공간·시간 리스너 기반 머신러닝 모델 시각화 프레임워크
본 논문은 모델을 1차 분석 객체로 삼는 새로운 모델‑중심 시각화 프레임워크를 제안한다. 모델의 공간적·시간적 행동을 추출하는 추상 ‘리스너’ 층을 두 단계로 설계하고, 이를 기존 정보시각화(InfoVis) 파이프라인에 연결한다. 대규모 논문·그림 코딩을 위해 인간‑LLM 협업 추출 워크플로우를 구축했으며, 128편의 VIS/VAST 논문(331개 그림)에서 모델 시각화의 현황을 정량·정성 분석하였다. 결과는 현재 모델 시각화가 결과‑중심, 정…
저자: Siyu Wu, Lei Shi, Lei Xia
본 논문은 머신러닝 모델 시각화(ModelVis) 분야가 급속히 성장하고 있음에도 불구하고, 기존의 분류 체계가 데이터·작업 중심으로만 구성돼 모델 자체를 충분히 다루지 못한다는 점을 문제 제기로 삼는다. 이를 해결하기 위해 ‘모델‑중심’ 두 단계 프레임워크를 제안한다. 첫 번째 단계는 모델을 핵심 객체로 두고, ‘모델 리스너’라는 추상 레이어를 모델에 삽입해 공간적·시간적 행동을 캡처한다. 공간 리스너는 입력 데이터, 중간 레이어, 출력, 파라미터, 구조 등 정적인 요소를, 시간 리스너는 학습, 재구성, 추론 과정에서의 동적 변화를 기록한다. 리스너는 수동형(모델에 영향을 주지 않음)과 능동형(특정 변조를 통해 추가 정보를 얻음)으로 구분되며, 예를 들어 입력 특성을 교란해 활성화 맵을 시각화하는 경우가 능동형에 해당한다.
두 번째 단계에서는 캡처된 원시 신호를 ‘정량화 알고리즘’ 층을 통해 의미 있는 데이터 객체로 변환한다. 여기에는 성능 지표 계산, 레이어별 활성도 추출, LRP·디컨볼루션 같은 역전파 기반 해석 기법이 포함된다. 변환된 데이터는 n차원 정량 데이터, 1차원 시계열, 관계형, 명목형 등 다양한 형태로 정형화되며, 이는 기존 정보시각화(InfoVis) 파이프라인—데이터 조직, 변환, 시각화, 인터랙션—에 그대로 투입될 수 있다. 따라서 모델‑중심 프레임워크는 기존 InfoVis 파이프라인을 재활용하면서도 모델 특유의 복합 데이터를 효과적으로 다룰 수 있다.
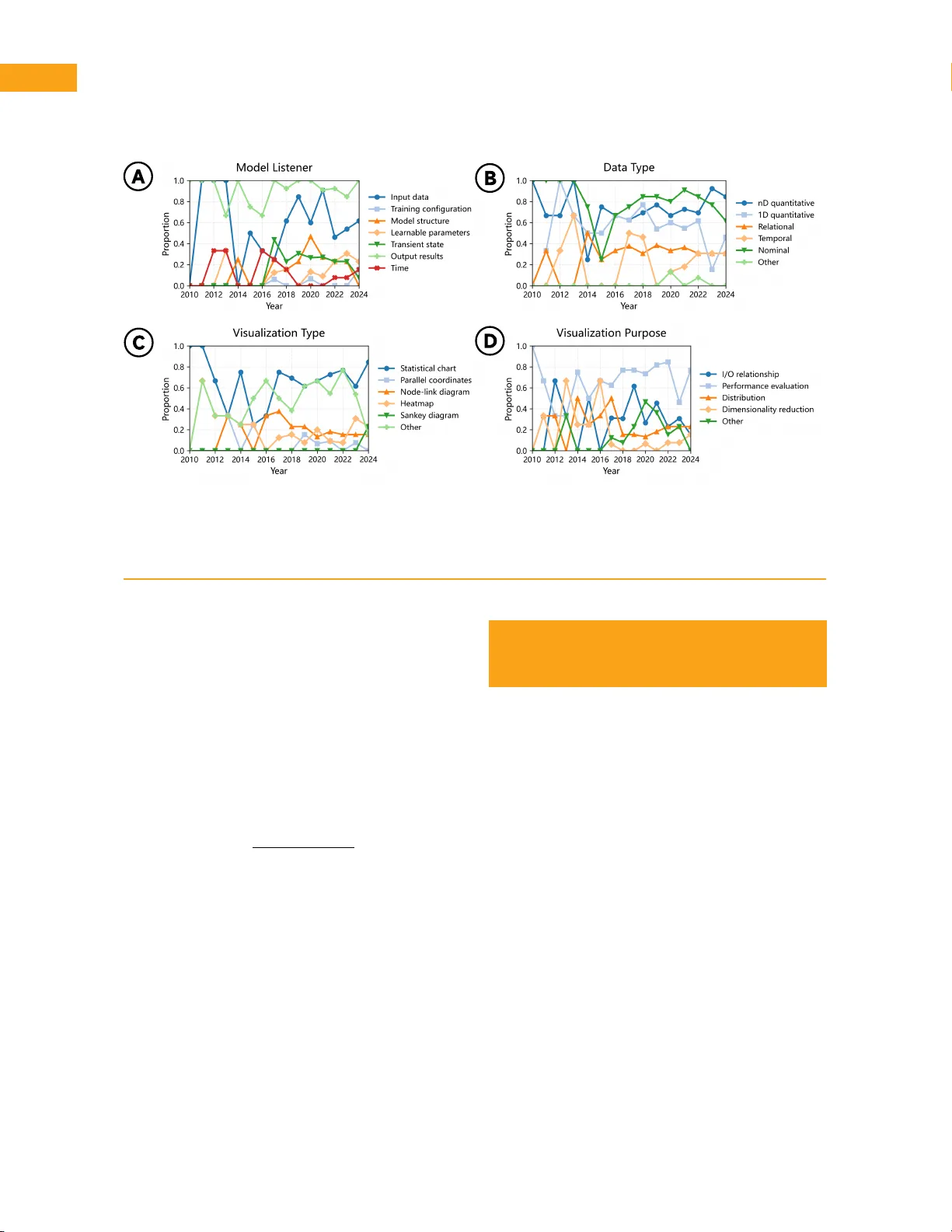
프레임워크의 실증을 위해 저자들은 대규모 문헌 메타분석 파이프라인을 구축했다. IEEE VIS/VAST 2010‑2024년 논문 메타데이터를 기반으로 1052편의 후보 논문을 수집하고, 키워드 기반 전처리와 인간‑LLM 협업 추출을 통해 모델 시각화와 직접 연관된 128편(331개 그림)을 선별했다. 세 단계(논문 수준 스크리닝, 그림 수준 관련도 검출, 프레임워크 차원 라벨링)를 거쳐 각 그림에 대해 ‘모델 리스너 종류(공간·시간·수동·능동)’, ‘데이터 타입’, ‘시각화 유형’, ‘시각화 목적’ 네 차원을 자동 라벨링하고 인간 검증을 수행했다.
분석 결과는 다음과 같다. 첫째, 대부분(≈70%)의 연구가 ‘결과‑중심’ 시각화, 즉 예측값·오차·성능 지표를 시각화하는 데 초점을 맞추고 있다. 둘째, 사용되는 데이터 타입은 정량·명목형이 압도적이며, 다차원(다변량) 데이터 시각화는 상대적으로 적다. 셋째, 시각화 장르는 통계 차트(히스토그램, 박스플롯, 바 차트 등)가 가장 많이 사용되고, 네트워크·히트맵·시계열 차트는 소수에 불과하다. 넷째, 인용 가중치를 적용한 트렌드 분석에서 ‘모델 메커니즘‑중심’ 연구(구조·학습 과정·동적 상태 해석)는 전체 비중이 낮지만 평균 인용수가 높아 높은 학술적 영향을 미치고 있음을 확인했다. 다섯째, 최근 3년간 메커니즘‑중심 연구는 감소 추세이며, 대신 성능 비교·베이스라인 평가가 주를 이루고 있다.
이러한 결과는 현재 ModelVis 연구가 모델의 최종 결과에 초점을 맞추는 경향이 강하고, 모델 내부 구조·동적 과정에 대한 탐구는 상대적으로 소홀히 다루어지고 있음을 시사한다. 저자들은 프레임워크가 모델을 첫 번째 객체로 삼아 설계·평가·비교를 일관된 방식으로 수행하도록 돕는 동시에, 인간‑LLM 협업 추출이 대규모 문헌 분석을 효율적으로 가능하게 함을 강조한다. 한계점으로는 LLM 기반 라벨링의 정확도 검증 부족, 비정형·멀티모달 모델에 대한 적용 검증 미비, 그리고 사용자 인터랙션 설계와 폐쇄 루프 피드백 메커니즘에 대한 구체적 논의가 부족한 점을 들었다. 향후 연구 방향은 (1) 리스너 구현 자동화 도구 개발, (2) 다양한 정량화 알고리즘(예: 그래디언트 기반 해석, 샘플링 기반 동적 분석) 확장, (3) 사용자 중심 인터랙션 및 실시간 피드백 루프 구축, (4) 강화학습, 생성형 모델 등 비전통적 모델에 대한 프레임워크 적용 검증이다. 최종적으로 이 프레임워크는 ModelVis 분야의 체계적 정리와 새로운 설계 템플릿을 제공함으로써, 모델 해석·디버깅·설계 전 과정을 통합적으로 지원하는 기반을 마련한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기