Visualization of Machine Learning Models through Their Spatial and Temporal Listeners
Model visualization (ModelVis) has emerged as a major research direction, yet existing taxonomies are largely organized by data or tasks, making it difficult to treat models as first-class analysis objects. We present a model-centric two-stage framew…
Authors: Siyu Wu, Lei Shi, Lei Xia
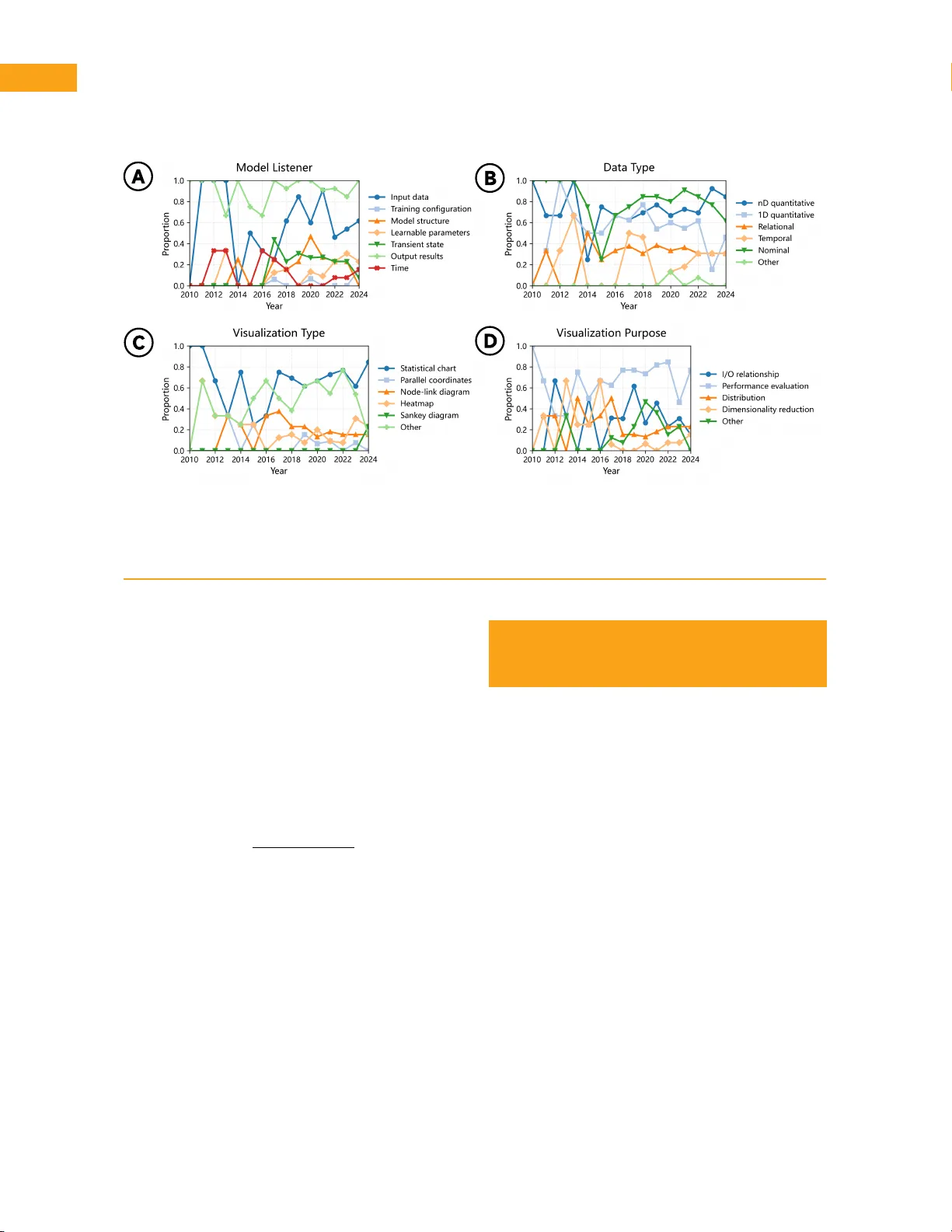
arXiv:2603.27527v1 [cs.LG] 29 Mar 2 026 Visualization of Machine Learning Models thr ough Their Spatial and T emporal Listener s Siyu W u, School of Computer Science & Engineering, Beihang University , Beijing, 100191, China Lei Shi*, School of Computer Science & Engineering, Beihang University , Beijing, 100191, China Lei Xia, School of Computer Science & Engineering, Beihang University , Beijing, 100191, China Ceny ang Wu, Institute of Medical T echnology , P eking Univ ersity Health Science Center and National Institute of Health Data Science, P eking University , Beijing, 100191, China Zipeng Liu, School of Software, Beihang Univ ersity , Beijing, 100191, China Yingchaojie F eng*, National University of Singapore, Singapore Liang Zhou*, Institute of Medical T echnology , P eking University Health Science Center and National Institute of Health Data Science, P eking University , Beijing, 100191, China W ei Chen, State K ey Laboratory of CAD&CG, Zhejiang University , Hangzhou, 310058, China Abstract—Model visualization (ModelVis) has emerged as a major research direction, yet existing taxonomies are largely organized by data or tasks, making it difficult to treat models as first-class analysis objects. W e present a model-centric two-stage frame work that employs abstract listeners to capture spatial and temporal model behaviors , and then connects the translated model behavior data to the classical InfoVis pipeline. T o apply the frame work at scale, we build a retriev al-augmented human–large language model (LLM) extr action workflow and curate a cor pus of 128 VIS/V AST ModelVis papers with 331 coded figures. Our analysis shows a dominant result-centric pr iority on visualizing model outcomes, quantitativ e/nominal data type, statistical char ts, and performance ev aluation. Citation-weighted trends fur ther indicate that less frequent model-mechanism-oriented studies hav e dispropor tionately high impact while are less inv estigated recently . Over all, the frame work is a general approach f or compar ing existing ModelVis systems and guiding possible future designs. M odel visualization (ModelVis)—the use of computer-generated, visual representation of mathematical models (instead of data) to gain insights—has emerged as a new area in visualiza- tion, data science, and ar tificial intelligence (AI). With- out the loss of generality , we refer to models as both predictive and descr iptiv e ones, although the f ocus of the comm unity is on the f or mer , which is also known as machine lear ning models. Numerous aliases exist for ModelVis and are used interchangeably: inter pretable machine learning, explainability of machine learning models, XAI, open the black-bo x of models, etc. The topic becomes impor tant as models become black- bo xes after the introduction of comple x model-building algorithms such as deep learning. Humans can hardly recognize the internal mechanism of models ev en XXXX-XXX © 2026 Digital Object Identifier XX.XXXX/XXX.0000.0000000 though they have designed the training algor ithm. As more data is applied to train the model, the predictive power is increasingly being shaped by the underlying data, but not the human designer of the algor ithm. On the other hand, modern machine lear ning models, for e xample, LLMs , are huge in v olume and e volv e quic kly , ov erwhelming any human being without appropriate visual guidance. Visualization has been successfully applied to un- derstand machine lear ning models. Zeiler and F ergus le verage visualization and an inter pretation method, namely , deconv olution, to win the ImageNet Challenge in 2013 [ 1 ], right after the deep lear ning breakthrough by Ale xNet in 2012. The T ensorFlow Playground by Google [ 2 ] introduces an inter active educational tool f or lear ning the inter nal mechanism of basic multi- la yer neural networks. Users without prior knowledge of machine learning or e ven computer science can understand and diagnose deep lear ning models via Month Not Published Publication Name 1 FIGURE 1 . Overview of our model-centric ModelVis framework. (A) A model listener layer captures model e vidence from input data , training configuration , model structure , lear nab le parameters , transient state , dynamics (time) , and output results , and quantifies these observations into analysis-ready data. (B) The quantified outputs are then mapped to the classical InfoVis pipeline, including data organization, transf or mation, visualization, and interaction. the interactive visualization platf or m. Eventually , as hundreds or more ModelVis techniques hav e been proposed, the community calls f or ModelVis frame- works and taxonomies that can help to comprehend, compare, and apply existing methods according to their rele vant usage scenar ios and problem settings. T axonomies of ModelVis are av ailable in sur v eys. Howe v er , most existing taxonomies use visualization- oriented perspectives , e.g., b y visualization goals [ 3 ]– [ 7 ], inf or mation visualization (InfoVis) and visual ana- lytics (V A) pipelines [ 7 ]–[ 11 ], visualization data and users [ 6 ], [ 12 ], [ 13 ]. Model-centric taxonomies are rare, although model is the primar y subject in Mod- elVis, as opposed to data/visualization subject in In- f oVis/V A. Therefore , our main motivation in this paper is to inv estigate the possibility of de veloping a model- centric taxonomy/framew ork that can encapsulate ex- isting and future ModelVis techniques . Fur thermore, we ask what are the similar ities and dissimilar ities of such a ModelVis framew ork compared to classical Inf oVis/V A pipelines. T o this end, this work is initiated based on two obser v ations. First, machine lear ning models are com- ple x systems composed of multiple components, e.g., input data (independent variables), model str ucture, learning algorithm, and output data (dependent vari- ables). Meanwhile, InfoVis techniques are studied and designed according to the type of data to consume, f or example , text, tables, or networks. This introduces a mismatch where the ke y lies in that—models are typi- cally not singular-typed data. Second, to o vercome this limitation, most existing ModelVis techniques translate machine learning models into separate types of data f or visualization, though this could be unintentional, e.g., extr acting the model structure as networks, com- puting the performance of models as 1D data, map- ping and correlating input and output data into multi- dimensional data. According to these obser v ations, 2 Publication Title Month 2026 the main idea of this work is to introduce an abstract model listening lay er (Figure 1 .A), which captures dif- f erent aspects of a machine learning model f or pos- sible visualization. Model quantification algorithms are deplo yed after the listening lay er to fur ther translate model behavior information into consumable data ob- jects. Subsequently , as the output data objects become the rela yed ne w input, the classical Inf oVis pipeline can be reused to ser v e the f ollow-up visualization and interaction tasks (Figure 1 .B). With this new ModelVis frame work, we present a literature analysis method and examine a large cor pus of V A papers that could be related to the ModelVis topic. The method f eatures a three-stage workflow le veraging the synergy of humans and LLMs to e xtract rele vant ModelVis dimensions in the new framew ork from these papers. P ost-hoc analysis on the LLM extraction result re- veals the distributions and trends of ModelVis tech- niques and validates the feasibility of our new frame- work. The main contr ib utions of this paper are as f ollows. • A new model-centr ic taxonomy that categor izes ModelVis techniques pr imarily by their listen- ing mechanism on model behavior , from both spatial and temporal dimensions. The frame- work e xtends the classical Inf oVis pipeline by abstracting the essential model-data translation mechanism. • An LLM-based literature analysis method that maps state-of-the-ar t ModelVis techniques onto the new framework without the need of full, costly human annotations, while still preser ving high accuracy . On a core ModelVis literature collection, the mapping result validates the eff ec- tiveness of the proposed model-centr ic frame- work. • The post-hoc analysis on framework/taxonomy mapping elicits sev eral interesting results while suggesting potential limitations on the current ModelVis research. For example , the impor tance of multi-dimensional data visualization and com- modity statistical char ts in ModelVis, and the recent decline of in vestigation into deeper mech- anism (e.g., model structure, transient states) and the temporal dynamics of machine lear ning models. RELA TED W ORK W e summarize related approaches on the taxonomy of model visualization. According to the sur ve y of sur v eys on ModelVis published in 2020 [ 14 ], 18 note wor th y surve ys or taxonomy-discussing papers on inter preting machine learning models are av ailable . W e manually supple- ment with fiv e more appearing after 2020. Out of these 23 sur v eys, 16 e xplicitly propose at least one technical taxonomy of model visualization works. The first group of surveys adopts the most popular categorization that classifies techniques according to their high-le vel visualization goals and tasks [ 3 ]– [ 7 ]. A typical example is by Choo and Liu [ 5 ], which e xplicitly discusses three ke y goals of visual analytics f or explainab le deep lear ning: understanding, debug- ging/diagnosis, and refinement/steering. This catego- rization is follow ed in a large por tion of related wor k on model visualization goals [ 4 ], [ 7 ]. Another collection of sur ve ys repor ts model vi- sualization literature b y their stages in visualization and visual analytics pipelines, as well as visualization methods [ 7 ]–[ 10 ], [ 15 ]. Specifically , W ang et al. [ 10 ] re view visual analytics pipelines by examining individ- ual modules from the perspectives of data, visualiza- tion, models, and knowledge . Advancing this pipeline concept into the realm of deep lear ning. Alicioglu and Sun [ 15 ] re view visual analytics for XAI, categor izing the current literature based on visual approaches and model usage—such as feature selection, performance analysis, and architecture understanding. Further more, the two works on predictive visual analytics [ 8 ], [ 9 ] discuss relev ant techniques on stages such as data pre-processing, feature engineer ing, model training, and model selection&validation [ 6 ], [ 12 ], [ 13 ], [ 16 ]. Some studies apply miscellaneous or multiple tax- onomies, including data perspectiv es [ 12 ] and user types [ 6 ]. The notable work by Hohman et al. [ 16 ] organizes the role of visual analytics in deep lear ning according to the five Ws (Why , Who , What, When, Where) and How . The “Where” dimension refers to the application domain of models, b ut does not indicate the model space taxonomy used in our work. Sur v eys of the f our th group are most rele vant to our taxonomy [ 11 ], [ 17 ]–[ 19 ]. Sacha et al. [ 11 ] propose a pipeline using a machine lear ning model to analyze data, and then discuss techniques on each stage of the pipeline. Howe v er , this pipeline largely remains data- centric rather than model-centric. Garcia et al. [ 17 ] study the low-le v el tasks for model visualization, which are related to the model quantification concept of our work. Howe ver , only three types of model quantifica- tion, model architecture, training, and features of deep learning models are discussed. La Rosa et al. [ 18 ] also introduce multiple model-related categor ization methods, similar to ours, such as visualization types, Month 2026 Pub lication Title 3 analysis methods, and subjects, but their primar y cat- egor y is deter mined by the explanation method and is essentially not a model-centric taxonomy . The work by Y uan et al. [ 19 ] is similar to our proposal in that they also proposed the temporal taxonomy that classifies techniques as before/during/after model training. Be- yond that, they do not utilize the model space concept in their classification, which is central to our proposal. Unlike these related studies, our work introduces a new taxonomy designed from a spatial and temporal perspective . Moreover , our taxonomy aims to general- ize f or both traditional machine lear ning models and modern deep learning models. MODEL VISU ALIZA TION FRAMEWORK BY SP A TIAL AND TEMPORAL LISTENERS W e introduce a model-centr ic frame work that orches- trates ModelVis techniques according to their spatial and/or temporal attachment to the machine learning models inter preted while still maintaining compatibility with the classical InfoVis pipeline. Here, space ref ers to the abstract spatial extension of a model (e.g., input/intermediate/output data por ts, data processing la yers, neural modules computing activations, and the ov erall interconnection topology within a model), while time ref ers to the temporal dynamics of all these spatial elements of a model (e.g., dur ing re-configuration, training, or inference). As shown in Figure 1 , the framew or k is composed of two stages. In the first stage, the model to be visualized becomes the first-class, central object. The analysis is fur ther conducted through multiple spatial and temporal listeners attached to the model object. The listening outcomes are then translated into rele- vant, consumable data objects by ex ecuting quantifi- cation algorithms, e.g., performance index computer . In the second stage, the data objects describing the spatial and temporal behavior of a model are visualized through the classical InfoVis pipeline after customiza- tion according to the ModelVis context. Model Listeners Model listeners (Figure 1 .A) are defined to be the software lay er (or AI hardware) embedded inside the machine lear ning system, which capture the signals related to the model behavior . For e xample, listeners can repor t input data, training configuration, model structure, lear nable parameters, transient state, output results, and their temporal dynamics (colored-bordered bo xes in Figure 1 .A). In our frame work, the listeners are classified into spatial and temporal categor ies, f ocusing on the model’s static and dynamic behavior . F rom another perspectiv e, the listeners can also be classified as passive model listeners and active model listeners. In most cases, passiv e listeners are deplo yed in which the model is agnostic to the listening soft- ware/hardw are mechanism, so that the model behavior is undisturbed. For some minor cases, e.g. when the full model machiner y should be mapped, activ e model listeners can be applied, so that more model behavior can be e xposed and studied. A typical e xample is the per turbation-based model inter pretability method where the input data/f eature is manipulated to visu- alize cer tain patter n in resulting predictive outcomes (e.g., activation maximization) and/or the input-output correlation. Quantification Algorithms T o br idge the model evidence from the listening la yer and the follow-up visualization and visual analysis, we introduce a quantification algor ithm lay er which translates the ra w signals captured by the model listeners into structured data objects describing the concerning aspect of a machine lear ning model. The most straightforw ard example lies in the computation of v ar ious performance indicators by compar ing the model inference outcomes with their ground-truths. Y et, more complicated quantification algor ithms are also essential to understand the sophisticated model behavior . For instance, the deconvolution and la yer wise relev ance propagation (LRP) quantification algo- rithms are model-inter pretation methods that rev erse the f orward processing of a model (typically a neural network) to highlight the most impor tant input features with respect to a selected model outcome. Compatibility with the Inf oVis Pipeline After quantification, listener outputs are organized into standard data objects with multiple types—multi- dimensional (nD) quantitative, one-dimensional (1D) quantitative , relational, temporal, nominal—and other miscellaneous data types. This data abstraction en- ables the reuse of well-estab lished Inf oVis pipeline (Figure 1 .B): data, transf ormation, visualization, and interaction. F or example, the transf or mation operators in InfoVis are then applicable, including filtering, ag- gregation, projection, distributional summar ization, and comparison. Model-centr ic visualizations can then be decomposed into concurrent, multiple usage of the classical pipeline, which are finally linked together into a visual analytics system, such as correlating output predictive errors with the inter nal model states, sim- 4 Publication Title Month 2026 plifying large model structures, or comparing model perf or mance under different training settings. We note that the data transformation module in the second stage of our frame work bears subtle difference from the model quantification algorithms. The quantification al- gorithm focuses on computing semantically significant representation of a model while the data transf ormation in InfoVis f ocuses on prepar ing structured data for visual representation, i.e., semantic vs. visual. Specially in the visualization stage, the structured and transformed data objects are mapped to classical visualization genres such as statistical char ts, node- link diagrams, parallel coordinates, heatmaps, Sankey diagrams , and other glyphs. The usual ModelVis sys- tem combining coordinated multiple views are also suppor ted by our frame work as the separate usage of the pipeline and finally linking coordinated analysis together . Users iteratively construct, refine, and diag- nose hypotheses through ModelVis systems, and re- route the findings back to the model (listening) lay er f or updates, f or ming a closed analysis loop . Therefore, the framework can be seen as not only a ModelVis taxonomy b ut also a design template f oster ing ne w ModelVis techniques and applications. APPLICA TION ON V AST P APER COLLECTION W e apply the proposed framew ork to a large-scale V AST literature corpus. W e first build a high-recall candidate set from publication metadata, then obtain a high-precision ModelVis subset at the paper le vel, and subsequently perf orm figure-le vel framew ork e xtraction f or cross-paper analysis. Our method is organized into three stages as de- tailed in the next section: • Stage 1: paper-le vel ModelVis screening. • Stage 2: figure-lev el ModelVis rele vance detec- tion with representative-figure selection. • Stage 3: frame work-aligned four-dimension ex- traction, including model listener , data type, vi- sualization type, and visualization pur pose . Data Collection and Preprocessing Model visualization research is predominantly dev el- oped within the model-centric visual analytics commu- nity . Therefore , we focus on papers from IEEE V AST (2010—2020), a primar y ven ue f or visual analytics studies closely related to model inter pretation and diagnosis. Since 2021, V AST has been integrated into the unified IEEE VIS proceedings, making it difficult to reliably separate V AST papers from the other tracks FIGURE 2 . Annual distribution of the 136 identified ModelVis papers in our VIS/V AST cor pus. The red line shows the number of papers per publication year , highlighting a mar ked increase after 2016 (11-16 papers/year). using metadata alone. T o ensure consistent coverage after this integration, we include all IEEE VIS papers from 2021 to 2024, and then retriev e paper metadata, f or e xample, title, abstract, and keyw ords when av ail- able , from VisPubData [ 20 ], resulting in an initial pool of 1052 papers. Because a large por tion of papers in this pool are unrelated to model visualization, we apply a ke yword- based preprocessing step to remov e non-ModelVis pa- pers. Specifically , we manually curate a list of keyw ords and require each retained paper to contain at least one keyw ord in its title, abstract, or author-provided ke ywords. The ke yword list includes model , lear ning , analytics , and analysis . After this filtering step, 514 papers remain for subsequent analyses. LLM-based ModelVis P aper Selection An LLM retriev al-augmented paper-classification work- flow is designed to classify each paper into ModelVis topic and non-ModelVis topic. Initially , 68 papers are randomly selected and manually deter mined to be ModelVis-related (35 papers) or unrelated (33 papers). The manually-curated dataset is used as both the e valuation ref erence and the f ew-shot e xample pool f or LLM classification. F or each target paper to be classified, we use the BM25 algorithm to retr ie ve the top-6 neighbors from the labeled pool using title and abstract, while enforc- ing mixed positive and negative examples in the prompt conte xt. T wo LLMs are then quer ied independently , and a paper is categor ized as ModelVis only when both models predict positive . On lea ve-one-out ev aluation ov er the 68 labeled papers, this method reaches a precision of 0.939 Month 2026 Pub lication Title 5 (T able 1 ). Applying the same workflow to the 514 candidates yields 136 ModelVis papers (including the 35 man ually labeled positiv es), which form the input f or figure-le vel analysis. The annual distr ib ution of these 136 papers is shown in Figure 2 . Operational Categories f or Human–LLM Extraction W e select four impor tant dimensions along the Mod- elVis pipeline to conduct the follow-up study . On each dimension, multiple categor ies are manually created and then refined during the manual annotation pro- cess. • Model listener: input data, training configu- ration, model structure, learnable parameters, transient state, dynamics (time), output results. • Data type: multi-dimensional quantitative, one- dimensional quantitativ e, relational, temporal, nominal, and other . • Visualization type: statistical char t, node-link diagram, parallel coordinates, heatmap, Sanke y diagram, and others. • Visualization purpose: perf or mance e valua- tion, I/O relationship , distribution, dimensionality reduction, and other . LLM-scaled Model Visualization Lear ning W e collect full PDF files f or the 136 ModelVis papers, conv er ting them into plain-te xt representations, and then extr act figure-lev el context from the conv er ted te xt as evidence for downstream retr ie val and LLM e xtractions. Then, we extend paper-lev el screening to figure-le vel framework e xtractions with a human– LLM wor kflo w . The objective is to identify key model listeners of each work and map them into a four-field pipeline: model listener, data type, visualization type, and visualization pur pose. The figure-lev el rele vance detection is performed in Stage 2. Using the 46 manually coded papers as samples, we retr ie ve similar papers by BM25 on title and abstract, construct positiv e and negative figure e xemplars , and classify each target figure as ModelVis- rele vant with confidence and shor t te xtual evidence. The sources of these 46 papers are sho wn in Figure 3 . T o limit the annotation workload, Stage 2 keeps at most three representative figures per paper , pr iori- tizing ov er vie w , performance, and mechanism-related e vidence. In Stage 3, each figure selected in Stage 2 is coded f or four framew or k dimensions: model listener, data type, visualization type, and visualization pur pose . For Mo d e l V i s p a p e r s (1 3 6 ) Mo d e l V i s p a p e r s (1 3 6 ) Mo d e l V i s p a p e r s (1 3 6 ) Mo d e l V i s p a p e r s (1 3 6 ) ModelVis papers (136) H u m a n l a b e l e d (3 5 ) H u m a n l a b e l e d (3 5 ) H u m a n l a b e l e d (3 5 ) H u m a n l a b e l e d (3 5 ) Humanlabeled (35) L L M- l a b e l e d (1 0 1 ) L L M- l a b e l e d (1 0 1 ) L L M- l a b e l e d (1 0 1 ) L L M- l a b e l e d (1 0 1 ) LLM-labeled (101) A n n o t a t e d (4 6 ) A n n o t a t e d (4 6 ) A n n o t a t e d (4 6 ) A n n o t a t e d (4 6 ) Annotated (46) N o t a n n o t a t e d (9 0 ) N o t a n n o t a t e d (9 0 ) N o t a n n o t a t e d (9 0 ) N o t a n n o t a t e d (9 0 ) Not annotated (90) FIGURE 3 . Summarizing the sampling of the 136 identified ModelVis papers. Papers are first grouped by identification source (human-labeled, n = 35; LLM-labeled, n = 101) and then by whether they were selected for Stage 3 figure-lev el annotation ( n = 46) or not ( n = 90). each target figure, we retr ie ve top- k similar labeled figures from a figure-lev el BM25 cor pus and provide them as in-context examples . Predicted labels are normalized to a controlled vocab ular y , and unmatched values are mapped to “other” for schema consistency . Results and Analysis W e e v aluate the quality of extractions with leav e- one-out e xperiments on the 46 manually coded pa- pers. Stage-wise quantitative results are summarized in T able 1 . Stage 2 (figure-lev el rele vance detection) achie ves an F1 of 0.798 on all folds. Stage 3 achie ves a micro-F1 of 0.848 for model listener , 0.743 for data type, 0.753 for visualization type, and 0.808 for visual- ization pur pose on selected figures with all labels. W e then run the full pipeline on 90 unlabeled target papers with the same 46-paper sample librar y . Stage 2 selects at least one representative figure for 82 papers and outputs 226 selected figures for extrac- tions in Stage 3. The remaining 8 unlabeled papers hav e no ModelVis-relev ant figure detected in Stage 2 and are therefore e xcluded from subsequent figure- le vel analysis. Combining the 82 retained unlabeled papers with the 46 manually coded papers yields a final analysis set of 128 papers (from the initial 136 ModelVis papers) with at least one ModelVis figure and 331 coded ModelVis figures. This final 128-paper cor pus (2010–2024) also shows a clear growth trend after 2017 in Figure 2 , indicating that ModelVis has e volv ed from ear ly explor ator y eff or ts to a sustained research stream in recent VIS/V AST publications. T o formalize the transitions within these figures, we derive ModelVis paths b y establishing all possible pair- 6 Publication Title Month 2026 I n p u t d a t a ( 2 1 7 ) I n p u t d a t a ( 2 1 7 ) I n p u t d a t a ( 2 1 7 ) I n p u t d a t a ( 2 1 7 ) Input data (217) T r a i n i n g c o n f i g u r a t i o n ( 1 0 ) T r a i n i n g c o n f i g u r a t i o n ( 1 0 ) T r a i n i n g c o n f i g u r a t i o n ( 1 0 ) T r a i n i n g c o n f i g u r a t i o n ( 1 0 ) T raining configuration (10) M o d e l s t r u c t u r e ( 5 8 ) M o d e l s t r u c t u r e ( 5 8 ) M o d e l s t r u c t u r e ( 5 8 ) M o d e l s t r u c t u r e ( 5 8 ) Model structure (58) L e a r n a b l e p a r a m e t e r s ( 4 2 ) L e a r n a b l e p a r a m e t e r s ( 4 2 ) L e a r n a b l e p a r a m e t e r s ( 4 2 ) L e a r n a b l e p a r a m e t e r s ( 4 2 ) Learnable parameters (42) T r a n s i e n t s t a t e ( 1 0 9 ) T r a n s i e n t s t a t e ( 1 0 9 ) T r a n s i e n t s t a t e ( 1 0 9 ) T r a n s i e n t s t a t e ( 1 0 9 ) T ransient state (109) O u t p u t r e s u l t s ( 5 2 7 ) O u t p u t r e s u l t s ( 5 2 7 ) O u t p u t r e s u l t s ( 5 2 7 ) O u t p u t r e s u l t s ( 5 2 7 ) Output results (527) T i m e ( 3 7 ) T i m e ( 3 7 ) T i m e ( 3 7 ) T i m e ( 3 7 ) Time (37) M u l t i d i m e n s i o n a l q u a n t i t a t i v e ( 3 0 4 ) M u l t i d i m e n s i o n a l q u a n t i t a t i v e ( 3 0 4 ) M u l t i d i m e n s i o n a l q u a n t i t a t i v e ( 3 0 4 ) M u l t i d i m e n s i o n a l q u a n t i t a t i v e ( 3 0 4 ) Multidimensional quantitative (304) O n e d i m e n s i o n a l q u a n t i t a t i v e ( 1 8 3 ) O n e d i m e n s i o n a l q u a n t i t a t i v e ( 1 8 3 ) O n e d i m e n s i o n a l q u a n t i t a t i v e ( 1 8 3 ) O n e d i m e n s i o n a l q u a n t i t a t i v e ( 1 8 3 ) Onedimensional quantitative (183) R e l a t i o n a l ( 8 6 ) R e l a t i o n a l ( 8 6 ) R e l a t i o n a l ( 8 6 ) R e l a t i o n a l ( 8 6 ) Relational (86) T e m p o r a l ( 9 4 ) T e m p o r a l ( 9 4 ) T e m p o r a l ( 9 4 ) T e m p o r a l ( 9 4 ) T emporal (94) N o m i n a l ( 3 2 9 ) N o m i n a l ( 3 2 9 ) N o m i n a l ( 3 2 9 ) N o m i n a l ( 3 2 9 ) Nominal (329) O t h e r ( 4 ) O t h e r ( 4 ) O t h e r ( 4 ) O t h e r ( 4 ) Other (4) St a t i s t i c a l c h a r t ( 4 8 7 ) St a t i s t i c a l c h a r t ( 4 8 7 ) St a t i s t i c a l c h a r t ( 4 8 7 ) St a t i s t i c a l c h a r t ( 4 8 7 ) Statistical chart (487) P a r a l l e l c o o r d i n a t e s ( 2 7 ) P a r a l l e l c o o r d i n a t e s ( 2 7 ) P a r a l l e l c o o r d i n a t e s ( 2 7 ) P a r a l l e l c o o r d i n a t e s ( 2 7 ) P arallel coordinates (27) N o d e l i n k d i a g r a m ( 1 0 3 ) N o d e l i n k d i a g r a m ( 1 0 3 ) N o d e l i n k d i a g r a m ( 1 0 3 ) N o d e l i n k d i a g r a m ( 1 0 3 ) Nodelink diagram (103) He a t m a p ( 9 4 ) He a t m a p ( 9 4 ) He a t m a p ( 9 4 ) He a t m a p ( 9 4 ) Heatmap (94) Sa n k e y d i a g r a m ( 1 3 ) Sa n k e y d i a g r a m ( 1 3 ) Sa n k e y d i a g r a m ( 1 3 ) Sa n k e y d i a g r a m ( 1 3 ) Sankey diagram (13) O t h e r ( 2 7 6 ) O t h e r ( 2 7 6 ) O t h e r ( 2 7 6 ) O t h e r ( 2 7 6 ) Other (27 6) I / O r e l a t i o n s h i p ( 2 3 5 ) I / O r e l a t i o n s h i p ( 2 3 5 ) I / O r e l a t i o n s h i p ( 2 3 5 ) I / O r e l a t i o n s h i p ( 2 3 5 ) I/O relationship (235) P e r f o r m a n c e e v a l u a t i o n ( 5 3 3 ) P e r f o r m a n c e e v a l u a t i o n ( 5 3 3 ) P e r f o r m a n c e e v a l u a t i o n ( 5 3 3 ) P e r f o r m a n c e e v a l u a t i o n ( 5 3 3 ) P erformance evaluation (533) D i s t r i b u t i o n ( 9 8 ) D i s t r i b u t i o n ( 9 8 ) D i s t r i b u t i o n ( 9 8 ) D i s t r i b u t i o n ( 9 8 ) Distribution (98) D i m . r e d u c t i o n ( 3 5 ) D i m . r e d u c t i o n ( 3 5 ) D i m . r e d u c t i o n ( 3 5 ) D i m . r e d u c t i o n ( 3 5 ) Dim. reduction (35) O t h e r ( 9 9 ) O t h e r ( 9 9 ) O t h e r ( 9 9 ) O t h e r ( 9 9 ) Other (99) M o d e l L i s t e ne r D a t a T y p e V i s ua l i z a t i o n T y p e V i s ua l i z a t i o n P u r p o s e FIGURE 4 . A visualization of parallel sets of 1000 ModelVis paths at figure-level f or the final 331-figure corpus on model listener → data type → visualization type → visualization pur pose . Node heights and link widths indicate the relativ e pre valence of labels and cross-stage transitions. The dominant routes are output-or iented listening through quantitative/nominal representations to statistical char t and then to performance ev aluation , with secondar y flows toward I/O relationship and other visualization types. wise connections between labels in adjacent stages; f or instance, if a figure is annotated with labels A, B in one stage and C in the next, two distinct paths (A- C and B-C) are generated. This systematic expansion resulted in a total of 1,000 ModelVis paths e xtracted from the 331 figures. By summarizing these ModelVis paths, their distribution is visualized in Figure 4 . This Sanke y view rev eals a clear dominant chain across all f our dimensions: most paths star t from output results (527), are represented as nominal (329) or multi- /one-dimensional quantitative data (304/183), then flow to statistical char t (487), and finally end at perfor- mance e v aluation (533). The patter n indicates that cur- rent ModelVis studies are pr imarily organized around result-centric compar ison workflows, where str uctured categorical/quantitative e vidence is summarized b y char t-based visual encodings for model assessment. Secondar y but non-negligible routes include transi- tions to I/O relationship (235) and distribution (98), often through node-link diagram (103), heatmap (94), and other customized views (276), suggesting that mechanism-oriented and relation-oriented analysis is present but less dominant. Figure 5 fur ther re veals how label usage ev olv es ov er time. In the Model Listener panel (A), output results remains the most stable and prev alent target, while mechanism-related listeners ( model str ucture , learnable par ameters and transient state ) appear more frequently after 2017. In Data T ype (B), 1D/nD quanti- tative and nominal dominate most years , indicating that both categor ical and high-dimensional quantitative e v- idence are central in ModelVis studies. In visualization type (C), statistical char t remains the major categories throughout the period. In visualization pur pose (D), perf or mance ev aluation remains the primar y objectiv e, while I/O relationship and distrib ution analysis maintain visible propor tion in later years . Overall, the temporal pattern indicates a shift from predominantly result- oriented repor ting toward broader mechanism- and diagnosis-related analysis. As shown in Figure 6 , at the paper lev el, the output results is the dominant model listener (93.8%), f ollowed by the input data (58.6%); nominal (78.9%) and multi-dimensional quantitative (72.7%) are the most frequent structured data types; statistical char ts is the most frequent visualization type family (68.8%); and perf or mance e valuation is the dominant pur pose (69.5%). These results indicate a prev ailing result- Month 2026 Pub lication Title 7 FIGURE 5 . Y early categor y propor tions in the 128-paper ModelVis cor pus (2010—2024) across the f our framework labels. Char ts A–D correspond to the model listener, data type, visualization type, and visualization pur pose, respectively . Each cur ve repor ts the within-year propor tion of papers assigned to a categor y , showing sustained dominance of output-results listening and perf or mance-oriented analysis, with a stronger presence of mechanism-related categor ies after 2017. centric design patter n in current ModelVis literature. W e additionally collect citation counts for all 128 papers from IEEE Xplore. Since cumulative citations are conditioned on publication age, a direct cross- year compar ison introduces temporal e xposure bias tow ard earlier papers. T o obtain age-adjusted influence estimates, we define the annualized citation weight w f or each paper i : w i = citations i 2026 − year i + 1 . This nor malization yields a per-year citation-intensity pro xy and provides a time-standardized weighting scheme, so weighted label propor tions reflect relative impact r ather than only pre valence . W e then aggregate weighted paper cov erage within each label field and obtain citation-weighted categor y rankings. The com- parison between unweighted prev alence and citation- weighted impor tance is shown in Figure 6 . Notably , transient state and model str ucture show stronger citation-weighted impor tance than their unweighted pre valence, suggesting that mechanism-or iented stud- ies are fe wer but comparatively more influential. RETRIEV AL-A UGMENTED METHOD FOR HUMAN-LLM LITERA TURE EXTRA CTION The details of our literature extr action workflow are e xplained in this section. The core challenge is to map a large, weakly structured paper cor pus to a frame work-defined label space while preser ving pre- cision and consistency . We address this challenge with a retr ie val-augmented human–LLM pipeline that progressiv ely refines decisions from the paper lev el to the figure lev el, and ev entually to framework-aligned multi-label extraction. Problem Definition and Label Space Let C denote the candidate paper set after dataset preprocessing. Our goal is to construct a coded subset M ⊆ C and assign each selected figure four framework dimensions: model listener , data type, visualization type, and visualization purpose. The first tw o are multi- label dimensions, and the latter two are single-label dimensions. T o balance annotation cost and semantic coverage , we decompose the task into three stages as introduced in the last section. 8 Publication Title Month 2026 A C B D FIGURE 6 . Comparison between unweighted prev alence (blur bars) and citation-weighted impor tance (orange marks) across the f our framew ork labels. Char ts A–D correspond to model listener , data type, visualization type, and visualization pur pose. Stage 1: Retriev al-augmented P aper-le v el Screening This stage performs binar y classification (ModelVis, ˆ y = 1 vs. non-ModelVis, ˆ y = 0) using title and abstract. Given a target paper p , we retr ie ve similar labeled papers with the BM25 algorithm ov er title-and- abstract tokens. W e then build a fe w-shot conte xt from top-rank ed neighbors with class-balance constraints (def ault k = 6, with minimum positiv e and negativ e e xamples). Retriev ed neighbors are injected into a prompt template and sent to two LLMs (DeepSeek-V3.2 & ChatGPT -5.1) independently . W e adopt a str ict consen- sus policy: ˆ y ( p ) = 1 ⇐ ⇒ ˆ y DeepSeek ( p ) = 1 ∧ ˆ y ChatGPT ( p ) = 1 . Theref ore, only papers classified as ModelVis-relev ant by both models are retained. This r ule intentionally biases toward high precision, because f alse positives in Stage 1 could propagate substantial manual burden to subsequent figure-lev el e xtraction. Stage 2: Figure-le vel ModelVis Detection Figure-le vel e xtraction requires figure-g rounded textual e vidence. We theref ore conv er t each selected PDF file into a structured text representation, from which figure captions and surrounding prose can be consistently inde xed. W e then extr act figure context through keyw ord- based reference matching in the conv er ted text. Specif- ically , caption headers and in-te xt references contain- ing tokens such as “Fig. ” and “Figure” are used to locate figure-specific evidence paragraphs . The full text is segmented by paragraph, obvious non-body frag- ments are filtered, and the local context is expanded by retaining the previous and follo wing par agraphs around each direct hit. The final evidence for each figure is f or med by combining its caption with this expanded conte xt for subsequent retr ie val and prompting. F or each positiv e paper in Stage 1, we classify whether each figure is ModelVis-relev ant in Stage 2. This stage first retriev es top- k similar labeled papers by title-and-abstract BM25 (default k = 5), then samples positive and negative figure e xemplars from those Month 2026 Pub lication Title 9 neighbors. Each target figure is classified with confi- dence and shor t evidence snippets. T o control downstream scale and impro ve repre- sentativeness , Stage 2 enforces a top-3 representa- tive figure policy per paper. The retained figures are aligned to overview , perf or mance, and mechanism- oriented roles. P ost-processing ensures that each input figure has a valid output entry , confidence scores are clipped to [0, 1], and malformed responses are conv er ted to safe defaults . Stage 3: F rame work-aligned F our-field Extraction This stage labels each selected figure in Stage 2 on the four dimensions of our framework. We first build a figure-le vel BM25 cor pus from manually coded papers by aligning base figure identities with adjudi- cated labels. F or BM25 inde xing and quer ying, each figure is represented by concatenating its caption re- peated three times with its extr acted local conte xt. This caption-upweighting heur istic increases the le xical weight of figure-defining ter ms and reduces dilution from gener ic surrounding prose, so that the retriev al is better aligned with figure semantics. For each target figure, we retriev e top- k similar labeled figures (de- f ault k = 10, with a per-paper cap to a void source dominance), and f eed retr ie ved examples plus target e vidence into the final prompt. The LLM output is nor malized with str ict schema checks: • alias mapping for lexical variants, • inv alid-value fallbac k to “other”, • confidence clipping to [0, 1], • e vidence-length control for concise auditability . When sub-figures are mapped to the same base figure, we aggregate labels at base-figure granularity: multi-label dimensions are merged by set union, while single-label dimensions are resolved by vote; unre- solved conflicts are mapped to “other”. Ev aluation W e ev aluate the figure-lev el pipeline with leav e-one- out over manually extr acted papers. In each fold, one paper is held out as a target, and all remaining papers f or m the retrie val sample library , pre v enting target leak- age in both Stage 2 and Stage 3 retriev al. Stage 2 is e valuated as a binar y classification on e xplicitly labeled figures only . Stage 3 is ev aluated on figures with av ailab le labels. For all multi-label di- mensions (model listener and data type), we compute micro-F1 using: TP = | Y ∩ ˆ Y | , FP = | ˆ Y \ Y | , FN = | Y \ ˆ Y | . where Y is the set of true labels and ˆ Y is the set of predicted labels for a given figure. The full compar ison is summarized in T able 1 . In Stage 1, the BM25 major ity-v ote baseline yields precision 0.608, while DeepSeek-V3.2 in 0-shot al- ready reaches 0.933. Under 6-shot retr ie val augmen- tation, the single-model runs of DeepSeek-V3.2 and ChatGPT -5.1 both obtain precision 0.889, and the dual- model consensus reaches the best precision of 0.939. In Stage 2, the 0-shot setting obtains F1 0.722, and 5-shot improv es it to 0.798 (+0.076). In Stage 3, 10-shot consistently outperforms 0-shot across all f our dimensions: model listener (0.848 vs. 0.788), data type (0.743 vs. 0.706), visualization type (0.753 vs. 0.525), and visualization pur pose (0.808 vs. 0.754). DISCUSSION The LLM-based experiment of this work demonstrates the validity of the proposed ModelVis framew ork. Most papers in our studied collection relating to model visu- alization can be mapped to the framew ork with either spatial or temporal listeners e xtracted. The f ollow-up vi- sualization mostly f ollows the classical Inf oVis pipeline. Dissimilarity with Data Visualization W e also identify sev eral differences on the state-of- the-ar t model visualization research, in compar ison to the classical visualization study f ocusing on data. First, among ModelVis papers in our collection, there is fe w nov el visual metaphor design, which had been the core of traditional visualization research. The reason probably lies in that the machine learning models are already complex to comprehend, introducing new visualization design may further increases the lear ning difficulty and reduce usability . Second, the presents of temporal listeners and temporal data visualizations are still minority in ModelVis studies (Figure 4). We ascribe this to the relativ ely larger effort required to measure model dynamics in comparison to their static f eatures. Y et, visualizing model dynamics can be a promising, under-exploited topic. Finally , unlike the vi- sual analytics research highly concerning the analytics process, existing ModelVis proposals focus more on ke y dimensions of a model, mostly its output results and input data, as well as the input-output correlations. Delineating the ov erall model functioning process calls f or interdisciplinar y study , by joint-f orcing visualization and AI research communities. 10 Publication Title Month 2026 T ABLE 1 . Stage-wise comparativ e performance under leave-one-out ev aluation. The table includes Stage 1 paper-lev el screening baselines (BM25 majority vote, 0-shot, and 6-shot LLM settings), Stage 2 figure-lev el detection (0-shot vs. 5-shot), and Stage 3 f our-field e xtraction (0-shot vs. 10-shot). TP/FP/TN/FN are aggregated across f olds; reported scores are precision (Stage 1), F1 (Stage 2), and micro-F1 (Stage 3). Stage Method Model / Algorithm T arget Metric Repor ted score TP FP TN FN Stage 1 majority vote BM25 manually classified 68 papers 31 20 13 4 Precision = 0.608 0-shot DeepSeek-V3.2 28 2 31 7 Precision = 0.933 6-shot DeepSeek-V3.2 32 4 29 3 Precision = 0.889 ChatGPT -5.1 31 2 31 4 Precision = 0.889 ChatGPT -5.1 & DeepSeek-V3.2 consensus 31 2 33 2 Precision = 0.939 Stage 2 0-shot DeepSeek-V3.2 46 labeled ModelVis papers 61 3 / 44 F1 = 0.722 5-shot 73 5 / 32 F1 = 0.798 Stage 3 0-shot DeepSeek-V3.2 Model Listener 82 19 / 25 micro-F1 = 0.788 Data T ype 77 21 / 43 micro-F1 = 0.706 Visualization T ype 32 29 / 29 micro-F1 = 0.525 Visualization Purpose 46 15 / 15 micro-F1 = 0.754 10-shot Model Listener 106 16 / 22 micro-F1 = 0.848 Data T ype 101 27 / 43 micro-F1 = 0.743 Visualization T ype 55 18 / 18 micro-F1 = 0.753 Visualization Purpose 59 14 / 14 micro-F1 = 0.808 T rends on Model Visualization Research Our study also unv eils multiple trends on ModelVis research. The y ear-by-y ear curve on number of papers in Figure 2 shows the surge of the topic from 2017 in visualization community , the hotness of which still goes on now . Despite its popularity , we observe that visualization works on deeper mechanism of machine learning models, e.g., model str ucture, transient states , and input/output relationship, drop in recent y ears (Figure 5). A re-invent of ModelVis research can be essential currently to continue to open the black-bo x of highly valuable AI systems. Finally , on the data types listened from machine learning models , the multi- dimensional data still dominates (Figure 5.B), which renders the impor tance enduring significance of multi- dimensional data visualization in ModelVis research. Limitation and Future W ork The work presented here does hav e cer tain limitations due to its broad cov erage. First, the current cate- gories of ModelVis framew or k dimensions can be non- e xhaustive, and parts of the extraction process ma y be aff ected by subjective judgment. For example , we list se ven spatial and temporal model listeners through the discussion among co-authors and paper annotators. Conducting more user studies within the visualization and AI community , especially with machine lear ning practitioner , can help to enr ich the classification of our ModelVis frame work. Second, the framework is now applied to the ModelVis papers within the IEEE VIS collection, hence our result is influenced by the selected dataset and its cov erage. Expanding the study to all visualization ven ues as well as AI ev ents related to model visualization will fur ther generalize the result of this work and validate our framework more exten- sively . Finally , from the application perspective , the theoretic ModelVis framework ought to be deploy ed as software libraries enclosing all state-of-the-ar t model visualization techniques, facilitating the actual usage and implementation of ModelVis research. CONCLUSION W e revisit model visualization through a model-centric, spatial, and temporal perspectiv e, organizing prior work into an Inf oVis pipeline-inspired framework. We describe how abstract listeners can capture essential model behavior , how this model behavior informa- tion is translated and structured into analyzable data types, transformed into visualization-friendly represen- tations, and finally mapped to visualization designs and analysis pur poses. We fur ther demonstrate how the frame work can be operationalized via a reproducible e xtraction wor kflo w on a core ModelVis paper collec- tion, combining manual annotation with LLM-assisted Month 2026 Pub lication Title 11 augmentation. Our results and analysis suggest that the current ModelVis research concentrates on recurring patter ns, including a strong focus on output-or iented listening, quantitative/nominal data organization, and pur pose settings centered on performance e valuation and I/O relationship , while studies on deeper inter nal model mechanism remain comparativ ely sparse. In par ticular , richer treatments of spatiotemporal coupling, system- atic analysis of training configuration and data bias sources, and more complete interaction loops that connect diagnosis back to concrete model/data edits remain promising oppor tunities. Bey ond f or ming tax- onomy , our frame work can serve as a design checklist f or model builders, a positioning tool for researchers, and a scaffold for future literature organization. A CKNO WLEDGMENTS This work was suppor ted by NSFC Grant 62572026, National Social Science Fund of China 22&ZD153, State K ey Laboratory of Comple x & Cr itical Software Environment (SKLCCSE). Lei Shi, Yingchaojie Feng, Liang Zhou are the corresponding authors of this paper . REFERENCES 1. M. D . Zeiler and R. Fergus , “Visualizing and under- standing conv olutional networks, ” in Computer Vision – ECCV 2014 . Cham: Springer Inter national Pub- lishing, 2014, pp . 818–833. 2. D . Smilkov , S. Car ter , D . Sculley , F . B. Viégas, and M. Wattenberg, “Direct-manipulation visualization of deep networks, ” CoRR , vol. abs/1708.03788, 2017. [Online]. A vailab le: http://arxiv .org/abs/1708.03788 3. C . Seifer t, A. Aamir , A. Balagopalan, D . Jain, A. Sharma, S. Grottel, and S. Gumhold, Visualizations of Deep Neural Networks in Computer Vision: A Sur ve y . Cham: Springer International Publishing, 2017, pp. 123–144. [Online]. A vailab le: https://doi.org/10.1007/978- 3- 319- 54024- 5_6 4. S . Liu, X. W ang, M. Liu, and J. Zhu, “T owards better analysis of machine lear ning models: A visual analytics perspective, ” Visual Informatics , vol. 1, no . 1, pp . 48–56, 2017. [Online]. A vailab le: https://www .sciencedirect.com/ science/ar ticle/pii/S2468502X17300086 5. J . Choo and S. Liu, “Visual analytics for e xplainable deep learning, ” IEEE Computer Graphics and Appli- cations , v ol. 38, no . 4, pp . 84–92, 2018. 6. R. Y u and L. Shi, “A user-based taxonomy for deep learning visualization, ” Visual Inf ormatics , vol. 2, no . 3, pp . 147–154, 2018. [Online]. Av ail- able: https://www .sciencedirect.com/science/ar ticle/ pii/S2468502X1830038X 7. Q. Zhang and S. Zhu, “Visual inter pretability for deep lear ning: a surve y , ” F rontiers of Information T echnology & Electronic Engineering , vol. 19, no . 1, pp . 27–39, Jan 2018. [Online]. Av ailable: https://doi.org/10.1631/FITEE.1700808 8. J . Lu, W . Chen, Y . Ma, J . K e, Z. Li, F . Zhang, and R. Maciejewski, “Recent progress and trends in predictive visual analytics, ” F rontiers of Computer Science , v ol. 11, no . 2, pp . 192–207, Apr 2017. 9. Y . Lu, R. Garcia, B. Hansen, M. Gleicher , and R. Maciejewski, “The state-of-the-ar t in predictive visual analytics, ” Computer Graphics Forum , vol. 36, no . 3, pp. 539–562, 2017. [Online]. A vailab le: https: //onlinelibrary .wiley .com/doi/abs/10.1111/cgf .13210 10. X. W ang, T . Zhang, Y . Ma, J. Xia, and W . Chen, “A survey of visual analytic pipelines , ” Journal of Computer Science and T echnology , vol. 31, no . 4, pp . 787–804, Jul 2016. [Online]. A vailab le: https://doi.org/10.1007/s11390- 016- 1663- 1 11. D . Sacha, M. Sedlmair , L. Zhang, J . Lee, D . W eiskopf , S. Nor th, and D . Keim, “Human-centered machine learning through interactiv e visualization, ” in ESANN 2016: 24th European Symposium on Ar tificial Neural Networks, Computational Intelligence and Machine Lear ning Bruges, Belgium April 27-28- 29, 2016 Proceedings , 2016. [Online]. A vailab le: https://repository .mdx.ac.uk/item/86qv0 12. J . Wang, S. Liu, and W . Zhang, “Visual analytics for machine lear ning: A data perspective surve y , ” IEEE T ransactions on Visualization and Computer Graphics , v ol. 30, no . 12, pp . 7637–7656, 2024. 13. J . J. Dudley and P . O . Kr istensson, “A re view of user interface design for interactiv e machine learning, ” ACM T rans. Interact. Intell. Syst. , vol. 8, no . 2, Jun. 2018. [Online]. Av ailable: https://doi.org/ 10.1145/3185517 14. A. Chatzimpar mpas, R. M. Mar tins, I. J usufi, and A. K erren, “A sur ve y of surveys on the use of vi- sualization for interpreting machine learning models, ” Information Visualization , vol. 19, no . 3, pp . 207–233, 2020. 15. A. Gulsum and S. Bo, “A sur ve y of visual analytics for e xplainable artificial intelligence methods , ” Computers & Graphics , v ol. 102, pp. 502–520, 2022. [Online]. A vailab le: https://www .sciencedirect. com/science/ar ticle/pii/S0097849321001886 16. F . Hohman, M. Kahng, R. Pienta, and D . H. Chau, “Visual analytics in deep lear ning: An interrogative survey for the next frontiers, ” IEEE T ransactions on 12 Publication Title Month 2026 Visualization and Computer Graphics , v ol. 25, no . 8, pp . 2674–2693, 2019. 17. R. Garcia, A. C. T elea, B. Castro da Silva, J. T ø rresen, and J. L. Dihl Comba, “A task-and-technique centered surve y on visual analytics f or deep lear ning model engineering, ” Computers & Graphics , vol. 77, pp. 30–49, 2018. [Online]. A vailab le: https://www .sciencedirect.com/ science/ar ticle/pii/S0097849318301535 18. B . La Rosa, G. Blasilli, R. Bourqui, D . Auber , G. Santucci, R. Capobianco, E. Ber tini, R. Giot, and M. Angelini, “State of the ar t of visual analytics for explainab le deep lear ning, ” Computer Graphics Forum , vol. 42, no. 1, pp. 319–355, 2023. [Online]. Av ailable: https://onlinelibrar y .wile y .com/doi/ abs/10.1111/cgf.14733 19. J . Y uan, C. Chen, W . Y ang, M. Liu, J. Xia, and S. Liu, “A survey of visual analytics techniques f or machine learning, ” Computational Visual Media , vol. 7, no . 1, pp . 3–36, 2021. 20. P . Isenberg, F . Heimerl, S. K och, T . Isenberg, P . Xu, C . Stolper , M. Sedlmair , J. Chen, T . Möller , and J. Stasko , “vispubdata.org: A metadata collection about IEEE visualization (VIS) publications , ” IEEE T ransactions on Visualization and Computer Graphics , vol. 23, no. 9, pp. 2199– 2206, Sep. 2017. [Online]. Av ailable: https://tobias. isenberg.cc/VideosAndDemos/Isenberg2017VMC Siyu Wu is a Ph.D . student at School of Computer Science & Engineering, Beihang University at Bei- jing, 100191, China. His research interests include visualization, human-computer interaction, and ar tifi- cial intelligence. Wu received his Bachelor’ s degree in Information Engineering from Nanjing University of Inf or mation Science & T echnology . Contact him at siyuw@buaa.edu.cn. Lei Shi is a Professor in the School of Computer Science and Engineer ing, Beihang University , 100191, China. His current research interests are Data Mining, Visual Analytics, and AI, with more than 100 papers published in top-tier ven ues. He holds B .S. (2003), M.S . (2006) and Ph.D . (2008) degrees from Depar tment of Computer Science and T echnology , Tsinghua Univer- sity . He is the recipient of IBM Research Division A ward on “Visual Analytics” and the IEEE V AST Challenge A ward twice in 2010 and 2012. He has organized sev- eral workshops on combining visual analytics and data mining and served on the (senior) program committees of many related conf erences. He is an IEEE senior member . He is one of the corresponding authors of this ar ticle. Contact him at leishi@b uaa.edu.cn. Lei Xia is a Ph.D . student at School of Computer Science & Engineer ing, Beihang University at Beijing, 100191, China. His research interests include visual- ization, human-computer interaction, and artificial in- telligence. Xia received his Bachelor’ s degree in Com- puter Science from Beihang University . Contact him at lei_xiaaa@buaa.edu.cn. Ceny ang Wu is a Ph.D . student at the National Institute of Health Data Science, Peking University at Beijing, 100191, China. His research interests include scientific visualization, computer graphics, and generative mod- els. Wu received his bachelor’ s degree in Mathematics and Applied Mathematics from Beijing Nor mal Univer- sity . Contact him at wucen y@stu.pku.edu.cn. Zipeng Liu is an Associate Professor at School of Software , Beihang University , Beijing, 100191, China. His research interests include visualization, human- computer interaction, and inter pretab le AI. Liu receiv ed his Ph.D . in Computer Science from University of Br itish Columbia. Contact him at zipeng@buaa.edu.cn. Yingchaojie Feng is a research fello w at National University of Singapore at Singapore. His research interests include natural language processing, data visualization, and human computer interaction. Feng received his Ph.D . degree in visualization from Zhejiang University . He is one of the corresponding authors of this ar ticle. Contact him at f eng.y@nus .edu.sg. Liang Zhou is an Assistant Prof essor at the National Institute of Health Data Science, P eking University , Beijing, 100191, China. His research interests include visualization, visual analysis, and extended reality f or medicine. Dr . Zhou received his Ph.D . in Comput- ing from the Univ ersity of Utah. He is one of the corresponding authors of this ar ticle. Contact him at zhoulng@pku.edu.cn. W ei Chen is a Professor with the State Ke y Lab- oratory of CAD&CG, Zhejiang University , Hangzhou, 310058, China. His research interests include visu- alization and visual analytics. He has perf or med re- search in visualization and visual analysis and pub- lished more than 100 IEEE/ACM T ransactions and CCF-A papers. He actively ser v ed in many leading conf erences and jour nals. More information can be f ound at: http://www .cad.zju.edu.cn/home/chenwei/. Month 2026 Pub lication Title 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment