LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
Vision-Language-Action (VLA) models achieve strong performance in robotic manipulation by leveraging pre-trained vision-language backbones. However, in downstream robotic settings, they are typically fine-tuned with limited data, leading to overfitti…
Authors: Chanyoung Kim, Minwoo Kim, Minseok Kang
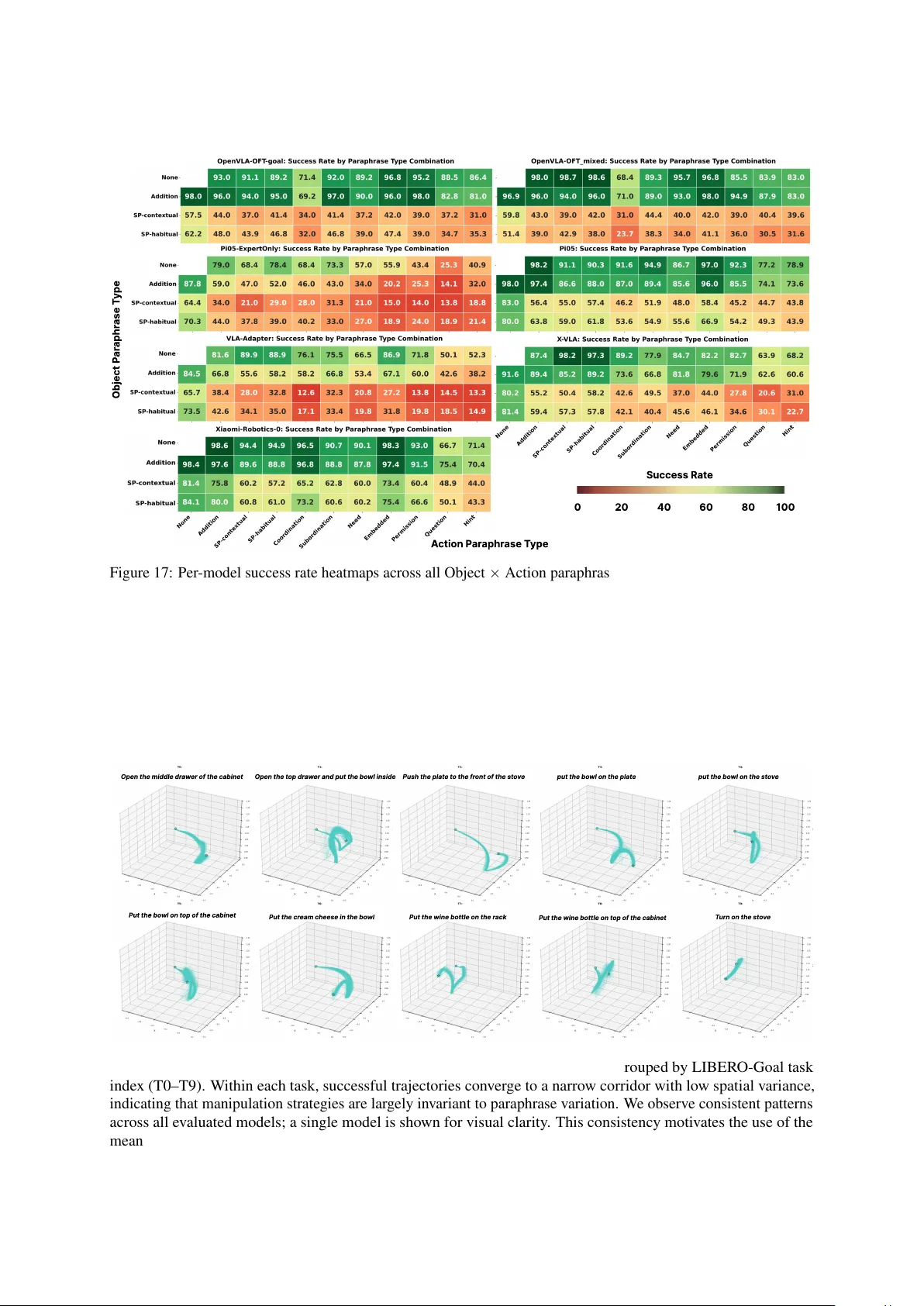
LIBER O-Para: A Diagnostic Benchmark and Metrics f or Paraphrase Rob ustness in VLA Models Chany oung Kim 1* Minwoo Kim 1* Minseok Kang 1 Hyunwoo Kim 2 Dahuin Jung 2† 1 Soongsil Uni versity 2 Chung-Ang Uni versity {verddak, alsdn5531, alstjrrkd201}@soongsil.ac.kr , {k980814h, dahuinjung}@cau.ac.kr Abstract V ision–Language–Action (VLA) models achiev e strong performance in robotic manipulation by lev eraging pre-trained vision–language backbones. Howe ver , in downstream robotic settings, the y are typically fine-tuned with limited data, leading to over - fitting to specific instruction formulations and leaving rob ustness to paraphrased instructions underexplored. T o study this gap, we introduce LIBER O-Para, a controlled benchmark that independently varies action e xpressions and object references for fine-grained analysis of linguistic generalization. Across se ven VLA configurations (0.6B–7.5B), we observe con- sistent performance degradation of 22–52 pp under paraphrasing. This degradation is pri- marily dri ven by object-le vel lexical v ariation: ev en simple synonym substitutions cause large drops, indicating reliance on surface-le vel matching rather than semantic grounding. Moreov er , 80–96% of failures arise from planning-le vel trajectory div ergence rather than ex ecution errors, showing that paraphrasing disrupts task identification. Binary success rate treats all paraphrases equally , obscuring whether models perform consistently across difficulty levels or rely on easier cases. T o address this, we propose PRIDE, a metric that quantifies paraphrase difficulty using semantic and syntactic factors. Our benchmark and corresponding code are available at: https: //github.com/cau- hai- lab/LIBERO- Para 1 Introduction V ision-Language-Action (VLA) models ha ve emerged as a promising paradigm for robotic manipulation ( Zitko vich et al. , 2023 ; Black et al. , 2024 ). By lev eraging large pre-trained vision-language models (VLMs) as backbones, VLA models acquire instruction-following capa- bilities through large-scale multimodal percep- * Equal contribution. † Corresponding author . T r ain “T urn on t he st o v e” T est “T urn on t he st o v e” Success R at e : 99% Fine-tuning “Car efully turn on t he st o v e” “T urn on t he hob” “Fir e up t he st o v e” “Initiat e t he hotplat e” “Could y ou turn on t he st o v e? ” Unseen Instructions R esult s Deplo y Figure 1: Illustration of paraphrase robustness gap un- der data-scarce fine-tuning: VLA models can ov erfit to seen instruction phrasings during fine-tuning and fail to generalize to paraphrased variants at deplo yment. tion ( Zitko vich et al. , 2023 ; Black et al. , 2024 ). T o deploy such models in specific en vironments (e.g., kitchens, homes, offices, or laundry rooms) ( Black et al. , 2024 ; Physical Intelligence et al. , 2025 ; Zitko vich et al. , 2023 ; Fu et al. , 2024 ; W u et al. , 2023 ), existing approaches typically perform fine- tuning using en vironment-specific demonstration data ( Fu et al. , 2024 ). Howe ver , acquiring such data entails considerable cost and labor o verhead. Consequently , real-world deplo yment often neces- sitates data-scarce fine-tuning, which can induce ov erfitting and degrade the general kno wledge em- bedded in pre-trained VLA models ( Y ada v et al. , 2025 ; Zhou et al. , 2025 ). Such ov erfitting raises a practical concern that models may perform well on seen instruction phrasings yet fail to generalize to unseen paraphrased instructions at deployment. Under these circumstances, as shown in Fig. 1 , benchmarks that rigorously assess robustness after fine-tuning become important ( Zhou et al. , 2025 ). 1 Ho wev er , the LIBER O benchmark ( Liu et al. , 2023 ), which has become widely adopted in cur- rent VLA research, e valuates models under identi- cal instructions during both training and e valuation. It primarily measures visual generalization to novel object configurations or scene layouts, while lea v- ing rob ustness to linguistic variation lar gely unex- amined. Consequently , the linguistic robustness of VLA models remains insuf ficiently v alidated ( Fei et al. , 2025 ; W ang et al. , 2024 ; Zhou et al. , 2025 ). Se veral benchmarks have examined linguistic v ariation in VLA e v aluation ( Mees et al. , 2021 ; W ang et al. , 2024 ). Howe ver , as summarized in T ab . 1 , these approaches exhibit key limitations for assessing paraphrase rob ustness. Paraphrasing is often treated as one axis among broader multi- modal perturbations ( Zhou et al. , 2025 ; Fei et al. , 2025 ; W ang et al. , 2026 ), or conflated with task- le vel semantic changes that alter the intended be- havior ( Hou and Zhao , 2026 ), rather than isolating meaning-preserving v ariation. Furthermore, lin- guistic properties specific to robotic manipulation instructions are not explicitly modeled, and the distance between paraphrases is not formally quan- tified, limiting the ability to analyze which types of v ariation most sev erely impact performance. T o address these limitations, we introduce LIBER O-Para, a controlled benchmark for e valuat- ing paraphrase rob ustness in VLA models, along with PRIDE (Paraphrase Rob ustness Index in Robotic Instructional DEviation), a metric that combines ke yword similarity (le xical shift) and structural similarity (syntactic v ariation) with task success to enable fine-grained robustness analysis. LIBER O-Para is grounded in the linguistic struc- ture of robotic manipulation instructions—where actions and objects serv e as core semantic ele- ments—and adopts a two-axis design that indepen- dently v aries action expressions and object refer - ences. Our analysis based on LIBER O-Para re veals three ke y findings: • Paraphrase Fragility P ersists: Performance consistently degrades under paraphrased in- structions across architectures, scales, and fine-tuning strategies. • Object-Lev el Bottleneck: Object-le vel lexi- cal v ariation is the dominant source of degra- dation, indicating reliance on surface-lev el matching rather than semantic grounding. • Planning-Lev el F ailures: 80–96% of failures Benchmark Scope Paraphrase Control V ariation Axis Para. T ypes CAL VIN Instruction × Sentence 1 LADEV Paraphrase × Sentence 1 LIBER O-PRO Multimodal ∆ Sentence 2 LIBER O-Plus Multimodal ∆ Sentence 5 LIBER O-X Multimodal ∆ Sentence 5 LangGap T ask Semantics × 4 Semantic dims 4 LIBER O-Para (Ours) Paraphrase ✓ Action × Object 43 T able 1: Comparison with existing benchmarks for lin- guistic rob ustness. LIBER O-Para provides full para- phrase control with fine-grained action × object v aria- tion axes and 43 linguistically grounded types. × : not supported, ∆ : partially supported, ✓ : fully supported. arise from trajectory div ergence, suggesting errors in task identification rather than action ex ecution. This work contrib utes to advancing VLA systems beyond high performance to ward rob ustness to lin- guistic v ariation and reliable task interpretation. 2 Related W ork 2.1 V ision-Language-Action Models V ision-Language-Action (VLA) models map vi- sual and linguistic input to robot actions. Early approaches extend LLM backbones to autore gres- si vely decode discrete action tokens ( Zitkovich et al. , 2023 ; Kim et al. , 2024 ). Recent work has di versified along se veral architectural ax es: paral- lel decoding with action chunking, which predicts all actions in a single forward pass for faster infer - ence ( Kim et al. , 2025 ); VLM coupled with a flow- matching action expert, which pairs a billion-scale VLM with a separate action decoder ( Black et al. , 2024 ; Physical Intelligence et al. , 2025 ; Cai et al. , 2026 ); lightweight bridge-based adaptation, which routes VLM representations to a compact policy head via cross-attention ( W ang et al. , 2025 ); and soft-prompted cross-embodiment designs, which encode embodiment-specific knowledge through learnable tokens ( Zheng et al. , 2025 ). The latter two operate at 0.6–0.9B scale, contrasting with ear- lier multi-billion-parameter designs. Despite this di versity , all models require en vironment-specific fine-tuning with limited demonstration data. In this work, we e v aluate representativ es from each fam- ily to assess whether paraphrase rob ustness is an architecture-specific issue or a shared vulnerability . 2.2 Benchmarks for VLA models A range of benchmarks have been proposed to ev al- uate linguistic conditioning in VLA models; T ab . 1 compares their design choices. CAL VIN ( Mees 2 LIBER Fine-t uning T r ain(LIBERO) T est Success Rat e : 99% Fine-t uning T r ain(LIBERO) T es Success Rat e : 71% LIBERO-P ar a (Ours T est Dat aset “T urn on t he st o v e” “Swit ch on t he st o v e” “ A ctiv at e t he cookt op” Pr agmat ic Le xical(A ct ) None A ddit ion SP -cont e xt ual SP -habit ual Coor dinat ion A ct ion axis Subor dinat ion Need-st at ement P ermission _ dir ect i v e Embedded-imper at i v e Q uest ion-dir ect i v e H int 4 3 cat egories(N = 4 , 092) “T urn on t he st o v e” “T urn on t he st o v e” “T urn on t he st o v e” LIBERO-P ar a T est R esult Analysi None 11 22 33 1 12 2 3 3 4 2 1 3 2 4 35 3 14 2 5 3 6 4 1 5 26 3 7 5 6 16 17 27 28 3 8 3 9 SUM 7 18 29 40 8 19 3 0 4 1 9 20 3 1 42 10 21 3 2 4 3 SUM : I’ v e got t his no w! Deplo y Go t o t he st o v e and turn it on Ho w did y ou pass t he t est? Object axis A ddit ion SP -cont e xt ual SP -habit ual Object A ct ion No w w e can analyz e it! St ruct ur al Le xical - 100 - 80 - 60 - 40 - 20 Success Rat e(%) - 0 Figure 2: Overvie w of LIBER O-Para. Compared to LIBER O, LIBER O-Para e valuates paraphrase rob ustness under data-scarce fine-tuning via a controlled two-axis design (action vs. object), enabling interpretable analysis. et al. , 2021 ) and LADEV ( W ang et al. , 2024 ) assess generalization to rephrased instructions, but treat paraphrasing as unstructured sentence-le vel vari- ation without linguistic categorization. LIBER O- PR O, LIBER O-Plus, and LIBER O-X ( Zhou et al. , 2025 ; Fei et al. , 2025 ; W ang et al. , 2026 ) intro- duce multimodal perturbation-based ev aluations that include linguistic v ariation as one of se veral axes, re vealing limited dependence on genuine lin- guistic understanding; howe ver , paraphrasing re- mains a secondary concern within their broader e valuation scope. LangGap ( Hou and Zhao , 2026 ) targets language conditioning more directly , but its perturbations alter the intended behavior (e.g., changing which object to grasp), conflating task- le vel semantic changes with linguistic variation. In contrast, our LIBER O-Para differs in two key as- pects: (1) it isolates meaning-preserving linguistic v ariation from task-level semantic changes, and (2) rather than applying sentence-le vel perturbations with ad-hoc categories, it identifies the essential lin- guistic components of robotic manipulation instruc- tions—action verbs and object references—and de- composes paraphrases along these two ax es based on established linguistic taxonomies ( Ko vatche v et al. , 2018 ; Ervin-T ripp , 1976 ), yielding 43 fine- grained v ariation types (T ab . 1 ). 3 LIBER O-Para: A Controlled VLA Benchmark f or Paraphrase Robustness W e introduce LIBER O-Para, a controlled bench- mark for ev aluating the paraphrase robustness of VLA models. As shown in T ab . 1 , existing bench- marks of fer limited control ov er paraphrase varia- tion; our design addresses this through a two-axis scheme that independently varies action expres- sions and object references—the two core linguistic components of robotic manipulation instructions. This separation enables controlled analysis of ho w dif ferent linguistic factors affect VLA performance. LIBER O-Para is constructed on top of LIBER O- Goal, a setting in which linguistic understanding is essential: all tasks start from an identical initial state, making the instruction the sole cue for task identification. W e generate the benchmark by para- phrasing only the instructions while k eeping all other factors fix ed. All paraphrases are held out for e valuation, allo wing assessment of generalization to unseen linguistic v ariations under data-scarce fine-tuning scenarios, as illustrated in Fig. 2 . 3.1 Action V ariation The action axis captures variation in how actions are linguistically expressed. W e define three types of action v ariation grounded in established para- phrase taxonomies. (1) Lexical v ariation modifies the action verb at the word le vel, including syn- onym substitution and adv erb insertion. (2) Struc- tural v ariation alters the sentence-lev el realization of the action e xpression, such as coordination and subordination. (3) Pragmatic v ariation expresses actions indirectly , covering indirect speech acts. Lexical and structural variations are instantiated based on the Extended Paraphrase T ypology ( K o- v atchev et al. , 2018 ). Pragmatic v ariations are de- fined in accordance with Ervin-Tripp ( 1976 ). Fig. 3 (bottom) presents representativ e examples for each type. 3.2 Object V ariation captures v ariation in how objects are referenced in instructions. In robotic manipulation, object refer- ences are typically realized as noun phrases with 3 A ddition : T urn on t he gas st o v e SP -cont e xtual : T urn on t he cookt op SP -habitual : T urn on t he cook er Obj Original : T urn on t he st o v e SP -habitual : Fir e up t he st o v e Coor dination : Go t o t he st o v e and turn it on Subor dination : T urn on t he st o v e so t hat it becomes hot Need-stat ement : I need t he st o v e turned on Embedded-imper ativ e : Could y ou turn on t he st o v e? P ermission-dir ectiv e : Ma y I ha v e t he st o v e turned on? Question-dir ectiv e : Is t he st o v e heating up? Hint : T he st o v e i s st ill o ff A ddition : Car efully turn on t he st o v e S P -cont e x t : Swi t c h on t he st o v e A ctio Figure 3: Examples of axis-specific paraphrases. Ob- ject v ariations modify target object references (e.g., same-polarity substitution, addition), while action varia- tions co ver lexical, structural, and pragmatic realizations grounded in established taxonomies. limited complexity (e.g., “ the stove ” → “ the cook- top ”). W e focus on lexical-le vel v ariation. Follo w- ing the Extended P araphrase T ypology ( Ko v atchev et al. , 2018 ), we define three subtypes: addition and same-polarity substitution (contextual and habitual v ariants). Fig. 3 (top) illustrates representati ve e x- amples. 3.3 Compositional V ariation Beyond individual ax es, we e valuate compositional paraphrases that v ary both action and object e xpres- sions. This setting enables analysis of whether the two axes have independent or interaction effects on VLA performance. Fig. 2 presents an exam- ple, including a success-rate grid over v ariation combinations and success rates for each axis. T o ensure balanced e valuation, the benchmark includes approximately 100 samples per v ariation type, resulting in a total of 4,092 paraphrased in- structions. Additional details on the taxonomy , paraphrase generation process, and excluded varia- tion types—including justifications for why certain types are inapplicable to robotic manipulation in- structions—are provided in Appendix A . 4 PRIDE: Paraphrase Rob ustness Index in Robotic Instructional DEviation Existing VLA benchmarks rely on a binary suc- cess metric, assigning 1 if the robot completes the instructed task and 0 otherwise. Ho wev er , this met- ric does not distinguish between easy and difficult paraphrases, obscuring whether performance re- flects rob ust linguistic understanding or reliance on simpler instruction v ariants. T o enable interpretable robustness ev aluation, we propose PRIDE, a metric that quantifies the lin- guistic de viation between an original instruction and its paraphrase. Unlike general-purpose metrics, PRIDE is tailored to robotic instructions and de- composes paraphrase variation along tw o axes: (1) ke yword variation and (2) structural v ariation. 4.1 Keyword Similarity S K K eyword similarity measures ho w much core ke y- words e xpressing actions and target objects are pre- served between an original instruction and its para- phrase. Robotic manipulation instructions are typ- ically structured around explicit actions and their corresponding objects, often following a canonical form such as “ [ACT] the [OBJ] ” (e.g., "pick up the bowl" ). As a result, the intended behavior is of- ten determined by a small set of task-critical tokens rather than by the sentence as a whole. This property limits the usefulness of form- based NLP metrics for paraphrased robotic in- structions. For example, n-gram metrics such as BLEU ( Papineni et al. , 2002 ) emphasize le xical ov erlap and may fa il to distinguish paraphrases that preserve actions and objects but differ in expres- sion, through synonym substitution or word-order v ariation. Function words can also cause superficial grammatical changes to overly influence similarity scores relati ve to action- or object-le vel semantics. In our setting, the two sentences are gi ven as a paraphrase pair . Thus, rather than reassessing ov erall semantic equi valence, it is more useful to analyze ho w task-critical components change. Ac- cordingly , we define a keyw ord-lev el similarity that focuses on content words expressing actions and objects excluding function w ords. Let O = { o 1 , . . . , o n } and P = { p 1 , . . . , p m } denote the sets of content words extracted from the original and paraphrased instructions, respec- ti vely . Each word is represented by an embed- ding e ( · ) obtained from Sentence-BER T ( Reimers and Gurevych , 2019 ). The keyword similarity S K ( O , P ) is computed by matching each content word o i in the original instruction to the most sim- ilar word in the paraphrase, measured by cosine similarity , and av eraging ov er all o i : S K ( O , P ) = 1 n n X i =1 max j ∈{ 1 ,...,m } cos e ( o i ) , e ( p j ) , (1) 4 :0 . 88 Put t he t he Put please st o v e st o v e bo wl bo wl on ? y ou t he t he W ould r oot dobj pobj ot her Put t he bo wl on t he st o v e Place t he container on t he cookt op on Structur al Similarity : 0 . 95 : 0 . 92 K e yw or d Similarity Figure 4: S K (top) and S T (bottom) computation. S K is based on semantic matching between task-critical content words, while S T uses dependency-tree edit dis- tance. Node colors indicate dependenc y relations: root (sentence root), dobj (direct object), pobj (object of preposition), and others (remaining types, simplified for visualization; all included in computation). where cos( · , · ) denotes cosine similarity . Fig. 4 (top) illustrates the computation of S K . A higher v alue of S K ( O , P ) indicates better preservation of the original instruction’ s key content words in the paraphrase. 4.2 Structural Similarity S T While ke yword similarity S K captures the preser - v ation of core lexical items, it does not account for syntactic changes. T ransformations such as acti ve-passi ve alternation or clause reordering can substantially alter the form of an instruction while preserving the same ke ywords. T o capture such v ariation, we introduce structural similarity S T . W e measure syntactic change using the tree edit distance (TED) ( Augsten and Böhlen , 2013 ) be- tween the dependency trees of the original and paraphrased instructions, denoted by T O and T P . TED is defined as the minimum number of edit op- erations—node and edge insertions, deletions, and substitutions—required to transform one tree into the other . T o focus on structural differences, we compute TED on dependency trees whose node la- bels are part-of-speech (POS) tags and whose edge labels are dependency relations rather than surface words, reducing sensiti vity to lexical substitutions. T o mitigate sentence-length ef fects, we normal- ize TED by the combined size of two trees and define structural similarity S T ( T O , T P ) as follo ws: S T ( T O , T P ) = 1 − TED( T O , T P ) | T O | + | T P | . (2) where |·| denotes the number of nodes in tree Method LIBER O-Goal LIBER O-Para SR SR (Drop) OpenVLA-OFT goal 97.9 64.7 ( -33.2 ) OpenVLA-OFT mixed 96.1 63.7 ( -32.4 ) π 0.5 97.6 71.4 ( -26.2 ) π 0.5 (expert-only) 78.6 39.1 ( -39.5 ) X-VLA 97.8 62.1 ( -35.7 ) VLA-Adapter 98.2 46.3 ( -51.9 ) Xiaomi-Robotics-0 98.8 76.0 ( -22.8 ) T able 2: Success rate (SR) comparison between LIBER O-Goal and LIBER O-Para. Drop denotes the absolute decrease in success rate. T . Fig. 4 (bottom) illustrates the computation of S T . Lower v alues of S T ( T O , T P ) indicate greater structural di vergence, such as word-order changes or reorg anization of modification relations. 4.3 PRIDE Score Robustly assessing paraphrased robotic manipu- lation instructions requires considering both (i) whether task-critical action/object ke ywords are preserved ( S K ) and (ii) ho w much the imperati ve structure is altered ( S T ). Accordingly , we define Paraphrase Distance (PD) by combining S K and S T to quantify the overall deviation between an original robotic instruction and its paraphrase: PD = 1 − αS K ( O , P ) + (1 − α ) S T ( T O , T P ) , (3) where α ∈ [0 , 1] controls the relativ e contribu- tion of ke yword and structural similarity ( α = 0 . 5 by default). Higher PD indicates greater semantic and structural de viation. PRIDE = ( PD , success 0 , failure. (4) This score complements binary success metrics by distinguishing whether a VLA model can suc- ceed under paraphrased instructions that exhibit larger semantic and structural de viations. 5 Experiment 5.1 Setup W e ev aluate sev en model configurations (0.6B– 7.5B) spanning four architecture families: par - allel decoding with action chunking (OpenVLA- OFT), VLMs with a flow-matching action expert ( π 0.5 , Xiaomi-Robotics-0), soft-prompted cross- embodiment (X-VLA), and bridge-based adapta- tion (VLA-Adapter). W ithin the same architecture, we include controlled comparisons on fine-tuning 5 Method SR PRIDE Overestimation (%) VLA-Adapter 46.3 36.1 22.0 π 0.5 (expert-only) 39.1 32.0 18.2 X-VLA 62.1 52.7 15.1 OpenVLA-OFT mixed 63.7 56.3 11.6 OpenVLA-OFT goal 64.7 58.8 9.1 Xiaomi-Robotics-0 76.0 69.2 8.9 π 0.5 71.4 65.4 8.4 T able 3: SR and PRIDE scores on LIBER O-Para, sorted by ov erestimation. Overestimation is computed as (SR – PRIDE) / SR, indicating ho w much uniform success rate ov erstates a model’ s paraphrase robustness. data scope (OFT goal vs. OFT mixed ) and VLM train- ing strategy ( π 0.5 full vs. expert-only). Full specifi- cations are in Appendix C.1 . 5.2 Results Success Rate Comparison. T ab. 2 compares suc- cess rates between LIBERO-Goal and LIBER O- Para. All models exhibit consistent performance degradation ranging from 22.8 pp to 51.9 pp, indi- cating that the ef fect is not architecture-specific b ut perv asiv e across models. Even the top-performing models on LIBER O-Goal (Xiaomi-Robotics-0: 98.8%, VLA-Adapter: 98.2%) suffer drops of 22.8 pp and 51.9 pp under paraphrasing, respec- ti vely , with VLA-Adapter losing nearly half of its performance. PRIDE Rev eals Hidden Severity . Uniform SR treats all paraphrases equally , assigning the same re ward to easy and dif ficult variations, and thus cannot distinguish success limited to easy para- phrases from success that generalizes to harder ones. PRIDE mitigates this limitation by weight- ing re wards by difficulty . T ab . 3 re-ev aluates the same results under PRIDE. VLA-Adapter (22.0%) and π 0.5 expert-only (18.2%) sho w large drops rel- ati ve to SR, indicating success mainly on easy para- phrases and systematic failures on harder variations. In contrast, π 0.5 (8.4%) and Xiaomi-Robotics-0 (8.9%) exhibit lower ov erestimation, sho wing more uniform robustness. Fig. 5 and Fig. 6 confirm these trends at cell level: degradation intensifies along both axes, with the sharpest drops when object paraphrasing combines with indirect actions. Notably , the gap between object-preserved rows (None, Addition) and object- paraphrased rows (SP-conte xtual, SP-habitual) is substantially larger than the action-type gap within the same object condition, suggesting that object- le vel v ariation is a stronger dri ver of failure than None Addition SP -contextual SP -habitual Coordination Subordination Need-Statement Embedded Permission Question Hint Act P araphrase T ype None Addition SP -contextual SP -habitual Obj P araphrase T ype 0.03 0.10 0.11 0.21 0.16 0.18 0.12 0.19 0.31 0.26 0.06 0.09 0.18 0.18 0.25 0.20 0.23 0.16 0.23 0.32 0.29 0.12 0.19 0.26 0.26 0.35 0.30 0.32 0.26 0.32 0.42 0.39 0.11 0.17 0.24 0.25 0.34 0.30 0.31 0.26 0.31 0.42 0.39 Lexical Structural Pragmatic 0.1 0.2 0.3 0.4 PRIDE Score Figure 5: A verage PRIDE score per Object × Action cell in LIBER O-Para (darker = harder). Scores increase along both axes, with the most indirect action types (Question, Hint) combined with object paraphrasing reaching the highest (SP-habitual × Question: 0.42). action indirectness. W e in vestigate this asymmetry and its underlying causes in Sec. 6.2 – 6.3 , after first examining whether architecture or training choices mitigate the ov erall degradation (Sec. 6.1 ). 6 Analysis 6.1 Finding 1: Paraphrase Fragility P ersists Across Ar chitectures, Data Scales, and Fine-tuning Strategies Before analyzing where and ho w failures occur in Sec. 6.2 and 6.3 , we examine whether paraphrase fragility can be attrib uted to specific factors by v arying architecture family , training data scope, and VLM fine-tuning strategy . Architectur e Diversity . Across sev en config- urations spanning four architecture families (OpenVLA-OFT , π 0.5 /Xiaomi-Robotics-0, X-VLA, VLA-Adapter), all models sho w substantial suc- cess rate drops under paraphrasing, ranging from 22.8 pp to 51.9 pp (T ab . 2 ). The 7.5B OpenVLA- OFT sho ws PRIDE scores comparable to the 0.9B X-VLA. All models exhibit PRIDE overestimation of 8.4–22.0% (T ab . 3 ). Overall, VLAs consistently experience significant performance degradation un- der paraphrased instructions, reg ardless of architec- ture or scale. Data Scope. OpenVLA-OFT mixed expands task- le vel data di versity by 4× compared to OpenVLA- OFT goal within the same architecture and simula- tor . Ho wev er , both models exhibit similar success rate drops on LIBER O-Para (32.4 pp vs. 33.2 pp), suggesting that increasing task div ersity through additional training samples does not improve ro- bustness to linguistic v ariation in learned tasks. VLM T raining Strategy . W e compare the stan- dard π 0.5 model (jointly fine-tuning the VLM and Action Expert) with a v ariant that freezes the VLM 6 Figure 6: Model-av erage success rate per Object × Action cell. Object-paraphrased rows drop sharply compared to object-preserved ro ws, reaching 30.4% at SP-habitual × Hint. of the base VLA and fine-tunes only the Action Ex- pert. The frozen-VLM variant sho ws substantially lo wer performance on LIBER O-Goal (97.6 → 78.6; T ab . 2 ) and does not exhibit improv ed robustness on LIBER O-Para (SR: 39.1, PRIDE: 32.0; T ab . 3 ). Al- though the jointly fine-tuned model achie ves higher success rates on LIBER O-Para (71.4 vs. 39.1), both v ariants still show substantial drops under para- phrasing. This suggests that joint adaptation of the VLM and Action Expert is essential for do wn- stream performance, while fine-tuning on limited demonstrations may degrade pretrained semantics, causing paraphrase vulnerability . T aken together , paraphrase fragility persists across all three fac- tors. This indicates that the robustness gap cannot be explained solely by architecture, data scope, or fine-tuning strate gy , b ut points to a deeper chal- lenge. Which linguistic variations, then, are most r esponsible for these failures? 6.2 Finding 2: Object Grounding Emer ges as a Primary Bottleneck Sec. 6.1 shows that paraphrase fragility persists re- gardless of architecture, data scope, or fine-tuning strategy . W e next examine where this degrada- tion concentrates. Our analysis rev eals an asymme- try: object-le vel v ariation emerges as the dominant source of failure, while action indirectness intro- duces additional degradation. Fig. 7 compares success rates between object- preserved and object-paraphrased instructions across models. When the object is para- phrased—e ven through common synonyms such as replacing stove with range —performance drops by 19.8 pp ( π 0.5 expert-only) to 51.0 pp (OpenVLA- OFT mixed ) across models. This gap appears con- sistently across architectures, suggesting that cur - rent VLAs rely more on surface-lev el keyword matching than on semantic understanding of ob- Success Rat e(%) 100 80 60 40 20 0 90 . 0 =-48 . 3 4 1 . 7 Open VL A-OF T ( goal) Object Pr eser v ed vs P ar aphr ased SR 89 .4 90 .4 88 . 5 80 .2 =- 25 . =- 32. 66 .2 =-51 . =- 34 . 63 . 8 56 . 0 50 . 0 =- 37 . 46 . 1 =-19 . 39 .4 29 . 1 30 .2 Obj Pr eser v ed Obj P ar aphr ased VL A-A dapt er X - VL A Xiaomi- R obotics Open VL A-OF T (mix ed) ( e xper t -only) 0 . 5 0 . 5 Figure 7: Success rate comparison between object- preserved (None, Addition) and object-paraphrased (SP- contextual, SP-habitual) instructions. All models show substantial drops, from 19.8 pp ( π 0 . 5 expert-only) to 51.0 pp (OpenVLA-OFT mixed ). ∆ annotated per pair . jects. Notably , OpenVLA-OFT mixed , trained with four times more tasks, e xhibits nearly the same gap as OpenVLA-OFT goal (51.0 pp vs. 48.3 pp; Fig. 7 ), indicating that task div ersity and object-paraphrase robustness are decoupled. PRIDE α sweep exper - iments further confirm that keyw ord-lev el lexical v ariation around object references dri ves most of the degradation, compared to syntactic restructur - ing (Appendix D.2 ). In addition, action indirect- ness introduces a stepwise performance decline: as instructions become less e xplicit, success rates drop from 82.7% (None) to around 48% (Question, Hint) (see Appendix D.2 for the full action-axis breakdo wn). This asymmetry reflects structural properties of tabletop manipulation. The action space is re- stricted to a small set of motor primiti ves (e.g., pick, place, push, open), and each object typically supports only a fe w feasible actions (e.g., stove → turn on), allo wing models to con verge to the cor - rect primiti ve e ven under v aried phrasing. In con- trast, the object space is much lar ger and lexically open-ended, concentrating combinatorial complex- ity on object references. This vulnerability may be amplified by current VLA training data, where 7 t=142 Stat e: Success Figure 8: (Left) LIBER O scene for T ask 2: Push the plate to the front of the stov e. (Right) 3D end- effector trajectories under a paraphrased instruction ( π 0.5 ). Green: successful episodes; black: their mean (GT); orange: Near -GT failure (tracks GT but fails); red: Far -GT failure (di verges early). objects are often referred to by a single canonical name (Fig. 12 ), making grounding sensitive ev en to simple synonym substitutions. These observations suggest that the primary bottleneck in paraphrase robustness lies in object grounding, with action indirectness introducing additional degradation. Having identified the dominant factor behind these failures, we ne xt ask: do these failures arise during e xecution of the corr ect task, or do models gener ate differ ent trajectories fr om the outset? 6.3 Finding 3: Failur es Are Pr edominantly Planning-Lev el, Not Execution-Level Sec. 6.2 identified object grounding as the primary bottleneck, with action indirectness introducing ad- ditional degradation. T o determine whether f ailures arise during execution of the correct task or from generating entirely different trajectories from the outset, we classify failures based on trajectory sim- ilarity to successful e xecutions. For each task, we define the mean successful trajectory as pseudo ground-truth (hereafter GT) and compute the Dy- namic T ime W arping (DTW) distance ( Sakoe and Chiba , 1978 ) between each failure trajectory and the GT . Because LIBERO-Goal training data fol- lo ws a fixed trajectory with minimal path variation, the mean success trajectory serves as a reliable pseudo GT . Failures within a threshold τ (the max- imum DTW distance among successful episodes) are categorized as Near -GT (ex ecution-lev el), in- dicating correct task execution b ut failure due to minor motor control errors. Failures exceeding τ are categorized as Far -GT (planning-level), in- dicating fundamentally different trajectories and thus failure in task identification. As shown in Fig. 8 , Near-GT trajectories remain close to suc- Model Success Failure Rate Near-GT Far-GT Far -GT(%) OpenVLA-OFT goal 64.7 1.6 33.7 95.5 Xiaomi-Robotics-0 76.0 1.8 22.2 92.5 VLA-Adapter 46.3 4.2 49.5 92.2 π 0.5 71.4 2.4 26.2 91.6 OpenVLA-OFT mixed 63.7 3.3 33.0 90.9 X-VLA 62.1 5.2 32.7 86.3 π 0.5 (expert-only) 39.1 12.5 48.4 79.5 T able 4: Failure classification on LIBER O-Para (by Far -GT (%)). Near-GT : execution-le vel failure near GT trajectory . Far -GT : planning-le vel failure from GT . Across models, 79.5–95.5% of failures are planning- lev el. cessful ones, whereas F ar-GT trajectories di verge substantially . Additional methodological details are provided in Appendix D.3 . T ab . 4 summarizes the classification results. Across models, 79.5%–95.5% of failures are Far - GT , while Near-GT cases account for less than 5% in most models. This indicates that under para- phrased instructions, models rarely fail along the correct trajectory but instead generate dif ferent tra- jectories from the outset. The only exception is π 0.5 expert-only (Near -GT : 12.5%), where the frozen VLM may identify the task correctly but the non- adapted Action Expert fails to e xecute it precisely , consistent with the VLM training strategy analy- sis in Sec. 6.1 . These findings align with Sec. 6.2 : when object grounding fails, the model plans ac- tions to ward incorrect targets, producing trajecto- ries that di verge from the GT . The dominant failure mode lies in task identification rather than motor control, suggesting that improving paraphrase ro- bustness should focus on instruction semantic-to- task mapping rather than action-ex ecution control. 7 Conclusion This work in vestigates paraphrase robustness in modern VLA models using LIBER O-Para, a con- trolled benchmark that independently varies action and object expressions, and PRIDE, a metric for fine-grained rob ustness assessment. W e find that paraphrase fragility persists across architectures, scales, and fine-tuning strategies, with object-lev el lexical v ariation as the dominant source of degrada- tion and 80–96% of failures arising from planning- le vel trajectory div ergence rather than execution errors. These results re veal a fundamental limita- tion: current VLA models struggle to map diverse linguistic instructions to correct task identification, relying on surface-le vel matching instead of ro- 8 bust object grounding. These findings suggest that improving rob ustness to paraphrased instructions requires prioritizing instruction-to-task identifica- tion ov er low-le vel control refinement, with object grounding as a ke y direction. Limitations This study ev aluates VLA models within the LIBER O simulation en vironment. As simulations dif fer from real-world settings in rendering fidelity , physics modeling, and sensor noise, further v al- idation is required to determine whether the ob- served vulnerabilities in paraphrase rob ustness per- sist on physical robotic platforms. In addition, our paraphrase design considers a single variation type along each axis at a time. In natural language use, ho wev er , multiple variations may co-occur—for example, synon ym substitution combined with ad- verb insertion, or structural reorganization coupled with indirect speech acts. Such compound varia- tions can introduce more complex linguistic shifts and may pose greater challenges to VLA models. While this work focuses on isolating and analyz- ing the ef fects of indi vidual variation types, the analysis of compound paraphrase v ariations is de- ferred to future work. Also, we do not in vestigate paraphrase-based data augmentation as a mitigation strategy , since augmentation using LLM-generated paraphrases could introduce distributional o verlap with the benchmark, which may confound the ev al- uation. References Anthropic. 2025. System card: Claude opus 4 & claude sonnet 4. Anthropic system card. Nikolaus Augsten and Michael H. Böhlen. 2013. Simi- larity Joins in Relational Database Systems . Synthe- sis Lectures on Data Management. Mor gan & Clay- pool Publishers. Shuai Bai, Qwen T eam, and 1 others. 2025. Qwen3-vl technical report . arXiv pr eprint arXiv:2511.21631 . Satanjeev Banerjee and Alon La vie. 2005. Meteor: An automatic metric for mt e valuation with improved cor- relation with human judgments. In Pr oceedings of the acl workshop on intrinsic and extrinsic e valuation measur es for machine translation and/or summariza- tion , pages 65–72. Ke vin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter , Szymon Jakubczak, T im Jones, Liyiming Ke, Ser gey Le vine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair , Karl Pertsch, Lucy Xiaoyang Shi, and 6 others. 2024. π 0 : A vision-language-action flow model for gen- eral robot control . arXiv preprint . Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Y an Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, and 1 others. 2025. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv pr eprint arXiv:2503.06669 . Rui Cai, Jun Guo, Xinze He, Piaopiao Jin, Jie Li, Bingx- uan Lin, Futeng Liu, W ei Liu, Fei Ma, Kun Ma, and 1 others. 2026. Xiaomi-robotics-0: An open-sourced vision-language-action model with real-time e xecu- tion. arXiv pr eprint arXiv:2602.12684 . Gheorghe Comanici, Eric Bieber , Mike Schaekermann, Ice Pasupat, No veen Sachde va, Inderjit Dhillon, Mar - cel Blistein, Ori Ram, Dan Zhang, Ev an Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with adv anced reasoning, multimodality , long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 . Susan Ervin-T ripp. 1976. Is Sybil there? The structure of some American English directi ves . Language in Society , 5(1):25–66. Senyu Fei, Siyin W ang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, Jinlan Fu, Jingjing Gong, and Xipeng Qiu. 2025. Libero-plus: In-depth robustness analysis of vision-language-action models . arXiv pr eprint arXiv:2510.13626 . Alvan R Feinstein and Domenic V Cicchetti. 1990. High agreement but low kappa: I. the problems of two paradoxes. Journal of clinical epidemiology , 43(6):543–549. Zipeng Fu, T ony Z. Zhao, and Chelsea Finn. 2024. Mo- bile ALOHA: Learning bimanual mobile manipula- tion with lo w-cost whole-body teleoperation . arXiv pr eprint arXiv:2401.02117 . Kilem Li Gwet. 2008. Computing inter-rater reliability and its variance in the presence of high agreement. British Journal of Mathematical and Statistical Psy- chology , 61(1):29–48. Y uchen Hou and Lin Zhao. 2026. Langgap: Diagnos- ing and closing the language gap in vision-language- action models. arXiv pr eprint arXiv:2603.00592 . Siddharth Karamcheti, Suraj Nair, W illiam Brown, Abhiram Maddukuri, T akuma Osa, Chelsea Finn, Percy Liang, Sergey Le vine, T ed Xiao, and 1 oth- ers. 2024. Prismatic vlms: In vestigating the de- sign space of visually-conditioned language models . arXiv pr eprint arXiv:2402.07865 . Alexander Khazatsky , Karl Pertsch, Suraj Nair , Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany , Mohan K umar Srirama, 9 Lawrence Y unliang Chen, Kirsty Ellis, and 1 others. 2024. Droid: A large-scale in-the-wild robot manip- ulation dataset. arXiv pr eprint arXiv:2403.12945 . Moo Jin Kim, Chelsea Finn, and Percy Liang. 2025. Fine-tuning vision-language-action models: Optimizing speed and success . arXiv pr eprint arXiv:2502.19645 . Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, T ed Xiao, Ashwin Balakrishna, Suraj Nair , Rafael Rafailov , Ethan Foster , Grace Lam, Pannag Sanketi, Quan V uong, Thomas K ollar , Benjamin Burchfiel, Russ T edrake, Dorsa Sadigh, Sergey Le vine, Percy Liang, and Chelsea Finn. 2024. Open vla: An open- source vision-language-action model . arXiv preprint arXiv:2406.09246 . V enelin K ovatche v , M. Antònia Martí, and Maria Salamó. 2018. ETPC - a paraphrase identification corpus annotated with extended paraphrase typology and negation . In Pr oceedings of the Ele venth In- ternational Confer ence on Language Resources and Evaluation (LREC 2018) , Miyazaki, Japan. European Language Resources Association (ELRA). Bo Liu, Y ifeng Zhu, Chongkai Gao, Y ihao Feng, Qiang Liu, Y uke Zhu, and Peter Stone. 2023. Libero: Benchmarking knowledge transfer for lifelong robot learning . In Advances in Neur al Information Pr ocess- ing Systems (NeurIPS), Datasets and Benchmarks T rack , v olume 36, pages 44776–44791. Ilya Loshchilov and Frank Hutter . 2017. Decou- pled weight decay regularization. arXiv pr eprint arXiv:1711.05101 . Oier Mees, Lukas Hermann, Erick Rosete-Beas, and W olfram Burgard. 2021. CAL VIN: A benchmark for language-conditioned policy learning for long- horizon robot manipulation tasks . arXiv pr eprint arXiv:2112.03227 . George A Miller . 1995. W ordnet: a lexical database for english. Communications of the A CM , 38(11):39–41. OpenAI. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 . Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar , Abraham Lee, Acorn Pooley , Agrim Gupta, Ajay Man- dlekar , Ajinkya Jain, and 1 others. 2024. Open x- embodiment: Robotic learning datasets and rt-x mod- els: Open x-embodiment collaboration 0. In 2024 IEEE International Confer ence on Robotics and Au- tomation (ICRA) , pages 6892–6903. IEEE. Kishore Papineni, Salim Roukos, T odd W ard, and W ei- Jing Zhu. 2002. Bleu: a method for automatic ev alu- ation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computa- tional Linguistics , pages 311–318. Physical Intelligence, K evin Black, Noah Bro wn, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker , Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter , Szymon Jakubczak, T im Jones, Liyiming K e, Devin LeBlanc, and 18 others. 2025. π 0 . 5 : a vision-language-action model with open-world generalization . arXiv pr eprint arXiv:2504.16054 . Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Pr oceedings of the 2019 Conference on Empirical Methods in Natural Languag e Pr ocessing and the 9th International Joint Conference on Natural Language Pr ocessing (EMNLP-IJCNLP) , pages 3982–3992. Hiroaki Sakoe and Seibi Chiba. 1978. Dynamic programming algorithm optimization for spok en word recognition . IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , 26(1):43–49. Stan Salvador and Philip Chan. 2007. T oward accu- rate dynamic time warping in linear time and space. Intelligent data analysis , 11(5):561–580. Andreas Steiner , André Susano Pinto, Michael Tschan- nen, Daniel Keysers, Xiao W ang, Y onatan Bitton, Alex ey Gritsenko, Matthias Minderer , Anthony Sher - bondy , Shangbang Long, Siyang Qin, Ree ve Ingle, Emanuele Bugliarello, Sahar Kazemzadeh, Thomas Mesnard, Ibrahim Alabdulmohsin, Lucas Beyer , and Xiaohua Zhai. 2024. Paligemma 2: A f am- ily of versatile vlms for transfer . arXiv pr eprint arXiv:2412.03555 . Qwen T eam. 2024. Qwen2.5 technical report . arXiv pr eprint arXiv:2412.15115 . Hugo T ouvron, Louis Martin, Ke vin Stone, Peter Al- bert, Amjad Almahairi, Y asmine Babaei, Nikolay Bashlykov , Soumya Batra, Prajjwal Bharg av a, Shruti Bhosale, and 1 others. 2023. Llama 2: Open foun- dation and fine-tuned chat models . arXiv pr eprint arXiv:2307.09288 . Guodong W ang, Chenkai Zhang, Qingjie Liu, Jin- jin Zhang, Jiancheng Cai, Junjie Liu, and Xin- min Liu. 2026. Libero-x: Robustness litmus for vision-language-action models. arXiv preprint arXiv:2602.06556 . Y ihao W ang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang T ong, W enxuan Song, Han Zhao, W ei Zhao, Pengxu Hou, and 1 others. 2025. Vla-adapter: An effecti ve paradigm for tiny- scale vision-language-action model. arXiv preprint arXiv:2509.09372 . Zhijie W ang, Zhehua Zhou, Jiayang Song, Y uheng Huang, Zhan Shu, and Lei Ma. 2024. LADEV: A language-driv en testing and e valuation platform for vision-language-action models in robotic manipula- tion . arXiv pr eprint arXiv:2410.05191 . 10 Jimmy W u, Rika Antonova, Adam Kan, Marion Lep- ert, Andy Zeng, Shuran Song, Jeannette Bohg, Szy- mon Rusinkiewicz, and Thomas Funkhouser . 2023. T idybot: Personalized robot assistance with lar ge language models . arXiv pr eprint arXiv:2305.05658 . Kun W u, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Y ang, Meng Li, Y inuo Zhao, Zhiyuan Xu, Guang Y ang, and 1 others. 2024. Robomind: Benchmark on multi-embodiment intelli- gence normati ve data for robot manipulation. arXiv pr eprint arXiv:2412.13877 . Bin Xiao, Haiping W u, W ei Xu, Jifeng Dai, Xiaowei Hu, Y ichen Lu, Michael Zeng, and 1 others. 2024. Florence-2: Advancing a unified representation for a v ariety of vision tasks . In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P at- tern Recognition (CVPR) , pages 4810–4821. Y ajat Y adav , Zhiyuan Zhou, Andrew W agenmaker , Karl Pertsch, and Serge y Levine. 2025. Robust finetuning of vision-language-action robot policies via parame- ter merging . arXiv pr eprint arXiv:2512.08333 . T ianyi Zhang, V arsha Kishore, Felix W u, Kilian Q W einberger , and Y oav Artzi. 2019. Bertscore: Ev al- uating text generation with bert. arXiv preprint arXiv:1904.09675 . Jinliang Zheng, Jianxiong Li, Zhihao W ang, Dongxiu Liu, Xirui Kang, Y uchun Feng, Y inan Zheng, Jiayin Zou, Y ilun Chen, Jia Zeng, and 1 others. 2025. X- vla: Soft-prompted transformer as scalable cross- embodiment vision-language-action model. arXiv pr eprint arXiv:2510.10274 . Xueyang Zhou, Y angming Xu, Guiyao T ie, Y ongchao Chen, Guowen Zhang, Duanfeng Chu, P an Zhou, and Lichao Sun. 2025. LIBER O-PR O: T ow ards ro- bust and fair ev aluation of vision-language-action models beyond memorization . arXiv pr eprint arXiv:2510.03827 . Brianna Zitko vich and 1 others. 2023. R T -2: V ision- language-action models transfer web knowledge to robotic control . In Proceedings of The 7th Confer- ence on Robot Learning (CoRL) , volume 229 of Pr o- ceedings of Machine Learning Researc h , pages 2165– 2183. 11 A P P E N D I X Contents A LIBERO-P ara: A Contr olled VLA Benchmark for P araphrase Robustness 13 A.1 Excluded T ypes from Extended Paraphrase T ypology . . . . . . . . . . . . . . 13 A.2 Excluded T ype from Directi ve T ypes . . . . . . . . . . . . . . . . . . . . . . . 14 A.3 Paraphrase Dataset Generation . . . . . . . . . . . . . . . . . . . . . . . . . . 14 A.4 Statistics of LIBER O-Para . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.5 Human Ev aluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 B PRIDE: Paraphrase Rob ustness Index in Robotic Instructional DEviation 16 C Experiment 17 C.1 Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 C.2 Result . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 D Analysis 18 D.1 Finding 1: Paraphrase Fragility Persists Across Architectures, Data Scales, and Fine-tuning Strategies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 D.2 Finding 2: Object Grounding Is the Primary Bottleneck . . . . . . . . . . . . . 19 D.3 Finding 3: Failures Are Predominantly Planning-Le vel, Not Execution-Le vel . 20 E AI Assistants 22 12 Category T ype Source (Y ear) Obj-Lexical same polarity habitual EPT (2018) Same polarity contextual Addition Act-Lexical Same polarity habitual EPT (2018) Same polarity contextual Addition Act-Structural Coordination EPT (2018) Subordination Act-Pragmatic Personal need Directiv e T ypes (1976) Question directiv e Embedded imperativ e Permission Hint T able 5: Selected paraphrase types in LIBER O-Para. T ypes are deri ved from Extended Paraphrase T ypol- ogy (EPT) ( Ko vatche v et al. , 2018 ) and Directiv e T ypes ( Ervin-Tripp , 1976 ). A LIBER O-Para: A Controlled VLA Benchmark f or Paraphrase Robustness This appendix details the paraphrase taxonomy adopted in LIBER O-Para and explains the ratio- nale for excluding certain types from the source taxonomies (EPT and Directi ve T ypes). Our tax- onomy is grounded in the Extended P araphrase T ypology (EPT) ( K ov atchev et al. , 2018 ) and the Directi ve types proposed by Ervin-Tripp ( 1976 ). From the 26 atomic paraphrase types in EPT and the six dif ferent types in Directiv e T ypes, we select 13 types that satisfy the follo wing criteria: (i) appli- cability to robotic manipulation instructions (i.e., direct imperativ es), (ii) preservation of the original meaning, (iii) compliance with visual and spatial constraints, and (i v) grammatical naturalness. All paraphrases are generated under these constraints and are used exclusi vely for e v aluation. A.1 Excluded T ypes from Extended Paraphrase T ypology While EPT provides a broad in ventory of para- phrase operations, many types are unsuitable for robotic manipulation instructions under our design constraints. T ab . 6 presents the Extended Para- phrase T ypology (EPT), summarizing its high-lev el categories along with their corresponding atomic types. Morphology . W e exclude the entire Morphol- ogy category . Inflectional changes may alter object cardinality (e.g., pluralization) or modify tempo- ral interpretation when applied to actions. Modal verb changes can shift intent, introducing seman- tic drift. Deriv ational changes alter part-of-speech (e.g., “ pick ” → “ pick er ”), which violates impera- Categories Atomic T ype Morphology Inflectional changes Modal verb changes Deriv ational changes Lexicon Spelling changes Same polarity substitution (habitual) Same polarity substitution (contextual) Same polarity substitution (named entities) Change of format Lexical- syntactic Opposite polarity substitution (habitual) Opposite polarity substitution (contextual) Synthetic/analytic substitution Con verse substitution Syntax Diathesis alternation Negation switching Ellipsis Coordination changes Subordination and nesting changes Discourse Punctuation changes Direct/indirect style alternations Sentence modality changes Syntax/discourse structure changes Other Addition/Deletion Change of order Semantic based Extremes Identity Non-paraphrase Entailment T able 6: Extended Paraphrase T ypology (EPT) cate- gories and atomic types ( K ov atchev et al. , 2018 ). ti ve structure or disrupts the intended reference. Lexicon. W e retain same polarity substitution (habitual and conte xtual) and exclude the remain- ing types. Spelling changes are insufficient to con- stitute meaningful v ariation. Same polarity substi- tution in volving named entities is rarely applicable, as robotic instructions predominantly use common nouns and generic v erbs. Change of format is often either tri vial or difficult to apply while preserving meaning. Lexical-syntactic. W e exclude this cate gory in its entirety . Opposite polarity substitution is un- natural for object nouns and leads to awkward or unintended speech acts when applied to actions. Synthetic/analytic substitutions (e.g., “ bowl ” ↔ “ r ound container ”) are unnatural in concise im- perati ves. Con verse substitutions introduce role- swapping constructions that are rarely natural in commands. Syntax. W e retain coordination and subordi- nation changes and exclude the remaining types. Diathesis alternation yields passi ve-like commands, which are unnatural in robotic instructions. Nega- tion switching ov erlaps with opposite polarity sub- stitutions. Ellipsis introduces ambiguity in short imperati ves and ov erlaps with addition/deletion. 13 “T urn on t he st o v e” P ar aphr ase Gener at or P ar aphr ase V erifier P ar aphr ase Mer ger P ar aphr ase V erifier A ction × Object P ar aphr ased Instructions P ar aphr ase A ction Axis P ar aphr ase Object Axis P ar aphr ase LLM LLM LLM LLM (1) (2) (3) (4) Figure 9: Overvie w of the LIBER O-Para dataset generation workflow . The process consists of four stages: (1) axis-wise paraphrase generation, (2) verification, (3) mer ging, and (4) final verification. Directi ve T ype Example Need statements “I need a match” Imperativ es “Gimme a match”, “a match’ ’ Embedded imperativ es “Could you gimme a match?” Permission directiv es “May I have a match?” Question directiv es “Gotta match?” Hints “The matches are all gone’ ’ T able 7: Six directiv e types from Directiv e T ypes ( Ervin- T ripp , 1976 ). Discourse. W e exclude this category entirely . Robotic commands are treated as direct impera- ti ves; alternations in style or sentence modality may alter the intended directiv e force. Syntax/discourse structure changes are o verly high-le vel relati ve to atomic instructions and hinder controlled e valua- tion. Other . W e retain only addition. Given the bre vity of imperati ve commands, deletion fre- quently remov es essential components or produces ungrammatical outputs. Change of order is often unnatural in short imperati ves. Semantic-based types lack a precise definition and are unsuitable for controlled e valuation. Extremes. W e exclude this category en- tirely . Identity in volves no transformation. Non- paraphrase violates meaning preserv ation. Entail- ment represents an inferential relation rather than a meaning-preserving transformation. A.2 Excluded T ype from Dir ective T ypes Ervin-T ripp proposed a directiv e taxonomy that categorizes Directi ve T ypes into six types ( Ervin- T ripp , 1976 ), as summarized in T ab . 7 . Among these, we select fi ve types for the Action-Pragmatic axis: need statements, embedded imperatives, per - mission directi ves, question directi ves, and hints. Imperatives. W e exclude the imperativ e type from our paraphrase taxonomy . Since imperativ es (e.g., “Pic k up the bowl” ) represent the canoni- cal form of robotic manipulation instructions, they serve as the original instruction rather than a para- phrase v ariant. In our benchmark design, this type corresponds to the baseline condition (Action axis: None) against which other pragmatic v ariations are compared. A.3 Paraphrase Dataset Generation This section describes the paraphrase dataset gener - ation process using LLMs. As illustrated in Fig. 9 , our workflo w consists of four stages: (1) axis-wise paraphrase generation, (2) paraphrase verification, (3) axis merging, and (4) final v erification. Axis-wise Paraphrase Generation Given an original instruction, a paraphrase generator (LLM) independently produces paraphrases along the ac- tion axis (10 types) and the object axis (3 types). Each generated paraphrase is filtered by a para- phrase verifier (LLM) to ensure meaning preserv a- tion and grammatical naturalness. Paraphrase Merging V erified action-axis and object-axis paraphrases modify independent com- ponents of the instruction and can therefore be combined. If n action paraphrases and m object paraphrases pass verification, up to n × m merged paraphrases are possible. Merged paraphrases are further validated by the verifier (LLM) before in- clusion in the dataset. Design Principles Rather than prompting a sin- gle LLM to generate all paraphrase types jointly , we adopt an axis-wise generation and merging strat- egy . This modular design assigns a single role to each LLM (generator , merger , and verifier), reduc- ing task comple xity and improving generation relia- bility . All LLM calls use Gemini 2.5 Pro. Detailed prompts used at each stage are provided at the end of the paper for readability , and are illustrated in Figs. 20 to 28 . 14 Act-Lexical Act-Structural Act-Pragmatic Object None add ctx hab coord subord need embed perm quest hint T otal None – 100 79 74 98 75 93 93 83 87 88 870 Addition 98 100 100 100 100 100 100 99 99 99 100 1,095 Contextual 87 100 100 100 100 99 100 100 100 94 96 1,076 Habitual 74 100 98 100 97 94 100 95 100 95 98 1,051 T otal 259 400 377 374 395 368 393 387 382 375 382 4,092 Abbr eviations: add = addition, ctx = same_polarity_contextual, hab = same_polarity_habitual, coord = coordination, subord = subordination, need = need_statement, embed = embedded_imperative, perm = permission_directi ve, quest = question_directiv e. T able 8: LIBER O-Para dataset statistics. Each cell sho ws the number of paraphrased instructions for the correspond- ing Object (row) and Action (column) v ariation type combination. “None” indicates no variation on that axis. Original Instruction Count Put the wine bottle on top of the cabinet 423 Open the middle drawer of the cabinet 416 T urn on the stove 414 Put the wine bottle on the rac k 413 Put the cream cheese in the bowl 411 Open the top drawer and put the bowl inside 410 Put the bowl on top of the cabinet 410 Push the plate to the fr ont of the stove 406 Put the bowl on the stove 403 Put the bowl on the plate 386 T otal 4,092 T able 9: Number of paraphrased instructions per origi- nal instruction in LIBER O-Para. A.4 Statistics of LIBERO-P ara LIBER O-Para consists of 4,092 paraphrases gener- ated from 10 original LIBER O-Goal instructions, selected from the four LIBER O task types (Spatial, Object, Goal, and Long) where linguistic under - standing is essential for successful ex ecution. The dataset is org anized along two axes: an Ob- ject axis with three lexical types, and an Action axis with ten types (three lexical, two structural, and fiv e pragmatic). This two-axis design yields 43 distinct paraphrase type combinations: three Object-only , ten Action-only , and thirty composi- tional types ( 3 × 10 ). T ab . 8 reports the number of paraphrases for each Object × Action combination. The dataset includes 259 Object-only paraphrases (Action = None), 870 Action-only paraphrases (Object = None), and 2,963 compositional paraphrases. T o facilitate di verse analyses, samples are distrib uted approximately uniformly across cells, with around 100 paraphrases per cell. T o examine ho w each component of PRIDE con- tributes to paraphrase difficulty , Figs. 10 and 11 present the average ke yword distance ( 1 − S K ) and structural distance ( 1 − S T ), respectiv ely , which cor- respond to isolating each term in the PD formula- None Addition SP -contextual SP -habitual Coordination Subordination Need-Statement Embedded Permission Question Hint Act P araphrase T ype None Addition SP -contextual SP -habitual Obj P araphrase T ype 0.07 0.04 0.04 0.40 0.32 0.25 0.24 0.34 0.40 0.32 0.09 0.16 0.17 0.16 0.44 0.38 0.34 0.31 0.40 0.43 0.37 0.07 0.13 0.10 0.10 0.41 0.36 0.29 0.28 0.36 0.39 0.34 0.05 0.11 0.07 0.07 0.40 0.34 0.28 0.27 0.33 0.39 0.32 Lexical Structural Pragmatic 0.1 0.2 0.3 0.4 Structural Distance (1 ST) Figure 10: A verage Structural Distance ( 1 − S T ) per Object × Action cell. This component reflects syntactic div ergence only (SK weight = 0.0, ST weight = 1.0 in PRIDE). Unlike k eyword distance, structural distance is dominated by action paraphrase type rather than object substitution: Coordination and Subordination columns uniformly score above 0.28 across all ro ws, while lexical action types remain belo w 0.17. This confirms that structural re writing primarily originates from act-lev el transformations. tion (Eq. 3 ). Ke yword distance is primarily driv en by the Object axis: contextual and habitual substi- tutions yield high distances (0.41–0.45) due to syn- onym replacement, while ro ws without object para- phrasing remain near zero. Structural distance, in contrast, is dominated by the Action axis: coordina- tion and subordination columns consistently score abov e 0.28 regardless of object type, whereas le xi- cal action types stay belo w 0.17. This decomposi- tion confirms that the two PRIDE components cap- ture complementary sources of dif ficulty—lexical di vergence from object paraphrasing and syntactic di vergence from action paraphrasing. Finally , T ab . 9 reports the number of paraphrases per original instruction. Each instruction yields 386–423 paraphrases, indicating a balanced distri- bution. A.5 Human Evaluation T o verify the semantic validity of LIBER O-Para, we conducted a human ev aluation on a randomly sampled 5% subset (205 samples) of the full bench- 15 None Addition SP -contextual SP -habitual Coordination Subordination Need-Statement Embedded Permission Question Hint Act P araphrase T ype None Addition SP -contextual SP -habitual Obj P araphrase T ype -0.00 0.17 0.17 0.03 0.00 0.10 -0.00 0.04 0.22 0.20 0.02 0.02 0.20 0.20 0.05 0.03 0.12 0.02 0.05 0.21 0.21 0.18 0.24 0.42 0.42 0.28 0.25 0.35 0.25 0.29 0.44 0.44 0.17 0.23 0.41 0.42 0.28 0.25 0.35 0.24 0.28 0.44 0.45 Lexical Structural Pragmatic 0.0 0.1 0.2 0.3 0.4 K eyword Distance (1 SK) Figure 11: A verage Keyw ord Distance (1 – S K ) per Object × Action cell. This component reflects lexical div ergence only (SK weight = 1.0, ST weight = 0.0 in PRIDE). Scores are dri ven primarily by object para- phrasing: rows with SP-contextual or SP-habitual sub- stitutions consistently score higher regardless of action type. Among action types, Question and Hint columns show the highest v alues, with SP-habitual × Hint reach- ing 0.45. mark. Fifteen annotators independently judged whether each original–paraphrase pair would elicit the same successful behavior in the given scene, using a binary Y es/No decision. Inter -Annotator Agreement. W e report Gwet’ s A C1 ( Gwet , 2008 ) as the inter -annotator agreement (IAA) metric. W e chose A C1 over Cohen’ s or Fleiss’ κ because our labels are heavily skewed to ward the positiv e class, a setting in which κ is kno wn to be substantially deflated despite high ob- served agreement ( Feinstein and Cicchetti , 1990 ). On our 15-annotator e valuation, Gwet’ s A C1 is 0.854 , indicating strong agreement. Consensus Statistics. Under a majority-vote cri- terion ( ≥ 8/15 annotators marking Y es), 204 out of 205 samples (99.51%) were judged as meaning- preserving. Under a stricter threshold requiring ≥ 12/15 agreement (80%), 183 out of 205 samples (89.27%) passed. Across all 205 samples, anno- tators selected Y es at an av erage rate of 14.13/15 (94.18%), further supporting high item-le vel con- sensus. Error Analysis. W e examined the 22 samples that failed the stricter criterion and found that dis- agreement was concentrated in paraphrases where the original imperativ e form was transformed into suggesti ve, declarati ve, or indirect speech-act forms. This indicates that disagreement primarily arose from dif ferences in annotator interpretation of speech-act form rather than semantic distortion of the paraphrase itself. At the same time, such cases confirm that the benchmark includes prag- matically challenging linguistic reformulations that Original Instructions Open t he middle dr aw er of t he cabinet Open t he t op dr aw er and put t he bo wl inside Push t he plat e t o t he fr ont of t he st o v e Put t he bo wl on t he plat e Put t he bo wl on t he st o v e Put t he bo wl on t op of t he cabinet Put t he cr eam cheese in t he bo wl Put t he wine bott le on t he r ack Put t he wine bott le on t op of t he cabinet T urn on t he st o v e Rack Canonical Name Cabinet Plat e Bo wl Wine bott le St o v e Cr ea cheese Figure 12: LIBER O-Goal task instructions (left) and corresponding scene with canonical object names (right). Each object is referred to by a single unique keyw ord throughout all instructions (e.g., sto ve , bowl , rac k ), with no lexical v ariation across tasks. go beyond simple le xical substitution. Annotation Protocol. Each annotator receiv ed an Excel spreadsheet containing 205 randomly sampled original–paraphrase pairs. They were instructed to mark O if the paraphrased instruc- tion would elicit the same successful behavior as the original instruction in the gi ven VLA scene (LIBER O-Goal initial scene), and X otherwise. The 15 annotators included participants with v ary- ing le vels of familiarity with robotic manipulation tasks, ranging from domain-familiar researchers to non-expert v olunteers. All annotators were in- formed that their responses would be used for re- search purposes. B PRIDE: Paraphrase Rob ustness Index in Robotic Instructional DEviation Motivation. General-purpose NLP distance metrics such as BER TScore ( Zhang et al. , 2019 ), BLEU ( Papineni et al. , 2002 ), and ME- TEOR ( Banerjee and Lavie , 2005 ) are designed to measure surface-le vel or semantic similarity between text pairs, without considering how lin- guistic changes af fect downstream task e xecution. In grounded robotic instruction following, ho wev er , not all lexical changes are equally disruptiv e: replacing a task-critical object noun (e.g., “sto ve” → “range”) directly impacts visual grounding and action selection, whereas syntactic additions (e.g., prepending “carefully”) leav e the core command intact. PRIDE is designed to reflect this asymmetry by decomposing paraphrase distance into two robot-rele vant axes: keyw ord di ver gence ( S K ), which captures whether task-critical referents are preserved, and structural div ergence ( S T ), which measures how far the utterance departs from the imperati ve form that VLA models are 16 Original Paraphrase T ype SR(%) PRIDE 1 − S K 1 − S T 1-BER T 1-BLEU 1-METEOR Put the cream cheese in the bowl “carefully put the cream cheese in the bowl” addition(act) 90.8 0.03 0.00 0.07 0.14 0.16 0.02 “put the cheese spread in the vessel” SP-contextual(obj) 70.3 0.35 0.27 0.43 0.12 0.80 0.36 “Is the spread supposed to go in the container?” SP-contextual(obj) & question 31.5 0.56 0.60 0.53 0.28 0.91 0.65 Turn on the sto ve “carefully turn on the stove” addition(act) 90.8 0.06 0.00 0.11 0.15 0.33 0.03 “turn on the range” SP-habitual(obj) 71.8 0.36 0.34 0.38 0.19 0.41 0.26 “Is the range hot yet?” SP-habitual(obj) & hint 33.2 0.65 0.70 0.60 0.40 0.92 0.88 Open the middle drawer of the cabinet “carefully open the middle drawer of the cabinet” addition(act) 90.8 0.03 0.00 0.05 0.10 0.12 0.01 “Find the cabinet, then proceed to open the middle drawer” coordination 80.2 0.25 0.00 0.50 0.10 0.12 0.01 “The storage unit’ s middle compartment is currently shut” SP-habitual(obj) & hint 31.6 0.46 0.41 0.50 0.19 0.72 0.49 T able 10: Qualitativ e comparison of PRIDE, a task-grounded paraphrase distance metric, with general-purpose NLP distance metrics on selected LIBER O-Para examples. Each task group presents three paraphrases of increasing lin- guistic distance: a minor addition, a lexical substitution, and a compound paraphrase combining object substitution with an indirect speech act. PRIDE increases monotonically as success rate (SR) degrades, reflecting its decomposi- tion into ke yword similarity ( S K ) and structural similarity ( S T ). In contrast, 1 − BER T lacks discriminativ e range, 1 − BLEU fluctuates inconsistently , and 1 − METEOR fails to capture structurally induced difficulty when k eywords are preserved (e.g., coordination in the third group scores 0.01 despite a 10.6%p SR drop). predominantly trained on. Qualitative Comparison with NLP Metrics. T ab . 10 illustrates how PRIDE captures task- rele vant linguistic v ariation compared to general- purpose NLP metrics. For each task group, we present three paraphrases of increasing difficulty: a minor addition (e.g., prepending “carefully”), a lexical substitution of the object or action, and a compound paraphrase combining object substitu- tion with an indirect speech act. PRIDE increases monotonically as success rate degrades—for in- stance, in the first group, PRIDE rises from 0.03 to 0.35 to 0.56 as SR drops from 90.8% to 70.3% to 31.5%. This graduated behavior stems from the complementary design of its two components: S K remains near zero for syntactic-only changes (e.g., addition) but sharply increases when task-critical ke ywords are replaced, while S T captures struc- tural diver gence from the imperative form even when ke ywords are preserved. In contrast, con ventional NLP metrics each ex- hibit notable limitations. 1 − BER TScore ( Zhang et al. , 2019 ) remains in a narrow range (0.10–0.28) across all paraphrase types, failing to distinguish between benign additions and highly disrupti ve compound paraphrases. 1 − BLEU ( Papineni et al. , 2002 ) behav es erratically: in the first group, it assigns a higher distance to a simple object sub- stitution (0.80) than the gap between that substi- tution and a far more disruptiv e compound form (0.80 → 0.91), compressing meaningful dif ficulty dif ferences. 1 − METEOR ( Banerjee and Lavie , 2005 ) tracks the overall degradation trend more faithfully than the other two metrics, o wing to its synonym and stem matching via W ordNet ( Miller , 1995 ). Howe ver , it still fails to capture struc- turally induced dif ficulty: in the third group, coor - dination (“Find the cabinet, then proceed to open the middle drawer”) recei ves the same score as a trivial addition (both 0.01), despite a 10.6 pp SR gap (90.8% → 80.2%), because the original ke ywords are largely preserv ed. More fundamen- tally , METEOR provides only a single scalar dis- tance and cannot decompose why a paraphrase is distant—whether due to keyword replacement or structural transformation—limiting its diagnostic utility . PRIDE addresses this through its e xplicit S K / S T decomposition, enabling researchers to at- tribute performance de gradation to specific linguis- tic dimensions. Quantitative V alidation. Beyond qualitati ve ex- amples, we verify that PRIDE correlates with ac- tual task performance. Fig. 16 plots the mean suc- cess rate of each paraphrase cell against its PRIDE score for all se ven models. All models exhibit sta- tistically significant negati ve correlations (Pearson r ranging from − 0 . 671 to − 0 . 877 , p < . 0001 ), confirming that higher paraphrase distance consis- tently leads to lower task success. This validates PRIDE as a meaningful dif ficulty metric for para- phrase robustness e valuation. C Experiment C.1 Setup Computing Infrastructure. All experiments were conducted on NVIDIA R TX A6000 and NVIDIA L40S GPUs. Specifically , OpenVLA- OFT variants were e valuated on R TX A6000 GPUs, while all other models (X-VLA, VLA-Adapter , π 0 . 5 , π 0 . 5 (expert-only), and Xiaomi-Robotics-0) were e valuated on L40S GPUs. The total ev aluation cost across all se ven model configurations amounts to approximately 194 GPU hours (T ab . 11 ). For π 0 . 5 (expert-only), the training was also performed 17 80 7 0 60 60 50 40 30 30 20 0 . 0 0 . 1 0 .2 0 . 3 Structur al Cen tric 0 .4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 K e yw or d Cen tric Figure 13: Effect of the weighting parameter α on PRIDE scores across all models. Left: as α in- creases from 0 (structure-centric) to 1 (ke yword-centric), PRIDE scores decrease consistently for all models, in- dicating that ke yword-based e valuation assigns higher credit to samples that models already solv e easily . Right: per-model linear slope of the PRIDE– α curve. Steeper negati ve slopes indicate stronger dependence on key- word similarity ov er structural similarity . on L40S GPUs following the original π 0 . 5 fine- tuning protocol (see T ab. 15 for training hyperpa- rameters and Fig. 15 for the training loss curve). Model GPU VRAM (GB) Eval Hours OpenVLA-OFT goal A6000 ∼ 16 ∼ 12 OpenVLA-OFT mixed A6000 ∼ 16 ∼ 12 X-VLA L40S ∼ 6.5 ∼ 11 VLA-Adapter L40S ∼ 3 ∼ 11 π 0.5 L40S ∼ 38 ∼ 70 π 0.5 (expert-only) L40S ∼ 38 ∼ 70 Xiaomi-Robotics-0 L40S ∼ 14 ∼ 8 T otal ∼ 194 T able 11: Evaluation GPU hours and peak VRAM usage per model configuration. Backbone and Data References. The VLM backbones used across ev aluated mod- els include Prismatic ( Karamcheti et al. , 2024 ) with Llama 2 ( T ouvron et al. , 2023 ), PaliGemma 2 ( Steiner et al. , 2024 ), Florence- 2 ( Xiao et al. , 2024 ), Qwen2.5 ( T eam , 2024 ), and Qwen3-VL ( Bai et al. , 2025 ). For pre-training data, OpenVLA-OFT uses the Open X-Embodiment (O XE) dataset ( O’Neill et al. , 2024 ), and X-VLA is pre-trained on Droid ( Khazatsk y et al. , 2024 ), RoboMind ( W u et al. , 2024 ), and Agibot ( Bu et al. , 2025 ). All π 0 . 5 v ariants use AdamW ( Loshchilov and Hutter , 2017 ) as the optimizer (T ab . 15 ). Model W eights and Code. All e valuated models use publicly released checkpoints and of ficial code- bases, except for π 0 . 5 (expert-only), which we fine- tuned from the base π 0 . 5 checkpoint by freezing the VLM and updating only the action expert. T ab . 13 summarizes architecture-le vel specifications, and None Addition SP -ctx SP -hab Coord Subord Need Embedded Permission Question Hint Act P araphrase T ype 0 20 40 60 80 100 Success Rate (%) 82.7 70.1 64.7 66.5 57.3 62.7 58.6 64.2 57.3 48.1 48.4 Lexical Structural Pragmatic Figure 14: Success rate breakdo wn by action paraphrase type, av eraged across all 7 model configurations. Para- phrase types are grouped into three linguistic categories: Lexical (surface-le vel word changes), Structural (syntac- tic reor ganization), and Pragmatic (indirect speech acts). Performance degrades progressi vely from the original instruction (82.7%) through le xical variants (66–70%) and structural variants (57–63%) to the most indirect pragmatic forms such as Question (48.1%) and Hint (48.4%). T ab . 14 details the fine-tuning configurations. The code repositories and pretrained weights are listed in T ab . 12 . Evaluation Protocol. Each model is ev aluated across 5 different random seeds (7, 8, 9, 10, 11) per task–paraphrase configuration. All reported success rates represent the mean over 5 seeds ; standard de viations are not reported, as our analy- sis focuses on aggregate robustness trends across paraphrase types rather than per-configuration vari- ance. W e use the LIBER O simulation environment with its default e valuation settings (i.e., maximum episode length and success criteria) as defined in the original LIBER O benchmark. C.2 Result Reporting Pr otocol. All success rate v alues re- ported in this paper are the mean of 5 independent e valuation runs with dif ferent random seeds. W e do not perform hyperparameter search for e valua- tion; all models are e valuated using their of ficially released or documented inference configurations. D Analysis D.1 Finding 1: Paraphrase Fragility Persists Across Ar chitectures, Data Scales, and Fine-tuning Strategies Fig. 17 presents per -model success rate heatmaps across all Object × Action paraphrase type com- binations. While all seven models degrade un- der object paraphrasing, the degradation manifests in two distinct patterns. OpenVLA-OFT v ariants 18 Model Code W eights OpenVLA-OFT goal https://github.com/moojink/openvla- oft https://huggingface.co/moojink/openvla- 7b-oft- finetuned- libero-goal OpenVLA-OFT mixed (same as above) https://huggingface.co/moojink/openvla- 7b-oft- finetuned-libero- spatial- object-goal- 10 π 0.5 https://github.com/Physical- Intelligence/openpi (J AX) gs://openpi-assets/checkpoints/pi05_libero π 0.5 (expert-only) (same as π 0 . 5 ) Fine-tuned from gs://openpi-assets/checkpoints/pi05_base X-VLA https://github.com/huggingface/lerobot https://huggingface.co/lerobot/xvla- libero VLA-Adapter https://github.com/OpenHelix- Team/VLA-Adapter https://huggingface.co/VLA- Adapter/LIBERO-Goal- Pro Xiaomi-Robotics-0 https://github.com/XiaomiRobotics/Xiaomi- Robotics-0 https://huggingface.co/XiaomiRobotics/Xiaomi- Robotics-0- LIBERO T able 12: Code repositories and pretrained weight sources for all ev aluated models. Model Release Arch. T ype VLM Backbone VLM P arams Action Module Action Params T otal Params OpenVLA-OFT 2025.03 Parallel Decoding Prismatic (Llama 2) 7B L1 MLP <1M 7.5B π 0.5 2025.09 VLM + Action Expert PaliGemma 2 3B Flow matching expert 0.3B 3.3B VLA-Adapter 2025.09 Bridge-based Prismatic (Qwen2.5-0.5B) 0.5B Bridge Attention Policy 97M 0.6B X-VLA 2026.01 Soft-prompted Florence-2 0.5B Flow matching transformer ∼ 0.4B 0.9B Xiaomi-Robotics-0 2026.02 VLM + Action Expert Qwen3-VL-4B 4B Flow matching DiT ∼ 0.7B 4.7B T able 13: Architecture-lev el specifications of the ev aluated VLA models. Release denotes the public code release date (YYYY .MM). Models span a range of architectural paradigms—from parallel decoding to bridge-based adapters to flow matching action e xperts—with total parameter counts ranging from 0.6B to 7.5B. OpenVLA-OFT variants (goal/mix ed) share the same architecture and are listed as a single entry . and VLA-Adapter e xhibit a sharp cliff between object-preserved rows (None, Addition) and object- paraphrased ro ws (SP-contextual, SP-habitual) — the top two rows remain nearly uniformly green while the bottom two ro ws shift abruptly to red. This two-band pattern directly reflects the lar ge preserved-vs-paraphrased g aps reported in Fig. 7 : OpenVLA-OFT goal (48.3 pp), OpenVLA-OFT mixed (51.0 pp), and VLA-Adapter (37.1 pp) all sho w a clear visual boundary at the object paraphrasing threshold. In contrast, π 0 . 5 , X-VLA, and Xiaomi- Robotics-0 display a more gradual degradation across both axes without a single sharp bound- ary , consistent with their comparativ ely smaller preserved-vs-paraphrased gaps (19.8–35.7 pp). Despite these dif ferences in degradation profile, the conclusion is shared: ev ery model falls belo w 50% in the most challenging compound cells, con- firming that paraphrase fragility is uni versal regard- less of architecture. D.2 Finding 2: Object Grounding Is the Primary Bottleneck Alpha Sensitivity Analysis. Fig. 13 exam- ines how the balance between the two PRIDE components—ke yword similarity ( S K ) and struc- tural similarity ( S T )—af fects the ov erall rob ustness score. As α shifts toward 1.0 (keyword-centric), PRIDE scores decrease across all models, re vealing that models generally succeed on samples where ke ywords are preserved and fail when ke ywords are paraphrased. Con versely , as α approaches 0.0 (structure-centric), scores rise uniformly , suggest- ing that structural variation alone is less disrup- ti ve than ke yword replacement. This confirms that object-le vel ke yword changes, rather than syntac- tic reformulations, are the dominant factor dri ving success rate degradation across current VLA archi- tectures. The per-model slopes in the right panel of Fig. 13 further rev eal architecture-specific sensitivities. OpenVLA-OFT goal and OpenVLA-OFT mixed ex- hibit the steepest slopes ( − 17 . 3 and − 18 . 7 , respec- ti vely), consistent with the lar ge success rate gaps between object-preserved and object-paraphrased conditions reported in Fig. 7 (48.3pp and 51.0pp, respecti vely). Their high keyword dependence indi- cates that these models rely hea vily on exact object noun matching for task ex ecution. Interestingly , at α ≥ 0 . 9 , X-VLA ov ertakes OpenVLA-OFT mixed in PRIDE score, indicating that despite lo wer structural robustness ov erall, X- VLA is more resilient to keyword-le vel variation. Similarly , π 0 . 5 (expert-only) closes the gap with VLA-Adapter at α = 1 . 0 , suggesting relati vely stronger ke yword rob ustness despite its lo wer abso- lute performance. These crossov er patterns demon- strate the diagnostic utility of α -tuning: by adjust- ing the weighting, practitioners can identify which robustness dimension—keyw ord preservation or structural flexibility—a gi ven model e xcels at, in- forming model selection for deployment en viron- ments where one linguistic dimension may be more pre valent than the other . Action Indirectness. Fig. 14 breaks down suc- cess rate by action paraphrase type across all models. Le xical-level changes (Addition, SP- contextual, SP-habitual) cause moderate de grada- tion (66–70%), while structural reorganizations 19 Model Pre-train LIBER O Data Fine-tune (Domain Adaptation) W eights Pre-train Data FT Method FT Scope OpenVLA-OFT goal O XE (970k traj) Goal only LoRA (r=32) All modules Released OpenVLA-OFT mixed O XE (970k traj) All 4 suites LoRA (r=32) All modules Released π 0.5 Proprietary + open (10K+ hrs) All 4 suites Full All modules Released π 0.5 (expert-only) Proprietary + open (10K+ hrs) All 4 suites Full Action Expert only Ours VLA-Adapter No robotic pretrain Goal only LoRA (r=64) All modules Released X-VLA Droid + Robomind + Agibot (290k) All 4 suites LoRA (r=64) All modules Released Xiaomi-Robotics-0 Open + in-house ( ∼ 200M steps) All 4 suites Full All modules Released T able 14: LIBERO fine-tuning configurations of the e valuated VLA models. All models are fine-tuned on LIBER O and e valuated on LIBER O-Para. “Released” denotes publicly a vailable checkpoints; “Ours” denotes checkpoints fine-tuned by us following the original training protocol (see Fig. 15 for the training loss curve). Models trained on “ All 4 suites” use the mixed configuration of LIBER O-Goal, LIBER O-Spatial, LIBERO-Object, and LIBER O-Long. Note that π 0 . 5 (expert-only) freezes the vision-language backbone and updates only the action e xpert. π 0.5 π 0.5 (expert-only) VLM (img + llm) Fine-tuned Frozen Action Expert Fine-tuned Fine-tuned T rainable Params ∼ 3.3B ∼ 300M Batch Size 256 256 Peak LR 5e-5 5e-5 Optimizer AdamW (grad clip 1.0) AdamW (grad clip 1.0) EMA Decay 0.999 0.999 W armup Steps 10k 10k T raining Steps 30k 30k Action Horizon 10 10 T able 15: Training configurations for π 0.5 v ariants. The expert-only variant freezes the VLM and fine-tunes only the Action Expert. (Coordination, Subordination) reduce success fur - ther to around 57–63%. The sharpest drops occur in the pragmatic category , where Question and Hint— forms that require pragmatic inference to recov er the underlying imperati ve—bring success do wn to ∼ 48%. Notably , the ov erall action-axis degradation is milder than the object-axis de gradation reported in Sec. 6.2 . W e attrib ute this to the constrained nature of tabletop manipulation: the action space is limited to a small set of motor primiti ves (pick, place, push, open, etc.), and each object typically af fords only a narro w range of feasible actions (e.g., stove → turn on ). This low action ambiguity al- lo ws models to conv erge on the correct primitiv e e ven under moderate linguistic variation. Ho wev er , when the directi ve intent itself becomes opaque— as in questions or hints—models can no longer reliably extract the intended action, leading to the steep drop in the pragmatic category . LIBER O-Goal Instructions. LIBER O-Goal in- structions refer to each object by a single fixed reference throughout all tasks. As sho wn in Fig. 12 , objects such as stove , bowl , and rack appear con- sistently under the same surface form, with no syn- onym or alternati ve reference used in an y instruc- tion. Because models are fine-tuned exclusi vely on these fixed references, they are ne ver exposed to lexical v ariation in object references during train- ing. This single-reference con vention likely rein- forces surface-le vel ke yword matching and con- tributes to the sharp performance drops observed when object nouns are replaced with semantically equi valent alternati ves in LIBER O-Para. D.3 Finding 3: Failur es Are Pr edominantly Planning-Lev el, Not Execution-Level DTW -Based T rajectory Classification. W e clas- sify each failed episode as Near-GT (ex ecution- le vel) or F ar-GT (planning-le vel) based on its Dy- namic T ime W arping (DTW) distance to a pseudo ground-truth (GT) trajectory , as formalized in Al- gorithm 1 . Why DTW . T rajectory lengths v ary across episodes—successful episodes may terminate early while failed episodes often run to the maximum step limit. Euclidean distance requires fixed-length inputs and cannot account for temporal misalign- ment between trajectories that follo w similar spa- 20 Figure 15: Training loss curve of π 0 . 5 (expert-only) fine-tuned on LIBER O. The model is trained for 30K steps, matching the original training configuration. The loss conv erges around 15K steps, indicating stable training completion. Near-GT % of T otal Far -GT % of T otal Model max p99 p95 p90 Model max p99 p95 p90 OpenVLA-OFT goal 1.6 1.4 0.4 0.3 OpenVLA-OFT goal 33.7 33.9 34.9 35.0 OpenVLA-OFT mixed 3.3 1.0 0.1 0.0 OpenVLA-OFT mixed 33.0 35.3 36.2 36.3 π 0.5 2.4 1.0 0.6 0.3 π 0.5 26.2 27.6 28.0 28.3 π 0.5 (expert-only) 12.5 6.2 2.1 0.9 π 0.5 (expert-only) 48.4 54.7 58.8 60.0 VLA-Adapter 4.2 2.2 0.5 0.0 VLA-Adapter 49.5 51.5 53.2 53.7 X-VLA 5.2 2.9 0.8 0.4 X-VLA 32.7 35.0 37.1 37.5 Xiaomi-Robotics-0 1.8 0.3 0.1 0.0 Xiaomi-Robotics-0 22.2 23.7 23.9 24.0 T able 16: τ threshold ablation for trajectory-based failure classification. “max” denotes the most lenient threshold (widest Near-GT boundary); p99, p95, and p90 progressi vely tighten the criterion. Across all thresholds, Far -GT (planning-lev el) failures consistently dominate, confirming that the finding is rob ust to threshold selection. tial paths at dif ferent speeds. DTW handles both v ariable-length sequences and temporal warping, making it suitable for comparing manipulation tra- jectories. W e use fastdtw ( Salv ador and Chan , 2007 ) with Euclidean distance as the local cost function, and normalize the resulting distance by sequence length to ensure comparability across episodes. Resampling. T o standardize input length for DTW , all trajectories are resampled to K =50 points via linear interpolation. This value w as cho- sen as a practical trade-off between spatial reso- lution and computational cost across ∼ 143K total episodes (4,092 paraphrases × 5 seeds × 7 mod- els). EEF Position Only . From the 7-dimensional pro- priocepti ve state ( x, y , z, r x , r y , r z , g ) , we use only the first three dimensions corresponding to the end- ef fector (EEF) absolute position ( x, y , z ) . The re- maining dimensions (orientation, gripper state) are excluded because spatial trajectory di vergence is the most direct indicator of whether the model planned to ward the correct target object—the core diagnostic question of this analysis. Threshold Robustness. The threshold τ t is set per-task as the maximum DTW distance among successful episodes (Algorithm 1 , line 12), repre- senting the most lenient Near -GT boundary . T o verify that our findings are not sensitiv e to this choice, we repeat the classification with progres- si vely stricter thresholds (p99, p95, p90 of success- ful DTW distances). As sho wn in T ab. 16 , F ar-GT failures remain dominant across all thresholds— tightening τ shifts some Near -GT episodes to Far - GT but does not alter the o verall conclusion. For example, ev en under the strictest criterion (p90), π 0 . 5 (expert-only) retains the highest Near -GT ratio among all models, consistent with the frozen-VLM 21 Success Rat e (%) Success Rat e (%) PRIDE PRIDE PRIDE PRIDE Figure 16: Correlation between PRIDE score (PD) and success rate (SR) for each VLA model on LIBER O-Para. Each point represents the mean SR of a paraphrase cell, with error bars indicating standard de viation. Colors are unified per model for visual clarity . All models exhibit statistically significant negati ve correlations ( p < . 0001 ), with Pearson r values ranging from − 0 . 671 to − 0 . 877 , validating that higher paraphrase distance consistently leads to lower task success. The summary table (bottom right) reports r and p for all models. interpretation discussed in Sec. 6.3 . GT T rajectory Consistency . Fig. 18 visualizes successful EEF trajectories for each LIBER O-Goal task. Within each task, successful trajectories con- ver ge to a narrow spatial corridor with low v ariance, v alidating the use of their mean as a pseudo GT . This consistenc y arises from the LIBER O-Goal training data, which contains a single fixed demon- stration path per task with no route di versity . Per -Model Failur e Decomposition. Fig. 19 pro- vides a fine-grained vie w of the failure classifica- tion from T ab . 4 , decomposed along the Object and Action axes for each model indi vidually . T wo ob- serv ations are consistent across all models. First, Near-GT (ex ecution-lev el) failures account for a small fraction in ev ery category , confirming that the dominance of Far -GT failures reported in Sec. 6.3 is not an artifact of aggregation but holds at the per-type lev el. Second, Near -GT failures do not concentrate along any particular paraphrase axis or type—they are distrib uted roughly uniformly , sug- gesting that ex ecution-lev el errors are not system- atically triggered by specific linguistic properties. The sole exception is π 0 . 5 (expert-only), which sho ws ele vated Near-GT ratios across most cate- gories. As discussed in Sec. 6.1 , this model freezes the VLM during fine-tuning, preserving pretrained language understanding that enables partial task identification. Ho wev er , the unadapted action ex- pert lacks the precision to con vert correct plans into successful ex ecutions, resulting in trajectories that track the GT path but ultimately f ail. These patterns reinforce the conclusion that para- phrase rob ustness improvements should tar get the instruction-to-task identification stage—where Far - GT failures originate—rather than low-le vel motor control refinement. E AI Assistants During the course of this work, we used Google’ s Gemini 2.5 Pro ( https://gemini. google.com/ ) ( Comanici et al. , 2025 ) for gener- ating paraphrase candidates in the LIBERO-P ara benchmark construction. All generated paraphrases were manually re viewed and filtered by the authors. Additionally , we used AI assistants including Ope- nAI’ s ChatGPT ( https://chatgpt.com/ ) ( Ope- nAI , 2023 ) and Anthropic’ s Claude ( https:// claude.ai/ ) ( Anthropic , 2025 ) to proofread and improv e the clarity of our writing. W e affirm that these tools serv ed solely as assistiv e aids and did not contribute to core research ideas, experimental design, analysis, or interpretation of results. The final scientific content and all claims made in this paper are the sole responsibility of the authors. 22 Object P ar aphr ase T ype A ction P ar aphr ase T ype 0 20 Success Rat e 40 60 80 100 Figure 17: Per-model success rate heatmaps across all Object × Action paraphrase type combinations on LIBERO- Para. Rows represent object paraphrase types and columns represent action paraphrase types. Each cell reports the mean success rate o ver 5 seeds. The None row/column indicates the original (unparaphrased) instruction. All models show consistent degradation as paraphrase distance increases from the top-left (original) to the bottom-right (most distant) cells. Open t he middle dr aw er of t he cabinet Put t he bo wl on t op of t he cabinet Open t he t op dr aw er and put t he bo wl inside Push t he plat e t o t he fr ont of t he st o v e Put t he cr eam cheese in t he bo wl Put t he wine bott le on t he r ack put t he bo wl on t he plat e Put t he wine bott le on t op of t he cabinet put t he bo wl on t he st o v e T urn on t he st o v e Figure 18: Successful EEF trajectories of Xiaomi-Robotics-0 on LIBER O-Para, grouped by LIBER O-Goal task index (T0–T9). W ithin each task, successful trajectories con verge to a narrow corridor with low spatial variance, indicating that manipulation strategies are largely in variant to paraphrase v ariation. W e observe consistent patterns across all e valuated models; a single model is sho wn for visual clarity . This consistency moti vates the use of the mean successful trajectory as a pseudo ground-truth (GT) in Algorithm 1 . 23 0 25 50 75 100 P er centage (%) 89 91 40 60 43 56 OpenVLA-OFT_goal Obj T ype 0 25 50 75 100 74 25 70 28 65 32 66 32 52 47 68 30 63 34 70 28 66 32 60 38 58 41 OpenVLA-OFT_goal Act T ype 0 25 50 75 100 P er centage (%) 90 91 42 52 37 59 OpenVLA-OFT_mixed Obj T ype 0 25 50 75 100 71 23 69 28 67 29 67 30 49 49 64 33 65 30 69 28 63 34 60 36 59 38 OpenVLA-OFT_mixed Act T ype 0 25 50 75 100 P er centage (%) 89 88 10 53 42 58 40 Pi05_full Obj T ype 0 25 50 75 100 89 81 18 73 25 71 25 71 28 73 25 68 30 80 18 67 31 59 36 58 38 Pi05_full Act T ype 0 25 50 75 100 P er centage (%) 59 28 42 44 26 62 33 56 Pi05_expert Obj T ype 0 25 50 75 100 75 16 54 35 42 48 48 44 46 43 44 45 34 51 27 53 26 61 18 65 28 61 Pi05_expert Act T ype 0 25 50 75 100 P er centage (%) 73 22 59 36 27 69 30 66 VLA-Adapter Obj T ype 0 25 50 75 100 73 25 58 40 50 45 52 42 41 54 50 46 39 56 53 43 39 56 32 63 29 67 VLA-Adapter Act T ype 0 25 50 75 100 P er centage (%) 82 14 77 19 45 49 46 45 X - VLA Obj T ype 0 25 50 75 100 85 12 73 22 73 22 72 22 62 33 56 38 62 32 62 32 52 42 44 50 44 47 X - VLA Act T ype None Addition SP -contextual SP -habitual 0 25 50 75 100 P er centage (%) 90 88 64 35 65 34 Xiaomi-Robotics-0 Obj T ype None Addition SP -contextual SP -habitual Coordination Subordination Need Statement Embedded Imperative Permission Directive Question Directive Hint 0 25 50 75 100 88 11 88 11 76 24 75 25 82 15 75 20 76 23 87 12 77 21 60 38 57 41 Xiaomi-Robotics-0 Act T ype Near-G T / F ar-G T F ailure Analysis per Model Success Near - G T F ail F ar - G T F ail Figure 19: Near-GT / F ar-GT failure breakdo wn per model, decomposed by Object axis (left) and Action axis (right). Each bar sho ws the proportion of Success (green), Near -GT failure (yello w , ex ecution-level), and Far -GT failure (red, planning-le vel) episodes. The threshold τ is set to the maximum DTW distance among successful episodes per task. Across all models and paraphrase types, Far -GT failures consistently dominate, with no concentration of Near-GT f ailures along any specific axis. The exception is π 0 . 5 (expert-only), which e xhibits a higher Near -GT ratio due to its frozen VLM preserving partial task identification while the unadapted action expert fails at e xecution. 24 Algorithm 1 T rajectory-based failure classification for Sec. 6.3 A pseudo ground-truth trajectory (GT) is constructed from successful episodes of each model on LIBER O-Para. Failed episodes are classified as Near-GT (e xecution-le vel) or F ar-GT (planning-le vel) based on DTW distance, with the threshold τ t set to the maximum distance among successes. Require: Set of episodes E = { e 1 , . . . , e N } for original LIBER O-Goal task index t ∈ { 0 , 1 , ..., 9 } , each with trajectory τ i ∈ R T i × 3 and outcome s i ∈ { 0 , 1 } ; resampling size K =50 Ensure: Classification of each failed episode as N E A R - G T or F A R - G T // Step 1: Partition episodes 1: S t ← { e i ∈ E | s i = 1 } ▷ successes 2: F t ← { e i ∈ E | s i = 0 } ▷ failures // Step 2: Construct pseudo-GT trajectory 3: for each e i ∈ S t do 4: ˆ τ i ← R E S A M P L E ( τ i [ : , : 3] , K ) ▷ first 3 dims of proprio: EEF absolute position (x,y ,z) 5: end for 6: τ GT ← 1 |S t | P e i ∈S t ˆ τ i // Step 3: Compute DTW distances 7: L max ← max e j ∈S t T j 8: for each e i ∈ E do 9: τ ′ i ← R E S A M P L E ( τ i [: L max , : 3] , K ) 10: d i ← D T W ( τ ′ i , τ GT ) ▷ DTW : Dynamic Time W arping 11: end for // Step 4: Threshold 12: τ t ← max e i ∈S t d i // Step 5: Classify failures 13: for each e i ∈ F t do 14: if d i ≤ τ t then 15: L A B E L ( e i ) ← N E A R - G T ▷ ex ecution-lev el 16: else 17: L A B E L ( e i ) ← F A R - G T ▷ planning-le vel 18: end if 19: end for 20: retur n { L A B E L ( e i ) } e i ∈F t 25 Generator Prompt Paraphrase the gi ven robot manipulation instruction while preserving semantic meaning. Rules: • Preserv e plurality (singular/plural must match original) • Do not add visual attrib utes (color , size, shape, material) • Do not add spatial attrib utes (position, location, direction) • Modify only what is specified in the task guidelines belo w Scope: • Object tasks: modify only object nouns, preserve verbs and structure • Action tasks: modify only action elements, preserve object nouns Output: One paraphrase per line. No explanations or alternati ves. Figure 20: Common prompt template for the Paraphrase Generator (LLM), shared across all paraphrase types. V erifier Prompt Criteria: • T ask compliance: Required transformations applied, prohibited changes av oided. – Object tasks (obj_*): only object nouns changed, verbs/structure intact – Action tasks (act_*): only action elements changed, object nouns intact • Semantic preserv ation: Core action and tar get objects unchanged. • Naturalness: Grammatically correct, natural phrasing. • F ormat: Single instruction only , no meta-commentary or explanations. • Lexical clarity: A void confusion with environment objects (stov e, bo wl, plate, rack, wine bottle, cream cheese, cabinet). – Acceptable: “cupboard” (distinct from cabinet) – Reject: “dish” (confusable with plate/bowl) Output: Accepted paraphrases only , one per line. Figure 21: Common prompt template for the Paraphrase V erifier (LLM), used to filter generated paraphrases. 26 Merge Generator Prompt Merge object paraphrases and action paraphrases into combined v ariants. Input: • Original instruction • Object paraphrase e xamples (nouns changed) • Action paraphrase examples (v erbs/structure changed) T ask: Create paraphrases with both object and action modifications applied. Process: 1. Identify object substitution patterns (e.g., “dra wer” → “compartment”) 2. Identify action modification patterns (e.g., “pick” → “grab”) 3. Apply both transformations coherently Example: • Original: “ pick the bowl and place on the stove ” • Object v ariant: “ pic k the container and place on the cooktop ” • Action v ariant: “ grab the bowl and put on the stove ” • Mer ged: “ grab the container and put on the cooktop ” Output: 5–10 merged paraphrases, one per line. No numbering or explanations. Figure 22: Prompt template for combining v alidated Object and Action paraphrases into merged v ariants. Merge V erifier Prompt Ev aluate merged paraphrases that combine object and action changes. Criteria: • Completeness: Both object nouns AND action elements must differ from original. Reject if only one type changed. • P attern consistency: Changes follow the provided e xamples. • Semantic preserv ation: T ask intent and outcome unchanged. • Naturalness: Grammatically correct, coherent combination. • F ormat: Single instruction, no meta-commentary . • Le xical clarity: No confusion with en vironment objects. Output: Accepted paraphrases only , one per line. Figure 23: Prompt template for verifying mer ged paraphrases before final inclusion in the dataset. 27 Object-Lexical T ypes Prompts obj_lexical_same_polarity_habitual Replace object nouns with general synonyms. EPT : Same-polarity substitution (habitual) Guidelines: • Use commonly accepted synon yms (bowl → cup, cabinet → cupboard) • Preserv e grammatical form • K eep verbs and structure unchanged Examples: • “ Pick the bowl and place on the stove ” → “ Pick the cup and place on the stove. ” • “ Open the middle layer of drawer ” → “ Open the middle layer of compartment. ” obj_lexical_same_polarity_contextual Replace object nouns with contextually appropriate alternati ves. EPT : Same-polarity substitution (contextual) Guidelines: • Use conte xtually similar items (bowl → container , stove → cooking surface) • Maintain semantic appropriateness for manipulation tasks • Preserv e structure Examples: • “ Pick the bowl and place on the stove ” → “ Pick the container and place on the cooking surface. ” • “ Open the middle layer of drawer ” → “ Open the middle tier of drawer . ” obj_lexical_addition Add functional descriptors from object names. EPT : Addition Guidelines: • Add functional/categorical adjecti ves (soup bowl, kitchen cabinet) • Exclude visual adjecti ves (color , size, material) • Exclude spatial adjecti ves (top, left, big) • Preserv e plurality Examples: • “ Pick the bowl and place on the stove ” → “ Pick the mixing bowl and place on the kitc hen stove . ” • “ Open the middle layer of drawer ” → “ Open the middle layer of storag e drawer . ” Figure 24: T ype-specific generation guidelines for Object-Lexical paraphrases. These guidelines are pro vided to the Generator for paraphrase generation and also appended to the V erifier to assess whether the generated output conforms to the intended variation type. 28 Action-Lexical T ypes Prompts act_lexical_same_polarity_habitual Replace action verbs with general synon yms. EPT : Same-polarity substitution (habitual) Guidelines: • Use common v erb synonyms (pick → grab, place → put) • Preserv e structure and arguments • K eep object nouns unchanged Examples: • “ Pick the bowl and place on the stove ” → “ Grab the bowl and put on the stove. ” • “ Open the middle layer of drawer ” → “ Pull the middle layer of drawer . ” act_lexical_same_polarity_contextual Replace action verbs with conte xtually appropriate alternativ es. EPT : Same-polarity substitution (contextual) Guidelines: • Use conte xt-appropriate alternativ es (pick → grasp, place → position) • Preserv e core action meaning • K eep object nouns unchanged Examples: • “ Pick the bowl and place on the stove ” → “ Grasp the bowl and position on the stove. ” • “ Open the middle layer of drawer ” → “ Access the middle layer of drawer . ” act_lexical_addition_deletion Add or remov e manner adverbs. EPT : Addition/Deletion Guidelines: • Add single-word adv erbs (carefully , gently , slowly) • F or phrasal additions, use act_structural_ellipsis instead • K eep verb and structure unchanged Examples: • “ Pick the bowl and place on the stove ” → “ Carefully pick the bowl and place on the stove. ” • “ Open the middle layer of drawer ” → “ Gently open the middle layer of drawer . ” Figure 25: T ype-specific generation guidelines for Action-Le xical paraphrases. These guidelines are pro vided to the Generator for paraphrase generation and also appended to the V erifier to assess whether the generated output conforms to the intended variation type. 29 Action-Structural T ypes Prompts act_structural_coordination Modify coordination structure. EPT : Coordination changes (syntax-based) Guidelines: • Split into separate sentences • Add explicit ordering (First... then...) • Combine with coordination • Preserv e all information Examples: • “ Pick the bowl and place on the stove ” → “ Pick the bowl. Place it on the stove. ” • “ Open the middle layer of drawer ” → “ Locate the drawer , then open the middle layer . ” act_structural_subordination Modify subordination structure. EPT : Subordination changes (syntax-based) Guidelines: • Con vert coordination to subordination • Use temporal subordinators (after , once, when) • Use purpose subordinators (so that, in order to) • Preserv e semantic relations Examples: • “ Pick the bowl and place on the stove ” → “ After picking the bowl, place it on the stove. ” • “ Open the middle layer of drawer ” → “ Open the middle layer of drawer in or der to access the contents. ” Figure 26: T ype-specific generation guidelines for Action-Structural paraphrases. These guidelines are provided to the Generator for paraphrase generation and also appended to the V erifier to assess whether the generated output conforms to the intended variation type. 30 Action-Pragmatic T ypes Prompts (1/2) act_pragmatical_need_statement Express as speaker’ s need. Ervin-T ripp T ype 1: Need Statements Guidelines: • Con vert to first-person need (I need, I want, I require) • F ocus on desired outcome rather than process • Preserv e core action and objects Examples: • “ Pick the bowl and place on the stove ” → “ I need the bowl placed on the stove. ” • “ Open the middle layer of drawer ” → “ I want the middle layer of drawer open. ” act_pragmatical_embedded_imperative Embed in question frame with modals. Ervin-T ripp T ype 3: Embedded Imperativ es Guidelines: • Use modal questions (Could you, W ould you, Can you) • K eep agent and action explicit b ut softened Examples: • “ Pick the bowl and place on the stove ” → “ Could you pick the bowl and place it on the stove? ” • “ Open the middle layer of drawer ” → “ Can you open the middle layer of drawer? ” act_pragmatical_permission_directi ve Frame as permission request. Ervin-T ripp T ype 4: Permission Directiv es Guidelines: • Request permission or access (May I ha ve, Can I ha ve access to) • F ocus on speaker’ s access requiring hearer’ s action Examples: • “ Pick the bowl and place on the stove ” → “ May I have the bowl placed on the stove? ” • “ Open the middle layer of drawer ” → “ Can I have access to the middle layer of drawer? ” Figure 27: T ype-specific generation guidelines for Action-Pragmatic paraphrases (a). These guidelines are provided to the Generator for paraphrase generation and also appended to the V erifier to assess whether the generated output conforms to the intended variation type. 31 Action-Pragmatic T ypes Prompts (2/2) act_pragmatical_question_directi ve Pose information question implying action. Ervin-T ripp T ype 5: Question Directiv es Guidelines: • Ask contextually rele vant question • Do not e xplicitly specify desired act • Action inferred from context Examples: • “ Pick the bowl and place on the stove ” → “ Is the bowl still sitting on the counter? ” • “ Open the middle layer of drawer ” → “ Do we know the contents of the middle layer of drawer? ” act_pragmatical_hint Make statement implying action through inference. Ervin-T ripp T ype 6: Hints Guidelines: • Use general statement, not surface directi ve • State condition or desired state • Rely on situational inference • Do not mention action directly Examples: • “ Pick the bowl and place on the stove ” → “ The stove surface is now clear for the bowl. ” • “ Open the middle layer of drawer ” → “ The middle layer of drawer is still closed. ” Figure 28: T ype-specific generation guidelines for Action-Pragmatic paraphrases (b), continued. These guidelines are provided to the Generator for paraphrase generation and also appended to the V erifier to assess whether the generated output conforms to the intended variation type. 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment