CARV: A Diagnostic Benchmark for Compositional Analogical Reasoning in Multimodal LLMs
Analogical reasoning tests a fundamental aspect of human cognition: mapping the relation from one pair of objects to another. Existing evaluations of this ability in multimodal large language models (MLLMs) overlook the ability to compose rules from …
Authors: Yongkang Du, Xiaohan Zou, Minhao Cheng
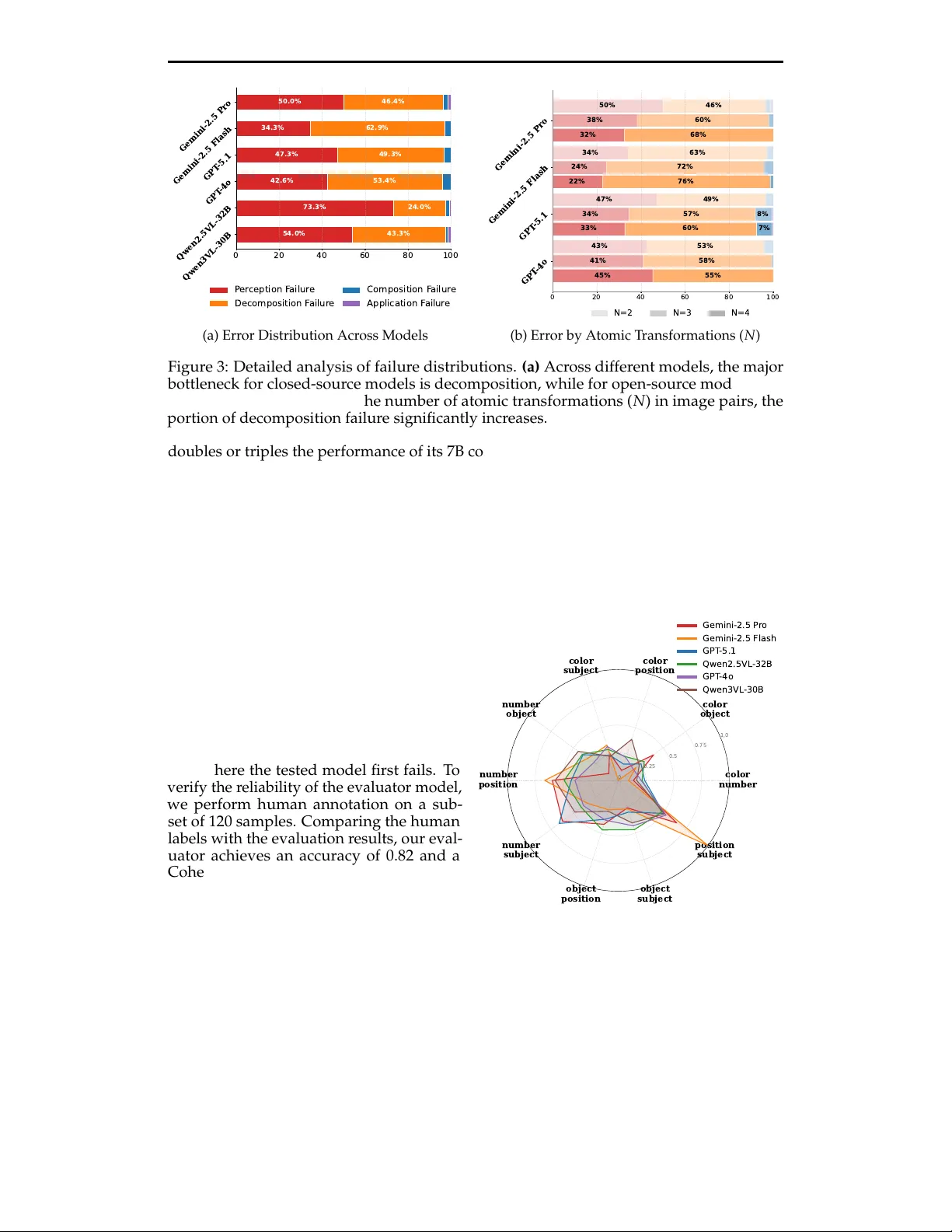
Preprint. Under review . CAR V : A Diagnostic Benchmark for Compositional Analogi- cal Reasoning in Multimodal LLMs Y ongkang Du, Xiaohan Zou, Minhao Cheng, Lu Lin Pennsylvania State University { ybd5136,xfz5266,mmc7149,lulin } @psu.edu Abstract Analogical reasoning tests a fundamental aspect of human cognition: map- ping the relation fr om one pair of objects to another . Existing evalua- tions of this ability in multimodal large language models (MLLMs) over- look the ability to compose r ules from multiple sour ces, a critical compo- nent of higher-or der intelligence. T o close this gap, we introduce CAR V ( C ompositional A nalogical R easoning in V ision), a novel task together with a 5,500-sample dataset as the first diagnostic benchmark. W e extend the analogy from a single pair to multiple pairs, which requir es MLLMs to extract symbolic rules fr om each pair and compose new transformations. Evaluation on the state-of-the-art MLLMs reveals a striking performance gap: even Gemini-2.5 Pr o achieving only 40.4% accuracy , far below human- level performance of 100%. Diagnostic analysis shows two consistent failure modes: (1) decomposing visual changes into symbolic rules, and (2) maintaining robust ness under diverse or complex settings, highlighting the limitations of current MLLMs on this task. 1 1 Introduction w o o d S am e t r an s f or m at i on S e t O p e r a t io n : Unio n ( ∪ ) S in g le - s t e p Ana lo g y Co m p o s it io n a l Ana lo g y S t a t e p a ir S t a t e p a ir 2 Q u e r y Ans we r Q u e r y Ans we r r e d C o lo r : w o o d r e d C o lo r : w o o d S t a t e p a ir 1 r e d C ol or : 1 2 Num b e r : w o o d r e d C o lo r : 1 2 Num b e r : Figure 1: Examples of single-step and com- positional analogy . The single-step analogy (left) delivers one transformation ( color ) from input to target, while the compositional anal- ogy (right) delivers the union of color (wood to red) and number (one to two) transforma- tions. The development of multimodal lar ge lan- guage models (MLLMs) ( Comanici et al. , 2025 ) has significantly advanced visual rea- soning, enabling models to tackle more complex tasks ( T eam , 2025 ; Chen et al. , 2024 ). As MLLMs approach human-level performance on many tasks, resear ch focus has shifted towar d evaluating their capacity for higher-or der cognition, including com- plex processes such as perception ( Galatzer - Levy et al. , 2024 ) and logical r easoning ( Ren et al. , 2025 ). Analogical reasoning, an essential part of human cognition, enables learning from diverse contexts in an adaptive and ro- bust way , supporting decision making and out-of-distribution generalization ( Mitchell , 2021 ; Y iu et al. , 2025 ). Current visual anal- ogy benchmarks ( Y iu et al. , 2025 ; Y ilmaz et al. , 2025 ) ar e mainly formulated as single- step analogy tasks (Figure 1 left), where models only need to identify and a pply the transformation rule derived fr om a sin- gle input pair . However , human analogical 1 The dataset will be released in the camera-r eady version. 1 Preprint. Under review . reasoning is often sequential and construc- tive ( Sternberg & Rifkin , 1979 ). It involves combining experiential knowledge from multiple sources to solve unfamiliar problems, rather than focusing on a single r elationship ( Fauconnier & T urner , 2008 ; 2003 ). Existing visual analogy evaluation paradigms are overly simplified and ther efore neglect the ability to derive novel solutions by composing and synthesizing knowledge fr om multiple, distinct sources. In this paper , we introduce C ompositional A nalogical R easoning in V ision ( CAR V ). W e differ fr om existing visual analogy settings by evaluating a higher -order , often overlooked capability of MLLMs, namely structuring and combining knowledge fr om multiple sources in analogical reasoning. As shown in Figure 1 , existing single-step visual analogy (left) typically involves extracting and mapping a single transformation, whereas our CAR V (right) goes further by demanding the ability to perform logical operations over multiple transformation sets derived from multiple image pairs. Furthermore, CAR V is developed in a controlled visual domain. As testing in open-world scenarios often contains visual noise, controlled domain allows us to strictly isolate models’ reasoning capabilities from their perception limits, which enable us to thor oughly study the failure modes. Our contributions are summarized as follows: • Novel T ask Formulation W e formally define the Compositional Analogical Reasoning in V ision (CAR V) task and construct a structur ed evaluation protocol to test a model’s ability to reconstr uct and apply visual transformations learned from multiple sour ces. • New CAR V Benchmark W e introduce a comprehensive dataset spanning diverse levels of analogical reasoning complexity . CAR V is carefully designed to cover orthogonal dimensions of visual transformations, including spatial and attribute transformations. • Detailed Diagnostic Analysis W e conduct extensive experiments on the state-of-the-art MLLMs and find that our task is challenging for most models. T o understand these limitations, we develop a fine-grained diagnosis pipeline that evaluates reasoning step by step. Our analysis reveals critical weaknesses of current MLLMs: they struggle to translate visual per ceptions into the symbolic, structur ed rules and are sensitive to increased contextual complexity . 2 Related W ork This work mainly explores whether MLLMs can perform compositional analogical r easoning. In light of this, we review two lines of r esearch that form the basis of this work: analogical reasoning and visual composition. Analogical Reasoning Analogical reasoning has long been focused in the AI community . T raditional studies primarily focus on lexical analogy ( Ushio et al. , 2021 ; Fournier et al. , 2020 ; Schluter , 2018 ), i.e., king to men as queen to women, examining word pairs that share similar semantic relations. Recently , as LLMs demonstrate advanced reasoning capabilities ( Liu et al. , 2024 ; Du et al. , 2025 ), resear ch on analogical reasoning has extended beyond lexical tasks. For example, exploring how LLMs construct analogies in real-world situations ( Sultan & Shahaf , 2022 ), applying analogical reasoning to storytelling ( Jiayang et al. , 2023 ) or scientific understanding ( Y uan et al. , 2024 ), and using analogical r easoning as prompting strategies ( Y asunaga et al. , 2024 ; Qin et al. , 2025 ). In the vision domain, analogical reasoning also gets significant attention ( Zhang et al. , 2019 ; Kamath et al. , 2023 ; Zhang et al. , 2023 ; Guo et al. , 2024 ; Lee et al. , 2024 ). The most recent benchmarks study analogical reasoning following the same format in lexical analogy , A to B as C to D , wher e the input image pair consists of A and B, the query image is C, and the desir ed output is D. KiV A ( Y iu et al. , 2025 ), draws inspiration from visual analogy tasks for children, employing basic image transformations (i.e., r otation and flipping) to construct the input image pair . VOILA ( Y ilmaz et al. , 2025 ) incorporates diverse action scenes (number , subject, and action) in the image where the transformation is derived from. Notably , both studies find that MLLMs struggle more with applying transformations than with identifying them. However , these prior approaches ar e limited by task formats that rely on a single sour ce, a constraint 2 Preprint. Under review . that our work aims to address. Instead of revisiting issues in applying transformations, we reveal the bottleneck of composition ability of curr ent MLLMs. V isual Composition Compositional ability is fundamental for MLLMs to understand complex scenes ( Y i et al. , 2018 ; W ang et al. , 2025 ) and create images with sophisticated instructions ( Premsri & Kor djamshidi , 2025 ; Zhu et al. , 2023 ). The study on visual composi- tion is first conducted on static scene. In CLEVR ( Johnson et al. , 2017 ) and GQA ( Hudson & Manning , 2019 ), models are trained to apply object attributes and spatial relations in question answering or caption generation. As vision language models become popular , the resear ch steers to the image generation process ( Farid et al. , 2025 ; Lu et al. , 2023 ), studying the composition of scene description ( Liu et al. , 2021 ; 2022 ) or task instruction ( Gu et al. , 2025 ). A VSD ( Chae et al. , 2025 ) studies decomposition ability over visual compr ehension tasks. However , previous work mainly focuses on composition of object attributes and ne- glects the composition of abstract spaces or r ules, which is found to be an essential cognitive process in human creation process ( Fauconnier & T urner , 2008 ; Fauconnier , 2001 ). T o fill this gap, our work studies composition of transformation rules observed from image pairs. 3 Compositional Analogical Reasoning In this section, we formally define compositional analogical reasoning and describe the tasks designed to evaluate MLLMs. 3.1 Problem Formulation Preliminary W e first introduce the single-step analogy . Figure 1 (left) describes two image pairs sharing the same transformation, denoted as ( I : I ′ ) : : ( I q : I a ) . W e formulate an image I as a state, defined as a set of properties p ∈ P and their corresponding values v ∈ V p , i.e., I = { ( p , v ) | p ∈ P , v ∈ V p } . W e define an Atomic T ransformation as a change in the value of a single property between two states, denoted by ( p , v , v ′ ) with v = v ′ and v , v ′ ∈ V p . Multiple properties may change between two states I and I ′ , and we use T to denote the set of atomic transformations between them. T ( I , I ′ ) = { ( p , v , v ′ ) | ( p , v ) ∈ I , ( p , v ′ ) ∈ I ′ } (1) In single-step analogy , the transformation set between the query and answer states is the same as that of the context pair , i.e., T ( I 1 , I ′ 1 ) = T ( I q , I a ) . Compositional Analogy W e extend single-step analogy to multiple state pairs ( I 1 : I ′ 1 ) , . . . , ( I n : I ′ n ) :: ( I q : I a ) . Rather than directly reapplying the same transformation, the target transformation set T ( I q , I a ) here is obtained by applying a set operation O over T ( I 1 , I ′ 1 ) , . . . , T ( I n , I ′ n ) . For example, in Figure 1 (right), each input state pair con- tains a single atomic transformation: T ( I 1 , I ′ 1 ) = { ( color , wood, red ) } and T ( I 2 , I ′ 2 ) = { ( number , one, two ) } . The target transformation is their union T ( I q , I a ) = T ( I 1 , I ′ 1 ) ∪ T ( I 2 , I ′ 2 ) = { ( color , wood, red ) , ( number , one, two ) } , which is later applied to the query image. 3.2 T ask Design In our setting, the property set is defined as P = { subject, subject number , object, object color , spatial relation } . The subject is an everyday item and the object is a piece of furniture. A typical state can be “two bottles on a red table” . Consistent with the previous definitions, we evaluate MLLMs under two settings. (1) Single- step Analogical Reasoning: This setting serves as a refer ence. The model identifies the transformation T ( I 1 , I ′ 1 ) from a single image pair and applies it to the query image I q . This serves as a baseline to measur e the model’s ability to map a transformation fr om a single source to a target. (2) Compositional Analogical Reasoning: Consider the case of n = 2 image pairs, i.e., ( I 1 : I ′ 1 )( I 2 : I ′ 2 ) : : ( I q : I a ) . The model needs to perceive a set of atomic transformations, synthesize a new tar get rule thr ough a logical operation, and apply it to 3 Preprint. Under review . a query image to pr oduce the final outcome. W e consider three logical operations, Union , Intersection , and Difference , O ∈ { ∪ , ∩ , \} . T o evaluate differ ent levels of generalization, we further design two task variants. • Shared Source Composition: The model is given two input state pairs in which the source images are the same as the query image, i.e., I q = I 1 = I 2 . This setting has relatively low contextual complexity . • Different Source Composition: The source images in the two state pairs and the query image ar e all different, i.e., I q = I 1 = I 2 . In this mor e general setting, the model must identify which properties change across dif ferent sour ce contexts and compose them to apply to a new context. This requires mor e advanced abilities to observe and decompose transformations without being distracted by varying visual contexts. T o constrain our task to reasoning, we ask the tested model only to generate a concrete caption of the target image instead of generating the image. 4 Dataset Construction In this section, we describe the image construction and data sampling process, and then provide the statistical information of the CAR V dataset. 