Empirical Bayes Predictive Density Estimation under Covariate Shift in Large Imbalanced Linear Mixed Models
We study empirical Bayes (EB) predictive density estimation in linear mixed models (LMMs) with large number of units, which induce a high dimensional random effects space. Focusing on Kullback Leibler (KL) risk minimization, we develop a calibration …
Authors: Abir Sarkar, Gourab Mukherjee, Keisuke Yano
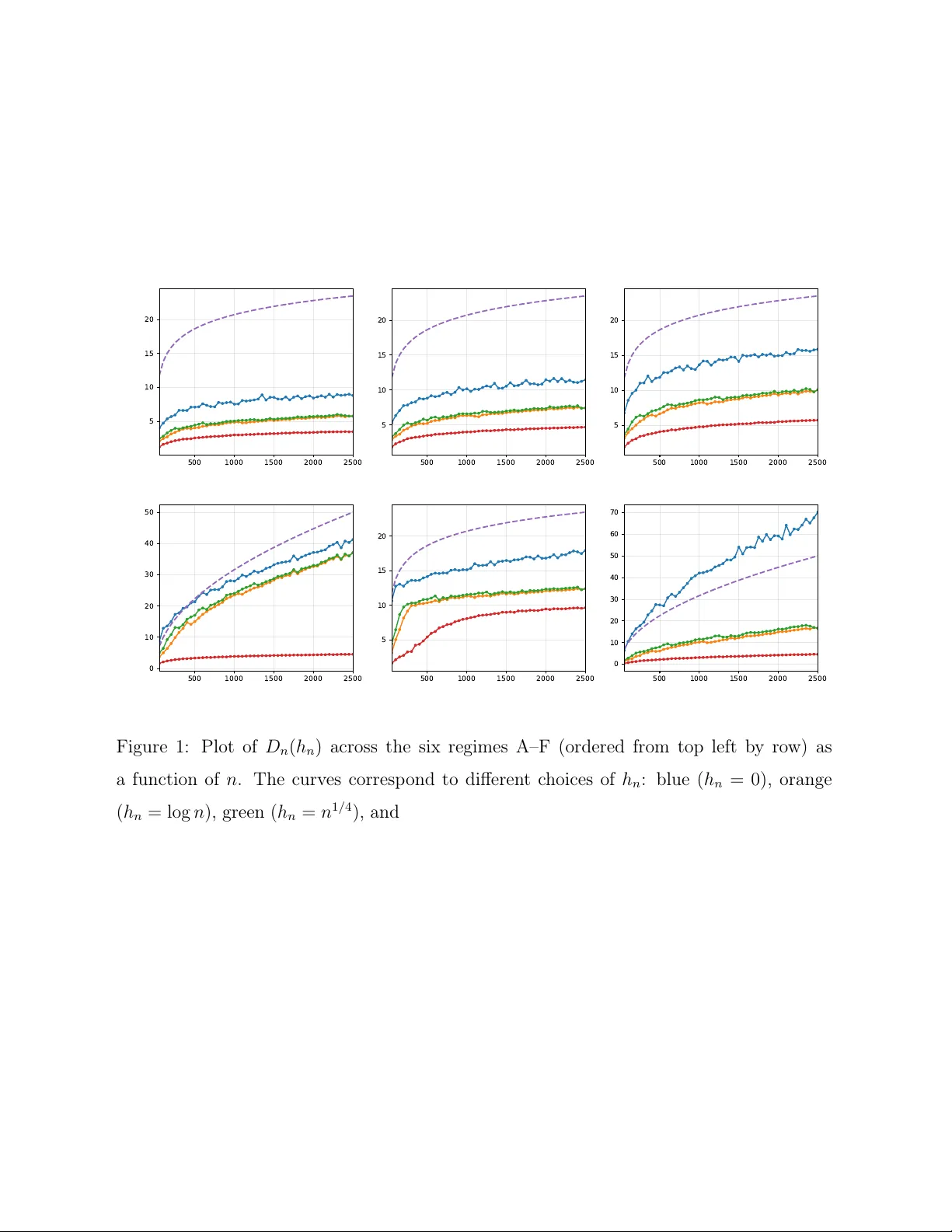
Empirical Ba y es Predictiv e Densit y Estimation under Co v ariate Shift in Large Im balanced Linear Mixed Mo dels Abir Sark ar Departmen t of Statistics and Data Science, Cornell Univ ersity and, Gourab Mukherjee Departmen t of Data Sciences and Op erations, Univ ersity of Southern California and, Keisuk e Y ano Departmen t of F undamen tal Statistical Mathematics, The Institute of Statistical Mathematics Marc h 31, 2026 Abstract W e study empirical Bay es (EB) predictive density estimation in linear mixed mo dels (LMMs) with large n um b er of units, which induce a high-dimensional random- effects space. F o cusing on Kullback–Leibler (KL) risk minimization, we develop 1 a calibration framework to optimally tune predictive densities deriv ed from on a broad class of flexible priors. Our prop osed metho d addresses t w o k ey c hallenges in predictiv e inference: (a) severe data scarcit y leading to highly imbalanced designs, in which replicates are av ailable for only a small subset of units; and (b) distributional shifts in future cov ariates. T o estimate predictiv e KL risk in LMMs, w e use a data-fission approac h that lev erages exchangeabilit y in the cov ariate distribution. W e establish con v ergence rates for our prop osed risk estimators and sho w ho w their efficiency deteriorates as data scarcit y increases. Our results imply the decision-theoretic optimality of the prop osed EB predictive densit y estimator. The theoretical developmen t relies on a no v el probabilistic analysis of the interaction b etw een data fission, sample reuse, and the predictive heat-equation representation of George et al. [2006], which expresses predictiv e KL risk through exp ected log-marginals. Extensive sim ulation studies demonstrate strong predictiv e p erformance and robustness of the proposed approac h across diverse regimes with v arying degrees of data scarcit y and co v ariate shift. Keywor ds: Predictive Densit y Estimation; Kullbac k-Leibler Loss; Linear Mixed Models; Risk Estimation; Empirical Ba yes; Sample Reuse; Cov ariate Shift. 2 1 In tro duction W e consider predictive densit y estimation [Aitchison and Dunsmore, 1975, Geisser, 1993] in linear mixed-effects mo dels (LMMs) [Demidenko, 2013, Pinheiro and Bates, 2000]. Our fo cus is on LMMs with a large n umber of units that need the use of large n umber of random effects. Suc h models are increasingly prev alent in contemporary applications (See Gao and Owen [2020], Ghosh et al. [2022] and the references therein). W e also allow for the p ossibility that past and future data ma y not b e exchangeable [Cauc hois et al., 2024], with future data in v olving cov ariates drawn from a differen t distribution (See Section 2 of Tibshirani et al. [2019]). This phenomenon, known as co v ariate shift, frequently arises in modern predictiv e inference problems [Gibbs and Candès, 2021]. Standard predictiv e metho ds t ypically perform p o orly under these regimes [Angelop oulos et al., 2022, Gibbs and Candès, 2024, Y ang et al., 2024]. Our ob jective is to estimate the future conditional densit y of the observ ations, commonly referred to as the predictiv e density [Aitc hison and Dunsmore, 1975, Geisser, 1993]. Existing approac hes to predictiv e inference under cov ariate shift t ypically pro ceed b y estimating the density ratio b etw een historical and future co v ariate distributions and subsequently rew eigh ting or adjusting the predictors. In contrast, w e directly target minimization of the predictiv e Kullback–Leibler (KL) loss b et w een the true predictiv e densit y and its estimator. This loss explicitly integrates o v er the future co v ariate distribution; consequen tly , minimizing it yields predictiv e densit y estimators that adapt naturally to the cov ariate distribution of the target p opulation. The KL loss is a w ell-studied metric in predictive densit y estimation and is known to pro duce estimators with fa v orable risk prop erties [F ourdrinier et al., 2011, George and Xu, 2008, Ghosh et al., 2008, K omaki, 2001, Marc hand and Sadeghkhani, 2018, Maruy ama and Strawderman, 2012, Mukherjee, 2013, Ročk ová, 2024]. W e adopt an empirical Bay es framew ork and seek predictiv e densities that minimize the predictive KL risk o ver a broad class of estimators indexed b y flexible prior families in LMMs. T o this end, w e construct predictive KL risk estimators that are uniformly w ell b eha v ed o v er the en tire candidate class and use them for risk minimization. 3 This setting presents several fundamental c hallenges. Using the predictiv e heat-equation represen tation (see Equation (16) of George et al. [2006]), the predictiv e KL loss can b e expressed as an expectation of the predictiv e marginal log-lik eliho o d. Unlik e p oin t estimation, this quan tit y do es not admit canonical un biased risk estimators unless the prior family is Gaussian. In this work, w e consider predictive densit y estimators (prde) arising from b oth Gaussian and non-Gaussian priors. T o address this difficulty , w e employ the sample splitting approach. F or point estimation in sequence mo dels Brown et al. [2013] prescrib ed a sample splitting strategy that has b een subsequen tly extended to complex settings (see Dharamshi et al. [2025], Leiner et al. [2025], Neufeld et al. [2024] and references therein). The role of sample splitting in predictive densit y estimation for LMMs has not b een previously studied. W e develop new theoretical results that enable efficien t estimation of the predictive KL risk under co v ariate shifts via sample splitting. W e next describ e our predictiv e setup. Detailed bac kground, references, and a full discussion of our contributions are provided subsequently . 1.1 Predictiv e Set-up: LMM with Co v ariate Shift F or eac h unit i = 1 , . . . , n in the linear mixed effects mo del consider observing K i replicates { Y ik : k = 1 , . . . , K i } . The expected v alue of the resp onse Y ik is linearly related to cov ariates x ik and u ik b y parameters β ∈ R d and γ i ∈ R respectively . The model is: y ik = x ′ ik β + u ik γ i + σ ϵ ik for k = 1 , . . . , K i and, i = 1 , . . . , n. (1) The noise terms ϵ ik ’s are independently distributed from standard normal distribution. Based on observing { y ik : k = 1 , . . . , K i ; i = 1 , . . . , n } , consider predicting future observ ations ˜ y ik from units i = 1 , . . . , n based on the follo wing mo del: ˜ y ik = ˜ x ′ ik β + v ik γ i + σ ˜ ϵ ik for k = 1 , . . . , ˜ K i and, i = 1 , . . . , n. (2) The co v ariates in (1) and (2) can differ, but all the parameters β , σ, γ i are in v arian t. The noise terms ˜ ϵ ik s ha v e standard normal distributions and are indep enden t not only across 4 ( i, k ) pairs in (2) but also with the noise terms in (1). The v ariance σ 2 is unknown. W e further assume that the random effects γ = { γ i : 1 ≤ i ≤ n } in (1)-(2) are indep endent and identically distributed (i.i.d.) from a unkno wn distribution g 0 . Let θ = ( β , σ, γ ) denote the full parameter vector, and let C = { ( x ik , u ik ) : 1 ≤ k ≤ K i , i = 1 , . . . , n } and ˜ C = { ( ˜ x ik , v ik ) : 1 ≤ k ≤ ˜ K i , i = 1 , . . . , n } denote the cov ariates in (1) and (2), resp ectively . Let Θ b e the parameter space. If the unkno wn parameter θ ∈ Θ w ere kno wn, the true future densit y is p ( ˜ Y | θ , ˜ C ) = n Y i =1 ˜ K i Y k =1 ϕ ( ˜ y ik ; ˜ x ′ ik β + v ik γ i , σ ) . where ϕ ( · ; me , sd ) denotes the normal density with mean me and standard deviation sd . Our goal is to construct an estimator ˆ p ( ˜ Y | Y , C , ˜ C ) of the future conditional density of ˜ Y = { ˜ y ik : i = 1 , . . . , n ; k = 1 , . . . , ˜ K i } based on the observ ed data Y = { y ik : i = 1 , . . . , n ; k = 1 , . . . , K i } . T o ev aluate the p erformance of ˆ p , w e use the information div ergence of Kullback and Leibler [1951] b etw een the true future densit y and its estimate as the loss function: L n [ C, ˜ C ]( θ , ˆ p ) = n X i =1 ˜ K i − 1 Z p ( ˜ Y | θ , ˜ C ) log p ( ˜ Y | θ , ˜ C ) ˆ p ( ˜ Y | y , C , ˜ C ) ! d ˜ Y . Henceforth, w e denote C ∪ ˜ C b y C . The corresponding predictive KL risk is obtained b y a v eraging o ver the distribution of the past observ ations: R n [ C ]( θ , ˆ p ) = Z p ( Y | θ , C ) L n [ C ]( θ , ˆ p ) d Y . (3) The predictive KL risk in (3) dep ends explicitly on the co v ariates C and ˜ C , and th us reflects c hanges arising from shifts b et w een the past and future co v ariate distributions. W e consider linear mixed mo dels with a large n um ber of units. Our fo cus is on data- scarce settings with limited replication, where only a small subset of units contr ibutes m ultiple observ ations, while the ma jority of units are observ ed at most once. Let η n denote the prop ortion of units with t w o or more replicates, defined as η n = n − 1 cardinalit y i : 1 ≤ i ≤ n and K i > 1 . 5 W e are particularly interested in regimes where η n is small, and esp ecially in the asymptotic setting where η n → 0 as n → ∞ . 1.2 Empirical Bay es Predictive Densit y Estimation Consider a broad class G of probabilit y distributions for the random effects γ defined in equations (1)–(2). F or a fixed parameter set ( β , σ ) = ( b , s ) , and for an y prior distribution g ∈ G , the conditional Bay es prdes is giv en b y: ˆ p [ b , s , g ]( ˜ Y ; Y , C ) = Z p ( ˜ Y | b , s , γ , ˜ C ) g [ b , s , C ]( γ | Y ) d γ , (4) where, g [ b , s , C ]( γ | Y ) is the p osterior distribution of γ based on the observing Y for fixed β = b and σ = s . It is given b y m [ b , s , g ]( Y ; C ) − 1 n Y i =1 g ( γ i ) K i Y k =1 p ( Y ik | b , s , γ i , u ik , a ik ) . Here, m [ b , s , g ]( Y ; C ) is the corresp onding normalizing constan t, represen ting the marginal conditional likelihoo d of Y under the prior g on γ . Consider the follo wing class of prdes: P G = ˆ p [ b , s , g ] : g ∈ G , s > 0 , b ∈ R d . W e adopt the empirical Ba y es framework of Efron [2012] and consider estimation of the h yp erparameter within the class P G . In particular, w e fo cus on estimating the distribution g that gov erns the exchangeable hierarchical structure of γ . F or a comprehensive review of empirical Bay es metho dologies, see Xie et al. [2012]. In this w ork, we prop ose an empirical Bay es prde by selecting a member of P G that minimizes (or appro ximately minimizes) the predictiv e KL risk (3) o ver this class. As a natural baseline, one may consider using non-informative priors for γ in (4). W e show that the proposed EB prde substantially outperforms all such uniform-prior-based prdes. Moreo v er, ev en when the true d ensit y g 0 / ∈ G , the inheren t ric hness of the class P G , combined with our flexible EB risk-estimation-based approach, often yields a prde whose risk is close to the optimal Ba yes risk. 6 1.3 Our Contributions Our main contributions are as follows. (a) The roles of shrink age in prde has b een studied primarily in Gaussian sequence mo dels [Liang, 2002, Marc hand and Sadeghkhani, 2018, Mukherjee, 2013, Mukherjee and Johnstone, 2015, Ročk o vá, 2024, Xu and Liang, 2010]. W e extend this line of w ork by studying optimal tuning of shrink age priors in linear mixed mo dels allowing for non- Gaussian random effects. (b) Risk-estimation-based empirical Ba yes prde has b een dev elop ed in Xu and Zhou [2011] and George et al. [2021] for in v arian t sequence models. In con trast, w e study prde in a co v ariate-shifted LMM framew ork, where the parameters are time-in v ariant but the design ev olves ov er time [Shimodaira, 2000]. The settings in George and Xu [2008] and Mukherjee and Y ano [2025] are closest to ours. The former can b e extended to Gaussian random effects, but not to the more general distributions considered here. The latter assumes known fixed effects and scale parameters for prde, imp oses stronger untestable assumptions on the design, and do es not study the risk prop erties of empirical Bay es prde under v arying cov ariate distributions or in regimes with differing lev els of data scarcity . (c) T o estimate the p redictiv e Kullback–Leibler (KL) risk, we build on the predictive heat-equation represen tation of George et al. [2006, Eq. (16)]. Ho w ev er, in the presence of non-Gaussian random effects, this represen tation do es not yield a tractable un biased risk estimator (see 14). W e therefore adopt a sample-splitting strategy to construct feasible KL risk estimates. Existing sample-splitting and data-fission tec hniques [Brown et al., 2013, Dharamshi et al., 2025, Leiner et al., 2025, Neufeld et al., 2024] are not directly applicable in the predictiv e KL setting, as these procedures induce v ariance inflation in the observ ed data, whereas predictiv e KL risk is highly sensitiv e to the ratio of past and future v ariances [Mukherjee and Johnstone, 2015, Y ano et al., 2021]. T o address this limitation, w e dev elop a no v el sample-reuse scheme based on data fission that exploits the exc hangeabilit y of the random effects. By carefully con trolling the dep endence structure in troduced through sample reuse, w e establish rates of con vergence for the resulting risk estimators. This 7 approac h con tributes new mathematical statistics p ersp ectiv es to the predictive sample- reuse literature (Chapter 5 of Geisser [1993]). (d) In the predictiv e framework of (1)– (2), g -mo deling approac hes [Efron, 2014] that estimate the random-effects distribution and plug it for prde can be substan tially sub optimal under co v ariate shift. In con trast, our predictiv e KL risk–based pro cedure adapts to the target co v ariate distribution and is asymptotically oracle optimal (Theorem 2 and Corollary 1); numerical evidence is provided in Sections 4. 1.4 Organization of the pap er The paper is organized as follo ws. Section 2 introduces the proposed empirical Bay es predictiv e density estimator based on risk estimation. Section 3 establishes its decision- theoretic prop erties, and Section 4 describ es implemen tation details. Section 5 presents n umerical exp erimen ts illustrating predictive p erformance across a range of regimes. All pro ofs are deferred to the App endix. 2 Prop osed EB Predictiv e Densit y Estimator Consider the prde p OR ∈ P G that minimizes the KL predictiv e loss in (3): p OR = arg min ˆ p ∈P G R n [ C ]( θ , ˆ p ) . (5) W e refer to p OR as the or acle predictor, since it dep ends on the unkno wn parameter vector θ and therefore is not implemen table in practice. It provides a theoretical lo w er b ound on the achiev able predictive loss within the class P G . Our ob jective is to construct data-driven predictors by minimizing risk estimates that do not dep end on unknown parameters. W e then compare their risk prop erties with those of the ideal oracle predictor p OR . In this sense, the oracle predictor serv es as a benchmark for ev aluating the performance of practical predictors. Under mo del (1), constructing asymptotically consistent estimators of β and σ is straigh tforw ard. T o dev elop the prop osed prde estimator, we consider estimators ˆ β and 8 ˆ σ that are O p ( n − α ) -consisten t for some α ∈ (0 , 1 / 2] . Details on their construction are pro vided later in Sec 2.2. W e next consider the risk R n [ C ]( θ , g ) of prdes ˆ p [ ˆ β , ˆ σ , g ] whic h are based on those estimates. W e estimate these risk functions b y ˆ R n [ C ]( g ) for all g ∈ G . W e will describ e the risk estimation elaborately later and show that these risk estimators are uniformly accurate ov er G as n → ∞ . Finally , by minimizing the estimated risk w e prop ose the predictor ˆ p [ ˆ β , ˆ σ , ˆ g ] from P G as our EB prde, where, ˆ g = arg min g ∈G ˆ R n [ C ]( g ) . (6) T o arrive at the risk estimates, w e use mathematical identities from George et al. [2006] and express the risk of ˆ p [ ˆ β , ˆ σ , g ] as a tractable (though still complex) difference of log- lik eliho o ds. Consider the follo wing functional of the observ ations that also dep end on ( β , σ ) : Z i ( β , σ ) = σ − 1 u − 2 i K i X k =1 u ik ( Y ik − x ′ ik β ) where, u i = K i X k =1 u 2 ik 1 / 2 for i = 1 , . . . , n . Note that, in (1) when β , σ are kno wn, Z i ( β , σ ) is the UMVUE for point estimate of γ i under squared error loss. Next, for i = 1 , . . . , n and k = 1 , . . . , ˜ K i , consider the functional ˜ Z ik ( β , σ ) = σ − 1 ( ˜ Y ik − ˜ x ′ ik β ) of the predictants in (2) and the following linear com bination of these t wo functionals: ˜ W ik ( β , σ ) = v ik ( u 2 i + v 2 ik ) − 1 { Z i ( β , σ ) + v ik ˜ Z ik ( β , σ ) } . The genesis for ˜ W ik ( β , σ ) is more complicated and can b e traced to George et al. [2006], K omaki [2001]. It is the UMVUE for p oint estimation of v ik × γ i where { Y ik : k = 1 , . . . , K i } as well as { ˜ Y ik : k = 1 , . . . , ˜ K i } are observ ed. W e will use ˜ W ik to express the predictive log-lik eliho o d, it is not kno wn as ˜ Y is not observed. W e use tilde to express this asp ect. Next, for any g ∈ G , consider the follo wing t w o Gaussian conv olution densities: m g ( a ; u, v , σ ) = Z ϕ ( a ; v γ σ − 1 , u − 1 v ) g ( γ ) dγ and, (7) ˜ m g ( a ; u, v , σ ) = Z ϕ ( a ; v γ σ − 1 , (1 + u 2 v − 2 ) − 1 / 2 ) g ( γ ) dγ . (8) 9 The follo wing result c haracterizes the predictive risk of ˆ p [ ˆ β , ˆ σ , g ] in terms of the preceding quan tities. W e first formalize the required assumptions. A1. F or some α ∈ (0 , 1 / 2] , the fixed effects estimator satisfies n α ∥ ˆ β − β ∥ → 0 in L 4 . The v ariance estimator satisfies ˆ σ − 1 − σ − 1 = O p ( n − α ) and ˆ σ ≥ c a.e. for some c > 0 . A2. The co v ariates x, ˜ x, u, v are uniformly b ounded aw ay from zero and from infinity , and lim sup n →∞ n − 1 P n i =1 γ 4 i < ∞ . A3. The prediction ob jectiv e spans across all units and is not dominated b y a subset. In particular, 1 ≤ inf i ˜ K i ≤ sup i ˜ K i < ∞ . Assumption A1 ensures that the fixed effects and scale estimators are sufficiently accurate so that the corresp onding plug-in errors are asymptotically negligible. As we are dealing with the risk (exp ected loss) function, w e require L r con v ergence of the fixed effects estimator. In the following subsection, w e show that constructing estimators satisfying A1 is straigh tforward. Assumption A2 rules out hea vy-tailed or unbounded designs, enabling uniform laws of large num b ers and central limit theorems without domination b y outliers. Note that, A2 is imp osed primarily to streamline the technical arguments; it can b e w eak ened at the expense of additional technical complexity . A3 prev ents the prediction target from b eing degenerate or driven b y a few units, ensuring stable cross-sectional aggregation. Theorem 1. F or any fixe d β and σ > 0 , under assumptions A1- A3 for some α ∈ [0 , 1 / 2] the risk of ˆ p [ ˆ β , ˆ σ , g ] is given by: R n [ θ , C ]( g ) = a n [ C ] + R 1 ,n [ θ , C ]( g ) − R 2 ,n [ θ , C ]( g ) + O p ( n − α ) as n → ∞ , (9) wher e, a n [ C ] = 1 2 κ n n X i =1 ˜ K i X k =1 log 1 + v 2 ik u 2 i and, κ n = n X i =1 ˜ K i , (10) R 1 ,n [ θ , C ]( g ) = 1 κ n n X i =1 ˜ K i X k =1 E γ i log m g ( v ik Z i ( β , σ ); u i , v ik , σ ) , (11) R 2 ,n [ θ , C ]( g ) = 1 κ n n X i =1 ˜ K i X k =1 E γ i log ˜ m g ( ˜ W ik ( β , σ ); u i , v ik , σ ) , (12) 10 wher e, the exp e ctations ar e b ase d on the mo del (1) - (2) and the functions m g and ˜ m g ar e define d in (7) - (8) . The first term a n in the right side of (9) do es not in v olve an y parameters and solely dep end on the design. The other t w o terms dep ends on the parameters. In (11)-(12), the exp ectations within the sum splits out separately for each { γ i : i = 1 , . . . , n } . They only dep end on γ i and σ and not of β as the v ariables are cen tered. The pro of is complicated and is provided in the app endix. It built on results in George et al. [2006]. Note that, if ( β , σ ) w ere kno wn, then for the risk of ˆ p [ β , σ, g ] w e ha ve an exact equality (non-asymptotic) in (9). Also, for this case we do not need the assumptions. This is an in termediate step in our pro of, for whic h Prop osition 4 in Mukherjee and Y ano [2025] can b e applied. Ho w ev er, obtaining the sharp er result presented here under unkno wn parameters requires substantial asymptotic analysis. When g is the uniform distribution, then the second and third term in (9) v anishes. Th us, the asymptotic risk of ˆ p U := ˆ p [ ˆ β , ˆ σ , U ] ∼ a n whic h is in v ariant across parameters and serv e as a b enchmark. W e w ould lik e to minimize the excess risk of Ba yes prdes ˆ p [ ˆ β , ˆ σ , g ] with resp ect to ˆ p U o v er the class G . How ever, as γ , σ are unknown, direct ev aluations of R 1 ,n [ θ , C ]( g ) and R 2 ,n [ θ , C ]( g ) are not p ossible. W e prop ose to estimate them by ˆ R g 1 ,n and ˆ R g 2 ,n resp ectiv ely . W e consider the following estimator for R 1 ,n [ θ , C ]( g ) : ˆ R g 1 ,n = n X i =1 ˜ K i − 1 n X i =1 ˜ K i X k =1 log m g ( v ik Z i ( ˆ β , ˆ σ ); u i , v ik , ˆ σ ) . (13) F or well-behav ed prior classes G , for an y fixed g we show that ˆ R g 1 ,n con v ergences to the true R 1 ,n [ θ , C ]( g ) at a near-parametric rate, | R 1 ,n [ θ , C ]( g ) − ˆ R g 1 ,n | = O p (max { n − 1 / 2 , n − α } ) as n → ∞ . A formal proof is presen ted within the proof of Theorem 2 in Sec 3. T o pro vide a reasonable estimate of R 2 ,n [ θ , C ]( g ) is straightforw ard. W e can not use the approac h used in constructing ˆ R 1 ,n as unlike R 1 ,n , R 2 ,n in v olves the predictiv e log-lik eliho o d through ˜ W ik ( β , σ ) [George et al., 2012]. Note that, ev en if β , σ w ere kno wn, w e do not observ e ˜ W ik unlik e Z i . Ho wev er, when G is Gaussian family of priors { ϕ ( · | 0 , τ 1 / 2 σ ) : τ > 0 } , 11 then efficien t estimates of R 2 ,n can b e easily constructed. In this case the risk function reduces to terms inv olving second momen ts of ˜ W ik whic h can b e easily calculated leading to quadratic functions of γ i . As suc h, for g = ϕ ( · | 0 , τ 1 / 2 σ ) , the difference R 1 ,n [ θ , C ]( g ) − R 2 ,n [ θ , C ]( g ) equals: − 1 m n n X i =1 ˜ K i X k =1 n log ( τ + u − 2 i )( v 2 ik + u 2 i ) τ ( v 2 ik + u 2 i ) + σ 2 + v 2 ik ( γ 2 i σ − 2 − τ ) ( τ u 2 i + 1) { τ ( v 2 ik + u 2 i ) + 1 } o . (14) It can be estimated by replacing γ 2 i ab o v e by Z i ( ˆ β , ˆ σ ) − u − 2 i . By Theorems 4.1 and 4.2 of George et al. [2021] we know that this estimate con v ergences at √ n rate. F or most p opular families of priors we do not hav e a natural estimate of R 2 ,n [ θ , C ] . In the follo wing section, w e develop a nov el metho d for estimating it b y using surrogates of ˜ W ik in the predictive log-lik eliho o d using data fission and sample reuse. 2.1 Estimating the fixed effects and the v ariance F or our prop osed metho dology , w e need go o d p oint estimates of β and σ . W e next pro vide a constructive pro cedure yielding estimators with a guaran teed rates of con vergence. Lemma 1. F or any β ∈ R d and σ > 0 , under A2- A3, ther e exist estimators ˆ β and ˆ σ such that ˆ σ ≥ c a.e. and lim sup n →∞ l − 4 n E ∥ ˆ β − β ∥ 4 < ∞ and | ˆ σ − 1 − σ − 1 | = O p ( l n ) , (15) wher e, l n = min { n − 1 / 4 , ( nη n ) − 1 / 2 } and c is a p ositive c onstant. A detailed pro of is giv en in the Supplementary Material. The construction proceeds in t w o regimes. First supp ose lim inf n →∞ n 1 / 2 η n > 0 . Then, a significan t prop ortion of units has replicates, and so, w e form contrasts that are indep endent of the random-effect γ for eac h replicated unit. Let I = { i : 1 ≤ i ≤ n, K i ≥ 2 } , and define, for i ∈ I , f ( i, β ) = { u i 2 ( Y i 1 − x ′ i 1 β ) − u i 1 ( Y i 2 − x ′ i 2 β ) } ( u 2 i 1 + u 2 i 2 ) − 1 / 2 . 12 Set ˆ β = arg min β P i ∈I f 2 ( i, β ) and ˆ σ 2 = |I | − 1 P i ∈I f 2 ( i, ˆ β ) . Under Assumptions A2- A3, these estimators satisfy (15) with rate |I | − 1 / 2 , whic h (since |I | is of order nη n ) yields the rate ( nη n ) − 1 / 2 . In the complemen tary regime, where replicates are scarce, w e employ batc hing. Partition the n units in to B n disjoin t batc hes of size √ n (so B n ≈ √ n ). Aggregate the resp onses within eac h batc h and fit a (missp ecified) linear mo del that ignores the random-effect mean to these aggregated observ ations; apply ordinary least squares to estimate β and σ on the aggregated data. The v ariance of the resulting estimators under the missp ecified model is O ( B − 1 n ) = O ( n − 1 / 2 ) , hence the parameter estimation error is O p ( n − 1 / 4 ) . Moreov er, since the random effects { γ i } are i.i.d. and satisfy Assumption A2, the bias induced b y the missp ecification is also O ( n − 1 / 4 ) . As the mo del is Gaussian, we also get L 4 con v ergence of the fixed effects at the same rate. Thus, the batc hing estimator attains the rate n − 1 / 4 . Com bining the t w o constructions yields estimators ˆ β and ˆ σ with con v ergence rate l n = min { n − 1 / 4 , ( nη n ) − 1 / 2 } , as stated in the result. 2.2 Estimating predictive log-lik eliho o d in KL risk F or any fixed β , σ , in mo del (1)-(2), ˜ W ik is Gaussian with the same mean as v ik Z i but lo wer v ariance. T o construct an estimate of R 2 ,n [ θ , C ]( g ) , w e plan to use estimates of ˜ W ik within the log-marginal likelihoo d that are based on a collection of { Z j : j = 1 , . . . , n } . Each of those estimates hav e the same v ariance as ˜ W ik but not necessarily the same mean. Ho w ever, as γ i ’s are exchangeable, w e exp ect the av erage of the log-lik elihoo d to well-estimate the predictiv e log-lik eliho o d at ˜ W ik . F or each i = 1 , . . . , n and k = 1 , . . . , ˜ K i define the set: S ik = { j ∈ { 1 , . . . , n } : u 2 j − u 2 i − v 2 ik ≥ 0 } . F or all j ∈ S ik define, d ikj = u − 2 j v 2 ik (( v 2 ik + u 2 i ) − 1 u 2 j − 1) . By construction note that d ikj ≥ 0 , so w e can add Gaussian noise with the righ t scale to v ik Z i to match the predictiv e v ariance target without destabilizing the construction. Next, for each i = 1 , . . . , n and k = 1 , . . . , ˜ K i and j ∈ S ik , w e construct a new v ariable b y adding scaled i.i.d. standard 13 normal noise ζ ikj : ˆ W ikj = v ik Z i ( ˆ β , ˆ σ ) + d 1 / 2 ikj ˆ σ ζ ij k . Note that, b y construction we ha ve: V ar ( ˆ W ikj )= V ar ( ˜ W ik ( β , σ )) + O p ( n − α ) and E ( ˆ W ikj − ˜ W ik ( β , σ )) = v ik ( γ j − γ i ) + O p ( n − α ) . Let | S ik | denote the cardinalit y of the set S ik . If | S ik | > 0 , we estimate E γ i log ˜ m g ( ˜ W ik ( β , σ ); u i , v ik , σ ) in (12) by ˆ r ik ( g ) = | S ik | − 1 X j ∈ S ik log ˜ m g ( ˆ W ikj ; u i , v ik , ˆ σ ) . (16) Let I ( h ) = { ( i, k ) : | S ik | ≥ h, i = 1 , . . . , n and k = 1 , . . . , ˜ K i } . F or an y fixed h ∈ N , w e prop ose to estimate R 2 ,n [ θ , C ]( g ) by ˜ R g 2 ,n ( h ) = n X i =1 ˜ K i − 1 n X i =1 ˜ K i X k =1 ˆ r ik ( g ) 1 { ( i, k ) ∈ I ( h ) } . (17) In (17), h is a tuning parameter, whic h, unless otherwise sp ecified, is set to 1 . W e also allo w h to v ary with n . In Section 4, we pro vide a comparativ e analysis of the b ehavior of our risk estimator for differen t c hoices of the sequence ( h n ) n ≥ 1 . The rationale b ehind our prop osed KL risk estimator is that though eac h of ˆ W ij k s used in (16) hav e different mean than ˜ W ik , as γ is an exchangeable sequence, the av erage risk estimator with b e a go o d estimate of the a verage risk pro vided w e ha ve enough mixing of Z i ( ˆ β , ˆ σ ) whic h heuristically can b e though t of is that the n um ber of unique members of { Z i ( ˆ β , ˆ σ ) : 1 ≤ i ≤ n } used in ˆ R g 2 ,n ( h ) is large. W e prov e this rigorously in Section 3. Our use of sample splitting differs from that in Brown et al. [2013], where the split v ariables hav e iden tical means but different v ariances. F or predictiv e KL risk, ˜ W ik has lo w er v ariance than Z i , so sample splitting based solely on Z i do es not yield a reliable estimate of the marginal log-likelihoo d. Instead of splitting Z i , we matc h the v ariance of v ik Z i to that of ˜ W ik using d ikj and additional noise. Note that, ˆ W ikj is a random quantit y as it was constructed by adding scaled white noise ζ . W e denote its dep endence on white noise by using ˆ W ikj ( ζ ) . Consider en umerating E ζ log ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) where the exp ectation of the predictiv e log-likelihoo d is 14 tak en o v er white noise. W e finally prop ose the follo wing estimator for R 2 ,n : ˆ R g 2 ,n ( h n ) = n X i =1 ˜ K i − 1 n X i =1 ˜ K i X k =1 | S ik | − 1 X j ∈ S ik E ζ log ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) 1 { ( i, k ) ∈ I ( h n ) } (18) W e prescrib e to use this in (16) and so, the resultan t risk estimate is not random and also has reduced v ariance than b efore (see Bro wn et al. [2013] for details on this Rao- Blac kw ellization step). Plugging in these tw o risk comp onen t estimates from (13) and (17) in (9) we get the risk estimate ˆ R g n ( h n ) . 3 Theory W e assume that the cov ariates follo w an exc hangeable design. Let { ( u i , v i ) : i = 1 , . . . , n } b e i.i.d. with marginal densities f u and f v . T o establish the asymptotic efficiency of the prop osed metho d, w e imp ose the follo wing additional assumptions. A4. The random v ariables U and V are b ounded and inf a ∈ A f u ( a ) /f v ( a ) > 0 , where A = { a : f v ( a ) > 0 } . Also, f u is contin uous and strictly p ositiv e on the b oundary . A5. G has uniformly b ounded fourth moments, i.e., sup g ∈G R g 4 ( a ) da < ∞ . A6. The sequence γ = ( γ 1 , . . . , γ n ) is exchangeable. A7. The sequence η n satisfies lim inf n →∞ n q η n > 0 for some q ∈ [0 , 1) . Assumption A4 ensures past–future co v ariate supp ort alignment and preven ts degeneracies in the predictive log-lik eliho o d. Assumption A5 guarantees in tegrabilit y and v ariance con trol for the Gaussian–con volution marginals, making the risk components w ell-defined and enabling uniform conv ergence. Assumption A6 reiterates the definition of random effects while assumption A7 regulates the prop ortion of replicates in the design. Under these assumptions, w e no w state our main result on the asymptotic b ehavior of our prop osed metho d. Theorem 2. Under assumptions A1- A7, for h n such that lim sup n →∞ n − 1 η − 1 n h n = 0 and g ∈ G , the estimate ˆ R g n ( h n ) of the KL pr e dictive risk of the pr de ˆ p [ ˆ β , ˆ σ , g ] in (1) - (2) 15 satisfies: R n [ θ , C ]( g ) − ˆ R g n ( h n ) = O p ( c n ) as n → ∞ , wher e, c n = max { n − (1 − q ) / 2 (log n ) , n − α } . Assumption A7 together with Lemma 1 implies that w e hav e α ≥ 2 − 1 max { 1 − q , 1 / 2 } . In particular, as q ↓ 0 (corresp onding to a nonv anishing fraction of units ha ving replicates), the rate c n in the risk b ounds approac hes the parametric rate. The con v ergence rate deteriorates as q increases, and consistency of the risk estimates is lost in the limit q ↑ 1 . Theorem 2 do es not address the highly data-scarce regime in whic h only finitely man y units ha v e replicates, that is, when lim sup n →∞ nη n < ∞ . This setting is discussed in Section 4. Asymptotically , the tuning parameter h n can b e as large as o p ( nη n ) , although in practice w e t ypically consider small fixed v alues. In Section 4, w e examine the empirical p erformance of the pro cedure for different c hoices of h n . Theorem 2 establishes that the risk estimates are asymptotically p oint wise consistent for any g satisfying Assumption A5. With the additional assumption A8 b elo w on the class G , w e next sho w that the prop osed prde is asymptotically optimal, in the sense that its risk conv erges to that of the oracle prde. The first tw o restrictions in A8 are standard conditions on the class of priors. The third condition is a regularit y assumption on the p osterior mean based on the deriv ative of the marginal log-likelihoo d. It ensures that the sensitivit y of the posterior mean gro ws at most quadratically , thereb y enabling stable risk estimation. A8. The class G of distributions satisfies the follo wing: (i) The L 1 -metric entrop y of G satisfies log N ( ε, G , ∥ · ∥ 1 ) < C G log ε − 1 , 0 < ε < diam( G ) , for some C G > 0 , where log N ( ε, G , ∥ · ∥ 1 ) is the metric en tropy of G with respect to ∥ · ∥ 1 , and diam( G ) is the diameter of G ; (ii) There exist constants M < ∞ and π ∗ > 0 suc h that inf g ∈G g ([ − M , M ]) ≥ π ∗ ; 16 (iii) F or σ ∈ (0 , ∞ ) , there exists L σ > 0 independent of g ∈ G such that for an y x ∈ R , ∂ ∂ x log Z ϕ ( x ; γ , σ ) g ( γ ) dγ + ∂ ∂ σ log Z ϕ ( x ; γ , σ ) g ( γ ) dγ ≤ L σ (1 + | x | + | x | 2 ); (19) Corollary 1. L et max i =1 ,...,n | γ i | = O p ( a n ) . Then, under assumptions A1-A8, the KL risk of our pr op ose d pr e dictor given by (6) satisfies: R n [ C ]( θ , ˆ p [ ˆ β , ˆ σ , ˆ g ]) − R n [ C ]( θ , p OR ) = O p ( c n a n log n ) as n → ∞ , wher e, c n = max { n − (1 − q ) / 2 (log n ) , n − α } . Corollary 1 applies to several commonly used prior families, three of whic h we highligh t here. F or spik e-and-slab priors, let g ( τ ) = (1 − η ) δ 0 + ( η a/ 2) e − a | τ | with h yp er-parameters ( η , a ) ∈ ( η , η ) × ( a, a ) , where 0 < η ≤ η < 1 and 0 < a ≤ a < ∞ are presp ecified b ounds ; this class G 1 is widely used in sparse estimation [Ročk ová and George, 2018]. F or scaled Gaussian mixtures, let g ( τ ) = P L l =1 π l ϕ ( τ ; 0 , ν l ) , where { ν l } L l =1 is a fixed v ariance grid and ( π 1 , . . . , π L ) are mixture weigh ts, so that G 2 is parameterized b y the L − 1 free prop ortions. F or discrete priors, let g ( τ ) = P L l =1 π l δ τ l , where { τ l } is a fixed grid and { π l } are probability w eigh ts, defining the class G 3 with L − 1 free weigh t parameters. The pro of that these families satisfy A8, used in Corollary 1, is pro vided in the app endix. Prop osition 1. The ab ove discusse d thr e e prior families satisfy Assumption A8. 3.1 Pro of Ov erview T o understand the mechanism driving the pro of, consider the dependency fraction D n ( h n ) = κ − 1 n n X i =1 ˜ K i X k =1 | S ik | − 1 1 {| S ik | ≥ h n } . Recall that Z i ( ˆ β , ˆ σ ) s are reused in constructing th e risk estimator ˆ R g 2 ,n . Heuristically , D n ( h n ) quantifies the o v erall fraction of reuse of the individual Z i ’s. | S ik | denotes the 17 effectiv e amoun t of historical information contributing to the ( i, k ) th comp onen t of the risk estimate. When | S ik | is large, each reused Z j ( β , σ ) has only minor influence. In con trast, small p o oling sets imply stronger individual influence and greater dep endence among the units used in the risk estimate. A k ey step in the pro of of Theorem 2 is to establish asymptotic con trol of D n ( h n ) . Smaller v alues of D n ( h n ) corresp ond to more effectiv e mixing across units and faster con v ergence of the risk estimator. F or additional in tuition regarding the gro wth of D n ( h n ) , consider the simplified highly data-scarce setting where h n = 1 and the v ik are uniformly small, in the sense that sup i,k v 2 ik ≤ inf 1 ≤ i = j ≤ n | u 2 i − u 2 j | . In this case, D n (1) ∼ log n (for deriv ation: see Lemma 3 in App endix). The pro of of Theorem 2 requires a more delicate asymptotic analysis to con trol D n ( h ) . W e b ound it by η − 1 n log n . In Section 4, we inv estigate the behavior of D n ( h ) under v arious designs and c hoices of h n via simulation. 3.2 Highly data scarce regime In the highly data-scarce regime, where only finitely man y units ha ve replicates so that lim sup n →∞ nη n < ∞ , the analysis of the previous section no longer applies. In constructing the risk estimator ˆ R g 2 ,n ( h ) , we ignored all ( i, k ) pairs not b elonging to I ( h ) . In this regime, ho w ever, the prop ortion of such pairs is non-negligible and can no longer b e disregarded. Here, we consider a mo dified prde that com bines ˆ p [ ˆ β , ˆ σ , g ] with the uniform-prior-based prde ˆ p U , using the latter for ( i, k ) pairs outside I ( h ) : ˆ p m [ ˆ β , ˆ σ , g ]( ˜ Y ; Y , C ) = Y ( i,k ) ∈I ( h ) ˆ p [ ˆ β , ˆ σ , g ]( ˜ Y ik ; Z i , u i , v ik ) Y ( i,k ) / ∈I ( h ) ˆ p [ ˆ β , ˆ σ , U ]( ˜ Y ik ; Z i , u i , v ik ) , where, ˆ p [ ˆ β , ˆ σ , g ]( ˜ Y ik ; Z i , u i , v ik ) ∝ R ϕ ( ˜ Y ik − ˜ x ′ ik ˆ β ; v ik γ , ˆ σ ) ϕ ( Z i [ ˆ β , ˆ σ ] , γ , ˆ σ ) dγ . Thus, no shrink age is applied to co ordinates outside I ( h n ) . W e define the impr ovement factor IF n ( h n ) = |I ( h n ) | /κ n , represen ting the prop ortion of co ordinates to which shrink age is applied. The risk of ˆ p m follo ws directly from the pro of of Theorem 1 and is given by (10) with the terms R 1 ,n 18 and R 2 ,n restricted to ( i, k ) ∈ I ( h ) and with κ n replaced b y |I ( h n ) | . The risk estimator is constructed as b efore. The following theorem pro vides the corresp onding asymptotic guaran tee. Theorem 3. Under assumptions A1- A6 and if lim sup n →∞ nη n < ∞ , for any g ∈ G we have R m n [ θ , C ]( g ) − ˆ R g n ( h n ) = O p ( c n ) , n → ∞ , wher e c n = max { n − 1 / 2 (log n ) , n − α } . In this regime the con vergence rate of the risk estimator is sharp er than in the replicate- ric h setting, but the improv ement factor is typically m uc h smaller. Under Assumption A5 one has IF n → 1 , whereas in the highly sparse regime IF n ma y b e substantially lo wer. In Section 4 w e study the finite-sample b eha vior of IF n using simulations. Below, in Theorem 4 w e sho w that IF n admits a nontrivial positive lo w er b ound in the highly data scarce case whic h exceeds 25% in symmetric designs. Theorem 4. Assume A1- A6 and lim sup n →∞ nη n < ∞ . Then, for any ω > 0 , lim inf n →∞ IF n (1) ≥ ω · F V 2 F − 1 U 2 (1) − F − 1 U 2 ( ω ) in P , wher e F U 2 and F V 2 denote the distribution functions of U 2 and V 2 r esp e ctively. In p articular, if F U 2 = F V 2 and the c ommon distribution is symmetric, then lim inf n →∞ IF n ≥ 1 / 4 in P . The b ound sho ws that even without replicates, a non trivial fraction of indices can b e impro v ed whenev er future magnitudes V t ypically fall below a certain gap in the past magnitudes U , namely F − 1 U 2 (1) − F − 1 U 2 ( ω ) . This gap captures the margin provided b y the upp er tail of U to accommo date future v ariabilit y . The larger this gap (relativ e to the mass of V ), the greater the improv ement fraction. Lemma 2. Under the assumptions of The or em 2, as n → ∞ , IF n ( h n ) P − → 1 . 19 4 Numerical Exp erimen ts Through sim ulation studies, we examine the finite-sample risk b ehavior of the prop osed predictiv e density estimator under six distinct designs. Figures 1 and 2 display the b ehavior of D n ( h n ) (the dependency factor go v erning the conv ergence rate) and the impro vemen t factor IF n as functions of n and h n . W e consider sample sizes n on the grid { 50 , 100 , . . . , 2500 } and rep ort av erages o v er 100 indep endent replications at eac h grid p oint. Throughout, a common color scheme denotes the threshold hyperparameter h n used in the risk estimator: blue ( h n = 1 ), orange ( h n = log n ), green ( h n = n 1 / 4 ), and red ( h n = n 1 / 2 ). The pro ofs of Theorems 2 and 4 sho w that asymptotically D n scales as log n in the highly data-scarce regime and as η − 1 n log n in the non-data scarce regime. Accordingly , the figures include in purple the growth rates predicted b y the asymptotic theory . F or fixed n , b oth D n ( h ) and IF n ( h ) decrease as h increases. Figures 1 and 2 illustrate this trade-off across the differen t designs. The reduction in D n ac hiev ed b y larger thresholds comes at the exp ense of the impro v ement factor: aggressiv e c hoices of h n substan tially lo wer IF n , indicating that ov erly large thresholds are undesirable in practice. F or mo derate sample sizes (e.g., n ≈ 500 ) and finite h n , the empirical growth of D n ( h n ) and IF n ( h n ) aligns closely with the asymptotic predictions indicated b y the purple reference curves. All co de required to repro duce the results is av ailable at https://github.com/AbirS2026/Simulations- prde . W e next describ e the individual predictiv e settings and summarize the findings. Case A. W e consider a no-replicate design with kno wn β and σ , corresp onding to the highly data-scarce regime of Section 3.2. The cov ariates ( U, V ) are drawn indep enden tly from N (2 , 1) truncated to [0 , 4] . Case B. This setting is identical to Case A except that the co v ariates are non-Gaussian: U, V iid ∼ Exp(1) truncated to [0 , 2] . In b oth Cases A and B, Figure 1 shows that the empirical tra jectories of D n remain uniformly b elow the theoretical b enchmark. Figure 2 rep orts the corresp onding improv ement fractions, which are b ounded a w a y from zero and exceed 25% , consisten t with the asymptotic theory . The impro v ement factor is noticeably larger in Case B than in Case A. 20 500 1000 1500 2000 2500 5 10 15 20 500 1000 1500 2000 2500 5 10 15 20 500 1000 1500 2000 2500 5 10 15 20 500 1000 1500 2000 2500 0 10 20 30 40 50 500 1000 1500 2000 2500 5 10 15 20 500 1000 1500 2000 2500 0 10 20 30 40 50 60 70 Figure 1: Plot of D n ( h n ) across the six regimes A–F (ordered from top left by row) as a function of n . The curves corresp ond to different choices of h n : blue ( h n = 0 ), orange ( h n = log n ), green ( h n = n 1 / 4 ), and red ( h n = n 1 / 2 ). The dotted purple lines represent the gro wth rates implied b y the asymptotic theory . 21 Case C. W e retain the no-replicate setting but in troduce dep endence betw een the co v ariates. The pair ( U, V ) has Exp(1) marginals with p ositive dep endence calibrated to ac hiev e correlation ρ = 0 . 5 . The tra jectories of D n and IF n are qualitativ ely similar to those in Case B, indicating robustness to moderate dependence. Case D. W e next consider a design with replication. A fraction η n = n − 1 / 2 of units, selected uniformly at random, receiv e t w o replicated observ ations. The co v ariates satisfy U, V iid ∼ N (1 , 1) truncated to [0 , 2] . The empirical growth of D n remains b ounded by the theoretical √ n b enchmark (purple line in the figures), while the impro v emen t fractions are adequately high even for mo derate sample sizes. Case E. W e consider a design com bining replication and co v ariate shift. W e generate U ∼ N (1 , 1) truncated to [0 , 2] and V ∼ χ 2 (1) truncated to [0 , 3] , indep enden tly , with η n = 1 / 10 . The resulting D n v alues remain well con trolled, and the impro v emen t fractions increase tow ard high lev els as n gro ws, in line with the asymptotic predictions. Case F. Finally , w e examine a setting in which the regularit y conditions of Section 3 are violated. With known β and σ , we consider a no-replicate design with indep endent co v ariates, dra wing V ∼ Unif (1 / 2 , 1) and U on [1 / 2 , 1] with cumulativ e distribution function F ( x ) = 1 − exp( − (1 − x ) − 2 ) , x ∈ [1 / 2 , 1] . Under this sp ecification Assumption A4 fails. F or h = 1 , D n ( h ) gro ws substantially faster than √ n ; for larger h the gro wth of D n ( h ) is con trolled, but the impro v ement fractions remain comparatively small and do not approac h the levels observed under the regular regimes. W e next compare the KL risk of the prop osed metho d, under the v arious c hoices of h n , with comp eting approaches. The true random-effects distribution g 0 is sp ecified as the t w o-comp onen t Gaussian mixture 0 . 7 N (0 , 0 . 5 2 ) + 0 . 3 N (0 , 1) . W e assume β and σ are kno wn and fo cus exclusiv ely on the random effects. F or our prop osed metho d, w e take G to b e the class of scaled tw o-comp onent Gaussian mixtures centered at zero. W e compare our approac h with t wo comp eting metho ds: (a) A naive plug-in prde that first computes point estimates of the random effects based on (1) and then substitutes these estimates into (2) for prediction. (b) A g -mo deling based 22 500 1000 1500 2000 2500 0.0 0.2 0.4 0.6 0.8 1.0 500 1000 1500 2000 2500 0.0 0.2 0.4 0.6 0.8 1.0 500 1000 1500 2000 2500 0.0 0.2 0.4 0.6 0.8 1.0 500 1000 1500 2000 2500 0.0 0.2 0.4 0.6 0.8 1.0 500 1000 1500 2000 2500 0.0 0.2 0.4 0.6 0.8 1.0 500 1000 1500 2000 2500 0.0 0.2 0.4 0.6 0.8 1.0 Figure 2: Plot of the impro v emen t factor IF n (expressed as fractions) across the six regimes A–F (ordered from top left b y row) as a function of n . The curv es correspond to differen t c hoices of h n : blue ( h n = 0 ), orange ( h n = log n ), green ( h n = n 1 / 4 ), and red ( h n = n 1 / 2 ). 23 plug-in approac h that estimates the random-effects distribution g 0 from the data in (1) b y fitting a mem ber of G via the EM algorithm, follo wing Efron [2016]. The resulting estimate ˆ g is then used to construct the prde in (2). In Figure 3, we rep ort the excess predictiv e KL risk of the comp eting prdes relativ e to the true Bay es risk across the six cases considered ab ov e. T able 1 summarizes the large-sample excess KL risk (after subtracting the Bay es risk) for eac h metho d. Our metho d consisten tly ac hiev es the low est predictive risk across all regimes. Its excess risk con v erges to zero as n increases. The naive plug-in estimator exhibits substantially higher risk in ev ery setting. The g -mo deling plug-in approach is also suboptimal and p erforms particularly p o orly in regimes inv olving cov ariate shift. 200 400 600 800 1000 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 200 400 600 800 1000 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 200 400 600 800 1000 0.0 0.2 0.4 0.6 0.8 1.0 1.2 200 400 600 800 1000 0.0 0.2 0.4 0.6 0.8 200 400 600 800 1000 0.0 0.2 0.4 0.6 0.8 200 400 600 800 1000 0.2 0.4 0.6 0.8 Figure 3: Plot of the excess KL risk of the comp eting prdes relativ e to the Ba y es b enchmark across the six regimes A–F (ordered from top left b y ro w) as a function of n . The curv es corresp ond to prdes for differen t h n : blue ( h n = 0 ), orange ( h n = log n ), green ( h n = n 1 / 4 ), and red ( h n = n 1 / 2 ), black (plu gin: g -mo deling), and purple (naiv e plugin). 24 Metho d Case 1 Case 2 Case 3 Case 4 Case 5 Case 6 Prop osed: h n = 1 0.0228 0.0238 0.0230 0.0187 0.0208 0.0650 Prop osed: h n = log( n ) 0.0323 0.0282 0.0382 0.0277 0.0313 0.1744 Prop osed: h n = n 1 / 4 0.0304 0.0273 0.0345 0.0255 0.0295 0.1608 Prop osed: h n = n 1 / 2 0.0946 0.0611 0.1018 0.0983 0.0947 0.3681 Plugin: g -mo deling 0.3398 0.4569 0.6021 0.4891 0.5045 0.1976 Plugin: Naive 0.7402 0.7083 1.0427 0.9213 0.8821 0.8248 T able 1: Large-sample excess KL risk (at n = 1000 ) of the comp eting prdes. 5 Discussion W e prop osed a risk-calibrated empirical Bay es framework for predictiv e densit y estimation in high-dimensional linear mixed mo dels under Kullbac k–Leibler loss. The metho d addresses sev ere data im balance due to sparse replication and distributional shifts in future co v ariates. By combining flexible prior mo deling with predictiv e KL risk estimation based on data fission and sample reuse, the resulting estimator achiev es asymptotic decision-theoretic optimalit y and robustness to cov ariate shift. Our analysis c haracterizes ho w the efficiency of risk estimation degrades as replication b ecomes scarce and quantifies the in terpla y b et w een shrink age, induced dep endence from sample reu se, and predictiv e calibration. The probabilistic arguments extend the predictive heat-equation framework of George et al. [2006] to settings with co v ariates and non- Gaussian random effects. Sev eral directions merit further in vestigation. First, while w e fo cus on KL loss, extending the calibration framew ork to broader divergence measures [Roy et al., 2026] would pro vide a unified treatmen t of predictiv e optimality b eyond the logarithmic score; related work in sequence models without co v ariates includes George et al. [2021], Ghosh and Kub ok a w a [2018], Maruyama et al. [2019], Matsuda and Strawderman [2021]. Second, it w ould 25 b e of in terest to generalize the metho dology to richer regression structures, including generalized linear mixed mo dels and partially linear or functional mixed-effects mo dels. Finally , understanding predictive calibration under more complex forms of co v ariate shift, including dep endent or non-exc hangeable designs, remains an imp ortan t op en problem. 26 6 App endix 6.1 Pro of of Theorem 1 W e b egin by establishing the result in the setting where ( β , σ ) are kno wn. In this case, equalit y in (9) holds exactly , without in v oking asymptotic arguments. W e then treat the practically relev ant setting in whic h ( β , σ ) are unknown and compare the risk of the plug-in estimator ˆ p [ ˆ β , ˆ σ , g ] with that of the oracle ˆ p [ β , σ, g ] , whic h assumes knowledge of the fixed effects and v ariance parameter. Let R n [ θ , C ]( ˆ β , ˆ σ , g ) denote the predictiv e KL risk of the prde ˆ p [ ˆ β , ˆ σ , g ] , and similarly let R n [ θ , C ]( β , σ, g ) denote the predictiv e KL risk of the prde ˆ p [ β , σ, g ] (i.e., the same Ba y es prde with ( β , σ ) treated as known). F or known ( β , σ ) , w e first prov e the follo wing equalit y: R n [ θ , C ]( β , σ, g ) = a n [ C ] + 1 κ n n X i =1 ˜ K i X k =1 E γ i h log m g v ik Z i ( β , σ ); u i , v ik , σ i − 1 κ n n X i =1 ˜ K i X k =1 E γ i h log ˜ m g f W ik ( β , σ ); u i , v ik , σ i . (20) By Assumption A1 and uniform boundedness in A2- A3, replacing ( ˆ β , ˆ σ ) by ( β , σ ) in the predictiv e densit y incurs an o (1) contribution to R n [ C ]( θ , ˆ p ) . Hence it suffices to work with the true ( β , σ ) . Let u 2 i := P K i k =1 u 2 ik , and define the training sufficient statistic and future residual Z i ( β , σ ) := 1 u i K i X k =1 u ik y ik − x ′ ik β σ , W ik ( β , σ ) := ˜ y ik − ˜ x ′ ik β σ . Conditional on γ i , we hav e, v ik Z i ( β , σ ) γ i ∼ N v ik γ i σ , v 2 ik u 2 i , W ik ( β , σ ) γ i ∼ N v ik γ i σ , 1 , indep enden tly . Hence the marginal (ov er g ) densities of these Gaussian mixtures are the 27 follo wing: m g a ; u i , v ik , σ = Z ϕ a ; v ik γ σ , v 2 ik u 2 i g ( γ ) dγ , ˜ m g a ; u i , v ik , σ = Z ϕ a ; v ik γ σ , 1 1+ v 2 ik /u 2 i g ( γ ) dγ , as in (7)– (8) (equiv alen tly using 1 + v 2 ik /u 2 i in the denominator). Consider the linear transform A ik := v ik Z i ( β , σ ) , f W ik ( β , σ ) := W ik ( β , σ ) − A ik p 1 + v 2 ik /u 2 i . The Jacobian of ( W ik , A ik ) 7→ ( A ik , f W ik ) con tributes (1 / 2) log 1+ v 2 ik /u 2 i to the log-density . Therefore, for each ( i, k ) , log p ˜ y ik | θ , ˜ C ˆ p ˜ y ik | Y , C , ˜ C = 1 2 log 1 + v 2 ik u 2 i + log m g A ik ; u i , v ik , σ − log ˜ m g f W ik ( β , σ ); u i , v ik , σ , where the estimator ˆ p factorizes in the transformed co ordinates, using the corresp onding Gaussian–mixture marginals m g and ˜ m g . A v eraging ov er ( i, k ) , in tegrating ov er Y (i.e., o v er ε and ˜ ε ) and γ i ∼ g 0 , and normalizing b y κ n = P n i =1 ˜ K i , we obtain R n [ C ]( θ , ˆ p ) = 1 2 κ n n X i =1 ˜ K i X k =1 log 1 + v 2 ik u 2 i + 1 κ n n X i =1 ˜ K i X k =1 E γ i h log m g v ik Z i ( β , σ ); u i , v ik , σ i − 1 κ n n X i =1 ˜ K i X k =1 E γ i h log ˜ m g f W ik ( β , σ ); u i , v ik , σ i , whic h is precisely (9)– (12). This completes the kno wn-parameter case. Similarly , define R n [ θ , C ]( g ) := R n [ θ , C ]( ˆ β , ˆ σ , g ) , i.e., the same functional as in (20) but ev aluated at ( ˆ β , ˆ σ ) . Therefore, R n [ θ , C ]( g ) = R n [ θ , C ]( β , σ, g ) + n R n [ θ , C ]( ˆ β , ˆ σ , g ) − R n [ θ , C ]( β , σ, g ) o . (21) 28 It suffices to sho w that the second term in (21) is O p ( n − α ) . T o conclude this, define R 1 ,n [ θ , C ]( β , σ, g ) := 1 κ n n X i =1 ˜ K i X k =1 E γ i h log m g v ik Z i ( β , σ ); u i , v ik , σ i , R 2 ,n [ θ , C ]( β , σ, g ) := 1 κ n n X i =1 ˜ K i X k =1 E γ i h log ˜ m g f W ik ( β , σ ); u i , v ik , σ i . Then (20) yields R n [ θ , C ]( β , σ, g ) = a n [ C ] + R 1 ,n [ θ , C ]( β , σ, g ) − R 2 ,n [ θ , C ]( β , σ, g ) , and the same iden tity holds with ( β , σ ) replaced by ( ˆ β , ˆ σ ) . Hence R n [ θ , C ]( ˆ β , ˆ σ , g ) − R n [ θ , C ]( β , σ, g ) = ∆ 1 ,n − ∆ 2 ,n , (22) where, ∆ 1 ,n := R 1 ,n [ θ , C ]( ˆ β , ˆ σ , g ) − R 1 ,n [ θ , C ]( β , σ, g ) , ∆ 2 ,n := R 2 ,n [ θ , C ]( ˆ β , ˆ σ , g ) − R 2 ,n [ θ , C ]( β , σ, g ) . Th us it is enough to pro ve ∆ 1 ,n = O p ( n − α ) and ∆ 2 ,n = O p ( n − α ) . F or fixed ( i, k ) , define the t wo scalar maps Φ ik ( β , σ ) := E γ i h log m g v ik Z i ( β , σ ); u i , v ik , σ i , Ψ ik ( β , σ ) := E γ i h log ˜ m g f W ik ( β , σ ); u i , v ik , σ i . Then, R 1 ,n [ θ , C ]( β , σ, g ) = 1 κ n n X i =1 ˜ K i X k =1 Φ ik ( β , σ ) , R 2 ,n [ θ , C ]( β , σ, g ) = 1 κ n n X i =1 ˜ K i X k =1 Ψ ik ( β , σ ) . W e claim that under A2 the functions ( β , σ ) 7→ Φ ik ( β , σ ) and ( β , σ ) 7→ Ψ ik ( β , σ ) are con tin uously differen tiable on sets of the form n ( β , σ ) : ∥ β − β 0 ∥ ≤ M , σ ≤ σ ≤ ¯ σ o 29 and their first deriv atives are uniformly bounded (in ( i, k ) ) on such sets, for an y fixed β 0 and 0 < σ < ¯ σ < ∞ . Indeed, by A3 the co v ariates x, ˜ x, u, v are b ounded; b y (1)– (2), Z i ( β , σ ) is affine in β and in σ − 1 , and f W ik ( β , σ ) is affine in β and in σ − 1 through Z i ( β , σ ) and ˜ Z ik ( β , σ ) ; and by (7)– (8), m g ( · ; u, v , σ ) and ˜ m g ( · ; u, v , σ ) are Gaussian conv olutions in the first argumen t and in σ . Thus, differentiation under the in tegral in (7)–(8) is justified on compact σ -interv als by dominated conv ergence (Gaussian kernels dominate uniformly b ecause the cov ariates are b ounded), and yields con tin uous first deriv ativ es. Moreo v er, the resulting deriv ativ es of log m g and log ˜ m g ha v e at most p olynomial gro wth in their first argumen ts, and the latter hav e uniformly bounded fourth momen ts under A2 since lim sup n →∞ n − 1 P n i =1 γ 4 i < ∞ and the noises are Gaussian. By A1, ˆ β → β and ˆ σ − 1 → σ − 1 in probabilit y , so ˆ σ → σ in probability . Hence there exist fixed constants 0 < σ < σ < ¯ σ < ∞ suc h that P ( ˆ σ ∈ [ σ , ¯ σ ]) → 1 . On the ev ent { ˆ σ ∈ [ σ , ¯ σ ] } , the multiv ariate mean v alue theorem giv es, for each ( i, k ) , Φ ik ( ˆ β , ˆ σ ) − Φ ik ( β , σ ) = ∇ β Φ ik ( β ⋆ ik , σ ⋆ ik ) ⊤ ( ˆ β − β ) + ∂ σ Φ ik ( β ⋆ ik , σ ⋆ ik ) ( ˆ σ − σ ) , (23) Ψ ik ( ˆ β , ˆ σ ) − Ψ ik ( β , σ ) = ∇ β Ψ ik ( ˜ β ⋆ ik , ˜ σ ⋆ ik ) ⊤ ( ˆ β − β ) + ∂ σ Ψ ik ( ˜ β ⋆ ik , ˜ σ ⋆ ik ) ( ˆ σ − σ ) , (24) for some intermediate p oints ( β ⋆ ik , σ ⋆ ik ) and ( ˜ β ⋆ ik , ˜ σ ⋆ ik ) on the line segment b etw een ( β , σ ) and ( ˆ β , ˆ σ ) . By the differen tiabilit y discussion ab ov e and A2-A3, there exists a (non-random) constant C < ∞ such that, with probability tending to one, sup 1 ≤ i ≤ n sup 1 ≤ k ≤ ˜ K i ∇ β Φ ik ( β ⋆ ik , σ ⋆ ik ) + sup 1 ≤ i ≤ n sup 1 ≤ k ≤ ˜ K i ∂ σ Φ ik ( β ⋆ ik , σ ⋆ ik ) ≤ C , (25) sup 1 ≤ i ≤ n sup 1 ≤ k ≤ ˜ K i ∇ β Ψ ik ( ˜ β ⋆ ik , ˜ σ ⋆ ik ) + sup 1 ≤ i ≤ n sup 1 ≤ k ≤ ˜ K i ∂ σ Ψ ik ( ˜ β ⋆ ik , ˜ σ ⋆ ik ) ≤ C . (26) 30 Summing (23) ov er ( i, k ) , dividing b y κ n , and using (25) yields, on { ˆ σ ∈ [ σ , ¯ σ ] } , | ∆ 1 ,n | = 1 κ n n X i =1 ˜ K i X k =1 Φ ik ( ˆ β , ˆ σ ) − Φ ik ( β , σ ) ≤ 1 κ n n X i =1 ˜ K i X k =1 ∇ β Φ ik ( β ⋆ ik , σ ⋆ ik ) · ∥ ˆ β − β ∥ + ∂ σ Φ ik ( β ⋆ ik , σ ⋆ ik ) · | ˆ σ − σ | ≤ C ∥ ˆ β − β ∥ + C | ˆ σ − σ | . By A1, ∥ ˆ β − β ∥ = O p ( n − α ) . Also, since σ > 0 is fixed and ˆ σ → σ in probabilit y , the map t 7→ t − 1 is differentiable at t = σ and ˆ σ − 1 − σ − 1 = − σ − 2 ( ˆ σ − σ ) + o p ( | ˆ σ − σ | ) , so A1 implies | ˆ σ − σ | = O p ( n − α ) . Therefore, ∆ 1 ,n = O p ( n − α ) . (27) An identical argumen t using (24) and (26) giv es ∆ 2 ,n = O p ( n − α ) . (28) Com bining (22), (27), and (28) yields R n [ θ , C ]( ˆ β , ˆ σ , g ) = R n [ θ , C ]( β , σ, g ) + O p ( n − α ) . Finally , substituting (20) in to (21) giv es R n [ θ , C ]( g ) = a n [ C ] + R 1 ,n [ θ , C ]( g ) − R 2 ,n [ θ , C ]( g ) + O p ( n − α ) , whic h is (9). Hence, the result follo ws. 6.1.1 Pro of of Lemma 1 W e observ e for unit i = 1 , . . . , n and replicate k = 1 , . . . , K i , y ik = x ′ ik β + u ik γ i + σ ε ik , ε ik iid ∼ N (0 , 1) , 31 and for future replicates, ˜ y ik = ˜ x ′ ik β + v ik γ i + σ ˜ ε ik , ˜ ε ik iid ∼ N (0 , 1) , with the same ( β , σ ) and { γ i } . W e denote the prop ortion of replicated units b y η n := 1 n n X i =1 1 { K i ≥ 2 } ∈ [0 , 1] and I := { i : K i ≥ 2 } , |I | = nη n . W e construct estimators in tw o regimes and then take the b etter rate. Regime I: replicate-rich case. Assume lim inf n →∞ n 1 / 2 η n > 0 , (29) so that |I | = nη n div erges at least of order √ n . F or eac h i ∈ I , c ho ose t wo replicates k = 1 , 2 and define the contrast w eights ν i 1 := u i 1 p u 2 i 1 + u 2 i 2 , ν i 2 := u i 2 p u 2 i 1 + u 2 i 2 , so that ν i 2 u i 1 − ν i 1 u i 2 = 0 and ν 2 i 1 + ν 2 i 2 = 1 . Define the p er-unit con trast f i ( β ) := ν i 2 y i 1 − x ′ i 1 β − ν i 1 y i 2 − x ′ i 2 β = s ′ i ( β 0 − β ) + σ ˜ ε i , (30) where β 0 is the true parameter, s i := ν i 2 x i 1 − ν i 1 x i 2 , ˜ ε i := ν i 2 ε i 1 − ν i 1 ε i 2 ∼ N (0 , 1) , Consider the least squares estimator based on these con trasts: ˆ β := arg min β X i ∈I f i ( β ) 2 . (31) Using (30), the first-order condition is 0 = X i ∈I s i f i ( ˆ β ) = X i ∈I s i s ′ i ( β 0 − ˆ β ) + σ X i ∈I s i ˜ ε i , 32 whic h yields the explicit linearization ˆ β − β 0 = σ S − 1 n M n , S n := X i ∈I s i s ′ i , M n := X i ∈I s i ˜ ε i . (32) By uniform b oundedness of s i and i.i.d. standard normal ˜ ε i , w e ha v e ∥ M n ∥ = O p ( |I | 1 / 2 ) . Moreo v er, b y a standard LLN and a design regularit y), 1 |I | S n p − → Q with Q := E ( s i s ′ i ) ≻ 0 , so that the smallest eigen v alue of S n satisfies λ min ( S n ) ≥ c |I | with probability tending to one. Combining these b ounds in (32) giv es ∥ ˆ β − β 0 ∥ = O p |I | − 1 / 2 = O p ( nη n ) − 1 / 2 . (33) F or σ , define the plug-in estimator ˆ σ 2 := 1 |I | X i ∈I f i ( ˆ β ) 2 . (34) Expanding (30) at ˆ β and using E [ ˜ ε 2 i ] = 1 , ˆ σ 2 − σ 2 = 1 |I | X i ∈I s ′ i ( β 0 − ˆ β ) 2 + 2 σ |I | X i ∈I ˜ ε i s ′ i ( β 0 − ˆ β ) . The first term is b ounded b y ∥ β 0 − ˆ β ∥ 2 · λ max ( S n ) / |I | = O p ( |I | − 1 ) , and the second term is O p ( |I | − 1 / 2 ) by Cauch y–Sch warz and (33). Th us ˆ σ 2 − σ 2 = O p |I | − 1 / 2 = ⇒ ˆ σ − 1 − σ − 1 = O p |I | − 1 / 2 , (35) using the delta metho d (or a T aylor expansion of x 7→ x − 1 ) and σ > 0 . Com bining (33) and (35) yields ( ˆ β , ˆ σ − 1 ) − ( β 0 , σ − 1 ) = O p ( nη n ) − 1 / 2 . Regime I I: replicate-scarce case. Assume the complementary regime where n 1 / 2 η n is not b ounded aw ay from zero, so that direct use of (31) would be slo w. W e emplo y batc hing and partition the n units into B n disjoin t batc hes {B b } B n b =1 of equal size m n := ⌈ √ n ⌉ , so 33 B n = ⌊ n/m n ⌋ ≍ √ n . Within each batc h, form an aggregated observ ation b y normalized a v eraging: ¯ y b := 1 √ m n X i ∈B b K i X k =1 w ik y ik , ¯ x b := 1 √ m n X i ∈B b K i X k =1 w ik x ik , (36) where the deterministic weigh ts w ik are uniformly b ounded and c hosen so that P i ∈B b P K i k =1 w 2 ik is uniformly b ounded (for normalization). F rom (1) and (2), ¯ y b = ¯ x ′ b β + ¯ v b + σ ¯ ε b , with ¯ v b := 1 √ m n X i ∈B b K i X k =1 w ik u ik γ i , ¯ ε b := 1 √ m n X i,k w ik ε ik . (37) By A2- A3 (boundedness of u ik , finite fourth momen t of γ i ) and the normalization, sup b E ¯ v 2 b ≲ 1 m n X i ∈B b E [ γ 2 i ] = O (1) , sup b E ¯ ε 2 b = O (1) . Hence, the composite batc h error e b := ¯ v b + σ ¯ ε b has v ariance uniformly bounded in b and n . Fit the missp ecified linear regression ¯ y b = ¯ x ′ b β + e b b y OLS ov er b = 1 , . . . , B n : ˆ β := arg min β B n X b =1 ¯ y b − ¯ x ′ b β 2 , ˆ σ 2 := 1 B n B n X b =1 ¯ y b − ¯ x ′ b ˆ β 2 . By boundedness of ¯ x b and a standard LLN, the Gram matrix B − 1 n P B n b =1 ¯ x b ¯ x ′ b con v erges in probabilit y to a p ositive definite limit (design regularity). With error v ariance uniformly b ounded, the OLS cov ariance satisfies V ar( ˆ β ) = O B − 1 n = ⇒ ∥ ˆ β − β 0 ∥ = O p B − 1 / 2 n = O p n − 1 / 4 . The residual v ariance estimator ˆ σ 2 has deviation ˆ σ 2 − σ 2 = O p ( B − 1 / 2 n ) , so ˆ σ − 1 − σ − 1 = O p ( B − 1 / 2 n ) = O p ( n − 1 / 4 ) b y the delta metho d. Poten tial misspecification bias originating from ¯ v b (e.g., due to a nonzero mean of γ i ) is of order O p ( m − 1 / 2 n ) = O p ( n − 1 / 4 ) by the CL T and uniform b oundedness of u ik , and hence does not alter the n − 1 / 4 rate. Therefore, we hav e ( ˆ β , ˆ σ − 1 ) − ( β , σ − 1 ) = O p min { n − 1 / 4 , ( nη n ) − 1 / 2 } = O p ( l n ) , whic h pro v es the lemma. 34 6.2 Pro of of Theorem 2 The pro of proceeds b y splitting the prediction risk of the proposed estimator into t w o natural pieces: one that reflects ho w well we fit with the observ ed data (the training part) and one that reflects how w ell w e forecast new outcomes (the forecasting part), and then sho wing that the empirical versions of b oth pieces concen trate tightly around their theoretical targets. F or the training p art, we control the v ariabilit y of a verages of log–mixture terms using simple conv exity argumen ts and moment b ounds, together with the consistency of the plug-in estimators for the n uisance parameters. F or the forecasting part, we exploit the structure of the estimator, built by av eraging ov er improv ed co ordinates and their lo cal neighborho o ds, so that it is unbiased and has small v ariance. A iterated- logarithm factor app ears when upgrading basic v ariance b ounds to uniform, high-probability statemen ts. The tec hnical pro of of the theorem inv olves the following steps. W e need to pro v e: Step 1. ˆ R g 1 ,n − R g 1 ,n = O p max n n − 1 / 2 , n − α o ; Step 2. ˜ R g 2 ,n ( h ) − ˆ R g 2 ,n ( h ) = O p r D n n ; Step 3. ˜ R g 2 ,n ( h ) − R g 2 ,n = O p r D n n . Pro of of Step 1 Let κ n := P n i =1 K i , recall ˆ R g 1 ,n := 1 κ n n X i =1 K i X k =1 log m g v ik Z i ( ˆ β , ˆ σ ); u i , v ik , ˆ σ , R g 1 ,n := 1 κ n n X i =1 K i X k =1 E γ i h log m g v ik Z i ( β , σ ); u i , v ik , σ i , By Assumption A1, ˆ β → β and ˆ σ → σ in probabilit y and, with probabilit y tending to one, ˆ σ ∈ [ σ , ¯ σ ] for fixed 0 < σ < ¯ σ < ∞ . By A3, { u i , v ik } are uniformly b ounded and 35 K i ≤ K max < ∞ . W rite ˆ R g 1 ,n − R g 1 ,n = ˆ R g 1 ,n − E [ ˆ R g 1 ,n ] | {z } sampling fluctuation + E [ ˆ R g 1 ,n ] − R g 1 ,n | {z } plug-in bias . W e set ψ ik := log m g v ik Z i ( ˆ β , ˆ σ ); u i , v ik , ˆ σ . Using that m g is a Gaussian con v olution with parameters uniformly b ounded b y A2 and that Z i ( ˆ β , ˆ σ ) is affine in γ i and Gaussian noise with b ounded coefficients ( A3), there exists a constan t C < ∞ such that sup i,k E ψ 2 ik ≤ C and sup i V ar K i X k =1 ψ ik ≤ C K 2 i , (38) with probability tending to one. Next, we defin e F i := P K i k =1 ψ ik ; then { F i } n i =1 are indep endent across i , and V ar ˆ R g 1 ,n = V ar κ − 1 n n X i =1 F i ≤ κ − 2 n n X i =1 V ar( F i ) ≤ C κ 2 n n X i =1 K 2 i ≤ C K max κ n , with probabilit y tending to one. Since κ n is of order n , a standard high-probabilit y refinemen t of Chebyshev’s inequalit y yields ˆ R g 1 ,n − E [ ˆ R g 1 ,n ] = O p n − 1 / 2 . b y the smo othness of ( β , σ ) 7→ E γ i [log m g ( v ik Z i ( β , σ ); u i , v ik , σ )] (DCT with the uniform second-momen t b ound ab ov e), E [ ˆ R g 1 ,n ] − R g 1 ,n ≤ C E ∥ ˆ β − β ∥ + | ˆ σ − σ | = O n − α . b y A1. Combining the tw o ab ov e panels giv es, ˆ R g 1 ,n − R g 1 ,n = O p max n n − 1 / 2 , n − α o . whic h completes the proof of Step 1. Pro of of Step 2. Hereafter, due to Lemma 1, without an y loss of generalit y w e assume ˜ K i = 1 for all i = 1 , . . . , n . W e denote S ik as S i as ˜ K i = 1 . W e recall the intermediate prop osed estimator for R 2 ,n ˜ R g 2 ,n ( h ) = n X i =1 ˜ K i − 1 n X i =1 ˜ K i X k =1 ˆ r ik ( g ) 1 { ( i, k ) ∈ I ( h ) } . (39) 36 Define s i = | S i | , and recall, the set of impro v ed co ordinates, I ( h ) . W e use ˆ r ik for i ∈ I ( h ) . W e note that: ˜ R g 2 ,n ( h ) = n X i =1 ˜ K i − 1 n X i =1 ˆ r ik ( g ) 1 { i ∈ I ( h ) } = n X i =1 ˜ K i − 1 X i ∈I ( h ) s − 1 i n X j =1 E γ j log ˜ m g ( ˆ W ikj ; u i , v ik , ˆ σ ) · 1 { j ∈ S i } Similarly , w e ha ve, ˆ R g 2 ,n ( h ) = n X i =1 ˜ K i − 1 X i ∈I ( h ) n X j =1 s − 1 i E ζ log ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) · 1 { j ∈ S i } (40) It is easy to see that ˆ R g 2 ,n is an unbiased estimate of R g 2 ,n ( h ) . W e next wan t to calculate its v ariance. F or that purp ose, w e represent the terms in the righ t side of (40) as functions of Z j ( ˆ β , ˆ σ ) for j = 1 , . . . , n and apply the following upp er bound V ar ˆ R g 2 ,n ( h ) ≤ n X i =1 ˜ K i − 1 X i ∈I ( h ) V ar n X j =1 s − 1 i E ζ log ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) · 1 { j ∈ S i } ! No w, let’s define A i = P n j =1 s − 1 i f ( v i Z j ( ˆ β , ˆ σ ); u i , v ik , ˆ σ ) · 1 { j ∈ S i } . Using independence of the sum, V ar ( A i ) ≤ n X j =1 s − 2 i · 1 { j ∈ S i } ! × { max 1 ≤ j ≤ n V ar ( f ( v i Z j ( ˆ β , ˆ σ ); u i , v ik , ˆ σ )) } Note that the second term is O (1) . Hence, we obtain the follo wing b ound V ar ( ˆ R g 2 ,n ( h )) ≤ n − 1 X i ∈I ( h ) V ar ( A i ) = O n − 1 X i ∈I ( h ) 1 /s i = O D n n . Consequen tly , b y Chebyshev’s inequalit y , ˆ R g 2 ,n ( h ) − E ˆ R g 2 ,n ( h ) = O p r D n n , whic h completes Step 2. 37 Pro of of Step 3. By definition, R g 2 ,n = 1 n n X i =1 f ( γ i , u i , v i ) , where, f ( γ , u, v ) = Z log Z ϕ γ − a σ ( v 2 r − 1 + u 2 ) − 1 / 2 + z g ( a ) da ϕ ( z ) dz . W e assume that γ are i.i.d. from ˜ g (this is different from g ), u , v are i.i.d. from p 1 and p 2 resp ectiv ely . Also, γ , u , v are indep enden t among themselves. Next, consider: ˆ R g 2 ,n ( h ) = 1 n n X i ∈I F,n n X j =1 s − 1 i f ( γ j , u i , v i )1 { j ∈ S i } . As γ , u and v are indep endent, b y T ow er prop erty of conditional exp ectation, w e ha ve: E { ˆ R g 2 ,n ( h ) } = E { R g 2 ,n } = Z f ( γ , u, v ) ˜ g ( γ ) p 1 ( u ) p 2 ( v ) dγ dudv . Next, note that V ar ( ˆ R g 2 ,n ( h )) = V ar ( E ( ˆ R g 2 ,n ( h ) | u , v )) + E ( V ar ( ˆ R g 2 ,n ( h ) | u , v )) . F ollowing the similar steps to the pro of of step 2, w e obtain the v ariance is of O ( D n /n ) . This completes step 3 of this pro of. W e are y et to assess the asymptotic order of D n . W e prov e the follo wings lemmas. 6.2.1 Supplementary Lemmas Lemma 3. L et { U i } i ≥ 1 and { V i } i ≥ 1 b e se quenc es of i.i.d. r andom variables satisfying A4. F or e ach n ∈ N and i = 1 , . . . , n , assume ˜ K i = 1 . Then, E [ D n (1)] = O (log n ) as n → ∞ . In p articular, D n (1) = O p (log n ) . 38 Pro of: Let F U 2 and F V 2 denote the distribution functions of U 2 and V 2 resp ectiv ely , and the supp ort of U 2 b e [0 , M ] for some M > 0 . F or notational simplicity , we rewrite U 2 and V 2 as U and V , respectively , and denote the corresp onding CDF s by F 1 , F 2 . The probabilit y density function for U is denoted by f U . Assumption A4 implies, there exist constan ts δ > 0 and c 0 > 0 suc h that, for all x ∈ [0 , δ ] , P ( U ≥ M − x ) = 1 − F 1 ( M − x ) ≥ c 0 x. Equiv alen tly , the upper tail of U at the right endp oint M is at least linear in the distance to M . Note that this is not to o restrictive assumption. Since most of U, V will b e truncated at M , Z M M − δ f U ( x ) dx ≥ ( M − ( M − δ )) inf x ∈ ( M − δ,M ] f U ( x ) = c 0 δ Hence, w e only need inf x ∈ ( M − δ,M ] f U ( x ) = 0 , which is usually true for most of the distributions unless the the tail probabilit y is slow er than a linear rate. Since ˜ K i = 1 , we can rewrite S ik ans S i and s i = | S i | . Hence, D n (1) = " n X i =1 1 { s i > 0 } s i # No w, w e fix n and i ∈ { 1 , . . . , n } , and set T i := U i + V i , p i := P ( U j ≥ T i | T i ) = 1 − F 1 ( T i ) . F or j = 1 , . . . , n and j = i , define I ij := 1 { U j ≥ T i } . Conditional on T i , the indicators { I ij } j = i are i.i.d. Bernoulli ( p i ) , so s i T i ∼ Binomial( n − 1 , p i ) . Note that if T i > M then p i = 0 and s i = 0 almost surely , so 1 { s i > 0 } /s i = 0 on { T i > M } . No w, note that, if S ∼ Binomial( m, p ) with m ≥ 1 and p ∈ (0 , 1] . Then 1 { S > 0 } S ≤ 2 S + 1 , hence, E 1 { S > 0 } S ≤ 2 E 1 S + 1 . 39 W e compute E h 1 S + 1 i = n X k =0 1 k + 1 m k p k (1 − p ) m − k . Using 1 k +1 m k = 1 m +1 m +1 k +1 , E h 1 S + 1 i = 1 m + 1 m X k =0 m + 1 k + 1 p k (1 − p ) m − k = 1 ( m + 1) p m +1 X j =1 m + 1 j p j (1 − p ) ( m +1) − j . The sum equals 1 − (1 − p ) m +1 , so E h 1 S + 1 i = 1 − (1 − p ) m +1 ( m + 1) p ≤ 1 ( m + 1) p . Th us, for p ∈ (0 , 1] , E 1 { S > 0 } S ≤ 2 ( m + 1) p ≤ 2 min 1 , 1 ( m + 1) p . (41) F or p = 0 we ha v e S = 0 almost surely and hence E 1 { S > 0 } /S = 0 , so (41) trivially holds if we interpret the right-hand side as 2 . Applying this with S = s i | p i , we obtain E 1 { s i > 0 } s i p i ≤ 2 min 1 , 1 np i , and hence, E 1 { s i > 0 } s i ≤ 2 E min 1 , 1 np i , (42) where the integrand is interpreted as 0 when p i = 0 . By symmetry , the distribution of p i do es not depend on i , so let p 1 denote a generic cop y . Then E [ D n ] = n X i =1 E 1 { s i > 0 } s i ≤ 2 n E min 1 , 1 np 1 . No w, define p 1 = p ( T 1 ) . By A4, for x ∈ [0 , δ ] , p ( M − x ) = P ( U 1 ≥ M − x ) ≥ c 0 x. Define p ∗ := p ( M − δ ) = P ( U 1 ≥ M − δ ) > 0 . 40 If T 1 ≤ M − δ , then p 1 = p ( T 1 ) ≥ p ∗ and th us cannot b e arbitrarily small. On the other hand, if T 1 ∈ ( M − δ, M ] , write T 1 = M − x with x ∈ (0 , δ ] , so that p 1 = p ( M − x ) ≥ c 0 x, hence p 1 ≤ y ⇒ x ≤ y /c 0 , T 1 ≥ M − y /c 0 . Also note that p 1 > 0 implies T 1 ≤ M , because U 1 ≤ M almost surely . Therefore, for an y y > 0 , { 0 < p 1 ≤ y } ⊆ { M − y /c 0 ≤ T 1 ≤ M } . Moreo v er, for y > 0 small enough so that y /c 0 ≤ δ , P (0 < p 1 ≤ y ) ≤ P ( M − y /c 0 ≤ T 1 ≤ M ) = Z M M − y /c 0 f T ( t ) dt ≤ C T y c 0 . where C T = sup t ∈ [ M − y /c 0 ,M ] f T ( t ) . Thus there exists y 0 > 0 and a constan t K > 0 such that, for all 0 < y ≤ y 0 , F P ( y ) := P (0 < p 1 ≤ y ) ≤ K y . (43) F or n large enough we ha v e 1 /n ≤ y 0 . W e do the follo wing split min 1 , 1 np 1 = 1 { 0 < p 1 < 1 /n } + 1 np 1 1 { p 1 ≥ 1 /n } . Hence, E min 1 , 1 np 1 ≤ P 0 < p 1 < 1 n + 1 n E 1 p 1 1 { p 1 ≥ 1 /n } . Using (43), P 0 < p 1 < 1 n ≤ K · 1 n = O 1 n . F or the second term, define the cdf F P of p 1 on (0 , 1] as ab o v e. Then, E 1 p 1 1 { p 1 ≥ 1 /n } = Z (1 /n, 1] 1 p dF P ( p ) . By integration by parts, Z 1 1 /n 1 p dF P ( p ) = F P ( p ) p 1 p =1 /n + Z 1 1 /n F P ( p ) p 2 dp. 41 Since F P (1) ≤ 1 and F P (1 /n ) ≤ K (1 /n ) , w e ha v e, F P ( p ) p 1 p =1 /n ≤ 1 + K. F or the in tegral, split at some fixed δ ′ ∈ (0 , 1] with δ ′ ≤ y 0 : Z 1 a/n F P ( p ) p 2 dp = Z δ ′ a/n F P ( p ) p 2 dp + Z 1 δ ′ F P ( p ) p 2 dp. F or p ∈ [1 /n, δ ′ ] , (43) gives F P ( p ) ≤ K p , hence Z δ ′ 1 /n F P ( p ) p 2 dp ≤ K Z δ ′ 1 /n 1 p dp = K log( δ ′ n ) = K log n + O (1) . F or p ∈ [ δ ′ , 1] , w e simply use F P ( p ) ≤ 1 : Z 1 δ ′ F P ( p ) p 2 dp ≤ Z 1 δ ′ 1 p 2 dp = 1 δ ′ − 1 = O (1) . Com bining these, E 1 p 1 1 { p 1 ≥ 1 /n } = O (1 + log n ) . Therefore, E min 1 , 1 np 1 ≤ O 1 n + 1 n O (1 + log n ) = O log n n . Returning to (42), w e obtain E 1 { s i > 0 } s i ≤ 2 E min 1 , 1 np i = O log n n , and by symmetry this b ound is the same for each i = 1 , . . . , n . Hence, E [ D n (1)] = n X i =1 E 1 { s i > 0 } s i = n · O log n n = O (log n ) . Finally , b y Marko v’s inequality , D n / log n is b ounded in probabilit y , i.e. D n = O p (log n ) . This completes the proof. Remark: Note that, D n ( h ) is a non-increasing random v ariable in h . Hence, E [ D n ( h n )] ≤ E [ D n (1)] = O (log n ) for all tuning parameters h n satisfying the regularity conditions in Section 2. 42 Lemma 4. Under assumption A4 and A7, and ˜ K i = 1 for al l i = 1 , 2 , . . . , n , and lim sup n →∞ n − 1 η − 1 n h n = 0 E D n ( h n ) = E X i ∈I ( h n ) 1 { s i > h n } s i = O log n η n as n → ∞ , and henc e D n = O p ( η − 1 n log n ) . Pr o of. F or i ∈ I ( h n ) , define p 1 i := P U ≥ U i + V i , p 2 i := P W ≥ U i + V i , where U is a single-replicate dra w and W is the sum of t w o indep endent replicates (both indep enden t of ( U i , V i ) ). Define p 1 i = P U > U i + V i , p 2 i = P W > U i + V i , W e are in terested in E " n X i =1 1 s i 1 { i ∈ I ( h n ) } # . Note that i / ∈ S i and for all i ∈ I ( h n ) , s i ∼ Bin nη n , p 2 i + Bin n (1 − η n ) − 1 , p 1 i ⇒ s i ≥ Bin nη n , p 2 i . Next, E 1 s i p 2 i ≤ E 1 nη n p 2 i . Hence, E " n X i =1 1 s i 1 { i ∈ I F,n } p 2 i # ≤ n (1 − η n ) E min 1 , 1 nη n p 2 i . F ollowing a similar argumen t as in Lemma 3, we conclude E min 1 , 1 nη n p 2 i = O log n nη n . Therefore, we can conclude E [ D n ( h n )] = E X i ∈I ( h n ) 1 s i = O (1 − η n ) log n η n = O log n η n . 43 This concludes the lemma. No w, note that if η n = n − β , this implies E [ D n ] = O n β log n . No w Theorem 2 follo ws from aggregating the results of Step 1-3 ab o v e and Lemma 4 6.3 Pro of of Theorem 3 This pro of directly follo ws f rom the steps 1-3 shown ab ov e in the pro of of Theorem 2 along with the rate calculation of D n for highly data-scarce model in Lemma 3. 6.4 Pro of of Theorem 4 Let the distribution functions of u 2 and v 2 b e denoted b y F 1 and F 2 , resp ectively . F or notational simplicit y , w e rewrite u 2 and v 2 as u and v , resp ectiv ely , for the rest of the pro of. F u rthermore, we assume K i = 1 for all i = 1 , 2 , . . . , n . Hence, S ik defined in Section 2 is no w considered as S i . Let U 1 ≤ U 2 ≤ · · · ≤ U n b e the ordered sample sim ulated from a con tin uous cdf F 1 with b ounded support. Consider any ω > 0 , Define, X n,ω = 1 ⌊ nω ⌋ ⌊ nω ⌋ X i =1 1 V i > U ⌊ n − h n ⌋ − U i , Y n,ω = 1 ⌊ nω ⌋ ⌊ nω ⌋ X i =1 1 V i > U ⌊ n − h n ⌋ − U ⌊ nω ⌋ . By monotonicity of the ordered sample, U i ≤ U ⌊ nω ⌋ for all i ≤ ⌊ nω ⌋ , hence X n,ω ≤ Y n,ω . (44) Let A n := U ⌊ n − h n ⌋ and B n := U ⌊ nω ⌋ . By standard order-statistic consistency , A n P − → F − 1 1 (1) , B n P − → F − 1 1 ( η ) . Conditional on U , w e hav e E Y n,ω U = 1 ⌊ nω ⌋ ⌊ nω ⌋ X i =1 1 − F 2 ( A n − B n ) = 1 − F 2 ( A n − B n ) . 44 By contin uity of F 2 , E [ Y n,ω ] = E U [1 − F 2 ( A n − B n )] − → 1 − F 2 F − 1 1 (1) − F − 1 1 ( ω ) . Moreo v er, writing Z i := I { V i > A n − B n } , V ar( Y n,ω ) = 1 ⌊ nω ⌋ V ar( Z 1 ) + ⌊ nω ⌋ − 1 ⌊ nω ⌋ Co v( Z 1 , Z 2 ) ≤ 1 4 ⌊ nω ⌋ + V ar U [ 1 − F 2 ( A n − B n ) ] − → 0 , where w e used conditional indep endence of V 1 , V 2 , b oundedness of the indicators, and dominated conv ergence for the U -v ariation. By Chebyshev’s inequality , Y n,ω P − → 1 − F 2 F − 1 1 (1) − F − 1 1 ( ω ) . F rom (44), for any a > 0 , P X n,ω ≤ 1 − F 2 F − 1 1 (1) − F − 1 1 ( ω ) + a − → 1 . Equiv alen tly , the prop ortion of “improv ed” co ordinates within the first ⌊ nω ⌋ indices, 1 − X n,ω ≥ F 2 F − 1 1 (1) − F − 1 1 ( ω ) − a, with probability tending to one. Hence the o vera ll improv ement fraction satisfies IF n ≥ ⌊ nω ⌋ n 1 − X n,ω ≥ ω · F 2 F − 1 1 (1) − F − 1 1 ( ω ) − a , and, for every a, ω > 0 , P IF n > ω · F 2 F − 1 1 (1) − F − 1 1 ( ω ) − a − → 1 . Hence, the result follo ws. Note that, if F 1 = F 2 = F is symmetric on [0 , M ] , F M − F − 1 (1 / 2) = F ( M / 2) = 1 2 . Consequen tly , for ω = 1 2 , lim inf n →∞ IF n ≥ 1 / 4 in probability . 45 6.4.1 Pro of of Lemma 2 W e recall the notations used in Section 2. The sample size is n and let K i = 1 ∀ i ≤ n (1 − η n ) , K i > 1 ∀ i > n (1 − η n ) . Define: U i = u 2 i 1 ∀ i ≤ n (1 − η n ) , U i = X j > 1 u 2 ij ∀ i > n (1 − η n ) . W e order { U 1 , U 2 , . . . , U ⌊ n (1 − η n ) ⌋ } by { ˜ U 1 , ˜ U 2 , . . . , ˜ U ⌊ n (1 − η n ) ⌋ } . Similarly , w e order { U ⌊ n (1 − η n ) ⌋ +1 , U ⌊ n (1 − η n ) ⌋ +2 , . . . , U n } by { ˜ U ⌊ n (1 − η n ) ⌋ +1 , ˜ U ⌊ n (1 − η n ) ⌋ +2 , . . . , ˜ U n } . W e also denote U ∗ n − h n = U ⌊ ( n − h n ) ⌋ , i.e., the ⌊ n − h n ⌋ -th order statistic of the entire data, for a tuning parameter h n . In the earlier sections, we ha v e already explained wh y {| S i | > h n } is an ev en t of in terest. F or pro viding more clarity to the reader, note that this ev ent corresp onds to shrink age for the i ’th v ariable, and we will be able to pro duce b etter shrunk en risk estimates in these cases. F or the i ’th co ordinate, w e w ould b e able to provide a better shrunk en risk estimate only when there exists at least one index j that satisfies U j ≥ U i + V i . In other w ords, we can not provide a b etter risk estimate for the i ’th co ordinate if V i > U ∗ n − h n − U i . Define: X n,η n = 1 ⌊ n (1 − η n ) ⌋ ⌊ n (1 − η n ) ⌋ X i =1 1 V i > U ∗ n − h n − U i , Y n,η n = 1 ⌊ n (1 − η n ) ⌋ ⌊ n (1 − η n ) ⌋ X i =1 1 n V i > ˜ U n − h n − ˜ U ⌊ n (1 − η n ) ⌋ o . W e note that, X n,η n ≤ Y n,η n , (45) since for each i ≤ ⌊ n (1 − η n ) ⌋ we hav e U ∗ n − h n − U i ≥ ˜ U n − h n − ˜ U ⌊ n (1 − η n ) ⌋ . The pro of goes as follo ws: 1. Y n,η n P − → 0 . 46 2. Com bining 1 and (45) w e conclude X n,η n P − → 0 , hence, for any δ > 0 P ( IF n > (1 − η n − δ )) → 1 . Define A n := ˜ U n − h n , note that by assumption n − 1 h n = o ( η n ) . Hence, ˜ U n − h n falls in the blo c k with replicates (where K i ≥ 2 ) and B n := ˜ U ⌊ n (1 − η n ) ⌋ , the maximum of the no-replicate blo c k (where K i = 1 ). Let the distribution functions of u 2 and v 2 b e denoted by F 1 and F 2 , resp ectively . Note that assumption A4 implies F 1 and F 2 ha v e same b ounded supp ort (sa y M ). Since F 1 is contin uous, within the no-replicate blo c k the U i ’s are i.i.d. with support con tained in [0 , M ] . Therefore, as ⌊ n (1 − η n ) ⌋ → ∞ , B n P − → M . Within the blo ck with replicates, the U i ’s are i.i.d. sums ov er indices j ≥ 2 of u 2 ij , so their supp ort is con tained in [0 , sM ] for some integer s ≥ 2 . Standard quantile consistency yields A n /G − 1 right (1 − n − 1 h n ) P − → 1 and G − 1 right (1 − n − 1 h n ) ↑ sM as n → ∞ , where G right is the CDF of U j ’s in the block with replicates. so, in particular, A n − B n P − → ( s − 1) M ≥ M . Using the contin uity of F 2 on [0 , M ] , w e hav e E [ Y n,η n ] = E U [1 − F 2 ( A n − B n )] − → 1 − F 2 ( M ) = 0 . W e similarly con trol the v ariance. Let Z i := I { V i > A n − B n } for i ≤ ⌊ n (1 − η n ) ⌋ . Then V ar( Y n,η n ) = 1 ⌊ n (1 − η n ) ⌋ V ar( Z 1 ) + ⌊ n (1 − η n ) ⌋ − 1 ⌊ n (1 − η n ) ⌋ Co v( Z 1 , Z 2 ) ≤ 1 4 ⌊ n (1 − η n ) ⌋ + V ar U [1 − F 2 ( A n − B n )] , 47 where we us ed conditional indep endence of V 1 , V 2 giv en U to obtain Co v( Z 1 , Z 2 ) = E U h 1 − F 2 ( A n − B n ) 2 i − E U [1 − F 2 ( A n − B n )] 2 = V ar U [1 − F 2 ( A n − B n )] . Since A n − B n P − → ( s − 1) M and 0 ≤ 1 − F 2 ( · ) ≤ 1 , dominated con v ergence implies V ar U [1 − F 2 ( A n − B n )] → 0 . Hence V ar( Y n,η n ) → 0 . By Chebyshev’s inequalit y , Y n,η n P − → 0 , completing Step 1 and the proof. By Step 1 and the inequality (45), we ha v e X n,η n P − → 0 . Recall that X n,η n a v erages the “no-impro v ement” indicators ov er the first L n := ⌊ n (1 − η n ) ⌋ ordered statistics { U i } , i.e., it is the prop ortion of non-impro ved co ordinates within this blo c k. Hence the fraction of impro v ed co ordinates within the blo ck is 1 − X n,η n P − → 1 . Consequen tly , the ov erall impro v ement factor satisfies IF n ≥ (1 − η n ) 1 − X n,η n . W e can therefore claim for an y fixed δ > 0 , P ( IF n > 1 − η n − δ ) − → 1 . This completes the proof of the lemma. 6.4.2 Pro of of Corollary 1 In the pro of, positive constants b 1 , b 2 , . . . do not depend on n and g , and notations ≲ and ≳ indicates inequalities with multiplicativ e constants indep enden t from n and g . F rom Assumption A1, we ha v e ˆ σ ∈ [ σ , σ ] for fixed 0 < σ < σ < ∞ and ∥ ˆ β − β ∥ < 1 with probabilit y tending to one. W e denote the corresp onding set of ( ˆ β , ˆ σ ) by H n := { ( ˆ β , ˆ σ ) : ˆ σ ∈ [ σ , σ ] , ∥ ˆ β − β ∥ < 1 } . 48 First, note that w e ha v e R n [ C ]( θ , ˆ p [ ˆ β , ˆ σ , ˆ g ]) − R n [ C ]( θ , p OR ) = R n [ C ]( θ , ˆ p [ ˆ β , ˆ σ , ˆ g ]) − ˆ R g OR n ( h n ) + ˆ R g OR n ( h n ) − R n [ C ]( θ , p OR ) ≤ R n [ C ]( θ , ˆ p [ ˆ β , ˆ σ , ˆ g ]) − ˆ R ˆ g n ( h n ) + ˆ R g OR n ( h n ) − R n [ C ]( θ , p OR ) ≤ 2 sup g ∈G | b ∆( g ) | + sup g ∈G | b P n [ g ] | where we defi ne b ∆ n [ g ] := R n [ θ , C ]( β , σ, g ) − ˆ R g n ( h n ) b P n [ g ] := R n [ C ]( θ , ˆ p [ ˆ β , ˆ σ , g ]) − R n [ C ]( θ , ˆ p [ β , σ, g ]) , resp ectiv ely . So, w e need to bound b ∆ n [ g ] and b P n [ g ] uniformly in g ∈ G . Fix ε > 0 arbitrarily , and tak e an ε -net { g 1 , . . . , g N ( ε ) } with N ( ε ) := N ( ε, G , ∥ · ∥ 1 ) . Then, w e decomp ose sup g ∈G | b ∆ n [ g ] | and sup g ∈G | b P n [ g ] | as sup g ∈G b ∆ n [ g ] ≤ max g ∈{ g 1 ,...,g N ( ε ) } b ∆ n [ g ] + sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε b ∆ n [ g ] − b ∆ n [ g ′ ] , sup g ∈G | b P n [ g ] | ≤ max g ∈{ g 1 ,...,g N ( ε ) } b P n [ g ] + sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε b P n [ g ] − b P n [ g ′ ] , resp ectiv ely . Step 0: Bounding the marginal densities. Before b ounding the target quan tities, we prepare the following lemma to b ound the marginal densities m g and ˜ m g . Lemma 5. Under Assumptions A2 and A8(ii), ther e exist p ositive c onstants b 1 , b 2 , b 3 indep endent fr om n and g for which we have − b 1 a 2 + b 2 ≤ log m g a ; u i , v ik , σ ≤ b 3 , a ∈ R , − b 1 a 2 + b 2 ≤ log ˜ m g a ; u i , v ik , σ ≤ b 3 , a ∈ R , (46) r esp e ctively. F urther, under Assumptions A1, A2, and A8(ii) , we have − b 1 Z 2 i ( β , σ ) + b 2 ≤ log m g v ik Z i ( ˆ β , ˆ σ ); u i , v ik , ˆ σ ≤ b 3 , ( ˆ β , ˆ σ ) ∈ H n , − b 1 f W 2 ik ( β , σ ) + b 2 ≤ log ˜ m g f W ik ( ˆ β , ˆ σ ); u i , v ik , ˆ σ ≤ b 3 , ( ˆ β , ˆ σ ) ∈ H n , (47) r esp e ctively. 49 Pr o of. First, observ e Z [ − M ,M ] ϕ a ; v ik γ σ , v 2 ik u 2 i g ( γ ) dγ ≤ Z ϕ a ; v ik γ σ , v 2 ik u 2 i g ( γ ) dγ ≤ 1 p 2 π ( v 2 ik /u 2 i ) , a ∈ R . Then, from Assumption A2, w e ha v e log m g a ; u i , v ik , σ ≤ − (1 / 2) log 2 π inf i,k v 2 ik /u 2 i := b 3 . F rom Assumption A8(ii) and Assumption A2, w e ha v e log m g a ; u i , v ik , σ ≥ −{ inf i,k v 2 ik /u 2 i } − 1 a 2 + log π ∗ − sup i u 2 i σ 2 M 2 := − b 1 a 2 + b 2 . Summarizing these, we obtain (46) for m g . In the same w a y , w e obtain (46) for ˜ m g . Observ e, b y definition of Z i ( β , σ ) and f W ik ( β , σ ) , Z i ( ˆ β , ˆ σ ) = σ ˆ σ Z i ( β , σ ) − 1 u i K i X k =1 u ik x ′ ik ( ˆ β − β ) ˆ σ , f W ik ( ˆ β , ˆ σ ) = σ ˆ σ f W ik ( β , σ ) − 1 p 1 + v 2 ik /u 2 i ( 1 u i K i X k =1 u ik x ′ ik ( ˆ β − β ) ˆ σ + ˜ x ′ ik ( ˆ β − β ) ˆ σ ) , resp ectiv ely . These, together with Assumptions A1 and A2 , yield | Z i ( ˆ β , ˆ σ ) | ≲ | Z i ( β , σ ) | + 1 for ( ˆ β , ˆ σ ) ∈ H n , | f W ik ( ˆ β , ˆ σ ) | ≲ | f W ik ( β , σ ) | + 1 for ( ˆ β , ˆ σ ) ∈ H n . (48) Th us com bining these with (46) completes the pro of. Step 1: Lipschitz con tin uity of b ∆ n [ g ] with resp ect to g . W e b egin with b ounding R n [ θ , C ]( β , σ, g ) − R n [ θ , C ]( β , σ, g ′ ) . Due to the singular b ehaviour of the log marginal densit y in regions where m g ( a ; u i , v ik , σ ) is close to zero, w e need to regularize m g as in Jiang and Zhang [2009]. Step 1 (i): b ounding the exp ectation part. F or δ > 0 , define R δ 1 ,n [ θ , C ]( β , σ, g ) = 1 κ n n X i =1 ˜ K i X k =1 E γ i log max { m g ( v ik Z i ( β , σ ); u i , v ik , σ ) , δ } , 50 and T 1 ,δ ( β , σ ) := sup g ∈G 1 κ n n X i =1 ˜ K i X k =1 E γ i h | log m g ( v ik Z i ( β , σ ); u i , v ik , σ ) | · 1 { m g ( v ik Z i ( β , σ ); u i , v ik , σ ) ≤ δ } i , resp ectiv ely . F rom the Lipsc hitz contin uity of log max {· , δ } and (46), w e hav e | R δ 1 ,n [ θ , C ]( β , σ, g ) − R δ 1 ,n [ θ , C ]( β , σ, g ′ ) | ≤ 1 δ sup a,u i ,v ik ,σ | m g ( a ; u i , v ik , σ ) − m g ′ ( a ; u i , v ik , σ ) | ≤ b 3 δ ∥ g − g ′ ∥ 1 . By definition of T 1 ,δ ( β , σ ) , we ha v e sup g ∈G | R δ 1 ,n [ θ , C ]( β , σ, g ) − R 1 ,n [ θ , C ]( β , σ, g ) | ≤ T 1 ,δ ( β , σ ) . W e proceed to b ound T 1 ,δ ( β , σ ) . Inequalit y (46) giv es T δ ( β , σ ) ≤ sup g ∈G 1 κ n n X i =1 ˜ K i X k =1 E γ i [ { b 1 v 2 ik Z 2 i ( β , σ ) + b 2 } · 1 { b 1 v 2 ik Z 2 i ( β , σ ) ≥ log(1 /δ ) } ] . F rom the conditional Gaussianity v ik Z i ( β , σ ) γ i ∼ N v ik γ i σ , v 2 ik u 2 i , we hav e E γ i [ { b 1 v 2 ik Z 2 i ( β , σ ) + b 2 } · 1 { b 1 v 2 ik Z 2 i ( β , σ ) ≥ log(1 /δ ) } ] ≲ Z v 2 ik σ 2 γ 2 i + a 2 ϕ a ; 0 , v 2 ik u 2 i · 1 {| a | ≥ ( v ik /σ ) | γ i | + b − 1 / 2 1 p log(1 /δ ) } da. Here, by d efinition of a n and from Assumption A2, taking a sufficiently small δ > 0 gives 1 {| a | ≥ ( v ik /σ ) | γ i | + b − 1 / 2 1 p log(1 /δ ) } ≤ 1 {| a | ≥ b 4 ( a n + p log(1 /δ )) } for some b 4 > 0 , where the asymptotic relation R a 2 ϕ ( a ; 0 , 1) 1 {| a | > M } da ∼ M ϕ ( M ; 0 , 1) as M → ∞ is used. This giv es E γ i [ { b 1 v 2 ik Z 2 i ( β , σ ) + b 2 } · 1 { b 1 v 2 ik Z 2 i ( β , σ ) ≥ log(1 /δ ) } ] ≲ Z a 2 ϕ ( a ; 0 , 1) · 1 {| a | ≥ b 4 ( a n + p log(1 /δ )) } da ≲ δ b 2 4 / 2 ( a n + p log(1 /δ )) , 51 where the Gaussian in tegral is used to obtain the second inequalit y . Thus w e hav e T 1 ,δ ( β , σ ) ≲ δ b 2 4 / 2 ( a n + p log(1 /δ )) . Also, define R δ 2 ,n [ θ , C ]( β , σ, g ) := n X i =1 ˜ K i − 1 E γ i h log max n ˜ m g f W ik ( β , σ ); u i , v ik , σ , δ oi and T 2 ,δ ( β , σ ) := sup g ∈G n X i =1 ˜ K i − 1 n X i =1 ˜ K i X k =1 E γ i h | log ˜ m g f W ik ( β , σ ); u i , v ik , σ | · 1 { m g ( f W ik ( β , σ ); u i , v ik , σ ) ≤ δ } i , resp ectiv ely . F rom (46) and the Lipsc hitz con tin uit y of log max {· , δ } , we hav e | R δ 2 ,n [ θ , C ]( β , σ, g ) − R δ 2 ,n [ θ , C ]( β , σ, g ′ ) | ≤ b 3 δ ∥ g − g ′ ∥ 1 . Since f W ik ( β , σ ) is conditional Gaussian, the same procedure as in bounding T 1 ,δ giv es T 2 ,δ ( β , σ, u i , v ik ) ≲ δ b 2 5 / 2 ( a n + p log(1 /δ )) for some b 5 > 0 . Th us w e obtain sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε |R n [ θ , C ]( β , σ, g ) − R n [ θ , C ]( β , σ, g ′ ) | ≤ sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε | R 1 ,n [ θ , C ]( β , σ, g ) − R 1 ,n [ θ , C ]( β , σ, g ′ ) | + sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε | R 2 ,n [ θ , C ]( β , σ, g ) − R 2 ,n [ θ , C ]( β , σ, g ′ ) | ≲ n ε δ + δ min { b 2 4 ,b 2 5 } / 2 max { a n , p log(1 /δ ) } o . (49) Step 1 (ii): b ounding the empirical part. W e pro ceed to b ound ˆ R g n ( h n ) − ˆ R g ′ n ( h n ) . Consider sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε | ˆ R g 1 ,n − ˆ R g ′ 1 ,n | . F or δ > 0 , define ˆ R g ,δ 1 ,n = 1 κ n n X i =1 ˜ K i X k =1 log max { m g ( v ik Z i ( ˆ β , ˆ σ ); u i , v ik , ˆ σ ) , δ } 52 and b T 1 ,δ := sup g ∈G 1 κ n n X i =1 ˜ K i X k =1 log m g ( v ik Z i ( ˆ β , ˆ σ ); u i , v ik , ˆ σ ) · 1 { m g ( v ik Z i ( ˆ β , ˆ σ ); u i , v ik , ˆ σ ) ≤ δ } , resp ectiv ely . Then, we ha v e | ˆ R g ,δ 1 ,n − ˆ R g ′ ,δ 1 ,n | ≲ 1 δ ∥ g − g ′ ∥ 1 , and | ˆ R g ,δ 1 ,n − ˆ R g 1 ,n | ≤ b T 1 ,δ . Here we b ound b T 1 ,δ . Recall Inequalit y (48): | Z i ( ˆ β , ˆ σ ) | ≲ | Z i ( β , σ ) | + 1 for ( ˆ β , ˆ σ ) ∈ H n . Then, we ha ve b T 1 ,δ ≲ 1 κ n n X i =1 ˜ K i X k =1 ( Z 2 i ( β , σ ) + 1) · 1 {| Z i ( β , σ ) | ≳ a n + p log(1 /δ ) } ≲ 1 κ n n X i =1 ˜ K i X k =1 E γ i h Z 2 i ( β , σ ) + 1) · 1 {| Z i ( β , σ ) | ≳ a n + p log(1 /δ ) } i p log n for ( ˆ β , ˆ σ ) ∈ H n , where the conditional Gaussianit y of Z i ( β , σ ) and the χ 2 -tail bound [Lauren t and Massart, 2000] are emplo y ed to obtain the latter inequality . So, noting that κ n is of order n , and taking a sufficien tly small δ > 0 , we conclude b T 1 ,δ ≲ δ b 6 max { a n , p log(1 /δ ) } p log n for some b 6 > 0 with probability tending to one. Therefore we obtain sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε ˆ R g 1 ,n − ˆ R g ′ 1 ,n ≲ n ε δ + δ b 6 p max { a 2 n , log (1 /δ ) } log n o (50) with probability tending to one. Consider next sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε | ˆ R g 2 ,n − ˆ R g ′ 2 ,n | . Recall that, for each i = 1 , . . . , n and k = 1 , . . . , ˜ K i and j ∈ S ik , w e constructed a new v ariable b y adding scaled i.i.d. standard normal noise ζ ikj , ˆ W ikj := v ik Z i ( ˆ β , ˆ σ ) + d 1 / 2 ikj ˆ σ ζ ij k . Due to Lemma 1, without any loss of 53 generalit y we assume ˜ K i = 1 for all i = 1 , . . . , n . W e denote S ik as S i as ˜ K i = 1 . Then w e ha v e ˆ R g 2 ,n := n − 1 X i ∈I ( h ) n X j =1 s − 1 i E ζ log ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) · 1 { j ∈ S i } . F or δ > 0 , define ˆ R g ,δ 2 ,n = n − 1 X i ∈I ( h ) n X j =1 s − 1 i E ζ log max { ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) , δ } · 1 { j ∈ S i } , b T 2 ,δ := n − 1 sup g ∈G X i ∈I ( h ) n X j =1 s − 1 i E ζ h log ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) · 1 { ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) ≤ δ, j ∈ S i } i , resp ectiv ely . Then, we ha v e | ˆ R g ,δ 2 ,n − ˆ R g ′ ,δ 2 ,n | ≲ 1 δ ∥ g − g ′ ∥ 1 , and | ˆ R g ,δ 2 ,n − ˆ R g 2 ,n | ≤ b T 2 ,δ . Recalling s i = | S i | , we hav e b T 2 ,δ ≤ sup g ∈G sup i,k,j,u i ,v ik E ζ h log ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) · 1 { ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) ≤ δ } i . By the same pro cedure as in bounding b T 1 ,δ , the righ t hand side abov e is shown to hav e of the following order: b T 2 ,δ ≲ δ b 7 max { a n , p log(1 /δ ) } p log n for some b 7 > 0 with probability tending to one. Therefore we obtain sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε ˆ R g 2 ,n − ˆ R g ′ 2 ,n ≲ n ε δ + δ b 7 p max { a 2 n , log (1 /δ ) } log n o (51) with probability tending to one. Com bining (49), (50), and (51), and taking δ = ε min { 1 / ( b 2 4 / 2) , 1 / ( b 2 5 / 2) , 1 / ( b 6 +1) , 1 / ( b 7 +1) } =: ε 1 / ( b 8 +1) , 54 w e obtain sup g ,g ′ ∈G : ∥ g − g ′ ∥ 1 ≤ ε b ∆ n [ g ] − b ∆ n [ g ′ ] ≲ ε b 8 / ( b 8+1 ) p max { a 2 n , log (1 /ε ) } log n. (52) Step 2: Bounding the uniform deviation. T o obtain a high-probabili t y b ound for max g ∈{ g 1 ,...,g N ( ε ) } | b ∆ n [ g ] | , we need a sharp er tail b ound than the Cheb yshev b ound used in the pro of of Theorem 2. Step 2 (i): Bounding the deviation ˆ R g 1 ,n − R g 1 ,n . First, consider ˆ R g 1 ,n − E [ ˆ R g 1 ,n ] . As in the pro of of Theorem 2, w e set ψ ik := log m g v ik Z i ( ˆ β , ˆ σ ); u i , v ik , ˆ σ and define F i := P K i k =1 ψ ik : then we h a ve ˆ R g 1 ,n − E [ ˆ R g 1 ,n ] = κ − 1 n n X i =1 { F i − E [ F i ] } . Here, from (47), the summand F i − E [ F i ] has an indep enden t sub-exp onen tial env elop e K i Z 2 i ( β , σ ) regardless of g , where Z 2 i ( β , σ ) is non-centered χ 2 . Note that the summands are uniformly sub-exp onential, so is their normalized sum. Therefore a standard exp onential deviation b ound and the union b ound give max g ∈{ g 1 ,...,g N ( ε ) } | ˆ R g 1 ,n − E [ ˆ R g 1 ,n ] | ≲ n − 1 / 2 log n with probability at least 1 − Pr( H c n ) − N ( ε ) n − ν for any ν > 0 . Next, consider E [ ˆ R g 1 ,n ] − R g 1 ,n . Using the mean v alue theorem with (19), w e ha v e E [ ˆ R g 1 ,n ] − R g 1 ,n ≲ κ − 1 n n X i =1 ˜ K i X k =1 E Z 2 i ( β ∗ , σ ∗ ) ∥ ˆ β − β ∥ + | ˆ σ − σ | , where ( β ∗ , σ ∗ ) lies on the line segmen t joining ( ˆ β , ˆ σ ) and ( β , σ ) . Here, by definition of Z i ( β , σ ) , we ha v e Z i ( β ∗ , σ ∗ ) = σ σ ∗ Z i ( β , σ ) − 1 u i K i X k =1 u ik x ′ ik ( β ∗ − β ) σ ∗ . The triangle inequality , together with Assumptions A1 and A2, giv es | Z i ( β ∗ , σ ∗ ) | ≲ Z i ( β , σ ) + ∥ β ∗ − β ∥ . 55 This, together with the Hölder inequalit y ( p = 1 / 4 and q = 3 / 4 ) and the conditional Gaussianit y of Z i ( β , σ ) , gives E [ ˆ R g 1 ,n ] − R g 1 ,n ≲ κ − 1 n n X i =1 ˜ K i X k =1 E Z 2 i ( β , σ ) ∥ ˆ β − β ∥ + | ˆ σ − σ | ≲ q E [ ∥ ˆ β − β ∥ 2 ] + q E [ ∥ ˆ β − β ∥ 4 ] = O ( n − α ) . Th us w e obtain max g ∈{ g 1 ,...,g N ( ε ) } | ˆ R g 1 ,n − R g 1 ,n ] | ≲ n − 1 / 2 log n + n − α (53) with probability at least 1 − Pr( H c n ) − N ( ε ) n − ν for any ν > 0 . Step 2 (ii): Bounding the deviation ˆ R g 2 ,n − R g 2 ,n . First, consider ˆ R g 2 ,n − E [ ˆ R g 2 ,n ] . Observ e that E ζ log ˜ m g ( ˆ W ikj ( ζ ); u i , v ik , ˆ σ ) has a sub-exp onen tial env elop e E i := cZ 2 i ( β , σ ) + c ′ for some c, c ′ > 0 that is independent across i . So, we hav e ˆ R g 2 ,n − E [ ˆ R g 2 ,n ] ≲ P n − 1 X i ∈I ( h ) E i n X j =1 1 { j ∈ S i } /s i | {z } =: e i , where A ≲ P B denotes Pr( A ≲ B ) = 1 . Here the follo wing lemma connects the co efficient e i to D n ( h n ) : D n ( h n ) := κ − 1 n n X i =1 ˜ K i X k =1 1 {| S ik | ≥ h n } / | S ik | = κ − 1 n X i ∈I ( h ) 1 /s i . Lemma 6. W e have n X j =1 e 2 j ≤ κ 2 n D n ( h n ) . Pr o of. W rite w i := 1 { s i ≥ h n } /s i . Then w e hav e e i = X j : j ∈ S i w j and n X i =1 e 2 i = n X i =1 n X i ′ =1 w i w i ′ | S i ∩ S i ′ | . By the Cauch y–Sch warz inequalit y , w e hav e | S i ∩ S i ′ | ≤ p | S i | | S i ′ | ; hence we obtain n X i =1 c 2 i ≤ n X i =1 w i p | S i | 2 ≤ n X i =1 1 n X i =1 w 2 i | S i | = κ n n X i =1 1 { s i ≥ h n } s i = κ 2 n D n ( h n ) . 56 Th us a standard exponential deviation bound and the union b ound giv e max g ∈{ g 1 ,...,g N ( ε ) } | ˆ R g 2 ,n − E [ ˆ R g 2 ,n ] | ≲ r D n ( h n ) n log n (54) with probability at least 1 − Pr( H c n ) − N ( ε ) n − ν for any ν > 0 . Finally , noting that R 2 ,n is the normalized sum of i.i.d. b ounded summands as in the pro of of Theorem 2 and considering the plug-in effect as in Step 2 (i), w e obtain max g ∈{ g 1 ,...,g N ( ε ) } | ˆ R g 2 ,n − R g 2 ,n ] | ≲ r D n ( h n ) n log n + n − α with probability at least 1 − Pr( H c n ) − N ( ε ) n − ν for any ν > 0 . Final step : Finally , we com bine (50), (53), and (54) to obtain sup g ∈G b ∆ n [ g ] ≲ c n log n + ε b 8 / ( b 8 +1) p max { a 2 n , log (1 /ε ) } log n with probability tending to one. Also, in the same pro cedure as in Step 2 (i), we can b ound sup g ∈G | b P n [ g ] | : sup g ∈G | b P n [ g ] | ≲ n − α . No w c ho ose ε = ε n = n − M for a sufficiently large constant M > 0 . By Assumption A8(i), log N ( ε n , G , ∥ · ∥ 1 ) ≲ log n, so taking M large enough yields ε b 8 / ( b 8 +1) n = n − M b 8 / ( b 8 +1) = O ( c n ) and the exclusion probabilit y tends to zero. Hence we obtain sup g ∈G | b ∆ n [ g ] | = O p ( c n a n log n ) , whic h concludes the proof. 6.4.3 Pro of of Prop osition 1 W e verify Assumption A8 for eac h class in turn. The pro of for G 3 is the same as that for G 2 , and is therefore omitted. Denote m g ( x ; σ ) := Z ϕ ( x ; γ , σ ) g ( γ ) dγ . 57 T o v erify Assumption A8 (iii) for G 1 , the following iden tities are useful: ∂ ∂ x log m g ( x ; σ ) = − 1 σ x + 1 σ R γ ϕ ( x ; γ , σ ) g ( γ ) dγ m g ( x ; σ ) , (55) ∂ ∂ σ log m g ( x ; σ ) = − 1 2 σ + 1 2 σ 2 R ( x − γ ) 2 ϕ ( x ; γ , σ ) g ( γ ) dγ m g ( x ; σ ) . (56) Class G 1 . Let g ( τ ) = (1 − η ) δ 0 + η a 2 e − a | τ | , ( η , a ) ∈ [ η , η ] × [ a, a ] , where 0 < η ≤ η < 1 and 0 < a ≤ a < ∞ . W e first v erify As sumption A8(i). Since G 1 is parameterized by the t w o-dimensional compact rectangle [ η , η ] × [ a, a ] , and the map ( η, a ) 7→ g η ,a is con tin uous in L 1 , the class is parametric of tw o dimension and th us log N ( ε, G 1 , ∥ · ∥ 1 ) ≲ log ( ε − 1 ) , which pro ves A8(i). W e next v erify Assumption A8(ii). Observ e that, for an y M > 0 , w e ha v e g ([ − M , M ]) = (1 − η ) + η Z M − M a 2 e − a | τ | dτ = 1 − η e − aM . By choosing M sufficiently large, this yields inf g ∈G 1 g ([ − M , M ]) ≥ 1 − η e − aM =: π ∗ > 0 . Th us Assumption A8(ii) holds. Finally , w e verify Assumption A8(iii). Denote g ( γ ) = (1 − η ) δ 0 + η h a ( γ ) with h a ( γ ) := a 2 e − a | γ | , where ( η , a ) ∈ [ η , η ] × [ a, a ] , with 0 < η ≤ η < 1 and 0 < a ≤ a < ∞ . Then w e hav e m g ( x ; σ ) = (1 − η ) ϕ ( x ; 0 , σ ) + η Z ϕ ( x ; γ , σ ) h a ( γ ) dγ , from which we ha v e a low er b ound on m g : m g ( x ; σ ) ≥ (1 − η ) ϕ ( x ; 0 , σ ) ≥ (1 − η ) ϕ ( x ; 0 , σ ) . 58 F rom (55) and (56), it suffices to con trol the p osterior moments up to second. F or r = 0 , 1 , 2 , let I r ( x ; σ, a ) := Z | γ | r ϕ ( x ; γ , σ ) h a ( γ ) dγ . F rom the lo w er bound m g ( x ; σ ) = (1 − η ) ϕ ( x ; 0 , σ ) + η I 0 ( x ; σ, a ) ≥ η I 0 ( x ; σ, a ) , w e obtain R | γ | r ϕ ( x ; γ , σ ) g ( γ ) dγ m g ( x ; σ ) = η I r ( x ; σ, a ) (1 − η ) ϕ ( x ; 0 , σ ) + η I 0 ( x ; σ, a ) ≤ I r ( x ; σ, a ) I 0 ( x ; σ, a ) . It therefore suffices to b ound I r /I 0 uniformly ov er a ∈ [ a, a ] . T o bound I r /I 0 , decomp ose I r ( x ; σ, a ) = I + r ( x ; σ, a ) + I − r ( x ; σ, a ) , where I + r ( x ; σ, a ) := Z ∞ 0 γ r ϕ ( x ; γ , σ ) h a ( γ ) dγ , and I − r ( x ; σ, a ) := Z 0 −∞ | γ | r ϕ ( x ; γ , σ ) h a ( γ ) dγ . Since I 0 = I + 0 + I − 0 , we hav e I r I 0 = I + r + I − r I + 0 + I − 0 ≤ max I + r I + 0 , I − r I − 0 . Th us it suffices to b ound I ± r /I ± 0 . F or the p ositiv e half-line integral, using h a ( γ ) = ( a/ 2) e − aγ for γ ≥ 0 , I + r ( x ; σ, a ) = a 2 Z ∞ 0 γ r ϕ ( x ; γ , σ ) e − aγ dγ . Completing the square, − ( x − γ ) 2 2 σ − aγ = − 1 2 σ γ − ( x − σ a ) 2 + σ a 2 2 − ax | {z } independent of γ , w e notice that the common factor e − ax + σ a 2 / 2 cancels in the ratio. Hence, with µ + ( x, a ) = µ + := x − σ a, w e obtain I + r ( x ; σ, a ) I + 0 ( x ; σ, a ) = R ∞ 0 γ r exp[ − ( γ − µ + ) 2 / (2 σ )] dγ R ∞ 0 exp[ − ( γ − µ + ) 2 / (2 σ )] dγ . 59 After the change of v ariables γ = µ + + √ σ z , this b ecomes I + r I + 0 = R ∞ − µ + / √ σ | µ + + √ σ z | r e − z 2 / 2 dz R ∞ − µ + / √ σ e − z 2 / 2 dz . Using | u + v | r ≤ 2( | u | r + | v | r ) ( r = 1 , 2 ), it follo ws that I + r I + 0 ≤ 2 | µ + | r + 2 σ r/ 2 R ∞ − µ + / √ σ | z | r e − z 2 / 2 dz R ∞ − µ + / √ σ e − z 2 / 2 dz . Here, if t := − µ + / √ σ ≤ 0 , then the denominator is b ounded b elo w b y R ∞ 0 e − z 2 / 2 dz > 0 , whereas the numerator is finite from the Gaussian in tegral. If t > 0 , then b y the standard Mills ratio b ounds, Z ∞ t z e − z 2 / 2 dz = e − t 2 / 2 ≲ t Z ∞ t e − z 2 / 2 dz , and Z ∞ t z 2 e − z 2 / 2 dz = te − t 2 / 2 + Z ∞ t e − z 2 / 2 dz ≲ (1 + t 2 ) Z ∞ t e − z 2 / 2 dz . Therefore, I + 1 I + 0 ≲ (1 + | µ + | ) , I + 2 I + 0 ≲ (1 + µ 2 + ) . The negative half-lin e in tegral is handled similarly and we obtain I − 1 ( x ; σ, a ) I − 0 ( x ; σ, a ) ≲ (1 + | µ − | ) , I − 2 ( x ; σ, a ) I − 0 ( x ; σ, a ) ≲ (1 + µ 2 − ) , where µ − := − x − σ a Since a ∈ [ a, a ] , we ha v e | µ + ( x, a ) | + | µ − ( x, a ) | ≲ (1 + | x | ) , µ + ( x, a ) 2 + µ − ( x, a ) 2 ≲ (1 + x 2 ) . Consequen tly , w e hav e I 1 ( x ; σ, a ) I 0 ( x ; σ, a ) ≲ (1 + | x | ) , I 2 ( x ; σ, a ) I 0 ( x ; σ, a ) ≲ (1 + x 2 ) . Th us, w e obtain ∂ ∂ x log m g ( x ; σ ) ≤ | x | σ + 1 σ I 1 ( x ; σ, a ) I 0 ( x ; σ, a ) ≲ (1 + | x | ) , 60 and, using ( x − γ ) 2 ≤ 2 x 2 + 2 γ 2 , ∂ ∂ σ log m g ( x ; σ ) ≤ 1 2 σ + x 2 σ 2 + 1 σ 2 I 2 ( x ; σ, a ) I 0 ( x ; σ, a ) ≲ (1 + x 2 ) . This prov es Assumption A8(iii) for G 1 , which completes the pro of for G 1 . Class G 2 . Let g ( τ ) = L X l =1 π l ϕ ( τ ; 0 , ν l ) , π l ≥ 0 , L X l =1 π l = 1 , where ν 1 , . . . , ν L is a fixed v ariance grid. Since the weigh t vector ( π 1 , . . . , π L ) ranges ov er the simplex, G 2 is a compact parametric family of dimension L − 1 . Therefore log N ( ε, G 2 , ∥ · ∥ 1 ) ≲ log ( ε − 1 ) , and A8(i) follo ws. Also, g ([ − M , M ]) = L X l =1 π l Z M − M ϕ ( τ ; 0 , ν l ) dτ ≥ min 1 ≤ l ≤ L Z M − M ϕ ( τ ; 0 , ν l ) dτ , whic h pro v es A8(ii). F or A8(iii), write m g ( x ; σ ) = Z ϕ ( x ; τ , σ ) g ( τ ) dτ = L X l =1 π l ϕ ( x ; 0 , σ + ν l ) . The deriv ative of log m g with resp ect to x , ∂ ∂ x log m g ( x ; σ ) = − x P L l =1 π l ( σ + ν l ) − 1 ϕ ( x ; 0 , σ + ν l ) P L l =1 π l ϕ ( x ; 0 , σ + ν l ) , giv es | ( ∂ /∂ x ) log m g ( x ; σ ) | ≤ | x | max 1 ≤ l ≤ L ( σ + ν l ) − 1 . Lik ewise, w e hav e ∂ ∂ σ log m g ( x ; σ ) ≤ max 1 ≤ l ≤ L 1 2( σ + ν l ) + x 2 2( σ + ν l ) 2 . Therefore we obtain | ∂ x log m g ( x ; σ ) | + | ∂ σ log m g ( x ; σ ) | ≲ (1 + | x | + | x | 2 ) , uniformly ov er g ∈ G 2 . Thus A8(iii) holds. Com bining these completes the pro of. 61 References J. Aitc hison and I. R. Dunsmore. Statistic al pr e diction analysis . Cambridge Univ ersity Press, 1975. A. N. Angelop oulos, S. Bates, T. Zrnic, and M. I. Jordan. Priv ate prediction sets. arXiv pr eprint arXiv:2202.08535 , 2022. L. D. Bro wn, E. Greensh tein, and Y. Rito v. The p oisson compound decision problem revisited. Journal of the Americ an Statistic al Asso ciation , 108:741–749, 2013. doi: 10. 1080/01621459.2012.753338. M. Cauc hois, S. Gupta, A. Ali, and J. C. Duchi. Robust v alidation: Confiden t predictions ev en when distributions shift. Journal of the Americ an Statistic al Asso ciation , pages 1–66, 2024. E. Demidenko. Mixe d mo dels: the ory and applic ations with R . John Wiley & Sons, 2013. A. Dharamshi, A. Neufeld, K. Motw ani, L. L. Gao, D. Witten, and J. Bien. Generalized data thinning using sufficien t statistics. Journal of the A meric an Statistic al Asso ciation , 120:1–26, 2025. doi: 10.1080/01621459.2024.2343834. B. Efron. L ar ge-sc ale infer enc e: empiric al Bayes metho ds for estimation, testing, and pr e diction , volume 1. Cambridge Un iv ersity Press, 2012. B. Efron. T w o mo deling strategies for empirical bay es estimation. Statistic al Scienc e , 29 (2):285–301, 2014. doi: 10.1214/13- STS455. B. Efron. decon v olv eR: A G-modeling program for deconv olution and empirical ba y es estimation. Journal of Statistic al Softwar e , 69(1):1–17, 2016. doi: 10.18637/jss.v069.i01. D. F ourdrinier, É. Marchand, A. Righi, and W. E. Stra wderman. On impro v ed predictive densit y estimation with parametric constraints. Ele ctr onic Journal of Statistics , 5:172– 191, 2011. ISSN 1935-7524. 62 K. Gao and A. B. Ow en. Estimation and inference for v ery large linear mixed effects mo dels. Statistic a Sinic a , 30(4):1741–1771, 2020. S. Geisser. Pr e dictive infer enc e , volume 55 of Mono gr aphs on Statistics and Applie d Pr ob ability . Chapman and Hall, New Y ork, 1993. ISBN 0-412-03471-9. E. George, G. Mukherjee, and K. Y ano. Optimal shrink age estimation of predictive densities under α -divergences. Bayesian A nalysis , 16(4):1139–1155, 2021. E. I. George and X. Xu. Predictiv e density estimation for m ultiple regression. Ec onometric The ory , 24(2):528–544, 2008. ISSN 0266-4666. doi: 10.1017/S0266466608080213. URL http://dx.doi.org/10.1017/S0266466608080213 . E. I. George, F. Liang, and X . Xu. Impro ved minimax predictiv e densities under Kullbac k– Leibler loss. The A nnals of Statistics , pages 78–91, 2006. E. I. George, F. Liang, and X. Xu. F rom minimax shrink age estimation to minimax shrink age prediction. Statistic al Scienc e , 27(1):82–94, 2012. ISSN 0883-4237. M. Ghosh and T. Kub ok aw a. Hierarc hical Ba y es versus empirical Bay es densit y predictors under general divergence loss. Biometrika , 2018. M. Ghosh, V. Mergel, and G. S. Datta. Estimation, prediction and the Stein phenomenon under divergence loss. Journal of Multivariate A nalysis , 99(9):1941–1961, 2008. ISSN 0047-259X. S. Ghosh, T. Hastie, and A. B. Owen. Bac kfitting for large scale crossed random effects regressions. The Annals of Statistics , 50(1):560–583, 2022. I. Gibbs and E. Candès. A daptiv e conformal inference under distribution shift. In A dvanc es in Neur al Information Pr o c essing Systems , volume 34, pages 1660–1672, 2021. I. Gibbs and E. J. Candès. Conformal inference for on line prediction with arbitrary distribution shifts. Journal of Machine L e arning R ese ar ch , 25(162):1–36, 2024. 63 W. Jiang and C.-H. Zhang. General maxim um lik elihoo d empirical Ba y es estimation of normal means. The A nnals of Statistics , 37(4):1647–1684, 2009. F. K omaki. A shrink age predictiv e distribution for multiv ariate normal observ ables. Biometrika , 88(3):859–864, 2001. ISSN 0006-3444. S. Kullback and R. A. Leibler. On information and sufficiency . A nn. Math. Statistics , 22: 79–86, 1951. ISSN 0003-4851. B. Laurent and P . Massart. Adaptiv e estimation of a quadratic functional b y mo del selection. Annals of statistics , pages 1302–1338, 2000. J. Leiner, B. Duan, L. W asserman, and A. Ramdas. Data fission: Splitting a single data p oin t. Journal of the A meric an Statistic al Asso ciation , 120:135–146, 2025. doi: 10.1080/ 01621459.2023.2270748. F. Liang. Exact minimax pr o c e dur es for pr e dictive density estimation and data c ompr ession . ProQuest LLC, Ann Arb or, MI, 2002. ISBN 978-0493-60397-1. Thesis (Ph.D.)–Y ale Univ ersit y . É. Marchand and A. Sadeghkhani. On predictive densit y estimation with additional information. Ele ctr onic Journal of Statistics , 12:4209–4238, 2018. Y. Maruyama and W. E. Strawderman. Bay esian predictiv e densities for linear regression mo dels under α -div ergence loss: Some results and op en problems. In Contemp or ary developments in Bayesian analysis and statistic al de cision the ory: a F estschrift for Wil liam E. Str awderman , volume 8, pages 42–57. Institute of Mathematical Statistics, 2012. Y. Maruy ama, T. Matsuda, and T. Ohnishi. Harmonic Ba y esian prediction under α - div ergence. IEEE T r ansactions on Information The ory , 2019. T. Matsuda and W. Stra wderman. Predictiv e densit y estimation under the Wasserstein loss. Journal of Statistic al Planning and Infer enc e , 210:53–63, 2021. 64 G. Mukherjee. Sp arsity and Shrinkage in Pr e dictive Density Estimation . PhD thesis, Stanford Universit y , 2013. G. Mukherjee and I. M. Johnstone. Exact minimax estimation of the predictiv e densit y in sparse Gaussian mo dels. The A nnals of Statistics , 43:937–961, 2015. G. Mukherjee and K. Y ano. Predictiv e inference in linear mixed models, 2025. URL https://gmukherjee.github.io/pdfs/predinf_lmm.pdf . A ccepted in Indian Journal of Pur e and Applie d Mathematics . A. Neufeld, A. Dharamshi, L. L. Gao, and D. Witten. Data thinning for conv olution-closed distributions. Journal of Machine L e arning R ese ar ch , 25:1–35, 2024. J. C. Pinheiro and D. M. Bates. Linear mixed-effects mo dels: basic concepts and examples. Mixe d-effe cts mo dels in S and S-Plus , pages 3–56, 2000. V. Ročk o vá. Adaptiv e bay esian predictive inference for sparse high-dimensional regression. arXiv:2309.02369v3[math.ST] , 2024. V. Ročko vá and E. I. George. The sp ik e-and-slab lasso. Journal of the A meric an Statistic al Asso ciation , 113(521):431–444, 2018. S. Ro y , A. Sark ar, A. Ghosh, and A. Basu. Asymptotic breakdo wn point analysis for a general class of minim um div ergence estimators. Bernoul li , 32(1):698–722, 2026. H. Shimodaira. Impro ving predictiv e inference under co v ariate shift by weigh ting the log- lik eliho o d function. Journal of statistic al planning and infer enc e , 90(2):227–244, 2000. R. J. Ti bshirani, R. F o ygel Barb er, E. Candès, and A. Ramdas. Conformal prediction under co v ariate shift. In A dvanc es in Neur al Information Pr o c essing Systems , v olume 32, 2019. X. Xie, S. K ou, and L. D. Bro wn. Sure estimates for a heteroscedastic hierarchical mo del. Journal of the Americ an Statistic al Asso ciation , 107(500):1465–1479, 2012. 65 X. Xu and F. Liang. Asymptotic minimax risk of predictive density estimation for non- parametric regression. Bernoul li , 16(2):543–560, 2010. ISSN 1350-7265. X. Xu and D. Zhou. Empirical Ba y es predictive densities for high-dimensional normal mo dels. Journal of Multivariate A nalysis , 102(10):1417–1428, 2011. Y. Y ang, A. K. Kuc hibhotla, and E. T c hetgen T c h etgen. Doubly robust calibration of prediction sets under co v ariate shift. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , page qk ae009, 2024. K. Y ano, R. Kaneko, and F. Komaki. Minimax predictive density for sparse count data. Bernoul li , 27:1212–1238, 2021. 66
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment