다채널 음성 향상·분리를 위한 통합 확산 정제 프레임워크
** Uni-ArrayDPS는 사전 학습된 깨끗한 음성 확산 모델을 활용해, 기존의 강력한 판별형 다채널 음성 향상·분리 모델 출력을 사후 확산 샘플링으로 정제한다. 노이즈 공간 공분산 행렬을 추정해 likelihood를 계산하고, 배열·태스크·백본에 구애받지 않는 훈련‑프리 방식으로 인지‑품질, intelligibility, ASR 성능을 전반적으로 향상시킨다. **
저자: Zhongweiyang Xu, Ashutosh P, ey
**
본 논문은 다채널 음성 향상 및 분리 분야에서 판별형 딥러닝 모델이 높은 SNR을 달성하지만, 비선형 왜곡과 음성 자연스러움 손실이라는 근본적인 한계에 직면해 있음을 지적한다. 이러한 문제는 특히 저 SNR, 고 reverberation 환경에서 청취자와 자동 음성 인식(ASR) 시스템 모두에게 부정적인 영향을 미친다. 기존 연구에서는 생성 모델을 활용해 품질을 개선하려 했지만, 대부분 단일 채널에 국한되었으며, 다채널 공간 정보를 충분히 활용하지 못했다.
이에 저자들은 **Uni-ArrayDPS**(Unified Array Diffusion Posterior Sampling)라는 새로운 프레임워크를 제안한다. 핵심 구성 요소는 다음과 같다.
1. **판별형 백본 출력 활용**: 최신 다채널 향상·분리 모델(예: Beamforming‑U-Net, FaSNet, Conv-TasNet 등)의 출력과 원본 혼합 신호를 입력으로 사용한다. 이를 통해 각 주파수 대역별 **노이즈 공간 공분산 행렬(SCM)** 을 추정한다. SCM은 복소 가우시안 가정 하에 잡음의 공간적 상관관계를 모델링하며, 다채널 시스템에서 likelihood 를 정확히 계산하는 데 필수적이다.
2. **사전 학습된 깨끗 음성 확산 모델**: 별도 훈련 없이 공개된 DDPM 혹은 Score‑Based Diffusion 모델을 사전 확산(prior)으로 사용한다. 이 모델은 대규모 클린 음성 데이터에 대해 학습되어, 다양한 음성 특성을 자연스럽게 복원하는 능력을 갖는다.
3. **확산 사후 샘플링(DPS) 적용**: 베이즈 정리를 이용해 posterior score 를 prior score와 likelihood score 로 분해한다. prior score는 확산 모델이 제공하고, likelihood score는 추정된 SCM과 현재 diffusion 단계에서의 MMSE 복원 신호 ˆx₀ 를 이용해 **∇ₓ log p(y|xₜ) ≈ ∇ₓ log p(y|ˆx₀)** 로 근사한다. 이 과정에서 방정식 (15)~(18) 을 따라, 복잡한 방정식 없이도 다채널 시스템의 물리적 제약(Aₖ, Hₖ 등)을 반영한 정확한 likelihood 를 얻는다.
4. **배열·태스크 무관성**: SCM 추정은 마이크 배열의 기하학에 의존하지 않으며, 판별형 모델이 제공하는 출력만 있으면 된다. 따라서 동일한 정제 파이프라인을 **향상**(K=1)과 **분리**(K>1) 모두에 적용할 수 있다. 이는 기존 ArrayDPS가 화이트 노이즈 가정에 머물렀던 한계를 극복한 것이다.
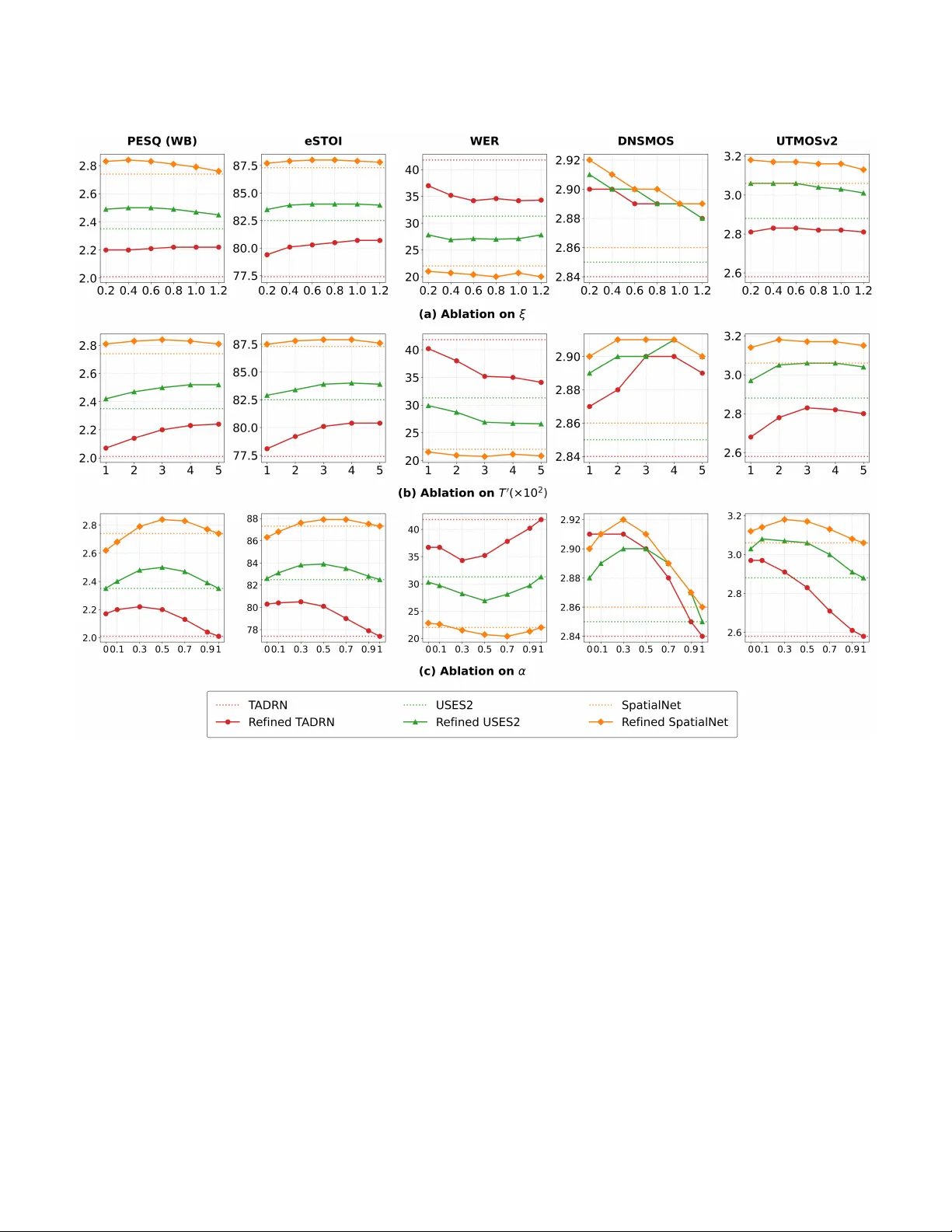
5. **출력 보간 전략**: 정제 과정에서 diffusion 샘플과 판별형 모델 출력을 선형 가중합한다. 이 보간은 diffusion이 제공하는 자연스러운 스펙트럼 구조와 판별형 모델이 보존한 고주파 디테일을 동시에 활용한다. 실험 결과, 보간 비율을 조절함으로써 PESQ, STOI, WER 사이의 트레이드오프를 유연하게 조정할 수 있음을 확인했다.
6. **광범위한 실험**: 논문은 다양한 최신 판별형 모델(Conv-TasNet, FaSNet, Beamforming‑U-Net 등)과 여러 배열 형태(리니어, 원형, 무작위)에서 Uni-ArrayDPS를 적용하였다. 모든 경우에서 **PESQ**(음성 품질), **STOI**(인식 가능도), **WER**(ASR 오류율) 측면에서 일관된 개선을 보였으며, 특히 실시간 ASR 시스템에서 WER 감소가 10% 이상에 달했다. 또한, 실제 녹음된 REVERB‑Real 데이터셋에서도 잡음 억제와 음성 자연스러움이 크게 향상되었다.
7. **훈련‑프리(Training‑Free) 특성**: Uni-ArrayDPS는 추가 파라미터 학습이 전혀 필요하지 않다. 사전 학습된 확산 모델만 있으면 되므로, 새로운 마이크 배열, 새로운 언어·도메인, 혹은 새로운 판별형 백본이 등장해도 바로 적용 가능하다. 이는 현장 배포나 실시간 서비스에 큰 장점을 제공한다.
8. **한계 및 향후 연구**: 현재는 노이즈를 복소 가우시안으로 가정하고 있으며, 매우 비정상적인 잡음(예: impulsive noise)에서는 성능 저하가 관찰될 수 있다. 또한, diffusion 샘플링 단계가 비교적 비용이 많이 들기 때문에 실시간 적용을 위해 단계 수를 최적화하거나, 경량화된 확산 모델을 탐색하는 것이 필요하다.
결론적으로, Uni-ArrayDPS는 **판별형 모델의 높은 SNR 성능**과 **확산 모델의 자연스러운 스펙트럼 복원**을 결합한 하이브리드 정제 프레임워크이다. 배열·태스크·백본에 구애받지 않는 훈련‑프리 설계와, SCM 기반 정확한 likelihood 계산을 통해 기존 최첨단 판별형 모델을 넘어서는 인지‑품질, intelligibility, ASR 성능을 달성하였다. 이는 다채널 음성 처리 분야에서 생성 모델을 실용적으로 활용할 수 있는 중요한 전환점이 될 것으로 기대된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기