공변량 이동을 고려한 대규모 불균형 선형 혼합모형의 경험적 베이즈 예측밀도 추정
본 논문은 단위 수가 매우 많고 복제 관측이 일부 단위에만 존재하는 불균형 선형 혼합모형(LMM)에서, 미래 공변량 분포가 과거와 달라지는 공변량 이동 상황을 전제로 경험적 베이즈(E‑B) 방법으로 예측밀도를 추정한다. Kullback‑Leibler(KL) 위험을 최소화하도록 위험 추정기를 설계하고, 데이터‑분할(data‑fission)과 샘플 재사용(sample‑reuse) 기법을 결합해 위험 추정의 수렴 속도를 이론적으로 분석한다. 제안 방…
저자: Abir Sarkar, Gourab Mukherjee, Keisuke Yano
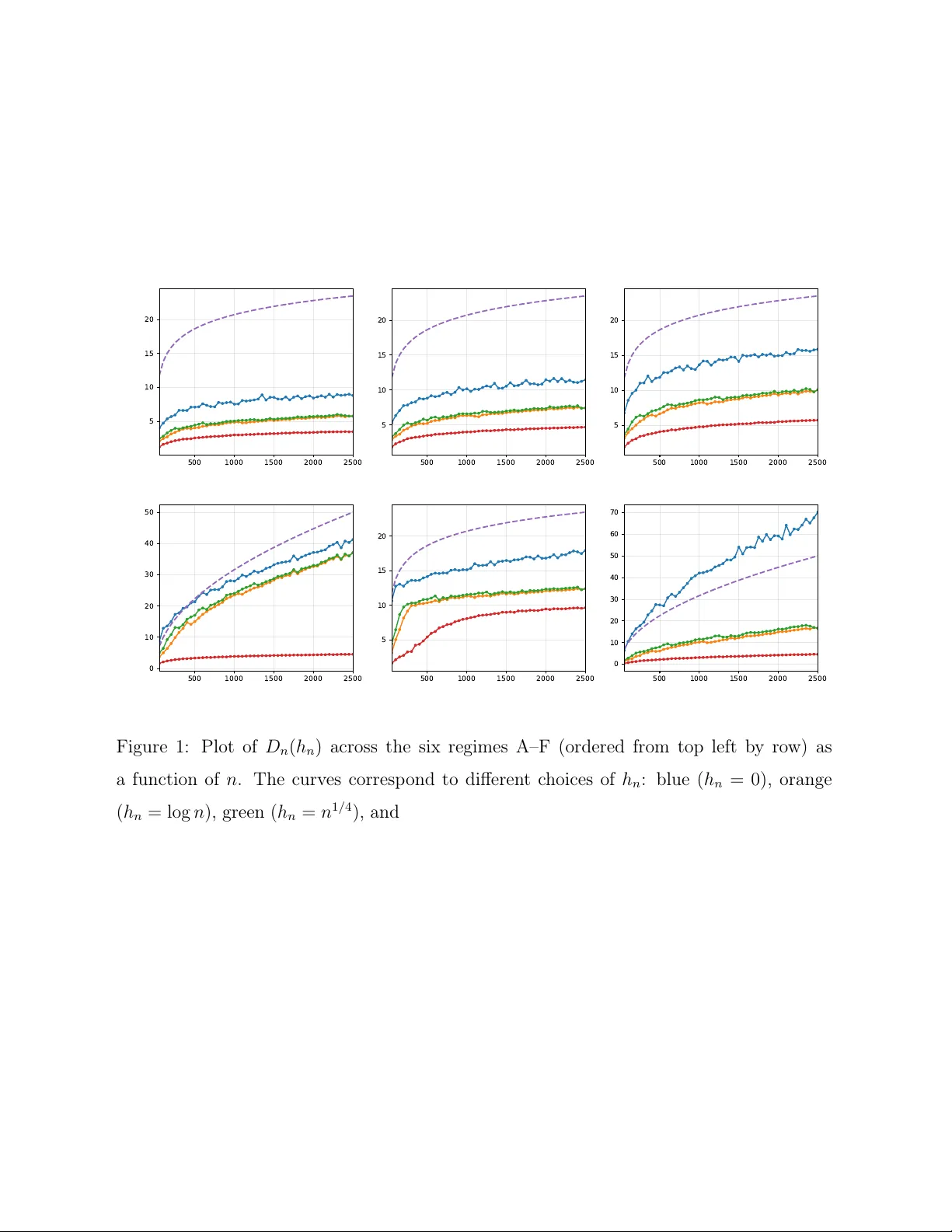
본 연구는 대규모 단위 수를 갖는 선형 혼합모형(LMM)에서, 복제 관측이 일부 단위에만 존재하는 심각한 데이터 불균형과, 과거와 미래 공변량 분포가 다르게 변하는 공변량 이동(covariate shift) 상황을 동시에 고려한다. 이러한 설정은 현대의 의료, 제조, 온라인 서비스 등에서 흔히 나타나며, 기존의 예측밀도 추정 방법은 두 문제를 동시에 다루기 어렵다.
논문은 먼저 예측밀도 추정의 목표를 Kullback‑Leibler(KL) 위험 최소화로 정의한다. KL 위험은 미래 설계(𝑥̃, v)의 분포를 직접 통합하므로, 공변량 이동에 자연스럽게 적응한다. 이를 위해 경험적 베이즈(E‑B) 프레임워크를 채택하고, 랜덤 효과 γ_i의 사전분포를 유연한 클래스 G (가우시안 및 비가우시안 포함) 안에서 선택한다.
핵심 기술은 ‘데이터‑분할(data‑fission)’과 ‘샘플 재사용(sample‑reuse)’이다. 랜덤 효과는 교환가능하다는 가정 하에, 관측 데이터를 두 부분으로 나누어 한쪽은 사전 g 의 추정에, 다른 쪽은 위험 추정에 사용한다. 이렇게 하면 동일 데이터를 두 번 활용하면서도 편향을 제어할 수 있다. 위험 추정기는 George et al. (2006)의 예측 열방정식 표현을 기반으로, 로그‑마진 형태로 변환된 위험을 차분 형태로 근사한다. 비가우시안 prior에 대해서는 무편향 추정기가 존재하지 않으므로, 샘플 스플리팅을 통해 편향을 억제하고, 위험 추정기의 수렴 속도를 O_p(n^{‑α}) 수준으로 보인다(α∈(0,½]).
수학적 가정은 크게 세 가지다. (A1) 고정 효과 β와 스케일 σ에 대한 플러그인 추정량이 O_p(n^{‑α}) 수렴한다. (A2) 설계 행렬(𝑥, 𝑥̃, u, v)가 유계이며, 랜덤 효과의 4차 모멘트가 평균적으로 유한하다. (A3) 미래 관측 수 ˜K_i가 모든 단위에 대해 일정 범위 내에 있다. 이러한 가정 하에, Theorem 1은 위험을 a_n(C) + R_{1,n} − R_{2,n} + 오차항으로 분해한다. a_n(C) 는 설계만 의존하는 상수이며, R_{1,n}와 R_{2,n}은 각각 관측 데이터와 미래 데이터에 대한 로그‑마진 기대값 차이이다.
위험 추정기를 이용해 모든 g∈G에 대해 ˆR_n(C; g)를 계산하고, 이를 최소화하는 ˆg를 선택한다. 최종 예측밀도는 ˆp
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기