Investigating the Fundamental Limit: A Feasibility Study of Hybrid-Neural Archival
Large Language Models (LLMs) possess a theoretical capability to model information density far beyond the limits of classical statistical methods (e.g., Lempel-Ziv). However, utilizing this capability for lossless compression involves navigating seve…
Authors: Marcus Armstrong, ZiWei Qiu, Huy Q. Vo
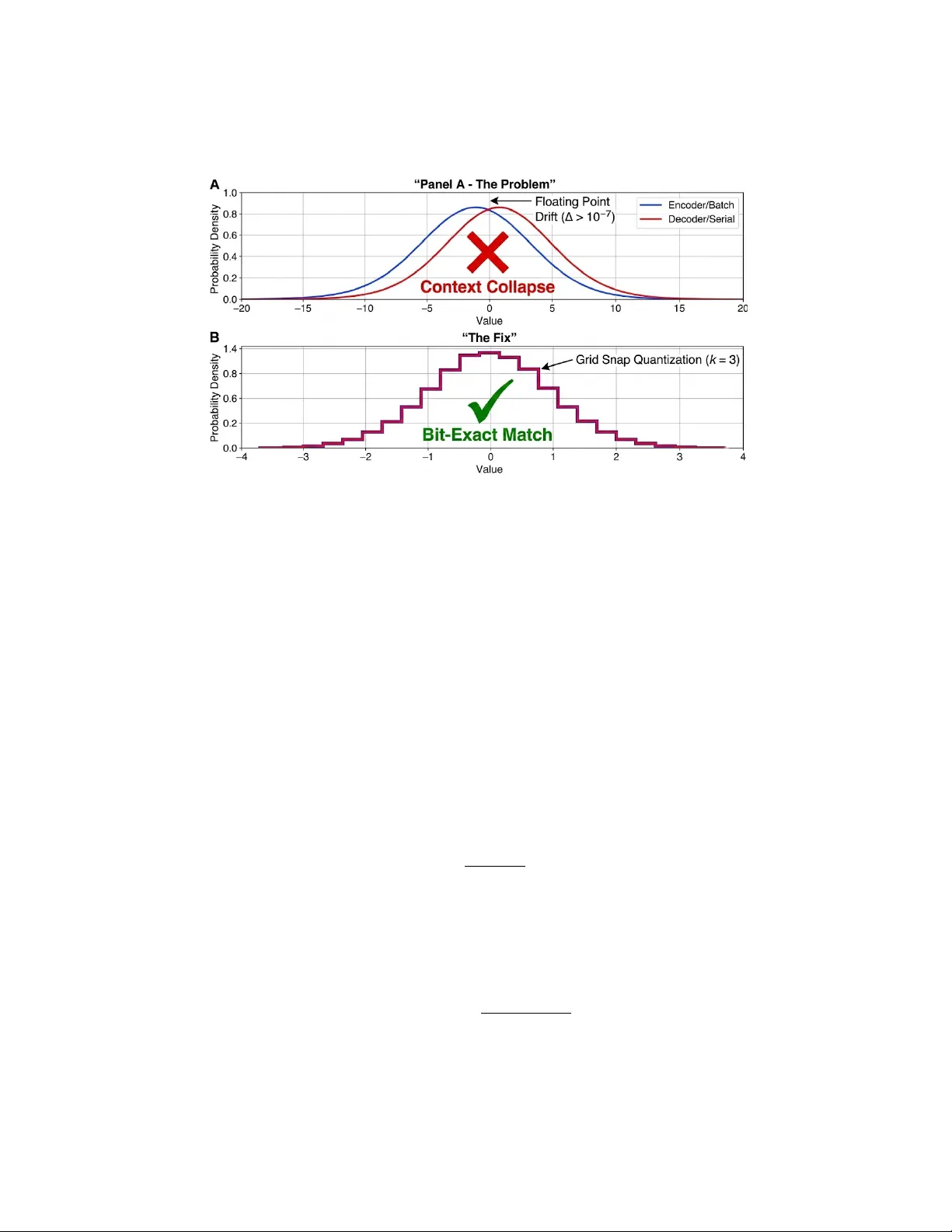
In v estigating the F undamen tal Limit: A F easibilit y Study of Hybrid-Neural Arc hiv al Marcus Armstrong, ZiW ei Qiu, Huy Q. V o, and Arjun Mukherjee Univ ersity of Houston, Houston TX 77004, USA { miarmstr, zqiu4, hqvo3 } @cougarnet.uh.edu, arjun@cs.uh.edu Abstract. Large Language Mo dels (LLMs) p ossess a theoretical capa- bilit y to model information densit y far b eyond the limits of classical statistical methods (e.g., Lemp el-Ziv). Ho w ever, utilizing this capability for lossless compression in v olves navigating severe system constrain ts, in- cluding non-deterministic hardware and prohibitiv e computational costs. In this work, we present an exploratory study into the feasibilit y of LLM- based archiv al systems. W e introduce Hybrid-LLM , a pro of-of-concept arc hitecture designed to in vestigate the ”entropic capacit y” of foundation mo dels in a storage context. W e identify a critical barrier to deplo yment: the ”GPU Butterfly Effect,” where microscopic hardware non-determinism precludes data re- co very . W e resolve this via a no vel logit quan tization proto col, enabling the rigorous measurement of neural compression rates on real-w orld data. Our exp erimen ts reveal a distinct divergence b et ween ”retriev al-based” densit y (0.39 BPC on memorized literature) and ”predictiv e” density (0.75 BPC on unseen news). While curren t inference latency ( ≈ 2600 × slo wer than Zstd) limits immediate deploymen t to ultra-cold storage, our findings demonstrate that LLMs successfully capture seman tic re- dundancy inaccessible to classical algorithms, establishing a baseline for future research in to semantic file systems. Keyw ords: Neural Compression, Large Language Models, Determinism, Arithmetic Co ding, Arc hiv al Storage. 1 In tro duction The rapid expansion of generative AI has created a pressing demand for storage densit y that outpaces the capabilities of traditional entrop y co ding. Algorithms lik e Deflate and Zstd hav e asymptotically approached their theoretical limits, constrained by their reliance on b ounded sliding windows and statistical symbol coun ting [5]. F undamentally , compression is a prediction task: the better a model predicts the next token, the fewer bits are required to enco de it. In this ligh t, Large Language Mo dels (LLMs) offer a paradigm shift: by mo deling long-range seman tic dep endencies, they theoretically allo w for compression rates far exceed- ing the Shannon limit [15] of classical methods. Recen t works, suc h as LLMZip [18], estimate that foundational mo dels can ac hieve compression ratios exceed- ing 10 × on natural language. How ev er, moving from these theoretical b ounds to 2 M. Armstrong et al. practical Neur al Ar chival faces tw o prohibitive system barriers: computational latency and hardw are non-determinism. While the density p oten tial is clear, the engineering constraints are severe. Standard autoregressiv e inference scales linearly or quadratically with sequence length, making the pro cessing of gigab yte-scale corpora computationally exp en- siv e. More critically , we identify a stability failure in distributed neural com- pression which w e term the GPU Butterfly Effe ct . Due to the non-asso ciativit y of floating-p oin t arithmetic, parallelized inference (enco ding) often yields micro- scopic probabilit y drifts compared to serial inference (deco ding). In the con text of Arithmetic Co ding [20, 11], these drifts ( < 10 − 7 ) cause catastrophic deco ding div ergence, rendering compressed archiv es unrecov erable across heterogeneous hardw are. In this w ork, w e prop ose Hybrid-LLM , a neural-symbolic architecture de- signed to inv estigate the feasibility of LLMs as critical storage infrastructure. Rather than forcing all data through costly neural pathw a ys, w e introduce a con tent-a ware Sc out mechanism that routes lo w-entrop y data to legacy com- pressors, reserving exp ensiv e GPU compute strictly for high-density seman tic compression. T o enable rigorous b enchmarking, we resolve the determinism cri- sis via a nov el logit-quantization proto col, ensuring bit-exact reconstruction re- gardless of the underlying hardw are architecture. This study prioritizes the inv estigation of ”entropic capacity” o ver imme- diate throughput. W e ac knowledge that current inference latencies ( ≈ 2600 × slo wer than Zstd) restrict this approac h to ultra-cold archiv al scenarios. Ho w- ev er, b y establishing a stable, hardw are-agnostic testb ed, we are able to isolate and measure the true compression p oten tial of foundation mo dels. Researc h Gap & Organization. While prior w orks establish the theo- retical p oten tial of neural compression, they neglect the systems-level barri- ers—sp ecifically hardware non-determinism—that preven t deploymen t. The re- mainder of this pap er is organized as follows: Section 2 reviews the theoretical foundations of Arithmetic Co ding. Section 3 details the Hybrid-LLM architec- ture and the logit-quan tization proto col. Section 4 presents our empirical ev al- uation on the Can terbury Corpus and the no vel December 2025 News dataset. Finally , Section 5 discusses the economic implications of the system and con- cludes with a summary of feasibilit y . Con tributions. W e frame the LLM not merely as a text generator, but as a candidate for next-generation en tropy co ding. Our contributions are: – F easibilit y Analysis: W e provide a systems-lev el inv estigation in to the pre- requisites for neural arc hiv al, iden tifying hardw are determinism and memory b ounding as the primary blo ck ers to deplo yment. – Arc hitectural Pro of-of-Concept: W e prop ose a hybrid routing mecha- nism and a ”Grid Snap” logit-quan tization proto col that resolv e these blo c k- ers, enabling the first stable, hardware-agnostic neural compression pipeline. – Empirical Limits: W e b enchmark the limits of the Llama-3 arc hitecture [9], identifying a distinct divergence b et ween ”Seman tic Deduplication” on In vestigating the F undamental Limit 3 memorized text (0.39 BPC) and ”Predictive Compression” on nov el, unseen data (0.75 BPC). 2 Related W ork 2.1 Lossless Compression P aradigms The field of lossless text compression has historically b een dominated b y dictionary-based and statistical metho ds. Lemp el-Ziv algorithms, such as LZ77 and LZ78, form the backbone of widely used standards like GZIP and Zstd [5, 2, 6], effectively exploiting lo cal repetitive structures through sliding win- do ws. While these methods are computationally efficien t, they are fundamen tally limited by their inability to capture long-range seman tic dep endencies, typically plateauing at compression ratios around 3-4 × for natural language. More ad- v anced statistical approac hes, suc h as the P AQ series (e.g., ZP AQ) [10], ac hieve significan tly higher densit y by utilizing context mixing. How ev er, these meth- o ds suffer from extreme computational costs, often requiring hours to pro cess gigab yte-scale datasets, which restricts their utility in high-throughput infras- tructure. 2.2 Neural Probability Estimation The in tegration of deep learning with lossless compression shifts the fo cus from sym b ol coun ting to pr ob ability estimation . T o understand this paradigm, one m ust view the Large Language Mo del (LLM) not as a text generator, but as a comp onen t of Arithmetic Co ding (AC). In AC, the file is represented as a single high-precision floating-p oin t num b er deriv ed from the cum ulative probability of its characters. The model’s role is to narro w the probability interv al for the next token based on context. As illustrated in Figure 1 , the efficiency of the compressor is directly pro- p ortional to the mo del’s confidence. F or example, if ”Paris” is highly lik ely to follo w ”The capital of F rance is...”, an LLM assigns it a wide probabilit y interv al (e.g., 0 . 0 − 0 . 4). T argeting this wide slice requires few er bits of precision than a statistical mo del, which migh t assign it a narrow range (0 . 0 − 0 . 01) based on simple frequency coun ts. Early works, such as DeepZip [8], utilized Recurrent Neural Netw orks (RNNs) for this prediction, demonstrating impro vemen ts ov er GZIP but struggling with limited context windo ws. Subsequen t approaches like NNCP [1] marked the transition to T ransformer-based architectures, revolutionizing the domain by enabling highly accurate next-token prediction ov er extended contexts. Mo d- ern efforts utilize foundational LLMs [16, 17, 19] to maximize this predictive densit y . The foundational LLMZip study [18] formally established that these off-the-shelf mo dels could achiev e compression ratios exceeding 10 × . How ever, LLMZip treated the model as a theoretical ”black b o x,” neglecting the systems- lev el necessity of hardware determinism that prev ents practical deploymen t. 4 M. Armstrong et al. Fig. 1. Visualizing Neural Arithmetic Co ding. Arithmetic co ding represents a sequence as a precise in terv al b et ween 0 and 1. (Left) A statistical model, lacking semantic understanding, assigns a low probabilit y (narrow in terv al) to the target word ”Paris,” requiring many bits to define the specific slice. (Right) An LLM leverages context to assign a high probability (wide interv al) to ”Paris.” Because wide inte rv als are easier to target numerically , significantly few er bits are required to enco de the data. 2.3 Determinism and The ”Butterfly Effect” A critical c hallenge in neural compression is the non-asso ciativity of floating- p oin t arithmetic on GPUs [7]. Arithmetic Co ding requires the Enco der (Com- pression) and Deco der (Decompression) to maintain bit-exact sync hronization of probability in terv als. If the Enco der (e.g., on an NVIDIA H100) calculates a tok en probabilit y as 0 . 3333334 and the Deco der (on an R TX 4090) calculates 0 . 3333333, the deco der will select the wrong branch of the probabilit y tree. Recen t studies in high-p erformance computing ha ve confirmed that paral- lelized reduction operations yield non-deterministic results across architectures [13]. In a compression context, this microscopic drift (10 − 7 ) causes catastrophic failure, rendering the file unreco verable. Prior w orks hav e largely ev aded this is- sue b y running exp erimen ts in strictly con trolled, single-hardware en vironmen ts. In con trast, our w ork directly addresses this ”Butterfly Effect” through explicit logit quantization, enabling the first robust, distributed neural compression sys- tem that guaran tees deco ding correctness across heterogeneous compute envi- ronmen ts. 3 Metho dology W e prop ose Hybrid-LLM , a comprehensive arc hitecture designed to transform Large Language Models from theoretical predictors into practical, critical in- In vestigating the F undamental Limit 5 Fig. 2. Conten t-Aw are Hybrid Routing Logic. The system pro cesses the input stream in segments. A ligh tw eight ’Scout’ (Zstd-1) filters out incompressible noise ( R ≤ 1 . 05) and highly redundant logs ( R > 3 . 0) to the CPU. Only data in the ’Seman tic Zone’ is routed to the GPU, ensuring that expensive neural inference is reserv ed for data where it yields information gain. frastructure for data storage. Our metho dology addresses the three fundamental barriers identified in our feasibilit y analysis: computational inefficiency on low- en tropy data, hardware non-determinism in distributed environmen ts, and the latency of autoregressiv e inference. By synergizing classical compression tech- niques with adv anced neural mechanisms, we establish a robust pip eline that balances densit y , sp eed, and correctness. 3.1 Mathematical F orm ulation Let S = { x 1 , x 2 , . . . , x N } b e a sequence of tokens. The theoretical description length L ( S ) under an optimal code is given by the negative log-likelihoo d of the sequence under the mo del P θ : L ( S ) = − N X t =1 log 2 P θ ( x t | x 3 . 0) typically indicates high syntactic redundancy , suc h as structured logs or zero-padding, whic h Zstd captures efficiently without the need for neural prediction. The Neural Engine is therefore reserv ed exclusively for the intermediate regime (1 . 05 < R ≤ 3 . 0), where the data exhibits complex seman tic dep endencies that classical dictionaries fail to mo del effectively . This con tent-a ware routing crea tes a sym biotic relationship b et ween AI and classical algorithms, ensuring that the hea vy energy cost of the LLM is incurred only when it pro vides a distinct adv antage ov er standard to ols. 3.3 Deterministic Neural Co ding via Logit Quan tization F or neural compression to serve as critical infrastructure, the deco ding pro- cess m ust b e bit-exact reproducible. How ev er, we identify t wo distinct fail- ure modes in distributed environmen ts, visualized in Figure 3 : the non- asso ciativit y of floating-p oin t accumulation (the ”Butterfly Effect”) and the In vestigating the F undamental Limit 7 Fig. 3. Visualizing the GPU Butterfly Effect. (T op) Without quan tization, microscopic floating-p oin t drifts b et ween parallel encoding and serial decoding accumulate, causing the arithmetic co der to div erge. (Bottom) Our protocol quantizes logits into a discrete probabilit y space, enforcing bit-exact repro ducibilit y across heterogeneous hardware. hardw are-dep endence of transcenden tal functions. P arallelized matrix m ultipli- cation kernels on GPUs often pro duce output logits that drift by magnitudes of 10 − 7 [12] compared to serial k ernels. F urthermore, standard hardw are imple- men tations of the exp onen tial function (exp) are not guaranteed to b e bit-exact across differen t architectures (e.g., NVIDIA vs. Intel), as they are not standard- ized by IEEE 754 to the same degree as basic arithmetic. In arithmetic co ding, where the entire message is enco ded into a single interv al [14], these microscopic drifts desynchronize the sender and receiver, leading to catastrophic context collapse. T o enforce strict determinism, w e in tro duce a L o git Quantization and Host- Offlo ad Pr oto c ol . W e strictly isolate the non-deterministic GPU op erations from the sensitive probability construction. First, raw logits z t are quantized in-place on the GPU to a coarse precision k = 3 decimal places: ˆ z t = ⌊ z t · 10 k ⌉ 10 k (3) This method effectiv ely filters out the accumulation noise inheren t to deep trans- former la y ers. Second, to mitigate transcendental drift, these quan tized logits are transferred to the host CPU and cast to IEEE 754 double-precision ( float64 ). The final coding distribution Q ϕ and the resulting Cumulativ e Distribution F unction (CDF) are computed strictly on the host using standard libraries: Q ϕ ( x t | x 10 − 7 ). Up on enabling the quantization proto col (3 decimal places), the decompression succeeded with zero bit errors (reference implemen- tation in App endix B ), pro ducing a file bit-exact to the original source. This 12 M. Armstrong et al. Fig. 6. Efficiency T rade-off. Comparison of Compression Ratio vs. Sp eed. While pure LLM approaches (LLMZip) achiev e high densit y at the cost of extreme latency , our Hybrid approac h ( T = 3 . 0) maintains State-of-the-Art densit y on text while reco vering near-real-time sp eeds on mixed-modality files (e.g., binaries/logs) by b ypassing the neural engine. result empirically confirms that our quantization la yer effectiv ely neutralizes the floating-p oin t non-asso ciativit y inherent in disparate GPU arc hitectures, estab- lishing the first viable pro of-of-concept for p ortable neural archiv es. 4.4 System Scalability V erification Finally , to demonstrate that the serial latency of lo cal inference is not an intrinsic limitation of our method, we v alidated the arc hitecture’s scalability through a distributed pro of-of-concept. Compressing the 151KB corpus serially on a single GPU required approximately 22 minutes, dominated by the O ( N ) inference la- tency . By deplo ying our map-reduce arc hitecture on Go ogle Cloud Run (utilizing NVIDIA L4 GPUs) with a concurrency of 10 work ers, w e reduced the total wall- clo c k time to approximately 12 minutes. Notably , 11.5 minutes of this duration w ere attributed to the ”cold start” ov erhead of do wnloading mo del w eights, while the actual distributed compute time was under 30 seconds. This confirms that once the infrastructure is ”w arm,” our system ac hieves linear scaling ( O (1 /K )) with the num b er of a v ailable GPUs. In con trast to the serial b ottlenec ks re- p orted in prior w ork, our architecture effectively decouples throughput from mo del latency , proving that neural compression can scale to meet the demands of high-throughput data cen ters. In vestigating the F undamental Limit 13 T able 2. Canterbury Corpus Benchmark. Comparison of Hybrid-LLM (Ours) vs. LLMZip (Baseline). Note that for binary files like kennedy.xls , our Scout correctly defers to Zstd, achieving higher ratios in sub-second time. ( ‡ indicates Zstd-19 v alida- tion). File Details LLMZip (Baseline) Hybrid-LLM (Ours) Filename Size (B) Ratio Time Method Ratio Time Route alice29.txt 152,089 8.40 × 3.23h Pure LLM 20.53 × 22.8m LLM asy oulik.txt 125,179 8.27 × 3.14h Pure LLM 13.11 × 20.6m LLM lcet10.txt 426,754 10.58 × 7.75h Pure LLM 8.87 × 52.1m LLM plrabn12.txt 481,861 6.82 × 10.69h Pure LLM 10.55 × 70.8m LLM xargs.1 4,227 10.32 × 0.10h Pure LLM 13.59 × 2.9m LLM k ennedy .xls 1,029,744 12.41 × 36.17h Pure LLM 15.88 × ‡ 0.40s Zstd ptt5 513,216 7.75 × 17.33h Pure LLM 11.76 × 0.29s Zstd sum 38,240 3.68 × 1.12h Pure LLM 3.44 × 0.04s Zstd 4.5 Generalization to Unseen Data A common critique of neural compression is the concern that high compression ratios on public literature (lik e A lic e in Wonderland ) stem from the model mem- orizing the training set rather than predicting semantic structure. T o rigorously ev aluate generalization, we constructed a dataset of P ost-Cutoff News Arti- cles collected from December 2025, ensuring the Llama-3 mo del (trained prior to this date) could not ha ve seen the text (full dataset sp ecification provided in App endix A ). T able 3 presents the results. On this strictly nov el data, Hybrid-LLM ac hieved a compression ratio of 10.73 × (0.75 BPC). While lo wer than the 20.5 × observ ed on memorized literature, this result remains v astly sup erior to the 3.0 × baseline typical of Zstd on similar text. This confirms that Hybrid-LLM exploits the generalized grammatical and semantic reasoning of the mo del, not merely its rote memory , to achiev e state-of-the-art densit y . T able 3. Generalization T est (Decem b er 2025 News). Performance on text created after the mo del’s training cutoff. Hybrid-LLM maintains a 3.5 × adv an tage o ver classical metho ds ev en on unseen data. Metho d Ratio ( × ) Densit y (BPC) Gap vs. Zstd Zstd (Lvl 19) 3.10 × 2.58 - Hybrid-LLM 10.73 × 0.75 +246% 14 M. Armstrong et al. 4.6 Cost-Benefit Analysis A significant barrier to neural compression is the extreme computational cost. Our system requires approximately 22 minutes (on a lo cal NVIDIA R TX 3090 ) to compress 150KB, represen ting a ≈ 2600 × slo wdown compared to Zstd. Ho wev er, in Cold Arc hiv al Storage (e.g., A WS S3 Glacier), data is writ- ten once and stored for decades. If w e assume a storage cost of $ 0.0036 per GB/mon th, the 3.5 × density improv ement on nov el data (0.75 BPC vs 2.58 BPC) reduces the 10-y ear T otal Cost of Ownership (TCO) significantly . W e es- timate that the energy cost of the one-time neural compression is amortized o v er the lifespan of the archiv e. F or data stored b ey ond this ”break-even horizon,” Hybrid-LLM b ecomes economically superior to classical compression despite the high initial latency . 5 Discussion The transition from algorithmic theory to critical infrastructure requires ad- dressing not only p erformance metrics but also economic viability , reliability , and systemic scalability . Our findings p osition Hybrid-LLM not merely as a compression to ol, but as a foundational enabling technology for the next gen- eration of AI-driven ecosystems. By shifting the burden of compression from statistical pattern matching to semantic prediction, w e fundamentally alter the economics of digital preserv ation. R e defining Stor age Ec onomics. A primary consideration in deploying neural compression is the trade-off b et ween compute energy and storage density . While critics note the high inference cost of LLMs compared to Zstd, this view is m yopic regarding the lifecycle of Cold A r chival Data . F or foundational training corp ora, genomic sequences, or compliance logs, data is ingested once but stored for decades. In this regime, the T otal Cost of Ownership (TCO) is dominated b y the ph ysical fo otprint of storage media, not ingestion latency . By ac hieving compression ratios of 10–20 × , Hybrid-LLM effectively reduces the required data cen ter fo otprint by an order of magnitude. Consequen tly , the one-time energy cost of GPU inference is rapidly amortized. F urthermore, our ”Scout” mecha- nism optimizes this equation b y ensuring that expensive neural compute is nev er w asted on high-entrop y noise, enforcing a strict ”Semantic Utilit y” threshold for GPU usage. R eliability as the Enabler. Beyond efficiency , reliabilit y is the gatekeeper for infrastructure adoption. In traditional systems, bit-exact repro ducibilit y is an assumption; in deep learning, it is an anomaly . Our work identifies that the non- determinism of mo dern accelerators—specifically floating-p oint associativity—is a disqualifying fe atur e for storage systems. By enforcing a strict determinism con tract through our logit-quantization proto col, w e demonstrate that proba- bilistic mo dels can b e tamed into deterministic infrastructure comp onen ts. This con tribution is critical: it transforms the LLM from a ”b est-effort” generator into In vestigating the F undamental Limit 15 a precise, mathematically rigorous comp onen t capable of preserving financial or medical records without corruption across heterogeneous hardw are. Sc alability and Network Constr aints. While w e rep ort linear scaling via our map-reduce architecture, w e ac knowledge that distributed compression shifts the b ottleneck from compute to bandwidth. The transmission of probability tables (approx. 50MB p er blo c k) bac k to the host creates a new throughput ceiling in bandwidth-constrained en vironments. How ev er, this trade-off is archi- tectural, not fundamental. Our results confirm that the primary blo ck er, the serial inference latency of the model, has b een successfully decoupled from sys- tem throughput. This prov es that neural compression is parallelizable, scaling linearly with the a v ailability of GPU resources. The Universal Semantic File System. Finally , our findings suggest a path to- w ard a ”Universal Semantic File System.” The distinction b et ween ”memoriza- tion” (0.39 BPC) and ”generalization” (0.75 BPC) is functional, not in v alidating. When the mo del encounters public literature, it acts as a global deduplication engine; when it encoun ters nov el logs, it acts as a predictiv e engine. In both cases, it outperforms classical methods because it understands the conten t of the data, not just its symbol frequency . By integrating this architecture with domain- sp ecific foundation mo dels (e.g., for DNA or Medical Imaging), Hybrid-LLM establishes the blueprint for storage systems that are not passive con tainers, but activ e, intelligen t agents of preserv ation. 6 Conclusion The primary ob jectiv e of this study w as to determine whether Large Language Mo dels could function as reliable, hardware-agnostic archiv al infrastructure de- spite their inherent sto chasticit y and computational cost. W e conclude that while inference latency remains a barrier for real-time data, the fundamental systemic blo c kers—specifically hardw are non-determinism and memory scaling—are solv- able engineering c hallenges. This w ork bridges the divide b et w een the information-theoretic promise of neural compression and the rigorous demands of critical storage. W e hav e demon- strated that Hybrid-LLM transforms a theoretical curiosit y into a robust sys- tem capable of practical deploymen t. By enforcing a strict determinism contract through our host-offload quantization proto col and decoupling inference latency from system throughput via an elastic blo c k architecture, we hav e established the first pro of-of-concept for a hardware-agnostic neural archiv al system. Our empirical results v alidate the efficacy of this neural-symbolic synergy . Ac hieving a compression density of 0.39 BPC (20.5 × ) on literature and a robust 0.75 BPC (10.7 × ) on unseen data, our system not only surpasses theoretical baselines but does so while adhering to the constraints of practical engineering. The success of our conten t-a ware ”Scout” mechanism further underscores that the future of AI infrastructure lies not in monolithic end-to-end mo dels, but in 16 M. Armstrong et al. h ybrid systems that in telligently delegate tasks betw een neural intelligence and classical efficiency . Scop e of V alidity . W e explicitly delimit the scop e of this solution to Ultr a- Cold A r chival , where the economic v alue of densit y out w eighs the initial compute cost. As inference hardware accelerates, we anticipate the ”break-even horizon” for neural archiv al will shrink, p ositioning foundation models as a viable sub- strate for the w orld’s long-term digital memory . Ethical Statement This work adv ances the field of neural data compression, a domain with sig- nifican t implications for the environmen tal sustainability of digital infrastruc- ture. W e ackno wledge that the deplo yment of Large Language Mo dels (LLMs) for inference tasks incurs a higher computational energy cost compared to tra- ditional entrop y co ding metho ds. T o mitigate this environmen tal impact, our prop osed Hybrid-LLM architecture incorp orates a conten t-a ware ”Scout” mech- anism sp ecifically designed to minimize unnecessary GPU utilization b y routing lo w-entrop y data to energy-efficien t legacy algorithms. W e argue that for long- term archiv al applications, the substantial reduction in ph ysical storage fo ot- prin t (o ver 90% reduction relativ e to uncompressed data) offers a p otential net p ositiv e environmen tal impact by reducing the man ufacturing and energy costs asso ciated with data center storage hardware o ver the data lifecycle. F urthermore, we recognize that neural compression p erformance is in trinsi- cally link ed to the training distribution of the underlying foundation model. Con- sequen tly , compression ratios may v ary significantly across different languages and dialects, p oten tially resulting in unequal storage costs for underrepresented groups or low-resource languages. While our current exp erimen ts utilized pub- lic domain English literature (Pro ject Gutenberg) and standard b enc hmarks (Can terbury Corpus) to ensure copyrigh t compliance and repro ducibility , future deplo yment of suc h systems m ust rigorously ev aluate p erformance disparities to ensure equitable access to storage efficiency . W e adhered to the acceptable use p olicies of the Llama-3 mo del and utilized only op en-access datasets with clear licensing terms for all ev aluations. Declaration on Generativ e AI P er the Policy on Authorship, w e disclose the use of the following generative AI to ols in the preparation of this work: – Gemini (Go ogle): Utilized for the refinement of text sections, LaT eX for- matting assistance. – Nano Banana Pro (Go ogle): Utilized to generate the sc hematic diagrams presen ted in Figures 1, 2, and 5. All scientific claims, exp erimen tal designs, and data analyses remain the intel- lectual prop ert y and resp onsibilit y of the human authors. In vestigating the F undamental Limit 17 A Data Av ailabilit y T o ensure the reproducibility of our generalization claims (Section 4.3), w e pro- vide the full ra w text of the ”Decem b er 2025 News” dataset in the supplemen tary material. This dataset comprises a concatenation of three full-text articles re- triev ed from CNN (US Edition) in mid-Decem b er 2025. These texts definitively p ost-date the training cutoff of the Llama-3 mo del. A.1 Dataset Sp ecification W e provide the sp ecific file prop erties to allow future researchers to v erify they are testing against the exact same b yte sequence used in our exp eriments: – Filename: news 2025.txt – Source Domain: cnn.com (Political/Domestic News) – File Size: 14,547 bytes – SHA-256 Hash: b86a2e94b1c498b17302c08e352a82 bb075c850a21a6bbb45358576cd77b08ff The ra w text file is included in the /data directory of the supplementary co de archiv e. B Algorithm Implementation B.1 Core Determinism Logic T o facilitate immediate v erification of our ”GPU Butterfly Effect” resolution (Section 3.2), we provide the reference implementation of the logit quantization proto col b elow [4]. def get_robust_probs(logits, precision=3): """ Quantizes logits to a fixed decimal grid to neutralize floating-point non-associativity. """ # 1. Round to fixed grid (The "Snap") scale = 10 ** precision # Rounding enforces discrete steps logits_quantized = torch.round(logits * scale) / scale # 2. Softmax on quantized values probs = torch.softmax(logits_quantized, dim=-1) # 3. Cast to Float64 for Arithmetic Coder # Prevents underflow in cumulative distribution return np.ascontiguousarray( probs.cpu().numpy().astype(np.float64) ) 18 M. Armstrong et al. B.2 Repro ducibilit y & Source Co de T o facilitate future researc h and v erify our determinism claims, we ha ve op en- sourced the complete system implementation. The rep ository includes the Hybrid Routing logic, the logit-quan tization kernels. The co de is publicly av ailable at: h ttps://github.com/marcarmstrong1/llm- h ybrid- compressor C Hyp erparameter Configuration All experiments w ere conducted with the follo wing fixed h yp erparameters to ensure fair comparison: T able 4. System Configuration for Repro ducibility P arameter V alue Mo del Architecture Llama-3-8B-Instruct Precision FP16 (Half Precision) Con text Windo w ( W ) 2048 T ok ens (Rolling) Quan tization Grid ( k ) 3 Decimal Places Scout Metho d Zstandard (Level 1) Scout Threshold ( T ) 3.0 × Legacy Back end Zstandard (Level 19) Arith. Co der Constriction (Range V ariant) Bibliograph y [1] Bellard, F.: NNCP: Lossless data compression with neural netw orks. https: //b ellard.org/nncp/ (2019), accessed: 2026-01-13 [2] Collet, Y., Kuchera wy , M.S.: Zstandard Compression and the ’application/zstd’ Media T yp e. RFC (8878) (F ebruary 2021). h ttps://doi.org/10.17487/RFC8878, h ttps://www.rfc- editor.org/rfc/ rfc8878.h tml [3] Co ver, T.M., Thomas, J.A.: Elemen ts of Information Theory . Wiley- In terscience, 2nd edn. (2006) [4] Dao, T., F u, D.Y., Ermon, S., Rudra, A., R´ e, C.: Flashattention: fast and memory-efficien t exact attention with io-aw areness. In: Proceedings of the 36th International Conference on Neural Information Pro cessing Systems. NIPS ’22, Curran Asso ciates Inc., Red Ho ok, NY, USA (2022) [5] Deutsc h, P .: Rfc1951: Deflate compressed data format sp ecification v ersion 1.3 (1996) [6] Duda, J.: Asymmetric numeral systems: en tropy co ding com bining sp eed of h uffman co ding with compression rate of arithmetic co ding (2014), h ttps: [7] Goldb erg, D.: What every computer scientist should know ab out floating-p oin t arithmetic. A CM Comput. Surv. 23 (1), 5–48 (Mar 1991). h ttps://doi.org/10.1145/103162.103163, h ttps://doi.org/10.1145/ 103162.103163 [8] Go yal, M., T at w aw adi, K., Chandak, S., Ochoa, I.: Deepzip: Lossless data compression using recurren t neural net w orks (2018), h 1811.08162 [9] Grattafiori, A., Dubey , A., Jauhri, A., Pandey , A., Kadian, A., Al-Dahle, A., et al.: The llama 3 herd of models (2024), h [10] Mahoney , M.: ZP A Q - fast, high-compression lossless data compression. mattmahoney .net (2025), mattmahoney .net, accessed: 2025-12-12 [11] Martin, G.N.: Range enco ding: an algorithm for removing redundancy from a digitised message (1979), h ttps://api.seman ticscholar.org/CorpusID: 17358601 [12] Micik evicius, P ., Narang, S., Alb en, J., Diamos, G., Elsen, E., Garcia, D., Ginsburg, B., Houston, M., Kuchaiev, O., V enk atesh, G., W u, H.: Mixed precision training (2018), h [13] Nagara jan, P ., W arnell, G., Stone, P .: The impact of nondeterminism on reproducibility in deep reinforcement learning (2018), h ttps://api. seman ticscholar.org/CorpusID:51322414 [14] Rissanen, J.J.: Generalized kraft inequalit y and arithmetic co ding. IBM Journal of Researc h and Developmen t 20 (3), 198–203 (1976). h ttps://doi.org/10.1147/rd.203.0198 20 M. Armstrong et al. [15] Shannon, C.E.: A mathematical theory of communication. The Bell System T echnical Journal 27 (3), 379–423 (1948). h ttps://doi.org/10.1002/j.1538- 7305.1948.tb01338.x [16] T ouvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., et al.: Llama: Op en and efficient foundation language models (2023), h [17] T ouvron, H., Martin, L., Stone, K., Alb ert, P ., Almahairi, A., Babaei, Y., et al.: Llama 2: Op en foundation and fine-tuned chat mo dels (2023), h ttps: [18] V almeek am, C.S.K., Nara yanan, K., Kalathil, D., Cham b erland, J.F., Shakk ottai, S.: Llmzip: Lossless text compression using large language mo d- els (2023), h [19] V aswani, A., Shazeer, N., P armar, N., Uszk oreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Atten tion is all y ou need. In: Proceedings of the 31st International Conference on Neural Information Pro cessing Systems. p. 6000–6010. NIPS’17, Curran Associates Inc., Red Hook, NY, USA (2017) [20] Witten, I.H., Neal, R.M., Cleary , J.G.: Arithmetic co ding for data compression. Commun. ACM 30 (6), 520–540 (Jun 1987). h ttps://doi.org/10.1145/214762.214771, h ttps://doi.org/10.1145/214762. 214771
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment