하이브리드 신경 압축으로 보는 저장 한계 탐구
본 논문은 대형 언어 모델(LLM)을 활용한 손실 없는 압축 가능성을 탐색한다. GPU 연산의 비결정성(“GPU Butterfly Effect”)을 로그잇 양자화로 해결하고, 저엔트로피 데이터는 기존 압축기로, 고엔트로피 데이터는 LLM으로 라우팅하는 Hybrid‑LLM 아키텍처를 제안한다. 실험 결과, 기억된 문학 텍스트에서는 0.39 BPC, 새로운 뉴스에서는 0.75 BPC의 압축 효율을 보였으며, 현재 추론 지연이 Zstd 대비 2600…
저자: Marcus Armstrong, ZiWei Qiu, Huy Q. Vo
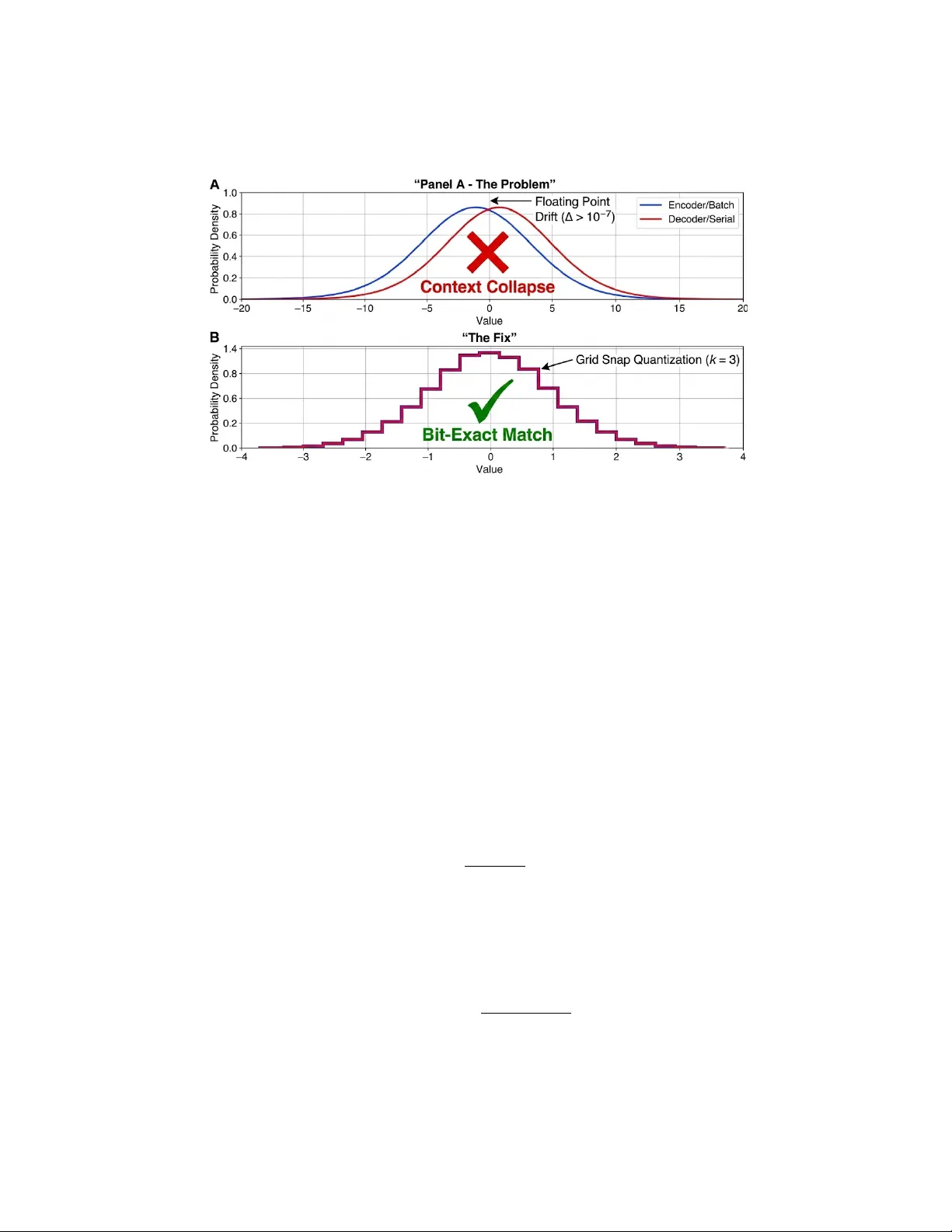
본 연구는 대형 언어 모델(LLM)이 전통적인 손실 없는 압축 알고리즘의 한계를 뛰어넘을 수 있는 가능성을 탐구한다. 서론에서는 압축이 본질적으로 다음 토큰을 예측하는 작업이며, 예측 정확도가 높을수록 필요한 비트 수가 감소한다는 점을 강조한다. LLM은 장거리 의미적 종속성을 모델링함으로써 기존 Lempel‑Ziv 기반 방법이 포착하지 못하는 구조적 중복을 포착할 수 있다. 그러나 실제 적용에는 두 가지 주요 시스템적 제약이 있다. 첫째는 연산 지연으로, 현재의 트랜스포머 기반 모델은 시퀀스 길이에 선형·제곱적으로 시간이 증가한다. 둘째는 GPU와 CPU 사이의 부동소수점 연산 비결정성, 즉 “GPU Butterfly Effect”라 명명된 현상이다. 이 현상은 병렬 연산 시 미세한 확률값 차이가 발생해 Arithmetic Coding(AC) 디코더와 인코더가 동기화되지 않아 복원 불가능한 파일을 만든다.
이를 해결하기 위해 저자들은 Hybrid‑LLM이라는 하이브리드 아키텍처를 설계한다. 핵심 아이디어는 데이터 블록을 사전 분석하여 저엔트로피와 고엔트로피 구간을 구분하고, 각각 기존 압축기와 LLM에 라우팅하는 것이다. 구체적으로, Zstd‑1 수준의 “Scout” 모듈이 각 블록의 압축 비율 R_zstd(b)를 측정한다. R_zstd(b) ≤ 1.05인 경우는 압축 불가능한 노이즈(예: 암호화 데이터)로 간주해 CPU‑Zstd‑19으로 처리하고, R_zstd(b) > 3.0인 경우는 고중복 로그 등 전통적인 사전 압축으로 충분히 처리 가능하므로 CPU‑Zstd‑1로 라우팅한다. 중간 구간(1.05 < R_zstd(b) ≤ 3.0)만 GPU‑LLM으로 인코딩한다. 이 방식은 GPU 연산을 의미 있는 데이터에만 집중시켜 전체 지연을 크게 감소시킨다.
비결정성 문제를 해결하기 위해 로그잇 양자화와 호스트 오프로드 프로토콜을 도입한다. GPU에서 출력된 로그잇 z_t를 소수점 셋째 자리까지 양자화(ˆz_t = round(z_t·10³)/10³)하고, 양자화된 값을 CPU로 전송한다. CPU에서는 IEEE‑754 double‑precision으로 Softmax를 재계산해 확률 분포 Qϕ(x_t|x
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기