H 2 2 ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1/2 ) + η 2 H 2 2 ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1 ) + KL ( u ∥ p t + 1 ) − KL ( u ∥ p t + 1/2 ) + η 2 H 2 2 = KL ( u ∥ p t ) − KL ( u ∥ p t + 1 ) + ϵ t + η 2 H 2 2 . (i) drops the first term due to the optimality condition fr om Eq. (8) . (ii) applies the thr ee-point property of Bregman diver gence ( Lemma B.2 ) by setting x = u , y = p t + 1/2 , and z = p t . (iii) follows from the Hölder ’s inequality and then the Y oung’s inequality (i.e., ⟨ u , v ⟩ ≤ ∥ u ∥ 1 ∥ v ∥ ∞ ≤ ∥ u ∥ 2 1 / 2 + ∥ v ∥ 2 ∞ / 2 ) , and (iv) applies the Pinkster ’s inequality and g t ≤ H . Summing up the above inequality from t = 1 to T yields that T ∑ t = 1 u − p t , η g t = T ∑ t = 1 KL ( u ∥ p t ) − KL ( u ∥ p t + 1 ) + T ∑ t = 1 ϵ t + η 2 H 2 T 2 = KL ( u ∥ p 1 ) − KL ( u ∥ p T + 1 ) + T ∑ t = 1 ϵ t + η 2 H 2 T 2 (v) ≤ KL ( u ∥ p 1 ) + T ∑ t = 1 ϵ t + η 2 H 2 T 2 ≤ ∑ a ∈ A u ( a ) log ( u ( a )) − ∑ a ∈ A u ( a ) log ( p 1 ( a ) ) + T ∑ t = 1 ϵ t + η 2 H 2 T 2 (vi) ≤ log | A | + T ∑ t = 1 ϵ t + η 2 H 2 T 2 . (v) follows from the fact that KL -divergence is non-negative, and (vi) stands because the first term is negative, and for the second term, p 1 is a uniform distribution. Dividing both side by η , we have that T ∑ t = 1 u − p t , g t ≤ log |A | + ∑ T t = 1 ϵ t η + η H 2 T 2 . This concludes the proof. B.2 Projection Error (Proof of Lemma 4.1 ) Proof of Lemma 4.1 . First, we define Φ as the log-sum-exp mirror map and Φ ⋆ as negative entropy , its Fenchel conjugate. Based on this, for any softmax policy π , we can also define its logit as z : = ∇ Φ ⋆ ( π ) = 22 ( ∇ Φ ) − 1 ( π ) . Consequently , π = ∇ Φ ( z ) . Additionally , for any two softmax policies π , π ′ and their corre- sponding logits z , z ′ , it holds that, D Φ ( z , z ′ ) = KL ( π ′ , π ) . Since we are using the log-linear policy class, we have z t h ( s , a ) = D φ ( s , a ) , b θ t h E for any ( s , a ) ∈ S × A where b θ t h repr esents the parameters we attain at episode t . Therefore, for any s ∈ S , ϵ t h ( s ) = KL ( π ⋆ ( · | s ) ∥ π t + 1 h ( · | s ) ) − KL ( π ⋆ h ( · | s ) ∥ π t + 1/2 h ( · | s ) ) = D Φ ( z t + 1 h ( · | s ) , z ⋆ h ( s , · )) − D Φ ( z t + 1/2 h ( · | s ) , z ⋆ h ( · | s ) ) (i) = D ∇ Φ ( z t + 1 h ( s , · )) ) − ∇ Φ ( z ⋆ h ( s , · )) ) , z t + 1 h ( s , · )) − z t + 1/2 h ( · | s ) ) E − D Φ ( z t + 1/2 h ( · | s ) , z t + 1 h ( · | s ) ) = D π t + 1 h ( s , · ) − π ⋆ h ( s , · ) , z t + 1 h ( s , · )) − z t + 1/2 h ( s , · )) E − KL ( π t + 1 h ( · | s ) ) ∥ π t + 1/2 h ( · | s ) ) ) (ii) ≤ D π t + 1 h ( · | s ) − π ⋆ h ( · | s ) , z t + 1 h ( s , · )) − z t + 1/2 h ( s , · )) E (iii) ≤ π t + 1 h ( · | s ) − π ⋆ ( · | s ) 2 z t + 1 h ( s , · )) − z t + 1/2 h ( s , · )) 2 ≤ √ 2 z t + 1 h ( s , · ) − z t + 1/2 h ( s , · ) 2 (iv) = √ 2 D φ ( s , · ) , b θ t + 1 h − b θ t h E − η b Q t h ( s , · ) 2 (v) ≤ √ 2 D φ ( s , · ) , b θ t + 1 h − b θ t h E − η b Q t h ( s , · ) . (i) follows from the thr ee-point property of Bregman divergence ( Lemma B.2 ) by setting x = z t + 1/2 h ( · | s ) , y = z t + 1 h ( · | s ) , and z = z ⋆ h ( · | s ) where z ⋆ is the logit of π ⋆ . (ii) is based on the fact that KL -divergence is non-negative. (iii) uses the Cauchy-Schwarz inequality . (iv) uses the NPG update. (v) holds because ∥ · ∥ 2 ≤ ∥ · ∥ 1 . Since the actor is designed to minimize the ridge regression in Algorithm 2 , the minimizer can be written as b θ t , ⋆ h = arg min θ h 1 2 ∑ ( s , a ) ∈D exp ρ ( s , a ) h ⟨ φ ( s , a ) , θ h ⟩ − b Z t h ( s , a ) i 2 , where b Z t h ( s , a ) : = D φ ( s , · ) , b θ t h ( s , · ) E + η b Q t h ( s , a ) for all t ∈ [ T ] . W e define b θ t , ⋆ h as the minimizer , and it has the following explicit solution: b θ t , ⋆ h = G − 1 ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) b Z t h ( s ′ , a ′ ) φ ( s ′ , a ′ ) , where G : = ∑ ( s , a ) ∈D exp ρ ( s , a ) φ ( s , a ) φ ( s , a ) ⊤ ∈ R d a × d a . Suppose θ t , ⋆ h is the minimizer of the r egression loss over the entire state-action space, b θ t , ⋆ h is the minimizer over the coreset, and b θ t h is the parameters pr oduced by the actor after K t rounds of gradient descent as shown in Algorithm 2 . Under Assumptions 4.1 and 4.2 , we know that for any t and h , D φ ( s , a ) , b θ t , ⋆ h E − b Z t h ( s , a ) ) ≤ p 2 ϵ bias , D φ ( s , a ) , b θ t h E − D φ ( s , a ) , b θ t , ⋆ h E ≤ q 2 ϵ opt . 23 Then, for any arbitrary ( s , a ) ∈ S × A , using the triangular inequality , we have that D φ ( s , a ) , b θ t h E − b Z t h ( s , a ) ) ≤ D φ ( s , a ) , θ t , ⋆ h E − b Z t h ( s , a ) ) + D φ ( s , a ) , b θ t h E − D φ ( s , a ) , θ t , ⋆ h E = p 2 ϵ bias + D φ ( s , a ) , b θ t h E − D φ ( s , a ) , θ t , ⋆ h E ≤ p 2 ϵ bias + D φ ( s , a ) , b θ t h E − D φ ( s , a ) , b θ t , ⋆ h E + D φ ( s , a ) , b θ t , ⋆ h E − D φ ( s , a ) , θ t , ⋆ h E = p 2 ϵ bias + q 2 ϵ opt + D φ ( s , a ) , b θ t , ⋆ h − θ t , ⋆ h E . Therefor e, it suffices to bound D φ ( s , a ) , b θ t , ⋆ h ( s , a ) − θ t , ⋆ h ( s , a ) E . T o do that, we first define Υ ( s ′ , a ′ ) : = b Z t h ( s ′ , a ′ ) − D φ ( s ′ , a ′ ) , θ t , ⋆ h E for any ( s ′ , a ′ ) ∈ D exp . Then, we have that b θ t , ⋆ h = G − 1 ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) h Υ ( s ′ , a ′ ) + D φ ( s ′ , a ′ ) , θ t , ⋆ h Ei φ ( s ′ , a ′ ) = G − 1 ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) φ ( s ′ , a ′ ) φ ( s ′ , a ′ ) ⊤ θ t , ⋆ h + G − 1 ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) Υ ( s ′ , a ′ ) φ ( s ′ , a ′ ) = θ t , ⋆ h + G − 1 ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) Υ ( s ′ , a ′ ) φ ( s ′ , a ′ ) . This implies that b θ t , ⋆ h − θ t , ⋆ h = G − 1 ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) Υ ( s ′ , a ′ ) φ ( s ′ , a ′ ) . Hence, for any arbitrary ( s , a ) ∈ S × A , D φ ( s , a ) , b θ t , ⋆ h − θ t , ⋆ h E = ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) Υ ( s ′ , a ′ ) φ ( s , a ) ⊤ G − 1 φ ( s ′ , a ′ ) (vi) ≤ ∑ ( s ′ , a ′ ) ∈ D exp Υ ( s ′ , a ′ ) ρ ( s ′ , a ′ ) φ ( s , a ) ⊤ G − 1 φ ( s ′ , a ′ ) ≤ max ( s ′ , a ′ ) ∈ D exp Υ ( s ′ , a ′ ) ! ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) φ ( s , a ) ⊤ G − 1 φ ( s ′ , a ′ ) ≤ p 2 ϵ bias ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) φ ( s , a ) ⊤ G − 1 φ ( s ′ , a ′ ) = p 2 ϵ bias r E ( s ′ , a ′ ) ∼ ρ φ ( s , a ) ⊤ G − 1 φ ( s ′ , a ′ ) 2 (vii) ≤ p 2 ϵ bias q E ( s ′ , a ′ ) ∼ ρ φ ( s , a ) ⊤ G − 1 φ ( s ′ , a ′ ) 2 = p 2 ϵ bias v u u u t φ ( s , a ) ⊤ G − 1 ∑ ( s ′ , a ′ ) ∈ D exp ρ ( s ′ , a ′ ) φ ( s ′ , a ′ ) φ ( s ′ , a ′ ) ⊤ G − 1 φ ( s , a ) 24 = p 2 ϵ bias ∥ φ ( s , a ) ∥ G − 1 . (vi) applies the Cauchy-Schwarz inequality , and (vii) follows from Jensen’s inequality . Putting everything together , we have that D φ ( s , a ) , b θ t h E − b Z t h ( s , a ) ) ≤ √ 2 ( ∥ φ ( s , a ) ∥ G − 1 + 1 ) √ ϵ bias + √ ϵ opt ≤ √ 2 ( φ G + 1 ) √ ϵ bias + √ ϵ opt . Recall that ϵ t h ( s ) ≤ √ 2 D φ ( s , · ) , b θ t + 1 h ( s , · ) E − b Z t h ( s , · ) 2 . Therefor e, for any s ∈ S , ϵ t h ( s ) ≤ √ 2 D φ ( s , · ) , b θ t h E − b Z t h ( s , a ) ) ≤ 2 ( φ G + 1 ) √ ϵ bias + 2 √ ϵ opt . This concludes the proof. B.3 Instantiating the Actor with SPMA Lemma 4.1 can not only be applied to NPG but also other mirror descent-based policy optimization methods such as MDPO ( T omar et al. , 2020 ) and SPMA ( Asad et al. , 2025 ). In this section, as an example, we show that the projected variant of SPMA (projected SPMA ) is also compatible with our framework and can enjoy similar sample complexity guarantees as projected NPG . W e can instantiate the actor in Algorithm 1 with the pr ojected SPMA by setting the actor loss in Algorithm 2 as ˜ ℓ t h ( θ ) = 1 2 ∑ ( s , a ) ∈D exp ρ exp ( s , a ) h ⟨ φ ( s , a ) , θ ⟩ − b Z t h ( s , a ) i 2 , where b Z t h ( s , a ) : = D φ ( s , a ) , b θ t h E + log ( 1 + η A π t ( s , · )) . Equivalently , the projected SPMA update can be expressed as follows. For any s ∈ S , π 1 ( · | s ) is a uniform distribution, and π t + 1/2 ( · | s ) = arg min p ∈ ∆ A nD π t ( · | s ) , − log 1 + η A π t ( s , · ) E + KL p ∥ π t ( · | s ) o , π t + 1 ( · | s ) = Proj Π ( π t + 1/2 ( · | s ) ) . Hence, we introduce the following alternative lemma to show that Theorem 4.1 also holds for the pr ojected SPMA . Lemma B.1. Given a sequence of linear functions { p t , g t } t ∈ [ T ] for a sequence of vectors { g t } t ∈ [ T ] where for any t ∈ [ T ] , p t ∈ ∆ ( A ) , g t ∈ R |A | , and g t ( a ) ∈ [ 0, H ] for all a ∈ A . Consider p t ∈ [ T ] where p 1 is the uniform distribution, and for all t ∈ [ T ] , p t + 1/2 = arg min p ∈ ∆ A p , − log 1 + η g t − p t , g t 1 + KL ( p ∥ p t ) , p t + 1 = Proj Π ( p t + 1/2 ) , where 1 ∈ R |A | is an all-one vector . Let ϵ t : = KL ( u ∥ p t + 1 ) − KL ( u ∥ p t + 1/2 ) be the projection error induced by Eq. (4) . If η ≤ 1 2 H , then for any comparator u ∈ ∆ ( A ) , it holds that T ∑ t = 1 u − p t , g t ≤ log | A | + ∑ T t = 1 ϵ t η + 3 η H 2 T 2 . 25 Proof of Lemma B.1 . W e first denote that d t = log 1 + η g t − p t , g t 1 for all t ∈ [ T ] . Then, for all a ∈ A , since η ≤ 1 2 H and g t ( a ) − p t , g t ∈ [ − H , H ] , we have η g t ( a ) − p t , g t > − 1 2 and therefor e d t ( a ) (i) ≤ η g t ( a ) − p t , g t ≤ η H , d t ( a ) (ii) ≥ η g t ( a ) − p t , g t − η 2 g t ( a ) − p t , g t 2 ≥ η g t ( a ) − p t , g t − η H 2 , where (i) follows from log ( 1 + x ) ≤ x for all x > − 1, and (ii) holds because log ( 1 + x ) ≥ x − x 2 for all x > − 1 2 . Given the update of p t + 1/2 and the fact that ∆ ( A ) is a convex set, we have the following optimality condition: D u − p t + 1/2 , − d t + log ( p t + 1/2 ) − log ( p t ) E ≥ 0 . (9) Then, for all t ∈ [ T ] , we have that u − p t , d t = D u − p t + 1/2 , d t E + D p t + 1/2 − p t , d t E = D u − p t + 1/2 , d t − log ( p t + 1/2 ) + log ( p t ) E + D u − p t + 1/2 , log ( p t + 1/2 ) − log ( p t ) E + D p t + 1/2 − p t , d t E (iii) ≤ D u − p t + 1/2 , log ( p t + 1/2 ) − log ( p t ) E + D p t + 1/2 − p t , d t E (iv) = KL ( u ∥ p t ) − KL ( u ∥ p t + 1/2 ) − KL ( p t + 1/2 ∥ p t ) + D p t + 1/2 − p t , d t E (v) ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1/2 ) − KL ( p t + 1/2 ∥ p t ) + 1 2 p t + 1/2 − p t 2 1 + 1 2 d t 2 ∞ (vi) ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1/2 ) − KL ( p t + 1/2 ∥ p t ) + KL ( p t + 1/2 ∥ p t ) + η 2 H 2 2 ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1/2 ) + η 2 H 2 2 ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1 ) + KL ( u ∥ π t + 1 ) − KL ( u ∥ p t + 1/2 ) + η 2 H 2 2 = KL ( u ∥ p t ) − KL ( u ∥ p t + 1 ) + ϵ t + η 2 H 2 2 . (iii) drops the first term due to the optimality condition from Eq. (9) . (iv) applies the three-point property of Bregman diver gence ( Lemma B.2 ) by setting x = u , y = p t + 1/2 , and z = p t . (v) follows from the Hölder ’s inequality and then the Y oung’s inequality (i.e., ⟨ u , v ⟩ ≤ ∥ u ∥ 1 ∥ v ∥ ∞ ≤ ∥ u ∥ 2 1 / 2 + ∥ v ∥ 2 ∞ / 2 ) , and (vi) applies the Pinkster ’s inequality and d t ∞ ≤ H . Moreover , we have that u − p t , d t (vii) ≥ u − p t , η g t − p t , g t 1 − η H 2 (viii) ≥ u − p t , η g t − η H 2 , where (vii) comes fr om the fact that d t ( a ) ≥ η g t ( a ) − p t , g t − η H 2 for all a ∈ A , and (viii) follows from the fact that p t , g t ≥ 0 since p t ∈ ∆ ( A ) and g t ( a ) ∈ [ 0, H ] for all a ∈ A . This implies that u − p t , η g t ≤ u − p t , d t + η H 2 ≤ KL ( u ∥ p t ) − KL ( u ∥ p t + 1 ) + ϵ t + 3 η 2 H 2 2 . 26 Summing up the above inequality from t = 1 to T yields that T ∑ t = 1 u − p t , η g t = T ∑ t = 1 KL ( u ∥ p t ) − KL ( u ∥ p t + 1 ) + T ∑ t = 1 ϵ t + 3 η 2 H 2 T 2 = KL ( u ∥ p 1 ) − KL ( u ∥ p T + 1 ) + T ∑ t = 1 ϵ t + 3 η 2 H 2 T 2 (ix) ≤ KL ( u ∥ p 1 ) + T ∑ t = 1 ϵ t + 3 η 2 H 2 T 2 ≤ ∑ a ∈ A u ( a ) log ( u ( a )) − ∑ a ∈ A u ( a ) log ( p 1 ( a ) ) + T ∑ t = 1 ϵ t + 3 η 2 H 2 T 2 (x) ≤ log | A | + T ∑ t = 1 ϵ t + 3 η 2 H 2 T 2 . (ix) follows from the fact that KL -divergence is non-negative, and (x) stands because the first term is negative, and for the second term, p 1 is a uniform distribution. Dividing both side by η , we have that T ∑ t = 1 u − p t , g t ≤ log |A | + ∑ T t = 1 ϵ t η + 3 η H 2 T 2 . This concludes the proof. In order to obtain a meaningful r egret bound, we should set η = min 1 2 H , q 2 ( log |A | + ϵ T ) 3 H 2 T . Therefor e, under Assumptions 4.1 and 4.2 , we can easily pr ove that Lemma 4.1 also holds for the projected SPMA , and consequently , all the sample complexity guarantees for the projected NPG should also hold. B.4 T echnical T ools Lemma B.2 (Three-Point Pr operty of Bregman Diver gence) . Suppose X ⊆ R d is closed and convex. Consider a strictly convex function Φ : X → R . For all x ∈ X and y , z ∈ int X , D Φ ( x , y ) + D Φ ( y , z ) − D Φ ( x , z ) = ⟨ ∇ Φ ( z ) − ∇ Φ ( y ) , x − y ⟩ . C Constructing D exp and ρ exp via Experimental Design In this section, we intr oduce various methods of experimental design to bound φ G defined in Lemma 4.1 . The experimental design problem can be written as inf D exp ∈S ×A ρ exp ∈ ∆ ( D exp ) sup ( s , a ) ∈S ×A ∥ φ ( s , a ) ∥ G − 1 s.t. G = ∑ ( s , a ) ∈D exp ρ exp ( s , a ) φ ( s , a ) φ ( s , a ) ⊤ . In Section C.1 , we consider constructing a coreset for the policy features. The Kiefer–W olfowitz theorem guarantees that there exists a coreset that can ensure that φ G is bounded, and that such a coreset has a small O ( d ) size. Such a coreset can be formed using G-experimental design. In Section C.2 , we consider using the linear MDP featur es as the policy featur es and constr ucting D exp through limited interaction with the environment. 27 C.1 Kiefer–W olfowitz Theorem and G-Experimental Design W e first introduce the Kiefer–W olfowitz theorem ( Kiefer and W olfowitz , 1960 ) which guarantees that there exists a coreset D exp and its corresponding distribution ρ exp that can be used to bound φ G . Proposition C.1 (Kiefer–W olfowitz) . Let G : = ∑ ( s , a ) ∈D exp ρ exp ( s , a ) φ ( s , a ) φ ( s , a ) ⊤ be the covariance matrix for any D exp ⊂ S × A and ρ ∈ ∆ ( D exp ) . There exists a coreset D exp and a distribution ρ exp such that sup ( s , a ) ∈D exp ∥ φ ( s , a ) ∥ G − 1 ≤ 2 d a and | D exp | ≤ 4 d a log log ( d a + 4 ) + 28 . Note that the size of D exp is also bounded by e O ( d a ) , suggesting that the computation cost of calculating the actor loss over D exp is inexpensive. The problem of constructing such a coreset is often framed as G- experimental design, and it can typically be solved using numerous efficient appr oximation algorithms such as the Franke-W olfe algorithm ( Frank et al. , 1956 ) as mentioned in T odd ( 2016 ); Lattimore and Szepesvári ( 2020 ). Using D exp and ρ exp produced by such methods to constr uct the actor loss in Algorithm 2 offers the guarantees that φ G ≤ O ( d a ) , which is consequently used to bound the projection error in Lemma 4.1 as ϵ ≤ O ( d a ϵ bias + ϵ opt ) . W e remark that the coreset construction can be done befor e the learning process in the actor-critic algorithm since it is independent of the linear MDP environment. However , these algorithms typically r equire traversing through all the policy featur es in S × A , which is not ideal for large state-action spaces. C.2 Exploratory Policy and Minimum Eigenvalue Alternatively , we can choose to use the linear MDP features as the policy features (i.e., φ = ϕ ) and construct D exp via interacting with the environment. Note that bounding φ G is equivalent to controlling ∥ ϕ ( s , a ) ∥ G − 1 for all ( s , a ) ∈ S × A . Consequently , given that ∥ ϕ ( s , a ) ∥ 2 ≤ 1 by the linear MDP assumption and since ∥ ϕ ( s , a ) ∥ G − 1 ≤ ∥ ϕ ( s , a ) ∥ 2 λ min ( G ) = 1 λ min ( G ) , we only need a well-conditioned covariance matrix G that has a positive minimum eigenvalue. Several existing works ( Hao et al. , 2021 ; Agarwal et al. , 2021b ) assume access to an exploratory (not necessarily optimal) policy π exp that is able to collect such covariance matrices with minimum eigenvalue bounded away from 0. Given that, we can directly apply π exp to roll-out trajectories and collect observations, which can be used to construct D exp and the corresponding covariance G . However , in practice, we rarely have access to such an oracle policy . Consequently , W agenmaker et al. ( 2022 ) proposed a r ewar d-free approach, CoverTraj , that can ef fectively collect such observations without assuming access to an exploratory policy . In particular , the CoverTraj algorithm offers the following theoretical guarantee. Proposition C.2 ( W agenmaker et al. 2022 , Theorem 4) . Fix h ∈ [ H ] and γ ∈ [ 0, 1 ] . Suppose there exists a problem-dependent constant ϵ M > 0 such that sup π ∈ Π λ min E π ϕ ( s , a ) ϕ ( s , a ) ⊤ ≥ ϵ M . Running K rounds of CoverTraj to collect D exp = ( s τ h , a τ h ) K τ = 1 where K = e O 1 ϵ M · max d c γ 2 , d 4 c H 3 log 3 1 δ ensures that for any δ ∈ ( 0, 1 ) , with probability of at least 1 − δ , λ min ( G ) ≥ ϵ M γ 2 , where G = ∑ ( s , a ) ∈D exp ϕ ( s , a ) ϕ ( s , a ) ⊤ . 28 Note that CoverTraj does not utilize the r eward function of the MDP and merely use the transition kernel when interacting with the environment. Alternatively , W agenmaker and Jamieson ( 2022 ) provides another approach, OptCov , that utilizes r egret minimization algorithms to construct the desir ed covariance matrix. According to W agenmaker and Jamieson ( 2022 , Theorem 9), OptCov can also offer a similar guarantee of the minimum eigenvalue ensuring that λ min ( G ) ≥ max d c log 1 δ , ϵ M . T o conclude, the Frank-W olfe algorithm can be used to form a cor eset and subsequently bound φ G for any given policy features. If we use the linear MDP features as the policy features, we can construct D exp by interacting with the environment. Either having access to an exploratory policy or running CoverTraj or OptCOv can offer guarantees on the minimum eigenvalues of the covariance matrix, which will consequently control φ G . D Analyses for the Critic D.1 Proof of Lemma 5.1 In order to pr ove Lemma 5.1 , we introduce the following “good” event for the estimated value function. Lemma D.1 (Good Event) . There exists some C δ > 0 such that for any fixed δ ∈ ( 0, 1 ) , the following event, E δ : = ∀ ( t , h ) ∈ [ T ] × [ H ] : ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) h b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) i ( Λ t h ) − 1 ≤ C δ H √ d c , holds with probability at least 1 − δ (i.e., Pr ( E δ ) ≥ 1 − δ ). The exact definition of C δ varies between the on-policy and the off-policy settings. W e will prove that Pr ( E δ ) ≥ 1 − δ for the on-policy and off-policy setting in Section E and Section F r espectively . Next, conditioned on the above event, we present a formal version of Lemma 5.1 , which provides an upper and a lower bound for the model prediction err or induced by the LMC critic. Lemma D.2 (Formal version of Lemma 5.1 ) . Consider Algorithm 1 with the LMC critic from Algorithm 3 . Condi- tioned on E δ defined in Lemma D.1 , if we choose that λ = 1 , ζ = 2 H √ d c C δ + 8 /3 − 2 , α h , t c = 1 / 2 λ max ( Λ t h , J t ≥ 2 κ t log ( 1/ σ ) , and M = log ( H T / δ ) / log ( 1/ ( 1 − c ) ) where κ t = max h ∈ [ H ] λ max ( Λ t h ) / λ min ( Λ t h ) , σ = 1 / 4 H D t + 1 √ d c , and c = 1 / ( 2 √ 2 e π ) , then, for all ( t , h , s , a ) ∈ [ T ] × [ H ] × S × A and for any δ ∈ ( 0, 1 ) , with probability at least 1 − δ , − Γ LMC × ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ ι t h ( s , a ) ≤ 0 , (10) where Γ LMC = C δ H √ d c + 4 3 q 2 d c log ( 1/ δ ) 3 ζ + 4 3 ≤ O C δ H d c p log ( 1 / δ ) . D.1.1 Preliminary Properties In this section, we introduce some useful properties of LMC and state the supporting lemmas that will be helpful in proving the above r esult. First, we obtain the derivative of the critic loss defined in Algorithm 3 . ∇ L t h ( w h ) = Λ t h w h − b t h , (11) 29 where Λ t h : = ∑ ( s , a ) ∈D t h ϕ ( s , a ) ϕ ( s , a ) ⊤ + λ I and b t h : = ∑ ( s , a , s ′ ) ∈ D t h h r h ( s , a ) + b V t h + 1 ( s ′ ) i ϕ ( s , a ) . Consequently , by setting ∇ L t h ( w h ) = 0, we get the minimizer of L t h ( w h ) as b w t h : = ( Λ t h ) − 1 b t h . (12) W e now introduce the following lemma, showing that the noisy gradient descent performed by the LMC critic ensures that the sampled critic parameter w follows a Gaussian distribution. Lemma D.3 ( Ishfaq et al. 2024a , Proposition B.1) . Consider Algorithm 1 with the LMC critic from Algorithm 3 . For any ( t , h , m ) ∈ [ T ] × [ H ] × [ M ] , the sampled parameters w t , m , J t h follows a Gaussian distribution N µ t , m , J t h , Σ t , m , J t h . The mean and the covariance are defined as µ t , J t h = A J t t . . . A J 1 1 w 1,0 + t ∑ i = 1 A J t t . . . A J i + 1 i + 1 ( I − A J i i ) b w i h , (13) Σ t , J t h = 1 ζ t ∑ i = 1 A J t t . . . A J i + 1 i + 1 ( I − A 2 J i i ) ( Λ i h ) − 1 ( I + A i ) − 1 A J i + 1 i + 1 . . . A J t t , (14) where A t : = I − α t c Λ t h for all t ∈ [ T ] . Since w t , m , J t h follows the Gaussian distribution of N µ t , m , J t h , Σ t , m , J t h , D ϕ h ( s , a ) , w t , m , J t h E also follows the Gaus- sian distribution of N ϕ h ( s , a ) ⊤ µ t , m , J t h , ϕ h ( s , a ) ⊤ Σ t , m , J t h ϕ h ( s , a ) . Therefor e, we intr oduce the following lemmas to bound the terms related to the mean and variance. Lemma D.4. Consider Algorithm 1 with the LMC critic from Algorithm 3 . If we follow the hyperparameter choices of Lemma D.2 , then for any ( s , a ) ∈ S × A , D ϕ ( s , a ) , µ t , J t h − b w t h E ≤ 4 3 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . Lemma D.5. Consider Algorithm 1 with the LMC critic from Algorithm 3 . If we follow the hyperparameter choices of Lemma D.2 , then for any ( s , a ) ∈ S × A , 1 2 √ 6 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ ∥ ϕ ( s , a ) ∥ Σ t , m , J t h ≤ 4 3 s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . Additionally , we outline the necessary supporting lemmas that are useful for bounding the model pr ediction error . Recall that D t : = sup h ∈ [ H ] |D t h | repr esents the number of trajectories in D t or the number of ( s h , a h , s h + 1 ) tuples in D t h , where D t = N in the on-policy setting, and D t = t in the off-policy setting. Lemma D.6. Consider Algorithm 1 with the LMC critic from Algorithm 3 . For any ( t , h ) ∈ [ T ] × [ H ] , it holds that b w t h 2 ≤ 2 H q d c | D t | / λ . Lemma D.7. Consider Algorithm 1 with the LMC critic from Algorithm 3 . If we follow the hyperparameter choices of Lemma D.2 , then for any ( t , m , h ) ∈ [ T ] × [ M ] × [ H ] and for any δ ∈ ( 0, 1 ) , with probability at least 1 − δ , w t , m , J t h 2 ≤ W t δ : = 16 3 H q d c | D t | + s 2 d 3 c t 3 ζ δ . Lemma D.8. Consider Algorithm 1 with the LMC critic from Algorithm 3 . If we follow the hyperparameter choices of Lemma D.2 , then for any ( t , m , h , s , a ) ∈ [ T ] × [ M ] × [ H ] × S × A and for any δ ∈ ( 0, 1 ) , with probability at least 1 − δ , D ϕ ( s , a ) , b w t h − w t , m , J t h E ≤ 8 3 s 2 d c log ( 1 / δ ) 3 ζ + 4 3 ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . 30 Lemma D.9. Consider Algorithm 1 with the LMC critic from Algorithm 3 . Conditioned on E δ defined in Lemma D.1 , if we follow the hyperparameter choices of Lemma D.2 , then for any ( t , h , s , a ) ∈ [ T ] × [ H ] × S × A and for any δ ∈ ( 0, 1 ) , it holds that ϕ ( s , a ) , b w t h − r h ( s , a ) − P h b V t h + 1 ( s , a ) ≤ 3 C δ H p d c ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . D.1.2 Main Analysis W e will use the above lemmas to complete the main proof in this section. Proof of Lemma D.2 . Optimism (RHS of Eq. (10) ) Using the definition of the model prediction err or , we need to show that with high probability , b Q t h ( s , a ) ≥ r h ( s , a ) + P h b V t h + 1 ( s , a ) . Recall that b Q t h ( s , a ) = min nD ϕ ( s , a ) , w t , m , J t h E , H − h + 1 o . Since r h ( s , a ) + P h b V t h + 1 ( s , a ) ≤ H − h + 1, when D ϕ ( s , a ) , w t , m , J t h E > H − h + 1, the statement is trivially true. Thus, we only need to consider the case when D ϕ ( s , a ) , w t , m , J t h E ≤ H − h + 1 and thus b Q t h ( s , a ) = D ϕ ( s , a ) , w t , m , J t h E . Based on the mean and covariance matrix defined in Lemma D.3 , we have that D ϕ ( s , a ) , w t , m , J t h E follows the distribution N ϕ ( s , a ) ⊤ µ t , J t h , ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) . In order to pr ove that b Q t h ( s , a ) ≥ r h ( s , a ) + P h b V t h + 1 ( s , a ) , we consider the following variable: X t : = r h ( s , a ) + P h b V t h + 1 ( s , a ) − D ϕ ( s , a ) , µ t , J t h E q ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) , and will next show that | X t | ≤ 1. First, we have that r h ( s , a ) + P h b V t h + 1 ( s , a ) − D ϕ ( s , a ) , µ t , J t h E (i) ≤ r h ( s , a ) + P h b V t h + 1 ( s , a ) − ϕ ( s , a ) , b w t h + D ϕ ( s , a ) , b w t h − µ t , J t h E (ii) ≤ C δ H p d c ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + 4 3 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 = C δ H p d c + 4 3 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 , where (i) uses the triangular inequality , and (ii) is implied by Lemmas D.4 and D.9 . Therefore, | X t | = r h ( s , a ) + P h b V t h + 1 ( s , a ) − D ϕ ( s , a ) , µ t , J t h E q ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) ≤ p ζ 2 H p d c C δ + 8 /3 . Since we choose ζ = 2 H √ d c C δ + 8 /3 − 2 , we have that | X t | ≤ 1. Then, using Lemma D.12 , we can get that Pr D ϕ ( s , a ) , w t , m , J t h E ≥ r h ( s , a ) + P h b V t h + 1 ( s , a ) 31 = Pr D ϕ ( s , a ) , w t , m , J t h E − D ϕ ( s , a ) , µ t , J t h E q ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) ≥ r h ( s , a ) + P h b V t h + 1 ( s , a ) − D ϕ ( s , a ) , µ t , J t h E q ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) = Pr D ϕ ( s , a ) , w t , m , J t h E − D ϕ ( s , a ) , µ t , J t h E q ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) ≥ X t ≥ 1 2 √ 2 π exp ( − X 2 t /2 ) ≥ 1 2 √ 2 e π . The above result holds for any m ∈ [ M ] . Since we have M parallel critic parameters, it holds that Pr ∃ ( s , a ) ∈ S × A : b Q t h ( s , a ) ≤ r h ( s , a ) + P h b V t h + 1 ( s , a ) = Pr ∃ ( s , a ) ∈ S × A : max m ∈ [ M ] b Q t , m h ( s , a ) ≤ r h ( s , a ) + P h b V t h + 1 ( s , a ) = Pr ∃ ( s , a ) ∈ S × A : ∀ m ∈ [ M ] , b Q t , m h ( s , a ) ≤ r h ( s , a ) + P h b V t h + 1 ( s , a ) ≤ Pr ∀ m ∈ [ M ] , ∃ ( s m , a m ) ∈ S × A : b Q t , m h ( s m , a m ) ≤ r h ( s m , a m ) + P h b V t h + 1 ( s m , a m ) = M ∏ m = 1 Pr ∃ ( s , a ) ∈ S × A : b Q t , m h ( s , a ) ≤ r h ( s , a ) + P h b V t h + 1 ( s , a ) = M ∏ m = 1 1 − Pr ∀ ( s , a ) ∈ S × A : b Q t , m h ( s , a ) ≥ r h ( s , a ) + P h b V t h + 1 ( s , a ) = M ∏ m = 1 1 − Pr ∀ ( s , a ) ∈ S × A : D ϕ ( s , a ) , w t , m , J t h E ≥ r h ( s , a ) + P h b V t h + 1 ( s , a ) ≤ 1 − 1 2 √ 2 e π M . This further implies that Pr ∀ ( s , a ) ∈ S × A : ι t h ( s , a ) ≤ 0 = Pr ∀ ( s , a ) ∈ S × A : b Q t h ( s , a ) ≥ r h ( s , a ) + P h b V t h + 1 ( s , a ) = 1 − Pr ∃ ( s , a ) ∈ S × A : b Q t h ( s , a ) ≤ r h ( s , a ) + P h b V t h + 1 ( s , a ) = 1 − 1 − 1 2 √ 2 e π M . Let 1 − 1 − 1 2 √ 2 e π M ≥ 1 − δ / ( H T ) , which yields that M = log ( H T / δ ) / log ( 1/ ( 1 − c ) ) where c = 1/ ( 2 √ 2 e π ) . Therefor e, we have that Pr ι t h ( s , a ) ≤ 0, ∀ ( s , a ) ∈ S × A ≥ 1 − δ H T . Applying union bound over [ H ] and [ T ] , we have that ι t h ( s , a ) ≤ 0 with pr obability 1 − δ . 32 Error Bound (LHS of Eq. (10) ) W e can lower bound ι t h as follows. − ι t h ( s , a ) = b Q t h ( s , a ) − r h ( s , a ) − P h b V t h + 1 ( s , a ) = min max m ∈ [ M ] D ϕ ( s , a ) , w t , m , J t h E , H − h + 1 + − r h ( s , a ) − P h b V t h + 1 ( s , a ) ≤ max m ∈ [ M ] D ϕ ( s , a ) , w t , m , J t h E − r h ( s , a ) − P h b V t h + 1 ( s , a ) = max m ∈ [ M ] D ϕ ( s , a ) , w t , m , J t h E − ϕ ( s , a ) , b w t h + ϕ ( s , a ) , b w t h − r h ( s , a ) − P h b V t h + 1 ( s , a ) ≤ max m ∈ [ M ] D ϕ ( s , a ) , w t , m , J t h E − ϕ ( s , a ) , b w t h + ϕ ( s , a ) , b w t h − r h ( s , a ) − P h b V t h + 1 ( s , a ) (iii) ≤ C δ H p d c + 4 3 s 2 d c log ( 1/ δ ) 3 ζ + 4 3 ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 , where (iii) is derived fr om Lemmas D.8 and D.9 . This concludes the proof. D.2 Proofs of Preliminary Properties D.2.1 Proof of Lemma D.3 Proof. For any ( t , m ) ∈ [ T ] × [ M ] , the critic update rule at j -th round can be written as w t , m , j h = w t , m , j − 1 h − α h , t c ∇ L t h ( w t , m , j − 1 h ) + q α h , t c ζ − 1 ν t , m , j h . Considering j = J t and plugging in Eq. (11) , we have that w t , m , J t h = w t , m , J t − 1 h − α h , t c Λ t h w t , m , J t − 1 h − b t h + q α h , t c ζ − 1 ν t , m , J t h = I − α h , t c Λ t h w t , m , J t − 1 h + α h , t c b t h + q α h , t c ζ − 1 ν t , m , J t h (i) = I − α h , t c Λ t h J t w t , m ,0 h + J t − 1 ∑ l = 0 I − α h , t c Λ t h l α h , t c b t h + q α h , t c ζ − 1 ν t , m , J t − l h = I − α h , t c Λ t h J t w t , m ,0 h + α h , t c J t − 1 ∑ l = 0 I − α h , t c Λ t h l b t h + q α h , t c ζ − 1 J t − 1 ∑ l = 0 I − α h , t c Λ t h l ν t , m , J t − l h (ii) = A J t t w t , m ,0 h + α h , t c J t − 1 ∑ l = 0 A l t Λ t h b w t h + q α h , t c ζ − 1 J t − 1 ∑ l = 0 A l t ν t , m , J t − l h (iii) = A J t t w t , m ,0 h + ( I − A t ) A 0 t + A 1 t + . . . + A J t − 1 t b w t h + q α h , t c ζ − 1 J t − 1 ∑ l = 0 A l t ν t , m , J t − l h (iv) = A J t t w t , m ,0 h + I − A J t t b w t h + q α h , t c ζ − 1 J t − 1 ∑ l = 0 A l t ν t , m , J t − l h . (i) comes fr om telescoping the previous equation from l = 0 to J t − 1. (ii) uses the definition that A t = I − α h , t c Λ t h and b t h = Λ t h b w t h . (iii) uses the definition of A t . (iv) follows from I + A + . . . + A n − 1 = ( I − A n )( I − A ) − 1 . Since we set α h , t c = 1 / 2 λ max ( Λ t h , A t satisfies I ≻ A t ≻ 0 for all t ∈ [ T ] . Note that we 33 warm-start the parameters from the pr evious episode and set w t , m ,0 h = w t − 1, m , J t − 1 h . Therefor e, by telescoping the above equation from i = 0 to t , we further have that w t , m , J t h = A J t t w t − 1, m , J t − 1 h + I − A J t t b w t h + q α h , t c ζ − 1 J t − 1 ∑ l = 0 A l t ν t , m , J t − l h = A J t t . . . A J 1 1 w 1, m ,0 h + t ∑ i = 1 A J t t . . . A J i + 1 i + 1 I − A J i i b w i h + t ∑ i = 1 q α i c ζ − 1 A J t t . . . A J i + 1 i + 1 J i − 1 ∑ l = 0 A l i ν i , J i − l h . Note that if ξ ∼ N ( 0, I d × d ) , then we have that A ξ + µ ∼ N ( µ , A A ⊤ ) for any A ∈ R d × d and µ ∈ R d . This implies that w t , m , J t h follows the Gaussian distribution N ( µ t , m , J t h , Σ t , m , J t h ) , where µ t , m , J t h = A J t t . . . A J 1 1 w 1, m ,0 h + t ∑ i = 1 A J t t . . . A J i + 1 i + 1 I − A J i i b w i h . W e then derive the covariance matrix Σ t , m , J t h . For any i ∈ [ t ] , we denote that A i + 1 = A J t t . . . A J i + 1 i + 1 . Therefor e, q α i c ζ − 1 A i + 1 J i − 1 ∑ l = 0 A l i ν i , J i − l h = J i − 1 ∑ l = 0 q α i c ζ − 1 A i + 1 A l i ν i , J i − l h ∼ N 0, J i − 1 ∑ l = 0 α i c ζ − 1 A i + 1 A l i ( A i + 1 A l i ) ⊤ ! ∼ N 0, α i c ζ − 1 A i + 1 J i − 1 ∑ l = 0 A 2 l i ! A ⊤ i + 1 ! . This further implies that Σ t , m , J t h = t ∑ i = 1 α i c ζ − 1 A i + 1 J i − 1 ∑ l = 0 A 2 l i ! A ⊤ i + 1 = t ∑ i = 1 α i c ζ − 1 A J t t . . . A J i + 1 i + 1 J i − 1 ∑ l = 0 A 2 l i ! A J i + 1 i + 1 . . . A J t t (v) = t ∑ i = 1 α i c ζ − 1 A J t t . . . A J i + 1 i + 1 I − A 2 J i i I − A 2 i − 1 A J i + 1 i + 1 . . . A J t t = t ∑ i = 1 α i c ζ − 1 A J t t . . . A J i + 1 i + 1 I − A 2 J i i Λ i h Λ i h − 1 ( I − A i ) − 1 ( I + A i ) − 1 A J i + 1 i + 1 . . . A J t t (vi) = t ∑ i = 1 ζ − 1 A J t t . . . A J i + 1 i + 1 I − A 2 J i i Λ i h − 1 ( I + A i ) − 1 A J i + 1 i + 1 . . . A J t t . (v) uses the fact that I + A + . . . + A n − 1 = ( I − A n )( I − A ) − 1 , and (vi) uses the fact that α h , t c Λ t h = I − A t . This concludes the proof. D.2.2 Proof of Lemma D.4 Proof. Using Lemma D.3 , we first have that µ t , J t h = A J t t . . . A J 1 1 w 1, m ,0 h + t ∑ i = 1 A J t t . . . A J i + 1 i + 1 I − A J i i b w i h = A J t t . . . A J 1 1 w 1, m ,0 h + t ∑ i = 1 A J t t . . . A J i + 1 i + 1 b w i h − t ∑ i = 1 A J t t . . . A J i i b w i h 34 = A J t t . . . A J 1 1 w 1, m ,0 h + t − 1 ∑ i = 1 A J t t . . . A J i + 1 i + 1 b w i h − b w i + 1 h − A J t t . . . A J 1 1 b w 1 h + b w t h = A J t t . . . A J 1 1 w 1, m ,0 h − b w 1 h + t − 1 ∑ i = 1 A J t t . . . A J i + 1 i + 1 b w i h − b w i + 1 h + b w t h . This implies that D ϕ ( s , a ) , µ t , J t h − b w t h E = ϕ ( s , a ) ⊤ A J t t . . . A J 1 1 w 1, m ,0 h − b w 1 h + ϕ ( s , a ) ⊤ t − 1 ∑ i = 1 A J t t . . . A J i + 1 i + 1 b w i h − b w i + 1 h (i) = ϕ ( s , a ) ⊤ t − 1 ∑ i = 0 A J t t . . . A J i + 1 i + 1 b w i h − b w i + 1 h = t − 1 ∑ i = 0 ϕ ( s , a ) ⊤ A J t t . . . A J i + 1 i + 1 b w i h − b w i + 1 h (ii) ≤ t − 1 ∑ i = 0 t ∏ j = i + 1 1 − α h , j c λ min Λ j h J j ∥ ϕ ( s , a ) ∥ 2 ∥ b w i h − b w i + 1 h ∥ 2 (iii) ≤ t − 1 ∑ i = 0 t ∏ j = i + 1 1 − α h , j c λ min Λ j h J j ∥ ϕ ( s , a ) ∥ 2 ∥ b w i h ∥ 2 + ∥ b w i + 1 h ∥ 2 (iv) ≤ 4 H q d c | D t | / λ t − 1 ∑ i = 0 t ∏ j = i + 1 1 − α h , j c λ min Λ j h J j ∥ ϕ ( s , a ) ∥ 2 (v) ≤ 4 H D t + 1 p d c / λ t − 1 ∑ i = 0 t ∏ j = i + 1 1 − α h , j c λ min Λ j h J j ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 (vi) ≤ 4 H D t + 1 p d c t − 1 ∑ i = 0 σ t − i ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 (vii) ≤ 4 H D t + 1 p d c t − 1 ∑ i = 0 σ t − i ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ 4 H D t + 1 p d c t − 1 ∑ i = 0 σ t − i ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 = 4 H D t + 1 p d c t − 1 ∑ i = 1 σ i ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 (viii) ≤ 4 H D t + 1 p d c σ 1 − σ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 = 1 1 − σ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ 4 3 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . For (i), we choose w 1, m ,0 h = 0 and denote that b w 0 h = 0 . (ii) comes from A i ≺ ( 1 − α h , j c λ min Λ j h ) I and the Hölder ’s inequality . (iii) uses the triangular inequality . (iv) uses Lemma D.6 . (v) uses the fact that ∥ ϕ ( s , a ) ∥ ≤ p | D t | + 1 ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 . (vi) hold because we set λ = 1 and uses Lemma D.16 by setting J j ≥ κ j log ( 1/ σ ) where σ = 1 / 4 H D t + 1 √ d c . (vii) follows from ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 ≤ ∥ ϕ ( s , a ) ∥ 2 ≤ 35 p | D t | + 1 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . (viii) follows from ∑ t i = 1 σ t ≤ ∑ ∞ i = 1 σ i ≤ σ / ( 1 − σ ) . This concludes the proof. D.2.3 Proof of Lemma D.5 Proof. W e first bound the RHS. Using Lemma D.3 , we have that ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) = 1 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A J t t . . . A J i + 1 i + 1 I − A 2 J i Λ i h − 1 ( I + A i ) − 1 A J i + 1 i + 1 . . . A J t t ϕ ( s , a ) (i) = 1 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 I − A 2 J i Λ i h − 1 ( I + A i ) − 1 A ⊤ i + 1 ϕ ( s , a ) (ii) ≤ 2 3 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 Λ i h − 1 − A J i i Λ i h − 1 A J i i A ⊤ i + 1 ϕ ( s , a ) = 2 3 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 Λ i h − 1 A ⊤ i + 1 ϕ ( s , a ) − t ∑ i = 1 ϕ ( s , a ) ⊤ A i Λ i h − 1 A ⊤ i ϕ ( s , a ) ! (iii) ≤ 2 3 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 Λ i h − 1 A ⊤ i + 1 ϕ ( s , a ) = 2 3 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ i h ) − 1 + t − 1 ∑ i = 1 A ⊤ i + 1 ϕ ( s , a ) 2 ( Λ i h ) − 1 ! ≤ 2 3 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 + 2 3 ζ t − 1 ∑ i = 1 t ∏ j = i + 1 1 − α c λ min ( Λ j h ) 2 J j ∥ ϕ ( s , a ) ∥ 2 ( Λ i h ) − 1 . For (i), we denote A i + 1 = A J t t . . . A J i + 1 i + 1 . (ii) follows from I + A i ⪰ 3 2 I since we set α h , j c = 1 / 2 λ max ( Λ j h ) . In particular , it is easy to prove that A and ( Λ t h ) − 1 are commuting matrices and thus A 2 J i Λ i h − 1 = A 2 J i − 1 ( I − α h , t c Λ t h ) ( Λ t h ) − 1 = A 2 J i − 1 ( Λ t h ) − 1 ( I − α h , t c Λ t h ) = A 2 J i − 1 ( Λ t h ) − 1 A . . . = A J i ( Λ t h ) − 1 A J i . (iii) follows from the fact that ∑ t i = 1 ϕ ( s , a ) ⊤ A i Λ i h − 1 A ⊤ i ϕ ( s , a ) > 0. Therefor e, ϕ ( s , a ) ⊤ Σ t , J t h 1/2 2 = q ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) (iv) ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + s 2 3 ζ t − 1 ∑ i = 1 t ∏ j = i + 1 1 − α c λ min ( Λ j h ) J j ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 (v) ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + s 2 3 ζ t − 1 ∑ i = 1 σ t − i ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 (vi) ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + s 2 ( | D t | + 1 ) 3 ζ t − 1 ∑ i = 1 σ t − i ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 36 (vii) ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + s 2 ( | D t | + 1 ) 3 ζ σ 1 − σ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + 1 4 s 2 3 ζ 1 1 − σ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ s 2 3 ζ + 1 3 s 2 3 ζ ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ 4 3 s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . (iv) follows fr om the fact that √ a + b ≤ a + b for all a , b > 0. (v) uses Lemma D.16 by setting J j ≥ 2 κ j log ( 1/ σ ) where σ = 1 / 4 H D t + 1 √ d c . (vi) follows from ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 ≤ ∥ ϕ ( s , a ) ∥ 2 ≤ q | D t | + 1 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . (vii) follows from ∑ t i = 1 σ t − i ≤ ∑ ∞ i = 1 σ i ≤ σ / ( 1 − σ ) . W e then proceed to bound the LHS. Using the definition of Σ t , J t h from Eq. (14) , we have ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) = t ∑ i = 1 1 ζ ϕ ( s , a ) ⊤ A J t t . . . A J i + 1 i + 1 I − A 2 J i Λ i h − 1 ( I + A i ) − 1 A J i + 1 i + 1 . . . A J t t ϕ ( s , a ) (iii) ≥ 1 2 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 I − A 2 J i Λ i h − 1 A ⊤ i + 1 ϕ ( s , a ) = 1 2 ζ t ∑ i = 1 1 2 ζ ϕ ( s , a ) ⊤ A i + 1 Λ i h − 1 − A J t t Λ i h − 1 A J t t A ⊤ i + 1 ϕ ( s , a ) = 1 2 ζ t − 1 ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 ( Λ i h ) − 1 − ( Λ i + 1 h ) − 1 A ⊤ i + 1 ϕ ( s , a ) − 1 2 ζ ϕ ( s , a ) ⊤ A J t t . . . A J 1 1 ( Λ 1 h ) − 1 A J 1 1 . . . A J t t ϕ ( s , a ) + 1 2 ζ ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ϕ ( s , a ) , where (iii) follows fr om ( I + A t ) − 1 ⪰ 1 2 I for all t ∈ [ T ] . ϕ ( s , a ) ⊤ A i + 1 ( Λ i h ) − 1 − ( Λ i + 1 h ) − 1 A ⊤ i + 1 ϕ ( s , a ) ≤ ϕ ( s , a ) ⊤ A i + 1 ( Λ i h ) − 1 A ⊤ i + 1 ϕ ( s , a ) + D ϕ ( s , a ) , A i + 1 ( Λ i + 1 h ) − 1 A ⊤ i + 1 ϕ ( s , a ) E ≤ ϕ ( s , a ) ⊤ A i + 1 ( Λ i h ) − 1/ 2 2 + ϕ ( s , a ) ⊤ A i + 1 ( Λ i + 1 h ) − 1/ 2 2 = t ∏ j = i + 1 1 − α h , j c λ min ( Λ j h ) 2 J j ∥ ϕ ( s , a ) ∥ 2 ( Λ i h ) − 1 + ∥ ϕ ( s , a ) ∥ 2 ( Λ i + 1 h ) − 1 ≤ 2 t ∏ j = i + 1 1 − α h , j c λ min ( Λ j h ) 2 J j ∥ ϕ ( s , a ) ∥ 2 2 , 37 where we used 0 < ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 ≤ ∥ ϕ ( s , a ) ∥ 2 . Therefor e, we have that ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) ≥ 1 2 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 − 1 2 ζ t ∏ i = 1 1 − α h , j c λ min ( Λ i h ) 2 J i ∥ ϕ ( s , a ) ∥ 2 2 − 1 ζ t − 1 ∑ i = 1 t ∏ j = i + 1 1 − α h , j c λ min ( Λ j h ) 2 J j ∥ ϕ ( s , a ) ∥ 2 2 (iv) ≥ 1 2 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 − σ t ∥ ϕ ( s , a ) ∥ 2 2 − t − 1 ∑ i = 1 2 σ i ∥ ϕ ( s , a ) ∥ 2 2 ! (v) ≥ 1 2 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 1 − D t + 1 σ t − 2 D t + 1 t − 1 ∑ i = 1 σ i ! ≥ 1 2 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 1 − σ t − 1 − 1 2 ( 1 − σ ) ≥ 1 2 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 1 − 1 4 − 2 3 = 1 24 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 , where (iv) uses Lemma D.16 by setting J j ≥ 2 κ j log ( 1/ σ ) where σ = 1 / 4 H D t + 1 √ d c , and (v) use ∥ ϕ ( s , a ) ∥ 2 ≤ p | D t | + 1 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . This concludes the proof. D.2.4 Proof of Lemma D.6 Proof. Given the definition of b w t h in Eq. (12) , we have that b w t h = Λ t h − 1 ∑ ( s , a ) ∈D t h h r h ( s , a ) + b V t h + 1 ( s ) i · ϕ ( s h , a ) ≤ r | D t | λ ∑ ( s , a ) ∈D t h h r h ( s , a ) + b V t h + 1 ( s ) i · ϕ ( s , a ) 2 ( Λ t h ) − 1 1/2 ≤ 2 H r | D t | λ ∑ ( s , a ) ∈D t h ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 1/2 ≤ 2 H q d c | D t | / λ , where the first inequality follows from Lemma D.15 , the second inequality is due to the fact that V t h ∈ [ 0, H ] and the rewar d function is bounded by 1, and the last inequality follows from Lemma D.10 . D.2.5 Proof of Lemma D.7 Proof. From Lemma D.3 , we know w t , m , J t h follows Gaussian distribution N ( µ t , J t h , Σ t , J t h ) . Therefore, we have w t , m , J t h 2 = µ t , J t h + ξ t , J t h 2 ≤ µ t , J t h 2 | {z } (I) + ξ t , J t h 2 | { z } (II) , 38 where ξ t , J t h ∼ N ( 0, Σ t , J t h ) . W e first start by bounding T erm (I). Given Lemma D.3 , by setting w 1, m ,0 h = 0 , we can obtain that µ t , J t h 2 = A J t t . . . A J 1 1 w 1, m ,0 h + t ∑ i = 1 A J t t . . . A J i + 1 i + 1 I − A J i i b w i h 2 ≤ t ∑ i = 1 A J t t . . . A J i + 1 i + 1 I − A J i i b w i h 2 (i) ≤ t ∑ i = 1 A J t t . . . A J i + 1 i + 1 I − A J i i 2 b w i h 2 (ii) ≤ 2 H q d c | D t | t ∑ i = 1 A J t t . . . A J i + 1 i + 1 I − A J i i 2 (iii) ≤ 2 H q d c | D t | t ∑ i = 1 ∥ A t ∥ J t 2 . . . ∥ A i + 1 ∥ J i + 1 2 I − A J i i 2 (iv) ≤ 2 H q d c | D t | t ∑ i = 1 t ∏ j = i + 1 1 − α h , j c λ min ( Λ j h ) J j ∥ I ∥ 2 + ∥ A J i i ∥ 2 (v) ≤ 2 H q d c | D t | t ∑ i = 1 t ∏ j = i + 1 1 − α h , j c λ min ( Λ j h ) J j ∥ I ∥ 2 + ∥ A i ∥ J i 2 (vi) ≤ 2 H q d c | D t | t ∑ i = 1 t ∏ j = i + 1 1 − α h , j c λ min ( Λ j h ) J j 1 + 1 − α i c λ min ( Λ i h ) J i ≤ 2 H q d c | D t | t ∑ i = 1 t ∏ j = i + 1 1 − α h , j c λ min ( Λ j h ) J j + t ∏ j = i 1 − α h , j c λ min ( Λ j h ) J j ! (vii) ≤ 2 H q d c | D t | t ∑ i = 1 t ∏ j = i + 1 1 − 1 / ( 2 κ j ) J j + t ∏ j = i 1 − 1 / ( 2 κ j ) J j ! , (i) uses the definition of the matrix norm (i.e., ∥ A ∥ 2 : = max x ∥ A x ∥ 2 ∥ x ∥ = ⇒ ∥ A x ∥ 2 ≤ ∥ A ∥ 2 ∥ x ∥ 2 ). (ii) uses Lemma D.6 and sets λ = 1. (iii) and (v) come from the submultiplicativity of matrix norm. (iv) and (vi) use the fact that ∥ A ∥ 2 ≤ λ max ( A ) , and (iv) also uses the triangular inequality . (vii) uses the fact that we set α h , j c = 1 / 2 λ max ( Λ j h ) and denotes that κ j = max h ∈ [ H ] λ max ( Λ j h ) / λ min ( Λ j h ) . Using Lemma D.16 . we can set J j ≥ 2 κ j log ( 1/ σ ) where σ = 1 / 4 H D t + 1 √ d c . W e can further get ∥ µ t , J t h ∥ 2 ≤ 2 H q d c | D t | t ∑ i = 1 σ t − i + σ t − i + 1 ≤ 4 H q d c | D t | ∞ ∑ i = 0 σ i = 4 H q d c | D t | 1 1 − σ = 16 3 H q d c | D t | . 39 Next, we continue to bound T erm (II). Since ξ t , J t h ∼ N ( 0, Σ t , J t h ) , using Lemma D.11 , we have that Pr ξ t , J t h 2 ≤ r 1 δ T r Σ t , J t h ! ≥ 1 − δ . Recall from Lemma D.3 that Σ t , J t h = t ∑ i = 1 1 ζ A J t t . . . A J i + 1 i + 1 I − A 2 J i i Λ i h − 1 ( I + A i ) − 1 A J i + 1 i + 1 . . . A J t t . Therefor e, we can use Lemma D.13 and derive that T r Σ t , J t h = t ∑ i = 1 1 ζ T r A J t t . . . A J i + 1 i + 1 I − A 2 J i i Λ i h − 1 ( I + A i ) − 1 A J i + 1 i + 1 . . . A J t t ≤ t ∑ i = 1 1 ζ T r A J t t . . . T r A J i + 1 i + 1 T r I − A 2 J i i T r Λ i h − 1 T r ( I + A i ) − 1 T r A J i + 1 i + 1 . . . T r A J t t . T o bound each term, we first have, T r A J i i ≤ T r 1 − α i c λ min ( Λ i h ) J i I ≤ d c 1 − α i c λ min ( Λ i h ) J i ≤ d c σ ≤ 1 , where the first inequality follows from the fact that A J i i ≺ 1 − α t c λ min ( Λ t h ) J j I . Similarly , since we set 0 < α h , j c < 1 / 2 λ max ( Λ j ) , we have A J i i ≻ 1 2 J i I and therefor e, T r I − A 2 J i i ≤ 1 − 1 2 2 J i d c < d c . Similarly , since we set 0 < α h , j c < 1 / 2 λ max ( Λ j ) and thus I + A i ≻ 3 2 I , we have that T r ( I + A i ) − 1 ≤ 2 3 d c . Additionally , since all eigenvalues of Λ i h are gr eater than or equal to 1, T r ( Λ i h ) − 1 ≤ d c · 1 = d c . Finally , we have that T r Σ t , J t h ≤ t ∑ i = 1 1 ζ · 2 3 · d 3 c = 2 d 3 c 3 ζ t . Therefor e, using Lemma D.11 , we have that Pr ξ t , J t h 2 ≤ s 1 δ · 2 d 3 c 3 ζ T ≥ Pr ξ t , J t h 2 ≤ r 1 δ T r Σ t , J t h ! ≥ 1 − δ . Putting everything together , with probability at least 1 − δ , we can obtain that w t , m , J t h 2 ≤ W δ : = 16 3 H q d c | D t | + s 2 d 3 c t 3 ζ δ . This concludes the proof. 40 D.2.6 Proof of Lemma D.8 Proof. T o start, we decompose the LHS using the triangle inequality , D ϕ ( s , a ) , w t , m , J t h − b w t h E ≤ D ϕ ( s , a ) , w t , m , J t h − µ t , J t h E | {z } (I) + D ϕ ( s , a ) , µ t , J t h − b w t h E | {z } (II) , where µ t , J t h is defined in Eq. (13) . T o bound T erm (I), we first apply Hölder ’s inequality and obtain that D ϕ ( s , a ) , w t , m , J t h − µ t , J t h E ≤ ϕ ( s , a ) ⊤ Σ t , J t h 1/2 2 Σ t , J t h − 1/ 2 w t , m , J t h − µ t , J t h 2 . Since w t , m , J t h ∼ N ( µ t , J t h , Σ t , J t h ) , we know that Σ t , J t h − 1/ 2 w t , m , J t h − µ t , J t h ∼ N ( 0, I d c × d c ) . Therefore, Pr Σ t , J t h − 1/ 2 w t , m , J t h − µ t , J t h 2 ≥ 2 q d c log ( 1/ δ ) ≤ δ 2 . Then, we continue to bound ϕ ( s , a ) ⊤ Σ t , J t h 1/2 2 . ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) = 1 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A J t t . . . A J i + 1 i + 1 I − A 2 J i Λ i h − 1 ( I + A i ) − 1 A J i + 1 i + 1 . . . A J t t ϕ ( s , a ) (i) = 1 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 I − A 2 J i Λ i h − 1 ( I + A i ) − 1 A ⊤ i + 1 ϕ ( s , a ) (ii) ≤ 2 3 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 Λ i h − 1 − A J i i Λ i h − 1 A J i i A ⊤ i + 1 ϕ ( s , a ) = 2 3 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 Λ i h − 1 A ⊤ i + 1 ϕ ( s , a ) − t ∑ i = 1 ϕ ( s , a ) ⊤ A i Λ i h − 1 A ⊤ i ϕ ( s , a ) ! (iii) ≤ 2 3 ζ t ∑ i = 1 ϕ ( s , a ) ⊤ A i + 1 Λ i h − 1 A ⊤ i + 1 ϕ ( s , a ) = 2 3 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ i h ) − 1 + t − 1 ∑ i = 1 A ⊤ i + 1 ϕ ( s , a ) 2 ( Λ i h ) − 1 ! ≤ 2 3 ζ ∥ ϕ ( s , a ) ∥ 2 ( Λ t h ) − 1 + 2 3 ζ t − 1 ∑ i = 1 t ∏ j = i + 1 1 − α c λ min ( Λ j h ) 2 J j ∥ ϕ ( s , a ) ∥ 2 ( Λ i h ) − 1 . For (i), we use the denotation that A i + 1 = A J t t . . . A J i + 1 i + 1 . (ii) follows from I + A i ≻ 3 2 I since we set α h , j c = 1/ 2 λ max ( Λ j h ) . (iii) follows from the fact that ∑ t i = 1 ϕ ( s , a ) ⊤ A i Λ i h − 1 A ⊤ i ϕ ( s , a ) > 0. Therefor e, ϕ ( s , a ) ⊤ Σ t , J t h 1/2 2 = q ϕ ( s , a ) ⊤ Σ t , J t h ϕ ( s , a ) (iv) ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + s 2 3 ζ t − 1 ∑ i = 1 t ∏ j = i + 1 1 − α c λ min ( Λ j h ) J j ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 41 (v) ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + s 2 3 ζ t − 1 ∑ i = 1 σ t − i ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 (vi) ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + s 2 ( | D t | + 1 ) 3 ζ t − 1 ∑ i = 1 σ t − i ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 (vii) ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + s 2 ( | D t | + 1 ) 3 ζ σ 1 − σ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 + 1 4 s 2 3 ζ 1 1 − σ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ s 2 3 ζ + 1 3 s 2 3 ζ ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ 4 3 s 2 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . (iv) follows from the fact that √ a + b ≤ a + b for all a , b > 0. (v) uses Lemma D.16 by setting J j ≥ κ j log ( 1/ σ ) where σ = 1 / 4 H D t + 1 √ d c . (vi) follows from ∥ ϕ ( s , a ) ∥ ( Λ i h ) − 1 ≤ ∥ ϕ ( s , a ) ∥ 2 ≤ p | D t | + 1 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . (vii) follows from ∑ t i = 1 σ t − i ≤ ∑ ∞ i = 1 σ i ≤ σ / ( 1 − σ ) . Therefore, we have Pr D ϕ ( s , a ) , w t , m , J t h − µ t , J t h E ≥ 8 3 s 2 d c log ( 1 / δ ) 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ! ≤ Pr ϕ ( s , a ) ⊤ Σ t , J t h 1/2 2 Σ t , J t h − 1/ 2 w t , m , J t h − µ t , J t h 2 ≥ 2 q d c log ( 1/ δ ) ϕ ( s , a ) ⊤ Σ t , J t h 1/2 2 = Pr Σ t , J t h − 1/ 2 w t , m , J t h − µ t , J t h 2 ≥ 2 q d c log ( 1/ δ ) = δ 2 ≤ δ . This implies that Pr D ϕ ( s , a ) , w t , m , J t h − µ t , J t h E ≤ 8 3 s 2 d c log ( 1 / δ ) 3 ζ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ! ≥ 1 − δ . Putting everything together , with probability at least 1 − δ , D ϕ ( s , a ) , w t , m , J t h − b w t h E ≤ D ϕ ( s , a ) , w t , m , J t h − µ t , J t h E + D ϕ ( s , a ) , µ t , J t h − b w t h E ≤ 8 3 s 2 d c log ( 1 / δ ) 3 ζ + 4 3 ! ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . D.2.7 Proof of Lemma D.9 Proof. Recall that P h V ( s , a ) : = E s ′ ∼ P h ( · | s , a ) V ( s ′ ) and P h ( · | s , a ) = ⟨ ϕ ( s , a ) , ψ h ( · ) ⟩ due to the linear MDP assumption ( Definition 2.1 ). W e also denote that b Ψ t h : = D ψ h , b V t h + 1 E S and thus P h b V t h + 1 ( s , a ) = D ϕ ( s , a ) , b Ψ t h E . Then, we have that P h b V t h + 1 ( s , a ) = D ϕ ( s , a ) , b Ψ t h E 42 = ϕ ( s , a ) ⊤ Λ t h − 1 Λ t h b Ψ t h = ϕ ( s , a ) ⊤ Λ t h − 1 ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) ϕ ( s , a ) ⊤ + λ I b Ψ t h = ϕ ( s , a ) ⊤ Λ t h − 1 ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) ( P h b V t h + 1 )( s , a ) + λ b Ψ t h . This further implies that ϕ ( s , a ) , b w t h − r h ( s , a ) − P h b V t h + 1 ( s , a ) = ϕ ( s , a ) ⊤ Λ t h − 1 ∑ ( s , a , s ′ ) ∈ D t h h r h ( s , a ) + b V t h + 1 ( s ′ ) i · ϕ ( s , a ) − r h ( s , a ) − ϕ ( s , a ) ⊤ Λ t h − 1 ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) ( P h b V t h + 1 )( s , a ) + λ b Ψ t h = ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) h b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) i | {z } (I) + ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ∑ ( s , a , s ′ ) ∈ D t h r h ( s , a ) ϕ ( s , a ) − r h ( s , a ) | {z } (II) − λ ϕ ( s , a ) ⊤ ( Λ t h ) − 1 b Ψ t h | {z } (III) . W e first start by bounding T erm (I). W ith pr obability at least 1 − δ , it holds that ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) h b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) i (i) ≤ ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) h b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) i ( Λ t h ) − 1 ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 (ii) ≤ C δ H p d c ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 , where (i) follows from the Cauchy-Schwarz inequality , and (ii) follows from the good event defined in Lemma D.1 . Next, we continue to bound T erm (II). W e observe that ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ∑ ( s , a , s ′ ) ∈ D t h r h ( s , a ) ϕ ( s , a ) − r h ( s , a ) (iii) = ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ∑ ( s , a , s ′ ) ∈ D t h r h ( s , a ) ϕ ( s , a ) − ϕ ( s , a ) ⊤ θ h = ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ∑ ( s , a , s ′ ) ∈ D t h r h ( s , a ) ϕ ( s , a ) − Λ t h θ h 43 = ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ∑ ( s , a , s ′ ) ∈ D t h r h ( s , a ) ϕ ( s , a ) − ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) ϕ ( s , a ) ⊤ θ h − λ θ h (iv) = ϕ ( s , a ) ⊤ ( Λ t h ) − 1 ∑ ( s , a , s ′ ) ∈ D t h r h ( s , a ) ϕ ( s , a ) − ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) r h ( s , a ) − λ θ h = − λ ϕ ( s , a ) ⊤ ( Λ t h ) − 1 θ h (v) ≤ λ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ∥ θ h ∥ ( Λ t h ) − 1 (vi) ≤ p λ d c ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . (iii) and (iv) follow fr om the definition r h ( s , a ) = ⟨ ϕ ( s , a ) , θ h ⟩ . (v) applies the Cauchy-Schwarz inequality . (vi) follows from ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 ≤ √ 1/ λ ∥ ϕ ( s , a ) ∥ 2 and ∥ θ h ∥ 2 ≤ √ d c ( Definition 2.1 ). Lastly , we derive the bound for T erm (III). λ ϕ ( s , a ) ⊤ ( Λ t h ) − 1 b Ψ t h (vii) ≤ λ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 b Ψ t h ( Λ t h ) − 1 (viii) ≤ √ λ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 b Ψ t h 2 ≤ √ λ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 D ψ h , b V t h + 1 E S 2 = H √ λ ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 Z s ∈ S ψ h ( s ) b V t h + 1 ( s ) / H d s 2 (xiv) ≤ H p λ d c ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . (vii) applies the Cauchy-Schwarz inequality . (viii) follows fr om b Ψ t h ( Λ t h ) − 1 ≤ √ λ b Ψ t h 2 . (xiv) comes from the assumption that R s ∈ S ψ h ( s ) b V t h + 1 ( s ) / H d s 2 ≤ √ d c ( Definition 2.1 ). Putting everything together and setting λ = 1, we have with probability at least 1 − δ , ϕ ( s , a ) , b w t h − r h ( s , a ) − P h b V t h + 1 ( s , a ) ≤ C δ H p d c + p λ d c + H p λ d c ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 = 3 C δ H p d c ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 . This concludes the proof. D.3 T echnical T ools Lemma D.10 ( Jin et al. 2020 , Lemma D.1) . Let Λ = λ I + ∑ t i = 1 ϕ i ϕ ⊤ i , where ϕ i ∈ R d and λ > 0 . Then, t ∑ i = 1 ϕ ⊤ i ( Λ ) − 1 ϕ i ≤ d . 44 Lemma D.11 ( Ishfaq et al. 2024a , Lemma E.1) . Given a multivariate normal distribution X ∼ N ( 0, Σ d × d ) , for any δ ∈ ( 0, 1 ] , it hold that Pr ∥ X ∥ 2 ≤ r 1 δ T r ( Σ ) ! ≥ 1 − δ . Lemma D.12 ( Abramowitz and Stegun 1948 ) . Suppose X is a Gaussian random variable X ∼ N ( µ , σ 2 ) , where σ > 0 . For z ∈ [ 0, 1 ] , it holds that Pr ( X > µ + z σ ) ≥ e − z 2 /2 √ 8 π and Pr ( X < µ − z σ ) ≥ e − z 2 /2 √ 8 π . Additionally , for any z ≥ 1 , e − z 2 /2 2 z √ π ≤ Pr ( | X − µ | > z σ ) ≤ e − z 2 /2 z √ π . Lemma D.13. If A and B are positive semi-definite squar e matrices of the same size, then [ T r ( A B ) ] 2 ≤ T r ( A 2 ) T r ( B 2 ) ≤ [ T r ( A ) ] 2 [ T r ( B ) ] 2 . Lemma D.14. Given two symmetric positive semi-definite squar e matrices A and B such that A ⪰ B , it holds that ∥ A ∥ 2 ≥ ∥ B ∥ 2 . Proof. Note that A − B is also positive semi-definite. Then, we have that ∥ B ∥ 2 = sup ∥ x ∥ = 1 x ⊤ B x ≤ sup ∥ x ∥ = 1 x ⊤ B x + x ⊤ ( A − B ) x = sup ∥ x ∥ = 1 x ⊤ A x = ∥ A ∥ 2 . Lemma D.15. Let A ∈ R d × d be a positive definite matrix where its largest eigenvalue λ max ( A ) ≤ λ . Given that v 1 , . . . , v n are n vectors in R d , it holds that A n ∑ i = 1 v i ≤ s λ n n ∑ i = 1 ∥ v i ∥ 2 A . Lemma D.16. Let Λ be a positive definite matrix and κ = λ max ( Λ ) λ min ( Λ ) be the condition number of Λ . If Λ ≻ I and J ≥ 2 κ log ( 1/ σ ) , then, for any σ > 0 , ( 1 − 1 / ( 2 κ )) J < σ . Proof. The statement is equivalent to proving that J ≥ log ( 1/ σ ) log 1 1 − 1 / ( 2 κ ) . Since κ ≥ 1 and for any x ∈ ( 0, 1 ) , e − x > 1 − x , we have that e − 1/ ( 2 κ ) > 1 − 1/ ( 2 κ ) = ⇒ log 1 1 − 1 / ( 2 κ ) ≥ 1 2 κ . Therefor e, we have that J ≥ 2 κ log ( 1/ σ ) ≥ log ( 1 / σ ) log 1 1 − 1 / ( 2 κ ) . This concludes the proof. 45 E Sample Complexity in the On-Policy Setting E.1 Proof of Good Event Lemma E.1. Consider Algorithm 1 in the on-policy setting with λ = 1 . Then, for any δ ∈ ( 0, 1 ) , with probability at least 1 − δ , it holds that ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) h b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) i ( Λ t h ) − 1 ≤ C on δ H p d c , where C on δ = log ( N / δ ) . Proof of Lemma E.1 . Recall that P h b V t h + 1 ( s , a ) = E s ′ ∼ P h h b V t h + 1 ( s ′ ) i . Thus, E [ b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) ] = 0. Also, b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) ≤ H . Therefor e, b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) is zero-mean and H -sub Gaussian. Given that, we can invoke Lemma E.3 . ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) h b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) i ( Λ t h ) − 1 ≤ √ 2 H v u u t log " det ( Λ t h ) 1/2 det ( Λ 0 h ) − 1/ 2 δ # = √ 2 H v u u t log " N + λ λ d / 2 # − log ( δ ) = √ 2 H r d c 2 log ( N / δ ) = H q d c log ( N / δ ) , where the first equality follows from Lemma E.4 , and the second equality holds by setting λ = 1. This concludes the proof. E.2 Proof of Theorem 6.1 Using Lemma E.1 , we can instantiate Lemma D.2 in the on-policy setting with Γ on LMC = C on δ H p d c + 4 3 s 2 d c log ( 1/ δ ) 3 ζ + 4 3 = H q d c log ( N / δ ) + 4 3 s 2 d c log ( 1/ δ ) 3 ζ + 4 3 . Proof of Theorem 6.1 . The optimal gap for the mixture policy can be written as E h V ⋆ 1 ( s 1 ) − V π T 1 ( s 1 ) i = 1 T T ∑ t = 1 V ⋆ 1 ( s 1 ) − V π t 1 ( s 1 ) . 46 Then, to decompose the above summation, we have that T ∑ t = 1 V ⋆ 1 ( s 1 ) − V π t 1 ( s 1 ) = T ∑ t = 1 V ⋆ 1 ( s 1 ) − b V t 1 ( s 1 ) + T ∑ t = 1 b V t 1 ( s 1 ) − V π t 1 ( s 1 ) . W e can further decompose the first term by invoking Lemma E.2 with π = π ⋆ and obtain that V ⋆ 1 ( s 1 ) − b V t 1 ( s 1 ) = H ∑ h = 1 E π ⋆ hD π ⋆ h ( · | s ) − π t h ( · | s ) , b Q t h ( s , · ) Ei + H ∑ h = 1 E π ⋆ h r h ( s , a ) + P h b V t h + 1 ( s , a ) − b Q t h ( s , a ) i . Similarly , we can decompose the second term by invoking Lemma E.2 with π = π t and get that b V t 1 ( s 1 ) − V π t 1 ( s 1 ) = H ∑ h = 1 E π t hD π t h ( · | s ) − π t h ( · | s ) , b Q t h ( s , · ) Ei − H ∑ h = 1 E π t h r h ( s , a ) + P h b V t h + 1 ( s , a ) − b Q t h ( s , a ) i = − H ∑ h = 1 E π t h r h ( s , a ) + P h b V t h + 1 ( s , a ) − b Q t h ( s , a ) i . Therefor e, using the definition of the model prediction err or ι in Definition 5.1 , we have T ∑ t = 1 V ⋆ 1 ( s 1 ) − V π t 1 ( s 1 ) = T ∑ t = 1 H ∑ h = 1 E π ⋆ hD π ⋆ h ( · | s ) − π t h ( · | s ) , b Q t h ( s , · ) Ei | {z } (I) policy optimization (actor) error + T ∑ t = 1 H ∑ h = 1 E π ⋆ [ ι t h ( s , a ) ] − E π t [ ι t h ( s , a ) ] | {z } (II) policy evaluation (critic) error . Policy optimization error . W e first start by bounding T erm (I), the policy optimization (actor) error . T erm (I) = T ∑ t = 1 H ∑ h = 1 E s ∼ π ⋆ hD π ⋆ h ( · | s ) − π t h ( · | s ) , b Q t h ( s , · ) Ei = H ∑ h = 1 E s ∼ π ⋆ T ∑ t = 1 D π ⋆ h ( · | s ) − π t h ( · | s ) , b Q t h ( s , · ) E ! ≤ H max ( h , s ) ∈ [ H ] × S T ∑ t = 1 D π ⋆ h ( · | s ) − π t h ( · | s ) , b Q t h ( s , · ) E ! (i) ≤ H log |A | + ∑ T t = 1 ϵ t h ( · ) ∞ η + η H 2 T 2 ! (ii) ≤ H 2 q ( log |A | + ϵ T ) /2 √ T (iii) ≤ O H 2 q log |A | √ T + H 2 √ ϵ T . (i) follows from Theorem 4.1 with u = π ∗ h ( · | s ) . (ii) is obtained by setting η = √ 2 ( log |A | + ϵ T ) H √ T . (iii) is based on that for all a , b ≥ 0, √ a + b ≤ √ a + √ b . Policy evaluation error . Then, we continue to bound T erm (II), the policy evaluation (critic) error . T erm (II) = T ∑ t = 1 H ∑ h = 1 E π ⋆ [ ι t h ( s , a ) ] − E π t [ ι t h ( s , a ) ] 47 (iv) ≤ − T ∑ t = 1 H ∑ h = 1 E π t [ ι t h ( s , a ) ] (v) ≤ Γ on LMC T ∑ t = 1 H ∑ h = 1 E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i ≤ Γ on LMC T max t ∈ [ T ] H ∑ h = 1 E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i . (iv) and (v) both follow from Lemma D.2 , where (iv) is based on the optimism guarantee (RHS of Eq. (10) ), while (v) is based on the error bound (LHS of Eq. (10) ). Bounding the sum of bonuses. Since Γ on LMC is bounded, it suffices to bound E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i . Note that Λ t h = ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) ϕ ( s , a ) ⊤ + λ I , and D t h only depends on π t in the on-policy setting. (This is not true for the off-policy setting since Λ t h would depend on { π 1 , . . . , π t } .) W e then index each data point in D t h as n ( s i h , a i h , s i h + 1 ) o i ∈ [ N ] . Let Λ t , i h = ∑ i j = 1 ϕ ( s j h , a j h ) ϕ ( s j h , a j h ) ⊤ + λ I . Then, we have that H ∑ h = 1 E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i (vi) ≤ 1 N N ∑ i = 1 H ∑ h = 1 E π t " ∥ ϕ ( s , a ) ∥ Λ t , i h − 1 # = 1 N N ∑ i = 1 H ∑ h = 1 ϕ ( s i h , a i h ) Λ t , i h − 1 + 1 N N ∑ i = 1 H ∑ h = 1 E s h ∼ P ( · | s t h − 1 a t h − 1 ) a h ∼ π t h ( · | s h ) " ∥ ϕ ( s , a ) ∥ Λ t , i h − 1 # − ϕ ( s i h , a i h ) Λ t , i h − 1 | {z } : = M on i , h , (15) where (vi) follows fr om the fact that Λ t , i h ⪯ Λ t h . Applying the elliptical potential lemma. For the first term of Eq. (15) , we have that 1 N N ∑ i = 1 H ∑ h = 1 ϕ ( s i h , a i h ) Λ t , i h − 1 = 1 N H ∑ h = 1 N ∑ i = 1 ϕ ( s i h , a i h ) Λ t , i h − 1 (vii) ≤ 1 N H ∑ h = 1 √ N N ∑ i = 1 ϕ ( s i h , a i h ) 2 Λ t , i h − 1 ! 1/2 (viii) ≤ O r d c H 2 log ( N / δ ) N ! . (vii) applies the Cauchy-Schwarz inequality , and (viii) follows the elliptical argument fr om Lemma E.5 . A martingale difference sequence. For the second term of Eq. (15) , since for a fixed i ∈ [ N ] , n M on i , h o h ∈ [ H ] forms a martingale sequence adapted to the filtration, F on i , h = n ( s i τ , a i τ ) o τ ∈ [ h − 1 ] , 48 such that E h M on i , h | F on i , h i = 0, where the expectation is with respect to the randomness in the policy and the environment at step h . Since | M on i , h | ≤ 1, we can apply the Azuma–Hoeffding inequality and obtain that Pr N ∑ i = 1 H ∑ h = 1 M on i , h ≥ m ! ≥ exp − m 2 2 H N . Setting m = p 2 H N log ( 1 / δ ) and using a union bound over i ∈ [ N ] , with probability at least 1 − δ , it holds that 1 N N ∑ i = 1 H ∑ h = 1 M on i , h ≤ r 2 H log ( 1 / δ ) N ≤ O r H log ( 1/ δ ) N ! . Putting everything together . Therefore, we have that H ∑ h = 1 E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i = 1 N N ∑ i = 1 H ∑ h = 1 ϕ ( s i h , a i h ) Λ t , i h − 1 + 1 N N ∑ i = 1 H ∑ h = 1 M on i , h ≤ O r d c H 2 log ( N / δ ) N ! . It further implies that, with probability at least 1 − δ , T erm (II) ≤ Γ on LMC T max t ∈ [ T ] H ∑ h = 1 E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i (ix) ≤ O s d 3 c H 4 log 2 ( N / δ ) N T ≤ e O H 2 q d 3 c log | A | √ T , where (ix) comes fr om setting N = T log | A | = H 4 ϵ 2 . Finally , putting everything together , with probability at least 1 − δ , E h V ⋆ 1 ( s 1 ) − V π T 1 ( s 1 ) i = 1 T ( T erm (I) + T erm (II) ) = e O H 2 p d 3 c log |A | √ T + H 2 √ ϵ ! . This concludes the proof. E.3 T echnical T ools Lemma E.2 (Extended V alue Differ ence) . Given any π , π ′ ∈ ∆ ( A | S , H ) and any Q -function b Q ∈ R H × |S |×| A | , we define b V h ( · ) = E a ∼ π ′ h ( s , · ) b Q h ( · , a ) for any h ∈ [ H ] . Then, b V 1 ( s 1 ) − V π 1 ( s 1 ) = H ∑ h = 1 E s ∼ π hD π ′ h ( s , · ) − π h ( s , · ) , b Q h ( s , · ) Ei + H ∑ h = 1 E ( s , a ) ∼ π " b Q h ( s , a ) − r h ( s , a ) − ∑ s ′ ∈S P h ( s ′ | s , a ) b V h + 1 ( s ′ ) # . 49 Lemma E.3 (Concentration of Self-Normalized Processes ( Abbasi-Y adkori et al. , 2011 , Theorem 1)) . Let { x t } ∞ t = 1 be a real-valued stochastic pr ocess with the corr espond filtration {F t } ∞ t = 0 such that x t is F t − 1 -measurable, and x t is conditionally σ -sub-Gaussian for some σ > 0 , i.e., ∀ λ ∈ R , E [ exp ( λ x t ) | F t − 1 ] = exp ( λ 2 σ 2 /2 ) . Let { ϕ t } ∞ t = 1 be an R d -valued stochastic process such that ϕ t is F t − 1 -measurable. Assume Λ 0 is a d × d positive definite matrix, and let Λ t = Λ 0 + ∑ t i = 1 ϕ i ϕ ⊤ i . Then, for any δ > 0 , with pr obability at least 1 − δ , for all t ≥ 0 , it holds that t ∑ i = 1 ϕ i x i 2 Λ − 1 t ≤ 2 σ 2 log " det ( Λ t ) 1/2 det ( Λ 0 ) − 1/ 2 δ # . Lemma E.4 (Determinant-T race Inequality ( Abbasi-Y adkori et al. , 2011 , Lemma 10)) . Suppose X 1 , X 2 , . . . , X t ∈ R d and for any s ∈ [ t ] , ∥ X ∥ 2 ≤ L . Let Λ t = λ I + ∑ t s = 1 X s X ⊤ s for some λ > 0 . Then, for all t, it holds that det ( Λ t ) ≤ ( λ + t L 2 / d ) d . Lemma E.5 ( Abbasi-Y adkori et al. 2011 , Lemma 11) . Suppose X 1 , X 2 , . . . , X t ∈ R d and for any s ∈ [ t ] , ∥ X ∥ 2 ≤ L . Let Λ t = Λ 0 + ∑ t s = 1 X s X ⊤ s and λ min ( Λ 0 ) ≥ max 1, L 2 . Then, for all t , it hold that log det ( Λ t ) det ( Λ 0 ) ≤ t ∑ s = 1 ∥ X t ∥ 2 ( Λ t ) − 1 ≤ 2 log det ( Λ t ) det ( Λ 0 ) . F Sample Complexity in the Of f-Policy Setting F .1 Covering Number (Proof of Lemma 6.1 ) W e first present a bound for the norm of the logit. Lemma F .1. Consider Algorithm 1 with the NPG actor in Algorithm 2 . Then, under Assumptions 4.1 and 4.2 , for all ( t , h , s , a ) ∈ [ T ] × [ H ] × S × A , it holds that D φ ( s , a ) , θ t , K t h ( s , a ) E ≤ ( ϵ + η H ) t , where ϵ is defined in Lemma 4.1 . Proof of Lemma F .1 . W e will prove this by induction. When t = 0, since we set θ 0 h = 0 , the statement is trivially true. For t ≥ 1, assume that the statement stands true for t − 1. Since Algorithm 1 optimizes the actor loss up to some errors that ar e assumed to be bounded, using the triangular inequality , we have that D φ ( s , a ) , θ t , K t h ( s , a ) E = D φ ( s , a ) , θ t , K t h − b θ t , ⋆ h E + D φ ( s , a ) , b θ t , ⋆ h ( s , a ) E ≤ ϵ opt + D φ ( s , a ) , b θ t , ⋆ h ( s , a ) E ≤ ϵ opt + D φ ( s , a ) , b θ t , ⋆ h ( s , a ) − θ t − 1, K t − 1 h ( s , a ) E − η b Q t h ( s , a ) + D φ ( s , a ) , θ t − 1, K t − 1 h ( s , a ) E + η b Q t h ( s , a ) ≤ ϵ opt + ϵ bias + D φ ( s , a ) , θ t − 1, K t − 1 h ( s , a ) E + η b Q t h ( s , a ) ≤ ϵ + D φ ( s , a ) , θ t − 1, K t − 1 h ( s , a ) E + η b Q t h ( s , a ) 50 ≤ ( ϵ + η H ) t , where b θ t , ⋆ h denotes the optimal actor parameters when optimizing over D exp and ρ exp , D φ ( s , a ) , θ t − 1, K t − 1 h ( s , a ) E + η b Q t h ( s , a ) is the optimization target in the actor loss of the projected NPG , and the last inequality uses the inductive hypothesis. This concludes the proof. Proof of Lemma 6.1 . Consider any Q , Q ′ ∈ Q such that Q ( · , · ) = min { ⟨ ϕ ( · , · ) , w ⟩ , H } + and Q ′ ( · , · ) = min { ⟨ ϕ ( · , · ) , w ′ ⟩ , H } + . Therefor e, we have that sup ( s , a ) ∈S ×A Q ( s , a ) − Q ′ ( s , a ) ≤ sup ( s , a ) ∈S ×A ϕ ( s , a ) , w − w ′ ≤ sup ( s , a ) ∈S ×A ∥ ϕ ( s , a ) ∥ w − w ′ ≤ 2 W , where the first inequality uses the Cauchy-Schwarz inequality , and the second inequality uses Definition 2.1 , the triangular inequality , and the definition of W . Consider any π , π ′ ∈ Π lin such that π ( · | s ) ∝ exp ( ⟨ ϕ ( s , · ) , θ ⟩ ) and π ′ ( · | s ) ∝ exp ( ⟨ ϕ ( s , · ) , θ ′ ⟩ ) . By invoking Lemma F .6 and using Lemma F .1 , we can observe that for a fixed s ∈ S , sup a ∈ A π ( s , a ) − π ′ ( s , a ) ≤ π ( s , · ) − π ′ ( s , · ) 1 ≤ 2 r sup a |⟨ φ ( s , a ) , θ − θ ′ ⟩| ≤ 2 p 2 Z . T aking the sup over S , we get that sup ( s , a ) ∈S ×A π ( s , a ) − π ′ ( s , a ) ≤ 2 p 2 Z . Therefor e, we can bound the logarithm of the covering number of the value function class as follows. log N ∆ ( V ) ≤ log N ∆ / 2 ( Q ) + log N ∆ / ( 2 H ) ( Π lin ) ≤ d c log 1 + 4 W ∆ ! + d a log 1 + 8 H √ 2 Z ∆ ! , where the first inequality follows from Lemma F .3 , and the second inequality uses Lemma F .5 . This concludes the proof. F .2 Proof of Good Event Lemma F .2. Consider Algorithm 1 in the off-policy setting with λ = 1 . Then, for any δ ∈ ( 0, 1 ) , with probability at least 1 − δ , it holds that ∑ ( s , a ) ∈D t h ϕ ( s , a ) h b V t h + 1 ( s ) − P h b V t h + 1 ( s , a ) i ( Λ t h ) − 1 ≤ C off δ H p d c , where C off δ = 3 v u u t 1 2 log ( T + 1 ) + log 2 √ 2 T H ! + log 2 δ + V , 51 V = d c log 1 + 4 W + 4 H √ 2 Z ∆ ! + d a log 1 + 4 H √ 2 Z ∆ ! , W = 16 3 H p d c T + s 2 d 3 c T 3 ζ δ , Z = ( ϵ + η H ) T . Proof of Lemma F .2 . Since b V ( · ) ∈ [ 0. H ] , we can invoke Lemma F .4 . Then, we have that for any ∆ > 0, with probability at least 1 − δ , ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) h b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) i ( Λ t h ) − 1 ≤ 4 H 2 d c 2 log T + λ λ + d c log N ∆ ( V ) ∆ + log 2 δ + 8 T 2 ∆ 2 λ 1/2 ≤ 2 H d c 2 log T + λ λ + d c log N ∆ ( V ) ∆ + log 2 δ 1/2 + 2 √ 2 T ∆ √ λ . Setting λ = 1, ∆ = H 2 √ 2 T , we have that with probability at least 1 − δ , ∑ ( s , a , s ′ ) ∈ D t h ϕ ( s , a ) h b V t h + 1 ( s ′ ) − P h b V t h + 1 ( s , a ) i ( Λ t h ) − 1 ≤ 2 H p d c 1 2 log ( T + 1 ) + log N ∆ ( V ) H 2 √ 2 T + log 2 δ 1/2 + H ≤ 3 H p d c " 1 2 log ( T + 1 ) + log 2 √ 2 T H ! + log 2 δ + V # 1/2 , where the last inequality uses Lemma 6.1 to bound the logarithm of the covering number . This concludes the proof. F .3 Proof of Theorem 6.2 W e first instantiate Lemma D.2 in the off-policy setting. Given the above good event, we have that Γ off LMC ≤ O C off δ H d c q log ( 1 / δ ) = e O H q d 3 c max { d c , d a } . Proof of Theorem 6.2 . Following the proof of Theorem 6.1 ( Section E.2 ), we can use the same regr et decomposition as follows. T ∑ t = 1 V ⋆ 1 ( s 1 ) − V π t 1 ( s 1 ) = T ∑ t = 1 H ∑ h = 1 E π ⋆ hD π ⋆ h ( · | s ) − π t h ( · | s ) , b Q t h ( s , · ) Ei | {z } (I) policy optimization (actor) error + T ∑ t = 1 H ∑ h = 1 E π ⋆ [ ι t h ( s , a ) ] − E π t [ ι t h ( s , a ) ] | {z } (II) policy evaluation (critic) error . 52 T erm (I) can be bounded the same way as the proof in Section E.2 . Hence, it suffices to only bound T erm (II). T erm (II) = T ∑ t = 1 H ∑ h = 1 E π ⋆ [ ι t h ( s , a ) ] − E π t [ ι t h ( s , a ) ] (i) ≤ − T ∑ t = 1 H ∑ h = 1 E π t [ ι t h ( s , a ) ] (ii) ≤ Γ off LMC T ∑ t = 1 H ∑ h = 1 E π t h ϕ ( s t h , a t h ) ( Λ t h ) − 1 i . (i) and (ii) both follow from Lemma D.2 , where (i) is based on the optimism guarantee (RHS of Eq. (10) ), while (ii) is based on the error bound (LHS of Eq. (10) ). Bounding the sum of bonuses. Since Γ off LMC is bounded, it suffices to bound E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i . W e then index each data point in D t h as n ( s i h , a t h , s t h + 1 ) o t ∈ [ T ] and get that Λ t h = ∑ T t = 1 ϕ ( s t h , a t h ) ϕ ( s t h , a t h ) ⊤ + λ I . Then, we have that T ∑ t = 1 H ∑ h = 1 E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i = T ∑ i = 1 H ∑ h = 1 ϕ ( s t h , a t h ) Λ t , i h − 1 + T ∑ t = 1 H ∑ h = 1 E s h ∼ P ( · | s t h − 1 a t h − 1 ) a h ∼ π t h ( · | s h ) ∥ ϕ ( s h , a h ) ∥ ( Λ t h ) − 1 − ϕ ( s t h , a t h ) ( Λ t h ) − 1 | {z } : = M off t , h . (16) Applying the elliptical potential lemma. For the first term of Eq. (16) , we have that T ∑ t = 1 H ∑ h = 1 ϕ ( s t h , a t h ) ( Λ t h ) − 1 = H ∑ h = 1 T ∑ t = 1 ϕ ( s t h , a t h ) ( Λ t h ) − 1 (iii) ≤ H ∑ h = 1 √ T T ∑ t = 1 ϕ ( s t h , a t h ) 2 ( Λ t h ) − 1 ! 1/2 (iv) ≤ O q d c H 2 T log ( T / δ ) . (iii) applies the Cauchy-Schwarz inequality , and (iv) follows the elliptical potential argument from Lemma E.5 . A martingale difference sequence. For the second term of Eq. (16) , since n M off t , h o ( t , h ) ∈ [ T ] × [ H ] forms a martingale sequence adapted to the filtration, F off t , h = n ( s i τ , a i τ ) o ( i , τ ) ∈ [ t − 1 ] × [ H ] ∪ ( s t τ , a t τ ) τ ∈ [ h − 1 ] , such that E h M off t , h | F off t , h i = 0. Since |M off i , h | ≤ 1, we can apply the Azuma–Hoeffding inequality and obtain that Pr T ∑ t = 1 H ∑ h = 1 M off t , h ≥ m ! ≥ exp − m 2 2 H T . 53 Setting m = p 2 H T log ( 1 / δ ) , with probability at least 1 − δ , it holds that T ∑ t = 1 H ∑ h = 1 M off t , h ≤ q 2 H T log ( 1 / δ ) ≤ O q H T log ( 1/ δ ) . Therefor e, we have that T ∑ t = 1 H ∑ h = 1 E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i = T ∑ t = 1 H ∑ h = 1 ϕ ( s i h , a i h ) Λ t , i h − 1 + T ∑ t = 1 H ∑ h = 1 M off i , h ≤ O q d c H 2 T log ( T / δ ) . It further implies that, with probability at least 1 − δ , T erm (II) ≤ Γ off LMC T ∑ t = 1 H ∑ h = 1 E π t h ∥ ϕ ( s , a ) ∥ ( Λ t h ) − 1 i ≤ e O q d 3 c max { d c , d a } H 4 T . Putting everything together . Therefore, we have that with pr obability at least 1 − δ , E h V ⋆ 1 ( s 1 ) − V π T 1 ( s 1 ) i = 1 T ( T erm (I) + T erm (II) ) = e O H 2 p d 3 c max { d c , d a } log |A | √ T + H 2 √ ϵ ! . This concludes the proof. F .4 T echnical T ools Lemma F .3 ( Zhong and Zhang , 2023 , Lemma B.1) . Consider the value function class V = { ⟨ Q ( · , · ) , b π ( · | · ) ⟩ A | Q ∈ Q , b π ∈ Π } . Then, it holds that N ∆ ( V ) ≤ N ∆ / 2 ( Q ) · N ∆ / ( 2 H ) ( Π ) . Lemma F .4 (V alue-A war e Uniform Concentration ( Jin et al. , 2020 , Lemma D.4)) . Let { s t } ∞ t = 1 be a stochastic process on the state space S with the correspond filtration {F t } ∞ t = 0 such that s t is F t − 1 -measurable. Let { ϕ t } ∞ t = 1 be an R d -valued stochastic process such that ϕ t is F t − 1 -measurable, and ∥ ϕ t ∥ ≤ 1 . Let Λ t = I + ∑ t s = 1 ϕ s ϕ ⊤ s . Assume V is a value function class such that sup s ∈ S | V ( s ) | ≤ H . Then, for any δ > 0 , with probability at least 1 − δ , for all t ≥ 0 and any V ∈ V , it holds that t ∑ i = 1 ϕ i { V ( s i ) − E [ V ( s i ) | F i − 1 ] } 2 Λ − 1 t ≤ 4 H 2 d 2 log t + λ λ + log N ∆ δ + 8 t 2 ∆ 2 λ , where N ∆ repr esents the ∆ -covering number of V with the distance measured by dist ( V , V ′ ) = sup s ∈ S | V ( s ) − V ′ ( s ) | . Lemma F .5 (Covering Number of Euclidean Ball) . For any ∆ > 0 , the ∆ -covering number , N ∆ , of the Euclidean ball of radius B > 0 in R d satisfies that N ∆ ≤ 1 + 2 B ∆ d . Lemma F .6 ( Zhong and Zhang 2023 , Lemma B.3) . For π , π ′ ∈ ∆ ( A ) and Z , Z ′ : A → R + , if π ( · ) ∝ exp ( Z ( · ) ) and π ′ ( · ) ∝ exp ( Z ′ ( · ) ) , then it holds that π − π ′ 1 ≤ 2 q ∥ Z − Z ′ ∥ ∞ . 54 G Experiments In this section, we evaluate the performance of our proposed algorithm with other methods on various benchmarks. In Section G.1 , we test our pr oposed algorithm in two specific environments of linear MDPs. In Section G.2 , we further conduct some ablation studies in the same two environments. In Section G.3 , we test our proposed algorithm in lar ge-scale deep RL applications (Atari ( Mnih et al. , 2013 )) and compare its performance to two commonly used deep RL algorithms, PPO ( Schulman et al. , 2017b ) in the on-policy setting and DQN ( Mnih et al. , 2015 ) in the off-policy setting. G.1 Experiments in Linear MDPs First, we test our proposed algorithm in the randomly generated linear MDPs (Random MDP) and the linear MDP version of the Deep Sea ( Osband et al. , 2019 ). G.1.1 Environment Setup Our experimental setup is an extension of Ishfaq et al. ( 2024a ). In particular , we extend the prior off-policy setting to test our proposed algorithm in the linear MDP version of the Deep Sea ( Osband et al. , 2019 ) and the Random MDP . In both experiments, we use the linear MDP featur es as the policy featur es (i.e., ϕ = φ ), and we set d : = d c = d a to repr esent the feature dimension for both the actor and the critic parameters. Figure 2: Example of the Deep Sea environment from Osband et al. ( 2019 ). For the Random MDP envir onment, we consider 15 states and 5 actions. For each state s ∈ S , we generate ψ h ( s ) ∈ R d uniformly at random in [ 0, 1 ] and constr uct tile coded features. The agent always starts fr om state 0, receiving a small rewar d of 0.1 upon taking action 0, and obtains the maximum reward when r eaching the final state and taking action 1. All other state-action pairs yield zero rewar d. Given this reward function and a randomly generated transition kernel, we solve for ψ h and υ h via minimizing least square errors following Definition 2.1 and use the corresponding P h and r h to set up the environment. For the Deep Sea environment, we use a N × N grid with N = 10 where the agent always starts at ( 1, 1 ) and can move either bottom-right or bottom-left, receiving rewar ds of 0 and − 0.01 / N respectively . Reaching the bottom-right corner yields a reward of 1. Furthermore, we generate the actor and critic features by projecting each state-action pair uniformly between [ 0, d − 1 ] , which recovers one-hot encoded featur es when d = | S | × | A | . Given the true transition pr obabilities and r ewards, we solve for ψ h and υ h via minimizing least square errors following Definition 2.1 and use the corresponding P h and r h to ensure the linearity of the MDP . 55 G.1.2 Coreset Construction T o implement our proposed algorithm, we need to conduct the experimental design to obtain D exp and ρ exp . For this, we follow the offline G-Experimental design outlined in Algorithm 4 to construct a coreset. In particular , in each iteration, this greedy iterative algorithm traverses the entire state-action space and adds a data point to the cor eset that has the highest mar ginal gain g ( s , a ) = ∥ φ ( s , a ) ∥ G − 1 . For a specific thr eshold ϵ G , the algorithm only terminates when g max = max s , a ∈ ( S × A ) g ( s , a ) ≤ ϵ G , hence giving us direct control over sup ( s , a ) ∈S ×A ∥ φ ( s , a ) ∥ G − 1 . In practice, we find that it often selects too many data points, so we cap the coreset at 80% of the total data. Algorithm 4 Coreset Constr uction Using G-Experimental Design 1: Input : features φ : S × A 7 → R d a , threshold ϵ G ∈ R 2: Initialize : G = I d a × d a , D exp = ∅ , g max = ∞ 3: while g max > ϵ G do 4: g max = 0 5: for ( s , a ) ∈ S × A do 6: g ( s , a ) = ∥ φ ( s , a ) ∥ G − 1 7: if g max < g ( s , a ) then 8: ( s ⋆ , a ⋆ ) = ( s , a ) 9: g max = g ( s , a ) 10: D exp = D exp ∪ { ( s ⋆ , a ⋆ ) } 11: G = G + φ ( s ⋆ , a ⋆ ) φ ( s ⋆ , a ⋆ ) ⊤ G.1.3 Algorithms and Hyperparameters W e denote by LMC-NPG-EXP our proposed algorithm with an explicit log-linear policy parameterization that uses LMC for policy evaluation and projected NPG for policy optimization over the obtained coreset. W e denote by LMC-NPG-IMP an idealized variant of NPG that does not have an explicit policy parameterization and maintains an implicit policy by storing all parameterized Q functions (and hence requir es significantly more memory). As a baseline, we also consider the value-based algorithm LMC ( Ishfaq et al. , 2024a ). In T able 3 , we list the hyperparameters used across all experiments. For log-linear policies, the actor loss in Eq. (6) admits a closed-form solution, allowing us to avoid tuning of the actor learning rate α a and the number of actor updates K t , by minimizing the objective exactly . In general, for non-linear models, inexact optimization (e.g., stochastic gradient descent) is usually requir ed to optimize the actor loss. Hyperparameter LMC LMC-NPG-IMP LMC-NPG-EXP Policy Optimization Learning Rate ( η ) ✗ [ 0.1, 1, 10, 100 ] [ 0.1, 1, 10, 100 ] Inverse T emperature ( ζ − 1 ) [ 10 − 2 , 10 − 3 , 10 − 4 , 10 − 5 ] Number of Critic Updates ( J t ) 100 Critic Learning Rate ( α c ) [ 10 − 2 , 10 − 3 , 10 − 4 , 10 − 5 ] Number of Episodes ( T ) 600 Horizon Length ( H ) 100 T able 3: Hyperparameter search space for our experiments in linear MDPs. G.1.4 Experimental Results Following the protocol of Ishfaq et al. ( 2024a ), each algorithm is run with 20 random seeds. W e sweep the hyperparameters as shown in T able 3 and report the best performance with 95% confidence intervals. 56 Figure 3: Comparison of LMC-NPG-EXP (our proposed framework), LMC-NPG-IMP (memory-intensive variant), and LMC (value-based baseline) in the Deep Sea environment. For the Random MDP , Figure 1 indicates that LMC-NPG-EXP closely matches LMC-NPG-IMP while outperforming the value-based baseline, LMC . For the linear MDP version of Deep Sea, Figure 3 showcases that LMC-NPG-EXP can achieve comparable performance with LMC-NPG-IMP and LMC . G.2 Ablation Studies G.2.1 Ablation on Exploration T o study the impact of the exploration mechanism, LMC , in our proposed algorithm, we perform an ablation in the linear MDP variant of Deep Sea. For the baseline without exploration, we consider the same algorithm design as LMC-NPG-EXP and simply do not inject any noise into the LMC update. The results in Figure 4 indicate that when the feature dimensions of the critic and the actor are relatively small, the exploration mechanism is crucial for our pr oposed algorithm to achieve decent performance. Figure 4: Ablation of the exploration mechanism for LMc-NPG-EXP . G.2.2 Ablation on Feature Dimensions W e also study the effect of the featur e dimensions. W e use the same feature for the MDP environment and the policy (i.e., ϕ = φ ), and we denote that d : = d c = d a . The results in Figure 5 show that larger feature dimensions d for both the actor and the critic lead to greater performance of the proposed algorithm. 57 Figure 5: Effect of feature dimension d in Deep Sea. Figure 6: LMC-NPG-EXP exhibits robustness to differ ent choices of ζ − 1 . Figure 7: LMC-NPG-EXP exhibits robustness to differ ent choices of M . G.2.3 Sensitivity to Inverse T emperature ( ζ − 1 ) W e study the sensitivity of our algorithm to the inverse temperature hyperparameter , ζ − 1 , in the Deep Sea environment. As shown Figure 6 , we observe relatively robust performance for different choices of this hyperparameter across a range of dif ferent featur e dimensions. G.2.4 Sensitivity to the Number of Critic Samples ( M ) W e further study the effect of the number of critic samples, M , in the Deep Sea environment. W e vary M across a range of differ ent feature dimensions. Similarly , as shown in Figure 7 , we find that the performance of our proposed algorithm r emains relatively stable acr oss the tested range of dif ferent featur e dimensions. 58 G.3 Experiments Beyond Linear MDPs: Atari G.3.1 Extension to Deep RL Applications Compared to our theor etical results in the finite-horizon linear MDP setting, the Atari benchmark requir es handling discounted pr oblems with complex nonlinear function approximation. Consequently , starting from our theoretically principled algorithm, we make three mild changes and follow the same protocol as the practical version of LMC in Ishfaq et al. ( 2024a ). Since we are not in the finite-horizon setting, we compute the value functions and Q functions in a forward fashion ( h = 1, . . . ) rather than backwards ( h = H , . . . , 1), which changes how the critic loss is formed in Algorithm 3 . Moreover , instead of using stochastic gradient descent to optimize the LMC critic loss, we follow Ishfaq et al. ( 2024a ) and use the practical version of LMC that integrates Adam. Finally , rather than relying on the experimental design, at iteration t , we roll out the current policy to stor e state–action pairs in a buffer D t and minimize the actor objective over (a subset of) it. Following such changes, we can extend our proposed algorithm beyond the linear function appr oximation and empirically test its performance against other commonly used algorithms. G.3.2 Environment Setups and Hyperparameters In the Atari experiments, we use the following setups. In the on-policy setting, we adopt the recommended hyperparameters from Raffin ( 2020 ) for PPO and our algorithm. In the off-policy setting, following prior work ( T omar et al. , 2020 ), we use the default hyperparameters fr om stable baselines ( Raffin et al. , 2021 ) for DQN and our algorithm. These setups are motivated by two considerations. First, we aim to evaluate the effect of differ ent objectives without performing an extensive hyperparameter search. Second, the CNN-based actor and the critic architectur es make lar ge grid searches over multiple hyperparameters (e.g., framestack, λ in GAE, horizon length, and discount factor) computationally prohibitive. A complete list of hyperparameters used in the on-policy and of f-policy Atari experiments is pr ovided in T ables 4 and 5 . Additionally , for the policy optimization learning rate η in our algorithm, we perform a grid search over { 0.01, 0.1, 1.0 } . G.3.3 Experimental Results As illustrated in Figure 8 , our algorithm can achieve comparable or even better performance than PPO in the on-policy setting. Similarly , in the of f-policy setting, our algorithm’s performance is comparable to or exceeds DQN in most considered games, as shown in Figure 9 . These results underscor e that our theoretically grounded appr oach holds significant practical value for large-scale deep RL applications. 59 Hyperparameter LMC-NPG-EXP PPO Reward normalization ✗ ✗ Observation normalization ✗ ✗ Orthogonal weight initialization ✓ ✓ V alue function clipping ✗ ✗ Gradient clipping ✗ ✓ Probability ratio clipping ✗ ✓ Clip range ✗ 0.1 Entropy coef ficient 0 0.01 Number of inner loop updates ( m ) 5 4 Adam step-size 3 × 10 − 4 2.5 × 10 − 4 V alue Function Coefficient ✗ 0.5 Minibatch size 256 Framestack 4 Number of environment copies 8 GAE ( λ ) 0.95 Horizon ( T ) 128 Discount factor 0.99 T otal number of timesteps 10 7 Number of runs for plot averages 5 Confidence interval for plot runs ∼ 95% T able 4: Hyperparameters for the Atari experiments in the on-policy setting. Hyperparameter LMC-NPG-EXP DQN Reward normalization ✗ ✗ Observation normalization ✗ ✗ Orthogonal weight initialization ✗ ✗ V alue function clipping ✗ ✗ Gradient clipping ✗ ✗ Probability ratio clipping ✗ ✗ Exploration LMC ϵ -greedy Adam step-size 3 × 10 − 4 Buffer size 10 6 Minibatch size 256 Framestack 4 Number of environment copies 8 Discount factor 0.99 T otal number of timesteps 10 7 Number of runs for plot averages 5 Confidence interval for plot runs ∼ 95% T able 5: Hyperparameters for the Atari experiments in the off-policy setting. 60 Figure 8: In the on-policy setting, LMC-NPG-EXP achieves comparable or better performance compared to PPO . Figure 9: In the off-policy setting, LMC-NPG-EXP achieves comparable or better performance compared to DQN . 61
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment