교사와 AI가 만든 피드백, 누가 어떻게 고치는가
본 연구는 1,349개의 LLM‑생성 피드백과 117명의 교사가 편집한 최종 피드백을 분석해, 교사의 수정 행동, 수정 예측 가능성, 그리고 수정이 피드백 유형에 미치는 변화를 조사한다. 교사는 전체 사례의 약 80%를 그대로 수용하고, 수정할 경우 길이를 크게 줄이며, 수정 여부는 피드백 길이와 의미적 유사도 등 텍스트 특성으로 어느 정도 예측할 수 있다(AUC 0.75). 수정된 피드백은 고정보다 간결하고 교정 중심으로 전환되는 경향이 있다…
저자: Conrad Borchers, Luiz Rodrigues, Newarney Torrezão da Costa
본 논문은 LLM이 자동으로 생성한 형성 피드백이 교사에게 전달된 뒤, 교사가 어떻게 수정·수용·거부하는지를 체계적으로 분석한다. 연구 배경으로는 LLM 기반 피드백이 교육 현장에 빠르게 도입되고 있지만, 그 품질·교육학적 적합성이 교사에 의해 중재된다는 점을 강조한다. 기존 연구는 주로 학습자 관점(피드백 인지도·학습 효과)이나 AI 자체의 품질 평가에 초점을 맞췄으나, 교사의 ‘게이트키퍼’ 역할에 대한 실증적 데이터는 부족했다.
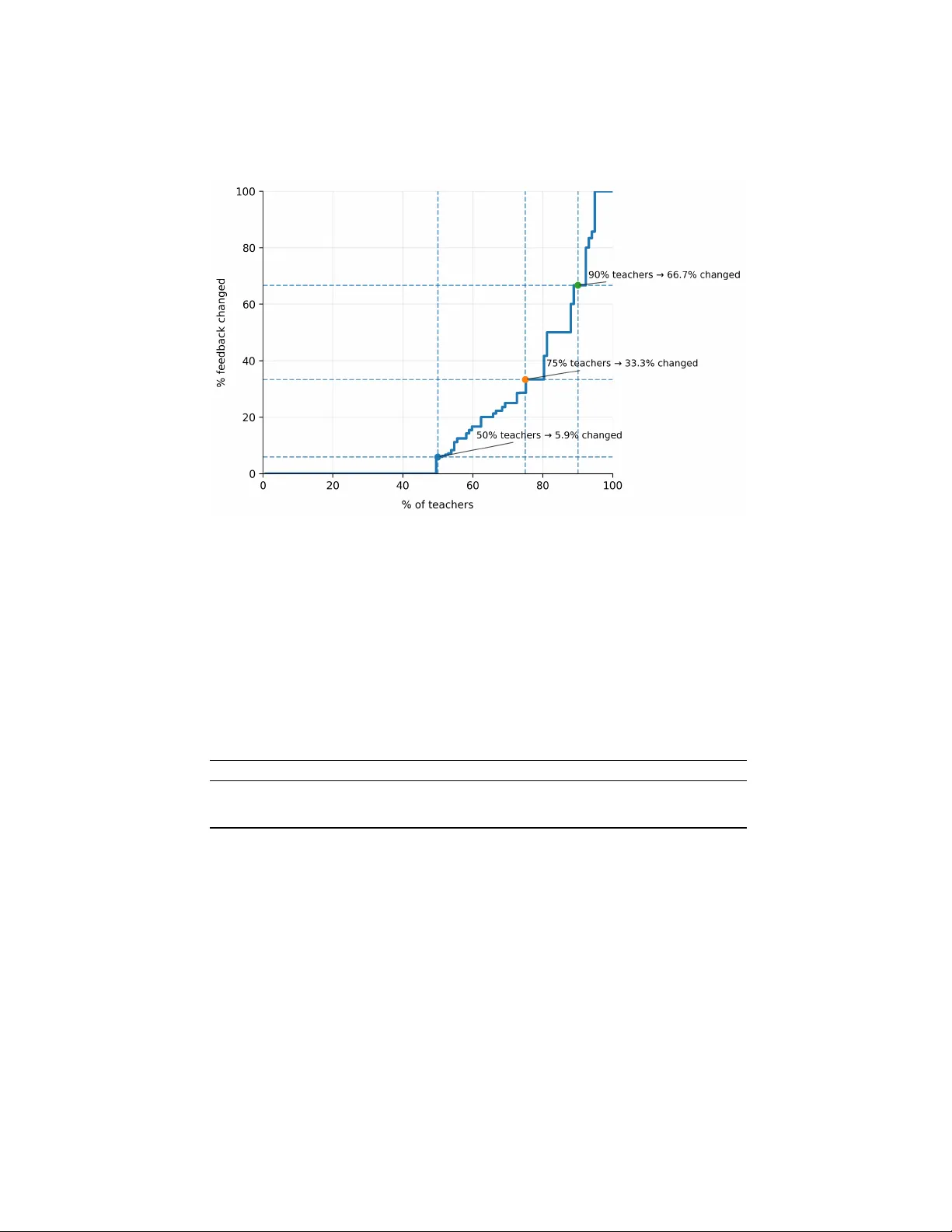
데이터는 브라질의 고등학교 화학, 대학 수준 컴퓨터 과학 등 다양한 교육 맥락에서 Tutoria 플랫폼을 이용해 수집된 1,349개의 피드백 사례와 117명의 교사 편집 로그이다. 각 사례는 (1) 학생 답안, (2) 교사가 부여한 정답 라벨, (3) LLM이 생성한 초안 피드백, (4) 교사가 최종 전달한 피드백으로 구성된다. 교사 인구통계는 주로 30대 중반 남성 교사이며, 전체 교사 중 절반은 한 번도 수정하지 않았다.
연구 방법은 네 단계로 진행된다. 첫째, 교사가 수정한 경우와 수정하지 않은 경우의 텍스트 특성을 비교했다. 여기서는 단어 수, 문장 수, 의미적 유사도(코사인) 등을 측정했으며, 수정된 피드백이 원본보다 평균 1.8배 길고, 교사 편집 후 평균 30% 단축된다는 결과를 얻었다. 둘째, AI 피드백 텍스트만을 입력으로 한 머신러닝 모델을 구축해 수정 여부를 예측했다. 로지스틱 회귀, 얕은 신경망, Gradient Boosted Trees를 비교했으며, 가장 좋은 모델이 AUC 0.75를 기록했다. 이는 피드백 길이·복잡성·특정 어휘가 교사의 수정 의사결정에 영향을 미친다는 증거다. 셋째, 피드백 유형 코딩을 통해 교사 수정이 교육학적 특성에 미치는 변화를 분석했다. 코딩 체계는 ‘강화/처벌’, ‘교정’, ‘고정보’, ‘기타’ 네 가지이며, AI 초안의 42%가 고정보였지만 교사 편집 후에는 18%로 감소하고 교정 피드백이 55%까지 늘어났다. 마지막으로, 연구 결과를 바탕으로 AI 피드백 시스템 설계 시 고려해야 할 실천적 시사점을 제시한다. 구체적으로는 (1) 교사가 자주 수정하는 피드백 특성을 사전 감지해 자동으로 간결화하거나 교정 중심으로 변환하는 후처리 모듈, (2) 교사의 편집 부담을 줄이기 위해 프롬프트 설계 단계에서 ‘핵심 교정·요약’ 지시를 강화, (3) 교사별 편집 성향을 학습해 맞춤형 피드백 제안을 제공하는 개인화 기능을 도입할 것을 권고한다.
결론적으로, 교사는 LLM이 만든 피드백을 대부분 그대로 수용하지만, 수정이 필요할 경우 핵심 정보를 압축하고 교정 지시로 전환한다. 텍스트 기반 특성만으로도 수정 여부를 예측할 수 있어, 향후 AI 피드백 시스템에 교사 편집 예측 모델을 내장함으로써 교사의 작업량을 크게 경감시킬 가능성이 있다. 또한, 교사의 수정이 피드백의 교육학적 품질을 ‘고정보’→‘교정’으로 전환한다는 점은, AI 설계자가 교사의 우선순위(간결성·명확성)를 사전에 반영하도록 프롬프트·후처리 전략을 재구성해야 함을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기