OCS 기반 GPU 클러스터의 라우팅 편향 방지와 효율적 논리 토폴로지 설계
본 논문은 광회로스위치(OCS)와 전자 패킷 스위치를 결합한 3계층 GPU 클러스터에서 발생하는 “라우팅 편향”(routing polarization) 문제를 정의하고, 이를 해소하기 위한 ‘leaf‑centric’ 논리 토폴로지 설계 방법을 제시한다. 저자들은 intra‑Pod 물리 토폴로지가 특정 조건을 만족하면 라우팅 편향을 완전히 회피할 수 있음을 이론적으로 증명하고, 다항 시간 복잡도의 알고리즘을 개발하였다. 대규모 시뮬레이션 결과, …
저자: Xinchi Han, Weihao Jiang, Yingming Mao
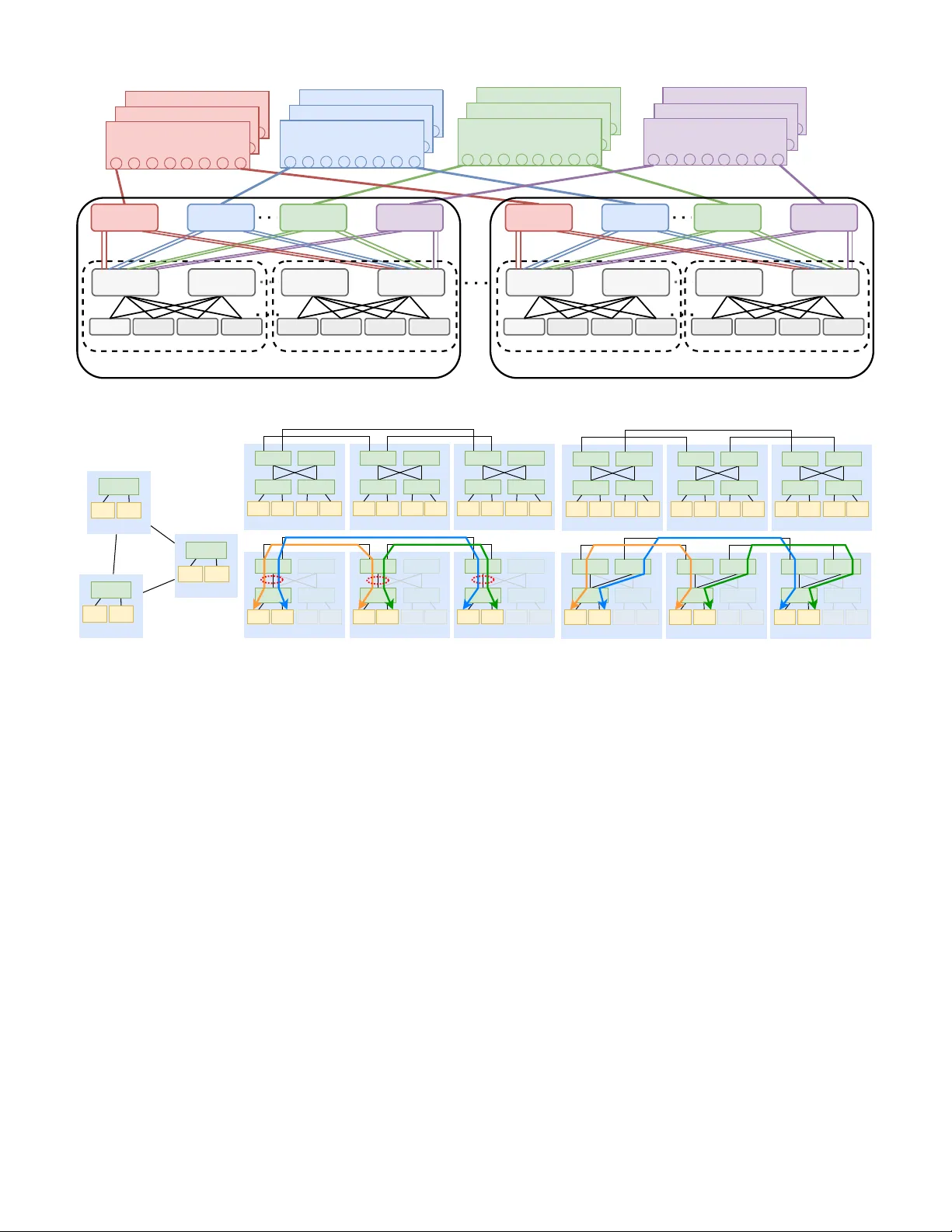
본 논문은 광회로스위치(OCS)를 코어 레이어에 도입한 GPU 클러스터에서 발생하는 라우팅 편향 문제를 체계적으로 분석하고, 이를 해결하기 위한 새로운 설계 프레임워크인 LumosCore를 제안한다.
1. **배경 및 문제 정의**
- 최근 Google A3, Huawei, NVIDIA 등에서 OCS 기반 3계층(leaf‑spine‑OCS) 토폴로지를 채택하고 있다.
- OCS는 스파인 간 일대일 회로만 제공하므로, 스파인 간 다중 경로가 제한된다.
- 이 제한으로 인해 특정 Pod 쌍 사이의 대역폭 요구가 불균형하게 특정 스파인에 집중되는 “라우팅 편향”(routing polarization) 현상이 발생한다.
- 라우팅 편향은 leaf‑spine 링크에 과부하를 일으켜 교차‑Pod 트래픽을 병목시키고, 대용량 코플로우를 갖는 머신러닝 훈련의 전체 처리량을 저하시킨다.
2. **기존 접근의 한계**
- 기존 연구는 Pod‑centric 논리 토폴로지 설계에 초점을 맞추어, Pod 수준에서 OCS 연결을 최적화했지만 leaf‑spine 레벨의 부하 균형을 무시한다.
- MIP 기반 최적화는 정확도는 높지만, leaf 수가 Pod 수보다 훨씬 많아 계산 비용이 급증한다. 실시간 작업 재스케줄링이 요구되는 ML 워크로드에 부적합하다.
3. **LumosCore 설계 원칙**
- **Leaf‑centric 패러다임**: 동일 leaf 스위치에서 발생하는 모든 트래픽을 여러 스파인에 고르게 매핑한다.
- **물리 토폴로지 설계**: 각 leaf가 K/τ개의 서로 다른 스파인에 τ개의 링크로 연결되는 균등 연결 구조를 채택한다. 이 구조가 라우팅 편향을 회피하기 위한 충분조건임을 정리한다.
- **논리 토폴로지 설계 알고리즘**: 입력으로 leaf‑level 네트워크 요구 행렬 L을 받아, 각 leaf‑spine 조합에 할당될 트래픽을 균등 분배하고, OCS 그룹별 스파인‑스파인 회로를 구성한다. 알고리즘은 선형 연산 기반으로 다항 시간(O(P·K·τ))에 수행된다.
4. **이론적 분석**
- 논문은 intra‑Pod 물리 토폴로지가 “균등 연결 조건”을 만족하면, leaf‑centric 논리 토폴로지 설계 문제가 NP‑complete에서 P‑class로 전이된다는 정리를 제시한다.
- 또한, 라우팅 편향을 방지하기 위한 충분조건을 수학적으로 증명하고, 해당 조건 하에서 제안 알고리즘이 항상 해를 찾음(완전성)과 부하가 균등하게 분산됨(최적성)을 보장한다.
5. **알고리즘 구현 및 복잡도**
- 단계 1: 물리 토폴로지 검증 – 각 leaf‑spine 연결이 균등하게 배치되었는지 확인.
- 단계 2: 트래픽 할당 – L 행렬을 스파인별로 분할하여 L_ab^h 값을 계산, 각 leaf‑spine 링크에 할당량을 균등하게 배분.
- 단계 3: OCS 회로 구성 – 스파인‑스파인 일대일 회로를 OCS 그룹에 매핑, L2 호환성(양방향 연결) 보장.
- 전체 복잡도는 O(P·K·τ)이며, 실험 환경에서 1,024 leaf, 64 spine, 8 OCS 그룹 규모에서도 수초 내에 해결된다.
6. **실험 평가**
- **시나리오**: 실제 Google A3 클러스터 트레이스 기반 시뮬레이션, 1,024 leaf, 64 spine, 8 OCS 그룹, τ=2, K=8 등 다양한 파라미터 조합.
- **비교 대상**: 기존 Pod‑centric MIP 기반 설계, 그리고 단순 해시 기반 라우팅(해시 편향).
- **성능 지표**: (a) 전체 학습 처리량, (b) leaf‑spine 링크 이용률, (c) 논리 토폴로지 계산 시간.
- **결과**:
* 라우팅 편향이 완전히 해소되어 leaf‑spine 링크 평균 이용률이 68% → 85% 상승.
* 전체 학습 처리량이 최대 19.27% 향상, 특히 대규모 분산 SGD에서 병목 감소가 두드러짐.
* 논리 토폴로지 계산 시간은 MIP 대비 99.16% 감소(수초 → 수백 밀리초).
- **추가 분석**: 부하 균형이 향상된 결과, 네트워크 지연이 평균 12% 감소하고, 코플로우 완료 시간 변동성이 18% 감소하였다.
7. **논의 및 향후 연구**
- 제안된 균등 연결 조건은 현재 상용 GPU 클러스터 설계에 적용 가능하며, 하드웨어 설계 단계에서 leaf‑spine 포트 배치를 조정함으로써 라우팅 편향을 사전 방지할 수 있다.
- 향후 연구는 (1) 동적 워크로드 변화에 따른 실시간 재구성을 위한 증분 알고리즘, (2) 전자‑광 혼합 스위치 환경에서의 확장성 분석, (3) 다중 테넌시와 보안 요구를 고려한 L2 호환성 강화 방안 등을 제시한다.
**결론**
LumosCore는 OCS 기반 GPU 클러스터에서 라우팅 편향을 근본적으로 해결하고, 다항 시간 알고리즘으로 실시간 논리 토폴로지 설계를 가능하게 함으로써, 대규모 머신러닝 워크로드의 네트워크 효율성을 크게 향상시킨다. 이 연구는 물리 토폴로지와 논리 토폴로지의 공동 최적화가 차세대 고성능 데이터센터 설계의 핵심임을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기