MuonEq: Balancing Before Orthogonalization with Lightweight Equilibration
Orthogonalized-update optimizers such as Muon improve training of matrix-valued parameters, but existing extensions mostly act either after orthogonalization by rescaling updates or before it with heavier whitening-based preconditioners. We introduce…
Authors: Da Chang, Qiankun Shi, Lvgang Zhang
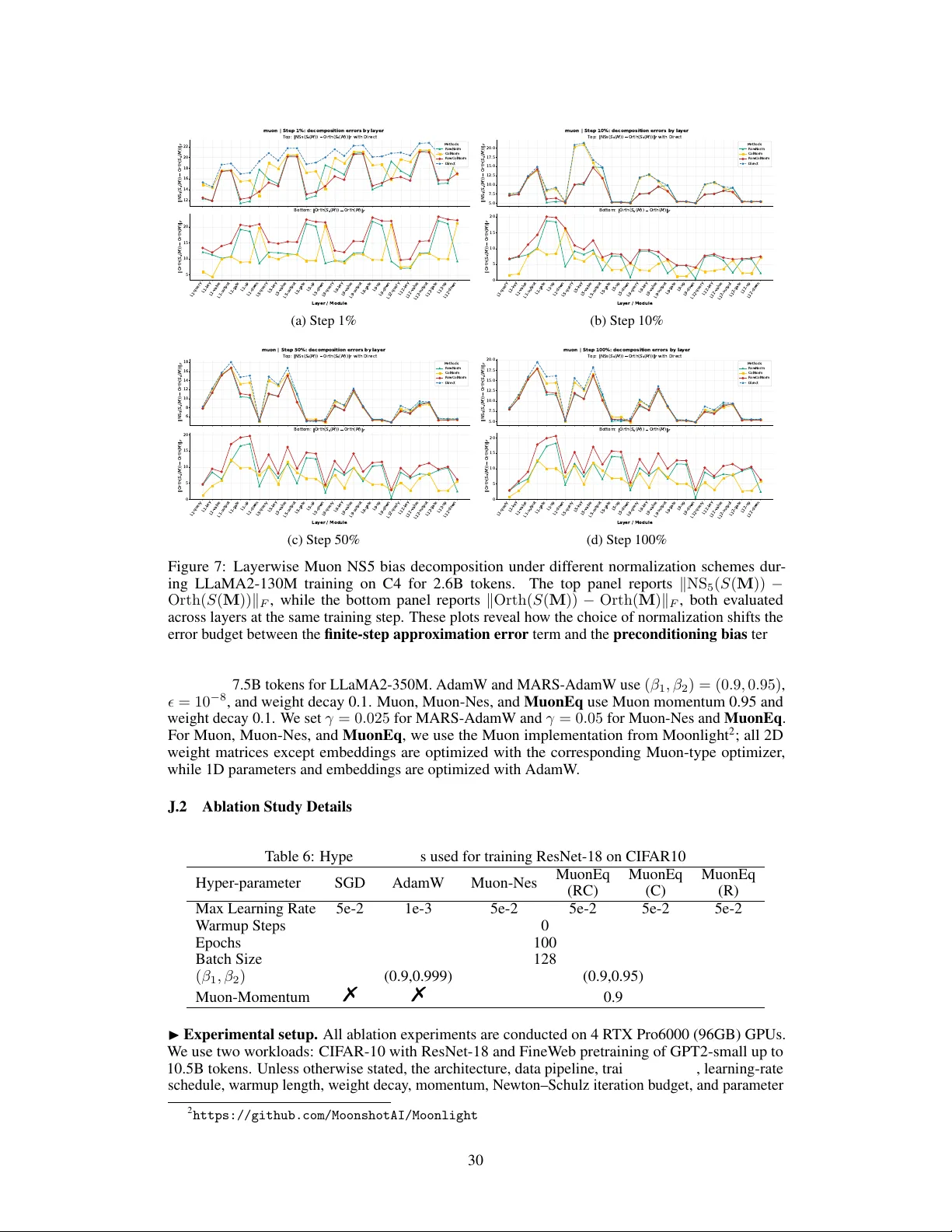
MuonEq: Balancing Bef or e Orthogonalization with Lightweight Equilibration Da Chang 137 , Qiankun Shi 34 , Lvgang Zhang 45 , Y u Li 6 , Ruijie Zhang 7 Y ao Lu 3 , Y ongxiang Liu 3 ∗ , Ganzhao Y uan 2 ∗ 1 Shenzhen Institute of Advanced T echnology , Chinese Academy of Sciences 2 Shenzhen Univ ersity of Advanced T echnology 3 Pengcheng Laboratory 4 Sun Y at-sen Uni versity 5 Southern Univ ersity of Science and T echnology 6 George W ashington Uni versity 7 Univ ersity of Chinese Academy of Sciences Abstract Orthogonalized-update optimizers such as Muon impro ve training of matrix-v alued parameters, but existing extensions mostly act either after orthogonalization by rescaling updates or before it with hea vier whitening-based preconditioners. W e introduce MuonEq , a lightweight f amily of pre-orthogonalization equilibration schemes for Muon in three forms: two-sided ro w/column normalization (RC), row normalization (R), and column normalization (C). These v ariants rebalance the mo- mentum matrix before finite-step Newton–Schulz using ro w/column squared-norm statistics and only O ( m + n ) auxiliary state. W e show that finite-step orthogonal- ization is gov erned by input spectral properties, especially stable rank and condition number , and that row/column normalization is a zeroth-order whitening surrogate that remov es marginal scale mismatch. For the hidden matrix weights tar geted by MuonEq , the row-normalized variant R is the natural default and preserves the e O ( T − 1 / 4 ) stationarity guarantee of Muon-type methods. In LLaMA2 pretraining on C4, the default R v ariant consistently outperforms Muon on 130M and 350M models, yielding faster con ver gence and lower v alidation perplexity . 1 Introduction As the computational and data costs of large language model pretraining grow , optimization increas- ingly determines sample efficiency , throughput, and scalability . Beyond coordinate-wise adaptive methods such as AdamW [ 1 ], Adan [ 2 ], and MARS [ 3 ], recent work has shifted to ward a geometric view of matrix-valued updates. Muon [ 4 ], for instance, uses a Newton–Schulz approximation to the polar factor of the momentum matrix to produce spectrally aligned updates [ 5 , 6 ]. It has shown strong empirical scalability in LLM pretraining, often improving the trade-off among data ef ficiency , compute, and wall-clock time at fixed tar get loss [ 7 , 8 ]. Recent theory further characterizes Muon as spectral-norm steepest descent and establishes nonconv ex con ver gence guarantees for both exact and approximate orthogonalization [9, 10, 11, 12, 13, 14, 15]. Follo w-up work around Muon mainly proceeds along two directions. (i) P ost-orthogonalization r escaling augments an already constructed orthogonal update with additional magnitude correc- tion. Muon+ [ 16 ], NorMuon [ 17 ], and AdaMuon [ 18 ] respecti vely add ro w/column normalization, neuron-wise normalization, or element-wise variance adaptation after orthogonalization. These variants sho w that orthogonal updates remain compatible with later adaptiv e scaling, but they do not change the matrix that finite-step Newton–Schulz actually sees. (ii) Pre-ortho gonalization geometric corr ection instead modifies the coordinate system before spectral optimization. SO AP [ 19 ] connects ∗ Corresponding authors: liuyx@pcl.ac.cn and yuanganzhao@foxmail.com Preprint. Shampoo [ 20 ] with Adam/Adafactor [ 21 , 22 ] through a preconditioned basis, while FISMO [ 23 ] and Mousse [ 24 ] further perform spectral optimization in whitened coordinates. These methods suggest that improving geometry before orthogonalization is the more direct le ver , but doing so usually requires maintaining left and right preconditioners together with extra matrix operations such as eigendecomposition, in verse po wer iteration, and whitening/dewhitening maps. These works moti vate a more precise question: Is ther e a lightweight design between post-orthogonalization r escaling and full whitening-based pr econditioning that dir ectly impr oves the input geometry for orthogonalization? Our starting point is that, in Muon, the relev ant object is not only the exact polar factor but also the finite-step Ne wton–Schulz approximation used in practice. Section 3.1 shows that both the con ver gence speed of Newton–Schulz iterations and the gap between finite-step iterations and e xact orthogonalization are gov erned by input spectral geometry , especially stable rank and condition number . This points to a simple design principle: improv e the geometry before orthogonalization, but do so with the smallest possible intervention. A natural formalization is the optimal diagonal preconditioning problem: min D 1 , D 2 ≻ 0 κ D 1 / 2 1 AD − 1 / 2 2 . Qu et al. [ 25 ] deriv e an optimal diagonal preconditioner , but applying it online typically requires an auxiliary iterativ e solve. Classical row/column equilibration is less exact yet much lighter- weight [ 26 ]; moreov er , recent operator-geometry results identify ro w and column normalization as steepest-descent directions under the p → ∞ and 1 → q geometries, respecti vely [ 27 ]. This makes diagonal equilibration a natural lightweight way to improve the matrix presented to Muon-style orthogonalization. Based on this observation, we propose MuonEq , a lightweight family of pre-orthogonalization equilibration schemes for Muon. MuonEq has three forms: two-sided ro w/column normalization (RC), row normalization (R), and column normalization (C). All three act directly on the momentum matrix before Ne wton–Schulz using only ro w/column squared-norm statistics and O ( m + n ) auxiliary state. Detailed justification is deferred to Section 3: Theorem 3.1 quantifies the spectral sensiti vity of finite-step orthogonalization, Proposition 3.2 shows that row/column normalization is a zeroth- order surrogate for whitening, and Proposition 3.4 together with Theorem 3.5 clarify the trade-of f between stronger two-sided equilibration and cleaner one-sided geometry . For the hidden Transformer weight matrices targeted by MuonEq , recent architecture-a ware analyses by [ 27 ] identify row-sided geometry as the natural one-sided choice, whereas column-sided geometry is more closely associated with embedding matrices; accordingly , we adopt R as the default and treat RC and C as companion forms for analysis and ablation. Compared with Muon+ [ 16 ], which rescales the update after orthogonalization, MuonEq modifies the matrix fed into orthogonalization. Unlike whitening-based methods such as FISMO and Mousse [ 23 , 24 ], it avoids Kroneck er factors, matrix-valued second- order statistics, eigendecomposition, and momentum transport, and requires only O ( m + n ) auxiliary state. Our contributions are threefold. 1. First, we propose MuonEq , a lightweight family of pre-orthogonalization equilibration schemes for Muon with three forms: RC, R, and C; these variants rebalance the matrix before Ne wton–Schulz using only ro w/column squared-norm statistics, with R as the default for hidden matrix weights. 2. Second, we sho w that finite-step Newton–Schulz is go verned by the input spectrum, espe- cially stable rank and condition number; that ro w/column normalization acts as a zeroth-order surrogate for whitening; and that RC and R admit a clear trade-of f between stronger spectral correction and cleaner one-sided conv ergence structure, with the default R variant satisfying a e O ( T − 1 / 4 ) noncon ve x guarantee under standard assumptions. 3. Third, empirically , the default R v ariant consistently outperforms Muon across model sizes and token b udgets, while ablations ov er RC, R, and C sho w that R is the strongest def ault form for the hidden-weight setting targeted by MuonEq . 2 2 Method Notation and setup. Scalars are denoted by non-bold letters, vectors by bold lo wercase letters, and matrices by bold uppercase letters. On R d , we use the Euclidean inner product ⟨ x , y ⟩ 2 := x ⊤ y and norm ∥ x ∥ 2 . For matrices, ⟨ A , B ⟩ F := tr( A ⊤ B ) and ∥ A ∥ F denote the Frobenius inner product and norm, and ∥ A ∥ ∗ denotes the nuclear norm. W e write [ m ] := { 1 , 2 , . . . , m } and let N be the set of non-negati ve integers. The model parameter is a matrix X ∈ R m × n , and, unless otherwise stated, we assume m ≥ n . For any matrix A ∈ R m × n with rank r ≤ n , we write its compact singular value decomposition as A = U Σ V ⊤ , where Σ = diag ( σ 1 , . . . , σ r ) and σ 1 ≥ · · · ≥ σ r > 0 , and define Orth( A ) := UV ⊤ . In finite-data form, the training objective can be written as f ( X ) := 1 N P i ∈ [ N ] f i ( X ) , where f i ( X ) is the loss associated with the i -th sample z i . Equiv alently , we use the stochastic formulation min X ∈ R m × n f ( X ) , f ( X ) = E ξ ∼D [ f ( X ; ξ )] , (1) where f may be nonconv ex, ξ is independent of X , and E ξ [ · ] denotes expectation with respect to ξ . For any matrix A with singular values { σ i ( A ) } r i =1 , we further use sr( A ) := ∥ A ∥ 2 F ∥ A ∥ 2 2 , κ 2 ( A ) := σ 1 ( A ) σ r ( A ) , p i := σ i ( A ) 2 ∥ A ∥ 2 F , H ( p ) := − P r i =1 p i log p i . Muon as finite-step orthogonalized momentum. For matrix parameters, Muon constructs the update by orthogonalizing the momentum matrix. Let M t denote the momentum at iteration t . The abstract Muon update is U t = Orth( ˜ M t ) , X t +1 = X t − η t U t , (2) where ˜ M t is either the standard momentum or its Nestero v variant [ 4 , 7 , 9 ]. In practice, Orth( ˜ M t ) is implemented by a small fixed number of Newton–Schulz iterations rather than exact polar decom- position [ 4 ]. The design question is therefore not only what direction is desirable in the e xact limit, but also what matrix should be fed into finite-step Ne wton–Schulz. Pre-orthogonalization equilibration family . MuonEq inserts diagonal preconditioning before orthogonalization: ˆ M t = DiagPre ( ˜ M t ; s ) , U t = Orth( ˆ M t ) , X t +1 = X t − η t U t , (3) where the mode s ∈ { RC , R , C } selects one of three equilibration forms. Let D r,t = diag ro wsum( ˜ M t ⊙ ˜ M t ) + ε , D c,t = diag colsum( ˜ M t ⊙ ˜ M t ) + ε . W e consider the following three maps: DiagPre ( ˜ M t ; s ) = D − 1 / 2 r,t ˜ M t D − 1 / 2 c,t , s = RC , D − 1 / 2 r,t ˜ M t , s = R , ˜ M t D − 1 / 2 c,t , s = C . (4) Since these maps use only row and column squared norms, the extra state is O ( m + n ) , in the factorized spirit of Adafactor [ 21 ]. Unlike methods that rely on matrix-valued or adapti ve preconditioners [ 20 , 21 , 22 , 23 ], MuonEq changes only the matrix fed to Newton–Schulz. Relativ e to Muon [ 4 ], the orthogonalization routine itself is unchanged; relati ve to Muon+, NorMuon, and AdaMuon [ 16 , 17 , 18], MuonEq rebalances the input rather than rescales the output. Why the default variant is R. This choice is block-dependent rather than a univ ersal preference for row normalization. The trade-off is guided by ∥ NS K ( S ( M )) − Orth( M ) ∥ F ≤ ∥ NS K ( S ( M )) − Orth( S ( M )) ∥ F | {z } finite-step approximation error + ∥ Orth( S ( M )) − Orth( M ) ∥ F | {z } preconditioning bias , (5) where S is one of RC, R, or C. The first term is the finite-step Newton–Schulz error and depends on the spectrum of S ( M ) ; Theorem 3.1 therefore explains why the more aggressi ve two-sided RC 3 Algorithm 1 MuonEq (mode s ∈ { RC , R , C } ; default s = R ) 1: Input: Initial parameters X 1 ∈ R m × n , learn- ing rates η t > 0 , momentum coefficients β t ∈ [0 , 1) , weight decay λ ≥ 0 , mode s ∈ { R C , R , C } , stability term ε > 0 , Nesterov flag, scaling constant a = 0 . 2 p max( m, n ) 2: Initialize M 0 = 0 3: f or t = 1 to T do 4: G t = ∇ f ( X t ; ξ t ) 5: M t = β t M t − 1 + (1 − β t ) G t 6: if Nesterov then 7: ˜ M t = β t M t + (1 − β t ) G t 8: else 9: ˜ M t = M t 10: end if 11: ˆ M t = DiagPre ( ˜ M t , s, ε ) 12: O t = NS5( ˆ M t ) 13: X t +1 = (1 − λη t ) X t − aη t O t 14: end f or Algorithm 2 DiagPre 1: Input: Momentum ˜ M t , mode s ∈ { R C , R , C } , stability term ε > 0 2: if s ∈ { RC , R } then 3: D r,t = diag(rowsum( ˜ M t ⊙ ˜ M t ) + ε ) 4: end if 5: if s ∈ { RC , C } then 6: D c,t = diag(colsum( ˜ M t ⊙ ˜ M t ) + ε ) 7: end if 8: ˆ M t = D − 1 / 2 r,t ˜ M t D − 1 / 2 c,t , s = RC ; D − 1 / 2 r,t ˜ M t , s = R ; ˜ M t D − 1 / 2 c,t , s = C . 9: retur n ˆ M t Remark 2.1. Unless otherwise stated, we use the r ow-normalized variant s = R . The RC and C modes are kept as equally lightweight companion forms for analysis and ablation. map often giv es the largest spectral correction. The second term is the bias induced by preprocessing. Proposition 3.2 sho ws that row/column normalization is a zeroth-order surrogate for whitening, removing marginal scale mismatch before orthogonalization. Among the one-sided variants, re- cent operator-geometry analyses identify row-sided geometry as the natural choice for the hidden T ransformer weight matrices targeted by MuonEq , whereas column-sided geometry is more closely associated with embedding matrices [ 27 ]. This makes R the most appropriate default in our set- ting. Consistent with this picture, Proposition 3.4 characterizes the pure RC regime as a stronger two-sided spectral corrector , whereas Theorem 3.5 gi ves the cleanest noncon v ex guarantee for the row-normalized v ariant. 3 Analysis The analysis follows the logic of MuonEq : Section 3.1 establishes the spectrum sensitivity of finite- step Ne wton–Schulz; Section 3.2 interprets row/column normalization as a zeroth-order surrogate for whitening; and Section 3.3 moti vates the R rather than RC, with ro w normalization admitting a clean stochastic noncon ve x guarantee. T ogether , Theorem 3.1, Proposition 3.2, Proposition 3.4, and Theorem 3.5 justify the MuonEq family and the default choice of R. 3.1 Why spectral geometry matters f or finite-step Newton–Schulz orthogonalization For clarity , the theorem below is stated for the wide case p ≤ q ; the tall case follows by transposition. Theorem 3.1. Let G ∈ R p × q have rank r ≥ 1 , with compact SVD G = U Σ V ⊤ , and suppose p ≤ q . Fix α ≥ ∥ G ∥ 2 , set X 0 = α − 1 G , and define X k +1 = a I p + b X k X ⊤ k + c ( X k X ⊤ k ) 2 X k for k ∈ N , wher e a = 3 . 4445 , b = − 4 . 7750 , and c = 2 . 0315 ar e the coefficients used in Muon’ s Newton–Sc hulz iteration in [ 4 ]. Let ϕ ( s ) = as + bs 3 + cs 5 . Then, for each k ∈ N , X k = U diag ( s ( k ) 1 , . . . , s ( k ) r ) V ⊤ , s (0) i = σ i /α, s ( k +1) i = ϕ s ( k ) i , i ∈ [ r ] , and hence 1 √ r ∥ X k − Orth( G ) ∥ F ≥ 1 √ r r X i =1 1 − a k σ i /α 2 + ! 1 / 2 . Her e ( x ) + := max { x, 0 } . See Appendix A for details. 4 Remark 3.1. Under the normalization α = ∥ G ∥ F , which is common in pr actical Newton–Schulz implementations [4, 7], let p i := σ 2 i ∥ G ∥ 2 F , τ i := log a ∥ G ∥ F σ i = log a 1 √ p i . Then Theor em 3.1 implies 1 √ r X k − Orth( G ) F ≥ 1 √ r r X i =1 1 − a k − τ i 2 + ! 1 / 2 . Thus τ i is precisely the iteration at which the i -th singular dir ection leaves the linear re gime. In particular , τ 1 = log a p sr( G ) , τ r = log a κ 2 ( G ) p sr( G ) , τ r − τ 1 = log a κ 2 ( G ) . Ther efor e, the stable rank determines when the first singular direction enters the nonlinear r e gime, wher eas the condition number determines the width of the transition window o ver which the r emaining singular dir ections follow . Theorem 3.1 shows that broad spectra slow finite-step orthogonalization by delaying contraction along small singular directions. T o isolate this effect, Figure 1 uses random Gaussian matrices with controlled shapes and spectral spreads. The top row sho ws the finite-step error in Theorem 3.1, and the bottom row sho ws the corresponding condition numbers before and after normalization. T o verify the same mechanism on real training trajectories, Figure 2 uses pre-NS momentum matrices from a 2.6B-token Muon run on LLaMA2-130M [ 28 ] trained on C4 [ 29 ]. The top row sho ws the module-wise median of the error in Theorem 3.1, and the bottom row sho ws the corresponding mean. 0 1 2 3 4 5 Steps 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Orthogonality Error (a) 1024 × 1024 0 1 2 3 4 5 Steps 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 (b) 1024 × 4096 0 1 2 3 4 5 Steps 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 (c) 4096 × 1024 0 1 2 3 4 5 Steps 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Methods Dir ect ColNor m R owNor m R owColNor m (d) 4096 × 4096 Dir ect ColNor m R owNor m R owColNor m 1 0 4 1 0 5 Condition Number (e) 1024 × 1024 Dir ect ColNor m R owNor m R owColNor m 1 0 1 1 0 2 (f) 1024 × 4096 Dir ect ColNor m R owNor m R owColNor m 1 0 1 1 0 2 (g) 4096 × 1024 Dir ect ColNor m R owNor m R owColNor m 1 0 4 1 0 5 Spr ead: 0.0 Spr ead: 0.5 Spr ead: 1.0 Spr ead: 1.5 Spr ead: 2.0 W ide: raw cond Nar r ow : pr econd cond (h) 4096 × 4096 Figure 1: Random Gaussian matrices with controlled shapes and spectral spreads. T op: finite-step relativ e Frobenius error to the exact polar factor across Newton–Schulz steps. Bottom: ra w and post-normalization condition numbers. T wo-sided row/column normalization yields the smallest error and the most consistent spectral compression. 3.2 Row/column normalization as a zer oth-order surrogate f or whitening The next result shows that normalization is not merely heuristic rescaling. It is the leading-order term of exact whitening/orthogonalization when the normalized Gram matrix is close to identity . Consequently , normalization remo ves mar ginal scale mismatch first and leav es only the correlation correction to the polar step. Proposition 3.2. The following first-or der expansions hold. (i) Column/right whitening. Let M ∈ R p × q have full column rank, and set D c := diag( ∥ M : , 1 ∥ 2 , . . . , ∥ M : ,q ∥ 2 ) ≻ 0 , N c := MD − 1 c , and C c := N ⊤ c N c − I q . If ∥ D c C c D c ∥ 2 is sufficiently small, then Orth r ( M ) := M ( M ⊤ M ) − 1 / 2 = N c − N c L c D − 1 c + O ∥ D c C c D c ∥ 2 2 , 5 0 1 2 3 4 5 NS step (k) 0.5 0.6 0.7 0.8 0.9 1.0 Module median Orthogonality Error Dir ect ColNor m R owNor m R owColNor m Median 25%-75% IQR (a) Step 1% 0 1 2 3 4 5 NS step (k) 0.2 0.4 0.6 0.8 1.0 Dir ect ColNor m R owNor m R owColNor m Median 25%-75% IQR (b) Step 10% 0 1 2 3 4 5 NS step (k) 0.2 0.4 0.6 0.8 1.0 Dir ect ColNor m R owNor m R owColNor m Median 25%-75% IQR (c) Step 50% 0 1 2 3 4 5 NS step (k) 0.2 0.4 0.6 0.8 1.0 Dir ect ColNor m R owNor m R owColNor m Median 25%-75% IQR (d) Step 100% 0 1 2 3 4 5 NS step (k) 0.5 0.6 0.7 0.8 0.9 1.0 Module mean Orthogonality Error Dir ect ColNor m R owNor m R owColNor m Mean 25%-75% IQR (e) Step 1% 0 1 2 3 4 5 NS step (k) 0.2 0.4 0.6 0.8 1.0 Dir ect ColNor m R owNor m R owColNor m Mean 25%-75% IQR (f) Step 10% 0 1 2 3 4 5 NS step (k) 0.2 0.4 0.6 0.8 1.0 Dir ect ColNor m R owNor m R owColNor m Mean 25%-75% IQR (g) Step 50% 0 1 2 3 4 5 NS step (k) 0.2 0.4 0.6 0.8 1.0 Dir ect ColNor m R owNor m R owColNor m Mean 25%-75% IQR (h) Step 100% Figure 2: Finite-step orthogonalization error across Ne wton–Schulz steps at 1%, 10%, 50%, and 100% of training. T op: module-wise median; bottom: module-wise mean; shaded bands denote the 25%–75% range. T wo-sided row/column normalization decays f astest. wher e L c is the unique solution of D c L c + L c D c = D c C c D c . In particular , Orth r ( M ) = N c + O ∥ C c ∥ 2 . (ii) Row/left whitening. Let M ∈ R p × q have full r ow rank, and set D r := diag( ∥ M 1 , : ∥ 2 , . . . , ∥ M p, : ∥ 2 ) ≻ 0 , N r := D − 1 r M , and C r := N r N ⊤ r − I p . If ∥ D r C r D r ∥ 2 is sufficiently small, then Orth ℓ ( M ) := ( MM ⊤ ) − 1 / 2 M = N r − D − 1 r L r N r + O ∥ D r C r D r ∥ 2 2 , wher e L r is the unique solution of D r L r + L r D r = D r C r D r . In particular , Orth ℓ ( M ) = N r + O ∥ C r ∥ 2 . See Appendix C for details. Corollary 3.3. Under the assumptions of the r ow/left part of Pr oposition 3.2, if ∥ C r ∥ 2 is sufficiently small, then Orth ℓ ( N r ) = ( I p + C r ) − 1 / 2 N r = N r − 1 2 C r N r + O ∥ C r ∥ 2 2 , and hence ∥ Orth ℓ ( N r ) − N r ∥ 2 ≤ 1 2 ∥ N r ∥ 2 ∥ C r ∥ 2 + O ∥ C r ∥ 2 2 . In particular , since diag( N r N ⊤ r ) = I p , r ow normalization r emoves the mar ginal scale mismatch, so the leading whitening corr ection acts only on the r esidual off-diagonal Gr am err or . Remark 3.2. By contrast, the corresponding bound for Orth ℓ ( M ) − M contains the additional zer oth-or der term ∥ D r − I p ∥ 2 ∥ N r ∥ 2 . Thus r ow normalization separates mar ginal r escaling fr om the genuine whitening step. The column- normalized/right analogue and the corr esponding two-sided normalization statements ar e completely symmetric; see Appendix D. T ogether , Proposition 3.2, Corollary 3.3, and Remark 3.2 explain the di vision of labor in MuonEq : normalization remov es marginal-scale mismatch at zeroth order, and the subsequent Newton–Schulz orthogonalization handles the remaining correlation structure. This is exactly why DiagPr e Eq. (4) is a meaningful lightweight surrogate for a much more expensi ve whitening step. 6 3.3 Con vergence analysis of the RC and R v ariants T o analyze the MuonEq family , we focus on the two v ariants that are most informativ e theoretically: the two-sided RC map and the default ro w-normalized R map. RC is the strongest spectral corrector among the three forms b ut induces a more in volv ed alignment term, whereas R yields the cleanest one- sided geometry and conv ergence ar gument. Accordingly , Proposition 3.4 studies the pure RC variant, and Theorem 3.5 provides the main guarantee for the default R variant. The column-normalized C map is retained as the embedding-aligned companion in the method family and empirical ablations. Assumption 3.1. The objective is bounded below: there e xists f ⋆ > −∞ such that f ( X ) ≥ f ⋆ for all X ∈ R m × n . Assumption 3.2. The function f is L -smooth, that is, ∥∇ f ( Y ) − ∇ f ( X ) ∥ F ≤ L ∥ Y − X ∥ F for all X , Y ∈ R m × n . Assumption 3.3. The stoc hastic gradient is unbiased with bounded variance. Specifically , ther e exists σ > 0 suc h that, for all X ∈ R m × n , E [ ∇ f ( X ; ξ )] = ∇ f ( X ) , E ∥∇ f ( X ; ξ ) − ∇ f ( X ) ∥ 2 F ≤ σ 2 . These assumptions are standard in analyses of adaptiv e and Muon-type methods [ 2 , 6 , 30 , 31 , 32 , 33 ]. Proposition 3.4. Assume Assumptions 3.1, 3.2, and 3.3. Moreo ver , assume ther e exists G ∞ > 0 such that ∥ G t ∥ ∞ ≤ G ∞ almost surely . Consider the RC variant (4) with λ = 0 and Nestero v disabled, so that ˆ M t = D − 1 / 2 r,t M t D − 1 / 2 c,t for all t ∈ [ T ] . Let η t = t − 3 / 4 , β t = 1 − t − 1 / 2 , h t := 1 − β t = t − 1 / 2 , and a := 0 . 2 p max { m, n } . Suppose further that ε ≥ 4 5 G 2 ∞ max { m, n } , and define ρ r := q 1 + nG 2 ∞ ε , ρ c := q 1 + mG 2 ∞ ε , χ ε := ( ρ r +1)( ρ c +1) 4 ρ r ρ c − 3 ρ r ρ c − ρ r − ρ c − 1 4 . Then ρ r , ρ c ≤ 3 / 2 and hence χ ε ≥ 1 / 144 . Consequently , 1 T T X t =1 E ∥∇ f ( X t ) ∥ F ≤ f ( X 1 ) − f ⋆ + C 1 (1 + ln T ) + C 2 aχ ε · T 1 / 4 , wher e C 1 = a L 2 √ 2 L 2 a 2 n + σ 2 + aL χ ε + ρ r ρ c √ n 2 , C 2 = aσ 2 L + 3 La 2 n 2 . Theorem 3.5. Assume Assumptions 3.1, 3.2, and 3.3. Consider the pr actical r ow-normalized R variant (4) , with Nester ov disabled and λ = 0 , ε = 0 . Let η t = t − 3 / 4 , β t = 1 − t − 1 / 2 , h t := 1 − β t = t − 1 / 2 , a := 0 . 2 p max { m, n } , and suppose the trajectory-wise NS5 polar-appr oximation err or ε ns defined in Lemma G.2 satisfies ε ns < 1 . Then, for every T ≥ 1 , 1 T T X t =1 E ∥∇ f ( X t ) ∥ F ≤ f ( X 1 ) − f ⋆ + C ns 1 (1 + ln T ) + C ns 2 a (1 − ε ns ) / √ m · T 1 / 4 , wher e C ns 1 = a L 2 √ 2 L 2 a 2 (1 + ε ns ) 2 n + σ 2 + aL 1 − ε ns √ m + (1 + ε ns ) √ n 2 , C ns 2 = aσ 2 L + 3 La 2 (1+ ε ns ) 2 n 2 . Remark 3.3. Setting ε ns = 0 r ecovers the exact-polar theor em for the r ow-normalized R variant. Mor e generally , compar ed with the two-sided RC analysis, the descent coefficient is now the fixed positive constant (1 − ε ns ) / √ m , so no auxiliary condition of the form χ ε > 0 is needed. Remark 3.4. Equation (5) clarifies the differ ence between the RC and R variants. The first term is the finite-step orthogonalization err or . By Theor em 3.1, it is contr olled by the singular spectrum of S ( M ) , so the two-sided RC map can pr ovide a str onger spectr al corr ection. The second term is the bias intr oduced by pr epr ocessing. Pr oposition 3.4 shows that the pur e RC update preserves descent only under the auxiliary positivity condition χ ε > 0 . By contrast, the r ow-normalized map admits the fixed alignment lower bound ⟨ M , Orth( P ( M ) M ) ⟩ ≥ 1 √ m ∥ M ∥ F , P ( M ) := diag ro wsum( M ⊙ M ) − 1 / 2 , which is e xactly why Theor em 3.5 no longer needs a condition of the form χ ε > 0 . Thus RC should be viewed as the str onger two-sided spectr al corr ector , wher eas R is the cleaner one-sided variant and ther efor e the default choice for the hidden-weight setting consider ed in this paper . The column- normalized C variant is retained as the embedding-aligned companion and is studied empirically rather than thr ough a separ ate main theor em. 7 Remark 3.5. Theor em 3.5 yields the sublinear stationarity estimate 1 T T X t =1 E ∥∇ f ( X t ) ∥ F = O 1 + ln T T 1 / 4 . Hence, up to the logarithmic factor and the explicit pr oblem-dependent constants, the default R variant has the same T − 1 / 4 -type baseline dependence as the curr ently known con ver gence theory for standar d stochastic noncon vex Muon-type methods [ 6 , 9 , 14 , 15 ]. Impr ovements be yond this baseline typically r equir e additional mechanisms such as variance r eduction [3, 9, 33, 34, 35, 36, 37, 38]. 4 Experiments 4.1 Main Result 0 2 4 6 8 10 T raining tok ens (B) 3.0 3.2 3.3 3.5 T raining L oss A damW Muon Muon-Nes MARS- A damW MuonEq (a) T raining Loss 2 4 6 8 10 T raining tok ens (B) 3.0 3.2 3.3 3.5 V alidation L oss A damW Muon Muon-Nes MARS- A damW MuonEq (b) V alidation Loss 0.0 0.3 0.6 0.9 1.2 1.5 T raining wall-clock time on 32x910C (hours) 3.0 3.2 3.3 3.5 V alidation L oss A damW Muon Muon-Nes MARS- A damW MuonEq (c) W all-clock time Figure 3: The training and validation loss curves, plotted against both training tokens and w all-clock time on LLaMA-2 130M. 0 4 8 12 16 20 T raining tok ens (B) 2.7 2.8 2.9 3.0 3.1 3.2 T raining L oss A damW Muon Muon-Nes MARS- A damW MuonEq (a) T raining Loss 0 4 8 12 16 20 T raining tok ens (B) 2.7 2.8 2.9 3.0 3.1 3.2 V alidation L oss A damW Muon Muon-Nes MARS- A damW MuonEq (b) V alidation Loss 0.0 0.8 1.6 2.4 3.2 T raining wall-clock time on 64x910C (hours) 2.7 2.8 2.9 3.0 3.1 3.2 V alidation L oss A damW Muon Muon-Nes MARS- A damW MuonEq (c) W all-clock time Figure 4: The training and validation loss curves, plotted against both training tokens and w all-clock time on LLaMA-2 350M. In this section, we e valuate the performance of the proposed MuonEq optimizers on LLM pretraining. All experiments are conducted using 64 Ascend 910C (64GB) NPUs. Detailed experimental settings are provided in Appendix J. ▶ LLaMA2 on C4 Dataset. W e compare MuonEq with AdamW , MARS-AdamW , Muon, and Muon- Nes on LLaMA2-130M and LLaMA2-350M trained on C4 [ 29 ]. For the main comparison, LLaMA2- 130M and LLaMA2-350M are trained for 10.5B and 21.0B tokens, respecti vely . W e tune the learning rate using shorter pilot runs of 2.6B tok ens for 130M and 7.5B tokens for 350M, with search grids { 5e − 4 , 1e − 3 , 2e − 3 , 3e − 3 , 5e − 3 , 8e − 3 , 1e − 2 } and { 5e − 4 , 1e − 3 , 1 . 5e − 3 , 2e − 3 , 3e − 3 , 5e − 3 } , re- spectiv ely; Appendix J gi ves the remaining hyperparameters. For MARS-AdamW , we use the best searched value γ = 0 . 025 reported in [3]. Figure 3 reports training loss versus tokens, v alidation loss versus tokens, and v alidation loss versus wall-clock time for LLaMA2-130M trained to 10.5B tokens. Figure 4 reports the corresponding validation-loss comparison for LLaMA2-350M trained to 21.0B tokens. T able 1 reports the best validat ion perplexity , peak memory (GB) usage, and training wall-clock time (Second/Step) for these main comparison runs. Across Figure 3, Figure 4, and T able 1, MuonEq consistently improves o ver Muon. 8 T able 1: Best v alidation perplexity , peak memory usage, and wall-clock training time on LLaMA2/C4. Optimizer 130M 350M Perplexity Memory T ime Cost Perplexity Memory Time Cost AdamW [1] 21.35 12.94 0.21 16.25 29.43 0.53 MARS-AdamW [3] 20.03 12.99 0.23 15.62 29.47 0.57 Muon [4, 7] 20.52 12.52 0.25 15.21 28.18 0.61 Muon-Nes [4, 7, 9] 20.18 12.52 0.25 15.19 28.18 0.61 MuonEq 19.56 ↓ 0.47 12.52 0.26 14.96 ↓ 0.23 28.18 0.63 T raining T ok ens 10.5B 21.0B 4.2 Ablation Study W e ablate the three MuonEq v ariants RC, R, and C to isolate pre-orthogonalization geometry . All variants use the same optimizer states, scalar hyperparameters, and Ne wton–Schulz budget; only the pre-orthogonalization diagonal map changes. W e take R as the default v ariant. All ablations run on 4 R TX Pro6000 (96GB) GPUs; details are deferred to Appendix J.2. The results consistently fa vor R. Among the three static v ariants, R performs best on both CIF AR- 10/ResNet-18 and FineW eb/GPT2-small, reaching 94.53% test accuracy on CIF AR-10 and 24.94 validation perplexity on FineW eb/GPT2-small. RC is competitive but falls short of R, while C is weaker in this hidden-weight setting. Full static-variant comparisons appear in T ables 2 and 3. This pattern matches the trade-off in Eq. (5) and the analysis in Section 3. RC provides stronger two-sided spectral correction and can reduce the finite-step Ne wton–Schulz term more aggressiv ely , but also introduces lar ger preconditioning bias. For the hidden matrix weights tar geted by MuonEq , the more rele vant one-sided geometry is ro w-sided, so R of fers the best trade-of f between spectral correction and geometric alignment. This interpretation is consistent with [ 27 ]. Comparisons with [ 39 ] and [ 40 ] require care because their ro w/column terminology depends on parameter layout and task setting; we discuss this point in the appendix J.3. T able 2: Ablation on CIF AR-10 with ResNet-18. Method Component T est Acc. (%) Row Col Baseline Experiments SGD 92.84 AdamW 93.42 Muon-Nes 94.41 Ablation Experiments MuonEq (RC) ✓ ✓ 94.23 MuonEq (C) ✓ 94.44 MuonEq (R) ✓ 94.53 ↑ 0.12 T able 3: Ablation on Fineweb-10.5B tok ens with GPT2-small. Method Component V alidation Perplexity Row Col Baseline Experiments AdamW 26.60 Muon-Nes 25.31 Ablation Experiments MuonEq (RC) ✓ ✓ 24.98 MuonEq (C) ✓ 25.23 MuonEq (R) ✓ 24.94 ↓ 0.37 5 Related W ork MuonEq is vie wed as a lightweight pre-balanced Muon family rather than as a fully whitened opti- mizer . It inserts diagonal equilibration before Newton–Schulz orthogonalization and includes three forms: two-sided row/column normalization (RC), ro w normalization (R), and column normalization (C), with R as the default choice for the hidden matrix weights considered in this paper . All three use only row/column squared-norm statistics and preserv e the O ( m + n ) state profile. Muon and orthogonalized-update optimizers. Muon [ 4 ] introduced the core design of orthogonal- izing matrix-valued momentum with a small fixed number of Ne wton–Schulz iterations. Subsequent work has expanded this idea into a broader family of orthogonalized-update optimizers, includ- ing post-orthogonalization normalization and rescaling methods such as Muon+, NorMuon, and AdaMuon [ 16 , 17 , 18 ]; adapti ve stepsize v ariants such as AdaGO and N AMO [ 41 , 42 ]; distributed 9 and communication-aware e xtensions such as Dion and MuLoCo [ 43 , 44 ]; reduced-state implementa- tions [ 45 ]; and fine-tuning-oriented variants [ 46 ]. These methods mainly alter the orthogonalized update itself or the surrounding optimization machinery . By contrast, MuonEq modifies the matrix fed into orthogonalization through lightweight pre-orthogonalization equilibration. Theory of Muon-style methods. Recent theory interprets Muon as steepest descent under spectral- norm or nuclear-norm geometry [ 5 , 6 ], establishes stochastic and noncon vex con v ergence guaran- tees [ 12 , 9 , 47 , 48 ], and analyzes practical ingredients such as weight decay , critical batch size, and inexact orthogonalization [ 10 , 14 , 15 ]. This literature is directly relev ant to MuonEq because we retain the same finite-step orthogonalization primitiv e as Muon and change only the geometry of its input. Our analysis further highlights the role of input spectrum in finite-step Ne wton–Schulz and clarifies how diagonal equilibration trades stronger spectral correction ag ainst preprocessing bias. Structured preconditioning, factorized statistics, and whitening-inspired methods. A sepa- rate line of work studies matrix-aware preconditioning, including Shampoo [ 20 ], K-F A C [ 49 , 50 ], SO AP [ 19 ], Sketchy [ 51 ], and ASGO [ 52 ]. Adafactor [ 21 ] is especially relev ant from a systems perspectiv e because it shows ho w row- and column-factorized second-moment statistics reduce optimizer state to O ( m + n ) for matrix-v alued parameters. Recent Muon-adjacent whitening or preconditioned-polar methods, including FISMO and Mousse [ 23 , 24 ], pursue a similar high-le vel goal: improve the geometry before imposing spectral constraints. The key dif ference is that these methods rely on richer matrix- or Kronecker -structured preconditioners, whereas MuonEq restricts the intervention to diagonal ro w/column equilibration. In this sense, MuonEq is closer to low-cost equilibration than to full whitening. Orthogonalization algorithms. There is also a complementary numerical literature on faster and more accurate polar/orthogonalization routines, including improved Newton–Schulz variants and matrix-sign methods such as CANS and Polar Express [ 53 , 54 ]. This literature matters because Muon-style optimizers operate in the re gime of approximate orthogonalization, where only a small number of iterations is affordable; MuonEq is designed e xplicitly for this setting. 6 Conclusion W e study how to improv e the matrix geometry seen by finite-step orthogonalization in Muon- style optimization without the cost of full whitening. MuonEq does so with a lightweight family of pre-orthogonalization equilibration schemes: two-sided row/column normalization (RC), ro w normalization (R), and column normalization (C). These variants modify the input to Ne wton–Schulz orthogonalization while preserving the O ( m + n ) memory profile of factorized methods. For the hidden matrix weights studied here, we use R as the default v ariant. The analysis sho ws that finite-step orthogonalization is highly sensiti ve to the input spectrum and that row/column normalization acts as a zeroth-order whitening surrogate by remo ving marginal scale mismatch. It also clarifies the trade-off within the MuonEq family: RC giv es stronger two-sided spectral correction, whereas R yields cleaner one-sided geometry and the main e O ( T − 1 / 4 ) noncon ve x guarantee. Empirically , the default R variant consistently outperforms Muon in LLaMA2 pretraining on C4 across ev aluated model sizes and token budgets. Ablations over RC, R, and C further support R as the strongest default for the hidden-weight setting considered here. References [1] Ilya Loshchilov and Frank Hutter . Decoupled weight decay regularization. In 7th International Confer ence on Learning Repr esentations, ICLR 2019 . OpenRevie w .net, 2019. [2] Xingyu Xie, Pan Zhou, Huan Li, Zhouchen Lin, and Shuicheng Y an. Adan: Adaptive nestero v momentum algorithm for faster optimizing deep models. IEEE T ransactions on P attern Analysis and Machine Intelligence , 46(12):9508–9520, 2024. [3] Y ifeng Liu, Angela Y uan, and Quanquan Gu. Mars-m: When variance reduction meets matrices. arXiv pr eprint arXiv:2510.21800 , 2025. [4] Keller Jordan, Y uchen Jin, Vlado Boza, Y ou Jiacheng, Franz Cecista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjor dan. github . io/posts/muon , 6. 10 [5] Jeremy Bernstein and Laker Newhouse. Old optimizer , ne w norm: An anthology . arXiv pr eprint arXiv:2409.20325 , 2024. [6] Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints. arXiv pr eprint arXiv:2506.15054 , 2025. [7] Jingyuan Liu, Jianlin Su, Xingcheng Y ao, Zhejun Jiang, Guokun Lai, Y ulun Du, Y idao Qin, W eixin Xu, Enzhe Lu, Junjie Y an, et al. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982 , 2025. [8] Ishaan Shah, Anthony M Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluv araju, Andrew Hojel, Andre w Ma, Anil Thomas, Ashish T anwer , Darsh J Shah, et al. Practical ef ficiency of muon for pretraining. arXiv preprint , 2025. [9] Da Chang, Y ongxiang Liu, and Ganzhao Y uan. On the con ver gence of muon and beyond. arXiv pr eprint arXiv:2509.15816 , 2025. [10] Naoki Sato, Hiroki Naganuma, and Hideaki Iiduka. Con ver gence bound and critical batch size of muon optimizer . 2025. [11] Jiaxiang Li and Mingyi Hong. A note on the conv ergence of muon. 2025. [12] W ei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the con ver gence analysis of muon. arXiv preprint , 2025. [13] Maria-Eleni Sfyraki and Jun-Kun W ang. Lions and muons: Optimization via stochastic frank- wolfe. arXiv pr eprint arXiv:2506.04192 , 2025. [14] Min-hwan Oh Gyu Y eol Kim. Conv ergence of muon with ne wton-schulz. In The F ourteenth International Confer ence on Learning Repr esentations , 2026. [15] Egor Shulgin, Sultan AlRashed, Francesco Orabona, and Peter Richtárik. Beyond the ideal: Analyzing the inexact muon update. arXiv pr eprint arXiv:2510.19933 , 2025. [16] Ruijie Zhang, Y equan Zhao, Ziyue Liu, Zhengyang W ang, and Zheng Zhang. Muon+: T ow ards better muon via one additional normalization step. arXiv preprint , 2026. [17] Zichong Li, Liming Liu, Chen Liang, W eizhu Chen, and T uo Zhao. Normuon: Making muon more efficient and scalable. arXiv pr eprint arXiv:2510.05491 , 2025. [18] Chongjie Si, Debing Zhang, and W ei Shen. Adamuon: Adaptiv e muon optimizer . arXiv pr eprint arXiv:2507.11005 , 2025. [19] Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, Da vid Brandfonbrener , Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam. arXiv pr eprint arXiv:2409.11321 , 2024. [20] V ineet Gupta, T omer Koren, and Y oram Singer . Shampoo: Preconditioned stochastic tensor optimization. In International Confer ence on Machine Learning , pages 1842–1850. PMLR, 2018. [21] Noam Shazeer and Mitchell Stern. Adafactor: Adaptiv e learning rates with sublinear memory cost. ArXiv , abs/1804.04235, 2018. [22] Diederik P . Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Y oshua Bengio and Y ann LeCun, editors, 3r d International Confer ence on Learning Repr esentations, ICLR 2015 , 2015. [23] Chenrui Xu, W enjing Y an, and Y ing-Jun Angela Zhang. Fismo: Fisher-structured momentum- orthogonalized optimizer . ArXiv , abs/2601.21750, 2026. [24] Y echen Zhang, Shuhao Xing, Junhao Huang, Kai Lv , Y unhua Zhou, Xipeng Qiu, Qipeng Guo, and Kai Chen. Mousse: Rectifying the geometry of muon with curv ature-aware preconditioning. 2026. 11 [25] Zhaonan Qu, W enzhi Gao, Oliv er Hinder , Y inyu Y e, and Zhengyuan Zhou. Optimal diagonal preconditioning. Operations Resear ch , 73(3):1479–1495, 2025. [26] Daniel Ruiz. A scaling algorithm to equilibrate both rows and columns norms in matrices. T echnical report, CM-P00040415, 2001. [27] Ruihan Xu, Jiajing Li, and Y iping Lu. On the width scaling of neural optimizers under matrix operator norms i: Row/column normalization and hyperparameter transfer . 2026. [28] Hugo T ouvron, Louis Martin, Ke vin R. Stone, Peter Albert, Amjad Almahairi, Y asmine Babaei, Nikolay Bashlyko v , Soumya Batra, Prajjwal Bhar gav a, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher , Cristian Cantón Ferrer, Mo ya Chen, Guillem Cucurull, David Esiob u, Jude Fernandes, Jeremy Fu, W enyin Fu, Brian Fuller , Cynthia Gao, V edanuj Goswami, Naman Goyal, Anthon y S. Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, V iktor Kerk ez, Madian Khabsa, Isabel M. Kloumann, A. V . K orene v , Punit Singh K oura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Lisk ovich, Y inghai Lu, Y uning Mao, Xavier Martinet, T odor Mihaylov , Pushkar Mishra, Igor Molybog, Y ixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia T an, Binh T ang, Ross T aylor , Adina W illiams, Jian Xiang Kuan, Puxin Xu, Zhengxu Y an, Iliyan Zarov , Y uchen Zhang, Angela Fan, Melissa Hall Melanie Kambadur , Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Serge y Edunov , and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. ArXiv , abs/2307.09288, 2023. [29] Colin Raf fel, Noam Shazeer , Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Y anqi Zhou, W ei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-te xt transformer . Journal of machine learning r esear ch , 21(140):1–67, 2020. [30] Haochuan Li, Alexander Rakhlin, and Ali Jadbabaie. Con vergence of adam under relaxed assumptions. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023. [31] Bohan W ang, Jingwen Fu, Huishuai Zhang, Nanning Zheng, and W ei Chen. Closing the gap between the upper bound and lower bound of adam’ s iteration complexity . In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2023. [32] Da Chang and Ganzhao Y uan. MGUP: A momentum-gradient alignment update policy for stochastic optimization. In The Thirty-ninth Annual Conference on Neur al Information Pr ocess- ing Systems , 2025. [33] Feihu Huang, Y uning Luo, and Songcan Chen. Limuon: Light and fast muon optimizer for large models. arXiv pr eprint arXiv:2509.14562 , 2025. [34] Xun Qian, Hussein Rammal, Dmitry Ko vale v , and Peter Richtarik. Muon is provably faster with momentum variance reduction. arXiv pr eprint arXiv:2512.16598 , 2025. [35] Cong Fang, Chris Junchi Li, Zhouchen Lin, and T . Zhang. Spider: Near-optimal non-con ve x optimization via stochastic path integrated dif ferential estimator . ArXiv , abs/1807.01695, 2018. [36] Dongruo Zhou, Pan Xu, and Quanquan Gu. Stochastic nested variance reduction for noncon vex optimization. Journal of machine learning r esear ch , 21(103):1–63, 2020. [37] Ashok Cutkosky and Francesco Orabona. Momentum-based variance reduction in non-con ve x sgd. ArXiv , abs/1905.10018, 2019. [38] Feihu Huang, Junyi Li, and Heng Huang. Super -adam: Faster and universal framework of adaptiv e gradients. ArXiv , abs/2106.08208, 2021. [39] Thomas Pethick, W anyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-F alls, and V olkan Cevher . T raining deep learning models with norm-constrained lmos. arXiv preprint arXiv:2502.07529 , 2025. [40] Athanasios Glentis, Jiaxiang Li, Andi Han, and Mingyi Hong. A minimalist optimizer design for llm pretraining. arXiv preprint , 2025. 12 [41] Minxin Zhang, Y uxuan Liu, and Hayden Schaeffer . Adagrad meets muon: Adaptiv e stepsizes for orthogonal updates. 2025. [42] Minxin Zhang, Y uxuan Liu, and Hayden Scheaffer . Adam improv es muon: Adaptive moment estimation with orthogonalized momentum. arXiv preprint , 2026. [43] Kwangjun Ahn, Byron Xu, Natalie Abreu, Y ing Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates. arXiv pr eprint arXiv:2504.05295 , 2025. [44] Benjamin Thérien, Xiaolong Huang, Irina Rish, and Eugene Belilovsk y . Muloco: Muon is a practical inner optimizer for diloco. arXiv preprint , 2025. [45] Aman Gupta, Rafael Celente, Abhishek Shiv anna, DT Braithwaite, Gregory De xter, Shao T ang, Hiroto Udagaw a, Daniel Silva, Rohan Ramanath, and S Sathiya Keerthi. Effecti ve quantization of muon optimizer states. arXiv preprint , 2025. [46] Saurabh Page, Adv ait Joshi, and SS Sonawane. Muonall: Muon variant for ef ficient finetuning of large language models. arXiv pr eprint arXiv:2511.06086 , 2025. [47] Shuntaro Nagashima and Hideaki Iiduka. Improv ed conv ergence rates of muon optimizer for noncon ve x optimization. arXiv pr eprint arXiv:2601.19400 , 2026. [48] Y ubo Zhang and Junhong Lin. On con ver gence of muon for noncon vex stochastic optimization under generalized smoothness. Author ea Pr eprints , 2026. [49] James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approx- imate curv ature. In International confer ence on mac hine learning , pages 2408–2417. PMLR, 2015. [50] Runa Eschenhagen, Alexander Immer , Richard T urner , Frank Schneider , and Philipp Hennig. Kronecker -factored approximate curvature for modern neural network architectures. Advances in Neural Information Pr ocessing Systems , 36:33624–33655, 2023. [51] Vladimir Feinberg, Xinyi Chen, Y Jennifer Sun, Rohan Anil, and Elad Hazan. Sketchy: Memory- efficient adaptiv e regularization with frequent directions. Advances in Neural Information Pr ocessing Systems , 36:75911–75924, 2023. [52] Kang An, Y uxing Liu, Rui Pan, Y i Ren, Shiqian Ma, Donald Goldfarb, and T ong Zhang. Asgo: Adaptiv e structured gradient optimization. arXiv preprint , 2025. [53] Ekaterina Grishina, Matve y Smirnov , and Maxim Rakhuba. Accelerating newton-schulz itera- tion for orthogonalization via chebyshe v-type polynomials. arXiv pr eprint arXiv:2506.10935 , 2025. [54] Noah Amsel, David Persson, Christopher Musco, and Robert M Gower . The polar express: Optimal matrix sign methods and their application to the muon algorithm. arXiv pr eprint arXiv:2505.16932 , 2025. [55] Rajendra Bhatia. Positi ve definite matrices. In P ositive Definite Matrices . Princeton university press, 2009. 13 A ppendix A Proofs of Theor em 3.1 Pr oof. The claim for k = 0 is immediate from X 0 = α − 1 G = U diag σ 1 α , . . . , σ r α V ⊤ . Assume that, for some k ≥ 0 , X k = U diag s ( k ) 1 , . . . , s ( k ) r V ⊤ . Then X k X ⊤ k = U diag ( s ( k ) 1 ) 2 , . . . , ( s ( k ) r ) 2 U ⊤ . Substituting this into the iteration and using U ⊤ U = I r , we obtain X k +1 = U diag ϕ ( s ( k ) 1 ) , . . . , ϕ ( s ( k ) r ) V ⊤ . Hence, by induction, X k = U diag s ( k ) 1 , . . . , s ( k ) r V ⊤ , s ( k +1) i = ϕ s ( k ) i . Moreov er , we have Orth( G ) = UV ⊤ = U I r V ⊤ , X k − Orth( G ) = U diag( s ( k ) 1 , . . . , s ( k ) r ) − I r V ⊤ . Since left and right multiplication by matrices with orthonormal columns preserv es the Frobenius norm, it follows that X k − Orth( G ) 2 F = r X i =1 ( s ( k ) i − 1) 2 , which prov es the exact error representation. W e next prov e the lower bound. Define q ( t ) := a + bt + ct 2 , t ∈ [0 , 1] . Then q ′ ( t ) = b + 2 ct = − 4 . 7750 + 4 . 0630 t < 0 , t ∈ [0 , 1] . Hence q is strictly decreasing on [0 , 1] , and in particular 0 < q (1) = a + b + c = 0 . 701 ≤ q ( t ) ≤ q (0) = a, t ∈ [0 , 1] . Fix any i ∈ { 1 , . . . , r } and k ≥ 0 . If a k σ i /α ≥ 1 , then trivially | 1 − s ( k ) i | ≥ 0 = 1 − a k σ i α + . Now suppose that a k σ i /α < 1 . W e claim that, for e very 0 ≤ j ≤ k , 0 < s ( j ) i ≤ a j σ i α < 1 . The case j = 0 is immediate. Suppose the claim holds for some j < k . Then s ( j ) i ∈ (0 , 1) , so ( s ( j ) i ) 2 ∈ (0 , 1) and thus 0 < q ( s ( j ) i ) 2 ≤ a. Therefore, 0 < s ( j +1) i = s ( j ) i q ( s ( j ) i ) 2 ≤ as ( j ) i ≤ a j +1 σ i α . Since j + 1 ≤ k , we further ha ve a j +1 σ i α ≤ a k σ i α < 1 . 14 This prov es the claim. In particular, 0 < s ( k ) i ≤ a k σ i α < 1 , and hence | 1 − s ( k ) i | = 1 − s ( k ) i ≥ 1 − a k σ i α = 1 − a k σ i α + . Combining the two cases, we conclude that, for e very i , | 1 − s ( k ) i | ≥ 1 − a k σ i α + . Squaring both sides, summing ov er i , and in voking the exact error representation established abo ve yields 1 √ r X k − Orth( G ) F ≥ 1 √ r r X i =1 1 − a k σ i α 2 + ! 1 / 2 . This completes the proof. Remark A.1. Since ϕ (1) = a + b + c = 0 . 701 = 1 , the scalar map induced by the abo ve Muon coefficients does not have 1 as a fixed point. Therefor e, T ε in the theor em should be interpr eted as the first hitting time of the err or thr eshold ε , rather than as the number of iterations r equir ed for asymptotic con ver gence to Orth( G ) . B Lemmas f or Proposition 3.2 B.1 Lemma B.1 Lemma B.1. Let A ∈ R n × n be symmetric positive definite, and let E ∈ R n × n be symmetric. Define g ( X ) = X 1 / 2 , f ( X ) = X − 1 / 2 . Then g and f ar e F réchet differ entiable at A . If S = A 1 / 2 , L = L g ( A ; E ) , then L is the unique symmetric solution of the Sylvester equation SL + LS = E . Mor eover , L f ( A ; E ) = − A − 1 / 2 LA − 1 / 2 . Consequently , for ∥ E ∥ 2 sufficiently small, ( A + E ) − 1 / 2 = A − 1 / 2 − A − 1 / 2 LA − 1 / 2 + O ( ∥ E ∥ 2 2 ) . Pr oof. For completeness, differentiate the identity g ( X ) 2 = X at A in the direction E . Writing L = L g ( A ; E ) and S = A 1 / 2 giv es SL + LS = E . Since S ≻ 0 , the Sylvester operator X 7→ SX + XS is in vertible, so the solution L is unique. Next, since f = inv ◦ g , the chain rule and the Fréchet deri vati ve of the matrix in verse, L inv ( Z ; W ) = − Z − 1 WZ − 1 , yield L f ( A ; E ) = − S − 1 LS − 1 = − A − 1 / 2 LA − 1 / 2 . The stated first-order expansion follo ws from the Fréchet differentiability of f at A . 15 B.2 Lemma B.2 Lemma B.2. Let A ≻ 0 and set S = A 1 / 2 ≻ 0 . Consider the Sylvester equation SL + LS = E . Its unique solution is given by [55] L = Z ∞ 0 e − t S E e − t S dt. Mor eover , in the operator norm, ∥ L ∥ 2 ≤ 1 2 λ min ( S ) ∥ E ∥ 2 = 1 2 p λ min ( A ) ∥ E ∥ 2 . The same bound also holds for the F r obenius norm, and mor e g enerally for any unitarily in variant norm. Pr oof. Dif ferentiate the integrand: d dt e − t S E e − t S = − S e − t S E e − t S − e − t S E e − t S S . Integrating from 0 to ∞ yields SL + LS = E , which prov es the integral representation. For the norm bound, using submultiplicati vity and the fact that ∥ e − t S ∥ 2 = e − tλ min ( S ) , we hav e ∥ L ∥ 2 ≤ Z ∞ 0 ∥ e − t S ∥ 2 2 ∥ E ∥ 2 dt = ∥ E ∥ 2 Z ∞ 0 e − 2 tλ min ( S ) dt = 1 2 λ min ( S ) ∥ E ∥ 2 . Since λ min ( S ) = p λ min ( A ) , the stated bound follows. C Proofs of Pr oposition 3.2 Pr oof. For the column/right statement, we ha ve M ⊤ M = D c ( I n + C c ) D c = D 2 c + D c C c D c . Apply Lemma B.1 with A = D 2 c , E = D c C c D c . Then ( M ⊤ M ) − 1 / 2 = D − 1 c − D − 1 c L c D − 1 c + O ( ∥ D c C c D c ∥ 2 2 ) , where L c solves D c L c + L c D c = D c C c D c . Multiplying on the left by M yields Orth r ( M ) = MD − 1 c − MD − 1 c L c D − 1 c + O ( ∥ D c C c D c ∥ 2 2 ) = N c − N c L c D − 1 c + O ( ∥ D c C c D c ∥ 2 2 ) . Moreov er , by Lemma B.2, we have ∥ L c ∥ 2 ≤ 1 2 λ min ( D c ) ∥ D c C c D c ∥ 2 ≤ ∥ D c ∥ 2 2 2 λ min ( D c ) ∥ C c ∥ 2 . Hence ∥ L c D − 1 c ∥ 2 ≤ ∥ L c ∥ 2 ∥ D − 1 c ∥ 2 ≤ κ ( D c ) 2 2 ∥ C c ∥ 2 . Therefore the first-order correction is O ( ∥ C c ∥ 2 ) , and Orth r ( M ) = N c + O ( ∥ C c ∥ 2 ) . 16 For the ro w/left statement, we hav e MM ⊤ = D r ( I m + C r ) D r = D 2 r + D r C r D r . Applying Lemma B.1 with A = D 2 r , E = D r C r D r giv es ( MM ⊤ ) − 1 / 2 = D − 1 r − D − 1 r L r D − 1 r + O ( ∥ D r C r D r ∥ 2 2 ) , where L r solves D r L r + L r D r = D r C r D r . Multiplying on the right by M yields Orth ℓ ( M ) = D − 1 r M − D − 1 r L r D − 1 r M + O ( ∥ D r C r D r ∥ 2 2 ) = N r − D − 1 r L r N r + O ( ∥ D r C r D r ∥ 2 2 ) . Again by Lemma B.2, we hav e ∥ L r ∥ 2 ≤ 1 2 λ min ( D r ) ∥ D r C r D r ∥ 2 ≤ ∥ D r ∥ 2 2 2 λ min ( D r ) ∥ C r ∥ 2 , so ∥ D − 1 r L r ∥ 2 ≤ ∥ D − 1 r ∥ 2 ∥ L r ∥ 2 ≤ κ ( D r ) 2 2 ∥ C r ∥ 2 . Therefore Orth ℓ ( M ) = N r + O ( ∥ C r ∥ 2 ) . D Normalization and whitening This appendix records the normalization–whitening estimates omitted from the main text. W e use the notation of Proposition 3.2. All O ( · ) terms are understood in operator norm; the implied constants may depend on the fixed matrices in Proposition 3.2, b ut not on the perturbation terms. Proposition D .1. The following perturbative statements hold. (a) In the column/right setting of Pr oposition 3.2, if ∥ C c ∥ 2 is small enough, then Orth r ( N c ) = N c ( I n + C c ) − 1 / 2 = N c − 1 2 N c C c + O ( ∥ C c ∥ 2 2 ) , so ∥ Orth r ( N c ) − N c ∥ 2 ≤ 1 2 ∥ N c ∥ 2 ∥ C c ∥ 2 + O ( ∥ C c ∥ 2 2 ) . Also, ∥ Orth r ( M ) − M ∥ 2 ≤ ∥ N c ∥ 2 ∥ D c − I n ∥ 2 + κ ( D c ) 2 2 ∥ N c ∥ 2 ∥ C c ∥ 2 + O ( ∥ D c C c D c ∥ 2 2 ) . (b) In the r ow/left setting of Pr oposition 3.2, if ∥ C r ∥ 2 is small enough, then Orth ℓ ( N r ) = ( I m + C r ) − 1 / 2 N r = N r − 1 2 C r N r + O ( ∥ C r ∥ 2 2 ) , so ∥ Orth ℓ ( N r ) − N r ∥ 2 ≤ 1 2 ∥ N r ∥ 2 ∥ C r ∥ 2 + O ( ∥ C r ∥ 2 2 ) . Also, ∥ Orth ℓ ( M ) − M ∥ 2 ≤ ∥ D r − I m ∥ 2 ∥ N r ∥ 2 + κ ( D r ) 2 2 ∥ N r ∥ 2 ∥ C r ∥ 2 + O ( ∥ D r C r D r ∥ 2 2 ) . Pr oof. For (a), Lemma B.1 with A = I n and E = C c giv es the Sylvester equation L + L = C c , hence L = 1 2 C c and ( I n + C c ) − 1 / 2 = I n − 1 2 C c + O ( ∥ C c ∥ 2 2 ) . Left multiplication by N c gi ves the expansion of Orth r ( N c ) , and the norm bound follows from submultiplicati vity . For the comparison with M , Proposition 3.2 gi ves Orth r ( M ) = N c − N c L c D − 1 c + O ( ∥ D c C c D c ∥ 2 2 ) . Since M = N c D c , Orth r ( M ) − M = N c ( I n − D c ) − N c L c D − 1 c + O ( ∥ D c C c D c ∥ 2 2 ) . Lemma B.2 yields ∥ L c D − 1 c ∥ 2 ≤ 1 2 κ ( D c ) 2 ∥ C c ∥ 2 , which giv es the estimate. 17 The proof of (b) is the same. Lemma B.1 with A = I m and E = C r giv es ( I m + C r ) − 1 / 2 = I m − 1 2 C r + O ( ∥ C r ∥ 2 2 ) , hence Orth ℓ ( N r ) = ( I m + C r ) − 1 / 2 N r = N r − 1 2 C r N r + O ( ∥ C r ∥ 2 2 ) . The norm bound again follows from submultiplicativity . Proposition 3.2 also giv es Orth ℓ ( M ) = N r − D − 1 r L r N r + O ( ∥ D r C r D r ∥ 2 2 ) , so Orth ℓ ( M ) − M = ( I m − D r ) N r − D − 1 r L r N r + O ( ∥ D r C r D r ∥ 2 2 ) . Using ∥ D − 1 r L r ∥ 2 ≤ 1 2 κ ( D r ) 2 ∥ C r ∥ 2 completes the proof. Remark D.1. Pr oposition D.1 shows that one-sided normalization r emoves the zer oth-or der mar ginal scale terms ∥ N c ∥ 2 ∥ D c − I n ∥ 2 and ∥ D r − I m ∥ 2 ∥ N r ∥ 2 . Whitening then acts only on the first-order Gram err or . Since diag( N ⊤ c N c ) = I n and diag( N r N ⊤ r ) = I m , this leading corr ection is purely off-dia gonal. Corollary D.2. Assume that every r ow and every column of M is nonzer o, and set ˆ M := D − 1 / 2 r MD − 1 / 2 c . (a) If M has full column rank and ˆ C c := ˆ M ⊤ ˆ M − I n , then for ∥ ˆ C c ∥ 2 small enough, Orth r ( ˆ M ) = ˆ M ( I n + ˆ C c ) − 1 / 2 = ˆ M − 1 2 ˆ M ˆ C c + O ( ∥ ˆ C c ∥ 2 2 ) , so ∥ Orth r ( ˆ M ) − ˆ M ∥ 2 ≤ 1 2 ∥ ˆ M ∥ 2 ∥ ˆ C c ∥ 2 + O ( ∥ ˆ C c ∥ 2 2 ) . (b) If M has full r ow rank and ˆ C r := ˆ M ˆ M ⊤ − I m , then for ∥ ˆ C r ∥ 2 small enough, Orth ℓ ( ˆ M ) = ( I m + ˆ C r ) − 1 / 2 ˆ M = ˆ M − 1 2 ˆ C r ˆ M + O ( ∥ ˆ C r ∥ 2 2 ) , so ∥ Orth ℓ ( ˆ M ) − ˆ M ∥ 2 ≤ 1 2 ∥ ˆ M ∥ 2 ∥ ˆ C r ∥ 2 + O ( ∥ ˆ C r ∥ 2 2 ) . Pr oof. The same expansion applies to the two-sided normalized matrix ˆ M . For (a), Lemma B.1 with A = I n and E = ˆ C c giv es ( I n + ˆ C c ) − 1 / 2 = I n − 1 2 ˆ C c + O ( ∥ ˆ C c ∥ 2 2 ) , which yields the expansion of Orth r ( ˆ M ) and the norm bound. For (b), Lemma B.1 with A = I m and E = ˆ C r giv es ( I m + ˆ C r ) − 1 / 2 = I m − 1 2 ˆ C r + O ( ∥ ˆ C r ∥ 2 2 ) , which yields the expansion of Orth ℓ ( ˆ M ) and its norm bound. Remark D.2. After two-sided normalization, whitening is center ed at the identity Gr am matrix of ˆ M . It no longer corr ects mar ginal r ow or column scales; it only removes the r esidual mismatc h left after diagonal equilibration. E Lemmas f or Proposition 3.4 E.1 Lemma E.1 Lemma E.1. Let the momentum iterate satisfy M t = β M t − 1 + (1 − β ) G t , β ∈ [0 , 1) , and assume ther e exists a constant G ∞ > 0 such that ∥ G t ∥ ∞ ≤ G ∞ , ∥ M 0 ∥ ∞ ≤ G ∞ . F or ε > 0 , define D r,t := diag ro wsum( M t ⊙ M t ) + ε , D c,t := diag colsum( M t ⊙ M t ) + ε , and P t := D − 1 / 2 r,t , Q t := D − 1 / 2 c,t . Then, for all t , ( nG 2 ∞ + ε ) − 1 / 2 I m ⪯ P t ⪯ ε − 1 / 2 I m , ( mG 2 ∞ + ε ) − 1 / 2 I n ⪯ Q t ⪯ ε − 1 / 2 I n . Mor eover , √ ε I m ⪯ P − 1 t ⪯ p nG 2 ∞ + ε I m , √ ε I n ⪯ Q − 1 t ⪯ p mG 2 ∞ + ε I n . Pr oof. W e first sho w that the momentum iterate M t is uniformly bounded entrywise. Since M t = β M t − 1 + (1 − β ) G t , we hav e ∥ M t ∥ ∞ ≤ β ∥ M t − 1 ∥ ∞ + (1 − β ) ∥ G t ∥ ∞ ≤ β ∥ M t − 1 ∥ ∞ + (1 − β ) G ∞ . 18 Using ∥ M 0 ∥ ∞ = 0 ≤ G ∞ , an induction on t yields ∥ M t ∥ ∞ ≤ G ∞ , ∀ t. Therefore, ev ery entry of M t satisfies | ( M t ) ij | ≤ G ∞ , ∀ i, j, t. Now fix an y row i . Since that row has n entries, n X j =1 ( M t ) 2 ij ≤ nG 2 ∞ . Hence each diagonal entry of D r,t satisfies ε ≤ ( D r,t ) ii = n X j =1 ( M t ) 2 ij + ε ≤ nG 2 ∞ + ε. Similarly , for an y column j , m X i =1 ( M t ) 2 ij ≤ mG 2 ∞ , so each diagonal entry of D c,t satisfies ε ≤ ( D c,t ) j j = m X i =1 ( M t ) 2 ij + ε ≤ mG 2 ∞ + ε. Since P t = D − 1 / 2 r,t and Q t = D − 1 / 2 c,t are diagonal matrices, their diagonal entries are ( P t ) ii = n X j =1 ( M t ) 2 ij + ε − 1 / 2 , ( Q t ) j j = m X i =1 ( M t ) 2 ij + ε ! − 1 / 2 . Using the bounds abov e, we obtain ( nG 2 ∞ + ε ) − 1 / 2 ≤ ( P t ) ii ≤ ε − 1 / 2 , ( mG 2 ∞ + ε ) − 1 / 2 ≤ ( Q t ) j j ≤ ε − 1 / 2 . Since positiv e diagonal matrices are ordered entrywise in the Loewner sense, it follo ws that ( nG 2 ∞ + ε ) − 1 / 2 I m ⪯ P t ⪯ ε − 1 / 2 I m , ( mG 2 ∞ + ε ) − 1 / 2 I n ⪯ Q t ⪯ ε − 1 / 2 I n . Because P t and Q t are symmetric positive definite diagonal matrices, their singular v alues are exactly their diagonal entries. Therefore, ( nG 2 ∞ + ε ) − 1 / 2 ≤ σ min ( P t ) ≤ ∥ P t ∥ 2 ≤ ε − 1 / 2 , ( mG 2 ∞ + ε ) − 1 / 2 ≤ σ min ( Q t ) ≤ ∥ Q t ∥ 2 ≤ ε − 1 / 2 . Finally , in v erting the above matrix inequalities gi ves √ ε I m ⪯ P − 1 t ⪯ p nG 2 ∞ + ε I m , √ ε I n ⪯ Q − 1 t ⪯ p mG 2 ∞ + ε I n . This completes the proof. E.2 Lemma E.2 Lemma E.2. Suppose that { E t , A t } ar e nonne gative sequences. Assume E t +1 ≤ (1 − α t +1 ) E t + A t +1 wher e α t = t − p , p ∈ (0 , 1] . Then α t E t ≤ 2( E t − E t +1 + A t +1 ) . Pr oof. See [9], Lemma A.3. 19 E.3 Lemma E.3 Lemma E.3. F or Algorithm 1, the accumulated error between the momentum term and the true gradient is bounded for t ≥ 1 : E ∥ M t +1 − ∇ f ( X t +1 ) ∥ 2 F ≤ β t +1 E ∥ M t − ∇ f ( X t ) ∥ 2 F + β 2 t +1 1 − β t +1 L 2 η 2 t a 2 n + (1 − β t +1 ) 2 σ 2 . Pr oof. First, we hav e ∥ M t +1 − ∇ f ( X t +1 ) ∥ 2 F = ∥ β t +1 M t + (1 − β t +1 ) ∇ f ( X t +1 ; ξ t +1 ) − ∇ f ( X t +1 ) ∥ 2 F = ∥ β t +1 ( M t − ∇ f ( X t )) + (1 − β t +1 )( ∇ f ( X t +1 ; ξ t +1 ) − ∇ f ( X t +1 )) + β t +1 ( ∇ f ( X t ) − ∇ f ( X t +1 )) ∥ 2 F = β 2 t +1 ∥ M t − ∇ f ( X t ) ∥ 2 F + β 2 t +1 ∥∇ f ( X t ) − ∇ f ( X t +1 ) ∥ 2 F + (1 − β t +1 ) 2 ∥∇ f ( X t +1 ; ξ t +1 ) − ∇ f ( X t +1 ) ∥ 2 F + 2 β 2 t +1 ⟨ M t − ∇ f ( X t ) , ∇ f ( X t ) − ∇ f ( X t +1 ) ⟩ F + 2 β t +1 (1 − β t +1 ) ⟨ M t − ∇ f ( X t ) , ∇ f ( X t +1 ; ξ t +1 ) − ∇ f ( X t +1 ) ⟩ F + 2 β t +1 (1 − β t +1 ) ⟨∇ f ( X t ) − ∇ f ( X t +1 ) , ∇ f ( X t +1 ; ξ t +1 ) − ∇ f ( X t +1 ) ⟩ F . According to Assumption 3.3. T aking the e xpectation of its squared norm, and using the unbiasedness and independence of the stochastic gradient, we obtain: E [ ∥ M t +1 − ∇ f ( X t +1 ) ∥ 2 F ] = β 2 t +1 E [ ∥ M t − ∇ f ( X t ) ∥ 2 F ] + (1 − β t +1 ) 2 E [ ∥∇ f ( X t +1 ; ξ t +1 ) − ∇ f ( X t +1 ) ∥ 2 F ] + β 2 t +1 E [ ∥∇ f ( X t ) − ∇ f ( X t +1 ) ∥ 2 F ] + 2 β 2 t +1 E [ ⟨ M t − ∇ f ( X t ) , ∇ f ( X t ) − ∇ f ( X t +1 ) ⟩ ] . Applying Y oung’ s inequality with a parameter ( ab ≤ ϵ 2 a 2 + 1 2 ϵ b 2 ), we hav e ⟨ M t − ∇ f ( X t ) , ∇ f ( X t ) − ∇ f ( X t +1 ) ⟩ F ≤ ϵ 2 ∥ M t − ∇ f ( X t ) ∥ 2 F + 1 2 ϵ ∥∇ f ( X t ) − ∇ f ( X t +1 ) ∥ 2 F . Thus, we hav e: E ∥ M t +1 − ∇ f ( X t +1 ) ∥ 2 F ≤ β 2 t +1 (1 + ϵ ) E ∥ M t − ∇ f ( X t ) ∥ 2 F + β 2 t +1 1 + 1 ϵ E ∥∇ f ( X t ) − ∇ f ( X t +1 ) ∥ 2 F + (1 − β t +1 ) 2 E ∥∇ f ( X t +1 ; ξ t +1 ) − ∇ f ( X t +1 ) ∥ 2 F . According to Assumption 3.2, ∥∇ f ( X t ) − ∇ f ( X t +1 ) ∥ 2 F ≤ L 2 ∥ X t − X t +1 ∥ 2 F = L 2 η 2 t ∥ O t ∥ 2 F ≤ L 2 η 2 t a 2 n. Therefore: E h ∥ M t +1 − ∇ f ( X t +1 ) ∥ 2 F i ≤ β 2 t +1 (1 + ϵ ) E h ∥ M t − ∇ f ( X t ) ∥ 2 F i + β 2 t +1 1 + 1 ϵ L 2 η 2 t a 2 n + (1 − β t +1 ) 2 σ 2 . Then, by letting ϵ := 1 − β t +1 β t +1 , t ≥ 1 , we hav e E ∥ M t +1 − ∇ f ( X t +1 ) ∥ 2 F ≤ β t +1 E ∥ M t − ∇ f ( X t ) ∥ 2 F + β 2 t +1 1 − β t +1 L 2 η 2 t a 2 n + (1 − β t +1 ) 2 σ 2 . (6) 20 F Proofs of Pr oposition 3.4 Pr oof. By Assumption 3.2 and the descent lemma, f ( X t +1 ) ≤ f ( X t ) + ⟨∇ f ( X t ) , X t +1 − X t ⟩ + L 2 ∥ X t +1 − X t ∥ 2 F = f ( X t ) − aη t ⟨∇ f ( X t ) , O t ⟩ + La 2 η 2 t 2 ∥ O t ∥ 2 F ≤ f ( X t ) − aη t ⟨∇ f ( X t ) , O t ⟩ + La 2 n 2 η 2 t , where the last step uses ∥ O t ∥ 2 F ≤ n . Let S t := ∇ f ( X t ) − M t , r ε := √ ε, R ε := p nG 2 ∞ + ε, C ε := p mG 2 ∞ + ε. Define the midpoint-rescaled matrices e P t := R ε + r ε 2 P t , e Q t := C ε + r ε 2 Q t , e A t := e P − 1 t , e B t := e Q − 1 t . Since the rescaling is by positiv e scalars, p olar( e P t M t e Q t ) = p olar( P t M t Q t ) = O t . Hence ⟨∇ f ( X t ) , O t ⟩ = D e A t ∇ f ( X t ) e B t , e P t O t e Q t E . By Lemma E.1, we hav e R − 1 ε I m ⪯ P t ⪯ r − 1 ε I m , C − 1 ε I n ⪯ Q t ⪯ r − 1 ε I n . Since R ε = r ε ρ r , C ε = r ε ρ c , we obtain ρ r + 1 2 ρ r I m ⪯ e P t ⪯ ρ r + 1 2 I m , ρ c + 1 2 ρ c I n ⪯ e Q t ⪯ ρ c + 1 2 I n . Therefore, we hav e ∥ e A t ∥ 2 ≤ 2 ρ r ρ r + 1 , ∥ e B t ∥ 2 ≤ 2 ρ c ρ c + 1 , ∥ e A t − I m ∥ 2 ≤ ρ r − 1 ρ r + 1 , ∥ e B t − I n ∥ 2 ≤ ρ c − 1 ρ c + 1 . Using ∇ f ( X t ) = M t + S t , we split ⟨∇ f ( X t ) , O t ⟩ = D e A t M t e B t , e P t O t e Q t E + D e A t S t e B t , e P t O t e Q t E = ∥ e P t M t e Q t ∥ ∗ + D e A t S t e B t , e P t O t e Q t E + D e A t M t e B t − M t , e P t O t e Q t E . First, by the singular-v alue inequality σ i ( AXB ) ≥ σ min ( A ) σ i ( X ) σ min ( B ) , we hav e ∥ e P t M t e Q t ∥ ∗ ≥ ( ρ r + 1)( ρ c + 1) 4 ρ r ρ c ∥ M t ∥ ∗ . Second, using Hölder’ s inequality , ∥ O t ∥ 2 = 1 , and the bounds abov e, D e A t S t e B t , e P t O t e Q t E ≤ ∥ e A t S t e B t ∥ ∗ ∥ e P t O t e Q t ∥ 2 ≤ ∥ e A t ∥ 2 ∥ e B t ∥ 2 ∥ S t ∥ ∗ ∥ e P t ∥ 2 ∥ e Q t ∥ 2 ≤ ρ r ρ c ∥ S t ∥ ∗ ≤ ρ r ρ c √ n ∥ S t ∥ F . Third, we use the symmetric decomposition e A t M t e B t − M t = ( e A t − I m ) M t + M t ( e B t − I n ) + ( e A t − I m ) M t ( e B t − I n ) . 21 Hence ∥ e A t M t e B t − M t ∥ ∗ ≤ ρ r − 1 ρ r + 1 + ρ c − 1 ρ c + 1 + ( ρ r − 1)( ρ c − 1) ( ρ r + 1)( ρ c + 1) ∥ M t ∥ ∗ . Therefore, we hav e D e A t M t e B t − M t , e P t O t e Q t E ≤ ∥ e A t M t e B t − M t ∥ ∗ ∥ e P t O t e Q t ∥ 2 ≤ 3 ρ r ρ c − ρ r − ρ c − 1 4 ∥ M t ∥ ∗ . Combining the abov e bounds, we obtain ⟨∇ f ( X t ) , O t ⟩ ≥ χ ε ∥ M t ∥ ∗ − ρ r ρ c √ n ∥ S t ∥ F . Under the setting ε ≥ 4 5 G 2 ∞ max { m, n } , we hav e ρ r = q 1 + nG 2 ∞ ε ≤ q 1 + 5 n 4 max { m,n } ≤ 3 2 , ρ c = q 1 + mG 2 ∞ ε ≤ q 1 + 5 m 4 max { m,n } ≤ 3 2 . Let ψ ( x, y ) := ( x +1)( y +1) 4 xy − 3 xy − x − y − 1 4 , x, y ≥ 1 . A direct calculation gi ves ∂ x ψ ( x, y ) = 1 − x − 2 − x − 2 y − 1 − 3 y 4 < 0 , ∂ y ψ ( x, y ) = 1 − y − 2 − x − 1 y − 2 − 3 x 4 < 0 , for all x, y ≥ 1 . Hence ψ is de- creasing in each argument on [1 , ∞ ) 2 . Therefore, we have χ ε = ψ ( ρ r , ρ c ) ≥ ψ 3 2 , 3 2 = 1 144 > 0 . Since χ ε > 0 , ∥ M t ∥ ∗ ≥ ∥ M t ∥ F , and ∥ M t ∥ F ≥ ∥∇ f ( X t ) ∥ F − ∥ S t ∥ F , it follows that ⟨∇ f ( X t ) , O t ⟩ ≥ χ ε ∥∇ f ( X t ) ∥ F − χ ε + ρ r ρ c √ n ∥ S t ∥ F . Substituting the abov e inequality into the descent bound yields f ( X t +1 ) ≤ f ( X t ) − aχ ε η t ∥∇ f ( X t ) ∥ F + a χ ε + ρ r ρ c √ n η t ∥ S t ∥ F + La 2 n 2 η 2 t . Apply Y oung’ s inequality with parameter h t +1 /L : a χ ε + ρ r ρ c √ n η t ∥ S t ∥ F ≤ ah t +1 2 L ∥ S t ∥ 2 F + aL 2 χ ε + ρ r ρ c √ n 2 η 2 t h t +1 . Hence f ( X t +1 ) ≤ f ( X t ) − aχ ε η t ∥∇ f ( X t ) ∥ F + ah t +1 2 L ∥ S t ∥ 2 F + aL 2 χ ε + ρ r ρ c √ n 2 η 2 t h t +1 + La 2 n 2 η 2 t . T aking e xpectations and summing the above inequality o ver t = 1 , . . . , T , then using f ( X T +1 ) ≥ f ⋆ , we hav e aχ ε T X t =1 η t E ∥∇ f ( X t ) ∥ F ≤ f ( X 1 ) − f ⋆ + a 2 L T X t =1 h t +1 E ∥ S t ∥ 2 F + aL 2 χ ε + ρ r ρ c √ n 2 T X t =1 η 2 t h t +1 + La 2 n 2 T X t =1 η 2 t . By Lemma E.3, E ∥ S t +1 ∥ 2 F ≤ (1 − h t +1 ) E ∥ S t ∥ 2 F + (1 − h t +1 ) 2 h t +1 L 2 η 2 t a 2 n + h 2 t +1 σ 2 . Since (1 − h t +1 ) 2 ≤ 1 and η 2 t h t +1 = t − 3 / 2 ( t + 1) − 1 / 2 = √ t + 1 t 3 / 2 ≤ 2 √ 2 t + 1 = 2 √ 2 h 2 t +1 , 22 we hav e E ∥ S t +1 ∥ 2 F ≤ (1 − h t +1 ) E ∥ S t ∥ 2 F + h 2 t +1 (2 √ 2 L 2 a 2 n + σ 2 ) . According to Lemma E.2, by letting E t = E ∥ S t ∥ 2 F , A t +1 = h 2 t +1 (2 √ 2 L 2 a 2 n + σ 2 ) , we hav e h t E ∥ S t ∥ 2 F ≤ 2 E ∥ S t ∥ 2 F − E ∥ S t +1 ∥ 2 F + A t +1 . Moreov er , since β 1 = 0 , E ∥ S 1 ∥ 2 F = E ∥∇ f ( X 1 ) − M 1 ∥ 2 F = E ∥∇ f ( X 1 ) − ∇ f ( X 1 ; ξ 1 ) ∥ 2 F ≤ σ 2 . It follows that T X t =1 h t E ∥ S t ∥ 2 F ≤ 2 T X t =1 E ∥ S t ∥ 2 F − E ∥ S t +1 ∥ 2 F + A t +1 ≤ 2 E ∥ S 1 ∥ 2 F + 2(2 √ 2 L 2 a 2 n + σ 2 ) T X t =1 1 t + 1 ≤ 2 σ 2 + 2(2 √ 2 L 2 a 2 n + σ 2 )(1 + ln T ) . Hence, since h t +1 ≤ h t , T X t =1 h t +1 E ∥ S t ∥ 2 F ≤ 2 σ 2 + 2(2 √ 2 L 2 a 2 n + σ 2 )(1 + ln T ) . Also, T X t =1 η 2 t h t +1 = T X t =1 t − 3 / 2 ( t + 1) − 1 / 2 ≤ 2(1 + ln T ) , T X t =1 η 2 t = T X t =1 t − 3 / 2 ≤ 3 . Substituting these bounds into the previous inequality , we get aχ ε T X t =1 η t E ∥∇ f ( X t ) ∥ F ≤ f ( X 1 ) − f ⋆ + C 1 (1 + ln T ) + C 2 , where C 1 = a L 2 √ 2 L 2 a 2 n + σ 2 + aL χ ε + ρ r ρ c √ n 2 , C 2 = aσ 2 L + 3 La 2 n 2 . Finally , since η t = t − 3 / 4 ≥ T − 3 / 4 for all 1 ≤ t ≤ T , T − 3 / 4 T X t =1 E ∥∇ f ( X t ) ∥ F ≤ T X t =1 η t E ∥∇ f ( X t ) ∥ F . Therefore, we hav e 1 T T X t =1 E ∥∇ f ( X t ) ∥ F ≤ f ( X 1 ) − f ⋆ + C 1 (1 + ln T ) + C 2 aχ ε · T 1 / 4 . This completes the proof. G Lemmas f or Theorem 3.5 G.1 Lemma G.1 Lemma G.1. Let D r,t := diag ro wsum( M t ⊙ M t ) , R t := D − 1 / 2 r,t M t , O t := Orth( R t ) . Then, for all t , ⟨ M t , O t ⟩ ≥ 1 √ m ∥ M t ∥ F , ∥ O t ∥ 2 F = rank( R t ) ≤ n. 23 Pr oof. If M t = 0 , then R t = O t = 0 and the claim is immediate. Assume M t = 0 . Write d i,t := ∥ ( M t ) i, : ∥ 2 , D t := diag( d 1 ,t , . . . , d m,t ) , so that D t = D 1 / 2 r,t and M t = D t R t . Let H t := ( R t R ⊤ t ) 1 / 2 . If R t = U t Σ t V ⊤ t is a compact SVD, then O t = U t V ⊤ t and therefore O t R ⊤ t = H t . Hence ⟨ M t , O t ⟩ = tr( O ⊤ t D t R t ) = tr( D t O t R ⊤ t ) = tr( D t H t ) = m X i =1 d i,t ( H t ) ii . If d i,t > 0 , then the i th row of R t has unit Euclidean norm, so 1 = e ⊤ i R t R ⊤ t e i = e ⊤ i H 2 t e i ≤ ∥ H t ∥ 2 e ⊤ i H t e i = ∥ R t ∥ 2 ( H t ) ii . Thus ( H t ) ii ≥ ∥ R t ∥ − 1 2 whenev er d i,t > 0 . If d i,t = 0 , the corresponding term vanishes. Therefore, ⟨ M t , O t ⟩ ≥ 1 ∥ R t ∥ 2 m X i =1 d i,t . Now each nonzero ro w of R t has norm 1 , so ∥ R t ∥ 2 F ≤ m , hence ∥ R t ∥ 2 ≤ √ m . Also, P m i =1 d i,t ≥ ∥ M t ∥ F . It follows that ⟨ M t , O t ⟩ ≥ 1 √ m ∥ M t ∥ F . Finally , if r t := rank( R t ) , then the nonzero singular values of O t are all equal to 1 , so ∥ O t ∥ 2 F = r t ≤ n . G.2 Lemma G.2 Consider the practical row-normalized R v ariant (4) , with Nesterov disabled and λ = 0 , ε = 0 . Then the update is D r,t := diag ro wsum( M t ⊙ M t ) , ˆ M t := ( D 1 / 2 r,t ) † M t , O t := NS5( ˆ M t ) , X t +1 = X t − aη t O t , where a := 0 . 2 p max { m, n } . Here † denotes the Moore–Penrose pseudoinv erse, so a zero row remains zero after row normalization, and we adopt the con v ention Orth( 0 ) = 0 . Remark G.1. F ollowing the practical Muon implementation [ 4 ] and Theor em 3.1, we write NS5 as the five-step pr e-scaled Newton–Sc hulz map. F or any A ∈ R m × n , define α ( A ) := max { 1 , ∥ A ∥ F } , Y (0) ( A ) := A /α ( A ) , and, for k = 0 , 1 , 2 , 3 , 4 , Y ( k +1) ( A ) = p ns Y ( k ) ( A ) Y ( k ) ( A ) ⊤ Y ( k ) ( A ) , p ns ( Z ) := a ns I m + b ns Z + c ns Z 2 . W e then define NS5( A ) := Y (5) ( A ) . Remark G.2. F ollowing the trajectory-wise err or formalism in [ 14 , Definition 3 and Theor em 2], we work with the NS5 polar-appr oximation err or along the algorithmic trajectory . W e define ε ns := sup t ≥ 1 NS5( ˆ M t ) − Orth( ˆ M t ) 2 . In subsequent derivations, we assume ε ns < 1 . The quantity ε ns plays the same r ole as the trajectory- wise polar-appr oximation err or ε q in [14, Definition 3 and Theor em 2]. Lemma G.2. Let A ∈ R m × n . If A = 0 , define Orth( A ) = 0 and NS5( A ) = 0 . Otherwise, let A = UΣV ⊤ be the compact SVD, and set Q := Orth( A ) = UV ⊤ and O := NS5( A ) . Then ther e exists a diagonal matrix e Σ such that O = U e ΣV ⊤ . Mor eover , for every r ow-normalized input A = ˆ M t along the algorithmic trajectory , ∥ NS5( A ) − Orth( A ) ∥ 2 ≤ ε ns . Consequently , e very diagonal entry ˜ σ i of e Σ satisfies 1 − ε ns ≤ ˜ σ i ≤ 1 + ε ns , i ∈ [rank( A )] . In particular , whenever A = ˆ M t = 0 , we have Orth(NS5( A )) = Orth( A ) . 24 Pr oof. If A = 0 , the conclusion is immediate by definition. Assume A = 0 . The internal scaling multiplies A by a positive scalar and hence does not change its left or right singular vectors. Thus Y (0) ( A ) = UΣ (0) V ⊤ for some diagonal matrix Σ (0) . Assume inductiv ely that Y ( k ) ( A ) = UΣ ( k ) V ⊤ with diagonal Σ ( k ) . Then Y ( k ) ( A ) Y ( k ) ( A ) ⊤ = U Σ ( k ) 2 U ⊤ , and therefore Y ( k +1) ( A ) = U p ns ( Σ ( k ) ) 2 Σ ( k ) V ⊤ . Hence ev ery iterate has the same left and right singular vectors as A , and in particular NS5( A ) = U e ΣV ⊤ for some diagonal matrix e Σ . Now , if A = ˆ M t is a ro w-normalized input on the algorithmic trajectory , then by the definition of ε ns , ∥ NS5( A ) − Orth( A ) ∥ 2 = ∥ U ( e Σ − I ) V ⊤ ∥ 2 = ∥ e Σ − I ∥ 2 ≤ ε ns . Hence max i | ˜ σ i − 1 | ≤ ε ns , which is equiv alent to 1 − ε ns ≤ ˜ σ i ≤ 1 + ε ns for all i. Since ε ns < 1 , these diagonal entries are strictly positiv e. Therefore Orth(NS5( A )) = Orth( A ) whenev er A = ˆ M t = 0 . G.3 Lemma G.3 Lemma G.3. Under Lemma G.2, for all t , ⟨ M t , O t ⟩ ≥ 1 − ε ns √ m ∥ M t ∥ F , ∥ O t ∥ 2 F ≤ (1 + ε ns ) 2 n. Pr oof. If M t = 0 , then ˆ M t = O t = 0 and the claim is immediate. Assume M t = 0 . W e have d i,t := ∥ ( M t ) i, : ∥ 2 , D t := D 1 / 2 r,t = diag( d 1 ,t , . . . , d m,t ) , so that M t = D t ˆ M t . Let ˆ M t = U t Σ t V ⊤ t , H t := ( ˆ M t ˆ M ⊤ t ) 1 / 2 = U t Σ t U ⊤ t . By Lemma G.2, O t = U t e Σ t V ⊤ t with diagonal entries of e Σ t lying in [1 − ε ns , 1 + ε ns ] . Therefore, O t ˆ M ⊤ t = U t e Σ t Σ t U ⊤ t ⪰ (1 − ε ns ) U t Σ t U ⊤ t = (1 − ε ns ) H t . Hence ⟨ M t , O t ⟩ = tr( O ⊤ t D t ˆ M t ) = tr( D t O t ˆ M ⊤ t ) ≥ (1 − ε ns ) tr( D t H t ) = (1 − ε ns ) m X i =1 d i,t ( H t ) ii . 25 If d i,t > 0 , then the i -th row of ˆ M t has unit Euclidean norm, so 1 = e ⊤ i ˆ M t ˆ M ⊤ t e i = e ⊤ i H 2 t e i ≤ ∥ H t ∥ 2 e ⊤ i H t e i = ∥ ˆ M t ∥ 2 ( H t ) ii . Thus ( H t ) ii ≥ ∥ ˆ M t ∥ − 1 2 whenev er d i,t > 0 . If d i,t = 0 , the corresponding term vanishes. Conse- quently , tr( D t H t ) ≥ ∥ ˆ M t ∥ − 1 2 m X i =1 d i,t . Now each nonzero ro w of ˆ M t has norm 1 , so ∥ ˆ M t ∥ 2 F ≤ m , hence ∥ ˆ M t ∥ 2 ≤ √ m . Also, m X i =1 d i,t ≥ m X i =1 d 2 i,t 1 / 2 = ∥ M t ∥ F . Combining the abov e bounds giv es ⟨ M t , O t ⟩ ≥ 1 − ε ns √ m ∥ M t ∥ F . For the norm bound, let r t := rank( ˆ M t ) . Again by Lemma G.2, every nonzero singular v alue of O t is at most 1 + ε ns . Therefore ∥ O t ∥ 2 F = r t X i =1 ˜ σ 2 i,t ≤ (1 + ε ns ) 2 r t ≤ (1 + ε ns ) 2 n. This completes the proof. H Proofs of Theor em 3.5 Pr oof. Let S t := ∇ f ( X t ) − M t , γ ns := 1 − ε ns , c ns m,n := γ ns √ m + (1 + ε ns ) √ n . By Assumption 3.2 and the descent lemma, we hav e f ( X t +1 ) ≤ f ( X t ) + ⟨∇ f ( X t ) , X t +1 − X t ⟩ + L 2 ∥ X t +1 − X t ∥ 2 F = f ( X t ) − aη t ⟨∇ f ( X t ) , O t ⟩ + La 2 η 2 t 2 ∥ O t ∥ 2 F ≤ f ( X t ) − aη t ⟨∇ f ( X t ) , O t ⟩ + La 2 (1 + ε ns ) 2 n 2 η 2 t , (7) where the last step uses Lemma G.3. Again by Lemma G.3, ⟨∇ f ( X t ) , O t ⟩ = ⟨ M t , O t ⟩ + ⟨ S t , O t ⟩ ≥ γ ns √ m ∥ M t ∥ F − ∥ S t ∥ F ∥ O t ∥ F ≥ γ ns √ m ∥ M t ∥ F − (1 + ε ns ) √ n ∥ S t ∥ F ≥ γ ns √ m ∥∇ f ( X t ) ∥ F − γ ns √ m + (1 + ε ns ) √ n ∥ S t ∥ F . (8) Substituting (8) into (7), f ( X t +1 ) ≤ f ( X t ) − aγ ns √ m η t ∥∇ f ( X t ) ∥ F + ac ns m,n η t ∥ S t ∥ F + La 2 (1 + ε ns ) 2 n 2 η 2 t . (9) Apply Y oung’ s inequality with parameter h t +1 /L : ac ns m,n η t ∥ S t ∥ F ≤ ah t +1 2 L ∥ S t ∥ 2 F + aL 2 c ns m,n 2 η 2 t h t +1 . 26 Hence f ( X t +1 ) ≤ f ( X t ) − aγ ns √ m η t ∥∇ f ( X t ) ∥ F + ah t +1 2 L ∥ S t ∥ 2 F + aL 2 c ns m,n 2 η 2 t h t +1 + La 2 (1 + ε ns ) 2 n 2 η 2 t . T aking expectations and summing from t = 1 to T , then using f ( X T +1 ) ≥ f ⋆ , we obtain aγ ns √ m T X t =1 η t E ∥∇ f ( X t ) ∥ F ≤ f ( X 1 ) − f ⋆ + a 2 L T X t =1 h t +1 E ∥ S t ∥ 2 F + aL 2 c ns m,n 2 T X t =1 η 2 t h t +1 + La 2 (1 + ε ns ) 2 n 2 T X t =1 η 2 t . (10) A direct repetition of the proof of Lemma E.3, using ∥ O t ∥ 2 F ≤ (1 + ε ns ) 2 n from Lemma G.3, giv es E ∥ S t +1 ∥ 2 F ≤ (1 − h t +1 ) E ∥ S t ∥ 2 F + (1 − h t +1 ) 2 h t +1 L 2 η 2 t a 2 (1 + ε ns ) 2 n + h 2 t +1 σ 2 . Since (1 − h t +1 ) 2 ≤ 1 and η 2 t h t +1 = t − 3 / 2 ( t + 1) − 1 / 2 = √ t + 1 t 3 / 2 ≤ 2 √ 2 t + 1 = 2 √ 2 h 2 t +1 , we hav e E ∥ S t +1 ∥ 2 F ≤ (1 − h t +1 ) E ∥ S t ∥ 2 F + h 2 t +1 2 √ 2 L 2 a 2 (1 + ε ns ) 2 n + σ 2 . Applying Lemma E.2 with E t = E ∥ S t ∥ 2 F , A t +1 = h 2 t +1 2 √ 2 L 2 a 2 (1 + ε ns ) 2 n + σ 2 , we get h t E ∥ S t ∥ 2 F ≤ 2 E ∥ S t ∥ 2 F − E ∥ S t +1 ∥ 2 F + A t +1 . Moreov er , since β 1 = 0 , E ∥ S 1 ∥ 2 F = E ∥∇ f ( X 1 ) − M 1 ∥ 2 F = E ∥∇ f ( X 1 ) − ∇ f ( X 1 ; ξ 1 ) ∥ 2 F ≤ σ 2 . Thus, T X t =1 h t E ∥ S t ∥ 2 F ≤ 2 T X t =1 E ∥ S t ∥ 2 F − E ∥ S t +1 ∥ 2 F + A t +1 ≤ 2 E ∥ S 1 ∥ 2 F + 2 2 √ 2 L 2 a 2 (1 + ε ns ) 2 n + σ 2 T X t =1 1 t + 1 ≤ 2 σ 2 + 2 2 √ 2 L 2 a 2 (1 + ε ns ) 2 n + σ 2 (1 + ln T ) . Hence, since h t +1 ≤ h t , T X t =1 h t +1 E ∥ S t ∥ 2 F ≤ 2 σ 2 + 2 2 √ 2 L 2 a 2 (1 + ε ns ) 2 n + σ 2 (1 + ln T ) . Also, T X t =1 η 2 t h t +1 = T X t =1 t − 3 / 2 ( t + 1) − 1 / 2 ≤ 2(1 + ln T ) , T X t =1 η 2 t = T X t =1 t − 3 / 2 ≤ 3 . Substituting these bounds into (10), aγ ns √ m T X t =1 η t E ∥∇ f ( X t ) ∥ F ≤ f ( X 1 ) − f ⋆ + C ns 1 (1 + ln T ) + C ns 2 . 27 Finally , since η t = t − 3 / 4 ≥ T − 3 / 4 for all 1 ≤ t ≤ T , T − 3 / 4 T X t =1 E ∥∇ f ( X t ) ∥ F ≤ T X t =1 η t E ∥∇ f ( X t ) ∥ F . Therefore, 1 T T X t =1 E ∥∇ f ( X t ) ∥ F ≤ f ( X 1 ) − f ⋆ + C ns 1 (1 + ln T ) + C ns 2 aγ ns / √ m T 1 / 4 . This completes the proof. I More Results ▶ Learning Rate Search. Figure 5 sho ws the learning-rate sweeps for LLaMA2-130M and LLaMA2- 350M trained on C4 for 2.6B and 7.5B tokens, respecti vely . ▶ Module-wise Pre-NS Momentum Analysis. Since MuonEq acts directly on the matrix fed into Newton–Schulz, we analyze pre-NS momentum matrices along a 2.6B-token LLaMA2-130M/C4 training trajectory , tracking the query , key , value , output , gate , down , and up weights in layers 1, 5, 9, and 12 at 1%, 10%, 50%, and 100% of training. Figure 6 reports the singular-v alue entropy and stable rank of these matrices; empirically , RowColNorm consistently improv es both metrics ov er direct , ColNorm , and RowNorm . Figure 7 provides the empirical counterpart of Eq. (5) : the top ro w measures the finite-step NS5 approximation error after preprocessing, and the bottom ro w the bias introduced relative to the unpreconditioned polar direction. At 1% and 10% of training, two-sided RowColNorm is usually lowest or near-lo west in the top panels across layers, indicating that early RC equilibration most effecti vely impro ves the geometry seen by NS5, b ut it also yields the largest preconditioning bias. By 50% and 100%, the top-panel dif ferences shrink substantially while the extra bias of the two-sided map remains visible. These plots illustrate the same trade-off as Eq. (5) : RC provides stronger tw o-sided spectral correction but also larger preprocessing bias. For the hidden-weight setting studied here, R remains the more suitable default one-sided v ariant. 5e-4 1e-3 2e-3 3e-3 5e-3 8e-3 1e-2 L ear ning rate 3.10 3.15 3.20 3.25 3.30 3.35 3.40 3.45 L oss A damW Muon Muon-Nes MARS- A damW MuonEq (a) 130M 5e-4 1e-3 1.5e-3 2e-3 3e-3 5e-3 L ear ning rate 2.80 2.85 2.90 2.95 3.00 3.05 3.10 L oss A damW Muon Muon-Nes MARS- A damW MuonEq (b) 350M Figure 5: Learning-rate sweeps for LLaMA2-130M and LLaMA2-350M trained on C4 for 2.6B and 7.5B tokens, respecti vely . J Experimental Details J.1 Pretraining on C4 ▶ Experimental setup. W e use 64 Ascend 910C (64GB) NPUs for all e xperiments. W e compare AdamW , MARS-AdamW , Muon, Muon-Nes, and MuonEq on LLaMA2-130M and LLaMA2-350M trained on C4 [ 29 ]. W e keep the model architecture, dataset, and training recipe fixed across optimizers. The global batch size is 128 for LLaMA2-130M and 256 for LLaMA2-350M, and the maximum sequence length is 4096 for both models. Hyperparameters are selected according to validation performance. 28 3.0 3.5 4.0 4.5 5.0 Singular V alue Entropy R un muon | Step 1% | P r e-NS input Methods Dir ect ColNor m R owNor m R owColNor m L01-query L01-k ey L01- value L01- output L01-gate L01-up L01-down L05-query L05-k ey L05- value L05- output L05-gate L05-up L05-down L09-query L09-k ey L09- value L09- output L09-gate L09-up L09-down L12-query L12-k ey L12- value L12- output L12-gate L12-up L12-down La yer / Module 1 2 3 4 5 Effective Rank (a) Step 1% 4.5 5.0 5.5 6.0 6.5 Singular V alue Entropy R un muon | Step 10% | P r e-NS input Methods Dir ect ColNor m R owNor m R owColNor m L01-query L01-k ey L01- value L01- output L01-gate L01-up L01-down L05-query L05-k ey L05- value L05- output L05-gate L05-up L05-down L09-query L09-k ey L09- value L09- output L09-gate L09-up L09-down L12-query L12-k ey L12- value L12- output L12-gate L12-up L12-down La yer / Module 0 5 10 15 20 Effective Rank (b) Step 10% 4.5 5.0 5.5 6.0 6.5 Singular V alue Entropy R un muon | Step 50% | P r e-NS input Methods Dir ect ColNor m R owNor m R owColNor m L01-query L01-k ey L01- value L01- output L01-gate L01-up L01-down L05-query L05-k ey L05- value L05- output L05-gate L05-up L05-down L09-query L09-k ey L09- value L09- output L09-gate L09-up L09-down L12-query L12-k ey L12- value L12- output L12-gate L12-up L12-down La yer / Module 0 5 10 15 20 25 30 Effective Rank (c) Step 50% 3.5 4.0 4.5 5.0 5.5 6.0 6.5 Singular V alue Entropy R un muon | Step 100% | P r e-NS input Methods Dir ect ColNor m R owNor m R owColNor m L01-query L01-k ey L01- value L01- output L01-gate L01-up L01-down L05-query L05-k ey L05- value L05- output L05-gate L05-up L05-down L09-query L09-k ey L09- value L09- output L09-gate L09-up L09-down L12-query L12-k ey L12- value L12- output L12-gate L12-up L12-down La yer / Module 0 5 10 15 20 25 30 Effective Rank (d) Step 100% Figure 6: Singular-v alue entropy and stable rank of Muon momentum matrices under dif ferent nor- malization schemes during LLaMA2-130M training on C4 for 2.6B tok ens. RowColNorm consistently improv es both metrics over Direct , ColNorm , and RowNorm . T able 4: Hyperparameters used for training LLaMA2-130M on C4 Hyper-parameter AdamW MARS-AdamW Muon Muon-Nes MuonEq Max Learning Rate 5e-3 3e-3 3e-3 3e-3 3e-3 W armup Steps 500 Batch Size 128 Maximum Length 4096 W eight Decay 0.1 ( β 1 , β 2 ) (0.9,0.95) Muon-Momentum % % 0.95 Gamma % 0.025 % 0.05 T able 5: Hyperparameters used for training LLaMA2-350M on C4 Hyper-parameter AdamW MARS-AdamW Muon Muon-Nes MuonEq Max Learning Rate 1.5e-3 2e-3 1.5e-3 2e-3 2e-3 W armup Steps 500 Batch Size 256 Maximum Length 4096 W eight Decay 0.1 ( β 1 , β 2 ) (0.9,0.95) Muon-Momentum % % 0.95 Gamma % 0.025 % 0.05 ▶ Hyperparameter sear ch. The selected hyperparameters are summarized in T ables 4 and 5. For the main comparison, LLaMA2-130M and LLaMA2-350M are trained for 10.5B and 21.0B tokens, respectiv ely . Learning-rate sweeps are performed on shorter pilot runs of 2.6B tokens for LLaMA2- 29 12 14 16 18 20 22 N S 5 ( S s ( M ) ) O r t h ( S s ( M ) ) F T o p : N S 5 ( S s ( M ) ) O r t h ( S s ( M ) ) F w i t h D i r e c t Methods R owNor m ColNor m R owColNor m Dir ect L1-query L1-k ey L1- value L1- output L1-gate L1-up L1-down L5-query L5-k ey L5- value L5- output L5-gate L5-up L5-down L9-query L9-k ey L9- value L9- output L9-gate L9-up L9-down L12-query L12-k ey L12- value L12- output L12-gate L12-up L12-down La yer / Module 5 10 15 20 O r t h ( S s ( M ) ) O r t h ( M ) F B o t t o m : O r t h ( S s ( M ) ) O r t h ( M ) F muon | Step 1%: decomposition errors by la yer (a) Step 1% 5.0 7.5 10.0 12.5 15.0 17.5 20.0 N S 5 ( S s ( M ) ) O r t h ( S s ( M ) ) F T o p : N S 5 ( S s ( M ) ) O r t h ( S s ( M ) ) F w i t h D i r e c t Methods R owNor m ColNor m R owColNor m Dir ect L1-query L1-k ey L1- value L1- output L1-gate L1-up L1-down L5-query L5-k ey L5- value L5- output L5-gate L5-up L5-down L9-query L9-k ey L9- value L9- output L9-gate L9-up L9-down L12-query L12-k ey L12- value L12- output L12-gate L12-up L12-down La yer / Module 0 5 10 15 20 O r t h ( S s ( M ) ) O r t h ( M ) F B o t t o m : O r t h ( S s ( M ) ) O r t h ( M ) F muon | Step 10%: decomposition errors by la yer (b) Step 10% 6 8 10 12 14 16 18 N S 5 ( S s ( M ) ) O r t h ( S s ( M ) ) F T o p : N S 5 ( S s ( M ) ) O r t h ( S s ( M ) ) F w i t h D i r e c t Methods R owNor m ColNor m R owColNor m Dir ect L1-query L1-k ey L1- value L1- output L1-gate L1-up L1-down L5-query L5-k ey L5- value L5- output L5-gate L5-up L5-down L9-query L9-k ey L9- value L9- output L9-gate L9-up L9-down L12-query L12-k ey L12- value L12- output L12-gate L12-up L12-down La yer / Module 0 5 10 15 20 O r t h ( S s ( M ) ) O r t h ( M ) F B o t t o m : O r t h ( S s ( M ) ) O r t h ( M ) F muon | Step 50%: decomposition errors by la yer (c) Step 50% 5.0 7.5 10.0 12.5 15.0 17.5 20.0 N S 5 ( S s ( M ) ) O r t h ( S s ( M ) ) F T o p : N S 5 ( S s ( M ) ) O r t h ( S s ( M ) ) F w i t h D i r e c t Methods R owNor m ColNor m R owColNor m Dir ect L1-query L1-k ey L1- value L1- output L1-gate L1-up L1-down L5-query L5-k ey L5- value L5- output L5-gate L5-up L5-down L9-query L9-k ey L9- value L9- output L9-gate L9-up L9-down L12-query L12-k ey L12- value L12- output L12-gate L12-up L12-down La yer / Module 0 5 10 15 20 O r t h ( S s ( M ) ) O r t h ( M ) F B o t t o m : O r t h ( S s ( M ) ) O r t h ( M ) F muon | Step 100%: decomposition errors by la yer (d) Step 100% Figure 7: Layerwise Muon NS5 bias decomposition under different normalization schemes dur- ing LLaMA2-130M training on C4 for 2.6B tokens. The top panel reports ∥ NS 5 ( S ( M )) − Orth( S ( M )) ∥ F , while the bottom panel reports ∥ Orth( S ( M )) − Orth( M ) ∥ F , both ev aluated across layers at the same training step. These plots reveal ho w the choice of normalization shifts the error budget between the finite-step appr oximation error term and the preconditioning bias term. 130M and 7.5B tokens for LLaMA2-350M. AdamW and MARS-AdamW use ( β 1 , β 2 ) = (0 . 9 , 0 . 95) , ϵ = 10 − 8 , and weight decay 0.1. Muon, Muon-Nes, and MuonEq use Muon momentum 0.95 and weight decay 0.1. W e set γ = 0 . 025 for MARS-AdamW and γ = 0 . 05 for Muon-Nes and MuonEq . For Muon, Muon-Nes, and MuonEq , we use the Muon implementation from Moonlight 2 ; all 2D weight matrices except embeddings are optimized with the corresponding Muon-type optimizer , while 1D parameters and embeddings are optimized with AdamW . J.2 Ablation Study Details T able 6: Hyperparameters used for training ResNet-18 on CIF AR10 Hyper-parameter SGD AdamW Muon-Nes MuonEq (RC) MuonEq (C) MuonEq (R) Max Learning Rate 5e-2 1e-3 5e-2 5e-2 5e-2 5e-2 W armup Steps 0 Epochs 100 Batch Size 128 ( β 1 , β 2 ) (0.9,0.999) (0.9,0.95) Muon-Momentum % % 0.9 ▶ Experimental setup. All ablation experiments are conducted on 4 R TX Pro6000 (96GB) GPUs. W e use two workloads: CIF AR-10 with ResNet-18 and FineW eb pretraining of GPT2-small up to 10.5B tokens. Unless otherwise stated, the architecture, data pipeline, training budget, learning-rate schedule, warmup length, weight decay , momentum, Ne wton–Schulz iteration budget, and parameter 2 https://github.com/MoonshotAI/Moonlight 30 T able 7: Hyperparameters used for training GPT2-small on FineW eb Hyper-parameter AdamW Muon-Nes MuonEq (RC) MuonEq (C) MuonEq (R) Max Learning Rate 2e-3 2e-3 2e-3 2e-3 2e-3 W armup Steps 1000 T otal Steps 20000 Batch Size 128 Maximum Length 4096 W eight Decay 0.1 ( β 1 , β 2 ) (0.9,0.95) Muon-Momentum % 0.95 Gamma % 0.05 grouping are kept identical to the corresponding reference recipe; only the diagonal map before orthog- onalization is changed. The selected hyperparameters are summarized in T ables 6 and 7. For learning- rate tuning, we use discrete search grids that depend on the workload and optimizer family . On CIF AR- 10 with ResNet-18, the SGD baseline is tuned over { 1e − 1 , 5e − 2 , 1e − 2 , 5e − 3 } , AdamW over { 5e − 3 , 1e − 3 , 5e − 4 , 1e − 4 } , and Muon-type optimizers over { 1e − 1 , 5e − 2 , 1e − 2 , 5e − 3 , 1e − 3 } . W e use the Muon implementation from Moonlight 3 . On FineW eb pretraining of GPT2-small, all methods are tuned o ver the same learning-rate grid { 5e − 4 , 1e − 3 , 2e − 3 , 5e − 3 } . W e use the Muon implementation from Moonlight 4 W e compare the three MuonEq v ariants RC, R, and C. RC applies two-sided ro w/column normal- ization throughout training, R applies ro w normalization throughout training, and C applies column normalization throughout training. W e take R as the def ault v ariant. In all cases, the orthogonalization routine, optimizer states, and scalar hyperparameters are unchanged. The purpose of this ablation is to isolate the ef fect of pre-orthogonalization geometry rather than to redesign the optimizer for each variant. W e therefore use the same training budget and e valuation protocol across all runs. On CIF AR-10 we report final test accurac y . On FineW eb/GPT2-small we report validation perple xity at the end of the 10.5B-token b udget. This ablation is directly connected to Eq. (5) . RC provides the strongest two-sided spectral correction and mainly targets the finite-step Ne wton–Schulz term. R and C test the two one-sided geometries under the same optimizer configuration. Since MuonEq targets hidden matrix weights, R is the more relev ant default in our setting, while C is included as the column-sided companion form. J.3 A Note on Row/Column T erminology in Prior W ork A careful comparison to prior ro w/column normalization papers requires fixing the matrix conv ention. [ 40 ] write linear weights as θ ∈ R d in × d out and define column-wise normalization along the output dimension. Under the standard deep-learning storage layout W = θ ⊤ ∈ R d out × d in , this corresponds to ro w normalization of the stored hidden-weight matrix. Their empirical observation that ro w-wise normalization can be unstable is also traced lar gely to the LM-head, where row-wise normalization produces extreme gradient values. This is not the same setting as MuonEq , which is aimed at hidden matrix weights. By contrast, [ 39 ] use the standard con vention W ∈ R d out × d in , so their ColNorm is genuinely column- wise in the same orientation as ours. Their main recommendation for language models is first-layer ColNorm, hidden-layer Spectral, and last-layer Sign. W e therefore interpret our ro w-sided default choice as directly aligned with [ 27 ], compatible with [ 40 ] after accounting for layout con v entions, and not in tension with [ 39 ] once first-layer/input geometry is separated from hidden-layer geometry . 3 https://github.com/KellerJordan/cifar10- airbench 4 https://github.com/MoonshotAI/Moonlight 31
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment