Near-Optimal Primal-Dual Algorithm for Learning Linear Mixture CMDPs with Adversarial Rewards
We study safe reinforcement learning in finite-horizon linear mixture constrained Markov decision processes (CMDPs) with adversarial rewards under full-information feedback and an unknown transition kernel. We propose a primal-dual policy optimizatio…
Authors: Kihyun Yu, Seoungbin Bae, Dabeen Lee
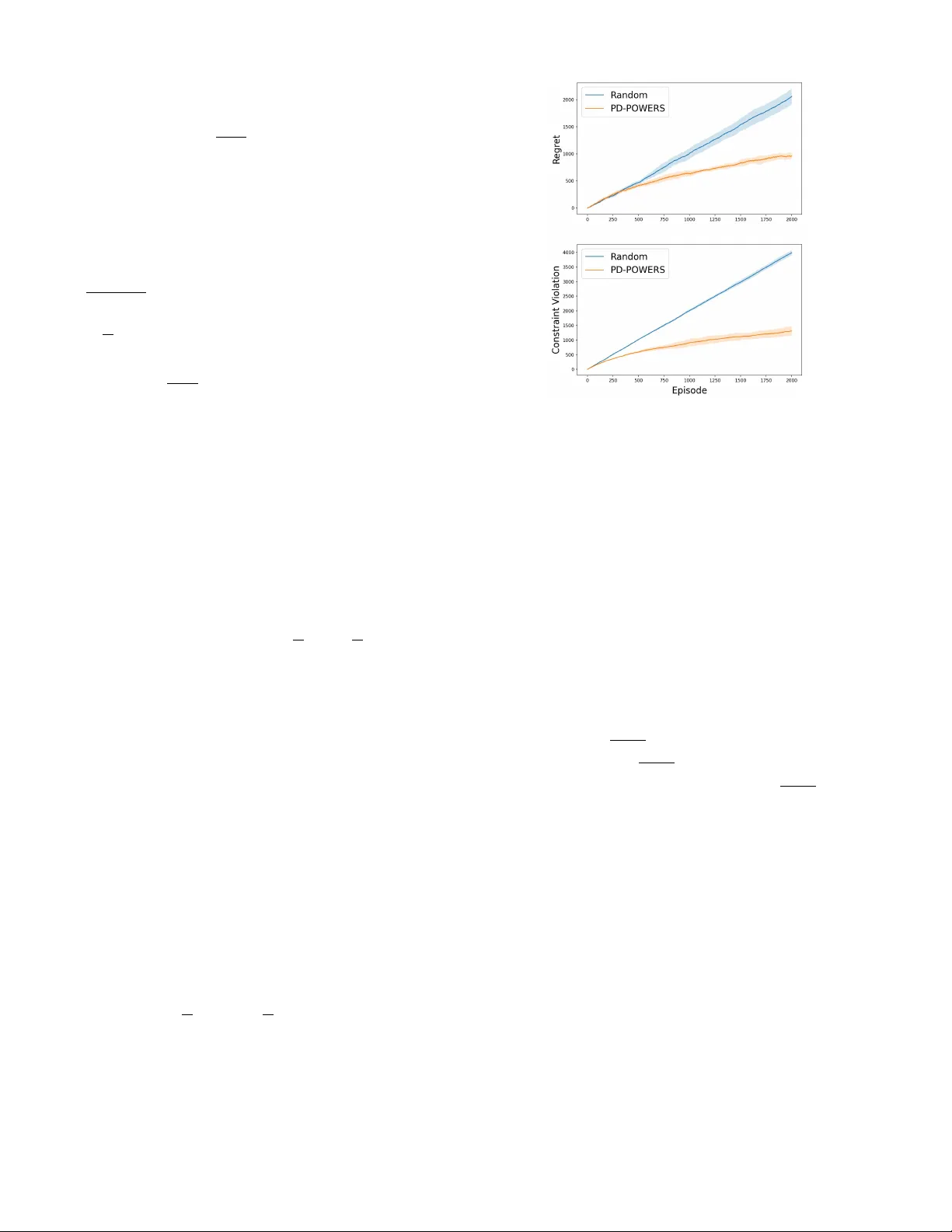
Near -Optimal Primal-Dual Algorithm f or Learning Linear Mixtur e CMDPs with Adversarial Rewards Kihyun Y u, Seoungbin Bae Department of Industrial and Systems Engineering, KAIST { khyu99, sbbae31 } @kaist.ac.kr Dabeen Lee* Department of Mathematical Sciences, Seoul National Univ ersity dabeenl@snu.ac.kr Abstract — W e study safe reinf orcement learning in finite- horizon linear mixture constrained Mark ov decision processes (CMDPs) with adversarial rewards under full-inf ormation feed- back and an unknown transition ker nel. W e propose a primal- dual policy optimization algorithm that achieves regret and constraint violation bounds of e O ( √ d 2 H 3 K ) under mild condi- tions, where d is the featur e dimension, H is the horizon, and K is the number of episodes. T o the best of our knowledge, this is the first pro vably efficient algorithm f or linear mixture CMDPs with adv ersarial r ewards. In particular , our regr et bound is near -optimal, matching the known minimax lower bound up to logarithmic factors. The key idea is to introduce a r egularized dual update that enables a drift-based analysis. This step is essential, as strong duality-based analysis cannot be directly applied when reward functions change across episodes. In addition, we extend weighted ridge r egression–based parameter estimation to the constrained setting, allowing us to construct tighter confidence intervals that are crucial for deriving the near -optimal regr et bound. I . I N T R O D U C T I O N In this paper , we study online linear mixture constrained Markov decision processes (CMDPs) with adversarial re- wards. A CMDP can be described by the following standard formulation: 1 max π V r , π 1 ( s 1 ) subject to V g , π 1 ( s 1 ) ≥ b , (1) where π denotes a policy , V r , π 1 ( s 1 ) = E π [ ∑ H h = 1 r h ( s h , a h ) | s 1 ] , V g , π 1 ( s 1 ) = E π [ ∑ H h = 1 g h ( s h , a h ) | s 1 ] , and b denotes the constraint threshold. Recently , a large number of algorithms for learning CMDPs have been proposed [1]. Howe ver , many existing ap- proaches are limited to settings with tabular state spaces [2], and their theoretical guarantees do not readily extend to large state spaces. T o address scalability , one common direction in RL is to consider linear function approximation, where transition kernels admit a linear representation. In the CMDP literature, [3]–[6] proposed algorithms in this setting; ho w- ev er, these works considered fixed re wards and constraints and thus could not capture non-stationary environments. T o address this limitation, more recently , [7], [8] proposed algorithms for non-stationary en vironments; howe ver , [7] *Additional affiliations: Research Institute of Mathematics, Seoul Na- tional Univ ersity; Interdisciplinary Program in Artificial Intelligence, Seoul National University; K orea Institute for Advanced Study . 1 W e note that ( 1 ) represents the standard CMDP formulation; the formal definition of linear mixture CMDPs with adversarial rewards will be introduced in Section II . required the variation budget—a quantity that characterizes the change in a CMDP—to be known and bounded, and [8] only attained suboptimal regret and violation bounds. In summary , the existing algorithms for safe RL with linear function approximation either suffer from suboptimal regret guarantees or rely on restrictiv e assumptions, such as sta- tionarity or a bounded variation b udget. Motiv ated by these limitations, we design an algorithm for linear mixture CMDPs with adversarial rew ards that achiev es near-optimal regret bounds. In this setting, the linear mixture structure enables function approximation, while adversarial rew ards capture non-stationary en vironments. This goal is particularly challenging. Specifically , when rew ards change arbitrarily , strong duality-based analysis— a key tool in previous works [3], [4]—cannot be directly applied. Moreov er , achieving the optimal sample complexity requires constructing tighter confidence intervals. Despite these challenges, our main contributions are as follows. • W e propose a prov ably efficient primal-dual policy optimization algorithm for finite-horizon linear mixture CMDPs with adversarial re ward functions under full- information feedback, a fixed constraint, and an un- known transition k ernel. • Our algorithm achiev es regret and constraint violation bounds of e O ( √ d 2 H 3 K ) . Here, d is the feature dimen- sion, H is the horizon, and K is the number of episodes. W e emphasize that our regret bound is near-optimal in the sense that it matches the kno wn minimax regret lower bound for unconstrained linear mixture MDPs up to logarithmic factors [9]. • The key idea of our algorithm is to combine primal- dual policy optimization with (i) a regularized dual update that enables a drift-based analysis, which does not rely on strong duality , and (ii) weighted ridge regression–based parameter estimation to obtain tighter confidence intervals, which are crucial for attaining near-optimal re gret bounds. In T able I , we compare algorithms for safe RL with linear function approximation. [10]–[12] consider infinite-horizon linear CMDPs, and [13] studies q π -realizable CMDPs. Al- though these works fall under safe RL with linear function approximation, their settings differ significantly from ours. T ABLE I: Comparison of safe RL with linear function approximation. Algorithm MDP Setting Rew ard Reg. & V io. [3] Linear Mixture Fixed e O ( √ d 2 H 4 K ) [4] Linear Fixed e O ( √ d 3 H 4 K ) [8] Linear Adversarial e O ( poly ( d , H ) K 3 / 4 ) Ours Linear Mixture Adversarial e O ( √ d 2 H 3 K ) A. Additional Related W orks W e provide additional prior works on learning CMDPs. [14]–[20] propose online algorithms for tabular CMDPs. [21]–[24] are particularly relev ant to our work as they con- sider adversarial rewards; howe ver , their results are restricted to the tabular setting. Beyond the tabular case, several works study CMDPs with function approximation. In particular , [25]–[28] focus on instantaneous constraints, where the con- straint must be satisfied at each step rather than in e xpectation ov er the entire trajectory . I I . P R O B L E M F O R M U L A T I O N Notation. F or a positi ve inte ger n , let [ n ] = { 1 , . . . , n } . For x ∈ R d , let ∥ x ∥ A = √ x ⊤ Ax for some positiv e definite matrix A ∈ R d × d . F or a , b ∈ R such that a ≤ b , let [ a , b ] = { x ∈ R : a ≤ x ≤ b } , let [ · ] + = max {· , 0 } , and let [ · ] [ a , b ] = max { min {· , b } , a } . Let I ∈ R d × d denote the identity matrix, let 0 0 0 ∈ R d denote the all-0 vector , and let ⟨· , ·⟩ denote the inner product. Let ∆ ( A ) denote the probability simplex ov er set A . Finite-Horizon CMDP . W e consider a finite-horizon CMDP with adversarial re wards and a fixed constraint function. A finite-horizon CMDP is defined by M = ( S , A , H , P , r , g , b , s 1 ) , where S is the finite state space, A is the finite action space, and H is the horizon. The collection of unkno wn transition kernels is denoted by P = { P h } h ∈ [ H ] , where P h ( s ′ | s , a ) is the probability of transitioning from state s to state s ′ by taking action a at step h . The collections of reward and constraint functions are denoted by r = { r k h } h ∈ [ H ] , k ∈ [ K ] and g = { g h } h ∈ [ H ] , where r k h , g h : S × A → [ 0 , 1 ] for each h , k . The constraint threshold is denoted by b ∈ [ 0 , H ] , and s 1 is the fixed initial state. W e assume adversarial deterministic rewards with full- information feedback, while the deterministic constraint function is fixed and kno wn. 2 . In particular , at the beginning of each episode k , an adversary chooses an arbitrary rew ard function r k = { r k h } h ∈ [ H ] . The full information of r k is rev ealed at the end of episode k . On the other hand, the constraint function g = { g h } h ∈ [ H ] is assumed to be fixed across all k ∈ [ K ] and known. The agent interacts with the en vironment as follo ws. At the beginning of episode k , the agent selects a policy { π k h } h ∈ [ H ] , where π k h ( a | s ) denotes the probability of taking action a at state s and step h . During episode k , for each step h , the agent observes the current state s k h and selects an action a k h ∼ π k h ( ·| s k h ) . The next state is then sampled as s k h + 1 ∼ P h ( ·| s k h , a k h ) . At the end of the episode, r k is rev ealed to the agent. 2 As in [3], [4], we assume the constraint function is fixed and determin- istic for simplicity . Our results can be extended to an unknown stochastic constraint function with linear structure under bandit feedback. Giv en P and π , we define the value function V ℓ, π h ( s ) = E π [ ∑ H j = h ℓ j ( s j , a j ) | s h = s ] , where ℓ = { ℓ h } h ∈ [ H ] is an y function such that ℓ h : S × A → [ 0 , 1 ] , and E π [ · ] denotes the expec- tation over the trajectory ( s h , a h , . . . , s H , a H ) induced by P and π . Likewise, we define the Q -function as Q ℓ, π h ( s , a ) = E π [ ∑ H j = h ℓ j ( s j , a j ) | s h = s , a h = a ] . The goal of the agent is to learn an optimal policy π ∗ ∈ Π for the follo wing optimization problem, where for the set of policies Π = {{ π h } h ∈ [ H ] : π h : S → ∆ ( A ) } : max π ∈ Π K ∑ k = 1 V r k , π 1 ( s 1 ) subject to V g , π 1 ( s 1 ) ≥ b . (2) The performance metrics are defined as follows. Gi ven a sequence of policies { π k } k ∈ [ K ] , we define the regret as Reg ( K ) = ∑ K k = 1 V r k , π ∗ 1 ( s 1 ) − V r k , π k 1 ( s 1 ) , and the constraint violation as V io ( K ) = h ∑ K k = 1 b − V g , π k 1 ( s 1 ) i + . W e introduce additional notations as follows. For any V : S → R , P h V ( s , a ) = ∑ s ′ P h ( s ′ | s , a ) V ( s ′ ) and V h V ( s , a ) = P h V 2 ( s , a ) − ( P h V ( s , a )) 2 . Moreov er , we present the Slater assumption, as in [8]. Assumption 1 (Slater condition): There exists a Slater policy ¯ π such that V g , ¯ π 1 ( s 1 ) ≥ b + γ , where γ > 0 is the Slater constant. Note that ¯ π and γ are unknown to the agent. Linear Mixture CMDP . Finally , we introduce the definition of linear mixture CMDPs, adapted from [29]–[31], which we assume throughout the paper . Definition 1 (Linear Mixtur e CMDP): W e say that M is an inhomogeneous, episodic B -bounded linear mixture CMDP if, for each h ∈ [ H ] , there exist a known feature mapping φ : S × A × S → R d and an unknown parame- ter θ ∗ h ∈ R d such that P h ( s ′ | s , a ) = ⟨ φ ( s ′ | s , a ) , θ ∗ h ⟩ for any ( s , a , s ′ ) ∈ S × A × S . Moreov er , we assume that ∥ θ ∗ h ∥ 2 ≤ B and ∥ φ V ( s , a ) ∥ 2 ≤ 1 for all ( s , a , h ) ∈ S × A × [ H ] and any V : S → [ 0 , 1 ] , where φ V ( s , a ) = ∑ s ′ ∈ S φ ( s ′ | s , a ) V ( s ′ ) . I I I . P R O P O S E D A L G O R I T H M In this section, we present our algorithm, called Primal- Dual Policy Optimization With BERnstein bonuS (PD- PO WERS, Algorithm 1 ), tailored for finite-horizon linear mixture CMDPs with adversarial rewards and a fixed con- straint function. Intuiti vely , PD-POWERS can be vie wed as a primal-dual variant of PO WERS, proposed in [9] for the unconstrained setting. A. Challenges in Algorithm Design T o extend an algorithm for the unconstrained problem to the constrained setting, a standard approach is to con- struct a primal-dual variant. In this framework, the primal variable—maximizing a Lagrangian objecti ve—and the dual variable—balancing rew ard maximization and constraint sat- isfaction—are updated alternately . The main challenge lies in the design of the dual update, as previously proposed dual updates do not directly apply to our setting with adversarial rewards. In the fixed-re ward setup, [3], [4] adopt a dual update that naturally leads to Algorithm 1 PD-POWERS Require: regularization parameter λ ; step sizes α , η ; mixing parameter θ ; the constraint function { g h ( · , · ) } h ∈ [ H ] Initialize: ∀ ( h , ℓ ) ∈ [ H ] × { r , g } , b Σ ℓ 1 , h , e Σ ℓ 1 , h ← λ I; b b ℓ 1 , h , e b ℓ 1 , h ← 0 0 0; b θ ℓ 1 , h , e θ ℓ 1 , h ← 0 0 0; V r 1 , H + 1 ( · ) , V g 1 , H + 1 ( · ) ; π 1 h ← π unif ; Y 1 ← 0; 1: f or k = 1 , . . . , K do 2: if k > 1 then 3: Update { π k h } h ∈ [ H ] as in ( 3 ) 4: Update Y k as in ( 4 ) 5: end if 6: for h = 1 , . . . , H do 7: T ake action a k h ∼ π k h ( · | s k h ) 8: Receiv e s k h + 1 ∼ P h ( · | s k h , a k h ) 9: end for 10: Receiv e { r k h ( · , · ) } h ∈ [ H ] 11: for h = H , . . . , 1 do 12: for ℓ = r , g do 13: Compute Q ℓ k , h ( · , · ) as in ( 6 ) 14: V ℓ k , h ( · ) ← ∑ a ∈ A π k h ( a | · ) Q ℓ k , h ( · , a ) 15: Set b θ ℓ k + 1 , h , b Σ ℓ k + 1 , h , b b ℓ k + 1 , h as in ( 8 ) 16: Set e θ ℓ k + 1 , h , e Σ ℓ k + 1 , h , e b ℓ k + 1 , h as in ( 10 ) 17: Set ¯ V h V ℓ k , h + 1 as in ( 9 ) 18: Set E ℓ k , h , ¯ σ ℓ k , h as in ( 11 ), ( 12 ) 19: end for 20: end for 21: end for a strong duality-based analysis. Howe ver , such an analysis becomes non-tri vial when the rew ards v ary across episodes. T o address this issue, our key idea is to introduce a regularized dual update, inspired by [8]. This update enables a drift-based analysis that does not rely on strong duality . In particular , the regularization term induces a negativ e drift in the dual variable, which plays a crucial role in controlling its growth. This justifies the suitability of our dual update in the adversarial-re ward setting. For more details, we refer the reader to III-B and IV -A . B. Description of PD-PO WERS W e now describe PD-POWERS. W e first introduce the policy optimization step, which combines entropy regular - ization with policy perturbation. W e then present the reg- ularized dual update and discuss its role in controlling the dual variable. Finally , we present the parameter estimation procedure based on weighted ridge regression. Policy Optimization (Line 3 ). Our polic y optimization step proceeds in the following two steps: e π k − 1 h ( ·| s ) ← ( 1 − θ ) π k − 1 h ( ·| s ) + θ π unif ( ·| s ) π k h ( ·| s ) ∝ e π k − 1 h ( ·| s ) exp ( α ( Q r k − 1 , h ( s , · ) + Y k − 1 Q g k − 1 , h ( s , · ))) (3) In the first step of ( 3 ), we define e π k − 1 h , which is a perturbed version of π k − 1 h . This step ensures that e π k − 1 h ( a | s ) ≥ θ / | A | for all a ∈ A , and hence keeps e π k − 1 h away from the boundary of the probability simplex. This is essential for controlling the growth of the dual v ariable. W e refer the reader to Section IV for further technical motiv ation. Moreov er , a key diff erence from [8] is that we perturb the policy at ev ery episode. In [8], the perturbation is applied ev ery K 3 / 4 episodes to handle the trade-of f between the cov ering number 3 and the dual variable, which leads to suboptimal dependence on K in the regret. In contrast, since our setting does not require such cov ering number ar guments, it allows more frequent perturbations and yields optimal dependence on K . In the second step of ( 3 ), we perform policy optimization following [32]. Equiv alently , it can be rewritten as the follo w- ing online mirror descent (OMD) step over the policy space: π k h ( ·| s ) ∈ arg max π ∈ Π ⟨ π ( ·| s ) , Q r k − 1 , h ( s , · ) + Y k − 1 Q g k − 1 , h ( s , · ) ⟩ − 1 α D ( π ( ·| s ) || e π k − 1 h ( ·| s )) , where D ( ·||· ) denotes the KL div er- gence, and Y k − 1 is the dual variable that balances between rew ard maximization and constraint satisfaction. The KL regularizer encourages the updated policy to remain close to e π k − 1 h . Regularized Dual Update (Line 4 ). Next, we present the dual update, inspired by [8]: Y k ← ( 1 − α η H 3 ) Y k − 1 + η ( b − V g k − 1 , 1 ( s 1 ) − α H 3 − 2 θ H 2 ) + . (4) The dual variable Y k increases when the estimated constraint value falls below the threshold b and decreases otherwise. Thus, it adaptively balances rew ard maximization and con- straint satisfaction. For comparison, we recall the dual update used in [3], [4] for the fixed-re ward setup: Y k ← h Y k − 1 + η ( b − V g k − 1 , 1 ( s 1 )) i [ 0 , 2 γ ] . (5) In this update, the dual variable is upper clipped by 2 / γ to prevent it from di ver ging. The threshold 2 / γ is chosen because it serves as a strict upper bound on the optimal dual variable under Assumption 1 . In contrast, our update ( 4 ) introduces additional regularizers − α η H 3 Y k − 1 − η ( α H 3 + 2 θ H 2 ) , instead of relying on upper clipping. Hence, our update does not require knowledge of γ . Parameter Estimation (Lines 11 - 19 ). T o obtain tighter confidence intervals, we extend the weighted ridge re- gression technique—pre viously used in unconstrained set- tings [31]—to our constrained setting. This differs from [3], which uses standard ridge regression and does not account for the conditional v ariance of the next-state value. In con- trast, we employ weighted ridge regression–based parameter estimation, where the weights are chosen as estimates of this variance, enabling Bernstein-type concentration inequalities and yielding optimal dependence on H in the regret bound. Before describing the weighted ridge regression step, we introduce the basic structure of the Q -function estimates, 3 Note that [8] considers linear CMDPs, while our setting is linear mixture CMDPs. In their setting, the covering number of the value function class must be controlled to ensure uniform con vergence over all possible value function estimates induced by their algorithm. denoted by Q r k , h , Q g k , h . These estimates are computed by backward induction from h = H to 1 as follows: Q r k , h ( · , · ) ← r k h ( · , · ) + ⟨ b θ r k , h , φ V r k , h + 1 ( · , · ) ⟩ + b β k φ V r k , h + 1 ( · , · ) ( b Σ r k , h ) − 1 [ 0 , H − h + 1 ] , Q g k , h ( · , · ) ← g h ( · , · ) + ⟨ b θ g k , h , φ V g k , h + 1 ( · , · ) ⟩ + b β k φ V g k , h + 1 ( · , · ) ( b Σ g k , h ) − 1 [ 0 , H − h + 1 ] , (6) where the optimistic bonus parameter b β k is giv en by b β k = 8 q d log ( 1 + k / λ ) log ( 8 H k 2 / δ ) + 4 √ d log ( 8 H k 2 / δ ) + √ λ B The intuition behind the Q -function estimates is as follows. Giv en a policy π k , we expect that Q r k , h ( s , a ) ≈ Q r k , π k h ( s , a ) = r k h ( s , a ) + P h V r k , π k h + 1 ( s , a ) , where the equality follows from the Bellman equation. Assuming b θ r k , h ≈ θ ∗ h , by the definition of linear mixture CMDPs (Definition 1 ), we hav e ⟨ b θ r k , h , φ V r k , h + 1 ( s , a ) ⟩ ≈ ⟨ θ ∗ h , φ V r k , h + 1 ( s , a ) ⟩ = ∑ s ′ ⟨ θ ∗ h , φ ( s ′ | s , a ) ⟩ V r k , h + 1 ( s ′ ) = P h V r k , h + 1 ( s , a ) . Moreov er , b β k ∥ φ V r k , h + 1 ( · , · ) ∥ ( b Σ r k , h ) − 1 serves as an optimistic bonus term to promote exploration. These arguments validate the design of Q r k , h in ( 6 ), and can be applied to Q g k , h as well. Now , we present how to obtain b θ r k , h and b θ g k , h through weighted ridge regression, which approximate θ ∗ h . For ℓ ∈ { r , g } , we define b θ ℓ k , h ← arg min θ ∈ R d λ ∥ θ ∥ 2 2 + k − 1 ∑ τ = 1 ⟨ φ V ℓ τ , h + 1 ( s τ h , a τ h ) , θ ⟩ − V ℓ τ , h + 1 ( s τ h + 1 ) 2 ( ¯ σ ℓ τ , h ) 2 , (7) where ( ¯ σ ℓ τ , h ) 2 is an upper bound on V h V ℓ τ , h + 1 ( s τ h , a τ h ) . Equa- tion ( 7 ) admits the following closed form: for ℓ ∈ { r , g } , b θ ℓ k , h ← b Σ ℓ k , h − 1 b b ℓ k , h , b Σ ℓ k , h ← λ I + k − 1 ∑ τ = 1 ¯ σ ℓ τ , h − 2 φ V ℓ τ , h + 1 ( s τ h , a τ h ) φ V ℓ τ , h + 1 ( s τ h , a τ h ) ⊤ , b b ℓ k , h ← k − 1 ∑ τ = 1 ¯ σ ℓ τ , h − 2 φ V ℓ τ , h + 1 ( s τ h , a τ h ) V ℓ τ , h + 1 ( s τ h + 1 ) . (8) W e emphasize that the weighted ridge regression in ( 7 ) is useful for handling heteroscedastic noise induced by the time-inhomogeneous transition kernel. Since P h V ℓ k , h + 1 ( s , a ) is not directly observable, we estimate b θ ℓ k , h by regressing the samples V ℓ τ , h + 1 ( s τ h + 1 ) . This introduces a noise term V ℓ τ , h + 1 ( s τ h + 1 ) − P h V ℓ τ , h + 1 ( s τ h , a τ h ) , whose conditional variance V h V ℓ τ , h + 1 ( s τ h , a τ h ) depends on h , resulting in heteroscedastic noise. In such cases, standard ridge regression is statistically inefficient due to the heteroscedastic structure [33]. In con- trast, weighted ridge regression effecti vely accounts for this heteroscedasticity [31], enabling the use of Bernstein-type concentration inequalities and yielding tighter confidence intervals. One remaining question for the parameter estimation step is how to construct ( ¯ σ r k , h ) 2 , ( ¯ σ g k , h ) 2 , which are upper bounds on V h V r k , h + 1 ( s k h , a k h ) , V h V g k , h + 1 ( s k h , a k h ) , respectiv ely . Again, since P h is unknown, we construct the following vari- ance estimate, motiv ated by the relation that V h V ℓ k , h + 1 ( s , a ) = ⟨ φ ( V ℓ k , h + 1 ) 2 ( s , a ) , θ ∗ h ⟩ − ⟨ φ V ℓ k , h + 1 ( s , a ) , θ ∗ h ⟩ 2 : for ℓ ∈ { r , g } , ¯ V h V ℓ k , h + 1 ( · , · ) = h ⟨ φ ( V ℓ k , h + 1 ) 2 , e θ ℓ k , h ( · , · ) ⟩ i [ 0 , H 2 ] − h ⟨ φ V ℓ k , h + 1 , b θ ℓ k , h ( · , · ) ⟩ i 2 [ 0 , H ] . (9) where b θ ℓ k , h is defined in ( 8 ) and e θ ℓ k , h ← e Σ ℓ k , h − 1 e b ℓ k , h , e Σ ℓ k , h ← λ I + k − 1 ∑ τ = 1 φ ( V ℓ τ , h + 1 ) 2 ( s τ h , a τ h ) φ ( V ℓ τ , h + 1 ) 2 ( s τ h , a τ h ) ⊤ , e b ℓ k , h ← k − 1 ∑ τ = 1 φ ( V ℓ τ , h + 1 ) 2 ( s τ h , a τ h )( V ℓ τ , h + 1 ) 2 ( s τ h + 1 ) . (10) Note that ( 10 ) is a consequence of standard ridge re gression with respect to ( V ℓ k , h + 1 ) 2 , so that ⟨ φ ( V ℓ k , h + 1 ) 2 , e θ ℓ k , h ( s , a ) ⟩ ≈ P h ( V ℓ k , h + 1 ) 2 ( s , a ) . Moreover , the following proposition char- acterizes the discrepancy between the variance estimated in ( 9 ) and its true value V h V ℓ k , h + 1 ( · , · ) . Pr oposition 1: For any ( s , a , h , k , ℓ ) ∈ S × A × [ H ] × [ K ] × { r , g } , ¯ V h V ℓ k , h + 1 ( s , a ) − V h V ℓ k , h + 1 ( s , a ) ≤ min H 2 , φ ( V ℓ k , h + 1 ) 2 ( s , a ) ( e Σ ℓ k , h ) − 1 e θ ℓ k , h − θ ∗ h e Σ ℓ k , h + min H 2 , 2 H φ V ℓ k , h + 1 ( s , a ) ( b Σ ℓ k , h ) − 1 b θ ℓ k , h − θ ∗ h b Σ ℓ k , h . Combining this with Theorem 4.1 in [31] implies that ∥ ( e θ ℓ k , h − θ ∗ h ) ∥ e Σ ℓ k , h ≤ e β k , ∥ b θ ℓ k , h − θ ∗ h ∥ b Σ ℓ k , h ≤ ˇ β k , where e β k = 8 H 2 q d log ( 1 + k H 4 / ( d λ )) log ( 8 H k 2 / δ ) + 4 H 2 log ( 8 H k 2 / δ ) + √ λ B , ˇ β k = 8 d q log ( 1 + k / λ ) log ( 8 H k 2 / δ ) + 4 √ d log ( 8 H k 2 / δ ) + √ λ B . Based on these observations, we hav e | ¯ V h V ℓ k , h + 1 ( s , a ) − V h V ℓ k , h + 1 ( s , a ) | ≤ E ℓ k , h , where the offset term E ℓ k , h is defined as follows: for ℓ ∈ { r , g } , E ℓ k , h = min ( H 2 , e β k φ ( V ℓ k , h + 1 ) 2 ( s , a ) ( e Σ ℓ k , h ) − 1 ) + min ( H 2 , 2 H ˇ β k φ V ℓ k , h + 1 ( s , a ) b Σ ℓ k , h − 1 ) . (11) Finally , we present ¯ σ r k , h and ¯ σ g k , h , defined for ℓ ∈ { r , g } as ( ¯ σ ℓ k , h ) 2 = max n H 2 / d , ¯ V h V ℓ k , h + 1 ( s k h , a k h ) + E ℓ k , h o . (12) The effecti veness of our estimates is supported by the following lemma. Lemma 1: For any ( k , h , ℓ ) ∈ [ H ] × [ K ] × { r , g } , with prob- ability at least 1 − 3 δ , θ ∗ h − b θ ℓ k , h b Σ ℓ k , h ≤ b β k , | V h V ℓ k , h + 1 ( s , a ) − ¯ V h V ℓ k , h + 1 ( s , a ) | ≤ E ℓ k , h . Remark 1: The computational complexity of PD- PO WERS is comparable to that of its unconstrained counterpart (PO WERS, [9]). Specifically , it is O ( min { d 3 H K 2 | A | , | S || A | K } + d 3 H K ) with O ( H K ) calls to the integrating oracle O for computing ∑ s ′ ψ ( s ′ ) V ( s ′ ) , where ψ : S → R d satisfies φ ( s ′ | s , a ) = ψ ( s ′ ) ⊙ µ ( s , a ) for some µ : S × A → R d , and ⊙ denotes the component-wise product. For more details, we refer the reader to [9]. I V . A N A L Y S I S In this section, we present our main result (Theorem 1 ), which establishes upper bounds on both the regret and the constraint violation. W e also provide a high-lev el ov erview of the analysis; the full proofs are deferred to the appendix. Theor em 1: Suppose that Assumption 1 holds and K ≥ max { 2 H , H 2 , d 3 H 3 } . Set λ = 1 / B 2 , α = 1 / ( H 2 √ K ) , η = 1 / ( H √ K ) , and θ = 1 / K . W ith probability at least 1 − 6 δ , Reg ( K ) = e O √ d H 4 K + √ d 2 H 3 K + H 5 √ K / γ 2 , V io ( K ) = e O √ d H 4 K + √ d 2 H 3 K + H 3 √ K / γ . Remark 2: The bounds in Theorem 1 depend on the Slater constant γ . Such dependence naturally arises in primal-dual approaches for CMDPs, where controlling the dual variable is essential for enforcing the constraint, as also observed in prior works such as [3], [4], [8]. Moreover , in many practical applications where the feature dimension d is large, this dependence need not be the leading term. In particular, when d = Ω ( H 3 . 5 log | A | / γ 2 ) , the regret bound in Theorem 1 matches the lo wer bound Ω ( √ d 2 H 3 K ) established in [9] 4 up to logarithmic factors. Under this condition on d , the regret bounds are summarized in T able I , highlighting that our algorithm guarantees the lowest regret among these methods. A. Limitations of Str ong Duality-Based Analysis Before presenting the overvie w of our analysis, we explain why the strong duality-based approach induced by ( 5 ) fails when the rew ards vary across episodes. On top of ( 5 ), the strong duality–based analysis [3], [4] begins by upper bounding the following composite regret term for any Y ∈ [ 0 , 2 / γ ] : K ∑ k = 1 V r , π ∗ 1 ( s 1 ) − V r , π k 1 ( s 1 ) + Y K ∑ k = 1 b − V g , π k 1 ( s 1 ) . (13) 4 Note that unconstrained adversarial linear mixture MDPs can be vie wed as a special case of our setting by introducing a trivial constraint. Therefore, the known lower bound Ω ( √ d 2 H 3 K ) for that setting also applies here. The next step is to separate the composite re gret into regret and violation terms. Here, [34] sho ws that the follo wing holds under strong duality: for an optimal policy π ∗ ∈ arg max π V r , π 1 ( s 1 ) s.t. V g , π 1 ( s 1 ) ≥ b and some ∆ k , if V r , π ∗ 1 ( s 1 ) − V r , π k 1 ( s 1 ) + 2 γ b − V g , π k 1 ( s 1 ) ≤ ∆ k , (14) then V r , π ∗ 1 ( s 1 ) − V r , π k 1 ( s 1 ) ≤ ∆ k and b − V g , π k 1 ( s 1 ) ≤ γ 2 ∆ k . (15) Applying this argument for all k ∈ [ K ] yields regret and violation bounds from a bound on ( 13 ). Now , let us examine whether the same argument can be applied in our setting. Since the re wards change ov er k , the analogue of ( 14 ) becomes V r k , π k , ∗ 1 ( s 1 ) − V r k , π k 1 ( s 1 ) + 2 γ b − V g , π k 1 ( s 1 ) ≤ ∆ k , where π k , ∗ ∈ arg max π V r k , π 1 ( s 1 ) s.t. V g , π 1 ( s 1 ) ≥ b for each k . Consequently , as the analogue of ( 13 ), the correspond- ing composite regret must use the sequence { π k , ∗ } k ∈ [ K ] as comparator policies, namely , K ∑ k = 1 V r k , π k , ∗ 1 ( s 1 ) − V r k , π k 1 ( s 1 ) + Y K ∑ k = 1 b − V g , π k 1 ( s 1 ) . Howe ver , obtaining an upper bound on this term is non-trivial unless r k is kno wn before episode k , which is not allowed in the adversarial-rew ard setting. This highlights the limitations of strong duality-based analysis in our setting. B. Our Analysis T o ov ercome these limitations, we establish a drift-based analysis based on ( 4 ), which does not rely on strong duality . As a first step, we provide decompositions of Reg ( K ) and V io ( K ) . Since the optimal policy π ∗ satisfies V g , π ∗ 1 ( s 1 ) ≥ b and Y k ≥ 0, we hav e Reg ( K ) ≤ K ∑ k = 1 V r k , π ∗ 1 ( s 1 ) + Y k V g , π ∗ 1 ( s 1 ) − V r k , 1 ( s 1 ) − Y k V g k , 1 ( s 1 ) + K ∑ k = 1 V r k , 1 ( s 1 ) − V r k , π k 1 ( s 1 ) + K ∑ k = 1 Y k V g k , 1 ( s 1 ) − b , V io ( K ) = K ∑ k = 1 ( b − V g k , 1 ( s 1 )) + K ∑ k = 1 ( V g k , 1 ( s 1 ) − V g , π k 1 ( s 1 )) . Since we employ weighted ridge re gression for parameter estimation, the bias terms appearing in both the regret and violation decompositions admit the following bounds. Lemma 2: Suppose that K ≥ d 3 H 3 . With probability at least 1 − 6 δ , K ∑ k = 1 V r k , h ( s k h ) − V r k , π k h ( s k h ) = e O √ d H 4 K + √ d 2 H 3 K , K ∑ k = 1 V g k , h ( s k h ) − V g , π k h ( s k h ) = e O √ d H 4 K + √ d 2 H 3 K . Next, we focus on ∑ K k = 1 ( b − V g k , 1 ( s 1 )) . By the dual update, K ∑ k = 1 ( b − V g k , 1 ( s 1 )) ≤ Y K + 1 η + α H 3 K ∑ k = 1 Y k + α K H 3 + 2 θ K H 2 . Therefore, it suffices to bound Y k uniformly ov er k . T o this end, we employ drift-based arguments [35], [36]. Based on the observation that our regularizer in ( 4 ) satisfies − α η H 2 ( 1 + Y k ) − 2 η θ H ≤ η ⟨ π k + 1 h − π k h , Q g k , h ⟩ (Lemma 18 ), we establish the following drift inequality: Y 2 k + 1 − Y 2 k 2 ≤ − γ η Y k + C (16) + η α E ¯ π " H ∑ h = 1 D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || π k + 1 h ( ·| s h )) # where C = α η H 3 2 + 2 η H 2 θ + 2 η H 2 + 2 η 2 ( H 2 + α 2 H 6 + 9 η 2 α 2 H 8 K 2 + 4 θ 2 H 4 ) . From ( 16 ), we observe that e π k h is a perturbed policy , and hence the KL div ergence term D ( ¯ π h ( ·| s h ) ∥ e π k h ( ·| s h )) admits a small upper bound. This highlights the necessity of the policy perturbation step. Without this perturbation, the KL div ergence term D ( ¯ π h ( ·| s h ) ∥ π k h ( ·| s h )) could be unbounded, as π k h approaches the boundary of the simple x. With further analysis, we obtain the following bound. Lemma 3: Suppose that Assumption 1 holds and K ≥ max { 2 H , H 2 } . For all k ∈ [ K ] , with probability at least 1 − 6 δ , Y k = e O ( H 2 / γ ) . Since Y k is bounded by Lemma 3 , it follo ws that ∑ K k = 1 Y k V g k , 1 ( s 1 ) − b = e O H √ K + H 5 √ K / γ 2 . The de- tailed deriv ation is deferred to the appendix. T o complete the analysis, it remains to bound ∑ K k = 1 V r k , π ∗ 1 ( s 1 ) + Y k V g , π ∗ 1 ( s 1 ) − V r k , 1 ( s 1 ) − Y k V g k , 1 ( s 1 ) . By Lemma 1 and the value difference lemma (Lemma 1 of [37]), this term can be bounded as K ∑ k = 1 E π ∗ " H ∑ h = 1 ⟨ Q r k , h ( s h , · ) + Y k Q g k , h ( s h , · ) , π ∗ h ( ·| s h ) − π k h ( ·| s h ) ⟩| s 1 # . Moreov er , since we employ the policy optimization ( 3 ), the abov e term can be effecti vely controlled. Specifically , we apply the standard OMD lemma [38], together with the policy perturbation step. Combining these ingredients, we obtain the following lemma. Lemma 4: Let K ≥ max { 2 H , H 2 } . W ith probability at least 1 − 6 δ , K ∑ k = 1 V r k , π ∗ 1 ( s 1 ) + Y k V g , π ∗ 1 ( s 1 ) − V r k , 1 ( s 1 ) − Y k V g k , 1 ( s 1 ) = e O H 5 √ K / γ 2 + H 3 √ K + H 4 / γ . V . N U M E R I C A L E X P E R I M E N T S In Figure 1 , we e valuate PD-PO WERS on a CMDP instance adapted from [9], with modifications including the addition of a constraint. The details of the setting are described below . W e conduct 5 simulations with K = 2 , 000 Fig. 1: Regret and constraint violation of PD-PO WERS. under different random seeds. Each plot shows the av erage, and the shaded regions indicate 95% confidence intervals. As in [9], we compare both the regret and violation of our algorithm with those of a random policy—one that selects a uniformly sampled action at each step. As shown in the figure, our algorithm exhibits sublinear growth in both regret and violation with respect to the number of episodes, while those of the random policy grow linearly . Therefore, the numerical results support our theoretical findings. Let H = 10 and d = 5. Let S = { 0 , . . . , H + 1 } and A = {− 1 , 1 } d − 1 . Let s = 0 be the initial state and b = 6. For s < H , we define P h ( s + 1 | s , a ) = − 0 . 01 · 1 1 1 ⊤ a + 0 . 95 and P h ( H + 1 | s , a ) = 1 − P h ( s + 1 | s , a ) . For s = H or H + 1, we set P h ( s | s , a ) = 1. For s < H , if ⌊ k / 10 ⌋ ≡ 0 mod 2, then r k ( s , a ) = 0 . 4 ∑ d − 1 i = 1 a i + 1 2 ( d − 1 ) , and if ⌊ k / 10 ⌋ ≡ 1 mod 2, then r k ( s , a ) = 0 . 4 ( 1 − ∑ d − 1 i = 1 a i + 1 2 ( d − 1 ) ) . For all k ∈ [ K ] , r k ( H , a ) = 0 and r k ( H + 1 , a ) = 1. Let g ( s , a ) = ∑ d − 1 i = 1 a i + 1 2 ( d − 1 ) if s < H , and g ( s , a ) = 0 otherwise. The code is av ailable at: https://github .com/kihyun-yu/pd-powers. V I . C O N C L U S I O N In this paper, we study online linear mixture CMDPs with adversarial rew ards under full-information feedback and a fixed constraint function. W e propose PD-POWERS, a primal-dual policy optimization algorithm combining a regularized dual update and weighted ridge regression-based parameter estimation. Moreov er , we show that PD-PO WERS achiev es a near-optimal regret bound. Despite these results, sev eral limitations remain. First, when the integration oracle O is not av ailable, the computational complexity may de- pend on | S | , making the algorithm inefficient for large state spaces. Second, the regret and constraint violation bounds become large when γ ≪ 1. Therefore, dev eloping algorithms that remain robust under such degenerate conditions is an important direction for future work. V I I . AC K N O W L E D G M E N T S This work w as supported by the National Research F oun- dation of Korea (NRF) grant (No. RS-2024-00350703) and the Institute of Information & communications T echnology Planning & e valuation (IITP) grants (No. IITP-2026-RS- 2024-00437268) and (No. RS-2021-II211343, Artificial In- telligence Graduate School Program (Seoul National Uni ver - sity)) funded by the Korea go vernment (MSIT). R E F E R E N C E S [1] Y . Efroni, S. Mannor , and M. Pirotta, “Exploration-exploitation in constrained mdps, ” arXiv preprint , 2020. [2] T . Liu, R. Zhou, D. Kalathil, P . Kumar , and C. Tian, “Learning policies with zero or bounded constraint violation for constrained mdps, ” Advances in Neural Information Processing Systems , vol. 34, pp. 17 183–17 193, 2021. [3] D. Ding, X. W ei, Z. Y ang, Z. W ang, and M. Jov anovic, “Prov ably efficient safe exploration via primal-dual policy optimization, ” in In- ternational conference on artificial intelligence and statistics . PMLR, 2021, pp. 3304–3312. [4] A. Ghosh, X. Zhou, and N. Shroff, “Prov ably efficient model-free constrained rl with linear function approximation, ” Advances in Neural Information Processing Systems , vol. 35, pp. 13 303–13 315, 2022. [5] ——, “T owards achieving sub-linear regret and hard constraint vi- olation in model-free rl, ” in International Confer ence on Artificial Intelligence and Statistics . PMLR, 2024, pp. 1054–1062. [6] T . Kitamura, A. Ghosh, T . Kozuno, W . Kumagai, K. Kasaura, K. Hoshino, Y . Hosoe, and Y . Matsuo, “Provably efficient rl under episode-wise safety in constrained mdps with linear function approx- imation, ” arXiv pr eprint arXiv:2502.10138 , 2025. [7] Y . Ding and J. Lavaei, “Provably ef ficient primal-dual reinforcement learning for cmdps with non-stationary objecti ves and constraints, ” in Pr oceedings of the AAAI Conference on Artificial Intelligence , vol. 37, no. 6, 2023, pp. 7396–7404. [8] K. Y u, S. Bae, and D. Lee, “Primal-dual polic y optimization for ad- versarial linear CMDPs, ” in The F ourteenth International Confer ence on Learning Repr esentations , 2026. [9] J. He, D. Zhou, and Q. Gu, “Near -optimal polic y optimization algo- rithms for learning adversarial linear mixture mdps, ” in International Confer ence on Artificial Intelligence and Statistics . PMLR, 2022, pp. 4259–4280. [10] A. Ghosh, X. Zhou, and N. Shroff, “ Achieving sub-linear regret in infinite horizon a verage reward constrained MDP with linear function approximation, ” in The Ele venth International Confer ence on Learning Repr esentations , 2023. [11] X. Liu, L. F . Y ang, and S. V aswani, “Sample complexity bounds for linear constrained mdps with a generative model, ” arXiv pr eprint arXiv:2507.02089 , 2025. [12] Y . W ei, X. Li, and L. F . Y ang, “Near-optimal sample complexity bounds for constrained average-re ward MDPs, ” in The F ourteenth International Conference on Learning Repr esentations , 2026. [13] T . T ian, L. F . Y ang, and C. Szepesv ´ ari, “Confident natural policy gra- dient for local planning in q π -realizable constrained mdps, ” Advances in Neural Information Pr ocessing Systems , vol. 37, pp. 76 139–76 176, 2024. [14] H. W ei, X. Liu, and L. Y ing, “Triple-q: A model-free algorithm for constrained reinforcement learning with sublinear regret and zero con- straint violation, ” in International Conference on Artificial Intelligence and Statistics . PMLR, 2022, pp. 3274–3307. [15] A. Bura, A. HasanzadeZonuzy , D. Kalathil, S. Shakkottai, and J.-F . Chamberland, “Dope: Doubly optimistic and pessimistic exploration for safe reinforcement learning, ” Advances in neural information pr ocessing systems , vol. 35, pp. 1047–1059, 2022. [16] K. Y u, D. Lee, W . Overman, and D. Lee, “Improved regret bound for safe reinforcement learning via tighter cost pessimism and re ward optimism, ” Reinforcement Learning Journal , 2025. [17] A. M ¨ uller , P . Alatur , V . Cevher , G. Ramponi, and N. He, “T ruly no- regret learning in constrained mdps, ” in International Conference on Machine Learning . PMLR, 2024, pp. 36 605–36 653. [18] J. Zhu, K. Y u, D. Lee, X. Liu, and H. W ei, “ An optimistic algorithm for online CMDPS with anytime adv ersarial constraints, ” in F orty-second International Conference on Machine Learning , 2025. [19] F . E. Stradi, M. Castiglioni, A. Marchesi, and N. Gatti, “Optimal strong regret and violation in constrained MDPs via policy optimization, ” in The Thirteenth International Conference on Learning Representations , 2025. [20] C. Liu, Y . Li, and L. Y ang, “Near-optimal sample complexity for online constrained MDPs, ” in The Thirty-ninth Annual Conference on Neural Information Processing Systems , 2025. [21] S. Qiu, X. W ei, Z. Y ang, J. Y e, and Z. W ang, “Upper confidence primal-dual reinforcement learning for cmdp with adversarial loss, ” Advances in Neural Information Processing Systems , vol. 33, pp. 15 277–15 287, 2020. [22] F . E. Stradi, J. Germano, G. Genalti, M. Castiglioni, A. Marchesi, and N. Gatti, “Online learning in cmdps: Handling stochastic and adversarial constraints, ” in F orty-first International Conference on Machine Learning , 2024. [23] F . E. Stradi, M. Castiglioni, A. Marchesi, and N. Gatti, “Learning adversarial MDPs with stochastic hard constraints, ” in F orty-second International Conference on Machine Learning , 2025. [24] F . E. Stradi, A. Lunghi, M. Castiglioni, A. Marchesi, and N. Gatti, “Policy optimization for cmdps with bandit feedback: Learning stochastic and adversarial constraints, ” in F orty-second International Confer ence on Machine Learning , 2025. [25] S. Amani, C. Thrampoulidis, and L. Y ang, “Safe reinforcement learn- ing with linear function approximation, ” in International Conference on Machine Learning . PMLR, 2021, pp. 243–253. [26] M. Shi, Y . Liang, and N. Shroff, “ A near-optimal algorithm for safe reinforcement learning under instantaneous hard constraints, ” in International Confer ence on Mac hine Learning . PMLR, 2023, pp. 31 243–31 268. [27] H. W ei, X. Liu, and L. Y ing, “Safe reinforcement learning with instantaneous constraints: The role of aggressive exploration, ” in Pr oceedings of the AAAI Conference on Artificial Intelligence , vol. 38, no. 19, 2024, pp. 21 708–21 716. [28] A. Roknilamouki, A. Ghosh, M. Shi, F . Nourzad, E. Ekici, and N. Shroff, “Provably ef ficient RL for linear MDPs under instantaneous safety constraints in non-conve x feature spaces, ” in F orty-second International Conference on Machine Learning , 2025. [29] Z. Jia, L. Y ang, C. Szepesvari, and M. W ang, “Model-based rein- forcement learning with value-tar geted regression, ” in Learning for Dynamics and Contr ol . PMLR, 2020, pp. 666–686. [30] A. A youb, Z. Jia, C. Szepesvari, M. W ang, and L. Y ang, “Model- based reinforcement learning with v alue-targeted regression, ” in Inter- national Confer ence on Machine Learning . PMLR, 2020, pp. 463– 474. [31] D. Zhou, Q. Gu, and C. Szepesvari, “Nearly minimax optimal rein- forcement learning for linear mixture markov decision processes, ” in Confer ence on Learning Theory . PMLR, 2021, pp. 4532–4576. [32] Q. Cai, Z. Y ang, C. Jin, and Z. W ang, “Prov ably efficient exploration in policy optimization, ” in International Conference on Machine Learning . PMLR, 2020, pp. 1283–1294. [33] J. Kirschner and A. Krause, “Information directed sampling and ban- dits with heteroscedastic noise, ” in Conference On Learning Theory . PMLR, 2018, pp. 358–384. [34] D. Ding, K. Zhang, T . Basar, and M. Jovanovic, “Natural policy gradient primal-dual method for constrained markov decision pro- cesses, ” Advances in Neur al Information Pr ocessing Systems , vol. 33, pp. 8378–8390, 2020. [35] H. Y u, M. Neely , and X. W ei, “Online con vex optimization with stochastic constraints, ” Advances in Neural Information Pr ocessing Systems , vol. 30, 2017. [36] X. W ei, H. Y u, and M. J. Neely , “Online primal-dual mirror descent under stochastic constraints, ” Proceedings of the ACM on Measur e- ment and Analysis of Computing Systems , vol. 4, no. 2, pp. 1–36, 2020. [37] L. Shani, Y . Efroni, A. Rosenberg, and S. Mannor , “Optimistic polic y optimization with bandit feedback, ” in International Conference on Machine Learning . PMLR, 2020, pp. 8604–8613. [38] E. Hazan, “Introduction to online conv ex optimization, ” F oundations and T rends in Optimization , vol. 2, no. 3-4, pp. 157–325, 2016. [39] C. Jin, Z. Allen-Zhu, S. Bubeck, and M. I. Jordan, “Is q-learning prov ably efficient?” Advances in neural information pr ocessing sys- tems , vol. 31, 2018. [40] Y . Abbasi-Y adkori, D. P ´ al, and C. Szepesv ´ ari, “Improv ed algorithms for linear stochastic bandits, ” Advances in neur al information process- ing systems , vol. 24, 2011. C O N T E N T S I Introduction 1 I-A Additional Related W orks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 II Problem Formulation 2 III Proposed Algorithm 2 III-A Challenges in Algorithm Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 III-B Description of PD-PO WERS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 IV Analysis 5 IV -A Limitations of Strong Duality-Based Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 IV -B Our Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 V Numerical Experiments 6 VI Conclusion 6 VII A CKNO WLEDGMENTS 7 References 7 Appendix I: A uxiliary Notions 8 Appendix II: Proof of Lemma 1 8 Appendix III: Proof of Lemma 2 12 Appendix IV : Proof of Lemma 3 17 Appendix V : Proof of Lemma 4 20 Appendix VI: Proof of Theorem 1 21 A P P E N D I X I A U X I L I A RY N OT I O N S Definition 2 (High-pr obability good event): W e define a high-probability good ev ent E as E = E 1 ∩ E 2 ∩ E 3 ∩ E 4 , where E 1 , E 2 , E 3 , E 4 hold when the statement of Lemmas 1 , 7 , 8 , and 9 hold, respectiv ely . Definition 3 (F iltration): Let F k , h denote the σ -algebra that includes all randomness up to step h and episode k , i.e., F k , h = σ n { ( s τ j , a τ j ) } τ ∈ [ k − 1 ] , j ∈ [ H ] ∪ { r τ } τ ∈ [ k ] ∪ { ( s k j , a k j ) } j ∈ [ h ] o . (17) Let G k , h denote the σ -algebra that includes all randomness fixed before sampling a k h , i.e., G k , h = σ n { ( s τ j , a τ j ) } τ ∈ [ k − 1 ] , j ∈ [ H ] ∪ { r τ } τ ∈ [ k ] ∪ { ( s k j , a k j ) } j ∈ [ h − 1 ] ∪ s k h o . (18) Since the adversarial rew ard in episode k is determined at the beginning of the episode, { r k h } h ∈ [ H ] is F k , 1 -measurable. Moreov er , we note that, { π k h } h ∈ [ H ] , { Q r k , h , Q g k , h } h ∈ [ H ] , and { V r k , h , V g k , h } h ∈ [ H ] are F k , 1 -measurable, since they are determined by { ( s τ j , a τ j ) } j ∈ [ H ] , τ ∈ [ k − 1 ] and { r τ } τ ∈ [ k ] . A P P E N D I X I I P RO O F O F L E M M A 1 Pr oposition 2 (Restatement of Pr oposition 1 ): For any ( s , a , h , k , ℓ ) ∈ S × A × [ H ] × [ K ] × { r , g } , ¯ V h V ℓ k , h + 1 ( s , a ) − V h V ℓ k , h + 1 ( s , a ) ≤ min H 2 , e Σ ℓ k , h − 1 / 2 φ ( V ℓ k , h + 1 ) 2 ( s , a ) 2 e Σ ℓ k , h 1 / 2 ( e θ ℓ k , h − θ ∗ h ) 2 + min H 2 , 2 H b Σ ℓ k , h − 1 / 2 φ V ℓ k , h + 1 ( s , a ) 2 b Σ ℓ k , h 1 / 2 ( b θ ℓ k , h − θ ∗ h ) 2 Pr oof: Consider the case of r . By definition and the triangle inequality , ¯ V h V r k , h + 1 ( s , a ) − V h V r k , h + 1 ( s , a ) ≤ h ⟨ φ ( V r k , h + 1 ) 2 ( s , a ) , e θ r k , h ⟩ i [ 0 , H 2 ] − ⟨ φ ( V r k , h + 1 ) 2 ( s , a ) , θ ∗ h ⟩ | {z } (a) + ⟨ φ V r k , h + 1 ( s , a ) , θ ∗ h ⟩ 2 − h ⟨ φ V r k , h + 1 ( s , a ) , b θ r k , h ⟩ i 2 [ 0 , H ] | {z } (b) . T erm (a) can be bounded as T erm (a) ≤ ⟨ φ ( V r k , h + 1 ) 2 ( s , a ) , e θ r k , h ⟩ − ⟨ φ ( V r k , h + 1 ) 2 ( s , a ) , θ ∗ h ⟩ ≤ e Σ r k , h − 1 / 2 φ ( V r k , h + 1 ) 2 ( s , a ) 2 e Σ r k , h 1 / 2 ( e θ r k , h − θ ∗ h ) 2 where the first inequality is due to the fact that ⟨ φ ( V r k , h + 1 ) 2 ( s , a ) , θ ∗ h ⟩ = P h ( V r k , h + 1 ) 2 ( s , a ) ≤ H 2 , and the second inequality is due to the Cauchy-Schwarz inequality . Furthermore, since term (a) ≤ H 2 , we hav e the following upper bound. T erm (a) ≤ min H 2 , e Σ r k , h − 1 / 2 φ ( V r k , h + 1 ) 2 ( s , a ) 2 e Σ r k , h 1 / 2 ( e θ r k , h − θ ∗ h ) 2 . Next, term (b) is bounded as T erm (b) = h ⟨ φ V r k , h + 1 ( s , a ) , b θ r k , h ⟩ i [ 0 , H ] + ⟨ φ V r k , h + 1 ( s , a ) , θ ∗ h ⟩ h ⟨ φ V r k , h + 1 ( s , a ) , b θ r k , h ⟩ i [ 0 , H ] − ⟨ φ V r k , h + 1 ( s , a ) , θ ∗ h ⟩ ≤ 2 H h ⟨ φ V r k , h + 1 ( s , a ) , b θ r k , h ⟩ i [ 0 , H ] − ⟨ φ V r k , h + 1 ( s , a ) , θ ∗ h ⟩ ≤ 2 H ⟨ φ V r k , h + 1 ( s , a ) , b θ r k , h ⟩ − ⟨ φ V r k , h + 1 ( s , a ) , θ ∗ h ⟩ ≤ 2 H b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s , a ) 2 b Σ r k , h 1 / 2 ( b θ r k , h − θ ∗ h ) 2 where the first and second inequalities are due to ⟨ φ V r k , h + 1 ( s , a ) , θ ∗ h ⟩ = P h V r k , h + 1 ( s , a ) ≤ H , and the last inequality is due to the Cauchy-Schwarz inequality . Again, since term (b) ≤ H 2 , we hav e T erm (b) ≤ min H 2 , 2 H b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s , a ) 2 b Σ r k , h 1 / 2 ( b θ r k , h − θ ∗ h ) 2 Combining those, we have the desired result. By applying the same argument to g , we conclude the proof. Lemma 5 (Restatement of Lemma 1 ): For any ( k , h , ℓ ) ∈ [ H ] × [ K ] × { r , g } , with probability at least 1 − 3 δ , b Σ ℓ k , h 1 / 2 ( θ ∗ h − b θ ℓ k , h ) 2 ≤ b β k , | V h V ℓ k , h + 1 ( s , a ) − ¯ V h V ℓ k , h + 1 ( s , a ) | ≤ E ℓ k , h . Pr oof: Consider the case of r . W e prove the first statement as follo ws. Let e C r k , h = θ ∗ h ∈ R d : e Σ r k , h 1 / 2 ( θ ∗ h − e θ r k , h ) 2 ≤ e β k , ˇ C r k , h = θ ∗ h ∈ R d : b Σ r k , h 1 / 2 ( θ ∗ h − b θ r k , h ) 2 ≤ ˇ β k , C r k , h = θ ∗ h ∈ R d : b Σ r k , h 1 / 2 ( θ ∗ h − b θ r k , h ) 2 ≤ b β k . For a fixed h ∈ [ H ] , we first show that θ ∗ h ∈ e C r k , h and θ ∗ h ∈ ˇ C r k , h for all k ∈ [ K ] with high probability . Based on these, we then show that θ ∗ h ∈ C r k , h . Proof of θ ∗ h ∈ e C r k , h . Fix h ∈ [ H ] . T ake µ ∗ = θ ∗ h , x k = φ ( V r k , h + 1 ) 2 ( s k h , a k h ) , y k = ( V r k , h + 1 ) 2 ( s k h + 1 ) , η k = ( V r k , h + 1 ) 2 ( s k h + 1 ) − ⟨ φ ( V r k , h + 1 ) 2 ( s k h , a k h ) , θ ∗ h ⟩ , Z k = e Σ r k , h = λ I + k − 1 ∑ i = 1 φ ( V r i , h + 1 ) 2 ( s i h , a i h ) φ ( V r i , h + 1 ) 2 ( s i h , a i h ) ⊤ , µ k = e θ k , h = e Σ r k , h − 1 k − 1 ∑ i = 1 ( V r i , h + 1 ) 2 ( s i h + 1 ) φ ( V r i , h + 1 ) 2 ( s i h , a i h ) ! . Here, V r k , h + 1 is F k , 1 -measurable, s k h , a k h are F k , h -measurable. So, x k is F k , h -measurable. Since s k h + 1 is F k , h + 1 -measurable, so is η k . Furthermore, F k , h + 1 ⊂ F k + 1 , h , η k is F k + 1 , h -measurable. Also, E [ η k | F k , h ] = 0. Now , we apply Lemma 16 with the following parameters. ∥ x k ∥ 2 ≤ H 2 , | η k | ≤ H 2 , E η 2 k | F k , h ≤ H 4 . Hence, with probability at least 1 − δ / ( 2 H ) , ∀ k ≥ 2 , e Σ r k , h 1 / 2 ( θ ∗ h − e θ r k , h ) 2 ≤ e β k . (19) where e β k = 8 H 2 q d log ( 1 + k H 4 / ( d λ )) log ( 8 H k 2 / δ ) + 4 H 2 log ( 8 H k 2 / δ ) + √ λ B . Proof of θ ∗ h ∈ ˇ C r k , h . Fix h ∈ [ H ] . T ake µ ∗ = θ ∗ h , x k = φ V r k , h + 1 ( s k h , a k h ) / ¯ σ r k , h , y k = V r k , h + 1 ( s k h + 1 ) / ¯ σ r k , h , η k = V r k , h + 1 ( s k h + 1 ) − ⟨ φ V r k , h + 1 ( s k h , a k h ) , θ ∗ h ⟩ / ¯ σ r k , h , Z k = b Σ r k , h = λ I + k − 1 ∑ i = 1 φ V r i , h + 1 ( s i h , a i h ) φ V r i , h + 1 ( s i h , a i h ) ⊤ / ( ¯ σ r i , h ) 2 , µ k = b θ r k , h = b Σ r k , h − 1 k − 1 ∑ i = 1 V r i , h + 1 ( s i h + 1 ) φ V r i , h + 1 ( s i h , a i h ) / ( ¯ σ r i , h ) 2 ! . Here, V r k , h + 1 is F k , 1 -measurable, ¯ σ r k , h , s k h , a k h are F k , h -measurable. So, x k is F k , h -measurable. Since s k h + 1 is F k , h + 1 -measurable, so is η k . Furthermore, F k , h + 1 ⊂ F k + 1 , h , η k is F k + 1 , h -measurable. Also, E [ η k | F k , h ] = 0. Now , we apply Lemma 16 with the following parameters. ∥ x k ∥ 2 ≤ H / q H 2 / d = √ d , | η k | ≤ H / q H 2 / d = √ d , E η 2 k | F k , h ≤ d . Hence, with probability at least 1 − δ / ( 2 H ) , ∀ k ≥ 2 , b Σ r k , h 1 / 2 ( θ ∗ h − b θ r k , h ) 2 ≤ ˇ β k . (20) where ˇ β k = 8 d q log ( 1 + k / λ ) log ( 8 H k 2 / δ ) + 4 √ d log ( 8 H k 2 / δ ) + √ λ B . a) Pr oof of θ ∗ h ∈ C r k , h .: Fix h ∈ [ H ] . T ake µ ∗ = θ ∗ h , x k = φ V r k , h + 1 ( s k h , a k h ) / ¯ σ r k , h , y k = ⟨ θ ∗ h , x k ⟩ + η k , η k = 1 { θ ∗ h ∈ e C r k , h ∩ ˇ C r k , h } V r k , h + 1 ( s k h + 1 ) − ⟨ φ V r k , h + 1 ( s k h , a k h ) , θ ∗ h ⟩ / ¯ σ r k , h , Z k = b Σ r k , h = λ I + k − 1 ∑ i = 1 φ V r i , h + 1 ( s i h , a i h ) φ V r i , h + 1 ( s i h , a i h ) ⊤ / ( ¯ σ r i , h ) 2 , µ k = Z − 1 k k − 1 ∑ i = 1 x i y i . (21) Note that 1 { θ ∗ h ∈ e C r k , h ∩ ˇ C r k , h } is F k , h -measurable. By applying the same argument in the proof of θ ∗ h ∈ ˇ C r k , h , it follo ws that E [ η 2 k | F k , h ] ≤ 1 { θ ∗ h ∈ e C r k , h ∩ ˇ C r k , h } ( ¯ σ r k , h ) − 2 [ V h V r k , h + 1 ]( s k h , a k h ) ≤ 1 { θ ∗ h ∈ e C r k , h ∩ ˇ C r k , h } ( ¯ σ r k , h ) − 2 · ¯ V h V r k , h + 1 ( s k h , a k h ) + min H 2 , e Σ r k , h − 1 / 2 φ ( V r k , h + 1 ) 2 ( s k h , a k h ) 2 e Σ r k , h 1 / 2 ( e θ k , h − θ ∗ h ) 2 + min H 2 , 2 H b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 b Σ r k , h 1 / 2 ( b θ k , h − θ ∗ h ) 2 ! ≤ ( ¯ σ r k , h ) − 2 · ¯ V h V r k , h + 1 ( s k h , a k h ) + min H 2 , e β k e Σ r k , h − 1 / 2 φ ( V r k , h + 1 ) 2 ( s k h , a k h ) 2 + min H 2 , ˇ β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 ! ≤ 1 where the second inequality follows from Proposition 1 , the second inequality is due to 1 { θ ∗ h ∈ e C r k , h ∩ ˇ C r k , h } , and the last inequality is due to the definition of ¯ σ r k , h . Again, by Lemma 16 , with probability at least 1 − δ / ( 2 H ) b Σ r k , h 1 / 2 ( θ ∗ h − µ k ) 2 ≤ b β k , h (22) where µ k is defined in ( 21 ) and b β k = 8 q d log ( 1 + k / λ ) log ( 8 H k 2 / δ ) + 4 √ d log ( 8 H k 2 / δ ) + √ λ B . By union bound, ( 19 ), ( 20 ), and ( 22 ) hold with probability at least 1 − 3 δ / ( 2 H ) . On this ev ent, since 1 { θ ∗ h ∈ e C r k , h ∩ ˇ C r k , h } = 1, y k and µ k defined in ( 21 ) become y k = V r k , h + 1 ( s k h + 1 ) / ¯ σ r k , h , µ k = b θ r k , h . Thus, we hav e θ ∗ h ∈ C r k , h , as ( 22 ) is assumed to be true. Moreover , we can apply the same ar gument to g . Finally , by taking union bound over h ∈ [ H ] and ℓ ∈ { r , g } , with probability at least 1 − 3 δ , ∀ ( k , h , ℓ ) ∈ [ K ] × [ H ] × { r , g } : θ ∗ h ∈ C ℓ k , h . (23) Additionally , on the ev ent ( 19 ), ( 20 ), and ( 23 ), by Proposition 1 , the second statement of the lemma is proved. Additionally , we introduce the following lemma, which follo ws from Lemma 1 . Lemma 6: Suppose that the statement of Lemma 1 holds. For an y ( s , a , h , k ) , r k h ( s , a ) + P h V r k , h + 1 ( s , a ) − Q r k , h ( s , a ) ≤ 0 , g h ( s , a ) + P h V g k , h + 1 ( s , a ) − Q g k , h ( s , a ) ≤ 0 . Moreov er , for all ( s , a , h , k ) ∈ S × A × [ H ] × [ K ] , V r k , h ( s ) ≥ V r k , π k k , h ( s ) , Q r k , h ( s , a ) ≥ Q r k , π k k , h ( s , a ) , V g k , h ( s ) ≥ V g , π k k , h ( s ) , Q g k , h ( s , a ) ≥ Q g , π k k , h ( s , a ) . Pr oof: Note that r k h ( s , a ) + ⟨ b θ r k , h , φ V r k , h + 1 ( s , a ) ⟩ + b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s , a ) 2 ≥ r k h ( s , a ) + [ P h V r k , h + 1 ]( s , a ) + b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s , a ) 2 − b Σ r k , h 1 / 2 ( θ ∗ h − b θ r k , h ) 2 b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s , a ) 2 ≥ r k h ( s , a ) + [ P h V r k , h + 1 ]( s , a ) where the first inequality is due to the triangle inequality and the Cauchy-Schwarz inequality , and the second inequality is due to Lemma 1 . Note that r k h ( s , a ) + [ P h V r k , h + 1 ]( s , a ) ≤ H − h + 1. Then it follo ws that r k h ( s , a ) + ⟨ b θ r k , h , φ V r k , h + 1 ( s , a ) ⟩ + b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s , a ) 2 [ 0 , H − h + 1 ] ≥ r k h ( s , a ) + [ P h V r k , h + 1 ]( s , a ) . Note that the left-hand side is equal to Q r k , h ( s , a ) . Moreover , we can apply the same argument to g . Then we conclude the proof of the first statement. Next, we prov e the second statement by induction. Consider the case of r . For h = H + 1, recall that V r k , H + 1 ( s ) = V r k , π k H + 1 ( s ) = 0 and Q r k , H + 1 ( s , a ) = Q r k , π k H + 1 ( s , a ) = 0. No w , suppose that V r k , h + 1 ( s ) ≥ V r k , π k h + 1 ( s ) and Q r k , h + 1 ( s , a ) ≥ Q r k , π k h + 1 ( s , a ) for all ( s , a ) . It follows that Q r k , h ( s , a ) ≥ r k h ( s , a ) + P h V r k , h + 1 ( s , a ) ≥ r k h ( s , a ) + P h V r k , π k h + 1 ( s , a ) = Q r k , π k h ( s , a ) where the first inequality follows from the first statement, the second inequality follo ws from the induction hypothesis, and the equality is due to the Bellman equation. Furthermore, it follows that V r k , h ( s ) = ∑ a π k h ( a | s ) Q r k , h ( s , a ) ≥ ∑ a π k h ( a | s ) Q r k , π k h ( s , a ) = V r k , π k h ( s ) . This concludes the induction. Since the same argument can be applied to g , the proof is completed. A P P E N D I X I I I P RO O F O F L E M M A 2 Lemma 7: W ith probability at least 1 − δ , K ∑ k = 1 H ∑ h = 1 V h V r k , π k h + 1 ( s k h , a k h ) ≤ 3 ( H T + H 3 log ( 2 / δ )) , K ∑ k = 1 H ∑ h = 1 V h V g , π k h + 1 ( s k h , a k h ) ≤ 3 ( H T + H 3 log ( 2 / δ )) . Pr oof: The statement is proved by Lemma C.5 in [39]. Lemma 8 (Lemma C.3 of [31]): For any h ∈ [ H ] , with probability at least 1 − δ , K ∑ k = 1 H ∑ j = h h P j ( V r k , j + 1 − V r k , π k j + 1 )( s k j , a k j ) − ( V r k , j + 1 − V r k , π k j + 1 )( s k j + 1 ) i ≤ 4 H p 2 T log ( 2 H / δ ) , K ∑ k = 1 H ∑ j = h h P j ( V g k , j + 1 − V g , π k j + 1 )( s k j , a k j ) − ( V g k , j + 1 − V g , π k j + 1 )( s k j + 1 ) i ≤ 4 H p 2 T log ( 2 H / δ ) . Pr oof: Consider the case of r . Recall that { r k h } h ∈ [ H ] , { V r k , h + 1 } h ∈ [ H ] , and { π k h } h ∈ [ H ] are F k , 1 -measurable, s k h , a k h are F k , h -measurable, and s k h + 1 is F k , h + 1 -measurable. Let X k , h = P h ( V r k , h + 1 − V r k , π k h + 1 )( s k h , a k h ) − ( V r k , h + 1 − V r k , π k h + 1 )( s k h + 1 ) . For an y h ∈ [ H ] , the following is a martingale difference sequence: { X 1 , h , . . . , X 1 , H , X 2 , h , . . . , X 2 , H , . . . , X K , h , . . . , X K , H } . Moreov er , we have P h ( V r k , h + 1 − V r k , π k h + 1 )( s k h , a k h ) − ( V r k , h + 1 − V r k , π k h + 1 )( s k h + 1 ) ≤ 4 H . Then the Azuma-Hoef fding inequality implies that for a giv en h ∈ [ H ] , with probability at least 1 − δ / ( 2 H ) , K ∑ k = 1 H ∑ j = h P j ( V r k , j + 1 − V r k , π k j + 1 )( s k j , a k j ) − ( V r k , j + 1 − V r k , π k j + 1 )( s k j + 1 ) ≤ 4 H p 2 T log ( 2 H / δ ) . By union bound over h ∈ [ H ] , we can prove that the abov e inequality holds for all j with probability at least 1 − δ / 2. Moreov er , the same argument can be applied to g , and by union bound, the statement of the lemma holds with probability at least 1 − δ . Lemma 9: For any h ∈ [ H ] , with probability at least 1 − δ , K ∑ k = 1 H ∑ j = h h V r k , j ( s k j ) − V r k , π k j ( s k j ) − Q r k , j ( s k j , a k j ) + Q r k , π k j ( s k j , a k j ) i ≤ 4 H p 2 T log ( 2 H / δ ) , K ∑ k = 1 H ∑ j = h h V g k , j ( s k j ) − V g , π k j ( s k j ) − Q g k , j ( s k j , a k j ) + Q g , π k j ( s k j , a k j ) i ≤ 4 H p 2 T log ( 2 H / δ ) . Pr oof: Consider the case of r . Note that E [ Q r k , j ( s k j , a k j ) − Q r k , π k j ( s k j , a k j ) | G k , j ] = V r k , j ( s k j ) − V r k , π k j ( s k j ) , where the only randomness comes from a k j ∼ π k j ( ·| s k j ) . Therefore, using the Azuma-Hoef fding inequality , it can be bounded with probability at least 1 − δ / ( 2 H ) , K ∑ k = 1 H ∑ j = h h V r k , j ( s k j ) − V r k , π k j ( s k j ) − Q r k , j ( s k j , a k j ) + Q r k , π k j ( s k j , a k j ) i ≤ 4 H p 2 T log ( 2 H / δ ) . By union bound over h ∈ [ H ] , we can prove that the above inequality holds for all h with probability at least 1 − δ / 2. Moreov er , the same argument can be applied to g , and by union bound, the statement of the lemma holds with probability at least 1 − δ . Lemma 10 (Lemma C.5 of [31]): On the good e vent E (Definition 2 ), for any h ∈ [ H ] , we have K ∑ k = 1 V r k , h ( s k h ) − V r k , π k h ( s k h ) ≤ 2 b β K v u u t K ∑ k = 1 H ∑ j = 1 ( ¯ σ r k , j ) 2 p 2 H d log ( 1 + K / λ ) + 8 H p 2 T log ( 2 H / δ ) , K ∑ k = 1 V g k , h ( s k h ) − V g , π k h ( s k h ) ≤ 2 b β K v u u t K ∑ k = 1 H ∑ j = 1 ( ¯ σ g k , j ) 2 p 2 H d log ( 1 + K / λ ) + 8 H p 2 T log ( 2 H / δ ) . Pr oof: Consider the case of r . Note that V r k , h ( s k h ) − V r k , π k h ( s k h ) = V r k , h ( s k h ) − V r k , π k h ( s k h ) − Q r k , h ( s k h , a k h ) + Q r k , π k h ( s k h , a k h ) + Q r k , h ( s k h , a k h ) − Q r k , π k h ( s k h , a k h ) . Note that Q r k , h ( s k h , a k h ) − Q r k , π k h ( s k h , a k h ) can be further deriv ed as follows. Q r k , h ( s k h , a k h ) − Q r k , π k h ( s k h , a k h ) ≤ ⟨ φ V r k , h + 1 ( s k h , a k h ) , b θ r k , h ⟩ + b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 − P h V r k , π k h + 1 ( s k h , a k h ) = ⟨ φ V r k , h + 1 ( s k h , a k h ) , b θ r k , h − θ ∗ h ⟩ + b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 + P h V r k , h + 1 − V r k , π k h + 1 ( s k h , a k h ) ≤ b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 b Σ r k , h 1 / 2 ( b θ r k , h − θ ∗ h ) 2 + b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 + P h V r k , h + 1 − V r k , π k h + 1 ( s k h , a k h ) ≤ 2 b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 + P h V r k , h + 1 − V r k , π k h + 1 ( s k h , a k h ) where the first inequality is due to the definition of Q r k , h , Q r k , π k h and that Q r k , h ( s , a ) ≥ Q r k , π k h ( s , a ) ≥ 0 (Lemma 6 ), the second inequality is due to the Cauchy-Schwarz inequality , and the last inequality is due to the good ev ent E . Note that Q r k , h ( s k h ) − Q r k , π k h ( s k h ) ≤ H . Then we take min { H , ·} on both sides. Q r k , h ( s k h , a k h ) − Q r k , π k h ( s k h , a k h ) ≤ min H , 2 b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 + P h V r k , h + 1 − V r k , π k h + 1 ( s k h , a k h ) ≤ min H , 2 b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 + P h V r k , h + 1 − V r k , π k h + 1 ( s k h , a k h ) = min H , 2 b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 + P h V r k , h + 1 − V r k , π k h + 1 ( s k h , a k h ) − V r k , h + 1 − V r k , π k h + 1 ( s k h + 1 ) + V r k , h + 1 − V r k , π k h + 1 ( s k h + 1 ) where the second inequality is true because P h V r k , h + 1 − V r k , π k h + 1 ( s k h , a k h ) ≥ 0 due to Lemma 1 . W e deduce that V r k , h ( s k h ) − V r k , π k h ( s k h ) ≤ V r k , h ( s k h ) − V r k , π k h ( s k h ) − Q r k , h ( s k h , a k h ) + Q r k , π k h ( s k h , a k h ) + min H , 2 b β k b Σ r k , h − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 + P h V r k , h + 1 − V r k , π k h + 1 ( s k h , a k h ) − V r k , h + 1 − V r k , π k h + 1 ( s k h + 1 ) + V r k , h + 1 ( s k h + 1 ) − V r k , π k h + 1 ( s k h + 1 ) Due to the above recursion, it follo ws that V r k , h ( s k h ) − V r k , π k h ( s k h ) ≤ H ∑ j = h V r k , j ( s k j ) − V r k , π k j ( s k j ) − Q r k , j ( s k j , a k j ) + Q r k , π k j ( s k j , a k j ) + H ∑ j = h P j V r k , j + 1 − V r k , π k j + 1 ( s k j , a k j ) − V r k , j + 1 − V r k , π k j + 1 ( s k j + 1 ) + H ∑ j = h min H , 2 b β k b Σ r k , j − 1 / 2 φ V r k , j + 1 ( s k j , a k j ) 2 . By summing over k = 1 , . . . , K , for all h ∈ [ H ] , we have K ∑ k = 1 V r k , h ( s k h ) − V r k , π k h ( s k h ) ≤ K ∑ k = 1 H ∑ j = h V r k , j ( s k j ) − V r k , π k j ( s k j ) − Q r k , j ( s k j , a k j ) + Q r k , π k j ( s k j , a k j ) | {z } (a) + K ∑ k = 1 H ∑ j = h P j V r k , j + 1 − V r k , π k j + 1 ( s k j , a k j ) − V r k , j + 1 − V r k , π k j + 1 ( s k j + 1 ) | {z } (b) + K ∑ k = 1 H ∑ j = h min H , 2 b β k b Σ r k , j − 1 / 2 φ V r k , j + 1 ( s k j , a k j ) 2 | {z } (c) . Now , we bound terms individually . On the good e vent E , (a) and (b) can be bounded as 4 H p 2 T log ( 2 H / δ ) . For (c), we bound it as follows. (c) ≤ K ∑ k = 1 H ∑ j = 1 2 b β k ¯ σ r k , j min ( H 2 b β k ¯ σ r k , j , b Σ r k , j − 1 / 2 φ V r k , j + 1 ( s k j , a k j ) / ¯ σ r k , j 2 ) ≤ K ∑ k = 1 H ∑ j = 1 2 b β k ¯ σ r k , j min 1 , b Σ r k , j − 1 / 2 φ V r k , j + 1 ( s k j , a k j ) / ¯ σ r k , j 2 ≤ 2 b β K K ∑ k = 1 H ∑ j = 1 ¯ σ r k , j min 1 , b Σ r k , j − 1 / 2 φ V r k , j + 1 ( s k j , a k j ) / ¯ σ r k , j 2 ≤ 2 b β K v u u t K ∑ k = 1 H ∑ j = 1 ( ¯ σ r k , j ) 2 v u u t K ∑ k = 1 H ∑ j = 1 min ( 1 , b Σ r k , j − 1 / 2 φ V r k , j + 1 ( s k j , a k j ) / ¯ σ r k , j 2 2 ) where the second inequality is due to H / ( 2 b β k ¯ σ r k , j ) ≤ 1, and the third inequality is due to the fact that b β K ≥ b β k for all k ∈ [ K ] . This is because H / ( 2 b β k ¯ σ r k , j ) ≤ H / ( √ d H / √ d ) = 1, due to b β k ≥ √ d , ¯ σ r k , j ≥ H / √ d . Furthermore, the last inequality is due to the Cauchy-Schwarz inequality . Finally , by Lemma 15 , term (c) is bounded as (c) ≤ 2 b β K v u u t K ∑ k = 1 H ∑ j = 1 ( ¯ σ r k , j ) 2 p 2 H d log ( 1 + K / λ ) . Consequently , we deduce that for all h ∈ [ H ] , K ∑ k = 1 V r k , h ( s k h ) − V r k , π k h ( s k h ) ≤ 2 b β K v u u t K ∑ k = 1 H ∑ j = 1 ( ¯ σ r k , j ) 2 p 2 H d log ( 1 + K / λ ) + 8 H p 2 T log ( 2 H / δ ) . W e conclude the proof by applying the same argument to g . Lemma 11 (Lemma C.6 of [31]): Let λ = 1 / B 2 . On the good ev ent E (Definition 2 ), for any ℓ ∈ { r , g } K ∑ k = 1 H ∑ h = 1 ( ¯ σ ℓ k , h ) 2 = e O H 2 T d + H T + H 5 d 2 + H 5 + H 4 d 3 . Pr oof: Consider the case of r . By the definition of ¯ σ r k , h , K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 ≤ K ∑ k = 1 H ∑ h = 1 H 2 d + K ∑ k = 1 H ∑ h = 1 ¯ V h V r k , h + 1 ( s k h , a k h ) + K ∑ k = 1 H ∑ h = 1 E r k , h = H 2 T d + K ∑ k = 1 H ∑ h = 1 ¯ V h V r k , h + 1 ( s k h , a k h ) − V h V r k , h + 1 ( s k h , a k h ) − E r k , h | {z } (a) + K ∑ k = 1 H ∑ h = 1 V h V r k , π k h + 1 ( s k h , a k h ) | {z } (b) + K ∑ k = 1 H ∑ h = 1 V h V r k , h + 1 ( s k h , a k h ) − V h V r k , π k h + 1 ( s k h , a k h ) | {z } (c) + 2 K ∑ k = 1 H ∑ h = 1 E r k , h | {z } (d) . Note that term (a) is nonpositive due to Lemma 1 , and Lemma 7 implies that term (b) is bounded as (b) ≤ 3 ( H T + H 3 log ( 2 / δ )) . Next, we bound term (c) as follows. (c) = K ∑ k = 1 H ∑ h = 1 ⟨ φ ( V r k , h + 1 ) 2 ( s k h , a k h ) , θ ∗ h ⟩ − ⟨ φ V r k , h + 1 ( s k h , a k h ) , θ ∗ h ⟩ 2 − K ∑ k = 1 H ∑ h = 1 ⟨ φ ( V r , π k h + 1 ) 2 ( s k h , a k h ) , θ ∗ h ⟩ − ⟨ φ V r , π k k , h + 1 ( s k h , a k h ) , θ ∗ h ⟩ 2 ≤ K ∑ k = 1 H ∑ h = 1 ⟨ φ ( V r k , h + 1 ) 2 ( s k h , a k h ) , θ ∗ h ⟩ − ⟨ φ ( V r , π k h + 1 ) 2 ( s k h , a k h ) , θ ∗ h ⟩ = K ∑ k = 1 H ∑ h = 1 P h V r k , h + 1 2 − V r , π k h + 1 2 ( s k h , a k h ) ≤ 2 H K ∑ k = 1 H ∑ h = 1 P h V r k , h + 1 − V r , π k h + 1 ( s k h , a k h ) where the first inequality is due to P h V r k , h + 1 ( s , a ) ≥ P h V r , π k h + 1 ( s , a ) by Lemma 6 , and the last inequality is due to V r k , h + 1 ( s , a ) + V r , π k h + 1 ( s , a ) ≤ 2 H . W e can further deduce as follows. K ∑ k = 1 H ∑ h = 1 P h V r k , h + 1 − V r , π k h + 1 ( s k h , a k h ) = K ∑ k = 1 H ∑ h = 1 P h V r k , h + 1 − V r , π k h + 1 ( s k h , a k h ) − V r k , h + 1 − V r , π k h + 1 ( s k h + 1 ) + K ∑ k = 1 H ∑ h = 1 V r k , h + 1 − V r , π k h + 1 ( s k h + 1 ) ≤ 4 H p 2 T log ( 2 H / δ ) + ( H − 1 ) 2 b β K s K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 p 2 H d log ( 1 + K / λ ) + 8 H p 2 T log ( 2 H / δ ) ! ≤ 2 H b β K s K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 p 2 H d log ( 1 + K / λ ) + 12 H 2 p 2 T log ( 2 H / δ ) where the first inequality is due to Lemmas 8 and 10 . Then, term (c) is bounded as (c) ≤ 4 H 2 b β K s K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 p 2 H d log ( 1 + K / λ ) + 24 H 3 p 2 T log ( 2 H / δ ) . Next, term (d) is bounded as follows. K ∑ k = 1 H ∑ h = 1 E r k , h = K ∑ k = 1 H ∑ h = 1 min n H 2 , e β k ( e Σ r k , h ) − 1 / 2 φ ( V r k , h + 1 ) 2 ( s k h , a k h ) 2 o + K ∑ k = 1 H ∑ h = 1 min n H 2 , 2 H ˇ β k ( b Σ r k , h ) − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) 2 o = K ∑ k = 1 H ∑ h = 1 e β k min ( H 2 e β k , ( e Σ r k , h ) − 1 / 2 φ ( V r k , h + 1 ) 2 ( s k h , a k h ) 2 ) + K ∑ k = 1 H ∑ h = 1 2 H ˇ β k ¯ σ r k , h min ( H 2 ˇ β k ¯ σ r k , h , ( b Σ r k , h ) − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) / ¯ σ r k , h 2 ) . Note that e β K ≥ e β k , ˇ β K ≥ ˇ β k for all k ∈ [ K ] . Furthermore, e β k ≥ H 2 , ˇ β k ¯ σ r k , h ≥ d p H 2 / d ≥ H , and ¯ σ r k , h is bounded as ¯ σ r k , h ≤ q max { H 2 / d , H 2 + 2 H 2 } ≤ 2 H . Then we hav e K ∑ k = 1 H ∑ h = 1 E r k , h ≤ e β K K ∑ k = 1 H ∑ h = 1 min n 1 , ( e Σ r k , h ) − 1 / 2 φ ( V r k , h + 1 ) 2 ( s k h , a k h ) 2 o + 4 H 2 ˇ β K K ∑ k = 1 H ∑ h = 1 min n 1 , ( b Σ r k , h ) − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) / ¯ σ r k , h 2 o ≤ e β K √ T s K ∑ k = 1 H ∑ h = 1 min 1 , ( e Σ r k , h ) − 1 / 2 φ ( V r k , h + 1 ) 2 ( s k h , a k h ) 2 2 + 4 H 2 ˇ β K √ T s K ∑ k = 1 H ∑ h = 1 min 1 , ( b Σ r k , h ) − 1 / 2 φ V r k , h + 1 ( s k h , a k h ) / ¯ σ r k , h 2 2 ≤ e β K √ T q 2 H d log ( 1 + H 4 K / ( d λ )) + 4 H 2 ˇ β K √ T p 2 H d log ( 1 + K / λ ) where the last inequality follows from Lemma 15 . Finally , with all things together , K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 ≤ H 2 T d + 3 ( H T + H 3 log ( 2 / δ )) + 4 H 2 b β K s K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 p 2 H d log ( 1 + K / λ ) + 16 H 3 p 2 T log ( 2 H / δ ) + 2 e β K √ T q 2 H d log ( 1 + H 4 K / ( d λ )) + 8 H 2 ˇ β K √ T p 2 H d log ( 1 + K / λ ) . For λ = 1 / B 2 , we hav e b β K = e O ( √ d ) , e β K = e O ( H 2 √ d ) , and ˇ β K = e O ( d ) . Then it can be rewritten as K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 = e O H 2 T d + H T + H 3 + H 2 √ d s K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 √ H d + H 3 √ T + H 2 √ T √ H d + H 2 d √ T √ H d ! = e O H 2 T d + H T + H 2 . 5 d s K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 + H 3 √ T + H 2 . 5 d 0 . 5 √ T + H 2 . 5 d 1 . 5 √ T ! . Due to the AM-GM inequality , we have H 3 √ T = e O H T + H 5 , H 2 . 5 d 0 . 5 √ T = e O H T + H 4 d , H 2 . 5 d 1 . 5 √ T = e O H T + H 4 d 3 . Then it follows that K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 = e O H 2 T d + H T + H 2 . 5 d ξ s K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 + H 5 + H 4 d 3 ! . Furthermore, we know that if x ≤ a √ x + b , then x ≤ ( 3 / 2 )( a 2 + b ) . Finally , we have K ∑ k = 1 H ∑ h = 1 ( ¯ σ r k , h ) 2 = e O H 2 T d + H T + H 5 d 2 + H 5 + H 4 d 3 . W e conclude the proof by applying the same argument to g . Pr oof: [Proof of Lemma 2 ] On the good ev ent E (Definition 2 ), by Lemmas 10 and 11 , we hav e K ∑ k = 1 V r k , h ( s k h ) − V r k , π k h ( s k h ) = e O √ d H 4 K + √ d 2 H 3 K + d 2 . 5 H 3 , K ∑ k = 1 V g k , h ( s k h ) − V g , π k h ( s k h ) = e O √ d H 4 K + √ d 2 H 3 K + d 2 . 5 H 3 . Moreov er , under K = Ω ( d 3 H 3 ) , we hav e d 2 . 5 H 3 = e O ( √ d 2 H 3 K ) . This concludes the proof. A P P E N D I X I V P RO O F O F L E M M A 3 In this section, we provide more detailed proof of Lemma 3 . Lemma 12: Suppose that η ≤ 1, α ≤ 1 / H 2 , and θ ≤ 1 / ( 2 H ) . For all k ∈ [ K ] , Y k ≤ 3 H η k . Pr oof: Note that our dual update can be written as Y k + 1 = h ( 1 − α η H 3 ) Y k + η b − V g k , 1 ( s 1 ) − α H 3 − 2 θ H 2 i + for k ≥ 1. It follo ws that Y k + 1 ≤ | ( 1 − α η H 3 ) Y k | + η b − V g k , h ( s 1 ) − α H 3 − 2 θ H 2 ≤ Y k + η b − V g k , h ( s 1 ) − α H 3 − 2 θ H 2 . where the second inequality follo ws from 0 ≤ ( 1 − α η H 3 ) Y k ≤ Y k by the assumption. Moreover , | b − V g k , h ( s 1 ) | ≤ H , α H 3 ≤ H , and 2 θ H 2 ≤ H . Then by the triangle inequality for all k , Y k + 1 ≤ Y k + 3 η H . Recall that Y 1 = 0. Then we have Y k + 1 ≤ 3 η H k . This concludes the proof. Lemma 13: Suppose that η ≤ 1, α ≤ 1 / H 2 , and θ ≤ 1 / ( 2 H ) . On the good e vent E (Definition 2 ), for all k ∈ [ K ] Y 2 k + 1 − Y 2 k 2 ≤ − γ η Y k + η α E ¯ π " H ∑ h = 1 D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || π k + 1 h ( ·| s h )) # + C (24) where C is defined as C = α η H 3 2 + 2 η H 2 θ + 2 η H 2 + 2 η 2 ( H 2 + α 2 H 6 + 9 η 2 α 2 H 8 K 2 + 4 θ 2 H 4 ) . Pr oof: The proof closely follows the proof of Lemma 17 in [8]. By the definition of Y k , we hav e Y 2 k + 1 ≤ Y 2 k + 2 Y k η b − V g k , 1 ( s 1 ) − α H 3 ( 1 + Y k ) − 2 θ H 2 + η 2 b − V g k , 1 ( s 1 ) − α H 3 ( 1 + Y k ) − 2 θ H 2 2 . W e rearrange it as follows. Y 2 k + 1 − Y 2 k 2 ≤ Y k η b − V g k , 1 ( s 1 ) − α H 3 ( 1 + Y k ) − 2 θ H 2 | {z } (I) + η 2 2 b − V g k , 1 ( s 1 ) − α H 3 ( 1 + Y k ) − 2 θ H 2 2 | {z } (II) . T erm (II) is bounded as (II) ≤ 2 η 2 (( b − V g k , 1 ( s 1 )) 2 + α 2 H 6 + α 2 H 6 Y 2 k + 4 θ 2 H 4 ) ≤ 2 η 2 ( H 2 + α 2 H 6 + 9 η 2 α 2 H 8 K 2 + 4 θ 2 H 4 ) where the first inequality follows from the Cauchy-Schwarz inequality , the second inequality follows from | b − V g k , 1 ( s 1 ) | ≤ H and 0 ≤ Y k ≤ 3 η H K for all k (Lemma 12 ). Now , we further deduce (I). Recall that ¯ π is the Slater policy that satisfies V g , ¯ π 1 ( s 1 ) ≥ b + γ for some γ > 0. W e hav e V g , ¯ π 1 ( s 1 ) − V g k , 1 ( s 1 ) = E ¯ π " H ∑ h = 1 ⟨ Q g k , h ( s h , · ) , ¯ π h ( ·| s h ) − π k h ( ·| s h ) ⟩| s 1 # + E ¯ π " H ∑ h = 1 g h ( s h , a h ) + P h V g h + 1 ( s h , a h ) − Q g k , h ( s h , a h ) | s 1 # ≤ E ¯ π " H ∑ h = 1 ⟨ Q g k , h ( s h , · ) , ¯ π h ( ·| s h ) − π k h ( ·| s h ) ⟩| s 1 # where the equality is due to Lemma 19 , and the inequality is due to Lemma 6 . Due to the Slater assumption, the abov e can be written as b − V g k , 1 ( s 1 ) ≤ E ¯ π " H ∑ h = 1 ⟨ Q g k , h ( s h , · ) , ¯ π h ( ·| s h ) − π k h ( ·| s h ) ⟩| s 1 # − γ . By adopting this into (I), it follows that (I) ≤ − γ η Y k + Y k η E ¯ π " H ∑ h = 1 ⟨ Q g k , h ( s h , · ) , ¯ π h ( ·| s h ) − π k h ( ·| s h ) ⟩| s 1 # − α H 3 ( 1 + Y k ) − 2 θ H 2 ! | {z } (III) . W e further deduce (III) as follo ws. Note that π k + 1 h ( ·| s ) ∈ arg max π ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π ( ·| s ) ⟩ − 1 α D ( π ( ·| s ) || e π k h ( ·| s )) . Then by Lemma 20 , ⟨ Q r k , h ( s h , · ) + Y k Q g k , h ( s h , · ) , π k + 1 h ( ·| s h ) ⟩ − 1 α D ( π k + 1 h ( ·| s h ) || e π k h ( ·| s h )) ≥ ⟨ Q r k , h ( s h , · ) + Y k Q g k , h ( s h , · ) , ¯ π h ( ·| s h ) ⟩ − 1 α D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) + 1 α D ( ¯ π h ( ·| s h ) || π k + 1 h ( ·| s h )) . It can be rewritten as Y k ⟨ Q g k , h ( s h , · ) , ¯ π h ( ·| s h ) − π k h ( ·| s h ) ⟩ ≤ ⟨ Q r k , h ( s h , · ) , π k + 1 h ( ·| s h ) − π k h ( ·| s h ) ⟩ − 1 α D ( π k + 1 h ( ·| s h ) || e π k h ( ·| s h )) + ⟨ Q r k , h ( s h , · ) , π k h ( ·| s h ) − ¯ π h ( ·| s h ) ⟩ + 1 α D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) − 1 α D ( ¯ π h ( ·| s h ) || π k + 1 h ( ·| s h )) + Y k ⟨ Q g k , h ( s h , · ) , π k + 1 h ( ·| s h ) − π k h ( ·| s h ) ⟩ ≤ α H 2 2 + 2 H θ + 2 H + 1 α D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) − 1 α D ( ¯ π h ( ·| s h ) || π k + 1 h ( ·| s h )) + Y k α H 2 ( 1 + Y k ) + 2 θ H where the second inequality comes from Lemma 17 and that ⟨ Q r k , h ( s h , · ) , π k + 1 h ( ·| s h ) − ¯ π h ( ·| s h ) ⟩ ≤ ∥ Q r k , h ( s h , · ) ∥ ∞ ∥ π k + 1 h ( ·| s h ) − ¯ π h ( ·| s h ) ∥ 1 ≤ 2 H (H ¨ older’ s inequality). Now , we take the sum ov er h = 1 , . . . , H and E ¯ π on both sides. Moreover , we multiply both sides by η . Then, it is written as Y k η E ¯ π " H ∑ h = 1 ⟨ Q g k , h ( s h , · ) , ¯ π h ( ·| s h ) − π k h ( ·| s h ) ⟩ # − α H 3 ( 1 + Y k ) − 2 θ H 2 ! ≤ α η H 3 2 + 2 η H 2 θ + 2 η H 2 + η α E ¯ π " H ∑ h = 1 D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || π k + 1 h ( ·| s h )) # Observe that the left-hand side equals (III). Thus, it follows that (I) ≤ − γ η Y k + α η H 3 2 + 2 η H 2 θ + 2 η H 2 + η α E ¯ π " H ∑ h = 1 D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || π k + 1 h ( ·| s h )) # . Finally , we hav e Y 2 k + 1 − Y 2 k 2 ≤ − γ η Y k + α η H 3 2 + 2 η H 2 θ + 2 η H 2 + η α E ¯ π " H ∑ h = 1 D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || π k + 1 h ( ·| s h )) # + 2 η 2 ( H 2 + α 2 H 6 + 9 η 2 α 2 H 8 K 2 + 4 θ 2 H 4 ) . Lemma 14 (Restatement of Lemma 3 ): Let K ≥ max { 2 H , H 2 } . Suppose that we set η = 1 / ( H √ K ) , α = 1 / ( H 2 √ K ) , θ = 1 / K and E (Definition 2 ) holds. For all k ∈ [ K ] , Y k = e O ( H 2 / γ ) . Pr oof: Under K ≥ 2 H , we know that η ≤ 1 , α ≤ 1 / H 2 , θ ≤ 1 / ( 2 H ) . Thus, Lemmas 12 and 13 are applicable. Note that | Y k + 1 − Y k | ≤ | − α η H 3 Y k + η ( b − V g k , 1 ( s 1 ) − α H 3 − 2 θ H 2 ) | ≤ 3 α η 2 H 4 k + 3 η H ≤ 3 α η 2 H 4 K + 3 η H (25) where the first inequality follows from that | max { 0 , x } − y | ≤ | x − y | for any x ∈ R and y ∈ R + , and the second inequality follows from Lemma 12 . Moreo ver , by summing ( 24 ) ov er from k to k + n 0 − 1 (later , n 0 will be specified), it follows that Y 2 k + n 0 − Y 2 k 2 ≤ − γ η k + n 0 − 1 ∑ τ = k Y τ + η α k + n 0 − 1 ∑ τ = k E ¯ π " H ∑ h = 1 D ( ¯ π h ( ·| s h ) || e π τ h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || π τ + 1 h ( ·| s h )) # | {z } (I) + C n 0 . T erm (I) can be bounded as (I) = k + n 0 − 1 ∑ τ = k E ¯ π " H ∑ h = 1 D ( ¯ π h ( ·| s h ) || e π τ h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || e π τ + 1 h ( ·| s h )) # + k + n 0 − 1 ∑ τ = k E ¯ π " H ∑ h = 1 D ( ¯ π h ( ·| s h ) || e π τ + 1 h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || π τ + 1 h ( ·| s h )) # ≤ H ∑ h = 1 E ¯ π h D ( ¯ π h ( ·| s h ) || e π k h ( ·| s h )) − D ( ¯ π h ( ·| s h ) || e π k + n 0 h ( ·| s h )) i + n 0 H θ log | A | ≤ H log ( | A | / θ ) + n 0 H θ log | A | where the second and third inequalities follo ws from Lemma 17 and that the nonne gativeness of KL diver gence. Therefore, we deduce that for any n 0 ≥ 1 and k ≤ K − n 0 , Y 2 k + n 0 − Y 2 k 2 ≤ − γ η k + n 0 − 1 ∑ τ = k Y τ + C ′ , (26) where C ′ = 3 γ η 2 H n 0 ( n 0 − 1 ) 2 ( α η H 3 K + 1 ) + η α ( H log ( | A | / θ ) + n 0 H θ log | A | ) + C n 0 . Suppose that there exists k ∈ [ K ] such that Y k > 2 C ′ η γ n 0 + n 0 ( 3 α η 2 H 4 K + 3 η H ) . Then we can take k hit = min { k ∈ [ K ] : Y k > 2 C ′ η γ n 0 + n 0 ( 3 α η 2 H 4 K + 3 η H ) } , i.e., the first episode such that Y k exceeds the threshold 2 C ′ η γ n 0 + n 0 ( 3 α η 2 H 4 K + 3 η H ) . Since | Y k + 1 − Y k | ≤ 3 α η 2 H 4 K + 3 η H , we know that k hit > n 0 and Y k hit − n 0 , . . . , Y k hit − 1 ≥ 2 C ′ η γ n 0 (If not, Y k hit nev er reach the threshold). Then, by ( 26 ), it implies that, Y 2 k hit − Y 2 k hit − n 0 2 ≤ − γ η k hit ∑ τ = k hit − n 0 Y τ + C ′ ≤ − C ′ < 0 . (27) This implies that Y k hit < Y k hit − n 0 < 2 C ′ η γ n 0 + n 0 ( 3 α η 2 H 4 K + 3 η H ) , where the second inequality follows from the fact that k hit − n 0 < k hit and k hit is the first episode that exceeds the threshold. This contradicts Y k hit > 2 C ′ η γ n 0 + n 0 ( 3 α η 2 H 4 K + 3 η H ) . Therefore, Y k ≤ 2 C ′ η γ n 0 + n 0 ( 3 α η 2 H 4 K + 3 η H ) for all k ∈ [ K ] . By taking n 0 = H √ K , η = 1 H √ K , α = 1 H 2 √ K , θ = 1 K , it follows that Y k = e O ( H 2 / γ ) . A P P E N D I X V P RO O F O F L E M M A 4 Pr oof: Fix k ∈ [ K ] . Note that V r k , π ∗ 1 ( s 1 ) + Y k V g , π ∗ 1 ( s 1 ) − V r k , 1 ( s 1 ) − Y k V g k , 1 ( s 1 ) = E π ∗ " H ∑ h = 1 ⟨ Q r k , h ( s h , · ) + Y k Q g k , h ( s h , · ) , π ∗ h ( ·| s h ) − π k h ( ·| s h ) ⟩| s 1 # + E π ∗ " H ∑ h = 1 r k h ( s h , a h ) + P h V r k , h + 1 ( s h , a h ) − Q r k , h ( s h , a h ) | s 1 # + Y k E π ∗ " H ∑ h = 1 g h ( s h , a h ) + P h V g k , h + 1 ( s h , a h ) − Q g k , h ( s h , a h ) | s 1 # . Note that the second and third terms are nonpositive by Lemma 6 . Thus, we focus on the first term. Since π k + 1 h ( ·| s ) ∈ arg max π ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π ( ·| s ) ⟩ − 1 α D ( π ( ·| s ) || e π k h ( ·| s )) , by Lemma 20 , for any s ∈ S , ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π k + 1 h ( ·| s ) ⟩ − 1 α D ( π k + 1 h ( ·| s ) || e π k h ( ·| s )) ≥ ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π ∗ h ( ·| s ) ⟩ − 1 α D ( π ∗ h ( ·| s ) || e π k h ( ·| s )) + 1 α D ( π ∗ h ( ·| s ) || π k + 1 h ( ·| s )) . By rearranging the inequality , we have ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π ∗ h ( ·| s ) − π k h ( ·| s ) ⟩ ≤ ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π k + 1 h ( ·| s ) − π k h ( ·| s ) ⟩ − 1 α D ( π k + 1 h ( ·| s ) || e π k h ( ·| s )) + 1 α D ( π ∗ h ( ·| s ) || e π k h ( ·| s )) − 1 α D ( π ∗ h ( ·| s ) || π k + 1 h ( ·| s )) = ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π k + 1 h ( ·| s ) − π k h ( ·| s ) ⟩ − 1 α D ( π k + 1 h ( ·| s ) || e π k h ( ·| s )) + 1 α D ( π ∗ h ( ·| s ) || π k h ( ·| s )) − 1 α D ( π ∗ h ( ·| s ) || π k + 1 h ( ·| s )) + 1 α D ( π ∗ h ( ·| s ) || e π k h ( ·| s )) − 1 α D ( π ∗ h ( ·| s ) || π k h ( ·| s )) . Then we take the sum over k = 1 , . . . , K . Then it follows that K ∑ k = 1 ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π ∗ h ( ·| s ) − π k h ( ·| s ) ⟩ ≤ K ∑ k = 1 ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π k + 1 h ( ·| s ) − π k h ( ·| s ) ⟩ − K ∑ k = 1 1 α D ( π k + 1 h ( ·| s ) || e π k h ( ·| s )) + 1 α D ( π ∗ h ( ·| s ) || π 1 h ( ·| s )) − 1 α D ( π ∗ h ( ·| s ) || π K + 1 h ( ·| s )) + 1 α K ∑ k = 1 D ( π ∗ h ( ·| s ) || e π k h ( ·| s )) − D ( π ∗ h ( ·| s ) || π k h ( ·| s )) ≤ K ∑ k = 1 ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π k + 1 h ( ·| s ) − π k h ( ·| s ) ⟩ + 1 α D ( π ∗ h ( ·| s ) || π 1 h ( ·| s )) + 1 α K ∑ k = 1 D ( π ∗ h ( ·| s ) || e π k h ( ·| s )) − D ( π ∗ h ( ·| s ) || π k h ( ·| s )) ≤ K ∑ k = 1 ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π k + 1 h ( ·| s ) − π k h ( ·| s ) ⟩ + log | A | α + 1 α K ∑ k = 1 D ( π ∗ h ( ·| s ) || e π k h ( ·| s )) − D ( π ∗ h ( ·| s ) || π k h ( ·| s )) where the second inequality follo ws from the nonnegati veness of KL di ver gence, and the last inequality is due to π 1 h ( ·| s ) = 1 / | A | for any s . Moreover , K ∑ k = 1 ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π k + 1 h ( ·| s ) − π k h ( ·| s ) ⟩ ≤ K ∑ k = 1 ∥ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) ∥ ∞ ∥ π k + 1 h ( ·| s ) − π k h ( ·| s ) ∥ 1 ≤ K ∑ k = 1 ∥ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) ∥ ∞ ∥ π k + 1 h ( ·| s ) − e π k h ( ·| s ) ∥ 1 + K ∑ k = 1 ∥ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) ∥ ∞ ∥ e π k h ( ·| s ) − π k h ( ·| s ) ∥ 1 ≤ K ∑ k = 1 α H 2 ( 1 + Y k ) 2 + θ K ∑ k = 1 ∥ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) ∥ ∞ ∥ π unif ( ·| s ) − π k h ( ·| s ) ∥ 1 = e O α H 6 K γ 2 + θ K H 3 γ (28) where the first inequality is due to H ¨ older’ s inequality , the second inequality is due to the triangle inequality , the third inequality is due to Lemma 21 and that e π k h ( ·| s ) = ( 1 − θ ) π k h ( ·| s ) + θ π unif ( ·| s ) , and the last equality is due to Lemma 3 . Moreov er , 1 α K ∑ k = 1 D ( π ∗ h ( ·| s ) || e π k h ( ·| s )) − D ( π ∗ h ( ·| s ) || π k h ( ·| s )) ≤ 1 α K ∑ k = 1 θ log | A | ≤ θ K log | A | α . (29) Finally , by applying ( 28 ) and ( 29 ), we have K ∑ k = 1 ⟨ Q r k , h ( s , · ) + Y k Q g k , h ( s , · ) , π ∗ h ( ·| s ) − π k h ( ·| s ) ⟩ = e O α H 6 K γ 2 + θ K α + 1 α + θ K H 3 γ . Then it follows that K ∑ k = 1 E π ∗ " H ∑ h = 1 ⟨ Q r k , h ( s h , · ) + Y k Q g k , h ( s h , · ) , π ∗ h ( ·| s h ) − π k h ( ·| s h ) ⟩| s 1 # = e O α H 7 K γ 2 + θ H K α + H α + θ K H 4 γ . Finally , we hav e K ∑ k = 1 V r k , π ∗ 1 ( s 1 ) + Y k V g , π ∗ 1 ( s 1 ) − V r k , 1 ( s 1 ) − Y k V g k , 1 ( s 1 ) = e O α H 7 K γ 2 + θ H K α + H α + θ K H 4 γ . Since we set α = 1 / ( H 2 √ K ) , θ = 1 / K , the proof is completed. A P P E N D I X V I P RO O F O F T H E O R E M 1 Pr oof: By Lemmas 1 , 7 , 8 , and 9 , by union bound, the good event E holds with probability at least 1 − 6 δ . Moreov er, under E and K ≥ max { 2 H , H 2 } , Lemma 3 holds. Therefore, with probability at least 1 − 6 δ , the good event E and Y k = e O ( H 2 / γ ) for all k . W e assume these throughout the proof. Next, we bound the regret. Note that the regret can be decomposed as follows. K ∑ k = 1 V r k , π ∗ 1 ( s 1 ) − V r k , π k 1 ( s 1 ) = K ∑ k = 1 V r k , π ∗ 1 ( s 1 ) + Y k b − V r k , 1 ( s 1 ) − Y k V g k , 1 ( s 1 ) + K ∑ k = 1 V r k , 1 ( s 1 ) − V r k , π k 1 ( s 1 ) + K ∑ k = 1 Y k V g k , 1 ( s 1 ) − b ≤ K ∑ k = 1 V r k , π ∗ 1 ( s 1 ) + Y k V g , π ∗ 1 ( s 1 ) − V r k , 1 ( s 1 ) − Y k V g k , 1 ( s 1 ) | {z } (I) + K ∑ k = 1 V r k , 1 ( s 1 ) − V r k , π k 1 ( s 1 ) | {z } (II) + K ∑ k = 1 Y k V g k , 1 ( s 1 ) − b | {z } (III) By Lemma 4 , (I) = e O H 5 √ K γ 2 + H 3 √ K + H 4 γ ! . By Lemma 2 , (II) = e O √ d H 4 K + √ d 2 H 3 K . Note that (III) can be bounded as follows. Due to the dual update 0 ≤ Y 2 K + 1 = K ∑ k = 1 ( Y 2 k + 1 − Y 2 k ) ≤ K ∑ k = 1 2 Y k η ( b − V g k , 1 ( s 1 ) − α H 3 ( 1 + Y k ) − 2 θ H 2 ) + η 2 ( b − V g k , 1 ( s 1 ) − α H 3 ( 1 + Y k ) − 2 θ H 2 ) 2 . It can be rewritten as (III) = K ∑ k = 1 Y k ( V g k , 1 ( s 1 ) − b ) ≤ − K ∑ k = 1 Y k ( α H 3 ( 1 + Y k ) + 2 θ H 2 ) + K ∑ k = 1 η 2 b − V g k , 1 ( s 1 ) − α H 3 ( 1 + Y k ) − 2 θ H 2 2 ≤ K ∑ k = 1 3 η 2 H 2 + α 2 H 6 ( 1 + Y k ) 2 + 4 θ 2 H 4 = e O H √ K + H 5 γ 2 √ K where the second inequality follows from the Cauchy-Schwarz inequality , and the equality follows from the choice of η , α , θ , the assumption K ≥ H 2 , and Lemma 3 . Finally , we deduce that Reg ( K ) = e O √ d H 4 K + √ d 2 H 3 K + H 5 √ K γ 2 + H 3 √ K + H 4 γ ! Next, we analyze constraint violation. Note that the violation can be decomposed as K ∑ k = 1 ( b − V g , π k 1 ( s 1 )) = K ∑ k = 1 ( b − V g k , 1 ( s 1 )) | {z } (IV) + K ∑ k = 1 ( V g k , 1 ( s 1 ) − V g , π k 1 ( s 1 )) | {z } (V) T o bound (IV), note that Y k + 1 ≥ ( 1 − α η H 3 ) Y k + η ( b − V g k , 1 ( s 1 ) − α H 3 − 2 θ H 2 ) . This leads to b − V g k , 1 ( s 1 ) ≤ Y k + 1 − Y k η + α H 3 Y k + α H 3 + 2 θ H 2 . By summing the above inequality o ver k = 1 , . . . , K , K ∑ k = 1 ( b − V g k , 1 ( s 1 )) ≤ Y K + 1 η + α H 3 K ∑ k = 1 Y k + α K H 3 + 2 θ K H 2 = e O H 3 γ √ K . By Lemma 2 , (V) = e O √ d H 4 K + √ d 2 H 3 K . Finally , V io ( K ) = e O √ d H 4 K + √ d 2 H 3 K + H 3 √ K γ ! . Lemma 15 (Lemma 11 in [40]): For any λ > 0 and sequence { x t } T t = 1 ⊂ R d for t ∈ { 0 , . . . , T } , define Z t = λ I + ∑ t i = 1 x i x ⊤ i . Then, provided that ∥ x t ∥ 2 ≤ L holds for all t ∈ [ T ] , we hav e T ∑ t = 1 min { 1 , ∥ x t ∥ 2 Z − 1 t − 1 } ≤ 2 d log d λ + T L 2 d λ . Lemma 16 (Theor em 4.1 in [31]): Let { G t } ∞ t = 1 be a filtration, { x t , η t } t ≥ 1 a stochastic process so that x t ∈ R d is G t - measurable and η t ∈ R is G t + 1 -measurable. Fix R , L , σ , λ > 0, µ µ µ ∗ ∈ R d . For t ≥ 1, let y t = ⟨ µ µ µ ∗ , x t ⟩ + η t and suppose that η t , x t also satisfy | η t | ≤ R , E [ η t | G t ] = 0 , E [ η 2 t | G t ] ≤ σ 2 , ∥ x t ∥ 2 ≤ L . Then, for any 0 < δ < 1, with probability at least 1 − δ , we hav e ∀ t > 0 , t ∑ i = 1 x i η i Z − 1 t ≤ β t , ∥ µ µ µ t − µ µ µ ∗ ∥ Z t ≤ β t + √ λ ∥ µ µ µ ∗ ∥ 2 , where for t ≥ 1, µ µ µ t = Z − 1 t b t , Z t = λ I + ∑ t i = 1 x i x ⊤ i , b t = ∑ t i = 1 y i x i and β t = 8 σ q d log ( 1 + t L 2 / ( d λ )) log ( 4 t 2 / δ ) + 4 R log ( 4 t 2 / δ ) . Lemma 17 (Lemma 31 of [36]): Let π 1 , π 2 be two probability distributions in ∆ ( A ) . Let ˜ π 2 = ( 1 − θ ) π 2 + θ / | A | where θ ∈ ( 0 , 1 ) . Then, D ( π 1 ∥ ˜ π 2 ) − D ( π 1 ∥ π 2 ) ≤ θ log | A | , D ( π 1 ∥ ˜ π 2 ) ≤ log ( | A | / θ ) . Lemma 18 (Lemma 22 of [8]): Let π k h : S → ∆ ( A ) be any policies. F or θ ∈ [ 0 , 1 ] , let e π k h ( ·| s ) = ( 1 − θ ) π k h ( ·| s ) + θ π unif ( ·| s ) . For Q r k , h , Q g k , h : S × A → [ 0 , H ] , Y k ∈ R + , and α > 0, let π k + 1 ( · | s ) ∝ e π k ( · | s ) exp ( α ( Q r k , h ( s , · ) + Y k Q g k , h ( s , · )) . For any s ∈ S , we hav e 1) ∥ π k + 1 h ( · | s ) − e π k h ( · | s ) ∥ 1 ≤ α H ( 1 + Y k ) , 2) ⟨ π k + 1 h ( ·| s ) − π k h ( ·| s ) , Q g k , h ( s , · ) ⟩ ≤ α H 2 ( 1 + Y k ) + 2 θ H . 3) ⟨ π k + 1 h ( ·| s ) − π k h ( ·| s ) , Q r k , h ( s , · ) ⟩ − 1 α D ( π k + 1 h ( ·| s ) || e π k h ( ·| s )) ≤ α H 2 / 2 + 2 H θ . Lemma 19 (Lemma 1 of [37]): Let π , π ′ be tw o policies, and let M = ( H , S , A , P , r , s 1 ) be an MDP . For all h ∈ [ H ] , let Q r h : S × A → R be an arbitrary function, and let V r h ( s ) = Q r h ( s , · ) , π ′ h ( · | s ) for all s ∈ S . Then, V r , π 1 ( s 1 ) − V r 1 ( s 1 ) = E π " H ∑ h = 1 Q r h ( s h , · ) , π h ( · | s h ) − π ′ h ( · | s h ) s 1 # + E π " H ∑ h = 1 r h ( s h , a h ) + P h V r h + 1 ( s h , a h ) − Q r h ( s h , a h ) s 1 # , where V r , π 1 = E π [ ∑ H j = 1 r h ( s h , a h ) | s 1 ] . Lemma 20 (Lemma 1 of [36]): Let ∆ , int ( ∆ ) be the probability simplex and its interior , respectively , and let f : C → R be a conv ex function. Fix α > 0 , y ∈ int ( ∆ ) . Suppose x ∗ ∈ ar g max x ∈ ∆ f ( x ) − ( 1 / α ) D ( x || y ) and x ∗ ∈ int ( ∆ ) , then, for any z ∈ ∆ , f ( x ∗ ) − 1 α D ( x ∗ || y ) ≥ f ( z ) − 1 α D ( z || y ) + 1 α D ( z || x ∗ ) . Lemma 21 (Lemma 33 of [6]): Let Q 1 , Q 2 : A → R be two functions. For α > 0, let π 1 ∝ e xp ( α Q 1 ) , π 2 ∝ e xp ( α Q 2 ) . Then we hav e ∥ π 1 − π 2 ∥ 1 ≤ 8 α ∥ Q 1 − Q 2 ∥ ∞ .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment