고차원 비라벨 데이터의 신뢰성 있는 활용
본 논문은 고차원 회귀 모델에서 라벨이 있는 데이터는 적고 비라벨 데이터가 풍부한 상황을 가정한다. 기존의 디바이어스 추정량은 조건부 평균 함수를 충분히 정확히 추정해야만 효율성을 얻을 수 있지만, 추정이 부정확하면 오히려 성능이 저하된다. 이를 해결하기 위해 저자들은 조건부 평균 함수의 추정 여부와 무관하게 라벨 데이터만을 이용한 기준 추정량보다 절대적으로 못 미치지 않는 새로운 반보정 추정량을 제안한다. 제안 방법은 무편향 추정함수를 구성하…
저자: Chao Ying, Siyi Deng, Yang Ning
1. 서론에서는 라벨 데이터가 제한적이고 비라벨 데이터가 고차원으로 풍부한 현대 데이터 환경을 소개한다. 의료 기록, 이미지·비디오, 자연어 텍스트 등에서 비라벨 데이터는 수십만·수백만 차원을 가질 수 있다. 이러한 상황에서 기존 반지도학습 방법들은 종종 “조건부 평균 함수 f(X) 를 정확히 추정한다”는 강한 가정을 필요로 하는데, 고차원에서는 이 가정이 현실적으로 깨지기 쉽다.
2. 문제 설정은 (X_i,Y_i)∼P 라벨 데이터 n 개와 X_j∼P_X 비라벨 데이터 N 개가 주어졌을 때, 회귀 파라미터 θ* 를 최소제곱 기준으로 정의한다. θ* 은 실제 f(X) 의 L2‑투영이며, 모델이 miss‑specified 되더라도 의미 있는 선형 요약을 제공한다. 목표는 θ* 의 선형 함수 v^Tθ* (v는 사전 지정된 가중치) 를 추정하는데, 라벨 데이터만을 이용한 디바이어스 라쏘와 비교했을 때 절대적으로 효율이 떨어지지 않는 추정량을 설계하는 것이다.
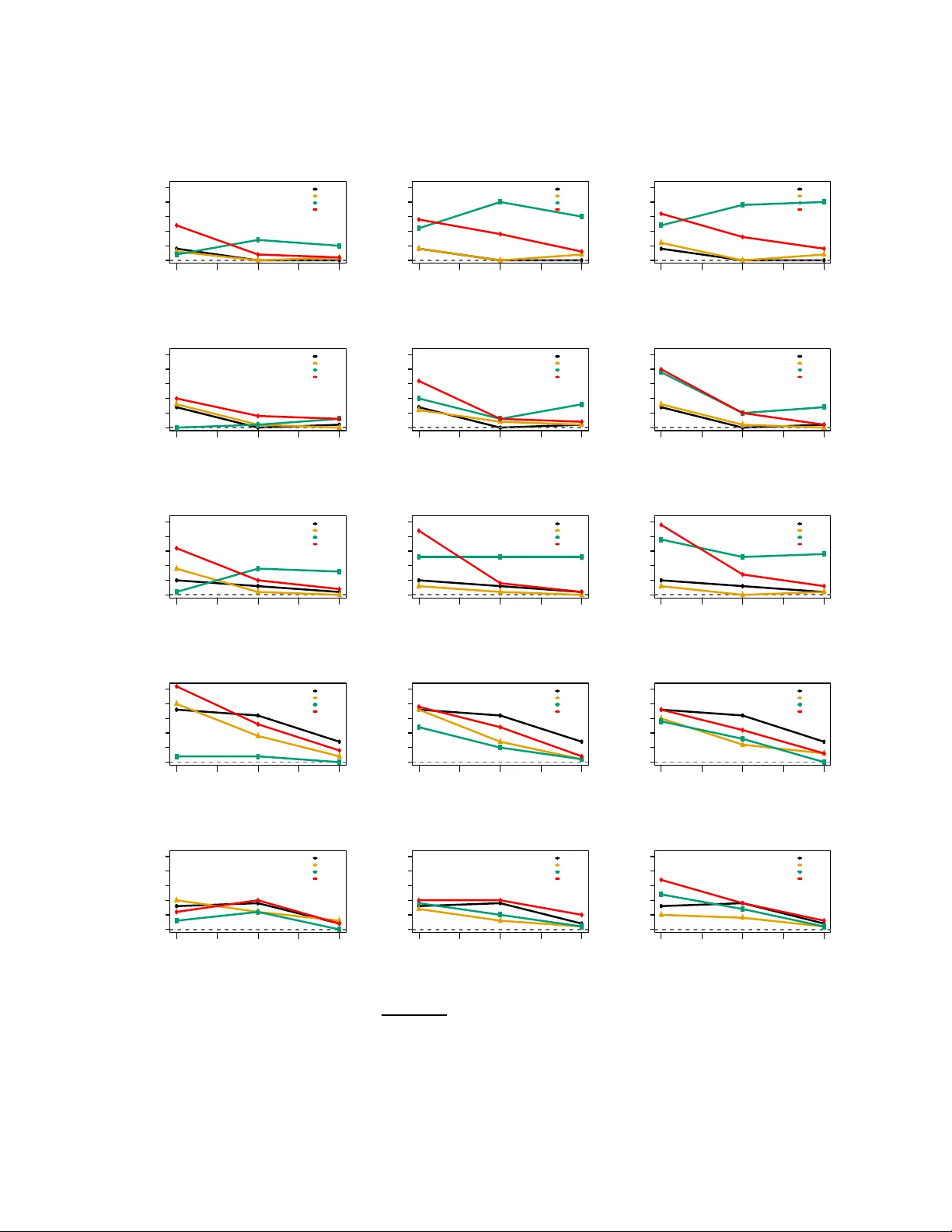
3. 기존 접근법(Section 2.2)에서는 조건부 평균 함수 f̂ 를 별도 추정하고, 이를 이용해 “semi‑supervised debiased estimator” pθ_d 를 만든다. 이 방법은 f̂ 가 충분히 빠른 속도로 수렴할 경우에만 asymptotic variance 가 감소한다. 그러나 f̂ 가 불안정하거나 고차원에서 불가능할 경우, pθ_d 의 분산은 오히려 증가한다.
4. 핵심 기여는 “dependable semi‑supervised estimator” pθ_{S,ψ} 를 제안하는 것이다. 이 추정량은 다음과 같은 두 가지 아이디어에 기반한다.
- **무편향 추정함수 구성**: 라벨 데이터와 비라벨 데이터를 동시에 사용해 ξ̂ = (1/n)∑X_i(Y_i−f̂(X_i)) + (1/N)∑X_j f̂(X_j) 형태의 추정함수를 만든다. 여기서 f̂ 은 실제로 필요하지 않으며, 대신 교차‑피팅을 통해 ξ̂ 를 직접 계산한다.
- **스코어 탈상관 및 ψ‑조정**: Ω̂ (공분산 행렬 Σ의 역) 로 스코어 h(X,Y;θ̂) 를 탈상관시킨 뒤, ψ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기