Off-Policy Learning with Limited Supply
We study off-policy learning (OPL) in contextual bandits, which plays a key role in a wide range of real-world applications such as recommendation systems and online advertising. Typical OPL in contextual bandits assumes an unconstrained environment …
Authors: Koichi Tanaka, Ren Kishimoto, Bushun Kawagishi
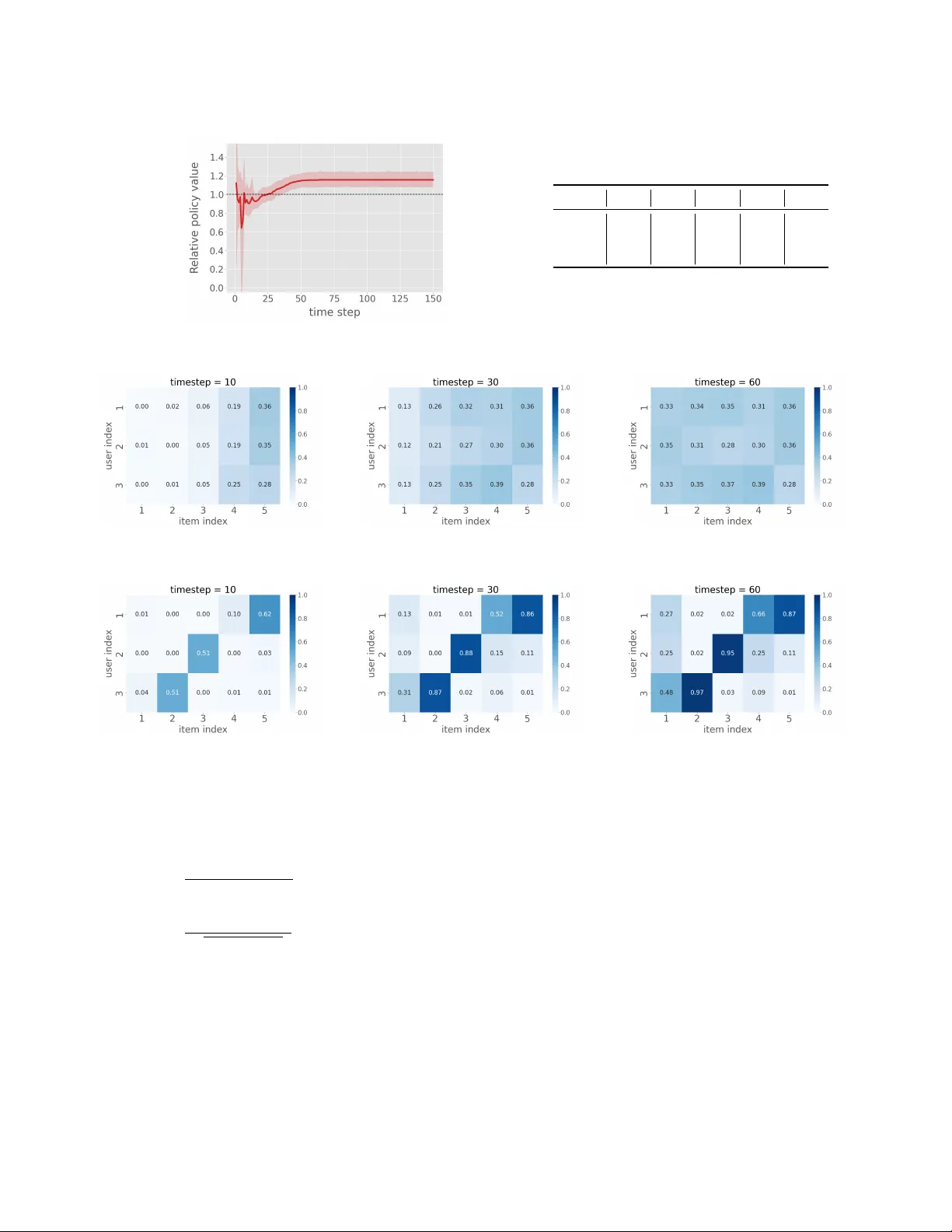
O-Policy Learning with Limited Supply Koichi T anaka ∗ Keio Univ ersity T okyo, Japan kouichi_1207@keio.jp Ren Kishimoto ∗ Institute of Science T okyo T okyo, Japan kishimoto.r .ab@m.titech.ac.jp Bushun Kawagishi Meiji University T okyo, Japan ee227051@meiji.ac.jp Y usuke Narita Y ale University New Haven, CT, USA yusuke.narita@yale.edu Y asuo Y amamoto L Y Corporation T okyo, Japan yasyamam@lycorp.co .jp Nobuyuki Shimizu L Y Corporation T okyo, Japan nobushim@lycorp.co .jp Y uta Saito Hanuku-kaso, Co., Ltd. T okyo, Japan saito@hanjuku- kaso.com Abstract W e study o-policy learning (OPL) in contextual bandits, which plays a key role in a wide range of real-world applications such as recommendation systems and online advertising. T ypical OPL in contextual bandits assumes an unconstrained environment where a policy can select the same item innitely . Howe ver , in many practical applications, including coupon allocation and e-commerce, limited supply constrains items through budget limits on distributed coupons or inventor y restrictions on products. In these settings, greedily selecting the item with the highest expe cted rewar d for the current user may lead to early depletion of that item, making it unavailable for future users who could potentially generate higher expected rewards. As a result, OPL methods that are optimal in unconstrained settings may become suboptimal in limited supply settings. T o address the issue, we provide a theoretical analysis showing that conventional gr eedy OPL approaches may fail to maximize the policy p erformance , and demonstrate that p olicies with superior performance must exist in limited supply settings. Based on this insight, we introduce a novel method called O-Policy learning with Limited Supply (OPLS). Rather than simply selecting the item with the highest expecte d r eward, OPLS focuses on items with relatively higher expected rewar ds compared to the other users, enabling more ecient allocation of items with limited supply . Our empirical results on both synthetic and real-world datasets show that OPLS outperforms existing OPL methods in contextual bandit problems with limited supply . CCS Concepts • Information systems → Recommender systems ; Personaliza- tion . ∗ Equal contribution. This work is licensed under a Creative Commons Attribution 4.0 International License. WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. © 2026 Copyright held by the owner/author(s). ACM ISBN 979-8-4007-2307-0/2026/04 https://doi.org/10.1145/3774904.3792181 Ke y wor ds O-Policy Learning, Contextual Bandits, Limited Supply . A CM Reference Format: Koichi T anaka, Ren Kishimoto, Bushun Kawagishi, Y usuke Narita, Y asuo Y amamoto, Nobuyuki Shimizu, and Y uta Saito. 2026. O-Policy Learning with Limited Supply . In Proceedings of the ACM W eb Conference 2026 (WW W ’26), April 13–17, 2026, Dubai, United A rab Emirates. A CM, New Y ork, NY, USA, 12 pages. https://doi.org/10.1145/3774904.3792181 1 Introduction Decision-making problems play a crucial role in various application domains such as recommender systems [ 8 , 10 , 21 , 22 , 25 ], online advertising [ 4 ], and search [ 16 ], where the use of data-driven algo- rithms has become increasingly imp ortant in recent years. These are often formulated as contextual bandit problems, where policies se- lect an action (e.g., products, movies) based on the observed context (e .g., user feature) and receive a reward (e.g., click, conv ersion). The goal of the contextual bandit problem is to learn a p olicy that maxi- mizes the expected reward. O-p olicy learning (OPL) [ 18 , 20 , 29 , 32 ] enables policy learning solely from logged data, without deploy- ing ne w policies online . This is particularly valuable because it allows for p olicy improvement without risking user experience or incurring the high cost of online experiments [ 12 , 22 ]. T ypi- cal OPL methods in contextual bandits assume an unconstrained environment where a policy can select each item innitely . How- ever , in many real-world applications, such as coupon allocation or e-commerce, popular or scarce items may run out o ver time or become unavailable because of limited supply [ 5 , 37 ]. Although conventional approaches that greedily aim to maximize the ex- pected reward for each incoming user are optimal under typical OPL settings, they can b ecome suboptimal with limited supply . This is because selecting an item that maximizes expe cted re ward for a user at each time step may deplete its inventory , preventing it from being allocated to another user in the future who would generate a higher expected reward. T o illustrate this issue, we present a simple coup on allocation example in T able 1. There is exactly one coupon available for each discount typ e: “30% OFF, ” “50% OFF, ” and “70% OFF. ” W e assume WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. Koichi T anaka et al. T able 1: Coupon allocation example: comparison between greedy and optimal methods. The left table shows 𝑞 ( 𝑥 , 𝑎 ) for each user–coupon pair . The right table illustrates allocations under dierent arrival or ders, along with the policy value 𝑉 ( 𝜋 ) . 𝑞 ( 𝑥 , 𝑎 ) 30%OFF 50%OFF 70%OFF 𝑥 1 80 250 200 𝑥 2 100 280 120 𝑥 3 60 100 70 Arrival order greedy optimal ( 𝑥 1 , 𝑥 2 , 𝑥 3 ) 50%OFF, 70%OFF, 30%OFF 70%OFF, 50%OFF, 30%OFF ( 𝑥 1 , 𝑥 3 , 𝑥 2 ) 50%OFF, 70%OFF, 30%OFF 70%OFF, 30%OFF, 50%OFF · · · · · · · · · ( 𝑥 3 , 𝑥 2 , 𝑥 1 ) 50%OFF, 70%OFF, 30%OFF 30%OFF, 50%OFF, 70%OFF 𝑉 ( 𝜋 ) 420 540 that three unique users ( 𝑥 1 , 𝑥 2 , 𝑥 3 ) arrive sequentially , each visiting once. Let 𝑞 ( 𝑥 , 𝑎 ) denote the expe cted reward to the platform for each user–coup on pair ( 𝑥 , 𝑎 ) . The optimal allo cation that maxi- mizes the total expected reward assigns the 70% OFF coupon to 𝑥 1 (reward 200), the 50% OFF coupon to 𝑥 2 (reward 280), and the 30% OFF coupon to 𝑥 3 (reward 60), yielding a total e xp ected rewar d of 540 regardless of the arrival order . In contrast, conventional gr e edy methods allocate to each user the item that yields the highest ex- pected reward among the remaining options. Since, for every user , the platform’s expected rewards are ranked in descending order as 50% OFF, 70% OFF, and 30% OFF , the greedy metho d allocates coupons in this order as users arrive . As a result, the total rewar d heavily depends on the arrival order . When we assume that all possible arrival orders occur uniformly at random, the policy per- formance of the greedy method is 420, denoted in the table as greedy (See App endix A for detailed calculations.). This value is strictly lower than the optimal policy performance of 540, demonstrating that a greedy method, which is optimal in unconstrained settings, fails to achieve optimality under inventory constraints. T o formally consider such supply limitations, we formulate the problem of OPL with limite d supply for the rst time in the rele- vant literature. T o do so, we start by analyzing a simplied setting where each item is available in a single unit and all users share the same preference or dering over items. W e theoretically prov e that there always e xists a policy that is comparable to or superior to the model-based greedy approach in terms of the policy performance under limited supply . Based on this analysis, we propose a novel method called O-Policy learning with Limited Supply (OPLS). In- stead of selecting items greedily based on their expected rewards, OPLS selects items based on the relative rewar d gap , calculated as a user’s expected reward minus the average expected reward across all users. This approach prioritizes allocating items to users who yield relatively higher expecte d rewards compared to the other users. Importantly , OPLS r e quir es no additional computational cost compared to existing model-based methods. In more realistic settings, items often dier substantially in their demand–supply conditions. For example, in e-commerce, popu- lar or trending items often have limited supply relative to their demand, whereas long-tail products usually keep sucient stock. Similarly , in coupon allocation, providers usually issue only a few high-discount coupons due to cost constraints, while they distribute low-discount coupons in large quantities. T o handle even such het- erogeneity , we further extend OPLS by applying dierent decision rules to dierent item groups: • Limited supply items , which will be sold out by the end of the horizon. For these, we select the item with the highest relative expected reward across users. • Abundant supply items , which will remain in stock by the end of the horizon. For these, we select the item with the highest absolute expecte d r eward. Finally , between the two item groups, OPLS chooses the one with the higher expecte d reward. This simple yet ee ctiv e mechanism in- tegrates the greedy strategy , which p erforms optimally when supply is abundant, and adapts to cases with limited supply , enabling OPLS to outperform the greedy metho d across a wide range of inventory conditions. Through both synthetic and real-world experiments, we demonstrate that OPLS achieves high policy performance in contextual bandit problems with limited supply , whereas existing methods perform po orly under such constraints. 2 O-Policy Learning without Limited Supply This section formulates the standard problem setting for o-policy learning (OPL) in contextual bandits without limited supply [ 23 , 24 ]. Let 𝑥 ∈ X ⊆ R 𝑑 𝑥 represent a context vector (e.g., user feature). Given a context 𝑥 , a possibly stochastic policy 𝜋 ( 𝑎 | 𝑥 ) selects an action 𝑎 ∈ A (e.g., pr o ducts, movies). Let 𝑟 ∈ R ≥ 0 denote a reward (e.g., a click or conversion), drawn from an unknown conditional distribution 𝑝 ( 𝑟 | 𝑥 , 𝑎 ) . In the OPL setting, we use a logged dataset D : = { ( 𝑥 𝑖 , 𝑎 𝑖 , 𝑟 𝑖 ) } 𝑛 𝑖 = 1 collected under the logging policy 𝜋 0 and the generative process produces each tuple accor ding to the distribu- tion ( 𝑥 , 𝑎, 𝑟 ) ∼ 𝑝 ( 𝑥 ) 𝜋 0 ( 𝑎 | 𝑥 ) 𝑝 ( 𝑟 | 𝑥 , 𝑎 ) . The expected reward under a policy 𝜋 , known as the policy value , is dened as 𝑉 ( 𝜋 ) : = E 𝑝 ( 𝑥 ) 𝜋 ( 𝑎 | 𝑥 ) 𝑝 ( 𝑟 | 𝑥 ,𝑎 ) [ 𝑟 ] = E 𝑝 ( 𝑥 ) 𝜋 ( 𝑎 | 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 ) ] , where 𝑞 ( 𝑥 , 𝑎 ) : = E [ 𝑟 | 𝑥 , 𝑎 ] is the expe cted reward function, also known as the q-function . The objective in OPL is to learn a policy 𝜋 that maximizes the p olicy value using only the logged dataset 𝜋 = arg max 𝑉 ( 𝜋 ) . One commonly used method in OPL is the greedy model-base d approach, which rst estimates the 𝑞 -function 𝑞 ( 𝑥 , 𝑎 ) using stan- dard supervised learning techniques. From the estimated function ˆ 𝑞 ( 𝑥 , 𝑎 ) , we typically obtain a policy by taking the action that maxi- mizes the estimated reward 𝜋 ( 𝑎 | 𝑥 ) = ( 1 if 𝑎 = arg max 𝑎 ′ ∈ A ˆ 𝑞 ( 𝑥 , 𝑎 ′ ) 0 otherwise . (1) When we know the true 𝑞 -function, this appr oach can always select the optimal action 𝑎 for a given context 𝑥 , thereby yielding the optimal p olicy . In practice, howev er , it may suer from bias due O-Policy Learning with Limited Supply WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. to estimation errors in the 𝑞 -function, yet it remains one of the simplest and most computationally ecient approaches [22, 26]. So far , we have discussed the standard formulation of OPL. This formulation assumes no constraints on item availability , meaning that a policy can select each item innitely if nee ded. How ever , in many real-world scenarios, such as coupon allocation, e-commer ce, popular or scarce items may run out over time or become unavail- able b ecause of limited supply . Therefore, we next consider the o-policy learning with limited supply . 3 Related W ork This section introduces key related work. O-Policy Evaluation and Learning . O-Policy Evaluation (OPE) and O-Policy Learning (OPL) [ 6 , 7 , 11 , 17 , 18 , 23 , 24 , 27 , 28 , 34 ] aim to estimate or optimize a policy using only logged data. A variety of methods and estimators have b een pr oposed in OPE to control the bias–variance tradeo when estimating the policy value [ 6 , 7 , 11 , 13 – 15 , 18 , 22 , 27 , 28 , 30 , 31 , 34 ]. These techniques achieve accurate policy value estimation in standard settings with- out limited supply [ 21 , 25 , 33 ], and have b een extended in OPL to estimate policy gradients and improve learning from logged data [ 24 ]. While many of these methods focus on standard contex- tual bandit settings, real-world applications often involve a limited supply . Our work is the rst to formulate OPL with inventor y con- straints in contextual bandits, providing a principled framework that existing methods cannot directly handle. Recommendation with Constraints . Sev eral prior studies have investigated recommendations under budget or inventory con- straints. Bandits with Knapsacks (BwK) framework [ 1 , 2 ] models multi-armed bandit problems with budget constraints. Since BwK does not utilize user features, it cannot provide personalized recom- mendations. Resourceful Contextual Bandits [ 3 ] extend this setting by incorporating contextual information, allowing for more person- alized decisions. Nevertheless, due to computational limitations, it is known to be challenging to apply these methods directly for p er- sonalized recommendation [ 35 , 36 ]. Importantly , these approaches primarily consider global budget constraints, where limitations ap- ply across all users and items, rather than per-item constraints. In contrast, our setting focuses on inventory constraints at the item level. Relatively few existing studies address inventory-constrained recommendations [ 5 , 37 ]. Christakopoulou et al . [5] proposes a matrix factorization-based approach that ensures item recommen- dations do not exceed item capacity , but their setting does not involve sequential user arrival as in the bandit framework. Zhong et al . [37] proposes a metho d for learning recommendations that en- sure item sales remain within inventory limits. While this method considers per-item inventory constraints, it does not incorporate user features. Our work, in contrast, explicitly considers user fea- tures to determine which item to recommend to which user , given the remaining inventory . Finally , while most of the aforementioned studies focus on online learning, our work considers the oine setting. T o the b est of our knowledge, this is the rst study to introduce a limited supply into OPL for contextual bandits. 4 O-Policy Learning with Limited Supply While the previous section focuse d on OPL in conventional con- textual bandit settings, in this section, we introduce a novel for- mulation of the OPL problem with limite d supply . In this setting, each item has an inv entory that evolves ov er time, and the set of available actions changes depending on the r emaining inventory . Consequently , we must r edene b oth the logged data and the policy value to properly capture the dynamics of limited supply . W e consider a recommendation horizon of 𝑇 rounds, during which the policy makes recommendations sequentially . In contrast to standard contextual bandits, we introduce two new variables, 𝑠 and 𝑐 , in order to represent the transitions of inventory . Let 𝑠 represent the inventory state, where 𝑠 𝑡 ∈ R | A | is a vector whose each element 𝑠 𝑎 𝑡 denotes the inventory count of an item 𝑎 at time 𝑡 . Let 𝑐 ∈ { 0 , 1 } be a binary inventory signal that indicates whether the system consumes the inventory . For example, in e-commerce, 𝑐 = 1 when a user purchases an item and its inventory decreases. In coupon allocation, 𝑐 = 1 if the platform distributes a coupon. At time 𝑡 , the platform deterministically updates the inventory from the previous state and the binary inv entor y signal through a kno wn transition function 𝑝 ( 𝑠 ′ | 𝑠 , 𝑎, 𝑐 ) . Specically , the platform updates the inventory of item 𝑎 at time 𝑡 as follows 𝑠 𝑎 𝑡 = 𝑠 𝑎 1 − 𝑡 ′ < 𝑡 𝑐 𝑡 ′ · I { 𝑎 𝑡 ′ = 𝑎 } . (2) Furthermore, we dene the policy as 𝜋 ( 𝑎 | 𝑥 , 𝑠 ) , which selects actions conditioned on both context 𝑥 and the current inventory 𝑠 . Given these denitions, we formulate the logged dataset as D : = n ( 𝑥 𝑖 , 𝑡 , 𝑎 𝑖 , 𝑡 , 𝑐 𝑖 , 𝑡 , 𝑟 𝑖 , 𝑡 , 𝑠 𝑖 , 𝑡 ) 𝑇 𝑡 = 1 o 𝑛 𝑖 = 1 , which is colle cted under a logging policy 𝜋 0 , and thus the generative process samples each tuple ( 𝑥 , 𝑎, 𝑐 , 𝑟 , 𝑠 ) ∼ 𝑝 ( 𝑥 ) 𝜋 0 ( 𝑎 | 𝑥 , 𝑠 ) 𝑝 ( 𝑐 | 𝑥 , 𝑎 ) 𝑝 ( 𝑟 | 𝑥 , 𝑎 ) 𝑝 ( 𝑠 ′ | 𝑠 , 𝑎, 𝑐 ) . W e consider a rewar d model where we obtain rewards only when the item is actually consumed ( 𝑐 = 1 ), such as when a purchase gen- erates revenue or distributing a coupon produces its eect. Hence, we dene the p olicy value as the expected value of the product 𝑐 · 𝑟 across all time steps: 𝑉 ( 𝜋 ) : = E 𝑝 ( 𝑠 1 ) Î 𝑇 𝑡 = 1 𝑝 ( 𝑥 𝑡 ) 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 ,𝑠 𝑡 ) 𝑝 ( 𝑐 𝑡 | 𝑥 𝑡 ,𝑎 𝑡 ) 𝑝 ( 𝑟 𝑡 | 𝑥 𝑡 ,𝑎 𝑡 ) 𝑝 ( 𝑠 𝑡 + 1 | 𝑠 𝑡 ,𝑎 𝑡 ,𝑐 𝑡 ) " 𝑇 𝑡 = 1 𝑐 𝑡 · 𝑟 𝑡 # . Since 𝑐 is binary and the transition 𝑝 ( 𝑠 ′ | 𝑠 , 𝑎, 𝑐 ) is deterministic, we then derive it as 𝑉 ( 𝜋 ) = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 𝑡 ) 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 ,𝑠 𝑡 ) 𝑝 ( 𝑐 𝑡 | 𝑥 𝑡 ,𝑎 𝑡 ) 𝑝 ( 𝑟 𝑡 | 𝑥 𝑡 ,𝑎 𝑡 ) [ 𝑐 𝑡 · 𝑟 𝑡 ] = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 𝑡 ) 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 ,𝑠 𝑡 ) [ 𝑞 𝑐 ( 𝑥 𝑡 , 𝑎 𝑡 ) · 𝑞 𝑟 ( 𝑥 𝑡 , 𝑎 𝑡 ) ] = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 𝑡 ) 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 ,𝑠 𝑡 ) [ 𝑞 ( 𝑥 𝑡 , 𝑎 𝑡 ) ] , (3) where 𝑞 𝑐 ( 𝑥 , 𝑎 ) : = E 𝑝 ( 𝑐 | 𝑥 , 𝑎 ) [ 𝑐 ] , 𝑞 𝑟 ( 𝑥 , 𝑎 ) : = E 𝑝 ( 𝑟 | 𝑥 , 𝑎 ) [ 𝑟 ] , and 𝑞 ( 𝑥 , 𝑎 ) : = E 𝑝 ( 𝑐 | 𝑥 , 𝑎 ) 𝑝 ( 𝑟 | 𝑥 ,𝑎 ) [ 𝑐 · 𝑟 ] . See Appendix B.1 for detaile d derivations. WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. Koichi T anaka et al. As in standard OPL, the goal of OPL with limited supply (our setup) is to learn a policy 𝜋 that maximizes the policy value 𝑉 ( 𝜋 ) . Howev er , the critical dierence lies in the dep endence of 𝜋 on the inventory state 𝑠 𝑡 , as seen in 𝜋 ( 𝑎 | 𝑥 , 𝑠 𝑡 ) . In the next section, we describe algorithms for solving this problem, b eginning with adaptations of existing OPL methods to the limited supply setting. 4.1 Conventional Greedy Approach Since no existing methods addr ess the limited supply setting, w e rst e xtend the standar d model-based approach to the settings with limited supply . Let A 𝑠 𝑡 : = { 𝑎 ∈ A | 𝑠 𝑎 𝑡 > 0 } denote the set of actions with remaining inventory at time 𝑡 . Then, Eq. (1) can b e extended to the limited supply setting as 𝜋 greedy ( 𝑎 𝑡 | 𝑥 𝑡 , 𝑠 𝑡 ) = ( 1 if 𝑎 𝑡 = arg max 𝑎 ∈ A 𝑠 𝑡 ˆ 𝑞 ( 𝑥 𝑡 , 𝑎 ) 0 otherwise . (4) This policy greedily selects the item with the highest predicted reward ˆ 𝑞 ( 𝑥 , 𝑎 ) among those with available inventory A 𝑠 𝑡 . In typ- ical contextual bandit settings, this greedy approach is optimal when ˆ 𝑞 ( 𝑥 , 𝑎 ) accurately estimates the true expected rewar d func- tion. Howev er , with limited supply , such greedy selection can be suboptimal. If the policy allocates the item that maximizes the ex- pected reward to a user at each time step, the item may be come unavailable to another user in the future who could generate a higher expected reward. A s discussed in the introduction section with the coup on allocation example in Table 1, the conventional greedy method performs worse than the optimal p olicy . This moti- vates the development of no vel inventory-aware OPL approaches as our main contribution. 4.2 The Proposed Method T o design an eective method to deal with the problem of OPL with limited supply , we begin by comparing the optimal policy with the greedy model-base d policy . W e rst present a theoretical result under a simplied setting. Theorem 4.1. Let there b e 𝐽 users 𝑥 1 , . . . , 𝑥 𝐽 and 𝐾 ac- tions 𝑎 1 , . . . , 𝑎 𝐾 , where each action has exactly one unit of inventory . Assume the re ward function satises 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 ) ≥ 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 + 1 ) for all 𝑗 and 𝑘 . Then, for any user 𝑥 𝑗 and item 𝑎 𝑘 , the follow- ing inequality holds: 𝑉 ( 𝜋 ∗ ) − 𝑉 ( 𝜋 greedy ) ≥ 𝑝 ( 𝑥 𝑗 ) n 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] − 𝑞 ( 𝑥 𝑗 , 𝑎 1 ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 1 ) ] o (5) where 𝑉 ( 𝜋 ∗ ) denotes the value of the optimal p olicy and 𝑉 ( 𝜋 greedy ) is the value of the greedy mo del-based policy . This theorem considers a simplied setting where each item has exactly one unit in stock and all users shar e the same preference order over items. It provides a lower bound on the dierence in policy values b etw e en the optimal p olicy and the greedy model- based p olicy . T o prove this result, we consider the dierence in policy values between the gree dy model-based policy 𝜋 greedy and a modied p olicy 𝜋 𝑗 ,𝑘 that selects item 𝑎 𝑘 for user 𝑥 𝑗 at time 𝑡 = 1 and follows the greedy model-based policy thereafter . W e derive the policy value of the greedy model-based p olicy as 𝑉 ( 𝜋 greedy ) = 𝐾 𝑘 = 1 E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] . (6) W e also derive the policy value of 𝜋 𝑗 ,𝑘 as 𝑉 ( 𝜋 𝑗 ,𝑘 ) = 𝑝 ( 𝑥 𝑗 ) 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] − ( 𝑞 ( 𝑥 𝑗 , 𝑎 1 ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 1 ) ] ) + 𝑉 ( 𝜋 greedy ) , (7) which yields the r esult in Theorem 4.1, and we provide the detailed proof in Appendix B.2 and B.3. Setting 𝑘 = 1 in Eq. (5) yields a lower b ound of zero , implying that there always exists a policy that outperforms or performs equally well as the greedy model-based policy . The key insight for obtaining a policy that p erforms better than the greedy policy comes from maximizing the lower b ound in Eq. (5) . T o maximize this b ound, it is desirable to choose an item 𝑎 𝑘 that maximizes 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] . In other words, it is important to allocate items to users who achiev e relatively higher e xpected rewards compared to others, which is intuitively reasonable as well. T o realize this idea, we propose a new method called O-Policy Learning with Limited Supply (OPLS), which selects items base d on the relative reward gap , dened as ˆ 𝑞 ( 𝑥 , 𝑎 ) − 1 𝑛 𝑛 𝑖 = 1 ˆ 𝑞 ( 𝑥 𝑖 , 𝑎 ) , that is, a user’s expected r eward minus the average expected reward across all users. Formally , we dene OPLS as 𝜋 OPLS ( 𝑎 𝑡 | 𝑥 𝑡 , 𝑠 𝑡 ) = 1 if 𝑎 𝑡 = argmax 𝑎 ∈ A 𝑠 𝑡 ( ˆ 𝑞 ( 𝑥 𝑡 , 𝑎 ) − 1 𝑛 𝑛 𝑖 = 1 ˆ 𝑞 ( 𝑥 𝑖 , 𝑎 ) ) 0 otherwise . This approach enables more eective allo cation than the greedy method by considering which users receive the limited items. T a- ble 2 illustrates the case where we apply OPLS to the simple coupon allocation example. W e compute the average expected reward for each coup on: 80 for the 30% OFF coupon, 210 for the 50% OFF coupon, and 130 for the 70% OFF coup on. OPLS selects the coupon that maximizes the dierence between a user’s expe cted reward and the average expected reward of that coupon. In this example, OPLS can make the same recommendation as the optimal alloca- tion, regardless of the order in which users arrive. Additionally , it requires no additional computation b e yond estimating ˆ 𝑞 , which can be learned using the same model as the conventional greedy approach. Extension to Mixed Supply Conditions. As we have discussed so far , we proposed OPLS as a method for handling limited supply conditions. In more realistic scenarios, however , items can dier signicantly in their demand–supply balance. For instance, in e- commerce, popular or trending items often have limited supply relative to demand, whereas long-tail products typically remain O-Policy Learning with Limited Supply WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. T able 2: Coupon allocation example: OPLS allocation. The left table shows the relative reward gap 𝑞 ( 𝑥 , 𝑎 ) − E [ 𝑞 ( 𝑥 , 𝑎 ) ] for each user–coupon pair . The right table illustrates allocations under dierent arrival orders, along with the policy value 𝑉 ( 𝜋 ) . 𝑞 ( 𝑥 , 𝑎 ) − E [ 𝑞 ( 𝑥 , 𝑎 ) ] 30%OFF 50%OFF 70%OFF 𝑥 1 0 (80 - 80) 40 (250 -210) 70 (200 -130) 𝑥 2 20 (100 - 80) 70 (280 -210) -10 (120 -130) 𝑥 3 -20 (60 - 80) -110 (100 -210) -60 (70 -130) Arrival order OPLS ( 𝑥 1 , 𝑥 2 , 𝑥 3 ) 70%OFF, 50%OFF, 30%OFF ( 𝑥 1 , 𝑥 3 , 𝑥 2 ) 70%OFF, 30%OFF, 50%OFF · · · · · · ( 𝑥 3 , 𝑥 2 , 𝑥 1 ) 30%OFF, 50%OFF, 70%OFF 𝑉 ( 𝜋 ) 540 well-stocked. W e can here extend OPLS to even eectively handle the challenging case where items dier in their demand–supply conditions. Let A sold denote the set of items that will b e sold out, and A unsold denote the set of items that will remain in stock at time 𝑇 , where A sold = { 𝑎 ∈ A | 𝑠 𝑎 𝑇 ≤ 0 } , A unsold = { 𝑎 ∈ A | 𝑠 𝑎 𝑇 > 0 } . For each group, we apply dier ent de cision rules. • Limited supply items ( 𝑎 ∈ A sold ): cho ose the item with the highest relative expected reward across users, 𝑎 sold , 𝑡 = arg max 𝑎 ∈ A sold , 𝑡 ( ˆ 𝑞 ( 𝑥 𝑡 , 𝑎 ) − 1 𝑛 𝑛 𝑖 = 1 ˆ 𝑞 ( 𝑥 𝑖 , 𝑎 ) ) . • Abundant supply items ( 𝑎 ∈ A unsold ): cho ose the item with the highest absolute expecte d r eward, 𝑎 unsold , 𝑡 = arg max 𝑎 ∈ A unsold , 𝑡 ˆ 𝑞 ( 𝑥 𝑡 , 𝑎 ) . Here, A sold , 𝑡 = { 𝑎 ∈ A sold | 𝑠 𝑎 𝑡 > 0 } and A unsold , 𝑡 = { 𝑎 ∈ A unsold | 𝑠 𝑎 𝑡 > 0 } denote the subsets of items with positive inventory at time 𝑡 . W e select the nal action from these two candidates 𝜋 OPLS ( 𝑎 𝑡 | 𝑥 𝑡 , 𝑠 𝑡 ) = arg max 𝑎 ∈ { 𝑎 sold , 𝑡 ,𝑎 unsold , 𝑡 } ˆ 𝑞 ( 𝑥 𝑡 , 𝑎 ) . (8) This extension allows OPLS to gr e edily select the highest-re ward items when they will remain in stock, while applying the relative- reward strategy when supply is scarce. OPLS thus integrates the conventional greedy method, achieving the same performance as greedy when items have sucient inventory . This ensures that OPLS consistently matches or outperforms the greedy method un- der a wide range of inventory conditions. T o implement this procedure, we must estimate which items will be sold out and obtain A sold . At time 𝑡 , we can express the probability that the policy consumes item 𝑎 as 𝜋 𝑡 ( 𝑎 ) = E 𝑝 ( 𝑥 ) [ 𝜋 ( 𝑎 𝑡 | 𝑥 , 𝑠 𝑡 ) · 𝑞 𝑐 ( 𝑥 , 𝑎 𝑡 ) ] , and the remaining inventory of item 𝑎 at time 𝑇 as 𝑠 𝑎 𝑇 = 𝑠 𝑎 0 − 𝑇 𝑡 = 1 𝜋 𝑡 ( 𝑎 ) . W e can thus estimate the set of sold-out items as A sold = { 𝑎 ∈ A | 𝑠 𝑎 𝑇 ≤ 0 } . However , since 𝜋 depends on A 𝑠 𝑡 and evolves over time, estimating this set be comes computationally intractable when the number of items or the horizon 𝑇 is large. 1 T o overcome this 1 Here, we use 𝜋 ( 𝑎 𝑡 | 𝑥 , 𝑠 𝑡 ) from the base OPLS before the extension. diculty , w e also adopt a naive approximation in which we assume that the policy selects all items uniformly at each time step 𝑠 𝑎 𝑇 = 𝑠 𝑎 0 − 𝑇 · 1 | A | 𝑛 𝑖 = 1 𝑞 𝑐 ( 𝑥 𝑖 , 𝑎 ) . W e empirically show that OPLS, even when using this naive es- timation, consistently outperforms existing methods in scenarios where items have varying levels of supply in Appendix D. 5 Synthetic Experiments This section empirically evaluates OPLS’s performance using syn- thetic data and identies the situations where OPLS is particularly more eective. 5.1 Setup T o generate synthetic data, we rst dene 200 users characterized by 10-dimensional context vectors ( 𝑥 ) sampled from the standard normal distribution. Then, we dene a click probability 𝑞 𝑐 ( 𝑥 , 𝑎 ) and an action value 𝑞 𝑟 ( 𝑥 , 𝑎 ) as follows. 𝑞 𝑐 ( 𝑥 , 𝑎 ) = 𝜆 · 𝑓 𝑐 ( 𝑥 , 𝑎 ) + ( 1 − 𝜆 ) · 𝑔 𝑐 ( 𝑥 , 𝑎 ) , (9) 𝑞 𝑟 ( 𝑥 , 𝑎 ) = 𝜆 · 𝑓 𝑟 ( 𝑥 , 𝑎 ) + ( 1 − 𝜆 ) · 𝑔 𝑟 ( 𝑥 , 𝑎 ) , (10) where 𝑔 ( 𝑥 , 𝑎 ) is a reward function that satises 𝑔 ( 𝑥 , 𝑎 𝑘 ) ≥ 𝑔 ( 𝑥 , 𝑎 𝑘 + 1 ) for all users. W e can control the popularity of actions among users by 𝜆 . If we set 𝜆 = 0 , all users prefer the actions in the same or der . Based on the ab o ve click probability , we sample a binary click signal 𝑐 from a binomial distribution whose mean is 𝑞 𝑐 ( 𝑥 , 𝑎 ) . W e then sample a reward 𝑟 from a normal distribution whose mean is 𝑞 𝑟 ( 𝑥 , 𝑎 ) and standard deviation 𝜎 is 3.0. W e then synthesize the logging policy as follows. 𝜋 0 ( 𝑎 𝑡 | 𝑥 𝑡 , 𝑠 𝑡 ) = exp ( 𝛽 · 𝑞 ( 𝑥 𝑡 , 𝑎 𝑡 ) ) Í 𝑎 ′ ∈ A 𝑠 𝑡 exp ( 𝛽 · 𝑞 ( 𝑥 𝑡 , 𝑎 ′ ) ) , (11) where 𝛽 is an experimental parameter to control the sto chastic- ity and optimality of the logging policy . W e use 𝛽 = − 1 . 0 in the synthetic experiments. T o summarize, we rst obser ve a user represented by 𝑥 and dene the click probability and action value as in Eq. (9) and Eq. (10) . W e then sample a discrete action 𝑎 from 𝜋 0 in Eq. (11) . The click signal 𝑐 is sampled from a binomial distribution whose mean is 𝑞 𝑐 ( 𝑥 , 𝑎 ) in Eq. (9) . The reward 𝑟 is sampled from a normal distribution whose mean is 𝑞 𝑟 ( 𝑥 , 𝑎 ) and standard deviation 𝜎 is 3.0. If 𝑐 = 1 , the supply of the recommended action reduces by one. Iterating this procedure 𝑇 times generates the logged data D = { ( 𝑥 𝑡 , 𝑎 𝑡 , 𝑐 𝑡 , 𝑟 𝑡 , 𝑠 𝑡 ) } 𝑇 𝑡 = 1 . WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. Koichi T anaka et al. Figure 1: Relative policy value ( 𝑉 ( 𝜋 OPLS ) / 𝑉 ( 𝜋 greedy ) ) at each time step T able 3: The expected reward function in the exper- iment of Figure 1 𝑞 ( 𝑥 , 𝑎 ) 𝑎 1 𝑎 2 𝑎 3 𝑎 4 𝑎 5 𝑥 1 0.799 1.011 1.047 2.521 3.046 𝑥 2 0.329 0.494 1.683 2.092 2.589 𝑥 3 1.287 1.718 1.984 2.932 3.369 Figure 2: The behavior of the conventional greedy method at 𝑡 = 10 , 30 , 60 Figure 3: The behavior of OPLS at 𝑡 = 10 , 30 , 60 Initial Supply . T o identify the situation where OPLS provides more improv ements, we dene the initial supply 𝑠 1 by three dier- ent ways as follows. 𝑠 1 = 𝑠 max · E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 ) ] max 𝑎 ∈ A E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 ) ] (proportional) 𝑠 max · min 𝑎 ∈ A E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 ) ] E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 ) ] (inverse proportional) random.uniform(1, 𝑠 max ) (random) , where 𝑠 max is the maximum value of supply . First, "proportional supply" simulates the situation where item supply increases propor- tionally with user demand. The more users want an item, the more supply of the item we have. Second, "inv erse proportional supply" simulates the situation wher e item supply is inversely proportional to user demand. Items with low supply are typically in high demand. Finally , "random supply" denes initial supply at random. Compared methods. W e compare OPLS with the conventional greedy method in Eq. (4) . In synthetic experiments except for Fig- ure 4c, we use the true expected reward for both methods for the following reasons. First, we demonstrate OPLS can improve the policy value compared to the conventional greedy method that becomes the optimal policy with the true expected reward in the no limited supply setting. Se cond, this is the rst research for OPL with limited supply , so we identify the situation where supply con- straints have substantial eects on the performance of each method. Note that we also evaluate OPLS’s performance with an estimate d expected reward in the real-world e xperiments. 5.2 Results W e rst demonstrate how OPLS chooses actions compared to the conventional greedy method using small-scale experiments. Then, we evaluate OPLS’s performance in various settings. W e compute 100 simulations with dierent random seeds to produce synthetic data instances. Unless otherwise specied, the number of actions is O-Policy Learning with Limited Supply WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. (a) Relative p olicy values varying the action popularity ( 𝜆 ) (b) Relative policy values varying the number of users (c) Relative policy values varying estimation noise Figure 4: Comparisons of relative policy values with var ying (a)action popularity , (b)the numb er of users, and (c)estimation noise. The period 𝑇 is suciently large, and all items are sold out. Figure 5: Relative policy values varying max supply ( 𝑠 𝑚𝑎𝑥 ) set to | A | = 100 , the popularity of actions is 𝜆 = 0 . 5 and 𝑠 max = 20 . Except for Figure 5, the period 𝑇 is suciently large, and all items are sold out. How does OPLS choose actions compared to the conventional greedy metho d? T o demonstrate the b ehavior of OPLS, we con- duct a small-scale experiment where the number of users is set to 3 , the number of actions is | A | = 5 , the initial supply is random and 𝜆 = 0 . 0 . T able 3 reports the expected reward in this experiment. The actions with larger indices have higher expe cted re wards be- cause of 𝜆 = 0 . 0 . Figure 1 shows the relative policy values between OPLS and the conventional greedy method 𝑉 ( 𝜋 OPLS ) / 𝑉 ( 𝜋 greedy ) at each step. Note that the perio ds where the values remain con- stant indicate that the supply of all actions is zer o. From Figur e 1, we can se e that OPLS improves the nal policy value compared to the conventional greedy method. Figure 2 and 3 illustrate how each method selects an action for a user . The value in each grid cell represents the proportion of the supply allocated to a specic user for a particular action at that time. From Figure 2, we observe that the conventional greedy method recommends actions with the highest expected rewards in the early time steps. This is why the conventional greedy method outperforms OPLS at the initial time step in Figure 1. Eventually , the conventional greedy metho d recommends all actions evenly across all users. On the other hand, OPLS selectively recommends a spe cic action to a specic user . For example, approximately 80% of 𝑎 5 is recommended to 𝑥 1 . From T able 3, 𝑥 1 has the highest expected reward for 𝑎 5 among users, so OPLS achieves eective recommendations in limited supply set- tings. It is also the case for the other user-action pairs. Thus, OPLS achieves a high policy value by selectively recommending actions to users with higher expected rewards. How do es OPLS perform var ying the action popularity? Fig- ure 4a reports the relative policy values varying the action popu- larity ( 𝜆 ). The small values of 𝜆 mean that all users likely prefer the actions in the same or der . The results demonstrate that OPLS outperforms the conventional greedy method across all values of 𝜆 . Specically , OPLS signicantly improves policy values when 𝜆 is small. This is b ecause the more aligned the preferences are, the more crucial it is to recommend actions to the optimal users. In this situation, all users prefer the same action, so the conven- tional greedy method recommends actions ev enly to all users. In contrast, OPLS selectively recommends the p opular action to users with a high expected reward. Ther efore, OPLS demonstrates a clear advantage in scenarios where many users favor a specic action. Moreover , compared across the initial supply , OPLS improves policy values in the inverse proportional setting. This suggests that OPLS achieves superior performance when actions with high expected rewards are rare . This is because, in such situations, it is necessary to recommend the few valuable actions eectively . How does OPLS perform varying the the number of users? Figure 4b varies the number of users, while the number of actions is set to | A | = 100 . W e obser ve that the relative policy values gradually increase as the number of users increases. This is because, as the numb er of users increases, items with the high expected reward become more scarce, making it more necessary to consider limited supply . How does OPLS perform var ying estimation noises? In Fig- ure 4c, we use an estimate d expecte d reward ˆ 𝑞 ( 𝑥 , 𝑎 ) = 𝑞 ( 𝑥 , 𝑎 ) + N ( 0 , 𝜎 ) for both OPLS and the conventional greedy method. Fig- ure 4c reports the r elative policy value varying estimation noises 𝜎 . W e observe that OPLS outperforms the conventional greedy method acr oss various estimation noises, although its impro vement gradually decreases as the estimation noise b ecomes larger . This result suggests that OPLS provides substantial improvements with a reasonably accurate estimate of the expected reward. WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. Koichi T anaka et al. (a) Relative p olicy values var ying the number of users, using the estimated expecte d reward (b) Relative policy values varying estimation noise Figure 6: Comparisons of relative policy values with varying (a)the numb er of users and (b)estimation noise. The p eriod 𝑇 is suciently large, and all items are sold out. How does OPLS perform var ying the max supply 𝑠 𝑚𝑎𝑥 ? Fig- ure 5 varies the max supply 𝑠 𝑚𝑎𝑥 from 5 to 30. A s the max supply 𝑠 𝑚𝑎𝑥 increases, the limited supply setting gradually reduces to the NO limited supply setting. When the maximum supply is varied from 5 to 30, the proportion of unsold actions changes to approxi- mately 0%, 5%, 30%, 40%, and 50%. W e observe that OPLS improv es the policy value across various max supplies. Specically , OPLS provides substantial impro vements when the max supply is small. This result is consistent with the results of Figure 4. Moreover , OPLS exhibits performance equivalent to that of the conventional greedy method even when sucient items are available. This suggests that OPLS provides substantial performance in both limited and no limited supply settings. 6 Real- W orld Experiments This section demonstrates the eectiveness of OPLS in the limite d supply setting on a subset of the real-world recommendation dataset called KuaiRe c [ 9 ], which contains recommendation logs of the video-sharing app, Kuaishou. In our experiments, we use a subset of KuaiRec that contains 1,411 users and 3,327 items, for which user- item interactions are nearly fully observed (close to 100% density ). This property allows us to directly access the rewar d function. By leveraging this unique property , we can perform an OPL experiment on this dataset with a minimal synthetic component [ 9 ]. Since KuaiRec does not contain inventory information, we assign articial inventory to each video, using the same method as in our synthetic data experiments. This allows us to evaluate OPLS’s performance under limited supply . While this setup is purely a simulation for research purposes, introducing certain exposure constraints can also be relevant to real-world video recommendation systems. For example, constraints may be applied to limit the over-e xposure of popular videos, ensure div ersity across categories, or provide initial exposure guarantees for new items to address cold-start issues. T o perform an OPL experiment on this dataset, we sample 1,000 users and 1,000 items, and treat their interactions as the action value 𝑞 𝑟 ( 𝑥 , 𝑎 ) . W e set the click probability 𝑞 𝑐 ( 𝑥 , 𝑎 ) = 1 for every user–item pair . W e then dene the logging policy follo wing Eq. (11) , where we set 𝛽 = 1 . 0 . W e obtain an estimated expe cted rewar d ˆ 𝑞 ( 𝑥 , 𝑎 ) using a 3-layer neural netw ork and the logged data D . Results . In gure 6a, w e var y the number of users. W e xed the number of actions | A | = 1000 . W e observe that OPLS improves the policy value across various numbers of users. The results suggest that OPLS provides substantial improvements in more realistic situations where we have no access to the true e xpected reward. Figure 6b, we use estimated expected reward ˆ 𝑞 ( 𝑥 , 𝑎 ) = 𝑞 ( 𝑥 , 𝑎 ) + N ( 0 , 𝜎 ) for both OPLS and the conventional greedy metho d. W e observe that OPLS outperforms the conventional gree dy metho d across various estimation noises. Unlike Figure 4c, the relative policy value increases when estimation noises are small. This shows that OPLS could be more robust against estimation noise than the conventional greedy method. 7 Conclusion and Future W ork In this paper , we addr essed the problem of o-policy learning ( OPL) with limited supply . Existing OPL methods do not account for in- ventory constraints, which can lead to sub optimal allo cations since selecting the item that maximizes the expected rewar d for one user may forgo the opportunity to obtain a higher expected reward in the future. T o overcome this limitation, we proposed O-Policy Learning with Limited Supply ( OPLS), which selects items by maxi- mizing the relative expected reward across users. Moreov er , OPLS can incorporate supply prediction, enabling it to adaptively choose items according to supply conditions. Through experiments on both synthetic and real-w orld datasets, we demonstrated that OPLS consistently outperforms existing methods with limited supply . While this paper establishes the ee ctiv eness of OPLS under limited supply , several directions remain open for future research. In this work, we addressed the case where each item has an indi- vidual supply constraint. A natural extension is to consider global constraints that apply to the entire set of items, which w ould cap- ture more complex allocation scenarios. Moreover , since inventor y is limited, future work may nee d to incorporate fairness-aware objectives into OPLS to balance eciency with equity among users, rather than focusing solely on revenue maximization. References [1] Shipra Agrawal and Nikhil Devanur . 2016. Linear contextual bandits with knap- sacks. Advances in neural information processing systems 29 (2016). O-Policy Learning with Limited Supply WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. [2] Ashwinkumar Badanidiyuru, Robert Kleinberg, and Aleksandrs Slivkins. 2018. Bandits with knapsacks. Journal of the ACM ( JA CM) 65, 3 (2018), 1–55. [3] Ashwinkumar Badanidiyuru, John Langford, and Aleksandrs Slivkins. 2014. Re- sourceful contextual bandits. In Conference on Learning Theory . PMLR, 1109–1134. [4] Léon Bottou, Jonas Peters, Joaquin Quiñonero-Candela, Denis X Charles, D Max Chickering, Elon Portugaly , Dipankar Ray, Patrice Simard, and Ed Snelson. 2013. Counterfactual Reasoning and Learning Systems: The Example of Computational Advertising. Journal of Machine Learning Research 14, 11 (2013). [5] Konstantina Christakopoulou, Jaya Kawale , and Arindam Banerjee. 2017. Recom- mendation with capacity constraints. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management . 1439–1448. [6] Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. 2014. Doubly Robust Policy Evaluation and Optimization. Statist. Sci. 29, 4 (2014), 485–511. [7] Mehrdad Farajtabar , Yinlam Chow , and Mohammad Ghavamzadeh. 2018. More Robust Doubly Robust O-Policy Evaluation. In Proceedings of the 35th Interna- tional Conference on Machine Learning , V ol. 80. PMLR, 1447–1456. [8] Nicolo Felicioni, Maurizio Ferrari Dacrema, Marcello Restelli, and Paolo Cre- monesi. 2022. O-Policy Evaluation with Decient Support Using Side Informa- tion. Advances in Neural Information Processing Systems 35 (2022). [9] Chongming Gao, Shijun Li, W enqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and T at-Seng Chua. 2022. KuaiRec: A fully-obser ved dataset and insights for evaluating recommender systems. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management . 540–550. [10] Alexandre Gilotte, Clément Calauzènes, Thomas Nedelec, Alexandre Abraham, and Simon Dollé. 2018. Oine A/B T esting for Recommender Systems. In Pro- ceedings of the 11th A CM International Conference on W eb Search and Data Mining . 198–206. [11] Nathan Kallus, Yuta Saito, and Masatoshi Uehara. 2021. Optimal O-Policy Evaluation from Multiple Logging Policies. In Proceedings of the 38th International Conference on Machine Learning , V ol. 139. PMLR, 5247–5256. [12] Haruka Kiyohara, Ren Kishimoto, K osuke Kawakami, Ken K obayashi, Kazuhide Nakata, and Y uta Saito. 2024. T owards Assessing and Benchmarking Risk-Return Tradeo of O-Policy Evaluation. In International Conference on Learning Repre- sentations . [13] Haruka Kiyohara, Masahiro Nomura, and Yuta Saito . 2024. O-policy evaluation of slate bandit policies via optimizing abstraction. In Proceedings of the ACM on W eb Conference 2024 . 3150–3161. [14] Haruka Kiyohara, Yuta Saito, Tatsuya Matsuhiro, Yusuke Narita, Nobuyuki Shimizu, and Y asuo Y amamoto. 2022. Doubly Robust O-Policy Evaluation for Ranking Policies under the Cascade Behavior Model. In Proceedings of the 15th International Conference on W eb Search and Data Mining . [15] Haruka Kiyohara, Masatoshi Uehara, Y usuke Narita, Nobuyuki Shimizu, Y asuo Y amamoto, and Y uta Saito. 2023. O-Policy Evaluation of Ranking Policies under Diverse User Behavior . In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 1154–1163. [16] Lihong Li, Shunbao Chen, Jim Kleban, and Ankur Gupta. 2015. Counterfactual estimation and optimization of click metrics in search engines: A case study . In Proceedings of the 24th International Conference on World Wide W eb . 929–934. [17] Qiang Liu, Lihong Li, Ziyang T ang, and Dengyong Zhou. 2018. Breaking the curse of horizon: innite-horizon o-policy estimation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems . 5361–5371. [18] Alberto Maria Metelli, Alessio Russo, and Marcello Restelli. 2021. Subgaussian and Dierentiable Importance Sampling for O-Policy Evaluation and Learning. Advances in Neural Information Processing Systems 34 (2021). [19] Fabian Pedregosa, Gaël V aroquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer , Ron W eiss, Vincent Dubourg, Jake Vanderplas, Ale xandre Passos, David Cournapeau, Matthieu Brucher , Matthieu Perrot, and Édouard Duchesnay . 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12 (2011), 2825–2830. [20] Y uta Saito, Himan Abdollahpouri, Jesse Anderton, Ben Carterette , and Mounia Lalmas. 2024. Long-term O-Policy Evaluation and Learning. In Proceedings of the A CM on W eb Conference 2024 . 3432–3443. [21] Y uta Saito, Shunsuke Aihara, Megumi Matsutani, and Y usuke Narita. 2021. Open Bandit Dataset and Pipeline: T owards Realistic and Reproducible O-Policy Evaluation. In Thirty-fth Conference on Neural Information Processing Systems Datasets and Benchmarks Track . [22] Y uta Saito and Thorsten Joachims. 2021. Counterfactual Learning and Evaluation for Recommender Systems: Foundations, Implementations, and Recent Advances. In Proceedings of the 15th ACM Conference on Recommender Systems . 828–830. [23] Y uta Saito and Thorsten Joachims. 2022. O-Policy Evaluation for Large Action Spaces via Embeddings. In International Conference on Machine Learning . PMLR, 19089–19122. [24] Y uta Saito, Qingyang Ren, and Thorsten Joachims. 2023. O-Policy Evaluation for Large Action Spaces via Conjunct Eect Modeling. arXiv preprint (2023). [25] Y uta Saito, Takuma Udagawa, Haruka Kiyohara, Kazuki Mogi, Yusuke Narita, and Kei Tateno. 2021. Evaluating the Robustness of O-Policy Evaluation. In Proceedings of the 15th ACM Conference on Recommender Systems . 114–123. [26] Y uta Saito, Jihan Y ao, and Thorsten Joachims. 2024. POTEC: O-Policy Learning for Large Action Spaces via Two-Stage Policy De composition. arXiv preprint arXiv:2402.06151 (2024). [27] Yi Su, Maria Dimakopoulou, Akshay Krishnamurthy , and Miroslav Dudík. 2020. Doubly Robust O-Policy Evaluation with Shrinkage. In Proceedings of the 37th International Conference on Machine Learning , V ol. 119. PMLR, 9167–9176. [28] Yi Su, Lequn W ang, Michele Santacatterina, and Thorsten Joachims. 2019. Cab: Continuous adaptiv e blending for policy evaluation and learning. In International Conference on Machine Learning , V ol. 84. 6005–6014. [29] Adith Swaminathan and Thorsten Joachims. 2015. Batch learning from logged bandit fee dback through counterfactual risk minimization. The Journal of Machine Learning Research 16, 1 (2015), 1731–1755. [30] Adith Swaminathan and Thorsten Joachims. 2015. Counterfactual risk mini- mization: Learning from logged bandit feedback. In International Conference on Machine Learning . PMLR, 814–823. [31] Adith Swaminathan and Thorsten Joachims. 2015. The Self-Normalized Estimator for Counterfactual Learning. Advances in Neural Information Processing Systems 28 (2015). [32] Adith Swaminathan, Akshay Krishnamurthy , Alekh Agarwal, Miro Dudik, John Langford, Damien Jose, and Imed Zitouni. 2017. O-Policy Evaluation for Slate Recommendation. In Advances in Neural Information Processing Systems , V ol. 30. 3632–3642. [33] Masatoshi Uehara, Chengchun Shi, and Nathan Kallus. 2022. A review of o- policy evaluation in reinforcement learning. arXiv preprint (2022). [34] Y u-Xiang W ang, Alekh Agarwal, and Miroslav Dudık. 2017. Optimal and adaptive o-policy evaluation in contextual bandits. In International Conference on Machine Learning . PMLR, 3589–3597. [35] Huasen Wu, Rayadurgam Srikant, Xin Liu, and Chong Jiang. 2015. Algorithms with logarithmic or sublinear regr et for constrained contextual bandits. Advances in Neural Information Processing Systems 28 (2015). [36] Y afei Zhao and Long Y ang. 2024. Constrained contextual bandit algorithm for limited-budget recommendation system. Engineering Applications of Articial Intelligence 128 (2024), 107558. [37] W enliang Zhong, Rong Jin, Cheng Y ang, Xiaowei Y an, Qi Zhang, and Qiang Li. 2015. Stock constrained recommendation in tmall. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . 2287–2296. WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. Koichi T anaka et al. A Calculation of gree dy in T able 1 W e present the detailed calculation of the greedy method in Table 1. Let X = { 𝑥 1 , 𝑥 2 , 𝑥 3 } and A = { 30%OFF , 50%OFF , 70%OFF } with expected rewards 𝑞 ( 𝑥 , 𝑎 ) given in T able 1. Let 𝜎 = ( 𝑢 1 , 𝑢 2 , 𝑢 3 ) denote an arrival order of users, where 𝜎 is one of the 3! = 6 possible permutations of X . A greedy allo cation sequentially assigns to each arriving user 𝑢 𝑡 the remaining coupon 𝑎 ∈ A that maximizes 𝑞 ( 𝑢 𝑡 , 𝑎 ) . The total reward under or der 𝜎 is then given by Í 𝑥 ∈ X 𝑞 ( 𝑥 , 𝑎 𝜎 ) , where 𝑎 𝜎 denotes the coupon allocated to 𝑥 under 𝜎 . Assuming all six arrival orders occur uniformly at random, we compute the policy value as 𝑉 ( 𝜋 ) = 1 6 𝜎 𝑥 𝑞 ( 𝑥 , 𝑎 𝜎 ) . W e enumerate all six permutations 𝜎 and record the greedy choices and resulting rewar ds: Arrival order 𝜎 Greedy allocation ( 𝑎, 𝑞 ( 𝑥 , 𝑎 ) ) Í 𝑥 𝑞 ( 𝑥 , 𝑎 𝜎 ) ( 𝑥 1 , 𝑥 2 , 𝑥 3 ) 𝑥 1 → 50% OFF ( 250 ) , 𝑥 2 → 70% OFF ( 120 ) , 𝑥 3 → 30% OFF ( 60 ) 430 ( 𝑥 1 , 𝑥 3 , 𝑥 2 ) 𝑥 1 → 50% OFF ( 250 ) , 𝑥 3 → 70% OFF ( 70 ) , 𝑥 2 → 30% OFF ( 100 ) 420 ( 𝑥 2 , 𝑥 1 , 𝑥 3 ) 𝑥 2 → 50% OFF ( 280 ) , 𝑥 1 → 70% OFF ( 200 ) , 𝑥 3 → 30% OFF ( 60 ) 540 ( 𝑥 2 , 𝑥 3 , 𝑥 1 ) 𝑥 2 → 50% OFF ( 280 ) , 𝑥 3 → 70% OFF ( 70 ) , 𝑥 1 → 30% OFF ( 80 ) 430 ( 𝑥 3 , 𝑥 1 , 𝑥 2 ) 𝑥 3 → 50% OFF ( 100 ) , 𝑥 1 → 70% OFF ( 200 ) , 𝑥 2 → 30% OFF ( 100 ) 400 ( 𝑥 3 , 𝑥 2 , 𝑥 1 ) 𝑥 3 → 50% OFF ( 100 ) , 𝑥 2 → 70% OFF ( 120 ) , 𝑥 1 → 30% OFF ( 80 ) 300 Therefore, w e calculate the p olicy value of the gr eedy method as 𝑉 ( 𝜋 ) = 1 6 𝜎 𝑥 𝑞 𝑥 , 𝑎 𝜎 = 430 + 420 + 540 + 430 + 400 + 300 6 = 420 . B omitted proof Here, we pr ovide the derivations and proofs that are omitted in the main text. B.1 Derivation of p olicy value with limite d supply 𝑉 ( 𝜋 ) in Eq (3) 𝑉 ( 𝜋 ) = E 𝑝 ( 𝑠 1 ) Î 𝑇 𝑡 = 1 𝑝 ( 𝑥 𝑡 ) 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 ,𝑠 𝑡 ) 𝑝 ( 𝑐 𝑡 | 𝑥 𝑡 ,𝑎 𝑡 ) 𝑝 ( 𝑟 𝑡 | 𝑥 𝑡 ,𝑎 𝑡 ) 𝑝 ( 𝑠 𝑡 + 1 | 𝑠 𝑡 ,𝑎 𝑡 ,𝑐 𝑡 ) " 𝑇 𝑡 = 1 𝑐 𝑡 𝑟 𝑡 # = E 𝑝 ( 𝑠 1 ) h 𝑥 1 𝑝 ( 𝑥 1 ) 𝑎 1 𝜋 ( 𝑎 1 | 𝑥 1 , 𝑠 1 ) 𝑐 1 𝑝 ( 𝑐 1 | 𝑥 1 , 𝑎 1 ) 𝑟 1 𝑝 ( 𝑟 1 | 𝑥 1 , 𝑎 1 ) 𝑠 2 𝑝 ( 𝑠 2 | 𝑠 1 , 𝑎 1 , 𝑐 1 ) 𝑐 1 𝑟 1 + 𝑥 2 𝑝 ( 𝑥 2 ) 𝑎 2 𝜋 ( 𝑎 2 | 𝑥 2 , 𝑠 2 ) 𝑐 2 𝑝 ( 𝑐 2 | 𝑥 2 , 𝑎 2 ) 𝑟 2 𝑝 ( 𝑟 2 | 𝑥 2 , 𝑎 2 ) 𝑠 3 𝑝 ( 𝑠 3 | 𝑠 2 , 𝑎 2 , 𝑐 2 ) 𝑐 2 𝑟 2 + · · · i = E 𝑝 ( 𝑠 1 ) h 𝑥 1 𝑝 ( 𝑥 1 ) 𝑎 1 𝜋 ( 𝑎 1 | 𝑥 1 , 𝑠 1 ) 𝑝 ( 𝑐 1 = 1 | 𝑥 1 , 𝑎 1 ) 𝑟 1 𝑝 ( 𝑟 1 | 𝑥 1 , 𝑎 1 ) 𝑠 2 𝑝 ( 𝑠 2 | 𝑠 1 , 𝑎 1 , 𝑐 1 = 1 ) 𝑟 1 + 𝑥 2 𝑝 ( 𝑥 2 ) 𝑎 2 𝜋 ( 𝑎 2 | 𝑥 2 , 𝑠 2 ) 𝑝 ( 𝑐 2 = 1 | 𝑥 2 , 𝑎 2 ) 𝑟 2 𝑝 ( 𝑟 2 | 𝑥 2 , 𝑎 2 ) 𝑠 3 𝑝 ( 𝑠 3 | 𝑠 2 , 𝑎 2 , 𝑐 2 = 1 ) 𝑟 2 + · · · i (12) = E 𝑝 ( 𝑠 1 ) h 𝑥 1 𝑝 ( 𝑥 1 ) 𝑎 1 𝜋 ( 𝑎 1 | 𝑥 1 , 𝑠 1 ) 𝑝 ( 𝑐 1 = 1 | 𝑥 1 , 𝑎 1 ) 𝑟 1 𝑝 ( 𝑟 1 | 𝑥 1 , 𝑎 1 ) 𝑟 1 + 𝑥 2 𝑝 ( 𝑥 2 ) 𝑎 2 𝜋 ( 𝑎 2 | 𝑥 2 , 𝑠 2 ) 𝑝 ( 𝑐 2 = 1 | 𝑥 2 , 𝑎 2 ) 𝑟 2 𝑝 ( 𝑟 2 | 𝑥 2 , 𝑎 2 ) 𝑟 2 + · · · i (13) = E 𝑝 ( 𝑠 1 ) h 𝑥 1 𝑝 ( 𝑥 1 ) 𝑎 1 𝜋 ( 𝑎 1 | 𝑥 1 , 𝑠 1 ) 𝑝 ( 𝑐 1 = 1 | 𝑥 1 , 𝑎 1 ) 𝑞 𝑟 1 ( 𝑥 1 , 𝑎 1 ) + 𝑥 2 𝑝 ( 𝑥 2 ) 𝑎 2 𝜋 ( 𝑎 2 | 𝑥 2 , 𝑠 2 ) 𝑝 ( 𝑐 2 = 1 | 𝑥 2 , 𝑎 2 ) 𝑞 𝑟 2 ( 𝑥 2 , 𝑎 2 ) + · · · i = E 𝑝 ( 𝑠 1 ) h 𝑇 𝑡 = 1 𝑥 𝑡 𝑝 ( 𝑥 𝑡 ) 𝑎 𝑡 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 , 𝑠 𝑡 ) 𝑝 ( 𝑐 𝑡 = 1 | 𝑥 𝑡 , 𝑎 𝑡 ) 𝑞 𝑟 𝑡 ( 𝑥 𝑡 , 𝑎 𝑡 ) i = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 𝑡 ) 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 ,𝑠 𝑡 ) h 𝑞 𝑐 𝑡 ( 𝑥 𝑡 , 𝑎 𝑡 ) 𝑞 𝑟 𝑡 ( 𝑥 𝑡 , 𝑎 𝑡 ) i O-Policy Learning with Limited Supply WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 𝑡 ) 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 ,𝑠 𝑡 ) h 𝑞 ( 𝑥 𝑡 , 𝑎 𝑡 ) i = E 𝑝 ( 𝑠 1 ) h 𝑇 𝑡 = 1 𝑥 𝑡 𝑝 ( 𝑥 𝑡 ) 𝑎 𝑡 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 , 𝑠 𝑡 ) 𝑝 ( 𝑐 𝑡 = 1 | 𝑥 𝑡 , 𝑎 𝑡 ) 𝑞 𝑟 𝑡 ( 𝑥 𝑡 , 𝑎 𝑡 ) i = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 𝑡 ) 𝜋 ( 𝑎 𝑡 | 𝑥 𝑡 ,𝑠 𝑡 ) [ 𝑞 ( 𝑥 𝑡 , 𝑎 𝑡 ) ] , where we utilized that 𝑐 is binar y , and 𝑝 ( 𝑠 𝑡 + 1 | 𝑠 𝑡 , 𝑎 𝑡 , 𝑐 𝑡 = 1 ) is deterministic in Eq. (12) and (13), respectively . B.2 Derivation of 𝑉 ( 𝜋 greedy ) in Eq. (6) 𝑉 ( 𝜋 greedy ) = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 ) 𝜋 greedy ( 𝑎 | 𝑥,𝑠 𝑡 ) [ 𝑞 ( 𝑥 , 𝑎 ) ] = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 ) 𝑎 ∈ A 𝑠 𝑡 𝜋 greedy ( 𝑎 | 𝑥 , 𝑠 𝑡 ) 𝑞 ( 𝑥 , 𝑎 ) = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 ) 𝑎 ∈ A 𝑠 𝑡 𝑞 ( 𝑥 , 𝑎 ) I { 𝑎 = 𝑎 ( 𝑡 ) } = 𝑇 𝑡 = 1 E 𝑝 ( 𝑠 1 ) 𝑝 ( 𝑥 ) 𝑞 ( 𝑥 , 𝑎 ( 𝑡 ) ) = 𝐾 𝑘 = 1 E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] , (14) where we use 𝑝 ( 𝑠 1 ) = 1 and 𝑎 ( 𝑡 ) = 𝑎 𝑘 and in Eq. (14). B.3 Derivation of 𝑉 ( 𝜋 𝑗 ,𝑘 ) in Eq. (7) 𝑉 ( 𝜋 𝑗 ,𝑘 ) = 𝑝 ( 𝑥 𝑗 ) 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 ) + 𝑉 ( 𝜋 greedy , A / 𝑎 𝑘 ) + 𝑥 ∈ X / 𝑥 𝑗 𝑝 ( 𝑥 ) 𝑞 ( 𝑥 , 𝑎 1 ) + 𝑉 ( 𝜋 greedy , A / 𝑎 1 ) = 𝑝 ( 𝑥 𝑗 ) 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 ) + 𝑉 ( 𝜋 greedy ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] + 𝑥 ∈ X / 𝑥 𝑗 𝑝 ( 𝑥 ) 𝑞 ( 𝑥 , 𝑎 1 ) + 𝑉 ( 𝜋 greedy ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 1 ) ] = 𝑝 ( 𝑥 𝑗 ) 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 ) + 𝑉 ( 𝜋 greedy ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] + ( ( ( ( ( ( E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 1 ) ] + 𝑉 ( 𝜋 greedy ) − ( ( ( ( ( ( E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 1 ) ] − 𝑝 ( 𝑥 𝑗 ) 𝑞 ( 𝑥 𝑗 , 𝑎 1 ) + 𝑉 ( 𝜋 greedy ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 1 ) ] = 𝑝 ( 𝑥 𝑗 ) 𝑞 ( 𝑥 𝑗 , 𝑎 𝑘 ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] − ( 𝑞 ( 𝑥 𝑗 , 𝑎 1 ) − E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 1 ) ] ) + 𝑉 ( 𝜋 greedy ) , where 𝑉 ( 𝜋 greedy , A / 𝑎 ′ 𝑘 ) = Í 𝐾 𝑘 = 1 E 𝑝 ( 𝑥 ) [ 𝑞 ( 𝑥 , 𝑎 𝑘 ) ] I { 𝑘 ≠ 𝑘 ′ } . C EXTEN TION TO F AIRNESS Future work may need to incorp orate fairness-aware objectives into OPLS to balance eciency with equity among users, rather than focusing solely on revenue maximization. While addr essing such fairness concerns is outside the scope of this paper , if one aims to deal with it, it is indeed possible to extend OPLS to ensure fairness across users by intr o ducing a weighting parameter , 𝛽 ∈ [ 0 , 1 ] , into the decision rule. Specically , we can modify OPLS to select the action that maximizes the estimated re ward minus a beta-weighted term repr esenting the average rewar d across all users: 𝜋 OPLS ( 𝑎 𝑡 | 𝑥 𝑡 , 𝑠 𝑡 ) = 1 if 𝑎 𝑡 = argmax 𝑎 ∈ A 𝑠 𝑡 ( ˆ 𝑞 ( 𝑥 𝑡 , 𝑎 ) − 𝛽 · 1 𝑛 𝑛 𝑖 = 1 ˆ 𝑞 ( 𝑥 𝑖 , 𝑎 ) ) 0 otherwise . This allows beta to smoothly control the trade-o between individual optimality and global optimality . D DET AILED EXPERIMEN T SET TINGS AND RESULTS D .1 Synthetic Experiments Detailed Setup. W e describe synthetic experiment settings in detail. In the synthetic experiments, we dene a click probability 𝑞 𝑐 ( 𝑥 , 𝑎 ) and an action value 𝑞 𝑟 ( 𝑥 , 𝑎 ) as follows. 𝑞 𝑐 ( 𝑥 , 𝑎 ) = 𝜆 · 𝑓 𝑐 ( 𝑥 , 𝑎 ) + ( 1 − 𝜆 ) · 𝑔 𝑐 ( 𝑥 , 𝑎 ) , WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates. Koichi T anaka et al. 𝑞 𝑟 ( 𝑥 , 𝑎 ) = 𝜆 · 𝑓 𝑟 ( 𝑥 , 𝑎 ) + ( 1 − 𝜆 ) · 𝑔 𝑟 ( 𝑥 , 𝑎 ) , where 𝑔 ( 𝑥 , 𝑎 ) is a re ward function that satises 𝑔 ( 𝑥 , 𝑎 𝑘 ) ≥ 𝑔 ( 𝑥 , 𝑎 𝑘 + 1 ) for all users. W e synthesize 𝑓 𝑐 and 𝑓 𝑟 using obp.dataset.logistic_reward_function and obp.dataset.linear_re ward_function from OpenBanditPipeline [ 21 ], respectively . T o construct 𝑔 , we then sample elements of 𝑔 from a uniform distribution with range [ 0 , max ( 𝑓 ) ] , and sort them in descending order . Figure 7: Relative policy values var ying max sup- ply ( 𝑠 𝑚𝑎𝑥 ) Additional Result. Figure 7 reports relativ e policy values varying the max- imum supply 𝑠 𝑚𝑎𝑥 with naive estimation of A sold and A unsold . The number of actions is set to | A | = 100 , the popularity of actions is 𝜆 = 0 . 5 and 𝑇 = 2500 . In Figure 7, we observe that the relative policy values gradually de cr ease and converge to 1. This result is consistent with Figure 5, even though OPLS’ performance with the naive estimation is slightly worse than with the straight- forward estimation. Figure 7 suggests that OPLS with the naive estimation of sold actions pr ovides substantial improv ements in policy values with a reduction of computational costs. D .2 Real- W orld Experiments Detailed Setup. W e describe the real-world experiment settings on KuaiRec [ 9 ] in detail. KuaiRec has user features and user-item interactions which are almost fully obser ved with nearly 100% density for the subset of its users and items. W e consider user features as contexts 𝑥 , where we reduce feature dimensions based on PCA implemented in scikit-learn [ 19 ]. Then, we consider the user-item interactions 𝑟 as the action value 𝑞 𝑟 ( 𝑥 , 𝑎 ) . Since users swipe past videos without clicking in the vide o-sharing app , we set the click probability 𝑞 𝑐 ( 𝑥 , 𝑎 ) to 1 for every user–item pair ( 𝑥 , 𝑎 ) . In this setting, we sample a rewar d 𝑟 from a truncated normal distribution with mean 𝑞 𝑟 ( 𝑥 , 𝑎 ) and standard deviation 𝜎 = 1 . 0 . W e dene the logging policy based on the expe cted re ward function 𝑞 ( 𝑥 , 𝑎 ) as follows. 𝜋 0 ( 𝑎 𝑡 | 𝑥 𝑡 , 𝑠 𝑡 ) = exp ( 𝛽 · ˆ 𝑞 ( 𝑥 𝑡 , 𝑎 𝑡 ) ) Í 𝑎 ′ ∈ A 𝑠 𝑡 exp ( 𝛽 · ˆ 𝑞 ( 𝑥 𝑡 , 𝑎 ′ ) ) , (15) where we use 𝛽 = 1 . 0 , ˆ 𝑞 ( 𝑥 , 𝑎 ) = 𝑞 ( 𝑥 , 𝑎 ) + N ( 0 , 5 . 0 ) and 𝑞 ( 𝑥 , 𝑎 ) = 𝑞 𝑐 ( 𝑥 , 𝑎 ) · 𝑞 𝑟 ( 𝑥 , 𝑎 ) . Additional results. In Figure 8a, we var y the max supply 𝑠 𝑚𝑎𝑥 from 5 to 30. For computational eciency , we employ the naive method in this experiment. When the max supply 𝑠 max is small (e .g., 5 or 10), almost all items are sold out. As 𝑠 max increases further , the supply constraint becomes less restrictive, and the limited-supply setting gradually reduces to the NO limited supply setting. W e obser v ed that even when the naive method is employ e d, the impr ovement becomes more signicant when the max supply 𝑠 𝑚𝑎𝑥 is small. The naive method demonstrates performance equivalent to that of the conventional greedy method, when sucient items are available. Figure 8b, we vary the number of users. W e xed the number of actions | A | = 1000 . W e observe a trend similar to that in gure 4b, where the relative policy values gradually increase as the number of users increases. This is because, as the number of users increases, high-re ward items that improve the policy value become scarce, emphasizing the need to consider limited supply . (a) Relative policy values var ying max supply ( 𝑠 𝑚𝑎𝑥 ) (b) Relative policy values varying the number of users Figure 8: Comparisons of relative p olicy values with var ying (a) max supply ( 𝑠 𝑚𝑎𝑥 ) and ( b) the number of users using the true expected reward 𝑞 ( 𝑥 , 𝑎 ) in b oth cases. For ( b), the period 𝑇 is suciently large and all items are sold out.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment