자기지도 사전학습의 비대칭성 및 두 단계 M추정 이론
본 논문은 대규모 비지도 데이터로 사전학습된 표현을 downstream 선형 회귀에 활용하는 두 단계 M‑추정 프레임워크를 제시한다. 사전학습 파라미터가 군 대칭에 의해 식별되지 않는 문제를 리만 기하학적 기술자를 이용해 해결하고, 전 단계와 후 단계의 샘플 수 비율이 일정할 때 테스트 위험의 한계 분포를 명시적으로 도출한다. 스펙트럴 사전학습, 인자 모델, 가우시안 혼합 모델 등 여러 사례에 적용해 기존 이론보다 상수 계수에서 크게 개선된 결…
저자: Mohammad Tinati, Stephen Tu
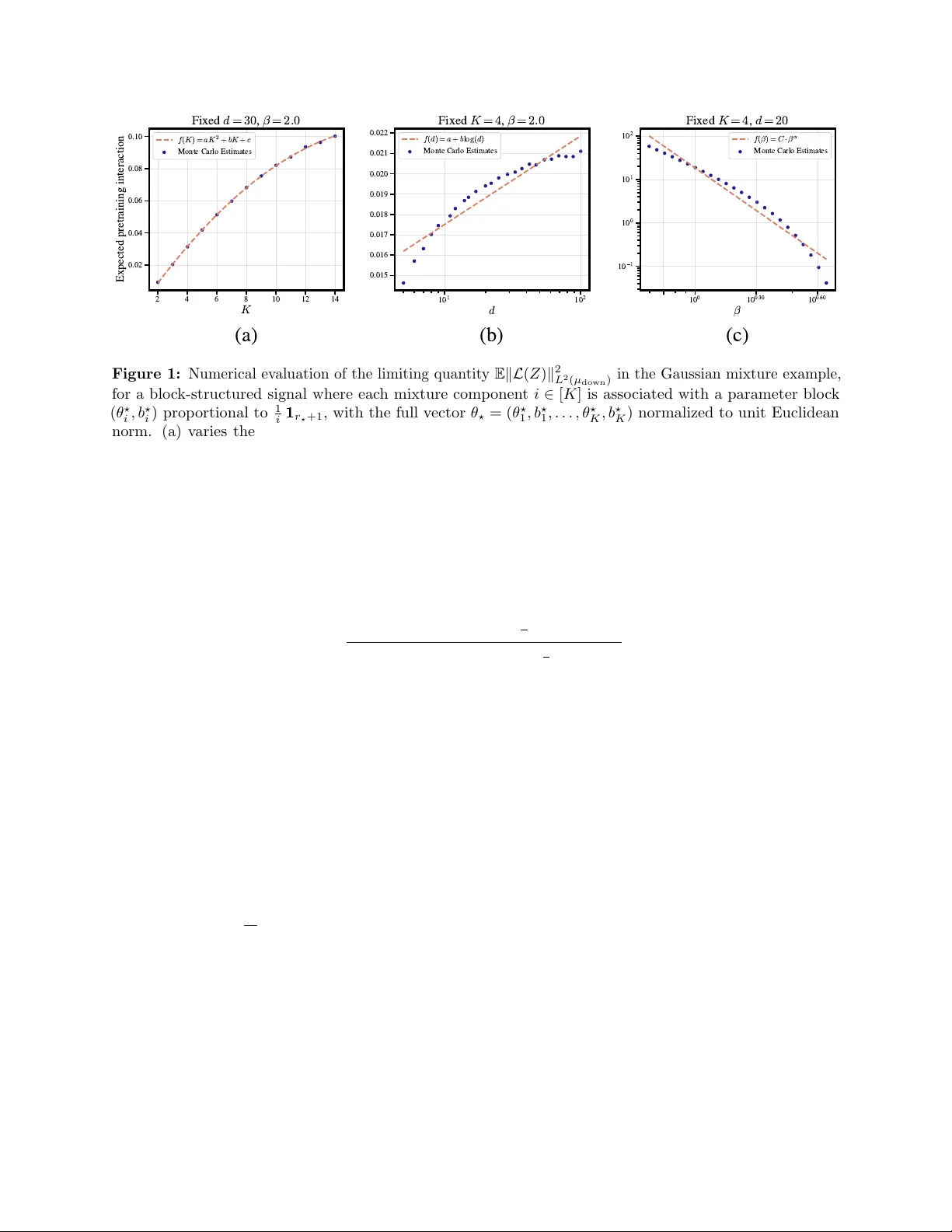
본 연구는 현대 머신러닝에서 핵심적인 역할을 차지하고 있는 자기지도 사전학습(pre‑training)과 downstream fine‑tuning의 통계적 상호작용을 이론적으로 규명하고자 한다. 저자는 사전학습 단계와 downstream 단계가 각각 독립적인 데이터셋 D^{pre}_m 과 D^{down}_n 을 사용한다는 설정을 채택하고, 두 단계 모두를 하나의 두 단계 M‑추정(framework)으로 모델링한다.
1. **문제 설정**
- 입력 공간 Z 과 X 에 대해 각각 확률분포 μ^{pre}, μ^{down} 을 가정한다.
- 사전학습 손실 ℓ_{pre}(w;z) 은 파라미터 w∈ℝ^{q₀} 에 대해 두 번 연속 미분 가능하고, i.i.d. z_j 에 대해 평균화된 경험 손실 \hat L_{pre}(w) 을 최소화한다.
- 사전학습 후 얻은 파라미터 \hat w_m 을 사용해, downstream 데이터에 대해 선형 회귀 f_{θ,w}(x)=⟨θ,ψ(x,w)⟩ 을 학습한다. 여기서 ψ 은 차원 p 의 특징 맵이며, θ∈ℝ^{p} 를 최소제곱법으로 추정한다.
2. **군 대칭과 식별성 문제**
- 많은 자기지도 손실은 군 G (예: 직교군 O(p) )에 대해 불변이다. 즉 ℓ_{pre}(g·w;z)=ℓ_{pre}(w;z) ∀ g∈G.
- 이 경우 파라미터 w 그 자체는 식별되지 않으며, 최소점은 궤도
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기