제한된 공급 상황에서의 오프‑정책 학습: 효율적 아이템 할당 방법
본 논문은 재고·쿠폰 등 제한된 공급을 가진 아이템을 대상으로 하는 컨텍스트 밴드잇에서의 오프‑정책 학습(OPL) 문제를 정의하고, 기존의 그리디 OPL이 최적이 아님을 이론적으로 증명한다. 이를 극복하기 위해 상대적 기대보상 차이를 활용하는 OPLS 알고리즘을 제안하고, 합성·실데이터 실험을 통해 기존 방법보다 우수함을 입증한다.
저자: Koichi Tanaka, Ren Kishimoto, Bushun Kawagishi
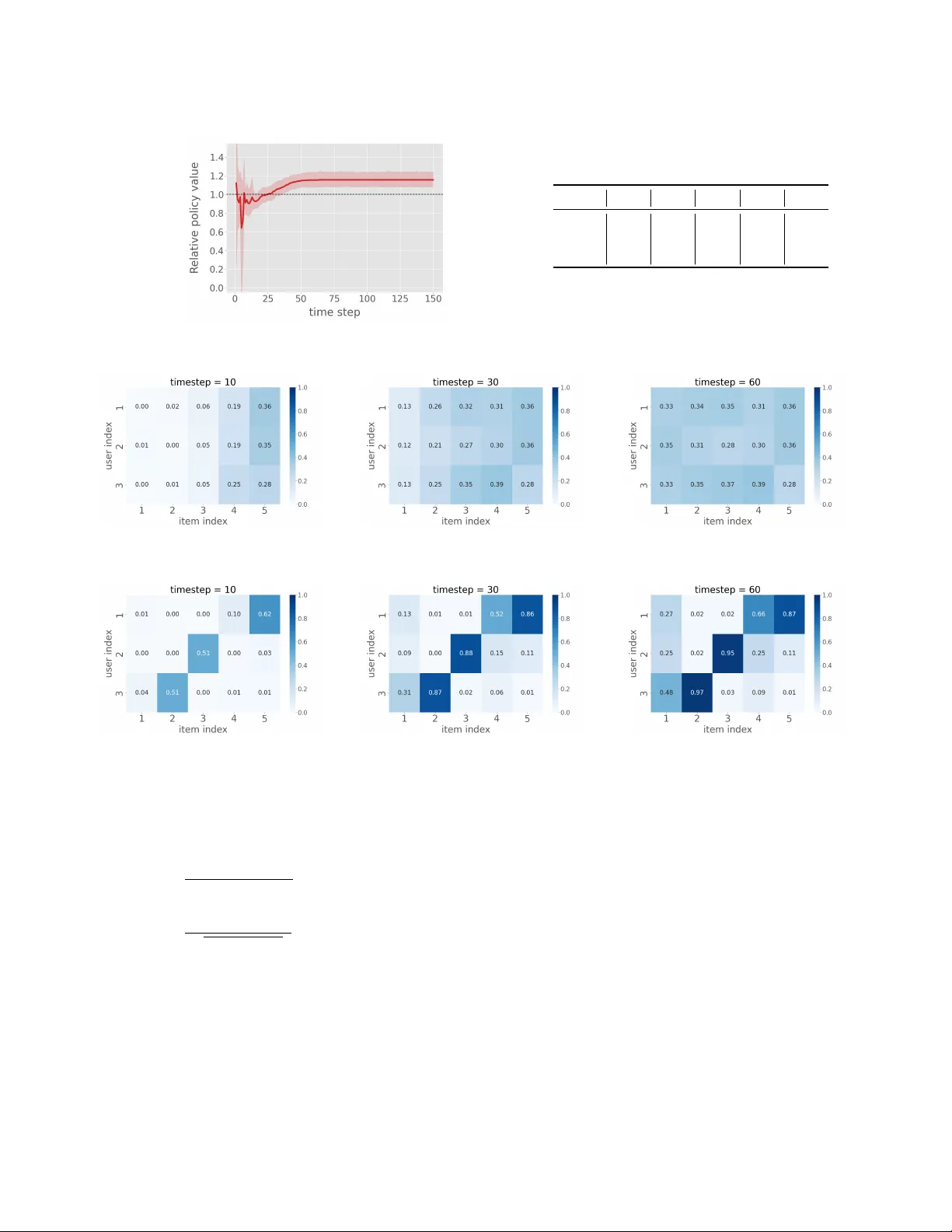
본 논문은 제한된 공급(재고·쿠폰 등) 상황에서 컨텍스트 밴드잇 기반 오프‑정책 학습(OPL)의 새로운 문제 정의와 해결책을 제시한다. 서론에서는 추천 시스템·온라인 광고·검색 등에서 OPL이 로그 데이터만으로 정책을 개선하는 핵심 기술임을 강조하고, 실제 서비스에서는 아이템이 무한히 제공되지 않는 경우가 빈번함을 지적한다. 특히 쿠폰 할당 예시를 들어, 그리디 OPL이 각 사용자에게 현재 기대보상이 가장 높은 아이템을 할당하면, 재고가 빨리 소진돼 향후 더 높은 기대보상을 가진 사용자에게 제공되지 못하는 비효율성을 보인다. 표 1의 쿠폰 할당 사례는 도착 순서에 따라 그리디 정책의 총 기대보상이 420에 불과한 반면, 최적 정책은 540을 달성함을 보여준다.
2절에서는 기존 OPL의 표준 설정을 정리한다. 컨텍스트 x∈ℝ^d, 행동 a∈A, 보상 r∈ℝ_+ 로 정의하고, 로그 데이터 D={(x_i,a_i,r_i)}를 로깅 정책 π_0 하에 수집한다. 정책 가치 V(π)=E_{x∼p(x),a∼π(·|x)}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기