시각적 복합 유추 추론을 위한 CARV 벤치마크
CARV는 다중 이미지 쌍에서 추출한 변환 규칙을 논리 연산으로 합성해 새로운 변환을 적용하도록 요구하는 시각적 유추 추론 벤치마크이다. 5,500개의 샘플로 구성된 데이터셋을 제공하고, 최신 멀티모달 LLM(Gemini‑2.5 Pro 등)의 성능을 평가한 결과 인간 수준(100%)에 크게 못 미치는 40%대 정확도를 보였다. 주요 실패 원인은 시각 변화를 기호화하는 과정과 복합 논리 연산에 대한 취약성이다.
저자: Yongkang Du, Xiaohan Zou, Minhao Cheng
본 논문은 멀티모달 대형 언어 모델(MLLM)이 인간 수준의 고차원 인지 능력을 보유했는지 평가하기 위해, 기존 단일 변환 유추 과제의 한계를 지적하고 새로운 “Compositional Analogical Reasoning in Vision”(CARV) 벤치마크를 제안한다. 인간의 유추 추론은 종종 여러 경험적 소스로부터 규칙을 추출하고 이를 조합해 새로운 상황에 적용하는 과정으로 이루어지며, 이는 단일 쌍 기반의 기존 시각 유추 평가와는 근본적으로 다르다.
CARV는 (I₁:I₁′), …, (Iₙ:Iₙ′) : : (I_q:I_a) 형태의 입력을 받아, 각 쌍에서 원자 변환 집합 T₁,…,Tₙ을 추출하고, 논리 연산 O∈{∪,∩,\}를 적용해 목표 변환 T = O(T₁,…,Tₙ) 를 만든 뒤, 이를 질의 이미지 I_q에 적용해 정답 이미지 I_a를 생성하도록 요구한다. 여기서 원자 변환은 속성(p)와 값(v→v′)의 변화로 정의되며, 속성 집합 P는 subject, subject number, object, object color, spatial relation 으로 구성된다.
데이터셋 구축은 통제된 시각 환경을 기반으로 한다. 원본 이미지는 일상 물체와 가구(테이블·의자)로 구성되며, Gemini‑2.5 Flash 이미지 편집기를 이용해 색상, 개수, 위치 등 다양한 변환을 적용한다. 품질 검수를 거쳐 5,500개의 과제가 생성되었으며, 과제는 다음과 같이 분류된다. (1) Single‑step 유추 500개 – 단일 변환을 그대로 적용하는 기본 과제. (2) Compositional – Shared Source(1,500개)와 Different Source(1,500개)로 나뉘며, 각각 Union, Intersection, Difference 연산을 균등하게 포함한다. (3) Complexity Scaling – 원자 변환 수를 3, 4개로 늘린 추가 2,000개가 포함되어 모델의 복합성 처리 능력을 평가한다.
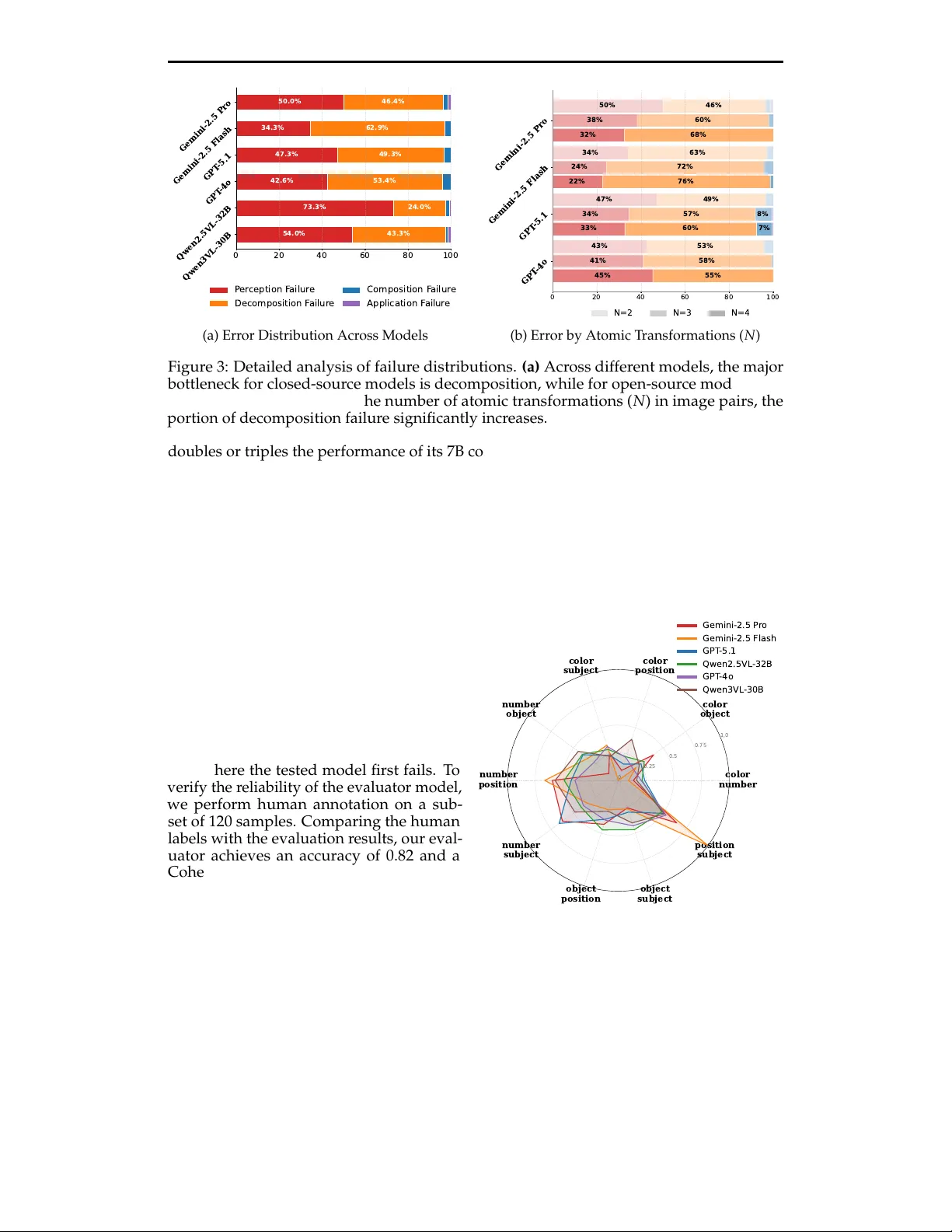
실험에서는 최신 폐쇄형 모델(GPT‑5.1, GPT‑4o, Gemini‑2.5 Pro, Gemini‑2.5 Flash)과 오픈소스 모델(QwenVL, InternVL, Llama‑3.2‑Vision) 총 10여 종을 평가하였다. 모델은 온도 0.2로 설정하고, 두 가지 프롬프트 방식을 사용한다. Direct Prompting은 전체 과제를 한 번에 제시하고 정답 캡션을 생성하도록 요구한다. Diagnosis Prompting은 인식, 분해, 합성, 적용 네 단계로 작업을 나누어 각 단계별 정답 여부를 평가한다.
성능 결과는 표 2에 요약된다. Single‑step에서는 Gemini‑2.5 Flash가 75% 수준으로 가장 높은 정확도를 보였으며, GPT‑5.1도 81%에 근접한다. 그러나 Compositional 과제에서는 정확도가 급격히 떨어져, 가장 좋은 모델인 Gemini‑2.5 Pro조차도 Different Source 설정에서 40%대(특히 Intersection, Difference)만을 기록했다. 오픈소스 모델은 전반적으로 10% 이하의 성능을 보이며, 특히 복합 연산에서 거의 실패한다.
진단 파이프라인을 통해 두 가지 주요 실패 모드가 확인되었다. 첫째, 시각 변화를 기호적 규칙으로 변환하는 단계에서 오류가 빈번히 발생한다. 모델이 이미지 속성을 정확히 인식하고 이를 언어 형태로 서술하는 능력이 제한적이다. 둘째, 추출된 규칙을 논리 연산으로 합성하는 과정에서 컨텍스트 복잡도(특히 Different Source)와 변환 수가 증가할수록 오류가 급증한다. 이는 현재 MLLM이 “시각 → 기호 → 논리” 흐름을 일관되게 처리하지 못함을 의미한다.
논문은 이러한 결과를 바탕으로 다음과 같은 시사점을 제시한다. (1) 멀티모달 모델 설계 시 변환 규칙 추출을 전용하는 모듈(예: 속성 디코더)과 논리 연산을 수행할 수 있는 별도 추론 엔진을 도입해야 한다. (2) 데이터셋이 통제된 도메인에 국한돼 있기 때문에, 실제 세계의 복잡한 배경·조명·오클루전 등을 포함한 오픈월드 버전이 필요하다. (3) 인간 수준의 유추 능력을 달성하려면, 모델이 “다중 소스에서 규칙을 추출 → 논리적으로 합성 → 새로운 상황에 적용”이라는 연쇄적 과정을 학습하도록 훈련 데이터와 목표 함수를 재설계해야 한다.
결론적으로, CARV는 멀티모달 LLM의 고차원 인지 능력을 정량화할 수 있는 최초의 시각적 진단 벤치마크이며, 현재 모델이 변환 규칙의 기호화와 복합 논리 연산에서 크게 부족함을 드러낸다. 향후 연구는 이 두 축을 강화하는 방향으로 진행될 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기