Machine Learning-Assisted High-Dimensional Matrix Estimation
Efficient estimation of high-dimensional matrices-including covariance and precision matrices-is a cornerstone of modern multivariate statistics. Most existing studies have focused primarily on the theoretical properties of the estimators (e.g., cons…
Authors: Wan Tian, Hui Yang, Zhouhui Lian
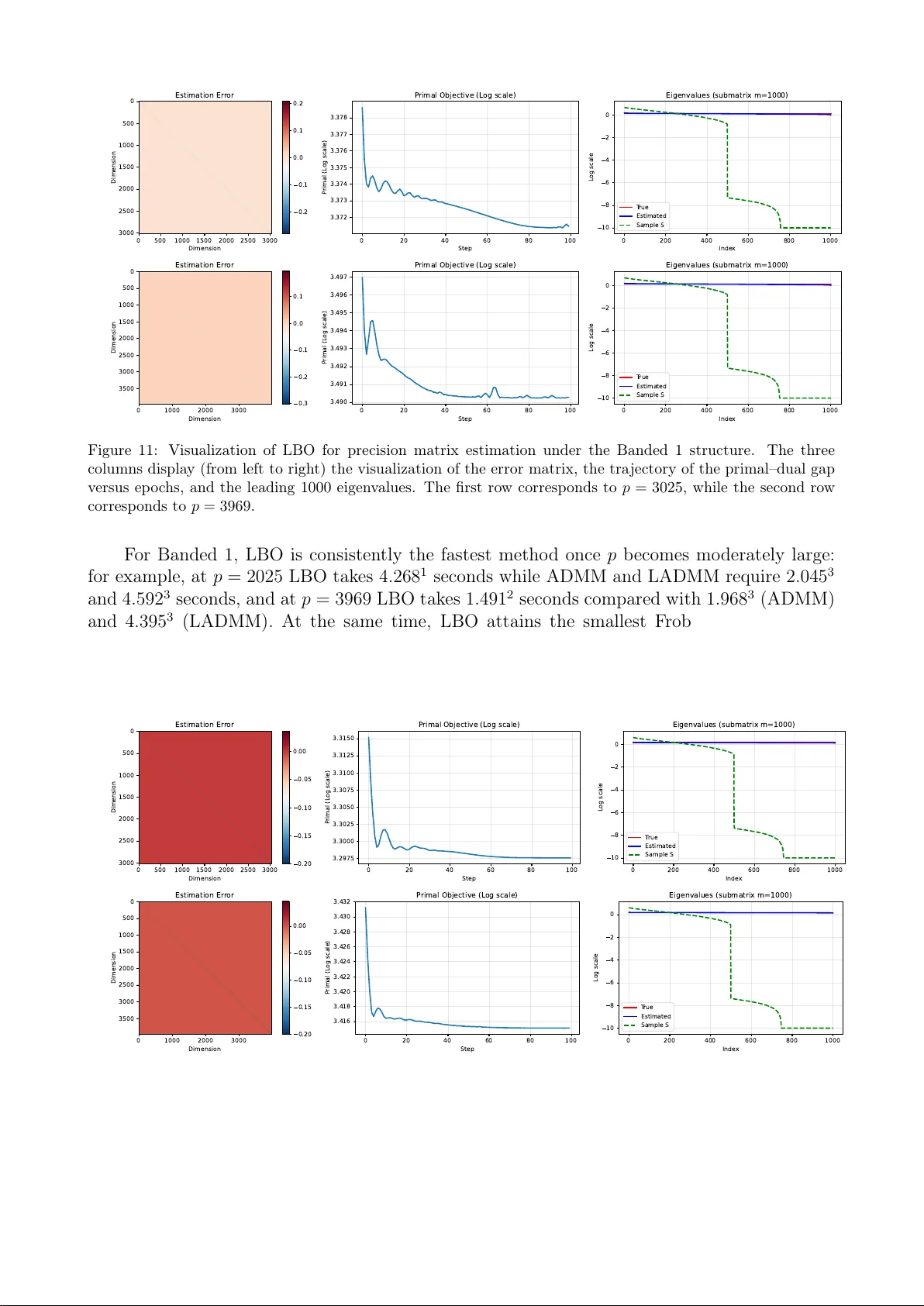
Mac hine Learning-Assisted High-Dimensional Matrix Estimation W an Tian a,b, ∗ , Hui Y ang f, ∗ , Zhouh ui Lian b , Lingyue Zhang c , Yijie P eng d,e,f, ∗∗ a A dvanc e d Institute of Information T e chnolo gy, Peking University b W angxuan Institute of Computer T e chnolo gy, Peking University, China, 100871 c Scho ol of Statistics, Dongb ei University of Financ e and Ec onomics, Dalian, China, 116025 d PKU-W uhan Institute for A rtificial Intel ligenc e e Xiangjiang L ab or atory, Changsha 410000, China f Guanghua Scho ol of Management, Peking University, Beijing, China, 100871 Abstract Efficien t estimation of high-dimensional matrices—including co v ariance and precision matri- ces—is a cornerstone of mo dern m ultiv ariate statistics. Most existing studies ha ve fo cused primarily on the theoretical properties of the estimators (e.g., consistency and sparsit y), while largely o verlooking the computational challenges inherent in high-dimensional settings. Moti- v ated b y recen t adv ances in learning-based optimization metho ds—which in tegrate data-driv en structures with classical optimization algorithms—we explore high-dimensional matrix estima- tion assisted b y machine learning. Sp ecifically , for the optimization problem of high-dimensional matrix estimation, w e first present a solution pro cedure based on the Linearized Alternating Direction Metho d of Multipliers (LADMM). W e then in tro duce learnable parameters and mo del the pro ximal op erators in the iterative scheme with neural netw orks, thereby improving esti- mation accuracy and accelerating conv ergence. Theoretically , we first pro ve the con vergence of LADMM, and then establish the con vergence, con vergence rate, and monotonicit y of its reparameterized coun terpart; imp ortan tly , we show that the reparameterized LADMM enjo ys a faster con vergence rate. Notably , the prop osed reparameterization theory and metho dology are applicable to the estimation of b oth high-dimensional co v ariance and precision matrices. W e v alidate the effectiveness of our method by comparing it with sev eral classical optimization algorithms across differen t structures and dimensions of high-dimensional matrices. Keywor ds: ADMM; High-dimensional; Learning-based optimization; Matrix estimation. 1. In tro duction High-dimensional matrix estimation—co vering b oth cov ariance and precision matrix es- timation—constitutes a cornerstone of mo dern statistics and data science [ 1 , 2 , 3 ]. A ccurate co v ariance estimation enables the c haracterization of dependence structures among a large n umber of v ariables [ 4 , 5 , 6 ], whic h is indisp ensable in div erse domains suc h as genomics [ 7 , 8 ], neuroscience [ 9 ], finance [ 10 , 11 , 12 ], and climate science [ 13 , 14 ]. Precision matrix estima- tion—often in terpreted as the learning of sparse graphical mo dels—sheds ligh t on conditional dep endencies and enables net work inference in complex systems [ 1 , 15 , 16 , 17 ], with significan t applications in brain connectivit y analysis [ 18 ], gene regulatory net w ork reconstruction [ 19 ], and ∗ Equal contribution ∗∗ Corresp onding author Email addr esses: wantian61@foxmail.com (W an Tian), yanghui6@stu.pku.edu.cn (Hui Y ang), lianzhouhui@pku.edu.cn (Zhouhui Lian), lingyue_zhang@126.com (Lingyue Zhang), pengyijie@pku.edu.cn (Yijie P eng) spatio-temp oral mo deling [ 20 ]. Consequently , accurate estimation of high-dimensional matrices is of fundamen tal imp ortance from b oth statistical and optimization p ersp ectives. Ov er the past tw o decades, substan tial progress has b een made in the statistical theory of high-dimensional matrix estimation, particularly with resp ect to the accuracy of estimators, including prop erties suc h as sparsistency and consistency [ 5 , 15 , 16 ]. These theoretical results are t ypically deriv ed under asymptotic regimes in which the dimensionalit y is assumed to grow large, ev en approaching infinit y . Ho wev er, in empirical studies, the dimensionalit y is often only on the order of tens to hundreds, and in many cases is comparable to the sample size [ 21 , 22 , 23 , 24 ]. This observ ation highlights a notable gap b et ween the statistical theory of estimators and the practical c hallenges of their computational implemen tation. F or the computation of high-dimensional cov ariance matrices, existing solution metho ds are primarily developed within the conv ex optimization framework. Among them, the ADMM is the most widely used [ 25 , 26 , 27 ]. By introducing an auxiliary v ariable, ADMM decouples the quadratic term from the non-smo oth ℓ 1 -p enalt y and lev erages proximal operators—such as soft-thresholding and eigen v alue pro jection—to ac hiev e efficien t iterations. This mak es it particularly suitable for medium- to high-dimensional settings; how ev er, the O ( p 3 ) complexit y of the eigen-decomp osition required at eac h iteration p oses a ma jor computational b ottleneck in ultra-high-dimensional regimes, where p denotes the matrix dimension. Other classical ap- proac hes include proximal gradien t descen t [ 28 , 29 ] and its accelerated v arian t, FIST A [ 30 ]. The former applies proximal op erators directly to handle the ℓ 1 -p enalt y and pro jection con- strain ts, offering a simple and easy-to-implement scheme but with relativ ely slo w con vergence. The latter improv es the con vergence rate from O (1 /k ) to O (1 /k 2 ) b y incorp orating Nestero v’s momen tum mec hanism, making it b etter suited for low-dimensional problems or rapid proto- t yping, where k denotes the iteration num b er. In addition, blo c k coordinate descen t [ 31 , 32 ] metho ds are effective for structured matrices, as they reduce computational burden b y opti- mizing o ver matrix blo cks. Semidefinite programming (SDP)-based approac hes, on the other hand, employ in terior-p oin t solv ers to obtain highly accurate solutions but require prohibitively large memory , thus limiting their use to low-dimensional settings [ 33 ]. F or the estimation of high-dimensional precision matrices, existing optimization metho ds are also primarily grounded in con v ex optimization tec hniques. Among them, the Graphi- cal Lasso (GLasso) [ 34 ] represen ts a pioneering approac h, ac hieving efficien t estimation b y iterativ ely solving row- or column-wise lasso [ 35 ] subproblems. While well-suited for mo derate- dimensional matrices, its O ( p 3 ) computational complexity limits its applicabilit y in u ltra-high- dimensional settings. T o ov ercome this limitation, v ariants of ADMM hav e b een widely adopted [ 36 , 37 , 38 , 39 ]. By in tro ducing auxiliary v ariables, these metho ds decouple the − log det term from the non-smo oth ℓ 1 -p enalt y , solving subproblems via pro ximal op erators, and can further accelerate conv ergence through linearization of the quadratic term and the addition of proxi- mal terms. The QUIC (Quadratic Inv erse Co v ariance) algorithm [ 40 , 41 ], based on a quadratic appro ximation within a Newton-type metho d, achiev es p erformance sev eral times faster than standard GLasso while remaining memory-efficient. Mean while, the Dual-Primal Graphical Lasso (DP-GLASSO) [ 42 ] lev erages a primal-dual framework to reduce the n umber of itera- tions and supp orts parallel computation. It is th us eviden t that these metho ds, developed within the con vex optimization frame- w ork, exhibit inheren t limitations in terms of scalabilit y and adaptabilit y to the data. Ev en algorithms suc h as QUIC, which outp erform the standard GLasso in computational efficiency , remain sensitiv e to the choice of regularization parameters, particularly when the matrix is near-singular. Moreo ver, QUIC has limited capacity to exploit the statistical properties of the data for adaptiv ely guiding the optimization path. Of course, in communities such as statistics and mac hine learning, researc hers often design task-sp ecific loss functions and estimate param- eters based on carefully crafted optimization strategies. Ho w ever, these approac hes ma y also 2 encoun ter similar computational challenges [ 43 ]. T o alleviate computational c hallenges, the framew ork of learning-based optimization (LBO) has b een prop osed, whic h com bines data-driv en learning with traditional optimization algo- rithms. The key idea of LBO is to reparameterize certain op erators within the optimization algorithm and in tro duce learnable parameters to enhance optimization p erformance [ 44 , 45 , 46 ]. Motiv ated by the success of deep learning across v arious applications, many studies hav e em- plo yed deep neural net works (DNNs) as the learning units to reparameterize the optimization pro cess [ 47 , 48 , 49 , 50 , 51 , 52 ]. F or example, Li et al. [ 47 ] and Y ang et al. [ 49 ] resp ectively de- v elop ed primal–dual hy brid gradient (PDHG)-based computational pro cedures for large-scale linear programming (in sup ervised learning settings) and quadratic programming (in unsup er- vised learning settings), in tro duced learnable parameters, and emplo yed graph neural net works to represen t the iterative pro cess. They further provided theoretical guaran tees on the num- b er of neurons required to achiev e a given accuracy . Similarly , Xie et al. [ 43 ] first deriv ed the iterative sc heme for linearly constrained conv ex optimization based on LADMM and then reparameterized the computation using neural netw orks. Notably , they were the first to theoret- ically demonstrate that such reparameterization can accelerate the con vergence rate. How ev er, these approac hes hav e not b een effectiv ely applied to high-dimensional matrix estimation. In this pap er, w e introduce LBO into the problem of high-dimensional matrix estimation to enhance b oth estimation accuracy and scalability . Sp ecifically , w e first deriv e an iterativ e sc heme based on LADMM, then in tro duce learnable parameters and reparameterize the pro xi- mal operators within the iterations using neural net works. This framework is applicable to b oth high-dimensional co v ariance and precision matrix estimation. Theoretically , we first establish the con vergence of LADMM; for the reparameterized LADMM, w e further pro ve con v ergence, an explicit con vergence rate, and a monotone descen t property . Importantly , w e show that the reparameterized v arian t achiev es a strictly faster rate. In the empirical analysis, we compare the prop osed method with several classical approaches for high-dimensional matrix estima- tion across matrices of div erse structures and dimensions, in order to demonstrate its sup erior p erformance. The remainder of this pap er is organized as follows. Section 2 and Section 3 discuss ho w to p erform high-dimensional cov ariance and precision matrix estimation within the prop osed LBO framew ork, resp ectively . Section 4 presents a theoretical analysis of LADMM and the prop osed LBO metho d. Section 5 rep orts numerical exp erimen ts that v alidate the effectiveness of our approac h. Finally , Section 6 concludes the pap er. 2. High-dimensional co v ariance matrix estimation In this section, we sho w how to leverage LBO to facilitate the estimation of high-dimensional co v ariance matrices. Sp ecifically , w e first formulate the original optimization problem and de- scrib e its ADMM and LADMM solution pro cedures. W e then in tro duce learnable parameters and reparameterize the pro ximal op erators via neural netw orks, and presen t the resulting iter- ativ e scheme. The estimation of a high-dimensional cov ariance matrix Σ = ( σ ij ) 1 ≤ i,j ≤ p can b e pursued via a v ariet y of metho ds, among whic h a particularly influential one is the soft-thresholding estimator [ 53 ]. By shrinking small off-diagonal en tries of the sample co v ariance tow ard zero, it yields a sparse and interpretable estimator that is computationally scalable and, under stan- dard sparsit y assumptions, comes with strong theoretical guaran tees (e.g., rate-optimalit y and consistency). In this pap er, w e adopt the soft-thresholding estimator as the ob jective of our optimization framew ork. This estimator is equiv alent to the follo wing optimization problem: min Σ 1 2 ∥ Σ − S ∥ 2 F + λ ∥ Σ ∥ 1 , off , 3 where S ∈ R p × p is the empirical co v ariance matrix computed from an observ ation matrix with n samples and p features, ∥ · ∥ F denotes the F rob enius norm of the matrix, and λ is the regularization parameter for promoting sparsit y in the estimation, and ∥ Σ ∥ 1 , off := P i = j | σ ij | . Ho wev er, the p ositive definiteness of the co v ariance matrix estimated based on this optimization problem is only guaranteed with high probability in an asymptotic setting, and it ma y not hold in real-world scenarios. F ollowing Xue et al. [ 54 ], we imp ose a p ositiv e definite constraint on the soft-thresholding optimization problem, formalized as: min Σ ⪰ ϵI 1 2 ∥ Σ − S ∥ 2 F + λ ∥ Σ ∥ 1 , off , (1) where ϵ is an arbitrarily small p ositive num b er that does not require tuning, and I ∈ R p × p denotes the iden tity matrix. Prior to describing the LADMM solution for optimization problem ( 1 ), w e first review the ADMM-based solution pro cedure. T o apply ADMM, we introduce an auxiliary v ariable W and rewrite problem ( 1 ) as min Σ , W 1 2 ∥ Σ − S ∥ 2 F + λ ∥ W ∥ 1 , off + I { Σ ⪰ ϵI } (Σ) s.t. Σ = W, where I { Σ ⪰ ϵI } is the indicator that equals 0 if Σ ⪰ ϵI and + ∞ otherwise. Introducing a dual v ariable (Lagrange m ultiplier) Λ ∈ R p × p and a p enalty parameter ρ > 0 , the augmented Lagrangian for the split form ulation is L ρ (Σ , W , Λ) = 1 2 ∥ Σ − S ∥ 2 F + λ ∥ W ∥ 1 , off + I { Σ ⪰ ϵI } (Σ) + ⟨ Λ , Σ − W ⟩ + ρ 2 ∥ Σ − W ∥ 2 F , (2) where ⟨ A, B ⟩ = T r( A ⊤ B ) denotes the F rob enius inner pro duct. ADMM then alternates b e- t ween minimizing L ρ with resp ect to Σ and W , follo wed by a dual ascen t step on Λ . This splitting decouples the smo oth quadratic fit, the non-smo oth off-diagonal ℓ 1 -p enalt y , and the PSD constrain t; in particular, the W -up date reduces to off-diagonal soft-thresholding, while the Σ -up date enforces Σ ⪰ ϵI . Giv en the iterates Σ ( k ) , W ( k ) , and Λ ( k ) at iteration k , the ( k + 1) -st up date pro ceeds as follo ws. The Σ -up date is obtained b y solving Σ ( k +1) = arg min Σ ⪰ ϵI 1 2 ∥ Σ − S ∥ 2 F + ⟨ Λ ( k ) , Σ ⟩ + ρ 2 ∥ Σ − W ( k ) ∥ 2 F , (3) whic h is a conv ex quadratic problem with a p ositiv e–semidefinite (PSD) constraint. Completing the square sho ws that ( 3 ) is equiv alent (up to an additiv e constan t) to Σ ( k +1) = arg min Σ ⪰ ϵI 1 + ρ 2 Σ − Σ ( k +1) 2 F , Σ ( k +1) = S + ρW ( k ) − Λ ( k ) 1 + ρ . Hence, Σ ( k +1) is the pro jection of Σ ( k +1) on to the conv ex cone { Σ ⪰ ϵI } . Let the eigendecom- p osition of Σ ( k +1) b e Σ ( k +1) = Q diag ( λ 1 , . . . , λ p ) Q ⊤ . The PSD pro jection with eigen v alue floor ϵ yields Σ ( k +1) = Q diag max { λ 1 , ϵ } , . . . , max { λ p , ϵ } Q ⊤ . W e next up date the auxiliary v ariable W by solving W ( k +1) = arg min W λ ∥ W ∥ 1 , off − ⟨ Λ ( k ) , W ⟩ + ρ 2 ∥ Σ ( k +1) − W ∥ 2 F , (4) 4 whic h, after completing the square, is equiv alent (up to an additiv e constan t) to W ( k +1) = arg min W λ ∥ W ∥ 1 , off + ρ 2 W − B ( k ) 2 F , B ( k ) := Σ ( k +1) + 1 ρ Λ ( k ) . This subproblem decouples elemen twise and admits the pro ximal (soft–thresholding) solution on the off–diagonals: W ( k +1) ij = ( sgn B ( k ) ij max( | B ( k ) ij | − λ/ρ, 0 , i = j , B ( k ) ii , i = j , i.e., W ( k +1) = S off λ/ρ B ( k ) where S off λ/ρ applies element wise soft–thresholding with threshold λ/ρ to the off–diagonal en tries and leav es the diagonal unc hanged. Finally , the dual v ariable is up dated b y Λ ( k +1) = Λ ( k ) + ρ Σ ( k +1) − W ( k +1) . (5) The core idea of LADMM is to linearize the quadratic terms in the cov ariance matrix esti- mation step ( 3 ) and the auxiliary v ariable estimation step ( 4 ) of ADMM, and to add pro ximal terms to ensure con vergence. The augmented Lagrangian ( 2 ) can b e equiv alen tly written as: L ρ (Σ , W, Λ) = 1 2 ∥ Σ − S ∥ 2 F + λ ∥ W ∥ 1 , off + I { Σ ⪰ ϵI } (Σ) + ρ 2 ∥ Σ − W + Λ /ρ ∥ 2 F . (6) A t this stage, the up date of the cov ariance matrix Σ is approximated b y solving the follo wing optimization problem: Σ ( k +1) = arg min Σ ⪰ ϵI 1 2 ∥ Σ − S ∥ 2 F + ⟨ ρ (Σ ( k ) − W ( k ) + Λ ( k ) /ρ ) , Σ − Σ ( k ) ⟩ + ρϕ 1 2 ∥ Σ − Σ ( k ) ∥ 2 F (7) = arg min Σ ⪰ ϵI 1 2 ∥ Σ − S ∥ 2 F + ρϕ 1 2 ∥ Σ − Σ ( k ) ∥ 2 F (8) = pro x f / ( ρϕ 1 ) Σ ( k ) , (9) where f (Σ) = 1 2 ∥ Σ − S ∥ 2 F + I { Σ ⪰ ϵI } (Σ) , Σ ( k ) = (( ϕ 1 − 1)Σ ( k ) + W ( k ) − Λ ( k ) /ρ ) /ϕ 1 . Analogously , the auxiliary v ariable W is up dated b y solving the following appro ximate optimization problem: W ( k +1) = arg min W λ ∥ W ∥ 1 + ⟨ ρ ( W ( k ) − Σ ( k +1) − Λ ( k ) /ρ ) , W − W ( k ) ⟩ + ρϕ 2 2 ∥ W − W ( k ) ∥ 2 F (10) = pro x λ/ ( ρϕ 2 ) ∥·∥ 1 ( W ( k ) ) , (11) where W ( k ) = (( ϕ 2 − 1) W ( k ) + Σ ( k +1) + Λ ( k ) /ρ ) /ϕ 2 . The appropriate c hoices of ϕ 1 and ϕ 2 will b e discussed later. A ccording to the preceding discussion, the iterative pro cedure for solving the optimization problem ( 1 ) using LADMM is as follo ws: Σ ( k +1) = pro x f / ( ρϕ 1 ) Σ ( k ) + 1 ϕ 1 ( W ( k ) − Λ ( k ) /ρ − Σ ( k ) ) , W ( k +1) = pro x λ/ ( ρϕ 2 ) ∥·∥ 1 W ( k ) + 1 ϕ 2 (Σ ( k +1) + Λ ( k ) /ρ − W ( k ) ) , Λ ( k +1) = Λ ( k ) + ρ (Σ ( k +1) − W ( k +1) ) . (12) Compared with standard ADMM, LADMM replaces the quadratic p enalties in the Σ - and W -subproblems with first–order (linearized) approximations around the current iterate and 5 adds pro ximal (quadratic) stabilization terms. This yields cheaper p er–iteration up dates, im- pro ves numerical stability , and— with appropriate choices of the pro ximal parameters—retains global conv ergence with faster practical progress. Using the scaled form of the dual v ariable, the augmen ted Lagrangian in ( 2 ) can b e equiv alen tly written as L ρ (Σ , W, Λ) = 1 2 ∥ Σ − S ∥ 2 F + λ ∥ W ∥ 1 , off + I { Σ ⪰ ϵI } (Σ) + ρ 2 Σ − W + Λ /ρ 2 F . (13) (Linearized Σ -up date). A t iteration k , linearize the quadratic term in Σ at Σ ( k ) and add a pro ximal term with parameter ϕ 1 > 0 : Σ ( k +1) = arg min Σ ⪰ ϵI 1 2 ∥ Σ − S ∥ 2 F + ρ Σ ( k ) − W ( k ) + Λ ( k ) /ρ , Σ − Σ ( k ) + ρϕ 1 2 ∥ Σ − Σ ( k ) ∥ 2 F = arg min Σ ⪰ ϵI 1 2 ∥ Σ − S ∥ 2 F + ρϕ 1 2 Σ − Σ ( k ) 2 F = prox f / ( ρϕ 1 ) Σ ( k ) , where f (Σ) = 1 2 ∥ Σ − S ∥ 2 F + I { Σ ⪰ ϵI } (Σ) and Σ ( k ) = Σ ( k ) − 1 ϕ 1 Σ ( k ) − W ( k ) + Λ ( k ) /ρ = ( ϕ 1 − 1)Σ ( k ) + W ( k ) − Λ ( k ) /ρ ϕ 1 . (Linearized W -up date). Analogously , linearize the quadratic term in W at W ( k ) and add a pro ximal term with parameter ϕ 2 > 0 : W ( k +1) = arg min W λ ∥ W ∥ 1 , off + ρ W ( k ) − Σ ( k +1) − Λ ( k ) /ρ , W − W ( k ) + ρϕ 2 2 ∥ W − W ( k ) ∥ 2 F = pro x ( λ/ ( ρϕ 2 )) ∥·∥ 1 , off W ( k ) , W ( k ) = W ( k ) − 1 ϕ 2 W ( k ) − Σ ( k +1) − Λ ( k ) /ρ = ( ϕ 2 − 1) W ( k ) + Σ ( k +1) + Λ ( k ) /ρ ϕ 2 . (Scaled dual up date). The (scaled) dual v ariable is then up dated b y Λ ( k +1) = Λ ( k ) + ρ Σ ( k +1) − W ( k +1) . Collecting the ab o ve steps, the LADMM scheme for ( 1 ) is Σ ( k +1) = pro x f / ( ρϕ 1 ) Σ ( k ) + 1 ϕ 1 W ( k ) − Λ ( k ) /ρ − Σ ( k ) , W ( k +1) = pro x ( λ/ ( ρϕ 2 )) ∥·∥ 1 , off W ( k ) + 1 ϕ 2 Σ ( k +1) + Λ ( k ) /ρ − W ( k ) , Λ ( k +1) = Λ ( k ) + ρ Σ ( k +1) − W ( k +1) . (14) Here pro x uφ ( V ) := arg min U { φ ( U ) + 1 2 u ∥ U − V ∥ 2 F } denotes the pro ximal op erator. LBO augments mo del–based iterative solvers with data–driven comp onen ts, yielding up- dates that (i) adapt to the target problem family , (ii) amortize computation across instances once trained, and (iii) accelerate con vergence while preserving the algorithmic structure and constrain ts. Motiv ated b y these adv antages—and b y the theoretically and empirically supe- rior conv ergence b ehavior of LADMM o ver ADMM—w e endo w the LADMM iteration in ( 14 ) with learnable, stage–wise parameters and reparameterize each up date as a neural blo ck. The resulting unrolled arc hitecture main tains the interpretabilit y and constrain t handling of the original metho d while enabling task-sp ecific adaptation and improv ed practical p erformance. 6 Concretely , for k = 0 , . . . , K − 1 , we set Σ ( k +1) = η ( ω 1 ) k Σ ( k ) − α k ⊙ Λ ( k ) + γ k ⊙ Σ ( k ) − W ( k ) , W ( k +1) = ξ ( ω 2 ) k W ( k ) + β k ⊙ Λ ( k ) + γ k ⊙ Σ ( k +1) − W ( k ) , Λ ( k +1) = Λ ( k ) + γ k ⊙ Σ ( k +1) − W ( k +1) , (15) where ⊙ denotes the Hadamard (elemen twise) pro duct. The collection { ( ω 1 ) k , ( ω 2 ) k , α k , β k , γ k } K k =1 comprises the learnable parameters: α k , β k , γ k are (scalar, diagonal, or entrywise) step–size/p enalt y sc hedules, while η ( ω 1 ) k and ξ ( ω 2 ) k are neural net work blo c ks that act as learned proximal op era- tors (mapping symmetric matrices to symmetric matrices and preserving the required structural constrain ts suc h as PSD enforcemen t or diagonal handling). Once trained, the unrolled K -block net work implemen ts an LBO solver that retains interpretabilit y and structure while ac hieving impro ved practical accuracy and conv ergence sp eed. Setting η ( ω 1 ) k = prox f / ( ρϕ 1 ) , ξ ( ω 2 ) k = prox ( λ/ ( ρϕ 2 )) ∥·∥ 1 , off , α k = 1 ϕ 1 , β k = 1 ϕ 2 , and γ k ≡ 1 reduces ( 15 ) to the classical LADMM iteration ( 14 ). Under learning, these components b ecome data–adaptive while preserving the interpretabilit y and feasibilit y constraints of the mo del–based solv er. F urthermore, as ( 1 ) is an unsup ervised optimization problem, and the iterativ e pro cedure in ( 15 ) requires parameter up dates via error bac kpropagation, w e must define an optimization ob jectiv e. The primal problem is min Σ f 1 (Σ) = 1 2 ∥ Σ − S ∥ 2 F + λ ∥ Σ ∥ 1 , off , with the corresp onding dual max Λ d 1 (Λ) = −⟨ Λ , S ⟩ − 1 2 ∥ Λ ∥ 2 F . In the experiments, w e emplo y the duality gap f 1 (Σ) − d 1 (Λ) as the p er-iteration loss to up date the blo ck neural net work. Assuming the final estimated co v ariance matrix is b Σ and the dual m ultiplier matrix is b Λ , 3. High-dimensional precision matrix estimation In this section w e consider high-dimensional precision–matrix estimation within the LBO framew ork. As our optimization target w e adopt the graphical Lasso [ 34 ], which solves min Θ ⪰ ϵI T r( S Θ) − log det(Θ) + λ ∥ Θ ∥ 1 , off . (16) This choice offers several adv antages: (i) the ob jectiv e is conv ex with an explicit PSD con- strain t, so a global minimizer exists and can b e found reliably; (ii) the off–diagonal ℓ 1 -p enalt y induces sparsity in Θ , yielding an in terpretable conditional-independence graph; (iii) the prob- lem admits efficien t pro ximal/ADMM/LADMM updates (soft-thresholding on off-diagonals and PSD pro jection), making it well suited to unrolling and LBO; and (iv) it enjoys well-studied statistical guaran tees in the high-dimensional regime. Moreo ver, many p opular noncon v ex p enalties—suc h as SCAD [ 55 ] and MCP [ 56 ]—can b e handled via lo cal linear appro ximation (LLA) [ 57 ], whic h conv erts each LLA step in to a w eigh ted graphical-Lasso subproblem. Thus graphical Lasso serves as a unifying and computationally con venien t ob jectiv e for LBO-based precision estimation. Analogous to Section 2 , we first deriv e an ADMM scheme for solving the graphical Lasso in ( 16 ). Introducing an auxiliary v ariable Z and enforcing Θ = Z yields the equiv alen t split form ulation min Θ ⪰ ϵI , Z T r( S Θ) − log det(Θ) + λ ∥ Z ∥ 1 , off s.t. Θ = Z . 7 With a Lagrange m ultiplier U and p enalt y parameter ρ > 0 , the augmented Lagrangian is L ρ (Θ , Z , U ) = T r( S Θ) − log det(Θ) + λ ∥ Z ∥ 1 , off + ⟨ U, Θ − Z ⟩ + ρ 2 ∥ Θ − Z ∥ 2 F , where ⟨ A, B ⟩ = T r( A ⊤ B ) . A t iteration k , ADMM p erforms the up dates Θ ( k +1) = arg min Θ ⪰ ϵI T r( S Θ) − log det(Θ) + ρ 2 Θ − Z ( k ) + U ( k ) /ρ 2 F , Z ( k +1) = pro x λ ρ ∥·∥ 1 , off Θ ( k +1) + U ( k ) /ρ , U ( k +1) = U ( k ) + ρ Θ ( k +1) − Z ( k +1) . (17) The Z -up date is an off–diagonal soft–thresholding operator, while the Θ -up date is a conv ex subproblem that can b e solved efficiently via an eigendecomp osition-based pro ximal step and PSD enforcemen t Θ ⪰ ϵI . Next, w e derive the LADMM algorithm. By linearizing the quadratic term and adding a pro ximal term, we obtain the following appro ximation: Θ ( k +1) = arg min Θ ⪰ ϵI T r( S Θ) − log det Θ + ρ (Θ ( k ) − Z ( k ) ) + U ( k ) , Θ − Θ ( k ) + ρϕ 1 2 ∥ Θ − Θ ( k ) ∥ 2 F = arg min Θ ⪰ ϵI T r( S Θ) − log det Θ + ρϕ 1 2 ∥ Θ − Θ ( k ) ∥ 2 F = pro x g / ( ρϕ 1 ) (Θ ( k ) ) , where Θ ( k ) = Θ ( k ) − (Θ ( k ) − Z ( k ) + U ( k ) /ρ ) /ϕ 1 , g (Θ) = T r( S Θ) − log det Θ + I { Θ ⪰ ϵI } (Θ) . Anal- ogously , Z ( k +1) = arg min Z λ ∥ Z ∥ 1 , off + ρ ( Z ( k ) − Θ ( k +1) ) − U ( k ) , Z − Z ( k ) + ρϕ 2 2 ∥ Z − Z k ∥ 2 F , = pro x ( λ/ ( ρϕ 2 )) ∥·∥ 1, off ( V ( k ) ) , where V ( k ) = Z ( k ) − ( Z ( k ) − Θ ( k +1) − U ( k ) /ρ ) /ϕ 2 . Based on the preceding discussion, the LADMM-based iterative pro cedure for Optimization Problem ( 16 ) consists of the follo wing three steps: Θ ( k +1) = pro x g / ( ρϕ 1 ) Θ ( k ) − 1 ϕ 1 (Θ ( k ) − Z ( k ) + U ( k ) /ρ ) , Z ( k +1) = pro x ( λ/ ( ρϕ 2 )) ∥·∥ 1, off Z ( k ) − 1 ϕ 2 ( Z ( k ) − Θ ( k +1) − U ( k ) /ρ ) , U ( k +1) = U ( k ) + ρ (Θ ( k +1) − Z ( k +1) ) . (18) Next, w e deriv e a LADMM scheme. A t each iteration w e linearize the quadratic coupling term in the ADMM subproblems at the curren t iterate and add a proximal (quadratic) sta- bilization. This yields cheaper, single–matrix up dates while preserving global conv ergence for suitable c hoices of the proximal parameters ϕ 1 , ϕ 2 > 0 (typically ϕ i ≥ 1 ). (Linearized Θ -up date). Starting from the Θ -subproblem in ADMM, we linearize ρ 2 ∥ Θ − 8 Z ( k ) + U ( k ) /ρ ∥ 2 F at Θ ( k ) and add ρϕ 1 2 ∥ Θ − Θ ( k ) ∥ 2 F , whic h gives the surrogate Θ ( k +1) = arg min Θ ⪰ ϵI T r( S Θ) − log det(Θ) + ρ (Θ ( k ) − Z ( k ) ) + U ( k ) , Θ − Θ ( k ) + ρϕ 1 2 ∥ Θ − Θ ( k ) ∥ 2 F = arg min Θ ⪰ ϵI T r( S Θ) − log det(Θ) + ρϕ 1 2 Θ − Θ ( k ) 2 F = prox g / ( ρϕ 1 ) Θ ( k ) , where Θ ( k ) = Θ ( k ) − 1 ϕ 1 Θ ( k ) − Z ( k ) + U ( k ) /ρ , g (Θ) = T r( S Θ) − log det(Θ) + I { Θ ⪰ ϵI } (Θ) . The pro ximal map of g admits a closed form via eigendecomp osition: letting Θ ( k ) − 1 ρϕ 1 S = Q diag ( d i ) Q ⊤ , one obtains pro x g / ( ρϕ 1 ) Θ ( k ) = Q diag max d i + r d 2 i + 4 ρϕ 1 2 , ϵ Q ⊤ . (Linearized Z -update). Analogously , linearizing the quadratic term at Z ( k ) and adding ρϕ 2 2 ∥ Z − Z ( k ) ∥ 2 F yields Z ( k +1) = arg min Z λ ∥ Z ∥ 1 , off + ρ ( Z ( k ) − Θ ( k +1) ) − U ( k ) , Z − Z ( k ) + ρϕ 2 2 ∥ Z − Z ( k ) ∥ 2 F = pro x ( λ/ ( ρϕ 2 )) ∥·∥ 1 , off V ( k ) , where V ( k ) = Z ( k ) − 1 ϕ 2 Z ( k ) − Θ ( k +1) − U ( k ) /ρ , This pro ximal map is the off–diagonal soft–thresholding op erator with threshold λ/ ( ρϕ 2 ) , leav- ing the diagonal unc hanged. Collecting the up dates, the LADMM pro cedure for ( 16 ) reads Θ ( k +1) = pro x g / ( ρϕ 1 ) Θ ( k ) − 1 ϕ 1 Θ ( k ) − Z ( k ) + U ( k ) /ρ , Z ( k +1) = pro x ( λ/ ( ρϕ 2 )) ∥·∥ 1 , off Z ( k ) − 1 ϕ 2 Z ( k ) − Θ ( k +1) − U ( k ) /ρ , U ( k +1) = U ( k ) + ρ Θ ( k +1) − Z ( k +1) . (19) Cho osing ϕ 1 , ϕ 2 ≥ 1 ma jorizes the linearized quadratic terms, guarantees monotone descent of the augmen ted ob jective, and yields numerically stable, single–pass up dates well suited for unrolling within the LBO framew ork. Motiv ated by the LBO algorithm, w e in tro duce learnable, stage–wise parameters and replace the pro ximal op erators by neural blo c ks. The resulting K - stage unrolled sc heme takes the form Θ ( k +1) = η ( ω 1 ) k Θ ( k ) − α k ◦ U ( k ) + γ k ◦ (Θ ( k ) − Z ( k ) ) , Z ( k +1) = ξ ( ω 2 ) k Z ( k ) + β k ◦ U ( k ) + γ k ◦ (Θ ( k +1) − Z ( k ) ) , U ( k +1) = U ( k ) + γ k ◦ Θ ( k +1) − Z ( k +1) , (20) for k = 0 , . . . , K − 1 , where ◦ denotes th e Hadamard (element wise) pro duct. The parameter 9 set { ( ω 1 ) k , ( ω 2 ) k , α k , β k , γ k } K − 1 k =0 is learned from data: α k , β k , γ k ma y b e scalars, diagonal (pre- conditioning) matrices, or en trywise tensors, while η ( ω 1 ) k and ξ ( ω 2 ) k are neural blo c ks acting as learned proximal operators that map symmetric inputs to symmetric outputs (and, if desired, incorp orate PSD enforcemen t and diagonal handling). Consequen tly , the classical LADMM up dates are recov ered b y setting η ( ω 1 ) k = pro x g / ( ρϕ 1 ) , ξ ( ω 2 ) k = pro x ( λ/ ( ρϕ 2 )) ∥·∥ 1 , off , α k = 1 ϕ 1 , β k = 1 ϕ 2 , and γ k ≡ 1 . Under learning, these comp o- nen ts b ecome data–driven: they adapt to the target problem family and amortize computation across instances, while preserving the algorithmic structure and feasibility constraints of the mo del–based solv er. T o solve optimization problem ( 16 ) using the proposed LBO algorithm, w e need to define a corresp onding loss function. The primal problem is min Θ f 2 (Θ) = − log det(Θ) + T r( S Θ) + λ ∥ Θ ∥ 1 , off , with the corresp onding dual max Ξ d 2 (Ξ) = − log det( S − Ξ) − p , sub ject to | ξ ij | ≤ λ for i = j , where Ξ = ( ξ ij ) 1 ≤ i,j ≤ p is the dual v ariable. In the exp eriments, w e employ the dualit y gap f 2 (Θ) − d 2 (Ξ) as the p er-iteration loss to up date the parameters. 4. Theoretical Prop erties In this section, we first discuss the con v ergence of LADMM and the reparameterized LADMM algorithm (i.e., our prop osed metho d). W e then analyze the statistical optimization error b ound betw een the high-dimensional matrix estimator obtained from the optimization pro cedure and the true high-dimensional matrix. Moreov er, since the essence of the reparam- eterized LADMM lies in approximating the proximal operator, we further analyze its appro xi- mation prop erties. 4.1. Conver genc e pr op erties of algorithms In this section w e presen t con vergence guaran tees for both the classical LADMM and the prop osed reparameterized (learned) LADMM. W e first show that LADMM con v erges to a Karush-Kuhn-T uck er (KKT) p oint of the uni fied con vex formulation, and then establish that the reparameterized scheme also conv erges under mild conditions. Moreov er, w e argue that suitable choices of the learned parameters can yield a strictly faster con vergence rate, thereby demonstrating the p oten tial sup eriority of the reparameterized metho d. The co v ariance and precision problems in ( 1 ) and ( 16 ) can be written in the split form min X,Y F ( X ) + G ( Y ) , s.t. X = Y , (21) where X , Y ∈ R p × p and F , G are proper, closed, conv ex functions. Here I { Σ ⪰ ϵI } (Σ) denotes the indicator that equals 0 if Σ ⪰ ϵI and + ∞ otherwise. The sp ecific c hoices of F and G are as follo ws. F or co v ariance estimation ( 1 ) with ( X, Y ) = (Σ , W ) , F ( X ) = 1 2 ∥ X − S ∥ 2 F + I { X ⪰ ϵI } ( X ) , G ( Y ) = λ ∥ Y ∥ 1 , off . F or precision (graphical Lasso) ( 16 ) with ( X , Y ) = (Θ , Z ) , F ( X ) = T r( S X ) − log det( X ) + I { X ⪰ ϵI } ( X ) , G ( Y ) = λ ∥ Y ∥ 1 , off . The PSD indicator with flo or ϵ > 0 enforces feasibility and, in the precision case, ensures that − log det( X ) is well defined on the domain X ⪰ ϵI . Let V denote the Lagrange m ultiplier and 10 Figure 1: Overview of the prop osed LBO algorithm framework. The left panel illustrates the forward pro cess with total K iterations of the algorithm, while the righ t panel sho ws the target loss function which is used to up date learnable parameters. The op erators η k , ξ k are parameterized b y ( w 1 ) k , ( w 2 ) k , resp ectively . ρ > 0 the p enalt y parameter used in the augmen ted Lagrangian and LADMM up dates. A t this p oin t, for the optimization problem ( 21 ), its LADMM up date at iteration k is: X ( k +1) = pro x F / ( ρϕ 1 ) X ( k ) − 1 ϕ 1 X ( k ) − Y ( k ) + V ( k ) /ρ , Y ( k +1) = pro x G/ ( ρϕ 2 ) Y ( k ) − 1 ϕ 2 Y ( k ) − X ( k +1) − V ( k ) /ρ , V ( k +1) = V ( k ) + ρ X ( k +1) − Y ( k +1) , (22) where ϕ 1 , ϕ 2 > 0 . In tro ducing learnable, stage-wise parameters and replacing the pro ximal maps b y neural blo cks yields X ( k +1) = η ( w 1 ) k X ( k ) − α k ◦ V ( k ) + γ k ◦ ( X ( k ) − Y ( k ) ) , Y ( k +1) = ξ ( w 2 ) k Y ( k ) + β k ◦ V ( k ) + γ k ◦ ( X ( k +1) − Y ( k ) ) , V ( k +1) = V ( k ) + γ k ◦ X ( k +1) − Y ( k +1) , (23) where ◦ denotes the Hadamard pro duct; the step/p enalt y schedules α k , β k , γ k ma y b e scalars, diagonal preconditioners, or entrywise tensors; and η ( w 1 ) k , ξ ( w 2 ) k are symmetric-preserving neural blo c ks acting as learned proximal op erators. W e b egin b y presenting the conv ergence results of LADMM ( 22 ) for the unified optimiza- tion problem ( 21 ). Theorem 4.1 (Conv ergence of LADMM) . If ϕ 1 , ϕ 2 > 1 , then the se quenc e { X ( k ) , Y ( k ) , V ( k ) } gener ate d by ( 22 ) c onver ges to a KKT p oint of pr oblem ( 21 ) . The requirement ϕ 1 , ϕ 2 > 1 enforces a prop er ma jorization of the linearized quadratic terms, turning eac h subproblem in to a strongly conv ex proximal step and thereb y yielding a F ejér decrease with resp ect to the KKT set via the Ly apunov potential E k := ( ϕ 1 − 1) ∥ X ( k ) − X ∗ ∥ 2 + ∥ Y ( k ) − Y ∗ ∥ 2 + ρ − 2 ∥ V ( k ) − V ∗ ∥ 2 , for an y KKT p oint ( X ∗ , Y ∗ , V ∗ ) . In particular, the proof establishes E k +1 ≤ E k − ( ϕ 1 − 1) ∥ X ( k +1) − X ( k ) ∥ 2 − ( ϕ 2 − 1) ∥ Y ( k +1) − Y ( k ) ∥ 2 − ρ − 1 ( V ( k +1) − V ( k ) )+ Y ( k +1) − Y ( k ) 2 , 11 so that ∥ X ( k +1) − X ( k ) ∥ → 0 , ∥ Y ( k +1) − Y ( k ) ∥ → 0 , ∥ V ( k +1) − V ( k ) ∥ → 0 , and the whole sequence con verges to a KKT p oint of ( 21 ). One may initialize with ϕ i = 1 and emplo y a backtrac king rule that increases ϕ i on-the-fly until a prescrib ed ma jorization is met; this empirical v ariant often works w ell. The theorem states a simple sufficien t (not necessary) condition that cov ers b oth co v ariance and precision instances through the unified split form ( 21 ). W e then discuss the conv ergence prop erties of the re-parameterized LADMM. F or analysis w e consider the case where the learned blo cks b ehav e as w eighted pro ximal maps of F and G : η ( w 1 ) k = pro x ( w 1 ) k F ( M ) := arg min X n F ( X ) + 1 2 1 √ ( w 1 ) k ◦ ( X − M ) 2 F o , ξ ( w 2 ) k = pro x ( w 2 ) k G ( M ) := arg min Y n G ( Y ) + 1 2 1 √ ( w 2 ) k ◦ ( Y − M ) 2 F o . Cho ose ( w 1 ) k = α k , ( w 2 ) k = β k , and γ k = 1 /β k . Then ( 23 ) can be rewritten as X ( k +1) = arg min X F ( X ) + 1 2 1 √ α k ◦ X − X ( k ) + α k ◦ V ( k ) + 1 β k ◦ ( X ( k ) − Y ( k ) ) 2 F , Y ( k +1) = arg min Y G ( Y ) + 1 2 1 √ β k ◦ Y − X ( k +1) − β k ◦ V ( k ) 2 F , V ( k +1) = V ( k ) + 1 β k ◦ X ( k +1) − Y ( k +1) . (24) Before discu ssing the theoretical results of re-parameterized LADMM, we first introduce some basic notations. Let S := { ( α, β ) : 0 < α < β , α, β ∈ R p × p } , and denote ω k := ( X ( k ) , Y ( k ) , V ( k ) ) ⊤ . Let ω ∗ := ( X ∗ , Y ∗ , V ∗ ) ⊤ b e a KKT p oin t of ( 21 ), and let Ω ∗ b e the set of all suc h p oints. Define the blo ck-diagonal, entrywise positive operator H k ( ω ) := 1 α k − 1 β k ◦ X , 1 β k ◦ Y , β k ◦ V ⊤ , ϕ ( ω ) := ( V , − V , Y − X ) ⊤ . F or an y ω , set ∥ ω ∥ 2 H k := ⟨ ω , H k ( ω ) ⟩ . W e call H k ≻ 0 (p ositive definite) if ∥ ω ∥ 2 H k > 0 for all ω = 0 . The induced op erator norm is ∥ H k ∥ := sup ω =0 ∥ ω ∥ 2 H k / ∥ ω ∥ 2 F . Then the conv ergence theorem can b e established as follo ws. Theorem 4.2 (Conv ergence of re-parameterized LADMM) . Ther e exist p ar ameters ( α k , β k ) ∈ S such that the se quenc e { ω k } gener ate d by ( 24 ) c onver ges to a KKT p oint of ( 21 ) . The learned sc heme is analyzed under the variable-metric in terpretation: the neural blo cks act as weigh ted proximal operators and the parameters ( α k , β k ) ∈ S induce an iteration- dep enden t geometry . This connects the reparameterized LADMM to preconditioned op erator- splitting metho ds. The pro of pro cess of this theorem shows that, provided the v ariable met- ric remains p ositiv e definite (i.e., 0 < α k < β k ), and slowly v arying, i.e., ∥ H k +1 − H k ∥ ≤ O (1 / ( k + 1) 2 ) , the metho d inherits global con v ergence to a KKT p oint of ( 21 ). In practice, ev en more general nonexpansiv e/av eraged learned maps often work, but the proximal surrogate assumption yields clean guaran tees. Building on the ab ov e discussion, w e observe that the reparameterized sc heme subsumes LADMM as a sp ecial case and enables data-adaptiv e preconditioning through α k , β k , γ k together with learned proximal surrogates η and ξ . The metric H k formalizes the iteration-dep enden t geometry induced by these weigh ts. Theorems 4.3 and 4.4 establish monotonicity and con ver- gence rates for ( 24 ). Moreov er, Theorem 4.5 sho ws that, under mild regularit y and suitable parameter sc hedules, the metho d achiev es pro v ably faster progress than baseline LADMM. Define the distance to the solution set in the H k -metric b y dist H k ( ω , Ω ∗ ) := inf ω ∗ ∈ Ω ∗ ∥ ω − ω ∗ ∥ H k . Then w e can sho w the monotonicit y prop erty of ( 24 ). 12 Theorem 4.3 (Monotonicit y of re-parameterized LADMM) . Ther e exist p ar ameters ( α k , β k ) ∈ S such that the se quenc e { ω k } gener ate d by ( 24 ) satisfies that dist H k ( ω k , Ω ∗ ) is nonincr e asing for al l sufficiently lar ge k . The quantit y dist H k ( ω k , Ω ∗ ) pla ys the role of a Lyapuno v function in a time-varying metric H k . Monotonicit y "for sufficien tly large k " reflects that once the parameter sc hedule stabilizes (or v aries slowly), the iteration con tracts to ward Ω ∗ in the induced metric. This clarifies wh y gen tle parameter up dates (or piecewise-constan t schedules) are n umerically robust, and wh y aggressiv e, rapidly changing weigh ts can transien tly break monotonicit y . F or rate statements, define the up date op erator T ( α k , β k )( ω k ) = ω k +1 and assume ( α k , β k ) → ( α ∗ , β ∗ ) ∈ S . W e then ha ve the con v ergence rate of ( 24 ). Theorem 4.4 (Con vergence rate of re-parameterized LADMM) . L et { ω k } b e gener ate d by ( 24 ) . Supp ose that for al l sufficiently lar ge k , dist 2 H ∗ ( e ω k +1 , Ω ∗ ) ≤ ( κ/ 16) ∥ e ω k +1 − ω k ∥ 2 H ∗ , wher e H ∗ is define d by ( α ∗ , β ∗ ) and e ω k +1 := T ( α ∗ , β ∗ )( ω k ) . Then ther e exist p ar ameters ( α k , β k ) ∈ S such that dist 2 H k +1 ( ω k +1 , Ω ∗ ) ≤ γ dist 2 H k ( ω k , Ω ∗ ) with 0 < γ < 1 , i.e., the c onver genc e is (asymptotic al ly) line ar in the H k -metric. The assumed inequality with H ∗ is an err or-b ound / quadr atic-gr owth type condition near the solution set and is closely related to the Kurdyk a–Ło jasiewicz framew ork [ 58 ]. Under this lo cal regularit y and stabilization of ( α k , β k ) → ( α ∗ , β ∗ ) , the mapping becomes a contraction in the H ∗ -metric, giving (asymptotically) linear rate with factor γ ∈ (0 , 1) . In strongly con vex instances one can often promote the assumption globally; otherwise the result should b e read as a lo cal rate around Ω ∗ . Theorem 4.5 (Sup eriorit y of re-parameterized LADMM) . Assume ρ < 1 in ( 22 ) and that the le arne d blo cks η , ξ in ( 23 ) ar e bije ctive. Then for any ω k / ∈ Ω ∗ ∪ Ω 0 and any ω ∗ ∈ Ω ∗ , wher e Ω 0 is a me asur e-zer o set, ther e exist ( w 1 ) k , ( w 2 ) k , α k , β k , γ k such that b ω k +1 − ω ∗ F < e ω k +1 − ω ∗ F , wher e e ω k +1 and b ω k +1 ar e gener ate d by ( 22 ) and ( 23 ) , r esp e ctively. This result is one-step and existential : outside a measure-zero exceptional set, there exist learned parameters that reduce the next-iterate error more than classical LADMM. It formalizes the in tuition that adaptiv e preconditioning and learned pro ximal surrogates can accelerate progress. Ho wev er, it do es not assert uniform dominance for arbitrary learned parameters: p o orly trained blo cks ma y stagnate or div erge. The bijectivit y assumption ensures a well- defined, rev ersible lo cal mapping, while ρ < 1 aligns the comparison with a stable LADMM baseline. 4.2. Statistic al–optimization err or analysis In this part, we sequen tially analyze the statistical optimization errors of the high-dimensional co v ariance and precision matrix estimators. Before doing so, we in tro duce some necessary no- tations and preliminaries. Let e X 1 , e X 2 , . . . , e X n ∈ R p b e i.i.d. sub-Gaussian random vectors with mean zero and true co v ariance matrix Σ ⋆ = ( σ ⋆ ij ) 1 ≤ i,j ≤ p ∈ S p + , Θ ⋆ = ( θ ⋆ ij ) 1 ≤ i,j ≤ p = (Σ ⋆ ) − 1 denote the corresp onding true precision matrix, and let S = 1 n P n i =1 e X i e X ⊤ i b e the sample cov ariance. W e estimate Σ ⋆ b y solving the optimization problem ( 1 ), and let b Σ ⋆ ∈ arg min Σ ⪰ ϵI f 1 (Σ) . Con- sidering that we are estimating a high-dimensional matrix, we define A := { ( i, j ) : i = j, ; σ ⋆ ij = 0 } to b e the off-diagonal supp ort with size |A| . 13 W e know that Σ ( k ) is the iterate pro duced b y a reparameterized optimization pro cedure after k s teps. W e then separate the total error ∥ Σ ( k ) − Σ ⋆ ∥ F in to a statistical part (intrinsic) ∥ b Σ ⋆ − Σ ⋆ ∥ F and an optimization part (algorithmic) ∥ Σ ( k ) − b Σ ⋆ ∥ F . Define the optimization sub optimalit y as ε opt ( k ) := f 1 (Σ ( k ) ) − f 1 ( b Σ ⋆ ) ≥ 0 . Before presen ting a theoretical upper bound for the total error ∥ Σ ( k ) − Σ ⋆ ∥ F , we first in tro duce a basic assumption and some preliminary results. Assumption 1 (Co ordinate sub-Gaussianity [ 59 ]) . Ther e exists K < ∞ such that e ach c o or- dinate e X ij of e X i is sub-Gaussian with ψ 2 -Orlicz norm b ounde d by K , i.e. ∥ X i ∥ ψ 2 ≤ K for al l j = 1 , . . . , p . Theorem 4.6 (Entrywise concen tration) . Under Assumption 1 , ther e exist c onstants c 0 , C 0 > 0 (dep ending only on the sub-Gaussian p ar ameter K and absolute c onstants) such that Pr ∥ S − Σ ⋆ ∥ ∞ ≤ C 0 r log p n ! ≥ 1 − 2 p − c 0 . Theorem 4.7 (T otal error decomp osition and statistically optimal early stopping) . Under Assumption 1 , cho ose λ ≥ 2 ∥ S − Σ ⋆ ∥ ∞ . Then with pr ob ability at le ast 1 − 2 p − c 0 , ∥ Σ ( k ) − Σ ⋆ ∥ F ≤ q 2 ε opt ( k ) | {z } optimization + 4 p |A| λ + 4 ∥ (Σ ⋆ ) A c ∥ 1 / p |A| | {z } statistic al . (25) If we stop when ε opt ( k ) ≤ C 2 |A| log p n (for a universal C absorbing c onstants in λ ), then ∥ Σ ( k ) − Σ ⋆ ∥ F ≲ q |A| log p n + ∥ (Σ ⋆ ) A c ∥ 1 / p |A| , which is minimax-optimal up to c onstants for sp arse mo dels. Similarly , for high-dimensional precision matrix estimation, we hav e an analogous b ound on the total error. W e define ε GL opt ( k ) := f 2 (Θ ( k ) ) − f 2 ( b Θ ⋆ ) ≥ 0 . Theorem 4.8 (T otal error decomposition and statistically optimal early stopping) . Assume sub-Gaussian sampling so that, with pr ob ability at le ast 1 − 2 p − c 0 , ∥ S − Σ ⋆ ∥ ∞ ≤ C 0 q log p n . Cho ose λ ≥ 2 ∥ S − Σ ⋆ ∥ ∞ . Assume ther e exist 0 < ϵ ≤ M < ∞ such that ϵI ⪯ Θ ⋆ ⪯ M I and b oth b Θ ⋆ and Θ ( k ) lie in { Θ : ϵI ⪯ Θ ⪯ M I } . L et B = { ( i, j ) : i = j, θ ⋆ ij = 0 } with size |B | . Then, ∥ Θ ( k ) − Θ ⋆ ∥ F ≤ q 2 M 2 ε GL opt ( k ) | {z } optimization + M 2 3 λ p |B | + 4 ∥ (Θ ⋆ ) B c ∥ 1 / p |B | | {z } statistical . If we stop when ε GL opt ( T ) ≲ |B | log p n and take λ ≍ q log p n , then ∥ Θ ( k ) − Θ ⋆ ∥ F ≲ M 2 q |B | log p n + M 2 ∥ (Θ ⋆ ) B c ∥ 1 / p |B | . 4.3. Appr oximation analysis of pr oximal op er ators In this section, we discuss the approximation prop erty of parameterized neural netw orks η , ζ . W e consider the case where η , ζ are parameterized b y narrow one-hidden-la y er ReLU net works. W e first analyze the prop ert y of target proximal op erators. 14 Prop osition 4.1. Supp ose that F : R p × p → R p × p is a pr op er, close d, c onvex function and w ∈ R p × p satisfies that c 1 ≤ w i,j ≤ c 2 , ∀ 1 ≤ i, j ≤ p , wher e c 1 , c 2 ar e c onstants which may dep end on α ∗ , β ∗ . Then pro x w,F is Lipschitz c ontinuous with pro x w,F ( M 1 ) − prox w,F ( M 2 ) F ≤ r c 2 c 1 ∥ M 1 − M 2 ∥ F , ∀ M 1 , M 2 ∈ R p × p . Based on the ab ov e result, we conclude that pro x w,F can b e approximated b y single lay er ReLU net work with the approximation rate of O ( d − 1 p 2 ) , where d is the n umber of neurons. Theorem 4.9. Under the same c onditions of Pr op osition 4.1 , ther e exists a single layer network N N : R p 2 → R p 2 that exhibits the form N N ( x ) = W ⊤ 2 σ W ⊤ 1 x + b 1 + b 2 , such that sup ∥ X ∥ 2 ≤ M ∥N N (v ec( X )) − v ec(prox ω ,F ( X )) ∥ F ≤ C ( p, M ) r c 2 c 1 log( d ) d 1 /p 2 . (26) Her e W 1 ∈ R d × p 2 , b 1 ∈ R d , W 2 ∈ R p 2 × d , b 2 ∈ R p 2 , σ ( · ) = ( · ) + is R eLU and the op er ator vec( · ) maps a matrix to a ve ctor by stacking its c olumns. 5. Sim ulation Studies In this section, we apply the prop osed LBO algorithm to high-dimensional matrix estima- tion problems with div erse structures and compare it against a wide arra y of existing metho ds to v alidate its sup erior p erformance. As w e aim to compare computational times and the reliabil- it y of results across these metho ds, it is essen tial to first rep ort the computational environmen t. All exp eriments were conducted on a workstation running Ubun tu 22.04.2 L TS (Lin ux kernel 5.15, x86_64). The machine is equipp ed with dual In tel Haswell pro cessors (4 logical CPUs), 19 GB RAM, and 2 GB sw ap space. W e used a single NVIDIA GeF orce R TX 3090 GPU (24 GB memory) with driv er v ersion 550.163.01 and CUDA 12.4. The soft ware environmen t is based on Python 3.10. 5.1. High-dimensional c ovarianc e matrix Our ob jective is to estimate the co v ariance matrix Σ ⋆ = ( σ ⋆ ij ) 1 ≤ i,j ≤ p based on an observ a- tion matrix with n samples and p features sampled from the m ultiv ariate normal distribution N (0 , Σ ⋆ ) . In this section, w e consider four distinct represen tative structures for the co v ariance matrix. The first structure considered is the T o eplitz cov ariance matrix, defined as σ ⋆ ij = ϱ | i − j | , for i, j = 1 , . . . , p , where | ϱ | < 1 . Here, ϱ represen ts the correlation decay co efficient, with larger v alues corresp onding to stronger long-range dep endencies. W e examine the follo wing v alues of ϱ : 0.1, 0.3, 0.5, 0.7, and 0.9. Figure 2 illustrates visualizations of the T oeplitz co v ariance matrices for p = 50 under v arious v alues of ρ . 15 % = 0 . 1 % = 0 . 3 % = 0 . 5 % = 0 . 7 % = 0 . 9 -1.0 -0.5 0.0 0.5 1.0 Figure 2: T o eplitz cov ariance matrices under different correlation decay co efficien ts ϱ . The second structure is the factor mo del (lo w-rank plus diagonal noise), in whic h the factor loading matrix B ∈ R p × m is first generated entrywise indep endently from N (0 , σ B ) , and the co v ariance matrix is then defined as d = B B ⊤ + σ N I , where m denotes the n umber of factors satisfying 1 ≤ m ≪ p , which controls the dimensionalit y of the low-rank comp onent; √ σ N is the noise standard deviation, go verning the strength of the diagonal noise; and σ B scales the magnitude of B , thereby determining the signal-to-noise ratio. In essence, larger v alues of m and σ B yield more prominent principal comp onents and a sharp er sp ectrum for Σ ⋆ . In the exp eriments, w e fix the factor strength σ B = 1 and the noise v ariance σ N = 0 . 04 , while v arying the n umber of factors m to tak e v alues 3, 5, 7, 9, and 10. Figure 3 illustrates visualizations of the cov ariance matrices for dimension p = 50 under differen t num b ers of factors. m = 3 m = 5 m = 7 m = 9 m = 1 0 -20 -10 0 10 20 Figure 3: F actor model under different num b ers of low-rank components m . The third structure is the sparse cov ariance matrix, c haracterized by random sparse off- diagonals and reinforced diagonal elements. The constru ction pro ceeds as follo ws: the diagonal elemen ts are indep endently uniformly sampled, while the off-diagonal elemen ts are set to non- zero with probabilit y q (with magnitudes uniformly sampled and randomly signed), follo wed b y symmetrization: σ ⋆ ii ∼ U ( a, b ) , σ ⋆ ij = σ ⋆ j i = ( ± U ( c, d ) , with probability 1 − q , 0 , with probabilit y q , i = j , where q denotes the sparsit y lev el, whic h con trols the prop ortion of non-zero off-diagonals; ( a, b ) is the diagonal in terv al; and ( c, d ) is the non-zero intensit y interv al, gov erning the magnitude and upp er b ound of the non-zero correlations. In the exp eriments, w e fix ( a, b ) = (0 . 5 , 2 . 0) and ( c, d ) = (0 . 1 , 0 . 8) , while primarily v arying the sparsit y level q ∈ { 0 . 1 , 0 . 3 , 0 . 5 , 0 . 7 , 0 . 9 } . Figure 4 presen ts visualizations of the co v ariance matrices for dimension p = 50 under these different sparsit y levels. 16 q = 0 . 1 q = 0 . 3 q = 0 . 5 q = 0 . 7 q = 0 . 9 -5.0 -2.5 0.0 2.5 5.0 Figure 4: Cov ariance matrices under differen t sparsit y levels q . The fourth structure is the block-diagonal co v ariance matrix, featuring strong correlations within clusters and sparse in ter-blo ck connections. The sp ecific construction pro ceeds as follows: first, a blo c k size is selected, and the p v ariables are partitioned into blo c ks; within each blo ck, an equicorrelation structure is adopted, giv en by the matrix with 1 s on the diagonal and ϱ w off the diagonal, i.e., 1 ϱ w · · · ϱ w ϱ w 1 · · · ϱ w . . . . . . . . . . . . ϱ w ϱ w · · · 1 , where ϱ w denotes the within-blo ck equicorrelation strength. F or inter-block connections, with probabilit y π b , a w eak edge of strength ϱ b is added to a pair of random p ositions across blo cks, follo wed by symmetrization. Thus, ϱ b can b e interpreted as the b etw een-blo c k w eak correlation strength, while π b balances cluster indep endence against global connectivit y . In the exp eri- men ts, w e fix ϱ w = 0 . 7 , ϱ b = 0 . 1 , and π b = 0 . 3 , while v arying the blo ck size to take v alues in 10 , 20 , 25 , 40 , 50 . Figure 5 visualizes the resulting blo ck co v ariance matrices for dimension p = 90 (solely to illustrate their structure). block size=3 block size=6 block size=9 block size=12 block size=15 -1.0 -0.5 0.0 0.5 1.0 Figure 5: Cov ariance matrices under differen t blo c k size. In addition to the aforementioned ADMM and LADMM metho ds, w e compare our pro- p osed approach against fiv e other represen tative optimization algorithms: the three-op erator splitting algorithm (TOSA) [ 60 ], the pro ximal forw ard-backw ard splitting algorithm (PFBS) [ 61 ], the fast iterative shrink age-thresholding algorithm (FIST A) [ 62 ]. In fact, at the initial stage of our simulations, w e also considered a semidefinite programming solv er implemented in CVXPY [ 63 ] and the ma jorize–minimize algorithm (MMA) [ 64 ]. How ev er, neither metho d demonstrated any adv an tage o ver the prop osed approach or the comp eting baselines (see Ap- p endix B ). W e therefore omit these t wo methods from the subsequent sim ulation studies. Giv en that the comparativ e metho ds are computationally in tensive in high dimensions and ma y encoun ter ill-conditioning issues, we fix the sample size at n = 500 and v ary the dimension p ∈ { 1000 , 2000 , 3000 , 4000 } . W e ev aluate the estimation p erformance using the con vergence time, F rob enius norm, n uclear norm, and dualit y gap as metrics. The exp erimental results of all methods are summarized in T ables 1 – 4 . The visualization results of LBO on the four co v ariance structures are presen ted in Figures 6 – 9 . 17 T able 1: Exp erimental results of differen t metho ds on the T o eplitz co v ariance structure ϱ Dimension Time (s) F rob enius norm Nuclear norm LBO/ADMM/LADMM/TOSA/PFBS/FIST A LBO/ADMM/LADMM/TOSA/PFBS/FIST A LBO/ADMM/LADMM/TOSA/PFBS/FIST A ϱ = 0 . 1 p = 1000 6 . 348 1 5 . 131 1 1 . 757 1 4 . 813 1 7 . 757 0 1 . 790 1 2 . 089 0 3 . 194 1 5 . 515 0 5 . 594 0 5 . 617 0 5 . 552 0 6 . 575 1 10 . 00 2 1 . 484 2 1 . 507 2 1 . 507 2 1 . 493 2 p = 2000 1 . 162 1 3 . 997 2 7 . 069 1 1 . 961 2 3 . 013 1 7 . 686 1 9 . 074 − 2 4 . 517 1 9 . 198 0 9 . 237 0 9 . 163 0 9 . 202 0 2 . 391 0 2 . 000 3 3 . 476 2 3 . 486 2 3 . 460 2 3 . 474 2 p = 3000 1 . 529 1 1 . 517 3 1 . 750 2 4 . 935 2 7 . 599 1 2 . 008 2 1 . 879 − 1 5 . 532 1 1 . 275 1 1 . 271 1 1 . 281 1 1 . 271 1 8 . 285 0 3 . 000 3 5 . 868 2 5 . 852 2 5 . 904 2 5 . 858 2 p = 4000 2 . 312 1 4 . 029 3 3 . 610 2 9 . 581 2 1 . 498 2 3 . 892 2 1 . 346 0 6 . 388 1 1 . 629 1 1 . 630 1 1 . 625 1 1 . 620 1 8 . 468 1 4 . 000 3 8 . 637 2 8 . 633 2 8 . 625 2 8 . 592 2 ϱ = 0 . 3 p = 1000 5 . 812 1 4 . 954 1 1 . 650 1 4 . 619 1 7 . 281 0 1 . 763 1 2 . 183 0 3 . 461 1 7 . 292 0 7 . 346 0 7 . 409 0 7 . 332 0 6 . 876 1 10 . 00 2 1 . 852 2 1 . 863 2 1 . 876 2 1 . 867 2 p = 2000 5 . 527 1 4 . 017 2 6 . 739 1 1 . 946 2 3 . 007 1 7 . 558 1 3 . 052 − 1 4 . 894 1 1 . 156 1 1 . 150 1 1 . 150 1 1 . 146 1 1 . 272 1 2 . 000 3 4 . 186 2 4 . 165 2 4 . 175 2 4 . 151 2 p = 3000 5 . 174 1 1 . 538 3 1 . 812 2 4 . 890 2 7 . 493 1 2 . 015 2 5 . 462 − 1 5 . 994 1 1 . 528 1 1 . 519 1 1 . 524 1 1 . 522 1 2 . 799 1 3 . 000 3 6 . 830 2 6 . 794 2 6 . 816 2 6 . 802 2 p = 4000 6 . 721 1 4 . 056 3 3 . 567 2 9 . 682 2 1 . 501 2 3 . 961 2 1 . 265 0 6 . 922 1 1 . 887 1 1 . 896 1 1 . 895 1 1 . 892 1 7 . 659 1 4 . 000 3 9 . 780 2 9 . 839 2 9 . 831 2 9 . 817 2 ϱ = 0 . 5 p = 1000 5 . 054 1 4 . 698 1 1 . 576 1 4 . 424 1 7 . 309 0 1 . 841 1 2 . 591 0 4 . 081 1 9 . 508 0 9 . 631 0 9 . 753 0 9 . 620 0 8 . 173 1 10 . 00 2 2 . 129 2 2 . 148 2 2 . 167 2 2 . 148 2 p = 2000 5 . 882 1 3 . 946 2 6 . 903 1 1 . 970 2 3 . 033 1 7 . 814 1 5 . 933 − 1 5 . 773 1 1 . 448 1 1 . 441 1 1 . 442 1 1 . 441 1 1 . 875 1 2 . 000 3 4 . 700 2 4 . 693 2 4 . 685 2 4 . 668 2 p = 3000 1 . 175 2 1 . 494 3 1 . 747 2 4 . 897 2 7 . 439 1 1 . 988 2 9 . 657 − 1 7 . 070 1 1 . 874 1 1 . 865 1 1 . 865 1 1 . 865 1 4 . 285 1 3 . 000 3 7 . 602 2 7 . 563 2 7 . 549 2 7 . 557 2 p = 4000 2 . 152 2 4 . 040 3 3 . 626 2 9 . 694 2 1 . 520 2 3 . 928 2 1 . 816 0 8 . 164 1 2 . 269 1 2 . 272 1 2 . 259 1 2 . 271 1 1 . 070 2 4 . 000 3 1 . 080 3 1 . 079 3 1 . 078 3 1 . 081 3 ϱ = 0 . 7 p = 1000 5 . 919 1 5 . 142 1 1 . 536 1 4 . 573 1 6 . 969 0 1 . 743 1 6 . 057 − 1 5 . 401 1 1 . 352 1 1 . 365 1 1 . 305 1 1 . 310 1 1 . 752 1 10 . 00 2 2 . 391 2 2 . 428 2 2 . 367 2 2 . 381 2 p = 2000 5 . 484 1 4 . 032 2 6 . 977 1 1 . 945 2 2 . 989 1 7 . 839 1 8 . 071 − 1 7 . 642 1 1 . 974 1 1 . 948 1 1 . 942 1 1 . 958 1 2 . 160 1 2 . 000 3 5 . 187 2 5 . 110 2 5 . 121 2 5 . 160 2 p = 3000 1 . 145 2 1 . 516 3 1 . 749 2 4 . 829 2 7 . 804 1 2 . 002 2 1 . 846 0 9 . 360 1 2 . 459 1 2 . 464 1 2 . 453 1 2 . 514 1 9 . 119 1 3 . 000 3 8 . 183 2 8 . 183 2 8 . 206 2 8 . 260 2 p = 4000 2 . 165 2 4 . 157 3 3 . 673 2 1 . 008 3 1 . 632 2 3 . 905 2 2 . 578 0 1 . 081 2 2 . 968 1 2 . 943 1 2 . 970 1 2 . 932 1 1 . 474 2 4 . 000 3 1 . 157 3 1 . 154 3 1 . 158 3 1 . 150 3 ϱ = 0 . 9 p = 1000 5 . 738 1 4 . 612 1 1 . 606 1 4 . 624 1 7 . 659 0 1 . 807 1 1 . 165 0 9 . 553 1 2 . 491 1 2 . 419 1 2 . 372 1 2 . 454 1 2 . 190 1 9 . 889 2 2 . 729 2 2 . 697 2 2 . 656 2 2 . 704 2 p = 2000 6 . 656 1 3 . 796 2 6 . 354 1 1 . 918 2 3 . 043 1 7 . 621 1 1 . 641 0 1 . 377 2 3 . 542 1 3 . 484 1 3 . 525 1 3 . 573 1 3 . 438 1 1 . 998 3 5 . 625 2 5 . 675 2 5 . 635 2 5 . 637 2 p = 3000 9 . 785 1 1 . 521 3 1 . 767 2 5 . 143 2 8 . 116 1 1 . 998 2 2 . 089 0 1 . 689 2 4 . 372 1 4 . 335 1 4 . 394 1 4 . 356 1 5 . 919 1 3 . 000 3 8 . 733 2 8 . 778 2 8 . 822 2 8 . 789 2 p = 4000 1 . 856 2 4 . 159 3 3 . 498 2 9 . 877 2 1 . 570 2 3 . 849 2 2 . 851 0 1 . 951 2 5 . 088 1 5 . 005 1 5 . 005 1 5 . 037 1 1 . 177 2 4 . 000 3 1 . 210 3 1 . 209 3 1 . 209 3 1 . 204 3 * Scien tific notation is used for the num b ers reported in the tables. F or example, 1 . 177 2 denotes 1 . 177 × 10 2 . The same notation applies throughout the follo wing tables. * W e use a color co de to indicate relative p erformance: far b etter, comparable, and w orse (relative to the comp eting metho ds). The same color scheme is used in the following tables. 18 T able 2: Exp erimental results of differen t metho ds on the F actor co v ariance structure F actor n umber Dimension Time (s) F rob enius norm Nuclear norm LBO/ADMM/LADMM/TOSA/PFBS/FIST A LBO/ADMM/LADMM/TOSA/PFBS/FIST A LBO/ADMM/LADMM/TOSA/PFBS/FIST A m = 3 p = 1000 6 . 605 1 9 . 947 1 7 . 239 1 1 . 780 2 8 . 210 1 1 . 221 3 3 . 218 1 1 . 465 2 1 . 465 2 1 . 469 2 1 . 463 2 1 . 465 2 8 . 149 2 6 . 546 2 6 . 546 2 7 . 388 2 6 . 406 2 6 . 546 2 p = 2000 4 . 229 1 6 . 151 2 6 . 249 2 7 . 954 2 2 . 664 2 5 . 530 3 4 . 357 1 4 . 465 2 4 . 465 2 4 . 471 2 4 . 463 2 4 . 465 2 1 . 483 2 1 . 586 3 1 . 586 3 1 . 812 3 1 . 543 3 1 . 586 3 p = 3000 8 . 342 1 1 . 542 3 1 . 697 3 1 . 705 3 3 . 798 2 1 . 171 4 6 . 528 1 4 . 385 2 4 . 385 2 4 . 400 2 4 . 380 2 4 . 385 2 2 . 377 2 2 . 211 3 2 . 211 3 2 . 591 3 2 . 135 3 2 . 211 3 p = 4000 2 . 877 1 1 . 040 4 1 . 437 4 2 . 114 4 5 . 231 3 1 . 690 5 8 . 746 1 5 . 919 2 5 . 919 2 5 . 940 2 5 . 912 2 5 . 919 2 3 . 018 2 3 . 148 3 3 . 148 3 3 . 708 3 3 . 032 3 3 . 148 3 m = 5 p = 1000 1 . 189 1 2 . 089 3 5 . 206 2 3 . 077 3 1 . 079 3 1 . 183 4 3 . 193 1 1 . 974 2 1 . 974 2 1 . 977 2 1 . 973 2 1 . 974 2 6 . 097 2 1 . 068 3 1 . 068 3 1 . 235 3 1 . 057 3 1 . 068 3 p = 2000 4 . 068 1 5 . 176 3 3 . 495 3 6 . 752 3 2 . 179 3 3 . 032 4 5 . 683 1 6 . 391 2 6 . 391 2 6 . 396 2 6 . 390 2 6 . 391 2 4 . 793 2 3 . 018 3 3 . 018 3 3 . 504 3 2 . 981 3 3 . 018 3 p = 3000 8 . 566 1 1 . 709 4 6 . 982 3 1 . 425 4 5 . 011 3 7 . 197 4 8 . 451 1 6 . 360 2 6 . 360 2 6 . 372 2 6 . 358 2 6 . 360 2 3 . 811 2 4 . 288 3 4 . 288 3 5 . 191 3 4 . 218 3 4 . 288 3 p = 4000 3 . 368 1 2 . 104 4 1 . 839 4 4 . 719 4 1 . 016 4 4 . 030 4 1 . 129 2 1 . 211 3 1 . 211 3 1 . 212 3 1 . 210 3 1 . 211 3 5 . 058 2 6 . 669 3 6 . 669 3 8 . 038 3 6 . 557 3 6 . 669 3 m = 7 p = 1000 1 . 747 1 1 . 782 2 1 . 010 2 2 . 332 2 8 . 350 1 1 . 097 3 3 . 345 1 3 . 691 2 3 . 691 2 3 . 693 2 3 . 691 2 3 . 691 2 1 . 777 2 1 . 589 3 1 . 589 3 1 . 784 3 1 . 581 3 1 . 589 3 p = 2000 4 . 095 1 7 . 901 2 4 . 753 2 1 . 099 3 3 . 798 2 4 . 760 3 6 . 671 1 6 . 626 2 6 . 626 2 6 . 631 2 6 . 625 2 6 . 626 2 3 . 598 2 3 . 646 3 3 . 646 3 4 . 239 3 3 . 622 3 3 . 646 3 p = 3000 8 . 113 1 1 . 772 3 1 . 215 3 2 . 461 3 8 . 408 2 1 . 042 4 1 . 001 2 1 . 085 3 1 . 085 3 1 . 086 3 1 . 085 3 1 . 085 3 5 . 365 2 5 . 933 3 5 . 933 3 7 . 041 3 5 . 886 3 5 . 933 3 p = 4000 2 . 731 1 3 . 320 3 1 . 965 3 2 . 125 3 7 . 795 2 9 . 776 3 1 . 332 2 1 . 282 3 1 . 282 3 1 . 283 3 1 . 282 3 1 . 282 3 6 . 846 2 8 . 324 3 8 . 324 3 1 . 005 4 8 . 255 3 8 . 324 3 m = 9 p = 1000 2 . 339 1 1 . 665 2 9 . 556 1 2 . 466 2 8 . 351 1 8 . 821 2 3 . 769 1 4 . 074 2 4 . 074 2 4 . 076 2 4 . 074 2 4 . 074 2 2 . 251 2 1 . 873 3 1 . 873 3 2 . 078 3 1 . 867 3 1 . 873 3 p = 2000 4 . 018 1 5 . 576 2 3 . 443 2 7 . 893 2 2 . 796 2 3 . 591 3 7 . 550 1 8 . 869 2 8 . 869 2 8 . 873 2 8 . 868 2 8 . 869 2 5 . 526 2 4 . 509 3 4 . 509 3 5 . 146 3 4 . 490 3 4 . 509 3 p = 3000 8 . 941 1 1 . 404 3 8 . 694 2 1 . 962 3 7 . 131 2 8 . 492 3 1 . 133 2 1 . 291 3 1 . 291 3 1 . 292 3 1 . 291 3 1 . 291 3 6 . 700 2 7 . 354 3 7 . 354 3 8 . 556 3 7 . 320 3 7 . 354 3 p = 4000 3 . 551 1 1 . 015 4 7 . 950 3 1 . 875 4 9 . 517 3 8 . 776 4 1 . 512 2 1 . 667 3 1 . 667 3 1 . 668 3 1 . 667 3 1 . 667 3 8 . 821 2 1 . 016 4 1 . 016 4 1 . 204 4 1 . 011 4 1 . 016 4 m = 10 p = 1000 1 . 200 1 1 . 518 3 6 . 111 2 2 . 019 3 7 . 805 2 8 . 644 3 5 . 424 1 3 . 955 2 3 . 955 2 3 . 957 2 3 . 955 2 3 . 955 2 1 . 386 3 1 . 942 3 1 . 942 3 2 . 150 3 1 . 936 3 1 . 942 3 p = 2000 4 . 085 1 4 . 138 3 2 . 237 3 5 . 862 3 1 . 989 3 2 . 580 4 8 . 209 1 9 . 161 2 9 . 161 2 9 . 165 2 9 . 161 2 9 . 161 2 1 . 347 3 4 . 658 3 4 . 658 3 5 . 305 3 4 . 641 3 4 . 658 3 p = 3000 8 . 636 1 7 . 705 3 4 . 750 3 1 . 093 4 2 . 926 3 7 . 969 4 1 . 196 2 1 . 385 3 1 . 385 3 1 . 386 3 1 . 385 3 1 . 385 3 7 . 412 2 7 . 687 3 7 . 687 3 8 . 923 3 7 . 656 3 7 . 687 3 p = 4000 2 . 647 1 2 . 740 4 1 . 582 4 3 . 222 4 1 . 256 4 1 . 423 5 1 . 595 2 1 . 828 3 1 . 828 3 1 . 828 3 1 . 827 3 1 . 828 3 9 . 894 2 1 . 101 4 1 . 101 4 1 . 294 4 1 . 096 4 1 . 101 4 19 T able 3: Exp erimental results of differen t metho ds on the sparse co v ariance structure Sparsit y lev el Dimension Time (s) F rob enius norm Nuclear norm LBO/ADMM/LADMM/TOSA/PFBS/FIST A LBO/ADMM/LADMM/TOSA/PFBS/FIST A LBO/ADMM/LADMM/TOSA/PFBS/FIST A q = 0 . 1 p = 1000 1 . 791 1 1 . 696 2 1 . 110 2 2 . 662 2 4 . 011 1 2 . 374 2 1 . 704 2 1 . 252 3 1 . 252 3 1 . 251 3 1 . 252 3 1 . 252 3 5 . 369 3 3 . 002 4 3 . 002 4 3 . 000 4 3 . 002 4 3 . 002 4 p = 2000 4 . 180 1 6 . 248 2 3 . 582 2 9 . 583 2 1 . 582 2 1 . 082 3 1 . 001 3 3 . 582 3 3 . 582 3 3 . 577 3 3 . 582 3 3 . 582 3 4 . 470 4 1 . 138 5 1 . 138 5 1 . 133 5 1 . 138 5 1 . 138 5 p = 3000 1 . 709 1 1 . 452 3 8 . 957 2 2 . 432 3 3 . 849 2 3 . 093 3 1 . 259 3 6 . 649 3 6 . 649 3 6 . 639 3 6 . 649 3 6 . 649 3 6 . 878 4 2 . 374 5 2 . 374 5 2 . 360 5 2 . 374 5 2 . 374 5 p = 4000 2 . 527 1 9 . 748 3 5 . 041 3 1 . 859 4 3 . 254 3 2 . 711 4 7 . 315 3 1 . 024 4 1 . 024 4 1 . 023 4 1 . 024 4 1 . 024 4 4 . 623 5 3 . 869 5 3 . 869 5 3 . 843 5 3 . 869 5 3 . 869 5 q = 0 . 3 p = 1000 1 . 649 1 7 . 722 2 3 . 542 2 1 . 063 3 3 . 105 2 1 . 134 3 6 . 421 0 1 . 089 3 1 . 089 3 1 . 088 3 1 . 089 3 1 . 089 3 1 . 702 2 2 . 616 4 2 . 616 4 2 . 614 4 2 . 616 4 2 . 616 4 p = 2000 9 . 777 0 2 . 427 3 1 . 220 3 4 . 435 3 6 . 604 2 4 . 640 3 3 . 174 1 3 . 180 3 3 . 180 3 3 . 175 3 3 . 180 3 3 . 180 3 7 . 241 2 1 . 011 5 1 . 011 5 1 . 007 5 1 . 011 5 1 . 011 5 p = 3000 1 . 019 1 6 . 433 3 4 . 159 3 1 . 113 4 2 . 108 3 1 . 372 4 2 . 635 1 5 . 800 3 5 . 800 3 5 . 790 3 5 . 800 3 5 . 800 3 1 . 009 3 2 . 070 5 2 . 070 5 2 . 056 5 2 . 070 5 2 . 070 5 p = 4000 9 . 667 1 1 . 749 4 1 . 283 4 2 . 776 4 4 . 261 3 3 . 263 4 3 . 891 1 9 . 005 3 9 . 005 3 8 . 991 3 9 . 006 3 9 . 005 3 1 . 728 3 3 . 397 5 3 . 397 5 3 . 372 5 3 . 398 5 3 . 397 5 q = 0 . 5 p = 1000 5 . 211 1 1 . 080 3 6 . 405 2 1 . 785 3 2 . 660 2 2 . 568 3 2 . 323 1 9 . 207 2 9 . 207 2 9 . 202 2 9 . 207 2 9 . 207 2 6 . 123 2 2 . 212 4 2 . 212 4 2 . 209 4 2 . 212 4 2 . 212 4 p = 2000 1 . 619 1 7 . 065 3 3 . 424 3 8 . 235 3 1 . 410 3 1 . 008 4 9 . 973 2 2 . 632 3 2 . 632 3 2 . 627 3 2 . 632 3 2 . 632 3 4 . 438 4 8 . 369 4 8 . 369 4 8 . 326 4 8 . 371 4 8 . 369 4 p = 3000 8 . 791 0 1 . 115 4 6 . 821 3 1 . 626 4 2 . 164 3 2 . 534 4 4 . 207 2 4 . 899 3 4 . 899 3 4 . 889 3 4 . 899 3 4 . 899 3 2 . 268 4 1 . 745 5 1 . 745 5 1 . 732 5 1 . 745 5 1 . 745 5 p = 4000 7 . 747 1 1 . 866 4 1 . 307 4 3 . 439 4 4 . 378 3 3 . 304 4 6 . 246 1 7 . 588 3 7 . 588 3 7 . 574 3 7 . 588 3 7 . 588 3 2 . 996 3 2 . 861 5 2 . 861 5 2 . 835 5 2 . 861 5 2 . 861 5 q = 0 . 7 p = 1000 2 . 716 1 1 . 054 3 6 . 755 2 1 . 732 3 3 . 837 2 1 . 776 3 1 . 865 1 6 . 913 2 6 . 913 2 6 . 908 2 6 . 913 2 6 . 913 2 4 . 845 2 1 . 660 4 1 . 660 4 1 . 658 4 1 . 661 4 1 . 660 4 p = 2000 9 . 958 0 4 . 075 3 3 . 201 3 1 . 096 4 1 . 084 3 8 . 237 3 1 . 706 2 1 . 996 3 1 . 996 3 1 . 991 3 1 . 996 3 1 . 996 3 7 . 298 3 6 . 332 4 6 . 332 4 6 . 289 4 6 . 334 4 6 . 332 4 p = 3000 1 . 500 1 1 . 943 4 1 . 320 4 1 . 551 4 1 . 557 3 1 . 613 4 5 . 924 2 3 . 724 3 3 . 724 3 3 . 714 3 3 . 724 3 3 . 724 3 3 . 223 4 1 . 324 5 1 . 324 5 1 . 312 5 1 . 325 5 1 . 324 5 p = 4000 1 . 185 2 7 . 080 3 1 . 965 3 4 . 827 3 7 . 751 2 6 . 137 3 1 . 919 4 5 . 779 3 5 . 779 3 5 . 765 3 5 . 779 3 5 . 779 3 1 . 212 6 2 . 172 5 2 . 172 5 2 . 147 5 2 . 173 5 2 . 172 5 q = 0 . 9 p = 1000 2 . 910 1 1 . 812 2 9 . 909 1 2 . 852 2 4 . 342 1 3 . 124 2 1 . 476 2 3 . 703 2 3 . 703 2 3 . 698 2 3 . 703 2 3 . 703 2 4 . 574 3 8 . 909 3 8 . 909 3 8 . 890 3 8 . 912 3 8 . 909 3 p = 2000 8 . 030 0 7 . 273 2 3 . 326 2 9 . 573 2 1 . 438 2 1 . 319 3 3 . 762 2 1 . 111 3 1 . 111 3 1 . 106 3 1 . 111 3 1 . 111 3 1 . 648 4 3 . 519 4 3 . 519 4 3 . 480 4 3 . 522 4 3 . 519 4 p = 3000 1 . 779 1 2 . 080 3 9 . 098 2 2 . 577 3 3 . 219 2 3 . 562 3 6 . 054 2 2 . 067 3 2 . 067 3 2 . 058 3 2 . 067 3 2 . 067 3 3 . 277 4 7 . 302 4 7 . 302 4 7 . 183 4 7 . 308 4 7 . 302 4 p = 4000 5 . 866 1 3 . 513 3 1 . 486 3 4 . 449 3 7 . 098 2 6 . 150 3 8 . 990 4 3 . 218 3 3 . 218 3 3 . 205 3 3 . 219 3 3 . 218 3 5 . 683 6 1 . 202 5 1 . 202 5 1 . 178 5 1 . 203 5 1 . 202 5 20 T able 4: Exp erimental results of differen t metho ds on the blo ck cov ariance structure Blo c k size Dimension Time (s) F rob enius norm Nuclear norm LBO/ADMM/LADMM/TOSA/PFBS/FIST A LBO/ADMM/LADMM/TOSA/PFBS/FIST A LBO/ADMM/LADMM/TOSA/PFBS/FIST A 10 p = 1000 6 . 510 1 6 . 161 1 3 . 976 1 2 . 071 2 3 . 660 1 8 . 718 1 9 . 091 0 1 . 398 1 1 . 398 1 1 . 398 1 1 . 398 1 1 . 398 1 2 . 754 2 2 . 898 2 2 . 898 2 2 . 898 2 2 . 898 2 2 . 898 2 p = 2000 3 . 115 1 5 . 935 2 3 . 615 4 1 . 016 4 1 . 122 2 2 . 695 2 1 . 747 1 2 . 667 1 2 . 667 1 2 . 667 1 2 . 667 1 2 . 667 1 7 . 655 2 8 . 791 2 8 . 791 2 8 . 791 2 8 . 791 2 8 . 791 2 p = 3000 7 . 809 1 1 . 501 3 1 . 240 4 1 . 927 3 2 . 875 2 1 . 030 4 2 . 510 1 4 . 230 1 4 . 230 1 4 . 201 1 4 . 273 1 4 . 230 1 1 . 356 3 1 . 771 3 1 . 771 3 1 . 750 3 1 . 791 3 1 . 771 3 p = 4000 1 . 110 2 2 . 822 3 2 . 972 3 4 . 434 3 7 . 198 2 1 . 337 4 3 . 961 1 6 . 118 1 6 . 118 1 6 . 069 1 6 . 291 1 6 . 118 1 2 . 480 3 2 . 962 3 2 . 962 3 2 . 917 3 3 . 051 3 2 . 962 3 20 p = 1000 1 . 463 2 1 . 086 2 6 . 271 1 2 . 053 2 2 . 297 1 7 . 434 1 1 . 026 1 1 . 659 1 1 . 659 1 1 . 659 1 1 . 659 1 1 . 659 1 2 . 875 2 2 . 281 2 2 . 281 2 2 . 281 2 2 . 281 2 2 . 281 2 p = 2000 1 . 083 2 4 . 595 2 2 . 816 2 8 . 456 2 1 . 250 2 3 . 036 2 2 . 958 1 2 . 731 1 2 . 731 1 2 . 731 1 2 . 731 1 2 . 731 1 1 . 277 3 6 . 107 2 6 . 107 2 6 . 107 2 6 . 107 2 6 . 107 2 p = 3000 1 . 378 2 1 . 810 3 9 . 195 2 3 . 200 3 3 . 506 2 8 . 730 2 2 . 417 1 3 . 432 1 3 . 432 1 3 . 432 1 3 . 432 1 3 . 432 1 1 . 273 3 1 . 082 3 1 . 082 3 1 . 082 3 1 . 082 3 1 . 082 3 p = 4000 2 . 131 2 5 . 439 3 1 . 088 4 3 . 391 3 5 . 844 2 9 . 225 3 2 . 883 1 4 . 526 1 4 . 526 1 4 . 512 1 4 . 554 1 4 . 526 1 1 . 760 3 1 . 795 3 1 . 795 3 1 . 778 3 1 . 814 3 1 . 795 3 25 p = 1000 9 . 749 1 5 . 469 1 3 . 902 1 1 . 182 2 2 . 031 1 4 . 207 1 5 . 476 0 1 . 803 1 1 . 803 1 1 . 803 1 1 . 803 1 1 . 803 1 1 . 513 2 2 . 246 2 2 . 246 2 2 . 246 2 2 . 246 2 2 . 246 2 p = 2000 5 . 059 1 2 . 774 2 1 . 618 2 4 . 594 2 6 . 818 1 1 . 559 2 1 . 959 1 2 . 541 1 2 . 541 1 2 . 541 1 2 . 541 1 2 . 541 1 8 . 293 2 4 . 896 2 4 . 896 2 4 . 896 2 4 . 896 2 4 . 896 2 p = 3000 1 . 031 2 6 . 965 2 4 . 540 2 3 . 223 4 9 . 475 3 2 . 300 4 3 . 132 1 3 . 610 1 3 . 610 1 3 . 610 1 3 . 610 1 3 . 610 1 1 . 659 3 1 . 001 3 1 . 001 3 1 . 001 3 1 . 001 3 1 . 001 3 p = 4000 2 . 002 2 7 . 551 4 1 . 606 4 2 . 168 3 3 . 224 2 7 . 248 3 3 . 152 1 4 . 276 1 4 . 276 1 4 . 273 1 4 . 279 1 4 . 276 1 1 . 894 3 1 . 475 3 1 . 475 3 1 . 472 3 1 . 478 3 1 . 475 3 40 p = 1000 6 . 530 1 1 . 542 2 9 . 000 1 2 . 263 2 3 . 570 1 8 . 461 1 8 . 135 0 2 . 085 1 2 . 085 1 2 . 085 1 2 . 085 1 2 . 085 1 2 . 087 2 2 . 176 2 2 . 176 2 2 . 176 2 2 . 176 2 2 . 176 2 p = 2000 4 . 518 1 3 . 075 4 1 . 531 4 8 . 015 2 1 . 164 2 2 . 636 2 2 . 149 1 3 . 009 1 3 . 009 1 3 . 009 1 3 . 009 1 3 . 009 1 8 . 180 2 4 . 781 2 4 . 781 2 4 . 781 2 4 . 781 2 4 . 781 2 p = 3000 9 . 057 1 1 . 387 3 7 . 799 2 2 . 261 3 3 . 378 2 8 . 672 2 5 . 749 1 3 . 979 1 3 . 979 1 3 . 979 1 3 . 979 1 3 . 979 1 3 . 062 3 7 . 840 2 7 . 840 2 7 . 840 2 7 . 840 2 7 . 840 2 p = 4000 2 . 496 2 1 . 417 4 3 . 208 3 8 . 529 3 6 . 988 2 1 . 353 4 8 . 680 1 4 . 754 1 4 . 754 1 4 . 754 1 4 . 754 1 4 . 754 1 5 . 411 3 1 . 104 3 1 . 104 3 1 . 104 3 1 . 104 3 1 . 104 3 50 p = 1000 6 . 172 1 9 . 923 1 6 . 181 1 1 . 823 2 2 . 731 1 6 . 458 1 1 . 018 1 2 . 493 1 2 . 493 1 2 . 493 1 2 . 493 1 2 . 493 1 2 . 688 2 2 . 278 2 2 . 278 2 2 . 278 2 2 . 278 2 2 . 278 2 p = 2000 4 . 625 1 3 . 972 2 2 . 225 2 7 . 073 2 1 . 049 2 2 . 211 2 1 . 426 1 3 . 751 1 3 . 751 1 3 . 751 1 3 . 751 1 3 . 751 1 3 . 403 2 4 . 930 2 4 . 930 2 4 . 930 2 4 . 930 2 4 . 930 2 p = 3000 8 . 846 1 1 . 138 3 7 . 045 2 2 . 066 3 3 . 131 2 8 . 167 2 4 . 141 1 4 . 414 1 4 . 414 1 4 . 414 1 4 . 414 1 4 . 414 1 2 . 061 3 7 . 819 2 7 . 819 2 7 . 819 2 7 . 819 2 7 . 819 2 p = 4000 5 . 232 1 4 . 255 3 2 . 890 3 3 . 315 3 1 . 212 3 2 . 626 4 4 . 669 1 5 . 317 1 5 . 317 1 5 . 317 1 5 . 317 1 5 . 317 1 2 . 667 3 1 . 117 3 1 . 117 3 1 . 117 3 1 . 118 3 1 . 117 3 21 0 1000 2000 Dimension 0 500 1000 1500 2000 2500 Dimension Estimation Error 0 5 10 15 20 Epoch -3.0 -2.5 -2.0 -1.5 -1.0 -0.5 Gap (Log scale) Primal Dual Gap 0 200 400 600 800 1000 Index -10 -8 -6 -4 -2 0 Log scale Eigenvalues (submatrix m=1000) True Estimated Sample S -0.1 0.0 0.1 0.2 0.3 0.4 0 500 1000 1500 Dimension 0 250 500 750 1000 1250 1500 1750 Dimension Estimation Error 0 20 40 60 80 100 Epoch -3.0 -2.5 -2.0 -1.5 -1.0 -0.5 0.0 Gap (Log scale) Primal Dual Gap 0 200 400 600 800 1000 Index -10 -8 -6 -4 -2 0 Log scale Eigenvalues (submatrix m=1000) True Estimated Sample S -0.2 0.0 0.2 0.4 0.6 Figure 6: Visualization of LBO for T o eplitz cov ariance matrix estimation. The three columns displa y (from left to right) the visualization of the error matrix, the tra jectory of the primal dual gap v ersus epo chs, and the leading 1000 eigenv alues. The first ro w corresp onds to ϱ = 0 . 1 and p = 3000 , while the second ro w corresp onds to ϱ = 0 . 3 and p = 2000 . T able 1 sho ws that LBO pro vides a uniformly sup erior accuracy–efficiency trade-off on T o eplitz co v ariance estimation. In terms of runtime, LBO is typically the fastest or among the fastest metho ds in mo derate to large dimensions: for example, at ϱ = 0 . 1 and p = 3000 , LBO finishes in 1 . 529 1 seconds, while ADMM and LADMM require 1 . 517 3 and 1 . 750 2 seconds, resp ectiv ely; at ϱ = 0 . 1 and p = 4000 , LBO takes 2 . 312 1 seconds compared with 4 . 029 3 (ADMM) and 3 . 610 2 (LADMM). More imp ortantly , LBO achiev es substantially b etter solution qualit y in b oth metrics: at ϱ = 0 . 1 and p = 2000 , LBO attains a F rob enius norm of 9 . 074 − 2 v ersus ≈ 9 . 2 0 for TOSA/PFBS/FIST A (ab out tw o orders of magnitude smaller), and a nuclear norm of 2 . 391 0 v ersus ≈ 3 . 47 2 (o ver 10 2 times smaller); similarly , at ϱ = 0 . 1 and p = 3000 , LBO yields 1 . 879 − 1 in F rob enius norm compared with ≈ 1 . 27 1 for TOSA/PFBS/FIST A, and 8 . 285 0 in n uclear norm compared with ≈ 5 . 85 2 . 0 500 1000 1500 Dimension 0 250 500 750 1000 1250 1500 1750 Dimension Estimation Error 0 20 40 60 80 100 Epoch -1 0 1 2 3 4 Gap (Log scale) Primal Dual Gap 0 200 400 600 800 1000 Index -10 -8 -6 -4 -2 0 2 Log scale Eigenvalues (submatrix m=1000) True Estimated Sample S -10 -5 0 5 10 0 1000 2000 Dimension 0 500 1000 1500 2000 2500 Dimension Estimation Error 0 20 40 60 80 100 120 140 Epoch -1.2 -1.0 -0.8 -0.6 -0.4 Gap (Log scale) Primal Dual Gap 0 200 400 600 800 1000 Index -10 -8 -6 -4 -2 0 2 Log scale Eigenvalues (submatrix m=1000) True Estimated Sample S -15 -10 -5 0 5 10 Figure 7: Visualization of LBO for factor co v ariance matrix estimation. The three columns display (from left to right) the visualization of the error matrix, the tra jectory of the primal–dual gap versus epo chs, and the leading 1000 eigenv alues. The first row corresp onds to m = 3 and p = 2000 , while the second ro w corresp onds to m = 3 and p = 3000 . 22 T able 2 demonstrates that LBO dominates all baselines on the factor co v ariance mo del across factor num b ers m ∈ { 3 , 5 , 7 , 9 , 10 } and dimensions p ∈ { 1000 , 2000 , 3000 , 4000 } . The run time adv antage is striking in large-scale regimes: for instance, when m = 3 and p = 4000 , LBO needs only 2 . 877 1 seconds, whereas ADMM, LADMM, TOSA, PFBS, and FIST A tak e 1 . 040 4 , 1 . 437 4 , 2 . 114 4 , 5 . 231 3 , and 1 . 690 5 seconds, resp ectively . A t the same time, LBO achiev es mark edly smaller errors: in the same setting ( m, p ) = (3 , 4000) , LBO reduces the F rob enius norm to 8 . 746 1 compared with 5 . 919 2 (ADMM/LADMM) and ≈ 5 . 93 2 (TOSA/PFBS/FIST A), and reduces the n uclear norm to 3 . 018 2 compared with 3 . 148 3 (ADMM/LADMM) and 3 . 708 3 (TOSA). A similar gap p ersists for larger factor num b ers, e.g., at m = 10 and p = 3000 , LBO ac hieves 1 . 196 2 (F rob enius) and 7 . 412 2 (n uclear) v ersus 1 . 385 3 and 7 . 687 3 for ADMM/LADMM, while remaining orders of magnitude faster than the competing solvers. 0 1000 2000 Dimension 0 500 1000 1500 2000 2500 Dimension Estimation Error 0 2 4 6 8 10 Epoch 5.2 5.4 5.6 5.8 Gap (Log scale) Primal Dual Gap 0 200 400 600 800 1000 Index -10 -8 -6 -4 -2 0 2 4 Log scale Eigenvalues (submatrix m=1000) True Estimated Sample S 0 200 400 600 800 0 1000 2000 3000 Dimension 0 500 1000 1500 2000 2500 3000 3500 Dimension Estimation Error 0 20 40 60 80 100 Epoch 0 1 2 3 4 5 6 Gap (Log scale) Primal Dual Gap 0 200 400 600 800 1000 Index -10 -8 -6 -4 -2 0 2 4 Log scale Eigenvalues (submatrix m=1000) True Estimated Sample S -200 -100 0 100 200 Figure 8: Visualization of LBO for sparse cov ariance matrix estimation. The three columns display (from left to right) the visualization of the error matrix, the tra jectory of the primal dual gap versus ep o chs, and the leading 1000 eigenv alues. The first row corresponds to q = 0 . 5 and p = 3000 , while the second ro w corresponds to q = 0 . 5 and p = 4000 . T able 3 rep orts results under sparse co v ariance mo dels with v arying sparsity lev els q ∈ { 0 . 1 , 0 . 3 , 0 . 5 , 0 . 7 , 0 . 9 } and dimensions p ∈ { 1000 , 2000 , 3000 , 4000 } . F or mo derately sparse regimes ( q ≤ 0 . 5 ), LBO consistently dominates all comp eting metho ds in b oth efficiency and accuracy . F or example, at q = 0 . 1 and p = 4000 , LBO terminates in 2 . 527 1 seconds, whereas ADMM, LADMM, and TOSA require 9 . 748 3 , 5 . 041 3 , and 1 . 859 4 seconds, resp ectiv ely; mean while, LBO attains a F rob enius norm of 7 . 315 3 v ersus ≈ 1 . 024 4 for ADMM/LADMM/- TOSA/PFBS/FIST A, and a n uclear norm of 6 . 878 4 at p = 3000 compared with ≈ 2 . 374 5 for the comp eting metho ds. A similar adv an tage p ersists at q = 0 . 3 and p = 3000 , where LBO runs in 1 . 019 1 seconds (versus 6 . 433 3 for ADMM and 1 . 113 4 for TOSA) and ac hieves mark edly smaller F rob enius and n uclear norms ( 2 . 635 1 and 1 . 009 3 ) than the baselines (on the order of 10 3 and 10 5 , resp ectively). As the sparsity lev el increases to dense regimes ( q ≥ 0 . 7 ), LBO re- mains substantially faster than all baselines, but its accuracy adv antage becomes less uniform and can ev en deteriorate in the most challenging dense settings. In particular, at q = 0 . 7 and p = 4000 , LBO is still orders of magnitude faster ( 1 . 185 2 seconds v ersus 7 . 080 3 for ADMM and 4 . 827 3 for TOSA), yet its F rob enius and n uclear norms increase to 1 . 919 4 and 1 . 212 6 , compared with ≈ 5 . 779 3 and ≈ 2 . 172 5 for the comp eting metho ds. A similar phenomenon is observ ed at q = 0 . 9 and p = 4000 , where LBO attains 8 . 990 4 (F rob enius) and 5 . 683 6 (n uclear), while the baselines remain around 3 . 2 3 and 1 . 2 5 . 23 0 1000 2000 3000 Dimension 0 500 1000 1500 2000 2500 3000 3500 Dimension Estimation Error 0 20 40 60 80 100 Epoch -2 -1 0 1 2 3 4 5 Gap (Log scale) Primal Dual Gap 0 200 400 600 800 1000 Index -10 -8 -6 -4 -2 0 2 Log scale Eigenvalues (submatrix m=1000) True Estimated Sample S 0 10 20 30 0 1000 2000 3000 Dimension 0 500 1000 1500 2000 2500 3000 3500 Dimension Estimation Error 0 2 4 6 8 10 Epoch -0.76 -0.75 -0.74 -0.73 -0.72 -0.71 -0.70 -0.69 Gap (Log scale) Primal Dual Gap 0 200 400 600 800 1000 Index -10 -8 -6 -4 -2 0 2 Log scale Eigenvalues (submatrix m=1000) True Estimated Sample S -10 0 10 20 30 40 50 60 Figure 9: Visualization of LBO for blo ck cov ariance matrix estimation. The three columns displa y (from left to righ t) the visualization of the error matrix, the tra jectory of the primal–dual gap v ersus ep o chs, and the leading 1000 eigen v alues. The first ro w corresp onds to block size 20 and p = 4000 , while the second ro w corresp onds to blo c k size 50 and p = 4000 . T able 4 reports results under blo c k cov ariance mo dels with v arying blo ck sizes and dimen- sions p ∈ { 1000 , 2000 , 3000 , 4000 } . Overall, LBO remains highly competitive in run time and ac hieves consisten tly smaller F rob enius norms across essen tially all settings, indicating a robust adv antage in estimation accuracy . F or instance, when the blo c k size is 10 and p = 4000 , LBO completes in 1 . 110 2 seconds, whereas ADMM/LADMM/TOSA require 2 . 822 3 / 2 . 972 3 / 4 . 434 3 seconds; mean while, LBO attains a F rob enius norm of 3 . 961 1 compared with ≈ 6 . 1 1 for the comp eting metho ds. A similar pattern holds at blo c k size 20 and p = 4000 , where LBO runs in 2 . 131 2 seconds (versus 5 . 439 3 for ADMM and 1 . 088 4 for LADMM) and yields a smaller F rob enius norm ( 2 . 883 1 v ersus ≈ 4 . 53 1 ). In terms of the nuclear norm, LBO p erforms well for small to mo derate blo ck sizes, often ac hieving the b est or comparable results. F or example, at block size 10 and p = 3000 , LBO reduces the nuclear norm to 1 . 356 3 v ersus ≈ 1 . 77 3 for ADMM/LADMM; at blo c k size 10 and p = 4000 , LBO attains 2 . 480 3 compared with ≈ 2 . 96 3 . How ev er, as the blo ck size increases, the nuclear-norm adv an tage b ecomes less uniform and can even rev erse: for blo c k size 40 and p = 4000 , LBO attains a nuclear norm of 5 . 411 3 whereas the comp eting metho ds are around 1 . 104 3 ; similarly , for blo ck size 50 and p = 3000 , LBO yields 2 . 061 3 compared with ≈ 7 . 819 2 . Notably , ev en in these c hallenging regimes where the nuclear norm is not the smallest, LBO still preserv es a substantial sp eed adv an tage (e.g., blo c k size 40 , p = 4000 : 2 . 496 2 seconds for LBO v ersus 1 . 417 4 for ADMM) and remains highly competitive in F rob enius accuracy . A cross the four cov ariance structures, LBO consisten tly demonstrates a clear adv an tage in large-scale cov ariance estimation. F or T o eplitz and F actor mo dels, LBO achiev es the b est o verall p erformance: it is t ypically the fastest (or among the fastest) while simultaneously attaining substan tially smaller F rob enius and nuclear norms, often b y one to t wo orders of magnitude relativ e to ADMM/LADMM and the first-order baselines (TOSA/PFBS/FIST A). F or sparse mo dels, LBO remains highly effectiv e in sparse-to-mo derately-sparse regimes ( q ≤ 0 . 5 ), where it mark edly improv es b oth metrics with dramatically reduced run time (e.g., at q = 0 . 1 , p = 4000 , LBO runs in 2 . 527 1 seconds versus 9 . 748 3 for ADMM and ac hiev es a F rob enius norm of 7 . 315 3 v ersus ≈ 1 . 024 4 ), whereas in dense regimes ( q ≥ 0 . 7 ) its main adv an tage is sp eed and the accuracy b enefit b ecomes less uniform. F or block mo dels, LBO yields consistently smaller F rob enius norms and substantial runtime reductions across all blo ck sizes (e.g., blo ck size 10 , 24 p = 4000 : 1 . 110 2 seconds for LBO v ersus 2 . 822 3 for ADMM), while its nuclear-norm adv an tage is strongest for small-to-mo derate blo c ks and ma y diminish for v ery large blo c ks. Overall, these results indicate that LBO offers sup erior scalability and robustness across div erse structural settings, delivering the most fa vorable balance b etw een computational efficiency and estimation qualit y among all compared metho ds. 5.2. High-dimensional pr e cision matrix In this section, we apply the prop osed LBO algorithm to high-dimensional precision matrix estimation. W e first describ e the precision matrix structures emplo yed in the exp erimen ts, follo wed b y an o verview of the optimization algorithms used for comparison. Our ob jective is to estimate the high-dimensional precision matrix Θ ⋆ = ( θ ⋆ ij ) 1 ≤ i,j ≤ p based on an observ ation matrix with n samples and p features sampled from the normal distribution N (0 , (Θ ⋆ ) − 1 ) . T o this end, w e consider three representativ e structures for the precision matrix. Banded 1: A banded precision matrix where θ ⋆ ii = 1 and θ ⋆ ij = 0 . 2 for 1 ≤ | i − j | ≤ 2 , and θ ⋆ ij = 0 otherwise. Banded 2: A banded precision matrix where θ ⋆ ii = 1 and θ ⋆ ij = 0 . 2 for 1 ≤ | i − j | ≤ 4 , and θ ⋆ ij = 0 otherwise. Grid: Let p b e a p erfect square, and set √ p ∈ N . The indices i = 1 , . . . , p are arranged in row-ma jor order into an √ p × √ p grid. The true precision matrix Θ ⋆ ∈ R p × p is defined as θ ⋆ ij = 1 , i = j, 0 . 2 , j = i + 1 and mo d( i, √ p ) = 0 (horizon tal neighbor) , 0 . 2 , j = i + √ p and i ≤ p − √ p (v ertical neighbor) , 0 , otherwise , where mo d( i, √ p ) = 0 indicates that i is not a m ultiple of √ p (i.e., not on the righ t b oundary of eac h ro w). This construction requires √ p to be an in teger. Since each no de has at most four neigh b ors and eac h off-diagonal entry is 0 . 2 , the matrix is strictly row-diagonally dominan t (with interior ro ws summing to at most 0 . 8 off the diagonal), and thus Θ ⋆ is symmetric p ositiv e definite. This is the grid model from Ravikumar et al. [ 65 ]. As an illustration, Figure 10 visualizes the precision matrices for these three structures when p = 100 . Band 1 Band 2 Grid 1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00 Figure 10: Visualization of the precision matrices for the three structures at dimension 100. Similar to Section 5.1 , w e fix the sample size at n = 500 and v ary the dimension p ∈ { 1024 , 2025 , 3025 , 3969 } , where eac h p is c hosen to be a p erfect square to meet the exp erimen- tal setup requirements. W e ev aluate all methods using w all-clo c k con vergence time, F rob e- nius norm, nuclear norm, and the duality gap. In addition to the ADMM and LADMM solv ers considered ab o ve, we further include three represen tative baselines: a pro ximal gradient (Pro xGrad) metho d [ 66 ] equipp ed with backtrac king line [ 67 ] searc h to guarantee descent of 25 the ob jectiv e, whic h is simple to implement and enjoys standard con vergence guarantees for general-purp ose use on mo derately sized problems; QUIC [ 41 , 40 ], an appro ximate second-order approac h that up dates along (quasi-)Newton directions with line searc h, typically achieving substan tially faster conv ergence in practice and b eing particularly effective when rapid con v er- gence is needed for medium-scale instances; and the sp ectral pro jected gradient (SPG) metho d [ 68 ], whic h combines Barzilai–Borw ein step sizes [ 69 ] with a nonmonotone acceptance criterion, pro viding adaptive step-size selection that often leads to fast conv ergence and go od scalability in large-scale settings. T able 5 rep orts the p erformance of LBO against ADMM, LADMM, Pro xGrad, QUIC, and SPG on three representativ e precision-matrix structures (t wo banded cases and a grid case) across increasing dimensions. The visualization results of LBO on the four co v ariance structures are presen ted in Figures 11 – 13 . 26 T able 5: Exp erimental results of differen t metho ds on the three precision matrix structures Matrix structures Dimension Time (s) F rob enius norm Nuclear norm LBO/ADMM/LADMM/Pro xGrad/QUIC/SPG LBO/ADMM/LADMM/Pro xGrad/QUIC/SPG LBO/ADMM/LADMM/Pro xGrad/QUIC/SPG Banded 1 p = 1024 1 . 704 1 1 . 879 1 3 . 668 1 1 . 209 1 1 . 241 1 8 . 694 0 7 . 887 0 9 . 874 0 9 . 872 0 9 . 875 0 9 . 209 0 9 . 875 0 2 . 207 2 2 . 535 2 2 . 535 2 2 . 535 2 2 . 449 2 2 . 535 2 p = 2025 4 . 268 1 2 . 045 3 4 . 592 3 3 . 423 2 4 . 649 2 4 . 244 2 1 . 129 1 1 . 491 1 1 . 490 1 1 . 491 1 1 . 581 1 1 . 491 1 4 . 444 2 5 . 533 2 5 . 532 2 5 . 533 2 5 . 663 2 5 . 533 2 p = 3025 8 . 675 1 1 . 958 3 3 . 164 3 9 . 287 2 9 . 456 2 8 . 344 2 1 . 412 1 1 . 936 1 1 . 935 1 1 . 936 1 2 . 006 1 1 . 936 1 3 . 452 2 8 . 902 2 8 . 907 2 8 . 902 2 8 . 876 2 8 . 902 2 p = 3969 1 . 491 2 1 . 968 3 4 . 395 3 1 . 974 3 1 . 261 3 8 . 140 2 1 . 632 1 2 . 324 1 2 . 330 1 2 . 324 1 2 . 371 1 2 . 324 1 4 . 340 2 1 . 232 3 1 . 238 3 1 . 232 3 1 . 209 3 1 . 232 3 Banded 2 p = 1024 1 . 783 1 5 . 804 2 2 . 281 3 7 . 400 2 7 . 344 2 6 . 306 2 1 . 266 1 1 . 588 1 1 . 588 1 1 . 588 1 1 . 636 1 1 . 588 1 3 . 408 2 3 . 404 2 3 . 404 2 3 . 404 2 3 . 412 2 3 . 404 2 p = 2025 4 . 371 1 1 . 452 3 1 . 682 3 3 . 213 2 7 . 639 2 4 . 266 2 1 . 793 1 2 . 299 1 2 . 294 1 2 . 299 1 2 . 363 1 2 . 299 1 6 . 936 2 7 . 343 2 7 . 359 2 7 . 343 2 7 . 220 2 7 . 343 2 p = 3025 8 . 431 1 3 . 283 3 2 . 984 3 1 . 376 3 1 . 217 3 8 . 575 2 2 . 182 1 2 . 882 1 2 . 877 1 2 . 882 1 2 . 897 1 2 . 882 1 5 . 114 2 1 . 165 3 1 . 186 3 1 . 165 3 1 . 101 3 1 . 165 3 p = 3969 1 . 477 2 2 . 609 3 4 . 258 3 1 . 623 3 3 . 997 2 8 . 492 2 2 . 475 1 3 . 373 1 3 . 404 1 3 . 373 1 3 . 103 1 4 . 079 3 5 . 435 2 1 . 599 3 1 . 675 3 1 . 599 3 1 . 483 3 2 . 252 5 Grid p = 1024 1 . 518 1 1 . 457 3 2 . 081 3 2 . 303 3 8 . 478 1 4 . 549 2 1 . 265 1 7 . 322 0 7 . 283 0 7 . 322 0 6 . 836 0 6 . 012 1 3 . 291 2 1 . 943 2 1 . 938 2 1 . 944 2 1 . 832 2 2 . 536 2 p = 2025 8 . 985 1 1 . 874 3 1 . 702 3 1 . 490 3 3 . 130 2 8 . 899 2 1 . 793 1 1 . 172 1 1 . 197 1 1 . 172 1 1 . 389 1 1 . 172 1 6 . 564 2 4 . 420 2 4 . 541 2 4 . 420 2 5 . 070 2 4 . 420 2 p = 3025 8 . 658 1 2 . 989 3 2 . 434 3 4 . 191 3 1 . 090 3 1 . 309 3 2 . 192 1 1 . 582 1 1 . 714 1 1 . 582 1 1 . 741 1 1 . 582 1 4 . 836 2 7 . 326 2 7 . 960 2 7 . 326 2 7 . 804 2 7 . 326 2 p = 3969 1 . 466 2 2 . 121 3 9 . 863 2 1 . 495 3 2 . 344 2 3 . 247 2 2 . 576 1 1 . 942 1 2 . 216 1 1 . 942 1 2 . 037 1 1 . 942 1 6 . 828 2 1 . 031 3 1 . 176 3 1 . 031 3 1 . 049 3 1 . 031 3 27 0 500 1000 1500 2000 2500 3000 Dimension 0 500 1000 1500 2000 2500 3000 Dimension Estimation Er r or 0 20 40 60 80 100 Step 3.372 3.373 3.374 3.375 3.376 3.377 3.378 P rimal (L og scale) P rimal Objective (L og scale) 0 200 400 600 800 1000 Inde x 10 8 6 4 2 0 L og scale Eigenvalues (submatrix m=1000) T rue Estimated Sample S 0.2 0.1 0.0 0.1 0.2 0 1000 2000 3000 Dimension 0 500 1000 1500 2000 2500 3000 3500 Dimension Estimation Er r or 0 20 40 60 80 100 Step 3.490 3.491 3.492 3.493 3.494 3.495 3.496 3.497 P rimal (L og scale) P rimal Objective (L og scale) 0 200 400 600 800 1000 Inde x 10 8 6 4 2 0 L og scale Eigenvalues (submatrix m=1000) T rue Estimated Sample S 0.3 0.2 0.1 0.0 0.1 Figure 11: Visualization of LBO for precision matrix estimation under the Banded 1 structure. The three columns display (from left to righ t) the visualization of the error matrix, the tra jectory of the primal–dual gap v ersus epo chs, and the leading 1000 eigenv alues. The first row corresp onds to p = 3025 , while the second row corresp onds to p = 3969 . F or Banded 1, LBO is consistently the fastest metho d once p b ecomes mo derately large: for example, at p = 2025 LBO takes 4 . 268 1 seconds while ADMM and LADMM require 2 . 045 3 and 4 . 592 3 seconds, and at p = 3969 LBO tak es 1 . 491 2 seconds compared with 1 . 968 3 (ADMM) and 4 . 395 3 (LADMM). A t the same time, LBO attains the smallest F rob enius and n uclear norms across all dimensions, e.g., at p = 3025 the F rob enius norm is 1 . 412 1 for LBO versus 1 . 936 1 for the remaining metho ds, and the n uclear norm is 3 . 452 2 for LBO versus ≈ 8 . 90 2 for the baselines. 0 500 1000 1500 2000 2500 3000 Dimension 0 500 1000 1500 2000 2500 3000 Dimension Estimation Er r or 0 20 40 60 80 100 Step 3.2975 3.3000 3.3025 3.3050 3.3075 3.3100 3.3125 3.3150 P rimal (L og scale) P rimal Objective (L og scale) 0 200 400 600 800 1000 Inde x 10 8 6 4 2 0 L og scale Eigenvalues (submatrix m=1000) T rue Estimated Sample S 0.20 0.15 0.10 0.05 0.00 0 1000 2000 3000 Dimension 0 500 1000 1500 2000 2500 3000 3500 Dimension Estimation Er r or 0 20 40 60 80 100 Step 3.416 3.418 3.420 3.422 3.424 3.426 3.428 3.430 3.432 P rimal (L og scale) P rimal Objective (L og scale) 0 200 400 600 800 1000 Inde x 10 8 6 4 2 0 L og scale Eigenvalues (submatrix m=1000) T rue Estimated Sample S 0.20 0.15 0.10 0.05 0.00 Figure 12: Visualization of LBO for precision matrix estimation under the Banded 2 structure. The three columns display (from left to righ t) the visualization of the error matrix, the tra jectory of the primal–dual gap v ersus epo chs, and the leading 1000 eigenv alues. The first row corresp onds to p = 3025 , while the second row corresp onds to p = 3969 . F or Banded 2, LBO again provides the b est ov erall p erformance: it is orders of magnitude faster in ev ery tested dimension (e.g., p = 1024 : 1 . 783 1 for LBO v ersus 5 . 804 2 for ADMM 28 and 2 . 281 3 for LADMM), while also ac hieving the smallest F rob enius norm throughout (e.g., p = 3025 : 2 . 182 1 for LBO v ersus ≈ 2 . 882 1 for the baselines). In terms of nuclear norm, LBO is comparable at p = 1024 ( 3 . 408 2 v ersus 3 . 404 2 ), and b ecomes clearly fa vorable as p increases (e.g., p = 3969 : 5 . 435 2 for LBO v ersus ≈ 1 . 60 3 for ADMM/Pro xGrad and ≈ 1 . 48 3 for QUIC). 0 500 1000 1500 2000 2500 3000 Dimension 0 500 1000 1500 2000 2500 3000 Dimension Estimation Er r or 0 20 40 60 80 100 Step 3.10 3.12 3.14 3.16 P rimal (L og scale) P rimal Objective (L og scale) 0 200 400 600 800 1000 Inde x 10 8 6 4 2 0 L og scale Eigenvalues (submatrix m=1000) T rue Estimated Sample S 0.20 0.15 0.10 0.05 0.00 0.05 0.10 0 1000 2000 3000 Dimension 0 500 1000 1500 2000 2500 3000 3500 Dimension Estimation Er r or 0 20 40 60 80 100 Step 3.20 3.21 3.22 3.23 3.24 3.25 3.26 3.27 3.28 P rimal (L og scale) P rimal Objective (L og scale) 0 200 400 600 800 1000 Inde x 10 8 6 4 2 0 L og scale Eigenvalues (submatrix m=1000) T rue Estimated Sample S 0.20 0.15 0.10 0.05 0.00 0.05 0.10 0.15 Figure 13: Visualization of LBO for precision matrix estimation under the Grid structure. The three columns displa y (from left to righ t) the visualization of the error matrix, the tra jectory of the primal–dual gap v ersus ep o c hs, and the leading 1000 eigenv alues. The first ro w corresponds to p = 3025 , while the second ro w corre- sp onds to p = 3969 . F or the grid precision matrices, LBO remains consistently faster than all comp etitors, particularly in larger dimensions (e.g., p = 1024 : 1 . 518 1 for LBO v ersus 1 . 457 3 for ADMM; p = 3969 : 1 . 466 2 for LBO versus 2 . 121 3 for ADMM). Regarding accuracy , LBO achiev es the b est or near-b est F rob enius norms across the tested dimensions (e.g., p = 1024 : 1 . 265 1 for LBO compared with 7 . 322 0 for ADMM), while its nuclear-norm behavior is structure-dep enden t: LBO is slightly w orse at smaller sizes (e.g., p = 1024 : 3 . 291 2 for LBO versus 1 . 943 2 for ADMM), but b ecomes adv antageous at larger dimensions (e.g., p = 3969 : 6 . 828 2 for LBO v ersus 1 . 031 3 for ADMM/Pro xGrad and 1 . 049 3 for QUIC). A cross the three precision-matrix structures (tw o banded cases and the grid case) in T a- ble 5 , LBO consistently exhibits superior scalability and competitive estimation quality . In the t wo banded settings, LBO is mark edly faster as the dimension increases and sim ultaneousl y ac hieves the smallest F rob enius and n uclear norms in most cases. F or the grid structure, LBO main tains a substantial run time adv antage throughout, while its estimation accuracy remains comparable in F rob enius norm and b ecomes more fav orable in nuclear norm for larger dimen- sions. Ov erall, these results suggest that LBO provides an effectiv e and scalable solver for large-scale precision matrix estimation across div erse sparsit y/structure patterns. 6. Conclusion In this pap er, w e inv estigated learning-assisted optimization for high-dimensional matrix estimation by in tegrating data-driven structures in to a principled LADMM framework. Start- ing from a baseline LADMM pro cedure, w e in tro duced learnable parameters and implemen ted the resulting proximal op erators via neural net w orks, whic h improv ed estimation accuracy and accelerated con vergence in practice. On the theoretical side, we established the con vergence of LADMM and further prov ed the con vergence, con vergence rates, and monotonicit y of the 29 reparameterized scheme, showing that the reparameterized LADMM enjoy ed a faster conv er- gence rate. Metho dologically , the prop osed reparameterization was general and applied to b oth co v ariance and precision matrix estimation. Extensiv e exp erimen ts corrob orated these theoretical findings. A cross m ultiple co v ariance structures (T o eplitz, factor, sparse, and blo c k) and a range of dimensions, the prop osed LBO approac h consisten tly ac hieved a fa vorable accuracy–efficiency trade-off relative to classical solv ers. In particular, LBO deliv ered markedly smaller estimation errors (in F rob enius and, in many regimes, n uclear norms) while substan tially reducing run time, especially in mo derate- to-large dimensions where several baselines b ecame computationally exp ensive. F or precision matrix estimation under banded and grid structures, LBO similarly exhibited strong scalability and competitive accuracy when compared with ADMM-t yp e metho ds and sp ecialized baselines, supp orting the broad applicabilit y of our framework. In the future, w e will extend our framew ork to join t estimation of m ultiple matrices (e.g., m ulti-task or m ulti-group settings) to b etter exploit shared structures across related problems. In addition, w e will generalize our metho dology from vector-v alued observ ations to matrix- v alued and tensor-v alued data, dev eloping learning-assisted estimators for structured matrix estimation and higher-order tensor estimation with theoretical guaran tees and scalable imple- men tations. 30 App endix A. Pro ofs for Results App endix A.1. Pr o of of The or em 4.1 T o pro of Theorem 4.1 , we first show the following Lemma: Lemma App endix A.1. Denote ( X ∗ , Y ∗ , V ∗ ) is any KKT p oint of pr oblem ( 21 ) , ϕ 1 , ϕ 2 > 1 , then we have fol lowing assertions (1). { ( ϕ 1 − 1) ∥ X ( k ) − X ∗ ∥ 2 + ∥ Y ( k ) − Y ∗ ∥ 2 + ρ − 2 ∥ V ( k ) − V ∗ ∥ 2 } is non-incr e asing. (2). ∥ X ( k +1) − X ( k ) ∥ → 0 , ∥ Y ( k +1) − Y ( k ) ∥ → 0 , ∥ V ( k +1) − V ( k ) ∥ → 0 . Pr o of. W e notice that ( ϕ 1 − 1) ∥ X ( k +1) − X ∗ ∥ 2 + ∥ Y ( k +1) − Y ∗ ∥ 2 + ρ − 2 ∥ V ( k +1) − V ∗ ∥ 2 =( ϕ 1 − 1) ∥ X ( k ) − X ∗ ∥ 2 + ∥ Y ( k ) − Y ∗ ∥ 2 + ρ − 2 ∥ V ( k ) − V ∗ ∥ 2 − ( ϕ 1 − 1) ∥ X ( k +1) − X ( k ) ∥ 2 − ρ − 2 ∥ V ( k +1) − V ( k ) ∥ 2 + ϕ 2 ∥ Y ( k +1) − Y ( k ) ∥ 2 + 2 ρ − 1 V ( k +1) − V ( k ) , Y ( k +1) − Y ( k ) − 2 ρ − 1 X ( k +1) − X ∗ , − ρ ( X ( k ) − Y ( k ) ) − V ( k ) + ρϕ 1 ( X ( k ) − X ( k +1) ) + V ∗ − 2 ρ − 1 Y ( k +1) − Y ∗ , ρ ( X ( k +1) − Y ( k ) ) + V ( k ) + ρϕ 2 ( Y ( k ) − Y ( k +1) ) − V ∗ . (A.1) Since the optimal conditions of pro ximal op erators in ( 22 ) giv e − ρ ( X ( k ) − Y ( k ) ) − V ( k ) + ρϕ 1 ( X ( k ) − X ( k +1) ) ∈ ∂ F ( X ( k +1) ) , − V ∗ ∈ ∂ F ( X ∗ ) , ρ ( X ( k +1) − Y ( k ) ) + V ( k ) + ρϕ 2 ( Y ( k ) − Y ( k +1) ) ∈ ∂ G ( Y ( k +1) ) , V ∗ ∈ ∂ G ( Y ∗ ) , th us by the monotonicity of subgradien ts, w e hav e X ( k +1) − X ∗ , − ρ ( X ( k ) − Y ( k ) ) − V ( k ) + ρϕ 1 ( X ( k ) − X ( k +1) ) + V ∗ ≥ 0 , Y ( k +1) − Y ∗ , ρ ( X ( k +1) − Y ( k ) ) + V ( k ) + ρϕ 2 ( Y ( k ) − Y ( k +1) ) − V ∗ ≥ 0 . Moreo ver, ϕ 2 > 1 implies that ρ − 2 ∥ V ( k +1) − V ( k ) ∥ 2 + ϕ 2 ∥ Y ( k +1) − Y ( k ) ∥ 2 + 2 ρ − 1 V ( k +1) − V ( k ) , Y ( k +1) − Y ( k ) = ∥ ρ − 1 ( V ( k +1) − V ( k ) ) + Y ( k +1) − Y ( k ) ∥ 2 + ( ϕ 2 − 1) ∥ Y ( k +1) − Y ( k ) ∥ 2 ≥ 0 , hence the first assertion holds. As { ( ϕ 1 − 1) ∥ X ( k ) − X ∗ ∥ 2 + ∥ Y ( k ) − Y ∗ ∥ 2 + ρ − 2 ∥ V ( k ) − V ∗ ∥ 2 } is non-increasing and non-negativ e, it has a finite limit, whic h implies that the nonnegative sum on the righ t-hand side of ( A.1 ) that constitutes the one-step decrease con v erges to zero as k → ∞ . ( ϕ 1 − 1) ∥ X ( k +1) − X ( k ) ∥ 2 → 0 , ( ϕ 2 − 1) ∥ Y ( k +1) − Y ( k ) ∥ 2 → 0 , ∥ ρ − 1 ( V ( k +1) − V ( k ) ) + Y ( k +1) − Y ( k ) ∥ 2 → 0 , th us the second assertion holds. Pr o of of The or em 4.1 . By Lemma App endix A.1 (1), the sequence { ( X ( k ) , Y ( k ) , V ( k ) ) } is b ounded, th us there exists at least one accum ulation point, denoted as { ( X ( ∞ ) , Y ( ∞ ) , V ( ∞ ) ) } . Let the sub- sequence { ( X ( k j ) , Y ( k j ) , V ( k j ) ) } satisfy ( X ( k j ) , Y ( k j ) , V ( k j ) ) → ( X ( ∞ ) , Y ( ∞ ) , V ( ∞ ) ) . First, we hav e lim k →∞ X ( k +1) − Y ( k +1) = 1 ρ lim k →∞ ( V ( k +1) − V ( k ) ) = 0 , th us X ( ∞ ) = Y ( ∞ ) , i.e., ( X ( ∞ ) , Y ( ∞ ) , V ( ∞ ) ) is feasible. 31 Second, b y the definition of subgradient, we obtain F ( X ) ≥ F ( X ( k j ) ) + X − X ( k j ) , − ρ ( X ( k j − 1) − Y ( k j − 1) ) − V ( k j − 1) + ρϕ 1 ( X ( k j − 1) − X ( k j ) ) . Notice that lim j →∞ ( X k j − 1 , Y k j − 1 , V k j − 1 ) = ( X ( ∞ ) , Y ( ∞ ) , V ( ∞ ) ) holds, th us F ( X ) ≥ F ( X ( ∞ ) ) + X − X ( ∞ ) , − V ( ∞ ) , whic h demonstrate that − V ( ∞ ) ∈ ∂ F ( X ( ∞ ) ) . Analogously , V ( ∞ ) ∈ ∂ G ( X ( ∞ ) ) , and th us ( X ( ∞ ) , Y ( ∞ ) , V ( ∞ ) ) is a KKT p oint of the problem ( 21 ). Thereby , { ( ϕ 1 − 1) ∥ X ( k ) − X ( ∞ ) ∥ 2 + ∥ Y ( k ) − Y ( ∞ ) ∥ + ρ − 2 ∥ V ( k ) − V ( ∞ ) ∥} is non-increasing and has a limit, whic h must be zero since it has a sub sequence whose limit is zero. Consequen tly , we ha ve sho wn that ( X ( k ) , Y ( k ) , V ( k ) ) → ( X ( ∞ ) , Y ( ∞ ) , V ( ∞ ) ) . App endix A.2. Pr o of of The or em 4.2 Lemma App endix A.2. F or any KKT p oint ω ∗ , ther e exists pr op er ( α k , β k ) ∈ S such that the se quenc e { ω k } gener ate d by ( 24 ) satisfy ⟨ ω k +1 − ω ∗ , H k ( ω k − ω k +1 ) ⟩ ≥ 0 , ∀ k ≥ 0 . (A.2) Thus we have ∥ ω k − ω ∗ ∥ 2 H k ≥ ∥ ω k +1 − ω ∗ ∥ 2 H k + ∥ ω k − ω k +1 ∥ 2 H k . (A.3) Pr o of. The optimalit y conditions in ( 24 ) give 1 α k ◦ ( X ( k ) − X ( k +1) ) − 1 β k ◦ ( X ( k ) − Y ( k ) ) − V ( k ) ∈ ∂ F ( X ( k +1) ) , V ( k ) − 1 β k ◦ ( Y ( k +1) − X ( k +1) ) ∈ ∂ G ( Y ( k +1) ) , hence b y the definition of subgradients, F ( X ) − F ( X ( k +1) ) + X − X ( k +1) , 1 α k ◦ ( X ( k +1) − X ( k ) ) + V ( k ) + 1 β k ◦ ( X ( k ) − Y ( k ) ) ≥ 0 , G ( Y ) − G ( Y ( k +1) ) + Y − Y ( k +1) , 1 β k ◦ ( Y ( k +1) − X ( k +1) ) − V ( k ) ≥ 0 . (A.4) Note that V ( k +1) = V ( k ) + 1 β k ◦ ( X ( k +1) − Y ( k +1) ) , thus b y summing up the tw o inequalities ab o ve, w e obtain ⟨ ω k +1 − ω , H k ( ω k − ω k +1 ) ⟩ ≥ F ( X ( k +1) ) + G ( Y ( k +1) ) − F ( X ) − G ( Y ) + ⟨ ω k +1 − ω , ϕ ( ω k +1 ) ⟩ + ⟨ X ( k +1) − X − Y ( k +1) + Y , 1 β k ◦ ( Y ( k +1) − Y ( k ) ) ⟩ . (A.5) W e take ω = ω ∗ , then X ∗ = Y ∗ . Since G ( · ) is con v ex and V ( k +1) ∈ ∂ G ( Y ( k +1) ) , w e hav e ⟨ X ( k +1) − Y ( k +1) , 1 β k ◦ ( Y ( k +1) − Y ( k ) ) ⟩ = ⟨ V ( k +1) − V ( k ) , Y ( k +1) − Y ( k ) ⟩ ≥ 0 . (A.6) 32 On the other hand, F ( X ( k +1) ) + G ( Y ( k +1) ) − F ( X ∗ ) − G ( Y ∗ ) + ⟨ ω k +1 − ω ∗ , ϕ ( ω k +1 ) ⟩ = F ( X ( k +1) ) + G ( Y ( k +1) ) − F ( X ∗ ) − G ( Y ∗ ) + ⟨ ω k +1 − ω ∗ , ϕ ( ω ∗ ) ⟩ ≥ 0 , (A.7) here the first equality holds since ⟨ ω k +1 − ω ∗ , ϕ ( ω ∗ ) − ϕ ( ω k +1 ) ⟩ = 0 . and the second inequality holds b y the optimal condition of KKT p oint. Com bining ( A.5 ), ( A.6 ) and ( A.7 ), w e can conclude that ⟨ ω k +1 − ω ∗ , H k ( ω k − ω k +1 ) ⟩ ≥ 0 . Consequen tly , w e obtain ∥ ω k − ω ∗ ∥ 2 H k = ∥ ω k − ω k +1 + ω k +1 − ω ∗ ∥ 2 H k = ∥ ω k +1 − ω ∗ ∥ 2 H k + ∥ ω k − ω k +1 ∥ 2 H k + 2 ⟨ ω k +1 − ω ∗ , H k ( ω k − ω k +1 ) ⟩ ≥ ∥ ω k +1 − ω ∗ ∥ 2 H k + ∥ ω k − ω k +1 ∥ 2 H k . Pr o of of The or em 4.2 . Giv en some ω ∗ ∈ Ω ∗ , b y the inequality ( A.3 ), w e hav e ∥ ω k − ω ∗ ∥ 2 H k ≥ ∥ ω k +1 − ω ∗ ∥ 2 H k + ∥ ω k − ω k +1 ∥ 2 H k ≥ ∥ ω k +1 − ω ∗ ∥ 2 H k +1 + ∥ ω k +1 − ω ∗ ∥ 2 ( H k − H k +1 ) . W e can tak e the appropriate parameters ( α k , β k ) → ( α ∗ , β ∗ ) suc h that and ∥ H k +1 − H k ∥ ≤ c 0 / ( k + 1) 2 ∥ H k +1 ∥ , where c 0 ≥ 0 is small enough. Then ∃ c 1 , c 2 > 0 , c 1 ≤ ∥ H k ∥ ≤ c 2 , and ∥ ω k − ω ∗ ∥ 2 H k ≥ 1 − c 0 ( k + 1) 2 ∥ ω k +1 − ω ∗ ∥ 2 H k +1 . Th us for any k ≥ 0 , we obtain ∥ ω 0 − ω ∗ ∥ 2 H 0 ≥ k Y u =0 1 − c 0 ( u + 1) 2 ! ∥ ω k +1 − ω ∗ ∥ 2 H k +1 . T ake small enough c 0 , such that Q ∞ u =0 1 − c 0 ( u +1) 2 = exp P ∞ u =0 log 1 − c 0 ( u +1) 2 > 0 . Then w e can conclude that { ω k } is a b ounded sequence. By the inequalit y ( A.3 ), we hav e k X u =0 ∥ ω u − ω u +1 ∥ 2 H u ≤ k X u =0 ( ∥ ω u − ω ∗ ∥ 2 H u − ∥ ω u +1 − ω ∗ ∥ 2 H u ) ≤ k X u =0 ∥ ω u − ω ∗ ∥ 2 H u − ∥ ω u +1 − ω ∗ ∥ 2 H u +1 + ∥ ω u +1 − ω ∗ ∥ 2 ( H u +1 − H u ) = ∥ ω 0 − ω ∗ ∥ 2 H 0 − ∥ ω k +1 − ω ∗ ∥ 2 H k +1 + k X u =0 ∥ ω u +1 − ω ∗ ∥ 2 ( H u +1 − H u ) ≤ ∥ ω 0 − ω ∗ ∥ 2 H 0 + k X u =0 |∥ ω u +1 − ω ∗ ∥ 2 ( H u +1 − H u ) | . Let k → ∞ , then P ∞ k =0 ∥ ω k − ω k +1 ∥ 2 H k ≤ ∥ ω 0 − ω ∗ ∥ 2 H 0 + P ∞ k =0 |∥ ω k +1 − ω ∗ ∥ 2 ( H k +1 − H k ) | . Since ∥ H k +1 − H k ∥ ≤ O (1 / ( k + 1) 2 ) , w e hav e P ∞ k =0 |∥ ω k +1 − ω ∗ ∥ 2 ( H k +1 − H k ) | < ∞ and thus 33 P ∞ k =0 ∥ ω k − ω k +1 ∥ 2 H k < ∞ . It follo ws that ∥ ω k − ω k +1 ∥ 2 H k → 0 . Denote { ω k j } as the subsequence that satisfies ω k j → ω ∞ . By ( A.4 ), if w e take k = k j and note that ∥ ω k − ω k +1 ∥ 2 H k → 0 gives ∥ ω k − ω k +1 ∥ 2 F → 0 , we hav e F ( X ) − F ( X ( ∞ ) ) + X − X ( ∞ ) , V ( ∞ ) ≥ 0 , G ( Y ) − G ( Y ( ∞ ) ) + Y − Y ( ∞ ) , − V ( ∞ ) ≥ 0 . (A.8) Th us ω ∞ is a KKT p oint of the problem ( 21 ). Use the inequality ( A.3 ) again, then ∀ j ≥ 0 , ∀ k > k j , ∥ ω k − ω ∞ ∥ 2 H k ≤ ∥ ω k j − ω ∞ ∥ 2 H 0 + k − 1 X u = k j ∥ ω u +1 − ω ∞ ∥ 2 ( H u +1 − H u ) − k − 1 X u = k j ∥ ω u − ω u +1 ∥ 2 H u . By the construction of H k , P ∞ u =0 |∥ ω u +1 − ω ∞ ∥ 2 ( H u +1 − H u ) | < ∞ and P ∞ u =0 ∥ ω u − ω u +1 ∥ 2 H u < ∞ , th us the canonical ϵ − δ argument gives the desired result of ∥ ω k − ω ∞ ∥ F → 0 . App endix A.3. Pr o of of The or em 4.3 Pr o of. W e assume that there exists α k , β k suc h that ω k +1 = ω k , otherwise w e ha ve completed the pro of by Lemma App endix A.3 . Hence we hav e ∥ ω k − ω k +1 ∥ H k = 0 , and ∃ ρ k > 0 , suc h that dist 2 H k ( ω k +1 , Ω ∗ ) ≤ ρ k ∥ ω k − ω k +1 ∥ 2 H k . Also, the inequalit y ( A.3 ) giv es dist 2 H k ( ω k +1 , Ω ∗ ) ≤ dist 2 H k ( ω k , Ω ∗ ) − ∥ ω k − ω k +1 ∥ 2 H k . Th us we obtain dist 2 H k ( ω k +1 , Ω ∗ ) ≤ (1 + 1 /ρ k ) − 1 dist 2 H k ( ω k , Ω ∗ ) . F or ω ∗ ∈ Ω ∗ suc h that dist 2 H k ( ω k +1 , Ω ∗ ) = ∥ ω k +1 − ω ∗ ∥ 2 H k , then dist 2 H k +1 ( ω k +1 , Ω ∗ ) ≤ ∥ ω k +1 − ω ∗ ∥ 2 H k + ∥ ω k +1 − ω ∗ ∥ 2 H k +1 − H k . Cho ose α k , β k accordingly suc h that ∥ H k +1 − H k ∥ ≤ τ k ∥ H k ∥ , where τ k is small enough, then (1 + τ k )(1 + 1 /ρ k ) − 1 < 1 , and thus dist 2 H k +1 ( ω k +1 , Ω ∗ ) ≤ (1 + τ k )(1 + 1 /ρ k ) − 1 dist 2 H k ( ω k , Ω ∗ ) < dist 2 H k ( ω k , Ω ∗ ) , whic h completes the pro of. Lemma App endix A.3 (Absorbing states) . Given ω k gener ate d by ( 24 ) . If for al l p ar ameters ( α k , β k ) ∈ S , ther e holds ω k +1 = ω k , then ∀ j ≥ k , ω j = ω k ∈ Ω ∗ . Pr o of of L emma App endix A.3 . The up date rule of V ( k +1) directly implies that X ( k +1) = Y ( k +1) . Using ω k +1 = ω k and the optimal conditions in ( 24 ), w e ha ve − V ( k ) ∈ ∂ F ( X ( k ) ) and V ( k ) ∈ ∂ G ( Y ( k ) ) , th us ω k ∈ Ω ∗ is a KKT p oint. W e can sho w that ω k is a fixed p oint b y induction. App endix A.4. Pr o of of The or em 4.4 Pr o of. By Lemma App endix A.3 , we assume without loss of generality that ∀ k ≥ 0 , ω k +1 = ω k . There exists K 0 > 0 , suc h that for k ≥ K 0 , w e ha v e dist 2 H ∗ ( e ω k +1 , Ω ∗ ) ≤ κ 16 ∥ e ω k +1 − ω k ∥ 2 H ∗ . T ak e ω ∗ ∈ Ω ∗ suc h that dist 2 H ∗ ( e ω k +1 , Ω ∗ ) = ∥ e ω k +1 − ω ∗ ∥ 2 H ∗ , then dist 2 H k +1 ( e ω k +1 , Ω ∗ ) ≤ dist 2 H ∗ ( e ω k +1 , Ω ∗ ) + ∥ e ω k +1 − ω ∗ ∥ 2 H k +1 − H ∗ . 34 There exists ( α k , β k ) → ( α ∗ , β ∗ ) with some deca y rate, i.e., for large enough k , ∥ H k +1 − H ∗ ∥ ≤ c k ∥ H k − H ∗ ∥ , where 0 ≤ c k < 1 is to b e determined. Also, we require that β k = β ∗ , α k ↑ α ∗ , then H k +1 ⪯ H k . Then dist 2 H k +1 ( e ω k +1 , Ω ∗ ) < 2 dist 2 H ∗ ( e ω k +1 , Ω ∗ ) , ∥ e ω k +1 − ω k ∥ 2 H ∗ < 2 ∥ e ω k +1 − ω k ∥ 2 H k . Th us we obtain dist 2 H k +1 ( e ω k +1 , Ω ∗ ) < κ 4 ∥ e ω k +1 − ω k ∥ 2 H k . By the triangle inequalit y under ∥ · ∥ H , w e hav e dist H k +1 ( ω k +1 , Ω ∗ ) ≤ ∥ ω k +1 − e ω k +1 ∥ H k +1 + dist H k +1 ( e ω k +1 , Ω ∗ ) < ∥ ω k +1 − e ω k +1 ∥ H k +1 + √ κ 2 ∥ e ω k +1 − ω k ∥ H k ≤ ∥ ω k +1 − e ω k +1 ∥ H k +1 + √ κ 2 ∥ e ω k +1 − ω k +1 ∥ H k + ∥ ω k +1 − ω k ∥ H k . Since the op erator T is lipschitz con tin uous w.r.t. α k , β k , th us ∥ ω k +1 − e ω k +1 ∥ H k +1 + √ κ 2 ∥ e ω k +1 − ω k +1 ∥ H k ≤ C ( ω ) O (∆ k ) , where ∆ k = | α k − α ∗ | + | β k − β ∗ | and C ( ω ) is the upp er bound of { ω k } . Let c k deca y fast sufficien tly , w e obtain C ( ω ) O (∆ k ) ≤ 1 2 dist H k +1 ( ω k +1 , Ω ∗ ) (There exists some parameters suc h that this holds, i.e., let ( α k , β k ) = ( α ∗ , β ∗ ) , whic h degenerates to LADMM). Thus ∥ ω k +1 − e ω k +1 ∥ H k +1 + √ κ 2 ∥ e ω k +1 − ω k +1 ∥ H k ≤ 1 2 dist H k +1 ( ω k +1 , Ω ∗ ) . Hence w e hav e for k ≥ K 0 , dist 2 H k +1 ( ω k +1 , Ω ∗ ) ≤ κ ∥ ω k +1 − ω k ∥ 2 H k . Since ∥ ω k +1 − ω k ∥ H k > 0 for all k , there exists e κ > 0 such that ∀ k < K 0 , we ha ve dist 2 H k +1 ( ω k +1 , Ω ∗ ) ≤ e κ ∥ ω k +1 − ω k ∥ H k . Denote ρ 0 = max { κ, e κ } , then for all k , dist 2 H k +1 ( ω k +1 , Ω ∗ ) ≤ ρ 0 ∥ ω k +1 − ω k ∥ 2 H k . Since H k +1 ⪯ H k , the pro of pro cess of Theorem 4.3 implies that dist 2 H k +1 ( ω k +1 , Ω ∗ ) ≤ dist 2 H k ( ω k +1 , Ω ∗ ) + ∥ ω k +1 − ω ∗ ∥ 2 H k +1 − H k ≤ dist 2 H k ( ω k +1 , Ω ∗ ) , dist 2 H k ( ω k +1 , Ω ∗ ) ≤ dist 2 H k ( ω k , Ω ∗ ) − ∥ ω k − ω k +1 ∥ 2 H k . Hence w e conclude that dist 2 H k +1 ( ω k +1 , Ω ∗ ) ≤ (1 + 1 /ρ 0 ) − 1 dist 2 H k ( ω k , Ω ∗ ) . App endix A.5. Pr o of of The or em 4.5 Pr o of. T ake ( w 1 ) k = 1 ρϕ 1 1 , ( w 2 ) k = 1 ρϕ 2 1 , α k = 1 ρϕ 1 1 , γ k = ρ 1 . Let b ω k +1 = ( b X ( k +1) , b Y ( k +1) , b V ( k +1) ) ⊤ , e ω k +1 = ( e X ( k +1) , e Y ( k +1) , e V ( k +1) ) ⊤ . Then the re-parameterized LADMM up date can b e rewritten 35 as b X ( k +1) = pro x F / ( ρϕ 1 ) X ( k ) − 1 ϕ 1 X ( k ) − Y ( k ) + V ( k ) /ρ , b Y ( k +1) = pro x G/ ( ρϕ 2 ) Y ( k ) + β k ◦ V ( k ) + ρ b X ( k +1) − Y ( k ) , b V ( k +1) = V ( k ) + ρ b X ( k +1) − b Y ( k +1) . (A.9) Denote η ( · ) = pro x F / ( ρϕ 1 ) ( · ) , ζ ( · ) = prox G/ ( ρϕ 2 ) ( · ) , β ∗ = 1 ρϕ 2 1 and R ( k ) = V ( k ) + ρ b X ( k +1) − Y ( k ) . W e claim that if R ( k ) satisfies that ( R ( k ) ) ij = 0 , ∀ i, j , then there exists c ∈ (0 , 1) and β k suc h that ζ Y ( k ) + β k ◦ R ( k ) − e Y k +1 = − c 1 + ρ 2 e Y k +1 − Y ∗ − ρ e V k +1 − V ∗ . (A.10) Indeed, since ζ is bijectiv e, the ab o ve equalit y can b e transformed as β k ◦ R ( k ) = ζ − 1 − c 1 + ρ 2 e Y k +1 − Y ∗ − ρ e V k +1 − V ∗ + e Y k +1 − Y ( k ) . As w e tak e a small enough c > 0 , w e can conclude that there exists β k suc h that ( A.10 ) holds. Moreo ver, define ∆ Y = ζ Y ( k ) + β k ◦ R ( k ) − e Y k +1 , if e Y k +1 − Y ∗ − ρ e V k +1 − V ∗ = 0 , then ∥ e ω k +1 − ω ∗ ∥ 2 F − ∥ b ω k +1 − ω ∗ ∥ 2 F = ∥ e Y k +1 − Y ∗ ∥ 2 F − ∥ e Y k +1 − Y ∗ + ∆ Y ∥ 2 F + ∥ e V k +1 − V ∗ ∥ 2 F − ∥ e V k +1 − V ∗ − ρ ∆ Y ∥ 2 F = 2 c − c 2 1 + ρ 2 ∥ e Y k +1 − Y ∗ − ρ e V k +1 − V ∗ ∥ 2 F > 0 . Note that Ω 0 = { ω k : ( R ( k ) ) ij = 0 } S { ω k : e Y k +1 − Y ∗ − ρ e V k +1 − V ∗ = 0 } is a set of measure zero, w e hav e completed the pro of. App endix A.6. Pr o of of The or em 4.6 Before proving Theorem 4.6 , we first presen t t wo fundamen tal facts in high-dimensional statistics: (i) If U, V are sub-Gaussian, then U V is sub-exp onen tial and ∥ U V ∥ ψ 1 ≤ C ∥ U ∥ ψ 2 ∥ V ∥ ψ 2 ; hence ∥ U V − E ( U V ) ∥ ψ 1 ≤ C ∥ U ∥ ψ 2 ∥ V ∥ ψ 2 . (ii) Bernstein inequality for sub-exp onential v ari- ables. If e X 1 , . . . , e X n are i.i.d. cen tered with ∥ e X k ∥ ψ 1 ≤ B , then for all t > 0 , Pr 1 n n X k =1 e X k ≥ t ! ≤ 2 exp − cn min t 2 B 2 , t B . Pr o of. Fix indices i, j ∈ { 1 , . . . , p } and define ( S − Σ ⋆ ) ij = 1 n n X k =1 e X ki e X kj − E [ e X i e X j ] = 1 n n X k =1 e Z ( ij ) k , where e Z ( ij ) k := e X ki e X kj − E [ e X i e X j ] are i.i.d. with mean zero. By the pro duct-sub-exp onen tial fact and Assumption 1 , w e hav e Z ( ij ) k ψ 1 ≤ C ∥ X k,i ∥ ψ 2 ∥ X k,j ∥ ψ 2 ≤ C K 2 =: B . 36 Applying the sub-exp onen tial Bernstein inequality yields, for any t > 0 , Pr ( S − Σ ⋆ ) ij ≥ t ≤ 2 exp − cn min t 2 B 2 , t B . (A.11) This holds for all pairs ( i, j ) , including the diagonal i = j (since X 2 i − E X 2 i is sub-exp onen tial with the same ψ 1 -norm b ound). No w take the union b ound ov er all p 2 en tries: Pr( ∥ S − Σ ⋆ ∥ ∞ ≥ t ) ≤ p X i,j =1 Pr ( S − Σ ⋆ ) ij ≥ t ≤ 2 p 2 exp − cn min n t 2 B 2 , t B o . Cho ose t = C 0 q log p n with C 0 = e C B . Pro vided n ≳ log p , we are in the quadratic branch of the minim um, hence Pr ∥ S − Σ ⋆ ∥ ∞ ≥ C 0 r log p n ! ≤ 2 p 2 exp − cn · C 2 0 log p nB 2 = 2 p 2 − c e C 2 . T ake e C large enough so that 2 − c e C 2 ≤ − c 0 for the desired c 0 > 0 . Equiv alen tly , Pr ∥ S − Σ ⋆ ∥ ∞ ≤ C 0 q log p n ≥ 1 − 2 p − c 0 . This completes the pro of. App endix A.7. Pr o of of The or em 4.7 Pr o of. Recall f 1 (Σ) = 1 2 ∥ Σ − S ∥ 2 F + λ ∥ Σ ∥ 1 , off and let b Σ ⋆ ∈ arg min Σ ⪰ ϵI f 1 (Σ) . Set ∆ := b Σ ⋆ − Σ ⋆ and d enote the off–diagonal support A := { ( i, j ) : i = j, σ ⋆ ij = 0 } with |A| elements. By optimalit y of b Σ ⋆ for ( 1 ), for an y feasible Σ , 1 2 ∥ b Σ ⋆ − S ∥ 2 F + λ ∥ b Σ ⋆ ∥ 1 , off ≤ 1 2 ∥ Σ − S ∥ 2 F + λ ∥ Σ ∥ 1 , off . Cho osing Σ = Σ ⋆ and expanding ∥ b Σ ⋆ − S ∥ 2 F − ∥ Σ ⋆ − S ∥ 2 F = ∥ ∆ ∥ 2 F + 2 ⟨ Σ ⋆ − S, ∆ ⟩ , we obtain the basic inequalit y 1 2 ∥ ∆ ∥ 2 F ≤ ⟨ S − Σ ⋆ , ∆ ⟩ + λ ∥ Σ ⋆ ∥ 1 , off − ∥ b Σ ⋆ ∥ 1 , off . (A.12) Decomp ose ∆ = ∆ A + ∆ A c on off–diagonals (diagonals are unp enalized). If λ ≥ 2 ∥ S − Σ ⋆ ∥ ∞ , then b y Hölder inequality , ⟨ S − Σ ⋆ , ∆ ⟩ ≤ ∥ S − Σ ⋆ ∥ ∞ ∥ ∆ ∥ 1 ≤ λ 2 ∥ ∆ ∥ 1 . By decomp osabilit y of ∥ · ∥ 1 , off , ∥ Σ ⋆ ∥ 1 , off − ∥ b Σ ⋆ ∥ 1 , off ≤ ∥ ∆ A ∥ 1 − ∥ ∆ A c ∥ 1 + 2 ∥ (Σ ⋆ ) A c ∥ 1 . Plugging these in to ( A.12 ) and dropping the nonnegativ e 1 2 ∥ ∆ ∥ 2 F yields the cone inequalit y ∥ ∆ A c ∥ 1 ≤ 3 ∥ ∆ A ∥ 1 + 4 ∥ (Σ ⋆ ) A c ∥ 1 . (A.13) Returning to ( A.12 ) and using the bounds ab ov e, 1 2 ∥ ∆ ∥ 2 F ≤ λ 2 ∥ ∆ A ∥ 1 + ∥ ∆ A c ∥ 1 + λ ∥ ∆ A ∥ 1 − ∥ ∆ A c ∥ 1 + 2 ∥ (Σ ⋆ ) A c ∥ 1 s ′ d = 3 λ 2 ∥ ∆ A ∥ 1 − λ 2 ∥ ∆ A c ∥ 1 + 2 λ ∥ (Σ ⋆ ) A c ∥ 1 . 37 Drop the negativ e term and use ∥ ∆ A ∥ 1 ≤ p |A| ∥ ∆ ∥ F to obtain 1 2 ∥ ∆ ∥ 2 F ≤ 3 λ 2 p |A| ∥ ∆ ∥ F + 2 λ ∥ (Σ ⋆ ) A c ∥ 1 . Solving the quadratic inequalit y in x = ∥ ∆ ∥ F giv es ∥ b Σ ⋆ − Σ ⋆ ∥ F ≤ 4 p |A| λ + 4 ∥ (Σ ⋆ ) A c ∥ 1 p |A| . (A.14) F rom the KKT conditions for ( 1 ), 0 ∈ ( b Σ ⋆ − S ) + λZ + I { Σ ⪰ ϵI } ( b Σ ⋆ ) , with Z ∈ ∂ ∥ · ∥ 1 , off ( b Σ ⋆ ) . On off–diagonals, the normal cone v anishes, hence | ( b Σ ⋆ − Σ ⋆ ) ij | ≤ | ( S − Σ ⋆ ) ij | + λ | Z ij | ≤ λ 2 + λ ≤ 3 λ, ( i = j ) , using λ ≥ 2 ∥ S − Σ ⋆ ∥ ∞ and | Z ij | ≤ 1 . W rite f 1 (Σ) with 1 2 ∥ Σ − S ∥ 2 F (1–strongly conv ex) and λ ∥ Σ ∥ 1 , off + I { Σ ⪰ ϵI } (Σ) (con vex). Hence f 1 (Σ) is 1–strongly con vex and, for any Σ , f 1 (Σ) − f 1 ( b Σ ⋆ ) ≥ 1 2 ∥ Σ − b Σ ⋆ ∥ 2 F . F or the iterate Σ ( k ) , this yields ∥ Σ ( k ) − b Σ ⋆ ∥ F ≤ q 2 ε opt ( k ) . (A.15) By the triangle inequalit y and ( A.15 ), ∥ Σ ( k ) − Σ ⋆ ∥ F ≤ ∥ Σ ( k ) − b Σ ⋆ ∥ F + ∥ b Σ ⋆ − Σ ⋆ ∥ F ≤ q 2 ε opt ( k ) + 4 p |A| λ + 4 ∥ (Σ ⋆ ) A c ∥ 1 / p |A| , whic h is exactly the claimed b ound ( 25 ). Under Assumption 1 , Theorem 4.6 ensures ∥ S − Σ ⋆ ∥ ∞ ≲ q log p n with probability at least 1 − 2 p − c 0 , so c ho osing λ ≍ q log p n mak es the statistical term optimal (up to constants). If we stop when ε opt ( k ) ≤ C 2 |A| log p n , the first term matc hes the statistical rate, yielding ∥ Σ ( k ) − Σ ⋆ ∥ F ≲ q |A| log p n + ∥ (Σ ⋆ ) A c ∥ 1 / p |A| . This completes the pro of. App endix A.8. Pr o of of the or em 4.8 Pr o of. The graphical Lasso ob jectiv e is f 2 (Θ) = T r( S Θ) − log det Θ + λ ∥ Θ ∥ 1 , off . Let ∆ := b Θ ⋆ − Θ ⋆ and denote the off–diagonal supp ort B = { ( i, j ) : i = j, θ ⋆ ij = 0 } , with size |B | . F or an y Θ ≻ 0 and direction U , ∇ 2 (T r( S Θ) − log det Θ)[ U, U ] = ⟨ Θ − 1 U Θ − 1 , U ⟩ = ∥ Θ − 1 / 2 U Θ − 1 / 2 ∥ 2 F . Hence on the SPD band { Θ : ϵI ⪯ Θ ⪯ M I } , ∇ 2 (T r( S Θ) − log det Θ)[ U, U ] ≥ 1 M 2 ∥ U ∥ 2 F . By the mean–v alue form of the Bregman div ergence, T r( S b Θ ⋆ ) − log det b Θ ⋆ ≥ T r( S Θ ⋆ ) − log det Θ ⋆ + S − (Θ ⋆ ) − 1 , ∆ + 1 2 M 2 ∥ ∆ ∥ 2 F , ∆ := b Θ ⋆ − Θ ⋆ . (A.16) 38 Optimalit y of b Θ ⋆ giv es 0 ≥ f 2 ( b Θ ⋆ ) − f 2 (Θ ⋆ ) = T r( S b Θ ⋆ ) − log det b Θ ⋆ − T r( S Θ ⋆ ) − log det Θ ⋆ + λ ∥ b Θ ⋆ ∥ 1 , off −∥ Θ ⋆ ∥ 1 , off . Com bining with ( A.16 ) and using ∇ (T r( S Θ ⋆ ) − log det Θ ⋆ ) = S − Σ ⋆ , 1 2 M 2 ∥ ∆ ∥ 2 F ≤ −⟨ S − Σ ⋆ , ∆ ⟩ − λ ∥ b Θ ⋆ ∥ 1 , off − ∥ Θ ⋆ ∥ 1 , off . (A.17) On the ev ent ∥ S − Σ ⋆ ∥ ∞ ≤ λ/ 2 (which holds w.p. ≥ 1 − 2 p − c 0 when λ ≥ 2 ∥ S − Σ ⋆ ∥ ∞ ), |⟨ S − Σ ⋆ , ∆ ⟩| ≤ ∥ S − Σ ⋆ ∥ ∞ ∥ ∆ ∥ 1 ≤ λ 2 ∥ ∆ ∥ 1 . F or the ℓ 1 term, b y decomp osability on off–diagonals and allowing appro ximate sparsit y , ∥ b Θ ⋆ ∥ 1 , off − ∥ Θ ⋆ ∥ 1 , off ≥ ∥ ∆ B c ∥ 1 − ∥ ∆ B ∥ 1 − 2 ∥ (Θ ⋆ ) B c ∥ 1 . Plugging these t wo b ounds in to ( A.17 ) yields 1 2 M 2 ∥ ∆ ∥ 2 F ≤ λ 2 ∥ ∆ B ∥ 1 + ∥ ∆ B c ∥ 1 + λ ∥ ∆ B ∥ 1 − ∥ ∆ B c ∥ 1 + 2 ∥ (Θ ⋆ ) B c ∥ 1 . (A.18) Rearranging, ∥ ∆ B c ∥ 1 ≤ 3 ∥ ∆ B ∥ 1 + 4 ∥ (Θ ⋆ ) B c ∥ 1 (cone condition). (A.19) F rom ( A.18 ), drop the negativ e term − ( λ/ 2) ∥ ∆ B c ∥ 1 , and use ∥ ∆ B ∥ 1 ≤ p |B | ∥ ∆ ∥ F : 1 2 M 2 ∥ ∆ ∥ 2 F ≤ 3 λ 2 p |B | ∥ ∆ ∥ F + 2 λ ∥ (Θ ⋆ ) B c ∥ 1 . Solving the quadratic inequalit y in x = ∥ ∆ ∥ F giv es ∥ b Θ ⋆ − Θ ⋆ ∥ F ≤ M 2 3 λ p |B | + 4 ∥ (Θ ⋆ ) B c ∥ 1 / p |B | . (A.20) On the band { Θ : ϵI ⪯ Θ ⪯ M I } , the function f 2 is 1 / M 2 –strongly conv ex. Therefore, for the k -th iterate, ε GL opt ( k ) := f 2 (Θ ( k ) ) − f 2 ( b Θ ⋆ ) ≥ 1 2 M 2 ∥ Θ ( k ) − b Θ ⋆ ∥ 2 F = ⇒ ∥ Θ ( k ) − b Θ ⋆ ∥ F ≤ q 2 M 2 ε GL opt ( k ) . Finally , by the triangle inequality and ( A.20 ), ∥ Θ ( k ) − Θ ⋆ ∥ F ≤ ∥ Θ ( k ) − b Θ ⋆ ∥ F + ∥ b Θ ⋆ − Θ ⋆ ∥ F ≤ q 2 M 2 ε GL opt ( k ) + M 2 3 λ p |B | +4 ∥ (Θ ⋆ ) B c ∥ 1 / p |B | . Cho osing λ ≍ q log p n on the concentration even t and stopping when ε GL opt ( k ) ≲ |B| log p n yields the stated rate. App endix A.9. Pr o of of Pr op osition 4.1 Pr o of. Recall that the w eighted proximal operator prox w,F : R p × p → R p × p b y pro x w,F ( M ) := arg min X ∈ R p × p n F ( X ) + 1 2 1 √ w ◦ ( X − M ) 2 F o , 39 where 1 √ w is tak en element-wise. Define the weigh ted inner pro duct ⟨ X , 1 w ◦ Y ⟩ := X i,j X ij Y ij w ij , and the asso ciated norm ∥ X ∥ 2 w − 1 := ⟨ X , 1 w ◦ X ⟩ . W e observe that 1 √ w ◦ ( X − M ) 2 F = X i,j X ij − M ij √ w ij 2 = X i,j ( X ij − M ij ) 2 w ij = X − M , 1 w ◦ ( X − M ) = ∥ X − M ∥ 2 w − 1 . Step 1: Nonexpansiv eness in the weigh ted norm ∥ · ∥ w − 1 . Let M 1 , M 2 ∈ R p × p and X 1 := prox w,F ( M 1 ) , X 2 := prox w,F ( M 2 ) . The optimal condition yields 0 ∈ ∂ F ( X 1 ) + 1 w ◦ ( X 1 − M 1 ) , 0 ∈ ∂ F ( X 2 ) + 1 w ◦ ( X 2 − M 2 ) . Th us there exist G 1 ∈ ∂ F ( X 1 ) and G 2 ∈ ∂ F ( X 2 ) suc h that G 1 + 1 w ◦ ( X 1 − M 1 ) = 0 , G 2 + 1 w ◦ ( X 2 − M 2 ) = 0 . Equiv alently , G 1 = 1 w ◦ ( M 1 − X 1 ) , G 2 = 1 w ◦ ( M 2 − X 2 ) . Since F is conv ex, its sub differen tial ∂ F is a monotone op erator. Hence X 1 − X 2 , G 1 − G 2 ≥ 0 . Denote that ∆ X := X 1 − X 2 , ∆ M := M 1 − M 2 , then w e hav e 0 ≤ ∆ X , G 1 − G 2 = ∆ X , 1 w ◦ (∆ M − ∆ X ) = ∆ X , 1 w ◦ ∆ M − ∆ X , 1 w ◦ ∆ X . Rearranging giv es ∥ ∆ X ∥ 2 w − 1 ≤ ∆ X , 1 w ◦ ∆ M . No w apply the Cauch y–Sc hw arz inequalit y: ∆ X , 1 w ◦ ∆ M = 1 √ w ◦ ∆ X , 1 √ w ◦ ∆ M ≤ ∥ 1 √ w ◦ ∆ X ∥ ∥ 1 √ w ◦ ∆ M ∥ = ∥ ∆ X ∥ w − 1 ∥ ∆ M ∥ w − 1 . Hence ∥ ∆ X ∥ 2 w − 1 ≤ ∥ ∆ X ∥ w − 1 ∥ ∆ M ∥ w − 1 . This implies that ∥ ∆ X ∥ w − 1 ≤ ∥ ∆ M ∥ w − 1 . That is, pro x w,F ( M 1 ) − prox w,F ( M 2 ) w − 1 ≤ ∥ M 1 − M 2 ∥ w − 1 , ∀ M 1 , M 2 . Th us prox w,F is nonexpansiv e in the norm ∥ · ∥ w − 1 . 40 Step 2: F rom ∥ · ∥ w − 1 to the F rob enius norm ∥ · ∥ F . By the elemen twise b ounds on w , for any Z ∈ R p × p w e hav e 1 c 2 ∥ Z ∥ 2 F ≤ ∥ Z ∥ 2 w − 1 ≤ 1 c 1 ∥ Z ∥ 2 F , Then ∥ ∆ X ∥ F ≤ √ c 2 ∥ ∆ X ∥ w − 1 ≤ √ c 2 ∥ ∆ M ∥ w − 1 ≤ r c 2 c 1 ∥ ∆ M ∥ F . That is, pro x w,F ( M 1 ) − prox w,F ( M 2 ) F ≤ r c 2 c 1 ∥ M 1 − M 2 ∥ F ∀ M 1 , M 2 ∈ R p × p . Therefore prox w,F is lipschitz contin uous with lipsc hitz constan t at most p c 2 /c 1 . This com- pletes the pro of. App endix A.10. Pr o of of The or em 4.9 Pr o of. Prop osition 4.1 implies that v ec(prox w,F ( · )) is p c 2 /c 1 -lipsc hitz con tinuous. Then the desired result is a direct corollary of Propositon 1 and Prop ositon 6 of [ 70 ]. App endix B. P erformance of CVXPY and MMA under the sparse cov ariance struc- ture In this section, T able B.6 rep orts the sim ulation results for ADMM, LADMM, TOSA, PFBS, FIST A, as well as CVXPY and MMA, under a sparse co v ariance structure (sparsity lev el q = 0 . 1 ) with dimensions p = 1000 , 2000 , 3000 . T able B.6: Exp erimental results of differen t metho ds on the sparse co v ariance structure Metric Dimension ADMM LADMM TOSA PFBS FIST A CVXPY MMA Time (s) p = 1000 1.696 × 10 2 1.110 × 10 2 2.662 × 10 2 4.011 × 10 1 2.374 × 10 2 2.427 × 10 2 1.157 × 10 4 p = 2000 6.248 × 10 2 3.582 × 10 2 9.583 × 10 2 1.582 × 10 2 1.082 × 10 3 1.602 × 10 3 3.817 × 10 4 p = 3000 1.452 × 10 3 8.957 × 10 2 2.432 × 10 3 3.849 × 10 2 3.093 × 10 3 5.038 × 10 3 6.702 × 10 5 F rob enius norm p = 1000 1.252 × 10 3 1.252 × 10 3 1.251 × 10 3 1.252 × 10 3 1.252 × 10 3 1.252 × 10 3 1.251 × 10 3 p = 2000 3.582 × 10 3 3.582 × 10 3 3.577 × 10 3 3.582 × 10 3 3.582 × 10 3 3.582 × 10 3 3.600 × 10 3 p = 3000 6.649 × 10 3 6.649 × 10 3 6.639 × 10 3 6.649 × 10 3 6.649 × 10 3 6.649 × 10 3 6.738 × 10 3 Nuclear norm p = 1000 3.002 × 10 4 3.002 × 10 4 3.000 × 10 4 3.002 × 10 4 3.002 × 10 4 3.002 × 10 4 3.002 × 10 4 p = 2000 1.138 × 10 5 1.138 × 10 5 1.133 × 10 5 1.138 × 10 5 1.138 × 10 5 1.138 × 10 5 1.144 × 10 5 p = 3000 2.374 × 10 5 2.374 × 10 5 2.360 × 10 5 2.374 × 10 5 2.374 × 10 5 2.374 × 10 5 2.410 × 10 5 F rom T able B.6 , it is eviden t that under the sparse cov ariance structure with q = 0 . 1 , neither MMA nor CVXPY pro vides a practically meaningful adv antage. W e therefore exclude these t wo metho ds from the remaining exp erimen ts. F or MMA, the main issue is computa- tional efficiency . MMA is consistently the slow est metho d, and its runtime grows dramatically with the dimension: 1 . 157 × 10 4 seconds at p = 1000 , 3 . 817 × 10 4 seconds at p = 2000 , and 6 . 702 × 10 5 seconds at p = 3000 . In contrast, first-order splitting metho ds such as PFBS/LAD- MM/ADMM typically complete within 10 1 - 10 3 seconds at the same dimensions. This sev ere lac k of scalabilit y renders MMA impractical in our large-scale sim ulations. F or CVXPY, the main issue is solution qualit y rather than sp eed. CVXPY do es not yield an y noticeable im- pro vemen t in either the F rob enius norm or the n uclear norm: across all three dimensions, the F rob enius and n uclear norms pro duced by CVXPY are essentially identical to those achiev ed b y ADMM/LADMM/FIST A. F or instance, at p = 1000 , CVXPY attains a F rob enius norm of 41 1 . 252 × 10 3 and a nuclear norm of 3 . 002 × 10 4 , which are nearly the same as the corresp ond- ing v alues of the comp eting metho ds; similar b ehavior is observed for p = 2000 and p = 3000 . Moreo ver, CVXPY is also slo w er than efficient alternatives (e.g., 5 . 038 × 10 3 seconds at p = 3000 v ersus 3 . 849 × 10 2 seconds for PFBS), leading to a strictly w orse time–accuracy trade-off. 42 References [1] J. F an, Y. Liao, H. Liu, An ov erview of the estimation of large cov ariance and precision matrices, The Econometrics Journal 19 (2016) C1–C32. [2] M. J. W ainwrigh t, High-dimensional statistics: A non-asymptotic viewp oint, volume 48, Cam bridge universit y press, 2019. [3] C. Giraud, In tro duction to high-dimensional statistics, Chapman and Hall/CR C, 2021. [4] T. W. Anderson, An in tro duction to multiv ariate statistical analysis, v olume 2, Wiley New Y ork, 1958. [5] C. Lam, J. F an, Sparsistency and rates of con v ergence in large co v ariance matrix estima- tion, Annals of statistics 37 (2009) 4254. [6] M. P ourahmadi, High-dimensional cov ariance estimation: with high-dimensional data, John Wiley & Sons, 2013. [7] F. Li, N. R. Zhang, Bay esian v ariable selection in structured high-dimensional cov ariate spaces with applications in genomics, Journal of the American statistical asso ciation 105 (2010) 1202–1214. [8] A. Serra, P . Coretto, M. F ratello, R. T agliaferri, Robust and sparse correlation matrix estimation for the analysis of high-dimensional genomics data, Bioinformatics 34 (2018) 625–634. [9] R. P ang, B. J. Lansdell, A. L. F airhall, Dimensionalit y reduction in neuroscience, Curren t Biology 26 (2016) R656–R660. [10] J. F an, Y. F an, J. Lv, High dimensional co v ariance matrix estimation using a factor mo del, Journal of Econometrics 147 (2008) 186–197. [11] J. F an, Y. Liao, M. Minchev a, High dimensional cov ariance matrix estimation in approxi- mate factor mo dels, Annals of statistics 39 (2011) 3320. [12] G. V. Moura, A. A. San tos, E. Ruiz, Comparing high-dimensional conditional co v ariance matrices: Implications for p ortfolio s election, Journal of Banking & Finance 118 (2020) 105882. [13] A. Sarhadi, D. H. Burn, G. Y ang, A. Gho dsi, Adv ances in pro jection of climate c hange impacts using sup ervised nonlinear dimensionalit y reduction techniques, Climate dynamics 48 (2017) 1329–1351. [14] A. Miftakho v a, K. L. Judd, T. S. Lontzek , K. Sc hmedders, Statistical approximation of high-dimensional climate mo dels, Journal of Econometrics 214 (2020) 67–80. [15] X. Chen, M. Xu, W. B. W u, Co v ariance and precision matrix estimation for high- dimensional time series, Annals of Statistics 41 (2013) 2994–3021. [16] M. A v ella-Medina, H. S. Battey , J. F an, Q. Li, Robust estimation of high-dimensional co v ariance and precision matrices, Biometrik a 105 (2018) 271–284. [17] J. Janko vá, S. v an de Geer, Honest confidence regions and optimality in high-dimensional precision matrix estimation, T est 26 (2017) 143–162. 43 [18] C.-M. Ting, H. Om bao, S.-H. Salleh, A. Z. Ab d Latif, Multi-scale factor analysis of high- dimensional functional connectivit y in brain netw orks, IEEE T ransactions on Net work Science and Engineering 7 (2018) 449–465. [19] H. Ke, Z. Ren, J. Qi, S. Chen, G. C. T seng, Z. Y e, T. Ma, High-dimension to high- dimension screening for detecting genome-wide epigenetic and nonco ding rna regulators of gene expression, Bioinformatics 38 (2022) 4078–4087. [20] J. R. Bradley , S. H. Holan, C. K. Wikle, Multiv ariate spatio-temp oral mo dels for high- dimensional areal data with application to longitudinal employ er-household dynamics, The Annals of Applied Statistics 9 (2015) 1761. [21] Q. W ei, Z. Zhao, Large cov ariance matrix estimation with oracle statistical rate via ma jorization-minimization, IEEE T ransactions on Signal Pro cessing 71 (2023) 3328–3342. [22] G. F atima, P . Babu, P . Stoica, T w o new algorithms for maxim um likelihoo d estimation of sparse co v ariance matrices with applications to graphical modeling, IEEE T ransactions on Signal Pro cessing 72 (2024) 958–971. [23] V. A. Nguyen, D. Kuhn, P . Moha jerin Esfahani, Distributionally robust in verse co v ariance estimation: The w asserstein shrink age estimator, Op erations researc h 70 (2022) 490–515. [24] W. Zhu, X. Chen, W. B. W u, Online cov ariance matrix estimation in sto chastic gradien t descen t, Journal of the American Statistical Asso ciation 118 (2023) 393–404. [25] F. W en, L. Chu, R. Ying, P . Liu, F ast and p ositive definite estimation of large co v ariance matrix for high-dimensional data analysis, IEEE T ransactions on Big Data 7 (2019) 603– 609. [26] H. Sedghi, A. Anandkumar, E. Jonckheere, Multi-step stochastic admm in high dimen- sions: Applications to sparse optimization and matrix decomp osition, Adv ances in neural information pro cessing systems 27 (2014). [27] M. T an, Z. Hu, Y. Y an, J. Cao, D. Gong, Q. W u, Learning sparse p ca with stabilized admm metho d on stiefel manifold, IEEE T ransactions on Kno wledge and Data Engineering 33 (2019) 1078–1088. [28] J. Xu, K. Lange, A proximal distance algorithm for lik eliho o d-based sparse co v ariance estimation, Biometrik a 109 (2022) 1047–1066. [29] R. Tibshirani, et al., Proximal gradien t descent and acceleration, Lecture Notes (2010). [30] D. Kim, J. A. F essler, Another lo ok at the fast iterativ e shrink age/thresholding algorithm (fista), SIAM Journal on Optimization 28 (2018) 223–250. [31] E. T reister, J. T urek, A blo ck-coordinate descent approac h for large-scale sparse inv erse co v ariance estimation, A dv ances in neural information pro cessing systems 27 (2014). [32] Z. Qin, K. Sc heinberg, D. Goldfarb, Efficien t blo ck-coordinate descent algorithms for the group lasso, Mathematical Programming Computation 5 (2013) 143–169. [33] A. A. Amini, M. J. W ain wright, High-dimensional analysis of semidefinite relaxations for sparse principal comp onents, in: 2008 IEEE international symp osium on information theory , IEEE, 2008, pp. 2454–2458. 44 [34] J. F riedman, T. Hastie, R. Tibshirani, Sparse in verse co v ariance estimation with the graphical lasso, Biostatistics 9 (2008) 432–441. [35] R. Tibshirani, Regression shrink age and selection via the lasso, Journal of the Ro yal Statistical So ciet y Series B: Statistical Metho dology 58 (1996) 267–288. [36] M. Lin, D. Sun, K.-C. T oh, C. W ang, Estimation of sparse gaussian graphical mo dels with hidden clustering structure, Journal of Mac hine Learning Researc h 25 (2024) 1–36. [37] P . Danaher, P . W ang, D. M. Witten, Th e join t graphical lasso for inv erse co v ariance esti- mation across m ultiple classes, Journal of the Roy al Statistical So ciety Series B: Statistical Metho dology 76 (2014) 373–397. [38] L. Zhao, Y. W ang, S. Kumar, D. P . P alomar, Optimization algorithms for graph laplacian estimation via admm and mm, IEEE T ransactions on Signal Pro cessing 67 (2019) 4231– 4244. [39] D. Hallac, S. V are, S. Boyd, J. Lesko v ec, T o eplitz inv erse co v ariance-based clustering of m ultiv ariate time series data, in: Pro ceedings of the 23rd ACM SIGKDD in ternational conference on kno wledge discov ery and data mining, 2017, pp. 215–223. [40] C.-J. Hsieh, M. A. Sustik, I. S. Dhillon, P . Ra vikumar, Quic: Quadratic approximation for sparse inv erse co v ariance estimation, Journal of Machine Learning Researc h 15 (2014) 2911–2947. [41] C.-J. Hsieh, M. A. Sustik, I. S. Dhillon, P . K. Ra vikumar, R. P oldrack, Big & quic: Sparse inv erse cov ariance estimation for a million v ariables, Adv ances in neural information pro cessing systems 26 (2013). [42] Y. Zhang, N. Zhang, D. Sun, K.-C. T oh, A pro ximal point dual newton algorithm for solving group graphical lasso problems, SIAM Journal on Optimization 30 (2020) 2197– 2220. [43] X. Xie, J. W u, G. Liu, Z. Zhong, Z. Lin, Differen tiable linearized admm, in: In ternational Conference on Mac hine Learning, PMLR, 2019, pp. 6902–6911. [44] K. Gregor, Y. LeCun, Learning fast approximations of sparse co ding, in: Pro ceedings of the 27th international conference on in ternational conference on machine learning, 2010, pp. 399–406. [45] R. Liu, G. Zhong, J. Cao, Z. Lin, S. Shan, Z. Luo, Learning to diffuse: A new p ersp ective to design p des for visual analysis, IEEE transactions on pattern analysis and machine in telligence 38 (2016) 2457–2471. [46] Y. Chen, T. P o ck, T rainable nonlinear reaction diffusion: A flexible framew ork for fast and effectiv e image restoration, IEEE transactions on pattern analysis and mac hine in telligence 39 (2016) 1256–1272. [47] B. Li, L. Y ang, Y. Chen, S. W ang, Q. Chen, H. Mao, Y. Ma, A. W ang, T. Ding, J. T ang, et al., Pdhg-unrolled learning-to-optimize method for large-scale linear programming, arXiv preprin t arXiv:2406.01908 (2024). [48] Z. Lin, Z. Xiong, D. Ge, Y. Y e, Pdcs: A primal-dual large-scale conic programming solver with gpu enhancemen ts, arXiv preprin t arXiv:2505.00311 (2025). 45 [49] L. Y ang, B. Li, T. Ding, J. W u, A. W ang, Y. W ang, J. T ang, R. Sun, X. Luo, An efficient unsup ervised framew ork for conv ex quadratic programs via deep unrolling, arXiv preprint arXiv:2412.01051 (2024). [50] Q. Li, T. Ding, L. Y ang, M. Ouyang, Q. Shi, R. Sun, On the p o we r of small-size graph neu- ral netw orks for linear programming, Adv ances in Neural Information Pro cessing Systems 37 (2024) 38695–38719. [51] Q. Chen, T. Zhang, L. Y ang, Q. Han, A. W ang, R. Sun, X. Luo, T.-H. Chang, Symilo: A symmetry-a ware learning framew ork for integer linear optimization, A dv ances in Neural Information Pro cessing Systems 37 (2024) 24411–24434. [52] Q. Li, M. Ouy ang, T. Ding, Y. W ang, Q. Shi, R. Sun, T ow ards explaining the p ow er of constan t-depth graph neural netw orks for structured linear programming, in: The Thirteen th International Conference on Learning Representations, 2025. [53] A. J. Rothman, E. Levina, J. Zh u, Generalized thresholding of large co v ariance matrices, Journal of the American Statistical Association 104 (2009) 177–186. [54] L. Xue, S. Ma, H. Zou, P ositiv e-definite ℓ 1 -p enalized estimation of large co v ariance matri- ces, Journal of the American Statistical Asso ciation 107 (2012) 1480–1491. [55] J. F an, R. Li, V ariable selection via nonconcav e p enalized likelihoo d and its oracle prop- erties, Journal of the American statistical Asso ciation 96 (2001) 1348–1360. [56] C.-H. Zhang, Nearly un biased v ariable selection under minimax conca ve p enalty , The Annals of Statistics 38 (2010) 894. [57] H. Zou, R. Li, One-step sparse estimates in nonconcav e p enalized lik eliho o d mo dels, Annals of statistics 36 (2008) 1509. [58] H. Attouc h, J. Bolte, P . Redont, A. Soub eyran, Proximal alternating minimization and pro- jection metho ds for nonconv ex problems: An approach based on the kurdyk a-ło jasiewicz inequalit y , Mathematics of operations research 35 (2010) 438–457. [59] R. V ershynin, High-Dimensional Probabilit y: An Introduction with Applications in Data Science, volume 47 of Cambridge Series in Statistic al and Pr ob abilistic Mathematics , Cam- bridge Univ ersity Press, Cambridge, 2018. doi: 10.1017/9781108231596 . [60] D. Da vis, W. Yin, A three-op erator splitting sc heme and its optimization applications, Set-v alued and v ariational analysis 25 (2017) 829–858. [61] P . L. Com b ettes, V. R. W a js, Signal reco v ery by pro ximal forward-bac kw ard splitting, Multiscale mo deling & sim ulation 4 (2005) 1168–1200. [62] A. Beck, M. T eb oulle, A fast iterative shrink age-thresholding algorithm for linear inv erse problems, SIAM journal on imaging sciences 2 (2009) 183–202. [63] S. Diamond, S. Bo yd, CVXPY: A Python-embedded mo deling language for conv ex opti- mization, Journal of Mac hine Learning Researc h 17 (2016) 1–5. [64] D. R. Hun ter, K. Lange, A tutorial on mm algorithms, The American Statistician 58 (2004) 30–37. 46 [65] P . Ravikumar, M. J. W ain wright, G. Raskutti, B. Y u, High-dimensional cov ariance es- timation by minimizing l1-p enalized log-determinant div ergence, Electronic Journal of Statistics 5 (2011) 935–980. [66] D. Grishchenk o, F. Iutzeler, J. Malic k, Proximal gradien t metho ds with adaptive subspace sampling, Mathematics of Operations Research 46 (2021) 1303–1323. [67] F. P edregosa, G. Negiar, A. Ask ari, M. Jaggi, Linearly conv ergen t frank-wolfe with back- trac king line-searc h, in: In ternational conference on artificial intelligence and statistics, PMLR, 2020, pp. 1–10. [68] E. G. Birgin, J. M. Martínez, M. Raydan, Sp ectral pro jected gradient metho ds: review and p ersp ectiv es, Journal of Statistical Softw are 60 (2014) 1–21. [69] C. T an, S. Ma, Y.-H. Dai, Y. Qian, Barzilai-b orwein step size for sto c hastic gradient descen t, Adv ances in neural information processing systems 29 (2016). [70] F. Bac h, Breaking the curse of dimensionality with con vex neural net w orks, Journal of Ma- c hine Learning Research 18 (2017) 1–53. URL: http://jmlr.org/papers/v18/14- 546. html . 47
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment