Compressing Code Context for LLM-based Issue Resolution
Large Language Models (LLMs) are now capable of resolving real-world GitHub issues. However, current approaches overapproximate the code context and suffer from two compounding problems: the prohibitive cost of processing massive inputs, and low effe…
Authors: Haoxiang Jia, Earl T. Barr, Sergey Mechtaev
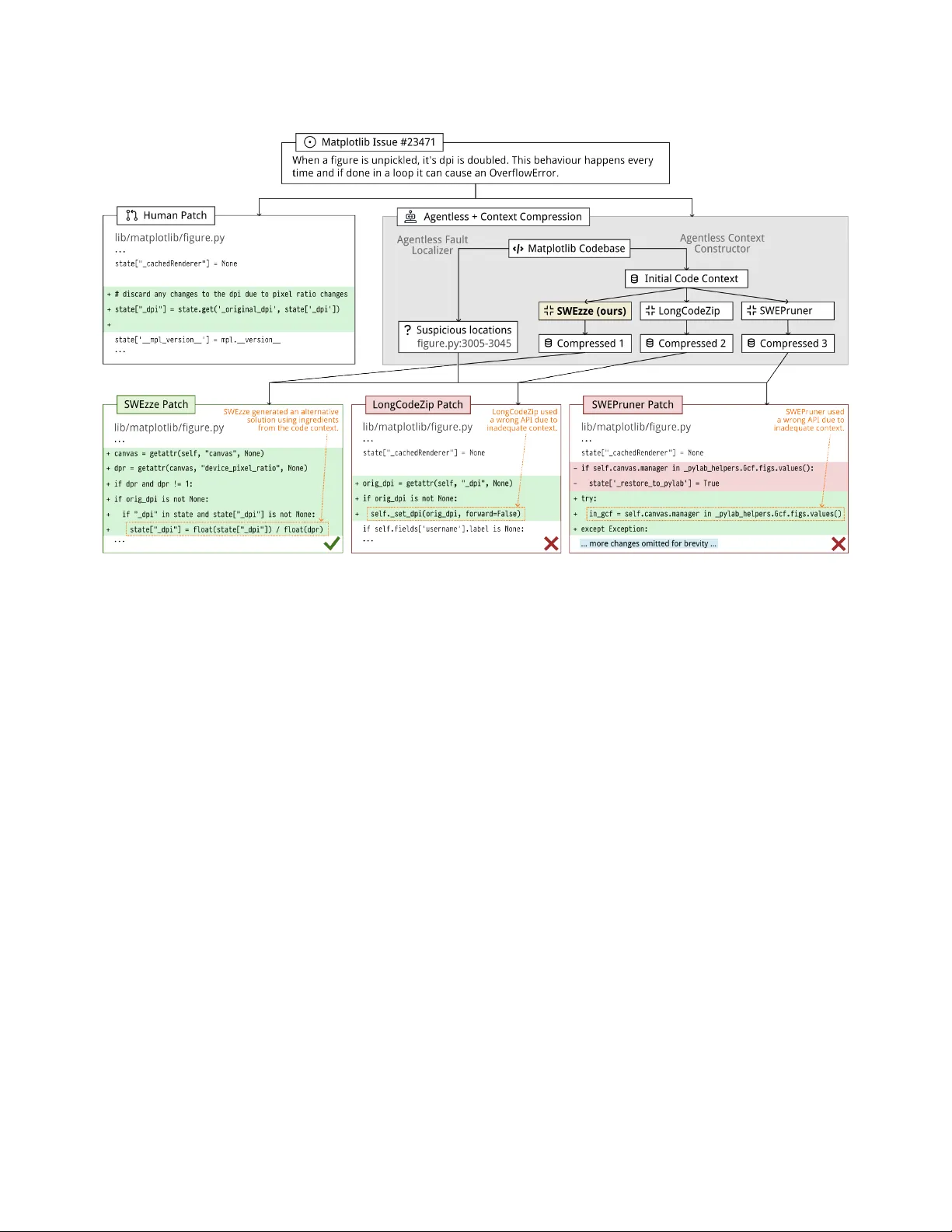
Compressing Code Context for LLM-base d Issue Resolution Haoxiang Jia haoxiangjia@stu.pku.edu.cn Peking University Beijing, China Earl T . Barr e.barr@ucl.ac.uk University College London London, UK Sergey Mechtaev ∗ mechtaev@pku.edu.cn Peking University Beijing, China ABSTRA CT Large Language Models (LLMs) are now capable of resolving real- world GitHub issues. However , current approaches overappro xi- mate the code context and suer fr om two compounding problems: the prohibitiv e cost of processing massive inputs, and low eective- ness as noise oods the context window and distracts the model from the bug-xing signal. Existing compression techniques fail to resolve this tension: generic compressors compromise the semantic integrity of code, while code-specic to ols lack awareness of code structure and task context to pr eserve essential patch ingredients. T o address this, we propose a nov el framework consisting of tw o components. First, Oracle-guided Code Distillation (OCD), a con- text distillation algorithm that combines genetic search and delta debugging to systematically reduce code contexts to their minimal sucient subsequence — retaining only the ingredients r equired for a successful x. W e use this distilled data to ne-tune SWEzze , a lightweight model that learns to compr ess code conte xt at inference time, ltering noise and combating distraction while preserving x ingredients. Evaluated on SWE-bench V eried across thr ee frontier LLMs, SWEzze maintains a stable compression rate of about 6 × across models, reduces the total token budget by 51.8%–71.3% rela- tive to the uncompressed setting, impr oves issue resolution rates by 5.0%–9.2%, and deliv ers the best overall balance among eective- ness, compression ratio, and latency compared with state-of-the-art context compression baselines. KEY W ORDS A utomated Issue Resolution, Code Context, Compression 1 IN TRODUCTION Issue resolution by Large Language Models (LLMs) has progressed from academic prototypes to practical adoption in industry . Sys- tems such as Agentless [ 29 ] and SWE- Agent [ 33 ] can localize faults, synthesize patches, and resolv e issues across real-world reposito- ries. Y et scaling these approaches r eveals a fundamental bottleneck: cost and eectively utilizing code context. Unlike many natural- language tasks, issue resolution requires reasoning over context scattered across multiple les — denitions, call chains, class hier- archies, modules, and interfaces — making context construction a critical component of the resolution pipeline [10]. T o extract relevant code context, existing approaches rely on heuristic retrieval or Retrieval- Augmented Generation (RAG) [ 9 ] to rank les according to lexical similarity , embeddings, or shallow structural signals. T o avoid missing crucial dependencies, these methods typically return top- 𝑘 les or functions that collectively span hundreds of lines to capture only a handful of relevant seg- ments. This leads to context overapproximation, where the true ∗ Sergey Mechtaev is the corresponding author . bug-xing signal is diluted by large amounts of irrele vant code. The impact is twofold. First, it imposes a direct computational inference cost: inference cost scales roughly with the size of the provided context [ 25 ]. Second, excessive context degrades eectiveness, as irrelevant code oods the context window [ 15 ] and distracts the model from the bug-xing signal [22]. A promising mitigation to this problem is to compress retrieved contexts: distilling the overappr oximate output of retrieval into a concise form that retains only the essential information, and use it as the input to the downstream issue-resolving LLM. However , existing compression strategies [ 12 ] are ineective for patch gener- ation. Generic compressors [ 6 ] that treat code as natural language tend to disrupt program structure and break semantic links (e .g., def- inition–use relations and type constraints) that are often required to construct a correct patch. Conversely , code-specic heuristic pruners [ 23 , 27 ] select context based on its similarity or relatedness to the issue description or the buggy code, but issue resolution of- ten depends on x ingredients [ 14 , 16 , 28 ], i.e. , code elements such as variables, expressions, and types that are needed to construct a correct patch, that may not bear obvious lexical or structural resemblance to the bug itself, causing these compressors to discard the necessary ingredients. T o address this problem, we propose a framework that distills high-quality training data from a computationally expensive ora- cle to train a lightweight, inference-r eady model. W e rst employ Oracle-guided Code Distillation (OCD ) to systematically reduce an initial context to a minimal sucient context (MSC) — a one- minimal subsequence where every retained fragment is functionally necessary for a successful repair . T o produce these MSCs, OCD uses a Genetic Algorithm (GA) to discov er patch-enabling congura- tions, which Hierarchical Delta Debugging (HDD ) [ 17 ] then mini- mizes. These distille d examples from the SWESmith dataset [ 34 ] serve as the training signal for SWEzze , a cross-encoder ne-tuned from Q wen3-Reranker-0.6B [ 38 ] via parameter-ecient LoRA adap- tation [ 4 ]. By learning to map initial code context 𝐶 init to its cor- responding MSC ( ˆ 𝐶 ), SWEzze captures the structured dependency patterns that distinguish x ingredients [ 16 ] from incidentally re- lated code. At inference time, SWEzze operates without oracle ac- cess, scoring segments and assembling compressed context through budget-aware greedy selection. W e evaluate SWEzze within the Agentless workow [ 29 ] on SWE-bench V eried across the GPT -5.2, DeepSeek- V3.2, and Qwen3- Coder-Next frontier models, and compare with state-of-the-art compressors. SWEzze achieves the best end-to-end issue resolution performance and the b est balance among repair eectiveness, com- pression strength, and runtime ov erhead. Across all three models, it maintains a stable compression rate of about 6 × , reduces the total token budget by 51.8%–71.3% relative to the uncompressed setting, and improves issue r esolution rates by 5.0%–9.2%. Compared with Haoxiang Jia, Earl T . Barr, and Sergey Mechtaev Figure 1: Agentless + SWEzze generates a correct patch b ecause SWEzze retains the x ingredients in the compressed context. In contrast, previous compressors (LongCodeZip and SWE-Pruner) degrade Agentless performance by removing these ingredients. prior compressors, SWEzze not only achieves higher o verall reso- lution rates, but also covers the broadest set of solvable instances, reaching 93.8%–99.2% of the union of all cases resolved by any baseline. Our results show that for r epositor y-level issue resolution compression is mor e eective when it preserves repair-sucient context, rather than maximizing token reduction or similarity . In summary , the paper makes the following contributions: • Oracle-guided Code Distillation, a novel framework for distill- ing minimal sucient context for LLM-based issue r esolution. • SWEzze , a nov el code context compression model that retains x ingredients while removing distracting noise. • Evaluation on SWE-Bench V eried that demonstrates that SWEzze signicantly reduces the cost of LLM-based issue resolution while at the same time improving success rate . All code, data, and reproduction scripts are available at https: //zenodo.org/records/19248411. 2 MOTIV A TING EXAMPLE W e illustrate SWEzze ’s ability to identify and retain x ingredi- ents for issue resolution using a case study from the widely-used Matplotlib library [ 3 ], extracted from SWE-Bench [ 7 ]. This issue, shown in Figure 1 (top), reports a bug in DPI calculation on Mac OS. The human patch for this issue (top left) simply inserts a state update statement inside the le figure . py , using the API call state . get( ' _original_dpi ' , state[ ' _dpi ' ]) . Although the x itself is small, it is representative of real-world issue resolution: constructing the patch requires understanding a project-spe cic API that is unlikely to appear in the issue description, making it essential for the compressor to retain the rele vant context. SWEzze compresses prompts by pruning their code segments to an issue’s x ingredients [ 16 ], the minimal set of semantic dependen- cies needed to resolve that issue. W e designed SWEzze to be model- and harness-agnostic, ensuring compatibility with any downstream repair workow . T o illustrate its operation, we integrate SWEzze into Agentless [ 29 ], a pip eline combining fault localization and context construction that is widely used to evaluate frontier LLMs on issue resolution [ 2 ]. The “ Agentless + Context Compression” module (Figure 1, top right) depicts Agentless localizing a bug and forwarding the initial code context to three compressors: SWEzze and two established baselines. The leaf nodes of Figure 1 present the repair patches generated by the frontier model when provided the suspicious locations and the compressed contexts from each tool. As you can see, the r esulting patches diverge signicantly . When using the contexts from Long- CodeZip [ 23 ] and SWE-Pruner [ 27 ], the model produces patches that do not resolve the issue. In contrast, SWEzze ’s context pre- serves the x ingredients, enabling the model to generate a patch that matches the logic of the human reference. A gentless’ success resolving this issue depends critically on the choice of context com- pressor: it resolv es the issue only when using SWEzze , because the baseline compressors discarded crucial, x-relevant information. T o understand this dierence, we compare the compressed con- texts in Figure 2. This gure shows a fragment of the initial code Compressing Code Context for LLM-based Issue Resolution Figure 2: A fragment of Agentless’ co de context for resolv- ing the issue in Figure 1. SWEzze ’s context has the higher correlation with a minimal sucient context computed via delta-debugging, and the only one that contains the ingredi- ents to correctly recompute DPI to address the issue. context C init , where the background color indicates whether a seg- ment appears in the x ingredients ˆ C identied via delta debug- ging [ 35 ]: light green denotes retained segments, light red denotes removed ones. Notably , although ˆ C does not contain any refer- ences to ' _original_dpi ' used in the human patch, it contains the statement scale = self . figure . dpi / self . device_pixel_ratio , which reveals how the scale is computed. With this fragment in its context, the downstream LLM correctly recomputes DPI as shown in the patch generated with SWEzze in Figure 1, b ottom left. SWEzze is the only compressor that retains this fragment: LongCodeZip selected irrelevant fragments, while SWE-Pruner retained only a single line from this function, which proved insucient for the model to construct a x. This performance reects SWEzze ’s core design: an oracle that protects x ingredients and a search strategy (GA and HDD) that maximizes our oracle budget. While baseline compressors rely on static heuristics, SWEzze ’s search-based OCD framework identies and retains the functional dependencies r equired for a successful repair . Consequently , SWEzze achieves a BERTScor e [ 37 ] of 0.44 against the minimal context ˆ 𝐶 , indicating high semantic overlap with the x-relevant fragments, more than doubling the delity of LongCodeZip (0.20) and SWE-Pruner (0.00). This approach allows SWEzze to pr eserve critical components like the ' resize ' method, which the baselines systematically strip away . 3 ORA CLE-GUIDED CON TEXT DISTILLA TION T o train a compression model that preserves x ingredients, we need training data in which these ingredients are distilled to their essence. W e op erationalize this through the notion of minimal sucient context . Given an issue description I , a fault location F , and an initial over-approximate code context C init retrieved from a repository , the goal is to identify a subset ˆ C ⊆ C init such that | ˆ C | ≪ | C init | . W e call ˆ C a sucient code context if an LLM can use I , F , and ˆ C to generate a patch P that passes the validation suite T . Sucient contexts are generally not unique: multiple distinct subsets of C init may independently satisfy suciency while being incomparable under set inclusion ( e.g. , tw o alternative helper functions may each enable a correct patch, yet neither subsumes the other). Our goal is to nd any sucient context that is also minimal. Finding a globally minimal (minimum-cardinality) sucient con- text would require enumerating all 2 | C init | subsets—computationally intractable for realistic codebases. Following delta debugging [ 35 ], we instead target 1-minimality , a local minimality criterion that is eciently computable y et provides strong compression guarantees: Denition 3.1 (Minimal Sucient Context). A sucient code con- text ˆ C ⊆ C init is minimal if removing any single element from ˆ C causes it to become insucient— i.e. , for every element 𝑒 ∈ ˆ C , ˆ C \ { 𝑒 } does not enable the LLM to generate a patch that passes T . The 1-minimality ensures that every retained element is individ- ually necessary , producing clean training signal without redundant context. At the same time, it is tractable: verifying 1-minimality requires at most | ˆ C | oracle calls per element, unlike the exponential cost of global minimality . The goal of Oracle-Guided Context Distillation (OCD) is to pro- duce high-quality training examples that map C init to a 1-minimal sucient subset ˆ C . Unlike prior compression methods that rely on perplexity or embedding similarity , we dene suciency through a functional criterion. W e formulate context distillation as a search problem guided by an execution oracle that evaluates candidate contexts by invoking the repair model and validating generated patches. Our approach comprises three components: (1) a hierar- chical search space r epresentation that ensures syntactic validity (§3.1); (2) priority scoring that leverages training-time informa- tion to guide search (§3.2); and (3) a two-phase search strategy combining genetic algorithm and delta debugging (§3.3). 3.1 Search Space Representation The eectiveness of search for minimal context dep ends on how the search space is structured. T oken-level representation, while exi- ble, frequently results in syntactically invalid code that may confuse the model. T o ensure that all candidate context subse quences re- main well-formed, we impose a hierar chical structur e on the search space that respects the syntactic rules. Haoxiang Jia, Earl T . Barr, and Sergey Mechtaev W e decompose each source le 𝐹 ∈ C init into a tree of nested structural units. Throughout this paper , we use the term “struc- tural unit” (or simply “unit”) to refer to any element at these three hierarchical levels; the hierar chy consists of three levels: • File Level: File-level decisions determine whether any con- tent from a source le appears in the compressed context. • Function Level: Within a le, we view function and method denitions as independent units. This level captures the orga- nizational structure of procedural and object-oriented code. • Block Level: Within a function, we partition statements into contiguous blocks. Each block represents a sequence of state- ments that can be independently included or excluded. W e refer to the leaf-level units produced by the hierarchical decomposition as code segments (or simply segments ). Concretely , a segment is one of ve AST -derived types: • method : a metho d denition bound to a class; • function : a top-level or nested function denition; • class_header : the signature and class-level statements of a class (excluding its method bodies); • block : a contiguous sequence of statements inside a function body that does not constitute a standalone denition; • le : a top-level fragment that is outside any class or function. Segments are the atomic scoring units used by SWEzze and the granularity at which inclusion/exclusion decisions are made during both data construction and inference. Rather than silently removing co de units, we replace omitte d content with placeholders. When a unit 𝑢 is excluded, w e substitute it with a template 𝜏 𝑢 that indicates the location and magnitude of the omission ( e.g., # ... N lines omitted , where 𝑁 denotes the number of source code lines in the original unit). This design preserves the code structure , allowing the LLM to r ecognize that additional context exists ev en if not explicitly provided. 3.2 Priority-Guided Search The search space of context subsequences is exponential in the number of structural units. T o make search tractable, we assign priority scores that guide the search towards promising regions. For each structural unit 𝑢 , we compute a priority score Φ ( 𝑢 ) that estimates its relevance to successful patch generation. The score aggregates three categories of signals: Patch O verlap. Let F patch denote the set of les modied by the ground-truth patch P gold . Units that belong to F patch receive elevated priority , as the developer’s patch serves as direct evidence of which les require modication. W e capture this signal using an indicator function I ( 𝑢 ∈ F patch ) that returns 1 if unit 𝑢 belongs to these patch-relevant les and 0 otherwise. T est Coverage. W e execute the failing tests and r ecord the set of cover ed lines L cov ( 𝑢 ) within each unit 𝑢 . Units containing mor e covered lines are prioritized, as test coverage indicates dynamic relevance to the failure. T o prevent bias fr om test cases that exercise large portions of the co debase, we apply logarithmic dampening to the coverage count. Symbol Overlap. W e extract identiers (variable, function, class names) from P gold and dene SymScore ( 𝑢, P gold ) as a function measuring lexical o verlap between these identiers and the content of unit 𝑢 . This heuristic captures semantic dependencies: if a patch Algorithm 1: Oracle-Guided Context Distillation Input: Context C init , oracle O , priority Φ Output: Minimal sucient context ˆ C /* Hierarchical Decomposition (§3.1) */ 1 U ← Decompose ( C init ) ; // file ⊃ function ⊃ block 2 Φ ( 𝑢 ) ← PriorityScore ( 𝑢 ) ∀ 𝑢 ∈ U ; // §3.2 /* Phase I: Genetic Algorithm Search (§3.3) */ 3 ˆ C GA ← GeneticSearch ( U , Φ , O ) ; 4 if no passing subset found then return C init ; /* Phase II: Hierarchical Delta Debugging (§3.3) */ 5 ˆ C ← ˆ C GA ; 6 foreach level ℓ ∈ { le , function , block } do 7 ˆ C ← ddmin ( ˆ C , ℓ , O , Φ ) ; // remove redundant units 8 return ˆ C ; references a particular function or variable, the code dening that symbol is likely necessar y for correct patch generation. The composite priority score combines these three signals: Φ ( 𝑢 ) = 𝑤 𝑝 · I ( 𝑢 ∈ F patch ) + 𝑤 𝑐 · log ( 1 + | L cov ( 𝑢 ) | ) + 𝑤 𝑠 · SymScore ( 𝑢 , P gold ) where 𝑤 𝑝 , 𝑤 𝑐 , and 𝑤 𝑠 are congurable weights controlling the relative importance of patch ov erlap, test coverage, and symb ol overlap signals, respectively . 3.3 T wo-P hase Search Strategy Having dene d the search space and priority scoring, we now describe the search algorithm itself. The initial conte xt C init may or may not enable successful patch generation — failure can stem from inherent task diculty or fr om distracting elements that mislead the model. Therefore, w e rst must identify a subset of C init that enables successful patch generation, before minimizing it. W e address this problem with a two-phase pipeline ( Algorithm 1): a Genetic Algorithm (GA) identies resolution-enabling subse- quences solution, and Hierarchical Delta Debugging (HDD ) mini- mizes them. The two phases ar e complementary: GA handles the combinatorial challenge of nding a sucient subset among expo- nentially many candidates, while HDD ensures the result contains no redundant units. Priority scores Φ guide both phases—biasing GA initialization and tness towar d high-priority congurations, and guiding HDD to remove lo w-priority units rst. 3.3.1 Phase I: Genetic Search. W e employ a Genetic Algorithm (GA) to explore the space of context congurations. GA ’s population- based search evolv es congurations toward pr omising regions of the search space. W e represent each candidate context as a binary genome g = ( 𝑔 1 , 𝑔 2 , . . . , 𝑔 𝑛 ) , where each gene 𝑔 𝑖 ∈ { 0 , 1 } corre- sponds to a structural unit 𝑢 𝑖 (le or function). A gene value of 1 indicates inclusion, while 0 indicates e xclusion. T o maintain syn- tactic validity , we enforce upward consistency: if a function gene is active, its parent le gene must also be active. This constraint is Compressing Code Context for LLM-based Issue Resolution enforced after each genetic operation thr ough a repair step. The t- ness function is designed to identify passing solutions while guiding failed congurations toward promising regions. For failed congu- rations, the tness function is the sum of retained code segment priority scor es which guides the search to ward larger , high-priority contexts more likely to contain patch-critical information. W e employ operators adapted for hierarchical code structure: • Initialization: The initial population is seeded with high- probability congurations derived from priority scores ( e.g. , con- text restricted to gold-patch les). Remaining slots ar e lled with randomly generated individuals whose inclusion proba- bility is biased by priority . • Selection: T ournament sele ction with elitism preserves the top 20% of individuals, ensuring good solutions are not lost while maintaining population diversity . • Crossover: Hierarchical crossover op erates at le granularity , swapping entire le subtr ees between parents. This preserves the internal coherence of le structures and respects the nat- ural modularity of code. • Mutation: Standard bit-ip mutation is applied with a con- gurable rate, followed by a repair step that enforces upward consistency and prevents degenerate empty individuals. GA stops immediately upon discovering any resolution-enabling subsequence solution rather than continuing to nd better ones. 3.3.2 Phase II: Hierarchical Delta Debugging. Once a resolution- enabling context subsequence is discovered, we apply Hierarchical Delta Debugging (HDD) [ 17 ] to systematically minimize it. HDD extends the classical delta debugging algorithm by e xploiting the hierarchical structure of our search space, ensuring the nal con- text is locally minimal. It operates in three sequential passes, each targeting a dierent level of the hierar chy: (1) File-Level Re duction: W e attempt to remo ve entire les from the context. Files that can be removed without breaking suciency are permanently excluded. (2) Function-Level Reduction: Within each retained le, we attempt to remove individual functions, identifying functions that were retrie ved but are not actually required for the x. (3) Block-Level Reduction: Within each retained function, we attempt to remove statement blocks, eliminating unnecessary implementation details while preserving essential logic. At each le vel, w e apply the ddmin algorithm [ 35 ] adapted for our setting. Given a set of currently retained units 𝑈 , ddmin iteratively partitions 𝑈 and tests whether smaller subsets maintain suciency . The algorithm terminates when removing any single remaining unit causes the context to become insucient, achieving 1-minimality . W e integrate priority scores by sorting units in ascending priority order before partitioning. This causes the algorithm to preferentially attempt removing low-priority units rst, accelerating convergence by front-loading the removal of r edundant content. 3.3.3 Candidate Evaluation. Each candidate context evaluation re- quires invoking the repair model to generate patches and executing the test suite to validate correctness. This process is computation- ally expensive, making evaluation eciency critical for scalable data construction. T o reduce variance from the stochastic nature of T able 1: O verview of the constructed training dataset based on SWE-Smith of minimal sucient contexts. Metric V alue Unique repositories 41 T otal instances ( bugs) 3,157 T otal co de segments 156,545 A vg. segments per instance 49.6 Positive segments (relevant) 13,102 Negative segments (irrelevant) 143,443 Relevance density 8.4% LLM generation, we generate multiple patch candidates per evalua- tion and apply majority voting. A context is deemed sucient if at least half of the generated patches pass all tests, providing more reliable suciency judgments. 3.4 OCD on SWE-Smith T o prepare training data for our compression model, we applied OCD to SWE-Smith [ 34 ], a large dataset of 50K issues sourced from 128 GitHub repositories, which does not intersect with our testing set. From this dataset, we uniformly sampled 10K issues, and distilled Agentless’ contexts for these with OCD by using Qwen3- Coder-30b to evaluate context suciency . Before ne-tuning a compressor , we analyzed the data that OCD produced from three dimensions: compression eectiveness, segment-level relevance , and context sparsity . T able 1 summarizes the distilled corpus. Across 3,157 instances from 41 Python r eposi- tories, for which a sucient context was found, the AST segmenter produces 156,545 labeled segments, or 49.6 segments per instance on average. Only 8.4% of segments are relevant to the x, we call this ratio relevance density ; on average, only 4.15 out of 49.6 segments p er instance are ne cessary for patch generation. This severe class imbalance shows why a compressor cannot be trained with a naive uniform loss: the easy all-negative decision rule is statistically attractive but useless for r epair . Figure 3 r eveals that the fraction of relevant segments decreases monotonically with context size: instances with small conte xt (1-20 segments) have a relevance density above 11%, while those with 200+ segments drop below 2%. At the segment lev el, method-level units constitute 78.0% of all segments but have a relevance density of only 7.5%, making method selection the primar y bottleneck of context compression. W e note that HDD is required to pr oduce minimal sucient con- texts by denition. T o understand the impact of GA, we conducted an ablation — when not using the genetic algorithm, the number of successfully minimized instances reduces by 52.7%. T o understand why certain segments are relevant, we classify each segment into semantic roles based on its structural relationship to the issue description and fault location (Figure 4). The Schema role (data classes and type denitions) achieves the highest rele- vance density at 39.2% , reecting the prevalence of type-mismatch and eld-naming bugs in SWE-bench. Denition segments (11.7%) and Call Chain segments (10.2%) conrm that structural proximity to the fault in the call graph is a strong predictor of r elevance. In contrast, Generic Utility segments exhibit the lo west relevance Haoxiang Jia, Earl T . Barr, and Sergey Mechtaev 1-20 21-40 41-60 61-80 81-100 101-150 151-200 200+ Number of Segments per Instance (binned) 0 2 4 6 8 10 12 P ositive R ate (%) n=908 n=779 n=510 n=321 n=236 n=311 n=73 n=19 Figure 3: Relevance density vs. context size. Relevance den- sity monotonically decreases with the increase of context size, conrming that broader retrieval introduces proportion- ally more noise. Error bars denote interquartile ranges. 1K 10K 100K T otal Segments (log scale) Schema Exception Definition Config Call Chain Behavior Similar Impl. Generic Util. (a) Role Support n=1,340 n=633 n=32,494 n=4,866 n=39,565 n=4,915 n=48,411 n=1,491 0 10 20 30 40 50 P ositive R ate (%) 39.2% 14.7% 11.7% 10.8% 10.2% 8.7% 7.4% 7.2% Whiskers: 95% CI (b) Role Relevance Figure 4: Relevance density per semantic role. Schema seg- ments achieve the highest relevance density (39.2%), while Generic Utility segments represent the strongest noise source (7.2%). The wide variance across roles motivates role-aware sample weighting in SWEzze training. density (7.2%), representing recall noise from broad le-level re- trieval. The ve-fold variance in relevance density across roles— from 7.2% to 39.2%—has a practical implication: a uniform loss function would under-weight rare but highly informativ e schema and denition segments while over-penalizing the mo del for re- taining generic utilities. This obser vation motivates the role-aware sample weighting strategy adopte d in SWEzze ’s training, where per-sample weights are modulated by semantic role to r eect the dierential informativeness of each segment category . 4 SWEZZE COMPRESSION MODEL Distillation in Section 3 yields training examples that map an over- approximate context to a minimal sucient subset. Formally , it produces a corpus D contains tuples of the form ( I , F , C init , ˆ C ) , where I is the issue description, F is the fault location, C init is the initial retrieved context, and ˆ C is the minimal sucient context identied by OCD. W e transform this corpus into a pointwise clas- sication dataset of ( 𝑞, 𝑠 , 𝑦 ) triples, where 𝑞 is a structured query , 𝑠 is a code segment, and 𝑦 ∈ { 0 , 1 } indicates whether the oracle retained that segment. Each initial context C init is parsed into a set of code segments { 𝑠 1 , . . . , 𝑠 𝑛 } . W e use this corpus to ne-tune Qwen3-Reranker-0.6B and obtain SWEzze , a lightweight cross-encoder that denes a scoring function 𝑓 ( 𝑞, 𝑠 ; 𝜃 ) ∈ [ 0 , 1 ] . Given a structured query 𝑞 built from the issue description and fault lo cation, with a code segment 𝑠 from the initial context, the model predicts whether 𝑠 should be retained to preserve patch suciency . A reranker model is well suited to this setting because the super vision is dened at the segment level, and inference only requires scoring a xed pool of candidate segments rather than generating context from scratch. W e employ Low-Rank Adaptation (LoRA) for parameter-ecient ne-tuning. This reduces trainable parameters by over an order of magnitude, making ne-tuning feasible on commodity har dware while preserving the base model’s code understanding. W e use LoRA with rank 𝑟 = 16 and scaling factor 𝛼 = 32 , applie d to the query , key , value, and output projection matrices. Training runs for 3 epochs with an eective batch size of 16 (per-device batch size 4 with 4 gradient accumulation steps), using AdamW with learning rate 2 × 10 − 4 , 10% linear warmup, weight decay of 0.01, and gradient clipping at norm 1.0. W e use boat16 mixed pr ecision with gradient checkpointing to t training within commodity GP U memor y . The best checkpoint is selecte d by AUC-ROC on a held-out validation set comprising 10% of instances. A key challenge in our dataset is that the oracle discards far mor e code segments than it retains—a typical instance has a compression ratio well below 50%, meaning negatives substantially outnumber positives. Without correction, the mo del would learn to trivially predict “discard” for all segments. W e address this through two complementary mechanisms: (1) a class-level weight that upscales the loss contribution of positive (retained) segments in proportion to the imbalance ratio, ensuring that missing a necessary segment is penalized more heavily than retaining a redundant one; and (2) the per-sample role-aware weights, which further modulate individual examples based on their structural informativ eness. T ogether , these mechanisms aim to encode that it is worse to lose a patch-critical dependency than to include a few extra lines of supporting code. At inference time, given a new instance , the system rst parses C init into segments and constructs the structured quer y 𝑞 as in training. Each segment is scored by the cross-encoder in batches. For segments that excee d the model’s context window , a sliding- window strategy scores ov erlapping windows independently and aggregates them, ensuring that long functions or class bodies are evaluated fairly rather than truncated. Finally , the system assembles the compressed context through budget-aware greedy sele ction. The token budget is controlled by a congurable compression rate. 5 EV ALU A TION Our evaluation answers the following r esearch questions: RQ1 How does SWEzze compare to existing compression baselines in terms of compression ratio and eciency? RQ2 Does SWEzze preserve or improve downstream issue r esolu- tion rates compared to baselines across dierent LLMs? RQ3 What compression-related root causes lead to faile d issue resolution? Dataset. W e conduct our evaluation on SWE-bench V erie d [ 7 ], a curated subset of 500 real-world GitHub issues spanning 12 popular Python repositories. Each instance consists of an issue description, the repository snapshot at the time of ling, a ground-truth patch, and a regression test suite. SWE-b ench V erie d is widely adopted as Compressing Code Context for LLM-based Issue Resolution T able 2: Comparison of context compression methods on SWE-bench V eried (500 instances). For each downstream LLM, the number in parentheses denotes the mean initial context length in tokens before compression. Compression is reported as the reduction rate relative to the initial context length (higher is more aggressive). Bold denotes the best result per column. Method DeepSeek- V3.2 (15,921 tokens) Q wen3-Coder-Next (7,761 tokens) GPT -5.2 (15,690 tokens) Resolved Rate Compression Resolved Rate Compression Resolved Rate Compression No_compression 239 0.478 1.00 × 200 0.400 1.00 × 266 0.532 1.00 × No_context 231 0.462 – 193 0.386 – 262 0.524 – LLMLingua-2 245 0.490 2.98 × 193 0.386 2.80 × 272 0.544 2.94 × LongCodeZip 238 0.476 5.02 × 199 0.398 7.40 × 284 0.568 7.67 × SWE-Pruner 233 0.466 4.10 × 192 0.384 49.75 × 270 0.540 22.37 × SWEzze 261 0.522 6.03 × 210 0.420 5.95 × 289 0.578 6.55 × a standard benchmark for LLM-base d issue resolution, providing a controlled yet realistic testbed where issues range from single-line xes to multi-le refactorings. W e obtain the code context for each instance using Agentless [ 29 ]. Agentless hierarchically localizes an issue by rst identifying rele- vant les, then classes and functions within those les, and nally pinpointing specic code elements. During this process, it retrieves a ranke d list of related elements at each granularity . W e use the top- 10 strategy to select elements from the ranked list, chosen to match the context size used in prior compression work [ 23 ]; since the total cost of our experiments already exceeds 2800$, we did not perform additional ablation over this parameter . After Agentless determines suspicious locations, we treat the edit targets as the focal point and retain the remaining top-ranked related elements as the supporting context. Baselines. W e compare SWEzze against three compression base- lines spanning distinct compression paradigms: • LLMLingua-2 : A token-level compression method that trains a compact encoder to predict per-token preservation proba- bilities via data distillation. • LongCodeZip : A hierarchical co de-specic compressor that ranks functions by conditional perplexity and prunes blocks. • SWE-Pruner : A task-aware code compressor that uses a lightweight reranker to estimate token rele vance and prunes lines whose aggregated scores fall below a threshold. • No Compression : The full evaluation conte xt is passed di- rectly to the repair model without any reduction. • No Context : Only the issue description and fault location are provided, with no supporting code context. T o ensure fairness, we congure each baseline at its recom- mended or b est-aligned operating point. For LLMLingua-2 and SWE-Pruner , we adopt default parameter settings specie d in their respective publications. For LongCodeZip, we derive the target compression ratio from the eective compression levels reported in LongCo deZip’s original experiments and set the compression rate to 5 × . For SWEzze , we also set the compression rate to 5 × . T able 3: Prompt and total token consumption per instance across downstream LLMs. SWEzze substantially reduces the end-to-end token cost relative to the uncompressed setting while retaining sucient context for repair . Method DeepSeek-V3.2 Qwen3-Coder-Next GPT -5.2 Prompt ↓ T otal ↓ Prompt ↓ T otal ↓ Prompt ↓ T otal ↓ No_compression 21 808 23 194 9457 13 901 16 893 17 408 No_context 6359 7627 1675 4394 2255 2767 LLMLingua-2 11 480 12 864 4408 7236 7237 7731 LongCodeZip 9177 10 569 2658 6028 4166 4667 SWE-Pruner 9834 11 214 1753 4822 2912 3393 SWEzze 8658 10 230 2922 6707 4492 4992 SWEzze vs. No_compression − 60 . 3% − 55 . 9% − 69 . 1% − 51 . 8% − 73 . 4% − 71 . 3% Models. T o assess generalizability of SWEzze across dierent LLMs, we evaluate each compression method under three down- stream repair models that dier in architecture, scale , and provider: GPT -5.2 [24], De epSeek- V3.2 [13], and Qwen3-Coder-Next [1]. Evaluation Metrics. W e assess compression methods along four dimensions that jointly capture the cost eectiveness trade-o of context compression: • Resolution Rate : The fraction of instances for which the repair model generates a patch that passes the full regression test suite. This is the primar y ee ctiveness metric, directly measuring whether compression preserves the semantic con- tent necessary for correct patch synthesis. • Compression Rate : The ratio | C init | / | ˆ C | measured in tokens, where high values indicate more aggressive compression. This metric quanties the reduction in context size. • T oken Count : The total number of tokens consumed during the repair step, comprising both compressed pr ompt tokens and completion tokens. • Compression Time : The wall-clock time required to com- press a single instance, measuring the computational overhead that the compression step introduces into the repair pipeline. Haoxiang Jia, Earl T . Barr, and Sergey Mechtaev (a) 0 50 100 150 200 250 Intersection size 223 12 10 5 5 4 2 1 DeepSeek-V3 (union = 263) 0 250 Set size LLMLingua-2 LongCodeZip SWE-Pruner SWEzze 245 238 233 261 (b) 0 50 100 150 200 170 8 8 7 7 5 5 4 Qwen3-Coder (union = 224) 0 250 Set size 193 199 192 210 (c) 0 100 200 300 254 8 7 7 7 5 3 2 GPT-5.2 (union = 299) 0 250 Set size 272 284 270 289 Figure 5: UpSet plots of resolved-instance overlaps across compression methods on SWE-bench V erie d. Each panel corresponds to one downstream repair model. T op bars show the size of resolved-instance interse ctions, while the left bars show the total number of resolved instances per method, with SWEzze highlighted in orange. The plots rev eal both the shared wins and the additional instances uniquely recover ed by SWEzze . T able 4: Mean compression latency per instance (seconds) for each method across the three LLMs. Lower is faster . Method DeepSeek- V3.2 Qwen3-Coder-Next GPT -5.2 LLMLingua-2 0.9 0.44 0.9 LongCodeZip 34.6 10.9 27.8 SWE-Pruner 1.2 0.48 1.1 SWEzze 10.0 2.5 5.9 5.1 RQ1: Compression Eciency and Cost T able 2 shows that across all three LLMs SWEzze ’s compression rate stays close to 6 × (6.03 × on DeepSeek- V3.2, 5.95 × on Qwen3- Coder-Next, and 6.55 × on GPT -5.2). This pattern is mor e stable than that of the baselines. LLMLingua-2 is conservative, remaining below 3 × compression in every setting. LongCodeZip compresses more , but its compression rate varies more across models. SWE-Pruner’s compression rate ranges from 4.10 × on DeepSeek- V3.2 to 49.75 × on Qwen3-Coder-Next. The weak result of SWE-Pruner on DeepSeek- V3.2 can be explained by the fact that the issue description and fault location consume much of SWE-Pruner’s hint-generation budget. The achieved compression rate may exceed the target rate b ecause the target denes only a minimum compression level. Once no budget remains for another code segment, or no remaining segment meets the selection threshold, the method stops adding segments. Higher compression rate leads to token cost savings. Compared with No_compression , SWEzze removes 13,150 pr ompt tokens per instance on DeepSeek- V3.2, 6,535 on Q wen3-Coder-Next, and 12,401 on GPT -5.2, which corresponds to prompt reductions of 60.3%, 69.1%, and 73.4%, respectively . The end-to-end token budget, measured as the sum of prompt and completion tokens, still falls by 55.9%, 51.8%, and 71.3% relative to the uncompressed setting. Compared with LLMLingua-2, SWEzze further reduces the total token budget by 20.5% on DeepSeek- V3.2 and 35.4% on GPT -5.2. On Qwen3-Coder- Next, howe ver , its total cost remains higher than that of the more aggressive LongCodeZip and SWE-Pruner . It shows that SWEzze does not optimize only for the smallest possible token cost, but aims for more balanced, controlled compression. A veraged over the three LLMs, LLMLingua-2 and SWE-Pruner are the fastest methods, r equiring only 0.75 and 0.93 seconds per instance, respectively , while LongCodeZip is much slower at 24.4 seconds. SWEzze lowers this o verhead to 6.1 seconds on average , making it about 4.0 × faster than LongCodeZip. The same pattern appears across all backends: relative to LongCodeZip, SWEzze reduces compression latency by 71.1% on DeepSeek- V3.2, 77.1% on Qwen3-Coder-Next, and 78.8% on GPT -5.2. At the same time, it is 8.2 × slower than LLMLingua-2 and 6.6 × slower than SWE- Pruner , which reects the extra cost of structured segmentation and reasoning on compr ession queries. While SWEzze is not the cheapest compressor in absolute terms, it oers a b etter balance among compression rate, stability , and latency than the baselines. RQ1: SWEzze achieves stable ∼ 6 × compression across LLMs, reduces the total token count by 51.8%–71.3% over No_compression ; it is 4.0 × faster than LongCodeZip on average . 5.2 RQ2: End-to-End Issue Resolution T able 2 shows that SWEzze achieves the best issue resolution per- formance across all three LLMs. Its resolution rate reaches 0.522 on DeepSeek- V3.2, 0.420 on Qwen3-Coder-Next, and 0.578 on GPT -5.2. Relative to No_compression, these results correspond to absolute gains of 4.4, 2.0, and 4.6 percentage points (relative impro vements of 9.2%, 5.0%, and 8.6%). When compared with No_context, SWEzze ’s gains are 6.0, 3.4, and 5.4 percentage points (13.0%, 8.8%, and 10.3% in relative improvement). This pattern suggests that repositor y context helps issue r esolution only when intelligently selected. The much smaller gap between No_compression and No_conte xt fur- ther suggests that a substantial part of the raw retrieved context is not necessary and may even hinder the repair process. Compressing Code Context for LLM-based Issue Resolution Importantly , SWEzze ’s improvements do not simply come from solving the same easy instances as the competing compressors. Figure 5 shows that the largest intersection in every panel is the four-way overlap, with 223 instances on De epSeek- V3.2, 170 on Qwen3-Coder-Next, and 254 on GPT -5.2. This indicates that all methods solve a large shared set of relatively easy instances. Even so, SWEzze still covers the largest resolved set on every comparison. Compared with the strongest baseline for each model, this adds 16 instances on DeepSeek- V3, 11 on Qwen3-Coder , and 5 on GPT - 5.2, which corresponds to relative gains of 6.5%, 5.5%, and 1.8%. Measured against the union of all resolved instances, the coverage of SWEzze reaches 99.2% on DeepSeek-V3, 93.8% on Qwen3-Coder , and 96.7% on GPT -5.2. This means that the advantage of SWEzze is not limited to higher overall accuracy . It also recovers a broader set of instances, including cases missed by other compressors. As shown in Figure 6, the baselines tend to fall into less favorable operating regions. LLMLingua-2 stays in a lo w-cost but low-gain region, oering only marginal impr ovement or ev en causing degra- dation. SWE-Pruner represents the other extreme. It can apply very aggressive compression, but its downstr eam behavior is unsta- ble, suggesting that excessiv e pruning often removes information needed for repair . LongCo deZip is more comp etitive in compression strength, but its gains are less consistent and come with substan- tially higher latency . In contrast, SWEzze consistently achieves the largest improv ements in resolution rate, while maintaining a moderate compression rate of about 6 × and a practical runtime overhead. These results support the central claim of this work: for repository-level issue resolution, the goal is not to maximize com- pression aggr essiveness, but to preserve the small subset of conte xt that is truly sucient for generating a correct patch. RQ2: SWEzze achieves the best issue resolution performance across all three LLMs, impro ving resolution rates by 5.0–13.0% to the uncompressed and no-context settings. It also covers the broadest set of resolved instances, reaching 93.8%–99.2% of the union of all solved cases. 5.3 RQ3: Analysis of Compression Failures Based on the UpSet plot, we manually inspected unresolved in- stances, and found three recurring typ es of failures. First, a com- pressor may retain distracting code, which pulls the LLM to ward irrelevant logic. Second, the model may not score code segments with enough precision. This problem often occurred in projects with overridden functions or multiple implementations that share the same signature and have similar function bodies. In such cases, small code dierences may lead to divergent behaviors, but the model cannot distinguish them reliably . Third, overly aggressiv e compression may damage the syntactic structure of the original code and produce fragmented contexts that obscure semantic rela- tions. W e uniformly sampled 30 instances unresolved by GPT -5.2 for which the uncompressed co de context produced a passing patch. Among these instances, 5 are due to distracting context, 8 to impr e- cise segment scoring, and 17 to disrupted syntactic structure. Figure 7 shows a representative case where retained context dis- tracts the repair model. The issue requires assigning the maxlength attribute to the username eld. In this case, SWEzze , No_context , 1x 2x 5x 10x 20x 50x Compression Factor -4% -2% 0% +2% +4% +6% +8% +10% Δ Resolution Rate (%) Comp. time 1s 10s 35s LLMLingua-2 LongCodeZip SWE-Pruner SWEzze LLMLingua-2 LongCodeZip SWE-Pruner SWEzze DeepSeek Qwen GPT No Compression baseline Figure 6: Tradeo between compression rate, resolution rate improvement over the no-compression baseline ( Δ = 0% , dashed), and compression latency ( bubble area) across four methods and three LLMs (marker shape). SWEzze (orange) achieves the highest resolution-rate gains ( + 5 . 0% – + 9 . 2% ) at a moderate compression rate ( ∼ 6 × ) and latency . and No_compression all resolve the issue successfully , whereas LongCodeZip and SWE-Pruner fail. The failure arises because these two methods, especially SWE-Pruner , discar d most of the surround- ing context and keep only the widget_attrs function. This func- tion contains a predicate that checks whether widget.is_hidden is false, and one branch assigns a value to widget.max_length . With only this compressed context, the r epair model generates a patch that adds an unnecessar y constraint on is_hidden , which causes the tests to fail. This example sho ws that context compres- sion can hurt repair performance not only by removing essential information, but also by keeping misleading fragments that divert the model from the true repair logic. RQ3 : Manual analysis shows that most failur es are due to dis- tracting retained context, insuciently precise semantic discrim- ination between similar code segments, and breaking syntactic structure through ov erly aggressive compression. 6 THREA TS TO V ALIDI T Y & DISCUSSION T o assess whether SWEzze generalizes across model families, we evaluate with three issue-resolution models from distinct providers and architectures: GPT -5.2, De epSeek- V3.2, and Qwen3-Coder-Next. Crucially , none of these is the model use d during OCD data construc- tion (Qwen3-Coder-30b), which means the compressed contexts were distilled under one model yet consistently benet dierent ones. This cross-model transfer suggests that the x ingredients extracted by OCD capture genuine semantic dependencies of the issue rather than artifacts of a particular model’s decoding strategy , and that the resulting compression is largely model-agnostic. The search process relies on ground-truth patches and test cov er- age information that are unavailable at inference time. This creates Haoxiang Jia, Earl T . Barr, and Sergey Mechtaev Figure 7: SWE-Pruner retains a distracting fragment that leads to an incorrect patch, whereas SWEzze removes it, en- abling correct resolution. The compressed context uses the same visual notation as Figure 2. a distribution gap b etween training and deployment: the model must learn to approximate the oracle’s judgments using only in- formation available from the issue description and r etrieved code. W e address this gap in the model training phase by formulating the task as learning to predict which units the oracle would re- tain. Importantly , the inputs required by OCD—(issue , patch, test suite) triples—are naturally produced by any software project that uses pull requests with continuous integration. This means OCD training data can in principle b e mined from any repositor y with a suciently rich merge history , not only from curated benchmarks. Our search explicitly targets minimal sucient contexts rather than merely sucient ones. This design choice reects the hypothe- sis that minimal conte xts provide cleaner supervision signals—they contain less noise and more directly captur e the causal dependen- cies required for repair . How ever , minimality is dened with respe ct to the specic LLM and generation parameters used during data construction; the truly minimal context may vary across models. 7 RELA TED WORK LLM Context. Previous research noticed that LLMs struggle with processing long contexts [ 11 , 15 ], raising the so-called “lost-in-the- middle” pr oblem. W orse, Shi et al [ 22 ] noticed that LLMs tend to be distracte d by irrelevant context, which signicantly degrades performance. Although recent work on long context handling par- tially alleviated this problem [ 36 ], state-of-the-art LLMs continue to exhibit this weakness. Context Retrieval. T o r esolve issues in real-world repositories, an LLM requires relevant code context containing necessary project- specic dependencies. FitRepair [ 30 ] uses hard-coded heuristics to augment prompts with contextual code data. LLM agents emplo y more exible mechanisms such as embedding-based retrieval [ 29 ], retrieval-augmented generation (RA G) [ 9 ] such as matching rele- vant code snippets with BM25 [ 20 ], or agentic retrieval that invokes code search APIs [ 39 ]. Because these techniques rely on syntac- tic similarity , and capture only shallow semantic properties, they typically overappro ximate the necessary context, which result in decreased generation eciency and increased cost. Prompt Compression. Prompt compression aims to reduce the length of prompts to improv e the eciency of processing LLM inputs [ 12 , 26 ]. A large body of works focus on task-agnostic nat- ural language compression, such as LlmLingua [ 5 ] and LlmLin- gua2 [ 18 ]. T echniques such as T A CO-RL [ 21 ] oer task-specic natural language compression, that optimizes prompt for a spe cic task. Despite their practicality , such approaches are ineective in selecting relevant code context for issue resolution, be cause source code demands strict syntactic integrity and requires taking into account structural dependencies. LLM-based Issue Resolution & Program Repair . LLMs enabled eective automated program repair [ 8 ] that can resolv e issues in real-world repositories, with r epresentative techniques including ChatRepair [ 31 ], SWE- Agent [ 33 ], and A utoCodeRover [ 39 ]. In this work we r ely on Agentless [ 29 ] because it represents a canonical issue resolution workow , which is widely used to e valuate fr ontier LLMs on issue resolution [2]. Code Compression & Information Selection. Early works such as Maniple [ 19 ] selecte d relevant code fragments for LLM-based program repair using a random forest, however this approach is not ne-grained enough to identify precise x ingredients. Xiao et al. [ 32 ] suggested to reduce agent traje ctories by removing useless, redundant, and e xpired information to reduces computational costs. In contrast to SWEzze , this approach is not code-specic. Long- CodeZip [ 23 ] introduced a code-specic compression framework; it rst ranks function-level chunks using conditional perplexity to align with the task, and then applies ne-grained block-level pruning via knapsack algorithm. Similarly , SWE-Pruner [ 27 ] ne- tunes a lightweight reranker to score each token’s task-conditioned relevance, and prunes lines whose aggregated scores fall below a threshold. Their key limitation is that the ranking criteria, per- plexity or relevance score , do not address the problem of retaining ingredients for issue resolution, since they merely measure relat- edness of code fragment to the bug. In contrast, SWEzze reframes Compressing Code Context for LLM-based Issue Resolution the problem from compressing for r elevance to distilling for su- ciency . By leveraging oracle feedback, we move beyond statistical proxies to explicitly sear ch for the minimal context conguration that enables the generation of a correct patch. 8 CONCLUSION W e presented a code context compression framework for LLM- based issue resolution. Unlike prior compressors that r ely on per- plexity or lexical similarity , SWEzze is trained on minimal sucient contexts produce d by Oracle-guide d Code Distillation (OCD), a two- phase search combining genetic algorithms and hierarchical delta debugging. OCD identies the smallest context subsequence that still enables a correct patch, thus capturing ingredients required for issue resolution rather than surface-level relatedness. Evalu- ated on SWE-bench V eried with three frontier LLMs, SWEzze achieves stable compression while also impro ving resolution rates over pre vious compression baselines. A CKNO WLEDGMEN TS W e thank Yue Pan for assistance with the implementation, and Yihan Dai, Haotian Xu, and Dimitrios Stamatios Bouras for their comments on an early draft. REFERENCES [1] Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Y unlong Feng, Binyuan Hui, Y uheng Jing, Kaixin Li, Mingze Li, Junyang Lin, et al . 2026. Q wen3-coder- next technical report. arXiv preprint arXiv:2603.00729 (2026). [2] Xiang Deng, Je Da, Edwin Pan, Y annis Yiming He, Charles Ide, Kanak Garg, Niklas Lauer , Andrew Park, Nitin Pasari, Chetan Rane, et al . 2025. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks? arXiv preprint arXiv:2509.16941 (2025). [3] The Matplotlib development team. 2026. Matplotlib: Visualization with Python. https://matplotlib.org/. Accessed on 2026-03-26.. [4] Edward J. Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean W ang, and W eizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. CoRR abs/2106.09685 (2021). arXiv:2106.09685 https://arxiv .org/abs/ 2106.09685 [5] Huiqiang Jiang, Qianhui Wu, Chin-Y ew Lin, Y uqing Yang, and Lili Qiu. 2023. Llmlingua: Compressing prompts for accelerated inference of large language models. In Proceedings of the 2023 conference on empirical methods in natural language processing . 13358–13376. [6] Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin- Y ew Lin, Yuqing Y ang, and Lili Qiu. 2024. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. In Proceedings of the 62nd A nnual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) . 1658–1677. [7] Carlos E Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, Kexin Pei, Or Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770 (2023). [8] Claire Le Goues, Michael Pradel, and Abhik Roychoudhury . 2019. Automated program repair . Commun. A CM 62, 12 (2019), 56–65. [9] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, W en-tau Yih, Tim Rock- täschel, et al . 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Conference on Neural Information Processing Systems . [10] Han Li, Letian Zhu, Bohan Zhang, Rili Feng, Jiaming W ang, Yue Pan, Earl T Barr , Federica Sarro, Zhaoyang Chu, and He Y e. 2026. ContextBench: A Benchmark for Context Retrieval in Coding Agents. arXiv preprint arXiv:2602.05892 (2026). [11] Jiaqi Li, Mengmeng W ang, Zilong Zheng, and Muhan Zhang. 2024. Loogle: Can long-context language models understand long contexts? . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Pap ers) . 16304–16333. [12] Zongqian Li, Yinhong Liu, Yixuan Su, and Nigel Collier . 2025. Prompt compres- sion for large language models: A survey . In Proceedings of the 2025 Conference of the Nations of the A mericas Chapter of the Association for Computational Lin- guistics: Human Language T e chnologies (Volume 1: Long Papers) . 7182–7195. [13] Aixin Liu, Bei Feng, Bing Xue, Bingxuan W ang, Bochao W u, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al . 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024). [14] Kui Liu, Anil Koyuncu, Kisub Kim, Dongsun Kim, and T egawendé F Bissyandé. 2018. LSRepair: Live search of x ingr edients for automated program repair . In 2018 25th Asia-Pacic Software Engineering Conference (APSEC) . IEEE, 658–662. [15] Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. T ransactions of the association for computational linguistics 12 (2024), 157–173. [16] Matias Martinez, W estley W eimer , and Martin Monperrus. 2014. Do the x ingredients already exist? an empirical inquiry into the redundancy assumptions of program repair approaches. In Companion Proceedings of the 36th international conference on software engine ering . 492–495. [17] Ghassan Misherghi and Zhendong Su. 2006. HDD: hierarchical delta debugging. In Proceedings of the 28th international conference on Software engine ering . 142– 151. [18] Zhuoshi Pan, Qianhui W u, Huiqiang Jiang, Menglin Xia, Xufang Luo , Jue Zhang, Qingwei Lin, Victor Rühle, Y uqing Y ang, Chin- Y ew Lin, et al . 2024. Llmlingua-2: Data distillation for ecient and faithful task-agnostic prompt compression. In Findings of the Association for Computational Linguistics: ACL 2024 . 963–981. [19] Nikhil Parasaram, Huijie Y an, Boyu Y ang, Zineb Flahy, Abriele Qudsi, Damian Ziaber , Earl Barr, and Sergey Mechtaev . 2024. The fact selection problem in llm-based program repair . arXiv preprint arXiv:2404.05520 (2024). [20] Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance frame- work: BM25 and beyond . V ol. 4. Now Publishers Inc. [21] Shivam Shandilya, Menglin Xia, Supriyo Ghosh, Huiqiang Jiang, Jue Zhang, Qianhui Wu, Victor Rühle , and Saravan Rajmohan. 2025. T aco-rl: T ask aware prompt compression optimization with reinforcement learning. In Findings of the Association for Computational Linguistics: A CL 2025 . 1582–1597. [22] Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning . PMLR, 31210–31227. [23] Y uling Shi, Yichun Qian, Hongyu Zhang, Beijun Shen, and Xiaodong Gu. 2025. Longcodezip: Compress long context for code language models. arXiv preprint arXiv:2510.00446 (2025). [24] Aaditya Singh, Adam Fry , Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky , Aidan McLaughlin, Aiden Low , AJ Ostrow , Akhila Ananthram, et al . 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025). [25] Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser , and Illia Polosukhin. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems 30: An- nual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA , Isab elle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. W allach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett (Eds.). 5998–6008. https://proceedings.neurips.cc/paper/2017/hash/ 3f5ee243547dee91f bd053c1c4a845aa- Abstract.html [26] Zhongwei W an, Xin W ang, Che Liu, Samiul Alam, Y u Zheng, Jiachen Liu, Zhong- nan Qu, Shen Y an, Yi Zhu, Quanlu Zhang, et al . 2023. Ecient large language models: A survey . arXiv preprint arXiv:2312.03863 (2023). [27] Y uhang W ang, Y uling Shi, Mo Y ang, Rongrui Zhang, Shilin He, Heng Lian, Yuting Chen, Siyu Y e, Kai Cai, and Xiaodong Gu. 2026. SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents. arXiv preprint arXiv:2601.16746 (2026). [28] Martin White, Michele T ufano, Matias Martinez, Martin Monperrus, and Denys Poshyvanyk. 2019. Sorting and transforming program repair ingredients via deep learning code similarities. In 2019 IEEE 26th international conference on software analysis, evolution and reengineering (SANER) . IEEE, 479–490. [29] Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents. arXiv preprint arXiv:2407.01489 (2024). [30] Chunqiu Steven Xia, Yifeng Ding, and Lingming Zhang. 2023. The plastic surgery hypothesis in the era of large language mo dels. In 2023 38th IEEE/ACM International Conference on Automated Software Engineering ( ASE) . IEEE, 522– 534. [31] Chunqiu Steven Xia and Lingming Zhang. 2024. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt. In Proceedings of the 33rd A CM SIGSOFT International Symposium on Software T esting and Analysis . 819–831. [32] Y uan-An Xiao, Pengfei Gao, Chao Peng, and Yingfei Xiong. 2025. Improving the eciency of LLM agent systems through traje ctory reduction. arXiv preprint arXiv:2509.23586 (2025). [33] John Yang, Carlos E. Jimenez, Alexander W ettig, Kilian Lieret, Shunyu Yao , Karthik Narasimhan, and Or Press. 2024. SWE-agent: Agent-Computer Inter- faces Enable Automated Software Engineering. In NeurIPS . [34] John Y ang, Kilian Lieret, Carlos E Jimenez, Alexander W ettig, Kabir Khand- pur , Y anzhe Zhang, Binyuan Hui, Or Press, Ludwig Schmidt, and Diyi Y ang. 2025. Swe-smith: Scaling data for software engineering agents. arXiv preprint arXiv:2504.21798 (2025). Haoxiang Jia, Earl T . Barr, and Sergey Mechtaev [35] Andreas Zeller and Ralf Hildebrandt. 2002. Simplifying and isolating failure- inducing input. IEEE Transactions on software engineering 28, 2 (2002), 183–200. [36] Alex L Zhang, Tim Kraska, and Omar Khattab . 2025. Recursive language models. arXiv preprint arXiv:2512.24601 (2025). [37] Tianyi Zhang, V arsha Kishore, Felix W u, Kilian Q. W einb erger , and Y oav Artzi. 2020. BERTScore: Evaluating T ext Generation with BERT. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, A pril 26-30, 2020 . Op enReview .net. https://openreview .net/forum?id=SkeHuCVFDr [38] Y anzhao Zhang, Ming xin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Y ang, Pengjun Xie, An Y ang, Dayiheng Liu, Junyang Lin, et al . 2025. Qwen3 embedding: Advancing text emb edding and reranking through foundation mo dels. arXiv preprint arXiv:2506.05176 (2025). [39] Y untong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury . 2024. Autocoderov er: Autonomous pr ogram improvement. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software T esting and A nalysis . 1592– 1604.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment