RSR코어 저비트 행렬벡터 곱을 위한 고성능 엔진
본 논문은 이진·삼진 가중치를 갖는 행렬과 고정밀 활성벡터 간의 행렬‑벡터 곱을 가속화하기 위해 Redundant Segment Reduction(RSR) 알고리즘을 CPU와 CUDA용 저수준 커널로 구현한 RSR‑core 엔진을 제안한다. 전처리 단계에서 동일한 열 패턴을 그룹화하고, 추론 단계에서는 그룹별로 한 번만 연산을 수행함으로써 연산량을 로그 수준으로 감소시킨다. 실험 결과, CPU에서는 최대 62배, GPU에서는 토큰 생성 단계에서…
저자: Mohsen Dehghankar, Abolfazl Asudeh
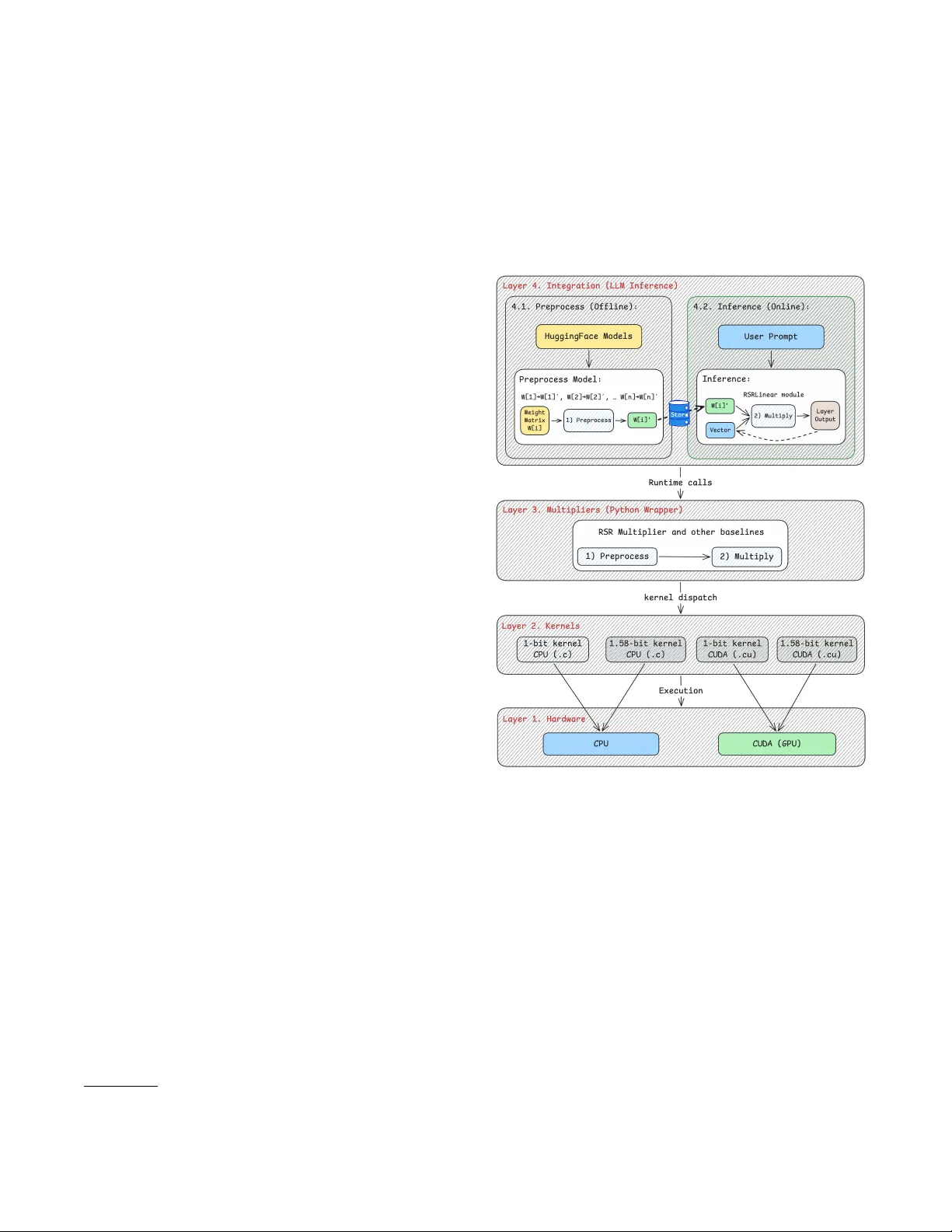
본 논문은 대규모 언어 모델(LLM)과 벡터 데이터베이스 등에서 핵심 연산인 행렬‑벡터 곱(M·v)의 효율성을 높이기 위해, 저비트 가중치(이진·삼진)와 고정밀 활성벡터 사이의 곱셈을 가속화하는 RSR‑core 엔진을 제안한다. 기존 연구는 저비트 양자화와 RSR 알고리즘을 각각 제시했지만, 구현이 애플리케이션 레벨에 머물러 하드웨어 커널에 직접 적용하기 어려웠다. 저자들은 이를 해결하고자 RSR 알고리즘을 CPU와 CUDA 환경 모두에 최적화된 저수준 커널로 구현하였다.
시스템 구조는 크게 네 계층으로 구성된다. 가장 아래층은 C와 CUDA로 작성된 RSR 커널이며, 그 위에 Python 기반의 Multiplier 추상화가 존재한다. Multiplier는 전처리(preprocess)와 곱셈(multiply) 두 인터페이스를 제공한다. 전처리 단계에서는 행렬을 k‑row 블록으로 나누고, 각 블록 내에서 동일한 열 패턴을 식별해 그룹화한다. 이때 카운팅 정렬을 사용해 O(n + 버킷) 시간에 패턴을 정렬하고, 그룹 경계, 퍼뮤테이션 인덱스, 스캐터 비트마스크 등을 16‑bit 정수와 고정‑크기 비트마스크 형태로 압축 저장한다. 전처리 결과는 모델당 한 번만 수행되며, 이후 추론 시 재사용된다.
CPU 커널은 gather‑aggregate를 단일 루프에서 수행하고, 스칼라 언롤링과 프리패치를 통해 메모리 접근 효율을 높였다. 바이너리 행렬은 스칼라 로드만으로 충분했으며, 삼진 행렬은 양·음 기여를 동시에 처리하기 위해 두 개의 비트마스크를 사용해 스캐터 연산을 고정 반복문으로 전개했다. 또한, 동일 입력 벡터를 공유하는 여러 선형 레이어를 하나의 호출로 결합해 파이썬 디스패치 오버헤드를 제거하고, 블록 단위 병렬화를 통해 멀티코어 활용도를 극대화했다.
GPU 구현에서는 각 행 블록을 스레드 블록에 매핑하고, 워프가 세그먼트 단위로 병렬 처리한다. 메타데이터는 64‑bit 워드 하나에 퍼뮤테이션 범위, 길이, 스캐터 마스크를 모두 포함시켜 전역 메모리 접근을 최소화했다. 공유 메모리 기반 부분 버퍼를 이용해 출력 충돌을 방지하고, 전처리 단계에서 기여가 0인 세그먼트를 제거해 불필요한 연산을 없앴다. k 값에 대한 컴파일 타임 특수화는 루프 전개를 가능하게 하여 레이턴시를 크게 낮추었다.
통합 측면에서 RSR‑core는 HuggingFace 모델 허브와 직접 연동된다. 사용자는 HuggingFace에서 ternary 모델(예: BitNet, Falcon‑3‑10B‑1.58b)을 다운로드하고, RSR‑core의 전처리 도구를 통해 메타데이터를 생성한다. 생성된 아티팩트는 로컬에 저장되어 추후 추론 시 재사용 가능하며, PyTorch와 호환되는 RSRLinear 모듈을 통해 기존 파이프라인에 최소한의 코드 변경만으로 적용할 수 있다. 웹 기반 데모 인터페이스는 모델 온보딩, 양쪽 백엔드(기존 bfloat16 vs RSR) 비교, 커널 레벨 마이크로벤치마크, CPU·GPU 간 교차 비교 등 네 가지 시나리오를 제공한다.
성능 평가에서는 PyTorch bfloat16 백엔드와 BitNet 구현을 기준으로 비교하였다. CPU 환경에서는 ternary LLM인 Falcon‑3‑10B‑1.58b와 Llama‑3‑8B‑1.58b에서 각각 62×, 53.8×의 토큰당 처리량 향상을 보였으며, BitNet‑2B‑4T 모델에서도 13.9×까지 가속했다. GPU 환경에서는 토큰 생성 단계에서 Falcon‑3‑10B‑1.58b와 Llama‑3‑8B‑1.58b가 각각 1.9×, 1.9×의 속도 향상을 기록했으며, BitNet‑2B‑4T에서도 1.4×~1.7×의 개선을 보였다. 이러한 결과는 RSR‑core가 단순 이론적 가속을 넘어 실제 추론 파이프라인에 적용 가능함을 입증한다.
마지막으로 논문은 저비트 양자화와 RSR 알고리즘을 결합한 최초의 하드웨어‑레벨 구현이라는 점에서 의의를 갖는다. 향후 연구 방향으로는 더 높은 차원의 텐서 연산 확장, 다양한 하드웨어(예: FPGA, ASIC) 포팅, 그리고 자동 k‑값 탐색을 통한 최적화 자동화가 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기