4.1 Data Construction Algorithm 1: Data Sampling for CAR V Require: T ransformation Set T 1 , T 2 , Set Operation O , Sample Size N Initialize dataset D ← ∅ Synthesize transformation T = O ( T 1 , T 2 ) For: | D | < N Sample source image I 1 if Shared Sour ce then Construct 1st pair: I 1 1 ← Apply ( T 1 , I 1 ) Construct 2nd pair: I 2 1 ← Apply ( T 2 , I 1 ) // Query image and label I q ← I 1 , I a ← Apply ( T , I q ) D = D ∪ { ( I 1 , I 1 1 ) , ( I 1 , I 2 1 ) , ( I q , I a )) } else if Different Sour ce then Sample I 2 , I q , where I q = I 1 = I 2 I ′ 1 ← Apply ( T 1 , I 1 ) , I ′ 2 ← Apply ( T 2 , I 2 ) I a ← Apply ( T , I q ) D = D ∪ { ( I 1 , I ′ 1 ) , ( I 2 , I ′ 2 ) , ( I q , I a ) } return D T o ensure a fair comparison and avoid distribution shift, we first construct a image set in a controlled setting and then sample image pairs for differ ent tasks with this image set. W e first ap- ply Gemini-2.5 Flash Image Fortin et al. ( 2025 ) to edit images from Kamath et al. ( 2023 ). Each original image can be de- scribed by a subject (an everyday item), an object (a piece of furniture), and their spatial position. T o adapt these images to our task, we edit them to in- clude varying numbers of subjects and diverse colors of objects, and manually remove the images (2.4%) with quality issues like overlapping objects or clip- ping. Then, we sample image pairs for single- step and compositional tasks fr om the image set. W e use Algorithm 1 to sam- ple images for the compositional ana- logical reasoning task. Given the nine properties in P , which result in a wide range of transformations, balanced sampling is necessary to prevent certain transformations fr om dominating the dataset. Algorithm 1 addresses this by sampling a fixed number of examples for each operation and transformation type. W e follow the same pipeline to sample data for the single-step task (one image pair for each query). 4.2 Dataset Statistic Our dataset consists of 5,500 unique visual analogical reasoning tasks, designed to evaluate models across varying levels of compositional complexity and logical abstraction. The statistical information is summarized in T able 1 . T ask Distribution T o establish a refer ence for standard analogy , we include 500 single- step samples , which requir e mapping the transformations from one sour ce pair to a query . 4 Preprint. Under review . State pair 1 State pair 2 One bowl on a wood chair Two bowls on a red chair One bowl on a wood chair Two bowls under a wood chair Number: Color: 1 → 2 wood → red Number: Position: 1 → 2 on → under Number: 1 → 2 Intersection Final answer Query (1) Perception (2) Decomposition (3) Composition (4) Application Two bowls on a wood chair Input Images MLLM Reasoning Query One bowl on a wood chair Figure 2: Overview of Diagnosis Pipeline. Given two image pairs, the model is instructed to describe the transformations, decompose the transformations into atomic transformations, perform the set operation, and apply the resulting transformation on the query image. Then we apply an evaluator model to check the correctness of each step. As for compositional samples , we start with data in which each image pair contains two atomic transformations | T | = 2. (1) Shared Source: 1,500 samples where transformations originate from the same image I 1 . Each set operation ( Union , Intersection , and Difference ) has 500 samples. (2) Different Source: 1,500 samples where input pairs share distinct source image. Each set operation has 500 samples. (3) Complexity Scaling: T o test how models perform in complex setting, we pr ovide another 2,000 samples by extending the Shared Source setting, wher e we scale the number of atomic transformations within each image pair , | T | from 2 to 3 and 4. For | T | = 3, we provide 1,000 samples (500 Union , 500 Intersection ), and the same for | T | = 4. T ask #Input #Atomic Count Single 1 2 500 Compos. Shared 2 2,3,4 3,500 Diff. 2 2 1,500 T otal 5,500 T able 1: Distribution of the dataset. #Input: number of input image pairs. #Atomic: num- ber of atomic transformations in each pair . V isual Domain The images are grounded in a controlled visual environment de- fined by the property set P (Section 3.2 ) and the corresponding value sets V p for property p ∈ P . Specifically , V subject contains 9 everyday items, and V object = { table , chair } includes 2 furniture types. Four spatial relations are available: V spatial r elation = { on , under , left , right } . In addition, V subject number = { one , two } and V object color = { wood , red , blue } . 5 Experiment In this section, we demonstrate the experiment settings and the overall performance of current MLLMs on the pr oposed tasks. W e first test the overall performance across dif ferent models and then apply the diagnosis pipeline to analyze the bottleneck and failure modes. 5.1 Experiment Setting Models W e evaluate state-of-the-art MLLMs, including a diverse set of closed-source and open-source models. For closed-source models, we consider GPT -5.1, GPT -4o, Gemini- 2.5 Pro and Gemini-2.5 Flash. The temperature is set to 0.2 to minimize variance in the generation process. For open-source models, we consider QwenVL, InternVL, and Llama, across various versions and parameter scales. For these models, we refer to the official configurations pr ovided on the HuggingFace 2 site. The experiments for open-source models 2 https://huggingface.co/ 5 Preprint. Under review . Model Single Union Intersection Difference SS DS SS DS SS DS Closed-source models: Gemini-2.5 Flash 75.0 49.4 37.4 60.2 64.2 41.4 33.2 Gemini-2.5 Pro 79.2 51.6 40.4 62.8 67.2 59.4 55.6 GPT -5.1 81.2 64.6 51.0 75.0 73.0 59.0 62.4 GPT -4o 44.8 27.2 9.0 34.0 36.0 25.6 21.2 Open-source models: Qwen3VL-8B-Thinking 66.7 33.6 20.8 56.8 59.2 33.3 25.0 Qwen2.5VL-7B 2.4 9.0 2.2 10.0 8.6 3.0 4.2 Qwen3VL-8B 4.8 5.0 0.6 13.8 8.2 3.2 5.4 InternVL3-8B 1.8 0.6 0.2 5.6 4.2 3.0 3.6 InternVL3.5-8B 3.2 3.2 1.6 7.2 2.4 2.8 0.8 Llama-3.2-11B-V ision 1.0 0.6 0.2 0.8 1.4 0.8 0.8 InternVL3-14B 4.6 1.4 0.0 7.8 5.4 4.0 2.0 Qwen2.5VL-32B 39.0 18.6 6.2 30.4 32.8 25.4 15.0 Qwen3VL-30B-A3B 33.4 21.7 4.2 18.4 17.6 10.82 9.88 Human - 100.0 100.0 100.0 100.0 100.0 100.0 T able 2: Performance Comparison on Compositional Analogical Reasoning T asks. SS stands for same sour ce setting and DS stands for different sour ce setting. The reasoning models are highlighted with gr een. are conducted on NVIDIA A100. For the human test, we recruit three participants fr om differ ent backgrounds, the instr uction for the participants is the same as direct pr ompting. Prompting Methods W e design two prompting methods. (1) Direct Prompting : Models are provided image pairs and the query image together with simple but clear task instruction to predict the answer image I a . (2) Diagnosis Prompting (Figur e 2 ): W e divide the task into four subtasks to better analyze the reasoning process. Per ception, captioning the images and describe the transformation. Decomposition, decomposing the transformation into atomic transformations. Composition, synthesizing new transformations with logical operations. Application, applying the transformations on the query image and captioning the resulting image. Models ar e pr ompted to finish the task by sequentially solving the subtasks. W e apply Direct Pr ompting for evaluating performance for single-step and compositional tasks and Diagnosis Prompting for understanding the bottleneck. All prompts used in this work is included in Appendix A.1 . Evaluation The gr ound truth target images ar e sampled during the data sampling stage. Since models’ responses may vary in linguistic phrasing, we instruct GPT -4o to evaluate the correctness of generated caption comparing with the ground truth image. T o ensure reliable evaluation r esult, we illustrate to the evaluator model that the tested model can use differ ent wording but cannot conflict with the ground tr uth when describing each property and value. And we use accuracy as the evaluation metric, representing the ratio of tasks where the pr edicted image caption matches the gr ound truth. W e manually annotated 200 data as the ground tr uth and GPT -4o achieves 98% accuracy . 5.2 Overall Experiment Result W e evaluate the performance of diverse MLLMs acr oss single-step analogy and composi- tional tasks. The comprehensive results ar e summarized in T able 2 . Closed-source models generally outperform open-source models. GPT -5.1 shows superior performance across nearly all task categories, and Gemini-2.5 series achieves competitive results on the compositional tasks. The majority of open-source models underperform significantly in our task, except the QwenVL series, where Qwen3VL-8B-Thinking shows outstanding performance, which underscores the advantage of the reasoning model. Larger models generally lead to better performance. For example, Qwen2.5VL-32B consistently 6 Preprint. Under review . 0 20 40 60 80 100 Qwen3VL-30B Qwen2.5VL-32B GPT -4o GPT -5.1 Gemini-2.5 Flash Gemini-2.5 Pro 54.0% 73.3% 42.6% 47.3% 34.3% 50.0% 43.3% 24.0% 53.4% 49.3% 62.9% 46.4% P er ception F ailur e Decomposition F ailur e Composition F ailur e Application F ailur e (a) Error Distribution Acr oss Models 0 20 40 60 80 100 GPT -4o GPT -5.1 Gemini-2.5 Flash Gemini-2.5 Pro 43% 47% 34% 50% 41% 34% 24% 38% 45% 33% 22% 32% 53% 49% 63% 46% 58% 57% 72% 60% 55% 60% 76% 68% 8% 7% N=2 N=3 N=4 (b) Error by Atomic T ransformations ( N ) Figure 3: Detailed analysis of failure distributions. (a) Across dif ferent models, the major bottleneck for closed-source models is decomposition, while for open-source models, it is perception. (b) As we scale the number of atomic transformations ( N ) in image pairs, the portion of decomposition failure significantly incr eases. doubles or triples the performance of its 7B counterpart. However , architectural efficiency varies; Llama-3.2-11B-V ision does not exhibit a significant advantage over smaller models from other families, indicating that the underlying vision-language backbone is also crit- ical for the reasoning tasks. Reasoning models outperform the non-reasoning versions. Comparing GPT -5.1 with GPT -4o and Gemini-2.5 Pro with Flash, models involving deeper thinking process get better performance. Surprisingly , Qwen3VL-8B-Thinking not only beats models in similar parameter scale but also beats lar ger models like Qwen3VL-30B. However , InternVL3.5-8B provides only limited improvements over its non-thinking predecessors, failing to match the performance of the Qwen thinking variants. 5.3 Analysis by Subtask and Data color number color object color position color subject number object number position number subject object position object subject position subject 0 0.25 0.5 0.75 1.0 Gemini-2.5 P r o Gemini-2.5 Flash GPT -5.1 Qwen2.5VL -32B GPT -4o Qwen3VL -30B Figure 4: Failure Contribution by Property Combinations. For most models, combina- tions among subject, number , and position contribute most to the failure. In this section, we study the err or distribu- tion among subtasks and how the image contexts affect models’ performance. Ac- cording to our diagnosis pipeline (Figur e 2 ), we instruct GPT -5.1 with the gr ound truth for each intermediate step, we identify the step where the tested model first fails. T o verify the reliability of the evaluator model, we perform human annotation on a sub- set of 120 samples. Comparing the human labels with the evaluation results, our eval- uator achieves an accuracy of 0.82 and a Cohen’s Kappa ( Cohen , 1960 ) of 0.63, indi- cating high agreement. Q1: Which part of the task do the MLLMs fail at first? Results in Figure 3a sug- gest that the major bottlenecks are percep- tion and decomposition . For closed-source models, they mostly fail at the decomposi- tion stage, suggesting that while these models can percept the changes, they struggle to abstract the changes into symbolic rules. However , for open-sour ce models, the challenge shifts into perception. Failures in composition and application remain relatively low , indi- cating that once the symbolic rules are corr ectly extracted, models are capable of performing the requir ed set operations and apply it on the query image. W e include failure examples in Appendix A.2 . Q2: Which property combination is most likely to lead to failure? Shifting focus from the task to image data, we investigate how specific property combinations in the transformations 7 Preprint. Under review . Gemini-2.5 Pro Gemini-2.5 Flash GPT -5.1 GPT -4o 0 20 40 60 80 100 82.2 79.4 64.6 43.2 78.6 67.8 57.4 26.8 71.8 62.3 55.8 14.0 Union Gemini-2.5 Pro Gemini-2.5 Flash GPT -5.1 GPT -4o 87.6 84.6 84.4 74.1 81.0 72.2 79.0 47.8 72.8 61.1 78.6 37.2 Intersection N=2 N=3 N=4 Figure 6: Accuracy by Number of Atomic T ransformations. The performance drops as the number of atomic transformations ( N ) incr eases. influence task difficulty . T o achieve this goal, we employ a logistic r egression model. For each task, the involved property combinations are encoded into a 10-dimensional one- hot vector (10 property combination in total). W e then use the model’s correctness as the binary label. By training the logistic regression model, we get weights that repr esent the contribution of each property combination toward the likelihood of failure. Figure 4 shows that the combinations between position, subject, and number , contribute most significantly to most models’ failure . For instance, the combination of position and subject shows high positive weights acr oss models, indicating it is a primary contributor to task failure. Furthermor e, we specifically analyze the failure mode of Gemini-2.5 Flash on subject- position and number-position. Figure 5 shows that the model suffers at decomposition for subject-position but for number-position, it also fails at counting the subjects in the images. P erception Decomposition Composition Application 0 10 20 30 40 50 60 70 80 19.6 42.3 74.5 50.0 3.9 5.8 2.0 1.9 Subject + P osition Number + P osition Figure 5: Error Distribution by Property Com- bination of Gemini-2.5 Flash. W e study the most challenging combinations, the failure mainly concentrates in decomposition. Q3: Are MLLMs able to generalize in dif- ferent source contexts? Our results indi- cate MLLMs generally struggle with the generalization ability , and get worse when switch from Shared Source to Different Source setting. As shown in T able 2 , nearly all models experience a performance drop when transitioning fr om Shared Source to Differ ent Sour ce setting. W e attribute this gap to the varying levels of abstraction r e- quired by the two settings. In the Shared Source setting, the query image I q is iden- tical to the source image I 1 , which allows models to potentially leverage shallow vi- sual features. In contrast, the Dif ferent Source setting requir es the model to per- form a higher-or der abstraction: it must de- couple the transformation T from the source pairs and map it to a differ ent query image. 5.4 Analysis by Numerical Complexity In this section, we study the numerical complexity in both input transformations and output transformations after the set operation. Q4: Are MLLMs robust to scaling input transformations? If not, why? W e expand the number of atomic transformations in the input pairs | T ( I , I ′ ) | from 2 to 3 and 4 within the Shared Source setting. As shown in Figure 6 , all evaluated models exhibit a consistent and significant performance decline as the number of atomic transformations increases. Theoretically , incr easing complexity impacts both visual per ception and logical composi- tion; however , our failure analysis reveals a counter-intuitive bottleneck. As illustrated in Figure 3b , the proportion of perception failur e actually decreases or remains stable as | T | increases. However , we can observe an upward trend in decomposition failure. This suggests that the fundamental challenge in scaling compositional reasoning is not 8 Preprint. Under review . the visual processing, but the model’s inability to disentangle and r epr esent the increased transformations as discrete symbolic r ules. Q5: Set operations leads to variance performances, is it caused by cardinality of output transformation set? In the previous experiment, we find that models performance varies with different set operations. But how the performance gap comes from, the underlying logic or the output cardinality (Union operation always increase the transformation set while the other two decrease it)? T o isolate the effect of cardinality , we design a comparison experiment involving two Union settings with identical input complexity ( | T | = 2 for each source pair) but dif ferent output cardinalities ( | T | = 3 vs. | T | = 4). As shown in T able 3 , merely incr easing the cardinality does not consistently decr ease performance. Our finding suggests that output cardinality is not the primary bottleneck; rather , task difficulty is driven by the reasoning process and the logical operations. 5.5 Ablation Study for Diagnosis Prompting Model | T | = 3 | T | = 4 GPT -4o 37.0% 46.0% GPT -5.1 85.0% 88.0% Gemini-2.5 Flash 85.0% 74.0% Gemini-2.5 Pro 82.0% 91.0% T able 3: Experiment on output cardinality . By increasing the output cardinality , there is no clear trend about models’ performance. From Section 5.3 , by applying the diagno- sis prompting, we find the main bottleneck of compositional task lies in the decompo- sition stage. However , we want to further ask the question that “is the model cannot decompose the rule” or “the model can decom- pose but cannot format it”? W e conduct an ablation study to decouple visual inference failures fr om formatting failures by evaluat- ing a subset of 100 samples from the Union task across four models under three settings. W ith Format: Models must follow the symbolic format in Diagnosis Pr ompting. W ithout Format: W e remove all symbolic formatting constraints and allow the models to describe the visual transformations in free-form natural language. Oracle Decomposition: W e pr ovide the ground-tr uth atomic transformations in the prompt and the model is only required to perform the composition and application steps. As detailed in T able 4 , our ablation study r eveals two key insights. (1) When the atomic transformations are pr ovided, models perform nearly perfect, indicating that they ar e able to compose and apply rules. The primary failur e mode is the inability to infer these rules from raw images. (2) While removing formatting constraints yields a slight to moderate per - formance boost across most evaluated models, the absolute accuracy r emains significantly lower than that achieved in the Oracle setting. Model W ith Format W ithout Format Oracle GPT -4o 42.0% 51.0% 86.0% GPT -5.1 60.0% 78.0% 94.0% Gemini-2.5 Flash 77.0% 90.0% 99.0% Gemini-2.5 Pro 86.0% 86.0% 97.0% T able 4: T ask performance in ablation study . The r esults strengthen our initial claim that models suf fer in decomposition step and the task format only slightly affect the models’ performance. 6 Conclusion In this paper , we introduce Compositional Analogical Reasoning in V ision (CAR V), a novel task designed to evaluate the higher-order r easoning capabilities of MLLMs, together with a 5,500-sample dataset. Our experiments show that current models mainly underperform on this task and the major bottleneck is decomposition from visual transformations into symbolic rules. Meanwhile, tested MLLMs struggle when changing the sour ce image or increasing the number of atomic transformations in the context image pairs, indicating 9 Preprint. Under review . insufficient generalization and robustness. Our findings suggest that achieving human-level analogical reasoning requires MLLMs to move beyond pattern recognition and toward higher-or der abstraction. W e hope the CAR V dataset serves as a valuable resour ce for developing future multimodal systems. Reproducibility Statement W e ar e committed to ensuring the full r eproducibility of our resear ch. T o this end, all prompt templates and instruction for human participants utilized in our experiments are in the Appendix. Detailed information r egarding the experimental setup, including the image data, exact model versions, and Python environment configurations, is provided in the Supplementary Material. Furthermore, we will fully open-source the CAR V dataset, along with the complete codebase and standardized evaluation scripts, upon the publication of the camera-ready version. References Hyunsik Chae, Seungwoo Y oon, Jaden Park, Chloe Y ewon Chun, Y ongin Cho, Mu Cai, Y ong Jae Lee, and Ernest K R yu. Decomposing complex visual compr ehension into atomic visual skills for vision language models. arXiv preprint , 2025. Zhe Chen, Jiannan W u, W enhai W ang, W eijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pp. 24185–24198, 2024. Jacob Cohen. A coefficient of agreement for nominal scales. Educational and psychological measurement , 20(1):37–46, 1960. Gheorghe Comanici, Eric Bieber , Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality , long context, and next generation agentic capabilities. arXiv preprint , 2025. Y ongkang Du, Jen-tse Huang, Jieyu Zhao, and Lu Lin. Faircoder: Evaluating social bias of llms in code generation. arXiv preprint , 2025. Karim Farid, Rajat Sahay , Y umna Ali Alnaggar , Simon Schrodi, V olker Fischer , Cordelia Schmid, and Thomas Brox. What Drives Compositional Generalization in V isual Genera- tive Models?, October 2025. URL . [cs]. Gilles Fauconnier . Conceptual blending and analogy . The analogical mind: Perspectives from cognitive science , 255:286, 2001. Gilles Fauconnier and Mark T urner . Conceptual blending, form and meaning. Recherches en communication , 19:57–86, 2003. Gilles Fauconnier and Mark T urner . The way we think: Conceptual blending and the mind’ s hidden complexities . Basic books, 2008. Alisa Fortin, Guillaume V ernade, Kat Kampf, and Ammaar Reshi. Introducing gem- ini 2.5 flash image, our state-of-the-art image model, 2025. URL https://developers. googleblog.com/introducing- gemini- 2- 5- flash- image/ . Accessed: 2025-12-21. Louis Fournier , Emmanuel Dupoux, and Ewan Dunbar . Analogies minus analogy test: measuring regularities in wor d embeddings. In Raquel Fern ´ andez and T al Linzen (eds.), Proceedings of the 24th Conference on Computational Natural Language Learning , pp. 365–375, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/ 2020.conll- 1.29. URL https://aclanthology.org/2020.conll- 1.29/ . 10 Preprint. Under review . Isaac R Galatzer-Levy , David Munday , Jed McGiffin, Xin Liu, Danny Karmon, Ilia Labzovsky , Rivka Moroshko, Amir Zait, and Daniel McDuff. The cognitive capabilities of generative ai: A comparative analysis with human benchmarks. arXiv preprint , 2024. Xinyi Gu, Jiayuan Mao, Zhang-W ei Hong, Zhuoran Y u, Pengyuan Li, Dhiraj Joshi, Rogerio Feris, and Zexue He. Composition-Grounded Instruction Synthesis for V isual Reasoning, October 2025. URL . arXiv:2510.15040 [cs]. Diandian Guo, Cong Cao, Fangfang Y uan, Dakui W ang, W ei Ma, Y anbing Liu, and Jianhui Fu. Can Multimodal Large Language Model Think Analogically?, November 2024. URL http://arxiv.org/abs/2411.01307 . arXiv:2411.01307 [cs] version: 1. Drew A. Hudson and Christopher D. Manning. GQA: A New Dataset for Real-W orld V isual Reasoning and Compositional Question Answering. In 2019 IEEE/CVF Conference on Computer V ision and Pattern Recognition (CVPR) , pp. 6693–6702, Long Beach, CA, USA, June 2019. IEEE. ISBN 978-1-7281-3293-8. doi: 10.1109/CVPR.2019.00686. URL https://ieeexplore.ieee.org/document/8953451/ . Cheng Jiayang, Lin Qiu, T sz Chan, T ianqing Fang, W eiqi W ang, Chunkit Chan, Dongyu Ru, Qipeng Guo, Hongming Zhang, Y angqiu Song, Y ue Zhang, and Zheng Zhang. StoryAnal- ogy: Deriving Story-level Analogies from Large Language Models to Unlock Analogical Understanding. In Houda Bouamor , Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pp. 11518–11537, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/ 2023.emnlp- main.706. URL https://aclanthology.org/2023.emnlp- main.706/ . Justin Johnson, Bharath Hariharan, Laurens V an Der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. CLEVR: A Diagnostic Dataset for Compositional Language and Elementary V isual Reasoning. In 2017 IEEE Conference on Computer V ision and Pattern Recognition (CVPR) , pp. 1988–1997, Honolulu, HI, July 2017. IEEE. ISBN 978-1-5386-0457-1. doi: 10.1109/CVPR.2017.215. URL https://ieeexplore.ieee.org/document/8099698/ . Amita Kamath, Jack Hessel, and Kai-W ei Chang. What’s “up” with vision-language models? Investigating their struggle with spatial reasoning. In Houda Bouamor , Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pp. 9161–9175, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp- main.568. URL https://aclanthology.org/ 2023.emnlp- main.568/ . Junlin Lee, Y equan W ang, Jing Li, and Min Zhang. Multimodal Reasoning with Multimodal Knowledge Graph. In Lun-W ei Ku, Andre Martins, and V ivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) , pp. 10767–10782, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.acl- long.579. URL https://aclanthology.org/2024. acl- long.579/ . Nan Liu, Shuang Li, Y ilun Du, Joshua B. T enenbaum, and Antonio T orralba. Learning to Compose V isual Relations, November 2021. URL . arXiv:2111.09297 [cs]. Nan Liu, Shuang Li, Y ilun Du, Antonio T orralba, and Joshua B. T enenbaum. Compositional V isual Generation with Composable Diffusion Models. In Shai A vidan, Gabriel Brostow , Moustapha Ciss ´ e, Giovanni Maria Farinella, and T al Hassner (eds.), Computer V ision – ECCV 2022 , volume 13677, pp. 423–439. Springer Nature Switzerland, Cham, 2022. ISBN 978-3-031-19789-5 978-3-031-19790-1. doi: 10.1007/978- 3- 031- 19790- 1 26. URL https://link.springer.com/10.1007/978- 3- 031- 19790- 1 26 . Series T itle: Lecture Notes in Computer Science. Ziyi Liu, Soumya Sanyal, Isabelle Lee, Y ongkang Du, Rahul Gupta, Y ang Liu, and Jieyu Zhao. Self-contradictory r easoning evaluation and detection. In Y aser Al-Onaizan, Mohit Bansal, and Y un-Nung Chen (eds.), Findings of the Association for Computational Linguistics: 11 Preprint. Under review . EMNLP 2024 , pp. 3725–3742, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings- emnlp.213. URL https: //aclanthology.org/2024.findings- emnlp.213/ . Shilin Lu, Y anzhu Liu, and Adams W ai-Kin Kong. Tf-icon: Diffusion-based training-free cross-domain image composition. In Proceedings of the IEEE/CVF International Confer ence on Computer V ision , pp. 2294–2305, 2023. Melanie Mitchell. Abstraction and analogy-making in artificial intelligence. Annals of the New Y ork Academy of Sciences , 1505(1):79–101, 2021. Liangming Pan, Alon Albalak, Xinyi W ang, and W illiam W ang. Logic-lm: Empowering large language models with symbolic solvers for faithful logical r easoning. In Findings of the Association for Computational Linguistics: EMNLP 2023 , pp. 3806–3824, 2023. T anawan Premsri and Parisa Kor djamshidi. Neuro-symbolic T raining for Reasoning over Spatial Language. In Luis Chiruzzo, Alan Ritter , and Lu W ang (eds.), Findings of the Association for Computational Linguistics: NAACL 2025 , pp. 2395–2414, Albuquerque, New Mexico, April 2025. Association for Computational Linguistics. ISBN 979-8-89176-195- 7. doi: 10.18653/v1/2025.findings- naacl.128. URL https://aclanthology.org/2025. findings- naacl.128/ . Chengwei Qin, W enhan Xia, T an W ang, Fangkai Jiao, Y uchen Hu, Bosheng Ding, Ruirui Chen, and Shafiq Joty . Relevant or Random: Can LLMs T ruly Perform Analogical Reasoning? In W anxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad T aher Pilehvar (eds.), Findings of the Association for Computational Linguistics: ACL 2025 , pp. 23993–24010, V ienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-256-5. URL https://aclanthology.org/2025.findings- acl.1230/ . Y uqi Ren, Renren Jin, T ongxuan Zhang, and Deyi Xiong. Do large language models mirr or cognitive language processing? In Proceedings of the 31st International Conference on Computational Linguistics , pp. 2988–3001, 2025. Natalie Schluter . The word analogy testing caveat. In Marilyn W alker , Heng Ji, and Amanda Stent (eds.), Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies, V olume 2 (Short Papers) , pp. 242–246, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. doi: 10.18653/v1/N18- 2039. URL https://aclanthology.org/N18- 2039/ . Robert J Sternberg and Bathsheva Rifkin. The development of analogical reasoning processes. Journal of experimental child psychology , 27(2):195–232, 1979. Oren Sultan and Dafna Shahaf. Life is a Circus and W e are the Clowns: Automatically Find- ing Analogies between Situations and Pr ocesses. In Y oav Goldberg, Zornitsa Kozareva, and Y ue Zhang (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pp. 3547–3562, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp- main.232. URL https://aclanthology.org/2022.emnlp- main.232/ . Qwen T eam. Qwen3 technical report, 2025. URL . Asahi Ushio, Luis Espinosa Anke, Steven Schockaert, and Jose Camacho-Collados. BERT is to NLP what AlexNet is to CV: Can pr e-trained language models identify analogies? In Chengqing Zong, Fei Xia, W enjie Li, and Roberto Navigli (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Pr ocessing (V olume 1: Long Papers) , pp. 3609–3624, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl- long. 280. URL https://aclanthology.org/2021.acl- long.280/ . Y anbo W ang, Justin Dauwels, and Y ilun Du. Compositional scene understanding through inverse generative modeling. arXiv preprint , 2025. 12 Preprint. Under review . Michihiro Y asunaga, Xinyun Chen, Y ujia Li, Panupong Pasupat, Jure Leskovec, Percy Liang, Ed H Chi, and Denny Zhou. LARGE LANGUAGE MODELS AS ANALOGICAL REASONERS. 2024. Kexin Y i, Jiajun W u, Chuang Gan, Antonio T orralba, Pushmeet Kohli, and Josh T enenbaum. Neural-symbolic vqa: Disentangling reasoning fr om vision and language understanding. Advances in neural information processing systems , 31, 2018. Nilay Y ilmaz, Maitreya Patel, Y iran Lawrence Luo, T ejas Gokhale, Chitta Baral, Suren Jayasuriya, and Y ezhou Y ang. VOILA: Evaluation of MLLMs For Per ceptual Understand- ing and Analogical Reasoning, March 2025. URL . arXiv:2503.00043 [cs]. Eunice Y iu, Maan Qraitem, Anisa Noor Majhi, Charlie W ong, Y utong Bai, Shiry Ginosar , Ali- son Gopnik, and Kate Saenko. KiV A: Kid-inspired V isual Analogies for T esting Large Mul- timodal Models, March 2025. URL . [cs]. Siyu Y uan, Cheng Jiayang, Lin Qiu, and Deqing Y ang. Boosting Scientific Concepts Un- derstanding: Can Analogy from T eacher Models Empower Student Models? In Y aser Al-Onaizan, Mohit Bansal, and Y un-Nung Chen (eds.), Proceedings of the 2024 Confer ence on Empirical Methods in Natural Language Processing , pp. 6026–6036, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024. emnlp- main.346. URL https://aclanthology.org/2024.emnlp- main.346/ . Chi Zhang, Feng Gao, Baoxiong Jia, Y ixin Zhu, and Song-Chun Zhu. Raven: A dataset for relational and analogical visual reasoning. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 5317–5327, 2019. Ningyu Zhang, Lei Li, Xiang Chen, Xiaozhuan Liang, Shumin Deng, and Huajun Chen. Multimodal Analogical Reasoning over Knowledge Graphs, March 2023. URL http: //arxiv.org/abs/2210.00312 . arXiv:2210.00312 [cs]. Sijie Zhu, Zhe Lin, Scott Cohen, Jason Kuen, Zhifei Zhang, and Chen Chen. T opnet: T ransformer-based object placement network for image compositing. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition , pp. 1838–1847, 2023. A Appendix A.1 Prompt T emplate In this section, we show the prompt template we use in our experiment. The templates for Direct Prompting and evaluation ar e listed in the following tables, T able 6 shows the template for Guided Prompting, and T able 7 shows the prompt used for identifying the bottleneck of the task. Direct Prompt Y ou are an expert visual r easoning AI. Y our task is to perform a visual reasoning task. Y ou are given two image pairs and a query image. Each image pair consists of two images, showing a set of transformations from the first image to the second. Extract the transformation from the first image pair as T1 and the second image pair as T2, perform the set operation operation on the T1 and T2 to obtain the final transformation. description Then apply the final transformation to the query image to predict the r esulting image. The final output should be a concise caption of the resulting image in JSON format. REQUIRED OUTPUT FORMA T { ”caption”: your concise caption of the resulting image } 13 Preprint. Under review . Evaluation Prompt Y ou are an evaluator for the image captioning task. Given the ground truth image and refer ence caption, please analyze the correctness of the model’s final answer . If ”under” is mentioned in the refer ence caption, it indicates that one object is positioned di- rectly below another object in the image. Please pay special attention to this spatial relationship when evaluating the model’s response. Here is the r eference caption: *** { ground truth caption } *** Here is the model’s r esponse: *** { model response } *** Return your analysis in the following format: { ”correctness”: true or false, ”reason”: ”brief explanation of why the answer is correct or incorr ect” } A.2 Failure Cases In the diagnosis stage, we examine four parts: perception, decomposition, composition, and application. For perception failure, the model mainly fails to identify the color , number , or the position in the image. For application failure, the model mainly fails to apply the corr ect target transformation on the query image. Here, we give case studies on decomposition failure and composition failur e, the two parts which are unique in our task. Decomposition Model’ s Response **Caption of (I1)**: A wooden table with two rolls of toilet paper on the floor to the right. **Caption of (I2)**: A wooden chair with two spatulas on the floor to the right. **T ransformation of (I1, I2)**: The table is replaced by a chair , and the toilet paper is replaced by spatulas. Both items remain on the floor to the right of the furniture. **Caption of (I3)**: A wooden table with two rolls of toilet paper on the floor to the right. **Caption of (I4)**: A wooden chair with two rolls of toilet paper on the chair ’s seat. **T ransformation of (I3, I4)**: The table is replaced by a chair , and the toilet paper moves from the floor to the seat of the chair . **T ransformation T1**: Furniture changes from table to chair; items change from toilet paper to spatulas on the floor to the right. **T ransformation T2**: Furniture changes from table to chair; toilet paper moves from the floor to the top of the chair . ... Reason In T ransformation T1, the model correctly extract the atomic transformation by using the format [pr operty] changes fr om A to B , where the property is the item. However , for T2, the model fails to extract the abstract rule but uses the specific term to describe the position transformation, which is going to cause the reasoning failure. The correct T2 should be item’ s position change from on the floor to on the chair . 14 Preprint. Under review . T ask I-S I-D U-S U-D Accuracy 37% 38% 20% 8% T able 5: Performance of GPT -4o with neuro-symbolic prompting Composition Failure Model’ s Response ... 2. **Decompose the T ransformation of Each Image Pair** *T ransformation T1**: [Color] changes from wooden to r ed. [Quantity] changes from two knives to one knife. *T ransformation T2**: [T ype] changes from chair to table. [Color] changes fr om wooden to red. [Quantity] remains the same (two knives). 3. **Derive a Final T arget T ransformation Rule** *T ar get T ransformation**: [T ype] changes from chair to table. [Color] changes from wooden to red. [Quantity] should be at most two knives, as a change from two to one is also possible. ... Reason Here, T1 contains quantity transformation (from two to one) while T2 doesn’t contain quantity transformation. As we doing UNION operation, the model should include the quantity change in the target transformation instead of being uncertain. A.3 Symbolic Reasoning W e try to ask GPT -4o to solve the compositional analogical reasoning in neuro-symbolic way . Here, we r efer the prompts in Pan et al. ( 2023 ). As shown in T able 5 , neuro-symbolic prompting is not as ef fective as expected. 15 Preprint. Under review . Diagnosis Prompt Y ou are an expert visual r easoning AI. Y our task is to perform a visual reasoning task. Each image pair consists of two images, showing a set of transformations from the first image to the second. Notes for describing the relation: Spatial relation must be one of the following: ”on”, ”under”, ”left”, ”right”. Notice, ”under” means the subject is directly below the refer ence object, not diagonally . If there is diagonally relation, use ”left” or ”right”. The refer ence object is a piece of furniture like table or chair . T ask Instruction: 1. Generate caption for images in image pairs (I1, I2) and (I3, I4) and describe the transforma- tions in natural language. Use the format: **Caption of (I1)**: [Concise caption of image I1] **Caption of (I2)**: [Concise caption of image I2] **T ransformation of (I1, I2)**: [Describe the differ ences of the two images, be specific and detailed] **Caption of (I3)**: [Concise caption of image I3] **Caption of (I4)**: [Concise caption of image I4] **T ransformation of (I3, I4)**: [Describe the differ ences of the two images, be specific and detailed] 2. Decompose the transformation of each image pair according to the property(s). Describe what changes, and fr om which to which. i.e. [texture] changes from [metal] to [glass]. Use the format: **T ransformation T1**: [Y our description of the transformation] **T ransformation T2**: [Y our description of the transformation] 3. Derive a final target transformation rule based on the set operation operation on T1 and T2. description When T1 or T2 contains items which indicate no change For example, T1 includes ”[property] r emains the same”, and T2 includes ”[property] changes from A to B”. When the operation is UNION, only consider the transformation that indicates a change for that property in the tar get transformation. When the operation is INTERSECTION, consider that there is no change for that pr operty in the target transformation. Describe what changes, and from which to which. i.e. [texture] changes from [metal] to [glass]. Use the format: **T arget T ransformation**: [Y our description of the final transformation] 4. Apply this final transformation rule to the query image I5 to predict the r esulting image. The final output should be a concise caption of the resulting image in JSON format. **REQUIRED OUTPUT FORMA T** { ”caption”: your concise caption of the resulting image } T able 6: T emplate for Guided Prompting 16 Preprint. Under review . Evaluation Prompt Y ou are an evaluator for a visual r easoning task. Y ou will receive the r esponse from a model. Y our task is to evaluate the response accor ding to the instruction below . Here is the model’s r esponse: { response } The evaluation tasks include: 1. Perception : Check whether the model correctly per ceives the visual changes in two image pairs (I1, I2) and (I3, I4). Instruction: (1) whether the response is corr ect according to the r eference captions. The r eference caption provides multiple details (color , number , position), the model’s response should r eflect these details accurately . Notice, if position in the reference caption is ”right/left” but the r esponse only says ”under”, consider it incorrect. For subject like scissors, ”one scissors” is the same as ”one pair of scissors” and ”two scissors” is the same as ”two pairs of scissors”. Reference captions: Image1: { caption1 } Image2: { caption2 } Image3: { caption3 } Image4: { caption4 } If the captions are corr ect, then according to the caption, check (2) whether the model’s transformation descriptions ar e correct; Consider the model correctly perceives the visual changes if the model correctly captions the images and describes the transformations for BOTH image pairs. 2. Decomposition : Check whether the model correctly decomposes the transformation of each image pair according to the pr operty(s). Instruction: (1) When describing one transformation, the model must follow [property] changes from [value A] to [value B]. The property must be a general concept, like ”position”, ”object”, ”subject”, ”color”, ”number”, ”furniture” or the combination of general concepts, i,.e., ”object position”, ”object color” etc. W rong examples could be: [position of the cup] changes from [on] to [under]; [object on table] changes from [cup] to [bowl]. Correct examples could be: [object position] changes from [on] to [under]; [object color] changes fr om [red] to [blue]. (2) Each transformation ([property] changes from [value A] to [value B]) must be atomic, de- scribing only one single, indivisible property change. **Car efully check if the model bundles multiple properties into one transformation.** W rong examples could be: [position] changes from [on chair] to [under table] (bundle position and object); [object] changes from [blue chair] to [red table] (bundle object and color). Notice, the model can describe transformations in one sentence or multiple sentences, as long as each transformation is atomic. If the r esponse violates any of the above two rules, consider it incorrect. If each transformation satisfies the above two rules, check (3) Compare T1 and T2 with the r eference transformations. The transformations in the r efer- ence must be included in the model’s response. Reference transformations: T ransformation T1: { ground truth T1 } T ransformation T2: { ground truth T2 } If any transformation in the refer ence is missing or inconsistent in the response, consider it incorr ect. 3. Composition : Check whether the model correctly derives the tar get transformation rule based on the set operation on T1 and T2. Reference target transformation: T ransformation T : { target transformation } 4. Application : Check whether the model correctly applies this final transformation r ule to the query image I5 to predict the r esulting image. Query image: { caption5 } **REQUIRED OUTPUT FORMA T** { ”failure stage”: 1,2,3, or 4 (indicating which evaluation task the model first failed at; if all tasks are corr ect, return 0), ”reasoning summary”: A brief explanation of your evaluation. } **Evaluate the response step-by-step and you MUST state all intermediate r easoning before giving the final answer .** T able 7: T emplate for Diagnosis Prompting 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment