선형 혼합 CMDP에서 적대적 보상에 맞선 근접 최적 프라임 듀얼 학습 알고리즘
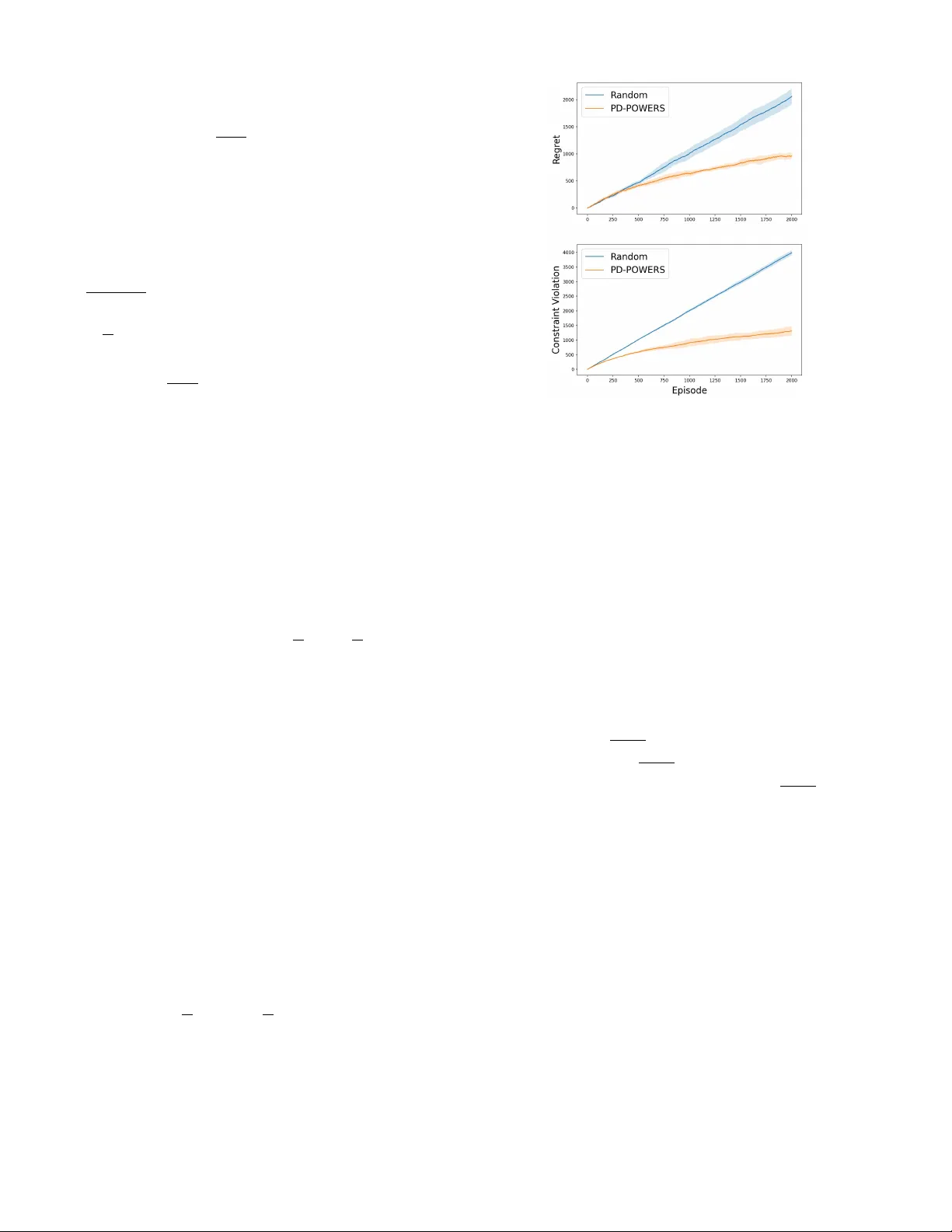
본 논문은 선형 혼합 구조를 갖는 유한‑ horizon CMDP에서 보상이 매 회마다 적대적으로 바뀌는 상황을 다룬다. 저자는 전 정보 피드백과 미지의 전이 커널을 전제로, 정규화된 듀얼 업데이트와 가중치 리지 회귀 기반 파라미터 추정을 결합한 프라임‑듀얼 정책 최적화 알고리즘 PD‑POWERS를 제안한다. 이 알고리즘은 regret와 제약 위반을 각각 \(\widetilde{O}(\sqrt{d^{2}H^{3}K})\) 로 제한하며, 이는 기존…
저자: Kihyun Yu, Seoungbin Bae, Dabeen Lee
본 논문은 “선형 혼합 제약 마코프 결정 과정(linear mixture CMDP)”이라는 모델을 정의하고, 이 모델에서 **적대적 보상(adversarial rewards)** 과 **고정된 제약 함수(constraint)** 가 동시에 존재하는 상황을 다룬다. 모델은 유한‑horizon(에피소드 길이 H)이며, 매 에피소드 k마다 적대자(adversary)가 보상 함수 \(r_k=\{r_{k,h}\}_{h=1}^H\) 를 임의로 선택하고, 에피소드 종료 후 전체 보상 정보를 전량 제공한다(full‑information feedback). 제약 함수 \(g=\{g_h\}_{h=1}^H\) 는 모든 에피소드에 걸쳐 고정이며, 슬레이터 조건을 만족하는 정책 \(\bar\pi\) 가 존재한다는 가정을 둔다(슬레이터 상수 \(\gamma>0\)). 전이 커널은 **선형 혼합 구조**를 갖는데, 즉 각 단계 h마다 알려진 피처 매핑 \(\phi(s'|s,a)\in\mathbb R^d\) 와 미지의 파라미터 \(\theta_h^\ast\) 로 \(\displaystyle P_h(s'|s,a)=\langle\phi(s'|s,a),\theta_h^\ast\rangle\) 로 표현된다. 파라미터는 \(\|\theta_h^\ast\|_2\le B\) 로 제한되고, 피처는 \(\|\phi_V(s,a)\|_2\le1\) 를 만족한다(여기서 \(\phi_V(s,a)=\sum_{s'}\phi(s'|s,a)V(s')\)).
목표는 **레지듀(Regret)** 와 **제약 위반(Constraint Violation)** 을 동시에 최소화하는 정책 시퀀스 \(\{\pi_k\}_{k=1}^K\) 를 학습하는 것이다. 레지듀는 \(\displaystyle \text{Reg}(K)=\sum_{k=1}^K\bigl
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기