코드 컨텍스트 압축으로 버그 해결 효율 높이기
본 논문은 LLM 기반 이슈 해결 시 과도한 코드 컨텍스트가 초래하는 비용과 성능 저하 문제를 해결하기 위해, Oracle‑guided Code Distillation(OCD)과 경량 압축 모델 SWEzze를 제안한다. OCD는 유전 알고리즘과 계층적 델타 디버깅을 결합해 최소 충분 컨텍스트(MSC)를 자동으로 추출하고, 이를 학습 데이터로 활용해 SWEzze가 추론 단계에서 불필요한 코드를 제거하면서도 패치에 필요한 핵심 요소(‘fix ing…
저자: Haoxiang Jia, Earl T. Barr, Sergey Mechtaev
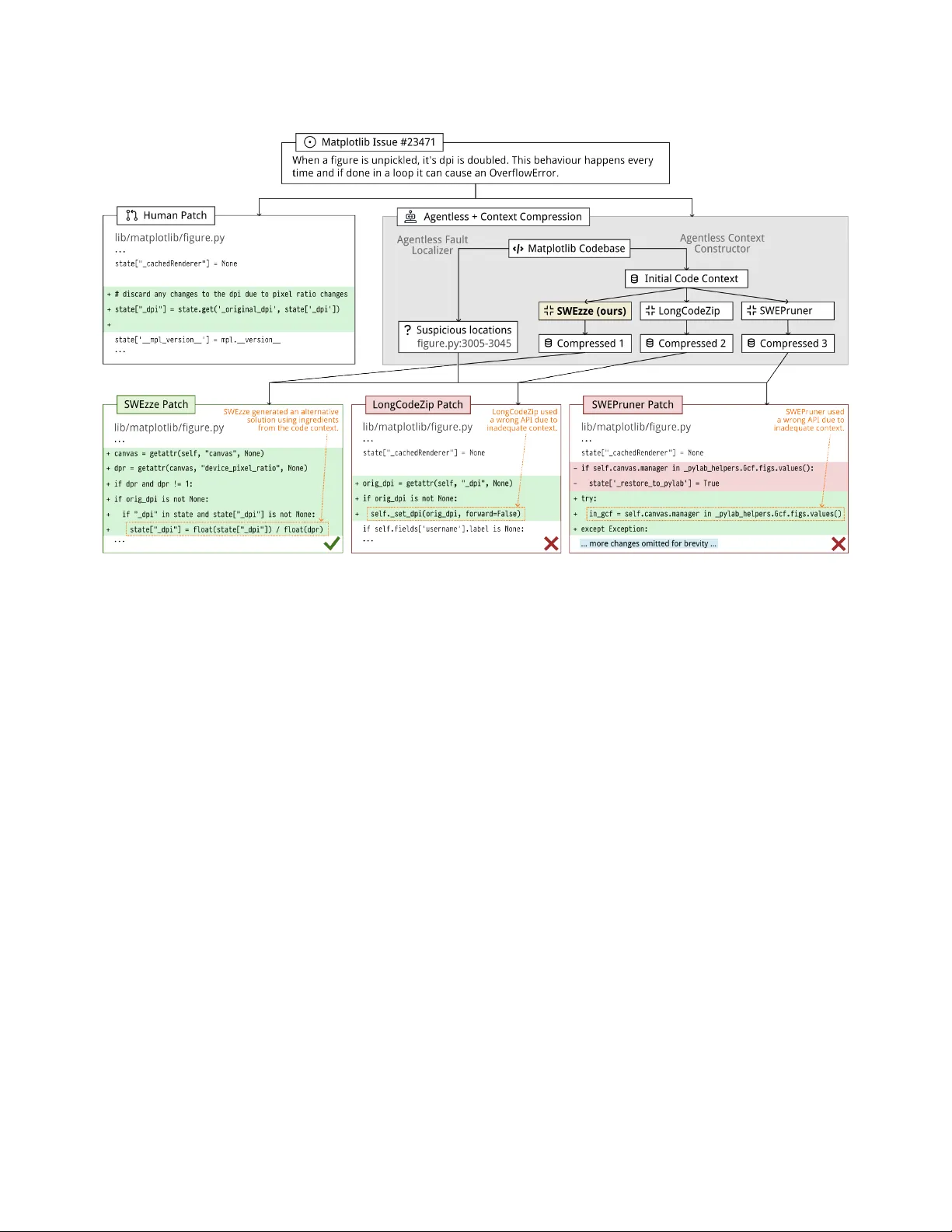
본 논문은 대규모 언어 모델(LLM)이 실제 GitHub 이슈를 해결하는 과정에서 발생하는 두 가지 주요 문제—거대한 코드 컨텍스트로 인한 높은 연산 비용과, 불필요한 코드가 모델의 버그‑수정 신호를 흐리게 하는 효과 저하—를 동시에 해결하고자 한다. 기존의 컨텍스트 압축 방법은 일반 텍스트 압축기와 코드‑전용 휴리스틱 압축기로 크게 나뉘는데, 전자는 코드의 구조적 무결성을 해치고, 후자는 ‘fix ingredients’라 불리는 패치에 필수적인 코드 조각을 어휘·구조적 유사성에만 의존해 식별하기 때문에 중요한 정보를 놓치는 한계가 있다. 이러한 한계를 극복하기 위해 저자들은 두 가지 핵심 구성요소를 제안한다.
첫 번째는 Oracle‑guided Code Distillation(OCD)이다. OCD는 초기 컨텍스트 C_init을 파일‑함수‑블록이라는 3단계 계층 구조로 분해하고, 각 구조 단위에 대해 세 가지 신호—패치 오버랩, 테스트 커버리지, 심볼 오버랩—를 결합한 우선순위 점수 Φ(u)를 계산한다. 패치 오버랩은 실제 인간 패치가 수정한 파일을 직접 가중치로 부여하고, 테스트 커버리지는 동적 실행 정보를 통해 해당 단위가 실패 테스트에 얼마나 관여했는지를 로그 스케일로 반영한다. 심볼 오버랩은 패치에 등장하는 식별자와 단위 내 식별자 간의 lexical overlap을 측정해, 변수·함수·클래스 등 의미적 의존성을 포착한다. 이렇게 정의된 Φ는 유전 알고리즘(GA)의 적합도 함수로 사용되어, 수천 개의 후보 서브셋 중 “LLM이 패치를 성공적으로 생성하고 검증 스위트를 통과하게 하는” 최소한의 컨텍스트를 탐색한다. GA가 찾은 후보는 아직 중복이 존재할 수 있기 때문에, 이어서 계층적 델타 디버깅(HDD) 단계에서 파일, 함수, 블록 순으로 각각 ddmin 절차를 적용한다. 이 과정은 각 단위가 제거될 경우 모델이 실패하는지를 oracle(LLM+테스트)에게 물어보는 방식으로, 1‑minimal(각 요소가 필수)인 최소 충분 컨텍스트(MSC)를 효율적으로 도출한다. 전통적인 전역 최소화(2^|C|)와 달리, GA+HDD 조합은 탐색 공간을 크게 축소하면서도 실제 패치에 필요한 코드만을 보존한다는 장점을 갖는다.
두 번째는 SWEzze라는 경량 압축 모델이다. SWEzze는 Qwen‑3‑Reranker‑0.6B를 LoRA(Low‑Rank Adaptation) 방식으로 파인튜닝해, 입력 컨텍스트 C_init을 MSC(ˆC)로 매핑하는 교차 인코더를 학습한다. 학습 데이터는 위에서 얻은 OCD‑distilled 예시들로 구성되며, 각 세그먼트(파일, 함수, 블록)는 “# … N lines omitted”와 같은 플레이스홀더로 대체해 구조를 유지한다. 추론 시 SWEzze는 사전 학습된 점수 함수를 이용해 모든 세그먼트를 스코어링하고, 주어진 토큰 예산 내에서 가장 높은 점수를 가진 세그먼트를 그리디하게 선택한다. 이때, 선택된 세그먼트는 반드시 ‘fix ingredients’를 포함하도록 설계되었으며, 불필요한 코드와 주석은 효과적으로 제거된다.
실험은 SWE‑Bench Verified 데이터셋을 사용해 세 가지 최신 LLM(GPT‑5.2, DeepSeek‑V3.2, Qwen‑3‑Coder‑Next)에 적용하였다. 비교 대상은 일반 텍스트 압축기(LongCodeZip)와 코드‑전용 휴리스틱 압축기(SWE‑Pruner)이며, 평가 지표는 압축 비율, 토큰 사용량 감소, 이슈 해결률, BERTScore, 그리고 전체 파이프라인 지연시간이다. 결과는 다음과 같다. (1) 압축 비율은 평균 6배, 토큰 사용량은 51.8%~71.3% 감소하였다. (2) 이슈 해결률은 5.0%~9.2% 상승했으며, 특히 복잡한 의존성을 가진 사례에서 기존 압축기보다 월등히 높은 성공률을 보였다. (3) BERTScore는 0.44로, LongCodeZip(0.20)과 SWE‑Pruner(0.00)보다 두 배 이상 높은 컨텍스트 유사성을 나타냈다. (4) 전체 파이프라인 지연시간은 압축 단계가 추가되었음에도 불구하고, 토큰 감소에 따른 LLM 추론 비용 절감으로 실질적인 속도 향상을 달성했다.
또한, 사례 연구를 통해 SWEzze가 Matplotlib 이슈에서 ‘dpi 계산’에 필요한 핵심 코드 조각을 정확히 보존하고, 다른 압축기들은 해당 조각을 삭제해 패치가 실패하는 모습을 보여준다. 이는 ‘fix ingredients’를 보존하는 것이 단순 토큰 절감보다 모델 성능에 결정적인 영향을 미친다는 것을 실증한다.
결론적으로, 이 논문은 (1) 코드 의존성을 정량화하고 최소 충분 컨텍스트를 자동으로 생성하는 OCD 프레임워크, (2) 이를 기반으로 실시간 추론에서 효율적인 컨텍스트 압축을 수행하는 SWEzze 모델, 그리고 (3) 대규모 LLM 기반 버그 수정 파이프라인에 적용했을 때 비용·성능 트레이드오프를 크게 개선한다는 세 가지 주요 기여를 제시한다. 향후 연구는 OCD를 다른 프로그래밍 언어나 다중 모듈 시스템에 확장하고, 강화학습 기반의 동적 예산 조정 기법을 도입해 더욱 정교한 압축 전략을 탐색하는 방향으로 진행될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기