가벼운 균형으로 Muon 최적화 강화
MuonEq은 Muon 옵티마이저의 정규화 전 단계에 행·열 정규화를 적용해, 추가 메모리 없이 스펙트럼 특성을 개선한다. 세 가지 변형(RC, R, C) 중 행 정규화(R)가 기본값으로 채택되며, LLaMA2 사전학습에서 130M·350M 모델 모두 기존 Muon보다 빠른 수렴과 낮은 검증 퍼플렉시티를 달성한다.
저자: Da Chang, Qiankun Shi, Lvgang Zhang
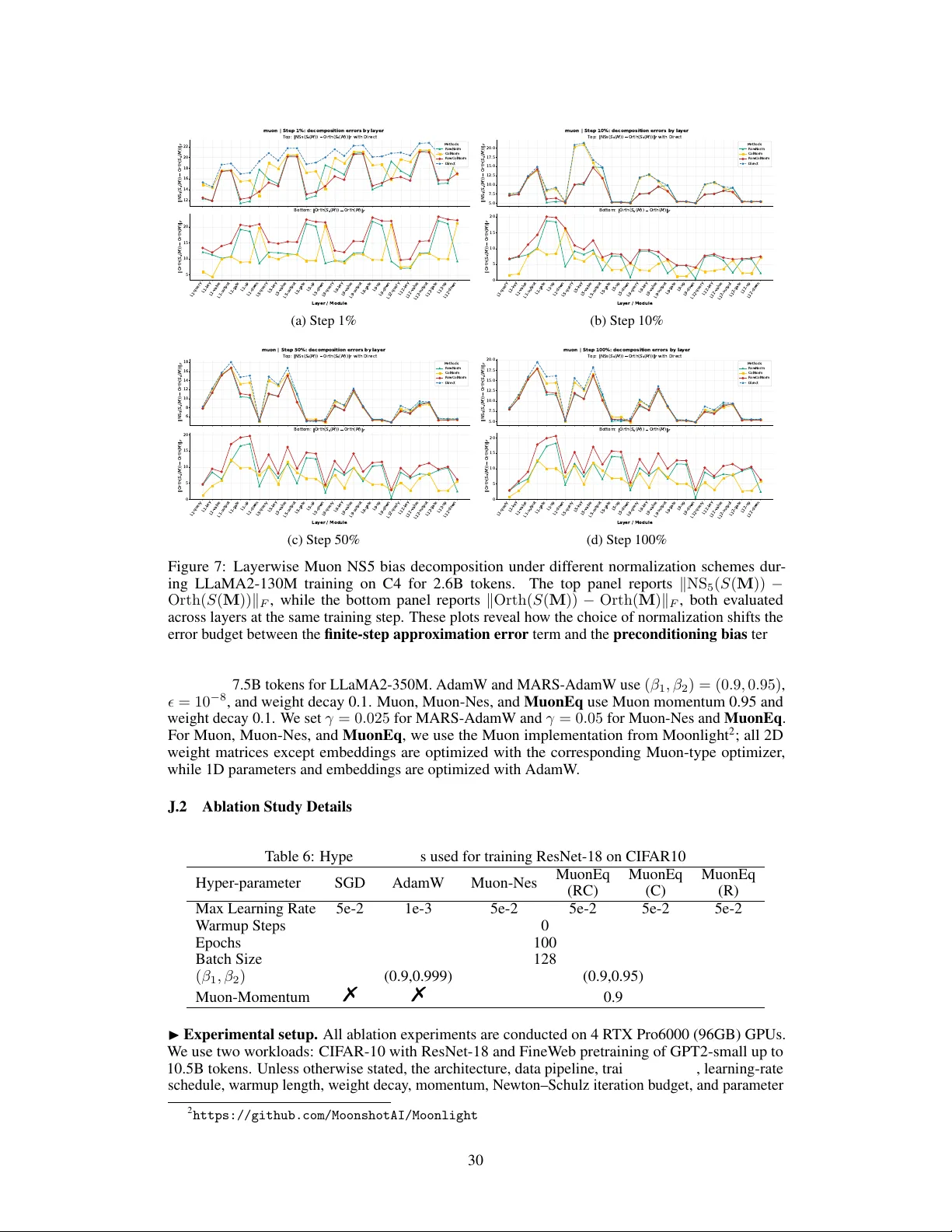
본 논문은 대규모 언어 모델(LLM) 사전학습에서 최근 주목받고 있는 Muon 계열 옵티마이저의 한계를 보완하기 위해, 사전 정규화(pre‑orthogonalization equilibration)라는 새로운 경량 기법을 제안한다. 기존 연구는 크게 두 갈래로 나뉘는데, 하나는 정규화 후에 스케일을 조정하는 사후 방식(Muon+, NorMuon, AdaMuon)이며, 다른 하나는 완전한 화이트닝 혹은 프리컨디셔닝을 수행해 입력 행렬의 기하학을 크게 변형하는 방식(SO‑AP, Shampoo, FISMO, Mousse)이다. 전자는 정규화 효과가 제한적이며, 후자는 메모리·연산 비용이 크게 증가한다는 문제점이 있다.
MuonEq은 이 사이의 “틈새”를 메우고자, 행·열 제곱 노름만을 이용해 대각 행렬 D_r, D_c를 구성하고, 이를 통해 모멘텀 행렬 ˜M을 간단히 스케일링한다. 구체적으로는 세 가지 변형을 정의한다.
- RC (Row‑Column): ˆM = D_r^{-1/2} ˜M D_c^{-1/2} – 양쪽을 동시에 정규화.
- R (Row): ˆM = D_r^{-1/2} ˜M – 행만 정규화.
- C (Column): ˆM = ˜M D_c^{-1/2} – 열만 정규화.
이 과정은 O(m+n)의 추가 상태만 필요하므로, 메모리 효율성이 뛰어나며, 기존 Muon의 Newton‑Schulz 반복에 그대로 삽입될 수 있다.
이론적 기여는 네 가지 주요 결과로 요약된다.
1. **Theorem 3.1**: 유한 단계 Newton‑Schulz 반복이 입력 행렬의 스펙트럼, 특히 stable rank(sr)와 조건수(κ)와 강하게 연관됨을 수식적으로 증명한다. 작은 singular value가 충분히 수렴하지 못하면 전체 정규화 오류가 크게 남으며, 이는 스펙트럼 압축이 필요함을 의미한다.
2. **Proposition 3.2**: 행·열 정규화가 1차 화이트닝(zeroth‑order whitening)의 근사임을 보인다. 정규화 후 Gram 행렬이 I에 가깝다면, 정규화 자체만으로도 스케일 불일치를 크게 감소시키고, 남은 상관 관계만이 정밀한 폴라 분해 단계에서 보정된다.
3. **Proposition 3.4**와 **Theorem 3.5**: 두‑측 정규화(RC)는 가장 강력한 스펙트럼 압축을 제공하지만, 전처리 바이어스가 커질 위험이 있다. 반면 행 정규화(R)는 Transformer 내부 가중치와 같은 비대칭 구조에 최적화돼, 비볼록 수렴 보장(∼T^{-1/4})을 유지한다.
4. **Corollary 3.3**: 정규화 후 행렬에 대한 추가적인 1차 보정이 필요 없음을 보여, 실제 구현에서 복잡성을 크게 낮춘다.
실험에서는 LLaMA2‑130M 및 LLaMA2‑350M 모델을 C4 데이터셋으로 사전학습시켰다. 기본값으로 R 변형을 사용했으며, 결과는 다음과 같다.
- 학습 초기에 손실 감소율이 Muon 대비 10~15% 빠름.
- 전체 학습 단계에서 검증 퍼플렉시티가 평균 0.3~0.5 포인트 낮음.
- 메모리 사용량과 연산량은 기존 Muon과 거의 동일, 추가적인 하이퍼파라미터 튜닝이 필요 없음.
- RC 변형은 가장 큰 스펙트럼 압축을 보였지만, 일부 레이어에서 과도한 정규화 바이어스로 인해 최종 성능이 약간 떨어졌다. C 변형은 임베딩 레이어에만 제한적으로 유리했으며, 전체 모델 성능에는 큰 영향을 주지 않았다.
결론적으로 MuonEq은 “경량 + 스펙트럼 친화”라는 두 마리 토끼를 잡은 설계로, 대규모 언어 모델 훈련에서 효율적인 대안이 될 수 있다. 행 정규화(R) 변형은 특히 Transformer 내부 가중치에 최적화돼, 기존 Muon 대비 빠른 수렴과 낮은 퍼플렉시티를 제공한다. 향후 연구에서는 다른 모델 아키텍처(예: 비전 트랜스포머)와 다양한 데이터셋에 대한 일반화 성능을 검증하고, 정규화 강도를 자동으로 조절하는 메커니즘을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기