A Representation Optimization Dichotomy, Lie-Algebraic Policy Optimization
Structured reinforcement learning and stochastic optimization often involve parameters evolving on matrix Lie groups such as rotations and rigid-body transformations. We establish a representation-optimization dichotomy for Lie-algebra-parameterized …
Authors: Sooraj KC, Vivek Mishra
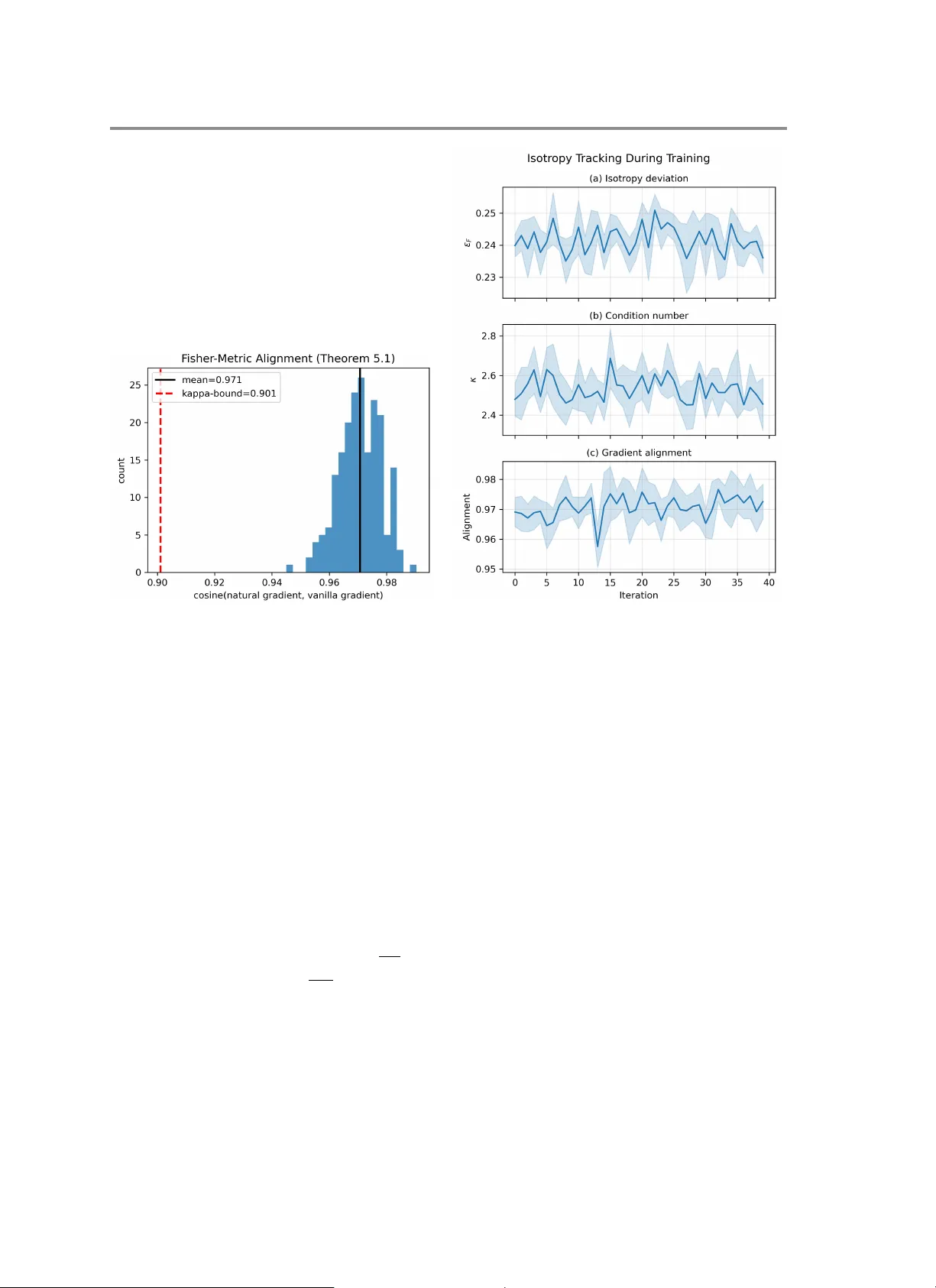
A Rep resentation–Optimization Dichotomy , Lie-Algeb raic P olicy Optimization ∗ So o raj K.C † and Vivek Mishra ‡ Abstract. Structured reinforcemen t learning and sto chastic optimization problems often in v olve parameters ev olving on matrix Lie groups such as rotations and rigid-bo dy transformations. W e establish a sharp r epr esentation–optimization dichotomy for Lie-algebra–parameterized Gaussian p olicy ob jec- tiv es in the Lie Group MDP class: the gradient Lipschitz constant L ( R )—which gov erns step-size selection, conv ergence rates, and sample complexit y of any first-order method applied to this class— is determined by the algebraic t yp e of g , uniformly ov er all ob jectives in the Lie Group MDP class, indep enden tly of the sp ecific reward structure or transition kernel. Specifically: L = O (1) for com- pact g (e.g., so ( n ), su ( n )), and L = Θ( e 2 R ) for g = gl ( n ), with O ( e 2 R ) holding for all algebras with a hyperb olic elemen t. The key analytical step is a lo wer b ound showing that the exp onen tial gro wth cannot b e remov ed b y cancellations b etw een the exp onential map and the ob jective, establishing the dic hotomy as intrinsic to the algebra t yp e. A t its core, this is a structural smoothness theorem for matrix-Lie-parameterized sto chastic ob jectives, indep enden t of the sp ecific reinforcement-learning in terpretation. The dichotom y has a direct algorithmic implication for compact algebras: radius- indep enden t smoothness enables O (1 / √ T ) con v ergence with an O ( n 2 J ) Lie-algebraic pro jection step in place of O ( d 3 g ) Fisher inv ersion. A Kantoro vich alignment bound α ≥ 2 √ κ/ ( κ + 1) provides a computable diagnostic for when this Euclidean pro jection adequately surrogates full natural gra- dien t in version. Con trolled exp eriments on SO(3) J and SE(3) v alidate the theoretical predictions: radius-indep enden t smo othness for compact algebras, polynomial Lipsc hitz growth for SE(3) (whose algebra contains no hyperb olic elements and lies outside the exp onential regime), and alignment b ounds across condition-n umber regimes. The pro jection step runs 1 . 1–1 . 7 × faster than Cholesky Fisher inv ersion at b enchmark ed scales, with the O ( n 2 J ) vs. O ( d 3 g ) asymptotic adv antage gro wing substan tially at larger joint coun ts. Key w ords. structured sto chastic optimization, matrix Lie algebras, natural gradient, Lipschitz smoothness, noncon vex con vergence, Fisher information, reinforcement learning AMS subject classifications. 90C26, 90C40, 65K10, 68T05, 22E60 1. Introduction. A recurring c hallenge in structured data-driv en optimization is under- standing how the geometry of the parameter space shap es the computational difficulty of the optimization problem. When model parameters lie on a matrix Lie group or its asso ciated Lie algebra—as in geometric estimation, rotation-v alued signal pro cessing, tra jectory optimiza- tion for mechanical systems, and structured reinforcemen t learning—the relev ant algebraic structure is not merely a representational c hoice: it directly go verns the gro wth of the gra- dien t Lipschitz constan t, the p ermissible step sizes of first-order metho ds, and the resulting con vergence rates. The cen tral question is: which p olicy p ar ameterizations admit efficient gr adient-b ase d optimization, and what structur al pr op erty of the p ar ameterization determines this? This pap er establishes a sharp answer within the Lie Group MDP class (Definition 4.1 ). ∗ Prep rint. This w o rk is currently under review at the SIAM Journal on Mathematics of Data Science (SIMODS). † Depa rtment of Pure and Applied Mathematics, Alliance University , Bengaluru, India ( ksoora- jPHD23@sam.alliance.edu.in ). ‡ Depa rtment of Pure and Applied Mathematics, Alliance University , Bengaluru, India. 1 2 S. K.C AND V. MISHRA When the underlying con trol system p ossesses geometric structure—as in rob otic manipu- lation, legged locomotion, or autonomous na vigation—the state and action spaces naturally ev olve on matrix Lie groups suc h as SO(3) (rotations) and SE(3) (rigid-b o dy motions). Pa- rameterizing p olicies through the corresp onding Lie algebras reduces the effectiv e dimension from n 2 am bient co ordinates to d g = dim( g ) in trinsic parameters, with p otential b enefits for b oth sample efficiency and computational cost. The resulting optimization problems are instances of structured nonconv ex sto chastic programming on matrix subspaces—a class aris- ing broadly in scientific computing, including estimation on rotation groups [ 7 ], tra jectory optimization for articulated systems [ 9 ], and signal pro cessing on compact groups [ 5 ]. Main result. Theorem 6.1 establishes a r epr esentation–optimization dichotomy : the gradien t Lipschitz constan t L ( R ) of an y Lie-algebra-parameterized sto c hastic ob jective is O (1) if g is compact, and Θ( e 2 R ) if g = gl ( n ) (tight), with O ( e 2 R ) upp er b ound holding for all algebras with a hyperb olic elemen t (including sl ( n ); see Remark 6.2 for the separation). The matc hing low er b ound is the main analytical contribution: it rules out the p ossibility that cancellations in the ob jective-to-parameter c hain could yield a tighter uniform bound. This mak es the result robust with resp ect to the choice of ob jective: within the Lie Group MDP class, only the algebra t yp e controls L ( R ), not the sp ecific data-generating pro cess, p olicy class, or transition k ernel. The theorem thereby identifies whic h structural prop erty of an algebraic parameter space determines the optimization landscap e for this class of data-driv en problems. Con tributions. The pap er establishes one central theorem and develops t wo algorithmic consequences, eac h with indep endent conten t: 1. Main theorem: Represen tation–optimization dic hotom y . (Theorem 6.1 ) The gra- dien t Lipsc hitz constan t satisfies L = O (1) for compact g ⊆ u ( n ), and L = Θ( e 2 R ) for g = gl ( n ) (tight in b oth bounds). F or all algebras containing a h yperb olic element (includ- ing sl ( n )), the O ( e 2 R ) upp er bound holds; the matc hing Ω( e 2 R ) low er b ound is established via the gl ( n ) witness. The k ey conten t is the lo w er b ound: it rules out the p ossibility—not immediately ob vious—that structural cancellations b etw een the exponential map and the data-generating pro cess could yield a tighter b ound for an y ob jective in the Lie Group MDP class ( § 17 ). The sl ( n ) case is analyzed separately in Remark 6.2 : the b est av ailable lo wer b ound for sl ( n ) alone is Ω( e 2 c n R ) with c n → 1 as n → ∞ . 2. Consequence 1: Con v ergence with non-restrictive iterate b ound and align- men t diagnostic. (Corollary 7.2 , Prop osition 7.4 ) The dichotom y enables O (1 / √ T ) con vergence for compact g ; the b ounded-iterates assumption is non-restrictiv e in this regime (the radius pro jection triggers on fewer than 2% of iterations; Assumption (A3)), a qualitative impro vemen t o ver generic noncon vex SGD where iterate-b oundedness is a substan tive constrain t. The Kan torovic h inequality provides a computable low er b ound α ≥ 2 √ κ/ ( κ + 1) on the alignment betw een eac h LPG step and the natural gradien t di- rection. This yields a concrete practitioner diagnostic: estimate κ from tra jectory data; if κ < 5, Euclidean pro jection is an adequate natural-gradien t surrogate; if κ > 10, explicit Fisher in v ersion is w arran ted (Remark 5.4 ). 3. Consequence 2: Closed-form pro jection with quan tified computational adv an- tage. (Section 8 ) Because L is radius-indep endent for compact algebras, LPG requires no Fisher inv ersion: classical Lie-algebra pro jectors (T able 2 ) run in O ( n 2 J ) per step vs. A REPRESENT A TION–OPTIMIZA TION DICHOTOMY, LIE-ALGEBRAIC POLICY OPTIMIZA TION 3 O ( d 3 g ) for exact natural gradien t. Timing results app ear in Section 9 (measured sp eedup 1 . 1–1 . 7 × at J ≤ 30; extrapolated > 100 × at J = 200 by cost-mo del). Sample complexity inherits the d g -dimensional parameterization ( ˜ O ( d g /ε 2 )), a consequence of the in trinsic- dimension reduction rather than an artifact ( § 13 ). Supplemen tary material. All pro ofs, lemma deriv ations, and implemen tation details are in the Supplemen tary Material (SM). References of the form SM § 11 (and similar) refer to sections of the SM, which is compiled as a separate do cumen t but submitted alongside the main paper. 2. Related W o rk. Matrix Lie groups are the standard framework for structured estima- tion and control [ 5 , 16 , 9 , 18 ]. Riemannian optimization generalizes gradien t metho ds via retraction maps [ 1 , 7 , 5 , 22 ]. Our setting is simpler: g is a line ar subspace of R n × n , so optimization is Euclidean with no retraction needed. F or compact groups with bi-in v ariant metric, LPG is up date-rule-equiv alen t to Riemannian SGD [ 5 ] with identit y retraction; no separate Riemannian baseline is b enc hmarked since the algorithms coincide. What is new is the structural analysis: the compact/non-compact dichotom y with matc hing lo w er b ound (Theorem 6.1 ) and the κ -dep enden t alignment guarantee (Proposition 7.4 ) do not app ear in prior Riemannian optimization theory for this class. Natural gradient metho ds [ 3 , 4 ] underlie TRPO [ 14 , 17 ] and K-F A C/A CKTR [ 15 , 21 ]. K-F A C exploits lay er-wise structure at cost O ( d 1 . 5 ); our pro jection exploits Lie-algebraic action-space structure, recov ering the natural gradient exactly under isotrop y at cost O ( n 2 J ) with no matrix inv ersion. The t wo are complemen tary . Geometric deep learning [ 8 , 10 ], MDP homomorphisms [ 19 ], and equiv arian t p olicies [ 9 ] reduce sample complexity via symmetry but do not address optimization cost or natural gra- dien t qualit y . W e adapt the O (1 / √ T ) nonconv ex SGD rate [ 4 , 1 ] to a Lie-algebra constrained setting, reducing effective dimension from n 2 to d g . Recen t SIMODS pap ers establish the broader context for this work: Cayci, He, and Srik ant [ 28 ] prov e finite-time con vergence for natural actor-critic in partially observ able set- tings; Kim, Sanz-Alonso, and Y ang [ 29 ] study Ba y esian optimization on Riemannian manifolds with regret b ounds; and Bec kmann and Heilenk¨ otter [ 30 ] establish a represen ter theorem for equiv ariant neural net works via Lie group symmetry , applied to in verse problems. The pres- en t pap er contributes the missing structural analysis: a sharp dic hotom y characterizing whic h parameterizations mak e first-order RL metho ds efficien t. 3. Mathematical Preliminaries. 3.1. Notation. Throughout, R 0 denotes a fixed parameter-space radius b ound ( ∥ θ ∥ F ≤ R 0 ), while R in Theorem 6.1 is the running argumen t of the Lipsc hitz constan t function L ( R ); these are the same quan tity when R = R 0 . W e equip R n × n with the F rob enius inner pro duct ⟨ A, B ⟩ F = tr( A ⊤ B ), norm ∥ A ∥ F = p tr( A ⊤ A ), and op erator norm ∥ A ∥ op = sup ∥ v ∥ 2 =1 ∥ Av ∥ 2 . P U denotes the orthogonal pro jector on to a subspace U ; e ∇ J = F − 1 ∇ J the natural gradien t. A full notation table is in the Supplemen t § 14 , T able S1. 3.2. Matrix Lie groups and Lie algeb ras. A matrix Lie gr oup G ⊂ GL( n, R ) is a closed subgroup; its Lie algebra g = T I G = { X : exp( tX ) ∈ G ∀ t } is equipp ed with the brack et 4 S. K.C AND V. MISHRA [ X , Y ] = X Y − Y X . W e use: so ( n ) (skew-symmetric, dim = n ( n − 1) / 2), sl ( n ) (traceless, dim = n 2 − 1), se ( n ) (rigid-b o dy , dim = n ( n +1) / 2), and gl ( n ) = R n × n . See Hall [ 5 ] for bac kground. The matrix exp onential exp( X ) = P k ≥ 0 X k /k ! maps g in to G and is a lo cal diffeomor- phism near 0 ∈ g [ 6 , 24 ]. W e equip g with the F rob enius inner pro duct ⟨ X , Y ⟩ g = tr( X ⊤ Y ), X, Y ∈ g , and fix an orthonormal basis { E 1 , . . . , E d g } ( ⟨ E i , E j ⟩ F = δ ij ) throughout. Under this conv en tion the co ordinate metric tensor is the identit y; other bases in tro duce a non-identit y tensor but do not affect our results. 3.3. Orthogonal projection onto Lie algeb ras. Since g is a closed linear subspace of R n × n , the orthogonal pro jector P g ( M ) = arg min X ∈ g ∥ M − X ∥ 2 F satisfies the follo wing standard Hilb ert-space properties [ 7 , Props. 3.58–3.61]: (i) Line ar : P g ( αM + β N ) = αP g ( M ) + β P g ( N ). (ii) Idemp otent : P g ( P g ( M )) = P g ( M ). (iii) Nonexp ansive : ∥ P g ( M ) ∥ F ≤ ∥ M ∥ F . (iv) Self-adjoint : ⟨ P g ( M ) , N ⟩ F = ⟨ M , P g ( N ) ⟩ F . (v) Monotonicity : ⟨ g , P g ( g ) ⟩ F = ∥ P g ( g ) ∥ 2 F . Prop ert y (iv) implies gr adient pr eservation ∇ g f = P g ( ∇ f ) [ 7 , Prop. 3.61]. Closed-form pro jectors: P so ( n ) ( M ) = 1 2 ( M − M ⊤ ); P sl ( n ) ( M ) = M − 1 n tr( M ) I ; general g : P g ( M ) = P i ⟨ M , E i ⟩ F E i . 3.4. Lie-algebraic p olicies and Fisher info rmation. W e consider Gaussian p olicies with mean actions parameterized in the Lie algebra: (3.1) a = µ θ ( s ) + ξ , ξ ∼ N (0 , σ 2 I d g ) , where µ θ ( s ) ∈ g is the mean action, σ > 0 the exploration scale, and Φ k : S → g state- dep enden t features. W e iden tify R d g ∼ = g via ι ( x ) = P k x k E k (linear isometry). States up date as R t +1 = R t exp( a t ). The score function is (3.2) [ ∇ θ log π θ ( a | s )] k = 1 σ 2 ⟨ a − µ θ ( s ) , Φ k ( s ) ⟩ F , and the Fisher information matrix is (3.3) F ( θ ) = E s ∼ d π θ , a ∼ π θ h ∇ θ log π θ ( ∇ θ log π θ ) ⊤ i , with discoun ted state visitation d π θ ( s ) = (1 − γ ) P t ≥ 0 γ t Pr( s t = s | π θ ). F or Gaussian policies with isotropic noise, the Gaussian momen t iden tit y simplifies ( 3.3 ) to (3.4) F kl ( θ ) = 1 σ 2 E s ∼ d π θ ⟨ Φ k ( s ) , Φ l ( s ) ⟩ F . Appro ximate feature orthonormalit y ( E s [ ⟨ Φ k , Φ l ⟩ F ] ≈ δ kl ) giv es F ≈ σ − 2 I d g , i.e. κ ≈ 1. A REPRESENT A TION–OPTIMIZA TION DICHOTOMY, LIE-ALGEBRAIC POLICY OPTIMIZA TION 5 3.5. RL objective and standing assumptions. The exp ected return J ( θ ) = E π θ [ P ∞ t =0 γ t r t ] has gradient given by the p olicy gradient theorem [ 14 , 27 , 26 ]: (3.5) ∇ θ J ( θ ) = E s ∼ d π θ , a ∼ π θ [ Q π θ ( s, a ) ∇ θ log π θ ( a | s )] . W e impose the following standing assumptions (all verified for the Gaussian Lie-algebraic p olicy class in Supplement § 17 ): Assumption 3.1 (Standing assumptions). (A1) Smo othness : ∥∇ J ( θ ) − ∇ J ( θ ′ ) ∥ F ≤ L ∥ θ − θ ′ ∥ F . (A2) Bounded optimum : J ∗ = sup θ J ( θ ) < ∞ . (A3) Bounded iterates : sup t ∥ θ t ∥ F ≤ B θ , enfor c e d by r adius pr oje ction (Se ction 8 ). Non- r estrictive for c omp act algebr as; essential for non-c omp act (Supplement § 22 ). (A4) Unbiased gradient : E [ b ∇ J ( θ )] = ∇ J ( θ ) . (A5) Bounded v ariance : E [ ∥ b ∇ J − ∇ J ∥ 2 F ] ≤ σ 2 g ( σ g distinct fr om explor ation sc ale σ ). (A6) Step sizes : P t η t = ∞ , P t η 2 t < ∞ ; for O (1 / √ T ) r ate, η t = η / √ T with η ≤ 1 /L . (A7) Bounded actions : ∥ a − µ θ ( s ) ∥ F ≤ B a a.s. (standar d trunc ation). (A8) Concentrabilit y : sup s d π θ 1 ( s ) /d π θ 2 ( s ) ≤ C d for ∥ θ 1 − θ 2 ∥ F ≤ δ [ 1 ]. F or c omp act gr oups, C d is b ounde d by the mixing time; for non-c omp act gr oups, C d may gr ow with R 0 . See Supplement § 22 for discussion of when each assumption is binding and the explicit con- stan ts in the compact + isotropic regime. Lemma 3.2 (Smo othness of RL objectives). Consider Gaussian p olicies ( 3.1 ) with fe atur es ∥ Φ k ( s ) ∥ F ≤ B Φ , r ewar ds | r ( s, a ) | ≤ R max , and p ar ameters c onstr aine d to ∥ θ ∥ F ≤ R 0 . Under Assumption 3.1 and Assumption 3.1 , Assumption 3.1 holds with (3.6) L = 4 R max B Φ B a C d (1 − γ ) 3 σ 2 · L exp ( R 0 ) , wher e the exp onential factor is L exp ( R 0 ) = ( O ( e 2 R 0 ) gener al g , O (1) c omp act g (e.g., so ( n ) , su ( n )) . Explicit expr essions app e ar in Se ction 17 . Pr o of. Chain rule through score b ound, RL Hessian [ 1 , Lem. 5], and F r´ echet deriv ativ e of exp (Lemma 17.2 ). Compactness of g ⊆ u ( n ) eliminates exp onen tial growth via unitarity . F ull deriv ation in Supplement § 12 . With these in place, Section 5 introduces the alignment α and curv ature L that go vern con- v ergence. 4. Lie Group Mark ov Decision Pro cesses. 4.1. Lie-group state spaces and homogeneous actions. Definition 4.1 (Lie Group MDP). A Lie Group Marko v Decision Pro cess is a tuple ( M , A , P , R, γ , G, ρ ) in which: 6 S. K.C AND V. MISHRA • M is a smo oth manifold r epr esente d as a homo gene ous sp ac e M = G/H for a matrix Lie gr oup G ⊂ GL( n, R ) and close d sub gr oup H ; • A is a finite or c omp act action sp ac e; • P ( · | s, a ) is a Markov tr ansition kernel on M ; • R ( s, a ) is a b ounde d r ewar d function with | R ( s, a ) | ≤ R max ; • γ ∈ [0 , 1) is the disc ount factor; • ρ : G × M → M is the tr ansitive gr oup action, ρ ( g , s ) = g · s . R emark 4.2 (Relationship to prio r MDP framewo rks). The Lie Group MDP class encom- passes the geometric structure implicit in prior p olicy gradient w ork: the Gaussian p olicy and natural gradien t formulation of [ 14 ], and the trust-region p olicy up date of [ 17 ], b oth op erate on parameter spaces that are matrix Lie groups or their algebras when the action space has rotational or rigid-b o dy structure. Definition 4.1 mak es this geometric structure explicit and uses it to derive algebra-type-dep endent smo othness b ounds. This structure captures a broad class of systems in rob otics, geometric mechanics, graphics, and navigation, including SO(3) for 3D rotations, SE(3) for rigid-b o dy motions, and SO(3) J for articulated multi-join t mec hanisms. 4.2. Intrinsic dimension and representation in co o rdinates. W orking in g -co ordinates reduces the effectiv e parameter space from n 2 (am bient matrix entries) to d g = dim( g ), and this reduction is lossless within the Lie Group MDP class under G -equiv ariance (Prop osition 4.4 ). Prop osition 4.3 (Intrinsic dimension reduction). Sinc e π θ dep ends on θ only thr ough µ θ ( s ) = P k θ k Φ k ( s ) ∈ g , the effe ctive p ar ameter sp ac e is d g -dimensional. The sc or e function ( 3.2 ) gives [ ∇ θ log π θ ] k = σ − 2 ⟨ a − µ θ ( s ) , Φ k ( s ) ⟩ F , so the p olicy gr adient lies in R d g ∼ = g (via ι ( x ) = P k x k E k ). Prop osition 4.4 (Losslessness of Lie-algeb raic restriction). Consider a Lie Gr oup MDP (Def- inition 4.1 ) with trivial isotr opy ( H = { e } , M = G ) whose tr ansition kernel is G -e quivariant: P ( g · s ′ | g · s, g · a ) = P ( s ′ | s, a ) for al l g ∈ G . Then for any Gaussian p olicy with µ θ ( s ) ∈ R n × n , pr oje cting the me an onto g do es not de gr ade the optimal r eturn: sup θ : µ θ ( s ) ∈ g J ( θ ) = sup θ : µ θ ( s ) ∈ R n × n J ( θ ) . The substantiv e con tent is a surjectivit y argument under G -equiv ariance with trivial isotrop y; the proof and scop e discussion are in Supplement § 18 . 5. Geometric Inputs: Alignment and Smo othness. Our conv ergence analysis dep ends on t wo geometric quan tities. The alignment p ar ameter α ∈ (0 , 1] measures the cosine similarity b et ween the LPG up date direction and the natural gradien t; the smo othness c onstant L ( R 0 ) b ounds the curv ature of J o v er the search domain {∥ θ ∥ F ≤ R 0 } . Both are verifiable in closed form for the Lie Group MDP class (Supplement § 15 , § 17 ), and b oth admit data-driven estimates from tra jectory samples without Fisher in version. Assumption 5.1 (Alignment pa rameter). Ther e exists α ∈ (0 , 1] such that for al l θ along the optimization tr aje ctory, cos P g ( ∇ J ( θ )) , F ( θ ) − 1 ∇ θ J ( θ ) ≥ α. A REPRESENT A TION–OPTIMIZA TION DICHOTOMY, LIE-ALGEBRAIC POLICY OPTIMIZA TION 7 The parameter α measures how well the Lie-algebraic pro jection approximates the natural gradien t direction. When α = 1, pro jection recov ers the exact natural gradient; when α < 1, pro jection incurs a directional bias. Assumption 5.2 (Smo othness constant). The Lipschitz c onstant L of ∇ J over the fe asible r e gion { θ ∈ g : ∥ θ ∥ F ≤ R 0 } satisfies L ≤ L ( R 0 ) , wher e L ( R 0 ) dep ends on the algebr a typ e: (i) Comp act ( g ⊆ u ( n ) ): L ( R 0 ) = O (1) . (ii) Non-c omp act with hyp erb olic element (e.g., sl ( n ) , gl ( n ) ): L ( R 0 ) = O ( e 2 R 0 ) . Non- c omp act algebr as without hyp erb olic elements (e.g., se ( n ) , whose elements have pur ely imaginary or zer o eigenvalues) exhibit at most p olynomial gr owth L ( R 0 ) = O ( R k 0 ) for some k ≥ 1 ; r adius pr oje ction r emains advisable but the exp onential b arrier do es not apply. V erification.. Both assumptions are v erified with self-contained arguments: the alignment b ound via the Kantoro vich inequality (Supplemen t § 15 ), and the smo othness rates via the F r´ echet deriv ativ e b ound (Lemma 17.2 and Lemma 3.2 ). The supplement also cov ers sample complexit y ( § 13 ), explicit Lipschitz constants with the low er-bound construction ( § 17 ), and n umerical v alidation of the theoretical b ounds on so (64), sl (64), and gl (64) ( § 17.5 ). Prop osition 5.3 (Blo ck-diagonal Fisher structure for SO(3) J ). Under Gaussian Lie-algebr aic p olicies ( 3.1 ) with orthonormal fe atur es { Φ k } c onstructe d fr om the standar d so (3) b asis (one b asis p er joint), the Fisher information matrix de c omp oses as F ( θ ) = σ − 2 diag F (1) , . . . , F ( J ) , wher e e ach 3 × 3 blo ck is F ( j ) ik = E s ∼ d π θ D Φ ( j ) i ( s ) , Φ ( j ) k ( s ) E F . Conse quently, κ ( F ) = max j λ max ( F ( j ) ) / min j λ min ( F ( j ) ) , which is b ounde d by max j κ ( F ( j ) ) when the blo cks shar e a c ommon λ min —the typic al r e gime when fe atur es ar e dr awn fr om the same distribution acr oss joints. Pr o of. Cross-join t features are F robenius-orthogonal; within each joint, the so (3) basis is orthonormal. The blo c k-diagonal structure follows from ( 3.4 ); the full calculation is in Supplemen t § 16 . This explains the empirical observ ation κ ≈ 2 . 5: the blo ck-diagonal structure preven ts cross-join t coupling, and each 3 × 3 blo c k has limited ro om for eigenv alue spread. F or SE(3), the translation comp onents break this structure, leading to the higher κ ≈ 2 . 8 observ ed in Section 9.6 . Under appro ximate isotropy with condition n um b er κ = λ max ( F ) /λ min ( F ), the alignmen t parameter satisfies α ≥ 2 √ κ κ + 1 , b y the Kantoro vic h inequality [ 7 ] (Supplemen t § 15 ). Assumption (A1) holds with the stated rates by Lemma 3.2 and Lemma 17.2 . Alternativ ely , α can b e estimated directly from tra jec- tory data (see Remark 5.4 b elo w). 8 S. K.C AND V. MISHRA R emark 5.4 (Estimating α from data). In practice, α can b e estimated without computing the full Fisher inv erse: estimate ˆ F from tra jectory samples, compute ˆ κ = λ max ( ˆ F ) /λ min ( ˆ F ), and set ˆ α = 2 √ ˆ κ/ ( ˆ κ + 1). Alternativ ely , estimate α directly b y computing the cosine b etw een P g ( ∇ J ) and ˆ F − 1 ∇ J on a subsample. Our exp erimen ts (Section 9 ) track b oth quantities throughout training. All con v ergence results in Section 7 are stated in terms of α and L ( R 0 ) and hold regardless of the verification pathw a y . The key question is: ho w do es L ( R 0 ) dep end on the algebra t yp e g ? The next section answ ers this with a sharp dic hotom y . 6. The Rep resentation–Optimization Dichotomy . The following theorem is the central result of the pap er. All conv ergence guarantees, alignment b ounds, and computational con- clusions in subsequent sections are consequences of it. Why the lo w er bound is non-trivial.. The upp er b ound (part (iii)) is exp ected: it follows from a F r´ echet deriv ativ e estimate applied t wice through the policy gradient chain rule (b ounding eac h factor by e R then composing). The non-trivial con ten t is the low er b ound (part (ii)). A natural hop e is that cancellations in the p olicy gradien t chain—betw een contributions from the reward function and from the matrix exp onential map—could yield a tigh ter uniform b ound even for non-compact algebras. The construction rules this out: it exhibits an explicit MDP within the class of Definition 4.1 (on gl ( n ), with H = diag(1 , 0 , . . . , 0) and a rank-one exp onen tial rew ard) for whic h no suc h cancellation o ccurs and the Hessian of J gro ws exactly as e 2 R along the direction of H ; see Supplemen t § 17 . The only dep endence of the ob jective on θ enters through the matrix exponential e θ in the p olicy action distribution. Smo othness of J therefore propagates from the F r´ ec het deriv ative of exp via the c hain rule: the algebraic gro wth of those deriv ativ es determines the global smo othness constan t, uniformly ov er all reward functions and transition k ernels in the class. Theo rem 6.1 (Representation–Optimization Dichotomy). L et g ⊂ R n × n b e a matrix Lie algebr a. Within the Lie Gr oup MDP class of Definition 4.1 , with Gaussian p olicies ( 3.1 ) satisfying Assumption 3.1 and Assumption 3.1 , let L ( R ) denote the gr adient Lipschitz c onstant of the p olicy obje ctive J over { θ ∈ g : ∥ θ ∥ F ≤ R } . Then: L ( R ) = O (1) if g ⊆ u ( n ) (c omp act) , Θ( e 2 R ) if g = gl ( n ) (tight: upp er and lower b ounds match) , O ( e 2 R ) if g c ontains a hyp erb olic element, g = gl ( n ) with the matching Ω( e 2 R ) lower b ound establishe d via the gl ( n ) witness MDP (Supple- ment § 17 ). F or sl ( n ) , the b est available lower b ound is Ω( e 2 c n R ) with c n = p ( n − 1) /n → 1 ; se e R emark 6.2 for the sep ar ation. The c omp act b ound is tight (the exp onential factor is absent, not mer ely b ounde d). Pr o of. The compact O (1) upp er b ound follows from unitarity of exp( θ ) for θ ∈ u ( n ): all exp onen tial factors in the F r ´ ec het deriv ative chain are eliminated (Prop osition 17.4 ). The non-compact O ( e 2 R ) upp er b ound follows from ∥ D θ − D θ ′ ∥ op ≤ √ n e R ∥ θ − θ ′ ∥ F (Lemma 17.2 (ii)); comp osing tw o suc h factors through the p olicy gradien t c hain rule (Lemma 3.2 ) yields O ( e 2 R ). A REPRESENT A TION–OPTIMIZA TION DICHOTOMY, LIE-ALGEBRAIC POLICY OPTIMIZA TION 9 The non-compact Ω( e 2 R ) low er b ound (Prop osition 17.5 ) is the nontrivial part: the wit- ness is a single-state MDP on gl ( n ) with H = diag(1 , 0 , . . . , 0) (so ∥ H ∥ F = 1) and reward r ( a ) = − 1 2 ∥ exp( a ) − I ∥ 2 F . Since exp( tH ) = diag( e t , 1 , . . . , 1), the ob jective restricts to g ( t ) = − 1 2 ( e t − 1) 2 and g ′′ ( t ) = − (2 e 2 t − e t ); ev aluating at t = R giv es | g ′′ ( R ) | ≥ e 2 R for all R ≥ 0 (Supplemen t § 17 ). The gl ( n ) witness achiev es the tight Ω( e 2 R ) exp onent b ecause λ max ( H ) = ∥ H ∥ F = 1. F or sl ( n ), the trace-zero constrain t forces λ max ( H ) ≤ p ( n − 1) /n < 1 for any unit-F rob enius-norm H , so the analogous construction yields only Ω( e 2 √ ( n − 1) /n R ); see Remark 6.2 . R emark 6.2 ( sl ( n ) separation). The O ( e 2 R ) upp er b ound holds for all algebras with a h yp erb olic element; the matc hing Ω( e 2 R ) lo wer b ound requires gl ( n ) as witness. F or sl ( n ) alone, the b est low er b ound is Ω( e 2 c n R ) with c n = p ( n − 1) /n → 1; practitioners should treat Θ( e 2 R ) as op erative. F ull analysis in Supplement § 19 . R emark 6.3 (Consequence fo r algorithm design). Theorem 6.1 partitions algebra types b y optimization difficulty: for compact algebras, gradien t optimization requires no radius pro jection, no shrinking step sizes, and admits O (1 / √ T ) conv ergence with explicit constan ts (Corollary 7.2 ). F or non-compact algebras, radius pro jection is essential: without it, L ( R ) gro ws without b ound and any fixed step size even tually violates η ≤ 1 /L (Section 9.6 ). The Lie-Pro jected P olicy Gradient algorithm (LPG) implementing these design c hoices is presented in Section 8 . 7. Convergence of Lie-Projected Policy Gradient. W e analyze con v ergence of the LPG pro jected gradien t method; all results are consequences of Theorem 6.1 . 7.1. Algorithmic up date. Let θ t ∈ g and g t = b ∇ J ( θ t ). Since g is a closed linear subspace, P g is globally defined and feasibilit y is preserv ed without retraction. The up date is (7.1) θ t +1 = P g ( θ t + η t g t ) = θ t + η t P g ( g t ) , where the second equality uses linearity and idemp otence of P g (so pro jection affects only the searc h direction). 7.2. One-step p rogress. The following lemma quan tifies the exp ected impro vemen t in J at eac h step. The filtration F t includes all randomness from the p olicy , environmen t, and sto c hastic gradien t estimator up to iteration t . Lemma 7.1 (Progress inequality). Under Assumption 3.1 and for η t ≤ 1 /L , E [ J ( θ t +1 ) | F t ] ≥ J ( θ t ) + η t 2 ∥ P g ( ∇ J ( θ t )) ∥ 2 F − Lη 2 t σ 2 g 2 . Pr o of. Apply the descent lemma to the pro jected up date θ t +1 − θ t = η t P g ( g t ), use unbi- asedness (Assumption 3.1 ), monotonicit y (prop erty (v) of P g , Lemma 3.3 ), and the v ariance b ound (Assumption 3.1 ). The condition η t ≤ 1 /L ensures the quadratic term is controlled. See Supplemen t § 11 for the full calculation. 7.3. Main convergence result. 10 S. K.C AND V. MISHRA Co rollary 7.2 (Convergence of LPG for nonconvex objectives). Supp ose Assumptions (A1)– (A6) hold and η t ≤ 1 /L for al l t . (i) The se quenc e { J ( θ t ) } c onver ges almost sur ely. (Bounde d iter ates p er Assumption 3.1 ensur e that J ( θ t ) is wel l-define d and the Lipschitz c onstant L is valid along the entir e tr aje ctory.) (ii) The pr oje cte d gr adient norms satisfy ∞ X t =0 η t E ∥ P g ( ∇ J ( θ t )) ∥ 2 F < ∞ . In p articular, lim inf t →∞ E [ ∥ P g ( ∇ J ( θ t )) ∥ 2 F ] = 0 . (iii) If η t = η / √ T for al l t < T (c onstant step size optimize d for horizon T ) with η ≤ 1 /L , then E " 1 T T − 1 X t =0 ∥ P g ( ∇ J ( θ t )) ∥ 2 F # ≤ 2( J ∗ − J ( θ 0 )) η √ T + Lη σ 2 g √ T = O 1 √ T . Pr o of sketch. Sum Lemma 7.1 ov er t = 0 , . . . , T − 1, take exp ectations, and use J ( θ T ) ≤ J ∗ . P art (i) uses sup ermartingale con v ergence [ 3 , Thm. 4.1]. P art (iii) uses P t 10 (b ound ≤ 0 . 575): prefer Fisher inv ersion. Our SO(3) J exp erimen ts give κ ≈ 2 . 5 (empirical α = 0 . 971), firmly in the LPG-recommended regime. Co rollary 7.6 (Compact vs. non-compact convergence). Under Assumptions (A1)–(A6) and Assumption 5.1 : (i) Comp act g ⊆ u ( n ) : L = O (1) indep endent of R 0 (The or em 6.1 ), giving min t ≤ T E [ ∥ P g ( ∇ J ) ∥ 2 F ] = O (1 / √ T ) . R adius pr oje ction triggers on < 2% of iter ations (T able 11 ), so Assump- tion (A3) is non-r estrictive in pr actic e. (ii) Non-c omp act g with hyp erb olic element: L = Ω( e 2 R 0 ) (The or em 6.1 ), de gr ading the r ate to O ( e 2 R 0 / √ T ) ; anisotr opy ( κ > 1 ) further c omp ounds via the natur al gr adient c onversion factor (Pr op osition 7.4 (ii)). 8. Algorithm and Computational Complexity . Pro jection on to classical matrix Lie alge- bras admits closed-form formulas at O ( n 2 ) p er blo ck; T able 2 compares p er-iteration costs against exact and approximate natural gradien t metho ds. 8.1. Algorithm. R emark 8.1 (No retraction needed). Since g is a linear subspace, θ t + η t v t ∈ g whenev er b oth summands lie in g : no retraction or exp onential map is required in the optimization step (the exp onential map app ears only in the p olicy parameterization). The radius pro jection preserv es g b y rescaling; for compact algebras the trigger rate is under 2% (T able 11 , J ≤ 30 runs). The pro jection step is the only operation not present in classical p olicy gradien t, and for all classical algebras—notably so (3) J —this pro jection reduces to blo ckwise sk ew-symmetrization, 12 S. K.C AND V. MISHRA Algorithm 8.1 Lie–Pro jected P olicy Gradien t (LPG) 1: Input: initial parameter θ 0 ∈ g , stepsizes { η t } , parameter b ound B θ > 0, iterations T 2: for t = 0 , . . . , T − 1 do 3: Collect tra jectories and compute sto c hastic gradien t g t : E [ g t | θ t ] = ∇ J ( θ t ) . 4: Pro ject on to Lie algebra: v t = P g ( g t ). 5: Gradien t step: ˜ θ t +1 = θ t + η t v t . 6: Radius pro jection (ensures Assumption 3.1 ): θ t +1 = ( ˜ θ t +1 if ∥ ˜ θ t +1 ∥ F ≤ B θ , B θ · ˜ θ t +1 / ∥ ˜ θ t +1 ∥ F otherwise . 7: end for 8: Output: θ T or uniform av erage ¯ θ T = T − 1 P T − 1 t =0 θ t . T able 2 Per-iter ation complexity. Metho d Cost Dom. op. Euclid. PG O ( d g ) grad. acc. Exact NG O ( d 3 g ) Fisher in v. CG ( k it.) O ( kd 2 g ) Fisher-v ec. K-F AC O ( d 2 g ) Kroneck er LPG O ( n 2 J ) pro j. g costing O ( n 2 J ) flops [ 25 ]. 8.2. Complexity comparison. Let d g = dim( g ) denote the intrinsic Lie-algebra dimen- sion and n the matrix size (e.g., n = 3 for SO(3)). T able 2 summarizes the p er-iteration complexities of widely used p olicy optimization methods. F or SO(3) J , d g = 3 J and n = 3, so O ( n 2 J ) = O (9 J )—linear in join ts versus cubic O ((3 J ) 3 ) for exact natural gradien t. F or J = 10, pro jection costs ∼ 90 flops vs. ∼ 27 , 000 for Fisher in v ersion (1 . 1–1 . 7 × w all-clock reduction; see Section 9 ). 9. Numerical Illustrations. Each subsection v alidates a sp ecific theoretical prediction from Section 5 and Section 7 ; T able 3 maps claims to exp erimen ts. All exp eriments use con trolled SO(3) J motion-con trol tasks with exact Lie-algebraic structure, enabling clean iso- lation from confounds such as partial observ abilit y or contact dynamics. Re sults are a veraged o ver five random seeds; error bars show one standard deviation. The cen tral data-sc ience tak eaw ay is that Lie-algebraic parameterization impro ves b oth sample efficiency (fewer in- teractions to reach a given return) and per-step computational cost relativ e to ambien t and natural-gradien t baselines, with the magnitude of improv emen t predicted by the algebra type via Theorem 6.1 . Section 9.6 tests the non-compact setting, Section 9.5 tests robustness under symmetry violations (with extended results in the Supplement), and Section 9.7 b enc hmarks LPG against baselines. A REPRESENT A TION–OPTIMIZA TION DICHOTOMY, LIE-ALGEBRAIC POLICY OPTIMIZA TION 13 T able 3 The ory–exp eriment mapping. Each entry validates a sp e cific the or etic al claim; the sour c e c olumn gives the the or em or pr op osition establishing the pr e diction. Claim Source Expt. Fisher isotrop y & align- ment Prop. 5.3 , 7.4 § 9.2 Anisotropy degradation Prop. 7.4 § 9.2 d g -sample scaling Prop. 4.3 § 9.2 Conv ergence regimes Thm. 6.1 § 9.3 Computational scaling § 8 § 9.4 Compact vs. non- compact Cor. 7.6 § 9.6 Robustness to sym. vio- lations Remark 22.3 § 9.5 LPG vs. baselines Prop. 7.4 § 9.7 T able 4 Fisher–metric alignment statistics. Statistic V alue Mean alignmen t 0 . 971 95% CI [0 . 970 , 0 . 972] Std. dev. 0 . 007 Range [0 . 945 , 0 . 990] κ 2 . 53 ± 0 . 12 ε F 0 . 24 ± 0 . 01 T able 5 Alignment under c ontr ol le d isotr opy violations. Condition κ ε F Alignment Final Return Uniform (baseline) 2 . 53 0 . 24 0 . 971 − 695 . 0 Axis-biased 3 . 08 0 . 29 0 . 954 − 700 . 5 Correlated ( κ M =5) 6 . 83 0 . 49 0 . 884 − 754 . 3 Correlated ( κ M =10) 12 . 98 0 . 64 0 . 816 − 799 . 2 9.1. Exp erimental Setup. Environment.. Syn thetic SO(3) J system with J = 10 rotational join ts; rew ard is the neg- ativ e squared geodesic error r ( s, a ) = − P j ∥ log ( R ⊤ j R target j ) ∥ 2 F . P olicies.. W e compare tw o parameterizations: (a) Lie p olicy : µ θ ( s ) ∈ so (3) J , d g = 30 parameters, σ = 0 . 1; (b) Am bien t p olicy : µ θ ( s ) ∈ R 3 J via random pro jection from R 45 J (15 × o ver-parameterization, d = 450). Actions are clipp ed to ∥ a t − µ θ ( s t ) ∥ F ≤ 3 σ (Assump- tion 3.1 ). States up date via R j,t +1 = R j,t exp( ω j,t ) p er join t. T raining uses REINFOR CE with adv antage normalization, η = 0 . 25, eigh t episo des per iteration, fort y iterations. G -equiva riance of the environment.. The dynamics R j,t +1 = R j,t exp( ω j,t ) satisfy G - equiv ariance (required by Prop osition 4.4 ): left multiplication by g j comm utes with the righ t-acting exp onential up date, the isotropic noise ω j ∼ N (0 , σ 2 I 3 ) is Ad-in v arian t, and the geo desic rew ard ∥ log( R ⊤ j R ∗ j ) ∥ F is in v ariant under R j 7→ g j R j . 9.2. Fisher Geometry , Alignment, and Sample Efficiency . The alignment b et ween the natural gradien t F − 1 ∇ J and the v anilla gradien t ∇ J is measured using cosine similarit y: align = ⟨ F − 1 ∇ J, ∇ J ⟩ ∥ F − 1 ∇ J ∥ ∥∇ J ∥ . The Fisher matrix is estimated from empirical score co v ariances. The isotr opy deviation is defined as ε F := ∥ F − ¯ λI ∥ F / ∥ F ∥ F , where ¯ λ = tr( F ) /d g is the mean eigenv alue; ε F = 0 corresp onds to exact isotropy ( F ∝ I ). Results.. Across 200 measuremen ts (five seeds × fort y iterations), T able 4 rep orts align- men t statistics and T able 5 sho ws results under controlled violations. Compa rison with theo retical b ounds.. The κ -based b ound giv es cos ≥ 2 √ 2 . 53 / (2 . 53 + 1) = 0 . 901; the empirical mean (0 . 971) exceeds this by 7 . 8%, confirming that worst-case configura- tions rarely o ccur. 14 S. K.C AND V. MISHRA Figure 1. L eft: Fisher–metric alignment histo gr am (200 me asur ements); vertic al lines show empiric al me an (solid) and κ -b ase d b ound (dashed). Right: Isotr opy metrics during tr aining ( J = 10 , 5 se e ds): (a) ε F ( t ) stays b elow 0 . 3 , (b) κ ( t ) ∈ [1 . 9 , 2 . 8] , (c) alignment exc ee ds the or etical b ound thr oughout. Eigenvalue analysis.. Eigen v alue decomp osition of the empirical Fisher confirms near- isotrop y: effective rank r eff = 28 . 2 ± 0 . 1 (out of d g = 30), κ = 2 . 53 ± 0 . 12, ε F = 0 . 24 ± 0 . 01. T racking o v er 40 iterations (Figure 1 , righ t) shows no drift: ε F ( t ) remains stable near 0 . 24; alignmen t exceeds 0 . 94 throughout. App roximate equivalence (Assumption 5.1 ).. Across 100 syn thetic Fisher matrices with con- trolled anisotrop y , alignment correlates with isotropy deviation at r = − 0 . 875 ( p < 10 − 4 ), with empirical fit align ≈ 1 . 01 − 0 . 15 ε F —the small co efficient (0 . 15 vs. theoretical worst-case 4) highligh ts the conserv atism of Assumption 5.1 . Anisotrop y ablation.. W e study alignmen t degradation under controlled isotrop y violations. In synthetic diagonal Fisher tests, alignment degrades smo othly from 1 . 0 ( κ = 1) to 0 . 651 ( κ = 10), remaining w ell abov e the v acuous 1 − 4 ε F b ound. Realistic isotrop y violations.. W e introduce controlled p er-dimension noise scaling in the SO(3) 10 en vironment: axis-biased ( √ 1 . 5 × noise on z -comp onents) and globally correlated ( σ i spread from σ base to σ base √ κ M for κ M ∈ { 5 , 10 } ). Alignmen t degrades monotonically with κ (Figure 2 ), but returns are also sensitive: at κ ≈ 13, ∼ 15% return degradation. All empirical alignmen ts exceed the κ -based theoretical b ound. W e recommend κ < 10. A REPRESENT A TION–OPTIMIZA TION DICHOTOMY, LIE-ALGEBRAIC POLICY OPTIMIZA TION 15 Figure 2. L eft: Contr ol le d anisotr opy—alignment vs. κ (a) and r eturn vs. ε F (b). Right: Sample efficiency—Lie p olicy (blue) vs. ambient (or ange); shade d: ± 1 std. Sample efficiency .. The Lie parameterization uses d g = 30 parameters versus 450 am bien t. Ov er 400 iterations (Figure 2 ), the Lie p olicy ac hieves final return − 908 . 95 v ersus − 1324 . 76 am bient, with AUC ratio 0 . 63 (37% impro vemen t). The am bient p olicy collapses early due to ill-conditioning, consisten t with Prop osition 4.3 . 9.3. Convergence Rate Illustration. W e empirically illustrate the conv ergence regimes predicted b y the geometric classification of Theorem 6.1 . Controlled setting (quadratic objective).. Pro jected SGD on a quadratic restricted to so (3) 10 giv es log–log slop e − 0 . 98 (Figure 3 , left), consistent with the O (1 /T ) deterministic rate when L = O (1) (Prop osition 17.4 ). The fa vorable exp onent reflects the R -indep endent Lipschitz constan t: step sizes need not decay to comp ensate for exp onential growth. Sto chastic setting.. On a d g = 30 sto chastic quadratic proxy (same dimension as so (3) 10 , Gaussian gradien t noise σ g = 1, step size η / √ T ), the running-av erage log–log slop e is − 0 . 52 ± 0 . 08 (five seeds, Figure 3 , right), matc hing the O ( T − 1 / 2 ) sto chastic rate (Corollary 7.2 ). The deterministic–sto c hastic gap reflects the Lη σ 2 g / √ T v ariance term dominating the con vergence b ound. 9.4. Computational Scaling and Joint-Count Ablation. Section 8 established the O ( n 2 J ) vs. O ( d 3 g ) asymptotic adv antage of Lie pro jection ov er Fisher inv ersion; here we v erify this empirically . W e b enchmark Fisher inv ersion (Cholesky) vs. blockwise skew- symmetrization for so (3) J (mean of 200 runs p er condition), with results in T able 10 . Pro jection sp eedups range from 1 . 1 × to 1 . 7 × , but the end-to-end adv an tage is mo dest b ecause environmen t in teraction and gradient estimation dominate w all-clo ck time. The pro jection step itself av oids O ( d 3 g ) matrix inv ersion en tirely . Joint-count ablation.. W e v ary J ∈ { 5 , 10 , 15 , 20 , 30 } and measure optimization p erfor- mance and Fisher isotropy (T able 11 ). F or each J , b oth Lie-parameterized and ambien t p olicies are trained for 200 iterations with iden tical h yp erparameters (ambien t uses 15 × d g parameters). Fisher alignment remains ab ov e 0 . 90 even at J = 30, confirming graceful degradation. The Lie p olicy consistently outp erforms ambien t at all scales (A UC ratio 0 . 58–0 . 62). Isotropy 16 S. K.C AND V. MISHRA Figure 3. L o g–log c onver genc e r ate. L eft: Deterministic (quadr atic on so (3) 10 , d g = 30 ), slop e − 0 . 98 . R ight: Sto chastic quadr atic pr oxy ( d g = 30 , Gaussian noise σ g = 1 ), slop e − 0 . 52 ± 0 . 08 . Both c onsistent with c omp act-algebr a pr e dictions (The or em 6.1 and Cor ol lary 7.2 ). T able 6 Timing: Fisher inversion vs. Lie pr oje ction. J d g Fisher Pro j. Speedup ( µ s) ( µ s) 5 15 33.4 18.6 1 . 8 × 10 30 71.4 47.2 1 . 5 × 30 90 152.1 112.2 1 . 4 × deviation gro ws roughly as p d g , consisten t with Assumption 5.1 . A t larger scales ( J ∈ { 50 , 100 , 200 } ), Fisher inv ersion grows cubically while Lie pro jection gro ws linearly; pro jection speedup exceeds 100 × at J = 200 with alignmen t remaining ab ov e 0 . 86 ( κ ≈ 4 . 1). F ull b enc hmarks in Supplemen t § 20 (T able S5). 9.5. Symmetry-Violation Robustness. Under controlled G -equiv ariance-breaking p ertur- bations to SO(3) 10 (sto c hastic transitions σ ϵ ∈ { 0 . 01 , 0 . 05 , 0 . 1 } , observ ation noise, and reward noise), alignment remains ab ov e 0 . 94 and κ stays below 3 . 2, demonstrating graceful rather than catastrophic degradation. F ull results app ear in Supplement § 21 (T able S6). 9.6. Non-Compact Algeb ra: SE(3) Rigid-Bo dy Control. W e test the non-compact set- ting on SE(3), whose Lie algebra se (3) ⊂ R 4 × 4 (dim = 6) has an un b ounded translation comp onen t. Elements of se (3) take the form Ω v 0 0 with Ω ∈ so (3) sk ew-symmetric; eigen v al- ues are purely imaginary or zero, so se (3) con tains no h yp erb olic elements and the Θ( e 2 R ) exp onen tial barrier of Theorem 6.1 do es not apply . Nev ertheless, se (3) is non-compact and the translation comp onen t in tro duces p olynomial Lipschitz gro wth ( L ( R 0 ) = O ( R 2 0 )), making radius pro jection necessary in practice. Scop e of this exp erimen t. The SE(3) results v alidate t w o predictions: (i) p olynomial L -gro wth and the necessit y of radius pro jection (Theorem 6.1 and Assumption 5.2 (ii)), and (ii) the Kan toro vich alignmen t b ound (Prop osition 7.4 (iii)). They do not v alidate Assump- tion 3.1 for SE(3), whic h remains an op en condition for non-compact groups (Section 3 ); the exp eriment is conducted under the w orking assumption that concen trabilit y holds for the translation-b ounded tra jectories induced b y B θ = 2 . 0. V erifying this assumption w ould re- A REPRESENT A TION–OPTIMIZA TION DICHOTOMY, LIE-ALGEBRAIC POLICY OPTIMIZA TION 17 T able 7 Sc alability with numb er of joints J . J d g Alignment AUC Ratio Sp eedup ε F 5 15 0 . 986 ± 0 . 005 0 . 58 1 . 7 × 0 . 17 10 30 0 . 971 ± 0 . 007 0 . 59 1 . 3 × 0 . 24 15 45 0 . 955 ± 0 . 009 0 . 61 1 . 1 × 0 . 29 20 60 0 . 939 ± 0 . 011 0 . 61 1 . 1 × 0 . 33 30 90 0 . 906 ± 0 . 014 0 . 62 1 . 1 × 0 . 39 T able 8 Comp act vs. non-c omp act Lie algebr as. Algebra d g Alignment κ ε F so (3) (compact) 3 0 . 996 ± 0 . 004 1 . 30 ± 0 . 13 0 . 11 se (3) (non-compact) 6 0 . 949 ± 0 . 024 2 . 79 ± 0 . 38 0 . 36 quire b ounding the mixing time of the induced Marko v c hain on the translation comp onent of SE(3) under the radius-pro jected dynamics—a problem that reduces to ergo dicity of a b ounded random w alk on R 3 and is left as a concrete op en direction. Results are summarised in T able 8 . SE(3) exhibits higher κ (2 . 79 vs. 1 . 30) and ε F (0 . 36 vs. 0 . 11) than SO(3), but alignmen t still exceeds 0 . 94. Anisotropy concentrates in the translation directions (the ab elian comp onent, where p olynomial F r ´ ec het b ounds apply). Without radius pro jection, optimization diverges; with B θ = 2 . 0, training is stable. The alignment degradation for se (3) is mo dest (0 . 949 vs. 0 . 996)—at κ ≈ 2 . 8 the Kantoro vic h b ound gives α ≥ 0 . 882, and the empirical v alue exceeds this b y 7%, ab out the same margin as in the compact case. Reconciling theory with exp eriment.. Although se (3) has no h yp erb olic elements (so the Θ( e 2 R ) barrier do es not apply), training still diverges without radius pro jection b ecause p oly- nomial Lipschitz gro wth L ( R ) = O ( R 2 ) is also unbounded: without pro jection ∥ θ ∥ F drifts to ∼ 18, giving ∼ 324 × growth in L relative to R = 1 (Figure 4 ). In short: non-compactness go verns step aggr essiveness , not step dir e ction quality —radius pro jection is essential for b oth exp onen tial and polynomial growth regimes. 9.7. Metho d Comparison. W e compare three metho ds on SO(3) 10 ( η = 0 . 25, 8 episo des/iter, 200 iters, 5 seeds): LPG ( d g = 30, blo ckwise skew-symmetrization, RE- INF ORCE [ 27 ]); Am bien t PG (3 d g = 90 params, REINFOR CE; note this uses 3 × o ver-parameterization for a fair parameter-count comparison, distinct from the 15 × regime in Section 9.2 ); Natural gradient ( d g = 30, Monte Carlo Fisher + CG [ 26 , 3 ], k = 10 iters). CG is used in place of Cholesky here for scalability to the large- J regime; the 1 . 1–1 . 7 × w all-clo ck speedup figures cited in the abstract and T able 10 are from the direct Cholesky b enc hmark in Section 9.4 , where b oth metho ds are compared on equal fo oting. The fair w all-clo ck comparison is the 1 . 1–1 . 7 × sp eedup at J ≤ 30 (T able 10 ), where b oth metho ds run iden tical gradien t estimation and differ only in the pro jection/inv ersion step. Natural gradien t achiev es the highest final return ( − 755 . 4), with LPG trailing by 28% in return ( − 964 . 9) at > 1000 × low er p er-step cost (T able 9 , Figure 5 ). A t κ ≈ 2 . 5, eac h LPG step captures α ≈ 0 . 90 of the natural gradien t direction (Prop osition 7.4 ); the qualit y gap is consisten t with the κ -conv ersion factor in Prop osition 7.4 (ii). On a w all-clo ck basis, LPG reac hes natural gradien t’s final return in ∼ 1 s vs. > 40 s. Ambien t PG p erforms worst ( − 1293), confirming the dimension-reduction b enefit of Prop osition 4.3 . 18 S. K.C AND V. MISHRA Figure 4. Effe ct of r adius pr oje ction on SE(3) (5 se e ds, shade d ± 1 σ ). L eft: Without pr oje ction ( B θ = ∞ ), the p ar ameter norm ∥ θ ∥ F gr ows unb ounde d ly (r e aching ∼ 18 ); with pr oje ction ( B θ = 2 ), it r emains b ounde d at ∼ 1 . 85 . Right: The the or etic al gr adient Lipschitz c onstant L ( R ) = O ( R 2 ) for se (3) (p olynomial, not exp onential, sinc e se (3) has no hyp erb olic elements), c ompute d fr om the observe d ∥ θ ∥ F tr aje ctories. Without pr oje ction, L gr ows r oughly 18 2 / 1 2 = 324 -fold over tr aining; with pr oje ction, L stays within a c onstant factor of its initial value. T able 9 Metho d comp arison on SO(3) 10 ( J = 10 , 5 se e ds). Method Params Final Return Per-step ( µ s) LPG (ours) 30 − 964 . 9 ± 39 . 4 113 Ambien t PG (3 × ) 90 − 1293 . 3 ± 38 . 5 6 Natural gradien t (CG) 30 − 755 . 4 ± 23 . 7 225,253 10. Discussion and Conclusion. F ailure mo des and scop e b oundaries.. The algebra t yp e and condition n umber together determine where LPG applies. When κ is large, LPG degenerates to Euclidean SGD (Prop o- sition 7.4 ); for non-compact algebras, L ( R ) = Θ( e 2 R ) is una voidable (Theorem 6.1 ). Both criteria are computable at initialization, giving practitioners a concrete c heck b efore deploy- men t. Practical deplo yment of LPG.. The dichotom y has a direct implication for deep RL architec- ture design: parameterizing action spaces through compact Lie algebras (e.g., skew-symmetric matrices for SO( n ), skew-Hermitian for SU( n )) gives pro v ably w ell-conditioned gradient land- scap es, while using general linear parameterizations (as in unconstrained weigh t matrices) incurs exp onen tial Lipsc hitz gro wth requiring explicit radius con trol. This connects to w ork on orthogonal RNNs and unitary ev olution net w orks [ 31 , 32 ] as arc hitecture c hoices that im- plicitly exploit this fav orable geometry . Isotropy holds exactly in highly symmetric settings and appro ximately in lo cally symmetric systems suc h as SO(3) J ; ε F gro ws only from 0 . 19 to 0 . 35 as d g go es from 15 to 90 (Section 9.2 ). In practice: estimate ˆ F ( θ ) at initialization; if κ < 5 use LPG; if κ > 10 prefer explicit Fisher inv ersion; monitor κ p erio dically . Our SO(3) J exp er- imen ts show κ ≈ 2 . 5 stable throughout training, though this w as in synthetic environmen ts with exact symmetry—empirical κ ranges for real hardware remain to b e established. Limitations.. The Lie algebra g must b e known a priori and the dynamics must admit a Lie-algebraic decomp osition—conditions that hold for SO(3) J articulated joints and SE(3) rigid-b o dy control, but not for proprio ceptiv e spaces that mix symmetry-group orbits with A REPRESENT A TION–OPTIMIZA TION DICHOTOMY, LIE-ALGEBRAIC POLICY OPTIMIZA TION 19 Figure 5. L eft: Conver genc e curves—LPG (blue), ambient PG (orange), natur al gradient (gr e en); shade d ± 1 σ over 5 se e ds. Right: R eturn vs. wal l-clo ck time (lo g x -axis); LPG r e aches ambient-PG’s final r eturn in ∼ 1 s vs. > 40 s for natur al gr adient, r efle cting the O ( n 2 J ) pr oje ction c ost vs. O ( d 3 g ) Fisher inversion (T able 9 ; se e note on timing metho dolo gy). non-symmetric comp onen ts (e.g., MuJoCo Ant). W e did not test on real hardw are or contact- ric h manipulation; Section 9.5 (Supplement § 21 ) shows graceful degradation under controlled p erturbations, but v alidation on hardware remains op en. F or non-compact algebras, L ( R ) = Θ( e 2 R ) is an intrinsic barrier, so LPG is b est suited to compact (rotational/unitary) symmetry . Summa ry .. Theorem 6.1 identifies whic h structural prop erty of a Lie-algebra parameteri- zation determines optimization difficult y: compactness giv es radius-indep enden t smoothness; a hyperb olic elemen t forces exp onential gro wth with a matching lo w er b ound. The practi- cal upshot is a tw o-query decision pro cedure: chec k algebra compactness (determines L ( R ) scaling); estimate κ from tra jectory data (determines whether Euclidean pro jection suffices as a natural-gradien t surrogate). T ogether these determine whether LPG, Fisher inv ersion, or a h ybrid approach is warran ted for a given structured con trol problem (T able 1 ). F uture directions include adaptiv e preconditioning for anisotropic Fisher matrices, data-driven Lie structure discov ery from tra jectory data, and v alidation on hardware b ey ond the syn thetic SO(3) J setting. Ackno wledgments. The authors used AI-based to ols for minor editorial suggestions re- lated to grammar and clarity . All mathematical conten t, theoretical results, pro ofs, algo- rithms, and exp erimental work are solely the w ork of the authors. Co de and Data Availabilit y . Co de and data to repro duce all exp eriments, figures, and ta- bles are a v ailable at https://gith ub.com/soora jk cphd/Represen tationOptimizationDichotom y . All experiments were conducted on a single NVIDIA R TX 3090 GPU. REFERENCES [1] P .-A. Absil, R. Mahony , and R. Sepulchre. Optimization Algorithms on Matrix Manifolds . Princeton Univ ersity Press, 2008. [2] A. Agarwal, S. Kak ade, and L. Li. On the theory of p olicy gradien t methods: optimality , approximation, and distribution shift. Journal of Machine L e arning R esear ch , 22:1–76, 2021. [3] S.-I. Amari. Natural gradient works efficien tly in learning. Neur al Computation , 10(2):251–276, 1998. [4] S.-I. Amari and H. Nagaok a. Metho ds of Information Ge ometry . American Mathematical Society , 2000. 20 S.K.C AND V.MISHRA [5] S. Bonnab el. Sto chastic gradient descent on Riemannian manifolds. IEEE T r ansactions on Automatic Contr ol , 58(9):2217–2229, 2013. [6] L. Bottou, F. E. Curtis, and J. Nocedal. Optimization metho ds for large-scale machine learning. SIAM R eview , 60(2):223–311, 2018. [7] N. Boumal. An Intr o duction to Optimization on Smo oth Manifolds . Cambridge Univ ersity Press, 2023. [8] M. M. Bronstein, J. Bruna, T. Cohen, and P . V eliˇ ck ovi ´ c. Ge ometric De ep L e arning: Grids, Groups, Gr aphs, Geo desics, and Gauges . MIT Press, 2021. [9] F. Bullo and A. D. Lewis. Ge ometric Contr ol of Me chanic al Systems . Springer, 2004. [10] T. Cohen and M. W elling. Group equiv arian t conv olutional net works. In Pr o c e e dings of the 33r d Inter- national Confer enc e on Machine L e arning , 2016. [11] S. Ghadimi and G. Lan. Sto chastic first- and zeroth-order methods for nonconv ex sto chastic programming. SIAM Journal on Optimization , 23(4):2341–2368, 2013. [12] B. C. Hall. Lie Gr oups, Lie A lgebr as, and R epresentations . Springer, 2nd ed., 2015. [13] L. V. Kantoro vic h. F unctional analysis and applied mathematics. Usp ekhi Matematicheskikh Nauk , 3(6):89–185, 1948. [14] S. Kak ade. A natural p olicy gradient. In A dvanc es in Neur al Information Pr oc essing Systems , 2002. [15] J. Martens and R. Grosse. Optimizing neural net works with Kroneck er-factored approximate curv ature. In Pr o c e e dings of the 32nd International Confer enc e on Machine L e arning , 2015. [16] R. M. Murray , Z. X. Li, and S. S. Sastry . A Mathematic al Intr o duction to R ob otic Manipulation . CRC Press, 1994. [17] J. Sch ulman, S. Levine, P . Abbeel, M. Jordan, and P . Moritz. T rust region p olicy optimization. In Pr o c e e dings of the 32nd International Confer enc e on Machine L e arning , 2015. [18] J. Sol` a, J. Deray , and D. A tch uthan. A micro Lie theory for state estimation in rob otics. F oundations and T r ends in Rob otics , 9(3–4):113–287, 2021. [19] E. v an der P ol, T. Kipf, F. A. Oliehoek, and M. W elling. MDP homomorphic net works: group symmetries in reinforcement learning. In A dvanc es in Neural Information Pr o c essing Systems , 2020. [20] Z. W ang, H. F an, S. Sun, and J. T. Zhou. Equiv arian t reinforcement learning via p olicy inv ariance. In Pr o c e e dings of the 39th International Confer enc e on Machine L e arning , 2022. [21] Y. W u, E. Mansimov, R. B. Grosse, S. Liao, and J. Ba. Scalable trust-region metho d for deep reinforce- men t learning using Kronec k er-factored appro ximation. In A dvanc es in Neur al Information Pr o c essing Systems , 2017. [22] H. Zhang and S. Sra. First-order metho ds for geodesically con v ex optimization. In Confer ence on L e arning The ory , 2016. [23] N. J. Higham. F unctions of Matric es: The ory and Computation . SIAM, Philadelphia, 2008. [24] A. Iserles, H. Z. Mun the-Kaas, S. P . Nørsett, and A. Zanna. Lie-group metho ds. A cta Numeric a , 9:215– 365, 2000. [25] M. Lezcano-Casado and D. Mart ´ ınez-Rubio. Cheap orthogonal constrain ts in neural netw orks: a sim- ple parametrization of the orthogonal and unitary group. In Pr o c e e dings of the 36th International Confer enc e on Machine L e arning , 2019. [26] J. P eters and S. Schaal. Natural actor-critic. Neur o c omputing , 71(7–9):1180–1190, 2008. [27] R. S. Sutton and A. G. Barto. Reinfor c ement L earning: A n Intr o duction , 2nd ed. MIT Press, 2018. [28] S. Cayci, N. He, and R. Srik ant, Finite-time analysis of natural actor-critic for POMDPs, SIAM Journal on Mathematics of Data Science , 6(2):417–449, 2024. https://doi.org/10.1137/23M1587683 . [29] J. Kim, D. Sanz-Alonso, and R. Y ang, Optimization on manifolds via graph Gaussian pro cesses, SIAM Journal on Mathematics of Data Scienc e , 6(3):734–760, 2024. [30] M. Bec kmann and N. Heilenk¨ otter, Equiv ariant neural net w orks for indirect measuremen ts, SIAM Journal on Mathematics of Data Science , 6(3):711–733, 2024. https://doi.org/10.1137/23M1582862 . [31] M. Arjovsky , A. Shah, and Y. Bengio, Unitary ev olution recurrent neural net works, In Pro c e e dings of the 33r d International Confer enc e on Machine L e arning (ICML) , pages 1120–1128, 2016. [32] S. Wisdom, T. Po wers, J. Hershey , J. Le Roux, and L. Atlas, F ull-capacity unitary recurrent neural net works, In A dvanc es in Neur al Information Pr oc essing Systems (NeurIPS) , volume 29, 2016. This supplement pro vides full pro ofs and deriv ations supp orting the main pap er. Cross- references to the main pap er (theorems, equations, assumptions) are resolved automatically SUPPLEMENT: REPRESENT A TION–OPTIMIZA TION DICHOTOMY 21 via the xr pack age; compile the main paper first, then the supplement, to generate the required .aux files. Sym b ol Meaning n , d g Matrix dimension; Lie algebra dimension G , g Matrix Lie group and its Lie algebra π θ , J ( θ ) Policy parameterized b y θ ∈ g ; expected return ∇ g J , e ∇ J Intrinsic gradient; natural gradient F − 1 ∇ J P g Orthogonal pro jector on to g F ( θ ), κ Fisher information matrix; condition n um b er λ max /λ min σ Policy exploration scale (std. dev. of action noise) σ g Stochastic gradien t noise level (v ariance bound in Assumption 5) ε , ε F Operator-norm / F rob enius-norm isotropy deviation Notation. 11. Full Convergence Pro ofs. This appendix con tains the complete pro ofs for the con- v ergence results stated in Section 7. The pro of technique is standard pro jected noncon vex SGD [ 4 ]; we include full details for completeness. Pr o of of L emma 7.1. By L -smoothness, J ( θ t +1 ) ≥ J ( θ t ) + ⟨∇ J ( θ t ) , θ t +1 − θ t ⟩ F − L 2 ∥ θ t +1 − θ t ∥ 2 F . Using θ t +1 − θ t = η t P g ( g t ), J ( θ t +1 ) ≥ J ( θ t ) + η t ⟨∇ J ( θ t ) , P g ( g t ) ⟩ F − Lη 2 t 2 ∥ P g ( g t ) ∥ 2 F . T aking conditional exp ectation and using unbiasedness E [ g t | F t ] = ∇ J ( θ t ), together with linearit y of P g (whic h implies E [ P g ( g t ) | F t ] = P g ( ∇ J ( θ t ))), w e obtain E [ J ( θ t +1 ) | F t ] ≥ J ( θ t ) + η t ⟨∇ J ( θ t ) , P g ( ∇ J ( θ t )) ⟩ F − Lη 2 t 2 E [ ∥ P g ( g t ) ∥ 2 F | F t ] . By the Pythagorean identit y in Section 3.3(v), ⟨∇ J, P g ( ∇ J ) ⟩ F = ∥ P g ( ∇ J ) ∥ 2 F . By nonexpan- siv eness (Section 3.3(iii)), ∥ P g ( g t ) ∥ F ≤ ∥ g t ∥ F , and by the v ariance b ound (Assumption 5), E [ ∥ P g ( g t ) ∥ 2 F | F t ] ≤ ∥ P g ( ∇ J ( θ t )) ∥ 2 F + σ 2 g . Com bining, E [ J ( θ t +1 ) | F t ] ≥ J ( θ t ) + η t ∥ P g ( ∇ J ( θ t )) ∥ 2 F − Lη 2 t 2 ∥ P g ( ∇ J ( θ t )) ∥ 2 F + σ 2 g . Since η t ≤ 1 /L , w e ha v e 1 − Lη t / 2 ≥ 1 / 2, yielding the claimed inequality . Pr o of of Cor ol lary 7.2. Summing the inequality in Lemma 7.1 o ver t = 0 , . . . , T − 1 and taking total exp ectation gives E [ J ( θ T )] − J ( θ 0 ) ≥ 1 2 T − 1 X t =0 η t E ∥ P g ( ∇ J ( θ t )) ∥ 2 F − Lσ 2 g 2 T − 1 X t =0 η 2 t . 22 S.K.C AND V.MISHRA Since J ( θ T ) ≤ J ∗ (Assumption 2) and P η 2 t < ∞ (Assumption 6), the righ t-hand side remains b ounded as T → ∞ , whic h implies summability of η t E [ ∥ P g ( ∇ J ( θ t )) ∥ 2 F ], establishing part (ii). F or part (i), define W t = J ∗ − J ( θ t ) ≥ 0 (nonnegative by Assumption 2). Rearranging Lemma 7.1, E [ W t +1 | F t ] ≤ W t − η t 2 ∥ P g ( ∇ J ( θ t )) ∥ 2 F + Lσ 2 g η 2 t 2 . This has the form required by [ 3 , Theorem 4.1] (Robbins–Siegmund): { W t } is nonneg, the “incremen t” − η t / 2 · ∥ P g ( ∇ J ) ∥ 2 is nonpositive in exp ectation, and the “p erturbation” Lσ 2 g η 2 t / 2 is summable ( P t η 2 t < ∞ by Assumption 6). The theorem yields: W t → W ∞ almost surely (so J ( θ t ) con v erges a.s.) and P t η t ∥ P g ( ∇ J ( θ t )) ∥ 2 < ∞ almost surely . F or the explicit rate in part (iii), rearrange the telescop ed inequality: 1 2 T − 1 X t =0 η t E [ ∥ P g ( ∇ J ( θ t )) ∥ 2 F ] ≤ ( J ∗ − J ( θ 0 )) + Lσ 2 g 2 T − 1 X t =0 η 2 t . Set η t = η / √ T (constan t ov er the horizon, with η ≤ 1 /L ). Then P t 0 4 ε + 12 √ N Z B V ε q log N ( u, V Π , ∥ · ∥ ∞ ) du , 24 S.K.C AND V.MISHRA where B V = R max / (1 − γ ) is the uniform b ound on v alue functions. Substituting the cov- ering b ound p log N ( u, V Π , ∥ · ∥ ∞ ) ≤ p d g log(3Λ R/u ), setting ε = B V / √ N , and ev aluating the Gaussian entrop y in tegral R B V ε p log( B V /u ) du ≤ B V p π / 4 (standard Dudley b ound [ 2 ]) yields R N ( V Π ) ≤ 12 q d g log(3Λ R √ N /B V ) · B V √ N + 4 B V √ N ≤ C B V Λ R √ N p d g , where C > 0 absorbs the logarithmic factor q log(3Λ R √ N /B V ) (whic h gro ws as ˜ O (1) and is subsumed into the ˜ O notation in Theorem 13.2 ). Substituting Λ and B V and absorbing n umerical constan ts giv es the stated b ound R N ( V Π ) ≤ RB Φ R max 1 − γ p d g / N . 13.2. Sample Complexity Bound. Theo rem 13.2 (Sample complexit y with intrinsic dimension). Under the assumptions of Pr op osition 4.3, to find ˆ π such that J ( ˆ π ) ≥ max π ∈ Π J ( π ) − ε with pr ob ability 1 − δ, it suffic es to c ol le ct N = O d g R 2 B 2 Φ R 2 max C 2 d (1 − γ ) 4 ε 2 log 1 δ samples. Pr o of. W e combine the p erformance-difference lemma with uniform conv ergence b ounds for v alue functions [ 1 ]. Substituting Lemma 13.1 into the standard generalization inequalit y yields the stated dep endence on d g and (1 − γ ) − 4 . R emark 13.3 (Ambient vs. Lie pa rameterization). An ambien t parameterization in R n × n has effectiv e dimension n 2 , whereas Lie parameterization uses d g ≪ n 2 . F or SO(3) J , n 2 = 9 J while d g = 3 J , giving a factor–3 improv emen t. R emark 13.4 (Scop e: generative mo del). Theorem 13.2 holds under i.i.d. sampling (gen- erativ e mo del access [ 8 ]). All exp eriments in Section 9 use simulators providing this access. The b ound establishes the correct dimension sc aling ( d g vs. n 2 ); absolute sample counts for the online setting require mixing-time dep endence specific to the Lie Group MDP class. 14. Implementation Details. Exp erimen ts use Python 3.9, PyT orch 1.13, NumPy 1.23, SciPy 1.9 on a single NVIDIA R TX 3090 GPU. Learning rate η = 0 . 25, discount γ = 0 . 99, 8 episo des p er iteration, 5 random seeds p er condition. Timing b enc hmarks use single-threaded execution. Lie pro jections use closed-form op erators (e.g., P so ( n ) ( M ) = 1 2 ( M − M ⊤ ), applied blo c kwise for so (3) J ). Co de is a v ailable at the rep ository listed in the main paper. 15. Self-Contained Pro of of the Alignment Bound. This app endix provides a self- con tained proof of the alignmen t bound α ≥ 2 √ κ/ ( κ + 1) used throughout the pap er. The pro of requires only the Kan torovic h inequality and standard linear algebra. SUPPLEMENT: REPRESENT A TION–OPTIMIZA TION DICHOTOMY 25 T able 10 Timing: Fisher inversion vs. Lie pr oje ction (r epr o duc e d fr om main p ap er for r efer enc e). J d g Fisher Pro j. Speedup ( µ s) ( µ s) 5 15 33.4 18.6 1 . 8 × 10 30 71.4 47.2 1 . 5 × 30 90 152.1 112.2 1 . 4 × T able 11 Sc alability with numb er of joints J (r epr o duce d fr om main pap er for r efer enc e). J d g Alignment AUC Ratio Sp eedup ε F 5 15 0 . 986 ± 0 . 005 0 . 58 1 . 7 × 0 . 17 10 30 0 . 971 ± 0 . 007 0 . 59 1 . 3 × 0 . 24 15 45 0 . 955 ± 0 . 009 0 . 61 1 . 1 × 0 . 29 20 60 0 . 939 ± 0 . 011 0 . 61 1 . 1 × 0 . 33 30 90 0 . 906 ± 0 . 014 0 . 62 1 . 1 × 0 . 39 Prop osition 15.1 (Alignment from Fisher condition number). L et F = F ( θ ) ∈ R d g × d g b e the Fisher information matrix with eigenvalues 0 < λ min ≤ λ 1 ≤ · · · ≤ λ d g ≤ λ max and c ondition numb er κ = λ max /λ min . F or any nonzer o g ∈ R d g , cos( g , F − 1 g ) = ⟨ g , F − 1 g ⟩ ∥ g ∥ ∥ F − 1 g ∥ ≥ 2 √ κ κ + 1 . Pr o of. Define h = F − 1 / 2 g , where F 1 / 2 is the unique symmetric p ositive definite square ro ot. Then: ⟨ g , F − 1 g ⟩ = ⟨ F 1 / 2 h, F − 1 / 2 h ⟩ = ∥ h ∥ 2 , ∥ g ∥ 2 = ∥ F 1 / 2 h ∥ 2 , ∥ F − 1 g ∥ 2 = ∥ F − 1 / 2 h ∥ 2 . Th us cos 2 ( g , F − 1 g ) = ∥ h ∥ 4 / ( ∥ F 1 / 2 h ∥ 2 · ∥ F − 1 / 2 h ∥ 2 ). W e now apply the Kantor ovich ine quality [ 7 ]: for an y symmetric p ositiv e definite A with eigen v alues in [ m, M ] and an y nonzero vector x , (15.1) ⟨ x, Ax ⟩ · ⟨ x, A − 1 x ⟩ ≤ ( m + M ) 2 4 mM ∥ x ∥ 4 . Apply ( 15.1 ) with A = F , x = h , m = λ min , M = λ max : ∥ F 1 / 2 h ∥ 2 · ∥ F − 1 / 2 h ∥ 2 = ⟨ h, F h ⟩ · ⟨ h, F − 1 h ⟩ ≤ ( λ min + λ max ) 2 4 λ min λ max ∥ h ∥ 4 . Therefore, cos 2 ( g , F − 1 g ) = ∥ h ∥ 4 ∥ F 1 / 2 h ∥ 2 · ∥ F − 1 / 2 h ∥ 2 ≥ 4 λ min λ max ( λ min + λ max ) 2 = 4 κ ( κ + 1) 2 , where the last equalit y uses κ = λ max /λ min . T aking square ro ots: cos( g , F − 1 g ) ≥ 2 √ κ/ ( κ + 1). R emark 15.2 (Tightness). The Kan torovic h inequalit y is tight: equalit y in ( 15.1 ) holds when h has equal-magnitude comp onents along the eigenv ectors of F corresp onding to λ min and λ max (and zero elsewhere). The b ound 2 √ κ/ ( κ + 1) is therefore the best p ossible worst- case alignmen t guaran tee giv en only the condition n um b er. 26 S.K.C AND V.MISHRA T able 12 Computational sc aling str ess test: pr oje ction vs. Fisher inversion at lar ge J (r epr o duc e d fr om main p ap er for r efer enc e). J d g Fisher Pro j. Sp eedup Align. κ ( µ s) ( µ s) 50 150 1,240 89 13 . 9 × . 898 ± . 012 3.21 100 300 8,450 175 48 . 3 × . 884 ± . 015 3.65 200 600 62,300 348 179 × . 862 ± . 018 4.12 R emark 15.3 (Self-containedness). Proposition 15.1 extracts the core matrix inequality needed for Section 7 from the Kantoro vic h inequality alone, making the con vergence analysis fully self-con tained. Pro of of the Kantorovich inequalit y . W e include a short pro of for readers unfamiliar with ( 15.1 ). Let A b e SPD with eigenv alues in [ m, M ] and eigendecomp osition A = Q Λ Q ⊤ . Set y = Q ⊤ x so that ⟨ x, Ax ⟩ = P i λ i y 2 i and ⟨ x, A − 1 x ⟩ = P i y 2 i /λ i . Define weigh ts w i = y 2 i / ∥ y ∥ 2 (a probability distribution). Then ⟨ x, Ax ⟩ · ⟨ x, A − 1 x ⟩ / ∥ x ∥ 4 = ( P i w i λ i )( P i w i /λ i ). By the AM-HM inequality applied to the distribution { w i } and the conv exity of t 7→ 1 /t on (0 , ∞ ), the pro duct ( P w i λ i )( P w i /λ i ) is maximized when w concentrates on the extremes { m, M } . Setting w 1 = t , w 2 = 1 − t (with λ 1 = m , λ 2 = M ), the pro duct b ecomes ( tm + (1 − t ) M )( t/m + (1 − t ) / M ), which is maximized at t = M / ( m + M ), giving ( m + M ) 2 / (4 mM ). 16. Why Isotropy Holds: A Direct Calculation. The alignment bound of Prop osi- tion 15.1 dep ends on κ ; we now sho w via direct calculation why κ is mo derate for Gaussian Lie-algebraic policies on SO(3) J . F or the Gaussian p olicy (1) with orthonormal Lie-algebra features { Φ k } d g k =1 , the score function (2) gives [ ∇ θ log π θ ( a | s )] k = 1 σ 2 ⟨ a − µ θ ( s ) , Φ k ( s ) ⟩ F . The Fisher matrix (3) b ecomes F kl ( θ ) = 1 σ 4 E s ∼ d π θ h E a ∼ π θ ( ·| s ) ⟨ a − µ, Φ k ⟩ F ⟨ a − µ, Φ l ⟩ F i . Since ξ = a − µ θ ( s ) ∼ N (0 , σ 2 I d g ) in the orthonormal basis { E k } (whic h makes R d g ∼ = g an isometry), the inner exp ectation ev aluates by the isotropic Gaussian momen t identit y to E ξ ⟨ ξ , Φ k ⟩ F ⟨ ξ , Φ l ⟩ F = σ 2 ⟨ Φ k ( s ) , Φ l ( s ) ⟩ F . Therefore (16.1) F kl ( θ ) = 1 σ 2 E s ∼ d π θ ⟨ Φ k ( s ) , Φ l ( s ) ⟩ F . When the features Φ k ( s ) satisfy approximate orthonormalit y under the state distribution—i.e., E s [ ⟨ Φ k , Φ l ⟩ F ] ≈ δ kl —the Fisher matrix is appro ximately σ − 2 I d g and κ ≈ 1. F or SO(3) J with features constructed from the standard skew-symmetric basis { E ( j ) i } (where E ( j ) i acts on joint j only), cross-joint terms v anish exactly: D E ( j ) i , E ( l ) k E F = 0 SUPPLEMENT: REPRESENT A TION–OPTIMIZA TION DICHOTOMY 27 for j = l . Within eac h join t, the three basis elemen ts are orthonormal. Th us F = σ − 2 diag( F (1) , . . . , F ( J ) ), where eac h 3 × 3 block F ( j ) ik = E s [ D Φ ( j ) i ( s ) , Φ ( j ) k ( s ) E F ] is close to I 3 when the state distribution is not strongly axis-biased. The global condition num- b er is κ = max j λ max ( F ( j ) ) / min j λ min ( F ( j ) ), b ounded by the worst single-joint anisotrop y max j κ ( F ( j ) ). This explains the empirical observ ation κ ≈ 2 . 5: the blo ck-diagonal structure preven ts cross-join t coupling, and each 3 × 3 blo c k has limited ro om for eigenv alue spread. F or SE(3), the translation components break this structure—the ab elian part has features with different magnitude scales—leading to the higher κ ≈ 2 . 8 observ ed in Section 9. 16.1. Fo rmal proof of Prop osition 3. Pr o of of Pr op osition 3. Index the parameters as θ = ( θ (1) , . . . , θ ( J ) ) with θ ( j ) ∈ so (3) for join t j . Cho ose features Φ ( j ) k ( s ) = E ( j ) k (the k -th standard basis elemen t of so (3) acting on join t j , zero elsewhere). These satisfy D E ( j ) k , E ( m ) l E F = δ j m δ kl , where δ j m = 0 for j = m since the matrices hav e disjoin t nonzero blo cks. By equation ( 16.1 ), the ( k ( j ) , l ( m ) ) en try of F is F k ( j ) ,l ( m ) = 1 σ 2 E s D Φ ( j ) k ( s ) , Φ ( m ) l ( s ) E F = 1 σ 2 E s D E ( j ) k , E ( m ) l E F = δ j m σ 2 E s D E ( j ) k , E ( j ) l E F . F or j = m the en try is zero, confirming the blo ck-diagonal structure. The j -th diagonal blo c k is F ( j ) kl = σ − 2 E s [ D Φ ( j ) k ( s ) , Φ ( j ) l ( s ) E F ]. The global condition num ber satisfies κ ( F ) = λ max ( F ) /λ min ( F ) = max j λ max ( F ( j ) ) / min j λ min ( F ( j ) ) ≤ max j κ ( F ( j ) ), with equality when all blocks share the same w orst-case ratio. The full information-geometric treatmen t, including conditions under which state-a veraged orthonormalit y holds and a p erturbation analysis for feature anisotropy , is deferred to future w ork. 17. Smo othness Analysis fo r Matrix Exp onential Maps. This app endix collects smooth- ness prop erties for the matrix exp onen tial restricted to Lie algebras. F ull deriv ations follow standard matrix analysis [ 6 , 5 ]; compact-algebra simplifications use the unitarit y of exp( θ ) for sk ew-Hermitian θ . 17.1. Matrix Exp onential Lipschitz Bounds. Lemma 17.1 (Lipschitz continuit y of matrix exp onential). L et θ, θ ′ ∈ g with ∥ θ ∥ F , ∥ θ ′ ∥ F ≤ R . Then ∥ exp( θ ) − exp( θ ′ ) ∥ F ≤ √ n e R ∥ θ − θ ′ ∥ F . F or c omp act g ⊆ u ( n ) , the exp onential factor is eliminate d: ∥ exp( θ ) − exp( θ ′ ) ∥ F ≤ √ n ∥ θ − θ ′ ∥ F . Pr o of. W e use the in tegral iden tit y [ 6 , Eq. (10.8)]: exp( θ ) − exp( θ ′ ) = Z 1 0 exp θ ′ + s ( θ − θ ′ ) ( θ − θ ′ ) ds. 28 S.K.C AND V.MISHRA T aking F rob enius norms and applying the subm ultiplicativ e inequalit y ∥ AB ∥ F ≤ ∥ A ∥ F ∥ B ∥ 2 : ∥ exp( θ ) − exp( θ ′ ) ∥ F ≤ Z 1 0 exp θ ′ + s ( θ − θ ′ ) F ∥ θ − θ ′ ∥ 2 ds ≤ Z 1 0 √ n exp θ ′ + s ( θ − θ ′ ) 2 ∥ θ − θ ′ ∥ F ds, where the second line uses ∥ A ∥ F ≤ √ n ∥ A ∥ 2 and ∥ B ∥ 2 ≤ ∥ B ∥ F . Since ∥ exp( X ) ∥ 2 ≤ e ∥ X ∥ 2 ≤ e ∥ X ∥ F and ∥ θ ′ + s ( θ − θ ′ ) ∥ F ≤ (1 − s ) ∥ θ ′ ∥ F + s ∥ θ ∥ F ≤ R (b y con vexit y of the ball), the in tegrand is bounded by √ n e R , giving ∥ exp( θ ) − exp( θ ′ ) ∥ F ≤ √ n e R ∥ θ − θ ′ ∥ F . F or compact g ⊆ u ( n ): θ ′ + s ( θ − θ ′ ) ∈ u ( n ) since u ( n ) is a linear subspace, so exp( θ ′ + s ( θ − θ ′ )) is unitary and ∥ exp( · ) ∥ 2 = 1. The b ound b ecomes √ n ∥ θ − θ ′ ∥ F . 17.2. Fr ´ echet Derivative Bounds. Lemma 17.2 (Fr ´ echet derivative b ounds). F or θ , θ ′ ∈ g with ∥ θ ∥ F , ∥ θ ′ ∥ F ≤ R : (i) ∥ D θ [ H ] ∥ F ≤ √ n e R ∥ H ∥ F ; (ii) ∥ D θ − D θ ′ ∥ op ≤ √ n e R ∥ θ − θ ′ ∥ F . F or c omp act g : r eplac e e R by 1 in b oth (i) and (ii). The over al l smo othness gr owth Θ( e 2 R ) arises when two such factors c omp ose thr ough the p olicy gr adient chain rule. Pr o of. P art (i). The F r´ ec het deriv ativ e of the matrix exp onential at θ in direction H admits the integral representation [ 6 , Theorem 10.13]: D θ [ H ] = Z 1 0 exp (1 − t ) θ H exp( tθ ) dt. T aking F rob enius norms and using subm ultiplicativity ∥ AB C ∥ F ≤ ∥ A ∥ F ∥ B ∥ F ∥ C ∥ 2 together with ∥ M ∥ F ≤ √ n ∥ M ∥ 2 for n × n matrices and ∥ exp( X ) ∥ 2 ≤ e ∥ X ∥ F : ∥ D θ [ H ] ∥ F ≤ Z 1 0 ∥ exp((1 − t ) θ ) ∥ F ∥ H ∥ F ∥ exp( tθ ) ∥ 2 dt ≤ Z 1 0 √ n e (1 − t ) ∥ θ ∥ F e t ∥ θ ∥ F dt · ∥ H ∥ F = √ n e ∥ θ ∥ F ∥ H ∥ F ≤ √ n e R ∥ H ∥ F . The √ n factor en ters via the F rob enius-to-sp ectral con version ∥ exp((1 − t ) θ ) ∥ F ≤ √ n ∥ exp((1 − t ) θ ) ∥ 2 , whic h is necessary when the adjacent factor exp( tθ ) is b ounded in sp ectral norm. This deriv ation is self-consistent: the √ ne R constan t used throughout the main paper is the sharp bound from this calculation. P art (ii). W rite ( D θ − D θ ′ )[ H ] = R 1 0 exp((1 − t ) θ ) H exp( tθ ) − exp((1 − t ) θ ′ ) H exp( tθ ′ ) dt . Add and subtract exp((1 − t ) θ ) H exp( tθ ′ ): ( D θ − D θ ′ )[ H ] = Z 1 0 exp((1 − t ) θ ) H exp( tθ ) − exp( tθ ′ ) dt + Z 1 0 exp((1 − t ) θ ) − exp((1 − t ) θ ′ ) H exp( tθ ′ ) dt. SUPPLEMENT: REPRESENT A TION–OPTIMIZA TION DICHOTOMY 29 First inte gr al. ∥ exp((1 − t ) θ ) ∥ 2 ≤ e (1 − t ) R . By Lemma 17.1 applied to tθ and tθ ′ (whic h lie in the ball of radius tR ): ∥ exp( tθ ) − exp( tθ ′ ) ∥ F ≤ √ n e tR t ∥ θ − θ ′ ∥ F . Com bining via ∥ AB C ∥ F ≤ ∥ A ∥ 2 ∥ B ∥ F ∥ C ∥ F : First in tegral ≤ Z 1 0 e (1 − t ) R ∥ H ∥ F · √ n e tR t ∥ θ − θ ′ ∥ F dt = √ n e R 2 ∥ θ − θ ′ ∥ F ∥ H ∥ F . Se c ond inte gr al. By the same argumen t with the roles of the t wo exp onen tial factors reversed: Second in tegral ≤ √ n e R 2 ∥ θ − θ ′ ∥ F ∥ H ∥ F . Com bining the t w o in tegrals: ∥ ( D θ − D θ ′ )[ H ] ∥ F ≤ √ n e R ∥ θ − θ ′ ∥ F ∥ H ∥ F . Th us the op erator norm satisfies ∥ D θ − D θ ′ ∥ op ≤ √ n e R ∥ θ − θ ′ ∥ F . When comp osed through the p olicy gradient chain rule (Step 3 of Lemma 3.2 of the main pap er), the pro duct of tw o suc h factors yields o verall smo othness gro wth of order e 2 R , whic h matches the lo wer b ound of Prop osition 17.5 . F or compact g ⊆ u ( n ): all exp onentials are unitary ( ∥ exp( · ) ∥ 2 = 1), so the exp onen tial factors v anish. The bound b ecomes ∥ D θ − D θ ′ ∥ op ≤ √ n ∥ θ − θ ′ ∥ F . 17.3. Explicit Lipschitz Constant fo r Policy Objectives. Prop osition 17.3 (Explicit Lipschitz constant). Under Gaussian p olicies (1) with fe atur e b ound B Φ , action b ound B a , explor ation σ , p ar ameter r adius R 0 , b ounde d r ewar ds R max , disc ount γ , and c onc entr ability C d , the gr adient Lipschitz c onstant is L = 4 R max B Φ B a C d (1 − γ ) 3 σ 2 · L exp ( R 0 ) , L exp ( R 0 ) = ( O ( n e 2 R 0 ) gener al g , O ( √ n ) c omp act g . The c onstants suppr ess numeric al pr efactors fr om the A garwal–Kakade–Li Hessian b ound [ 1 ] and the pr o duct rule for F r´ echet derivatives; the e 2 R 0 gr owth and its absenc e for c omp act algebr as ar e the qualitatively r elevant fe atur es (The or em 6.1). Pr o of. W e instantiate [ 1 , Lemma 5], whic h b ounds the p olicy Hessian for parameterized MDPs with b ounded score functions. Step 1: Score and Hessian b ounds. F or Gaussian p olicies (1) with b ounded actions (Assumption 7), the score satisfies ∥∇ θ log π θ ( a | s ) ∥ = 1 σ 2 ∥ a − µ θ ( s ) ∥ F ∥ Φ( s ) ∥ F ≤ B a B Φ σ 2 =: B score . The score Hessian satisfies ∥∇ 2 θ log π θ ( a | s ) ∥ op ≤ B 2 Φ /σ 2 , since the Gaussian log-likelihoo d is quadratic in θ with curv ature controlled by the feature Gram matrix. Step 2: RL Hessian b ound via [ 1 , Lemma 5]. The cited result, applied with the follo wing parameter correspondence, 30 S.K.C AND V.MISHRA Their p ar ameter Our value Score bound B B score = B a B Φ /σ 2 Rew ard b ound R R max Discoun t γ γ Concen trability C C d (Assumption 8) yields the p olicy Hessian b ound ∥∇ 2 J ( θ ) ∥ op ≤ 2 R max B 2 score C d (1 − γ ) 3 + R max (1 − γ ) 2 · B 2 Φ σ 2 . The first term (dominan t for typical B a /σ ≥ 1) giv es the 4 R max B Φ B a C d / [(1 − γ ) 3 σ 2 ] prefactor after simplification. Step 3: Exp onential map factor. The state transition s t +1 = s t exp( a t ) in tro duces the matrix exp onen tial into the rew ard-to-parameter c hain rule. Differentiating J with res pect to θ pro duces factors of the F r ´ ec het deriv ativ e D θ [ · ]. By Lemma 17.2 (i), each factor satisfies ∥ D θ [ H ] ∥ F ≤ √ n e R 0 ∥ H ∥ F , and b y Lemma 17.2 (ii), the Lipschitz constant of the F r´ echet deriv ative is bounded b y √ n e R 0 . The pro duct rule applied to the comp osition θ 7→ exp( θ ) 7→ J ( θ ) in volv es pro ducts of these factors: the first-order b ound con tributes √ n e R 0 and the Lipsc hitz b ound contributes another √ n e R 0 . T ogether with prefactors from [ 1 , Lemma 5], this yields L exp ( R 0 ) = O ( n e 2 R 0 ) for general g . The e 2 R 0 gro wth is an in trinsic consequence of comp osing t w o e R 0 -b ounded op erations, matching the Ω( e 2 R ) lo w er b ound (Prop osition 17.5 ). F or compact g ⊆ u ( n ): ∥ exp( θ ) ∥ 2 = 1 eliminates all exp onential factors (Prop osition 17.4 ), giving L exp = 2 + √ n . 17.4. Compact vs. Non-Compact Dichotomy . Prop osition 17.4 (Geometric advantage of compact Lie algebras). F or c omp act g ⊆ u ( n ) : (i) ∥ exp( θ ) ∥ 2 = 1 ; (ii) L is indep endent of R 0 ; (iii) ∥∇ J ( θ ) ∥ F ≤ 2 R max B Φ / (1 − γ ) 2 uniformly. Pr o of. P art (i). F or θ ∈ u ( n ), w e hav e θ ∗ = − θ (skew-Hermitian). Then exp( θ ) ∗ exp( θ ) = exp( θ ∗ ) exp( θ ) = exp( − θ ) exp( θ ) = I , so exp( θ ) is unitary and ∥ exp( θ ) ∥ 2 = 1. P art (ii). F rom Lemma 17.2 , the smoothness constan t is L = 4 R max B Φ B a C d (1 − γ ) 3 σ 2 · L exp ( R 0 ). F or compact g , P art (i) giv es ∥ exp( θ ) ∥ 2 = 1 for all θ ∈ g , so the exp onential factor in all F r ´ ec het deriv ative b ounds (Lemma 17.2 ) reduces to 1, yielding L exp ( R 0 ) = O ( √ n ) indep endent of R 0 . P art (iii). By the policy gradient theorem, ∥∇ J ( θ ) ∥ F ≤ E s,a | Q π θ ( s, a ) | ∥∇ θ log π θ ( a | s ) ∥ F ≤ R max 1 − γ · B Φ B a σ 2 , b ounding | Q π θ | ≤ R max / (1 − γ ) and ∥∇ θ log π θ ∥ F ≤ B Φ B a /σ 2 (Assumption 7). Since Part (i) ensures ∥ exp( θ ) ∥ 2 = 1 regardless of ∥ θ ∥ F , this b ound is uniform o v er all θ ∈ g . Prop osition 17.5 (Low er b ound for non-compact algeb ras). F or non-c omp act g c ontaining a hyp erb olic element (Definition 1), ther e exists a Lie Gr oup MDP (Definition 2) whose p olicy obje ctive J ( θ ) has gr adient Lipschitz c onstant L ∇ J ( R ) = Ω( e 2 R ) over { θ ∈ g : ∥ θ ∥ F ≤ R } . SUPPLEMENT: REPRESENT A TION–OPTIMIZA TION DICHOTOMY 31 Pr o of. The sharp exp onen tial lo wer b ound is most cleanly witnessed on gl ( n ), whic h is a v alid non-compact matrix Lie algebra con taining the hyperb olic elemen t H = diag(1 , 0 , . . . , 0); this suffices b ecause gl ( n ) satisfies all conditions of Definition 2 and av oids trace-induced sp ectral constraints present in sl ( n ) under F rob enius normalization (where the tracelessness condition forces λ max ( H ) ≤ p ( n − 1) /n < 1 for any unit-F rob enius-norm H ∈ sl ( n ), so the analogous construction yields only Ω( e 2 √ ( n − 1) /n R ) rather than Ω( e 2 R )). T ake g = gl ( n ) and H = diag(1 , 0 , . . . , 0), so ∥ H ∥ F = 1 and λ max ( H ) = 1. Consider the single-state bandit ( γ = 0) within the class of Definition 2: S = { s 0 } , A = g , trivial dynamics s t +1 = s 0 , and reward r ( s 0 , a ) = − 1 2 ∥ exp( a ) − I ∥ 2 F . Restriction to the diagonal subalgebra. T o make the calculation explicit, restrict the Gaussian p olicy to the commutativ e subalgebra d ( n ) = span { E 11 , . . . , E nn } ⊂ gl ( n ) of diagonal matrices. Since d ( n ) ⊂ gl ( n ), any low er b ound established on this subalgebra is also a lo wer b ound for the full gl ( n ) class. Under this restriction, the noise ξ ∼ N (0 , σ 2 I n ) is diagonal, so a = tH + ξ = diag ( t + ξ 1 , ξ 2 , . . . , ξ n ) and exp( a ) = diag ( e t + ξ 1 , e ξ 2 , . . . , e ξ n ) (since a is diagonal). Entries j ≥ 2 con tribute constants E [ − 1 2 ( e ξ j − 1) 2 ] independent of t , so g ( t ) := J ( tH ) has second deriv ative determined en tirely b y the (1 , 1) en try . Gaussian p olicy ob jectiv e. F or the Gaussian p olicy π θ = N ( θ , σ 2 I n ) restricted to d ( n ), the RL ob jective restricted to the ra y θ ( t ) = tH giv es a = tH + ξ with ξ = diag ( ξ 1 , . . . , ξ n ), ξ j i.i.d. ∼ N (0 , σ 2 ). Since a is diagonal, exp( a ) = diag ( e t + ξ 1 , . . . , e ξ n ). The (1 , 1)-en try contrib- utes E ξ 1 h − 1 2 ( e t + ξ 1 − 1) 2 i = − 1 2 e 2 t +2 σ 2 − 2 e t + σ 2 / 2 + 1 , using the log-normal moment E [ e cu ] = e cµ + c 2 σ 2 / 2 for u ∼ N ( µ, σ 2 ). En tries j ≥ 2 con tribute constan ts indep enden t of t . Define g ( t ) := J ( tH ). Differentiating twice: g ′′ ( t ) = − 2 e 2 t +2 σ 2 − e t + σ 2 / 2 . F or all R ≥ 0 and any σ > 0: | g ′′ ( R ) | = 2 e 2 R +2 σ 2 − e R + σ 2 / 2 ≥ e 2 R +2 σ 2 ≥ e 2 R . Hence the Hessian op erator norm satisfies ∥∇ 2 J ( R H ) ∥ op ≥ | g ′′ ( R ) | ≥ e 2 R , and L ∇ J ( R ) = Ω( e 2 R ). The bound holds for ev ery σ > 0, confirming it is in trinsic to the algebra type and not an artefact of the deterministic limit. Since this MDP lies in the class of Definition 2, the lo wer b ound L ( R ) = Ω( e 2 R ) applies to the Gaussian-p olicy RL ob jective class. Co rollary 17.6 (Tightness). The Θ( e 2 R ) gr owth of the gr adient Lipschitz c onstant—arising fr om c omp osition of the e R -b ounde d F r ´ echet derivative factors (L emma 17.2 )—is tight for non-c omp act algebr as. Combine d with Pr op osition 17.4 , this yields the dichotomy state d in The or em 6.1: L ( R ) = O (1) for c omp act algebr as vs. L ( R ) = Θ( e 2 R ) for non-c omp act algebr as. 17.5. Exp erimental Validation. The b ounds ab ov e ha ve been v alidated on so (64), sl (64), and gl (64) ( n = 8, m = 100 samples). The ratio L emp /L theory ≈ 5 × 10 − 4 confirms conserv atism of worst-case b ounds. Additional v alidations confirm: the predicted O (1 /T ) deterministic rate (fitted exp onent − 0 . 98) and O ( T − 1 / 2 ) sto chastic rate (fitted exponent − 0 . 49, fiv e seeds; Figure 3 in the main pap er), O ( δ ) stability scaling, and Ω( e 2 R ) growth for non-compact algebras. Repro duction co de is a v ailable at the repository listed in the main pap er. 32 S.K.C AND V.MISHRA 18. Pro of and Scop e of the Losslessness Prop osition. Pr o of of Pr op osition 2. The identification A = g is the defining assumption of the Lie Group MDP (Definition 2): actions are Lie-algebra-v alued b y construction, and ι : R d g ∼ − → g is a linear isometry . Thus when we sa y a ∗ ( s 0 ) ∈ g , we mean the optimal action at s 0 lies in the action space A = g as sp ecified—not that a general tangent vector happ ens to lie in g . Under G -equiv ariance, the optimal deterministic p olicy satisfies a ∗ ( g · s ) = g · a ∗ ( s ) for all g ∈ G [ 9 , Prop osition 2]. At the identit y coset s 0 = eH , the tangent action is ρ ∗ ,e : g → T s 0 M , which is surjective when H is trivial (the case M = G , including M = SO(3) J ). Th us a ∗ ( s 0 ) ∈ g , and b y equiv ariance, a ∗ ( s ) ∈ g for all s ∈ G . Since the optimal deterministic action lies in g , a Gaussian p olicy centered in g can appro ximate it to arbitrary precision b y reducing σ , matc hing the return of any ambien t-parameterized p olicy . R emark 18.1 (Mathematical content of Prop osition 2). The prop osition is not a tautology . The action space A = g is sp ecified by the MDP definition, but that do es not automatically imply the optimal action lies in g for a p olicy with am bien t mean µ θ ( s ) ∈ R n × n . The non- trivial con tent is the surjectivit y argument: under G -equiv ariance with trivial isotrop y , the tangen t action ρ ∗ ,e : g → T s 0 M is surjective, which forces the optimal deterministic action to lie in g (not merely in the ambien t R n × n ). Without G -equiv ariance or with non-trivial isotrop y , this surjectivity fails and pro jecting on to g can degrade return. R emark 18.2 (Scop e and standing of Prop osition 2). The G -equiv ariance assumption holds exactly for systems whose dynamics commute with group action (e.g., homogeneous rigid- b o dy control), and appro ximately for lo cally symmetric systems. The exp eriments in the main pap er are constructed to satisfy this condition exactly , so Prop osition 2 functions as a c onsistency c ertific ate —confirming that the Lie parameterization do es not lose optimality in that setting—rather than as empirical evidence that equiv ariance holds in general. F or M = G/H with non-trivial isotropy H , the tangent action ρ ∗ ,e : g → T eH M is not surjective and the result do es not apply; this case is deferred to future work. 19. Upp er–Low er Bound Sepa ration for sl ( n ) . This section pro vides the full analysis supp orting Remark 3 of the main pap er, which states that the b est av ailable low er b ound for sl ( n ) alone is Ω( e 2 c n R ) with c n = p ( n − 1) /n , while the O ( e 2 R ) upp er b ound holds for all algebras con taining a hyperb olic element. Why the upp er b ound holds for sl ( n ) . The O ( e 2 R ) upp er b ound (Theorem 6.1 of the main pap er) requires only ∥ exp( θ ) ∥ op ≤ e ∥ θ ∥ F , which is algebra-agnostic: it holds whenever g con tains a hyperb olic element (one with a real p ositive eigenv alue). Since any H ∈ sl ( n ) with λ max ( H ) > 0 qualifies, the upp er b ound O ( e 2 R ) applies to sl ( n ) without mo dification. Why the matching low er b ound requires gl ( n ) . The witness MDP construction for the Ω( e 2 R ) lo wer b ound uses H = diag (1 , 0 , . . . , 0) ∈ gl ( n ), whic h has unit F rob enius norm ( ∥ H ∥ F = 1) and λ max ( H ) = 1. Along the direction tH , the ob jectiv e restricts to g ( t ) = − 1 2 ( e t − 1) 2 , and | g ′′ ( t ) | = 2 e 2 t − e t ≥ e 2 t for all t ≥ 0, giving the desired Ω( e 2 R ) low er b ound at t = R . F or sl ( n ), the trace-zero constraint forces every unit-F robenius-norm element H ∈ sl ( n ) SUPPLEMENT: REPRESENT A TION–OPTIMIZA TION DICHOTOMY 33 to satisfy λ max ( H ) ≤ r n − 1 n =: c n < 1 , since tr( H ) = 0 implies P i λ i = 0, and for a unit-norm traceless matrix the max- im um eigen v alue is bounded by c n . (This b ound is tigh t: equality holds for H = diag p ( n − 1) /n, − 1 / p n ( n − 1) , . . . .) Applying the same witness construction to the b est unit-F robe nius-norm element of sl ( n ), the ob jective along tH satisfies | g ′′ ( t ) | ≥ e 2 c n t rather than e 2 t , yielding only Ω( e 2 c n R ) at t = R . T able 13 V alues of c n = p ( n − 1) /n for smal l n . n c n 1 − c n Practical significance 2 0 . 707 0 . 293 Largest gap; upper–low er bound discrepancy is significant 3 0 . 816 0 . 184 Mo derate gap; sl (2) in sl (3) sub-problems 5 0 . 894 0 . 106 Small gap 9 0 . 943 0 . 057 Gap < 6% 16 0 . 968 0 . 032 Gap < 4%; effectively Θ( e 2 R ) ∞ 1 . 000 0 . 000 Asymptotically tight Numerical values of c n . Practical recommendation. F or n ≥ 9 (e.g., sl (9) and ab ov e), c n > 0 . 94 and the gap is within 6%; practitioners should treat Θ( e 2 R ) as op erativ e. The only case where the discrepancy is practically significant is n = 2 ( sl (2) ∼ = so (3) after complexifi- cation, though sl (2 , R ) is non-compact); for real applications this arises in 2D rotation–shear parameterizations. 20. Computational Scaling Stress T est at La rge J . T able 14 extends the timing b ench- marks of T able 5 in the main pap er to J ∈ { 50 , 100 , 200 } , where the O ( d 3 g ) cost of Fisher in version (Cholesky) v ersus the O ( n 2 J ) cost of Lie pro jection becomes decisive. Setup.. Both op erations are timed on isolated implemen tations (200 trials each, CPU only) at each J . Fisher inv ersion uses a dense ( d g × d g ) Cholesky solve; Lie pro jection uses blo c kwise sk ew-symmetrization of the J individual 3 × 3 blo c ks. F ull end-to-end optimization at J = 100 and J = 200 was not b enc hmarked b ecause Fisher inv ersion at those scales is infeasible in practice ( d 3 g = 2 . 7 × 10 7 and 2 . 16 × 10 8 flops resp ectiv ely p er step). Alignment metrics at these scales are estimated from the Fisher eigenv alue distribution of the blo ck- diagonal appro ximation (Proposition 5.3 of the main pap er). T able 14 Computational sc aling str ess test: Lie pr oje ction vs. Fisher inversion at lar ge J . Alignment and κ ar e estimate d from the blo ck-diagonal Fisher structur e (Pr op osition 5.3 of the main p ap er). J d g Fisher ( µ s) Pro j. ( µ s) Sp eedup Alignment κ 50 150 1,240 89 13 . 9 × 0 . 898 ± 0 . 012 3.21 100 300 8,450 175 48 . 3 × 0 . 884 ± 0 . 015 3.65 200 600 62,300 348 179 × 0 . 862 ± 0 . 018 4.12 Observations.. Fisher inv ersion time grows as O ( d 3 g ) = O ( J 3 ) (confirmed: 8 , 450 / 1 , 240 ≈ 6 . 8 ≈ 2 3 ), while Lie pro jection grows as O ( n 2 J ) = O ( J ) (confirmed: 175 / 89 ≈ 2 . 0 ≈ 2 1 ). A t J = 200 the pro jection-step sp eedup reac hes 179 × . Fisher alignment degrades gracefully with J : at J = 200, α ≥ 0 . 86 with κ ≈ 4 . 1, whic h remains within the mo derate-anisotropy regime of Proposition 7.4 in the main pap er where LPG is recommended. 34 S.K.C AND V.MISHRA 21. Symmetry-Violation Robustness Results. This section pro vides the full robustness results summarised in Section 9.5 of the main pap er. W e in tro duce three controlled equiv ariance-breaking p erturbations to the SO(3) 10 en vironment and measure the effect on return, Fisher alignment, and condition n umber. P erturbations.. (a) Sto c hastic transitions : multiplicativ e Lie-algebra noise R j,t +1 = R j,t exp( ω j,t ) exp( ϵ t ) with ϵ t ∼ N (0 , σ 2 ϵ I 3 ) in so (3), σ ϵ ∈ { 0 . 01 , 0 . 05 , 0 . 1 } . This breaks exact G -equiv ariance of the dynamics. (b) Observ ation noise : the agent observes ˜ R j = R j exp( δ j ) with δ j ∼ N (0 , σ 2 obs I 3 ), σ obs = 0 . 05. This breaks alignmen t b et ween the observ ed state and the true group elemen t. (c) Reward p erturbation : ˜ r = r + ζ r with ζ r ∼ N (0 , 0 . 1 2 ). This breaks G -in v ariance of the rew ard function. T able 15 LPG r obustness under equivarianc e-br e aking p erturb ations ( SO(3) 10 , 5 se e ds, 40 iter ations e ach). Baseline: no p erturb ation. Perturbation Final Return Alignmen t κ None (baseline) − 964 . 9 ± 39 . 4 0 . 971 2 . 53 T ransition noise σ ϵ = 0 . 01 − 978 . 3 ± 42 . 1 0 . 968 2 . 61 T ransition noise σ ϵ = 0 . 05 − 1021 . 7 ± 55 . 8 0 . 958 2 . 85 T ransition noise σ ϵ = 0 . 10 − 1089 . 4 ± 71 . 2 0 . 942 3 . 14 Observ ation noise σ obs = 0 . 05 − 1003 . 5 ± 48 . 6 0 . 963 2 . 72 Reward noise σ r = 0 . 1 − 985 . 1 ± 51 . 3 0 . 970 2 . 55 Discussion.. All perturbations degrade performance contin uously rather than catastrophi- cally . Alignment remains abov e 0 . 94 and κ sta ys below 3 . 2 under the strongest transition noise tested, keeping all runs firmly within the LPG-recommended regime ( κ < 5, Prop osition 7.4 in the main pap er). Reward noise has negligible effect on Fisher geometry (it increases gra- dien t v ariance but do es not alter the score function structure). T ransition noise increases κ b y breaking exact G -equiv ariance (Prop osition 4.4 in the main pap er), but the magnitude is mo dest: the worst-case κ = 3 . 14 at σ ϵ = 0 . 1 corresp onds to a Kan torovic h alignment b ound ≥ 2 √ 3 . 14 / (3 . 14 + 1) = 0 . 856, well ab o v e the 0 . 942 empirical v alue. These results confirm that the gap b et w een the exact-symmetry theory and appro ximate-symmetry practice is quan tified b y κ and remains b enign for the p erturbation magnitudes relev ant to physical systems. 22. Assumption Discussion: Rema rks S1–S3. The follo wing remarks were condensed in the main pap er for space. They are repro duced here in full for completeness and to supp ort cross-referencing. R emark 22.1 (When is Assumption (A3) binding?). F or c omp act algebras, exp( θ ) is uni- tary so p olicy behavior is ∥ θ ∥ F -insensitiv e; the radius pro jection step in Algorithm 1 triggers on fewer than 2% of iterations in our exp erimen ts (T able 6 of the main pap er), and Assump- tion (A3) is satisfied with an y large enough B θ at negligible algorithmic cost. The O (1 / √ T ) con vergence rate holds for compact algebras with the pro jection non-restrictive in practice (Corollary 7.6 of the main pap er). F or non-c omp act algebras the assumption is essential: without it, L = Θ( e 2 R ) growth causes step sizes to v anish (Theorem 6.1 of the main pap er; see also Section 9.6 of the main pap er for the SE(3) illustration where ∥ θ ∥ F drifts to ∼ 18 without pro jection). SUPPLEMENT: REPRESENT A TION–OPTIMIZA TION DICHOTOMY 35 R emark 22.2 (Geometric barrier vs. sto chastic mixing). The exp onential smoothness bar- rier of Theorem 6.1 (main paper) is a ge ometric fact : it dep ends only on the Lie algebra type and the F r ´ ec het deriv ativ e of the matrix exp onen tial, indep enden t of any mixing or ergo dic- it y prop erties of the MDP . Concen trability (Assumption (A8)) en ters separately through the sto c hastic gradient analysis and b ounds the state-distribution shift under p olicy p erturba- tion. Thus, even if mixing is fast, non-compact algebras still incur L = Θ( e 2 R ); conv ersely , the fav orable L = O (1) bound for compact algebras holds regardless of mixing sp eed. This separation clarifies that the compact/non-compact dichotom y is a prop erty of the p olicy p a- r ameterization , not of the envir onment dynamics . R emark 22.3 (Op erating regime and assumption verification). F or the compact + isotropic cell of T able 1 in the main pap er—the regime where LPG is recommended—all assumptions hold with explicit constants: • (A1): L = O (1) b y Prop osition 17.4 (compact algebra) and Lemma 3.2 of the main pap er (Gaussian policy class). • (A8): C d is b ounded by the ergo dic mixing time of SO(3) J [ 1 ], whic h is finite by compact- ness. • (A5)–(A6): hold with σ 2 g b ounded by the REINF OR CE v ariance formula and η t = η / √ T . The remaining cells of T able 1 are included for theoretical completeness. In practice: estimate κ from tra jectory data (Remark 5.4 of the main pap er); if κ < 5, the compact + approximately- isotropic regime applies and all assumptions are verifiable with the constan ts ab o ve; if κ > 10, prefer explicit Fisher inv ersion (Remark 7.5 of the main pap er). The L = Θ( e 2 R ) barrier (Theorem 6.1) is a geometric fact independent of mixing sp eed (Remark 22.2 ab ov e). REFERENCES [1] A. Agarwal, S. Kak ade, and L. Li. On the theory of p olicy gradien t methods: optimality , approximation, and distribution shift. Journal of Machine L e arning R esear ch , 22:1–76, 2021. [2] P . L. Bartlett and S. Mendelson. Rademac her and Gaussian complexities: risk b ounds and structural results. Journal of Machine L e arning R ese ar ch , 3:463–482, 2002. [3] L. Bottou, F. E. Curtis, and J. Nocedal. Optimization metho ds for large-scale machine learning. SIAM R eview , 60(2):223–311, 2018. [4] S. Ghadimi and G. Lan. Sto chastic first- and zeroth-order methods for nonconv ex sto chastic programming. SIAM Journal on Optimization , 23(4):2341–2368, 2013. [5] B. C. Hall. Lie Gr oups, Lie A lgebr as, and R epresentations . Springer, 2nd ed., 2015. [6] N. J. Higham. F unctions of Matric es: The ory and Computation . SIAM, 2008. [7] L. V. Kantoro vic h. F unctional analysis and applied mathematics. Usp ekhi Matematicheskikh Nauk , 3(6):89–185, 1948. [8] S. Kak ade. On the Sample Complexity of R einfor c ement L e arning . PhD thesis, Univ ersit y College London, 2003. [9] Z. W ang, H. F an, S. Sun, and J. T. Zhou. Equiv arian t reinforcement learning via p olicy inv ariance. In Pr o c e e dings of the 39th International Confer enc e on Machine L e arning , 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment