Avoid Routing Polarization for OCS-based GPU Clusters
Recent years have witnessed the growing deployment of optical circuit switches (OCS) in commercial GPU clusters (e.g., Google A3 GPU cluster) optimized for machine learning (ML) workloads. Such clusters adopt a three-tier leaf-spine-OCS topology, ser…
Authors: Xinchi Han, Weihao Jiang, Yingming Mao
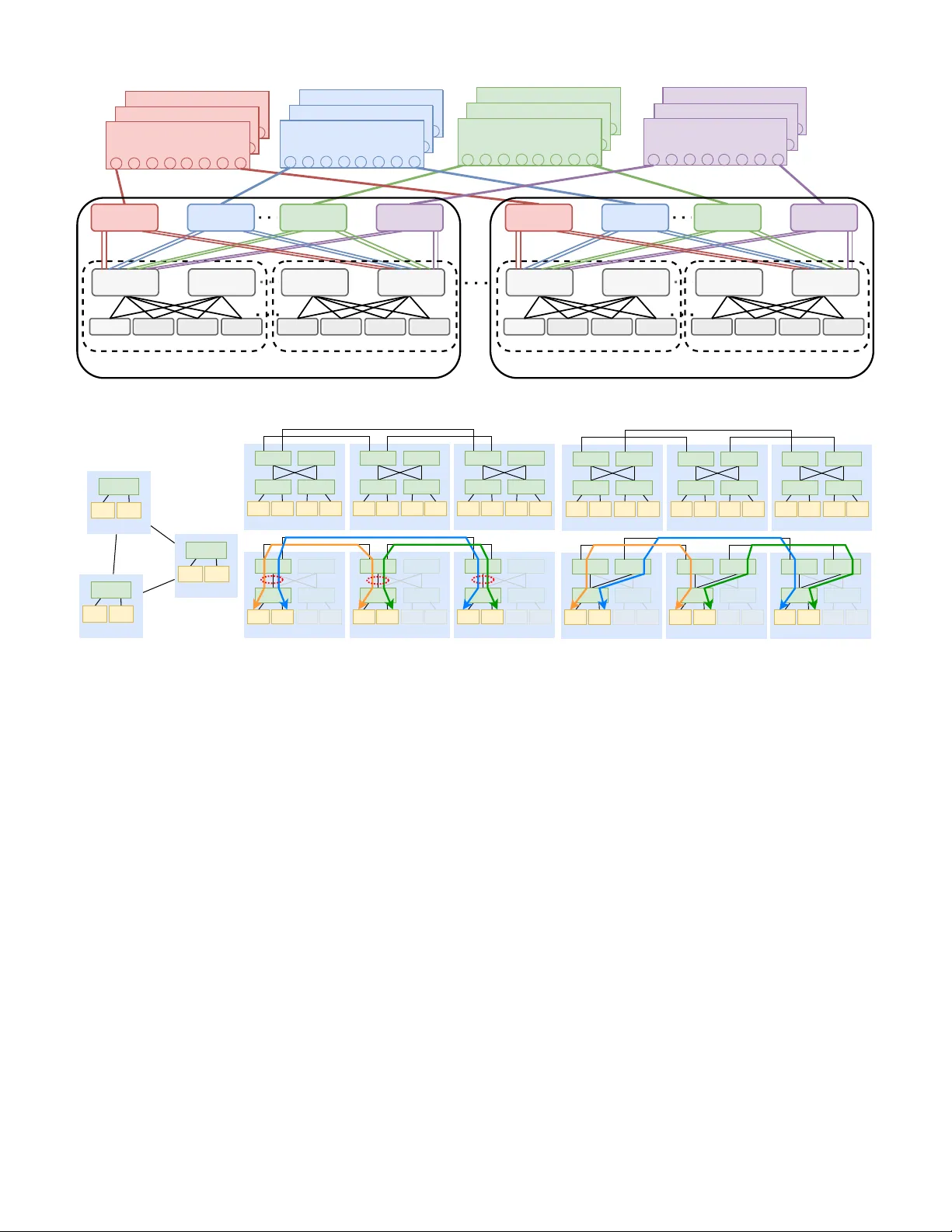
1 A v oid Routing Polarization for OCS-based GPU Clusters Xinchi Han ∥ , W eihao Jiang ∥ , Y ingming Mao † , Y ike Liu † , Zhuoran Liu ∥ , Y ongxi Lv ∥ , Peirui Cao ‡ , Zhuotao Liu § , Ximeng Liu ∥ , Xinbing W ang ∥ , Changbo W u ∗∗ , Zihan Zhu †† , W u Dongchao ¶ , Y ang Jian ¶ , Zhang Zhanbang ¶ , Y uansen Chen ¶ , Shizhen Zhao ∥ ,* ∥ Shanghai Jiao T ong University , Shanghai, China † Xi’an Jiao T ong University , Xi’an, China ‡ Nanjing University , Nanjing, China § Tsinghua University , Beijing, China ∗∗ University of Science and T echnology of China, Hefei, China & Shanghai Inno vation Institute, Shanghai, China †† University of Electr onic Science and T echnology of China, Chengdu, China ¶ Huawei, Dongguan, China hanxinchi@sjtu.edu.cn, weihao.jiang@sjtu.edu.cn, mao1234@stu.xjtu.edu.cn, cn-lyk@stu.xjtu.edu.cn, cocopromenade-9@sjtu.edu.cn, shjdblgklyx2435@sjtu.edu.cn, caopeirui@nju.edu.cn, zhuotaoliu@tsinghua.edu.cn, liuximeng@sjtu.edu.cn, xwang8@sjtu.edu.cn, wuchangbo@mail.ustc.edu.cn, 2021080911004@std.uestc.edu.cn, wudongchao@huawei.com, yangjian227@huawei.com, zhangzhanbang1@huawei.com, chengyuansen1@huawei.com, shizhenzhao@sjtu.edu.cn Abstract —Recent years ha ve witnessed the gro wing deploy- ment of optical circuit switches (OCS) in commer cial GPU clusters (e.g., Google’s A3 GPU cluster) optimized for machine learning (ML) workloads. Such clusters adopt a three-tier leaf–spine–OCS topology: servers attach to leaf-layer electronic packet switches (EPSes); these leaf switches aggregate into spine- layer EPSes to f orm a Pod; and multiple Pods ar e intercon- nected via core-lay er OCSes. Unlike EPSes, OCSes only support circuit-based paths between directly connected spine switches, potentially inducing a phenomenon termed routing polarization, which refers to the scenario where the band width requirements between specific pairs of Pods are unevenly fulfilled through links among different spine switches. The resulting imbalance induces traffic contention and bottlenecks on specific leaf-to-spine links, ultimately reducing ML training throughput. T o mitigate this issue, we intr oduce a leaf-centric paradigm to ensure traffic originating from the same leaf switch is evenly distributed across multiple spine switches with balanced loads. Through rigorous theoretical analysis, we establish a sufficient condition for avoiding routing polarization and propose a cor- responding logical topology design algorithm with polynomial- time complexity . Large-scale simulations validate up to 19.27% throughput impro vement and a 99.16% reduction in logical topology computation overhead compared to Mixed Integer Programming (MIP)-based methods. Index T erms —OCS-based GPU cluster; Architecture and de- sign of optical networks. I . I N T RO D U C T I O N I N recent years, optical circuit switches (OCS) have been increasingly adopted in cluster architectures and vendors including Google, Huawei, and NVIDIA have deployed or are acti vely e valuating OCS for GPU clusters specifically * Shizhen Zhao is the corresponding author . optimized to handle machine learning (ML) workloads [1]– [6]. Flo ws generated by ML workloads are distinguished by substantial data v olumes and complies with the coflo w property , where flows that complete transmission earlier may need to wait for those finishing later , thus rendering it highly sensitiv e to traffic contention [7]–[9]. Howe ver , unlike elec- tronic packet switches (EPSes), an OCS can only establish circuit-based paths between directly connected devices. This results in fewer a vailable routing paths for traffic tra versing the OCSes. Consequently , inadequate OCS configuration may lead to the traf fic contention caused by what we term the routing polarization issue. The routing polarization problem is an inherently unique issue to OCS-based clusters that has remained underex- plored . A typical OCS-based cluster [1], [4]–[6], [10], [11] adopts a three-tier leaf-spine-OCS architecture: specifically , servers are first connected to leaf-layer EPSes, which are further interconnected with spine-layer EPSes to form a single Pod , and multiple such Pods are interconnected via cor e- layer OCSes. Notably , an OCS is transparent to network packets, thereby enabling dynamic adjustments to the number of inter-Pod interconnection links through OCS reconfigura- tion. Follo wing prior work [10], [12], we define the Logical T opology as the interconnection pattern of spine switches, formed by the configuration of the OCS core layer . Traditional Clos-based clusters [8], [13] employ EPSes in the core layer to interconnect spine switches. By contrast, OCSes in the core layer only support the establishment of one-to-one inter - spine connections, whereas EPSes enable many-to-many inter- spine connections. This constraint can induce the Routing 2 Polarization problem 1 . Routing polarization refers to the scenario where the bandwidth requirements between specific pairs of Pods are unevenly fulfilled through links among different spine switches. W ithin a Pod, leaf switches are fully interconnected with spine switches via a limited number of links; as a result, the leaf-to-spine links connecting to spine switches with a higher density of established inter-Pod connections may become bottlenecks for cross-Pod commu- nications. In contrast, in Clos-based networks, spine switches achiev e full interconnection through core-layer EPSes, thereby av oiding such a issue. Existing works [10], [11], [14]–[16] design logical topologies based on the inter-Pod bandwidth re- quirement, overlooking the link establishment details between spine switches. Consequently , they fail to mitigate the routing polarization problem, and we term such an approach the Pod- centric logical topology design paradigm. T o address this routing polarization problem, logical topol- ogy design must ensure that traf fic originating from the same leaf switch is evenly distributed across multiple spine switches with balanced loads. W e therefore refer to this alternativ e methodology as the leaf-centric logical topology design paradigm. This shift, howe ver , is non-trivial for two critical reasons. First, the number of leaf switches far exceeds that of Pods. Adopting a leaf-centric perspectiv e can lead to a significant increase in computational overhead when relying on Mixed Integer Programming (MIP) for logical topology computation, consistent with industry practices (e.g., Google [10]). Second, we find that a poorly designed intra- Pod physical topology , specifically , the wiring configuration between leaf and spine switches within the same Pod, not only renders the leaf-centric logical topology design an NP- complete problem but also induces unavoidable routing po- larization. W e further find that when the intra-Pod physical topology satisfies certain conditions, this problem is no longer NP-Complete, which allows us to propose a polynomial-time solution. In this paper , we present LumosCore , a comprehensiv e framew ork that unifies a polynomial-time algorithm for leaf- centric logical topology design with the fundamental design principles of intra-Pod physical topologies. The principal contributions of this work are summarized as follows: • In contrast to the previous Pod-centric logical topol- ogy design algorithm [10], [14]–[17], we introduce a polynomial-time leaf-centric logical topology design al- gorithm specifically tailored to balance the traffic origi- nating from the same leaf among multiple spine switches. • Through rigorous theoretical analysis, we propose an intra-pod physical topology design and formally prov e that, under this physical topology , the proposed polynomial-time algorithm can a void routing polariza- tion . • Using large-scale simulations driven by production work- load traces, we further substantiate the superior per - formance of LumosCore, including up to a 19.27% 1 A well-recognized related issue is Hash Polarization [8], defined as a phenomenon where traf fic flo ws are unev enly distrib uted across multiple av ailable paths due to hashing-based load-balancing decisions. Notably , Hash Polarization may coexist with Routing Polarization. improv ement in training throughput compared to Pod- centric strategy and a 99.16% reduction in computational ov erhead for computing the logical topology compared to MIP-based strategy . I I . B A C K G RO U N D A N D M O T I V AT IO N A. The basic ar chitectur e of LumosCor e As illustrated in Fig. 1, LumosCore adopts a three-tier hybrid leaf–spine–OCS network architecture, analogous to designs previously deployed in large-scale GPU clusters (e.g., Google’ s A3/A4 OCS-based GPU clusters [1]–[3]). Intra-Pod Architectur e: Servers connect to the leaf switches using a commonly used Rail-Optimized configu- ration [8], enabling intra-Segment (A Segment consists of servers interconnected via the same leaf switch) communi- cation among servers via the leaf layer to reduce the inter - leaf traffic demand. Each leaf switch is provisioned with K leaf GPU-facing ports and an additional K leaf ports connected to the spine layer . More precisely , each leaf switch connects to K leaf /τ distinct spine switches, where τ denotes the number of links between each leaf and each spine within a Pod. Consequently , a single pod contains K spine /τ leaf switches and K leaf /τ spine switches. Inter -Pod Architectur e: Since each pod incorporates K leaf /τ spine switches, the architecture partitions all OCS devices into K leaf /τ disjoint groups for achieving higher scala- bility . The h -th spine switch in each pod is connected to the h - th OCS group, thereby enforcing a consistent and deterministic mapping across all pods. Each OCS group comprises K spine OCS devices, and each OCS device is equipped with one pair of egress and ingress ports that connect to distinct pods. Let K ocs denote the total number of egress/ingress port pairs per OCS device. Under this construction, up to K ocs pods can be mutually interconnected. B. Important Concepts in LumosCor e There are sev eral important concepts in LumosCor e that will be used throughout the paper . • Physical T opology characterizes the physical intercon- nection relationships among EPSes and between these switches and the OCSes. Existing work has predomi- nantly examined ho w to interconnect EPSes with the OCSes [12], [18]. In contrast, this paper focuses on de- termining ho w intra-Pod leaf and spine switches should be interconnected within a three-tier leaf–spine–OCS architecture. • Leaf-level Network Requirement quantifies the number of disjoint cross-pod paths between e very cross-pod leaf pair as Fig.2a sho ws. A Leaf-level Network Requirement is determined by the bandwidth requirements of jobs need cross-pod communication. In certain cases, we allow multiple flo ws to share one inter -Pod path if the impact of such sharing on the corresponding jobs is minimal. • Logical T opology is the topology among dif ferent spine switches, formed by configuring the OCS layer . An OCS is transparent to network packets. Thus, creating a circuit 3 OCS Group OCS Group OCS Group OCS Group Pod Segment Server Server Server Server Server Server Server Server Leaf Leaf Spine Spine Spine Spine Leaf Leaf Segment Pod Segment Server Server Server Server Server Server Server Server Leaf Leaf Spine Spine Spine Spine Leaf Leaf Segment Fig. 1: LumosCore adopts a typical three-tier topology comprising leaf layer, spine layer , and am optical core layer . E F POD 3 Leaf5 C D POD 2 Leaf3 A B POD 1 Leaf1 (a) A Leaf-level Network Requirement example A B POD 1 Spine Spine Leaf Leaf Host Host C D POD 2 Spine Spine Leaf Leaf Host Host E F POD 3 Spine Spine Leaf Leaf Host Host A B POD 1 Spine Spine Leaf Leaf Host Host C D POD 2 Spine Spine Leaf Leaf Host Host E F POD 3 Spine Spine Leaf Leaf Host Host (b) Pod-centric logical topology may introduce bottle- neck on intra-Pod links A B POD 1 Spine Spine Leaf Leaf Host Host C D POD 2 Spine Spine Leaf Leaf Host Host E F POD 3 Spine Spine Leaf Leaf Host Host A B POD 1 Spine Spine Leaf Leaf Host Host C D POD 2 Spine Spine Leaf Leaf Host Host E F POD 3 Spine Spine Leaf Leaf Host Host (c) Leaf-centric logical topology alleviates such bottle- neck by solving the routing polarization issue. Upper figur e shows the logical topology result under differ ent paradigms, lower figur e shows the routing result along with example flows under given logical topology . The bottleneck links, indicated by r ed cir cles, arise because the inter-P od bandwidth requir ements ar e unevenly fulfilled thr ough links among differ ent spine switches. Fig. 2: Pod-centric logical topology may result in the routing polarization issue. inside an OCS for two spines is equi valent to directly adding a link between these two spines. Logical T opology can be modified by reconfiguring the OCSes, which is a.k.a. T opology Engineering [10], [19], [20] . In OCS- based GPU clusers such as T opoOpt [21], whenev er a new task arri ves, the logical topology must be reconfigured to satisfy the bandwidth requirements of the ML training workload. • Routing P olarization refers to the scenario where the bandwidth requirements between specific pairs of Pods are unevenly fulfilled through links among different spine switches. W ithin a Pod, leaf switches are fully intercon- nected with spine switches through a limit number of links; consequently , the leaf-to-spine links connecting to spine switches with a higher density of established inter - Pod connections may become bottlenecks for cross-Pod communications. For instance, the logical topology in Fig. 2b satisfies the inter-Pod bandwidth requirements illustrated in Fig. 2a; howe ver , traffic originating from Leaf 1 in Pod 1 can only be transmitted to both Pod 2 and Pod 3 through Spine 1. In this case, the intra-Pod link connecting to Spine 1 in Pod 1 become the communica- tion bottleneck for cross-Pod traffic. It is noteworthy that Routing P olarization may be unavoidable if the physical topology is poorly designed. W e present an example in Fig. 3: gi ven the Leaf-level Network Requir ement illustrated in Fig. 3a, a link is established between Leaf 1 of Pod 1 and Leaf 1 of Pod 2, and another between Leaf 1 of Pod 3 and Leaf 1 of Pod 2 (see Fig. 3b). Howe ver , no additional free spine resources are a vailable to establish a link between Leaf 1 of Pod 1 and Leaf 1 of Pod 3, resulting in the unav oidable routing polarization depicted in Fig. 3c. C. Requirements for Logical T opology Design P ar adigms Logical topology design paradigms should meet the fol- lowing three requirements First, Layer 2 (L2) protocol com- patibility must be preserved. Specifically , if the ingress port 4 (a) An example of Leaf-level Network Requirement, where leaf1 in three dis- tinct Pods need to be interconnected with one bidirectional link. (b) The design of the intra-Pod physical topology may result in unavoidable routing polarization. Note that Spine 1 and Spine 2 connect to different OCS Groups. (c) The giv en physical topology may re- sult in unav oidable routing polarization, motiv ating us to further study how to design physical topology . Fig. 3: An illustrativ e example demonstrating that a poorly designed intra-Pod physical topology can give rise to inherently unav oidable routing polarization. Notably , the logical topology should meet the L2 compatibility constraint [10], [14], [15], [17], [18] which means that if the ingress port of an optical module A on a spine switch is connected to the egress port of an optical module B on another spine switch, then the egress port of A must also be connected to the ingress port of B . of an OCS-facing port A on one spine switch is connected via the OCS to the e gress port of an OCS-facing port B on another spine switch, then the egress port of A must correspondingly be connected via the OCS to the ingress port of B. This bidirectional connectivity constraint stems from the fact that standard L2 protocols (e.g., Address Resolution Protocol, ARP) una voidably assume symmetric, bidirectional links. An equiv alent constraint has also been imposed in prior OCS-based cluster deployments [10], [14], [15], [17], [18]. Second, the designed logical topology must av oid the rout- ing polarization issue. Unlik e con ventional data center netw ork (DCN) workloads, flows generated by ML workloads are characterized by large data volumes and comply with the coflow property , where flo ws completing transmission early may wait for those finishing later , making such traffic highly sensitiv e to congestion [7]–[9]. Third, the logical topology design algorithm should exhibit polynomial-time computational complexity . While companies like Google leverage MIP to solve Pod-centric logical topol- ogy design problems [10], the number of leaf switches far exceeds that of Pods, rendering the time overhead of MIP- based leaf-centric logical topology design prohibitive in large- scale clusters, particularly for ML workloads that require task-lev el recomputation of logical topologies [21], [22]. Fur- thermore, MIP solvers fall into three primary categories: (1) proprietary solvers developed in-house by tech giants (e.g., Google, Huawei) [23], [24]; (2) open-source solv ers (GLPK, LP-SOL VE, CBC) released under open-source licenses [25]– [27]; and (3) commercial solvers requiring paid licenses (Gurobi, COPT , SCIP) [28]–[30]. For small and medium- sized enterprises (SMEs) lacking the resources to build custom MIP solvers, adopting a polynomial-time algorithm for logical topology computation can significantly enhance the flexibility and practicality of deployment strategies. D. The basic model for Leaf-centric Logical topology design- ing. W e formulate an ILP (Integer Linear Programming) model to describe the designing of Leaf-centric logical topology as follows: Parameters : • P : the number of Pods in a OCS-based GPU cluster . • K spine : the number of OCS-faced ports in each spine switch. • K ocs : the number of ports in each OCS. • K leaf : the number of spine-faced ports in each leaf switch. • τ : the number of links between each leaf switch and each spine switch within a Pod. • L = [ L ab ] : The Leaf-level Network Requir ement L is generated based on the communication demand of each GPU for all tasks, where L ab means the number of required links between the a -th leaf and the b -th leaf in the cluster . Decision V ariables : • C ij h : The logical topology which means the number of connections between the h -th spine in the i -th Pod and the j -th Pod. • L abh : The number of connections between the a -th leaf and the b -th Leaf through the h -th spine in the i -th Pod and the j -th Pod, where a ∈ i -th Pod, b ∈ j -th Pod. Constraints : Giv en a Leaf-level Network Requir ement Matrix L = [ L ab ] , where L ab = L ba represents the inter-Pod network require- ment between the a -th leaf and the b -th leaf and L ab = 0 if both leaves belong to the same Pod. According to the definition, P a L ab ≤ K leaf , P b L ab ≤ K leaf . W e aim to find a Logical T opology C such that L can be scheduled without contention 2 . Note that leaf-lev el network requirements can be fulfilled via dif ferent spines. Let L abh denote the number of required links from the a -th leaf to the b -th leaf that are fulfilled by the h -th spine. The sum of the numbers of required links from the a -th leaf to the b -th leaf across all spines must then equal the 2 By “no contention”, we mean each leaf-level network requirement is fulfilled by a disjoint cross-Pod path. It is still possible for multiple flows to share one intra-Pod path. 5 total number of required links L ab between these two leav es, i.e., X h L abh = L ab . (1) Giv en L abh , we can readily compute the total number of required links from the a -th leaf to the h -th spine as P b L abh , and that from the h -th spine to the b -th leaf as P a L abh . T o av oid routing polarization , i.e., to prevent intra-Pod leaf- to-spine links from becoming communication bottlenecks, the aggregate network requirements P b L abh and P a L abh must satisfy: X b L abh ≤ τ , X a L abh ≤ τ . (2) Giv en L abh , we can compute C ij h , the total number of required links in the logical topology between the h -th spine in the i -th Pod and the h -th spine in the j -th Pod as: C ij h = X a ∈ i -th Pod X b ∈ j -th Pod L abh . (3) T o ensure compatibility with L2 protocols, we enforce the following L2-compatibility constr aint : X a ∈ i -th Pod X b ∈ j -th Pod L abh = X a ∈ i -th Pod X b ∈ j -th Pod L bah . (4) The abov e constraints (1), (2), and (4) formulate an op- timization model to deri ve the logical topology C = [ C ij h ] from the Leaf-level Network Requir ement Matrix L . This model can be solved using MIP solvers such as Gurobi [31]; howe ver , MIP incurs prohibiti ve computational costs, making it impractical for task-level OCS reconfiguration scenarios. W e therefore need to dev elop a polynomial-time algorithm for log- ical topology design. Regrettably , we prove that the problem becomes NP-complete when the intra-Pod physical topology is ill-configured, as formally demonstrated in Theorem 2.1. Theor em 2.1: The problem of designing a Leaf-centric log- ical topology is NP-complete for intra-Pod physical topologies with τ = 1 . Pr oof 1: W e prov e the NP-completeness of the proposed model with τ = 1 via a reduction by restriction. Specifically , we show that the general case of our model encompasses a special case that is polynomial-time equiv alent to the multi- coloring problem [15], [32], a well-known NP-complete prob- lem. By verifying this structural congruence and proving the NP-certificate property , we conclude the NP-completeness proof. W e impose the follo wing restrictions: • W e set τ = 1 , i.e. , there exists one link between each leaf and each spine in each Pod. • There e xists certain cases where ∃ a,b L ab > 0 . The above constraints (1)(2)(4) can be transformed as follows: X b L abh ≤ 1 , ∀ a, h (5) X a L abh ≤ 1 , ∀ b, h (6) L abh = L bah , ∀ a, b, h (7) W e consider a certain case where there exists at least a pair of ( a, b ) so that the a -th leaf and b -th leaf need at least one link ( L ab ≥ 1 , ∃ a, b ). Whene ver this condition holds, there must exist a, b ∈ V satisfying the connectivity requirement: X h L abh ≥ 1 , ∀ a, b ∈ V (8) By constructing a graph transformation where K leaf rep- resents the color palette size and each Pod pair connection ( a, b ) is modeled as a virtual node, which implies Eqs. (7), we establish correspondence with the multi-coloring prob- lem. V irtual links connect two virtual nodes precisely when their corresponding Pod pair connection ( a, b ) share common endpoints. Under this mapping, the constraint system (5)-(8) characterizes the generalized multi-coloring requirements: • Each virtual node must recei ve at least one color (Eq. (8)); • Adjacent virtual nodes require distinct color assignments (Eqs. (5)(6)). The fundamental problem can be reduced by determining the e xistence of a v alid coloring scheme using no more than K leaf colors, which is a classical NP-complete problem [32]. By restriction method [15], [33], we prov e the Theorem 2.1. This theoretical hardness, combined with the need for real- time computation, presents a significant challenge in practical deployment scenarios. Discuss: W e formally prov e that designing a logical topology is an NP-complete problem when τ = 1 . This observation motiv ates our analysis about the design of intra-Pod physical topology . E. Mathematical Pr eliminaries for LumosCore The design of LumosCore is founded on two fundamental theorems: the Symmetric Matrix Decomposition Theorem and the Integer Matrix Decomposition Theorem. These theorems play a central role in topology design and in the dev elopment of polynomial-time complexity algorithms. The Symmetric Matrix Decomposition Theorem was originally formulated and proved in [18], while the Integer Matrix Decomposition Theorem was initially introduced and established in [34]. Theor em 2.2: (Symmetric Matrix Decomposition Theor em) For any symmetric integer matrix L , there exists an integer matrix A , such that L = A + A T and ⌊ P b L ab 2 ⌋ ≤ X b A ab ≤ ⌈ P b L ab 2 ⌉ , ∀ a. ⌊ P a L ab 2 ⌋ ≤ X a A ab ≤ ⌈ P a L ab 2 ⌉ , ∀ b. Theor em 2.3: (Inte ger Matrix Decomposition Theorem) For any inte ger matrix A , there exists H integer matrices, such that A = A (1) + A (2) + · · · + A ( H ) , and for any a = 1 , . . . , I , b = 1 , . . . , J , h = 1 , 2 , . . . , H , ⌊ A ab H ⌋ ≤ A h ab ≤ ⌈ A ab H ⌉ , ⌊ P a A ab H ⌋ ≤ X a A h ab ≤ ⌈ P a A ab H ⌉ , 6 ⌊ P b A ab H ⌋ ≤ X b A h ab ≤ ⌈ P b A ab H ⌉ . I I I . P AT H T O L E A F - C E N T R I C L O G I C A L T O P O L O G Y D E S I G N P A R A D I G M Drawing upon the modeling framework introduced in § II-D, it is evident that the configuration of the intra-Pod physical architecture directly impacts the synthesis of the logical topol- ogy design. This section therefore details the design rationale underlying the leaf-centric logical topology design paradigm and characterizes the specific intra-Pod physical architecture conditions under which the corresponding design problem admits a polynomial-time solution for any gi ven valid Leaf- level Network Requir ement Matrix . A. Leaf-centric Logical T opology Design P ar adigm 1) A P olynomial-T ime Algorithm for Logical T opology De- sign: W e propose a Heuristic-Decomposition algorithm that constructs a logical topology C from the Leaf-level Network Requir ement Matrix L with polynomial time complexity . Step 1: By applying the Symmetric Matrix Decomposition Theorem (Theorem 2.2), we decompose L as L = A + A T , where the matrix A satisfies X b A ab ≤ l P b L ab 2 m , X a A ab ≤ l P a L ab 2 m . Step 2: Using the Integer Decomposition Theorem (Theorem 2.3), we further decompose A into H = K leaf /τ submatrices A (1) , A (2) , . . . , A ( H ) such that A = A (1) + A (2) + · · · + A ( H ) , and, for each h ∈ { 1 , . . . , H } , X a A h ab ≤ l P a A ab H m , X b A h ab ≤ l P b A ab H m . Step 3: Define L abh = A h ab + A h ba . The logical topology C ij h is then computed from { L abh } according to (3). B. T ime Complexity Analysis of Heuristic-Decomposition Al- gorithm Let the number of leav es in the cluster be denoted by η = K spine × P τ , where P is the number of Pods. The time complexity of each step in Algorithm 1 is analyzed as follows: • Step 1 : Construct a multi-commodity flow (MCF) model following [35], with time complexity O ( η 6 log η ) . • Step 2 : Construct an MCF model as described in [19], with time complexity O ( K leaf η 4 log η ) . • Step 3 : Direct computation of L abh and logical topology C ij h , with time complexity O ( K leaf η 2 ) . Since K leaf < η , by applying the Master Theorem [36], the overall time complexity of the Heuristic-Decomposition algorithm is dominated by Step 1 and is therefore O ( η 6 log η ) . Algorithm 1 Heuristic-Decomposition for Leaf-centric Logi- cal T opology Design Require: Leaf-lev el Network Requirement Matrix L , K spine , P , τ , K leaf Ensure: Logical topology C = { C ij h } 1: Step 1: Symmetric Matrix Decomposition of L 2: Compute A by decomposing L so that A + A T = L (via Symmetric Matrix Decomposition Theorem 2.2) 3: Step 2: Integer Decomposition of Matrix A 4: Compute H = K leaf τ 5: Compute A ( h ) by decomposing A so that P H h =1 A ( h ) = A (via Integer Decomposition Theorem 2.3) 6: Step 3: Construct Logical T opology 7: For all leaf nodes a, b and h ∈ { 1 , . . . , H } , compute L abh = A ( h ) ab + A ( h ) ba 8: For all Pod indices i, j and h ∈ { 1 , . . . , H } , compute logical topology via: 9: C ij h = P a ∈ i -th Pod P b ∈ j -th Pod L abh (via Eq.(3)) 10: return C C. How to design intra-P od ar chitectur e When designing the intra-Pod architecture, we follo w the leaf-spine structure commonly adopted in commercial cluster deployments [8], [10], [37], where leaf and spine switches are interconnected through a uniform full-mesh topology , as shown in Fig.1. In this section, we concentrate on the selection of the parameter τ , which denotes the number of links established between leaf and spine switches within a single Pod. When τ = 2 , implying that each leaf switch is connected to each spine switch within the same Pod via two parallel links, it follows directly from the inequalities established in Step 1 and Step 2 in § III-A1 that the solution produced by the Heuristic- Decomposition algorithm satisfies constraints (1), (2), and (4). This result is formally stated in Theorem 3.1. Given an OCS with a port count of K ocs , a three-tier OCS-based cluster can accommodate at most K leaf ∗ K spine ∗ K ocs /τ GPUs. Thus, a smaller value of τ allo ws the cluster to host a larger number of GPUs. Howe ver , setting τ = 1 may lead to the routing polarization issue. Therefore, according to Theorem 3.1, we set τ = 2 when designing intra-Pod architecture in LumosCore. Theor em 3.1: When τ = 2 , for any Leaf-le vel Network Requirement Matrix L , the solution produced by the Heuristic- Decomposition algorithm satisfies all constraints (1), (2), and (4). Equiv alently , there exists a logical topology L such that L can be scheduled without incurring any the routing polarization issue. Pr oof 2: Consider a leaf-le vel network demand matrix L , where L a,b denotes the traf fic requirement from the a -th leaf node to the b -th leaf node. By the theory of symmetric matrix decomposition, there exists a matrix A such that L a,b = A ab + A ba , for all leaf indices a, b . 7 Moreov er, the row and column sums of A are constrained by the following bounds: P a L a,b 2 ≤ X a A ab ≤ P a L a,b 2 , for ev ery column inde x b , and P b L a,b 2 ≤ X b A ab ≤ P b L a,b 2 , for ev ery row index a . These inequalities ensure that the aggre gated incoming and outgoing components encoded in A approximate, up to a rounding of at most one unit, half of the corresponding total demand specified by L . By applying Integer Matrix Decomposition Theorem on A , we can further decompose it into a three-dimensional tensor A h ab satisfying: X h A h ab = A ab A ab K leaf /τ ≤ A h ab ≤ A ab K leaf /τ P a A ab K leaf /τ ≤ X a A h ab ≤ P a A ab K leaf /τ P b A ab K leaf /τ ≤ X b A h ab ≤ P b A ab K leaf /τ W e then define L abh as: L abh = A h ab + A h ba T o complete the proof of Theorem 3.1, we verify that L abh satisfies constraints (1), (2), and (4). Constraint (1) V erification: X h L abh = X h ( A h ab + A h ba ) = A ab + A ba = L a,b Thus, constraint (1) is satisfied. Constraint (2) V erification: X a L abh = X a ( A h ab + A h ba ) Using the bounds derived earlier: X a L abh ≤ P a A ab K leaf /τ + P a A ba K leaf /τ Since P a A ab + P a A ba ≤ P a L a,b , we can derive: X a L abh ≤ 2 · P a L a,b 2 · K leaf /τ Similarly , we ha ve: X b L abh ≤ 2 · P b L a,b 2 · K leaf /τ Clearly , when τ = 2 , we can derive: X a L abh ≤ 2 X b L abh ≤ 2 This confirms that constraint (2) holds when τ = 2 . Constraint (4) V erification: X a X b L abh = X a X b ( A h ab + A h ba ) = X a X b L bah Thus, constraint (4) is satisfied. Since L abh satisfies constraints (1), (2), and (4), Theorem 3.1 is proved. Remark: Handle the case when τ =1 In certain scenarios, for instance, when a Pod has already been deployed and alterations to its topology are impractical, or when the cluster must scale to a very large size, it is still necessary to consider the setting in which the network is configured with τ = 1 . Under this configuration, the Heuristic- Decomposition algorithm described above can guarantee a maximum contention le vel of at most 2 , as Inequality (2) is no longer satisfied. This upper bound of 2 is in fact tight, as we hav e identified multiple instances of L for which the model (1)(2)(4) admits no feasible solution when τ = 1 (see Fig. 3). Nonetheless, as established by Theorem 3.2, contention-free schedules remain attainable provided that additional structural constraints are imposed on L . Theor em 3.2: For the special case τ = 1 , consider any matrix L such that ∀ a, P b L ab ≤ K leaf /τ 2 and ∀ b, P a L ab ≤ K leaf /τ 2 . Under these conditions, the model of equations (1), (2), and (4) admits a feasible solution that can be computed in time polynomial time. Theorem 3.2 demonstrates that, under τ = 1 , minimiz- ing cross-pod, inter-leaf communication demand is a critical design objectiv e for specifying Leaf-lev el Network Require- ments. This objecti ve can be realized through judicious GPU resource scheduling. T o establish Theorem 3.2, we consider a simple greedy assignment procedure. When the conditions stated in The- orem 3.2 are satisfied, we can greedily assign each leaf- lev el network requirement to an unoccupied spine switch. Concretely , suppose a network requirement must be satisfied between leaf switch a and leaf switch b . If leaf switch a has previously utilized at most K leaf 2 − 1 distinct spine switches for communication, and the same holds for leaf switch b , then there exist at least two spine switches that are simultaneously av ailable to satisfy the network requirement between leaf switches a and b . Consequently , such a greedy strategy ensures a feasible contention-free assignment. The time complexity of this greedy algorithm is O ( K leaf × η ) . I V . L A R G E S C A L E S I M U L A T I O N A. Simulation Setup T o address the computational inefficienc y of packet-lev el fine-grained network simulators [38], which can take days to 8 simulate a single ML task trace on a cluster contains 64 GPUs, we adopt RapidAISim, a coarse-grained flow-le vel simulator specifically tailored for OCS-based GPU clusters. W e conduct a comprehensiv e performance ev aluation across four cluster scales (2,048-GPU, 4,096-GPU, 8,192-GPU, and 16,384-GPU) to assess scalability and efficienc y . The OCS- based clusters integrate 32-port EPSes with 256-port MEMS- OCS. Our comparativ e ev aluation includes: (1) Leaf-centric approach with τ = 2 and τ = 1 ; (2) the Pod-centric approach used in works like Jupiter Evolving [10], [14], which lev erages inter-Pod link demands and MIP (with the high- performance Gurobi optimization library [31] adopted as the MIP solver) to generate logical topologies; (3) the widely adopted 3-tier Clos architecture without ov ersubscription [8], [39]–[41] (equipped with common EPSes using Broadcom BCM56980 [42] switch chip which provides 12.8 Tbps switch capacity); and (4) A classic OCS-based cluster Helios [43] which utilizes bipartite graph matching of traf fic features for T oE. W e make the following hardware assumptions: eight GPUs per server are interconnected via an intra-node fabric with 400 Gbps aggregate bandwidth, and inter-node GPU communication defaults to a 200 Gbps RDMA network [1], [44]. W e generate 1000 ML tasks based on the SenseTime dataset [39], with scheduling constraints: T ensor Parallelism (TP) traffic is confined to a single server , and Expert Parallelism (EP) traffic is restricted within a single Pod. T ask arri val intervals follo w a Poisson distribution, with adjustments to en- sure comparable workloads across architectures. W e quantify cluster load using the workload level , calculated via Equation (9), where λ k denotes the arriv al rate of jobs requiring k GPUs and T k represents their av erage runtime. Notably , k × λ k × T k corresponds to the expected GPU time occupied by jobs requiring k GPUs. W e set the workload lev el to 0.767 by default. Equal-cost multi-path routing (ECMP) [45] is adopted as the default load-balancing strategy . W e adopt the standard MurmurHash3 [46] algorithm as the hash function, and use the fi ve-tuple (source IP address, destination IP address, source port, destination port, and transport layer protocol) as the hash factor . W orkload-lev el = P k k ∗ λ k ∗ T k GP U N um (9) Performance e valuation is conducted through three key metrics: av erage job runtime ( Av g.J RT ), and average job completion time ( Av g .J C T ), where for each job J RT = T f − T s , and J C T = T f − T a with T a , T s , and T f representing the job’ s arriv al time, initiation time, and termination time respectiv ely . T o establish a theoretical upper bound for cluster performance assessment, we propose a hypothetical network topology featuring an idealized spine switch with unlimited port capacity , directly interconnecting all leav es under the Best architecture. The JR T v alues achiev ed in this optimal scenario are denoted as J RT B est for comparative analysis, while the performance degradation ratios are calculated as J RT − J RT Best J RT Best for the slow do wn ratio of JR T of each task. Leaf-centric( =2) Leaf-centric( =1) Pod-centric( =2) Pod-centric( =1) Helios Clos 0% 50% 100% 0.90 0.95 1.00 (a) CDF of JR T slow down ratio compared to Best Rehashing ECMP 3 . 0 3 . 5 4 . 0 4 . 5 A vg. JCT(s) × 1 0 4 (b) Performance under different load balance strategies 0.705 0.731 0.767 0.796 W orkload Level 3 . 0 3 . 5 4 . 0 4 . 5 5 . 0 A vg. JCT(s) × 1 0 4 (c) A vg.JCT under dif ferent workload-le vel. 2k 4k 8k 16k Cluster Scale (Number of GPUs) 2 . 0 2 . 2 2 . 4 A vg. JR T(s) × 1 0 4 (d) A vg.JR T under different clus- ter size. Fig. 4: The comparativ e performance of the ev aluated strate- gies highlights the critical role of leaf-centric logical topology design and intra-Pod physical topology design. Unless other- wise specified, the workload lev el is fixed at 0.767, and the cluster configuration comprises 8,192 GPUs by default. B. P erformance Analysis Fig. 4a presents the CDF of the JR T slowdo wn ratio across different strategies for an 8k-scale GPU cluster . Notably , the Leaf-centric strategy with τ = 2 outperforms all other approaches: compared to the Pod-centric strategy ( τ = 2 ), it achieves a maximum JR T reduction of 19.27%, with 4% of jobs experiencing a substantial JR T improv ement (exceeding 5%). Giv en that most jobs in the public dataset [39] are small and do not in volve cross-Pod communication, we further focus on large jobs requiring cross-P od communication : for this subset, the average JR T is reduced by 2.34%, and 16.67% of jobs achiev e a significant JR T reduction (exceeding 5%). This underscores that the Leaf-centric strategy effecti vely av oid routing polarization. W e further compare the Leaf-centric strategy under different intra-Pod configurations ( τ = 1 vs. τ = 2 ). For jobs with cross-Pod communication, Leaf-centric ( τ = 2 ) achiev es a maximum JR T reduction of 13.98% relati ve to Leaf-centric ( τ = 1 ), with 19.44% of tasks experiencing a JR T reduction exceeding 5%. This demonstrates that intra-Pod architectural design exerts a significant impact on ov erall cluster perfor- mance, when τ = 1 , constructing an effecti ve leaf-centric logical topology may be infeasible. It is worth noting that for suboptimal physical topology designs with τ = 1 , while the Leaf-centric strategy still pro vides marginal benefits, traffic contention remains a critical issue, this further emphasizes the paramount importance of rational physical topology design. Helios [43] exhibits suboptimal performance in large-scale clusters or at high workload levels, a phenomenon attributable to the increased complexity of logical topology computa- tion under intricate traffic characteristics, simple greedy-based strategies thus struggle to cope with such scenarios effecti vely . 9 Furthermore, Leaf-centric ( τ = 2 ) delivers performance com- parable to the Clos fabric while incurring substantially lower costs. The long-tail effect of JR T in Leaf-centric ( τ = 2 ) is significantly shorter , primarily because the Leaf-centric ( τ = 2 ) architecture only employs two tiers of EPSes, whereas the Clos fabric incorporates more tiers, thus incurring fewer hash function in vocations for the former . Con versely , a greater number of hash tiers can induce more severe Hash Polarization [8]. As illustrated in Fig. 4c, the proposed strategy yields ev en more pronounced improv ements in average A vg. JCT compared to A vg. JR T . This aligns with queueing theory [47], which posits that reductions in task queuing time can be substantially larger than those in task running time. C. Robustness Analysis Perf ormance under different load balancing strategies: T raffic load balancing strategies ex ert a profound impact on traffic contention caused by hash polarization. Beyond the widely adopted ECMP strategy , we additionally incorporate a rehash-based ECMP scheme (implemented in Alibaba’ s A CCL library [9], a strategy that mitigates the Hash Polarization problem by performing multiple rounds of hashing and se- lecting the least congested path, denoted as Rehashing ). As shown in Fig. 4b, more effecti ve load balancing strate gies yield reductions in average JR T across all approaches; ho wev er, the Leaf-centric method with τ = 2 remains superior to the other other OCS-based cluster designs. Perf ormance under different workload-level: W orkload ex erts a notable impact on the performance of different strate- gies. T o quantify this effect, we generate distinct datasets by adjusting λ k (the arriv al rate of jobs requiring k GPUs). As shown in Fig. 4c, the Leaf-centric strategy with τ = 2 consistently outperforms all other OCS-based cluster designs across datasets with varying workload le vels. Perf ormance across clusters of different scales: In indus- trial settings, cluster sizes often fluctuate ov er time in response to e volving workload demands [19]. Assessing the scalability of our strategy across varying cluster sizes is therefore critical. The results presented in Fig. 4d demonstrate that our strate gy sustains a consistent performance adv antage across compared with other OCS-based cluster designs di verse cluster scales. D. A vailability Analysis Unlike traditional DCN workloads, ML workloads often require job-le vel reconfiguration [21], resulting in JCT being directly tied to the o verhead of logical topology computation. As shown in Fig. 5, we ev aluate and compare the computa- tional ov erhead of logical topology deriv ation for our proposed LumosCore, alongside the MIP-based Pod-centric and leaf- centric approaches, across dif ferent cluster scales. When the cluster size reaches 16K, the MIP-based leaf-centric logical topology approach incurs an average computation time of 541.76 seconds, whereas our approach incurs merely 4.57 seconds on av erage. This 99.16% reduction in computational ov erhead highlights the efficienc y and ef ficacy of our algorith- mic design. Our proposed logical topology design algorithm 2k 4k 8k 16k Cluster Scale (Number of Nodes) 0 . 0 0 0 . 0 1 0 . 1 0 1 . 0 0 A vg. Over head (S) × 1 0 2 L eaf -centric( =2)+MCF P od-centric( =2)+MIP L eaf -centric( =2)+MIP Fig. 5: Comparativ e analysis of average time ov erhead in logical topology design achiev es a 6.26% reduction in average JCT for an 8k-scale cluster , in comparison with the MIP-based leaf-centric logical topology design approach. V . R E L A T E D W O R K A. Handle the hash polarization pr oblem Hash P olarization mitigation has emerged as a promi- nent research direction in GPU cluster network design, with numerous works addressing this challenge through diverse technical avenues. For instance, vClos [7], [48] mitigates com- munication bottlenecks by analyzing the traf fic characteristics of communication primitives and redesigning the underlying algorithms accordingly . Alibaba’ s HPN and other works [8], [49] minimizes cross-leaf traffic demand via a rail-optimized architectural design. A CCL [9] tackles traffic contention from the load-balancing perspective, lev eraging multi-choice hash- ing techniques to select the least congested paths dynamically . Our work, by contrast, focuses on mitigating the Routing Polarization problem specifically induced by OCS deploy- ments in GPU clusters. This unique focus makes our approach complementary to existing solutions, and it can be seamlessly integrated with these methods handling hash polarization to further enhance network performance. B. Designing of Curr ent OCS-based GPU Cluster The first large-scale commercial deployment of MEMS- OCS in production clusters was documented in Google’ s MinRewiring study , published in 2019 [19]. The primary objectiv e of MinRewiring was to reduce the rewiring overhead associated with dynamic cluster scaling by exploiting the re- configurability of MEMS-OCS. Building on this line of work, Google’ s Jupiter Ev olving architecture, presented in 2022 [10], introduced a three-tier OCS-based topology . This design satis- fies the traffic requirements of DCN workloads through traffic- aware logical topology construction and systematic topology engineering. With the rapid emergence of AI-oriented clusters, Google further employed similar architectures in its A3 and A4 [1]–[3] GPU clusters, lev eraging the reconfigurable prop- erties of OCS to accommodate the communication patterns and bandwidth demands of ML workloads. Simultaneously , companies such as NVIDIA [4] and Huawei [6] hav e also initiated research and dev elopment of GPU clusters optimized 10 for ML workloads using analogous OCS-based architectural principles. Prior studies, including TPUv4 [22], T opoOpt [21], MixNet [50], and InfiniteHBD [51], also in vestigate the design of OCS-based GPU cluster architectures, yet they primarily focus on systems with a limited number of network layers. Conse- quently , these works do not encounter the routing polarization issue that emer ges in the three or more tier OCS-based GPU clusters, the primary focus of this study . Ho wever , when these approaches are integrated with RDMA (Remote Direct Memory Access)-enabled networks [8] for cluster scaling (e.g., as exemplified by Google’ s presentation at OFC 2025 [52]), these issues become non-negligible and thus demand careful consideration. While companies such as Google [1], [3]–[6] have designed and ev en commercially deployed the three-tier OCS-based GPU clusters, they hav e not mentioned the problem of the routing polarization issue that this paper seeks to resolve. In this paper , we introduce a leaf-centric logical topology design methodology for OCS-based clusters. The proposed approach is specifically tailored to alleviate traffic contention on leaf- to-spine links, thereby improving the overall performance and scalability of OCS-based deployments. W orks like Interlea ved W iring [12], [18] ha ve in vestigated the design of inter-Pod physical topologies; howe ver , the de- sign of intra-Pod physical topologies and strategies to mitigate routing polarization remain open for further inv estigation. Our work can be integrated with these studies to guide the deployment of OCS-based GPU clusters. C. The tr affic pattern of ML workloads According to publicly av ailable information, Google has adopted OCS in three-tier OCS-based GPU clusters [1]. In contrast to DCN workloads, AI workloads are typically char- acterized as highly ske wed yet structurally regular due to the design of their underlying communication algorithms [4], [21]. This inherent regularity provides an opportunity to engineer OCS-based GPU clusters in a principled manner [4], [50]. A representativ e ML training workload can be abstracted under the T ensor Parallelism–Pipeline Parallelism–Data Paral- lelism–Expert Parallelism (TP–PP–DP–EP) paradigm as Fig.6 shows [53]. Among these, T ensor Parallelism (TP) is usually confined within a single server (or node) because of its extremely high communication volume, which makes intra- server communication preferable [37]. Expert Parallelism (EP) is commonly designed to be locality-aware and can be de- composed into multiple relatively independent communica- tion domains [50]. Although the all-to-all traffic induced by Mixture-of-Experts (MoE) layers in EP does not strictly follo w a perfectly regular pattern [50], EP communication domains are typically small. Therefore, in works such as MixNet [50], OCS reconfiguration can be exploited to accommodate the communication requirements of the EP communication domain. Data Parallelism (DP) and Pipeline Parallelism (PP) [53] communications typically exhibit stronger and more pre- dictable re gularity . This regularity enables the construction of Server 1 0 1 2 3 4 5 6 7 Server 2 0 1 2 3 4 5 6 7 Server 16 0 1 2 3 4 5 6 7 Pod 1 EP EP TP TP TP Server 1 0 1 2 3 4 5 6 7 Server 2 0 1 2 3 4 5 6 7 Server 16 0 1 2 3 4 5 6 7 Pod 2 EP EP TP TP TP PP PP PP Server 1 0 1 2 3 4 5 6 7 Server 2 0 1 2 3 4 5 6 7 Server 16 0 1 2 3 4 5 6 7 Pod 32 EP EP TP TP TP PP PP PP DP DP Fig. 6: Communication Pattern for Megatr on [53] with 4096 GPUs suitable leaf-lev el network requirement for the correspond- ing communication domains prior to job execution [21], [51].Overall, informed by existing industrial deployments such as those of Google, we infer that designing OCS-based GPU clusters is a technically viable and practically deployable solution. V I . D I S C U S S I O N Generating Leaf-level Network Requirement : While this paper primarily focuses on the details of logical topology design, we hav e not elaborated on the generating of the Leaf- level Network Requir ement Matrix . In fact, to minimize inter- leaf link demands as much as possible, it is essential to dev elop sophisticated communication algorithms and communication domain orchestration mechanisms. These critical components will be thoroughly detailed in our future work, where we will systematically address their design principles, implementa- tion frameworks, and performance implications for large-scale GPU cluster architectures. V I I . C O N C L U S I O N In this paper, we in vestigate logical topology design strate- gies for OCS-based GPU clusters and analyze how to design the intra-pod physical topology . Focusing on the pre viously ov erlooked yet inevitable issue of routing polarization in three- tier OCS-based GPU clusters, we develop a polynomial-time logical topology design strategy based on theoretical analy- sis. Furthermore, we propose an intra-pod physical topology design methodology that guarantees, for any gi ven leaf-lev el traffic matrix, the computation in polynomial time of a logical topology that av oids these routing polarization issue. R E F E R E N C E S [1] Google Cloud, “Introducing a3 supercomputers with n vidia h100 gpus, ” https://cloud.google.com/blog/products/compute/ introducing- a3- supercomputers- with- n vidia- h100- gpus, October 2023, accessed: 2025-04-05. [2] G. Cloud, “Kubernetes engine in ai infra, ” https://docs.cloud.google. com/kubernetes- engine/docs/integrations/ai- infra?hl=zh- cn. [3] Google, “Schedule gk e workloads on ai hypercomputer, ” https://docs.cloud.google.com/ai- hypercomputer/docs/workloads/ schedule- gke- workloads- tas. [4] G. Patronas, N. T erzenidis, P . Kashinkunti, E. Zahavi, D. Syrivelis, L. Capps, Z.-A. W ertheimer , N. Argyris, A. Fevgas, C. Thompson, A. Ganor , J. Bernauer , E. Mentovich, and P . Bakopoulos, “Optical switching for data centers and advanced computing systems, ” J. Opt. Commun. Netw . , vol. 17, no. 1, pp. A87–A95, Jan 2025. [Online]. A v ailable: https://opg.optica.org/jocn/abstract.cfm?URI=jocn- 17- 1- A87 11 [5] H. E. Business, “Huawei launches data center all-optical switch optixtrans dc808, ” Huawei Enterprise Business News, September 2024, accessed: 2025-08-28. [Online]. A vailable: https://e.huawei.com/cn/ news/2024/industries/grid/all- optical- switch- optixtrans- dc808 [6] Huawei. (2025, 6) All-optical switching technology empo wers the construction of a new generation of optoelectronic fusion intelligent computing networks. Huawei Official Blog. [Online]. A v ailable: https://e.huawei.com/cn/blogs/2025/solutions/ enterprise- optical- network/optical- switch- intelligent- computing [7] X. Han, S. Zhao, Y . Lv , P . Cao, W . Jiang, Q. Y ang, Y . Liu, S. Lin, B. Jiang, X. Liu et al. , “vclos: Network contention aware scheduling for distributed machine learning tasks in multi-tenant gpu clusters, ” Computer Networks , p. 111285, 2025. [8] K. Qian, Y . Xi, J. Cao, J. Gao, Y . Xu, Y . Guan, B. Fu, X. Shi, F . Zhu, R. Miao et al. , “ Alibaba hpn: A data center network for lar ge language model training, ” in Pr oceedings of the ACM SIGCOMM 2024 Confer ence , 2024, pp. 691–706. [9] J. Dong, S. W ang, F . Feng, Z. Cao, H. Pan, L. T ang, P . Li, H. Li, Q. Ran, Y . Guo et al. , “ Accl: Architecting highly scalable distributed training systems with highly efficient collective communication library , ” IEEE micr o , vol. 41, no. 5, pp. 85–92, 2021. [10] L. Poutievski, O. Mashayekhi, J. Ong, A. Singh, M. T ariq, R. W ang, J. Zhang, V . Beauregard, P . Conner, S. Gribble et al. , “Jupiter evolving: transforming google’ s datacenter network via optical circuit switches and software-defined networking, ” in Proceedings of the A CM SIGCOMM 2022 Confer ence , 2022, pp. 66–85. [11] P . Cao, S. Zhao, M. Y . The, Y . Liu, and X. W ang, “T rod: Evolving from electrical data center to optical data center , ” in 2021 IEEE 29th International Conference on Network Protocols (ICNP) . IEEE, 2021, pp. 1–11. [12] S. Zhao, P . Cao, and X. W ang, “Understanding the performance guaran- tee of physical topology design for optical circuit switched data centers, ” Pr oceedings of the A CM on Measurement and Analysis of Computing Systems , vol. 5, no. 3, pp. 1–24, 2021. [13] A. Singh, J. Ong, A. Agarwal, G. Anderson, A. Armistead, R. Bannon, S. Boving, G. Desai, B. Felderman, P . Germano et al. , “Jupiter rising: A decade of clos topologies and centralized control in google’ s datacenter network, ” Communications of the ACM , vol. 59, no. 9, pp. 88–97, 2016. [14] M. Zhang, J. Zhang, R. W ang, R. Govindan, J. C. Mogul, and A. V ahdat, “Gemini: Practical reconfigurable datacenter networks with topology and traffic engineering, ” arXiv e-prints , 2021. [15] Q. Lv , Y . Zhang, S. Zhang, R. Li, K. Meng, B. Zhang, F . Huang, X. Chen, and Z. Zhu, “On the tpe design to efficiently accelerate hitless reconfiguration of ocs-based dcns, ” IEEE Journal on Selected Areas in Communications , pp. 1–1, 2025. [16] P . Cao, S. Zhao, D. Zhang, Z. Liu, M. Xu, M. Y . T eh, Y . Liu, X. W ang, and C. Zhou, “Threshold-based routing-topology co-design for optical data center, ” IEEE/ACM T ransactions on Networking , vol. 31, no. 6, pp. 2870–2885, 2023. [17] X. Dong, H. Y ang, Y . Zhang, X. Xie, and Z. Zhu, “On scheduling dml jobs in all-optical dcns with in-network computing, ” in GLOBECOM 2024 - 2024 IEEE Global Communications Conference . [18] X. Han, S. Zhao, Y . Lv , P . Cao, W . Jiang, S. Lin, and X. W ang, “ A highly scalable llm clusters with optical interconnect, ” arXiv preprint arXiv:2411.01503 , 2024. [19] S. Zhao, R. W ang, J. Zhou, J. Ong, J. C. Mogul, and A. V ahdat, “Minimal rewiring: Efficient liv e expansion for clos data center net- works, ” in 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19) , 2019, pp. 221–234. [20] P . Cao, S. Zhao, M. Y . The, Y . Liu, and X. W ang, “T rod: Evolving from electrical data center to optical data center , ” in 2021 IEEE 29th International Conference on Network Protocols (ICNP) , 2021, pp. 1–11. [21] W . W ang, M. Khazraee, Z. Zhong, Z. Jia, D. Mudigere, Y . Zhang, A. Ke witsch, and M. Ghobadi, “T opoopt: Optimizing the network topology for distributed dnn training, ” arXiv pr eprint arXiv:2202.00433 , 2022. [22] N. Jouppi, G. Kurian, S. Li, P . C. Ma, R. Nagarajan, L. Nai, N. Patil, S. Subramanian, A. Swing, and B. T owles, “Tpu v4: An optically recon- figurable supercomputer for machine learning with hardware support for embeddings, ” Pr oceedings of the 50th Annual International Symposium on Computer Arc hitecture , 2023. [23] L. Perron and V . Furnon, “Or-tools, ” Google.[Online]. A vailable: https://developers. google. com/optimization , 2019. [24] H. T . Lab, “T aylor solver: A high-performance mathematical programming solv er for large-scale and embedded scenarios, ” Online Resource, n.d., proprietary solver de veloped by Huawei TCS Lab, supporting the solution of mixed-inte ger programming (MIP), linear programming (LP), quadratic programming (QP), nonlinear programming (NLP), and satisfiability problems. It adopts the MIX ORCS Search framework integrating operations research (OR) and computer science (CS) technologies, capable of handling integer programming problems with tens of millions of variables and achieving millisecond-lev el solving for embedded nonlinear problems. Currently deployed across dozens of scenarios in Huawei’ s product lines including wireless communications, data communications, optics, cloud core, and HiSilicon, with performance outperforming other commercial solvers. [Online]. A v ailable: https://www .tcs- lab.com/zh/solv er/ [25] G. Project, “Glpk (gnu linear programming kit), ” Online Resource, 2012, open-source callable library written in ANSI C for solving large- scale linear programming (LP), mixed-integer programming (MIP), and related optimization problems. Core components include primal/dual simplex methods, primal-dual interior-point method, branch-and-cut method, GNU MathProg modeling language translator , application program interface (API), and stand-alone LP/MIP solver . Distributed via GNU FTP servers and mirrors; maintained by mao@gnu.org. [Online]. A v ailable: https://www .gnu.org/software/glpk/ [26] lp-solve Development T eam, “lp solve: Mixed integer linear pro- gramming (milp) solver , ” https://github.com/lp- solv e/lp solve, accessed: 2024-10-24. [27] C.-O. Project and J. Forrest, “Cbc user guide: Coin branch and cut solver , ” Online Resource, 2005, open-source mixed-integer programming (MIP) solver written in C++, implementing the branch- and-cut algorithm. Relies on the COIN Open Solver Interface (OSI) for LP solver integration and the COIN Cut Generation Library (CGL) for cut generators. The user guide details core functionalities including CbcModel class, node selection, branching strategies (pseudo cost, follow-on branching), heuristics, and quadratic MIP support. Last revised May 10, 2005. [Online]. A v ailable: https://www .coin- or .org/Cbc/cbcuser guide.html [28] L. Gurobi Optimization, “Gurobi optimizer: Downloads & licenses, ” Online Resource, n.d., commercial optimization solver supporting mixed-integer programming (MIP), linear programming (LP), quadratic programming (QP), and other optimization problem types. Offers multiple license options including 30-day commercial e valuation licenses, free academic licenses (unlimited model size), online course licenses (limited to 2000 variables/constraints), and cloud trial licenses (up to 20 free hours). A vailable for download with additional support for AMPL integration and Docker deployment. [Online]. A vailable: https://www .gurobi.com/downloads/ [29] C. Operations, “Copt (cardinal optimizer): Large-scale mathematical optimization solver, ” Online Resource, n.d. [Online]. A vailable: https://www .copt.de [30] Z. I. B. (ZIB), “Scip optimization suite: Open-source solver for mixed-integer programming and combinatorial optimization, ” Online Resource, n.d., an open-source, high-performance optimization suite centered on the SCIP (Solving Constraint Integer Programs) solver , supporting mixed-integer linear programming (MILP), mixed-integer nonlinear programming (MINLP), mix ed-integer quadratic programming (MIQP), and combinatorial optimization problems. Features a flexible plugin framew ork for integrating custom algorithms, heuristics, and constraint handlers. Widely adopted in academic research and industrial applications, with extensi ve documentation and community support. Compatible with major programming languages and modeling tools including C, C++, Python, Julia, GAMS, and AMPL. [Online]. A v ailable: https://scipopt.org [31] T . Achterberg, “What’ s new in gurobi 9.0, ” W ebinar T alk url: https://www . gurobi. com/wp-content/uploads/2019/12/Gurobi-90- Overview-W ebinar-Slides-1. pdf , vol. 5, no. 9, pp. 97–113, 2019. [32] M. M. Halld ´ orsson and G. K ortsarz, “Multicoloring: Problems and techniques, ” in International Symposium on Mathematical F oundations of Computer Science . Springer, 2004, pp. 25–41. [33] M. R. Garey , D. S. Johnson, and L. Stockmeyer , “Some simplified np- complete problems, ” in Pr oceedings of the sixth annual ACM symposium on Theory of computing , 1974, pp. 47–63. [34] S. Zhao, R. W ang, J. Zhou, J. Ong, J. C. Mogul, and A. V ahdat, “Min- imal rewiring: Efficient live expansion for clos data center networks: Extended version, ” in NSDI https:// ai.google/ resear ch/ pubs/ pub47492 , 2019. [35] Z. Kir ´ aly and P . Kov ´ acs, “Efficient implementations of minimum-cost flow algorithms, ” ArXiv , vol. abs/1207.6381, 2012. [36] J. L. Bentley , D. Haken, and J. B. Saxe, “ A general method for solving divide-and-conquer recurrences, ” A CM SIGA CT News , v ol. 12, no. 3, pp. 36–44, 1980. 12 [37] NVIDIA, “NVIDIA DGX SuperPOD: Next generation scalable infras- tructure for ai leadership, ” [Online]. A vailable: https://shorturl.at/mxzB2, accessed Dec., 2023. [38] S. Kassing, A. V aladarsky , and A. Singla, “Netbench, ” https: //github .com/ndal- eth/netbench. [Online]. A vailable: https://github .com/ ndal- eth/netbench. [39] Q. Hu, P . Sun, S. Y an, Y . W en, and T . Zhang, “Characterization and prediction of deep learning workloads in large-scale gpu datacenters, ” in SC21: International Confer ence for High P erformance Computing, Networking, Storage and Analysis , 2021, pp. 1–15. [40] K. Mahajan, A. Balasubramanian, A. Singhvi, S. V enkataraman, A. Akella, A. Phanishayee, and S. Chawla, “Themis: Fair and efficient { GPU } cluster scheduling, ” in 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20) , 2020, pp. 289–304. [41] Z. Gao, A. Abhashkumar , Z. Sun, W . Jiang, and Y . W ang, “Crescent: Emulating heterogeneous production network at scale, ” in 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) , 2024, pp. 1045–1062. [42] Broadcom Inc., “BCM56980: 12.8 Tb/s Multilayer Switch, ” Broadcom Inc., T ech. Rep. 56980-DS. [Online]. A v ailable: https://docs.broadcom. com/doc/56980- DS [43] N. Farrington, G. Porter, S. Radhakrishnan, H. H. Bazzaz, V . Subra- manya, Y . Fainman, G. Papen, and A. V ahdat, “Helios: a hybrid electri- cal/optical switch architecture for modular data centers, ” in Proceedings of the ACM SIGCOMM 2010 Conference , 2010, pp. 339–350. [44] E. Eshelman, “Dgx a100 revie w: Throughput and hardware summary , ” https://www .micro way .com/hardware/ dgx- a100- revie w- throughput- and- hardware- summary/, Jun. 2020. [45] H. K. Dhaliwal and C.-H. Lung, “Load balancing using ecmp in multi- stage clos topology in a datacenter , ” in 2018 IEEE Conference on Dependable and Secure Computing (DSC) . IEEE, 2018, pp. 1–7. [46] H. Senuma, “mmh3: A python extension for murmurhash3. ” [47] I. Adan and J. Resing, “Queueing theory , ” Eindhoven University of T echnology , vol. 180, 2002. [48] X. Han, W . Jiang, P . Cao, Q. Y ang, Y . Liu, S. Qi, S. Lin, and S. Zhao, “Isolated scheduling for distributed training tasks in gpu clusters, ” arXiv pr eprint arXiv:2308.05692 , 2023. [49] W . W ang, M. Ghobadi, K. Shakeri, Y . Zhang, and N. Hasani, “Rail-only: A low-cost high-performance network for training llms with trillion parameters, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2307.12169 [50] X. Liao, Y . Sun, H. Tian, X. W an, Y . Jin, Z. W ang, Z. Ren, X. Huang, W . Li, K. F . Tse, Z. Zhong, G. Liu, Y . Zhang, X. Y e, Y . Zhang, and K. Chen, “Mixnet: A runtime reconfigurable optical-electrical fabric for distributed mixture-of-experts training, ” in Pr oceedings of the ACM SIGCOMM 2025 Conference . A CM, Aug. 2025, p. 554–574. [Online]. A v ailable: http://dx.doi.org/10.1145/3718958.3750465 [51] C. Shou, G. Liu, H. Nie, H. Meng, Y . Zhou, Y . Jiang, W . Lv , Y . Xu, Y . Lu, Z. Chen, Y . Y u, Y . Shen, Y . Zhu, and D. Jiang, “Infinitehbd: Building datacenter-scale high-bandwidth domain for llm with optical circuit switching transceivers, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2502.03885 [52] N. Jouppi, “Impact of optical circuit switching on ai clusters, ” in Optical Fiber Communication Conference (OFC) 2025 , Optica Publishing Group (OPG). Optica, 2025, p. M4H.6. [Online]. A v ailable: https://opg.optica.org/abstract.cfm?uri=OFC- 2025- M4H.6 [53] M. Shoeybi, M. Patwary , R. Puri, P . LeGresley , J. Casper , and B. Catan- zaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism, ” arXiv pr eprint arXiv:1909.08053 , 2019.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment