Distributed User Scheduling in Multi-Cell MIMO O-RAN with QoS Constraints
Distributed scheduling is essential for open radio access network (O-RAN) employing advanced physical-layer techniques such as multi-user MIMO (MU-MIMO), carrier aggregation (CA), and joint transmission (JT). This work investigates the multi-componen…
Authors: Tenghao Cai, Lei Li, Tsung-Hui Chang
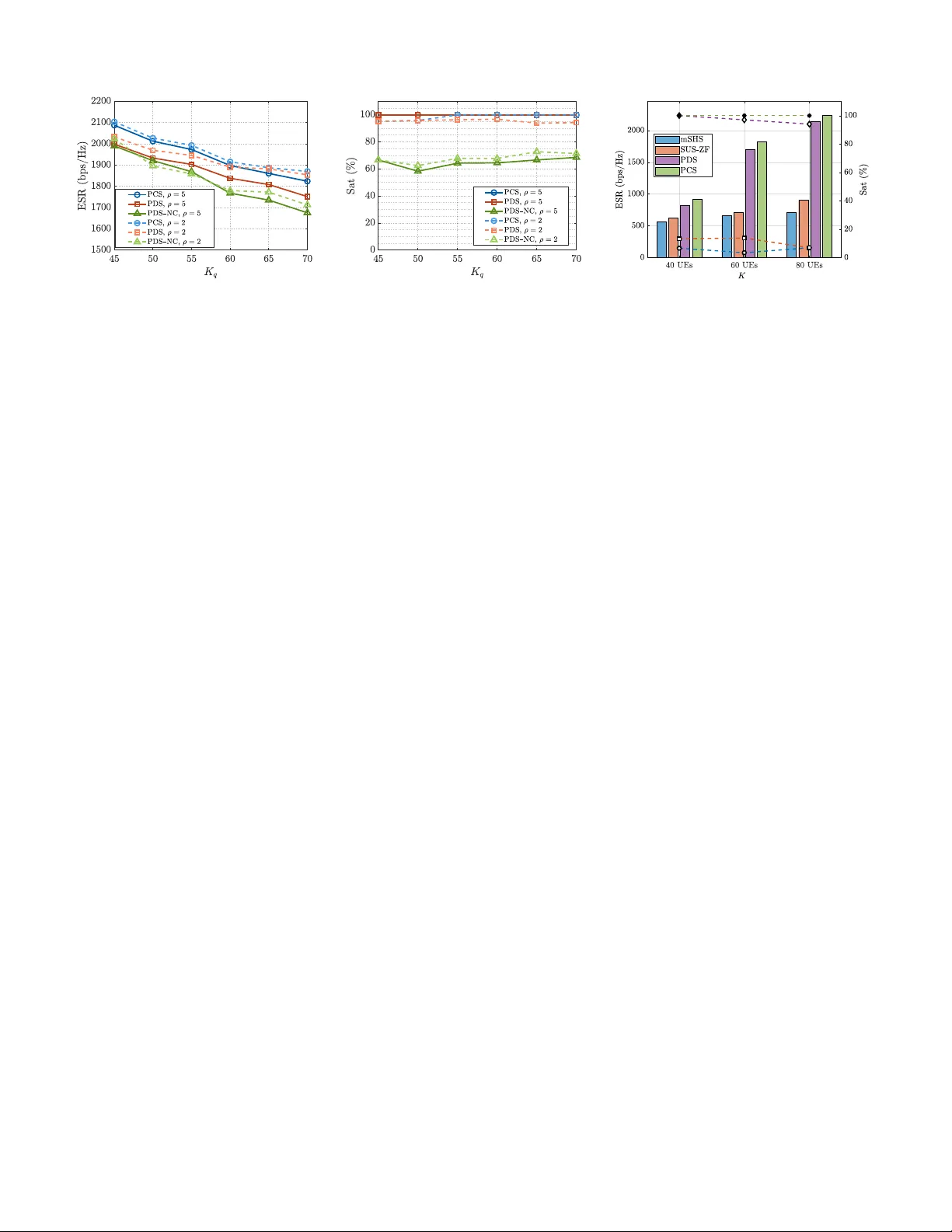
1 Distrib uted User Scheduling in Multi-Cell MIMO O-RAN with QoS Constraints T enghao Cai, Lei Li, Member , IEEE and Tsung-Hui Chang, F ellow , IEEE Abstract —Distributed scheduling is essential for open radio ac- cess network (O-RAN) employing advanced ph ysical-layer tech- niques such as multi-user MIMO (MU-MIMO), carrier aggrega- tion (CA), and joint transmission (JT). This work in vestigates the multi-component-carrier (multi-CC) resource block gr oup (RBG) scheduling in MU-MIMO O-RAN with both JT and non-JT users. W e formulate a scheduling optimization problem to maximize throughput subject to user -specific quality of service (QoS) requir ements while ensuring consistent allocations across cooper- ating O-RAN radio units (O-R Us) requir ed by JT transmission. The str ong variable coupling, non-con vexity , and combinatorial complexity mak e the pr oblem highly challenging . T o tackle this, we extend the eigen-based zero-f orcing transceiv er design to JT users and le verage massiv e MIMO asymptotic properties to derive a tractable, separable rate approximation. Building on this, we de velop two solutions: a centralized block coordinate descent benchmark and a distrib uted scheduler aligned with the O-RAN architecture. The proposed distributed scheme achieves near -centralized performance with only one round of lightweight coordination among cells, significantly reducing complexity and delay . Extensive simulations validate that our distributed sched- uler achie ves high scalability , fast con vergence, and better QoS satisfaction rate in large-scale MU-MIMO networks. I . I N T R O DU C T I O N The growing div ersity of user services and rising demands for quality of service (QoS) ha ve placed unprecedented pres- sure on wireless networks. T o satisfy these requirements, multi-user multi-input multiple-output (MU-MIMO) systems hav e become a cornerstone of 5G and beyond, enabling base stations (BSs) to serv e multiple user equipments (UEs) concur - rently within the same time-frequency resources through spa- tial multiplexing. In parallel, to further boost capacity , carrier aggregation (CA) [1, 2] allows UEs to simultaneously access multiple component carriers (CCs) operating at distinct center frequencies. Each CC is divided into resource block groups (RBGs), pro viding finer spectrum granularity . Ho wev er , ev en with enhanced frequency-domain flexibility and spatial multi- plexing, cell-edge UEs still suf fer from weak signal strength and strong inter-cell interference (ICI). T o address this issue, joint transmission (JT) was introduced to allo w multiple BSs to coherently serve the same UE to improv e the received signal quality [3]. T o fully harness these benefits of MU- MIMO, multi-CC, and JT , it is essential to design an efficient scheduler that allocates the RBGs across multiple CCs to UEs in multiple cells to maximize system throughput while meeting QoS requirements. Howe ver , designing such a scheduler is notoriously non-trivial due to the following complexities [4]: T . Cai is with the School of Science and Engineering, The Chinese Univ ersity of Hong Kong, Shenzhen (CUHK-Shenzhen), China, and with the Shenzhen Research Institute of Big Data (SRIBD). L. Li and T .- H. Chang are with School of Artificial Intelligence, CUHK-Shenzhen and with the SRIBD. (email: 221019048@link.cuhk.edu.cn, lei.ap@outlook.com, tsunghui.chang@ieee.org). • Scheduling Consistency : For UEs jointly served by multiple BSs, referred to as JT -UEs, the scheduler must ensure consistent RBG allocations across all coordinating BSs for each CC. • QoS Guarantee : For UEs with stringent QoS require- ments, the scheduler design needs to coordinate across BSs and CCs to jointly satisfy the UE’ s QoS requirement. This is particularly challenging since communications across BSs and CCs are strictly limited. • Coupled Scheduling and T ransmit Beamforming (TBF) Design : Mitigating ICI requires multi-user TBF , whose design depends on the scheduling pattern. Y et, the scheduling itself depends on the interference induced by TBF , creating a tightly coupled optimization problem. Accordingly , MU-MIMO scheduling exhibits strong non- con vexity and coupling across CCs, BSs, and JT -UEs, yielding an NP-hard integer optimization problem [5]. Moreov er, an efficient scheduler must be computation-fast and scalable with respect to the network size. Distributed scheduling addresses this by offloading RBG allocation across network nodes and lev eraging multi-core parallelism within each node. T o this end, the scheduling design must align with the network architecture well. Among various wire- less network architectures, the open radio access network (O-RAN), with its promoted openness and modularity , has emerged as a paradigm-shifting framework for next-generation wireless systems [6]. In O-RAN’ s disaggreg ated architecture, the open radio unit (O-R U) is responsible for RF signal transmission and reception, while the open distributed unit (O-DU), connected to multiple O-R Us, performs baseband processing and scheduling functions. In practical deployments, an O-DU is commonly realized as a computing platform equipped with multiple processing units (PUs) or accelerator cards, interconnected through high-speed on-board links to support parallel processing and lightweight inter-unit coordi- nation [7]. Under this architecture, beyond the intrinsic non- con vexity and tight coupling of MU-MIMO scheduling across cells, carriers, and JT -UEs, the scheduler must ef fectively exploit the internal parallelism of the O-DU while maintaining scheduling consistency . Meanwhile, the information exchange among computational units is latency-sensitiv e and cannot be arbitrarily frequent. This makes the corresponding algorithm design more challenging. Although scheduling optimization in multi-cell networks has been widely studied, distributed multi-cell, multi-CC scheduling for MU-MIMO O-RAN that explicitly accounts for JT and QoS constraints remains unexplored. For example, algorithms in [4, 5, 8–10] considered joint optimization of user scheduling and resource allocation, but they focused on centralized processing. Moreover , the works [4, 5, 9, 10] were 2 restricted to the MISO scenario. In contrast, the distributed schemes in [11–14] ignored QoS constraints, rendering them unsuitable for burst-demand services such as extended reality . While [15] considered QoS requirements, it took multiple rounds of information exchange between BSs due to the iterativ e TBF design, incurring substantial signaling overhead and latency that hinder practical deployment. In this work, we study cross-CC scheduling in MU-MIMO O-RAN in volving both JT -UEs and NJT -UEs (i.e., UEs served by a single BS), and propose a highly parallel scheduling framew ork. By judiciously decomposing the scheduling prob- lem into multiple subproblems and exploiting the parallel pro- cessing capability of the O-DU, our proposed scheme achieves distributed scheduling with only a single round of information coordination among multiple PUs of the O-DU, significantly reducing the cross-PU signaling overhead while effecti vely balancing spectral efficiency and div erse QoS requirements. The main contributions are summarized as follows: 1) Multi-Cell Cross-CC Scheduling Formulation f or MU- MIMO O-RAN : W e consider general multi-cell cross- CC scheduling in MU-MIMO O-RAN, including both JT -UEs and NJT -UEs with heterogeneous QoS require- ments. Giv en practical computational constraints where iterativ e TBF solutions are often prohibiti ve, we adopt eigen-based zero-forcing TBF (EZF-TBF) with a closed- form transceiv er design, and formulate a scheduling opti- mization problem that jointly maximizes throughput and satisfies QoS constraints. Unlike prior work restricted to single-cell scheduling [16], single-CC operation [15], or scheduling without e xplicit QoS guarantees [14], our model captures the intrinsic complexity of practical scheduling and incorporates inter-cell JT scheduling con- sistency and cross-CC QoS coupling. 2) Efficient Problem Approximation : T o handle the highly non-con vex problem with strong coupling between binary scheduling variables and intermediate TBF variables, we dev elop a novel approximation scheme. First, by exploit- ing the structural properties of EZF-TBF and the charac- teristics of ICI, we deriv e closed-form approximate rate expressions for JT -UEs, substantially alleviating cross- cell coupling. Lev eraging massiv e MIMO asymptotics, we further remove the dependence on intermediate TBF variables, yielding simplified rate expressions that are amenable to distributed and parallel optimization. 3) Distributed Scheduling with Lightweight Coordina- tion : Building on the simplified problem, we dev elop a distributed scheduling scheme that fully exploits the parallel computing capabilities of multiple PUs within the O-DU while requiring only a single round of coor- dination. The scheme consists of three stages: decompo- sition, coordination, and refinement. First, the network- wide scheduling problem is decomposed into parallel sub-tasks executed across computational cores within the PUs, enabling scalable decision-making. Next, limited coordination occurs at two levels: within each PU, cores exchange local information to align NJT -UE QoS con- straints across CCs; in parallel, a dedicated PU per- forms inter-PU coordination to ensure consistent JT -UE scheduling across cells. Finally , each core refines its local NJT -UE scheduling based on the feedback, further improving performance through localized optimization. 4) Extensive V alidation : Extensi ve simulations demonstrate that the proposed distributed scheduler achieves near- centralized performance in terms of throughput and QoS satisfaction, while reducing computational time by more than an order of magnitude, making it well-suited for large-scale O-RAN deployments. A. Related W ork As a cornerstone of modern wireless networks, the multi- cell user scheduling problem is inherently complex due to intertwined factors such as resource coordination and het- erogeneous QoS requirements. The scheduling optimization is typically cast as an integer programming problem with combinatorial complexity and is well known to be NP-hard. Accordingly , exhausti ve search with a prohibitiv e computa- tional burden is impractical for real-world systems. Simi- larly , scheduling schemes based on commercial solvers like Gurobi often suffer from prohibiti ve computational comple xity and poor scalability [17], particularly under explicit QoS constraints. Consequently , researchers have explored various centralized/distributed strategies, including relaxation-based methods [5], genetic algorithms [8], branch-and-bound [10], and Hungarian algorithm [9]. In parallel, lightweight heuristic schemes such as proportional fairness [18] have been adopted, offering low-complexity implementations at the expense of performance loss. Centralized scheduling typically relies on a central unit that collects global information and optimizes network-wide decisions. In [8], genetic algorithms were employed to evolv e user scheduling patterns to maximize the throughput in multi- cell MIMO systems under successive interference cancella- tion decoding strategies. The work [9] integrated fractional programming with the Hungarian algorithm for multi-band scheduling, alternately optimizing user assignments and TBF to maximize the weighted sum rate. While effective , these designs shar e a critical limitation: the y predominantly tar geted throughput maximization while neglecting explicit per-user QoS constraints. Compared with unconstrained formulations, incorporating QoS constraints makes multi-cell scheduling considerably harder . First, the feasible region becomes drasti- cally compressed and typically non-conv ex. Second, existing methods based on dual-decomposition for these problems of- ten introduce additional optimization v ariables or parameters, which further increase computational complexity . Third, unlike unconstrained cases where each RB can be optimized indepen- dently , the scheduler needs to handle the variable coupling due to QoS constraints and jointly determine allocations across all RBs. This further increases the computational burden. In existing literature, [10] studied multi-subchannel schedul- ing to maximize the number of scheduled users under QoS constraints, and proposed a joint scheduling and TBF algo- rithm via branch-and-bound. T o enhance the QoS of users under weak coverage, cooperative transmissions hav e also been explored. The work [4] proposed alternating optimization of user scheduling and TBF to maximize sum rate under 3 QoS and power constraints in multi-cell JT networks. Further, in the cell-free massive MIMO, [5] proposed a grouping- based carrier and power allocation approach under multi-band QoS constraints, utilizing Lagrangian relaxation for carrier assignment to user clusters and sequential conv ex approxima- tion for power control. Howe ver , these centralized approaches inevitably impose a substantial computational load on the central unit, especially in large-scale networks. This makes distributed scheduling schemes with lower complexity and better scalability particularly important. Distributed approaches delegate scheduling optimization to individual BSs, thereby alleviating the computation load at a single node. Ho wev er, the corresponding design faces se veral fundamental challenges. First, the strong inter-dependencies among variables make the problem difficult to decompose. Second, the limited local information at each node impedes accurate ICI estimation and results in imprecise rate predic- tions. Third, multi-round coordination among distributed nodes is often required to reach consensus, entailing substantial signaling overhead and delay . In the literature, early designs often relied on simple operational assumptions. For instance, [11] de vised a scheduling approach in a two-cell system, where each cell first selects candidate UEs via local semi-orthogonal user selection (SUS), exchanges these sets with the other BS, and then performs coordinated zero-forcing (ZF) TBF to cancel ICI. This was extended to multiple cells in [12] through sequential scheduling, where cells were activ ated in a predefined order , and each subsequent BS made scheduling decisions based on ICI from previously scheduled cells, albeit with latency scaling linearly with network size. Besides, a leakage-based distributed scheme was proposed in [13], where the ICI was approximated by the leakage to the activ e users in other cells, estimated by a traffic-a ware statistical model. While reducing signaling, this scheme cannot reliably handle explicit QoS constraints due to the inherent inaccuracy of leakage-based approximations for rate prediction. In addition, [15] introduced rate relaxation variables (RR Vs) to allow soft violations of rate requirements and dev eloped a primal–dual algorithm enabling distributed implementation via iterativ e ex- change of dual variables and interference messages. Howe ver , this approach suffered from high signaling overhead due to the iterativ e message passing, and its RR V -based soft constraints inherently fav ored users with strong channels, further degrad- ing cell-edge UE rates. In [14], a real-time multi-cell MIMO scheduler for O-RAN was dev eloped, lev eraging GPU-based parallel processing to jointly optimize RB allocation, MCS selection, and TBF . Howe ver , this design does not consider QoS constraints, and extending it to handle QoS requirements across multiple RBs remains challenging. I I . S Y S T E M M O D E L A N D P R O B L E M F O R M U L A T I O N A. System Model As sho wn in Fig. 1, we consider an O-RAN with M cells and K UEs, each equipped with N r receiv e antennas. Each cell has an O-RU with N t antennas at its center, connected to a shared O-DU via fronthaul. The O-DU, responsible for baseband processing and scheduling tasks for the network, is O - DU co re co re … 𝐏𝐔 𝟏 c o re co re … 𝐏𝐔 𝟎 co re co re … 𝐏𝐔 𝒎 … … C el l C en ter C el l Edge NJ T UE JT O - RU 𝒎 Fronth aul 𝒕 Co re 𝟏 Co re 𝑪 𝒕 𝒇 … 𝒇 … … 𝐏𝐔 𝒎 CC - 𝟏 CC - 𝑪 … R BG ( 𝟏 , 𝟏 ) R BG ( 𝟏 , 𝑹 ) R BG ( 𝟏 , 𝟐 ) … R BG ( 𝟏 , 𝟏 ) RBG ( 𝟏 , 𝟐 ) R BG ( 𝟏 , 𝑹 ) … R BG ( 𝑪 , 𝟏 ) R BG ( 𝑪 , 𝑹 ) R BG ( 𝑪 , 𝟐 ) … R BG ( 𝟏 , 𝟏 ) R BG ( 𝑪 , 𝟐 ) R BG ( 𝑪 , 𝑹 ) co re co re … 𝐏𝐔 𝑀 Fig. 1: System Model composed of multiple PUs. Each PU contains multiple inter - connected computational cores to enable parallel processing, and the PUs themselv es are connected via high-speed on-board links to support coordination and information exchange. In practice, a PU can be realized on various hardware platforms, such as multi-core CPUs, system-on-chip (SoC) modules, or FPGA-based accelerators [7]. The set A m of UEs associated with O-R U m is assumed known and is partitioned based on their experienced inter- ference into A m ≜ {K m , U m } . Here, K m represents cell- center UEs primarily affected by intra-cell interference, and U m stands for the set of cell-edge UEs that experience strong ICI. T o improve the service quality of cell-edge UEs, multiple O-R Us in adjacent cells employ JT to conv ert detrimental ICI into coherent useful signals, and these UEs are named JT -UEs. Meanwhile, cell-center UEs are served exclusi vely by their associated O-R U without JT and are referred to as NJT -UEs. The network operates under a time-slotted scheduling mech- anism. W e focus on scheduling within a single interval, during which the total av ailable bandwidth comprises C CCs, each of which occupies R RBGs. W ithout loss of generality (w .l.o.g.), we assume that the O-DU comprises M + 1 PUs, each containing C computational cores. For PU 1 to PU M , core c on PU m is responsible for scheduling UEs of cell m over the c -th CC, while PU 0 handles inter-cell coordination. T able I lists the key notations used in the paper . Denote b c,r m,k ∈ { 0 , 1 } as the scheduling variable indicating whether UE k ∈ A m is allocated to RBG r of the c -th CC, b c,r m,k = ( 1 , if UE k is scheduled on RBG ( c, r ) , 0 , otherwise. (1) Assume that the channel from O-R U m to UE k on RBG ( c, r ) as H c,r m,k ∈ C N r × N t is av ailable. The transmit data symbol for UE k satisfies E [ | x k | 2 ] = 1 and is assumed to be mutually independent across different UEs. After applying the TBF w c,r m,k and the receiv e combiner u c,r k , the receiv ed signal of NJT -UE k in cell m on RBG ( c, r ) is written as y c,r m,k =( u c,r k ) H H c,r m,k w c,r m,k x k + X n ∈M X t ∈K n ,t = k ( u c,r k ) H b c,r n,t H c,r n,k w c,r n,t x t (2) + X i ∈I X ℓ ∈B i ( u c,r k ) H b c,r ℓ,i H c,r ℓ,k w c,r ℓ,i x i + ( u c,r k ) H n k , 4 T ABLE I: Notations Notation Definition M ≜ { 1 , . . . , M } Set of O-RUs K ≜ { 1 , . . . , K } Set of UEs I ≜ { 1 , . . . , I } Set of JT -UEs B i ⊆ M Subset of serving O-RUs for JT -UE i K m ⊆ K Set of cell-center/NJT -UEs in cell m U m ⊆ I Set of cell-edge/JT -UEs in cell m K Q m ⊆ K m Set of NJT -UEs with QoS requirement in cell m ˆ K Q m ⊆ K m Set of NJT -UEs w/o QoS requirement in cell m U Q m ⊆ U m Set of JT -UEs with QoS requirement in cell m ˆ U Q m ⊆ U m Set of JT -UEs w/o QoS requirement in cell m I Q ⊆ I Set of JT -UEs with QoS requirement ˆ I Q ⊆ I Set of JT -UEs w/o QoS requirement C ≜ { 1 , . . . , C } Set of CCs R ≜ { 1 , . . . , R } Set of RBGs RBG ( c, r ) r -th RBG in the c -th CC u c,r k ∈ C N r × 1 Receiv e combiner for UE k on RBG ( c, r ) w c,r m,k ∈ C N t × 1 TBF from O-RU m to UE k on RBG ( c, r ) where n k ∼ C N (0 , σ 2 I N r ) is the additiv e white Gaussian noise (A WGN). The first three terms in (2) represent the desired signal, the interference from co-scheduled NJT -UEs, and the interference from co-scheduled JT -UEs, respecti vely . The receiv ed signal y c,r i of JT -UE i over RBG ( c, r ) is y c,r i = X ℓ ∈B i ( u c,r i ) H H c,r ℓ,i w c,r ℓ,i x i + X ℓ ∈M X t ∈K ℓ ( u c,r i ) H b c,r ℓ,t H c,r ℓ,i w c,r ℓ,t x t (3) + X j ∈I ,j = i X ℓ ∈B j ( u c,r i ) H b c,r ℓ,j H c,r ℓ,i w c,r ℓ,j x j + ( u c,r i ) H n i , where the first three terms comprise the desired signal from its serving cells, along with interference from all co-scheduled NJT -UEs and other co-scheduled JT -UEs. Then, from (2), the signal-to-interference-plus-noise-ratio (SINR) of NJT -UE k ∈ K m on RBG ( c, r ) is γ c,r m,k ( { b c,r m,k , w c,r m,k } ) = | ( u c,r k ) H H c,r m,k w c,r m,k | 2 × X n ∈M X t ∈K n ,t = k | ( u c,r k ) H b c,r n,t H c,r n,k w c,r n,t | 2 (4) + X i ∈I X ℓ ∈B i ( u c,r k ) H b c,r ℓ,k H c,r ℓ,k w c,r ℓ,i 2 + σ 2 − 1 , and, from (3), the SINR for JT -UE i is γ c,r i ( { b c,r m,k , w c,r m,k } ) = X ℓ ∈B i ( u c,r i ) H H c,r ℓ,i w c,r ℓ,i 2 × X ℓ ∈M X t ∈K ℓ | ( u c,r i ) H b c,r ℓ,t H c,r ℓ,i w c,r ℓ,t | 2 (5) + X j ∈I ,j = i X ℓ ∈B j ( u c,r i ) H b c,r ℓ,j H c,r ℓ,i w c,r ℓ,j 2 + σ 2 − 1 . Thus, the data rate for NJT -UE k in cell m on RBG ( c, r ) is f c,r m,k ( { b c,r m,k , w c,r m,k } ) = b c,r m,k log(1 + γ c,r m,k ) , (6) and the rate for JT -UE i in cell m on RBG ( c, r ) is f c,r i ( { b c,r m,k , w c,r m,k } ) = b c,r m,i log(1 + γ c,r i ) . (7) Note that the scheduling indicators for JT -UE i need to be consistent across all its serving O-R Us, i.e., b c,r m,i = b c,r n,i , ∀ m, n ∈ B i , to ensure coherent joint transmission. B. T ransceiver Design Based on EZF Giv en limited computational resources and real-time pro- cessing requirements, (semi-)closed-form BF solutions are generally preferred over iterative methods in practice. This motiv ates us to formulate the scheduling problem using EZF- BF [19]. Unlike ZF-BF that directly inv erts the channel matrix and can be sensitiv e to poor conditioning, EZF-BF oper- ates in the dominant channel eigenspace obtained via eigen- decomposition. By suppressing interference across the most significant eigenmodes, EZF-BF impro ves numerical stability and robustness in ill-conditioned channel scenarios [20]. Specifically , for each NJT -UE k ∈ K m scheduled on RBG ( c, r ) , with the intra-cell CSI H c,r m,k , the serving O-R U m ∈ M first conducts singular value decomposition (SVD) as H c,r m,k = T c,r k Λ c,r k ( V c,r m,k ) H , where Λ c,r k is an N r × N t diagonal matrix containing singular values of H c,r m,k in the decreasing order along its main diagonal, the largest of which is denoted by λ c,r k . The terms T c,r k ∈ C N r × N r and V c,r m,k ∈ C N t × N t are the corresponding unitary matrix composed of the left singular vectors and right singular vectors, respectiv ely . Similarly , for JT -UE i ∈ U m served by multiple O-R Us, the transceiv er is jointly designed based on all channels from its serving O-R Us. Specifically , by stacking all the channel matrices from the serving O-R Us m ∈ B i to JT -UE i , its aggregated channel matrix on RBG ( c, r ) is H c,r i ≜ [ H c,r m,i ] m ∈B i ∈ C N r ×|B i | N t . (8) Let its SVD be expressed as H c,r i = T c,r i Σ c,r i ( V c,r i ) H , where V c,r i ∈ C |B i | N t ×|B i | N t is the unitary right singular vector matrix. Σ c,r i ∈ C N r ×|B i | N t holds the singular values in descending order , with its largest λ c,r i . It can be found from (8) that { H c,r m,i } m ∈B i share the same left singular vectors and singular v alues, i.e., H c,r m,i ≜ T c,r i Σ c,r i ( V c,r m,i ) H , where V c,r m,i is the corresponding sub-matrix that can be attained from V c,r i . While it is possible to consider global EZF [11], which jointly nulls both intra- and inter-cell interference, it may not be a good choice in practice. First, its matrix in version complexity scales with the total number of scheudled users, and with a limited number of transmit antennas, the available spatial degrees of freedom may be insufficient for effecti ve global nulling. Moreov er, since cell-center users experience negligible ICI, enforcing global nulling can waste spatial resources. Therefore, we adopt intra-cell EZF in this work, where each cell only nulls the intra-cell interference among its scheduled UEs. T o illustrate this, we consider both NJT and JT UEs A m in each cell m . Let t c,r k and v c,r m,k be the first column of T c,r k and V c,r m,k , respectiv ely . T o maximize the receive SNR of UE k ∈ A m in RBG ( c, r ) , we set u c,r k = t c,r k and it leads to ( u c,r k ) H H c,r m,k = λ c,r k ( v c,r m,k ) H . (9) Based on the equiv alent channel in (9), EZF projects intended signals onto the orthogonal complement of its interference channel subspace, thereby mitigating inter-UE interference. Specifically , denote the set of UEs in cell m that are scheduled ov er RBG ( c, r ) as A c,r m ≜ { a 1 , ..., a m } ∈ A m , whose cardinality is giv en by |A c,r m | = P t ∈A m b c,r m,t . By stacking the right singular v ectors of these UEs as 5 ˆ V c,r m ≜ v c,r m,a 1 , . . . , v c,r m,a m , (10) the EZF TBF at O-RU m o ver RBG ( c, r ) is computed by ˆ W c,r m = ˆ V c,r m (( ˆ V c,r m ) H ˆ V c,r m ) − 1 = ˆ w c,r m,a 1 , . . . , ˆ w c,r m,a m . (11) Giv en that the total transmit power per RBG ( c, r ) in each O-R U m as P , each EZF-TBF with equal power allocation (EP A) is w c,r m,j = q P / |A c,r m | ˆ w c,r m,j / ∥ ˆ w c,r m,j ∥ . (12) Notice that the structure of the spatial direction matrix ˆ V c,r m in (10) and the unnormalized TBF matrix ˆ W c,r m in (11) lead to the orthogonality ( ˆ V c,r m ) H ˆ W c,r m = I , ∀ m, c, r . Accordingly , for any two UEs j and k in cell m , w c,r m,j in (12) satisfies ( v c,r m,k ) H w c,r m,j = ( p P / |A c,r m | / ∥ ˆ w c,r m,k ∥ , if j = k, 0 , otherwise. (13) C. Multi-Dimensional User Sc heduling Pr oblem Building upon the EZF transceiv er design, we dev elop a scheduling framework that supports a multi-service coexis- tence scenario with tw o types of UEs: • UEs with QoS requirement : These UEs require low- delay guarantees—treated as a key QoS metric—such as image deli very for interactive applications. Generally , they have a finite data v olume at the O-DU. • UEs without QoS requir ement : These UEs do not hav e stringent delay constraints and primarily aim to maximize sustained throughput, such as high-definition video downloads. Their traffic is typically characterized by continuous data generation at the O-DU. In this work, our design aims to maximize the sum rate of the second type of UEs k ∈ ˆ K Q m , m ∈ M , i ∈ ˆ I Q , while ensuring the QoS requirements { Q k , Q i } of the first type of UEs k ∈ K Q m , m ∈ M , i ∈ I Q . Accordingly , the multi-dimensional user scheduling optimization can be formulated as the following nonlinear integer programming (NLIP) problem max { b c,r m,k } X ( c,r ) X m ∈M X k ∈ ˆ K Q m f c,r m,k + X i ∈ ˆ I Q f c,r i (14a) s.t. b c,r m,k ∈ { 0 , 1 } , ∀ m, c, r, k , (14b) b c,r m,i = b c,r n,i , ∀ m, n ∈ B i , ∀ i ∈ I , ∀ c, r, (14c) X ( c,r ) f c,r m,k ≥ Q k , ∀ m, k ∈ K Q m , (14d) X ( c,r ) f c,r i ≥ Q i , ∀ i ∈ I Q , (14e) where the rate function { f c,r m,k , f c,r i } is derived from (6) and (7). In addition, constraint (14c) enforces scheduling consistency for JT -UEs across all coordinating O-R Us per RBG. Meanwhile, constraints (14d) and (14e) specify QoS requirements for NJT -UEs and JT -UEs, respectively . In problem (14), the TBF and the scheduling spans over multiple dimensions, including cells, CCs, JT -UEs, and NJT - UEs with or without QoS constraints. This makes (14) far more intricate than con ventional formulations [14], which are limited to parts of these dimensions. Optimization of (14) is quite challenging due to the follo wing factors: 1) Combinatorial Explosion : As an NLIP problem, its solution space gro ws exponentially as O (2 K × C × R ) with increasing UEs ( K ) and RBGs ( C × R ), rendering ex- haustiv e search computationally prohibitive; 2) Strong Coupling : The generation of EZF beamformers { w c,r m,j } depends on the scheduling decisions { b c,r m,k } . Accordingly , the scheduling v ariables and TBF variables are strongly coupled across multiple dimensions; 3) NP-hardness : The non-conv exity and the non-smooth structure of problem (14) make it NP-hard [5]. Even without considering distributed optimization tailored to the O-RAN architecture, these characteristics render the design of a polynomial-complexity algorithm for achieving a local optimum highly non-trivial. T o tackle them, we first propose a nov el reformulation scheme to simplify the problem structure. I I I . A N OV E L P R O B L E M R E F O R M U L AT I O N In this section, we propose a novel reformulation to simplify problem (14) by lev eraging the system properties. Notice that the problem complexity primarily stems from the rate expressions { f c,r m,k , f c,r i } . T o handle them, our proposed re- formulation scheme comprises two phases: Phase 1 lev erages interference characteristics and the EZF transceiv er structure to simplify the SINR formulation. Using the log-fractional form of the rate and Jensen’ s inequality , a closed-form rate approximation for JT -UEs is deriv ed, which decouples vari- ables across PUs and reduces coordination complexity . Phase 2 applies massive MIMO asymptotic analysis [21] to eliminate the implicit dependence on EZF TBF in (6) and (7), achieving tractable rate expressions. A. Phase 1 Recall that transmission strategies dif fer between cell-center and cell-edge UEs. For cell-center UEs, the desired signal from the serving O-R U typically dominates ICI, as the serving link’ s channel gain is much stronger than others. Hence, NJT is sufficient for these UEs. In contrast, cell-edge UEs experience comparable signal strengths from multiple O-R Us, necessitating JT to mitigate interference. Accordingly , it is reasonable to make the follo wing assumption [22, 23]. Assumption 1 : The ICI from the non-serving O-R Us to NJT - UEs is negligible, while JT -UEs only experience interference from their served O-R Us. Based on this assumption, the ICI term in the SINR (4) of NJT - UE k ∈ K m can be omitted, yielding an approximate SINR expression (15) shown at the top of the next page. In (15), the first and second terms in the denominator represent the intra- cell interference caused to user k by the NJT -UEs and JT -UEs jointly scheduled on RBG ( c, r ) from cell m , respecti vely . For JT -UEs i , the interference is more complex and origi- nates from three types of UEs (see Fig. 2): 1) Co-scheduled JT -UEs with identical serving O-R U set ( ∩ m ∈B i U m , area A); 2) P artially overlapping JT -UEs sharing subsets of B i ( ∪ m ∈B i U m \ ∩ m ∈B i U m , area B); 3) NJT -UEs served by B i ’ s O-R Us (area C). Accounting for these interference sources, the SINR for JT -UE i ∈ I in (16) is sho wn at the top of next page. 6 UE A B C C Fig. 2: The interference sources (circled by dashed lines) experienced by JT -UE i . The denominators in (15) (for NJT -UEs) and (16) (for JT - UEs) reveal that every term of inter-UE interference suffered by one UE stems from its serving O-R Us. Based on the properties in (9) and (13), the SINR expression for NJT -UE k ∈ K m in (15) can be simplified as γ c,r m,k =( λ c,r k ) 2 P / ( |A c,r m | · ∥ ˆ w c,r m,k ∥ 2 σ 2 ) , (17) where ∥ ˆ w c,r m,k ∥ 2 depends on the scheduling variables of O-R U m implicitly , as shown in (10) and (11). Similarly , the SINR for JT -UE i on RBG ( c, r ) in (16) can be further expressed as γ c,r i = X m ∈B i λ c,r i √ P / ( q |A c,r m | · ∥ ˆ w c,r m,i ∥ σ ) 2 . (18) Since RBGs in MU-MIMO systems are typically allocated to UEs with good channel quality and low inter -UE interfer- ence, the resulting SINR on scheduled RBGs is generally high [24]. Therefore, the rate expression can be approximated by log(1 + γ ) ≈ log ( γ ) , enabling the rates of both NJT -UE k and JT -UE i on RBG ( c, r ) to be respectively expressed as ˜ f c,r m,k ≈ b c,r m,k log( γ c,r m,k ) , k ∈ K m , (19a) ˜ f c,r i ≈ b c,r m,i log( γ c,r i ) , i ∈ I . (19b) Howe ver , unlike the NJT -UE rate in (19a), the JT -UE rate (19b) exhibits coupling across multiple O-R Us, posing a challenge for distributed scheduling. T o ov ercome this, we construct a separable lower bound for ˜ f c,r i using the decomposition technique in [25]. Specifically , we ha ve ˜ f c,r i ( a ) ≥ b c,r m,i log X m ∈B i γ c,r m,i , (20a) ( b ) ≥ X m ∈B i b c,r m,i log |B i | γ c,r m,i / |B i | ≜ X m ∈B i ˜ f c,r m,i , (20b) where each γ c,r m,i shares the same structural form as (17). Inequality (a) holds by the Cauchy–Schw arz inequality since all terms in the numerator of (18) are positiv e, while (b) follows from Jensen’ s inequality . Comparing (20b) with (7) for JT -UEs (and (19a) with (6) for NJT -UEs), one can observ e that the coupling in the original rate expressions has been effecti vely alleviated. T o streamline subsequent analysis, we unify the rate expressions of NJT -UEs in (19a) and sub-terms within the rate expressions of JT -UEs in (20b) into a compact form as follows ˜ f c,r m,t = ( b c,r m,t log( γ c,r m,t ) , if UE t ∈ K m , b c,r m,t log |B t | γ c,r m,t / |B t | , if UE t ∈ U m . (21) B. Phase 2 So far , the rate expression { ˜ f c,r m,t } appears to depend only on scheduling variables and TBFs of O-RU m over RBG ( c, r ) . Howe ver , the TBFs in (17) are still implicitly cou- pled with the scheduling decisions within the cell, as their structure depends on the set of concurrently scheduled users. Moreov er, ˆ w c,r m,t exists in a fractional structure as in (11), making the optimization of problem (14) still challenging. T o address these challenges, it is essential to characterize how scheduling decisions influence the achiev able rates through the TBF structure. T oward this goal, we establish the following theorem by leveraging massi ve MIMO asymptotics [21] and the structure of EZF-TBF . Theorem 1. When the number of transmit antennas is suf- ficiently larg e, the rate for NJT -UE k served by cell m associated with RBG ( c, r ) con ver ges to ˜ f c,r m,k ≈ b c,r m,k ( ψ c,r m,k + X j ∈A m \{ k } b c,r m,j d c,r m,j,k − g c,r m ) , (22) wher e ψ c,r m,k ≜ log (( λ c,r k ) 2 | v c,r m,k | 2 P /σ 2 ) , d c,r m,j,k ≜ log (1 − η c,r m,j,k ) , η c,r m,j,k ≜ | ( v c,r m,j ) H v c,r m,k | 2 / ( | v c,r m,j | 2 | v c,r m,k | 2 ) , g c,r m ≜ log( ϕ c,r m ) and ϕ c,r m ≜ P t ∈A m b c,r m,t . Pr oof. As the SINR deriv ations across different RBGs follow the same procedure, we drop the superscript ( c, r ) in the following for notational simplicity . First, from the EZF-TBF construction in (11), it holds that ˆ W H m ˆ W m = ( ˆ V H m ˆ V m ) − 1 . W .l.o.g., assume that the TBF ˆ w m,k of UE k occipies the j -th column of ˆ W m in (11), then ∥ ˆ w m,k ∥ 2 2 = ( ˆ V H m ˆ V m ) − 1 j,j . (23) Denote ˆ V m, ¯ j as the sub-matrix of ˆ V m without the j -th column v m,k . Applying the block matrix in version formula [12] yields ( ˆ V H m ˆ V m ) − 1 j,j = 1 v H m,k ( I − ˆ V m, ¯ j ( ˆ V H m, ¯ j ˆ V m, ¯ j ) − 1 ˆ V H m, ¯ j ) v m,k . (24) Combining (24) with (23) leads to 1 / ∥ ˆ w m,k ∥ 2 2 = v H m,k ( I − ˆ V m, ¯ j ( ˆ V H m, ¯ j ˆ V m, ¯ j ) − 1 ˆ V H m, ¯ j ) v m,k . (25) Further , it follo ws from (10) that the diagonal elements of ˆ V H m, ¯ j ˆ V m, ¯ j are given by v H m,z v m,z , z = k , while its off- diagonal elements represent the inner products between the right singular vectors associated with dif ferent UEs on the same RBG. According to the asymptotic properties of massive MIMO [21], as the number of transmit antennas N t approaches infinity , the orthogonality condition v H m,z v m,k → 0 holds for any pair of users z = k with different channels. Hence, ˆ V H m, ¯ j ˆ V m, ¯ j is asymptotically diagonal for large N t , allowing (25) to be well approximated as 7 γ c,r m,k ≈ | ( u c,r k ) H H c,r m,k w c,r m,k | 2 X j = k,j ∈K m | ( u c,r k ) H b c,r m,j H c,r m,k w c,r m,j | 2 + X i ∈U m | ( u c,r k ) H b c,r m,i H c,r m,k w c,r m,i | 2 + σ 2 − 1 (15) γ c,r i ≈ X m ∈B i ( u c,r i ) H H c,r m,i w c,r m,i 2 X j ∈ ( ∩ m ∈B i U m ) ,j = i X m ∈B i ( u c,r i ) H b c,r m,j H c,r m,i w c,r m,j 2 + (16) X j / ∈ ( ∩ m ∈B i U m ) ,j ∈ ( ∪ m ∈B i U m ) X m ∈ ( B i ∩B j ) ( u c,r i ) H b c,r m,j H c,r m,i w c,r m,j 2 + X m ∈B i X j ∈K m | ( u c,r i ) H b c,r m,j H c,r m,i w c,r m,j | 2 + σ 2 − 1 | v m,k | 2 1 − X z ∈A m ,z = k b m,z | v H m,z v m,k | 2 / ( | v m,z | 2 | v m,k | 2 ) . (26) Moreov er, since the approximation 1 − P n i =1 x i ≈ Q n i =1 (1 − x i ) holds when x i ≈ 0 , we have 1 − X z ∈A m ,z = k b m,z | v H m,z v m,k | 2 / ( | v m,z | 2 | v m,k | 2 ) (27) ≈ Y z ∈A m ,z = k 1 − b m,z | v H m,z v m,k | 2 / ( | v m,z | 2 | v m,k | 2 ) . Substituting (27) and (26) into (17) obtains the (22). Compared to (19a), (22) successfully eliminates the interme- diate TBF variables and depends solely on the scheduling variables within serving cell m . Moreover , it rev eals the interplay among different UEs’ scheduling decisions. From (22), we observe that the rate is influenced by the following three components: 1) ψ c,r m,k , corresponds to the rate contribution from the SNR of UE k when scheduled exclusiv ely on RBG ( c, r ) ; 2) P j ∈A m \{ k } b c,r m,j d c,r m,j,k , where d c,r m,j,k is negati ve, quan- tifies the loss due to interference from other UEs with correlated channels (i.e., co-channel interference); 3) g c,r m , captures the impact of power sharing among co- scheduled UEs. Analogously , by applying Theorem 1 to the first term in (20b), we hav e for the JT -UE i ∈ U m that ˜ f c,r m,i ≈ b c,r m,i ( ˜ ψ c,r m,i + X j ∈A m \{ i } b c,r m,j d c,r m,j,i − g c,r m ) / |B i | , (28) where ˜ ψ c,r m,i = log( |B i | ) + ψ c,r m,i . Follo wing the above two-phase reformulation, one can ob- serve that the original multiplicativ e structures in (4) and (5) are transformed into a more tractable summation form. I V . P R OP O S E D C E N T R A L I Z E D A L G O R I T H M In this section, we first develop a centralized algorithm for problem (14) as a benchmark. By applying our proposed reformulation scheme in (20b), (14) can be approximated to max { b c,r m,k } X ( c,r ) X m ∈M X k ∈ ˆ K Q m ˜ f c,r m,k + X i ∈ ˆ U Q m ˜ f c,r m,i (29a) s.t. b c,r m,k ∈ { 0 , 1 } , ∀ m, c, r, k , (29b) b c,r m,i = b c,r n,i , ∀ m, n ∈ B i , ∀ i ∈ I , ∀ c, r, (29c) X ( c,r ) ˜ f c,r m,k ≥ Q k , ∀ m, k ∈ K Q m , (29d) X ( c,r ) X m ∈B i ˜ f c,r m,i ≥ Q i , ∀ i ∈ I Q . (29e) Compared with (14), problem (29) no longer has the interme- diate TBF variables. Howe ver , as shown in (22) and (28), the rate expression { ˜ f c,r m,t } in (29a) remains non-con vex, while the non-con vex constraints in (29c)-(29e) further exacerbate the optimization challenge. T o address this, we first employ a min -based penalty function [26] to the rate constraints (29d) and (29e), and reformulate problem (29) as max { b c,r m,k } G (30a) s.t. b c,r m,k ∈ { 0 , 1 } , ∀ m, c, r, k , (30b) b c,r m,i = b c,r n,i , ∀ m, n ∈ B i , ∀ i ∈ I , ∀ c, r, (30c) where G ≜ X m ∈M X k ∈ ˆ K Q m X ( c,r ) ˜ f c,r m,k + ρ X k ∈K Q m min X ( c,r ) ˜ f c,r m,k , Q k + X i ∈ ˆ I Q X m ∈B i X ( c,r ) ˜ f c,r m,i + ρ X i ∈I Q min X m ∈B i X ( c,r ) ˜ f c,r m,i , Q i , (31) and ρ > 0 is a penalty parameter . For the abo ve transforma- tion, the following theorem [26] holds true. Theorem 2. There exists an ρ ∗ > 0 , when ρ > ρ ∗ , the local optimal solution of the above pr oblem (30) is also the local optimal solution of the original constr aint pr oblem (29) . Secondly , to maintain the scheduling consistency of JT -UEs, we introduce global variables { b c,r i } into constraint (30c) such that b c,r i = b c,r m,i , ∀ m ∈ B i . W e propose to solve problem (30) directly over binary v ariables in a BCD manner . Specifically , for each scheduling variable b c,r m,k or b c,r i , when the remaining scheduling variables are fix ed, the gain of scheduling a UE t on RBG ( c, r ) is defined as gain [ c, r , t ] = ( G ( b c,r m,t = 1) − G ( b c,r m,t = 0) , if t ∈ K m , G ( b c,r t = 1) − G ( b c,r t = 0) , if t ∈ I . (32) If the gain [ c, r , t ] is positi ve, the corresponding scheduling variable will be set to 1; otherwise, it will be set to 0. By iterativ ely applying this process to all variables, we obtain a centralized scheduling algorithm as detailed in Algorithm 1. It is not dif ficult to verify that Algorithm 1 will generate a non-decreasing sequence of objectiv e values and con verge to a local optimal solution [27]. V . D I S T R I B U T E D F R A M E W O R K A N D A L G O R I T H M D E S I G N While effecti ve, Algorithm 1 is a centralized scheme that can only be executed sequentially on a single computational node (e.g., a PU) and underutilizes the parallel processing resources of O-DU. As the network scales, this imposes a considerable computational burden on the single node. There- fore, it is crucial to design a distrib uted scheduling scheme that fully e xploits the multi-PU and multi-core parallelism within 8 Algorithm 1 Proposed Centralized Scheduling Algorithm 1: Initialize { b c,r m,k , b c,r i } ; 2: for each UE t do 3: for each RBG ( c, r ) do 4: if gain [ c, r, t ] > 0 then 5: b c,r m,t = 1 , t ∈ K m or b c,r t = 1 , t ∈ I ; 6: else 7: b c,r m,t = 0 , t ∈ K m or b c,r t = 0 , t ∈ I ; 8: end if 9: end for 10: end for 11: Repeat Steps 2-10 until maximum iterations reached. … Stage 2.1: JT - UE Scheduling Coordination at … Info. Upload Info. Feedback Core [ , ] optimizes UE scheduling on CC - Core [ , ] optimizes UE scheduling on CC - Stage 1: Local Optimization at (for cell 1 ) … … Stage 2.2: NJT - UE QoS Decoupling at (for cell 1 ) Info. Ex. Core [ , ] decides QoS contribution in other CCs Core [ , ] decides QoS contribution in other CCs … Core [ , ] optimizes NJT - UE scheduling on CC - Core [ , ] optimizes NJT - UE scheduling on CC - Stage 3: Refining NJT - UE Scheduling at (for cell 1 ) … Core [ , ] … Core [ , ] … Core [ , ] … Stage 3: Refining NJT - UE Scheduling at (for cell ) Stage 1: Local Optimization at (for cell ) Stage 2.2: NJT - UE QoS Decoupling at (for cell ) Fig. 3: Proposed distrib uted scheduling frame work. the O-DU. This will not only reduce the computational load on each PU but also enable concurrent processing, thereby improving scheduling scalability in large-scale deployments. The key to distributed design is to offload the scheduling optimization to multiple cores in PU 1 ∼ PU M to enable parallel processing, leaving only lightweight coordination to PU 0 . For problem (29), the QoS requirements in (29d) need to be satisfied across CCs within one PU, and (29e) needs be jointly satisfied across PUs, which are strongly coupled. Besides, the scheduling consistency of JT -UE across different cells in (14c) makes the distributed design more difficult. A natural candidate for handling such constraints typically employs consensus alternating direction method of multipliers (ADMM) [28], which decomposes the problem by indepen- dently optimizing local JT -UE variables across distributed cores and then coordinating them via a central aggregation step. Howe ver , such consensus-based algorithms are known to often require excessi ve iterations to conv erge, incurring substantial communication ov erhead and latency that render them impractical for scheduling [29]. Considering these limitations, we instead devise a new distributed scheduling framework that not only fully utilizes the computation resources at the cores but also takes only one round of information exchange between PU 0 and other PUs. As shown in Fig. 3, our proposed framework consists of three stages as follows, while the information exchange in the framew ork is illustrated in Fig. 4. Stage 1: Local Optimization at PU 1 to PU M . In this stage, each core within the PUs independently optimizes the scheduling variables on its corresponding CC using only local information. This serves as the initial step of distrib uted Core [1,1] Core [1,C] … … Core [M,1] Core [M,C] … { 1 , , , INF 1 , ,: , } , , { , , , INF , ,: , } , , { , } , , { 1 , , } , , { , } , , { , , } , , { 1 , 1 , } , { 1 , , } , { , 1 , } , { , , } , Fig. 4: Information e xchange between nodes. decision-making. The local optimization across PUs is ex- ecuted in parallel. Upon completion, each PU uploads its optimized results to PU 0 , and simultaneously , its internal cores share optimized results with each other . Stage 2: JT -UE Scheduling Coordination at PU 0 and concurrent NJT -UE QoS Decoupling at PU 1 to PU M . • Stage 2.1 : PU 0 coordinates the scheduling of JT -UEs based on the information receiv ed from PU 1 to PU M . By fusing the uploaded local results, PU 0 resolves potential inconsistencies and ensures coherent joint scheduling decisions across cells. • Stage 2.2 : Meanwhile, each core within PU 1 to PU M uses the scheduling information exchanged from other cores within the same PU to ev aluate the rate contributions of RBGs allocated on different CCs. This ev aluation enables decoupling the rate constraints of NJT -UEs with QoS requirements and f acilitates coordinated scheduling across multiple CCs. After the Stage 2.1 optimization, PU 0 distributes the updated JT -UE scheduling results to the corresponding PUs, while the refined scheduling results for NJT -UEs in Stage 2.2 are shared among the cores within each PU. Stage 3: Refining NJT -UE Scheduling at PU 1 to PU M : Lev eraging the updated information from Stage 2.1 (via PU 0 feedback) and Stage 2.2 (QoS decoupling to each core), each core refines the scheduling decisions for its associated NJT - UEs. This stage aims to further enhance the ov erall network performance through localized adjustments based on the most recent inter-PU and intra-PU information. The detailed design of each stage is elaborated as follows. A. Stage 1: Local Optimization at PU 1 to PU M This stage is conducted at PU 1 to PU M in parallel. For illustration, the index [ m, c ] is used to denote the c -th core at PU m . T o optimize the scheduling ov er the RBGs in the c -th CC for the JT -UEs and NJT -UE associated with cell m , core [ m, c ] needs to solv e max { b c,r m,k } r,k ∈A m G c m s.t. (14b) , (33) where G c m = X r X k ∈ ( ˆ K Q m ∪ ˆ U Q m ) ˜ f c,r m,k + ρ X z ∈ ( K Q m ∪U Q m ) min X r ˜ f c,r m,z , Q z . (34) Problem (33) is constructed as a subproblem of the original formulation (30a) from the local viewpoint of core [ m, c ] based on its av ailable information. As such, it addresses QoS 9 demands using only local resources without accounting for JT coordination or inter-CC QoS collaboration. Therefore, di- rectly optimizing (33) could result in system-lev el allocations that exceed the actual QoS requirements in (29d) and (29e). T o avoid it, we introduce a heuristic selection mechanism with two e valuation metrics. First, like (32), the gain of scheduling UE z ∈ A m on RBG ( c, r ) gain [ c, r, m, z ] is defined as gain [ c, r , m, z ] = G c m ( b c,r m,z = 1) − G c m ( b c,r m,z = 0) . (35) Second, the rate increment of assigning RBG ( c, r ) to UE z ∈ A m , i.e., ˜ f c,r m,z , is ev aluated. Based on these two metrics { gain [ c, r , m, z ] , ˜ f c,r m,z } , PU m filters out RBGs with marginal rate contributions, retaining only those that provide significant gains for scheduling. That is, the values of { b c,r m,z } are deter- mined by the follo wing criterion b c,r m,z = ( 1 if gain [ c, r, m, z ] > 0 & ˜ f c,r m,z / ˜ f c, max m,z > α 0 otherwise , (36) where ˜ f c, max m,z ≜ max r { ˜ f c,r m,z } is the maximum achiev able rate of user z among RBGs of CC- c , and α ∈ [0 , 1) is a threshold. Here, we choose a relative threshold α rather than an absolute one. This is because achiev able rates may dif fer significantly across CCs, and an absolute threshold easily leads to either ov erly conservati ve or ov erly aggressiv e RBG allocations on certain CCs. By iterati vely applying (36) to all UEs, the pro- cedure effecti vely eliminates the scheduling of the RBGs that only bring marginal contribution to UE’ s rate improv ement and av oid excessi ve RBG allocation. Accordingly , the scheduling optimization at core [ m, c ] is detailed in Algorithm 2. W ith the outputs of Algorithm 2, each core at PU 1 to PU M computes the necessary information for coordination in subsequent stages. Specifically , each core [ m, c ] first ev aluates the achie vable rates of its associated JT -UEs { ¯ f c,r m,i } i ∈U m by temporarily setting b c,r m,i = 1 , irrespectiv e of the scheduling results from Algorithm 2. Moreover , each core [ m, c ] computes the interference variations caused by scheduling-state changes of its JT -UEs. When b c,r m,i switches from 1 to 0, the values of interference variation are computed based on (22) by INF c,r m,i, 1 → 0 = − X k ∈A m b c,r m,k d c,r m,i,k + X z ∈A m b c,r m,z (log( ϕ c,r m ) − log( ϕ c,r m − 1)) , (37) where the first term accounts for the reduced interference to other users, and the second term reflects the gain from po wer redistribution. Similarly , for the switch b c,r m,i : 0 → 1 , the interference variation is computed as INF c,r m,i, 0 → 1 = X k ∈A m b c,r m,k d c,r m,i,k + X z ∈A m b c,r m,z (log( ϕ c,r m ) − log( ϕ c,r m + 1)) . (38) The values { ¯ f c,r m,i } i ∈U m and { INF c,r m,i, : } will be uploaded to PU 0 for the JT -UE scheduling coordination in Stage 2.1. Meanwhile, each core [ m, c ] also computes the rates of its activ e NJT -UEs { ¯ f c,r m,k | b c,r m,k = 1 } k ∈K m determined by Al- gorithm 2, and exchanges this information locally with other cores in the same PU for the QoS coordination in Stage 2.2. Algorithm 2 Local Scheduling Optimization at Core [ m, c ] 1: Initialize { b c,r m,k } 2: for each UE z ∈ A m do 3: for each RBG ( c, r ) do 4: Calculate gain [ c, r, m, z ] and rate ˜ f c,r m,z ; 5: end for 6: Find ˜ f c,max m,z = argmax r { ˜ f c,r m,z } ; 7: for each RBG r do 8: if gain [ c, r, m, z ] > 0 and ˜ f c,r m,z / ˜ f c,max m,z > α then 9: b c,r m,z = 1 , 10: else 11: b c,r m,z = 0 , 12: end if 13: end for 14: end for 15: repeat steps 2-14 until certain conditions are met. B. Stage 2.1: JT -UE Scheduling Coordination at PU 0 Since the scheduling variables of JT -UEs are optimized independently at PU 1 to PU M in Stage 1, the scheduling con- sistency is not guaranteed. T o resolve the issue, it is necessary to design a fusion strategy at PU 0 based on the uploaded information { ¯ f c,r m,i } and { INF c,r m,i, : } . The main principle is to determine a unified scheduling decision for each inconsistent JT -UE across cells based on which option deliv ers better ov erall system performance. Consider a representati ve conflict scenario: suppose JT -UE i requires the joint transmission from both cell m and cell n . If JT -UE i is scheduled by cell m on RBG ( c, r ) but is not scheduled by cell n on the same RBG, it will violate the joint scheduling consistency . T o resolve the conflict, our proposed strategy first quantifies the performance impact of the following alternative scheduling choices: 1) Scheduling: If JT -UE i is ultimately scheduled on RBG ( c, r ) , the gain to the overall network is: F c,r i, 0 → 1 = ¯ f c,r n,i + INF c,r n,i, 0 → 1 , where INF c,r n,i, 0 → 1 captures the negati ve impact caused by the interference that would decrease the rate of other UEs scheduled on RBG ( c, r ) . 2) Non-scheduling: If UE i is not scheduled on RBG ( c, r ) , the gain is: F c,r i, 1 → 0 = − ¯ f c,r m,i + INF c,r m,i, 1 → 0 , where the change of JT -UE i ’ s state on RBG ( c, r ) from ‘scheduled’ to ‘unscheduled’ would decrease its transmission rate and alleviate the interference to other UEs. Based on the values { F c,r i, : } , for JT -UEs without QoS require- ments, PU 0 generates the scheduling decisions based on the following criterion b c,r i = ( 1 , if F c,r i, 0 → 1 > F c,r i, 1 → 0 0 , otherwise. (39) For JT -UEs with QoS requirements, the above criterion cannot be adopted directly . Instead, for a JT -UE i ∈ I Q , PU 0 determines its scheduling state across RBGs by solving the following optimization problem to avoid the resource wastage 10 min { b c,r i } c,r X ( c,r ) b c,r i (40a) s.t. X ( c,r ) b c,r i X m ∈B i ¯ f c,r m,i ≥ Q i , (40b) F c,r i, 0 → 1 > F c,r i, 1 → 0 . (40c) Although problem (40) appears complex, its solution is rela- tiv ely straightforw ard: select the RBGs that satisfy constraint (40c) and sort their corresponding contributions P m ∈B i ¯ f c,r m,i in a decreasing order; then, choose the top-performing RBGs among them to meet constraint (40b). It is worth noting that the optimization for each UE can be executed in parallel, as their scheduling decisions hav e been fully decoupled at this stage, thereby significantly reducing the processing time. After applying (39) and (40) to all JT -UEs, PU 0 updates their achiev able rates as ˆ f c,r m,i = ( ¯ f c,r m,i , if b c,r i = 1 , m ∈ B i 0 , otherwise. (41) W ith the updated scheduling states and rates of JT -UEs, PU 0 further computes the QoS contribution for JT -UE i from all the other cores e xcept core [ m, c ] as QoS ¯ c m,i = X c ′ = c X r ∈R ˆ f c ′ ,r m,i + X ℓ ∈B i ,ℓ = m X ( c,r ) ˆ f c,r ℓ,i , (42) where the first term quantifies the QoS contrib ution from the RBGs scheduled on other CCs by cell m , and the second one accounts for the QoS contributed by other cells. The values { b c,r i } and { QoS ¯ c m,i } are then distributed to PU m for the final refinement in Stage 3. C. Stage 2.2: NJT -UE QoS Decoupling at PU 1 to PU M When PU 0 conducts the scheduling coordination for JT - UEs, the cores within PU 1 to PU M can simultaneously process the results generated from Stage 1 to resolve the scheduling coupling across multi-CCs due to the QoS constraints for NJT - UEs. The key idea of the decoupling is to decompose each UE’ s QoS requirement into per-CC contribution similar to (42): by quantifying how much rate each CC should provide, the QoS requirement is distributed across CCs. Specifically , with the exchanged { ¯ f c,r m,k | b c,r m,k = 1 } k ∈K m from other cores, the scheduling states across multi-CCs of the NJT -UEs are optimized by solving the following problem min { b c,r m,k } X ( c,r ) b c,r m,k (43a) s.t. X ( c,r ) b c,r m,k ¯ f c,r m,k ≥ Q k . (43b) Compared with (40), problem (43) does not impose the condition in (40c), since the scheduling of NJT -UEs is only related to their serving cell, without cross-cell inconsisten- cies. Similar to (40), problem (43) can be solved efficiently by sorting the rate contributions { ¯ f c,r m,k } and only selecting these high-contribution RBGs to meet the QoS requirement. Moreov er, optimizing (43) tends to change some RBGs to an “unscheduled” state, alleviating the possible excessiv e RBG allocations in Stage 1 due to the limitations of local optimiza- tion. Meanwhile, releasing the RBGs previously allocated to NJT -UEs benefits the QoS performance of co-scheduled JT - UEs, as the interference they experience is reduced. After solving (43), PU m updates the achiev able rates { ˆ f c,r m,k } k ∈K Q m similar to (41). Then, the QoS contribution for an NJT -UE k ∈ K Q m from all the other cores except core [ m, c ] is computed as QoS ¯ c m,k = P c ′ = c P r ∈R ˆ f c ′ ,r m,k , which will be used for the parallel refinement in Stage 3. D. Stage 3: Refining NJT -UE Sc heduling at PU 1 to PU M After completing Stage 2.1, PU 0 feeds back the updated scheduling states { b c,r m,i } and the associated QoS contribution { QoS ¯ c m,i } of the JT -UEs to PU m . W ith the feedback, PU m further refines the scheduling of NJT -UEs associated with cell m . Moreover , with the QoS contributions from other CCs { QoS ¯ c m,k } k ∈K Q m , (30a) can be fully decoupled across cores, thereby enabling parallel refinement. Specifically , each core [ m, c ] refines the scheduling of NJT -UEs k ∈ K m on CC- c by solving a sub-problem of (30a) as max { b c,r m,k } r,k ˜ G c m ≜ X k ∈ ˆ K Q m X r ∈R ˜ f c,r m,k + X i ∈ ˆ U Q m X r ∈R ˜ f c,r m,i + ρ X z ∈ ( K Q m ∪U Q m ) min n X r ∈R ˜ f c,r m,z + QoS ¯ c m,z , Q z o . Here, we refrain from re-optimizing the JT -UE scheduling to av oid introducing inconsistencies across different cells and additional rounds of coordination to resolve them. While the adjustment of NJT -UE scheduling may affect the rates of JT -UEs, their QoS requirements can be activ ely reinforced with a proper penalty parameter ρ . Since the abov e problem shares a similar structure with (30a), it can be efficiently solved in a BCD manner . With this refinement, this stage further enhances the ov erall network performance. Eventually , a distributed scheduling scheme aligned with the O-RAN structure is established by integrating the abo ve three stages. V I . S I M U L A T I O N R E S U LT S In the simulation, we consider an O-RAN with 3 cells. The O-R Us, each equipped with N t = 64 antennas unless other- wise specified, are located at [0 , − 300 , 25] , [ − 1000 , − 300 , 25] , and [ − 500 , − 1200 , 25] (unit: m). A total of K UEs (height = 1 . 5 m) equipped with N r = 4 antennas are randomly dis- tributed in the rectangular region [ x min , x max , y min , y max ] = [ − 1400 , 400 , − 1400 , − 100] (unit: m). The system uses three CCs centered at 3.2 GHz, 3.5 GHz, and 3.8 GHz. Each CC comprises 624 subcarriers grouped into 13 RBGs of 48 subcarriers each. P = 10 dBm and the power spectral density of noise is − 174 dBm/Hz. Channels are generated using Quadriga [30]. The O-R U–UE association follows a channel- strength-based strategy [31], where each UE is primarily connected to the O-RU with the strongest large-scale channel gain. T o enable JT , a UE is also associated with other O- R Us if the difference between their channel gains and the strongest one is within 10 dB. Among the K UEs, K q ≤ K are randomly selected to hav e heterogeneous QoS demands, with thresholds { Q k , Q i } randomly drawn from [0 , 60] bps/Hz. W e ev aluate the proposed designs using two performance metrics: the effecti ve sum rate (ESR) G esr defined as 11 Fig. 5: Conv ergence of the proposed centralized scheduling. G esr ≜ X i ∈ ˆ I Q X ( c,r ) f c,r i + X i ∈I Q min X ( c,r ) f c,r i , Q i + X m ∈M X k ∈ ˆ K Q m X ( c,r ) f c,r m,k + X k ∈K Q m min X ( c,r ) f c,r m,k , Q k where { f c,r m,k , f c,r i } from (6) and (7) take the original achie v- able rates without approximation, and Sat represents the ratio of UEs whose QoS requirements are met. A. Con verg ence of Pr oposed Centralized Algorithm Fig. 5 shows the objecti ve value of problem (30a) achiev ed by the proposed centralized scheduling (PCS) Algorithm 1 versus iterations, with K = 45 and K q = 25 . Specifically , f a ≜ G/ ( C RK ) , with G in (31) with ρ = 1 , denotes the averaged approximate ESR per RBG per UE, while f t ≜ G esr / ( C R K ) is the attained av eraged ESR without approximation. Fig. 5 presents that the value of f a increases rapidly and gets stable within about 5 iterations, indicating the fast conv ergence of our proposed design. Moreover , f t closely follows that of f a , with a relativ e error consistently below 3% for N t = 32 and 64, validating the effecti veness of our proposed approximation in Sec. III. B. P erformance of Pr oposed Sc heduling Schemes Fig. 6 and Fig. 7 compare the performance of our proposed distributed scheduling (PDS) with that of PCS under different penalty parameters ( ρ ) values. The performance of PDS with- out PU coordination (Stage 2.2 in Sec. V-C, named as “PDS- NC”) is also presented to ev aluate the improv ement enabled by this step. As shown in Fig. 6, the ESR achieved by all schemes decreases as K q increases. This is expected since more spec- trum resources will be allocated to meet the stringent QoS requirements. From an optimization perspectiv e, more QoS- constrained UEs further restrict the feasible set of problem (14), yielding a smaller ESR. Among the three schemes, PCS performs best due to its global coordination. Howe ver , this comes at the cost of intensive computation at a single node, limiting its applicability in large-scale networks. While PDS achiev es a lower ESR than PCS, it distributes the compu- tational load across multiple nodes with only one round of coordination, greatly improving scalability . Compared with T ABLE II: Computational T ime (s) Scheme K = 40 K = 60 K = 80 PCS 559 1042 1450 PDS 18 40 64 PDS, the ESR of PDS-NC gets worse. This stems from its uncoordinated scheduling: each core makes isolated RBG de- cisions with intra-PU coordination, often resulting in excessiv e resources for some UEs and insuf ficiency for others. Additionally , Fig. 7 shows that both PCS and PDS maintain high Sat values across all ρ values, while PDS-NC achiev es significantly lower Sat (below 78% in all cases) due to its lack of PU coordination. Combined with Fig. 6, these results demonstrate the critical role of coordination in distributed scheduling. Further , comparing ρ = 2 and 5 re veals the penalty parameter’ s trade-off effect: smaller ρ improves ESR while larger ρ enhances Sat , as a stronger penalty on QoS violations (see (31)) shifts optimization priority from throughput to constraint satisfaction. Among the three schemes, PCS shows the least sensitivity to ρ variation, while PDS maintains Sat abov e 93% even when ρ decreases from 5 to 2. In T able II, the computational time of our proposed PCS and PDS is compared. One can observe that the computation of PDS is much faster than that of PCS. In all scenarios, the computation time of PDS is under 1 / 20 of PCS’ s. This owes to the parallel processing enabled by our distributed design, making PDS a scalable solution for large networks. C. Comparison with Other Schemes In this subsection, we compare our proposed designs with two existing schemes under varying numbers of UEs K : SUS- ZF [12] with ZF-TBF , and a modified SINR-based heuristic scheme ( mSHS ), which modifies SHS [32] by weighting the user selection according to individual QoS demands. Fig. 8 shows that PCS consistently achiev es the highest ESR with 100% Sat across all scenarios. In contrast, mSHS fails to satisfy QoS demands due to insufficient RBGs per UE; its aggressiv e QoS prioritization also hinders the scheduling of UEs with good channels, leading to the lowest ESR and satisfaction. SUS-ZF outperforms mSHS but falls short of our methods, especially as K gro ws. Meanwhile, PDS closely follows the trend of PCS, achieving over 95% of its ESR and maintaining Sat above 94%, confirming the ef fectiv eness. V I I . C O N C L U S I O N In this work, we have in vestigated the distributed user scheduling problem in MU-MIMO O-RAN serving both JT and NJT UEs with heterogeneous QoS requirements. T o handle the comple x rate expression in volving strong v ariable coupling across carriers, users, and cells, we have extended the EZF-TBF to JT -UEs, and proposed a novel reformulation scheme that achiev es a tractable approximate rate suitable for distributed optimization. Building upon this reformula- tion, in addition to a BCD-based centralized algorithm, we hav e proposed a three-stage ‘decomposition – coordination – refinement’ distributed scheduling scheme fully tailored to the O-RAN architecture. This distributed scheme only takes a single round of information exchange between nodes, making 12 Fig. 6: ESR v ersus the number of QoS- constrained UEs K q , with K = 75 . Fig. 7: Sat versus the number of QoS- constrained UEs K q , with K = 75 . Fig. 8: ESR (bars) and Sat (dashed lines) achiev ed by different schemes versus K . it suitable for practical latency- and fronthaul-constrained deployments. Simulation results demonstrate that the proposed distributed scheme achieves performance comparable to the centralized benchmark while significantly outperforming ex- isting designs, providing a scalable and efficient solution for large-scale O-RAN deployments with diverse QoS demands. R E F E R E N C E S [1] P . Lin, C. Hu, X. Li, J. Y u, and W . Xie, “Research on Carrier Aggregation of 5G NR, ” in Proc. IEEE BMSB , Bilbao, Spain, Jun. 2022, pp. 1–5. [2] Z. Zhou, C.-X. W ang, X. Chen, L. Zhang, J. Huang, L. Xin, and X. W u, “Multi-Frequency Wireless Channel Measurements and Modeling in Urban Macro Scenarios, ” IEEE T rans. V eh. T echnol. , 2025. [3] P . Marsch and G. P . Fettweis, Coordinated Multi-P oint in Mobile Communications: F r om Theory to Practice . Cambridge Univ ersity Press, 2011. [4] S. He, Z. An, J. Zhu, M. Zhang, Y . Huang, and Y . Zhang, “Cross-Layer Optimization: Joint User Scheduling and Beamforming Design W ith QoS Support in Joint Transmission Networks, ” IEEE T rans. Commun. , vol. 71, no. 2, pp. 792–807, 2022. [5] J. Denis and M. Assaad, “Improving Cell-Free Massiv e MIMO Networks Performance: A User Scheduling Approach, ” IEEE T rans. W ireless Commun. , vol. 20, no. 11, pp. 7360–7374, 2021. [6] M. Polese, L. Bonati, S. D’oro, S. Basagni, and T . Melodia, “Under- standing O-RAN: Architecture, Interfaces, Algorithms, Security , and Research Challenges, ” IEEE Commun. Surv . T utor . , vol. 25, no. 2, pp. 1376–1411, 2023. [7] B. Agarwal, R. Irmer , D. Lister , and G.-M. Muntean, “Open RAN for 6G Networks: Architecture, Use Cases and Open Issues, ” IEEE Commun. Surv . T utor . , vol. 28, pp. 2881–2924, 2026. [8] F . Sun, M. Y ou, J. Liu, Z. Shi, P . W en, and J. Liu, “Genetic Algorithm Based Multiuser Scheduling for Single- and Multi-Cell Systems with Successiv e Interference Cancellation, ” in Pr oc. IEEE PIMRC , Istanbul, T urkey , Sep. 2010, pp. 1230–1235. [9] A. A. Khan, R. S. Adve, and W . Y u, “Optimizing Downlink Resource Allocation in Multiuser MIMO Networks via Fractional Programming and the Hungarian Algorithm, ” IEEE Tr ans. W ir eless Commun. , vol. 19, no. 8, pp. 5162–5175, 2020. [10] L. Y u, E. Karipidis, and E. G. Larsson, “Coordinated Scheduling and Beamforming for Multicell Spectrum Sharing Networks Using Branch & Bound, ” in Pr oc. EUSIPCO , Bucharest, Romania, Aug. 2012, pp. 819–823. [11] M. Li, C. Liu, I. B. Collings, and S. V . Hanly , “Multicell Coordinated Scheduling with Multiuser ZF Beamforming, ” in Proc. IEEE ICC , Sydney , Australia, Jun. 2014, pp. 5006–5011. [12] M. Li, I. B. Collings, S. V . Hanly , C. Liu, and P . Whiting, “Multicell Coordinated Scheduling with Multiuser Zero-Forcing Beamforming, ” IEEE Tr ans. W ireless Commun. , vol. 15, no. 2, pp. 827–842, 2015. [13] T . Gamvrelis, Z. Li, A. A. Khan, and R. S. Adve, “SLINR-Based Downlink Optimization in MU-MIMO Netw orks, ” IEEE Access , vol. 10, pp. 123 956–123 970, 2022. [14] Y . Chen, Y . T . Hou, W . Lou, J. H. Reed, and S. Kompella, “OM 3 : Real- T ime Multi-Cell MIMO Scheduling in 5G O-RAN, ” IEEE J. Sel. Ar eas Commun. , vol. 42, no. 2, pp. 339–355, 2023. [15] R. P . Antonioli, G. Fodor , P . Soldati, and T . F . Maciel, “Decentralized User Scheduling for Rate-Constrained Sum-Utility Maximization in the MIMO IBC, ” IEEE T rans. Commun. , vol. 68, no. 10, pp. 6215–6229, 2020. [16] Y . Chen, Y . W u, Y . T . Hou, and W . Lou, “mCore: Achieving Sub- millisecond Scheduling for 5G MU-MIMO Systems, ” in Pr oc. IEEE INFOCOM , V ancouver , BC, Canada, Jul. 2021, pp. 1–10. [17] T . Bischoff, M. Kasparick, E. T ohidi, and S. Sta ´ nczak, “Real-time Algorithms for Combined eMBB and URLLC Scheduling, ” in Proc. WSA , Nuremberg, Germany , Mar . 2024, pp. 1–5. [18] E. A. Jorswieck, A. Sezgin, and X. Zhang, “Throughput V ersus Fairness: Channel-A ware Scheduling in Multiple Antenna Downlink, ” EURASIP J. W irel. Commun. Netw . , vol. 2009, no. 1, p. 271540, 2009. [19] L. Sun and M. R. McKay , “Eigen-Based Transcei vers for the MIMO Broadcast Channel with Semi-Orthogonal User Selection, ” IEEE T rans. Signal Process. , vol. 58, no. 10, pp. 5246–5261, 2010. [20] B. Kaziu, N. Shanin, D. Spano, L. W ang, W . Gerstacker , and R. Schober, “Approximate Partially Decentralized Linear EZF Precoding for Massi ve MU-MIMO Systems, ” in Pr oc. IEEE VTC-F all , Los Angeles, CA, USA, Oct. 2024, pp. 1–6. [21] R. V ershynin, “High-dimensional probability , ” 2009. [22] Y . Chen, Y . T . Hou, W . Lou, J. H. Reed, and S. Kompella, “M 3 : A Sub- Millisecond Scheduler for Multi-Cell MIMO Networks under C-RAN Architecture, ” in Pr oc. IEEE INFOCOM , 2022, pp. 130–139. [23] N. Seifi, M. Matthaiou, and M. V iberg, “Coordinated User Scheduling in the Multi-Cell MIMO Downlink, ” in Pr oc. IEEE ICASSP , Prague, Czech Republic, May 2011, pp. 2840–2843. [24] Y . Wu, Y . Shi, Y . T . Hou, W . Lou, J. H. Reed, and L. A. DaSilva, “R 3 : A Real-Time Robust MU-MIMO Scheduler for O-RAN, ” IEEE T rans. W ir eless Commun. , vol. 23, no. 11, pp. 17 727–17 743, 2024. [25] X. Bian, Y . Liu, Y . Xu, T . Hou, W . W ang, Y . Mao, and J. Zhang, “Decentralizing Coherent Joint Transmission Precoding via F ast ADMM with Deterministic Equi valents, ” arXiv pr eprint arXiv:2403.19127 , 2024. [26] J. Nocedal and S. J. Wright, Numerical optimization . Springer , 1999. [27] S. J ¨ ager and A. Sch ¨ obel, “The blockwise coordinate descent method for integer programs, ” Mathematical Methods of Operations Resear ch , vol. 91, no. 2, pp. 357–381, 2020. [28] B. Houska, J. Frasch, and M. Diehl, “An augmented Lagrangian based algorithm for distributed nonconv ex optimization, ” SIAM J OPTIMIZ , vol. 26, no. 2, pp. 1101–1127, 2016. [29] Y . Xu, E. G. Larsson, E. A. Jorswieck, X. Li, S. Jin, and T .-H. Chang, “Distributed signal processing for extremely large-scale antenna array systems: State-of-the-art and future directions, ” IEEE J. Sel. T op. Signal Pr ocess , 2025. [30] S. Jaeckel, L. Raschkowski, K. B ¨ orner , and L. Thiele, “QuaDRiGa: A 3-D Multi-cell Channel Model with Time Evolution for Enabling V irtual Field T rials, ” IEEE T rans. Antennas Propag . , vol. 62, no. 6, pp. 3242– 3256, 2014. [31] R. T anbourgi, S. Singh, J. G. Andrews, and F . K. Jondral, “ Analysis of Non-Coherent Joint-Transmission Cooperation in Heterogeneous Cellu- lar Networks, ” in Proc. IEEE ICC , Sydne y , Australia, Jun. 2014, pp. 5160–5165. [32] M. Idrees, X. Qi, A. Zaib, A. T ariq, I. Ullah, Z. Mahmood, and S. Khattak, “Throughput Maximization in Clustered Cellular Networks by Using Joint Resource Scheduling and Fractional Frequency Reuse- Aided Coordinated Multipoint, ” Arab . J. Sci. Eng. , pp. 1–15, 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment