On the Asymptotics of Self-Supervised Pre-training: Two-Stage M-Estimation and Representation Symmetry
Self-supervised pre-training, where large corpora of unlabeled data are used to learn representations for downstream fine-tuning, has become a cornerstone of modern machine learning. While a growing body of theoretical work has begun to analyze this …
Authors: Mohammad Tinati, Stephen Tu
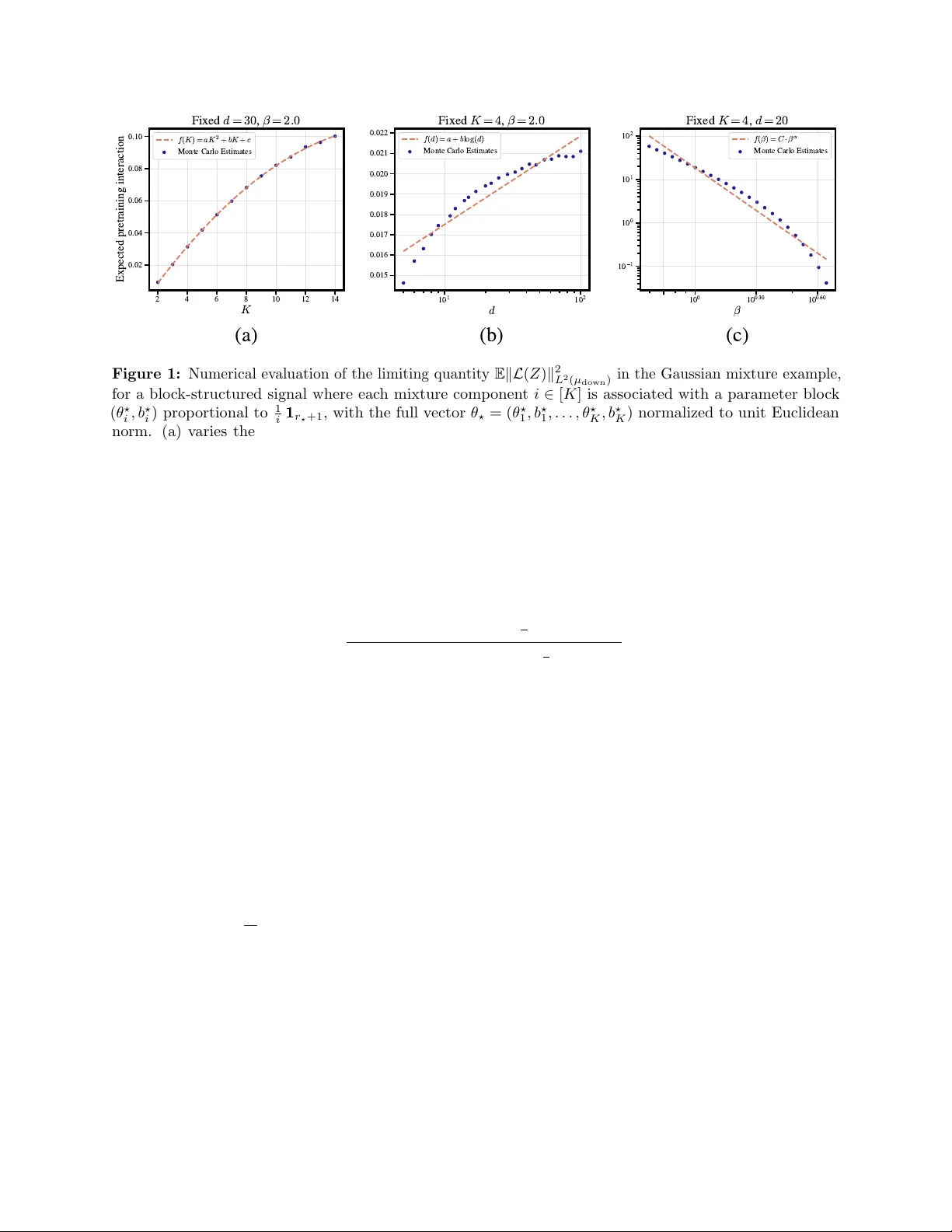
On the Asymptotics of Self-Sup ervised Pre-training: Tw o-Stage M -Estimation and Represen tation Symmetry Mohammad Tinati and Stephen T u Ming Hsieh Departmen t of Electrical and Computer Engineering, Univ ersity of Southern California Marc h 31, 2026 Abstract Self-sup ervised pre-training, where large corp ora of unlab eled data are used to learn repre- sen tations for downstream fine-tuning, has b ecome a cornerstone of modern machine learning. While a growing b ody of theoretical work has b egun to analyze this paradigm, existing b ounds lea ve op en the question of how sharp the current rates are, and whether they accurately capture the complex interaction b et ween pre-training and fine-tuning. In this pap er, we address this gap by developing an asymptotic theory of pre-training via tw o-stage M -estimation. A key c hallenge is that the pre-training estimator is often identifiable only up to a group symmetry , a feature common in representation learning that requires careful treatment. W e address this issue using to ols from Riemannian geometry to study the intrinsic parameters of the pre-training represen tation, whic h w e link with the downstream predictor through a notion of orbit-invarianc e , precisely c haracterizing the limiting distribution of the do wnstream test risk. W e apply our main result to several case studies, including sp ectral pre-training, factor mo dels, and Gaussian mixture mo dels, and obtain substan tial impro vemen ts in problem-sp ecific factors ov er prior art when applicable. 1 In tro duction Self-sup ervised pre-training has emerged as a p o werful paradigm for learning representations from large corp ora of unlab eled data, which are subsequently adapted to do wnstream tasks via fine-tuning. This approach has achiev ed striking empirical success across a wide range of domains in mo dern mac hine learning. F or instance in computer vision, a growing b ody of contrastiv e and self-distillation metho ds ( Chen et al. , 2020b ; Zb on tar et al. , 2021 ; Grill et al. , 2020 ; Oord et al. , 2018 ; He et al. , 2020 ; W ang and Isola , 2020 ; Chen and He , 2021 ; Bardes et al. , 2022 ) ha v e demonstrated that high-quality features can be learned without manual annotation and transferred effectiv ely across tasks. More broadly , large language models and vision-language mo dels trained on massive unlab eled or w eakly lab eled corp ora hav e shown that pre-training can endow mo dels with general-purpose capabilities that substantially reduce the amoun t of lab eled data required for do wnstream adaptation ( Devlin et al. , 2019 ; Brown et al. , 2020 ; Radford et al. , 2021 ; Oquab et al. , 2024 ). Motiv ated b y these empirical adv ances, a growing bo dy of theoretical work has b egun to in vestigate self-sup ervised pre-training, including contrastiv e learning and other v arian ts, from a 1 statistical persp ective ( Saunshi et al. , 2019 ; T osh et al. , 2021 ; Lee et al. , 2021 ; HaoChen et al. , 2021 ; Cabannes et al. , 2023 ; Saunshi et al. , 2022 ; Ge et al. , 2023 ; Lin and Mei , 2025 ). Despite the v arying problem setups, loss functions, and structural assumptions in these w orks, a cen tral question across m uch of this literature is: when do es the t wo-stage pip eline of pre-training on unlab elled data follo wed by fine-tuning on do wnstream task data pr ovably outp erform tr aining fr om scr atch on the downstr e am data alone? A closely related question in v olves the marginal v alue of pre-training data: when is the downstream tas k error fundamen tally b ottlenec k ed by the amoun t of labeled fine-tuning data, so that additional pr e-tr aining samples yield diminishing impr ovement? While recent w orks ha v e made some progress to w ards answ ering these questions, w e still lac k an instance-optimal theory that precisely c haracterizes the role of pre-training loss, data distribution, and representation prop erties in do wnstream task p erformance. Indeed, m uc h of the existing theory fo cuses on sufficien t conditions and upper b ounds, leaving op en the question of ho w sharply current rates capture true b eha vior. Moreov er, av ailable results are typically not instance-adaptive: they do not explicitly reflect the in teraction betw een the sp ecific pre-training and fine-tuning distributions, losses, mo dels, and represen tation structure. Con trast this to standard supervised learning, where classical M -estimation theory pro vides optimal, instance-sp ecific asymptotic characterization of the excess risk; these bounds then serve as a b enc hmark for deriving sharp non-asymptotic results (see e.g. Sp okoin y , 2012 ; F rostig et al. , 2015 ; Ostrovskii and Bac h , 2021 ). In this pap er, w e take a step tow ards bridging this gap b y dev eloping an asymptotic theory of self-sup ervised pre-training in the joint limit of pre-training and fine-tuning data. A key c hallenge is that pre-training estimators are often iden tifiable only up to a group symmetry , which complicates the direct application of tw o-stage M -estimation theory (see e.g., P agan , 1986 ; New ey and McF adden , 1994 ). W e address this c hallenge in the setting of a general pre-training loss that learns a represen tation subsequently used for downstream linear regression. W e first establish asymptotic normality of the intrinsic pre-training represen tation via a Riemannian M -estimation result that ma y b e of independent in terest. W e then link pre-training and do wnstream regression through our main result c haracterizing the limiting distribution of the downstream test risk; a k ey conceptual step is iden tifying the structural conditions on the learned features that ensure orbit-invarianc e of the do wnstream predictor. Finally , w e apply our main result to sev eral case studies, include pre-training with a sp ectral loss, factor mo del, and a Gaussian mixture mo del. When applicable, our results illustrate substantial gaps in problem-specific factors in prior art. 2 Related W ork Early theoretical attempts to explain the success of self-sup ervised pre-training, particularly con- trastiv e learning, fo cused on relating the pre-training loss to do wnstream performance via sp ecific laten t v ariable settings ( Saunshi et al. , 2019 ; T osh et al. , 2021 ). F ollow up w orks hav e p oin ted out the role of data-augmentation ( HaoChen et al. , 2021 ; Chen et al. , 2020a ), reconstruction pretext ( Lee et al. , 2021 ), and inductiv e bias ( Saunshi et al. , 2022 ; HaoChen and Ma , 2022 ) in do wnstream task error. More recently , Lin and Mei ( 2025 ) control do wnstream error in terms of an approximate sufficiency loss whic h is w ell con trolled when pre-training with SimCLR. Most related to our work are Cabannes et al. ( 2023 ); Ge et al. ( 2023 ). First, Cabannes et al. ( 2023 ) study a VICReg-st yle ( Balestriero and LeCun , 2022 ) pre-training loss combined with a do wnstream RKHS regression problem. Their main result bounds the downstream test risk b y the (scaled) pretrain loss, the latter whic h they con trol using Rademac her complexit y arguments. While 2 their downstream setup is more flexible than ours (their RKHS setup allows for infinite-dimensional parameterizations downstream), our analysis holds for general pre-training losses. More imp ortan tly , the optimalit y of their bounds, in terms of the sharpness of the dep endence on problem-sp ecific constan ts, is left op en. Next, Ge et al. ( 2023 ) view the pre-train and fine-tune pipeline through the lens of com bining an MLE pre-training loss coupled with ERM fine-tuning, and pro vide end-to- end downstream risk b ounds using the pre-trained features. W e remark that their κ -informative c ondition shares high-level similarity with our goal of quan tifying inv ariance in pre-training; how ev er, the sp ecific details differ substantially from our geometric approac h. While their problem setup is p erhaps the most general to date, again the sharpness of their results is not addressed; in Section 6 , w e will show non-trivial gaps b etw een their results and those that arise from our asymptotic analysis in the factor mo del example. More broadly , t w o-stage M -estimation has a ric h literature in b oth statistics and economics (see e.g., Newey , 1984 ; Pagan , 1986 ; New ey and McF adden , 1994 ), and is often deploy ed in semi- parametric estimation (see e.g., Andrews , 1994 ), where a n uisance parameter is first estimated, and then plugged in to a second-stage estimator for the target parameters. As mentioned already , the standard tw o-stage theory do es not directly apply to our setting, as one t ypically assumes consistency of the first-stage in parameter space. T o handle this, our analysis in volv es a Riemannian M -estimation argument; a similar argumen t for the orthogonal group is used in Bastani ( 2024 ) to study the asymptotics of lo w-rank matrix sensing. W e also men tion that Zhang et al. ( 2019 ) study the asymptotics of semi-sup ervised learning, but in the simpler setting of mean estimation. 3 Problem F orm ulation Let µ pre and µ down b e probability measures on input spaces Z and X , respectively . W e consider t wo training datasets: (i) a pr e-tr aining dataset D ( m ) pre : = { z j } m j =1 , where z j i . i . d . ∼ µ pre , and (ii) a downstr e am dataset D ( n ) down : = { ( x i , y i ) } n i =1 , where ( x i , y i ) i . i . d . ∼ ( X , Y ) and X ∼ µ down . The datasets D ( m ) pre and D ( n ) down are drawn indep enden tly . The pair ( X , Y ) is further assumed to satisfy: Y = f ⋆ ( X ) + ε, E [ ε | X ] = 0 , σ 2 : = E [ ε 2 | X ] < ∞ , (3.1) for some unkno wn regression function f ⋆ : X 7→ R . T o wards parameterizing f ⋆ , we fix a feature dimension p ∈ N + , and consider a differen tiable represen tation ψ ( x, w ) ∈ R p , where w ∈ R q 0 is the represen tation parameter. F or eac h w , define the linear hypothesis class H w : = { f θ,w | θ ∈ R p } with f θ,w ( x ) : = ⟨ θ , ψ ( x, w ) ⟩ . W e assume that f ⋆ in ( 3.1 ) is wel l-sp e cifie d with resp ect to F : = S w ∈ R q 0 H w , i.e., f ⋆ ∈ F . Let ( w ⋆ , θ ⋆ ) denote a pair suc h that f ⋆ = f θ ⋆ ,w ⋆ . Notation. Throughout, L 2 down : = L 2 ( µ down ) denotes the Hilbert space of real-v alued square- in tegrable functions g : X 7→ R with inner pro duct ⟨ g , h ⟩ : = E X ∼ µ down [ g ( X ) h ( X )]. The notation d ⇝ denotes conv ergence in distribution, and P − → denotes conv ergence in probability . The set B d ( w , r ) : = { w ∈ R d | ∥ w ∥ ⩽ r } denotes the closed ℓ 2 -ball of radius r in R d ; we drop the subscript d when the dimension is implicit. The set O ( p ) denotes the orthogonal group O ( p ) : = { Q ∈ R p × p | Q ⊤ Q = QQ ⊤ = I } . Finally , ( · ) + denotes the Moore-Penrose pseudo-inv erse for a matrix. 3 3.1 Pre-training Loss, Do wnstream Least-Squares Estimation, and Final T est Risk Pre-training ob jectiv e. Let ˆ L pre ( w ; D ( m ) pre ) b e an unsup ervised/self-sup ervised empirical pre- training loss. W e assume the pre-training loss decomposes as ˆ L pre ( w ; D ( m ) pre ) = 1 m P m j =1 ℓ pre ( w ; z j ), where ℓ pre : R q 0 × Z 7→ R is a per-sample loss function. Let L pre ( w ) : = E Z ∼ µ pre ℓ pre ( w ; Z ) denote the corresponding p opulation-lev el pre-training ob jective. W e assume that ℓ pre ( w ; Z ) is twice con tinuously differen tiable with resp ect to w for almost ev ery Z . The pre-training stage then solv es: ˆ w m ∈ arg min w ∈ R q 0 ˆ L pre ( w ; D ( m ) pre ) . (3.2) Our notation deliberately abstracts aw ay the sp ecific form of the pre-training loss; the analysis applies broadly to standard con trastiv e and representation-learning losses used in practice. Do wnstream estimation. Giv en represen tation w ∈ R q 0 , define the downstream empirical loss: ˆ L down ( θ ; w, D ( n ) down ) : = 1 n n X i =1 y i − ⟨ θ , ψ ( x i , w ) ⟩ 2 . The downstream estimator uses b oth the pre-trained parameter ˆ w m ∈ R q 0 and the downstream training data D ( n ) down to compute: 1 ˆ θ m,n ∈ arg min θ ∈ R p ˆ L down ( θ ; ˆ w m , D ( n ) down ) . (3.3) The resulting predictor for the downstream task is then ˆ f m,n ( · ) : = ⟨ ˆ θ m,n , ψ ( · , ˆ w m ) ⟩ ∈ H ˆ w m . Final test risk. Let ( X new , Y new ) b e an indep enden t test pair with the same distribution as ( X , Y ) (cf. ( 3.1 ) ). W e focus on a c onditional notion of test-time risk that conditions on the realized pre-training dataset and downstream design, while still av eraging o ver do wnstream lab el noise. Sp ecifically , write X 1: n : = ( X 1 , . . . , X n ) and define the (conditional) test-time risk: R ( D ( m ) pre , X 1: n ) : = E [ Y new − ˆ f m,n ( X new ) 2 | D ( m ) pre , X 1: n ] . (3.4) The conditional exp ectation is tak en o ver the randomness in ( X new , Y new ) and ov er the downstream lab el noise in D ( n ) down (i.e., o ver ( Y 1 , . . . , Y n ) conditional on X 1: n ), holding fixed D ( m ) pre and X 1: n . Hence, this quantit y is itself random through ( D ( m ) pre , X 1: n ). Our main goal is to characterize the joint-sample asymptotic distribution of the (scaled) excess test risk, i.e., to describe E α suc h that: E m,n : = n R ( D ( m ) pre , X 1: n ) − σ 2 d ⇝ E α (3.5) along limits ( m, n ) → ( ∞ , ∞ ) with m/n → α ∈ (0 , ∞ ), thereb y quantifying the leading-order fluctuations arising from downstream sampling and pre-training randomness. W e note that the conditional risk analysis is inten tional. The fully av eraged risk E [( Y new − ˆ f m,n ( X new )) 2 ] = E [ R ( D ( m ) pre , X 1: n )] t ypically requires tail assumptions on the co v ariance matrices 1 When ˆ θ m,n is not unique, w e define it as the minimum Euclidean norm solution. 4 ˆ Σ n,m = n − 1 P n i =1 ψ ( x i , ˆ w m ) ψ ( x i , ˆ w m ) ⊤ to interc hange limits and exp ectations. When the random design ˆ Σ n,m is ill-conditioned, its minimum eigenv alue can b e very small with non-negligible probabilit y , leading to hea vy-tailed in verse-co v ariance terms that complicate av eraged risk analysis. By conditioning on the realized do wnstream co v ariates, we av oid these tec hnicalities while still measuring performance under lab el noise and a fresh test pair. If sufficien tly strong anti-concen tration b ounds on ˆ Σ n,m are av ailable (cf. Mourtada , 2022 ), the same conditional error expansion could b e in tegrated, yielding an asymptotic c haracterization of the fully a veraged risk. In terpreting the distributional limit ( 3.5 ) . F rom ( 3.5 ) , several conclusions are immediate. By F atou’s lemma, w e ha v e the low er b ound E [ E α ] ⩽ lim m,n E [ E m,n ] (here, lim m,n is understo o d as ( m, n ) → ∞ with m/n → α ), which gives statistical lo w er bounds on the do wnstream p erformance; if the sequence {E m,n } m,n can b e sho wn to b e uniformly integrable, then this low er b ound can b e upgraded to equalit y , which yields an exact characterization of the asymptotic excess risk in exp ectation. Absen t uniform in tegrability , w e can still exact asymptotic high-probabilit y upp er b ounds: since P ( E α ⩾ t ) = lim m,n P ( E m,n ⩾ t ) for an y t > 0 (assuming E α is a con tinuous distribution), letting t ( δ ) be suc h that P ( E α ⩾ t ( δ )) = δ , w e ha ve that P ( E m,n ⩾ t ( δ )) = δ + o m,n (1). 4 Symmetries of the Tw o-Stage Pip eline Section 3.1 defines a t wo-stage M -estimation pro cedure via ( 3.2 ) and ( 3.3 ) . Our analysis is largely built from the usual to olkit for classical M -estimation: consistency , asymptotic normality , and delta-metho d expansions ( V an der V aart , 2000 ). W e adapt these to ols to our tw o-step setting to obtain an asymptotic c haracterization of the conditional risk ( 3.4 ) . A crucial tec hnical c hallenge, ho wev er, is that many pre-training ob jectiv es are inv arian t under symmetries: there exists a compact Lie group G acting smo othly on feature parameters R q 0 suc h that ℓ pre ( g · w ; z ) = ℓ pre ( w ; z ) , for all g ∈ G, w ∈ R q 0 , z ∈ Z . (4.1) As a concrete example of this inv ariance, consider a simple setting where Z = R d and w e aim to learn a linear representation ψ ( x, M ) = M x with M ∈ R p × d in pre-training. Now, consider an y family of pre-training losses (e.g., con trastive losses suc h as SimCLR ( Chen et al. , 2020b ; Oord et al. , 2018 )) that act on this representation through a similarity measure sim ( x, x ′ ; M ) = ⟨ ψ ( x, M ) , ψ ( x ′ , M ) ⟩ . It is immediate to see that the similarity measures, and hence the pre-training loss, is inv arian t under an y orthogonal transform Q ∈ O ( p ), i.e., sim( x, x ′ ; M ) = sim( x, x ′ ; QM ). Consequen tly , p opulation minimizers are typically not identifiable: if w minimizes L pre ( w ), then the en tire orbit [ w ] : = { g · w | g ∈ G } do es as w ell. This lack of iden tifiability rules out consistency for w itself, and also rules out the usual route to asymptotic normality for the direct parameter. Th us, one of our key contributions is to make explicit the types of symmetry encountered in se lf-supervised pre-training, in a wa y that remains compatible with asymptotic analysis. T o do this, we utilize basic concepts from Riemannian geometry and smooth manifolds ( Lee , 2018 ). 4.1 Manifold Identifiabilit y and Asymptotic Normalit y The in v ariance ( 4.1 ) implies that the in trinsic parameter is an orbit [ w ], i.e., an elemen t of the quotien t R q 0 /G . Rather than w ork directly with the quotient, we represent it through a descriptor map R : R q 0 7→ R q that is (i) constant along orbits: R ( g · w ) = R ( w ) for all g ∈ G, w ∈ R q 0 , and (ii) 5 separates orbits lo cally around w ⋆ : ∃ r > 0 such that for w , w ′ ∈ B ( w ⋆ , r ), we hav e R ( w ) = R ( w ′ ) iff w ′ ∈ [ w ]. W e will also require that M : = R B ( w ⋆ , r ′ ) ⊂ R q , for some 0 < r ′ ⩽ r , is a well-defined C 2 em b edded sub-manifold with Ω ⋆ : = R ( w ⋆ ) in its in terior; Assumption C.1 details the minimal assumptions needed for R to satisfy these requirements. W e endo w M with the Riemannian metric inherited from the ambien t Euclidean space R q . Accordingly , for Ω ∈ M w e write T Ω M for the tangen t space, and denote b y grad L pre (Ω) ∈ T Ω M and Hess L pre (Ω) : T Ω M → T Ω M the Riemannian gradient and Hessian of L pre restricted to M . Iden tifiability in descriptor co ordinates. W e will study pre-training through the induced estimator ˆ Ω m : = R ( ˆ w m ), rather than through the non-identifiable representativ e ˆ w m itself. With this setup, w e assume that the p opulation minimizer is unique in descriptor space: Ω ⋆ := arg min Ω ∈ R ( R q 0 ) : = { R ( w ) | w ∈ R q 0 } L pre (Ω) . (4.2) W e ov erload the notation L pre (Ω) : = L pre ( w ) for any w ∈ R − 1 (Ω), which is well-defined as L pre is G -in v arian t (cf. ( 4.1 ) ). Since Ω ⋆ is the unique minimizer in ( 4.2 ) , and lies in the in terior of the manifold M , w e ha ve grad L pre (Ω ⋆ ) = 0. T o obtain lo cal quadratic con trol and a well-posed second-order expansion on M , we further ass ume that Hess L pre (Ω ⋆ ) is in vertib le on the tangen t space: there exists µ > 0 suc h that for all v ∈ T Ω ⋆ M , v , Hess L pre (Ω ⋆ ) v ⩾ µ ∥ v ∥ 2 . Asymptotic normalit y on the descriptor manifold. With this setup in place, w e define the follo wing tangen t-space Hessian and Fisher-Information matrices: H ⋆ : = Hess L pre (Ω ⋆ ) , Σ ⋆ : = E h grad ℓ pre (Ω ⋆ ; Z ) grad ℓ pre (Ω ⋆ ; Z ) ⊤ i . (4.3) The follo wing CL T result describ es the asymptotic normality of the lo garithm log Ω ⋆ ( ˆ Ω m ) of the pretraining estimator, and is a key part of our analysis. Theorem 4.1 (Asymptotic normality on the descriptor manifold, informal) . Assume the smo othness and identifiability c onditions on Ω ⋆ describ e d ab ove, in addition to the lo c al uniform laws ne e de d for a se c ond-or der exp ansion of ˆ L pre ar ound Ω ⋆ . Define v m : = log Ω ⋆ ( ˆ Ω m ) ∈ T Ω ⋆ M . Then: √ m v m d ⇝ N 0 , H − 1 ⋆ Σ ⋆ H − 1 ⋆ in T Ω ⋆ M . The full set of regularity assumptions, in addition to the formal statement, can b e found in Assumption B.5 and Theorem B.7 , resp ectiv ely . W e remark that the regularit y assumptions in The- orem 4.1 ha ve a direct corresp ondence in standard, Euclidean asymptotic normality results ( V an der V aart , 2000 ); a detailed discussion is pro vided in Appendix B . 4.2 Relating Pre-training and Do wnstream Estimation via Orthogonal Equiv ari- ance As detailed in Section 3 , the downstream stage dep ends on the pre-training stage through the represen tation map ψ ( · , ˆ w m ). Ho wev er, as the symmetry in ( 4.1 ) precludes ˆ w m from asymptotically con verging to a fixed optimal parameter v alue, this implies that the con vergence of b oth ψ ( · , ˆ w m ) and its induced linear h yp othesis class H ˆ w m are not w ell-defined without extra structure. T o handle 6 this issue, w e assume that the symmetry of pre-training is compatible with do wnstream prediction in the sense that the induced hypothesis class is orbit-invariant : H g · w = H w for all g ∈ G, w ∈ R q 0 . This condition expresses that different represen tativ es within the same orbit [ w ] yield the same family of predictors. How ever, this assumption alone is insufficien t: when the OLS minimizer ( 3.3 ) is not unique, different pre-training parameters ˆ w m within the same orbit can still lead to differen t minim um-norm c hoices. Therefore, w e in tro duce the following condition, whic h w e call ortho gonal e quivarianc e to address this issue. Sp ecifically , we assume there exists a homomorphism ρ : G 7→ O ( p ) (i.e., ρ ( g 1 g 2 ) = ρ ( g 1 ) ρ ( g 2 ) for all g 1 , g 2 ∈ G ) suc h that ψ ( x, g · w ) = ρ ( g ) ψ ( x, w ) , for all g ∈ G, w ∈ R q 0 , x ∈ X . (4.4) Under condition ( 4.4 ) , since differen t represen tatives w in the same orbit corresp ond to orthogonal co ordinate c hanges in feature space, the corresp onding OLS minimizer will be constan t on the orbit. Lemma 4.2 (Orbit-in v ariance of the minim um-norm do wnstream predictor) . Assume the ortho gonal e quivarianc e c ondition ( 4.4 ) . Fix a downstr e am dataset D ( n ) down and a p ar ameter w ∈ R q 0 . L et ˆ θ w denote the minimum norm solution of the downstr e am OLS ( 3.3 ) with fe atur es ψ ( · , w ) , and ˆ f w ( x ) : = ⟨ ˆ θ w , ψ ( x, w ) ⟩ . Then for every g ∈ G , ˆ f g · w ( · ) = ˆ f w ( · ) . Lemma 4.2 states that under ( 4.4 ) , an intrinsic downstream feature map can b e naturally defined on the orbit [ w ] of eac h parameter. T o see this, since R is constant on orbits, it induces a map on the quotien t, and w e use the descriptor Ω := R ( w ) as a represen tative co ordinate for the orbit [ w ]. Then, Lemma 4.2 implies the feature map ϕ ( x, Ω) : = ψ x, s (Ω) is intrinsic for Ω ∈ M , where s : M ∩ B (Ω ⋆ , r ′′ ) 7→ B ( w ⋆ , r ′ ) is a C 2 lo cal lift 2 for some r ′′ > 0, satisfying R ( s (Ω)) = Ω. 5 Main Result: Asymptotic Beha vior of the T est Risk This section describ es our main result, whic h characterizes the asymptotic behavior of the test risk ( 3.4 ) . Section 5.1 b egins with a basic identit y that decomposes the do wnstream test error of minim um-norm least squares under a fixed feature parameter, conditioned on the realized pre-training data and do wnstream design. W e then state our main asymptotic result in Section 5.2 . 5.1 Exact Decomp osition of the Conditional T est Risk Recalling the pre-trained descriptor ˆ Ω m = ˆ Ω m ( D ( m ) pre ) ∈ M from Section 4 , w e condition on D ( m ) pre and treat Ω : = ˆ Ω m as fixed throughout this subsection. Assume E ∥ ϕ ( X , Ω) ∥ 2 2 < ∞ . W e define the p opulation forw ard op erator T Ω : R p 7→ L 2 down as ( T Ω θ )( x ) : = ⟨ θ , ϕ ( x, Ω) ⟩ , and its adjoin t T adj Ω : L 2 down 7→ R p as T adj Ω g : = E [ g ( X ) ϕ ( X , Ω)]. These op erators yield the p opulation feature co v ariance via Σ(Ω) : = T adj Ω T Ω = E [ ϕ ( X , Ω) ϕ ( X , Ω) ⊤ ]. Let H Ω = Im ( T Ω ) ⊆ L 2 down b e the function class induced by T Ω . The population L 2 down -orthogonal pro jector on to H Ω is defined as Π Ω : = T Ω Σ(Ω) + T adj Ω . W e use this pro jector to define the residual e Ω : = ( I − Π Ω ) f ⋆ and squared represen tation error Rep(Ω) : = ∥ e Ω ∥ 2 ; since w e assumed f ⋆ is well-specified, then e Ω ⋆ = 0. 2 The choice of s is not unique; App endix C.2 develops a vector-bundle viewp oint showing that (i) the induced represen tation is well-defined on the quotient and (ii) the feature map ϕ ( x, Ω) is differentiable whenever s and ψ are. 7 Similarly , w e can define the (do wnstream) empirical adjoin t and empirical cov ariance as T adj Ω ,n g : = 1 n P n i =1 g ( x i ) ϕ ( x i , Ω) and Σ n (Ω) : = 1 n P n i =1 ϕ ( x i , Ω) ϕ ( x i , Ω) ⊤ , and the empirical pro jector Π Ω ,n g : = T Ω Σ n (Ω) + T adj Ω ,n g . By construction, the minimum-norm OLS predictor ˆ f Ω ,n : = T Ω ˆ θ Ω ,n satisfies ˆ f Ω ,n = Π Ω ,n y for an y y ( x i ) = y i for i ∈ [ n ] (cf. App endix A ). Similarly , let ε ( · ) denote the noise function on the design, defined by ε ( x i ) = ε i for i ∈ [ n ]. Remark 5.1 (Represen tation dep endence vs. intrinsic ob jects) . In Se ction 4.2 , we define d an intrinsic r epr esentation ϕ ( · , Ω) via a (lo c al) choic e of orbit r epr esentative. Similar ar guments show that the quantities H Ω , Π Ω , Π Ω ,n , and Rep(Ω) ar e also intrinsic al ly define d on the quotient. The following prop osition decomp oses the conditional test risk ( 3.4 ) in to three key terms. This is a non-asymptotic expansion that forms the starting p oint of our main analysis. Prop osition 5.2 (Exact conditional risk decomp osition) . F or the minimum-norm OLS pr e dictor ˆ f Ω ,n , the c onditional test risk admits the de c omp osition: E h Y new − ˆ f Ω ,n ( X new ) 2 D ( m ) pre , X 1: n i = σ 2 + Rep(Ω) + E h Π Ω ,n f ⋆ − Π Ω f ⋆ ( X new ) 2 D ( m ) pre , X 1: n i | {z } =: Leak age n (Ω) + σ 2 n tr(Σ(Ω)Σ n (Ω) + ) | {z } =: V ar n (Ω) . (5.1) Prop osition 5.2 states a bias-v ariance decomp osition t ypical in the analysis of OLS regression (see e.g., Hsu et al. , 2014 ). Regarding the bias, ( 5.1 ) decomp oses it into tw o sources: (i) Rep (Ω) whic h measures mismatc h in the hypothesis class H Ω (due to finite pre-training data m ), and (ii) Leak age n (Ω) whic h quan tifies the discrepancy b et ween the empirical and p opulation pro jection op erators on f ⋆ (due to finite do wnstream data n ). Under a standard wel l-p ose dness condition that the empirical inner pro duct is non-degenerate on H Ω , one has Π Ω ,n f ⋆ − Π Ω f ⋆ = Π Ω ,n e Ω . 5.2 Asymptotic Behavior of the Conditional T est Risk W e no w state our main join t-sample result. Recall our main ob ject of study is the scaled excess test-risk E m,n in ( 3.5 ) , obtained by conditioning on the realized pre-training sample and downstream design, and av eraging only ov er the downstream lab el noise and the test pair. Accordingly , E m,n is a random v ariable measurable with respect to the join t la w ( D ( m ) pre , X 1: n ), whic h w e tak e all conv ergences b elo w with resp ect to. T o state our result, define the effective dimension d eff (Ω) : = rank (Σ(Ω)) for a descriptor Ω, and let L : T Ω ⋆ M 7→ L 2 ( µ down ) b e the linear map: L ( v ) : = − D Π Ω ⋆ [ v ] f ⋆ , v ∈ T Ω ⋆ M , (5.2) where D Π Ω ⋆ is the F r´ ec het deriv ativ e of Ω 7→ Π Ω at Ω ⋆ in normal co ordinates. The follo wing result c haracterizes the asymptotic behavior of the conditional excess test risk. Theorem 5.3 (Main result: asymptotic b eha vior of the conditional excess test risk) . Assume b oth the pr e-tr aining r e gularity c onditions in Assumption B.5 , in addition to the downstr e am r e gularity c onditions Assumption E.1 – E.4 . Then, along any joint se quenc e ( m, n ) → ( ∞ , ∞ ) with m/n → α ∈ (0 , ∞ ) , the (sc ale d) c onditional exc ess risk E m,n admits the distributional limit E m,n = n R ( D ( m ) pre , X 1: n ) − σ 2 d ⇝ σ 2 d eff (Ω ⋆ ) | {z } Wel l-sp e cifie d OLS term + α − 1 ∥L ( Z ) ∥ 2 L 2 ( µ down ) | {z } Pr e-tr aining interaction term , (5.3) 8 wher e Z ∼ N (0 , V ) with V := H − 1 ⋆ Σ ⋆ H − 1 ⋆ , wher e H ⋆ (r esp. Σ ⋆ ) denotes the Hessian (r esp. Fisher- Information matrix) of the pr e-tr aining loss (cf. ( 4.3 ) ). Theorem 5.3 sho ws that the (scaled) conditional excess risk E m,n con verges in distribution to a random v ariable with t w o distinct terms. The first term, σ 2 d eff (Ω ⋆ ), is precisely the contribution of the excess risk of well-specified OLS regression on the features ψ ( · , w ⋆ ). The second term α − 1 ∥L ( Z ) ∥ 2 L 2 down on the other hand captures the in teractions betw een the pre-training loss and the do wnstream regression problem. The scaling factor of 1 /α in the second term captures the ratio m/n in the join t limit. As the pre-training data starts to dominate the do wnstream data (i.e., α → ∞ ), the contribution of the second term correctly v anishes, since the problem effectively reduces to w ell-sp ecified OLS. On the other hand, when pre-training data is relativ ely scarce compared to do wnstream (i.e., α → 0), the second term is dominan t in ( 5.3 ) , as the bias of the learned pre-training features b ecomes the limiting factor in the tw o-stage estimator. In Section 6 , w e instan tiate our main theorem Theorem 5.3 on sev eral examples to illustrate ho w the assumptions translate o ver to concrete problem instances, and ho w the pre-training interaction term scales in practice. Fine-tuning only baseline. T o further interpret Theorem 5.3 , w e compare to a baseline where only the downstream data D ( n ) down is used to learn a predictor. Sp ecifically , define ( ˆ θ base n , ˆ w base n ) ∈ arg min θ ∈ R p ,w ∈ R q 0 ˆ L down ( θ ; w , D ( n ) down ) and predictor ˆ f base n : = ⟨ ˆ θ base n , ψ ( · , ˆ w base n ) ⟩ . This estimator is an instance of classical M -estimation with the square-loss, a w ell-sp ecified mo del, and homosk edastic noise. Th us, the asymptotic limit of n ( E [( Y new − ˆ f base n ( X new )) 2 ] − σ 2 ) → σ 2 ( p + q 0 ), assuming (for sak e of comparison) that the join t parameters ( θ , w ) are identifiable. Hence, comparing to ( 5.3 ) and supp osing that d eff (Ω ⋆ ) = p , we see that the phase transition for whic h pre-training has lo w er do wnstream risk than the fine-tune only baseline is when α > α 0 : = ∥L ( Z ) ∥ 2 L 2 ( µ down ) /q 0 . Pro of ideas. F rom Proposition 5.2 , we hav e E m,n = n V ar n ( ˆ Ω m ) + n Leak age n ( ˆ Ω m ) + n Rep ( ˆ Ω m ), where w e recall ˆ Ω m = R ( ˆ w m ) is the descriptor co ordinates of the pre-training estimator (cf. Sec- tion 4.1 ). By studying the limiting distributions under the join t ( m, n ) scaling, we show that (i) n V ar n ( ˆ Ω m ) P − → σ 2 d eff (Ω ⋆ ), (ii) n Leak age n ( ˆ Ω m ) P − → 0, and (iii) m Rep ( ˆ Ω m ) d ⇝ ∥L ( Z ) ∥ 2 L 2 ( µ down ) where Z ∼ N (0 , V ), with V = H − 1 ⋆ Σ ⋆ H − 1 ⋆ . Th us, ( 5.3 ) follo ws by Slutsky’s theorem and the scaling n/m → 1 /α . A crucial comp onen t underlying these limits (i)–(iii) is the asymptotic normality of ˆ Ω m , which is co vered by Theorem 4.1 (cf. Section 4.1 ). The full pro of is giv en in App endix E . 6 Examples Here, w e illustrate our main result on a few examples to make the theory concrete. F or each example there are tw o k ey steps: (i) defining the minimal problem-sp ecific structure to satisfy the assumptions of Theorem 5.3 , and (ii) calculating the instance-sp ecific b ound from ( 5.3 ) . Here, we simply describ e the main setup, deferring sp ecific computations to the appendix. 6.1 Linear Sp ectral Pre-training Inspired by the problem setting considered in Cabannes et al. ( 2023 ), we first consider a linear sp ectral contrastiv e ob jective; pro ofs for this case study are given in App endix F . 9 Data mo del. Let x ∈ R d denote a generic unlabeled pre-training sample with mean zero and co v ariance Σ pre : = E [ xx ⊤ ] ∈ R d × d . A p ositive p air consists of tw o augmented views ( x, x + ) of the same underlying instance. W e define the cross-co v ariance matrix Σ + pre : = E [ x + x ⊤ ] and assume that ( x, x + ) is exchangeable whic h implies that Σ + pre is symmetric. A ne gative sample x − is an indep enden t copy of x , indep enden t of ( x, x + ). W e group the samples as z : = ( x, x + , x − ). Represen tative-lev el linear features and sp ectral loss. Fix a representation dimension k ∈ [ d ] and consider linear r epr esentative-level feature maps ψ ( x, A ) : = Ax ∈ R k for A ∈ R k × d . F or an y suc h A , define the Gram matrix (descriptor) M A : = A ⊤ A ∈ R d × d . Here, w e retain the notation A for the representativ e parameter (corresponding to w ) and write M for the Gram descriptor (corresp onding to Ω). Motiv ated b y prior w ork on sp ectral contrastiv e ob jectiv es ( HaoChen et al. , 2021 ), we consider the following (single-negativ e) spectral loss and define the per-sample ob jective ℓ spec ( A ; z ) : = − 2 ⟨ ψ ( x, A ) , ψ ( x + , A ) ⟩ + ⟨ ψ ( x, A ) , ψ ( x − , A ) ⟩ 2 . (6.1) Symmetry , quotient, and descriptor. The loss ( 6.1 ) dep ends on w only through M A = A T A . Let G : = O ( k ) denote the group of k × k orthogonal matrices acting on R k × d b y left multiplication, Q · A : = QA . Then ℓ spec ( QA ; z ) = ℓ spec ( A ; z ) for all Q ∈ O ( k ) and all z , and hence ˆ L spec and L spec are inv ariant under this action (cf. ( 4.1 ) ). Moreov er, the represen tative-lev el feature map is orthogonally equiv arian t (cf. ( 4.4 ) ), that is, ψ ( x, Q · A ) = Qψ ( x, A ) for all x ∈ R d and Q ∈ O ( k ). A natural orbit-inv ariant descriptor map is R ( A ) : = M A = A T A whic h is constan t along O ( k )-orbits. On the regular regime rank ( A ) = k , the action is free, and R lo cally iden tifies nearb y O ( k )-orbits with nearby p oints in the rank- k PSD cone M d,k : = { M ∈ R d × d | M ≽ 0 , rank ( M ) = k } . In particular, M d,k is a smooth em b edded submanifold of the space of symmetric matrices, and we ma y endo w it with the induced Riemannian metric from the ambien t F robenius inner pro duct. On a neighborho o d of M ⋆ there exists a C 2 lo cal section s with s ( M ) ⊤ s ( M ) = M , and w e define the quotien t feature map b y ϕ ( x, M ) := s ( M ) x ; see App endix F.1 for the construction and smo othness. P opulation target in descriptor space. Assume Σ pre is inv ertible and define C : = Σ − 1 / 2 pre Σ + pre Σ − 1 / 2 pre . W e impose the follo wing eigengap condition on the matrix C . Assumption 6.1. The matrix C satisfies γ : = λ k ( C ) − max { λ k +1 ( C ) , 0 } > 0 . Under Assumption 6.1 , the p opulation descriptor minimizer M ⋆ ∈ M d,k exists and is unique (and admits a closed form via a rank- k truncation of C ; see Appendix F.2 ). Corollary 6.2 (Linear sp ectral model) . Assume Assumption 6.1 and E µ pre ∥ Z ∥ 4 , E µ down ∥ x ∥ 4 < ∞ . Then the line ar sp e ctr al mo del satisfies the assumptions of The or em 5.3 . Concrete example. While the limiting expressions in Theorem 5.3 admit an explicit character- ization in this linear sp ectral model, its general form is inv olved. T o obtain explicit closed-form expressions, w e consider a simplified linear model inspired b y Saunshi et al. ( 2022 , Ex. 1). W e fo cus on a diagonal setting that captures the essential sp ectral structure while allowing for precise calculations. Assume that Σ pre = I d and Σ + pre = diag (1 , 1 / 2 , . . . , 1 /d ), so that the whitened cross-co v ariance matrix is C = Σ − 1 / 2 pre Σ + pre Σ − 1 / 2 pre = diag(1 , 1 / 2 , . . . , 1 /d ) . 10 The top- k p opulation represen tation is therefore giv en b y the first k co ordinates. W e consider a linear do wnstream target f ⋆ ( x ) = β ⊤ ⋆ A ⋆ x where A ⋆ = [ diag (1 , 1 / √ 2 , . . . , 1 / √ k ) , 0 k × ( d − k ) ] and β ⋆ = (1 , . . . , 1) ⊤ . This ensures that the task is realizable. W e further assume the do wnstream data distribution satisfies µ down = N (0 , I d ). Corollary 6.3. Under the ab ove setup, as ( m, n ) → ( ∞ , ∞ ) with m/n → α ∈ (0 , ∞ ) , n R ( D ( m ) pre , X 1: n ) − σ 2 d ⇝ σ 2 k + 2 α k X i =1 i (1 + i − 2 + τ ) ! χ 2 d − k , τ = k X j =1 j − 2 . In p articular, the pr e-tr aining inter action term 1 m ∥L ( Z ) ∥ 2 L 2 ( µ down ) sc ales as Θ k 2 ( d − k ) m . W e compare Corollary 6.3 with the general upp er b ound of Cabannes et al. ( 2023 , Thm. 4), where the pre-training con tribution is con trolled b y a conditioning factor ∥ C − 1 A ⊤ ⋆ β ⋆ ∥ 2 2 m ultiplied b y a sub-optimality term of order O ( k ( d − k ) /m ), given by the excess exp ected sp ectral loss (see App endix F.9 ). In the present mo del, ∥ C − 1 A ⊤ ⋆ β ⋆ ∥ 2 2 = k X i =1 i = Θ( k 2 ) , whic h leads to a pre-training contribution of order O k 3 ( d − k ) m . Thus, our result improv es the dep endence on the represen tation dimension by a factor of k compared to Cabannes et al. ( 2023 ). 6.2 F actor Mo del Pre-training W e next sp ecialize our main result to the latent factor example from Ge et al. ( 2023 , Sec. 4). This setting is structurally similar to Section 6.1 : the latent low-rank structure makes unsup ervised pretraining natural, while a rotational in v ariance renders represen tation-lev el parameters non- iden tifiable. Pro ofs for this case study are presented in Appendix G . F actor mo del and pre-training. Let x ∈ R d b e generated according to the factor mo del x = A ⋆ h + µ where h ∼ N (0 , I k ) is a latent factor, µ ∼ N (0 , I d ) is indep endent noise, and A ⋆ ∈ R d × k is an unkno wn full-rank factor loading matrix. W e assume that k ≪ d . Pre-training observ es m i.i.d. draws { z i } m i =1 from the same distribution as x , and uses MLE to estimate the factor loading matrix. Do wnstream regression. W e observe lab eled samples ( x, y ) satisfying y = β ⊤ ⋆ h + ν where ν ∼ N (0 , σ 2 ν ) and independent of ( h, µ ). The do wnstream learner do es not observe h and fits a linear predictor based on features extracted from x using the pretrained representation. Specifically , under the Gaussian factor mo del, the regression function is linear and admits a closed form f ⋆ ( x ) = β ⊤ ⋆ A ⊤ ⋆ ( I d + A ⋆ A ⊤ ⋆ ) − 1 x . Accordingly , w e can write the do wnstream lab els as Y = f ⋆ ( X ) + ε where ε | X ∼ N (0 , σ 2 ) and σ 2 : = σ 2 ν + β ⊤ ⋆ ( I d + A ⋆ A ⊤ ⋆ ) − 1 β ⋆ . 11 Reduction to the linear case. F or any candidate loading matrix A ∈ R d × k w e define the r epr esentative-level feature map ψ ( x, A ) : = W ( A ) x ∈ R k with W ( A ) : = A ⊤ ( I d + AA ⊤ ) − 1 . W riting the orbit-inv arian t descriptor as M = AA ⊤ ∈ M d,k and choosing any lo cal section s ( M ) with s ( M ) s ( M ) ⊤ = M , an y represen tativ e A on the same orbit can b e expressed as A = s ( M ) Q for some Q ∈ O ( k ), which yields ψ ( x, A ) = Q ⊤ ϕ ( x, M ) with ϕ ( x, M ) : = s ( M ) ⊤ ( I d + M ) − 1 x . Thus, passing from A to M remo ves the rotational non-identifiabilit y . Consequently , this factor-mo del instance is a direct specialization of the linear example at the descriptor lev el, with the do wnstream class determined solely by the k -dimensional subspace range ( M ). Let M ⋆ = U ⋆ Σ ⋆ 0 0 0 U ⊤ ⋆ with Σ ⋆ = diag( σ 1 , . . . , σ k ) and U ⋆ = [ U 1 U 2 ], where U 1 ∈ R d × k spans range( M ⋆ ). Corollary 6.4. F or the factor mo del example, as ( m, n ) → ( ∞ , ∞ ) with m/n → α ∈ (0 , ∞ ) , n R ( D ( m ) pre , X 1: n ) − σ 2 d ⇝ σ 2 k + 1 α ∥ ( I k + Σ ⋆ ) − 1 / 2 U ⊤ 1 A ⋆ β ⋆ ∥ 2 2 χ 2 d − k . Compared to Ge et al. ( 2023 , Thm. 4.4), which states that w.h.p., 3 E m,n ≲ D 4 k + α − 1 D 12 ( D 4 + σ − 4 min ( A ⋆ )) d whenev er m ≳ D 4 d , n ⩾ D 4 k where D : = max {∥ A ⋆ ∥ op , ∥ β ⋆ ∥ , 1 } (here, w e ignore all log (1 /δ ) for simplicity), we see that Corollary 6.4 provides a substan tial impro vemen t. In particular, it implies a sharp er b ound of the form E m,n ≲ ( σ 2 ν + D 2 ) k + α − 1 D 2 ( d − k ) w.h.p. for large m, n , yielding a significan t impro vemen t on the dep endence of D . 6.3 Gaussian Mixture Pre-training with Subspace-Aw are Gating Our example considers unlab eled pretraining dra wn from a Gaussian mixture (MoG) with unknown cen ters, while the do wnstream predictor uses subsp ac e-awar e p osterior resp onsibilities that dep end only on a lo w-dimensional cen tered-mean subspace. This example is motiv ated b y the latent classification mo dels studied in e.g. W ei et al. ( 2021 ); Ge et al. ( 2023 ); Lin and Mei ( 2025 ), whic h w e naturally extend to regression setting. F rom a technical p erspective, it also instantiates the quotien t-descriptor viewp oint in a setting with discrete non-identifiabilit y . As b efore, we discuss only the minimal ingredien ts needed to inv ok e Theorem 5.3 , and we defer many details to App endix H . Pre-training data and loss. Fix d ⩾ 1 and K ⩾ 2. Let U ⋆ = ( u ⋆ 1 , . . . , u ⋆ K ) ∈ ( R d ) K b e unkno wn centers and let τ ∼ Unif ([ K ]). The unlabeled distribution is the Gaussian mixture Z | ( τ = i ) ∼ N ( u ⋆ i , I d ) for i ∈ [ K ]. Giv en m i.i.d. pre-training samples Z i i . i . d . ∼ 1 K P K i =1 N ( u ⋆ i , I d ), w e estimate the mixture cen ters by MLE using ℓ pre ( U ; Z ) : = − log ( 1 K P K i =1 φ ( Z − u i )) where φ ( · ) is the density of the isotropic Gaussian distribution. Subspace-a w are features. Define the empirical mean ¯ u ( U ) := 1 K P K i =1 u i and centered second- momen t matrix S ( U ) := P K i =1 u i − ¯ u ( U ) u i − ¯ u ( U ) ⊤ . Let r ⋆ := rank ( S ( U ⋆ )) and define P U ∈ O ( d ) to b e the orthogonal pro jector onto the leading r ⋆ -dimensional eigenspace of S ( U ) (on the regular neigh b orho od where this eigenspace is w ell-defined); cen tering via S ( U ) remo ves an irrelev an t global 3 T echnically , Ge et al. ( 2023 , Thm. 4.4) controls the excess risk without av eraging ov er the conditional lab els, as w e do in ( 3.4 ) . Since we can b ound their excess risk definition by a constan t factor of R ( D ( m ) pre , X 1: n ) via Marko v’s inequalit y (on a constan t probability even t), we ignore this difference in our comparison. 12 2 4 6 8 10 12 14 K 0.02 0.04 0.06 0.08 0.10 Expected pretraining interaction (a) F i x e d d = 3 0 , β = 2 . 0 f ( K ) = a K 2 + b K + c Monte Carlo Estimates 1 0 1 1 0 2 d 0.015 0.016 0.017 0.018 0.019 0.020 0.021 0.022 (b) F i x e d K = 4 , β = 2 . 0 f ( d ) = a + b l o g ( d ) Monte Carlo Estimates 1 0 0 1 0 0 . 3 0 1 0 0 . 6 0 β 1 0 1 1 0 0 1 0 1 1 0 2 (c) F i x e d K = 4 , d = 2 0 f ( β ) = C · β α Monte Carlo Estimates Figure 1: Numerical ev aluation of the limiting quantit y E ∥L ( Z ) ∥ 2 L 2 ( µ down ) in the Gaussian mixture example, for a blo c k-structured signal where each mixture comp onen t i ∈ [ K ] is asso ciated with a parameter blo c k ( θ ⋆ i , b ⋆ i ) prop ortional to 1 i 1 r ⋆ +1 , with the full v ector θ ⋆ = ( θ ⋆ 1 , b ⋆ 1 , . . . , θ ⋆ K , b ⋆ K ) normalized to unit Euclidean norm. (a) v aries the n umber of blocks K with d = 30 and β = 2 . 0, showing a monotonically increasing conca ve trend well captured b y a quadratic fit aK 2 + bK + c ( R 2 = 0 . 99); (b) v aries the ambien t dimension d with K = 4 and β = 2 . 0, exhibiting slow growth consistent with a logarithmic fit a + b log d ( R 2 = 0 . 89); (c) v aries β with K = 4 and d = 20, displaying rapid decay consistent with a p o wer-la w fit C β α ( R 2 = 0 . 90). These results suggest that the scaling b eha vior of the interaction term is complex and may differ across parameter regimes, with distinct b eha viors p oten tially emerging at small and large v alues of K , d , and β . shift and isolates the effe ctive subspace in which the mixture geometry v aries. F or U in the regular neigh b orho od, define resp onsibilities based on the pr oje cte d mixture: π i ( x ; U ) := exp ⟨ P U u i , P U x ⟩ − 1 2 ∥ P U u i ∥ 2 2 P K j =1 exp ⟨ P U u j , P U x ⟩ − 1 2 ∥ P U u j ∥ 2 2 , i ∈ [ K ] . (6.2) These are exactly the Ba yes p osteriors π i ( x ; U ) = P U ( Z = i | P U X = P U x ) for the pro jected mo del P U X | ( Z = i ) ∼ N ( P U u i , I r ⋆ ). Define the feature map ψ U : R d → R K ( d +1) b y ψ U ( x ) := π 1 ( x ; U ) P U ( x − u 1 ) , π 1 ( x ; U ) , . . . , π K ( x ; U ) P U ( x − u K ) , π K ( x ; U ) . (6.3) F or parameters θ = ( θ 1 , b 1 , . . . , θ K , b K ) with θ i ∈ R r ⋆ and b i ∈ R , the induced predictor is the linear mo del in features: f θ,U ( x ) = ⟨ θ , ψ U ( x ) ⟩ . Descriptor. The pretraining ob jectiv e for the unlabeled mixture is in v ariant under permutations of the K comp onen ts. W e take G = S K , the p erm utation group, and define its action on the parameter U = ( u 1 , · · · , u k ) b y relabeling. The do wnstream h yp othesis class depends on U only through its orbit U = [ U ] ∈ ( R d ) K . Assumption 6.5 b elo w guaran tees that U ⋆ lies in the regular regime of the group action. Th us, we can define the quotien t feature via an y lo cal lift, i.e., c hoice of ordering. See App endix H.1 for the exact constructions. Assumption 6.5 (Regular set for the mixture example) . The c enters ar e distinct and the c enter e d- me an subsp ac e is lo c al ly stable, i.e., (i) u ⋆ i = u ⋆ j for al l i = j , (ii) the matrix has an eigengap b etwe en its r ⋆ -th and ( r ⋆ + 1) -th eigenvalues, and (iii) rank( E [ ψ U ⋆ ( X ) ψ U ⋆ ( X ) T ]) = K ( r ⋆ + 1) . Lemma 6.6. Under Assumption 6.5 , the MoG example satisfies the assumptions of The or em 5.3 . 13 Explicit computation of rates. While Lemma 6.6 allows us to use Theorem 5.3 to study this Gaussian mixture example, the expression in ( 5.3 ) do es not admit a simple closed form solution, ev en for very basic problem instances of U ⋆ e.g., u ⋆ i = β e i for e i ∈ R d denoting the standard basis. Here, the asymptotic v ariance of the descriptor U estimated in pre-training is simple to characterize (i.e., inv erse of the Fisher-information matrix), but the expression ∥L ( Z ) ∥ 2 L 2 ( µ down ) , which inv olves the deriv atives of the pro jection op erator Π Ω , do es not admit an analytical form. Nev ertheless, the limiting expression in ( 5.3 ) can b e ev aluated n umerically via Monte-Carlo sim ulation. Figure 1 rep orts such an ev aluation for a blo c k-structured signal, where eac h block has constan t v alue prop ortional to 1 /i . The results rev eal a m onotone and concav e dep endence on the num b er of blo c ks K , a slo w gro wth with the am bient dimension d , and a rapid decay as β increases. All quan tities are estimated via Mon te-Carlo sampling. Specifically , we use 10 5 samples from µ pre to estimate the Fisher information, 10 6 samples from µ down to compute the pro jection operator Π Ω ⋆ in L ( Z ), and 10 6 samples from µ down to ev aluate ∥L ( Z ) ∥ 2 L 2 ( µ down ) . Code for repro ducing the sim ulations is a v ailable at https://github.com/mtinati/mog- subspace- jax . 7 Conclusion and Discussion W e developed an asymptotic theory of self-sup ervised pre-training through a tw o-stage M -estimation framew ork, lev eraging to ols from Riemannian geometry to handle group symmetries arising in the pre-training stage. Our w ork opens up several promising future directions. On the technical side, a natural next step is to extend the do wnstream model to more general parametric regression settings. The main c hallenge lies in generalizing our notion of orthogonal equiv ariance (cf. Section 4.2 ) to accommodate orbit-in v ariance for estimators b ey ond OLS solutions. Another direction is the dev elopment of non-asymptotic b ounds for pre-training whose leading-order terms match the asymptotic limits derived in this w ork. More broadly , our asymptotic characterizations suggest a principled wa y to guide the design of pre-training losses and data-augmen tation strategies, b y directly optimizing the b ound on the do wnstream risk o ver a diverse family of problem instances. This connection b etw een asymptotic theory and practical pre-training design is an esp ecially exciting a ven ue for future exploration. References Donald W. K. Andrews. Asymptotics for semiparametric econometric mo dels via sto c hastic equicon tinuit y . Ec onometric a , 62(1):43–72, 1994. Randall Balestriero and Y ann LeCun. Contrastiv e and non-contrastiv e self-sup ervised learning reco ver global and local spectral em b edding metho ds. In S. Ko yejo, S. Mohamed, A. Agarwal, D. Belgrav e, K. Cho, and A. Oh, editors, A dvanc es in Neur al Information Pr o c essing Systems , v olume 35, pages 26671–26685. Curran Asso ciates, Inc., 2022. Adrien Bardes, Jean P once, and Y ann LeCun. VICReg: V ariance-inv ariance-cov ariance regularization for self-sup ervised learning. In International Confer enc e on L e arning R epr esentations , 2022. Osb ert Bastani. Asymptotic normalit y of generalized lo w-rank matrix sensing via riemannian geometry . arXiv pr eprint arXiv:2407.10238 , 2024. 14 T om Brown, Benjamin Mann, Nic k Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariw al, Arvind Neelak antan, Prana v Shy am, Girish Sastry , Amanda Ask ell, Sandhini Agarw al, Ariel Herb ert-V oss, Gretchen Krueger, T om Henighan, Rewon Child, Adit ya Ramesh, Daniel Ziegler, Jeffrey W u, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Lit win, Scott Gra y , Benjamin Chess, Jac k Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ily a Sutsk ev er, and Dario Amo dei. Language mo dels are few-shot learners. In H. Laro c helle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, A dvanc es in Neur al Information Pr o c essing Systems , v olume 33, pages 1877–1901. Curran Asso ciates, Inc., 2020. Vivien Cabannes, Bobak Kiani, Randall Balestriero, Y ann Lecun, and Alb erto Bietti. The SSL in terplay: Augmentations, inductiv e bias, and generalization. In Andreas Krause, Emma Brunskill, Kyungh yun Cho, Barbara Engelhardt, Siv an Sabato, and Jonathan Scarlett, editors, Pr o c e e dings of the 40th International Confer enc e on Machine L e arning , v olume 202 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 3252–3298. PMLR, 23–29 Jul 2023. Sh uxiao Chen, Edgar Dobriban, and Jane H Lee. A group-theoretic framew ork for data augmen tation. Journal of Machine L e arning R ese ar ch , 21(245):1–71, 2020a. Ting Chen, Simon Korn blith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastiv e learning of visual represen tations. In Hal Daum ´ e I I I and Aarti Singh, editors, Pr o c e e dings of the 37th International Confer enc e on Machine L e arning , v olume 119 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 1597–1607. PMLR, 13–18 Jul 2020b. Xinlei Chen and Kaiming He. Exploring simple siamese represen tation learning. In Pr o c e e dings of the IEEE/CVF c onfer enc e on c omputer vision and p attern r e c o gnition , pages 15750–15758, 2021. Chandler Da vis and William Morton Kahan. The rotation of eigen vectors by a perturbation. iii. SIAM Journal on Numeric al Analysis , 7(1):1–46, 1970. Jacob Devlin, Ming-W ei Chang, Ken ton Lee, and Kristina T outano v a. BER T: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christ y Doran, and Thamar Solorio, editors, Pr o c e e dings of the 2019 Confer enc e of the North Americ an Chapter of the Asso ciation for Computational Linguistics: Human L anguage T e chnolo gies, V olume 1 (L ong and Short Pap ers) , pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19- 1423. Ro y F rostig, Rong Ge, Sham M. Kak ade, and Aaron Sidford. Comp eting with the empirical risk minimizer in a single pass. In Peter Gr ¨ un wald, Elad Hazan, and Saty en Kale, editors, Pr o c e e dings of The 28th Confer enc e on L e arning The ory , v olume 40 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 728–763, P aris, F rance, 03–06 Jul 2015. PMLR. Jia wei Ge, Shange T ang, Jianqing F an, and Chi Jin. On the pro v able adv antage of unsupervised pretraining. arXiv pr eprint arXiv:2303.01566 , 2023. Gene H Golub and Victor Pereyra. The differentiation of pseudo-inv erses and nonlinear least squares problems whose v ariables separate. SIAM Journal on numeric al analysis , 10(2):413–432, 1973. Jean-Bastien Grill, Florian Strub, Florent Altc h´ e, Coren tin T allec, Pierre Ric hemond, Elena Buc hatsk a ya, Carl Do ersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, 15 Bilal Piot, kora y k avuk cuoglu, Remi Munos, and Mic hal V alko. Bo otstrap your o wn laten t - a new approach to self-sup ervised learning. In H. Laro c helle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, A dvanc es in Neur al Information Pr o c essing Systems , v olume 33, pages 21271–21284. Curran Asso ciates, Inc., 2020. Jeff Z HaoChen and T engyu Ma. A theoretical study of inductive biases in con trastive learning. arXiv pr eprint arXiv:2211.14699 , 2022. Jeff Z HaoChen, Colin W ei, Adrien Gaidon, and T engyu Ma. Prov able guaran tees for self-sup ervised deep learning with sp ectral con trastive loss. A dvanc es in neur al information pr o c essing systems , 34:5000–5011, 2021. Kaiming He, Haoqi F an, Y uxin W u, Saining Xie, and Ross Girshic k. Momentum contrast for unsup ervised visual representation learning. In Pr o c e e dings of the IEEE/CVF c onfer enc e on c omputer vision and p attern r e c o gnition , pages 9729–9738, 2020. Daniel Hsu, Sham M Kak ade, and T ong Zhang. Random design analysis of ridge regression. F oundations of Computational Mathematics , 14(3):569–600, 2014. Jason D Lee, Qi Lei, Nikunj Saunshi, and Jiacheng Zhuo. Predicting what you already know helps: Pro v able self-sup ervised learning. A dvanc es in Neur al Information Pr o c essing Systems , 34: 309–323, 2021. John M Lee. Intr o duction to R iemannian manifolds , v olume 2. Springer, 2018. Licong Lin and Song Mei. A statistical theory of contrastiv e learning via approximate sufficient statistics. arXiv pr eprint arXiv:2503.17538 , 2025. Jaouad Mourtada. Exact minimax risk for linear least squares, and the lo w er tail of sample co v ariance matrices. The A nnals of Statistics , 50(4):2157–2178, 2022. Whitney K. New ey . A metho d of moments interpretation of sequential estimators. Ec onomics L etters , 14(2):201–206, 1984. ISSN 0165-1765. Whitney K. New ey and Daniel McF adden. Chapter 36 large sample estimation and hypothesis testing. v olume 4 of Handb o ok of Ec onometrics , pages 2111–2245. Elsevier, 1994. Rob erto Imbuzeiro Oliv eira. The low er tail of random quadratic forms with applications to ordinary least squares. Pr ob ability The ory and R elate d Fields , 166(3–4):1175–1194, 2016. doi: 10.1007/s00440- 016- 0738- 9. Aaron v an den Oord, Y azhe Li, and Oriol Viny als. Represen tation learning with con trastive predictiv e coding. arXiv pr eprint arXiv:1807.03748 , 2018. Maxime Oquab, Timoth ´ ee Darcet, Th´ eo Moutak anni, Huy V. V o, Marc Szafraniec, V asil Khalidov, Pierre F ernandez, Daniel HAZIZA, F rancisco Massa, Alaaeldin El-Noub y , Mido Assran, Nicolas Ballas, W o jciech Galuba, Russell How es, P o-Y ao Huang, Shang-W en Li, Ishan Misra, Mic hael Rabbat, V asu Sharma, Gabriel Synnaev e, Hu Xu, Herve Jegou, Julien Mairal, Patric k Labatut, Armand Joulin, and Piotr Bo janowski. DINOv2: Learning robust visual features without sup ervision. T r ansactions on Machine L e arning R ese ar ch , 2024. ISSN 2835-8856. F eatured Certification. 16 Dmitrii M. Ostro vskii and F rancis Bac h. Finite-sample analysis of m -estimators using self- concordance. Ele ctr onic Journal of Statistics , 15(1):326–391, 2021. doi: 10.1214/20- EJS1780. Adrian Pagan. Two stage and related estimators and their applications. The R eview of Ec onomic Studies , 53(4):517–538, 1986. ISSN 0034-6527. doi: 10.2307/2297604. Alec Radford, Jong W o ok Kim, Chris Hallacy , Adit ya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Pamela Mishkin, Jac k Clark, Gretchen Krueger, and Ily a Sutsk ever. Learning transferable visual mo dels from natural language sup ervision. In Marina Meila and T ong Zhang, editors, Pr o c e e dings of the 38th International Confer enc e on Machine L e arning , volume 139 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 8748–8763. PMLR, 18–24 Jul 2021. Nikunj Saunshi, Orestis Plevrakis, Sanjeev Arora, Mikhail Kho dak, and Hrishik esh Khandepark ar. A theoretical analysis of con trastive unsup ervised representation learning. In Kamalik a Chaudhuri and Ruslan Salakh utdinov, editors, Pr o c e e dings of the 36th International Confer enc e on Machine L e arning , v olume 97 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 5628–5637. PMLR, 09–15 Jun 2019. Nikunj Saunshi, Jordan Ash, Surbhi Go el, Dip endra Misra, Cyril Zhang, Sanjeev Arora, Sham Kak ade, and Akshay Krishnam urthy . Understanding con trastive learning requires incorp orating inductiv e biases. In Kamalik a Chaudhuri, Stefanie Jegelk a, Le Song, Csaba Szep esv ari, Gang Niu, and Siv an Sabato, editors, Pr o c e e dings of the 39th International Confer enc e on Machine L e arning , v olume 162 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 19250–19286. PMLR, 17–23 Jul 2022. Vladimir Sp ok oiny . Parametric estimation. Finite sample theory. The A nnals of Statistics , 40(6): 2877 – 2909, 2012. doi: 10.1214/12- AOS1054. Mic hael E Tipping and Christopher M Bishop. Probabilistic principal comp onen t analysis. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 61(3):611–622, 1999. Christopher T osh, Aksha y Krishnamurth y , and Daniel Hsu. Con trastive estimation reveals topic p osterior information to linear mo dels. Journal of Machine L e arning R ese ar ch , 22(281):1–31, 2021. Aad W V an der V aart. Asymptotic statistics , volume 3. Cam bridge univ ersity press, 2000. Roman V ersh ynin. High-dimensional pr ob ability: An intr o duction with applic ations in data scienc e , v olume 47. Cambridge universit y press, 2018. T ongzhou W ang and Phillip Isola. Understanding con trastive representation learning through alignmen t and uniformit y on the h yp ersphere. In Hal Daum ´ e II I and Aarti Singh, editors, Pr o c e e dings of the 37th International Confer enc e on Machine L e arning , v olume 119 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 9929–9939. PMLR, 13–18 Jul 2020. Colin W ei, Sang Michael Xie, and T engyu Ma. Why do pretrained language mo dels help in do wnstream tasks? an analysis of head and prompt tuning. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P .S. Liang, and J. W ortman V aughan, editors, A dvanc es in Neur al Information Pr o c essing Systems , v olume 34, pages 16158–16170. Curran Asso ciates, Inc., 2021. 17 Jure Zb ontar, Li Jing, Ishan Misra, Y ann LeCun, and Stephane Deny . Barlow twins: Self-sup ervised learning via redundancy reduction. In Marina Meila and T ong Zhang, editors, Pr o c e e dings of the 38th International Confer enc e on Machine L e arning , v olume 139 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 12310–12320. PMLR, 18–24 Jul 2021. Anru Zhang, La wrence D Brown, and T T ony Cai. Semi-sup ervised inference: General theory and estimation of means. 2019. 18 Con ten ts 1 In tro duction 1 2 Related W ork 2 3 Problem F orm ulation 3 3.1 Pre-training Loss, Downstream Least-Squares Estimation, and Final T est Risk . . . 4 4 Symmetries of the Two-Stage Pip eline 5 4.1 Manifold Iden tifiability and Asymptotic Normalit y . . . . . . . . . . . . . . . . . . . 5 4.2 Relating Pre-training and Do wnstream Estimation via Orthogonal Equiv ariance . . . 6 5 Main Result: Asymptotic Beha vior of the T est Risk 7 5.1 Exact Decomposition of the Conditional T est Risk . . . . . . . . . . . . . . . . . . . 7 5.2 Asymptotic Behavior of the Conditional T est Risk . . . . . . . . . . . . . . . . . . . 8 6 Examples 9 6.1 Linear Spectral Pre-training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 6.2 F actor Mo del Pre-training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 6.3 Gaussian Mixture Pre-training with Subspace-Aware Gating . . . . . . . . . . . . . . 12 7 Conclusion and Discussion 14 A Empirical Pro jection Op erators and Linear-Algebra Preliminaries 21 A.1 Empirical inner products and ev aluation maps . . . . . . . . . . . . . . . . . . . . . 21 A.2 Pseudoin v erse iden tities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 A.3 Design matrices and hat matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 A.4 Empirical least-squares pro jection onto H Ω . . . . . . . . . . . . . . . . . . . . . . . 22 A.5 Effectiv e dimension and degrees of freedom . . . . . . . . . . . . . . . . . . . . . . . 25 A.6 Benefits of an op erator-theoretic formulation . . . . . . . . . . . . . . . . . . . . . . 26 B Riemannian Geometry and M -estimation Bac kground 26 B.1 Basic Riemannian notions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 B.2 T a ylor expansions in normal co ordinates . . . . . . . . . . . . . . . . . . . . . . . . . 27 B.3 Euclidean M -estimation: consistency and asymptotic normality . . . . . . . . . . . . 29 B.4 M -estimation on a Riemannian manifold . . . . . . . . . . . . . . . . . . . . . . . . . 32 C Symmetry , Identifiabilit y , and Quotient Geometry 35 C.1 Quotients by group actions and lo cal descriptor c harts . . . . . . . . . . . . . . . . . 35 C.2 V ector-bundle viewp oint: quotient-lev el features and the co ordinate feature map ϕ ( x, M ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36 D Pro of of Prop osition 5.2 39 D.1 Empirical pro jection notation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 D.2 Population decomp osition and orthogonalit y . . . . . . . . . . . . . . . . . . . . . . . 40 D.3 Exact risk decomp osition conditional on ( D ( m ) pre , X 1: n ) . . . . . . . . . . . . . . . . . . 40 19 D.4 W ell-p osedness sp ecialization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 E Pro of of Theorem 5.3 42 E.1 Do wnstream estimation terms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 E.2 Pretraining fluctuations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 F Pro ofs of Section 6.1 55 F.1 Quotien t feature map construction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55 F.2 P opulation descriptor problem and regularit y of M ⋆ . . . . . . . . . . . . . . . . . . 56 F.3 Quotien t features and smo oth dep endence on M . . . . . . . . . . . . . . . . . . . . 57 F.4 Do wnstream cov ariance, stable rank, and effectiv e dimension . . . . . . . . . . . . . 57 F.5 W ell-p osedness of the empirical pro jector . . . . . . . . . . . . . . . . . . . . . . . . 58 F.6 Differen tiabilit y of the population pro jector map M 7→ Π M . . . . . . . . . . . . . . 59 F.7 Pretraining consistency and manifold CL T for the linear spectral loss . . . . . . . . . 59 F.8 Explicit Calculations of the Concrete Example . . . . . . . . . . . . . . . . . . . . . 62 F.9 Comparison to Cabannes et al. (2023) . . . . . . . . . . . . . . . . . . . . . . . . . . 68 G Pro ofs of Section 6.2 75 H Pro ofs of Section 6.3 81 H.1 Model, features, and the quotient-lev el descriptor . . . . . . . . . . . . . . . . . . . . 81 H.2 Local-uniform momen t bounds for ψ ( · , U ) . . . . . . . . . . . . . . . . . . . . . . . . 83 H.3 Rank stability and eigengap for the do wnstream second momen t . . . . . . . . . . . 83 H.4 Pretraining CL T for the quotien t estimator ˆ U m = [ ˆ U m ] . . . . . . . . . . . . . . . . . 84 H.5 F r ´ echet differen tiability of U 7→ Π U . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86 H.6 Conclusion: pro of of Corollary 6.6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87 20 A Empirical Pro jection Op erators and Linear-Algebra Preliminar- ies This appendix collects basic facts used rep eatedly in the pro ofs of Prop osition 5.2 and Theorem 5.3 . The statemen ts are standard; we include them to (i) make explicit whic h inner product each pro jection is tak en with respect to, and (ii) clarify what is unique (fitted v alues on the sample) v ersus what is a chosen conv ention (a minim um-norm represen tative in coe fficien t space) when the design is rank-deficient. All statemen ts in this app endix are deterministic once the design points X 1: n are fixed; in particular, they are tailored to our conditional-on-design viewp oin t in the main text. A.1 Empirical inner pro ducts and ev aluation maps Let X b e the input space (e.g. X = R d in the linear–Gaussian example), and let G b e a class of measurable functions g : X → R (for instance G = L 2 ( µ down ), or an y function space con taining the h yp othesis classes used in the main text). Fix design p oin ts x 1: n : = ( x 1 , . . . , x n ) ∈ X n . F or g , h ∈ G suc h that g ( x i ) , h ( x i ) ∈ R for all i ∈ [ n ], define the empirical bilinear form ⟨ g , h ⟩ n : = 1 n n X i =1 g ( x i ) h ( x i ) , ∥ g ∥ 2 n : = ⟨ g , g ⟩ n . In general, ∥ · ∥ n is only a seminorm : it dep ends only on the v alues of a function on the finite set { x 1 , . . . , x n } . Consequen tly , the fitted v alues of any empirical least-squares pro jection are uniquely determined only through these n v alues. T o isolate this dep endence, define the ev aluation map at x 1: n b y Ev n : G → R n , Ev n ( g ) : = g ( x 1 ) , . . . , g ( x n ) ⊤ . Whenev er g ( x i ) ∈ R for all i , w e ha ve Ev n ( g ) ∈ R n and ⟨ g , h ⟩ n = 1 n Ev n ( g ) ⊤ Ev n ( h ) , ∥ g ∥ 2 n = 1 n ∥ Ev n ( g ) ∥ 2 2 . Th us, empirical least-squares pro jection statements can be prov ed equiv alen tly in the finite- dimensional space R n b y w orking with the vectors of function v alues Ev n ( g ). A.2 Pseudoin v erse iden tities W e use ( · ) + to denote the Mo ore–P enrose pseudoin v erse. Lemma A.1 (Basic pseudoin verse iden tities) . F or any matrix A (not ne c essarily squar e), AA + A = A, A + AA + = A + , ( AA + ) ⊤ = AA + , ( A + A ) ⊤ = A + A. Mor e over, AA + is the Euclide an ortho gonal pr oje ctor onto Im ( A ) and A + A is the Euclide an ortho gonal pr oje ctor onto Im( A ⊤ ) . 21 Lemma A.2 (T race equals rank for symmetric PSD matrices) . If S ∈ R p × p is symmetric p ositive semidefinite, then tr( S + S ) = rank( S ) . Remark A.3 (On conditioning and inv erse-eigenv alue effects) . The identities in this se ction ar e pur ely algebr aic and hold deterministic al ly for any r e alization of the design. When taking exp e ctations over r andom designs, quantities involving S + c an b e sensitive to smal l eigenvalues of S , and additional tail c ontr ol is typic al ly ne e de d to justify inter changing limits and exp e ctations. This sensitivity motivates the c onditional-on-design risk formulation adopte d in the main text. A.3 Design matrices and hat matrices Fix a feature parameter Ω ∈ R q and design points x 1: n . Define the feature matrix Φ Ω ∈ R n × p , (Φ Ω ) i, : : = ϕ ( x i , Ω) ⊤ , and the empirical cov ariance Σ n (Ω) = 1 n Φ ⊤ Ω Φ Ω . Define the hat matrix H Ω ,n : = Φ Ω (Φ ⊤ Ω Φ Ω ) + Φ ⊤ Ω = 1 n Φ Ω Σ n (Ω) + Φ ⊤ Ω . Lemma A.4 (Hat matrix is an orthogonal pro jector) . H Ω ,n is the Euclide an ortho gonal pr oje ctor in R n onto Im(Φ Ω ) . In p articular, H 2 Ω ,n = H Ω ,n , H ⊤ Ω ,n = H Ω ,n , and tr( H Ω ,n ) = rank(Φ Ω ) = rank(Σ n (Ω)) . Pr o of. By Lemma A.1 , Φ Ω (Φ ⊤ Ω Φ Ω ) + Φ ⊤ Ω is the orthogonal pro jector on to Im (Φ Ω ). The trace of an orthogonal pro jector equals its rank. Finally , rank(Φ Ω ) = rank(Φ ⊤ Ω Φ Ω ) = rank(Σ n (Ω)). A.4 Empirical least-squares pro jection on to H Ω Recall the linear class H Ω : = { T Ω θ : θ ∈ R p } , ( T Ω θ )( x ) : = ⟨ θ , ϕ ( x, Ω) ⟩ . P arameterization v ersus functions. The parametrization θ 7→ T Ω θ need not b e injective: if v ∈ R p satisfies ⟨ v , ϕ ( x, Ω) ⟩ = 0 for all x ∈ X (equiv alently , T Ω v ≡ 0), then T Ω ( θ + v ) = T Ω θ as functions on X . Th us, ev en when the induced function is unique, the coefficient vector representing it may not be. Giv en design p oin ts x 1: n , define the empirical adjoin t T adj Ω ,n g : = 1 n n X i =1 g ( x i ) ϕ ( x i , Ω) ∈ R p . Lemma A.5 (Empirical adjoin t iden tity) . F or any θ ∈ R p and any function g , we have ⟨ T Ω θ , g ⟩ n = ⟨ θ , T adj Ω ,n g ⟩ R p . 22 Pr o of. This is simply a consequence of the follo wing equalities: ⟨ T Ω θ , g ⟩ n = 1 n n X i =1 ⟨ θ , ϕ ( x i , Ω) ⟩ g ( x i ) = * θ , 1 n n X i =1 g ( x i ) ϕ ( x i , Ω) + = ⟨ θ , T adj Ω ,n g ⟩ R p . Empirical pro jection: what is unique and what is a conv en tion. Since ∥ · ∥ n is only a seminorm, the empirical least-squares problem min h ∈H Ω ∥ g − h ∥ 2 n ∥ g − h ∥ 2 n = 1 n n X i =1 ( g ( x i ) − h ( x i )) 2 can determine only the v alues of the minimizer on the sample points. In particular, the ob jectiv e dep ends on h only through the vector Ev n ( h ) = ( h ( x 1 ) , . . . , h ( x n )) ⊤ , and an y t wo functions that agree on { x i } n i =1 are indistinguishable under ∥ · ∥ n . W riting h = T Ω θ so that Ev n ( h ) = Φ Ω θ , the problem reduces to Euclidean least squares in R n . Lemma A.6 (Least-squares equiv alence) . The empiric al pr oje ction pr oblem is e quivalent to the Euclide an le ast-squar es pr oblem min θ ∈ R p 1 n ∥ Ev n ( g ) − Φ Ω θ ∥ 2 2 . Pr o of. By definition, ∥ g − h ∥ 2 n = 1 n n X i =1 ( g ( x i ) − h ( x i )) 2 = 1 n ∥ Ev n ( g ) − Ev n ( h ) ∥ 2 2 . Ev ery h ∈ H Ω can b e written as h = T Ω θ for some θ ∈ R p , and then Ev n ( h ) = ( T Ω θ )( x 1 ) , . . . , ( T Ω θ )( x n ) ⊤ = ⟨ θ , ϕ ( x 1 , Ω) ⟩ , . . . , ⟨ θ , ϕ ( x n , Ω) ⟩ ⊤ = Φ Ω θ . Substituting this iden tity in to the empirical ob jectiv e giv es ∥ g − T Ω θ ∥ 2 n = 1 n ∥ Ev n ( g ) − Φ Ω θ ∥ 2 2 , whic h pro v es the claim. Ev en when Φ Ω is rank-deficient, the fitte d values are unique: the Euclidean orthogonal pro jection of Ev n ( g ) onto Im(Φ Ω ) ˆ g 1: n : = H Ω ,n Ev n ( g ) ∈ R n (A.1) is uniquely determined by Lemma A.4 . In contrast, the co efficien t v ector θ ac hieving these fitted v alues need not be unique when Φ Ω is rank-deficien t: if θ ⋆ is one minimizer then all minimizers are θ ⋆ + v with v ∈ ker (Φ Ω ), and they all satisfy Φ Ω θ = ˆ g 1: n . Whether these distinct minimizers define the same function on X dep ends on the feature represen tation: if k er (Φ Ω ) ⊆ ker ( T Ω ) then all minimizers induce the same function in 23 H Ω , whereas if there exists v = 0 with Φ Ω v = 0 but T Ω v ≡ 0, then differen t minimizers agree on the sample p oints but can differ off-sample. Throughout the pap er, we follow the con ven tion fixed in the main text: the empirical pro jector Π Ω ,n is defined via the Moore–Penrose pseudoin verse (see Section 5 ), so that the associated co efficien t v ector is the minimum-Euclidean-norm least-squares solution. Imp ortan tly , all fitted-v alue iden tities b elo w hold regardless of this conv ention. Definition A.7 (Canonical empirical pro jector) . F or g with finite evaluations on { x i } n i =1 , define ˆ θ Ω ,n ( g ) : = Σ n (Ω) + T adj Ω ,n g ∈ R p , and set Π Ω ,n g : = T Ω ˆ θ Ω ,n ( g ) ∈ H Ω . Lemma A.8 (Least-squares c haracterization and empirical orthogonality) . F or any g we have Π Ω ,n g ∈ arg min h ∈H Ω ∥ g − h ∥ 2 n . Mor e over, the fitte d values satisfy Ev n (Π Ω ,n g ) = H Ω ,n Ev n ( g ) , and the r esidual is empiric al ly ortho gonal to H Ω in the sense that ⟨ g − Π Ω ,n g , h ⟩ n = 0 ∀ h ∈ H Ω . Pr o of. W rite h = T Ω θ . Then ∥ g − h ∥ 2 n = 1 n ∥ Ev n ( g ) − Φ Ω θ ∥ 2 2 . Th us minimizing o ver h ∈ H Ω is equiv alen t to least squares in R n . By Definition A.7 , ˆ θ Ω ,n ( g ) is the Mo ore–Penrose minim um-norm least-squares solution, hence Π Ω ,n g = T Ω ˆ θ Ω ,n ( g ) is a minimizer. F urthermore, Ev n (Π Ω ,n g ) = Φ Ω ˆ θ Ω ,n ( g ) = Φ Ω (Φ ⊤ Ω Φ Ω ) + Φ ⊤ Ω Ev n ( g ) = H Ω ,n Ev n ( g ) . F or empirical orthogonalit y , let r : = Ev n ( g ) − Ev n (Π Ω ,n g ). Since Ev n (Π Ω ,n g ) = H Ω ,n Ev n ( g ) and H Ω ,n is the orthogonal pro jector onto Im (Φ Ω ), we hav e r ⊥ Im (Φ Ω ). F or any h = T Ω θ ∈ H Ω , Ev n ( h ) = Φ Ω θ ∈ Im(Φ Ω ), hence n ⟨ g − Π Ω ,n g , h ⟩ n = r ⊤ Ev n ( h ) = 0 . Lemma A.9 (Repro ducing property on the sample p oin ts) . F or any h ∈ H Ω , Ev n (Π Ω ,n h ) = Ev n ( h ) , and henc e ∥ h − Π Ω ,n h ∥ n = 0 . Pr o of. If h ∈ H Ω then Ev n ( h ) ∈ Im (Φ Ω ), so H Ω ,n Ev n ( h ) = Ev n ( h ) b y Lemma A.4 . No w apply Lemma A.8 . 24 Definition A.10. F or any ve ctor v ∈ R n , we define lift n ( v ) as any arbitr ary me asur able function g : X → R that satisfies Ev n ( g ) = v (the values of g off { x i } n i =1 ar e irr elevant). Sinc e Π Ω ,n dep ends on an input only thr ough its evaluations on the design p oints, Π Ω ,n lift n ( v ) is wel l-define d. Let y 1: n = ( y 1 , · · · , y n ) ⊤ , and recall the minimum-norm least-squares solution ˆ θ Ω ,n and ˆ f Ω ,n = T Ω ˆ θ Ω ,n . Lemma A.11 (OLS equals empirical pro jection) . The OLS pr e dictor satisfies ˆ f Ω ,n = Π Ω ,n lift n ( y 1: n ) , and henc e Ev n ( ˆ f Ω ,n ) = H Ω ,n ( y 1 , . . . , y n ) ⊤ . Pr o of. By definition, ˆ θ Ω ,n minimizes ∥ lift n ( y 1: n ) − T Ω θ ∥ 2 n , whic h is exactly the least-squares problem enco ded in Definition A.7 with g = lift n ( y 1: n ). Therefore T Ω ˆ θ Ω ,n coincides with Π Ω ,n lift n ( y 1: n ), and ev aluating yields the hat-matrix iden tity . A.5 Effectiv e dimension and degrees of freedom Recall the empirical effective dimension d eff ,n (Ω) : = tr Σ n (Ω) + Σ n (Ω) = rank(Σ n (Ω)) . Lemma A.12 (Equiv alen t c haracterizations of d eff ,n ) . F or any Ω and design p oints x 1: n , d eff ,n (Ω) = rank(Σ n (Ω)) = rank(Φ Ω ) = tr( H Ω ,n ) . Pr o of. Com bine Lemma A.2 with Lemma A.4 . Lemma A.13 (Pro jected-noise iden tity conditional on the design) . L et ε 1: n = ( ε 1 , . . . , ε n ) ⊤ with E [ ε 1: n | x 1: n ] = 0 and E [ ε 1: n ε ⊤ 1: n | x 1: n ] = σ 2 I n , and assume ε 1: n is c onditional ly indep endent of x 1: n . Then, for any Ω , E 1 n ∥ H Ω ,n ε 1: n ∥ 2 2 x 1: n = σ 2 n tr( H Ω ,n ) = σ 2 n d eff ,n (Ω) . Pr o of. Condition on x 1: n and use H ⊤ Ω ,n = H Ω ,n and H 2 Ω ,n = H Ω ,n : E ∥ H Ω ,n ε 1: n ∥ 2 2 x 1: n = E h ε ⊤ 1: n H Ω ,n ε 1: n x 1: n i = tr H Ω ,n E [ ε 1: n ε ⊤ 1: n | x 1: n ] = σ 2 tr( H Ω ,n ) . Divide by n and in vok e Lemma A.12 . Remark A.14. L emma A.12 is the line ar-algebr aic r e ason the le ading noise-estimation c onstant is a de gr e es-of-fr e e dom term: under homoske dastic noise, the c onditional exp e cte d squar e d norm of the pr oje cte d noise dep ends on the design only thr ough tr ( H Ω ,n ) , which e quals d eff ,n (Ω) by L emma A.12 . 25 A.6 Benefits of an op erator-theoretic form ulation The downstream stage do es not use Ω as an ob ject in isolation; it uses only the linear function class it induces together with the least-squares fit of the lab els on to this class. In tro ducing the linear map T Ω pac k ages all do wnstream quan tities in a coordinate-free form. (i) Invarianc e b e c omes explicit. If t wo feature parametrizations induce the same subspace H Ω ⊆ L 2 down , then do wnstream predictions after refitting are iden tical. In the op erator language, all p opulation ob jects dep end on Ω only through H Ω , summarized by the pro jector Π Ω = T Ω Σ(Ω) + T adj Ω . (ii) Population and empiric al stages have the same algebr aic structur e. The empirical pro jector Π Ω ,n is obtained from Π Ω b y replacing exp ectations with sam ple a verages, i.e., T adj Ω b y T adj Ω ,n and Σ(Ω) b y Σ n (Ω). (iii) Bridge to the manifold pr e-tr aining limit the ory. Our m -asymptotics en ter through how p opulation quantities c hange with Ω near Ω ⋆ . When M is a Riemannian manifold, the pre-training estimator satisfies a log-map CL T √ m log Ω ⋆ ( ˆ Ω m ) d ⇝ N (0 , V ) in T Ω ⋆ M , under the assumptions in the main text. The op erator viewpoint makes it natural to apply a delta-metho d argumen t to maps of the form Ω 7→ Π Ω and Ω 7→ Rep (Ω), after passing to the appropriate descriptor/quotient parametrization described in Section 4 . B Riemannian Geometry and M -estimation Background This app endix collects the minimal differen tial-geometric and M -estimation background used in our quotien t/descriptor-manifold asymptotic analysis. Our Riemannian conv entions follow Lee ( 2018 ). F or classical references on Euclidean M -estimation, see V an der V aart ( 2000 ). B.1 Basic Riemannian notions Smo oth manifolds and tangen t spaces. A smooth q -dimensional manifold M is a Hausdorff, second-coun table top ological space equipped with a smo oth atlas { ( U α , φ α ) } , where φ α : U α → φ α ( U α ) ⊆ R q is a homeomorphism and all transition maps φ β ◦ φ − 1 α are smo oth on o verlaps. F or Ω ∈ M , the tangen t space T Ω M is a q -dimensional real vector space. F or a smo oth map F : M → N , w e write dF Ω : T Ω M → T F (Ω) N for its differen tial. A smo oth vector field X assigns to eac h Ω ∈ M a vector X (Ω) ∈ T Ω M smo othly in c harts. Riemannian metrics and induced metrics. A Riemannian metric on M is a c hoice of inner pro duct ⟨· , ·⟩ Ω on each tangen t space T Ω M that dep ends smo othly on Ω. The pair ( M , ⟨· , ·⟩ ) is called a Riemannian manifold. If M ⊆ R q 0 is an em b edded C k submanifold of R q 0 , the induced (am bient) metric is ⟨ u, v ⟩ Ω : = u ⊤ v for u, v ∈ T Ω M ⊆ R q 0 . F or a piecewise C 1 curv e γ : [0 , 1] → M , its length is L ( γ ) = Z 1 0 ∥ ˙ γ ( t ) ∥ γ ( t ) dt, ∥ v ∥ Ω : = p ⟨ v , v ⟩ Ω . 26 The asso ciated Riemannian distance is defined by d M (Ω 1 , Ω 2 ) = inf γ (0)=Ω 1 , γ (1)=Ω 2 L ( γ ) , where the infim um ranges o ver piecewise C 1 curv es γ : [0 , 1] → M . Levi–Civita connection, geodesics, gradients, and Hessians. There is a unique connection ∇ on M (the Levi–Civita connection) that is torsion-free and metric-compatible. A C 2 curv e γ is a geo desic if it satisfies ∇ ˙ γ ( t ) ˙ γ ( t ) = 0 for all t . F or a smooth function f : M → R , the Riemannian gradient grad f (Ω) ∈ T Ω M is defined by the identit y d f Ω ( v ) = ⟨ grad f (Ω) , v ⟩ Ω , v ∈ T Ω M . The Riemannian Hessian at point Ω is the linear map Hess f (Ω) : T Ω M → T Ω M given by Hess f (Ω)[ v ] : = ∇ V (grad f )(Ω) , where V is any smo oth lo cal extension of v ∈ T Ω M . W e also use the associated bilinear form as Hess f (Ω)( u, v ) = ⟨ u, Hess f (Ω)[ v ] ⟩ Ω . Exp onen tial map, normal neigh b orho o ds, and logarithm map. Fix Ω ∈ M . F or each v ∈ T Ω M , let γ v : [0 , 1] → M denote the unique geo desic with γ v (0) = Ω and ˙ γ v (0) = v . The exp onen tial map at Ω is exp Ω : T Ω M → M , exp Ω ( v ) : = γ v (1) . Moreo ver, there exists δ Ω > 0 such that exp Ω restricts to a diffeomorphism from B (Ω , δ Ω ) ⊂ T Ω M on to its image. On an y set where this restriction is inv ertible, we write log Ω for the lo cal inv erse of exp Ω . Definition B.1 (Normal neigh b orho od and normal co ordinates) . A n op en subset U ⊆ M is a normal neighborho o d of Ω if ther e exists a δ > 0 such that U = exp Ω ( B (Ω , δ )) and the r estriction exp Ω : B (Ω , δ ) → U is a diffe omorphism. On such a U , the lo garithm map at Ω is the inverse chart log Ω : U → T Ω M , and the r esulting chart log Ω defines the normal coordinates at Ω . B.2 T a ylor expansions in normal co ordinates This subsection records the T a ylor expansions w e use to linearize first-order optimality conditions on the descriptor manifold. Normal co ordinates and pullbacks. Let U ⊆ M b e a normal neighborho o d of Ω (Definition B.1 ). Giv en a function f : M → R , w e pull f bac k to the tangent space via ˜ f ( v ) : = f (exp Ω ( v )) , v ∈ B (Ω , δ ) ⊆ T Ω M . Equiv alently , for Ω ′ ∈ U , we write v = log Ω (Ω ′ ) and view ˜ f as f expressed in normal coordinates around Ω. 27 First- and second-order expansions of a smooth function. Let U b e a normal neigh b orho od of Ω 1 and write Ω 2 = exp Ω 1 ( v ) with v ∈ T Ω 1 M . If f is C 1 ( M , R ) on U , then as v → 0 in T Ω 1 M , f (exp Ω 1 ( v )) = f (Ω 1 ) + ⟨ grad , f (Ω 1 ) , v ⟩ Ω 1 + o ( ∥ v ∥ Ω 1 ) . (B.1) If f is C 2 ( M , R ) on U , then as v → 0 in T Ω 1 M , f (exp Ω 1 ( v )) = f (Ω 1 ) + ⟨ grad , f (Ω 1 ) , v ⟩ Ω 1 + 1 2 v , Hess , f (Ω 1 )[ v ] Ω 1 + o ( ∥ v ∥ 2 Ω 1 ) . (B.2) The restriction to a normal neigh b orho od ensures that nearby p oin ts admit a unique represen tation via the logarithm map, so that the ab o v e expansions are w ell-defined and in trinsic. T a ylor expansion of the gradien t via parallel transp ort. Fix Ω 1 ∈ M and let U b e a normal neigh b orho od of Ω 1 . F or v ∈ T Ω 1 M sufficiently small, define the unique geo desic γ ( t ) : = exp Ω 1 ( tv ) , t ∈ [0 , 1] , so that γ (0) = Ω 1 and γ (1) = Ω 2 : = exp Ω 1 ( v ). Par al lel tr ansp ort. Let P Ω 1 → Ω 2 : T Ω 1 M → T Ω 2 M denote parallel transp ort along γ . Given w ∈ T Ω 1 M , let W ( t ) ∈ T γ ( t ) M b e the unique vector field along γ that has the following prop ert y ∇ ˙ γ ( t ) W ( t ) = 0 , W (0) = w , and set P Ω 1 → Ω 2 w : = W (1). W e write P Ω 2 → Ω 1 : = P − 1 Ω 1 → Ω 2 . Gr adient exp ansion. If f : M → R is C 2 on U , then as v → 0, P Ω 2 → Ω 1 grad f (Ω 2 ) = grad f (Ω 1 ) + Hess f (Ω 1 )[ v ] + r f ( v ) , (B.3) where r f ( v ) = o ( ∥ v ∥ Ω 1 ). If, in addition, Hess f is locally Lipsc hitz on U (with respect to d M ), then there exist constan ts C > 0 and ε > 0 suc h that ∥ r f ( v ) ∥ Ω 1 ⩽ C ∥ v ∥ 2 Ω 1 for all ∥ v ∥ Ω 1 ⩽ ε . (B.4) Empirical ob jectives. The expansion ( B.3 ) applies to empirical ob jectiv es of the form ˆ f : = 1 m m X i =1 f i , pro vided eac h f i is C 2 on a common normal neighborho o d U of Ω ⋆ , and the corresponding deriv atives admit lo cal bounds on U (so that the remainder is uniform for ∥ v ∥ Ω ⋆ small). In particular, for v ∈ T Ω ⋆ M small and ˆ Ω : = exp Ω ⋆ ( v ), P ˆ Ω → Ω ⋆ grad ˆ f ( ˆ Ω) = grad ˆ f (Ω ⋆ ) + Hess ˆ f (Ω ⋆ )[ v ] + r ˆ f ( v ) , (B.5) where r ˆ f ( v ) = o ( ∥ v ∥ Ω ⋆ ) as v → 0. If, in addition, Hess ˆ f is lo cally Lipsc hitz on U , then ∥ r ˆ f ( v ) ∥ Ω ⋆ = O ( ∥ v ∥ 2 Ω ⋆ ). 28 Remark (normal co ordinates vs. parallel transp ort). In normal co ordinates at Ω, one ma y view ( B.3 ) as an ordinary Euclidean T a ylor expansion of the pullbac k ˜ f ( v ) = f ( exp Ω ( v )) at v = 0. The parallel-transp ort form is conv enien t because it compares v ectors in a single space T Ω M . B.3 Euclidean M -estimation: consistency and asymptotic normality Let ( Z , G ) b e a measurable space and let Z 1 , . . . , Z m b e i.i.d. with law P on Z . Let Θ ⊆ R p b e the parameter set. Given a measurable loss ℓ : Θ × Z → R , define ˆ L m ( θ ) : = 1 m m X i =1 ℓ ( θ ; Z i ) , L ( θ ) : = E [ ℓ ( θ ; Z )] , where Z ∼ P and we assume L ( θ ) is w ell-defined (p ossibly + ∞ ) for all θ ∈ Θ. An M -estimator is an y measurable selection ˆ θ m from the set of empirical minimizers, ˆ θ m ∈ arg min θ ∈ Θ ˆ L m ( θ ) , whenev er this set is nonempt y . Assumption B.2 (Euclidean M -estimation conditions) . Ther e exist θ ⋆ ∈ Θ , an op en set U ⊆ R p with θ ⋆ ∈ U , and r > 0 with B ( θ ⋆ , r ) ⊆ U ∩ Θ such that: (i) (Identific ation and sep ar ation). θ ⋆ is the unique minimizer of L on Θ and for every ϵ > 0 , inf θ ∈ Θ: ∥ θ − θ ⋆ ∥ ⩾ ϵ L ( θ ) − L ( θ ⋆ ) > 0 . (ii) (Uniform LLN on a c omp act set). On the c omp act set B ( θ ⋆ , r ) , we have sup θ ∈ B ( θ ⋆ ,r ) ˆ L m ( θ ) − L ( θ ) P − − → 0 , and ˆ θ m ∈ B ( θ ⋆ , r ) with pr ob ability tending to one. (iii) (L o c al C 2 smo othness and sc or e moments). F or P -a.e. z , the map θ 7→ ℓ ( θ ; z ) is C 2 on U , and E [ ∥∇ ℓ ( θ ⋆ ; Z ) ∥ 2 ] < ∞ . (iv) (Nonde gener ate minimizer). The matrix H ⋆ : = ∇ 2 L ( θ ⋆ ) is invertible. (v) (Uniform Hessian c onver genc e on B ( θ ⋆ , r ) ). sup θ ∈ B ( θ ⋆ ,r ) ∇ 2 ˆ L m ( θ ) − ∇ 2 L ( θ ) P − − → 0 . Define Σ ⋆ : = V ar ∇ ℓ ( θ ⋆ ; Z ) = E h ∇ ℓ ( θ ⋆ ; Z ) ∇ ℓ ( θ ⋆ ; Z ) ⊤ i , where E [ ∇ ℓ ( θ ⋆ ; Z )] = ∇ L ( θ ⋆ ) = 0. 29 Prop osition B.3 (Euclidean M -estimator consistency) . Assume Assumption B.2 (i)–(ii). Then ˆ θ m P − − → θ ⋆ . Pr o of. The argument follo ws standard M -estimation pro ofs (see, e.g., V an der V aart ( 2000 )); we include it as a reference, since w e will so on generalize this argument to Riemannian manifolds. Fix ϵ > 0 and define the separation gap ∆ ϵ : = inf θ ∈ Θ: ∥ θ − θ ⋆ ∥ ⩾ ϵ L ( θ ) − L ( θ ⋆ ) , so that ∆ ϵ > 0 b y Assumption B.2 (i). Consider the ev en t E m : = ( sup θ ∈ B ( θ ⋆ ,r ) ˆ L m ( θ ) − L ( θ ) ⩽ ∆ ϵ 3 ) ∩ { ˆ θ m ∈ B ( θ ⋆ , r ) } . By the uniform law of large num b ers on B ( θ ⋆ , r ) and the lo calization P ( ˆ θ m ∈ B ( θ ⋆ , r )) → 1, we ha ve P ( E m ) → 1. On the ev ent E m , for an y θ ∈ B ( θ ⋆ , r ) with ∥ θ − θ ⋆ ∥ ⩾ ϵ w e ha ve ˆ L m ( θ ) ⩾ L ( θ ) − ∆ ϵ 3 ⩾ L ( θ ⋆ ) + ∆ ϵ − ∆ ϵ 3 = L ( θ ⋆ ) + 2∆ ϵ 3 , while ˆ L m ( θ ⋆ ) ⩽ L ( θ ⋆ ) + ∆ ϵ 3 . Hence, on E m , inf θ ∈ B ( θ ⋆ ,r ): ∥ θ − θ ⋆ ∥ ⩾ ϵ ˆ L m ( θ ) > ˆ L m ( θ ⋆ ) . In particular, an y minimizer of ˆ L m o ver B ( θ ⋆ , r ) must lie in B ( θ ⋆ , ϵ ). Since ˆ θ m ∈ B ( θ ⋆ , r ) on E m and ˆ θ m is (by assumption) an empirical minimizer, w e conclude that ∥ ˆ θ m − θ ⋆ ∥ < ϵ on E m . Therefore, P ∥ ˆ θ m − θ ⋆ ∥ ⩾ ϵ ⩽ P ( E c m ) → 0 , whic h pro v es ˆ θ m → θ ⋆ in probability . Theorem B.4 (Euclidean M -estimator CL T) . Under Assumption B.2 , √ n ( ˆ θ n − θ ⋆ ) d ⇝ N 0 , H − 1 ⋆ Σ ⋆ H − 1 ⋆ . Pr o of. The argument follo ws standard M -estimation pro ofs (see, e.g., V an der V aart ( 2000 )); we include it as a reference, since w e will so on generalize this argument to Riemannian manifolds. By Prop osition B.3 and Assumption B.2 (i)–(ii), we hav e ˆ θ m P − − → θ ⋆ . In particular, since ˆ θ m ∈ B ( θ ⋆ , r ) with probability tending to one b y Assumption B.2 (ii), all argumen ts below may b e restricted to the even t { ˆ θ m ∈ B ( θ ⋆ , r ) } . 30 On the ev ent { ˆ θ m ∈ B ( θ ⋆ , r ) } , the first-order condition for the empirical minimizer gives ∇ ˆ L m ( ˆ θ m ) = 0 . Since ℓ ( · ; z ) is C 2 on U for P -a.e. z b y Assumption B.2 (iii), the map θ 7→ ∇ ˆ L m ( θ ) is differen tiable on U and we ma y apply the mean-v alue form of T a ylor’s theorem: there exists a p oin t ˜ θ m on the line segment b et ween θ ⋆ and ˆ θ m suc h that 0 = ∇ ˆ L m ( ˆ θ m ) = ∇ ˆ L m ( θ ⋆ ) + ∇ 2 ˆ L m ( ˜ θ m ) ( ˆ θ m − θ ⋆ ) . (B.6) Rearranging yields √ m ( ˆ θ m − θ ⋆ ) = − ∇ 2 ˆ L m ( ˜ θ m ) − 1 √ m ∇ ˆ L m ( θ ⋆ ) , (B.7) on the ev ent that ∇ 2 ˆ L m ( ˜ θ m ) is in vertible. Since ˜ θ m lies on the segmen t betw een θ ⋆ and ˆ θ m , we ha ve ˜ θ m ∈ B ( θ ⋆ , r ) whenever ˆ θ m ∈ B ( θ ⋆ , r ). Moreo ver, b y consistency ˆ θ m → θ ⋆ in probability , hence ˜ θ m → θ ⋆ in probability as w ell. By the uniform Hessian con vergence in Assumption B.2 (v), sup θ ∈ B ( θ ⋆ ,r ) ∇ 2 ˆ L m ( θ ) − ∇ 2 L ( θ ) P − − → 0 , and therefore ∇ 2 ˆ L m ( ˜ θ m ) − ∇ 2 L ( ˜ θ m ) P − − → 0 . Since L is twice differentiable at θ ⋆ and ˜ θ m → θ ⋆ in probability , we also hav e ∇ 2 L ( ˜ θ m ) → ∇ 2 L ( θ ⋆ ) = H ⋆ in probability . Com bining these giv es ∇ 2 ˆ L m ( ˜ θ m ) P − − → H ⋆ . (B.8) By Assumption B.2 (iv), H ⋆ is inv ertible, hence b y con tin uity of matrix in version, ∇ 2 ˆ L m ( ˜ θ m ) − 1 P − − → H − 1 ⋆ . (B.9) In particular, ∇ 2 ˆ L m ( ˜ θ m ) is in vertible with probability tending to one. By definition, ∇ ˆ L m ( θ ⋆ ) = 1 m m X i =1 ∇ ℓ ( θ ⋆ ; Z i ) . Since θ ⋆ is a minimizer of L and L is differen tiable at θ ⋆ , we hav e E [ ∇ ℓ ( θ ⋆ ; Z )] = ∇ L ( θ ⋆ ) = 0, hence the summands are mean-zero. By Assumption B.2 (iii), E [ ∥∇ ℓ ( θ ⋆ ; Z ) ∥ 2 ] < ∞ , so the m ultiv ariate CL T yields √ m ∇ ˆ L m ( θ ⋆ ) d ⇝ N (0 , Σ ⋆ ) . (B.10) Com bining ( B.7 ), ( B.9 ), and ( B.10 ), and applying Slutsky’s theorem, we obtain √ m ( ˆ θ m − θ ⋆ ) d ⇝ − H − 1 ⋆ G, G ∼ N (0 , Σ ⋆ ) . Since − H − 1 ⋆ G ∼ N (0 , H − 1 ⋆ Σ ⋆ H − 1 ⋆ ), this pro ves the claim. 31 B.4 M -estimation on a Riemannian manifold Let ( M , ⟨· , ·⟩ ) b e a finite-dimensional C 2 Riemannian manifold. Let ( Z , G ) b e a measurable space and let Z 1 , . . . , Z m b e i.i.d. with common la w P on Z . Let f : M × Z → R b e a measurable loss suc h that the expectations below are w ell-defined. Define ˆ F m (Ω) : = 1 m m X i =1 f (Ω; Z i ) , F (Ω) : = E [ f (Ω; Z )] , Ω ∈ M . An M -estimator is a measurable map ˆ Ω m = ˆ Ω m ( Z 1 , . . . , Z m ) suc h that ˆ Ω m ∈ arg min Ω ∈M ˆ F m (Ω) whenev er the argmin set is nonempty . Fix Ω ⋆ ∈ M . F or ϵ > 0, define the tangen t-space ball B (Ω ⋆ , ϵ ) : = { v ∈ T Ω ⋆ M : ∥ v ∥ Ω ⋆ < ϵ } , B (Ω ⋆ , ϵ ) : = { v ∈ T Ω ⋆ M : ∥ v ∥ Ω ⋆ ⩽ ϵ } . Let exp Ω ⋆ denote the exponential map and U = exp Ω ⋆ B (Ω ⋆ , ε 0 ) denote a normal neighborho o d. Assumption B.5 (Riemannian M -estimation conditions) . Ther e exist Ω ⋆ ∈ M , a normal neigh- b orho o d U = exp Ω ⋆ B (Ω ⋆ , ϵ 0 ) , and ϵ ′ ∈ (0 , ϵ 0 ) such that exp Ω ⋆ B (Ω ⋆ , ϵ ′ ) ⊆ U and: (i) (Identific ation and sep ar ation). Ω ⋆ is the unique minimizer of F on M and for every ϵ > 0 , inf Ω ∈M : d M (Ω , Ω ⋆ ) ⩾ ϵ F (Ω) − F (Ω ⋆ ) > 0 . (ii) (Uniform LLN on a c omp act set). On the c omp act set exp Ω ⋆ B (Ω ⋆ , ϵ ′ ) , we have sup Ω ∈ exp Ω ⋆ ( B (Ω ⋆ ,ϵ ′ )) ˆ F m (Ω) − F (Ω) P − − → 0 , and ˆ Ω m ∈ exp Ω ⋆ B (Ω ⋆ , ϵ ′ ) with pr ob ability tending to one. (iii) (L o c al C 2 smo othness and sc or e m oments). F or P -a.e. z , the map Ω 7→ f (Ω; z ) is C 2 on U , and E ∥ grad f (Ω ⋆ ; Z ) ∥ 2 Ω ⋆ < ∞ . (iv) (Nonde gener ate minimizer). The line ar map H ⋆ : = Hess F (Ω ⋆ ) : T Ω ⋆ M → T Ω ⋆ M is invertible. (v) (Uniform tr ansp orte d Hessian c onver genc e on exp Ω ⋆ ( B (Ω ⋆ , ϵ ′ )) ). F or Ω ∈ exp Ω ⋆ B (Ω ⋆ , ϵ ′ ) , define e H m (Ω) : = P Ω → Ω ⋆ ◦ Hess ˆ F m (Ω) ◦ P Ω ⋆ → Ω , e H (Ω) : = P Ω → Ω ⋆ ◦ Hess F (Ω) ◦ P Ω ⋆ → Ω . Then sup Ω ∈ exp Ω ⋆ ( B (Ω ⋆ ,ϵ ′ )) e H m (Ω) − e H (Ω) P − − → 0 . Define the co v ariance operator Σ ⋆ on T Ω ⋆ M by ⟨ u, Σ ⋆ v ⟩ Ω ⋆ = E h ⟨ u, grad f (Ω ⋆ ; Z ) ⟩ Ω ⋆ ⟨ v , grad f (Ω ⋆ ; Z ) ⟩ Ω ⋆ i , u, v ∈ T Ω ⋆ M . 32 Prop osition B.6 (Riemannian M -estimator consistency) . Assume Assumption B.5 (i)–(ii). Then ˆ Ω m P − − → Ω ⋆ . Pr o of. Fix ϵ > 0 and define the separation gap ∆ ϵ : = inf Ω ∈M : d M (Ω , Ω ⋆ ) ⩾ ϵ F (Ω) − F (Ω ⋆ ) , so that ∆ ϵ > 0 b y Assumption B.5 (i). Consider the ev en t E m : = ( sup Ω ∈ exp Ω ⋆ ( B (Ω ⋆ ,ϵ ′ )) ˆ F m (Ω) − F (Ω) ⩽ ∆ ϵ 3 ) ∩ n ˆ Ω m ∈ exp Ω ⋆ ( B (Ω ⋆ , ϵ ′ )) o . By the uniform law of large n umbers on exp Ω ⋆ ( B (Ω ⋆ , ϵ ′ )) and the lo calization in Assumption B.5 (ii), w e ha v e P ( E m ) → 1. On the ev ent E m , for an y Ω ∈ exp Ω ⋆ ( B (Ω ⋆ , ϵ ′ )) with d M (Ω , Ω ⋆ ) ⩾ ϵ w e hav e ˆ F m (Ω) ⩾ F (Ω) − ∆ ϵ 3 ⩾ F (Ω ⋆ ) + ∆ ϵ − ∆ ϵ 3 = F (Ω ⋆ ) + 2∆ ϵ 3 , while ˆ F m (Ω ⋆ ) ⩽ F (Ω ⋆ ) + ∆ ϵ 3 . Hence, on E m , inf Ω ∈ exp Ω ⋆ ( B (Ω ⋆ ,ϵ ′ )): d M (Ω , Ω ⋆ ) ⩾ ϵ ˆ F m (Ω) > ˆ F m (Ω ⋆ ) . In particular, an y minimizer of ˆ F m o ver exp Ω ⋆ ( B (Ω ⋆ , ϵ ′ )) must lie in the metric ball B d M (Ω ⋆ , ϵ ) : = { Ω ∈ M : d M (Ω , Ω ⋆ ) < ϵ } . Since ˆ Ω m ∈ exp Ω ⋆ ( B (Ω ⋆ , ϵ ′ )) on E m and ˆ Ω m is (by definition) an empirical minimizer, we conclude that d M ( ˆ Ω m , Ω ⋆ ) < ϵ on E m . Therefore, P d M ( ˆ Ω m , Ω ⋆ ) ⩾ ϵ ⩽ P ( E c m ) → 0 , whic h pro v es ˆ Ω m → Ω ⋆ in probability . The following result is the full statemen t of Theorem 4.1 from the main text. Theorem B.7 (Riemannian M -estimator CL T, full statemen t of Theorem 4.1 ) . Under Assump- tion B.5 , we have √ m log Ω ⋆ ( ˆ Ω m ) d ⇝ N 0 , H − 1 ⋆ Σ ⋆ H − 1 ⋆ , wher e H ⋆ : = Hess F (Ω ⋆ ) : T Ω ⋆ M → T Ω ⋆ M and Σ ⋆ : = V ar grad f (Ω ⋆ ; Z ) = E h grad f (Ω ⋆ ; Z ) grad f (Ω ⋆ ; Z ) ⊤ i , with E [grad f (Ω ⋆ ; Z )] = grad F (Ω ⋆ ) = 0 . 33 Pr o of. By Prop osition B.6 and Assumption B.5 (i)–(ii), we hav e ˆ Ω m P − − → Ω ⋆ . In particular, b y Assumption B.5 (ii), with probability tending to one we hav e ˆ Ω m ∈ U ′ : = exp Ω ⋆ B Ω ⋆ ( ϵ ′ ) , so that v m : = log Ω ⋆ ( ˆ Ω m ) ∈ T Ω ⋆ M is well-defined and satisfies v m → 0 in probability . On the ev ent { ˆ Ω m ∈ U ′ } , the first-order condition for an empirical minimizer gives grad ˆ F m ( ˆ Ω m ) = 0 . Applying the transported gradient expansion ( B.5 ) with Ω 1 = Ω ⋆ , Ω 2 = ˆ Ω m = exp Ω ⋆ ( v m ), and f = ˆ F m , we obtain 0 = P ˆ Ω m → Ω ⋆ grad ˆ F m ( ˆ Ω m ) = grad ˆ F m (Ω ⋆ ) + Hess ˆ F m (Ω ⋆ )[ v m ] + r m , where r m = o ( ∥ v m ∥ Ω ⋆ ) in probabilit y as m → ∞ . Rearranging yields √ m v m = − Hess ˆ F m (Ω ⋆ ) − 1 √ m grad ˆ F m (Ω ⋆ ) − Hess ˆ F m (Ω ⋆ ) − 1 √ m r m , (B.11) on the ev ent that Hess ˆ F m (Ω ⋆ ) is in vertible. By Assumption B.5 (v) applied at Ω = Ω ⋆ (so that P Ω ⋆ → Ω ⋆ = Id), Hess ˆ F m (Ω ⋆ ) − Hess F (Ω ⋆ ) = e H m (Ω ⋆ ) − e H (Ω ⋆ ) P − − → 0 . Hence, Hess ˆ F m (Ω ⋆ ) P − − → H ⋆ . (B.12) By Assumption B.5 (iv), H ⋆ is inv ertible, and b y con tin uity of inv ersion w e ha ve Hess ˆ F m (Ω ⋆ ) − 1 P − − → H − 1 ⋆ . (B.13) In particular, Hess ˆ F m (Ω ⋆ ) is in vertible with probability tending to one. By definition, grad ˆ F m (Ω ⋆ ) = 1 m m X i =1 grad f (Ω ⋆ ; Z i ) . Since Ω ⋆ is a minimizer of F and F is differentiable at Ω ⋆ , w e hav e E [ grad f (Ω ⋆ ; Z )] = grad F (Ω ⋆ ) = 0. By Assumption B.5 (iii), E [ ∥ grad f (Ω ⋆ ; Z ) ∥ 2 Ω ⋆ ] < ∞ , so the m ultiv ariate CL T yields √ m grad ˆ F m (Ω ⋆ ) d ⇝ N (0 , Σ ⋆ ) . (B.14) Since r m = o ( ∥ v m ∥ Ω ⋆ ) in probabilit y , w e hav e ∥ r m ∥ Ω ⋆ ∥ v m ∥ Ω ⋆ P − − → 0 , 34 with the con ven tion that the ratio is set to 0 on the ev en t { v m = 0 } . Moreo ver, from ( B.11 ) and ( B.13 ) we hav e Hess ˆ F m (Ω ⋆ ) − 1 = O P (1) and √ m grad ˆ F m (Ω ⋆ ) = O P (1), hence √ m ∥ v m ∥ Ω ⋆ = O P (1) . Consequen tly , √ m ∥ r m ∥ Ω ⋆ = √ m ∥ v m ∥ Ω ⋆ · ∥ r m ∥ Ω ⋆ ∥ v m ∥ Ω ⋆ P − − → 0 , and therefore √ m r m P − − → 0 . (B.15) Com bining ( B.11 ), ( B.13 ), ( B.14 ), and ( B.15 ), and applying Slutsky’s theorem, w e obtain √ m v m = √ m log Ω ⋆ ( ˆ Ω m ) d ⇝ − H − 1 ⋆ G, G ∼ N (0 , Σ ⋆ ) . Since − H − 1 ⋆ G ∼ N (0 , H − 1 ⋆ Σ ⋆ H − 1 ⋆ ), this pro ves the claim. Remark (Euclidean case as a sp ecial case). If M = R p with the Euclidean metric, then exp θ ⋆ ( v ) = θ ⋆ + v , log θ ⋆ ( θ ) = θ − θ ⋆ , geo desics are line segments, and parallel transp ort is the iden tity . In this case e H n ( θ ) = ∇ 2 ˆ L n ( θ ). C Symmetry , Iden tifiabilit y , and Quotien t Geometry This appendix formalizes how symmetry-induced non-iden tifiability in pretraining is handled in our analysis. C.1 Quotien ts b y group actions and lo cal descriptor charts Smo oth group actions. Let G b e a Lie group acting smo othly on a smo oth manifold A . W e write the action as ( g , a ) 7→ g · a . F or a ∈ A , the orbit is [ a ] = { g · a : g ∈ G } and the stabilizer (isotropy subgroup) is G a = { g ∈ G : g · a = a } . The orbit space (quotien t set) is A /G = { [ a ] : a ∈ A} with the quotient top ology , and the canonical pro jection is denoted π : A → A /G , π ( a ) = [ a ]. Regular neigh b orho ods and smo oth quotients. A smo oth action is called fr e e if G a = { e } for all a ∈ A . It is called pr op er if the map G × A → A × A , ( g , a ) 7→ ( a, g · a ) is prop er. A sufficien t condition for prop erness is that G is compact (e.g., an orthogonal group) or finite (e.g., a p erm utation group). If the action of G on A is smo oth, free, and proper on an op en set U ⊆ A , then the orbit space B : = U /G admits a unique smo oth manifold structure suc h that the pro jection π : U → B is a smo oth submersion. In this case, π : U → B is a principal G -bundle. If the action is prop er but not free, one ma y restrict atten tion to a regular stratum on which the orbit type is constan t; on such a neigh b orho od the quotient is again a smo oth manifold. This is the regime implicitly used in the main text. 35 Lo cal quotien t charts via inv arian t descriptors. Rather than working directly with the abstract quotien t manifold B , we represent a lo cal neigh b orho od of B using an orbit-in v arian t descriptor map . The following assumption makes this precise. Assumption C.1 (Lo cal quotient chart via an in v ariant descriptor) . L et U ⊆ A b e an op en set on which the action of G is smo oth, fr e e, and pr op er, and let B = U /G with pr oje ction π : U → B . Ther e exists a map R : U → R q such that: (i) (Orbit-c onstancy). F or al l a ∈ U and g ∈ G , R ( g · a ) = R ( a ) . (ii) (L o c al chart for the quotient). Ther e exist op en neighb orho o ds V ⊆ B and W ⊆ R q , and a C k diffe omorphism ¯ R : V → W , such that on π − 1 ( V ) we have R = ¯ R ◦ π . Consequences. Under Assumption C.1 , the following hold. (i) Lo cal orbit separation. F or a, a ′ ∈ π − 1 ( V ), R ( a ) = R ( a ′ ) ⇐ ⇒ π ( a ) = π ( a ′ ) ⇐ ⇒ a ′ ∈ [ a ] . (ii) Descriptor manifold. W e identify the lo cal quotien t neighborho o d V ⊆ B with its descriptor co ordinates W ⊆ R q via ¯ R , and write M : = W . Th us M is a smo oth manifold (indeed, an op en subset of R q ) equipped with the induced Euclidean metric. (iii) Existence of smo oth lifts. Since π : U → B is a principal bundle, there exists a smo oth lo cal section σ : V → U . Defining s : = σ ◦ ¯ R − 1 : M → U , w e obtain a C k lift satisfying R ( s ( M )) = M for all M ∈ M . (iv) W ell-defined induced ob jectiv es. Any G -in v arian t function on U induces a w ell-defined function on M by ev aluation at any represen tative in R − 1 ( M ) ∩ π − 1 ( V ). C.2 V ector-bundle viewp oin t: quotien t-level features and the co ordinate feature map ϕ ( x, M ) This subsection formalizes ho w equiv ariant represen tative-lev el features induce in trinsic quotien t-level features, and ho w coordinate feature maps arise from choosing local lifts. 36 C.2.1 Setup: principal bundle and equiv ariant features Let U ⊆ R q 0 b e an op en set on which a Lie group G acts smoothly , freely , and properly , and let B = U /G with pro jection π : U → B . Fix a feature dimension p ∈ N + and let ρ : G → O ( p ) b e a smo oth group homomorphism. Let ψ : X × U → R p b e measurable in x and C k in its second argumen t. W e assume the orthogonal equiv ariance condition ψ ( x, g · A ) = ρ ( g ) ψ ( x, A ) , x ∈ X , A ∈ U , g ∈ G. C.2.2 Associated v ector bundle and in trinsic feature section Define an equiv alence relation on U × R p b y ( A, v ) ∼ ( g · A, ρ ( g ) v ) , g ∈ G. The asso ciated rank- p v ector bundle ov er B is E : = ( U × R p ) / ∼ , with pro jection π E ([ A, v ]) = [ A ]. The Euclidean inner product on R p descends to a well-defined fib erwise inner product on E . F or eac h x ∈ X , define the in trinsic feature section Φ x : B → E , Φ x ([ A ]) : = [ A, ψ ( x, A )] . Prop osition C.2 (W ell-definedness and smo othness) . Under the e quivarianc e assumption ab ove, Φ x is wel l-define d. If A 7→ ψ ( x, A ) is C k on U , then Φ x is a C k se ction of E . Pr o of. If A ′ = g · A , then b y equiv ariance, [ A ′ , ψ ( x, A ′ )] = [ g · A, ρ ( g ) ψ ( x, A )] = [ A, ψ ( x, A )] , so Φ x dep ends only on the orbit. Smo othness follo ws by expressing Φ x in lo cal trivializations induced by smo oth lo cal sections of the principal bundle π : U → B . C.2.3 Descriptor co ordinates and the co ordinate feature map Let M ⊆ R q b e the descriptor manifold pro vided b y Assumption C.1 , and let s : M → U b e the asso ciated C k lift, i.e., R ( s (Ω)) = Ω for all Ω in a local neigh b orhoo d. Co ordinate feature map. Define ϕ : X × M → R p , ϕ ( x, M ) : = ψ ( x, s ( M )) . Lemma C.3 (Differen tiabilit y of ϕ ) . If A 7→ ψ ( x, A ) is C k and s is C k , then for e ach fixe d x ∈ X the map M 7→ ϕ ( x, M ) is C k on M . Pr o of. Fix x ∈ X and define ψ x : U → R p b y ψ x ( A ) : = ψ ( x, A ). By assumption, ψ x is a C k map on U , and s is C k on M . Hence ϕ x : M → R p giv en b y ϕ x ( M ) : = ϕ ( x, M ) = ψ x s ( M ) is the comp osition ϕ x = ψ x ◦ s of t wo C k maps betw een smo oth manifolds, and is therefore C k . 37 Gauge transformations. If s ′ is another C k lift on M , then for each M ∈ M there exists a unique g ( M ) ∈ G such that s ′ ( M ) = g ( M ) · s ( M ). The map M 7→ g ( M ) is C k . Lemma C.4 (Gauge transformation rule) . If ϕ and ϕ ′ ar e induc e d by lifts s and s ′ r esp e ctively, then ϕ ′ ( x, M ) = ρ ( g ( M )) ϕ ( x, M ) , x ∈ X , M ∈ M . Pr o of. By equiv ariance, ϕ ′ ( x, M ) = ψ ( x, s ′ ( M )) = ψ ( x, g ( M ) · s ( M )) = ρ ( g ( M )) ϕ ( x, M ) . In trinsic meaning. The in trinsic ob ject is the bundle section Φ x . Cho osing a lift s iden tifies eac h fiber with R p and yields the co ordinate represen tation ϕ ( x, M ). Differen t lifts correspond to orthogonal changes of coordinates. C.2.4 Orbit-in v ariance of minim um-norm OLS The proof of Lemma 4.2 in the main text follo ws directly from orthogonal equiv ariance and is given b elo w for completeness. Pr o of of L emma 4.2 . Fix a downstream dataset D ( n ) down = { ( x i , y i ) } n i =1 and write Y : = ( y 1 , . . . , y n ) ⊤ ∈ R n . F or any w ∈ R q 0 , define the design matrix Ψ w ∈ R n × p b y (Ψ w ) i, : : = ψ ( x i , w ) ⊤ . The minimum Euclidean norm solution of the OLS problem is giv en b y ˆ θ w = Ψ + w Y , where ( · ) + denotes the Moore–Penrose pseudoinv erse. By the orthogonal equiv ariance condition ( 4.4 ), for any g ∈ G and each i , ψ ( x i , g · w ) ⊤ = ( ρ ( g ) ψ ( x i , w )) ⊤ = ψ ( x i , w ) ⊤ ρ ( g ) ⊤ . Therefore, Ψ g · w = Ψ w ρ ( g ) ⊤ . F or an y matrix M ∈ R n × p and any orthogonal matrix Q ∈ O ( p ), ( M Q ) + = Q ⊤ M + . Applying this iden tity with M = Ψ w and Q = ρ ( g ) ⊤ yields ˆ θ g · w = Ψ + g · w Y = (Ψ w ρ ( g ) ⊤ ) + Y = ρ ( g )Ψ + w Y = ρ ( g ) ˆ θ w . F or an y x ∈ X , ˆ f g · w ( x ) = ⟨ ˆ θ g · w , ψ ( x, g · w ) ⟩ = ⟨ ρ ( g ) ˆ θ w , ρ ( g ) ψ ( x, w ) ⟩ = ⟨ ˆ θ w , ψ ( x, w ) ⟩ = ˆ f w ( x ) , where we used the orthogonality of ρ ( g ) in the third equalit y . This sho ws that the minimum-norm do wnstream predictor dep ends on w only through its orbit [ w ]. 38 D Pro of of Prop osition 5.2 Recall the do wnstream regression mo del in Equation ( 3.1 ) Y = f ⋆ ( X ) + ε, X ∼ µ down , E [ ε | X ] = 0 , σ 2 : = E [ ε 2 | X ] < ∞ . Let { ( x i , y i ) } n i =1 b e i.i.d. copies of ( X , Y ) and write D ( n ) down = { ( x i , y i ) } n i =1 for the labeled sample and X 1: n = ( x 1 , . . . , x n ) for the downstream design. Let ( X new , Y new ) be an independent copy of ( X , Y ). Define ε i : = y i − f ⋆ ( x i ) for i ∈ [ n ] and ε new : = Y new − f ⋆ ( X new ). Manifold-v alued feature parameters and quenc hed conditioning. In the main text, the feature parameter i s learned in pre-training: Ω = ˆ Ω m ( D ( m ) pre ), and Ω ma y tak e v alues on a Riemannian manifold M . All iden tities b elo w are deterministic once ( D ( m ) pre , X 1: n ) is fixed, because conditioning on D ( m ) pre freezes Ω, and conditioning on X 1: n freezes the empirical pro jection operator Π Ω ,n . This viewp oin t isolates the do wnstream lab el noise and the fresh test pair randomness, without av eraging o ver pre-training and do wnstream design. D.1 Empirical pro jection notation Recall the empirical inner product ⟨ g , h ⟩ n = 1 n n X i =1 g ( x i ) h ( x i ) . Let H Ω = { T Ω θ : θ ∈ R p } denote the induced linear class and Π Ω ,n b e the Mo ore–P enrose empirical least-squares map defined in Appendix A (Definition A.7 ). W e will inv ok e the following prop erties (Lemma A.8 and Lemma A.9 ): for an y g with finite ev aluations on { x i } n i =1 , 1. Π Ω ,n g ∈ H Ω and ⟨ g − Π Ω ,n g , h ⟩ n = 0 for all h ∈ H Ω ; 2. Ev n (Π Ω ,n h ) = Ev n ( h ) for all h ∈ H Ω (equiv alently , ∥ h − Π Ω ,n h ∥ n = 0). When ⟨· , ·⟩ n is non-degenerate on H Ω (equiv alently , Ev n is injective on H Ω ), these prop erties imply Π Ω ,n h = h for all h ∈ H Ω , i.e. Π Ω ,n is the unique empirical orthogonal pro jector on to H Ω . OLS as empirical pro jection. Let ˆ θ Ω ,n b e the minimum-norm OLS solution and set ˆ f Ω ,n = T Ω ˆ θ Ω ,n . W rite the sample-v alue vectors y 1: n : = ( y 1 , . . . , y n ) ⊤ , ε 1: n : = ( ε 1 , . . . , ε n ) ⊤ , f ⋆, 1: n : = f ⋆ ( x 1 ) , . . . , f ⋆ ( x n ) ⊤ , so that y 1: n = f ⋆, 1: n + ε 1: n . By Lemma A.11 , ˆ f Ω ,n = Π Ω ,n lift n ( y 1: n ) . By linearity of Π Ω ,n and y 1: n = f ⋆, 1: n + ε 1: n , ˆ f Ω ,n = Π Ω ,n f ⋆ + Π Ω ,n lift n ( ε 1: n ) . (D.1) F or brevit y , we will write Π Ω ,n ε instead of Π Ω ,n lift n ( ε 1: n ), with the understanding that this means applying Π Ω ,n to any measurable represen tative whose ev aluations on { x i } n i =1 equal ε 1: n . 39 D.2 P opulation decomp osition and orthogonality Recall the population pro jector Π Ω = T Ω Σ(Ω) + T adj Ω on to H Ω in L 2 ( µ down ) and define e Ω : = ( I − Π Ω ) f ⋆ , Rep(Ω) : = ∥ e Ω ∥ 2 L 2 ( µ down ) . Since Π Ω is the L 2 ( µ down )-orthogonal pro jector onto H Ω , we hav e e Ω ⊥ H Ω in L 2 ( µ down ) , i.e. ⟨ e Ω , h ⟩ L 2 ( µ down ) = 0 ∀ h ∈ H Ω . W e will use the decomposition f ⋆ = Π Ω f ⋆ + e Ω . (D.2) D.3 Exact risk decomp osition conditional on ( D ( m ) pre , X 1: n ) W e no w restate and pro v e Proposition 5.2 . Prop osition 5.2 (Exact conditional risk decomp osition) . F or the minimum-norm OLS pr e dictor ˆ f Ω ,n , the c onditional test risk admits the de c omp osition: E h Y new − ˆ f Ω ,n ( X new ) 2 D ( m ) pre , X 1: n i = σ 2 + Rep(Ω) + E h Π Ω ,n f ⋆ − Π Ω f ⋆ ( X new ) 2 D ( m ) pre , X 1: n i | {z } =: Leak age n (Ω) + σ 2 n tr(Σ(Ω)Σ n (Ω) + ) | {z } =: V ar n (Ω) . (5.1) Pr o of. Start from the identit y Y new = f ⋆ ( X new ) + ε new and write Y new − ˆ f Ω ,n ( X new ) = ε new + f ⋆ − ˆ f Ω ,n ( X new ) . Using ( D.1 ), we ha ve ˆ f Ω ,n = Π Ω ,n f ⋆ + Π Ω ,n ε. Substituting and then adding and subtracting Π Ω f ⋆ yields Y new − ˆ f Ω ,n ( X new ) = ε new + f ⋆ − Π Ω ,n f ⋆ − Π Ω ,n ε ( X new ) = ε new + ( f ⋆ − Π Ω f ⋆ ) − (Π Ω ,n f ⋆ − Π Ω f ⋆ ) − Π Ω ,n ε ( X new ) = ε new + e Ω − (Π Ω ,n f ⋆ − Π Ω f ⋆ ) − Π Ω ,n ε ( X new ) , (D.3) where in the last step we used ( D.2 ). Square ( D.3 ) and take conditional exp ectation giv en ( D ( m ) pre , X 1: n ): E h Y new − ˆ f Ω ,n ( X new ) 2 D ( m ) pre , X 1: n i = E h ε 2 new D ( m ) pre , X 1: n i + E h e Ω − (Π Ω ,n f ⋆ − Π Ω f ⋆ ) − Π Ω ,n ε ( X new ) 2 D ( m ) pre , X 1: n i + 2 E h ε new e Ω − (Π Ω ,n f ⋆ − Π Ω f ⋆ ) − Π Ω ,n ε ( X new ) D ( m ) pre , X 1: n i . (D.4) 40 Cross term with ε new . Condition on ( D ( m ) pre , X 1: n , X new , ε 1: n ). The brac keted term in ( D.4 ) ev aluated at X new is measurable with resp ect to ( D ( m ) pre , X 1: n , X new , ε 1: n ), while E [ ε new | X new ] = 0. Therefore, we hav e E h ε new e Ω − (Π Ω ,n f ⋆ − Π Ω f ⋆ ) − Π Ω ,n ε ( X new ) D ( m ) pre , X 1: n i = E " E h ε new e Ω − (Π Ω ,n f ⋆ − Π Ω f ⋆ ) − Π Ω ,n ε ( X new ) X new , ε 1: n i D ( m ) pre , X 1: n # = E " E [ ε new | X new , ε 1: n ] e Ω − (Π Ω ,n f ⋆ − Π Ω f ⋆ ) − Π Ω ,n ε ( X new ) D ( m ) pre , X 1: n # = 0 . Since ( X new , ε new ) is an indep enden t cop y of ( X, ε ) and is independent of ( D ( m ) pre , X 1: n , ε 1: n ), E h ε 2 new D ( m ) pre , X 1: n i = E [ ε 2 ] = σ 2 . Set g : = Π Ω ,n f ⋆ − Π Ω f ⋆ ∈ H Ω , u : = Π Ω ,n ε ∈ H Ω . Then p oint wise, ( e Ω − g − u ) 2 = e 2 Ω + g 2 + u 2 − 2 e Ω g − 2 e Ω u + 2 g u. Ev aluating at X new and taking E [ · | D ( m ) pre , X 1: n ] gives E h ( e Ω − g − u )( X new ) 2 D ( m ) pre , X 1: n i = E h e Ω ( X new ) 2 D ( m ) pre , X 1: n i + E h g ( X new ) 2 D ( m ) pre , X 1: n i − 2 ⟨ e Ω , g ⟩ L 2 ( µ down ) − 2 ⟨ e Ω , u ⟩ L 2 ( µ down ) + 2 E h g ( X new ) u ( X new ) D ( m ) pre , X 1: n i + E h u ( X new ) 2 D ( m ) pre , X 1: n i . (D.5) Orthogonalit y kills the e Ω cross terms. Since g , u ∈ H Ω and e Ω ⊥ H Ω in L 2 ( µ down ), we hav e ⟨ e Ω , g ⟩ L 2 ( µ down ) = ⟨ e Ω , u ⟩ L 2 ( µ down ) = 0 . The remaining cross term a v erages to zero. Condition on ( D ( m ) pre , X 1: n , X new ). Giv en ( D ( m ) pre , X 1: n ), the function g is deterministic (b ecause Ω is D ( m ) pre -measurable and Π Ω ,n dep ends only on (Ω , X 1: n )), while u = Π Ω ,n ε is linear in the noise v ector ε 1: n . Using E [ ε 1: n | X 1: n ] = 0 and indep endence of D ( m ) pre from the do wnstream noise, w e obtain E h u ( X new ) D ( m ) pre , X 1: n , X new i = 0 , and hence E h g ( X new ) u ( X new ) D ( m ) pre , X 1: n , X new i = 0 . Therefore, E h g ( X new ) u ( X new ) D ( m ) pre , X 1: n i = 0 . 41 Conclusion. Using E [ e Ω ( X new ) 2 ] = ∥ e Ω ∥ 2 L 2 ( µ down ) = Rep (Ω) in ( D.5 ) and substituting in to ( D.4 ) yields ( 5.1 ). D.4 W ell-p osedness sp ecialization Corollary D.1 (W ell-p osedness implies Π Ω ,n f ⋆ − Π Ω f ⋆ = Π Ω ,n f Ω ) . Assume ⟨· , ·⟩ n is non-de gener ate on H Ω (e quivalently, Ev n is inje ctive on H Ω ). Then Π Ω ,n h = h for al l h ∈ H Ω , and ther efor e Π Ω ,n f ⋆ − Π Ω f ⋆ = Π Ω ,n e Ω . Conse quently, ( 5.1 ) r e duc es to E h Y new − ˆ f Ω ,n ( X new ) 2 D ( m ) pre , X 1: n i = E [ ε 2 ] + Rep(Ω) + E h (Π Ω ,n e Ω )( X new ) 2 D ( m ) pre , X 1: n i + E h (Π Ω ,n ε )( X new ) 2 D ( m ) pre , X 1: n i . Pr o of. Under the stated condition, Π Ω ,n h = h holds for all h ∈ H Ω . Since Π Ω f ⋆ ∈ H Ω and f ⋆ = Π Ω f ⋆ + e Ω , we hav e Π Ω ,n f ⋆ = Π Ω ,n (Π Ω f ⋆ + e Ω ) = Π Ω ,n (Π Ω f ⋆ ) + Π Ω ,n e Ω = Π Ω f ⋆ + Π Ω ,n e Ω , whic h implies Π Ω ,n f ⋆ − Π Ω f ⋆ = Π Ω ,n e Ω . Substituting this identit y into ( 5.1 ) giv es the claimed form ula. Bridge to the Riemannian log-map CL T. In the main text w e set Ω = ˆ Ω m ( D ( m ) pre ) ∈ M . The conditional risk is R ( D ( m ) pre , X 1: n ) = E h Y new − ˆ f ˆ Ω m ,n ( X new ) 2 D ( m ) pre , X 1: n i , whic h is obtained by substituting Ω = ˆ Ω m in to ( 5.1 ) . The Riemannian structure en ters when analyzing the fluctuations of ˆ Ω m around Ω ⋆ through the log map: under the assumptions stated in the main text, √ m log Ω ⋆ ( ˆ Ω m ) d ⇝ Z , Z ∼ N (0 , V ) in T Ω ⋆ M . Since the decomposition ( 5.1 ) holds conditionally on ( D ( m ) pre , X 1: n ) for eac h m, n , one can com bine this log-map CL T with a delta-metho d argument for the map Ω 7→ R ( D ( m ) pre , X 1: n ) in a normal neigh b orho od of Ω ⋆ , without taking exp ectations ov er D ( m ) pre . E Pro of of Theorem 5.3 E.1 Do wnstream estimation terms This section studies the tw o do wnstream estimation terms that appear in the exact conditional risk decomp osition (Prop osition 5.2 ) where b oth the pre-training and do wnstream sample sizes diverge with an asymptotic constan t rate m n → α ∈ (0 , ∞ ). Throughout we work on a coupled probability space supp orting three m utually independent ob jects: (i) An i.i.d. pre-training sequence ( Z pre j ) j ⩾ 1 , 42 (ii) An i.i.d. downstream sequence ( X i , ε i ) i ⩾ 1 with X i ∼ µ down and E [ ε i | X i ] = 0, (iii) An independent test co v ariate X new ∼ µ down (and an independent noise ε new ) F or eac h m , define the pre-training dataset D ( m ) pre : = ( Z pre 1 , . . . , Z pre m ) and the feature parameter Ω m : = ˆ Ω m D ( m ) pre . W e allo w the pretraining sample size to depend on the downstream sample size: Fix α ∈ (0 , ∞ ). F or eac h n let m : = ⌊ αn ⌋ . Then m → ∞ and m/n → α as n → ∞ . Conditioning con v ention. All conditional exp ectations in this app endix are tak en given D ( m ) pre (and, when appropriate, given X 1: n as w ell). Once w e condition on D ( m ) pre , Ω m is fixed, and the do wnstream sample ( X i , ε i ) n i =1 remains i.i.d. and indep enden t of D ( m ) pre . E.1.1 Estimation terms and the compatible regime The conditional risk at stage n is R ( D ( m ) pre , X 1: n ) : = E h Y new − ˆ f Ω m ,n ( X new ) 2 D ( m ) pre , X 1: n i . Recall from Proposition 5.2 that the tw o do wnstream estimation terms are V ar n : = E h Π Ω m ,n ε ( X new ) 2 D ( m ) pre , X 1: n i , (E.1) Leak age n : = E h Π Ω m ,n f ⋆ − Π Ω m f ⋆ ( X new ) 2 D ( m ) pre , X 1: n i . (E.2) Here Π Ω m is the p opulation L 2 ( µ down ) pro jector onto H Ω m and Π Ω m ,n is the canonical empirical pro jector from App endix A (Definition A.7 ). Define the p opulation residual e Ω : = ( I − Π Ω ) f ⋆ , so that e Ω ⊥ H Ω in L 2 ( µ down ). Under the w ell-p osedness condition in Assumption E.3 (stated below), one has Π Ω m ,n f ⋆ − Π Ω m f ⋆ = Π Ω m ,n e Ω m , (E.3) and hence Leak age n reduces to a residual-leak age term. Compatible limit. In the main theorem w e w ork in the c omp atible regime where f ⋆ ∈ H Ω ⋆ for the limit feature parameter Ω ⋆ , equiv alen tly e Ω ⋆ = ( I − Π Ω ⋆ ) f ⋆ = 0 . (E.4) As a consequence, once Ω m → Ω ⋆ in probabilit y , w e will show that the signal estimation term Leak age n v anishes at the scale n . 43 E.1.2 Setup and standing regularit y (triangular array) F or eac h n , define the p opulation and empirical cov ariances Σ m : = Σ(Ω m ) : = E h ϕ ( X , Ω m ) ϕ ( X , Ω m ) ⊤ D m pre i , Σ m,n : = Σ n (Ω m ) : = 1 n n X i =1 ϕ ( X i , Ω m ) ϕ ( X i , Ω m ) ⊤ , where the expectation in Σ m is o ver X ∼ µ down and all quan tities are random through D ( m ) pre (and, for Σ m,n , also through X 1: n ). Assumption E.1 (Stable rank and eigengap along (Ω m )) . Ther e exist an inte ger r ∈ { 0 , 1 , . . . , p } and c onstants κ, K < ∞ such that P rank(Σ m ) = r , λ r (Σ m ) ⩾ κ, ∥ Σ m ∥ op ⩽ K → 1 as m → ∞ , wher e λ r (Σ) denotes the smal lest p ositive eigenvalue (the c ondition is vacuous if r = 0 ). Assumption E.2 (Lo cal-uniform momen t bounds near Ω ⋆ ) . Ther e exist δ > 0 , a neighb orho o d U of Ω ⋆ in M , and c onstants C ϕ , C e < ∞ such that sup Ω ∈U E h ∥ ϕ ( X , Ω) ∥ 4+ δ i ⩽ C ϕ . Mor e over, for the signal term, sup Ω ∈U E h e Ω ( X ) 2 ∥ ϕ ( X , Ω) ∥ 2+ δ i ⩽ C e . Assumption E.3 (W ell-p osedness for identifying the leak age term) . With pr ob ability tending to 1 as m → ∞ (under the joint law of ( D ( m ) pre , X 1: n ) ), the empiric al inner pr o duct ⟨· , ·⟩ n is non-de gener ate on H Ω m (e quivalently, the evaluation map on { X i } n i =1 is inje ctive on H Ω m ). On this event, Π Ω m ,n h = h for al l h ∈ H Ω m , and henc e ( E.3 ) holds (App endix D.4 ). Assumption E.4 (Lo cal C 1 regularit y of the feature map in Ω with moment con trol) . Work in normal c o or dinates on a neighb orho o d U of Ω ⋆ . Assume that for µ down -a.e. x , the map Ω 7→ ϕ ( x, Ω) ∈ R p is differ entiable on U . Mor e over, ther e exist δ > 0 (the same δ as in Assumption E.2 ) and a c onstant C ∂ ϕ < ∞ such that sup Ω ∈U E h ∥ D Ω ϕ ( X , Ω) ∥ 4+ δ op i ⩽ C ∂ ϕ , (E.5) wher e D Ω ϕ ( x, Ω) : T Ω M → R p denotes the derivative in normal c o or dinates and ∥ · ∥ op is the op er ator norm. 44 Differen tiabilit y of the p opulation pro jector. In the next results w e v erify that the p opulation L 2 ( µ down )-orthogonal pro jector Π Ω on to the downstream hypothesis class H Ω is F r´ echet differen tiable in Ω near Ω ⋆ . The k ey input is differentiabilit y of the pseudoinv erse on the stable-rank region (Assumption E.1 ). Lemma E.5 (Differentiabilit y of the pseudoin v erse on the stable-rank region) . L et A ≽ 0 b e symmetric with rank ( A ) = r and λ r ( A ) ⩾ κ > 0 . Then the r estriction of the Mo or e–Penr ose map to the stable-r ank r e gion R r,κ : = { B ≽ 0 : B = B ⊤ , rank( B ) = r , λ r ( B ) ⩾ κ } is F r´ echet differ entiable at A (in op er ator norm). Its derivative in dir e ction H is D ( A + )[ H ] = − A + H A + + A +2 H ( I − AA + ) + ( I − A + A ) H A +2 . (E.6) In p articular, ther e exists a c onstant C κ < ∞ dep ending only on κ such that ∥ D ( A + )[ H ] ∥ op ⩽ C κ ∥ H ∥ op . Pr o of. This is a standard result in p erturbation theory . F or the proof see Golub and Pereyra ( 1973 ). Prop osition E.6 (Differentiabilit y of Ω 7→ Π Ω on a constan t-rank region) . Fix Ω ⋆ ∈ M . Assume Assumption E.2 and Assumption E.4 . Assume mor e over that ther e exist an op en neighb orho o d U of Ω ⋆ and c onstants r ∈ { 0 , 1 , . . . , p } and κ > 0 such that for al l Ω ∈ U , rank Σ(Ω) = r , λ r Σ(Ω) ⩾ κ ( vacuous if r = 0) . Then the map Ω 7→ Π Ω is F r´ echet differ entiable at Ω ⋆ as a map into B ( L 2 ( µ down )) (op er ator norm). In p articular, for v ∈ T Ω ⋆ M , Π exp Ω ⋆ ( v ) − Π Ω ⋆ − D Π Ω ⋆ [ v ] op = o ( ∥ v ∥ ) as v → 0 . In the r e gion of differ entiability, the derivative c an b e obtaine d by D Π Ω ⋆ [ v ] g = ( D T Ω ⋆ [ v ]) Σ + ⋆ c ⋆ g + T Ω ⋆ D Σ(Ω ⋆ ) + [ v ] c ⋆ g + T Ω ⋆ Σ + ⋆ D c g (Ω ⋆ )[ v ] . (E.7) Pr o of. Fix v ∈ T Ω ⋆ M and write Ω( v ) : = exp Ω ⋆ ( v ). Throughout w e w ork for ∥ v ∥ small enough so that Ω( v ) ∈ U . By Assumption E.2 , sup Ω ∈U E ∥ ϕ ( X , Ω) ∥ 2 < ∞ , hence T Ω : R p → L 2 ( µ down ) is b ounded for eac h Ω ∈ U and sup Ω ∈U ∥ T Ω ∥ op < ∞ where we define ∥ T Ω ∥ op : = sup ∥ θ ∥ =1 ∥ T Ω θ ∥ L 2 down . W e sho w that Ω 7→ T Ω is F r ´ echet differentiable at Ω ⋆ as a map into B ( R p , L 2 ( µ down )) equipp ed with ∥ · ∥ op , with deriv ativ e ( D T Ω ⋆ [ v ] θ )( x ) = θ ⊤ D Ω ϕ ( x, Ω ⋆ )[ v ] . 45 By Assumption E.4 , for µ down -a.e. x the map Ω 7→ ϕ ( x, Ω) ∈ R p is F r ´ echet differentiable at Ω ⋆ . Equiv alently , there exists a remainder term r ( x, v ) ∈ R p suc h that for all v sufficiently small, ϕ ( x, Ω( v )) = ϕ ( x, Ω ⋆ ) + D Ω ϕ ( x, Ω ⋆ )[ v ] + r ( x, v ) , ∥ r ( x, v ) ∥ ∥ v ∥ → 0 as v → 0 . (E.8) T o upgrade ( E.8 ) to an L 2 statemen t we need an in tegrable domination. By the moment domination part of Assumption E.2 (together with Assumption E.4 ), there exists δ > 0 and an in tegrable en v elop e G ∈ L 2 ( µ down ) such that for all ∥ v ∥ ⩽ δ , ϕ ( x, Ω( v )) − ϕ ( x, Ω ⋆ ) − D Ω ϕ ( x, Ω ⋆ )[ v ] ∥ v ∥ ⩽ G ( x ) for µ down -a.e. x. (E.9) (Concretely , one may tak e G ( x ) = sup Ω ∈U ∥ D Ω ϕ ( x, Ω) ∥ op on a sufficien tly small neighborho o d U of Ω ⋆ , and Assumption E.2 ensures G ∈ L 2 .) Com bining ( E.8 )–( E.9 ) and dominated conv ergence yields ∥ ϕ ( · , Ω( v )) − ϕ ( · , Ω ⋆ ) − D Ω ϕ ( · , Ω ⋆ )[ v ] ∥ L 2 ( µ down ; R p ) = o ( ∥ v ∥ ) . (E.10) F or an y θ ∈ R p with ∥ θ ∥ 2 = 1, using ( E.10 ) and Cauc hy–Sc h warz giv es T Ω( v ) − T Ω ⋆ − D T Ω ⋆ [ v ] θ L 2 = θ ⊤ ( ϕ ( · , Ω( v )) − ϕ ( · , Ω ⋆ ) − D Ω ϕ ( · , Ω ⋆ )[ v ]) L 2 ⩽ ∥ ϕ ( · , Ω( v )) − ϕ ( · , Ω ⋆ ) − D Ω ϕ ( · , Ω ⋆ )[ v ] ∥ L 2 ( µ down ; R p ) = o ( ∥ v ∥ ) . T aking the suprem um o v er ∥ θ ∥ 2 = 1 yields ∥ T Ω( v ) − T Ω ⋆ − D T Ω ⋆ [ v ] ∥ op = o ( ∥ v ∥ ) , whic h is the claimed F r´ ec het differen tiability in op erator norm. Fix g ∈ L 2 ( µ down ) and define c g (Ω) : = E [ ϕ ( X , Ω) g ( X )] ∈ R p . By Cauch y–Sc hw arz and Assumption E.2 , sup Ω ∈U ∥ c g (Ω) ∥ ≲ ∥ g ∥ L 2 down since ∥ c g (Ω) ∥ ⩽ ( E [ ϕ ( X , Ω) 2 ]) 1 2 ( E [ g ( X ) 2 ]) 1 2 . Next, Dominated con vergence again gives ∥ c g (Ω( v )) − c g (Ω ⋆ ) − D c g (Ω ⋆ )[ v ] ∥ = o ( ∥ v ∥ ) , D c g (Ω ⋆ )[ v ] = E [ D Ω ϕ ( X , Ω ⋆ )[ v ] g ( X )] . Similarly , Ω 7→ Σ(Ω) = E [ ϕ ( X, Ω) ϕ ( X , Ω) ⊤ ] is F r ´ echet differen tiable at Ω ⋆ , with ∥ Σ(Ω( v )) − Σ(Ω ⋆ ) − D Σ(Ω ⋆ )[ v ] ∥ op = o ( ∥ v ∥ ) , where D Σ(Ω ⋆ )[ v ] = E h D Ω ϕ ( X , Ω ⋆ )[ v ] ϕ ⋆ ( X ) ⊤ + ϕ ⋆ ( X ) D Ω ϕ ( X , Ω ⋆ )[ v ] ⊤ i . 46 By the stable-rank h yp othesis on U , for all Ω ∈ U w e ha ve rank (Σ(Ω)) = r and λ r (Σ(Ω)) ⩾ κ (v acuous if r = 0), hence sup Ω ∈U ∥ Σ(Ω) + ∥ op ⩽ 1 /κ . Applying Lemma E.5 at A = Σ ⋆ giv es ∥ Σ(Ω( v )) + − Σ + ⋆ − D Σ(Ω ⋆ ) + [ v ] ∥ op = o ( ∥ v ∥ ) , where D Σ(Ω ⋆ ) + [ v ] : = D (Σ + ⋆ )[ D Σ(Ω ⋆ )[ v ]]. F or an y g ∈ L 2 ( µ down ), we hav e Π Ω g = T Ω Σ(Ω) + c g (Ω) . W rite ∆ T : = T Ω( v ) − T Ω ⋆ , ∆Σ + : = Σ(Ω( v )) + − Σ + ⋆ , and ∆ c : = c g (Ω( v )) − c g (Ω ⋆ ). Then Π Ω( v ) g − Π Ω ⋆ g = (∆ T ) Σ(Ω( v )) + c g (Ω( v )) + T Ω ⋆ (∆Σ + ) c g (Ω( v )) + T Ω ⋆ Σ + ⋆ (∆ c ) whic h can b e written as Π Ω( v ) g − Π Ω ⋆ g − D Π Ω ⋆ [ v ] g = R 1 ( v ) g + R 2 ( v ) g + R 3 ( v ) g , where D Π Ω ⋆ [ v ] g = ( D T Ω ⋆ [ v ]) Σ + ⋆ c ⋆ g + T Ω ⋆ D Σ(Ω ⋆ ) + [ v ] c ⋆ g + T Ω ⋆ Σ + ⋆ D c g (Ω ⋆ )[ v ] , R 1 ( v ) g : = ∆ T − D T Ω ⋆ [ v ] Σ(Ω( v )) + c g (Ω( v )) , R 2 ( v ) g : = T Ω ⋆ ∆Σ + − D Σ(Ω ⋆ ) + [ v ] c g (Ω( v )) , R 3 ( v ) g : = T Ω ⋆ Σ + ⋆ ∆ c − D c g (Ω ⋆ )[ v ] . Next, b ecause of the differentiabilit y of T , Σ + , and c g (Ω), we hav e ∥ ∆ T − D T Ω ⋆ [ v ] ∥ op = o ( ∥ v ∥ ) and ∥ ∆Σ + − D Σ(Ω ⋆ ) + [ v ] ∥ op = o ( ∥ v ∥ ), while ∥ ∆ c − D c g (Ω ⋆ )[ v ] ∥ = o ( ∥ v ∥ ). Moreov er, on U w e ha ve uniform bounds sup Ω ∈U ∥ T Ω ∥ op < ∞ , sup Ω ∈U ∥ Σ(Ω) + ∥ op ⩽ 1 /κ , and sup Ω ∈U ∥ c g (Ω) ∥ ≲ ∥ g ∥ L 2 . Therefore, ∥ R 1 ( v ) g ∥ L 2 + ∥ R 2 ( v ) g ∥ L 2 + ∥ R 3 ( v ) g ∥ L 2 = o ( ∥ v ∥ ) ∥ g ∥ L 2 . T aking the suprem um o v er ∥ g ∥ L 2 ⩽ 1 yields ∥ Π Ω( v ) − Π Ω ⋆ − D Π Ω ⋆ [ v ] ∥ op = o ( ∥ v ∥ ) , whic h is exactly F r ´ ec het differen tiability at Ω ⋆ in op erator norm. Corollary E.7 (Compatible limit implies v anishing residual) . Assume ther e exists Ω ⋆ such that Ω m → Ω ⋆ in pr ob ability and f ⋆ ∈ H Ω ⋆ (e quivalently, Π Ω ⋆ f ⋆ = f ⋆ in L 2 ( µ down ) ). Assume mor e over that the p opulation pr oje ctor map Ω 7→ Π Ω is c ontinuous at Ω ⋆ in op er ator norm, i.e. ∥ Π Ω − Π Ω ⋆ ∥ op → 0 as Ω → Ω ⋆ , wher e ∥ · ∥ op denotes the op er ator norm on B ( L 2 ( µ down )) . Then ∥ e Ω m ∥ L 2 ( µ down ) = ∥ ( I − Π Ω m ) f ⋆ ∥ L 2 ( µ down ) → 0 in pr ob ability. 47 Pr o of. Since f ⋆ ∈ H Ω ⋆ , we hav e Π Ω ⋆ f ⋆ = f ⋆ , hence e Ω m = ( I − Π Ω m ) f ⋆ = (Π Ω ⋆ − Π Ω m ) f ⋆ . Therefore, ∥ e Ω m ∥ L 2 ( µ down ) ⩽ ∥ Π Ω m − Π Ω ⋆ ∥ op ∥ f ⋆ ∥ L 2 ( µ down ) . By the assumed con tin uity of Ω 7→ Π Ω at Ω ⋆ and the conv ergence Ω m → Ω ⋆ in probabilit y , we ha ve ∥ Π Ω m − Π Ω ⋆ ∥ op → 0 in probability , whic h implies the claim. Remark E.8. In view of Pr op osition E.6 , if Ω 7→ Π Ω is F r´ echet differ entiable at Ω ⋆ in op er ator norm (e.g. on the r ank-stable str atum with a C 1 fe atur e map in Ω and the lo c al-uniform moment b ounds), then the op er ator-norm c ontinuity r e quir e d ab ove holds automatic al ly. E.1.3 Tw o p erturbation lemmas for pseudoinv erses Lemma E.9 (Empirical span is contained in the p opulation span) . Fix m and c ondition on D ( m ) pre . Assume E [ ∥ ϕ ( X , Ω m ) ∥ 2 | D ( m ) pre ] < ∞ , so that Σ m is wel l-define d. L et S : = Im (Σ m ) . Then ϕ ( X , Ω m ) ∈ S almost sur ely. In p articular, Im (Σ m,n ) ⊆ S and rank (Σ m,n ) ⩽ rank (Σ m ) almost sur ely. Pr o of. Let K : = k er(Σ m ) and let v be an y unit v ector in K . Then 0 = v ⊤ Σ m v = E h ( v ⊤ ϕ ( X , Ω m )) 2 i , so v ⊤ ϕ ( X , Ω m ) = 0 almost surely . Hence ϕ ( X , Ω m ) ∈ K ⊥ = Im (Σ m ) almost surely . Applying the same argument to eac h X i yields the claims for Σ m,n . Lemma E.10 (Rank stabilit y and Lipsc hitz con trol for the pseudoin verse) . Assume Assumption E.2 . Fix m and c ondition on D ( m ) pre . L et R m : = n rank(Σ m ) = r , λ r (Σ m ) ⩾ κ o . On the event R m ∩ {∥ Σ m,n − Σ m ∥ op ⩽ κ/ 2 } , almost sur ely: (i) rank(Σ m,n ) = rank(Σ m ) = r and Im(Σ m,n ) = Im(Σ m ) ; (ii) ∥ Σ + m,n ∥ op ⩽ 2 /κ ; (iii) ∥ Σ + m,n − Σ + m ∥ op ⩽ 2 κ 2 ∥ Σ m,n − Σ m ∥ op Pr o of. Assume R m and ∥ Σ m,n − Σ m ∥ op ⩽ κ/ 2. By W eyl’s inequality , λ r (Σ m,n ) ⩾ λ r (Σ m ) − ∥ Σ m,n − Σ m ∥ op ⩾ κ/ 2 , so rank (Σ m,n ) ⩾ r . On the other hand, Lemma E.9 giv es Im (Σ m,n ) ⊆ Im (Σ m ) almost surely , hence rank(Σ m,n ) ⩽ r . Therefore rank(Σ m,n ) = r , and since Im(Σ m,n ) ⊆ Im(Σ m ) with equal dimension, Im(Σ m,n ) = Im(Σ m ) =: S. 48 This pro ves (i). F or (ii), on S the matrix Σ m,n is in vertible and λ min (Σ m,n | S ) = λ r (Σ m,n ) ⩾ κ/ 2, so ∥ (Σ m,n | S ) − 1 ∥ op ⩽ 2 /κ . Since Σ + m,n coincides with (Σ m,n | S ) − 1 on S and is 0 on S ⊥ , (ii) follo ws. F or (iii), on S , (Σ m,n | S ) − 1 − (Σ m | S ) − 1 = (Σ m,n | S ) − 1 (Σ m | S − Σ m,n | S ) (Σ m | S ) − 1 . T aking operator norms and using ∥ (Σ m,n | S ) − 1 ∥ op ⩽ 2 /κ and ∥ (Σ m | S ) − 1 ∥ op ⩽ 1 /κ yields the stated b ound, which extends to R p since b oth pseudoin verses v anish on S ⊥ . Lemma E.11 (Op erator-norm consistency of Σ m,n (fixed p )) . Assume Assumption E.2 and let n → ∞ . Then ∥ Σ m,n − Σ m ∥ op P − → 0 . Pr o of. The claim is a standard consequence of matrix La w of Large Num b ers for sample co v ariance matrices (in fixed dimension) under the momen t condition in Assumption E.2 ; see, e.g., V ersh ynin ( 2018 ). Fix ε > 0. Condition on D ( m ) pre , so that Ω m and n are fixed and X 1 , . . . , X n are i.i.d. with la w µ down . W rite Σ m,n − Σ m = 1 n P n i =1 U m,i with U m,i : = ϕ ( X i , Ω m ) ϕ ( X i , Ω m ) ⊤ − E h ϕ ( X , Ω m ) ϕ ( X , Ω m ) ⊤ i . F or each entry ( j, k ), let U ( j k ) m,i b e the ( j, k ) entry of U m,i . Then E [ U ( j k ) m,i | D ( m ) pre ] = 0 and, by Assumption E.2 , there is a constant C < ∞ such that on the high-probabilit y ev ent { Ω m ∈ U } , E h ( U ( j k ) m, 1 ) 2 D ( m ) pre i ⩽ C . Hence, still on { Ω m ∈ U } , Chebyshev gives P 1 n n X i =1 U ( j k ) m,i > ε p D ( m ) pre ! ⩽ C p 2 n ε 2 . T aking a union b ound o ver the p 2 en tries yields P ∥ Σ m,n − Σ m ∥ F > ε D ( m ) pre ⩽ C p 4 n ε 2 on { Ω m ∈ U } . Since ∥ · ∥ op ⩽ ∥ · ∥ F , the same b ound holds for the operator norm. Now uncondition: P ( ∥ Σ m,n − Σ m ∥ op > ε ) ⩽ P (Ω m / ∈ U ) + E C p 4 n ε 2 . Because Ω m → Ω ⋆ in probability , P (Ω m / ∈ U ) → 0 for an y neighborho o d U of Ω ⋆ . Also, n → ∞ in probabilit y implies 1 /n → 0 in probabilit y , and since 0 ⩽ 1 /n ⩽ 1, we ha ve E [1 /n ] → 0. Therefore the right-hand side tends to 0, pro ving the claim. Lemma E.12 (Effective dimension stabilizes) . Assume Assumption E.1 . Then d eff (Ω m ) = tr(Σ m Σ + m ) = rank(Σ m ) = rank(Σ(Ω ⋆ )) = d eff (Ω ⋆ ) with pr ob ability tending to one as m → ∞ . Pr o of. By Assumption E.1 , rank (Σ m ) = r with probabilit y tending to one. Since Ω m → Ω ⋆ in probabilit y , and on the ev ent in Assumption E.1 the eigengap λ r (Σ m ) ⩾ κ prev ents rank c hanges in a neigh b orho o d. In particular, rank (Σ(Ω ⋆ )) = r and hence d eff (Ω m ) = d eff (Ω ⋆ ) = r with probabilit y tending to one. 49 E.1.4 Noise estimation term Lemma E.13 (Closed form for the noise term) . F or e ach m , V ar n = σ 2 n tr Σ m Σ + m,n . Pr o of. Fix n and condition on ( D ( m ) pre , X 1: n , X new ). By Definition A.7 (App endix A ), Π Ω m ,n ε = T Ω m ˆ θ ε , ˆ θ ε = Σ + m,n 1 n n X i =1 ε i ϕ ( X i , Ω m ) . Let g m : = 1 n P n i =1 ε i ϕ ( X i , Ω m ), so ˆ θ ε = Σ + m,n g m and (Π Ω m ,n ε )( X new ) = ϕ ( X new , Ω m ) ⊤ Σ + m,n g m . Since E [ ε i | X i ] = 0 and E [ ε 2 i | X i ] = σ 2 , E [ g m g ⊤ m | D ( m ) pre , X 1: n ] = 1 n 2 n X i =1 E [ ε 2 i | X i ] ϕ ( X i , Ω m ) ϕ ( X i , Ω m ) ⊤ = σ 2 n Σ m,n . Therefore, V ar n = E h ϕ ( X new , Ω m ) ⊤ Σ + m,n g m g ⊤ m Σ + m,n ϕ ( X new , Ω m ) D ( m ) pre , X 1: n , X new i = σ 2 n ϕ ( X new , Ω m ) ⊤ Σ + m,n ϕ ( X new , Ω m ) , using Σ + m,n Σ m,n Σ + m,n = Σ + m,n . T aking conditional expectation o ver X new yields V ar m = σ 2 n tr Σ m Σ + m,n . Prop osition E.14 (Noise estimation term) . Assume Assumption E.1 and Assumption E.2 . Then, as n → ∞ , n V ar n P − − → σ 2 d eff (Ω ⋆ ) , d eff (Ω) : = tr Σ(Ω)Σ(Ω) + . Pr o of. By Lemma E.13 , n V ar m = σ 2 tr Σ m Σ + m,n . Let A m : = tr (Σ m Σ + m,n ) and A ⋆ m : = tr (Σ m Σ + m ) = d eff (Ω m ). Define R m : = { rank (Σ m ) = r , λ r (Σ m ) ⩾ κ, ∥ Σ m ∥ op ⩽ K } . On the ev ent R m ∩ E m where E m : = {∥ Σ m,n − Σ m ∥ op ⩽ κ/ 2 } , Lemma E.10 (iii) implies | A m − A ⋆ m | = tr Σ m (Σ + m,n − Σ + m ) ⩽ rank(Σ m ) ∥ Σ m ∥ op ∥ Σ + m,n − Σ + m ∥ op ⩽ 2 r K κ 2 ∥ Σ m,n − Σ m ∥ op . By Assumption E.1 , P ( R m ) → 1. By Lemma E.11 , ∥ Σ m,n − Σ m ∥ op → 0 in probability , hence P ( E m ) → 1 and A m − A ⋆ m → 0 in probability . Multiplying b y σ 2 giv es n V ar m − σ 2 d eff (Ω m ) → 0 in probabilit y . Finally , Lemma E.12 gives d eff (Ω m ) = d eff (Ω ⋆ ) with probability tending to one, which yields n V ar m → σ 2 d eff (Ω ⋆ ) in probabilit y . 50 E.1.5 Leak age Estimation T erm Under Assumption E.3 , ( E.3 ) yields Leak age n = E h Π Ω m ,n e Ω m ( X new ) 2 D ( m ) pre , X 1: n i . Define the (random) p opulation matrix Σ e,m : = Σ e (Ω m ) : = E h e Ω m ( X ) 2 ϕ ( X , Ω m ) ϕ ( X , Ω m ) ⊤ D ( m ) pre i , X ∼ µ down . Lemma E.15 (V anishing signal co v ariance in the compatible limit) . Assume Assumption E.2 and Assumption E.4 . Then tr(Σ e,m ) P − − → 0 . Pr o of. W e ha ve tr(Σ e,m ) = E h e Ω m ( X ) 2 ∥ ϕ ( X , Ω m ) ∥ 2 D ( m ) pre i . By H¨ older with exp onen ts 2+ δ δ and 2+ δ 2 , tr(Σ e,m ) ⩽ E [ e Ω m ( X ) 2 | D ( m ) pre ] δ 2+ δ E [ ∥ ϕ ( X , Ω m ) ∥ 2+ δ | D ( m ) pre ] 2 2+ δ . By C orollary E.7 , E [ e Ω m ( X ) 2 ] → 0 in probabilit y . By Assumption E.2 and ∥ ϕ ∥ 2+ δ ⩽ 1 + ∥ ϕ ∥ 4+ δ , the second factor is bounded in probability . Therefore tr(Σ e,m ) → 0 in probability . Prop osition E.16 (Leak age estimation term) . Assume Assumption E.1 , Assumption E.2 , Assump- tion E.3 , and Assumption E.4 . Then n Leak age n P − − → 0 as n → ∞ . Pr o of. Fix n and condition on ( D ( m ) pre , X 1: n ). Under Assumption E.3 , we ma y write Leak age n = Π Ω m ,n e Ω m = T Ω m Σ + m,n g m , g m : = 1 n n X i =1 e Ω m ( X i ) ϕ ( X i , Ω m ) . Th us (Π Ω m ,n e Ω m )( X new ) = ϕ ( X new , Ω m ) ⊤ Σ + m,n g m , and taking conditional exp ectation ov er X new yields the quadratic form Leak age m = g ⊤ m Σ + m,n Σ m Σ + m,n g m . Therefore n Leak age m = ( √ n g m ) ⊤ B m ( √ n g m ) , B m : = Σ + m,n Σ m Σ + m,n . 51 √ n m g m → 0 in probabilit y . Condition on D ( m ) pre . Then the random vectors W m,i : = e Ω m ( X i ) ϕ ( X i , Ω m ) , i = 1 , . . . , n m , are i.i.d. with conditional mean zero, b y orthogonalit y of e Ω m to H Ω m . Moreo ver, E h ∥ √ n m g m ∥ 2 D ( m ) pre i = tr(Σ e,m ) . Hence, for an y ε > 0, Mark o v’s inequalit y yields P ∥ √ n m g m ∥ > ε D ( m ) pre ⩽ tr(Σ e,m ) ε 2 . Fix δ > 0 and define the ev ent A m : = tr(Σ e,m ) ⩽ δ . Then P ( ∥ √ n m g m ∥ > ε ) ⩽ P ( A c m ) + E h 1 A m P ∥ √ n m g m ∥ > ε D ( m ) pre i ⩽ P (tr(Σ e,m ) > δ ) + δ ε 2 . By Lemma E.15 , tr (Σ e,m ) → 0 in probabilit y , hence the first term v anishes as m → ∞ . Since δ > 0 is arbitrary , letting δ ↓ 0 yields √ n m g m P − − → 0 under the join t la w. On the ev ent R m ∩ E m defined in the proof of Prop osition E.14 , Lemma E.10 (ii) and ∥ Σ m ∥ op ⩽ K imply ∥ B m ∥ op ⩽ ∥ Σ + m,n ∥ 2 op ∥ Σ m ∥ op ⩽ 4 K κ 2 . Since P ( R m ) → 1 by Assumption E.1 and P ( E m ) → 1 by Lemma E.11 , we conclude ∥ B m ∥ op = O P (1). Finally , w e ha ve the following 0 ⩽ n Leak age m ⩽ ∥ B m ∥ op ∥ √ n g m ∥ 2 . The right-hand side con verges to 0 in probabilit y , hence n Leak age m → 0 in probability . E.2 Pretraining fluctuations This app endix studies the effect of pre-training randomness on the r epr esentation term Rep(Ω) : = ∥ ( I − Π Ω ) f ⋆ ∥ 2 L 2 ( µ down ) , where, for any descriptor v alue Ω in the descriptor manifold M , Π Ω denotes the L 2 ( µ down )-orthogonal pro jector on to the do wnstream h yp othesis class H Ω . 52 E.2.1 Main statements W rite e Ω : = ( I − Π Ω ) f ⋆ , Rep(Ω) = ∥ e Ω ∥ 2 L 2 ( µ down ) . Let Ω ⋆ ∈ M denote the population limit descriptor. In the compatible regime, Rep(Ω ⋆ ) = 0 , equiv alently e Ω ⋆ = 0 . (E.11) The leading behavior of Rep (Ω m ) is quadratic in the local estimation error of Ω m around Ω ⋆ . The next proposition giv es the distributional limit at the 1 /m scale. Prop osition E.17 (Represen tation term: distributional limit in the compatible case) . Assume the pr etr aining data satisfies Assumption B.5 Z m : = √ m log Ω ⋆ (Ω m ) d ⇝ Z , Z ∼ N (0 , V ) , in T Ω ⋆ M . Mor e over, assume Assumption E.4 so that Ω 7→ Π Ω b e F r´ echet differ entiable at Ω ⋆ in normal c o or dinates, and define the b ounde d line ar map L : T Ω ⋆ M → L 2 ( µ down ) , L ( v ) : = − D Π Ω ⋆ [ v ] f ⋆ . Then m Rep(Ω m ) d ⇝ ∥L ( Z ) ∥ 2 L 2 ( µ down ) . The next prop osition records the 1 /m expansion in exp ectation. Since the limiting random v ariable has finite mean, it suffices to assume uniform integrabilit y of { m Rep (Ω m ) } to upgrade distributional conv ergence to con vergence of exp ectations. E.2.2 Setup and a sufficien t uniform integrabilit y condition W e w ork on a normal neighborho o d of Ω ⋆ in M (Definition B.1 ). Define v m : = log Ω ⋆ (Ω m ) ∈ T Ω ⋆ M , Z m : = √ m v m . By the Theorem B.7 , Z m d ⇝ Z in T Ω ⋆ M for Z ∼ N (0 , V ). E.2.3 Linearization in normal co ordinates Lemma E.18 (Deterministic first-order remainder b ound) . Assume ( E.11 ) and Assumption E.4 . Then ther e exists a function ω : [0 , ∞ ) → [0 , ∞ ) with ω ( t ) → 0 as t → 0 such that for al l v ∈ T Ω ⋆ M in a neighb orho o d of 0 , e exp Ω ⋆ ( v ) − L ( v ) L 2 ( µ down ) ⩽ ω ( ∥ v ∥ ) ∥ v ∥ . Pr o of. W rite Π ⋆ : = Π Ω ⋆ . By compatibility , Π ⋆ f ⋆ = f ⋆ in L 2 ( µ down ), hence e exp Ω ⋆ ( v ) = ( I − Π exp Ω ⋆ ( v ) ) f ⋆ = − (Π exp Ω ⋆ ( v ) − Π ⋆ ) f ⋆ . By Lemma E.6 , Π exp Ω ⋆ ( v ) − Π ⋆ = D Π Ω ⋆ [ v ] + R ( v ) , ∥ R ( v ) ∥ op = o ( ∥ v ∥ ) . 53 Define ω ( t ) : = sup ∥ v ∥ ⩽ t, v =0 ∥ R ( v ) ∥ op ∥ v ∥ , so that ω ( t ) → 0 as t → 0. Then e exp Ω ⋆ ( v ) = − D Π Ω ⋆ [ v ] f ⋆ − R ( v ) f ⋆ = L ( v ) + r ( v ) , r ( v ) : = − R ( v ) f ⋆ . Moreo ver, ∥ r ( v ) ∥ L 2 ( µ down ) ⩽ ∥ R ( v ) ∥ op ∥ f ⋆ ∥ L 2 ( µ down ) ⩽ ω ( ∥ v ∥ ) ∥ v ∥ ∥ f ⋆ ∥ L 2 ( µ down ) . Absorb the constan t ∥ f ⋆ ∥ L 2 ( µ down ) in to ω . E.2.4 Distributional limit of the representation term By Lemma E.18 , e Ω m = e exp Ω ⋆ ( v m ) = L ( v m ) + r ( v m ) , ∥ r ( v m ) ∥ L 2 ( µ down ) ⩽ ω ( ∥ v m ∥ ) ∥ v m ∥ . Multiplying by √ m yields √ m e Ω m = L ( Z m ) + √ m r ( v m ) , ∥ √ m r ( v m ) ∥ L 2 ( µ down ) ⩽ ω ( ∥ v m ∥ ) ∥ Z m ∥ . Lemma E.19 (The linearization remainder is negligible in probabilit y) . Assume A ssumption B.5 and Assumption E.4 . Then ∥ √ m r ( v m ) ∥ L 2 ( µ down ) → 0 in pr ob ability. Pr o of. Since Ω m → Ω ⋆ in probability and v m = log Ω ⋆ (Ω m ) on a normal neigh b orho od, we ha ve ∥ v m ∥ → 0 in probabilit y . Moreov er, ∥ Z m ∥ is tight by the CL T. Fix η > 0 and c ho ose t 0 > 0 such that ω ( t ) ⩽ η for all t ⩽ t 0 . Then ∥ √ m r ( v m ) ∥ L 2 ( µ down ) ⩽ η ∥ Z m ∥ on the ev ent {∥ v m ∥ ⩽ t 0 } . Since P ( ∥ v m ∥ ⩽ t 0 ) → 1 and ∥ Z m ∥ is tigh t, the claim follows. Lemma E.20 (Quadratic appro ximation) . Assume Assumption B.5 and Assumption E.4 . Then m Rep(Ω m ) − ∥L ( Z m ) ∥ 2 L 2 ( µ down ) → 0 in pr ob ability. Pr o of. Expanding the square, m Rep(Ω m ) = ∥ √ m e Ω m ∥ 2 L 2 = ∥L ( Z m ) ∥ 2 L 2 + 2 ⟨L ( Z m ) , √ m r ( v m ) ⟩ L 2 + ∥ √ m r ( v m ) ∥ 2 L 2 . By ( E.6 ) , ∥L ( Z m ) ∥ L 2 ⩽ C L ∥ Z m ∥ , hence ∥L ( Z m ) ∥ L 2 is tight. By Lemma E.19 , ∥ √ m r ( v m ) ∥ L 2 → 0 in probability , which implies b oth the cross term and the squared term v anish in probability . Pr o of of Pr op osition E.17 . By Lemma E.20 , it suffices to iden tify the limit law of ∥L ( Z m ) ∥ 2 L 2 . Since Z m d ⇝ Z in T Ω ⋆ M and z 7→ ∥L ( z ) ∥ 2 L 2 is contin uous, the con tinuous mapping theorem yields ∥L ( Z m ) ∥ 2 L 2 d ⇝ ∥L ( Z ) ∥ 2 L 2 . Com bining with Lemma E.20 giv es the claim. 54 F Pro ofs of Section 6.1 This app endix verifies that the linear sp ectral con trastive mo del of Section 6.1 satisfies the standing assumptions of Theorem 5.3 . Once these c hecks are in place, the corollary follows by a direct in vocation of Theorem 5.3 . W e k eep the v erification mo dular and explicitly p oin t to the app endices where the general results are pro ved: App endix E.1 controls the do wnstream estimation terms and provides the needed p erturbation/differentiabilit y to ols, while Appendix E.2 provides the 1 /m pretraining fluctuation analysis from the manifold CL T for ˆ M m . F.1 Quotien t feature map construction Quotien t feature map ϕ ( x, M ) via a lo cal section. T o express do wnstream prediction purely in quotient co ordinates, we define a feature map that dep ends on the descriptor M ∈ M d,k . Fix a regular point M ⋆ ∈ M d,k and a neighborho o d W ⊂ M d,k of M ⋆ on whic h there exists a C 2 lo c al se ction s : W → R k × d , s ( M ) T s ( M ) = M for all M ∈ W , as constructed in App endix C.2 . W e then define the quotient fe atur e map ϕ ( x, M ) : = s ( M ) x ∈ R k , ( x, M ) ∈ R d × W . (F.1) An y tw o choices of lo cal section differ b y a left-m ultiplication s ′ ( M ) = Q ( M ) s ( M ) with Q ( M ) ∈ O ( k ), hence they generate features related by an orthogonal transform. Concrete lo cal choice of the section s ( M ) . Fix a reference p oint M ⋆ ∈ M d,k and c ho ose an orthonormal basis U ⋆ ∈ R d × k of range ( M ⋆ ) (so U ⊤ ⋆ U ⋆ = I k ). F or M in a sufficiently small neigh b orho od W of M ⋆ , let P ( M ) denote the orthogonal pro jector onto range( M ). Define B ( M ) : = U ⊤ ⋆ P ( M ) U ⋆ ∈ R k × k , U ( M ) : = P ( M ) U ⋆ B ( M ) − 1 / 2 ∈ R d × k , so that U ( M ) ⊤ U ( M ) = I k and range( U ( M )) = range( M ). Next set Λ( M ) : = U ( M ) ⊤ M U ( M ) ∈ R k × k , whic h is p ositiv e definite on W and satisfies M = U ( M )Λ( M ) U ( M ) ⊤ . A concrete lo cal section is then s ( M ) : = Λ( M ) 1 / 2 U ( M ) ⊤ ∈ R k × d , so that s ( M ) ⊤ s ( M ) = M . Consequen tly , the quotient-lev el feature map can b e written explicitly as ϕ ( x, M ) = s ( M ) x = Λ( M ) 1 / 2 U ( M ) ⊤ x ∈ R k . All smo othness claims (existence of W and differentiabilit y of M 7→ s ( M )) are pro ved in Ap- p endix C.2 . 55 F.2 P opulation descriptor problem and regularit y of M ⋆ P opulation loss in descriptor space. The follo wing lemma expresses the population ob jective in terms of M A . Lemma F.1. Assume E ∥ x ∥ 4 < ∞ . Then L spec ( w ) = − 2 tr M Σ + pre + tr ( M Σ pre ) 2 . (F.2) If furthermor e Σ pre is ful l-r ank, then L spec ( w ) = Σ 1 / 2 pre M Σ 1 / 2 pre − C 2 F − ∥ C ∥ 2 F , (F.3) wher e C : = Σ − 1 / 2 pre Σ + pre Σ − 1 / 2 pre . Pr o of. Let Σ : = Σ pre = E [ xx ⊤ ]. W e hav e L spec ( w ) = − 2 E [ x ⊤ M x + ] + E [( x ⊤ M x − ) 2 ] = − 2 tr( E [ M x + x ⊤ ) + tr( E [ M x ( x − ) ⊤ M xx ⊤ ]) = − 2 tr( M Σ + pre ) + tr( M Σ M Σ) whic h pro v es ( F.2 ). If Σ is full rank, write tr ( M Σ) 2 = ∥ Σ 1 / 2 M Σ 1 / 2 ∥ 2 F , tr( M Σ + ) = Σ 1 / 2 M Σ 1 / 2 , C F , with C = Σ − 1 / 2 Σ + Σ − 1 / 2 . Completing the square gives ( F.3 ). Remark F.2. Even though Σ pre and M ar e PSD, the matrix C c an b e indefinite: augmentations may induc e ne gative c orr elations along some dir e ctions. Uniqueness of the descriptor minimizer. By Lemma F.1 , the population minimization in descriptor space reduces to M ⋆ ∈ arg min M ∈M d,k Σ 1 / 2 pre M Σ 1 / 2 pre − C 2 F . (F.4) W e no w state a simple eigengap condition that guarantees uniqueness. Assume throughout Σ pre ≻ 0 and Assumption 6.1 . Recall the whitened matrix C : = Σ − 1 / 2 pre Σ + pre Σ − 1 / 2 pre , and the descriptor manifold M d,k : = { M ≽ 0 : rank ( M ) = k } . Th us, the p opulation minimizer M ⋆ exists, is unique, and satisfies Σ 1 / 2 pre M ⋆ Σ 1 / 2 pre = U k Λ k U ⊤ k , where U k Λ k U ⊤ k is the rank- k truncation onto the top- k p ositive eigenv alues of C . In particular, M ⋆ ∈ M d,k is a regular p oin t of the fixed-rank PSD manifold. Lemma F.3 (Local rank stabilit y for M ⋆ (Assumption E.1 )) . Under Σ pre ≻ 0 and Assumption 6.1 , ther e exists a neighb orho o d U ⊂ M d,k of M ⋆ and c onstants κ ⋆ , K ⋆ ∈ (0 , ∞ ) such that, for al l M ∈ U , rank( M ) = k , λ k ( M ) ⩾ κ ⋆ , ∥ M ∥ op ⩽ K ⋆ . 56 Pr o of. Since M ⋆ ∈ M d,k has k strictly p ositiv e eigen v alues, w e ha v e λ k ( M ⋆ ) > 0. Eigenv alues depend con tinuously on M in operator norm by W eyl’s inequalit y . Hence there exists an operator-norm neigh b orho od U of M ⋆ suc h that λ k ( M ) ⩾ λ k ( M ⋆ ) / 2 for all M ∈ U , whic h implies rank ( M ) = k on U . The operator-norm b ound follo ws similarly by con tinuit y of M 7→ ∥ M ∥ op . Lemma F.3 is the model-sp ecific input needed to place the analysis on the regular stratum, whic h is exactly the regime required in App endix E.1 and App endix E.2 for differen tiability of pro jector-v alued maps and stable-rank pseudoin v erse calculus. F.3 Quotien t features and smo oth dep endence on M Fix the regular point M ⋆ ∈ M d,k and let s ( · ) be the C 2 lo cal section from Appendix C.2 (equiv alen tly , the concrete construction in Section 6.1 ), defined on a neighborho o d W ⊂ M d,k of M ⋆ and satisfying s ( M ) ⊤ s ( M ) = M . Define the quotien t feature map ϕ ( x, M ) : = s ( M ) x ∈ R k , ( x, M ) ∈ R d × W . By App endix C.2 , the map M 7→ s ( M ) is C 2 on W , hence M 7→ ϕ ( x, M ) is C 1 for each fixed x . Lemma F.4 (Lo cal-uniform feature and deriv ativ e moments(Assumption E.2 and Assumption E.4 )) . Assume E ∥ X ∥ 4+ δ < ∞ for some δ > 0 , wher e X ∼ µ down . Then ther e exists a neighb orho o d U ⊆ W of M ⋆ and a c onstant C < ∞ such that sup M ∈U E ∥ ϕ ( X , M ) ∥ 4+ δ ⩽ C , sup M ∈U E ∥ D M ϕ ( X , M ) ∥ 4+ δ op ⩽ C . Pr o of. Since s ( · ) is C 2 on W , its op erator norm and the operator norm of its deriv ative are locally b ounded. Cho ose a relativ ely compact neighborho od U ⋐ W of M ⋆ so that sup M ∈U ∥ s ( M ) ∥ op < ∞ , sup M ∈U ∥ D M s ( M ) ∥ op < ∞ . Then ∥ ϕ ( X , M ) ∥ ⩽ ∥ s ( M ) ∥ op ∥ X ∥ and ∥ D M ϕ ( X , M ) ∥ op ⩽ ∥ D M s ( M ) ∥ op ∥ X ∥ . Raising to the p o w er 4 + δ and taking exp ectations yields the stated b ounds. Lemma F.4 matc hes the lo cal-uniform moment assumptions used in App endix E.1 (and in the pro jector differen tiability result stated there). F.4 Do wnstream co v ariance, stable rank, and effectiv e dimension W rite Σ down : = E [ X X ⊤ ] and assume Σ down ≻ 0. F or M ∈ U , define the do wnstream feature co v ariance Σ( M ) : = E [ ϕ ( X , M ) ϕ ( X , M ) ⊤ ] = E [ s ( M ) X X ⊤ s ( M ) ⊤ ] = s ( M )Σ down s ( M ) ⊤ ∈ R k × k . Lemma F.5 (Stable rank/eigengap for Σ( M ) near M ⋆ ) . Assume Σ down ≻ 0 and let U b e as in L emma F.4 . Then ther e exist c onstants κ Σ , K Σ ∈ (0 , ∞ ) such that, for al l M ∈ U , rank(Σ( M )) = k , λ k (Σ( M )) ⩾ κ Σ , ∥ Σ( M ) ∥ op ⩽ K Σ . In p articular, d eff ( M ) = tr(Σ( M )Σ( M ) + ) = k for al l M ∈ U . 57 Pr o of. F or eac h M ∈ U , the matrix s ( M ) ∈ R k × d has rank k b ecause s ( M ) ⊤ s ( M ) = M and rank ( M ) = k . Since Σ down ≻ 0, the product s ( M )Σ down s ( M ) ⊤ is p ositiv e definite on R k , hence rank (Σ( M )) = k . The eigen v alue bounds follo w from contin uity of M 7→ s ( M ) and compactness of U : λ k (Σ( M )) = λ min ( s ( M )Σ down s ( M ) ⊤ ) is contin uous in M and strictly p ositiv e for each M , so it has a p ositiv e minim um on U . Similarly , ∥ Σ( M ) ∥ op attains a finite maximum on U . Finally , for in vertible Σ( M ) one has Σ( M )Σ( M ) + = I k , hence d eff ( M ) = k . Lemma F.5 v erifies the stable rank/eigengap condition for the downstream cov ariance used throughout App endix E.1 . F.5 W ell-p osedness of the empirical pro jector Recall that H M = { x 7→ θ ⊤ ϕ ( x, M ) : θ ∈ R k } is a k -dimensional linear class. The w ell-p osedness assumption of App endix E.1 is equiv alen t to requiring that the empirical inner product is non- degenerate on H M , or equiv alen tly that the k × k empirical cov ariance Σ n ( M ) has full rank. Lemma F.6 (W ell-p osedness holds almost surely for nondegenerate designs(Assumption E.3 )) . Assume µ down is nonde gener ate in the sense that X has a density on R d and Σ down ≻ 0 . Fix any M ∈ U and any n ⩾ k . Then, with pr ob ability one over X 1: n , rank Σ n ( M ) = k , Σ n ( M ) : = 1 n n X i =1 ϕ ( X i , M ) ϕ ( X i , M ) ⊤ . Conse quently, the empiric al pr oje ctor Π M ,n acts as the identity on H M . Pr o of. W rite Φ ∈ R n × k for the design matrix with rows ϕ ( X i , M ) ⊤ . Then Σ n ( M ) = 1 n Φ ⊤ Φ has rank k if and only if Φ has rank k . Since ϕ ( X i , M ) = s ( M ) X i and s ( M ) has rank k , the random v ector ϕ ( X i , M ) has a densit y on R k (b ecause X i has a density on R d and s ( M ) is a surjectiv e linear map R d → R k ). F or i.i.d. v ectors in R k with a densit y , the ev en t that k of them fall into a common proper h yp erplane has probabilit y 0, so Φ has rank k almost surely when n ⩾ k . The final claim is exactly the w ell-p osedness implication used in App endix E.1 . Since M m is indep enden t of the downstream sample, Lemma F.6 applies conditionally on M m and yields the well-posedness requiremen t along the triangular array ( M m , n ) used in the master theorem. Next, w e sho w that the momen t condition E [ ∥ X ∥ 4 ] < ∞ is in fact sufficien t for Assumption E.3 . Prop osition F.7 ( Oliv eira ( 2016 )) . Fix a δ ∈ (0 , 1) and supp ose ∥ x ∥ L 4 < ∞ . Define the c onstants: C X : = sup v ∈ S d − 1 q E [ ⟨ (Σ + ) 1 / 2 x, v ⟩ 4 ] , k : = rank(Σ) . (F.5) Supp ose that n ⩾ c 0 C 2 X ( k + log(1 /δ )) for a universal c 0 . Then with pr ob ability at le ast 1 − δ : Σ n ≽ 1 4 Σ . On this event, we also have that Col(Σ n ) = Col(Σ) . 58 Pr o of. The first part of the claim, that Σ n ≽ 1 4 Σ, is immediate from Oliv eira ( 2016 , Theorem 3.1). T o finish, supp ose that Σ n ≽ 1 4 Σ holds. Now, let q ∈ Kern(Σ n ). By the abov e, this implies that 0 = q T Σ n q ⩾ 1 4 q T Σ q ⩾ 0 , and hence q T Σ q = 0, whic h implies q ∈ Kern (Σ 1 / 2 ) = Kern (Σ). Therefore, Kern (Σ n ) ⊆ Kern (Σ), whic h b y Lemma E.9 implies Col(Σ n ) = Col(Σ). F.6 Differen tiabilit y of the p opulation pro jector map M 7→ Π M F or M ∈ U , define T M : R k → L 2 ( µ down ) by ( T M θ )( x ) = θ ⊤ ϕ ( x, M ). The p opulation pro jector on to H M = Im( T M ) admits the closed form Π M g = T M Σ( M ) + c g ( M ) , c g ( M ) : = E [ ϕ ( X , M ) g ( X )] . In Appendix E.1 , Prop osition E.6 prov es F r´ ec het differen tiability of M 7→ Π M at M ⋆ under: (i) stable rank/eigengap (Lemma F.5 ), (ii) local-uniform moments (Lemma F.4 ), and (iii) C 1 dep endence of ϕ ( · , M ) with a suitable deriv ative momen t bound (Lemma F.4 ). Therefore the differen tiability assumption used in App endix E.2 is satisfied in this model. F.7 Pretraining consistency and manifold CL T for the linear sp ectral loss In this subsection w e deriv e the asymptotic normalit y of the descriptor estimator ˆ M m directly from the structure of the linear spectral loss and the pretraining data mo del, without appealing to the abstract M -estimation app endix beyond standard empirical-process inputs (LLN and CL T for i.i.d. a verages). Mo del and loss. A pretraining observ ation is z = ( x, x + , x − ) ∈ ( R d ) 3 , where ( x, x + ) is a positive pair and x − is an indep enden t negativ e: x − is an indep enden t cop y of x , indep endent of ( x, x + ). Assume E [ x ] = 0 and define Σ pre : = E [ xx ⊤ ] , Σ + pre : = E [ x + ( x ) ⊤ ] . F or M ∈ M d,k , recall the p er-sample loss (w ell-defined for all symmetric M ) ℓ spec ( M ; z ) = − 2 x ⊤ M x + + ( x ⊤ M x − ) 2 . W e minimize the empirical loss ov er the rank- k PSD manifold M d,k = { M ≽ 0 : rank( M ) = k } : ˆ L m ( M ) : = 1 m m X j =1 ℓ spec ( M ; z j ) , ˆ M m ∈ arg min M ∈M d,k ˆ L m ( M ) . Let L ( M ) : = E [ ℓ spec ( M ; z )] be the p opulation loss. Momen t assumption (for LLN and CL T of deriv atives). Assume there exists δ > 0 such that E ∥ x ∥ 8+ δ < ∞ , E ∥ x ∥ 4+ δ ∥ x + ∥ 4+ δ < ∞ . (F.6) This ensures in tegrability of the score and Hessian random fields used b elo w. 59 F.7.1 P opulation ob jectiv e, score, and Hessian Let sym ( A ) : = ( A + A ⊤ ) / 2. Viewing ℓ spec ( · ; z ) as a function on M d,k with the F rob enius inner pro duct, its Euclidean gradien t is ∇ M ℓ spec ( M ; z ) = − 2 sym( x ( x + ) ⊤ ) + 2 ( x ⊤ M x − ) sym( x ( x − ) ⊤ ) . (F.7) Its Euclidean Hessian is the linear map H 7→ D ( ∇ M ℓ spec )( M ; z )[ H ] giv en by D ( ∇ M ℓ spec )( M ; z )[ H ] = 2 ( x ⊤ H x − ) sym( x ( x − ) ⊤ ) . (F.8) T aking expectations and using x − indep enden t of ( x, x + ) with E [ x − ( x − ) ⊤ ] = Σ pre , we obtain ∇ L ( M ) = − 2 Σ + pre + 2 Σ pre M Σ pre , (F.9) D ( ∇ L )( M )[ H ] = 2 Σ pre H Σ pre . (F.10) In particular, the population Hessian is constan t (indep enden t of M ) and is p ositive definite on M d,k ‘ since ⟨ H , 2Σ pre H Σ pre ⟩ F = 2 ∥ Σ 1 / 2 pre H Σ 1 / 2 pre ∥ 2 F . F.7.2 Consistency of ˆ M m W e record a standard consistency statement. Lemma F.8 (Consistency) . Assume Σ pre ≻ 0 , Assumption 6.1 , and ( F.6 ) . Then ˆ M m → M ⋆ in pr ob ability. Pr o of sketch. By ( F.9 ) – ( F.10 ) and Σ pre ≻ 0, the p opulation ob jectiv e is co ercive on M d,k : L ( M ) → ∞ as ∥ M ∥ F → ∞ within M d,k . Hence the sublevel set { M ∈ M d,k : L ( M ) ⩽ L ( M ⋆ ) + 1 } is compact (in the induced topology on M d,k ). Under ( F.6 ) , ℓ spec ( M ; z ) is in tegrable uniformly o ver that compact set and ˆ L m → L uniformly in probabilit y on it (standard uniform LLN for finite- dimensional parametric c harts on compact sets). Since M ⋆ is the unique minimizer, the argmin theorem yields ˆ M m → M ⋆ in probability . F.7.3 Manifold CL T in normal co ordinates Let log M ⋆ ( · ) b e the Riemannian log map on the smooth manifold M d,k (with the induced metric) defined on a normal neigh b orhoo d of M ⋆ , and define the tangen t error v m : = log M ⋆ ( ˆ M m ) ∈ T M ⋆ M d,k . W rite Pro j T for the orthogonal pro jection (in F rob enius) onto T M ⋆ M d,k . Define the tangen t-space score random v ector (a tangen t elemen t) φ ( z ) : = Pro j T ∇ M ℓ spec ( M ⋆ ; z ) ∈ T M ⋆ M d,k , Σ ⋆ : = Co v ( φ ( z )) . (F.11) Define the (Riemannian) Hessian operator on the tangen t space H ⋆ : = Hess L ( M ⋆ ) : T M ⋆ M d,k → T M ⋆ M d,k . (F.12) 60 Lemma F.9 (Nondegeneracy of the tangent Hessian) . Assume Σ pre ≻ 0 and that M ⋆ is a (Rieman- nian) lo c al minimizer of L on M d,k . Then H ⋆ is p ositive definite and henc e invertible. Mor e over, with the induc e d F r ob enius metric, ⟨ v , H ⋆ v ⟩ = 2 ∥ Σ 1 / 2 pre v Σ 1 / 2 pre ∥ 2 F for al l v ∈ T M ⋆ M d,k . Pr o of. W ork in normal co ordinates M = exp M ⋆ ( v ) on a neighborho od of M ⋆ . The ambien t T a ylor expansion of L on M d,k at M ⋆ is exact to second order since ( F.10 ) is constant: L ( M ⋆ + ∆) = L ( M ⋆ ) + ⟨∇ L ( M ⋆ ) , ∆ ⟩ F + 1 2 ⟨ ∆ , 2Σ pre ∆Σ pre ⟩ F . F or M = exp M ⋆ ( v ), we ha ve M = M ⋆ + v + o ( ∥ v ∥ ) in the am bien t space. Since M ⋆ is a Riemannian minimizer on M d,k , the Riemannian gradien t v anishes, whic h means Pro j T ( ∇ L ( M ⋆ )) = 0. Equiv- alen tly , ∇ L ( M ⋆ ) is orthogonal to T M ⋆ M d,k , so ⟨∇ L ( M ⋆ ) , v ⟩ F = 0 for all v ∈ T M ⋆ M d,k . Plugging ∆ = v + o ( ∥ v ∥ ) in to the expansion yields L (exp M ⋆ ( v )) = L ( M ⋆ ) + 1 2 ⟨ v , 2Σ pre v Σ pre ⟩ F + o ( ∥ v ∥ 2 ) , whic h iden tifies the Riemannian Hessian quadratic form at M ⋆ on tangen t directions as claimed. Since Σ pre ≻ 0, the form is strictly p ositive for v = 0, hence H ⋆ is inv ertible. Prop osition F.10 (CL T for ˆ M m in normal co ordinates) . Assume Σ pre ≻ 0 , Assumption 6.1 , and ( F.6 ) . L et ˆ M m b e a me asur able empiric al minimizer of ˆ L m over M d,k . Then √ m log M ⋆ ( ˆ M m ) d ⇝ Z , Z ∼ N (0 , V ) , V : = H − 1 ⋆ Σ ⋆ H − 1 ⋆ , as a r andom element in T M ⋆ M d,k . Pr o of. Let v m : = log M ⋆ ( ˆ M m ). By Lemma F.8 , v m → 0 in probabilit y and, for all large m , ˆ M m lies in a normal neighborho o d where the log map is defined. Define the empirical Riemannian gradien t at M ∈ M d,k b y grad ˆ L m ( M ) : = 1 m m X j =1 Pro j T M ∇ M ℓ spec ( M ; z j ) , and similarly grad L ( M ). Since ˆ M m is a minimizer, grad ˆ L m ( ˆ M m ) = 0. T ransp ort gradients to the fixed tangent space T M ⋆ M d,k using normal coordinates and apply a T aylor expansion: 0 = grad ˆ L m (exp M ⋆ ( v m )) = grad ˆ L m ( M ⋆ ) + H ⋆ v m + r m , where r m = o p ( ∥ v m ∥ ) + o p ( m − 1 / 2 ). This remainder control follo ws from the smoothness of M 7→ Pro j T M on the regular stratum and the momen t bound ( F.6 ) , whic h implies local uniform in tegrability of the first tw o deriv atives of ℓ spec ( M ; z ). Next, by definition of φ ( z ) in ( F.11 ), √ m grad ˆ L m ( M ⋆ ) = 1 √ m m X j =1 φ ( z j ) , E [ φ ( z )] = 0 , 61 and ( F.6 ) implies E ∥ φ ( z ) ∥ 2 < ∞ . Hence the m ultiv ariate CL T in the finite-dimensional space T M ⋆ M d,k yields √ m grad ˆ L m ( M ⋆ ) d ⇝ N (0 , Σ ⋆ ) . Lemma F.9 giv es in vertibilit y of H ⋆ . Solving the linearized equation giv es √ m v m = − H − 1 ⋆ √ m grad ˆ L m ( M ⋆ ) + o p (1) , and Slutsky’s theorem yields √ m v m d ⇝ N (0 , H − 1 ⋆ Σ ⋆ H − 1 ⋆ ). F.8 Explicit Calculations of the Concrete Example In this section, w e first derive an asymptotic distribution for the sp ectral pretraining estimator in a general Gaussian model b y computing the closed-form c haracterization of the limiting cov ariance op erator V ⋆ = H − 1 ⋆ Σ ⋆ H − 1 ⋆ in Prop osition F.10 . W e then sp ecialize the result to the concrete diagonal example presen ted in Section 6.1 . F ully Gaussian assumption. Assume ( X , X + ) is join tly Gaussian, and X − is an independent cop y of X , independent of ( X , X + ). In particular, E [ X X ⊤ ] = Σ pre , E [ X ( X + ) ⊤ ] = Σ + pre . Bilinear form for the score co v ariance. Let S k b e the space of d b y d symmetric matrices. F or a symmetric direction H ∈ S d , define the scalar score functional at M ⋆ b y S H ( Z ) : = ⟨∇ M ℓ spec ( M ⋆ ; Z ) , H ⟩ = − 2 X ⊤ H X + + 2 ( X ⊤ M ⋆ X − ) ( X ⊤ H X − ) . where Z = ( X , X + , X − ). Recall that Σ ⋆ = Co v ( φ ( Z )) with φ ( Z ) = Pro j T ( ∇ M ℓ spec ( M ⋆ ; Z )) where Pro j T is the orthogonal pro jection onto T M ⋆ M d,k . W e know that Pro j T is self-adjoint and E [ φ ( Z )] = 0. Thus, for all v 1 , v 2 ∈ T M ⋆ M d,k w e ha v e ⟨ v 1 , Σ ⋆ v 2 ⟩ = Cov S v 1 ( Z ) , S v 2 ( Z ) . (F.13) The following prop osition gives Cov( S H 1 , S H 2 ) in closed form under joint Gaussianit y . Prop osition F.11 (Exact score co v ariance under joint Gaussianity) . Under the ful ly Gaussian assumption, for any H 1 , H 2 ∈ S d , Co v S H 1 ( Z ) , S H 2 ( Z ) = 4 C aa ( H 1 , H 2 ) − C ab ( H 1 , H 2 ) − C ab ( H 2 , H 1 ) + C bb ( H 1 , H 2 ) , (F.14) wher e the terms ar e given as fol lows: (i) Positive-p air term: C aa ( H 1 , H 2 ) : = tr( H 1 Σ pre H 2 Σ pre ) + tr( H 1 Σ + pre H 2 Σ + pre ) . (F.15) (ii) Cr oss term: L et P i : = M ⋆ Σ pre H i . Then C ab ( H 1 , H 2 ) : = tr( P 2 Σ pre H 1 Σ + pre ) + tr( P 2 Σ + pre H 1 Σ pre ) . (F.16) 62 (iii) Ne gative-sample term: L et Q : = M ⋆ Σ pre M ⋆ . Then C bb ( H 1 , H 2 ) = tr( P 1 Σ pre ) tr( P 2 Σ pre ) + 2 tr( P 1 Σ pre P 2 Σ pre ) + tr( H 1 Σ pre H 2 Σ pre ) tr( Q Σ pre ) + 4 tr( H 1 Σ pre H 2 Σ pre Q Σ pre ) . (F.17) W e will rep eatedly use the follo wing standard lemmas in the pro of. Lemma F.12 (Bilinear–bilinear moment) . L et ( U, V ) b e jointly Gaussian with E [ U ] = E [ V ] = 0 , E [ U U ⊤ ] = Σ U , E [ V V ⊤ ] = Σ V , and E [ U V ⊤ ] = Σ U V . Then for any A, B ∈ R d × d , E ( U ⊤ AV )( U ⊤ B V ) = tr( A Σ U V ) tr( B Σ U V ) + tr( A Σ U B Σ V ) + tr( A Σ U V B ⊤ Σ ⊤ U V ) . (F.18) Conse quently, Co v ( U ⊤ AV , U ⊤ B V ) = tr( A Σ U B Σ V ) + tr( A Σ U V B ⊤ Σ ⊤ U V ) . (F.19) Lemma F.13 (Quadratic–quadratic momen t) . L et U ∼ N (0 , Σ) and let A, B ∈ R d × d . Then E ( U ⊤ AU )( U ⊤ B U ) = tr( A Σ) tr( B Σ) + tr( A Σ B Σ) + tr( A Σ B ⊤ Σ) . (F.20) Conse quently, Co v ( U ⊤ AU, U ⊤ B U ) = tr( A Σ B Σ) + tr( A Σ B ⊤ Σ) . (F.21) Pr o of of L emmas F.12 – F.13 . Both iden tities follo w b y expanding the products comp onen t wise and applying Isserlis’ form ula to fourth moments. F or instance, for Lemma F.12 , E [( U ⊤ AV )( U ⊤ B V )] = X i,j,p,q A ij B pq E [ U i V j U p V q ] , and Isserlis gives E [ U i V j U p V q ] = E [ U i V j ] E [ U p V q ] + E [ U i U p ] E [ V j V q ] + E [ U i V q ] E [ V j U p ], whic h sums to ( F.18 ). Lemma F.13 is analogous. Pr o of of Pr op osition F.11 . W rite S H ( Z ) = − 2 a H ( Z ) + 2 b H ( Z ) with a H ( Z ) : = X ⊤ H X + , b H ( Z ) : = ( X ⊤ M ⋆ X − )( X ⊤ H X − ) . Then, for an y H 1 , H 2 ∈ S d , Co v ( S H 1 ( Z ) , S H 2 ( Z )) = 4 Co v ( a H 1 , a H 2 ) − Cov( a H 1 , b H 2 ) − Cov( a H 2 , b H 1 ) + Cov( b H 1 , b H 2 ) . (F.22) W e compute the four co v ariance terms under join t Gaussianity using Isserlis’ form ula. First, we will compute Co v ( a H 1 , a H 2 ). Apply Lemma F.12 with ( U, V ) = ( X , X + ), Σ U = Σ V = Σ pre and Σ U V = Σ + pre . Since H 1 , H 2 are symmetric and Σ + pre is symmetric, ( F.19 ) yields C aa ( H 1 , H 2 ) = Co v ( a H 1 , a H 2 ) = tr( H 1 Σ pre H 2 Σ pre ) + tr( H 1 Σ + pre H 2 Σ + pre ) . Next, we will compute the cross term Cov( a H 1 , b H 2 ). Fix H 1 , H 2 and write b H 2 = ( X ⊤ M ⋆ X − )( X ⊤ H 2 X − ) = ( X − ) ⊤ ( M ⋆ X X ⊤ H 2 ) X − . 63 Condition on ( X, X + ) and use that X − is indep endent of ( X , X + ) with co v ariance Σ pre : E [ b H 2 | X , X + ] = E ( X ⊤ M ⋆ X − )( X ⊤ H 2 X − ) | X , X + = X ⊤ M ⋆ Σ pre H 2 X . (F.23) Hence, E [ a H 1 b H 2 ] = E h ( X ⊤ H 1 X + ) E [ b H 2 | X , X + ] i = E h ( X ⊤ H 1 X + ) ( X ⊤ P 2 X ) i , (F.24) where B 2 : = M ⋆ Σ pre H 2 . W e next compute the mixed moment in ( F.24 ). Expand ( X ⊤ H 1 X + )( X ⊤ P 2 X ) = X i,j,p,q ( H 1 ) ij ( P 2 ) pq X i X + j X p X q . Apply Isserlis to E [ X i X + j X p X q ] for the jointly Gaussian pair ( X, X + ): E [ X i X + j X p X q ] = E [ X i X + j ] E [ X p X q ] + E [ X i X p ] E [ X + j X q ] + E [ X i X q ] E [ X + j X p ] . Using E [ X i X + j ] = (Σ + pre ) ij and E [ X p X q ] = (Σ pre ) pq , this yields E ( X ⊤ H 1 X + )( X ⊤ P 2 X ) = tr( H 1 Σ + pre ) tr( P 2 Σ pre ) + tr( P 2 Σ pre H 1 Σ + pre ) + tr( P 2 Σ + pre H 1 Σ pre ) . (F.25) Moreo ver, E [ a H 1 ] = tr( H 1 Σ + pre ) , E [ b H 2 ] = E [ X ⊤ P 2 X ] = tr( P 2 Σ pre ) . Therefore, subtracting E [ a H 1 ] E [ b H 2 ] from ( F.25 ) gives C ab ( H 1 , H 2 ) = Co v ( a H 1 , b H 2 ) = tr( P 2 Σ pre H 1 Σ + pre ) + tr( P 2 Σ + pre H 1 Σ pre ) . Finally , w e will compute the negative-sample term Cov( b H 1 , b H 2 ). W rite b H i = ( X ⊤ M ⋆ X − )( X ⊤ H i X − ) = ( X − ) ⊤ A i ( X ) X − , A i ( X ) : = M ⋆ X X ⊤ H i . F rom the total law of co v ariance, w e ha ve C bb ( H 1 , H 2 ) = Co v ( b H 1 , b H 2 ) = E [Co v ( b H 1 , b H 2 | X )] + Cov( E [ b H 1 | X ] , E [ b H 2 | X ]) . W e apply Lemma F.13 to X − ∼ N (0 , Σ pre ): Co v ( b H 1 , b H 2 | X ) = tr( A 1 ( X )Σ pre A 2 ( X )Σ pre ) + tr( A 1 ( X )Σ pre A 2 ( X ) T Σ pre ) = ( X T M ⋆ Σ pre H 1 X X T M ⋆ Σ pre H 2 X ) + ( X T H 1 Σ pre H 2 X X T M ⋆ Σ pre M ⋆ X ) = ( X T P 1 X X T P 2 X ) + ( X T H 1 Σ pre H 2 X X T QX ) . Therefore, we hav e E [Co v ( b H 1 , b H 2 | X )] = tr( P 1 Σ pre ) tr( P 2 Σ pre ) + tr( P 1 Σ pre P 2 Σ pre ) + tr( H 1 Σ pre H 2 Σ pre ) tr( Q Σ pre ) + 3 tr( H 1 Σ pre H 2 Σ pre Q Σ pre ) . 64 Similarly , Co v ( E [ b H 1 | X ] , E [ b H 2 | X ]) = Co v ( X T P 1 X , X T P 2 X ) = tr( P 1 Σ pre P 2 Σ pre ) + tr( H 1 Σ pre H 2 Σ pre Q Σ pre ) . Therefore, we get C bb ( H 1 , H 2 ) = tr( P 1 Σ pre ) tr( P 2 Σ pre ) + 2 tr( P 1 Σ pre P 2 Σ pre ) + tr( H 1 Σ pre H 2 Σ pre ) tr( Q Σ pre ) + 4 tr( H 1 Σ pre H 2 Σ pre Q Σ pre ) . Corollary F.14. Under the ful ly Gaussian assumption, for any H 1 , H 2 ∈ S d , we have ⟨ H 1 , V ⋆ H 2 ⟩ = C aa ( H ′ 1 , H ′ 2 ) − C ab ( H ′ 1 , H ′ 2 ) − C ab ( H ′ 2 , H ′ 1 ) + C bb ( H ′ 1 , H ′ 2 ) (F.26) wher e H ′ i = Σ − 1 pre H i Σ − 1 pre for i = { 1 , 2 } . Pr o of. According to Lemma F.9 , for any v ∈ S d , we hav e H ⋆ v = 2Σ pre v Σ pre , H − 1 ⋆ v = 1 2 Σ − 1 pre v Σ − 1 pre . Therefore, we hav e ⟨ H 1 , V ⋆ H 2 ⟩ = ⟨ H 1 , H − 1 ⋆ Σ ⋆ H − 1 ⋆ H 2 ⟩ = ⟨ H − 1 ⋆ H 1 , Σ ⋆ H − 1 ⋆ H 2 ⟩ = 1 4 ⟨ Σ − 1 pre H 1 Σ − 1 pre , Σ ⋆ H − 1 ⋆ Σ − 1 pre H 2 Σ − 1 pre ⟩ = 1 4 ⟨ H ′ 1 , Σ ⋆ H ′ 2 ⟩ = 1 4 Co v S H ′ 1 ( Z ) , S H ′ 2 ( Z ) . Equation ( F.26 ) follo ws after plugging this equation into Equation ( F.14 ). Linearization of the represen tation error. Fix M in a neigh b orho od of M ⋆ and let A := s ( M ) ∈ R k × d b e the lo cal section so that A ⊤ A = M . Consider the operator T M : R k → L 2 ( µ down ) defined by ( T M b )( x ) := ⟨ b, Ax ⟩ = b ⊤ Ax, b ∈ R k . Its adjoint T adj M : L 2 ( µ down ) → R k satisfies, for an y g ∈ L 2 ( µ down ), T adj M g = E g ( X ) AX = A E g ( X ) X , where X ∼ µ down and we used linearit y of A . Let Σ down := E [ X X ⊤ ] , Σ( M ) := T adj M T M = E [( AX )( AX ) ⊤ ] = A Σ down A ⊤ . The orthogonal pro jector on to Range( T M ) is giv en b y Π M = T M Σ( M ) + T adj M . Therefore, for an y g ∈ L 2 ( µ down ), (Π M g )( x ) = T M Σ( M ) + T adj M g ( x ) = D Σ( M ) + T adj M g , Ax E = Σ( M ) + A E [ g ( X ) X ] , Ax = x ⊤ A ⊤ Σ( M ) + A E [ g ( X ) X ] . (F.27) 65 Define the induced matrix P ( M ) := A ⊤ Σ( M ) + A ∈ R d × d . Then ( F.27 ) becomes the compact form (Π M g )( x ) = x ⊤ P ( M ) E [ g ( X ) X ] . W e kno w that the target function is f ⋆ ( x ) = β ⊤ ⋆ A ⋆ x for some β ⋆ ∈ R k and A ⋆ := s ( M ⋆ ). Then E [ f ⋆ ( X ) X ] = E [ X X ⊤ ] A ⊤ ⋆ β ⋆ = Σ down A ⊤ ⋆ β ⋆ , and therefore (Π M f ⋆ )( x ) = x ⊤ P ( M ) Σ down A ⊤ ⋆ β ⋆ . (F.28) W e linearize ( F.28 ) around M ⋆ using Prop osition E.6 . In the constant-rank region, the map Ω 7→ Π Ω is F r ´ echet differen tiable at Ω ⋆ , and for v ∈ T Ω ⋆ M , Π exp Ω ⋆ ( v ) = Π Ω ⋆ + D Π Ω ⋆ [ v ] + o ( ∥ v ∥ ) . Define, for an y M ∈ S d + with rank( M ) = k , the whitene d descriptor B ( M ) := Σ 1 / 2 down M Σ 1 / 2 down ∈ S d + . Let Π( B ) denote the Euclidean orthogonal pro jector onto range ( B ). Then the induced matrix in ( F.27 ) admits the M –only represen tation P ( M ) = Σ − 1 / 2 down Π B ( M ) Σ − 1 / 2 down = Σ − 1 / 2 down B ( M ) B ( M ) + Σ − 1 / 2 down . (F.29) F or the fixed target f ⋆ , define m ⋆ := E [ f ⋆ ( X ) X ] ∈ R d . Since m ⋆ is indep endent of M , we hav e for any tangent direction v ∈ T M ⋆ M d,k , D Π M ⋆ [ v ] f ⋆ ( x ) = x ⊤ D P ( M ⋆ )[ v ] m ⋆ , ( L ( v ) f ⋆ )( x ) := − D Π M ⋆ [ v ] f ⋆ ( x ) = − x ⊤ D P ( M ⋆ )[ v ] m ⋆ . (F.30) Deriv ativ e of P ( M ) . Let B ⋆ := B ( M ⋆ ) = Σ 1 / 2 down M ⋆ Σ 1 / 2 down and ˙ B := D B ( M ⋆ )[ v ] = Σ 1 / 2 down v Σ 1 / 2 down . Differen tiating ( F.29 ) yields D P ( M ⋆ )[ v ] = Σ − 1 / 2 down D Π( B ⋆ )[ ˙ B ] Σ − 1 / 2 down . (F.31) Assume an eigengap at k for B ⋆ , so that Π( · ) is F r´ ec het differen tiable at B ⋆ . Let B ⋆ = U diag (Λ 1 , Λ 2 ) U ⊤ with U = [ U 1 , U 2 ], Λ 1 = diag ( λ 1 , . . . , λ k ), Λ 2 = diag ( λ k +1 , . . . , λ d ), and min i ⩽ k 0. Lemma F.15. F or any symmetric dir e ction ˙ B ∈ S d , D Π( B ⋆ )[ ˙ B ] = U 2 ( G ⊘ ∆) U ⊤ 1 + U 1 G ⊤ ⊘ ∆ ⊤ U ⊤ 2 , (F.32) wher e G := U ⊤ 2 ˙ B U 1 ∈ R ( d − k ) × k , ∆ ai := λ i − λ k + a , and ⊘ is the elementwise division. 66 Pr o of. W e w ork in the eigen basis of B ⋆ , i.e. replace ˙ B b y e ˙ B := U ⊤ ˙ B U and write the pro jector in this basis. Since Π( B ) is orthogonally equiv ariant, it suffices to pro ve the claim for B ⋆ = diag (Λ 1 , Λ 2 ), in which case Π( B ⋆ ) = P ⋆ := diag( I k , 0). Let Γ b e a p ositively oriented contour in the complex plane enclosing { λ 1 , . . . , λ k } and excluding { λ k +1 , . . . , λ d } . By the Riesz pro jector form ula, Π( B ) = 1 2 π i I Γ ( z I − B ) − 1 dz (F.33) for all B in a neighborho o d of B ⋆ . Differentiating ( F.33 ) at B ⋆ in direction ˙ B and using the standard resolv ent iden tity D ( z I − B ) − 1 B = B ⋆ [ ˙ B ] = ( z I − B ⋆ ) − 1 ˙ B ( z I − B ⋆ ) − 1 , w e obtain D Π( B ⋆ )[ ˙ B ] = 1 2 π i I Γ ( z I − B ⋆ ) − 1 ˙ B ( z I − B ⋆ ) − 1 dz . (F.34) Since B ⋆ = diag ( λ 1 , . . . , λ d ) is diagonal in this basis, ( z I − B ⋆ ) − 1 is also diagonal with entries ( z − λ j ) − 1 . Therefore, the ( p, q ) en try of the integrand in ( F.34 ) equals ( z I − B ⋆ ) − 1 ˙ B ( z I − B ⋆ ) − 1 pq = ˙ B pq ( z − λ p )( z − λ q ) . Hence D Π( B ⋆ )[ ˙ B ] pq = ˙ B pq · 1 2 π i I Γ dz ( z − λ p )( z − λ q ) . (F.35) No w consider cases. (i) p, q ⩽ k : If b oth λ p and λ q lie inside of the con tour Γ, then we ha ve I pq : = 1 2 π i I Γ dz ( z − λ p )( z − λ q ) = 1 2 π i I Γ 1 λ p − λ q ( 1 z − λ p − 1 z − λ q ) dz = 1 2 π i ( λ p − λ q ) (1 − 1) = 0 . (ii) p, q > k : If b oth λ p and λ q lie outside of the contour Γ, then the in tegrand in ( F.35 ) is holomorphic inside Γ and the contour in tegral v anishes. (iii) p ⩽ k < q : Then λ p is inside Γ and λ q is outside, so the in tegrand in ( F.35 ) has a single p ole inside Γ at z = λ p with residue 1 / ( λ p − λ q ). Therefore 1 2 π i I Γ dz ( z − λ p )( z − λ q ) = 1 λ p − λ q , and thus D Π( B ⋆ )[ ˙ B ] pq = ˙ B pq λ p − λ q . By symmetry , the case q ⩽ k < p giv es the transp ose. 67 W riting this in blo ck form with respect to the split R d = R k ⊕ R d − k yields D Π( B ⋆ )[ ˙ B ] = 0 H ⊤ H 0 , H ai = ˙ B k + a,i λ i − λ k + a . Returning to the original basis (undoing the U -conjugation) gives ( F.32 ) with G := U ⊤ 2 ˙ B U 1 and ∆ ai := λ i − λ k + a . Pretraining fluctuations. W e will derive the asymptotic distribution of m ∥L (log M ⋆ ( ˆ M m ) ∥ . m ∥L (log M ⋆ ( ˆ M m )) ∥ 2 L 2 ( µ down ) = ∥ x ⊤ D P ( M ⋆ )[ √ m log M ⋆ ( ˆ M m )] m ⋆ ∥ 2 L 2 ( µ down ) = β ⊤ ⋆ A ⋆ Σ down D P ( M ⋆ )[ √ m log M ⋆ ( ˆ M m )] T D P ( M ⋆ )[ √ m log M ⋆ ( ˆ M m )]Σ down A ⊤ ⋆ β ⋆ d ⇝ β ⊤ ⋆ A ⋆ Σ down D P ( M ⋆ )[ Z ] T D P ( M ⋆ )[ Z ]Σ down A ⊤ ⋆ β ⋆ (F.36) where the exact form of D P ( M ⋆ ) is calculated in Equation ( F.31 ) and ( F.32 ) , and Z is a mean-zero Gaussian with the cov ariance V ⋆ (Equation ( F.26 )). F.9 Comparison to Cabannes et al. ( 2023 ) W e now study the follo wing concrete example to compare our asymptotic result with the general upp er b ound of Cabannes et al. ( 2023 , Thm. 4). Assume that Σ down = I d and Σ pre = Σ pre , 1 0 0 Σ pre , 2 , Σ + pre = Σ + pre , 1 0 0 Σ + pre , 2 with Σ pre , 1 = diag( a 1 , . . . , a k ) , Σ pre , 2 = diag( b 1 , . . . , b d − k ) , and Σ + pre , 1 = diag( c 1 , . . . , c k ) , Σ + pre , 2 = diag( e 1 , . . . , e d − k ) . F urthermore, w e assume that all diagonal en tries are strictly positive and c i a i > e j b j , ∀ i ∈ { 1 , . . . , k } , ∀ j ∈ { 1 , . . . , d − k } . In this case, the whitened cross-co v ariance matrix C = Σ − 1 / 2 pre Σ + pre Σ − 1 / 2 pre is diagonal and given by C = diag c 1 a 1 , . . . , c k a k , e 1 b 1 , . . . , e d − k b d − k . By the ordering assumption, the top- k eigen v alues of C are c 1 a 1 , . . . , c k a k , so the constrained p opulation minimizer ov er M d,k is M ⋆ = R 0 0 0 where R := diag ( r 1 , . . . , r k ) and r i := c i a 2 i . An y tangen t matrix H ∈ T M ⋆ M d,k has the block form H = A B B ⊤ 0 , A ∈ S k , B ∈ R k × ( d − k ) . 68 Let µ i : = e i b i , λ i : = c i a i , and τ : = P k i =1 λ 2 i . By Corollary ( F.26 ) , the co v ariance operator V ⋆ is given b y ⟨ H 1 , V ⋆ H 2 ⟩ = C aa ( H ′ 1 , H ′ 2 ) − C ab ( H ′ 1 , H ′ 2 ) − C ab ( H ′ 2 , H ′ 1 ) + C bb ( H ′ 1 , H ′ 2 ) , where H ′ ℓ = Σ − 1 pre H ℓ Σ − 1 pre = Σ − 1 pre , 1 A ℓ Σ − 1 pre , 1 Σ − 1 pre , 1 B ℓ Σ − 1 pre , 2 Σ − 1 pre , 2 B ⊤ ℓ Σ − 1 pre , 1 0 . W e now compute the three terms in ( F.15 ) – ( F.17 ) . Using the block-diagonal form of Σ pre and Σ + pre , a direct multiplication giv es H ′ 1 Σ pre = Σ − 1 pre , 1 A 1 Σ − 1 pre , 1 B 1 Σ − 1 pre , 2 B ⊤ 1 0 , H ′ 2 Σ pre = Σ − 1 pre , 1 A 2 Σ − 1 pre , 1 B 2 Σ − 1 pre , 2 B ⊤ 2 0 . Hence tr( H ′ 1 Σ pre H ′ 2 Σ pre ) = tr(Σ − 1 pre , 1 A 1 Σ − 1 pre , 1 A 2 ) + 2 tr(Σ − 1 pre , 1 B 1 Σ − 1 pre , 2 B ⊤ 2 ) . Similarly , tr( H ′ 1 Σ + pre H ′ 2 Σ + pre ) = tr(Σ − 1 pre , 1 A 1 Σ + pre , 1 Σ − 1 pre , 1 A 2 Σ + pre , 1 ) + 2 tr(Σ − 1 pre , 1 B 1 Σ + pre , 2 Σ − 1 pre , 2 B ⊤ 2 Σ + pre , 1 Σ − 1 pre , 1 ) . Since all these matrices are diagonal, this b ecomes entrywise C aa ( H ′ 1 , H ′ 2 ) = k X i,j =1 1 + λ i λ j a i a j ( A 1 ) ij ( A 2 ) ij + 2 k X i =1 d − k X j =1 1 + λ i µ j a i b j ( B 1 ) ij ( B 2 ) ij . Since M ⋆ = R Σ pre 0 0 0 , we obtain P ℓ = M ⋆ Σ pre H ′ ℓ = RA ℓ Σ − 1 pre , 1 RB ℓ Σ − 1 pre , 2 0 0 . Then C ab ( H ′ 1 , H ′ 2 ) = tr( P 2 Σ pre H ′ 1 Σ + pre ) + tr( P 2 Σ + pre H ′ 1 Σ pre ) = k X i,j =1 r i ( λ i + λ j ) a j ( A 1 ) ij ( A 2 ) ij + 2 k X i =1 d − k X j =1 λ 2 i a i b j ( B 1 ) ij ( B 2 ) ij . By symmetry , C ab ( H ′ 2 , H ′ 1 ) = k X i,j =1 r j ( λ i + λ j ) a i ( A 1 ) ij ( A 2 ) ij + 2 k X i =1 d − k X j =1 λ 2 i a i b j ( B 1 ) ij ( B 2 ) ij . W e ha ve Q := M ⋆ Σ pre M ⋆ = R Σ pre , 1 R 0 0 0 , so that tr( Q Σ pre ) = P k i =1 λ 2 i = τ . Also, tr( P ℓ Σ pre ) = P k i =1 r i ( A ℓ ) ii . F urther, tr( P 1 Σ pre P 2 Σ pre ) = k X i,j =1 r i r j ( A 1 ) ij ( A 2 ) ij . 69 Finally , using again that all matrices are diagonal in blo c k form, tr( H ′ 1 Σ pre H ′ 2 Σ pre Q Σ pre ) = k X i,j =1 λ 2 i a i a j ( A 1 ) ij ( A 2 ) ij + k X i =1 d − k X j =1 λ 2 i a i b j ( B 1 ) ij ( B 2 ) ij . Substituting into ( F.17 ), w e obtain C bb ( H ′ 1 , H ′ 2 ) = k X i =1 r i ( A 1 ) ii k X j =1 r j ( A 2 ) j j + τ k X i,j =1 1 a i a j ( A 1 ) ij ( A 2 ) ij + 2 τ k X i =1 d − k X j =1 1 a i b j ( B 1 ) ij ( B 2 ) ij + 4 k X i,j =1 λ 2 i a i a j ( A 1 ) ij ( A 2 ) ij + 4 k X i =1 d − k X j =1 λ 2 i a i b j ( B 1 ) ij ( B 2 ) ij . Substituting the previous expressions in to Corollary ( F.26 ) yields ⟨ H 1 , V ⋆ H 2 ⟩ = k X i =1 r i ( A 1 ) ii k X j =1 r j ( A 2 ) j j + k X i =1 1 + τ + 3 λ 2 i a 2 i ( A 1 ) ii ( A 2 ) ii + 2 X 1 ⩽ i 0 denote the eigengap. By W eyl’s inequality , | ˆ λ i − λ i (Σ ⋆ ) | ⩽ ∥ ∆ m ∥ op for all i ∈ [ d ] . Hence, for all m large enough so that ∥ ∆ m ∥ op ⩽ γ / 2, we get ˆ λ k ⩾ λ k (Σ ⋆ ) − ∥ ∆ m ∥ op ⩾ 1 + γ / 2 , and therefore ˆ λ i ⩾ ˆ λ k > 1 for all i ⩽ k . In particular, ˆ λ i − 1 > 0 for i ⩽ k . Next, define the rank- k truncation map Π k ( · ) by Π k ( B ) : = k X j =1 λ j ( B ) u j ( B ) u j ( B ) ⊤ , where λ 1 ( B ) ⩾ · · · ⩾ λ d ( B ) are the eigen v alues of B and u j ( B ) are corresp onding orthonormal eigen vectors. Then Π k ( S m ) = P k j =1 ˆ λ j ˆ u j ˆ u ⊤ j and ˆ M m = Π k ( S m ) − ˆ P m . Similarly , since λ k +1 (Σ ⋆ ) = · · · = λ d (Σ ⋆ ) = 1 and Σ ⋆ ≽ 0, Π k (Σ ⋆ ) = k X j =1 λ j (Σ ⋆ ) u j u ⊤ j = M ⋆ + P ⋆ , so that M ⋆ = Π k (Σ ⋆ ) − P ⋆ . Therefore, ˆ M m − M ⋆ = Π k ( S m ) − Π k (Σ ⋆ ) − ˆ P m − P ⋆ . (G.6) W e now control the t w o terms. F or the pro jector term we already hav e ∥ ˆ P m − P ⋆ ∥ F → 0 b y ( G.5 ). F or the truncated part, note that for an y symmetric B , B ′ , ∥ Π k ( B ) − Π k ( B ′ ) ∥ op ⩽ k ∥ B − B ′ ∥ op , since Π k ( B ) − Π k ( B ′ ) = P k j =1 λ j ( B ) u j ( B ) u j ( B ) ⊤ − λ j ( B ′ ) u j ( B ′ ) u j ( B ′ ) ⊤ and eac h rank-one term has op erator norm b ounded b y | λ j ( B ) − λ j ( B ′ ) | + ∥ B − B ′ ∥ op , while | λ j ( B ) − λ j ( B ′ ) | ⩽ ∥ B − B ′ ∥ op b y W eyl’s inequality . Consequently , ∥ Π k ( S m ) − Π k (Σ ⋆ ) ∥ F ⩽ √ k ∥ Π k ( S m ) − Π k (Σ ⋆ ) ∥ op ⩽ k 3 / 2 ∥ S m − Σ ⋆ ∥ op = k 3 / 2 ∥ ∆ m ∥ op → 0 . Com bining with ( G.6 ) yields ∥ ˆ M m − M ⋆ ∥ F → 0 along the fixed almost-sure outcome. This pro ves ˆ M m → M ⋆ almost surely . Asymptotic Normality Finally , w e will derive the asymptotic distribution of √ m ( ˆ M m − M ⋆ ). Let X ∼ N (0 , Σ x ) with Σ x = I d + M ⋆ , rank( M ⋆ ) = k . First, we write the eigendecomp osition Σ x = U ⋆ I k + D 0 0 I d − k U ⊤ ⋆ , D = diag ( σ 1 , . . . , σ k ) , σ k > 0 , 76 so M ⋆ = U ⋆ D 0 0 0 U ⊤ ⋆ . Let the sample cov ariance b e S m = 1 m P m i =1 X i X ⊤ i . Recall the (fixed- k ) PPCA MLE can b e written as ˆ M m = ˆ U k diag( ˆ λ 1 − 1 , . . . , ˆ λ k − 1) ˆ U ⊤ k , where ˆ λ 1 ⩾ · · · ⩾ ˆ λ d and ˆ U k are the top- k eigenpairs of S m . Since λ k (Σ x ) = 1 + σ k > 1, w e ha ve ˆ λ i > 1 for i ⩽ k with probability → 1, so the “( · ) + ” truncation is asymptotically inactive and the map is smooth at Σ x . The Gaussian fourth-momen t iden tity gives √ m v ec( S m − Σ x ) d ⇝ N 0 , ( I + K )(Σ x ⊗ Σ x ) , where K is the comm utation matrix. Define the smooth map (near Σ x ) g (Σ) : = “b est rank- k PSD appro ximation of Σ − I d ” , ˆ M m = g ( S m ) , M ⋆ = g (Σ x ) . Then Z m : = √ m ( ˆ M m − M ⋆ ) d ⇝ Z, Z = D g Σ x [ G ] , where G is the Gaussian matrix limit of √ m ( S m − Σ x ). Let U ⋆ = [ U 1 U 2 ] with U 1 ∈ R d × k spanning the signal subspace and U 2 ∈ R d × ( d − k ) spanning its orthogonal complement, and rotate ˜ G : = U ⊤ ⋆ GU ⋆ = ˜ G 11 ˜ G 12 ˜ G 21 ˜ G 22 . A first-order perturbation calculation (using the eigengap σ k > 0) yields the simple deriv ative D g Σ x [ G ] = U ⋆ ˜ G 11 ˜ G 12 ˜ G 21 0 U ⊤ ⋆ . Therefore the asymptotic fluctuation has the explicit form Z = U ⋆ ˜ G 11 ˜ G 12 ˜ G 21 0 U ⊤ ⋆ , ˜ G = U ⊤ ⋆ GU ⋆ , and in particular Z is mean-zero Gaussian (as a vector in R d ( d +1) / 2 ). If we define the linear op erator P : R d × d → R d × d b y P ( Y ) : = U ⋆ Y 11 Y 12 Y 21 0 U ⊤ ⋆ (blo c ks taken in the U ⋆ -basis), then vec( Z ) = ( P ⊗ I )v ec( G ) and hence v ec( Z ) ∼ N 0 , ( P ⊗ I ) ( I + K )(Σ x ⊗ Σ x ) ( P ⊗ I ) ⊤ . Equiv alently , Let P ⋆ b e the orthogonal pro jector on to range( M ⋆ ). Then, we ha ve Z = P ⋆ G + GP ⋆ − P ⋆ GP ⋆ . (G.7) 77 Let W ∈ R d × d ha ve i.i.d. N (0 , 1) en tries. Thus, G : = 1 √ 2 Σ 1 / 2 x ( W + W ⊤ )Σ 1 / 2 x . (G.8) Substituting the expression for G giv es the explicit represen tation of Z as a linear transform of a standard Gaussian matrix: Z = 1 √ 2 h P ⋆ Σ 1 / 2 x ( W + W ⊤ )Σ 1 / 2 x + Σ 1 / 2 x ( W + W ⊤ )Σ 1 / 2 x P ⋆ − P ⋆ Σ 1 / 2 x ( W + W ⊤ )Σ 1 / 2 x P ⋆ i . (G.9) Pretraining fluctuations. Fix Σ x : = I d + M ⋆ and write f ⋆ ( x ) = w ⊤ ⋆ x with w ⋆ = Σ − 1 x A ⋆ β ⋆ . A t M ⋆ , choose a lo cal section with s ( M ⋆ ) = A ⋆ and define U ⋆ : = ( I d + M ⋆ ) − 1 A ⋆ = Σ − 1 x A ⋆ . Let P ⋆ b e the Σ x -orthogonal pro jector onto range( U ⋆ ): P ⋆ = U ⋆ U ⊤ ⋆ Σ x U ⋆ − 1 U ⊤ ⋆ Σ x . Then (Π M ⋆ f ⋆ )( x ) = ( P (Σ x ) ⋆ w ⋆ ) ⊤ x and P (Σ x ) ⋆ w ⋆ = w ⋆ . Recall L ( v ) : = − D Π M ⋆ [ v ] f ⋆ . Since D Π M ⋆ [ v ] f ⋆ ( x ) = ( D P (Σ x ) ⋆ [ v ] w ⋆ ) ⊤ x , we hav e L ( v )( x ) = − ( D P (Σ x ) ⋆ [ v ] w ⋆ ) ⊤ x. Define for eac h M U M : = ( I d + M ) − 1 s ( M ) ∈ R d × k , S M : = range( U M ) , and let P (Σ x ) M denote the Σ x -orthogonal pro jector onto S M . By definition of an orthogonal pro jector on to S M , we hav e the matrix iden tit y P (Σ x ) M U M = U M . (G.10) Fix v ∈ T M ⋆ M d,k and consider a smo oth curv e M ( t ) in M d,k with M (0) = M ⋆ and ˙ M (0) = v . Define U ( t ) : = U M ( t ) and P ( t ) : = P (Σ x ) M ( t ) . Then ( G.10 ) becomes P ( t ) U ( t ) = U ( t ) for all t near 0. Differen tiating at t = 0 and applying the pro duct rule giv es ˙ P (0) U ⋆ + P ⋆ ˙ U (0) = ˙ U (0) , where U ⋆ : = U M ⋆ and P ⋆ : = P (Σ x ) M ⋆ . Rearranging yields the key iden tity ˙ P (0) U ⋆ = ( I d − P ⋆ ) ˙ U (0) . (G.11) 78 In terpreting ˙ P (0) = D P (Σ x ) ⋆ [ v ] and ˙ U (0) = D U ⋆ [ v ], we can rewrite ( G.11 ) as D P (Σ x ) ⋆ [ v ] U ⋆ = ( I d − P ⋆ ) D U ⋆ [ v ] . (G.12) Finally , since in our model w ⋆ ∈ S M ⋆ w e can write w ⋆ = U ⋆ β ⋆ for the same β ⋆ app earing in f ⋆ ( x ) = β ⊤ ⋆ U ⊤ ⋆ x . Multiplying ( G.12 ) on the righ t b y β ⋆ giv es D P (Σ x ) ⋆ [ v ] w ⋆ = D P (Σ x ) ⋆ [ v ] U ⋆ β ⋆ = ( I d − P ⋆ ) D U ⋆ [ v ] β ⋆ . (G.13) Moreo ver U M = ( I d + M ) − 1 s ( M ) implies D U ⋆ [ v ] β ⋆ = − Σ − 1 x v Σ − 1 x A ⋆ β ⋆ + Σ − 1 x D s ( M ⋆ )[ v ] β ⋆ . The section-dep enden t term do es not c hange range ( U M ) and is killed by ( I d − P (Σ x ) ⋆ ). Consequen tly , D P (Σ x ) ⋆ [ v ] Σ − 1 x A ⋆ β ⋆ = − ( I d − P (Σ x ) ⋆ )Σ − 1 x v Σ − 1 x A ⋆ β ⋆ , and therefore, for v = Z , L ( Z )( x ) = x ⊤ ( I d − P (Σ x ) ⋆ )Σ − 1 x Z Σ − 1 x A ⋆ β ⋆ . Define the coefficient vector g ( Z ) : = ( I d − P (Σ x ) ⋆ )Σ − 1 x Z Σ − 1 x A ⋆ β ⋆ ∈ R d , so that L ( Z )( x ) = x ⊤ g ( Z ). Then ∥L ( Z ) ∥ 2 L 2 ( µ down ) = E ( x ⊤ g ( Z )) 2 = g ( Z ) ⊤ Σ x g ( Z ) . Equiv alently , expanding g ( Z ), ∥L ( Z ) ∥ 2 L 2 ( µ down ) = Σ − 1 x A ⋆ β ⋆ ⊤ Z ⊤ Σ − 1 x ( I d − P (Σ x ) ⋆ ) ⊤ Σ x ( I d − P (Σ x ) ⋆ ) Σ − 1 x Z Σ − 1 x A ⋆ β ⋆ . Since P (Σ x ) ⋆ is Σ x -self-adjoin t and idemp oten t, ( P (Σ x ) ⋆ ) ⊤ Σ x = Σ x P (Σ x ) ⋆ , ( P (Σ x ) ⋆ ) 2 = P (Σ x ) ⋆ , w e ha v e the simplification ( I d − P (Σ x ) ⋆ ) ⊤ Σ x ( I d − P (Σ x ) ⋆ ) = Σ x ( I d − P (Σ x ) ⋆ ) . Moreo ver, at M ⋆ , we ha ve P (Σ x ) ⋆ = P ⋆ is the orthogonal pro jection onto the span of image ( M ⋆ ). Therefore, ∥L ( Z ) ∥ 2 L 2 ( µ down ) = Σ − 1 x A ⋆ β ⋆ ⊤ Z ⊤ Σ − 1 x ( I d − P ⋆ ) Σ − 1 x Z Σ − 1 x A ⋆ β ⋆ = ∥ ( I d − P ⋆ ) Σ − 1 x Z Σ − 1 x A ⋆ β ⋆ ∥ 2 = ∥ ( I d − P ⋆ ) Z Σ − 1 x A ⋆ β ⋆ ∥ 2 . (G.14) 79 Since Σ − 1 ⋆ acts as iden tity on I − P ⋆ . No w, w e plug eq. ( G.7 ) into Equation ( G.14 ) to get ∥L ( Z ) ∥ 2 L 2 ( µ down ) = ∥ ( I d − P ⋆ ) ( P ⋆ G + GP ⋆ − P ⋆ GP ⋆ ) Σ − 1 x A ⋆ β ⋆ ∥ 2 = ∥ ( I d − P ⋆ ) GP ⋆ Σ − 1 x A ⋆ β ⋆ ∥ 2 . (G.15) Finally , w e plug Equation ( G.8 ) into Equation ( G.15 ) ∥L ( Z ) ∥ 2 L 2 ( µ down ) = ∥ ( I d − P ⋆ ) ( 1 √ 2 Σ 1 / 2 x ( W + W ⊤ )Σ 1 / 2 x ) P ⋆ Σ − 1 x A ⋆ β ⋆ ∥ 2 = 1 2 ∥ ( I d − P ⋆ ) ( W + W ⊤ ) P ⋆ Σ − 1 / 2 x A ⋆ β ⋆ ∥ 2 . (G.16) Let M ⋆ = U ⋆ D 0 0 0 U ⊤ ⋆ with D = diag ( σ 1 , . . . , σ k ) and U ⋆ = [ U 1 U 2 ], where U 1 ∈ R d × k spans range( M ⋆ ). Then P ⋆ = U 1 U ⊤ 1 = U ⋆ I k 0 0 0 U ⊤ ⋆ , Σ x = I d + M ⋆ = U ⋆ I k + D 0 0 I d − k U ⊤ ⋆ , so Σ − 1 / 2 x = U ⋆ ( I k + D ) − 1 / 2 0 0 I d − k U ⊤ ⋆ . Rotate the standard Gaussian matrix by ˜ W : = U ⊤ ⋆ W U ⋆ (still i.i.d. N (0 , 1)). Then ( I d − P ⋆ )( W + W ⊤ ) P ⋆ Σ − 1 / 2 x A ⋆ β ⋆ = U ⋆ 0 0 ( ˜ W 21 + ˜ W ⊤ 12 ) 0 U ⊤ ⋆ U ⋆ ( I k + D ) − 1 / 2 0 0 0 U ⊤ ⋆ A ⋆ β ⋆ . Since A ⋆ β ⋆ ∈ range( U 1 ), letting a : = U ⊤ 1 A ⋆ β ⋆ ∈ R k giv es ( I d − P ⋆ )( W + W ⊤ ) P ⋆ Σ − 1 / 2 x A ⋆ β ⋆ = U 2 ( ˜ W 21 + ˜ W ⊤ 12 ) ( I k + D ) − 1 / 2 a. Because U 2 is orthonormal, ∥ U 2 v ∥ 2 = ∥ v ∥ 2 , hence the original quan tit y simplifies to 1 2 ( I d − P ⋆ )( W + W ⊤ ) P ⋆ Σ − 1 / 2 x A ⋆ β ⋆ 2 2 = 1 2 ( ˜ W 21 + ˜ W ⊤ 12 ) ( I k + D ) − 1 / 2 a 2 2 , a = U ⊤ 1 A ⋆ β ⋆ . In particular, since ˜ W 21 has i.i.d. N (0 , 1) entries and ˜ W 12 is indep endent with the same la w, the matrix 1 √ 2 ( ˜ W 21 + ˜ W ⊤ 12 ) has i.i.d. N (0 , 1) entries. Therefore 1 2 ( ˜ W 21 + ˜ W ⊤ 12 ) ( I k + D ) − 1 / 2 a 2 2 d = Ξ ( I k + D ) − 1 / 2 U ⊤ 1 A ⋆ β ⋆ 2 2 , Ξ ij iid ∼ N (0 , 1) . Equiv alently , w e ha v e ∥L ( Z ) ∥ 2 L 2 ( µ down ) d = ∥ ( I k + D ) − 1 / 2 U ⊤ 1 A ⋆ β ⋆ ∥ 2 2 χ 2 d − k . (G.17) 80 H Pro ofs of Section 6.3 This app endix v erifies that the Gaussian-mixture example from Section 6.3 satisfies the hypotheses of Theorem 5.3 , and hence yields Corollary 6.6 . The verification is mo dular: (i) lo cal-uniform momen t bounds for the feature map, (ii) rank stabilit y/eigengap for the population feature second- momen t Σ( M ), (iii) a manifold CL T for the (pretraining) descriptor estimator ˆ M m = R ( ˆ U m ) via an M -estimation CL T and a delta method, and (iv) v erification of the hypotheses of the general pro jector differen tiability result pro ved in App endix E.2 . Throughout, we work on the regular set from Assumption 6.5 and write M ⋆ : = R ( U ⋆ ). H.1 Mo del, features, and the quotien t-lev el descriptor Unlab eled distribution. Let K ⩾ 2 and d ⩾ 1. The unlab eled distribution is the spherical Gaussian mixture X | ( Z = i ) ∼ N ( u ⋆ i , I d ) , Z ∼ Unif ([ K ]) , with unknown centers U ⋆ = ( u ⋆ 1 , . . . , u ⋆ K ) ∈ ( R d ) K . Cen tered-mean subspace. Define the empirical mean and cen tered second-momen t matrix ¯ u ( U ) := 1 K K X i =1 u i , S ( U ) := K X i =1 u i − ¯ u ( U ) u i − ¯ u ( U ) ⊤ . Let r ⋆ := r ( U ⋆ ) and define P U to b e the orthogonal pro jector on to the leading r ⋆ -dimensional eigenspace of S ( U ) (on the regular neighborho o d where this eigenspace is w ell-defined). W rite P ⋆ := P U ⋆ and V ⋆ := Im( P ⋆ ). Subspace-a w are resp onsibilities. F or i ∈ [ K ], define π i ( x ; U ) = exp ⟨ P U u i , P U x ⟩ − 1 2 ∥ P U u i ∥ 2 2 P K j =1 exp ⟨ P U u j , P U x ⟩ − 1 2 ∥ P U u j ∥ 2 2 . These satisfy 0 ⩽ π i ⩽ 1 and P K i =1 π i = 1. F eature map and h yp othesis class. The induced feature map has dimension p ( U ) = K ( r ( U ) + 1): ψ U ( x ) = π 1 ( x ; U ) P U x − P U u 1 , π 1 ( x ; U ) , . . . , π K ( x ; U ) P U x − P U u K , π K ( x ; U ) . Let H U = {⟨ θ , ψ U ( · ) ⟩ : θ ∈ R p ( U ) } and Π U : L 2 ( µ down ) → L 2 ( µ down ) b e the orthogonal pro jector on to H U . 81 Group action and quotient parameter. Fix U = ( u 1 , . . . , u K ) ∈ ( R d ) K . The unlabeled mixture likelihoo d is in v ariant under relabeling of mixture comp onen ts. Accordingly , w e consider the action of the permutation group S K on ( R d ) K defined by ( g · U ) i := u g − 1 ( i ) , g ∈ S K . W e write U := [ U ] ∈ ( R d ) K /S K for the equiv alence class (orbit) of U under this action, and refer to U as the quotient-level p ar ameter . Regular regime and lo cal lifts. Throughout this app endix we restrict atten tion to the regular regime in whic h the cen ters are distinct: u i = u j for all i = j. In this regime the action of S K is free, and the quotien t ( R d ) K /S K is a smooth manifold of dimension K d . In particular, for any fixed U ⋆ = [ U ⋆ ] there exists a neighborho o d U and a smo oth lo cal section s : U → ( R d ) K , s ( U ) ∈ U , whic h amoun ts to c ho osing a deterministic ordering of the centers in a neighborho od of U ⋆ . All constructions b elow are indep enden t of the specific c hoice of section. P ermutation-in v ariant geometric quan tities. Both ¯ u ( U ) and P U are in v ariant under the action of S K , and therefore depend only on the quotient parameter U . W e may thus unam biguously write ¯ u ( U ) and P U . Resp onsibilities and equiv arian t feature map. F or a representativ e U ∈ U , define the pro jected responsibilities π i ( x ; U ) := exp ⟨ P U u i , P U x ⟩ − 1 2 ∥ P U u i ∥ 2 2 P K j =1 exp ⟨ P U u j , P U x ⟩ − 1 2 ∥ P U u j ∥ 2 2 , i ∈ [ K ] . Let ψ U : R d → R K ( r ⋆ +1) denote the block-structured feature map ψ U ( x ) = π 1 ( x ; U )( P U x − P U u 1 ) , π 1 ( x ; U ); . . . ; π K ( x ; U )( P U x − P U u K ) , π K ( x ; U ) . F or any g ∈ S K , let ρ ( g ) denote the blo c k-p ermutation matrix acting on R K ( r ⋆ +1) . A direct computation shows that the feature map is S K -equiv ariant: ψ g · U ( x ) = ρ ( g ) ψ U ( x ) . T o b e more precise, ρ ( G ) consists of those p erm utations in S 2 K that relab el π i ( x, U ) and π i ( x ; U )( P U x − P U u i ) tw o the same label. Therefore, we can define a feature map ϕ ( · , U ) on the quotien t manifold that satisfies all the assumptions of Appendix C.2 . 82 H.2 Lo cal-uniform moment b ounds for ψ ( · , U ) W e v erify the lo cal-uniform moment b ounds from Assumption E.2 for this model (with X ∼ µ down equal to the Gaussian mixture describ ed in the example). Lemma H.1 (Lo cal-uniform p olynomial moments of the Gaussian-mixture features(Assumption E.2 ) . Fix a c omp act neighb orho o d U of U ⋆ in ( R d ) K . Then for every q ⩾ 1 , sup U ∈U E ∥ ψ U ( X ) ∥ q < ∞ . Conse quently, for every neighb orho o d U of U ⋆ = [ U ⋆ ] c ontaine d in the quotient image [ U ] ⊂ ( R d ) K /S K and every q ⩾ 1 sup U ∈U E ∥ ψ s ( U ) ( X ) ∥ q < ∞ , wher e s : U → ( R d ) K is any lo c al se ction (lift) with s ( U ) ∈ U . Pr o of. Fix U ∈ U . Since 0 ⩽ π i ( x ; U ) ⩽ 1 and ∥ P U x ∥ 2 ⩽ ∥ x ∥ 2 , we hav e for each i π i ( X ; U ) P U X − P U u i 2 ⩽ ∥ X ∥ 2 + ∥ u i ∥ 2 , | π i ( X ; U ) | ⩽ 1 . Th us there exists a constan t C < ∞ dep ending only on K suc h that ∥ ψ U ( X ) ∥ ⩽ C 1 + ∥ X ∥ 2 + max i ∈ [ K ] ∥ u i ∥ 2 . T aking q -th moments and using sup U ∈U max i ∥ u i ∥ 2 < ∞ , it remains to note that all polynomial momen ts of X are finite under a spherical Gaussian mixture, giving the stated uniform bound. F or the quotien t-level statemen t, let U ⊂ [ U ] and let s b e a lo cal section on U . Then s ( U ) ∈ U for all U ∈ U , so the same bound applies uniformly to ψ s ( U ) ( X ). H.3 Rank stability and eigengap for the do wnstream second momen t Define the population second moment (feature co v ariance) Σ( U ) : = E ϕ U ( X ) ϕ U ( X ) ⊤ ∈ R p × p , where p is the feature dimension. T o inv oke Theorem 5.3 , w e need rank stability and an eigengap at 0 for Σ( U ) on a neighborho o d of U ⋆ . W e reduce this to (a) contin uity of U 7→ Σ( U ) and (b) an eigengap at U ⋆ . Lemma H.2 (Con tinuit y of U 7→ Σ( U ) in op erator norm) . L et U b e a c omap ct neighb orho o d of U ⋆ such that the c onclusion of L emma H.1 holds on s ( U ) for some exp onent 4 + δ . Then U 7→ Σ( U ) is c ontinuous at U ⋆ in op er ator norm. Pr o of. Fix U ∈ U and write Y U : = ϕ U ( X ) ϕ U ( X ) ⊤ . By Lemma H.1 (with exp onen t 1 + δ / 4) and Cauc hy–Sc h warz, sup U ∈U E ∥ Y U ∥ 1+ δ / 4 op ⩽ sup U ∈U E ∥ ϕ U ( X ) ∥ 2+ δ / 2 < ∞ , so {∥ Y U ∥ op : U ∈ U } is uniformly integrable. Since ϕ U is a contin uous function of U in U , Y U → Y U ⋆ almost surely as U → U ⋆ . Uniform integrabilit y then yields Σ( U ) − Σ( U ⋆ ) op = E Y U − Y U ⋆ op ⩽ E ∥ Y U − Y U ⋆ ∥ op → 0 , pro ving operator-norm con tinuit y at U ⋆ . 83 Lemma H.3 (Local uniform inv ertibilit y from full rank at U ⋆ ) . Assume Σ( U ⋆ ) ≻ 0 . If U 7→ Σ( U ) is c ontinuous at U ⋆ in op er ator norm (e.g. by L emma H.2 ), then ther e exist a neighb orho o d U of U ⋆ and a c onstant κ > 0 such that for al l U ∈ U , λ min Σ( U ) ⩾ κ. In p articular, Σ( U ) is invertible on U and Σ( U ) + = Σ( U ) − 1 . Pr o of. Since Σ( U ⋆ ) ≻ 0, w e ha ve λ min (Σ( U ⋆ )) > 0. Let κ := 1 2 λ min (Σ( U ⋆ )). By con tinuit y in op erator norm, for U close enough to U ⋆ w e ha ve ∥ Σ( U ) − Σ( U ⋆ ) ∥ op ⩽ κ . W eyl’s inequality then yields λ min Σ( U ) ⩾ λ min Σ( U ⋆ ) − ∥ Σ( U ) − Σ( U ⋆ ) ∥ op ⩾ 2 κ − κ = κ, pro ving the claim. H.4 Pretraining CL T for the quotient estimator ˆ U m = [ ˆ U m ] W e no w establish the pretraining fluctuation input required by App endix E.2 : a tangen t-space CL T for the quotien t-level estimator ˆ U m in normal coordinates around U ⋆ = [ U ⋆ ]. Pretraining estimator. F or concreteness, let ˆ U m b e a (measurable) lo cal minimizer of the empirical negative log-likelihoo d for the mixture with equal weigh ts and kno wn co v ariance: ℓ ( U ; x ) = − log 1 K K X i =1 exp − 1 2 ∥ x − u i ∥ 2 2 , ˆ U m ∈ arg min U 1 m m X j =1 ℓ ( U ; X j ) . Define the quotien t estimator ˆ U m : = [ ˆ U m ] ∈ ( R d ) K /S K . Lemma H.4 (Score and Hessian for the spherical equal-w eight MoG likelihoo d) . L et p U ( x ) : = 1 K K X i =1 φ d ( x − u i ) , φ d ( t ) : = (2 π ) − d/ 2 exp − 1 2 ∥ t ∥ 2 2 , ℓ ( U ; x ) : = − log p U ( x ) . Define the r esp onsibilities π i ( x ; U ) : = φ d ( x − u i ) P K j =1 φ d ( x − u j ) = exp( − 1 2 ∥ x − u i ∥ 2 2 ) P K j =1 exp( − 1 2 ∥ x − u j ∥ 2 2 ) , i ∈ [ K ] . Then ℓ ( U ; x ) is C ∞ in U , and the gr adient blo cks satisfy ∇ u i ℓ ( U ; x ) = − π i ( x ; U ) ( x − u i ) , i ∈ [ K ] . Mor e over, the blo ck Hessian ∇ 2 u i u j ℓ ( U ; x ) ∈ R d × d is given by ∇ 2 u i u j ℓ ( U ; x ) = π i ( x ; U ) I d − π i ( x ; U ) 1 − π i ( x ; U ) ( x − u i )( x − u i ) ⊤ , i = j, π i ( x ; U ) π j ( x ; U ) ( x − u i )( x − u j ) ⊤ , i = j. In p articular, for any b ounde d set U ⊂ ( R d ) K ther e exists C < ∞ (dep ending on U and K ) such that for al l U ∈ U and al l x ∈ R d , ∥∇ ℓ ( U ; x ) ∥ 2 ⩽ C 1 + ∥ x ∥ 2 , ∥∇ 2 ℓ ( U ; x ) ∥ op ⩽ C 1 + ∥ x ∥ 2 2 . 84 Pr o of. The smo othness of U 7→ ℓ ( U ; x ) follows from p U ( x ) > 0 and smoothness of u 7→ φ d ( x − u ). W rite Z ( U ; x ) : = P K j =1 φ d ( x − u j ) so that ℓ ( U ; x ) = − log Z ( U ; x ) + log K . Since ∇ u i φ d ( x − u i ) = φ d ( x − u i )( x − u i ), we hav e ∇ u i ℓ ( U ; x ) = − ∇ u i Z ( U ; x ) Z ( U ; x ) = − φ d ( x − u i ) P K j =1 φ d ( x − u j ) ( x − u i ) = − π i ( x ; U )( x − u i ) . F or the Hessian, first note that ∇ u j π i ( x ; U ) = π i ( x ; U ) δ ij − π j ( x ; U ) ( x − u j ) , whic h follo ws by differentiating the softmax form of π i . Using ∇ u j ( x − u i ) = − δ ij I d , we obtain ∇ 2 u i u j ℓ ( U ; x ) = −∇ u j π i ( x ; U )( x − u i ) = − ∇ u j π i ( x ; U ) ( x − u i ) ⊤ + π i ( x ; U ) δ ij I d . Substituting the expression for ∇ u j π i yields the displa yed blo c k form ulas for i = j and i = j . Finally , the b ounds use 0 ⩽ π i ⩽ 1 and, on a b ounded set U , the uniform bound max i ∥ u i ∥ 2 ⩽ C U : ∥∇ u i ℓ ( U ; x ) ∥ 2 ⩽ ∥ x − u i ∥ 2 ⩽ ∥ x ∥ 2 + C U , and each Hessian blo c k is a sum of terms b ounded by 1 and ∥ x − u i ∥ 2 ∥ x − u j ∥ 2 , hence by C (1 + ∥ x ∥ 2 2 ) uniformly o ver U ∈ U . Summing o ver the K × K blo c ks giv es the stated op erator-norm bound. Lemma H.5 (Lo cal uniqueness of the MLE after fixing the p ermutation symmetry) . L et L ( U ) = E [ ℓ ( U ; X )] and ˆ L m ( U ) = 1 m P m j =1 ℓ ( U ; X j ) , wher e X ∼ p U ⋆ . Fix a gauge-fixing set Θ ⊂ ( R d ) K that r emoves the p ermutation symmetry lo c al ly (e.g. a lo c al or dering rule), so that U ⋆ ∈ Θ and no nontrivial p ermutation of U ⋆ b elongs to Θ . Assume: (i) if p U = p U ⋆ then U e quals a p ermutation of U ⋆ (identifiability up to p ermutation); (ii) L is twic e differ entiable on Θ and ther e exist µ > 0 and ρ > 0 such that ∇ 2 L ( U ) ≽ µI for al l U ∈ Θ ∩ B ( U ⋆ , ρ ) ; (iii) sup U ∈ Θ ∩ B ( U ⋆ ,ρ ) ∥∇ 2 ˆ L m ( U ) − ∇ 2 L ( U ) ∥ op → 0 in pr ob ability. Then, with pr ob ability tending to one, ˆ L m is µ/ 2 -str ongly c onvex on Θ ∩ B ( U ⋆ , ρ ) and has a unique minimizer ther e, denote d ˆ U m , and ˆ U m → U ⋆ in pr ob ability. Pr o of. This is identical to the standard strong-conv exity plus uniform-Hessian-consistency argument; w e include it here for completeness. By (iii), with probabilit y tending to one, sup U ∈ Θ ∩ B ( U ⋆ ,ρ ) ∇ 2 ˆ L m ( U ) − ∇ 2 L ( U ) op ⩽ µ/ 2 . On this ev ent, (ii) implies ∇ 2 ˆ L m ( U ) ≽ ( µ/ 2) I for all U ∈ Θ ∩ B ( U ⋆ , ρ ), hence ˆ L m is µ/ 2-strongly con vex there and has a unique minimizer. Consistency follows from (i) together with uniform con vergence of ˆ L m to L on Θ ∩ B ( U ⋆ , ρ ), which is implied by the same regularit y underlying (iii) and the polynomial tail control of X under the mixture. 85 Prop osition H.6 (Euclidean M -estimation CL T for the gauge-fixed MLE) . Assume Assumption 6.5 and the c onditions of L emma H.5 for some gauge-fixing set Θ . Then any se quenc e of c onsistent lo c al minimizers ˆ U m ∈ Θ satisfies √ m v ec( ˆ U m − U ⋆ ) d ⇝ N (0 , Ω U ) , wher e Ω U = H − 1 U S U H − 1 U with H U = ∇ 2 L ( U ⋆ ) and S U = Co v ( ∇ ℓ ( U ⋆ ; X )) , al l c ompute d in the gauge c o or dinates on Θ . Pr o of. Under the spherical Gaussian mixture and Lemma H.4 , ℓ ( U ; x ) is smo oth in U and its deriv atives are dominated on b ounded neighborho ods of U ⋆ b y polynomials in ∥ x ∥ 2 . Since X has finite moments of all orders, the score ∇ ℓ ( U ⋆ ; X ) has finite second momen ts. Lemma H.5 provides lo cal consistency and uniqueness in the gauge. A T aylor expansion of the first-order condition ∇ ˆ L m ( ˆ U m ) = 0 around U ⋆ yields 0 = ∇ ˆ L m ( U ⋆ ) + ∇ 2 ˆ L m ( ˜ U m ) ( ˆ U m − U ⋆ ) , for some in termediate point ˜ U m on the segmen t betw een U ⋆ and ˆ U m . By a la w of large num b ers, ∇ 2 ˆ L m ( ˜ U m ) → H U in probability , and b y a CL T, √ m ∇ ˆ L m ( U ⋆ ) d ⇝ N (0 , S U ). Slutsky’s theorem giv es the stated sandwic h co v ariance. Prop osition H.7 (Manifold CL T for the quotien t parameter) . Assume the c onditions of Pr op o- sition H.6 . L et U ⋆ = [ U ⋆ ] ∈ ( R d ) K /S K and ˆ U m = [ ˆ U m ] . Then on a normal neighb orho o d of U ⋆ , Z m = √ m log U ⋆ ( ˆ U m ) d ⇝ Z , Z ∼ N (0 , V ) , in T U ⋆ ( R d ) K /S K , wher e V is the pushforwar d of Ω U thr ough the differ ential of the quotient map U 7→ [ U ] expr esse d in normal c o or dinates (e quivalently, thr ough any lo c al gauge chart s ar ound U ⋆ ). Pr o of. Since ˆ U m → U ⋆ in probability , we ha ve ˆ U m = [ ˆ U m ] → [ U ⋆ ] = U ⋆ in probability . Fix a lo cal section (gauge c hart) s defined on a neighborho od of U ⋆ with s ( U ⋆ ) = U ⋆ . In the associated local co ordinates on the quotien t, the map U 7→ [ U ] is C 1 on the regular set and agrees locally with the c hart map, so b y the delta method, √ m s ( ˆ U m ) − s ( U ⋆ ) = √ m ( ˆ U m − U ⋆ ) + o p (1) in the Euclidean gauge coordinates. Comp osing with the normal-co ordinate logarithm map log U ⋆ (whic h is C 1 on a normal neighborho o d) yields the stated tangen t-space CL T, with cov ariance V giv en b y the usual pushforward of Ω U through the co ordinate represen tations of the c hart and the logarithm map. H.5 F r´ echet differen tiabilit y of U 7→ Π U The master theorem requires F r´ echet differentiabilit y of U 7→ Π U at U ⋆ in op erator norm on L 2 ( µ down ). W e do not re-pro v e this here; instead we verify the h yp otheses of the general differen tiability result pro ved in App endix E.2 . Lemma H.8 (V erification of the pro jector differentiabilit y h yp otheses) . L et V b e a neighb orho o d of U ⋆ on which L emma H.1 holds. Then: 86 (i) In the lo c al chart fixing the p ermutation ambiguity, U 7→ ϕ ( · , U ) is C 1 on V . (ii) Ther e exist δ > 0 and C ∂ ϕ < ∞ such that sup U ∈V E ∥ D U ϕ ( X , U ) ∥ 4+ δ op ⩽ C ∂ ϕ . (iii) If, additional ly, Σ( U ) has stable r ank/eigengap on V (as in L emma H.3 ), then U 7→ Π U is F r´ echet differ entiable at U ⋆ in op er ator norm. Pr o of. (i) On the regular set, U 7→ P U and U 7→ ( P U u i ) are smo oth, and ( x, U ) 7→ π i ( x ; U ) is a softmax of smooth functions. In a lo cal c hart around U ⋆ fixing the permutation am biguity , these ob jects become smo oth functions of U , hence U 7→ ϕ ( x, U ) is C 1 for each x . (ii) Differentiating ϕ pro duces finite sums of terms in volving π i , D π i , P U , and D P U , multiplied b y x and the b ounded centers. On any b ounded neighborho o d of U ⋆ , these deriv atives are bounded b y p olynomials in ∥ x ∥ 2 , while 0 ⩽ π i ⩽ 1. Since X under the mixture has finite momen ts of all orders, we obtain the stated b ound for some δ > 0. (iii) This is exactly the implication of the general pro jector differentiabilit y result in Appendix E.2 once the momen t bounds and the stable-rank/eigengap condition are in place. H.6 Conclusion: pro of of Corollary 6.6 Pr o of of Cor ol lary 6.6 . Under Assumption 6.5 and the mo del-sp ecific verifications ab o ve: • Lemma H.1 giv es the lo cal-uniform moment b ounds in Assumption E.2 . • Lemma H.2 and Lemma H.3 giv e rank stabilit y/eigengap for Σ( M ) on a neigh b orho o d of M ⋆ . • Prop osition H.6 yields the manifold CL T Z m = √ m log M ⋆ ( ˆ M m ) d ⇝ Z ∼ N (0 , V ). • Lemma H.8 v erifies the hypotheses needed to inv oke the general differen tiability theorem for M 7→ Π M from App endix E.2 . Assuming compatibility Rep ( M ⋆ ) = 0, the h yp otheses of the master theorem in the compatible regime (Theorem 5.3 in the main text) hold for this model. Applying that theorem along any joint limit ( m, n ) → ( ∞ , ∞ ) with m/n → α ∈ (0 , ∞ ) yields the claimed limit in Corollary 6.6 , with L ( v ) = − D Π M ⋆ [ v ] f ⋆ . 87
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment