RSR-core: A High-Performance Engine for Low-Bit Matrix-Vector Multiplication
Matrix-vector multiplication is a fundamental building block in neural networks, vector databases, and large language models, particularly during inference. As a result, efficient matrix-vector multiplication engines directly translate into more effi…
Authors: Mohsen Dehghankar, Abolfazl Asudeh
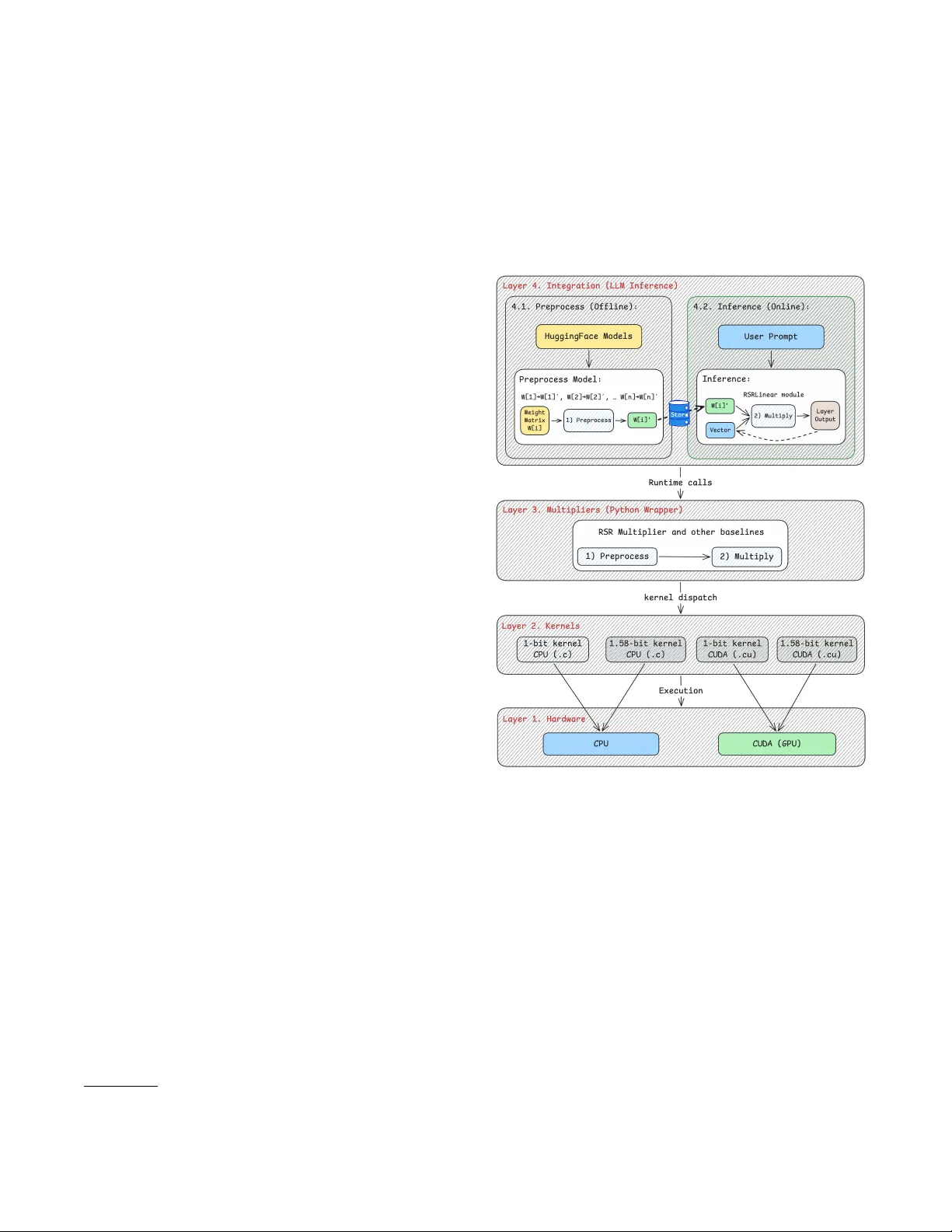
RSR-core: A High-Performance Engine for Low-Bit Matrix- V ector Multiplication Mohsen Dehghankar University of Illinois Chicago mdehgh2@uic.edu Abolfazl Asudeh University of Illinois Chicago asudeh@uic.edu ABSTRA CT Matrix–vector multiplication is a fundamental building block in neural networks, vector databases, and large language models, par- ticularly during inference. As a r esult, ecient matrix–vector mul- tiplication engines directly translate into more ecient inference. Recent work has e xplored low-bit quantization of model w eights, where matrices are r epresented using binary (1-bit) or ternary (1.58- bit) values while activation kept in higher pr ecision. These repre- sentations enable ecient hardware-level computation. In parallel, algorithms such as Redundant Segment Reduction (RSR) pro vide theoretical guarantees for accelerating low-bit matrix–vector mul- tiplication. Howev er , existing implementations operate at the ap- plication level and cannot be eciently integrated into har dware kernels, limiting practical performance. T o bridge this gap, we present RSR-core, a high-p erformance engine that implements the RSR algorithm as optimized low-level kernels for both CP U and CUDA envir onments. RSR-core supports ecient matrix–vector multiplication for binary and ternary weight matrices and general vectors while enabling practical deployment of RSR algorithm in real inference pipelines. RSR-core is provided as a production-ready engine with Hug- gingFace integration for preprocessing low-bit models and running accelerated inference. Experimental results demonstrate signicant performance im- provements over baseline HuggingFace PyT orch multiplication, achieving up to 62 × speedup on CP U and up to 1.9 × spee dup for token generation on CUDA for popular ternary LLMs. The source code is publicly available at RSR-core repository 1 . 1 IN TRODUCTION Inference is a critical stage in neural networks, particularly for large language mo dels (LLMs), where it dominates both energy consumption and resource allocation [ 7 , 12 ]. A key computational bottleneck during inference is matrix–vector multiplication 𝑀 𝑣 , where the matrix 𝑀 represents xed model weights after training and the vector 𝑣 corresponds to input activations generate d during execution. Improving the eciency of matrix–vector multiplication therefore directly translates into faster and more resource-ecient neural model inference. Ecient matrix–vector multiplication is also central to many data management and retrieval workloads beyond neural infer- ence [ 1 , 3 ]. For example, vector database systems compute inner products between a quer y vector and indexed data points for near- est neighb or retrieval, where the indexed dataset can be viewed as a matrix and the query as the input vector [ 4 ]. Similarly , ranking over tabular datasets applies user-dene d weight vectors to attribute 1 https://github.com/UIC-InDeXLab/RSR-core Figure 1: The layered architecture of RSR-core system. columns to compute scores for sorting and ltering, where the table rows form the matrix and the weight vector denes the ranking function [9, 10]. One common approach to accelerating matrix–vector multipli- cation, specically in model inference, is low-bit quantization of weight matrices [ 6 , 11 ]. In low-bit quantized LLMs, matrices are represented using binar y or ternary values while activation vectors remain in higher precision, enabling sp ecialized hardware-ecient implementations that reduce computation cost during inference. Orthogonal to hardwar e-aware quantization approaches, algo- rithmic metho ds aim to further accelerate matrix–vector multiplica- tion. In particular , Redundant Segment Reduction (RSR) [ 2 ] reduces the computational cost of low-bit matrix–vector multiplication by a logarithmic factor by exploiting redundancy in matrix structure. Mohsen Dehghankar and Abolfazl Asudeh Specically , identical column patterns 2 contribute identical partial results and can therefor e be aggregated before multiplication, re- ducing the total numb er of required op erations without aecting inference accuracy . However , existing implementations of RSR op- erate at the application lev el and cannot be eciently integrated into hardware kernel-le vel execution, limiting their practical per- formance benets in real inference systems. In this work, we address this gap by providing a kernel-level implementation of the RSR algorithm and enabling its deployment in practical inference pipelines. T o the best of our kno wledge, this is the rst implementation of RSR optimized for both CP U and CUD A inference environments. W e present RSR-core , a high-performance engine implement- ing RSR as optimized CP U and CUD A kernels for ecient low- bit matrix–vector multiplication. RSR-core pro vides a production- ready Python interface integrated with HuggingFace workows [ 5 ], enabling users to preprocess quantized models once and execute accelerated inference eciently through an end-to-end workow . W e benchmark RSR-core against widely used hardware-optimized matrix multiplication implementations provided by the Py T orch [ 8 ] backend and used within the HuggingFace inference interface, as well as BitNet [ 11 ]. Experimental results show substantial perfor- mance improvements, achieving up to 62 × speedup on CP U and up to 1 . 9 × speedup on CUDA for popular ternary LLM inference workloads compar ed to Py T orch bfloat16 computation, while pr e- serving exact inference accuracy . 2 SYSTEM O VERVIEW W e consider matrix–vector multiplication 𝑀 · 𝑣 , where 𝑀 is a binary matrix with entries in { 0 , 1 } or a ternary matrix with entries in {− 1 , 0 , + 1 } . The matrix corresponds to quantized model weights and remains xed after prepr ocessing, while the vector 𝑣 represents input activations arriving during inference, as discussed in the Introduction section. The goal is to accelerate this multiplication in practical inference pipelines while preserving exact computation. Algorithm overview . The Redundant Segment Reduction (RSR) algorithm [ 2 ] consists of two phases: an oine preprocessing ap- plied once to the matrix 𝑀 , followed by a fast online multiplication phase applied repeatedly during inference. During preprocessing , RSR splits the matrix into horizontal blocks of 𝑘 rows and identies identical column segments within each block, grouping columns that share the same bit pattern. The preprocessing stage produces auxiliary data structures—including column permutations, group boundaries, and scatter indices—that enable ecient reuse of inter- mediate results during inference. During infer ence , given an input vector 𝑣 , RSR aggregates vector entries corresponding to identical column segments before multiplication and distributes contribu- tions only once per unique segment. This r educes the number of arithmetic operations required for computing 𝑀 · 𝑣 while preserving exact multiplication results without sacricing the space usage. 2.1 System Architecture RSR-core is an optimize d RSR execution engine using a layered architecture illustrated in Figure 1. At its core, the system provides 2 In the original paper , the multiplication 𝑣 · 𝑀 is considered instead of 𝑀 𝑣 , and therefore rows (rather than columns) ar e grouped together . kernel-level implementations of RSR multiplication on both CP U (C kernels) and CUD A (GP U kernels). These kernels are exposed through intermediate multiplier abstractions and integrated into a Python interface that supp orts end-to-end preprocessing and inference workows. The architecture enables users to pr eprocess quantized models once and reuse the generated artifacts across repeate d inference calls. The full source code is publicly available at this repository . 2.2 Kernels Implementation While the RSR algorithm is conceptually straightforward, a direct Python implementation does not yield practical sp eedups due to interpreter o verhead, general-purpose sorting, and inecient mem- ory access patterns during the gather , aggregate, and scatter phases. RSR-core therefore provides native kernel implementations in C (CP U) and CUDA (GP U) for both binary (1-bit) and ternar y (1.58-bit) matrices. A key design choice spans all backends: preprocessing uses counting sort over the discrete pattern space ( 2 𝑘 buckets for binary , 4 𝑘 for ternar y), achieving 𝑂 ( 𝑛 + buckets ) complexity per block instead of 𝑂 ( 𝑛 log 𝑛 ) from comparison-based sorting. Meta- data is uniformly shrunk to compact types—permutation indices and group boundaries stored as 16-bit integers, and scatter targets encoded as xed-size bitmasks rather than variable-length index arrays—reducing bandwidth pressure in the inference hot path. On the CP U , the C kernels fuse the gather and aggregate phases into a single pass over the input vector , accumulating partial sums directly without materializing intermediate arrays. The binary ker- nel uses scalar-unrolled loads with software prefetch hints, which outperforms hardware vector gather instructions on the random- access pattern inherent to RSR. For ternary matrices, where each group must scatter both a p ositive and a negative contribution, the kernel replaces variable-length signed scatter lists with tw o com- pact bitmasks per group and iterates their set bits directly , making the per-group scatter cost independent of how many output rows are active. All CPU kernels are parallelized across row blocks. For end-to-end model inference on CP U , RSR-core further fuses activation quantization with the RSR matrix-vector multiply into a single native call, and batches sibling linear lay ers that share the same input vector (e .g., 𝑊 𝑞 , 𝑊 𝑘 , 𝑊 𝑣 ) into one combined operation. This eliminates repeated Python dispatch and redundant quantiza- tion, and exposes a larger pool of row blocks to distribute across cores—a layer of optimization that contributes substantially to the observed wall-clock sp eedups beyond the kernel itself. On CUD A, each row block is assigned to one thread block, and warps within a block process groups in parallel. Each group’s meta- data is packed into a single 64-bit word encoding the permutation range, length, and scatter masks, so the kernel loads one value per group and begins work immediately . Permutation indices are sorted within each group during preprocessing, which do es not aect the computed sum but improves cache locality on the gather reads. Per-warp shared-memory partial buers avoid contention on output writes, and zero-contribution groups are dr opped during preprocessing to eliminate useless work. Compile-time specializa- tions on 𝑘 allow the compiler to fully unroll scatter loops for each supported block height 3 . 3 See the code repository for more technical implementation detail. RSR-core: A High-Performance Engine for Low-Bit Matrix- V ector Multiplication Figure 2: Benchmarking the matrix multiplication on CUDA and CP U. Matrix is binar y while vector is float32 . 2.3 Multipliers On top of the kernel implementations, RSR-core provides a set of Python classes called Multiplier . These classes encapsulate multiplier-specic logic, including both RSR-base d multiplication and baseline multipliers such as BitNet. Each multiplier exposes two primary operations: preprocessing and multiplication. The preprocessing stage operates on a given low-bit matrix and produces reusable artifacts that encode segment-level structure for ecient inference-time execution. The multiplication stage then uses these artifacts together with an input vector 𝑣 to compute the exact matrix–vector product 𝑀 · 𝑣 . 4 2.4 Integration RSR-core provides an interface for executing inference with ternar y large language models and integrates directly with mo dels available through the HuggingFace model hub 5 . Models that use ternar y (BitLinear) layers, such as BitNet [ 11 ] and its variants, can be use d with RSR-core without modifying existing inference pipelines 6 . Users apply preprocessing once to a selected mo del downloaded from the HuggingFace model hub. The generated preprocessing artifacts are stored locally , with at most the same space usage as the models themselves, and reused for subsequent inference executions. During inference, users can interact with the model through stan- dard prompting worko ws and obtain responses using accelerate d matrix–vector multiplication provided by RSR-core (see demonstra- tion section). RSR-core also includes a lightweight user interface that simplies model selection, preprocessing management, storage monitoring of generated artifacts, and interactive prompting of the models. Integration with Py T orch-based infer ence pipelines is provided through a custom PyTorch module called RSRLinear , which re- places ternary linear layers with RSR-enable d implementations. A ny system using Py T orch for neural network inference can incor- porate RSR-core through this module with minimal changes. 2.5 Benchmarking Results T o e valuate the performance of RSR-core, we compar e multiplica- tion time against baseline implementations provided by Py T orch, which already use hardwar e-optimized kernels on both CP U and 4 Note that preprocessing is required only for RSR-based multipliers. 5 https://huggingface.co/models 6 For example, microsoft/bitnet-b1.58-xxx models. T able 1: T ernary (1.58-bit) LLM Inference Speedup over Hug- gingFace Py T or ch bfloat16 Model HF (T ok/s) RSR (T ok/s) Speed-up CP U Falcon3-10B-1.58b 0.2 11.3 62.0x Llama3-8B-1.58b 0.2 13.4 53.8x BitNet-2B-4T -bf16 2.1 28.8 13.9x BitNet-2B-4T 14.2 29.3 2.1x CUDA Falcon3-10B-1.58b 25.2 47.4 1.9x Llama3-8B-1.58b 31.9 59.3 1.9x BitNet-2B-4T -bf16 33.1 57.4 1.7x BitNet-2B-4T 41.6 57.1 1.4x CUD A platforms. W e also compare against BitNet [ 11 ] as an addi- tional baseline for low-bit matrix multiplication. The r esults (Fig- ure 2) show substantial speedups for matrix–vector multiplication on both CP U and CUD A. W e further evaluate end-to-end LLM inference performance during the decoding (token generation) phase and compare against HuggingFace Py T orch infer ence on b oth CPU and CUD A platforms. The results (T able 1) demonstrate signicant improvements in token generation throughput using RSR-core. A dditional benchmarking results are available in the project repository . 3 DEMONSTRA TION SCENARIOS During the demonstration, participants interact with RSR-core through an integrated web-based interface that supports model preprocessing, accelerated inference, and kernel-level performance exploration workows. Scenario 1: Model Onboarding. Participants search for a ternar y model on the HuggingFace Hub, select it, and congure RSR prepro- cessing parameters including the block height 𝑘 , multiplier v ersion, and target device. Upon launching pr eprocessing, the UI displays real-time progress as each layer is processed. Once complete, the model appears in the model list with metadata such as size, lay er count, and selected 𝑘 . RSR preprocessing is a one-time cost; the UI makes it accessible to non-experts. Figure 3a illustrates the prepro- cessing interface. Scenario 2: Side-by-Side Inference. Participants select a pre- processed model, enter a prompt, and run text generation with both the RSR backend and the HuggingFace bfloat16 baseline. The UI displays the generated text alongside p erformance metrics—tokens per se cond, generation latency , and model load time—and computes the end-to-end speedup factor . This scenario demonstrates RSR’s practical acceleration on real LLM inference . Figure 3b shows the inference comparison interface. Scenario 3: Kernel-Le vel Exploration. Participants navigate to the Matvec Benchmark tab, enter custom matrix shapes (e .g., matching a specic model’s weight dimensions), select a range of 𝑘 values and bit-width (1-bit or 1.58-bit), and launch kernel-lev el micro-benchmarks. The UI produces a bar chart comparing RSR against FP32 and BF16 baselines at the b est 𝑘 per shape, and a line chart showing how RSR latency varies across 𝑘 values. Participants Mohsen Dehghankar and Abolfazl Asudeh (a) Mo del preprocessing. (b) Model inference. (c) Kernel-level matvec b enchmarking. (d) Cross-conguration comparison. Figure 3: RSR-core web interface demonstration scenarios. can explore the parameter sensitivity of RSR on the demonstration hardware, validating that redundancy structure varies across shap es. Figure 3c illustrates the kernel-level benchmarking interface. Scenario 4: Cross-Conguration Comparison. Participants switch between CP U and CUDA using the device selector and com- pare pre-computed shap e benchmark results across bit-widths (1-bit vs. 1.58-bit). The Best K tab re veals how the optimal block height shifts across devices and matrix shapes, demonstrating that RSR’s advantage is hardware-dependent. The dashb oard enables rapid exploration across congurations without re-running experiments. Figure 3d shows the cross-conguration comparison interface . REFERENCES [1] Tingyang Chen, Cong Fu, Kun W ang, Xiangyu Ke, Y unjun Gao, W enchao Zhou, Y abo Ni, and Anxiang Zeng. 2025. Maximum inner product is query-scaled nearest neighbor . arXiv preprint arXiv:2503.06882 (2025). [2] Mohsen Dehghankar , Mahdi Erfanian, and Abolfazl Asudeh. 2024. An ecient matrix multiplication algorithm for accelerating inference in binar y and ternary neural networks. arXiv preprint arXiv:2411.06360 (2024). [3] Matthijs Douze. 2025. Machine learning and high dimensional vector search. arXiv preprint arXiv:2502.16931 (2025). [4] Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Je Johnson, Gergely Szilvasy , Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library . (2024). arXiv:2401.08281 [cs.LG] [5] Inc. Hugging Face. 2024. Hugging Face Model Hub and T ransformers Library . https://huggingface.co. [6] et al Ma, Shuming. 2024. The era of 1-bit llms: All large language models are in 1.58 bits. arXiv preprint arXiv:2402.17764 (2024). [7] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Hongyi Jin, Tianqi Chen, and Zhihao Jia. 2025. T owards ecient generative large language model serving: A survey from algorithms to systems. Comput. Sur veys 58, 1 (2025), 1–37. [8] et al Paszke, Adam. 2019. Pytorch: An imperative style, high-performance deep learning library . Advances in neural information processing systems 32 (2019). [9] Thomas Rölleke, Theodora T sikrika, and Gabriella Kazai. 2006. A general ma- trix framework for modelling information retrieval. Information processing & management 42, 1 (2006), 4–30. [10] Mohamed Trabelsi, Zhiyu Chen, Brian D Davison, and Je Hein. 2021. Neural ranking models for document retrieval. Information Retrieval Journal 24, 6 (2021), 400–444. [11] et al W ang, Hongyu. 2023. Bitnet: Scaling 1-bit transformers for large language models. arXiv preprint arXiv:2310.11453 (2023). [12] Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning W ang, Zhihang Yuan, Xiuhong Li, et al . 2024. A survey on ecient inference for large language models. arXiv preprint arXiv:2404.14294 (2024).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment