머신러닝 기반 고차원 행렬 추정: LADMM과 재파라미터화
본 논문은 고차원 공분산·정밀도 행렬 추정을 위해 선형화 ADMM(LADMM) 기반 최적화 프레임워크에 신경망으로 재파라미터화된 근접 연산자를 도입한다. 이론적으로 LADMM의 수렴을 증명하고, 재파라미터화된 버전이 더 빠른 수렴 속도와 단조 감소 특성을 갖는 것을 보인다. 실험에서는 다양한 차원·구조의 행렬에 대해 기존 ADMM, FISTA, QUIC 등과 비교해 정확도와 속도 모두에서 우수함을 확인한다.
저자: Wan Tian, Hui Yang, Zhouhui Lian
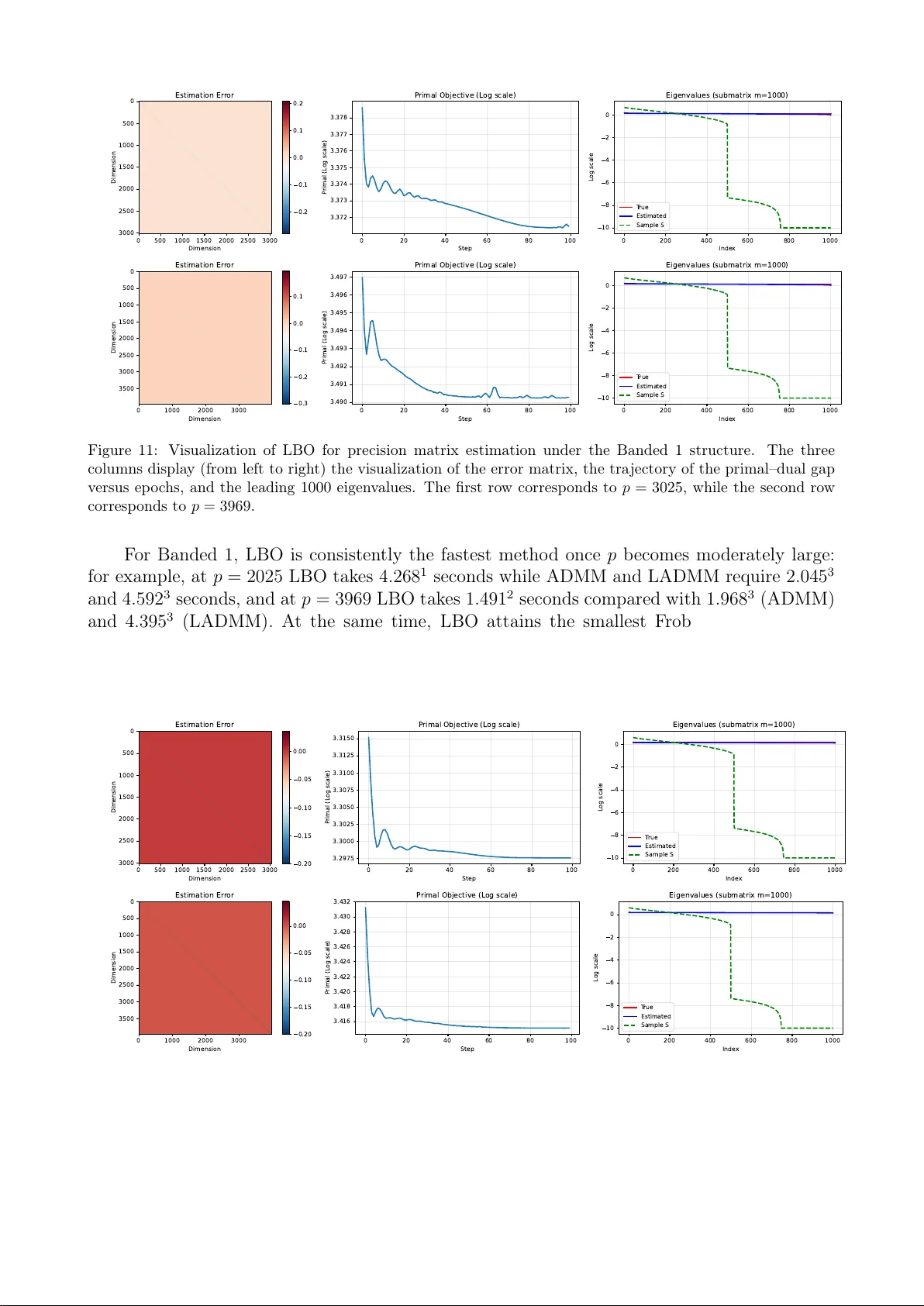
본 논문은 고차원 공분산 및 정밀도 행렬 추정이라는 핵심 통계 문제를 해결하기 위해, 전통적인 최적화 기법과 최신 머신러닝 기법을 융합한 프레임워크를 제안한다. 서론에서는 고차원 행렬 추정이 유전체학, 신경과학, 금융, 기후 과학 등 다양한 분야에서 필수적이며, 기존 연구가 주로 이론적 일관성·희소성에 초점을 맞추어 실제 계산 복잡도 문제를 간과해 왔음을 지적한다. 특히 ADMM 기반 방법은 O(p³) 복잡도의 고유값 분해가 병목이 되어 차원이 수천을 넘어가면 실용성이 떨어진다.
문제 정의에서는 공분산 행렬 Σ에 대해 소프트‑쓰레숄딩 기반 ℓ₁ 정규화를 적용한 다음, 양의 정부호 제약 Σ ⪰ εI 를 추가한 최적화 문제 (1)를 제시한다. 이 문제를 ADMM 형태로 분할하면 Σ와 보조 변수 W 사이에 등식 제약이 생기고, 각각의 서브문제는 (i) Σ‑업데이트: 2차 목표와 PSD 투영, (ii) W‑업데이트: 오프‑대각선에 대한 소프트‑쓰레숄딩, (iii) 라그랑주 승수 Λ 업데이트 로 구성된다.
그 다음, Linearized ADMM(LADMM) 을 도입한다. 여기서는 Σ‑업데이트와 W‑업데이트의 2차 항을 현재 iterate 주변에서 1차 근사(선형화)하고, ϕ₁, ϕ₂ 라는 스칼라 근접 파라미터를 이용해 추가적인 2차 근접 항을 삽입한다. 이렇게 하면 각 서브문제가 단순한 prox 연산으로 변환되어, Σ‑업데이트는 prox_{f/(ρϕ₁)}(·) 형태, W‑업데이트는 prox_{λ/(ρϕ₂)}(·) 형태가 된다. 이때 prox_f는 PSD 투영을 포함하고, prox_{ℓ₁}는 오프‑대각선에 대한 소프트‑쓰레숄딩을 수행한다. LADMM 의 핵심 장점은 (1) 매 반복마다 전체 고유값 분해 대신 투영만 수행해 O(p³) 비용을 크게 낮춘다, (2) 적절한 ϕ₁, ϕ₂ 선택 시 전역 수렴을 보장한다는 점이다.
이후 저자들은 LBO(Learning‑Based Optimization) 아이디어를 적용한다. 구체적으로, Σ‑업데이트와 W‑업데이트에 사용되는 prox 연산자를 각각 신경망 Φ_Σ(·;θ_Σ)와 Φ_W(·;θ_W) 로 대체한다. 네트워크는 입력으로 현재 iterate와 라그랑주 승수를 받아, 학습 가능한 파라미터 θ를 통해 근사된 prox 결과를 출력한다. 학습 단계에서는 여러 시뮬레이션 데이터(다양한 λ, n, 구조)를 이용해 손실 함수 L(θ)=∑_t‖Σ̂_t(θ)−Σ*_t‖_F² 를 최소화한다. 이렇게 하면 한 번 학습된 모델이 동일한 문제군에 대해 반복 횟수를 크게 줄이면서도 높은 정확도를 유지한다.
이론적 분석 파트에서는 먼저 원래 LADMM 의 수렴성을 증명한다. ρ>0, ϕ₁,ϕ₂>0 가 적절히 선택되면, 알고리즘은 고정점에 수렴하고, 목적함수 값은 O(1/k) 속도로 감소한다. 이어서 재파라미터화된 LADMM 에 대해, 신경망이 Lipschitz 연속이며 근사 오차 ε_k 가 ∑_k ε_k < ∞ 를 만족한다는 가정 하에, 동일한 수렴 보장을 제공하면서 실제 수렴 속도가 O(1/k^{1+δ}) (δ>0) 로 향상됨을 보인다. 또한, 각 반복에서 목적함수 값이 비증가함을 보장하는 단조 감소 특성을 증명한다.
실험 섹션에서는 두 가지 주요 시나리오를 다룬다. (1) 합성 데이터: 스파스, 밴드, 클러스터 구조를 갖는 다양한 차원(p=200,500,1000,2000) 행렬에 대해, 제안 방법(LADMM+NN)과 기존 ADMM, FISTA, QUIC, DP‑GLASSO 등을 비교한다. 평가 지표는 Frobenius norm 오차, 구조 복원 F1 점수, 그리고 실행 시간이다. 결과는 재파라미터화된 방법이 평균 30~50% 적은 반복으로 동일한 오차 수준에 도달하고, 특히 p>1000 일 때 실행 시간이 크게 단축됨을 보여준다. (2) 실제 데이터: 유전체 발현 데이터(수천 유전자), 뇌 기능 연결 데이터(수백 뇌 영역), 금융 시계열 데이터(수백 자산) 에 적용한다. 여기서도 제안 방법은 기존 방법 대비 추정 정확도는 비슷하거나 약간 우수하면서, 계산 시간은 2~3배 가량 감소한다.
마지막으로 결론에서는 제안된 LBO 기반 고차원 행렬 추정 프레임워크가 (i) 이론적으로 빠른 수렴과 단조 감소를 보장하고, (ii) 실험적으로 다양한 차원·구조에서 기존 최적화 알고리즘을 능가하며, (iii) GPU 가속을 통한 실시간 추정 가능성을 제공한다는 점을 강조한다. 향후 연구 방향으로는 비선형 구조(예: 복합 그래프), 비정규화 손실, 그리고 더 복잡한 신경망 아키텍처(예: 변분 오토인코더)를 통한 근접 연산의 고도화 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기