Understanding Teacher Revisions of Large Language Model-Generated Feedback
Large language models (LLMs) increasingly generate formative feedback for students, yet little is known about how teachers revise this feedback before it reaches learners. Teachers' revisions shape what students receive, making revision practices cen…
Authors: Conrad Borchers, Luiz Rodrigues, Newarney Torrezão da Costa
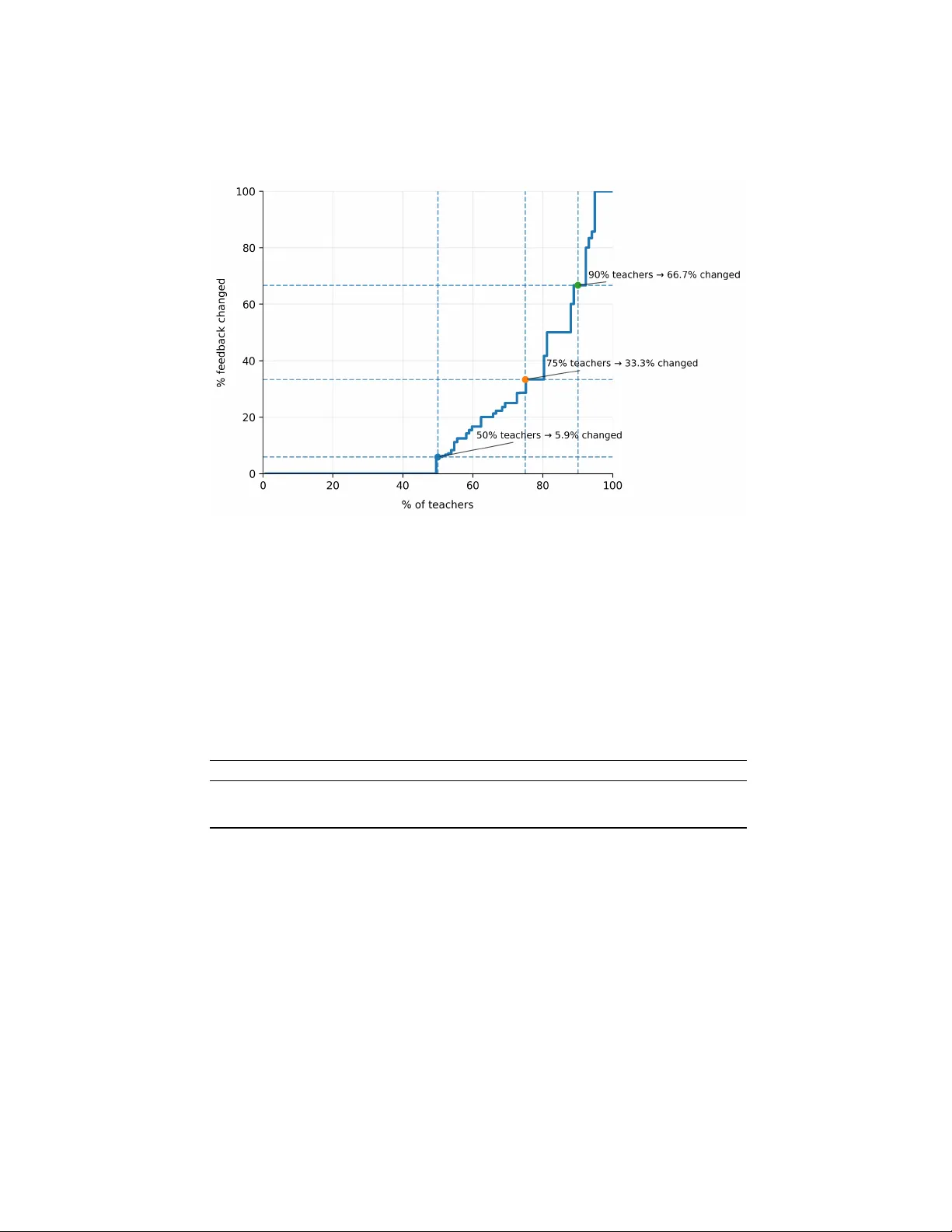
Understanding T eac her Revisions of Large Language Mo del-Generated F eedbac k Conrad Borc hers 1 , Luiz Ro drigues 2 , New arney T orrezão da Costa 3 , Cleon Xa vier 3 , and Rafael F erreira Mello 4 1 Carnegie Mellon Univ ersity cborcher@cs.cmu.edu 2 F ederal T echnological Univ ersity of P araná – UTFPR luizrodrigues@utfpr.edu.br 3 Instituto F ederal Goiano – IF Goiano {newarney,cleon.junior}@ifgoiano.edu.br 4 F ederal Rural Universit y of P ernambuco – UFRPE rafael.mello@ufrpe.br Abstract. Large language mo dels (LLMs) increasingly generate forma- tiv e feedback for students, yet little is known ab out ho w teachers revise this feedback b efore it reac hes learners. T eachers’ revisions shap e what studen ts receiv e, making revision practices cen tral to ev aluating AI class- ro om tools. W e analyze a dataset of 1,349 instances of AI-generated feed- bac k and corresponding teacher-edited explanations from 117 teachers. W e examine (i) textual characteristics associated with teacher revisions, (ii) whether revision decisions can be predicted from the AI feedback text, and (iii) how revisions c hange the pedagogical t yp e of feedbac k deliv ered. First, we find that teac hers accept AI feedback without mo di- fication in ab out 80% of cases, while edited feedback tends to b e signifi- can tly longer and subsequently shortened by teachers. Editing b eha vior v aries substantially across teachers: ab out 50% nev er edit AI feedback, and only ab out 10% edit more than tw o-thirds of feedback instances. Second, mac hine learning mo dels trained only on the AI feedback text as input features, using sen tence em b eddings, ac hieve fair p erformance in iden tifying which feedbac k will b e revised ( AU C =0.75). Third, qualita- tiv e co ding shows that when revisions occur, teachers often simplify AI- generated feedback, shifting it aw ay from high-information explanations to ward more concise, corrective forms. T ogether, these findings charac- terize ho w teac hers engage with AI-generated feedback in practice and highligh t opportunities to design feedback systems that b etter align with teac her priorities while reducing unnecessary editing effort. Keyw ords: Large language models · formativ e feedbac k · teac her revision · h uman-in-the-lo op AI · educational writing · learning analytics. 1 In tro duction Large language models (LLMs) ha ve b een increasingly used to support assess- men t and feedbac k in education, particularly in writing and tutoring [29,23]. 2 Borc hers et al. Their app eal is largely pragmatic: LLMs can generate timely , detailed feedback at scale, p oten tially reducing teac her w orkload and expanding access to forma- tiv e supp ort [27]. As these systems transition from exp erimen tal prototypes to routine classro om to ols, how ev er, a critical question is not only whether mo dels can generate plausible feedbac k, but how educators actually use, in terpret, and revise that feedbac k b efore it reac hes students. This question is esp ecially salien t giv en growing evidence that LLM-generated feedbac k can b e p edagogically misaligned. Prior work shows that LLMs may pro- duce feedback that v aries systematically with sup erficial cues such as gendered language [7], or that fav ors o verly direct, ov erscaffolded explanations that con- flict with learning sciences principle s [5,22], p oten tially undermining learning outcomes [8]. In classro om settings, these shortcomings are not merely theoret- ical: teac hers act as gatekeepers who decide whether, how, and to what extent AI-generated feedbac k is delivered to students. T eac her mediation matters b ecause educators ma y mitigate some of the ad- v erse effects of LLM-generated feedback describ ed ab o ve [5,7], suc h as misalign- men t with effective instructional principles [5]. How ev er, it cannot be assumed that suc h mediation will consistently impro ve feedbac k qualit y . Prior research sho ws that teachers, like other practitioners, may hold b eliefs ab out learning that are not supp orted by empirical evidence, such as the p ersisten t myth of learning styles [30]. At the same time, emerging evidence suggests that teachers often forw ard AI-generated feedback with little or no modification [28], raising the stakes of understanding when and why revisions o ccur. If teachers rarely edit AI-generated feedback, its p edagogical impact is largely determined by the mo del’s defaults, the prompt, and the system in whic h the AI is embedded. If teac hers do not frequently edit, then ineffective or biased mo del b eha vior (wh ic h can b e hard to detect) [7] in AI feedback can affect studen ts. Evidence suggests that LLMs often misalign with effectiv e instruction [5]. Most ev aluations of LLM-based feedbac k instead judge output qualit y in isolation, suc h as by comparing responses to rubrics or evidence-based prin- ciples [5,23], while ignoring the human-in-the-loop pro cesses that shap e what studen ts ultimately see. As a result, it remains unclear how AI-generated feed- bac k functions once teachers decide whether and ho w to pass it on, and where curren t systems may imp ose av oidable cognitive or editorial burden. W e address this gap by empirically examining how teachers revise AI-generated formativ e feedbac k through large-scale analysis of revision b ehavior, seman tic similarity measures, predictive mo deling, and theory-informed co ding of feedback types. In doing so, this work contributes to AIED b y identifying opp ortunities to de- sign feedback systems that b etter align with teacher priorities while reducing unnecessary editing effort. T eacher Revisions of LLM-Generated F eedback 3 2 Related W ork 2.1 AI F eedbac k AI-supp orted automated feedback, particularly using LLMs, has b een widely studied across educational contexts. Prior work has examined both learner re- ception and comparative effectiveness relative to human feedback. Letteri et al. [15] analyze students’ perceptions of an AI feedbac k system in data science edu- cation, showing that although learners find the feedbac k helpful, excessive detail can increase cognitiv e load and div ert atten tion from the task. Nygren et al. [18] empirically compare AI-generated and exp ert human feedbac k in a mixed-reality teac her education sim ulation, finding that AI provides timely supp ort for sim- pler tasks but lac ks the con textual sensitivit y required to identify p edagogical opp ortunities suc h as missed teachable moments or adaptive lesson structuring. Other studies emphasize hybrid approac hes and the so cial dimensions of feedbac k. Kho jasteh et al. [13] compare teac her, AI, and combined feedbac k for second-language writing, demonstrating that hybrid feedback yields greater gains in coherence and grammatical accuracy while also reducing student anxiety and increasing confidence. Nazaretsky et al. [16] fo cus on feedbac k attribution rather than con tent, showing in a large within-sub ject study that students sys- tematically p erceiv e AI-provided feedbac k as less credible and low er in qualit y than equiv alen t human feedback when its source is disclosed. T ogether, these studies establish the instructional promise of AI-generated feedbac k and the adv antages of combining AI with human exp ertise. Still, they predominan tly ev aluate feedback as receiv ed by students, using p erformance out- comes or sub jectiv e p erceptions. In contrast, the present study shifts atten tion to teac hers’ engagement with AI-generated feedback itself. W e examine how teach- ers revise LLM-pro duced feedback, whic h textual features predict revision deci- sions, and ho w p edagogical feedbac k types change through this pro cess, thereb y iden tifying systematic misalignments b et w een curren t AI-generated feedback and teac hers’ instructional priorities. 2.2 T eac her Engagement with AI F eedbac k Prior w ork consisten tly shows that teac hers do not treat AI feedbac k as au- thoritativ e; instead, they exercise judgment in interpreting and adapting it. F or instance, pre-service teachers reflect on the adequacy and contextual sensitivity of AI feedbac k as they mak e pedagogical decisions [18]. Related work p ositions teac hers not only as ev aluators but also as designers of AI feedback systems. One study found that instructors configure how AI-generated suggestions are presen ted to students in data science education, shaping both the timing and framing of feedbac k [15]. This highlights that teac hers actively orchestrate how automated feedbac k reaches students. Similarly , past w ork examines preservice English teac hers who compare their o wn feedback on authen tic student texts with GenAI-generated suggestions [9]. 4 Borc hers et al. P articipants rep ort concerns ab out the excessive length and density of AI fee d- bac k, prompting selective adoption based on accuracy , relev ance, and p edagog- ical tone. T eachers frequently revise or discard suggestions to prev ent cognitive o verload and preserve motiv ational balance. T ogether, these studies depict teachers as critical mediators who adapt AI feedbac k to pedagogical goals. The present work extends this literature by of- fering an automated, quantitativ e accoun t of such engagemen t. Analyzing 1,349 instances of AI feedback edited by 117 teachers, we identify systematic revision patterns, including substantial shortening, alongside mark ed individual v ariabil- it y . These results pro vide concrete design insigh ts for AI feedbac k tools that reduce unnecessary effort while strengthening teac her agency . 2.3 Limitations of AI F eedbac k and Instruction Recen t AIED w ork mo ves b ey ond studies of teac her p erceptions to examine tec hnical and p edagogical limitations of LLM-generated feedback using natural language pro cessing metho ds. Borchers and Shou [5] show that LLMs struggle to replicate the adaptivity of tutoring systems, exhibiting weak sensitivit y to learner errors and student help-seeking. As a result, feedback tends to b e ov erly direct, conflicting with learning science principles suc h as using op en-ended prompts to prob e understanding. Relatedly , Du et al. [7] quantify gender bias in LLM essa y feedback through con trolled prompt exp erimen ts. These findings point to the need for teacher interv ention to correct p edagogical incoherence, reduce prompt-driv en v ariability , and realign feedback with effectiv e p edagogy . Stamp er et al. [22] similarly identify structural w eaknesses in LLM feedbac k in tutoring contexts, including limited empirical v alidation of learning outcomes and reliance on fixed-resp onse patterns with minimal adaptation, esp ecially in ill-defined domains. These limitations manifest in feedback that ov erlooks com- mon student errors, prematurely rev eals answ ers, and fails to accoun t for prior kno wledge, scaffolding needs, or multimodal supp ort. Our study builds on this w ork by providing an in tegrated empirical accoun t of ho w teac hers systemati- cally reshape the p edagogical c haracter of AI-generated feedbac k. W e iden tify concrete patterns of correction and refinement that can inform the design of in terfaces and LLM b eha viors that b etter reflect instructional inten t. 2.4 The Present Study Recen t work in AIED argues for ev aluation metho ds that capture subtle but meaningful differences in mo del b eha vior [12]. Recent w ork shows that em b edding- based analyses can quantify how nuanced changes in LLM instruction can lead to significant semantic shifts in LLM resp onse distributions [5,7]. W e adopt this represen tational p ersp ectiv e to study teacher revision b eha vior by em b edding AI-generated feedback and teacher-edited versions in a shared semantic space. This allows us to measure alignment, c haracterize systematic deviations, and analyze v ariation across educators at scale. T eacher Revisions of LLM-Generated F eedback 5 F rom this framing, we examine how teac hers revise AI-generated formativ e feedbac k in practice. W e ask: RQ1 , what textual characteristics are asso ciated with teac hers revising AI-generated feedback; RQ2 , to what extent can revision decisions be predicted from the AI feedbac k text alone; and R Q3 , when revi- sions o ccur, ho w do es the p edagogical t yp e of feedback c hange. These questions are central because revisions reveal where teachers perceive AI feedback as mis- aligned with instructional inten t. Identifying these patterns can guide the design of feedbac k systems that b etter supp ort teacher judgment. 3 Metho ds 3.1 Dataset and Prepro cessing The study dra ws on log data from T utoria, an AI-supp orted feedback platform in tegrated with Mo o dle and Go ogle Classro om [19]. The platform supp orts grad- ing of short, op en-ended resp onses through a co-creation workflo w: for each stu- den t answer, an LLM generates an initial feedbac k draft that the teac her can accept as-is, edit, or fully rewrite before deliv ering it to the studen t. T eac hers also tag resp onses as correct, partially correct, or incorrect (either for selected spans or the full response); these tags are used as inputs to feedback gener- ation (Fig. 1). Our dataset p o ols interaction logs from prior controlled stud- ies of the platform and additional in-the-wild classro om deplo yments. In total, the dataset includes 1,349 AI-generated feedback drafts and corresp onding final teac her-delivered feedbac k messages authored by 117 teachers. T eac her demo- graphics were av ailable for a subset of the sample: in one set of contributing stud- ies, the participating teac hers w ere 68 Brazilian educators (50 male, 18 female; M ag e = 37 , S D = 6 ). The students who received feedbac k from teac hers simi- larly span m ultiple educational contexts and institutions. Con tributing contexts included (i) Brazilian high sc ho ol chemistry classes (perio dic table) completed in Mo odle, (ii) a controlled exp erimen t in which higher-education instructors pro vided feedback on op en-ended responses in introductory computer science, and (iii) additional extracurricular con texts where computer science students answ ered questions on topics such as algorithm analysis and computer architec- ture. Across settings, tasks consisted of comparable short open-ended resp onses, whic h teac hers ev aluated using the platform’s tagging in terface and then deliv- ered feedback based on the AI draft. All teachers and students provided informed consen t for the research use of their data. The platform used tw o large language mo dels during its developmen t. Early v ersions relied on GPT-4 (gpt-4-0613), while later stages adopted DeepSeek- V3, including multi-agen t configurations in the final phase (for more details, see [17]). Since our analysis focuses on teac hers’ in teractions with AI-generated feedbac k rather than on mo del quality, we do not analyze eac h LLM separately . Prompts follow ed established b est practices [5], combining explicit instructions, structured outputs, and examples. Each prompt included the question, the stu- den t’s resp onse, the teacher-assigned correctness lab el, and a request for feedback that appropriately praised the resp onse and/or offered guidance tow ard a more 6 Borc hers et al. Fig. 1. LLM-supp orted feedback generation. Screenshot of the teac her’s tag, ev alua- tion, and feedbac k module. The red area shows the feedback generated after clicking the Generate F eedback button. Additionally , the screen displa ys the student’s resp onse and t wo tags created b y a teacher. accurate answ er. All textual inputs were prepro cessed by replacing missing v al- ues with empty strings, standardizing format, removing newline c haracters, and truncating text to a fixed maxim um length. These steps were applied uniformly to AI-generated feedbac k and teacher-authored explanations. T ext was then conv erted to dense, 384-dimensional vector em b eddings using the pre-trained sentence embedding mo del all-MiniLM-L6-v2 from the Sentence T ransformers library , which is trained on large-scale natural language inference and paraphrase data [20]. Similar em b eddings hav e b een successfully used in past AIED researc h to understand LLM feedback and lab eling instruction [5,21], successfully ensuring that seman tically similar texts hav e similar vectors. 3.2 T extual Characteristics Explaining T eacher Revisions (R Q1) T o characterize textual prop erties asso ciated with teacher revision b eha vior, we analyzed surface-level and semantic features of AI-generated feedback. Sp ecifi- cally , we examined feedback length (word count) and semantic similarity b et ween AI feedbac k and the final teacher explanation, measured using cosine similar- it y b et ween their em b edding represen tations, following past w ork [5,21]. These measures capture both the amount of information pro vided and the exten t to whic h teachers preserved or altered the underlying conten t of the feedback. Analyses were primarily descriptive. W e compared these c haracteristics for feedbac k that was accepted unchanged versus edited. T o account for teacher- lev el differences in editing tendencies, we additionally conducted within-teacher comparisons, using paired nonparametric tests where applicable. These analyses w ere intended to identify patterns asso ciated with revision b eha vior rather than to establish causal relationships. T eacher Revisions of LLM-Generated F eedback 7 3.3 Predictiv e Accuracy for Revision Decisions (R Q2) W e mo deled teacher revision as a binary classification task, predicting whether AI-generated feedback was modified b efore delivery . T o preven t leak age, we con- structed a holdout test set comprising one third of the data using a group-based split, with no teacher app earing in b oth sets [2]. Mo del selection and tuning were conducted on the remaining data via group-based five-fold cross-v alidation. W e ev aluated regularized logistic regression, shallow neural netw orks, and gradien t- b oosted decision trees, testing 5, 48, and 81 configurations, resp ectiv ely; full de- tails are av ailable online [1]. Mo del classes represen t increasing complexit y , from linear baselines to nonlinear mo dels. Hyp erparameters w ere selected using A UC. T o mitigate outcome class im balance, logistic regression used class-balanced loss w eights, and ev aluation emphasized imbalance-robust metrics. Accordingly, we rep ort A UC, balanced accuracy , and Cohen’s κ , all standard in AIED [2]. Final p erformance w as computed on the holdout set, with 95% confidence interv als estimated via 10,000 group-b ootstrap resamples. 3.4 F eedbac k Type Differences After Revision (RQ3) T o examine ho w teacher revisions changed the p edagogical nature of feedback, w e co ded AI-generated feedbac k and final teacher explanations using a theory- informed co deb ook grounded in prior research on feedback effectiveness [10,6]. Consisten t with established frameworks [25], the co deb ook distinguished four m utually exclusiv e categories: Reinforcemen t/Punishmen t, comprising ev alua- tiv e statements with minimal informational con tent; Correctiv e feedback, which signals correctness or provides the correct answer with little explanation; High- information feedback, whic h extends corrective feedbac k with explanations, strate- gies, or prompts supp orting self-regulation; and Other. F ollo wing the original co deb ook [25], co ders assigned a single predominan t feedbac k type to each unique message. T o ease co ding workload, w e only co ded feedbac k messages with exact duplicates once, yielding a deduplicated sample of N=834. When AI feedback was accepted without revision, the same code w as applied to both the AI output and the final teacher explanation. F eedbac k co ded as Other required a brief written justification. Co ding was conducted indep enden tly , with an initial v alidation phase after 10% of the data (n=83) to surface and resolv e questions before pro ceeding. F our coders then indep en- den tly coded randomly assigned subsets of messages. This procedure aligns with in terpretivist qualitative researc h, where co ding reflects theoretically grounded judgmen t rather than an ob jective ground truth [3]. Consistency was supp orted b y a previously v alidated co debo ok with explicit definitions, rules, and exam- ples, and b y the v alidation phase, which ensured shared in terpretation b efore full-scale analysis [3]. W e op en-source our co ding instructions for repro ducibilit y [1]. W e analyzed feedback type distributions to examine the relationship b et ween revision status and explanatory form, using an α = 0 . 05 significance threshold. T o meet test assumptions, low-frequency categories ( < 10%) were excluded or 8 Borc hers et al. collapsed (see Section 4.3). F or unrevised feedback, a goo dness-of-fit test against a uniform distribution assessed whether feedbac k t yp es occurred equally often, indicating which types were more lik ely to b e revised. F or revised feedback, we compared AI-generated and teac her-adjusted distributions using a chi-square test of independence to assess pre-to-p ost c hanges in feedback types. Effect sizes (Cohen’s w, Cramér’s V) were rep orted, and statistically significan t shifts w ere in terpreted through qualitative analysis of teacher revisions. 4 Results 4.1 T extual Characteristics Explaining T eacher Revisions (R Q1) Descriptiv e statistics for ov erall and edited-only cases are summarized in T able 1. A cross all instances ( N = 1349 ), the a verage cosine similarity b et ween AI feed- bac k and the final teac her-provided explanation w as almost perfect ( M = 0 . 97 , S D = 0 . 09 ), indicating substantial ov erlap in conten t. On a verage, AI feedbac k con tained 43.2 words, while teac her explanations contained 41.6 words. T eac hers accepted AI feedback without mo dification in 77.8% of cases ( 1050 / 1349 ). Edited feedbac k was mo destly longer than unedited feedback (48.3 vs. 41.9 w ords), with a mean within-teacher difference of 6.4 words; this difference was statistically significan t based on a paired Wilcoxon signed-rank test ( W = 460.5, p = . 024 ). T able 1. Descriptive statistics for AI feedback and final teacher explanations. V alues are rep orted as mean (SD). Subset Similarit y AI F eedback Length Final F eedbac k Length All feedbac k 0.97 (0.09) 43.24 (19.60) 41.60 (19.81) Edited feedbac k only 0.88 (0.17) 48.38 (18.09) 41.00 (19.97) W e then analyzed editing b ehavior at the teacher level. Of 117 teachers, 60 (51.3%) edited AI-generated feedback at least once. T eac hers reviewed an a v- erage of 11.5 feedback messages ( S D = 39.6). Figure 2 plots the cum ulativ e distribution of editing rates by teacher. Half of teachers edited fewer than 6% of feedbac k instances, whereas the upp er quartile edited more than 33%, and the top decile revised roughly t wo-thirds. This pattern rev eals pronounced hetero- geneit y , with most teachers making minimal changes. 4.2 Predictiv e Accuracy for Revision Decisions (R Q2) T able 2 rep orts predictiv e p erformance on the holdout test set. A cross mo dels, p erformance was mo dest but consistently ab o ve chance (i.e., an AU C of .5). Logistic regression achiev ed a holdout AU C of .70 [.53, .72], the shallo w neural net work .74 [.52, .78], and gradient-bo osted trees .75 [.54, .77]. Balanced accuracy T eacher Revisions of LLM-Generated F eedback 9 Fig. 2. Cum ulative distribution of the percentage of messages changed b y teac hers. The x-axis shows the percentage of teac hers (sorted by c hange rate), and the y-axis sho ws the p ercen tage of messages mo dified. Dashed lines indicate teacher p ercen tiles. follo wed a similar pattern, and Cohen’s κ indicated close-to-mo dest performance in most models. Confidence interv als o v erlapp ed substantially across models, indicating no reliable p erformance differences in this dataset. T able 2. Holdout predictive p erformance for revision decision mo dels. V alues are re- p orted as p oin t estimate [95% group-b ootstrap CI], computed with 10,000 resamples. Model ROC AUC Balanced Accuracy Accuracy Cohen’s κ Logistic Regression 0.698 [0.534, 0.715] 0.672 [0.510, 0.688] 0.733 [0.712, 0.748] 0.322 [0.015, 0.358] MLP (1 lay er) 0.738 [0.518, 0.781] 0.535 [0.515, 0.550] 0.757 [0.740, 0.844] 0.095 [0.036, 0.134] Gradient-Boosted T rees 0.746 [0.539, 0.768] 0.651 [0.487, 0.668] 0.824 [0.807, 0.864] 0.387 [-0.039, 0.423] 4.3 F eedbac k Type Differences After Revision (RQ3) When AI-generated feedbac k w as not revised, feedbac k was most commonly Correctiv e ( n = 381, 58.1%), then High-information ( n = 275, 41.9%). A single instance of Reinforcement/Punishmen t was excluded from further analysis due to its rarity . A chi-square go o dness-of-fit test against a uniform distribution in- dicated that this im balance was statistically significant, χ 2 (1) = 17.13, p < .001, with a small-to-mo derate effect size (Cohen’s w = 0.16). This pattern suggests 10 Borc hers et al. that when AI feedbac k is deemed acceptable b y teac hers without revision, it is more often correctiv e than high-information. When AI-generated feedbac k was revised, the initial message was significan tly more often High-information ( n = 106, 59.9%) than Correctiv e ( n = 71, 40.1%), χ 2 (1) = 6.92, p = .009, with a small-to-moderate effect ( w = 0.20). After revi- sion, the distribution of final feedback explanations became more balanced, with 48.0% High-information and 43.5% Corrective, alongside a small proportion of Reinforcemen t/Punishment ( n = 13, 7.3%) and Other feedbac k (n = 2, 1.1%). Giv en the small prop ortion of Reinforcement/Punishmen t and Other types, a di- rect comparison of High-information v ersus all other feedbac k types b etw een the initial and final stages rev ealed a significan t shift, χ 2 (1) = 4.55, p = .033, with a small association (Cramér’s V = 0.12). Human revision reduced the relative prev alence of High-information feedback in fav or of other explanatory forms. T o b etter understand revision patterns, one researcher conducted an ex- ploratory study of feedback messages in whic h teachers reduced the complexity of AI-generated feedbac k. In some cases, teachers seemed to disagree with the AI’s assessment. F or instance, Congr atulations! Y ou wer e c orr e ct in stating that ... (i.e., high-information) w as revised to That’s a very generic and inc omplete answer. (i.e., corrective). Another case was when AI generated high-information feedbac k in English, which the teacher then revised into a correctiv e one in Brazil- ian Portuguese. Additionally , there w ere cases in whic h corrective feedbac k (e.g., Y our answer is c orr e ct. Y ou c orr e ctly mentione d "devic es," which ar e pr esent in the c ontext of the question r eferring to input and output devic es. Ke ep it up! ) was replaced by a Reinforcemen t/Punishment one due to plagiarism concerns (i.e., Y our answer is c orr e ct. But b e c ar eful of p ossible plagiarism. ). Lastly , there w ere cases in which the teacher seemed to disagree with the p edagogical approac h of the AI-generated feedbac k, replacing a high-information one with Congr atula- tions on c orr e ctly identifying that the CPU ... . T ogether, these insigh ts suggest that teac hers simplified feedbac k when it conflicted with ev aluative judgment, con textual aw areness, or feedback efficiency . 5 Discussion This study in vestigated how teachers revise and deliver LLM-generated forma- tiv e feedbac k. By comparing AI feedbac k with teacher-edited v ersions, w e shift atten tion from feedback qualit y in isolation to the human mediation that de- termines what students ultimately receive. This approach directly answers calls in AIED to examine AI systems in use [1 2,22,5]. W e synthesize our findings around three contributions: patterns of teacher revision, what these revisions rev eal ab out p edagogical alignment, and implications for feedback systems. 5.1 T eac her Revision as Selectiv e Mediation T eac hers accepted AI feedbac k without mo dification in nearly 80% of cases, and more than half of the teac hers never edited AI feedback at all. This pat- tern ec ho es recen t work suggesting that educators often forw ard AI-generated T eacher Revisions of LLM-Generated F eedback 11 feedbac k with minimal in terv ention [28]. F rom an AIED p ersp ectiv e, this re- sult highlights that exp ecting teac hers to contin uously and carefully monitor all AI-mediated instructional pro cesses migh t b e unrealistic, particularly in time- constrained classro om settings. Instead, our findings align with the theoretical p erspective of human–AI hybrid adaptivit y in AIED [11], whereb y resp onsibil- it y for moment-to-momen t instructional decisions is distributed b et ween human and system rather than centrally managed b y the teacher. In this view, teach- ers selectively interv ene when AI b eha vior violates p edagogical exp ectations or con textual constraints. Notably , revision b eha vior was highly heterogeneous. Only a few teachers edited a large prop ortion of feedback messages, in some cases revising more than t wo-thirds of AI outputs. This v ariability suggests that teac her mediation is an emergen t outcome shaped by individual beliefs, instructional norms, and time constrain ts. In future work, w e recommend further inv estigating which teacher and contextual attributes explain revision behavior, given substantial v ariation in teac her trust and self-efficacy for AI [24]. 5.2 Length, Density , and P edagogy T rigger Revision When teac hers revised AI-generated feedback, their revisions follow ed system- atic, in terpretable patterns. A ddressing RQ1, teacher edits t ypically reduced length while largely preserving semantic conten t, suggesting that revisions often functioned as compression rather than correction. This finding aligns with prior qualitativ e evidence that teac hers are concerned about the excessive volume of AI-generated feedback [9]. Extending this w ork, our results provide quantitativ e empirical evidence that v erb osit y itself is a trigger for teacher interv ention. Ev en after teac hers reduced the length, the semantic similarity b et ween AI- generated feedbac k and edited feedback remained high, indicating that most re- visions were rhetorical or structural. Qualitative cases nevertheless rev eal salien t exceptions in which teac hers in tervened b ecause of disagreement with the p ed- agogical framing of the feedbac k (RQ3). Unedited AI feedbac k was more often high-information than correctiv e. In contrast, revised feedbac k was dispropor- tionately high-information and shifted to ward a more balanced distribution after editing, suggesting that teachers t ypically reduced ov erly explanatory feedback. This pattern corrob orates long-standing concerns regarding the assistance dilemma and the risks of ov erscaffolding [22,14]. Prior analyses of LLM-generated tutoring and fee dbac k show that models frequen tly default to explicit expla- nations and direct answ ers, ev en when indirect prompts or opportunities for pro ductiv e struggle may b etter support learning [5]. Our findings suggest that teac hers sometimes coun teract this tendency by simplifying feedbac k, reassert- ing ev aluativ e judgment, or narrowing the instructional fo cus to what they deem p edagogically essen tial. Reducing explanation can low er cognitive load, but it ma y also strip aw ay conceptual scaffolds necessary for learner sensemaking [14]. T eac hers’ revisions rev eal ho w this trade-off is actively negotiated, exp osing di- v ergences b et ween AI defaults and human p edagogical judgment in practice. 12 Borc hers et al. F uture researc h should examine how teac hers calibrate LLMs’ tendency to o verscaffold, which can offload learner sensemaking and impair learning [8], or instead ov ercorrect and provide insufficien t supp ort [14]. Classro om exp erimen ts comparing edited and unedited AI feedback, combined with learning analytics that quan tify scaffolding from language, offer a promising path forward [4]. 5.3 Predictabilit y of Revision and the Limits of T ext-Only Signals A ddressing RQ2, our predictiv e mo deling results show that it is poss ible to iden- tify , at ab o ve-c hance lev els, which AI feedbac k messages will b e revised using only the AI-generated text as input. A t the same time, mo del performance re- mained mo dest (about 0.70-0.75 AU C and close to 0.4 κ ), with wide confidence in terv als (though the low er b ounds generally exceeded the at-c hance level of 0.5 AU C ) and no clear adv an tage for more complex architectures. Substan tively , the modest p erformance of text-only models shows that revision decisions are not determined solely by the prop erties of AI-generated feedback. Prior work suggests that teachers’ feedbac k practices are shap ed by additional factors such as the studen t’s response and error t yp e, the teac her’s grading in tent and ev al- uativ e stance [4], disciplinary conv en tions, and situational constraints suc h as time pressure. None of these signals were av ailable to the mo dels in the present study . Incorp orating such contextual information—p oten tially through multi- mo dal or task-aw are mo dels—ma y substan tially improv e predictive p erformance [26]. More accurate mo dels, in turn, could supp ort practical applications, suc h as prioritizing feedback instances lik ely to require h uman revision, thereby reducing unnecessary teac her effort while preserving p edagogical con trol. 5.4 Implications for AI F eedbac k Systems Our findings carry clear implications for AIED. The prev alence of unedited feed- bac k indicates that default AI b eha vior is instructionally consequential; ev alua- tion paradigms that assume routine teac her correction therefore underestimate the effects of bias, verbosity , and p edagogical misalignment [7,8,5]. When teach- ers do revise, they primarily shorten or reframe rather than rewrite. At the same time, mark ed v ariation across teac hers underscores the limits of uniform feed- bac k generation. Systems that adapt to patterns in a teacher’s prior edits ma y b etter align with classro om practice without constraining professional judgment. These findings call for ev aluating AI feedback as a co-created artifact shap ed through teacher in teraction, rather than fo cusing solely on raw mo del output [23]. Learning analytics and future researc h can capture revision traces and in- teraction costs and relate them to student outcomes, providing a foundation for designing feedbac k systems that b etter supp ort teachers in practice [4]. 5.5 Limitations and F uture Directions This study examines a retrosp ectiv e dataset of short, op en-ended tasks within a single platform, and revision behavior ma y differ across assessment t ypes, T eacher Revisions of LLM-Generated F eedback 13 in terface designs, and educational contexts. T reating revision as a binary out- come further masks meaningful v ariation b et ween minor edits and substan tive rewrites. F urther, acceptance of feedbac k should not b e equated with agreement or trust, as it may instead reflect time pressure, pedagogical inten t tow ard par- ticular students, or editing costs. It is also p ossible that em b eddings derived from LLMs fine-tuned on educational data w ould provide represen tations with greater predictive v alidity . Finally , controlled exp erimen ts that hold the LLM and prompts constant w ould enable clearer attribution of revision differences to sp ecific mo dels, an analysis b ey ond the scop e of the present study . 6 Conclusion This study argues that ev aluating LLM-generated formativ e feedbac k in iso- lation is no longer sufficient for AIED. In practice, feedback reac hes studen ts through a mediated pip eline in which teac hers are the final authors. Analysis of AI-generated feedback reviewed by 117 teachers shows that this mediation is selectiv e: most feedback is delivered unchanged, making default mo del behavior instructionally consequen tial. When revisions o ccur, ho wev er, they are system- atic and rev ealing, signaling where LLMs misalign with teachers’ priorities. W e conceptualize teacher revision as a measurable indicator of p edagogical alignmen t and sho w that it can b e studied at scale using surface features and represen tational similarity . T eachers most often compress and simplify AI drafts, shifting from explanatory to concise corrective feedback. This pattern captures a core tension in feedback design and highlights teacher judgmen t as an essential ob ject of inquiry for AIED. Mo ving forward, our field should pa y more atten tion to teacher revisions as a core ob ject of inquiry for AIED and a practical lever for designing systems that b etter reflect teacher preferences. References 1. Op en study rep ository , https://github.com/conradborchers/ teacher- revisions/ 2. Bak er, R.S.: Big Data and Education. Universit y of Pennsylv ania, 9 edn. (2025) 3. Blandford, A., F urniss, D., Makri, S.: Qualitative HCI researc h: Going behind the scenes. Morgan & Claypo ol Publishers (2016) 4. Borc hers, C., P atel, M., Lee, S.M., Botelho, A.F.: Disen tangling learning from judgmen t: Represen tation learning for open resp onse analytics. arXiv preprint arXiv:2512.23941 (2025) 5. Borc hers, C., Shou, T.: Can large language mo dels match tutoring system adaptiv- it y? A b enc hmarking study . In: International Conference on Artificial Intelligence in Education. pp. 407–420. Springer (2025) 6. Castro, M.S.d.O., Mello, R.F., Fiorentino, G., Viberg, O., Spik ol, D., Baars, M., Gašević, D.: Understanding peer feedback contributions using natural language pro cessing. In: European conference on technology enhanced learning. pp. 399– 414. Springer (2023) 14 Borc hers et al. 7. Du, Y., Borchers, C., Cukuro v a, M.: Benchmarking educational llms with analytics: A case study on gender bias in feedback. arXiv preprint arXiv:2511.08225 (2025) 8. F an, Y., T ang, L., Le, H., Shen, K., T an, S., Zhao, Y., Shen, Y., Li, X., Gašević, D.: Beware of metacognitive laziness: Effects of generative artificial intelligence on learning motiv ation, processes, and p erformance. British Journal of Educational T echnology (2024) 9. F redriksson, A.L.: Gift-ai: “ I’m scared that the ai feedbac k is to o m uch!”—preservice (english) teac hers’ feedback strategies and their use of genai for feedbac k. In: F rontiers in Education. v ol. 10, p. 1612398. F rontiers Media SA (2025) 10. Hattie, J., Timp erley , H.: The p o wer of feedback. Review of educational research 77 (1), 81–112 (2007) 11. Holstein, K., Aleven, V., Rummel, N.: A conceptual framework for human–ai hy- brid adaptivit y in education. In: Artificial In telligence in Education: 21st In ter- national Conference, AIED 2020, Ifrane, Moro cco, July 6–10, 2020, Pro ceedings, P art I 21. pp. 240–254. Springer (2020) 12. Karum baiah, S., Ganesh, A., Bharadwa j, A., Anderson, L.: Ev aluating b eha viors of general purpose language mo dels in a pedagogical con text. In: In ternational Conference on Artificial Intelligence in Education. pp. 47–61. Springer (2024) 13. Kho jasteh, L. , So ori, A., Jav ed, F.: Comparing teacher e-feedback, ai feedback, and h ybrid feedback in enhancing efl writing skills. T echnology in Language T eac hing & Learning 7 (3), 102626–102626 (2025) 14. K o edinger, K.R., Aleven, V.: Exploring the assistance dilemma in exp erimen ts with cognitiv e tutors. Educational Psychology Review 19 , 239–264 (2007) 15. Letteri, I., Vittorini, P .: Enhancing student feedbac k in data science education: Harnessing the p o wer of ai-generated approaches. International Journal of Artificial In telligence in Education pp. 1–24 (2025) 16. Nazaretsky , T., Mejia-Domenzain, P ., Sw amy , V., F rej, J., Käser, T.: Who giv es feedbac k matters: Student biases to wards human and ai-generated formativ e feed- bac k. Journal of Computer Assisted Learning 42 (1), e70153 (2026) 17. Neto, J.R., Alves, G., Mello, R.F.: Llmagentgrader: Sistema m ultiagente com deepseek para correçao automática aprimorada de resp ostas curtas. In: Simp ósio Brasileiro de Informática na Educação (SBIE). pp. 617–628. SBC (2025) 18. Nygren, T., Samuelsson, M., Hansson, P .O., Efimov a, E., Bachelder, S.: Ai versus h uman feedback in mixed reality simulations: Comparing llm and exp ert mentoring in preservice teacher education on con tro versial issues. International Journal of Artificial In telligence in Education pp. 1–33 (2025) 19. P ontual F alcão, T., Arêdes, V., de Souza, S.B.J., Fiorentino, G., Neto, J.R., Alv es, G., Mello, R.F.: T utoria: a softw are platform to improv e feedbac k in education. Journal on Interactiv e Systems 14 (1), 383–393 (Aug 2023). https://doi.org/10. 5753/jis.2023.3247 20. Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese b ert- net works. In: Pro ceedings of the 2019 Conference on Empirical Metho ds in Natural Language Pro cessing. Asso ciation for Computational Linguistics (11 2019) 21. Ro drigues, L., Pereira, F., Santos, J., Oliv eira, E., Gasparini, I., Mello, R., Mar- ques, L., Dermev al, D., Bittencourt, I.I., Isotani, S.: Question classification with constrained resources: a study with co ding exercises. In: International Conference on Artificial Intelligence in Education. pp. 734–740. Springer (2023) 22. Stamp er, J., Xiao, R., Hou, X.: Enhancing llm-based feedbac k: Insights from in- telligen t tutoring systems and the learning sciences. In: In ternational Conference on Artificial Intelligence in Education. pp. 32–43. Springer (2024) T eacher Revisions of LLM-Generated F eedback 15 23. Thomas, D.R., Borchers, C., Kak arla, S., Lin, J., Bhushan, S., Guo, B., Gatz, E., K o edinger, K.R.: Do tutors learn from equity training and can generativ e ai assess it? In: Pro ceedings of the 15th In ternational Learning Analytics and Knowledge Conference. pp. 505–515 (2025) 24. Vib erg, O., Cukuro v a, M., F eldman-Maggor, Y., Alexandron, G., Shirai, S., Kane- m une, S., W asson, B., Tømte, C., Spik ol, D., Milrad, M., et al.: What explains teac hers’ trust in ai in education across six countries? International Journal of Artificial In telligence in Education 35 (3), 1288–1316 (2025) 25. Wisniewski, B., Zierer, K., Hattie, J.: The p o wer of feedbac k revisited: A meta- analysis of educational feedback research. F ron tiers in psychology 10 , 487662 (2020) 26. W ong, K., W u, B., Bulathw ela, S., Cukurov a, M.: Rethinking the potential of mul- timo dalit y in collab orativ e problem solving diagnosis with large language mo dels. In: In ternational Conference on AI in Education. pp. 18–32. Springer (2025) 27. Xa vier, C., da Costa, N.T., V aldo, A.K., Alv es, G., Ro drigues, L., Ro drigues, L.F., Silv a, M., Neto, R., F alcão, T.P ., Gasevic, D., et al.: Human teacher vs. llm-generated feedbac k in secondary education: A comparative study on student p erceptions. In: Europ ean Conference on T echnology Enhanced Learning. pp. 534– 548. Springer (2025) 28. Xa vier, C., Ro drigues, L., Costa, N., Neto, R., Alv es, G., F alcão, T.P ., Gasevic, D., Mello, R.F.: Emp o wering instructors with ai: Ev aluating the impact of an ai-driven feedbac k to ol in learning analytics. IEEE T ransactions on Learning T echnologies (2025) 29. Xiao, C., Ma, W., Song, Q., Xu, S.X., Zhang, K., W ang, Y., F u, Q.: Human-ai collab orativ e essay scoring: A dual-pro cess framework with llms. In: Proceedings of the 15th International Learning Analytics and Knowledge Conference. pp. 293– 305 (mar 2025) 30. Zam brano, R.J., Chaguay , J., Ma yorga, J., Kirsc hner, P .A., Parra, W., Lazo, A.: Prev alence of educational myths among ecuadorian teac hers. T rends in Neuro- science and Education p. 100273 (2025)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment