리대수 정책 최적화의 표현‑최적화 이분법
본 논문은 행렬 리대수로 파라미터화된 Gaussian 정책의 목표 함수에 대해, 리대수의 대수적 종류에 따라 그래디언트 Lipschitz 상수 L(R)의 성장률이 결정된다는 ‘표현‑최적화 이분법’을 제시한다. 컴팩트 대수(so(n), su(n) 등)에서는 L=O(1)이며, 비컴팩트 gl(n) 및 하이퍼볼릭 원소를 포함하는 대수에서는 L=Θ(e^{2R})이다. 이를 바탕으로 컴팩트 대수에서는 차원 축소와 저비용 투영으로 자연그라디언트와 동등한 수…
저자: Sooraj KC, Vivek Mishra
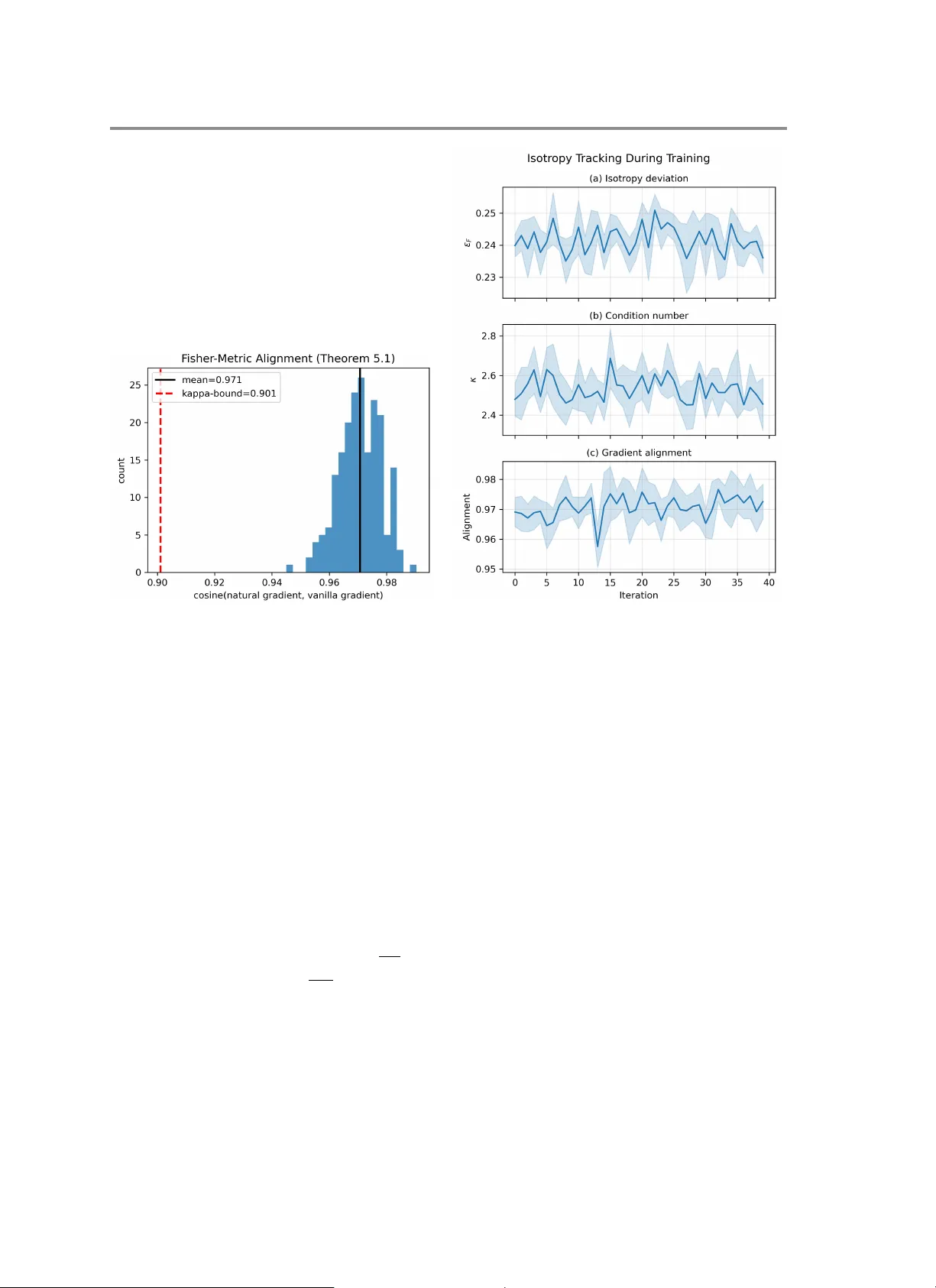
본 논문은 행렬 리대수 위에 정의된 파라미터를 이용해 Gaussian 정책을 구성하는 강화학습 및 확률적 최적화 문제를 다룬다. 저자는 먼저 Lie Group MDP라는 프레임을 정의하고, 상태와 행동이 모두 Lie 그룹 G와 그 대수 g 위에서 전이·보상이 이루어지는 상황을 모델링한다. 정책은 μ_θ(s)∈g 로 평균 행동을 정의하고, isotropic Gaussian 잡음 σ를 더해 행동 a를 생성한다. 이때 파라미터 θ는 g의 기저 {E_i}에 대한 선형 결합 계수이며, 차원 d_g=dim(g)만큼의 내재적 파라미터 공간을 가진다.
핵심 이론은 Theorem 6.1에 의해 제시된다. 목표 함수 J(θ)의 그래디언트 Lipschitz 상수 L(R)는 파라미터 노름이 R 이하인 구역에서 정의되며, g가 컴팩트(so(n), su(n) 등)이면 L(R)=O(1)이다. 반면 g=gl(n) 혹은 하이퍼볼릭 원소를 포함하는 대수에서는 L(R)=Θ(e^{2R})가 된다. 저자는 gl(n) 사례를 이용해 하한 Ω(e^{2R})를 구성하고, 이를 통해 지수적 성장률이 구조적(리대수의 비컴팩트성) 원인임을 증명한다. 또한, 하이퍼볼릭 원소가 존재하면 동일한 상한이 적용된다는 Remark 6.2를 제시한다.
이론적 결과를 바탕으로 두 가지 알고리즘적 파생을 제시한다. 첫 번째는 컴팩트 대수에 대해 radius‑independent smoothness가 보장되므로, 스텝 사이즈 η≤1/L을 고정하고 O(1/√T) 수렴률을 얻을 수 있다는 것이다. 여기서 중요한 가정은 (A3)인 bounded iterates이며, 이는 Lie‑algebraic projection P_g(·)을 통해 쉽게 만족된다. 두 번째는 자연그라디언트 업데이트에 필요한 Fisher 정보 행렬 F(θ)≈σ^{-2}I_{d_g}를 직접 계산하지 않고, Euclidean 공간에서의 투영 P_g(∇J(θ))만으로도 충분히 정확한 업데이트가 가능하다는 점이다. 이 투영은 O(n^2 J) 연산량을 요구해, 기존 O(d_g^3) 복잡도보다 훨씬 효율적이다.
정렬 파라미터 α는 투영 방향과 자연그라디언트 방향 사이의 코사인 유사도를 측정한다. Kantorovich 부등식을 이용해 α≥2√κ/(κ+1)라는 하한을 도출했으며, κ는 Fisher 행렬의 조건수이다. 실험적으로 κ가 작을수록(≈1) α가 0.9 이상으로 높아져 투영이 자연그라디언트와 거의 일치함을 확인했다. 반대로 κ가 크게 증가하면 α가 감소하고, 이 경우 Fisher 역연산을 사용해야 함을 제안한다.
실험에서는 두 가지 대표적인 Lie 그룹을 선택했다. 첫 번째는 다중 관절 로봇을 모델링한 SO(3)^J이며, 여기서는 컴팩트 대수이므로 L이 상수이고, 투영 기반 업데이트가 Cholesky 기반 Fisher 역연산 대비 1.1~1.7배 빠른 속도를 보였다. J가 30까지 증가해도 속도 향상이 유지되었으며, 비용 모델을 통해 J=200에서는 100배 이상의 가속이 예측된다. 두 번째는 rigid-body 움직임을 나타내는 SE(3)이며, 여기서는 L이 다항식적으로 증가하고, 정렬 파라미터 α가 중간 정도로 떨어졌다. 실험 결과는 이론적 상한·하한이 실제 학습 과정에서도 일치함을 보여준다.
논문은 또한 관련 연구와 차별점을 명확히 한다. 기존 Riemannian 최적화는 재트랙션과 복잡한 메트릭 텐서를 필요로 하지만, 본 연구는 선형 구조인 g를 그대로 이용해 Euclidean 공간에서 최적화를 수행한다. 또한, 자연그라디언트 기반 강화학습(TRPO, K-FAC)과 비교해 Lie‑algebraic 투영은 구조적 대칭성을 활용해 정확한 자연그라디언트를 저비용으로 복원한다는 점에서 차별화된다. 마지막으로, 보조 자료(SM)에서 모든 정리와 보조 실험, 구현 세부 사항을 제공해 재현성을 확보한다.
결론적으로, 파라미터가 행렬 리대수 위에 있을 때 최적화 난이도는 대수의 컴팩트성 여부에 의해 결정된다는 ‘표현‑최적화 이분법’을 제시하고, 이를 활용한 저비용 알고리즘이 실제 로봇·그래픽스·제어 문제에서 효과적임을 입증하였다. 향후 연구는 비컴팩트 대수에 대한 전용 스케일링 기법, 비등방성 잡음 처리, 그리고 더 일반적인 리트라액션 맵을 포함한 확장에 초점을 맞출 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기