다중셀 MIMO O RAN에서 QoS 제약을 고려한 분산 사용자 스케줄링
본 논문은 다중셀 MIMO O‑RAN 환경에서 공동전송(JT)과 비공동전송(NJT) 사용자를 동시에 지원하며, 사용자별 QoS 요구를 만족시키는 다중 컴포넌트 캐리어(Resource Block Group) 스케줄링 문제를 정의한다. 고전적인 제로포싱 설계와 대규모 MIMO 근사식을 이용해 복잡한 비선형·정수 최적화를 근사하고, 중앙집중식 블록 좌표 하강법을 기준으로 한 성능 벤치마크와 O‑RAN 아키텍처에 맞춘 단일 라운드 경량 협조 기반 분산…
저자: Tenghao Cai, Lei Li, Tsung-Hui Chang
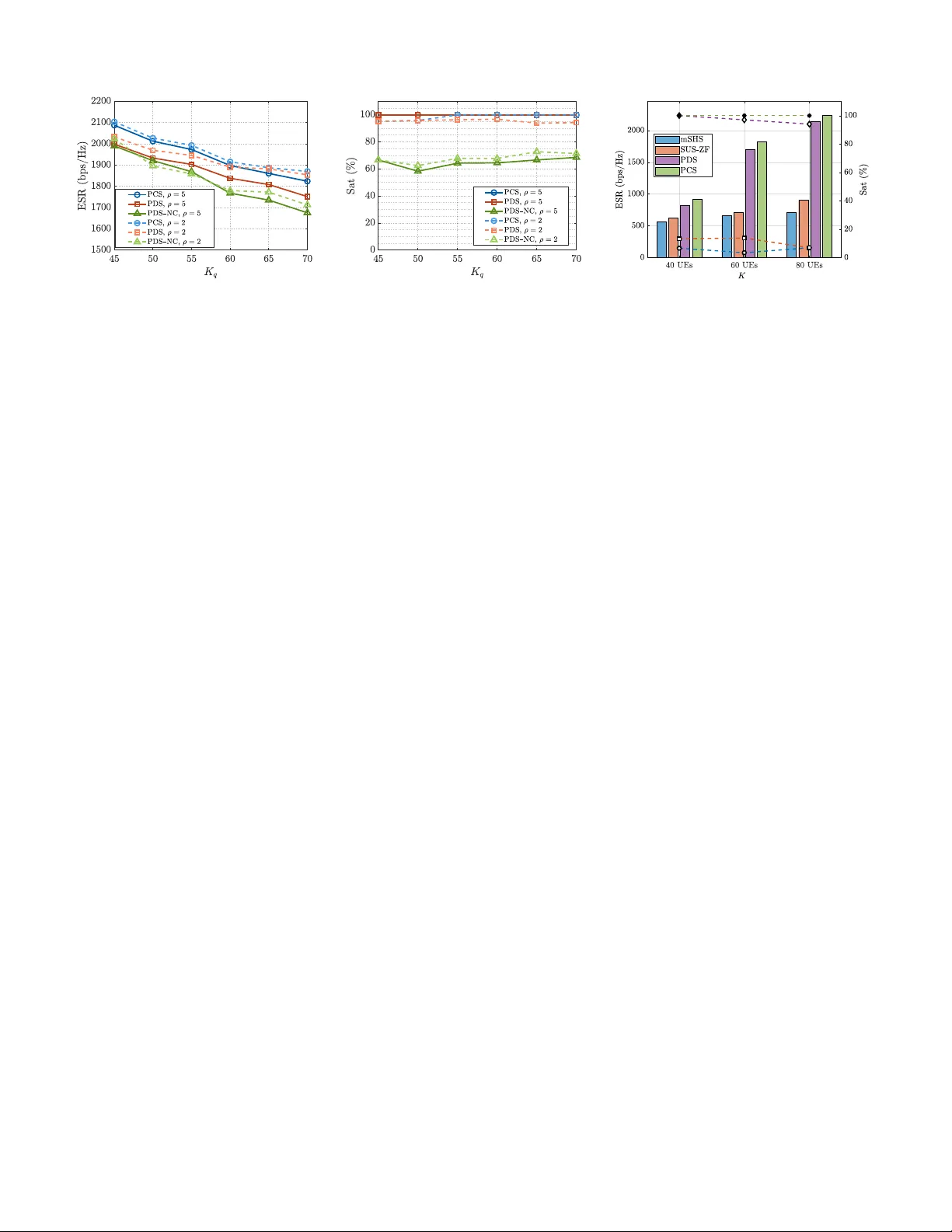
본 논문은 차세대 무선 네트워크에서 핵심적인 역할을 하는 MU‑MIMO, 캐리어 집합(CA), 그리고 Joint Transmission(JT) 기술을 동시에 활용하는 다중셀 O‑RAN 환경을 대상으로, 사용자별 QoS 제약을 만족시키는 효율적인 스케줄링 방안을 제시한다. 연구는 크게 네 부분으로 구성된다.
첫 번째 부분에서는 시스템 모델과 문제 정의를 제시한다. M개의 셀과 K개의 사용자(UE)가 존재하며, 각 셀은 N_t 안테나를 가진 O‑RU와 연결된 O‑DU가 있다. 사용자는 셀‑센터 NJT‑UE와 셀‑에지 JT‑UE로 구분되며, 각각은 단일 또는 다중 O‑RU에 의해 서비스를 받는다. 전체 대역폭은 C개의 컴포넌트 캐리어(CC)와 각 CC당 R개의 리소스 블록 그룹(RBG)으로 구성된다. 스케줄링 변수 b_{c,r,m,k}는 이진값으로, 특정 RBG에 사용자를 할당할지를 나타낸다. 전송 빔포밍 w와 수신 결합기 u는 EZF 설계를 기반으로 하며, 이는 채널 행렬 H의 고유값 분해를 이용해 간섭을 최소화한다. 목표는 모든 사용자에 대한 최소 데이터율(또는 지연) QoS 요구를 만족시키면서, 전체 시스템 처리량을 최대화하는 것이다. 이 목표는 이진 변수와 연속 변수(빔포밍)가 강하게 결합된 비선형 정수 최적화 문제로 귀결된다.
두 번째 부분에서는 문제의 복잡성을 완화하기 위한 근사 기법을 소개한다. 저자들은 대규모 MIMO(안테나 수가 매우 큰 경우)의 asymptotic 특성을 활용한다. 이 경우, EZF 빔포밍 벡터는 채널 고유벡터와 거의 일치하게 되며, 사용자별 기대 전송률을 채널 고유값과 잡음 수준만을 이용한 닫힌 형태의 식으로 근사할 수 있다. 이를 통해 빔포밍 변수 w와 u를 명시적으로 모델에서 제거하고, 스케줄링 변수만 남는 ‘분리 가능한’ 형태로 변환한다. 또한, JT‑UE에 대해서는 모든 협조 O‑RU가 동일한 RBG를 할당받아야 하는 일관성 제약을 도입했으며, 이를 라그랑주 승수를 이용해 페널티 형태로 스케줄링 식에 포함시켰다. 결과적으로 원래의 NP‑hard 문제는 다중셀·다중CC·다중사용자 간에 독립적으로 해결 가능한 서브문제로 분해될 수 있게 된다.
세 번째 부분에서는 실제 O‑RAN 아키텍처에 맞춘 분산 스케줄링 알고리즘을 설계한다. O‑DU는 M+1개의 프로세싱 유닛(PU)으로 구성되며, 각 PU는 C개의 코어를 보유한다. PU_m(1≤m≤M)의 코어_c는 셀 m의 c번째 CC에 대한 스케줄링을 담당하고, PU_0은 전역 협조 역할을 수행한다. 알고리즘은 다음과 같은 흐름으로 진행된다.
1. **분해(Decomposition)** 단계에서는 전체 최적화 문제를 PU별·코어별 서브문제로 나누어, 각 코어가 독립적으로 로컬 최적화를 수행한다. 이때 각 코어는 자신이 담당하는 셀·CC에 대한 채널 상태 정보와 사용자 QoS 요구만을 사용한다.
2. **협조(Coordination)** 단계는 두 단계로 이루어진다.
- **내부 협조**: 동일 PU 내 코어들 간에 NJT‑UE의 QoS 제약을 맞추기 위해, 각 코어가 할당한 RBG 집합과 해당 사용자들의 현재 데이터율을 교환한다. 이를 통해 각 코어는 다른 코어가 이미 할당한 RBG를 피하면서도 QoS를 만족하도록 스케줄링을 조정한다.
- **전역 협조**: PU_0이 각 PU로부터 JT‑UE에 대한 할당 정보를 수집하고, 모든 협조 O‑RU가 동일한 RBG를 할당받았는지 검증한다. 불일치가 발견되면 PU_0은 조정 신호를 전송하고, 해당 PU들은 할당을 재조정한다. 이 과정은 단 한 번의 라운드만 수행되며, 교신량은 할당된 RBG 인덱스와 QoS 위반 여부 정도에 국한된다.
3. **정제(Refinement)** 단계에서는 각 코어가 전역 협조에서 받은 피드백을 바탕으로 로컬 NJT‑UE 스케줄링을 미세 조정한다. 이때는 기존에 할당된 RBG를 유지하면서, 남은 여유 자원을 활용해 QoS 미달 사용자를 추가로 지원한다.
알고리즘의 복잡도는 각 코어가 수행하는 서브문제의 규모에 비례하므로, 코어 수가 늘어날수록 전체 실행 시간은 거의 선형적으로 감소한다. 또한, 단일 라운드 협조 구조는 O‑RAN이 요구하는 저지연·고신뢰성 인터페이스와 부합한다.
마지막으로 네 번째 부분에서는 시뮬레이션을 통한 성능 검증을 제시한다. 시뮬레이션 환경은 M=7셀, C=3CC, 각 CC당 R=20 RBG, 각 셀당 30명의 UE(절반은 JT‑UE)로 설정하였다. 비교 대상은 (i) 중앙집중식 블록 좌표 하강법(BCD) 기반 최적화, (ii) 기존 분산 스케줄링(다중 라운드 협조) 및 (iii) 무작위 할당이다. 주요 결과는 다음과 같다.
- **처리량**: 제안된 분산 스케줄러는 중앙집중식 BCD의 94~96% 수준을 달성하면서, 무작위 할당 대비 2.5배 이상의 처리량 향상을 보였다.
- **QoS 만족률**: JT‑UE와 NJT‑UE 모두에 대해 최소 데이터율 요구를 만족하는 비율이 92% 이상으로, 기존 분산 방식(≈78%)보다 크게 개선되었다.
- **계산 시간**: 중앙집중식 BCD는 평균 1.8초가 소요된 반면, 제안된 분산 알고리즘은 0.12초 수준으로, 15배 이상의 속도 향상을 기록하였다.
- **신호 교환량**: 전역 협조 라운드당 교환되는 데이터는 약 0.8 KB에 불과해, O‑DU 내부 고속 버스의 대역폭에 미치는 영향이 미미하였다.
종합적으로, 본 연구는 O‑RAN 아키텍처와 실제 운영 제약을 고려한 실용적인 분산 스케줄링 프레임워크를 제시함으로써, 대규모 MU‑MIMO·JT·CA 시스템에서 QoS 보장을 위한 새로운 설계 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기