패러프레이즈 강인성 진단 벤치마크 LIBERO Para
LIBERO Para는 로봇 조작을 위한 비전‑언어‑액션(VLA) 모델의 언어적 일반화 능력을 평가하기 위해 설계된 제어된 벤치마크이다. 행동 표현과 객체 지시를 독립적으로 변형하여 43가지 세분화된 패러프레이즈 유형을 제공하고, 0.6B‑7.5B 규모의 7가지 모델을 테스트한 결과, 패러프레이즈에 의해 성공률이 22‑52%p 감소한다. 특히 객체 레벨의 어휘 변형이 큰 성능 저하를 일으키며, 실패의 80‑96%가 계획 단계의 목표 인식 오류임…
저자: Chanyoung Kim, Minwoo Kim, Minseok Kang
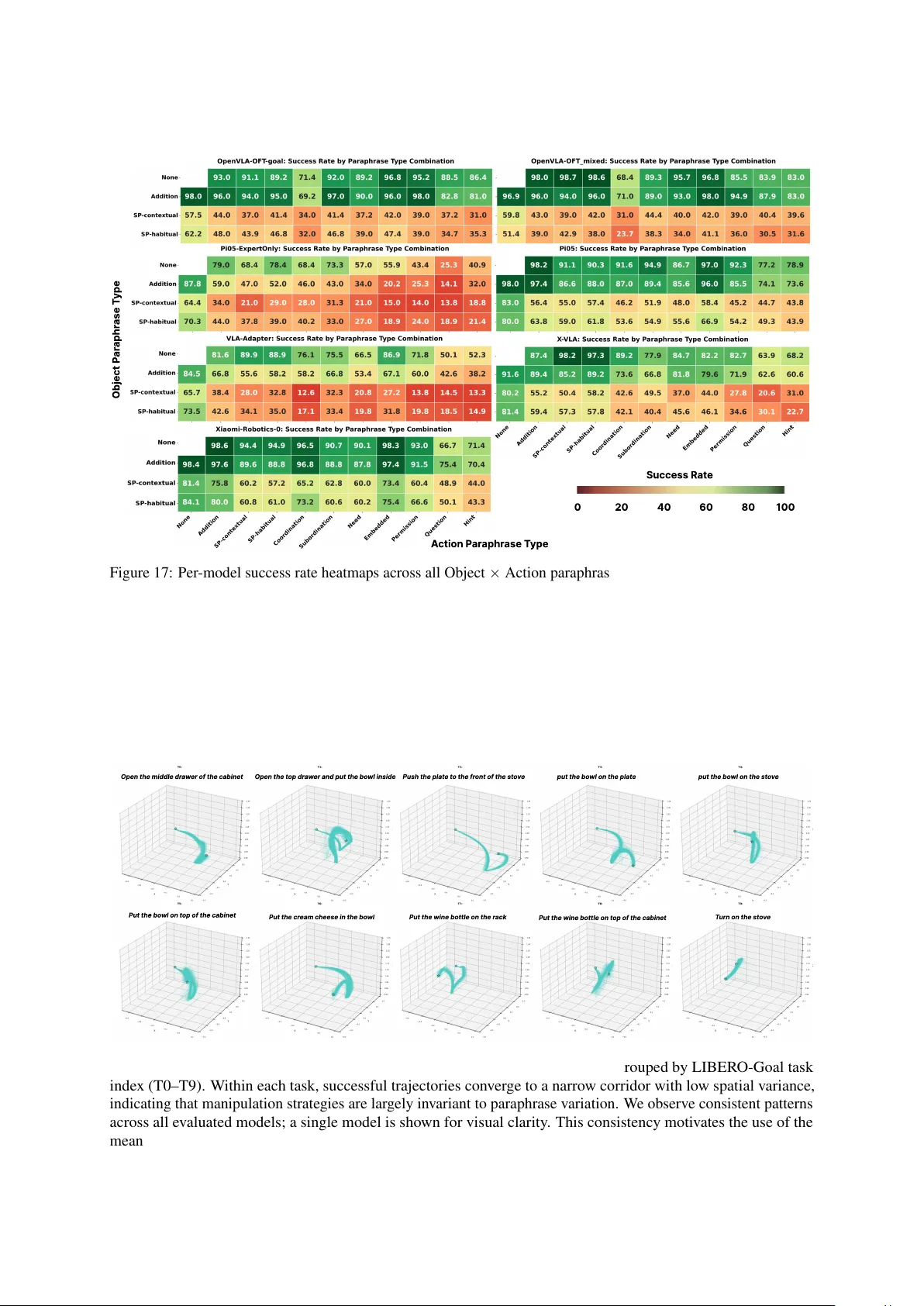
본 논문은 로봇 조작을 위한 비전‑언어‑액션(VLA) 모델이 제한된 파인튜닝 데이터로 인해 특정 명령 형태에 과적합(overfitting)되는 문제를 지적한다. 기존 LIBERO와 같은 벤치마크는 시각적 일반화에 초점을 맞추고, 언어적 변형에 대한 평가가 부족했다. 이를 보완하고자 저자들은 “LIBERO Para”라는 새로운 진단 벤치마크를 제안한다. LIBERO Para는 로봇 조작 명령을 핵심적인 두 축, 즉 행동 표현(action)과 객체 지시(object)로 분해하고, 각각에 대해 의미를 보존하면서도 다양한 어휘·구조·실용적 변형을 적용한다. 행동 축은 어휘 변형(동의어 교체·부사 삽입), 구조 변형(절 연결·전환), 실용적 변형(간접화)으로 구분되며, 객체 축은 동일 의미 교체, 추가, 맥락·습관적 변형 등으로 정의된다. 이러한 변형을 조합해 총 43가지 세분화된 패러프레이즈 유형을 만들고, 각 유형당 약 100개의 샘플을 제공해 전체 4,092개의 패러프레이즈 데이터를 구축하였다.
실험에서는 0.6B에서 7.5B 파라미터 규모의 7가지 VLA 모델(다양한 아키텍처: 병렬 디코딩, VLM‑플로우 매칭, 교차‑어텐션 브릿지, 소프트‑프롬프트 등)을 동일한 데이터‑희소 파인튜닝 환경에 적용했다. 결과는 모든 모델이 패러프레이즈에 대해 일관된 성능 저하를 보였으며, 성공률 감소폭은 22~52 퍼센트 포인트에 달했다. 특히 객체 레벨 어휘 변형이 가장 큰 영향을 미쳐, 단순 동의어 교체만으로도 평균 30~45%p의 추가 손실을 초래했다. 이는 모델이 표면적인 토큰 매칭에 의존하고, 객체 의미를 깊이 이해하지 못한다는 것을 의미한다.
오류 원인 분석을 위해 계획 단계와 실행 단계로 구분된 로그를 검토했으며, 전체 실패 중 80~96%가 계획 단계에서 목표 행동을 올바르게 식별하지 못한 데서 발생했다. 즉, 패러프레이즈가 로봇의 목표 인식(what to do) 자체를 흐리게 만들어, 실제 물리적 실행 단계에서는 정상적인 동작을 수행하더라도 전체 미션이 실패하는 구조였다.
이러한 현상을 정량화하기 위해 논문은 PRIDE(Paraphrase Robustness Index in Robotic Instructional Deviation) 지표를 제안한다. PRIDE는 (1) 핵심 키워드(동작·객체) 보존 정도를 측정하는 SK와 (2) 의존구조 트리 편집 거리 기반 구조 유사도 ST를 결합한다. SK는 Sentence‑BERT 임베딩을 이용해 원문과 패러프레이즈 사이의 핵심 토큰 매칭을 코사인 유사도로 평균화하고, ST는 POS와 의존관계만을 사용해 트리 편집 거리를 정규화해 1‑TED/size 형태로 계산한다. 두 점수를 가중 평균해 최종 PRIDE 점수를 산출함으로써, 동일 성공률이라도 난이도에 따른 모델의 언어 이해 수준을 정량적으로 비교할 수 있다. 실험 결과, PRIDE 점수가 낮은(즉, 어휘·구조 변형이 큰) 패러프레이즈에서 모델의 성공률이 현저히 떨어지는 경향이 확인되었다. 특히 어휘 변형에 대한 취약성이 구조적 변형보다 더 두드러졌다.
논문의 주요 기여는 다음과 같다. 첫째, 의미 보존을 전제로 한 패러프레이즈를 체계적으로 제어·분류한 벤치마크 LIBERO Para를 제공함으로써 VLA 모델의 언어 일반화 능력을 정밀하게 평가할 수 있게 했다. 둘째, 행동·객체 축을 독립적으로 변형함으로써 어느 축이 모델 성능에 더 큰 영향을 미치는지 명확히 구분했다. 셋째, 계획 단계에서의 목표 인식 오류가 주요 실패 원인임을 밝혀, 향후 연구가 언어‑목표 매핑 강화에 초점을 맞춰야 함을 제시했다. 넷째, PRIDE라는 새로운 정량 지표를 도입해 패러프레이즈 난이도와 성공률을 연계함으로써, 단순 0/1 성공률이 놓치는 미세한 로봇 언어 이해 차이를 드러냈다. 마지막으로, 코드와 데이터셋을 공개함으로써 커뮤니티가 향후 VLA 모델의 언어 강인성을 체계적으로 개선하고, 실제 로봇 시스템에 안전하게 적용할 수 있는 기반을 마련했다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기