Unified Diffusion Refinement for Multi-Channel Speech Enhancement and Separation
We propose Uni-ArrayDPS, a novel diffusion-based refinement framework for unified multi-channel speech enhancement and separation. Existing methods for multi-channel speech enhancement/separation are mostly discriminative and are highly effective at …
Authors: Zhongweiyang Xu, Ashutosh P, ey
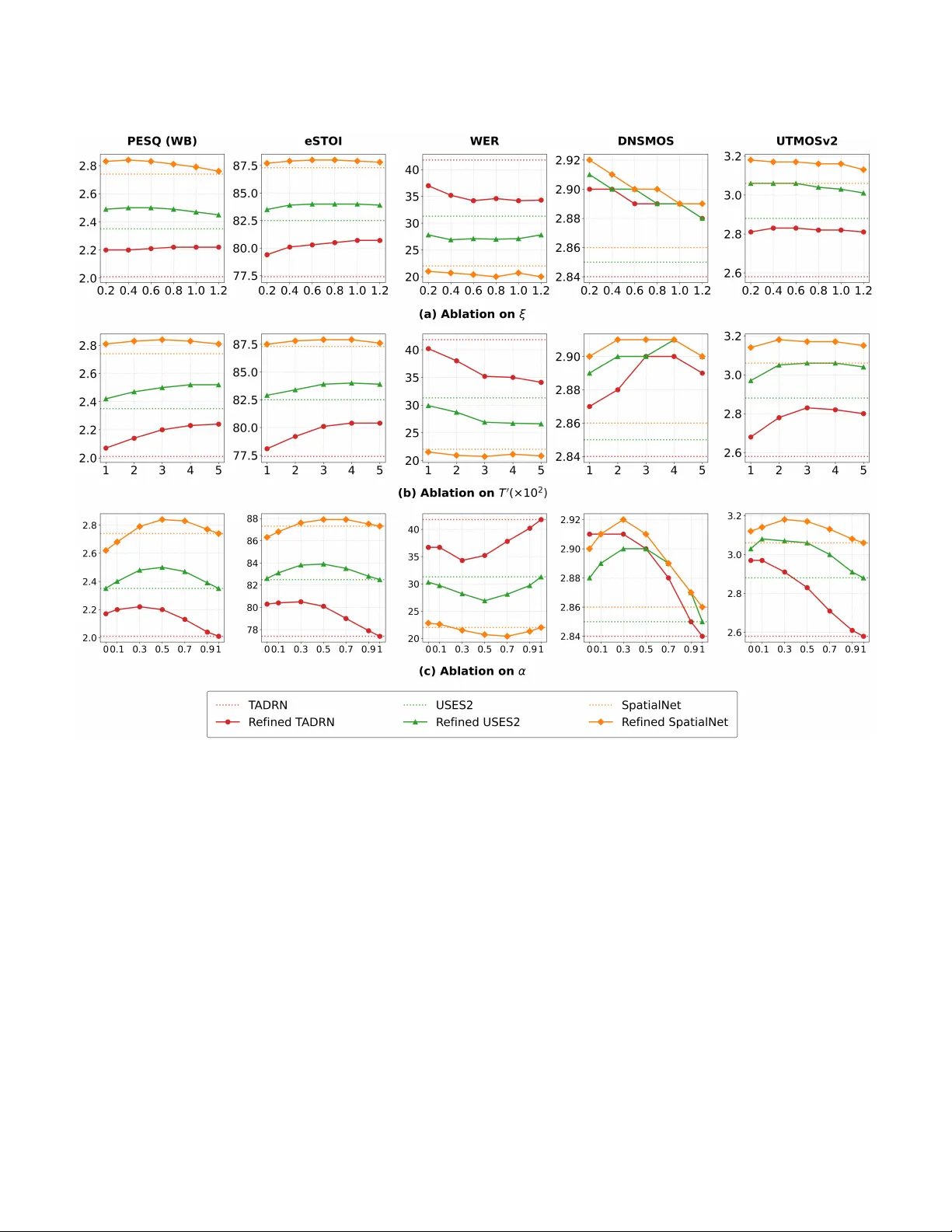
1 Unified Dif fusion Refinement for Multi-Channel Speech Enhancement and Separation Zhongweiyang Xu, Ashutosh Pande y , Juan Azcarreta, Zhaoheng Ni, Sanjeel Parekh, Buye Xu, and Romit Ro y Choudhury , F ellow , IEEE Abstract —W e propose Uni-ArrayDPS, a novel diffusion- based refinement framework for unified multi-channel speech enhancement and separation. Existing methods for multi-channel speech enhancement/separation are mostly discriminati ve and are highly effective at producing high-SNR outputs. However , they can still generate unnatural speech with non-linear distortions caused by the neural network and regression-based objectives. T o address this issue, we propose Uni-ArrayDPS, which refines the outputs of any str ong discriminative model using a speech diffusion prior . Uni-ArrayDPS is generative, array-agnostic, and training-free, and supports both enhancement and separation. Given a discriminative model’s enhanced/separated speech, we use it, together with the noisy mixtures, to estimate the noise spatial covariance matrix (SCM). W e then use this SCM to compute the likelihood requir ed f or diffusion posterior sampling of the clean speech source(s). Uni-ArrayDPS requir es only a pre-trained clean- speech diffusion model as a prior and does not require additional training or fine-tuning, allowing it to generalize directly across tasks (enhancement/separation), microphone array geometries, and discriminative model backbones. Extensi ve experiments show that Uni-ArrayDPS consistently improves a wide range of discriminative models for both enhancement and separation tasks. W e also report strong results on a real-world dataset. A udio demos are provided at https://xzwy .github .io/Uni-ArrayDPS/. Index T erms —Diffusion, Array Signal Processing, Multi- channel Speech Enhancement, Source Separation I . I N T RO D U C T I O N When multiple speakers talk simultaneously in a noisy room, the microphones record mixtures of the speakers’ voices and en vironmental noise. This is kno wn as the cocktail party problem [ 1 ], [ 2 ], where the goal is to extract clean speech sources from noisy mixtures. Speech enhancement typically assumes a single acti ve speaker , whereas speech separation assumes multiple speakers speaking simultaneously . Deep learning–based supervised methods have shown remarkable potential for both speech enhancement [ 3 ] and separation [ 4 ], [ 5 ]. Most of these methods are discriminativ e and are trained end-to-end to directly map noisy mixture features to clean speech features. A regression loss is typically used as the training objective for enhancement, while speech separation further incorporates permutation-in variant training (PIT) to compute the loss for separated sources. Although these discriminativ e models achie ve strong performance on objectiv e metrics such as signal-to-noise ratio (SNR), they Z. Xu and R. R. Choudhury are with the Department of Electrical and Computer Engineering, University of Illinois at Urbana-Champaign, Champaign, IL 61820, USA (e-mail: zx21@illinois.edu, croy@illinois.edu). A. Pandey , J. Azcarreta, Z. Ni, S. Parekh, and B. Xu are with the Reality Labs Research at Meta, Redmond, W A 98052, USA. often introduce non-linear distortions due to neural netw ork architectures, regression-based training objectiv es, and the ill-posed nature of speech enhancement and separation. These distortions not only degrade perceptual quality [ 6 ] but also reduce intelligibility [ 7 ]. This phenomenon is more pronounced in extremely noisy , lo w-SNR en vironments [8], [7], [9]. In addition to discriminativ e methods, generative enhancement and separation approaches have shown strong potential for improving perceptual quality [ 10 ], [ 11 ]. For speech enhancement, [ 12 ], [ 13 ] condition a speech diffusion model on noisy speech. SGMSE [ 10 ] starts the diffusion process from a mixture of noisy speech and Gaussian noise, and Flo wSE [ 14 ] further extends this idea with flow matching. For speech separation, Dif fSep [ 15 ] tailors a stochastic dif ferential equation (SDE) for source separation, and FLOSS [ 16 ] improv es it with flow matching. Although these methods achiev e strong perceptual quality , their objecti ve metrics are often substantially worse than those of state-of-the-art (SO T A) discriminativ e methods for both enhancement and separation. Motiv ated by this gap, StoRM [ 17 ] uses a discriminativ e enhancement model’ s output to initialize the dif fusion model, and Diffiner [ 18 ] uses a diffusion denoising restoration model (DDRM) [ 19 ] to refine single-channel discriminativ e enhancement outputs. Similarly , for separation, combining discriminati ve and generativ e methods can yield the best perfor- mance [ 11 ]. Howe ver , these hybrid approaches hav e so far been limited to single-channel speech enhancement and separation. Compared with the single-channel setting, multi-channel speech enhancement and separation can le verage spatial information, since speech and noise sources typically arrive from different directions. Spatial filtering (beamforming) enables effecti ve separation of different sources [ 20 ]. Similar to the single-channel case, discriminativ e models have also shown remarkable progress in multi-channel speech enhancement and separation. These architectures are designed to exploit spatial information either in the wav eform domain [ 21 ], [ 22 ], [ 23 ] or in the short-time Fourier transform (STFT) domain [ 24 ], [ 25 ], [ 26 ], [ 27 ], [ 28 ]. They can be adapted for enhancement and separation with slightly different training objectiv es, where separation still requires permutation-in variant training. By exploiting spatial information, these multi-channel models can achiev e superior enhancement and separation performance compared with their single-channel counterparts. Moreover , because microphone arrays come in a variety of configurations, some models are designed to be array-agnostic [ 23 ], [ 22 ], [ 24 ], [ 25 ], and once trained, can generalize across different array geometries. Despite carefully designed architectures for spatial 2 processing, these discriminati ve methods can still produce non-linear distortions [ 8 ], degrading perceptual quality and intelligibility , similar to single-channel discriminativ e methods. One way to mitigate these distortions is to use a deep learning model’ s output to estimate a traditional spatial filter , such as the minimum v ariance distortionless response (MVDR) beamformer [ 20 ]. Applying the estimated beamformer to the multi-channel mixtures can help enforce distortionless speech in the output. Howe ver , such linear beamformers often leav e more residual noise, necessitating additional post-processing [20]. T o further mitigate distortions, there is a gro wing trend to ward using generative models for multi-channel enhancement and separation [ 29 ], [ 30 ], [ 31 ], [ 32 ], [ 33 ]. [ 29 ], [ 30 ] use conditional diffusion for multi-channel enhancement, b ut with limited performance. [ 31 ] uses a diffusion module to refine a beamformer output, but the dif fusion component does not explicitly incorporate multi-channel spatial information. More recently , ArrayDPS [ 32 ] proposes a dif fusion posterior sampling (DPS) [ 34 ] framework for unsupervised, generati ve, and array- agnostic multi-channel speech separation. It uses a pre-trained speech diffusion model and estimates each source’ s room acous- tic transfer functions (A TF) jointly with the posterior-sampling process. Despite its unsupervised nature, it achieves separation performance on par with SOT A discriminative methods. The framew ork has also been extended to other multi-channel in- verse problems [ 35 ]. Howe ver , ArrayDPS assumes white noise and thus cannot be directly applied to speech enhancement. In contrast, ArrayDPS-Refine [ 33 ] is proposed to refine any dis- criminativ e multi-channel speech enhancement model using a pre-trained speech diffusion model. It first uses a discriminativ e model’ s output to estimate the noise spatial co variance matrix (SCM), and then uses the estimated SCM to compute the multi- channel mixture likelihood for diffusion posterior sampling. Although ArrayDPS-Refine can improve discriminativ e models in a training-free manner , it does not support speech separation. In this paper , we build on our pre vious work on ArrayDPS- Refine, which tar gets multi-channel enhancement as described abov e. W e propose Uni-ArrayDPS, a training-free, generati ve, and array-agnostic frame work that can refine an y state-of- the-art discriminative multi-channel speech enhancement or separation model. Similar to ArrayDPS and ArrayDPS-Refine, Uni-ArrayDPS requires only a pre-trained clean-speech diffusion model. It supports universal refinement across discriminativ e backbones, microphone array geometries, and tasks (enhancement and separation). As in ArrayDPS-Refine, it first uses the discriminati ve model’ s enhanced/separated outputs to estimate the noise SCM, which is then used during diffusion posterior sampling. W e extensi vely e valuate Uni-ArrayDPS for multi-channel enhancement and separation. Experiments sho w that Uni- ArrayDPS significantly improves perceptual quality , intelligibil- ity , and automatic speech recognition (ASR) across a range of discriminati ve models for both tasks. W e also present results on real-world multi-channel speech enhancement, demonstrating Uni-ArrayDPS’ s effecti veness in real-world scenarios. W e summarize our contrib utions as follows. Compared with ArrayDPS-Refine, we further extend the refinement approach to multi-channel speech separation, enabling more univ ersal multi- channel speech refinement. W e also improve performance by interpolating discriminative and generativ e outputs. In addition, we expand experiments to stronger SO T A discriminati ve models and a real-world recorded dataset. Finally , we provide more detailed ablations on likelihood-guidance parameters, diffusion sampling steps, and strategies for combining discriminativ e and generative outputs. Overall, we show that Uni-ArrayDPS can outperform SO T A discriminative models in perceptual , intelligibility , and ASR metrics for both multi-channel speech enhancement and separation. I I . B A C K G RO U N D A N D P RO B L E M F O R M U L A T I O N In a noisy , rev erberant acoustic en vironment, a C -channel mi- crophone array records mixtures of K speakers talking simulta- neously . Let X k ( ℓ,f ) ∈ C denote the k th anechoic clean speech source recorded at the reference microphone ( c = 1 ) in the short-time Fourier transform (STFT) domain, where k ∈ [1 ,K ] is the source index, ℓ ∈ [0 ,L − 1] is the STFT frame index, and f ∈ [0 ,F − 1] is the STFT frequency index. Then, the C -channel noisy mixtures recorded by the microphones are modeled as a sum of rev erberant speech sources and en vironmental noise: Y c ( ℓ,f ) = K X k =1 H k c ( ℓ,f ) ∗ ℓ X k ( ℓ,f ) + N c ( ℓ,f ) , c ∈ [1 ,C ] (1) where Y c ( ℓ, f ) ∈ C denotes the STFT -domain noisy mixture recorded by the c th microphone, H k c ( ℓ,f ) ∈ C denotes the STFT - domain room acoustic transfer functions (A TFs) from the k th speech source to the c th microphone, and N c ( ℓ,f ) ∈ C denotes the environmental noise recorded at the c th microphone. Here, ∗ ℓ denotes con volution across STFT frames, and the room A TF H k c ∈ C N H × F is a multi-frame filter with frame length N H . For con venience, we let Y ( ℓ,f ) = [ Y 1 ( ℓ,f ) , Y 2 ( ℓ,f ) , ...,Y C ( ℓ,f )] ∈ C C , and similarly for and N ( ℓ, f ) , H k ( ℓ, f ) ∈ C C . Similarly , we let X 1: K ( ℓ, f ) = [ X 1 ( ℓ, f ) , X 2 ( ℓ, f ) , ..., X K ( ℓ, f )] ∈ C K . Thus, Eq. 1 can be written in short as: Y ( ℓ,f ) = K X k =1 H k ( ℓ,f ) ∗ ℓ X k ( ℓ,f ) + N ( ℓ,f ) (2) In the context of multi-channel speech enhancement, we assume K = 1 and the goal is to e xtract X 1 giv en Y (i.e., to sample from p ( X 1 | Y ) ). For multi-channel speech separation, the goal is to extract X 1: K giv en Y (i.e., to sample from p ( X 1: K | Y ) ). In multi-channel speech enhancement and separation, spatial-domain information is extremely crucial [ 26 ], [ 20 ], so we mak e a spatially Gaussian assumption about the multi-channel noise N . W e assume that N ( ℓ, f ) follows a zero-mean complex Gaussian distrib ution C N 0 , Φ NN ( ℓ, f ) , where Φ NN ( ℓ, f ) = E N ( ℓ, f ) N ( ℓ, f ) H denotes the noise spatial covariance matrix (SCM). Gi ven this noise assumption and Eq. 2, we can write the likelihood of the noisy mixtures as: p Y ( ℓ,f ) | H 1: K ( ℓ,f ) ,X 1: K ( ℓ,f ) = C N Y ( ℓ,f ); K X k =1 H k ( ℓ,f ) ∗ ℓ X k ( ℓ,f ) , Φ NN ( ℓ,f ) , (3) 3 where in Eq. 3, Y ( ℓ, f ) follows comple x Gaussian with the mean to be the multi-channel mixture of re verberant sources, and the co v ariance to be the noise spatial cov ariance. A. Diffusion Model Diffusion models [ 36 ], [ 37 ], [ 38 ], [ 39 ] hav e shown remarkable progress in generati ve modeling across multiple domains, including speech generation [ 40 ]. A dif fusion model first defines a forw ard dif fusion process that gradually adds noise to clean data, and then generates samples by learning to remove Gaussian noise step by step. W e follow the Denoising Diffusion Probabilistic Model (DDPM) [ 36 ], [ 39 ] formulation. Starting from a data distribution p data ( x 0 ) , a forward diffusion process gradually transforms the clean signal x 0 to x 1 ,x 2 ,...,x T as follows: x t = √ α t x t − 1 + p β t ϵ t , ϵ t ∼ N (0 ,I ) , t ∈ [1 ,T ] (4) where t is the diffusion time step, β t ∈ (0 , 1) is a pre-defined noise variance schedule to determine the amount of noise added in dif ferent dif fusion steps. Then DDPM further defines α t := 1 − β t which gradually scales x t at each dif fusion step. From the forward process in Eq. 4, it is equiv alent to directly transform x 0 to x t by x t = √ ¯ α t x 0 + √ 1 − ¯ α t ϵ, ϵ ∼ N (0 ,I ) . (5) where ¯ α t := Q t s =1 α s . As t → T , √ ¯ α t → 0 , so that finally x T almost becomes Gaussian noise with distrib ution N (0 ,I ) . T o generate a sample from p ( x 0 ) , DDPM learns to rev erse the forward diffusion process. Starting from a noise x T ∼ N (0 , I ) , the sampling process rev erses each diffusion step (from t = T to t = 0 ) by sampling from a learned posterior p θ ( x t − 1 | x t ) , until a clean sample x 0 is sampled. The learned rev erse posterior is modeled as: p θ ( x t − 1 | x t ) = N µ θ ( x t ,t ) ,σ 2 t I , (6) where µ θ ( x t ,t ) = 1 √ α t x t − β t √ 1 − ¯ α t ϵ θ ( x t ,t ) , (7) and σ t = r 1 − ¯ α t − 1 1 − ¯ α t β t . (8) As shown in Eq. 7, ϵ θ ( x t , t ) is a neural network trained to estimate the noise ϵ in Eq. 5. Thus, the training objectiv e is to minimize: E t,x 0 ∼ p data ,ϵ ∼N (0 ,I ) h ϵ − ϵ θ ( √ ¯ α t x 0 + √ 1 − ¯ α t ϵ, t ) 2 2 i . (9) Since the noise ϵ in Eq. 5 can be estimated by ϵ θ for any x t , it also allo ws us to e stimate x 0 from x t using the estimated noise, which can be shown to be a Minimum Mean Square Error (MMSE) denoiser: E [ x 0 | x t ] ≃ ˆ x 0 ( x t ,t ) = x t − √ 1 − ¯ α t ϵ θ ( x t ,t ) √ ¯ α t (10) Note that this MMSE estimator is one-step, which allows a di- rect estimation from x t , and thus the denoised result would not be a realistic clean signal, but a smoothed and denoised signal. Theoretically equiv alent to DDPM, score-based diffusion [ 37 ], [ 38 ] formulates the forward dif fusion process and rev ersal diffusion process as stochastic differential equations (SDE). When T → ∞ , the diffusion forward process described by Eq. 4 becomes the forward SDE below: d x t = − 1 2 β t x t d t + p β t d w (11) where w in Eq. 11 is the Wiener process. Similarly , the rev ersal dif fusion process for sampling becomes another SDE: d x t = − 1 2 β ( t ) x t − β ( t ) ∇ x t log p t ( x t ) d t + p β ( t )d w (12) In Eq. 12, the score function ∇ x t log p t ( x t ) is usually approximated by a neural network s θ ( x t , t ) , trained with a conditional score matching loss [ 37 ]. With the score function, we then start from a noise x T ∈ N (0 ,I ) and solve the SDE in Eq. 12 to get x 0 ∼ p data , similar to DDPM sampling mentioned before. The score function and the MMSE denoiser discussed in Eq. 10 can be directly connected by T weedie’ s F ormula: E [ x 0 | x t ] = 1 √ ¯ α t x t + (1 − ¯ α t ) ∇ x t log p t ( x t ) . (13) From Eq. 10 and Eq. 13, there is a direct relationship between the score function and the noise estimator , which allows DDPM to also access the score estimator: ∇ x t log p t ( x t ) ≃ s θ ( x t ,t ) = − 1 √ 1 − ¯ α t ϵ θ ( x t ,t ) . (14) B. Diffusion P osterior Sampling and ArrayDPS This section giv es a background of diffusion posterior sampling (DPS) [ 34 ], which tries to solv e in verse problems using a pre-trained dif fusion prior . Assume y = A ( x ) + n , where x is the clean signal to recov er , A ( · ) is a known degradation operator, and n is the white noise with variance σ 2 y . T o recover the clean signal x from the noisy measurement y , DPS samples from p ( x | y ) using a pre-trained score dif fusion model for the clean signal x . As discussed in Sec. II-A , to sample from p data ( x ) , diffusion models need to train a diffusion noise estimator ϵ θ ( x t ,t ) or a score model s θ ( x t ,t ) to approximate the score ∇ x t log p t ( x t ) , and knowing one directly infers the other . Ho wev er , to sample from p ( x | y ) , the posterior score ∇ x t log p t ( x t | y ) is needed, so it is decomposed using Bayes’ theorem: ∇ x t log p ( x t | y ) = ∇ x t log p ( x t ) + ∇ x t log p ( y | x t ) . (15) Note that the prior score ∇ x t log p ( x t ) can be directly approximated by the pre-trained dif fusion model s θ ( x t ,t ) , but the likelihood score ∇ x t log p ( y | x t ) is still unkno wn. DPS then proposes to estimate the lik elihood score by: ∇ x t log p ( y | x t ) ≃ ∇ x t log p ( y | ˆ x 0 ( x t ,t )) (16) = 1 2 σ 2 y ∇ x t ∥ y − A ( ˆ x 0 ( x t ,t )) ∥ 2 2 (17) where ˆ x 0 ( x t ,t ) = x t − √ 1 − ¯ α t ϵ θ ( x t ,t ) √ ¯ α t (18) Eq. 18 uses the MMSE estimator ˆ x 0 ( x t ,t ) (cf. Eq. 10). The estimate ˆ x 0 can then be used to compute the likelihood in Eq. 16 and Eq. 17, since p ( y | x ) = N ( y ; A ( x ) ,σ 2 y ) . 4 DPS shows remarkable result for image and audio inv erse problems [ 34 ], [ 41 ], [ 42 ], [ 43 ], [ 44 ]. Howe ver , it makes two assumptions that are unrealistic: 1) the degradation operator A ( · ) is known in adv ance, and 2) the noise n has an analytical distribution like Gaussian or Laplace. There are a few methods proposed to solve the first problem of unkno wn operator A , where some solve for A during DPS [ 45 ], [ 46 ], [ 47 ], [ 48 ], some model A using another dif fusion model [ 49 ], and some train a latent surrogate for A [ 50 ]. In our problem formulation in Eq. 2, the degradation operator A ( · ) in DPS is the A TF filter and sum operation, where all the A TFs ( H 1: K ) are unknown. Also, the noise N in Eq. 2 is en vironmental noise, and thus the distribution is also unknown. C. ArrayDPS and FCP As discussed in Sec. II-B , DPS cannot be directly applied to multi-channel speech separation, and one reason is that all the room A TFs ( H 1: K ) are unkno wn. ArrayDPS [ 32 ] solves this by estimating the room A TFs ( H 1: K ) using Forward Con volutiv e Prediction (FCP) [ 51 ] at each DPS step for likelihood approximation. ArrayDPS is designed for multi-channel speech separation, which is unsupervised, generative, and array-agnostic. It also uses a pre-trai ned clean speech dif fusion model for diffusion posterior sampling. Its signal model follo ws Eq. 2, but only considers white noise, i.e., N ∼ N (0 , σ 2 Y I ) . Follo wing DPS, ArrayDPS’ s goal is to sample from p ( X 1: K | Y ) , which needs the posterior score ∇ X 1: K log p ( X 1: K | Y ) . Thus, the posterior score is first decomposed using Bayes theorem: ∇ X 1: K t log p ( X 1: K t | Y ) = K X k =1 ∇ X k t log p ( X k t ) + ∇ X 1: K t log p ( Y | X 1: K t ) (19) where X k t denotes the k th reference-channel clean source at diffusion step t . In Eq. 19, each speech source’ s prior score ∇ X t k log p ( X t k ) can be approximated by a pre-trained diffusion noise denoiser ϵ θ ( X k t ,t ) , following Eq. 14, and then the likelihood score ∇ X 1: K t log p ( Y | X 1: K t ) is approximated by: ∇ X 1: K t log p ( Y | X 1: K t ) ≃ ∇ X 1: K t log p ( Y | ˆ X 1: K 0 , ˆ H 1: K ) (20) = 1 σ 2 Y ∇ X 1: K t Y − K X k =1 ˆ H k ∗ l ˆ X k 0 2 2 (21) where ˆ X k 0 = X k t − √ 1 − ¯ α t ϵ θ ( X k t ,t ) √ ¯ α t , (22) and ˆ H k = FCP ( ˆ X k 0 ,Y ) , k ∈ [1 ,K ] . (23) Same as Eq. 18, Eq. 22 first denoises each speech source X k t , and then Eq. 23 uses the denoised source ˆ X k 0 and the multi-channel mixtures Y to estimate the room A TFs H k from source k to C microphones. The Forward Con volutiv e Prediction (FCP) algorithm in Eq. 23 is analytical and differentiable, which will be discussed later . Finally , Eq. 20 and Eq. 21 uses the estimated clean sources and the A TFs to estimate the lik elihood score, which can then be plugged into Eq. 19 for diffusion posterior sampling. ArrayDPS’ s main contribution is to use FCP to estimate the unknown A TFs for likelihood approximation, as in Eq. 23. FCP [ 51 ] is an STFT -domain filter estimation algorithm, which takes an input signal and a target signal. Intuitiv ely , it finds t he best filter such that after filtering the input with the filter, the filtered result matches the target signal the most. The problem formulation is shown as below: ˆ H k c = argmin H k c X l,f 1 ˆ λ l,f Y c ( l,f ) − N H − 1 X j =0 H k c ( j,f ) X k ( l − j,f ) 2 , (24) where ˆ λ l,f = 1 C C X c =1 | Y c ( l,f ) | 2 + γ · max l,f 1 C C X c =1 | Y c ( l,f ) | 2 (25) As in Eq. 24, FCP fromulates the filter estimation as a weighted least square problem, whose solution is analytical. N H is the number of frames of the A TFs, and the inv erse weight ˆ λ l,f is defined in Eq. 25 to prev ent overfitting to high-energy STFT bins. γ is a hyperparameter to tune the inv erse weight ˆ λ l,f . I I I . M E T H O D As discussed in Sec. II-C , ArrayDPS supports diffusion posterior sampling for unsupervised multi-channel speech separation under the white noise assumption. It sho ws impressiv e separation results, ev en compared with many discriminativ e models. Howev er, it does not work for real-world noisy en vironments, where noise sources coming from all directions can form a diffused sound field. Also, discriminativ e models like SpatialNet [ 26 ] show superior performance in multi-channel enhancement and separation. Thus, motiv ated by ArrayDPS and the effecti veness of discriminati ve models, we propose Uni-ArrayDPS, which uses an ArrayDPS-like module to further refine an y discriminative multi-channel enhancement and separation models. Uni-ArrayDPS’ s overall pipeline is shown in Fig. 1. First, the discriminativ e enhancement or separation model f ϕ ( · ) processes the multi-channel mixtures Y and outputs the estimated clean sources(s) ˜ X 1: K = f ϕ ( Y ) . Then, Y and ˜ X are used to estimate the noise spatial cov ariance matrix (SCM) ˆ Φ NN ( ℓ,f ) ∈ C C × C . This estimated SCM allows the lik elihood computation as mentioned in Sec. II Eq. 3. Finally , the Uni- ArrayDPS refinement module uses ˜ X as an initialization, and uses Y , ˆ Φ NN ( ℓ,f ) for arraydps-like diffusion posterior sampling. A. Spatial Covariance Matrix Estimation After the discriminati ve enhancement/separation model esti- mates the reference-channel clean speech source(s) ˜ X , we first use it to estimate the multi-channel noise inside the noisy mixtures. Note that the noisy mixtures are multi-channel ( Y ( ℓ,f ) ∈ C C ), while the denoised/separated source(s) are ane- choic reference-channel ( ˜ X k ( ℓ,f ) ∈ C ). Thus, we first use FCP to estimate the A TFs ˜ H ( ℓ,f ) ∈ C C , and then get an estimate of the multi-channel rev erberant clean source(s) ˜ X k rev erb ( ℓ,f ) ∈ C C : ˜ H k = FCP ( ˜ X k ,Y ) (26) ˜ X k rev erb = ˜ H k ∗ ℓ ˜ X k ,k ∈ [1 ,K ] (27) 5 Multi-channel Noisy Reverberant Mixtures Discriminative Model Reference-channel Enhanced/Separated Speech Noise Spatial Covaraince Matrix Estimator Uni-ArrayDPS Refinement for diffusion initialization for observation likelihood Refined Speech Fig. 1: Uni-ArrayDPS Refinement Pipeline. Then by subtracting the estimated multi-channel rev erberant sources ˜ X k from the mixtures Y , we can get an estimate of the multi-channel noise ˜ N ( ℓ,f ) ∈ C C : ˜ N = Y − K X k =1 ˜ X k rev erb (28) Using the estimated multi-channel noise, we then estimate the noise spatial covariance matrix in an e xponential moving av erage manner: ˆ Φ NN ( ℓ,f ) = η ˆ Φ NN ( ℓ − 1 ,f ) + (1 − η ) ˜ N ( ℓ,f ) ˜ N H ( ℓ,f ) , (29) where η is a smoothing coefficient for the SCM update. B. Diffusion Model and P osterior Scor e Estimation This section will first discuss Uni-ArrayDPS’ s diffusion model and then discuss ho w Uni-ArrayDPS updates at each diffusion step, using the estimated noise spatial cov ariance matrix (SCM) ˆ Φ NN mentioned in Sec. III-A. Similar to ArrayDPS, Uni-ArrayDPS trains a DDPM-based prior diffusion for anechoic clean speech. Howe ver , instead of using waveform-domain [ 42 ], [ 40 ], [ 32 ] or STFT domain diffusion [ 18 ], we apply dif fusion on the compressi ve STFT domain. Giv en the STFT of a clean signal, X , the compressive domain STFT is then ¯ X = | X | 0 . 5 exp j ∠ X . Since speech signals have much higher energy in lo w frequencies than high frequencies, the compression operation can effecti vely reduce the signal’ s dynamic range across frequencies. It has been sho wn that using these compressiv e STFT features can achieve better generation performance for dif fusion models [ 52 ]. Thus, the DDPM’ s forward dif fusion process and the re versal sampling process are all in this compressive STFT domain. Same as in Sec. II-A , the diffusion model trains a noise estimator ϵ θ ( ¯ X k ,t ) , which can then be used to sample from p ( ¯ X k ) using Eq. 6 in Sec. II-A . Since Uni-ArrayDPS’ s goal is to sample from p ( ¯ X 1: K | Y ) , we need to approximate the posterior score ∇ ¯ X 1: K log p ( ¯ X 1: K | Y ) , following ArrayDPS’ s frame work as in Sec. II-C . Thus, same as DPS and ArrayDPS, ∇ ¯ X 1: K log p ( ¯ X 1: K | Y ) is first decomposed into source prior scores and a likelihood score: ∇ ¯ X 1: K t log p ( ¯ X 1: K t | Y ) = K X k =1 ∇ ¯ X k t log p ( ¯ X k t ) + ∇ ¯ X 1: K t log p ( Y | ¯ X 1: K t ) (30) Each source prior score ∇ ¯ X k log log p ( ¯ X k ) can be directly approximated by s θ ( ¯ X k t ,t ) = − 1 √ 1 − ¯ α t ϵ θ ( ¯ X k t ,t ) (Eq. 14), and then Uni-ArrayDPS further approximates the likelihood score: ∇ ¯ X 1: K t log p ( Y | ¯ X 1: K t ) ≃ ∇ ¯ X 1: K t log p ( Y | ˆ X 1: K 0 , ˆ H 1: K , ˆ Φ NN ) (31) = − 1 2 ∇ ¯ X 1: K t X ℓ,f ˆ N ( ℓ,f ) H b Φ − 1 NN ( ℓ,f ) ˆ N ( ℓ,f ) , (32) where ˆ ¯ X k 0 = 1 √ ¯ α t ( ¯ X k t − √ 1 − ¯ α t ϵ θ ( ¯ X k t ,t ))) , (33) ˆ X k 0 = | ˆ ¯ X k 0 | 2 exp j ∠ ˆ ¯ X k 0 , (34) ˆ H k = FCP ( ˆ X k 0 ,Y ) , k ∈ [1 ,K ] , (35) and ˆ N = Y − K X k =1 ˆ X k 0 . (36) This approximation is v ery similar to Eq. 20 to Eq. 23, except Uni-ArrayDPS further considers real-world spatial noise. Eq. 33 firsts denoises the noisy speech features ¯ X k t to ˆ ¯ X k 0 , and then Eq. 34 transforms ˆ ¯ X k 0 to the STFT domain signal ˆ X k 0 . Then, Eq. 35 and Eq. 36 uses ˆ X k 0 to estimate the R TFs ˆ H k and the spatial noise ˆ N , respectively . Finally , Eq. 31 uses the estimated sources, A TFs, and noise SCMs, to estimate the likelihood using Eq. 3, with Eq. 32 as the deri vation result. Using the likelihood score approximation in Eq. 32 and Eq. 37, we can then approximate the posterior score as: ∇ ¯ X 1: K t log p ( ¯ X 1: K t | Y ) ≃ K X k =1 s θ ( ¯ X k t ) − 1 2 ∇ ¯ X 1: K t X ℓ,f ˆ N ( ℓ,f ) H b Φ − 1 NN ( ℓ,f ) ˆ N ( ℓ,f ) . (37) W e can then get the estimate the diffusion noise conditioned on Y : ϵ θ ( ¯ X k t , t | Y ) . Then, from the relationship between the noise estimator and the score (Eq. 14), we can then deriv e the conditional noise estimator ϵ θ ( ¯ X k t ,t | Y ) as: ϵ θ ( ¯ X k t ,t ) + 1 2 √ 1 − ¯ α t ∇ ¯ X 1: K t X ℓ,f ˆ N ( ℓ,f ) H b Φ − 1 NN ( ℓ,f ) ˆ N ( ℓ,f ) . (38) Finally , for the DDPM reversal sampling from p ( ¯ X 1: K ) , we can use Eq. 6 to Eq. 8 with ϵ θ ( ¯ X k t , t | Y ) to get the 6 Algorithm 1 Uni-ArrayDPS Require: Y , ˆ Φ NN , ˜ X 1: K ,T ′ ,ξ ,α,ϵ θ ( · ) , { σ 2 t } T ′ t =1 , { α t } T ′ t =1 , { ¯ α t } T ′ t =1 1: ¯ X 1: K ← | ˜ X 1: K | 0 . 5 exp j ∠ ˜ X 1: K ▷ to compressive domain 2: Sample ϵ ∼ C N (0 , 2 I ) ▷ N (0 ,I ) for both real and imag 3: ¯ X 1: K T ′ ← √ ¯ α T ′ ¯ X 1: K + √ 1 − ¯ α T ′ ϵ ▷ init. to step T’ 4: for t = T ′ ,..., 1 do 5: for k = 1 , ··· ,K do 6: ˆ ϵ ← ϵ θ ( ¯ X k t ,t ) ▷ diffusion model estimate noise 7: Sample Z ∼ C N (0 , 2 I ) ▷ N (0 ,I ) for both real and imag 8: ¯ X k t − 1 ← 1 √ α t ( ¯ X k t − 1 − α t √ 1 − ¯ α t ˆ ϵ ) + σ 2 t Z ▷ prior step 9: ˆ ¯ X k 0 ← 1 √ ¯ α t ( ¯ X t − √ 1 − ¯ α t ˆ ϵ ) ▷ one-step denoising 10: ˆ X k 0 ← | ˆ ¯ X k 0 | 2 exp j ∠ ˆ ¯ X k 0 ▷ transform to STFT domain 11: ˆ H k ← FCP ( ˆ X k 0 ,Y ) ▷ room A TF estimation 12: ˆ X k rev erb ← ˆ H k ∗ ℓ ˆ X k 0 ▷ estimate multi-channel reverb . speech 13: end for 14: ˆ N = Y − P K k =1 ˆ X k rev erb ▷ estimate multi-channel noise 15: G ← ∇ ¯ X t " − 1 2 P ℓ,f ˆ N ( ℓ,f ) H b Φ − 1 NN ( ℓ,f ) ˆ N ( ℓ,f ) # ▷ likelihood score 16: ¯ X t − 1 ← ¯ X 1: K t − 1 + ξ 1 − α t √ α t G ▷ likelihood step 17: end for 18: X 1: K 0 ← | ¯ X 1: K 0 | 2 exp j ∠ ¯ X 1: K 0 ▷ transform to STFT domain 19: for k = 1 , ··· ,K do 20: H k align ← FCP ( X k 0 , ˜ X k ) ▷ single-frame filter est. for alignment 21: X k align ← H k align ∗ ℓ X k 0 22: end for 23: X 1: K final = α ˜ X 1: K + (1 − α ) X 1: K align ▷ interpolate 24: retur n X 1: K final ▷ return aligned signal Uni-ArrayDPS’ s diffusion update: ¯ X k t − 1 = 1 √ α t ( ¯ X k t − 1 − α t √ 1 − ¯ α t ˆ ϵ ) + 1 − α t √ α t G + σ 2 t Z, (39) where G = − 1 2 ∇ ¯ X 1: K t X ℓ,f ˆ N ( ℓ,f ) H b Φ − 1 NN ( ℓ,f ) ˆ N ( ℓ,f ) , (40) and Z ∼ C N (0 , 2 I ) . (41) Eq. 41 samples from complex Gaussian with variance 2 because our diffusion is defined on the real and imaginary components of the compressi ve STFT features. Eq. 39 is then the Uni- ArrayDPS’ s one step update for dif fusion posterior sampling. C. Uni-ArrayDPS Algorithm This section then explains the Uni-ArrayDPS algorithm in detail, which is shown in Algorithm 1. Uni-ArrayDPS takes the noisy multi-channel speech Y , the discriminativ e enhanced/separated speech source(s) ˜ X 1: K , the estimated noise SCM ˆ Φ NN , and a fe w hyper-parameters as inputs. In line 1, ˜ X 1: K is first transformed to the compressiv e STFT domain sources ¯ X 1: K . Then, line 2-3 applies a forward diffusion process to ¯ X 1: K , getting ¯ X 1: K T ′ , which is at dif fusion step T ′ ∈ [1 ,T ] . This is the same as ArrayDPS [ 32 ], where the DPS does not start from diffusion step ( t = T ), but from an intermediate dif fusion step ( t = T ′ ) initialized from ¯ X 1: K . Similar to Eq. 41, line 2 is also sampling from C N (0 , 2 I ) because the dif fusion takes place in the real and imaginary components of the signal. Line 4-17 in Algorithm 1 shows the dif fusion posterior sampling, which gradually transforms the initialization ¯ X 1: K T ′ to the refined compressiv e STFT ¯ X 1: K 0 . The DPS update follows the deri vation in Sec. III-B , where Eq. 39 is the final update rule. F or the specific implementation of Eq. 39, line 6 first estimates the dif fusion noise, and then lines 7-8 apply a prior diffusion sampling step. Line 9 further denoises ¯ X k t using the estimated diffusion noise, to get the clean source estimate ˆ ¯ X k 0 . Then, line 10 transforms ˆ ¯ X k 0 back to STFT domain, line 11 uses FCP to estimate the k th source’ s A TFs ˆ H k , and line 12 applies the A TFs to ˆ X k 0 to get an estimate of the multi-channel reverberant source ˆ X k rev erb . While all K sources are processed, line 15 calculates the lik elihood score as in Eq. 40. Finally , line 16 applies the lik elihood score update, which is the same as in Eq. 39, except we add a ξ > 0 hyper-parameter to control likelihood guidance. Although ξ is empirical, it allo ws control of a trade-of f between naturalness and hallucination, which we will later show in Sec. V -B2. The DPS sampling output ¯ X 1: K 0 is still in the compressiv e domain, so line 18 transforms it back to the STFT domain signal X 1: K 0 . Howe ver , during sampling, the lik elihood guidance does not constrain that X 1: K 0 would align with the reference-channel clean signal, which is a known problem in UNSSOR [ 53 ] and ArrayDPS [ 32 ]. Thus, line 20 estimates a one-frame ( N H = 1 ) filter that can align X k 0 to the discriminativ e enhancement/separation output X k 0 . Since the discriminative model is trained to align with the reference-channel signal, X k align will also be aligned. Finally , line 23 interpolates the final aligned outputs X 1: K align with the discriminativ e model’ s output ˜ X 1: K , output the final sources X 1: K final . W e call α in line 23 the discriminative-generati ve interpolation coefficient. This trick is also shown to be effecti ve in other discriminati ve-generativ e hybrid approaches [54]. I V . E X P E R I M E N TA L S E T U P This section discusses the Uni-ArrayDPS h yper-parameter configurations, all the discriminativ e model baselines, simulated and real-w orld datasets, and e valuation metrics. A. Uni-ArrayDPS Configurations For the prior diffusion model, we follo w DDPM [ 36 ] and use a noise schedule β t that increases linearly from β 1 = 10 − 4 to β T = 0 . 02 , with T = 1000 steps. W e use a 2-D U-Net with residual blocks as the architecture of our dif fusion noise estimator ϵ θ ( ¯ X t ,t ) . The U-Net architecture is the same as the one used in Diffiner [ 18 ], modified from [ 39 ] to accommodate 2-D STFT . For the STFT in dif fusion, we use an FFT size of 512, a hop size of 128, and a square-root Hann window . W e pad the number of frames to 512 and remove the DC component, so the input to our U-Net is the real and imaginary channels of the noisy compressive STFT ¯ X t , with two channels, 256 frequency bins, and 512 frames. W e train the dif fusion model on about 220 hours of clean speech from the first DNS-Challenge [ 55 ]. Each training sample is a 4-second, 16-kHz clean speech utterance, and we normalize each sample’ s wa veform to [ − 1 , 1] . 7 W e use the Adam optimizer [ 56 ], with a learning rate of 10 − 4 and a batch size of 64, and train the model for 2 . 5 × 10 6 steps on 8 H100 GPUs. W e also use an exponential moving a verage (EMA) of the model weights with a decay of 0 . 9999 . W e estimate the noise SCM via the exponential moving av erage in Eq. 29, using η = 0 . 95 . For Uni-ArrayDPS (see Algorithm 1 and Sec. III-C ), diffusion sampling begins at an intermediate step T ′ . W e set this T ′ to be 300 by careful tuning, and study the effects of T ′ by sweeping T ′ ∈ { 100 , 200 , 300 , 400 , 500 } . W e also sweep the likelihood- guidance parameter ξ to study the balance between prior-dri ven quality and likelihood-dri ven mixture fidelity , and evaluate ξ ∈ { 0 . 4 , 0 . 6 , 0 . 8 , 1 . 0 , 1 . 2 } . In Algorithm 1 line 11, for FCP’ s parameter in Eq. 25, we use a N H = 13 -frame filter with γ = 10 − 3 , matching the setting in ArrayDPS [ 32 ]. For the alignment FCP (Algorithm 1 line 20), we set N H = 1 for single- frame alignment. For the discriminativ e-generativ e interpolation α in Algorithm 1 line 23, we find that α = 0 . 5 is a good default value, and we sweep through α ∈ { 0 , 0 . 1 , 0 . 3 , 0 . 5 , 0 . 7 , 0 . 9 , 1 . 0 } for ablations in the result section. B. Discriminative Baselines and Datasets For the discriminativ e baseline models, we use three array-agnostic models: FaSNet-T A C [ 23 ], T ADRN [ 22 ], and USES2 [ 25 ], which once trained, can directly be applied to any microphone-array geometry . W e also use one strong array-specific baseline model SpatialNet [ 26 ], which can only work for a fixed mumber of microphones. Note all these models can be trained to support either enhancement or separation by changing model’ s number of output channels. T o support array-agnostic enhancement/separation, FaSNet- T A C employs transform-average-concatenate (T A C) to multi-channel time-domain signals. W e use FaSNet-T A C’ s official implementation and configuration 1 . T ADRN is a strong time-domain enhancement/separation model, which uses a triple-path attention architecture to process information across frames, chunks, and channels; we use the same MIMO configuration as in the original paper [ 22 ]. USES2 [ 25 ] is an STFT -domain array-agnostic competitiv e model, and we use the USES2-Comp configuration as in the original paper , follo wing the of ficial implementation 2 , with FFT size 512, STFT hop size 256, and a square-root Hann windo w . SpatialNet is a state-of-the-art STFT -domain model, which uses narrow-band channel-wise attention to fully e xploit the spatial information. W e use the SpatialNet-Lar ge configuration in the original paper , follo wing the of ficial implementation 3 . For discriminati ve model training, we create ad-hoc micro- phone array datasets for both multi-channel speech enhance- ment and separation. Both tasks ha ve the exact same dataset simulation settings, except that enhancement simulates one target speaker and separation simulates two. T o simulate a data sample, a shoe-box room is randomly dra wn, with three dimensions uniformly sampled from 3 × 3 × 2 to 10 × 10 × 5 m. Similarly , we also uniformly sample the absorption coef ficient 1 https://github .com/yluo42/T AC/blob/master/F aSNet.py 2 https://github .com/espnet/espnet 3 https://github .com/Audio-W estlakeU/NBSS from 0 . 3 to 0 . 7 , resulting in a T 60 ∈ [0 . 13 , 0 . 55] s. W e then sample the microphone-array position in the room randomly , and then the positions of 8 microphones are randomly sampled inside a sphere centered at the array position, with a radius of 0 . 1 m. Thus, each sample’ s microphone array geometry is different in the dataset. W e also randomly sample 8 − 16 interference speakers to simulate bubble noise, and 1 − 50 noise sources to simulate dif fused noise field. W e sample 1 target speaker source for the enhancement datasets and sample 2 target speaker sources for the separation datasets. All sources’ locations and the microphone center location is randomly sam- pled in the room. The speech and noise sources are all sampled from the DNS-Challenge dataset [ 55 ]. W e uniformly sample the signal-to-noise ratio to be from [ − 10 , 5] dB, and the signal-to- interference ratio to be from [5 , 10] dB (signal-to-interference ratio is defined to be the target speakers’ energy ov er the interference speakers’ energy). The acoustic simulation uses the image-source method [ 57 ] (order 6) from the Pyroomacoustics toolbox [ 58 ]. For both enhancement and separation datasets, we simulate 80 , 000 10 -second training samples, 1 , 000 4 -second validation samples, and 1 , 000 4 -second test samples. For array-agnostic models including FaSNet-T A C, T ADRN, and USES2, we train one model for enhancement and another for separation. During training, the number of channels in each batch is randomly sampled from 2 to 8 , which allows training on variable number of channels. F or SpatialNet model training, since one model cannot w ork for variable number of channels, we train 4 dif ferent models, for 4-channel enhancement, 4-channel separation, 8-channel enhancement, and 8-channel separation, respecti vely . During training, each model is only trained on a fixed number of channels. F or all the models, we use the Phase Constrained Magnitude (PCM) loss [ 59 ] as the training objecti ve, which is a combination of time-domain loss and STFT magnitude loss. W e use the anechoic clean speech as the training target. For separation training, we further use the permutation in variant training (PIT) [ 22 ] to calculate the PCM loss. Adam optimizer with a learning rate of 10 − 4 is used. For FaSNet-T A C, T ADRN, and SpatialNet, we use a batch size of 16 and train for 80 epochs. For USES2, we use a batch size of 8 and train for 40 epochs. V . E V A L UAT I O N R E S U LT S This section sho ws the e valuation results of all the discriminativ e baselines, and Uni-ArrayDPS’ s refinement ov er these baselines. W e e valuate on both simulated and real-world datasets for multi-channel enhancement and separation. A. Evaluation Datasets and Metrics For e valuation, we use the simulated datasets discussed in Sec. IV -B , where we e valuate on both 4-channel (use first 4 channels) and 8-channel enhancement/separation. In addition to simulated dataset, we also ev aluate 4-channel and 8-channel enhancement on the RealMan dataset [ 60 ]. Following the official configuration 4 , we set the SNR range to be − 15 to 5 dB, speaker to be static, and the audio sample length to be 4 https://github .com/Audio-W estlakeU/RealMAN 8 T ABLE I: Uni-ArrayDPS ev aluation for multi-channel speech enhancement on the simulated adhoc microphone array dataset. row Methods ξ α 4-channel 8-channel STOI eSTOI PESQ(NB/WB) SI-SDR WER(%) DNSMOS UTMOSv2 STOI eSTOI PESQ(NB/WB) SI-SDR WER(%) DNSMOS UTMOSv2 A0 Noisy - - 0.622 0.347 1.38 / 1.07 -6.7 78.9 1.47 1.85 0.622 0.347 1.38 / 1.07 -6.7 78.9 1.47 1.85 A1 T ADRN [22] - - 0.893 0.774 2.83 / 2.01 8.9 41.8 2.84 2.58 0.909 0.805 2.94 / 2.16 9.8 35.4 2.86 2.67 A2 Refined T ADRN 0.4 0 0.907 0.803 2.95 / 2.17 10.0 36.7 2.91 2.97 0.925 0.835 3.09 / 2.36 11.0 29.0 2.91 3.02 A3 Refined T ADRN 0.4 0.5 0.906 0.801 2.98 / 2.20 9.8 35.2 2.90 2.83 0.922 0.830 3.10 / 2.38 10.7 29.3 2.90 2.90 A4 Refined T ADRN 0.8 0.5 0.908 0.805 2.99 / 2.22 9.9 34.6 2.89 2.82 0.924 0.836 3.12 / 2.41 10.9 28.3 2.90 2.89 A5 Refined T ADRN 1.0 0.5 0.908 0.807 2.98 / 2.22 9.9 34.2 2.89 2.82 0.925 0.837 3.12 / 2.41 10.9 27.3 2.89 2.89 B1 FaSNet-T A C [23] - - 0.833 0.664 2.49 / 1.61 5.4 57.7 2.54 1.77 0.853 0.698 2.57 / 1.70 6.3 50.7 2.58 1.89 B2 Refined FaSNet-T A C 0.4 0 0.859 0.721 2.68 / 1.82 6.6 47.8 2.73 2.56 0.885 0.763 2.82 / 1.98 7.6 39.4 2.75 2.66 B3 Refined FaSNet-T A C 0.4 0.5 0.854 0.706 2.68 / 1.79 6.2 48.0 2.67 2.21 0.875 0.743 2.79 / 1.93 7.2 41.0 2.70 2.35 B4 Refined FaSNet-T A C 0.8 0.5 0.857 0.712 2.68 / 1.80 6.3 47.5 2.65 2.18 0.878 0.748 2.79 / 1.94 7.2 39.7 2.69 2.28 B5 Refined FaSNet-T A C 1.0 0.5 0.858 0.713 2.68 / 1.81 6.3 46.0 2.64 2.14 0.879 0.749 2.79 / 1.95 7.3 38.7 2.67 2.27 C1 USES2 [25] - - 0.919 0.825 3.09 / 2.35 6.0 31.3 2.85 2.88 0.931 0.849 3.21 / 2.51 5.8 26.6 2.86 2.97 C2 Refined USES2 0.4 0 0.918 0.826 3.07 / 2.35 6.6 30.3 2.88 3.03 0.934 0.854 3.21 / 2.54 6.4 24.0 2.89 3.09 C3 Refined USES2 0.4 0.5 0.926 0.839 3.18 / 2.50 6.6 26.9 2.90 3.06 0.938 0.862 3.30 / 2.67 6.3 23.0 2.91 3.12 C4 Refined USES2 0.8 0.5 0.926 0.840 3.16 / 2.49 6.6 27.0 2.89 3.04 0.939 0.865 3.30 / 2.68 6.3 22.3 2.89 3.11 C5 Refined USES2 1.0 0.5 0.926 0.840 3.14 / 2.47 6.6 27.1 2.89 3.03 0.939 0.866 3.29 / 2.67 6.3 22.5 2.88 3.09 D1 SpatialNet [26] - - 0.944 0.873 3.32 / 2.74 13.5 22.0 2.86 3.06 0.959 0.904 3.49 / 3.01 14.7 16.8 2.88 3.18 D2 Refined SpatialNet 0.4 0 0.938 0.863 3.24 / 2.62 13.3 22.8 2.90 3.12 0.954 0.894 3.41 / 2.88 14.4 17.1 2.90 3.16 D3 Refined SpatialNet 0.4 0.5 0.946 0.879 3.38 / 2.84 14.0 20.7 2.91 3.17 0.961 0.909 3.55 / 3.12 15.2 15.6 2.92 3.25 D4 Refined SpatialNet 0.8 0.5 0.946 0.880 3.36 / 2.81 14.0 20.0 2.90 3.16 0.961 0.910 3.54 / 3.10 15.2 15.1 2.91 3.23 D5 Refined SpatialNet 1.0 0.5 0.946 0.879 3.34 / 2.79 14.0 20.7 2.89 3.16 0.961 0.909 3.52 / 3.08 15.2 15.5 2.90 3.22 4-second. W e also use the first 4 microphone or 8 microphone for enhancement e valuation. W e use extensi ve metrics to measure enhanced/separated speech’ s intelligibility , perceptual quality , and sample-le vel consistency . W e use Short-T ime Objective Intelligibility (STOI) [ 61 ], extended STOI [ 62 ], and w ord error rate (WER) or character error rate (CER) to measure speech intelligibilty . W e use the Whisper [ 63 ] base model to get transcripts of both the enhanced/separated signal and the ground-truth clean signal, and then calculate the WER for the simulated datasets (in English), or the CER for the RealMan dataset (in Chinese). W e further use Perceptual Ev aluation of Speech Quality (PESQ) [ 64 ], DNSMOS [ 65 ], and UTMOSv2 [ 66 ] to e valuate speech perceptual quality . For PESQ, we ev aluate both the narrow-band (NB) and the wide-band (WB) metrics. Also, DNSMOS and UTMOSv2 are all non-intrusi ve metrics which does not need a reference clean signal. Lastly , we calculate SI-SDR [67] to measure sample-lev el consistency . B. Enhancement Results and Analysis In this section, we first sho w the enhancement results on the simulated enhancement dataset described in Sec. V -B 1. Then we discuss the ef fects of the likelihood guidance ξ , the discriminativ e-generative interpolation coef ficient α , and the starting diffusion time T ′ , in Sec. V -B 2. In the end, we discuss the enhancement results on the RealMan dataset in Sec. V -B 3. 1) Simulated Dataset: W e first show the multi-channel enhancement ev aluation results on our simulated test dataset, in T able I. By observing the metrics of the baseline discriminativ e models and the Uni-ArrayDPS refinement, it is clear that our refinement method (ro w A3, B3, C3, D3 are default configurations) is able to consistently improv e the corresponding discriminative model, in all ev aluation metrics. By observing T ADRN’ s results in ro w A3, Uni-ArrayDPS refined T ADRN can improv e the original T ADRN by about 0.03 in eSTOI, 0.2 in wide-band PESQ, 1 dB in SI-SDR, 0.2 in UTMOSv2, and 6 percent in WER. In row A2, α = 0 means that the dif fusion posterior sampling result is directly used and there is no discriminati ve-generati ve interpolation, which sho ws much higher UTMOSv2 score. The same also happens to refined FaSNet-T A C in ro w B2, which is probably because time-domain architectures suffer in perceptual quality . row A5 further sho ws that higher likelihood guidance ξ can improv e speech intelligibility , since higher ξ means using more mixture information. W e will further discuss the effects of the likelihood ξ , starting dif fusion steps T ′ in Sec. V -B2, Fig. 2. For FaSNet-T A C’ s result in row B1-B5, we can see that Uni-ArrayDPS’ s default setting in ro w B3, can consistently improv e over the original FaSNet-T A C. It can improv e the baseline by about 0.04 in eSTOI, 0.2 in wide-band PESQ, 10 per cent in WER, and 0.5 in UTMOSv2. ro w B2 ( α = 0 ) shows even better improvements. For USES2’ s result in ro w C1-C5, the default Uni-ArrayDPS result in ro w C3 can impro ve original USES2 by about 0.015 in eSTOI, 0.15 in wide-band PESQ, 4 percent in WER, and 0.1 in UTMOSv2, for both 4-channel and 8-channel cases. Similarly , for SpatialNet’ s result in ro w D1-D5, Uni- ArrayDPS refinement can still impro ve the strong SpatialNet- Large model consistently in all metrics. As shown in ro w D3, Uni-ArrayDPS improv es SpatialNet by about 0.01 in eST OI, 0.1 in wide-band PESQ, 1 percent in WER, and 0.1 in UTMOSv2. 2) Ablation Studies: As shown in T able I, different configurations of the discriminativ e-generativ e interpolation coefficient α , likelihood guidance ξ can have an influence on the refinement performance. Also, note that as mentioned in Sec. IV -A , we set T ′ = 300 by default, which is also applied for all the experiments in T able I. Thus, we study the effects of these parameters in Fig. 2, where row (a) in Fig. 2 shows the ablations on ξ ∈ { 02 , 0 . 4 , 0 . 6 , 0 . 8 , 1 . 0 , 1 . 2 } , ro w (b) shows the ablations on T ′ ∈ { 100 , 200 , 300 , 400 , 500 } , and row (c) shows the ablations on α ∈ { 0 , 0 . 1 , 0 . 3 , 0 . 5 , 0 . 7 , 0 . 9 , 1 . 0 } . All results in Fig. 2 are from the 4-channel enhancement experiments on the simulated dataset. In row (a) of Fig. 2, we can observe fiv e different metrics’ relation with the likelihood guidance ξ . Note that ξ is a guidance term in line 16 of Algorithm 1, which determines ho w much likelihood guidance is used in each posterior sampling step. In- tuiti vely , a higher ξ would result in enhanced outputs more com- 9 Fig. 2: Uni-ArrayDPS refinement performance with ablations on likelihood guidance ξ , dif fusion starting step T ′ , and generati ve-discriminativ e interpolation coefficient α . The result is shown on 4-channel speech enhancement. plied with the original mixture, minimizing hallucination effects caused by the diffusion generation. This can then be confirmed in row (a) of Fig. 2. W e can see that a higher ξ hav e higher eSTOI and lower WER than lower ξ s, meaning that increasing ξ tends to improve speech intelligibility . This phenomenon is very obvious for T ADRN and USES2, but more subtle for SpatialNet. On the other hand, high ξ might include more noise from the noisy mixtures, resulting in noisier results. This can be verified in the PESQ, DNSMOS, and UTMOS chart in row (a) of Fig. 2, where these metrics degrade as ξ increase. This pattern is extremely obvious for SpatialNet and USES2, and less obvious for T ADRN. Overall, the likelihood guidance ξ can be used as a knob to balance the tradeoff between speech intelli- gibility and perceptual quality , tow ards solving the well-known hallucination problem in generati ve speech enhancement. Ro w (b) of Fig. 2 shows the different metrics with respect to the starting diffusion step T ′ introduced in Uni-ArrayDPS algorithm. T ′ determines at what diffusion time for Uni- ArrayDPS to start. For the two extreme cases, if T ′ = 0 , then Uni-ArrayDPS does not refine anything and just return the dis- criminati ve model’ s output. If T ′ = T = 1000 , then we start from Gaussian noise and our likelihood approximation in Sec. III-B would not be accurate, causing conv ergence issue [32]. If we start from our default T ′ = 300 , then we start our diffusion process from an initialization, which is a weighted sum of the discriminativ e model’ s output and Gaussian noise, and then Uni-ArrayDPS will learn to recover the information masked from the Gaussian noise, using the speech prior information along with the multi-channel mixtures. Thus, a higher T ′ means more noise in the initialization and more room to process. In Fig. 2 row (b), we can see that PESQ, eSTOI, and WER improv e when T ′ increases from 100 to 300 , and then roughly stay flat. DNSMOS and UTMOSv2 then increase or stay flat as T ′ increases to 400 , and then starts to de grade when T ′ = 500 . These finding shows that it is best to start from T ′ = 300 or 400 steps, which not only provides enough room for refinement, but also prev ents refinement from a very noisy initialization. Lastly , Fig. 2 row (c) shows ablations on the discriminative- generativ e interpolation coefficient α , which is introduced in Algorithm 1 (line 23). The coefficient α interpolates 10 T ABLE II: Uni-ArrayDPS ev aluation for multi-channel speech enhancement on the RealMan [60] dataset. row Methods ξ α 4-channel 8-channel STOI eSTOI PESQ(NB/WB) SI-SDR CER(%) DNSMOS UTMOSv2 STOI eSTOI PESQ(NB/WB) SI-SDR CER(%) DNSMOS UTMOSv2 A0 Noisy - - 0.712 0.533 1.58 / 1.11 -6.1 56.6 1.72 2.09 0.712 0.533 1.58 / 1.11 -6.1 56.6 1.72 2.09 A1 T ADRN [22] - - 0.772 0.650 2.25 / 1.57 -0.8 60.2 2.48 1.82 0.791 0.673 2.32 / 1.63 -0.6 57.0 2.46 1.84 A2 Refined T ADRN 0.4 0 0.770 0.646 2.32 / 1.63 -1.0 59.4 2.63 2.28 0.793 0.673 2.40 / 1.70 -0.8 55.4 2.60 2.29 A3 Refined T ADRN 0.4 0.5 0.781 0.664 2.35 / 1.67 -0.7 57.0 2.55 2.09 0.835 0.747 2.55 / 1.87 0.9 41.0 2.62 2.45 A4 Refined T ADRN 0.2 0.5 0.776 0.656 2.32 / 1.65 -0.8 58.9 2.56 2.07 0.832 0.743 2.54 / 1.86 0.9 42.2 2.63 2.45 A5 Refined T ADRN 0.6 0.5 0.784 0.669 2.37 / 1.68 -0.7 55.2 2.56 2.09 0.804 0.693 2.45 / 1.75 -0.5 52.0 2.54 2.10 B1 FaSNet-T A C [23] - - 0.776 0.652 2.26 / 1.48 -0.5 62.4 2.40 1.50 0.798 0.680 2.36 / 1.56 0.6 57.5 2.42 1.63 B2 Refined FaSNet-T A C 0.4 0 0.773 0.647 2.32 / 1.55 -0.4 62.9 2.56 2.07 0.796 0.677 2.43 / 1.64 0.7 57.2 2.56 2.14 B3 Refined FaSNet-T A C 0.4 0.5 0.788 0.668 2.37 / 1.58 -0.3 59.4 2.50 1.82 0.809 0.696 2.48 / 1.67 0.8 53.5 2.53 1.94 B4 Refined FaSNet-T A C 0.2 0.5 0.783 0.660 2.35 / 1.57 -0.4 61.1 2.52 1.82 0.804 0.689 2.45 / 1.66 0.7 56.4 2.54 1.93 B5 Refined FaSNet-T A C 0.6 0.5 0.791 0.673 2.39 / 1.59 -0.2 58.4 2.51 1.83 0.811 0.704 2.48 / 1.67 0.8 53.9 2.53 1.93 C1 USES2 [25] - - 0.863 0.778 2.80 / 2.09 1.09 40.2 2.69 2.71 0.876 0.798 2.87 / 2.19 2.2 35.6 2.71 2.78 C2 Refined USES2 0.4 0 0.847 0.749 2.64 / 1.91 1.1 46.9 2.70 1.54 0.862 0.772 2.73 / 2.01 2.3 40.7 2.73 2.58 C3 Refined USES2 0.4 0.5 0.864 0.778 2.81 / 2.14 1.3 39.3 2.73 2.76 0.877 0.799 2.90 / 2.24 2.4 35.5 2.74 2.80 C4 Refined USES2 0.2 0.5 0.862 0.775 2.81 / 2.13 1.2 40.8 2.74 2.76 0.875 0.795 2.88 / 2.24 2.4 35.7 2.76 2.81 C5 Refined USES2 0.6 0.5 0.865 0.780 2.81 / 2.12 1.3 39.0 2.71 2.75 0.878 0.800 2.89 / 2.23 2.4 33.7 2.73 2.79 D1 SpatialNet [26] - - 0.853 0.770 2.62 / 1.74 2.2 40.1 2.64 2.48 0.831 0.743 2.47 / 1.71 0.8 41.5 2.51 2.36 D2 Refined SpatialNet 0.4 0 0.836 0.739 2.52 / 1.73 2.1 46.6 2.70 2.37 0.817 0.718 2.45 / 1.77 0.7 45.9 2.62 2.33 D3 Refined SpatialNet 0.4 0.5 0.854 0.770 2.66 / 1.86 2.4 40.5 2.72 2.56 0.835 0.747 2.55 / 1.87 1.0 41.1 2.62 2.45 D4 Refined SpatialNet 0.2 0.5 0.853 0.767 2.65 / 1.86 2.3 41.5 2.73 2.57 0.832 0.743 2.54 / 1.86 0.9 42.5 2.63 2.45 D5 Refined SpatialNet 0.6 0.5 0.856 0.772 2.66 / 1.86 2.4 40.1 2.71 2.55 0.837 0.749 2.55 / 1.86 1.0 40.5 2.61 2.45 between the diffusion posterior sampling (DPS) output and the discriminative model’ s output. Thus, α = 1 corresponds to using only the discriminativ e model’ s output, whereas α = 0 corresponds to using only the DPS output. From Fig. 2 row (c), we observe that for all models, as α increases, the metrics first improv e and then start to de grade. F or T ADRN and USES2, most interpolation coef ficients yield consistent impro vements on most metrics. Howe ver , for SpatialNet, Uni-ArrayDPS improv es SpatialNet in PESQ, eSTOI, and WER only when α > 0 . 3 . Interestingly , UTMOS and DNSMOS tend to be better when α is small, suggesting that the DPS output has higher perceptual quality than the discriminati ve models. Overall, α = 0 . 5 is a safe choice that enables Uni-ArrayDPS to consistently impro ve dif ferent models across metrics. 3) RealMan Dataset: This section shows the multi-channel enhancement e valuation results on the RealMan test dataset discussed in Sec. V -A , in T able II. Similar to the enhancement result in the simulated dataset in T able I, Uni-ArrayDPS can also consistently improve over any discriminativ e models, in all metrics. Note that the prior dif fusion model is trained on DNS- Challenge, which is in English, while the RealMan dataset is in Chinese. This further shows Uni-ArrayDPS’ s domain generalization abilities. From T able II, we can observe that Uni- ArrayDPS provides consistent gains on this real-world recorded dataset. Note that for RealMan (Chinese), the ASR metric is character error rate (CER) instead of word error rate (WER). For T ADRN’ s results in row A1-A5, Uni-ArrayDPS consistently impro ves T ADRN in both 4-channel and 8-channel settings. In particular , for the 8-channel case, the default configuration (row A3) improv es the T ADRN (ro w A1) by 0.07 in eSTOI, 0.24 in wide-band PESQ, 16 percent in CER, and 0.61 in UTMOSv2. The improv ement is less pronounced for the 4-channel case, b ut is still consistent. For FaSNet-T A C’ s results in row B1-B5, we can see that the default configuration (row B3) improves FaSNet-T AC by about 0.02 in eSTOI, 0.01 in W ide-Band PESQ, 4 percent in CER, and 0.3 in UTMOSv2. Similar improvements are also sho wn for 4-channel enhancement. One interesting observ ation is that for the simulated dataset’ s result in T able I, T ADRN outperforms FaSNet-T A C by a large margin, while here in T able II, F aSNet-T A C has much better performance when generalizing to the RealMan dataset. For USES2’ s results in ro w C1-C5, USES (row C1) also shows great generalization ability tow ards the RealMan dataset, performing e ven better than the SpatialNet (row D1). Uni-ArrayDPS’ s default refinement (row C3) improv es USES2 by 0.016 in eSTOI, about 0.1 in wide-band PESQ, 1 percent in CER, and 0.05 in UTMOS v2 for the 4-channel case. Similar results are also shown for the 8-channel case. Also, with a larger ξ , row C5 shows much better impro vement in CER. Similarly , for SpatialNet’ s results in row D1-D5, default Uni- ArrayDPS (row D3) improves SpatialNet (D1) by about 0.1 in wide-band PESQ, and 0.1 for UTMOSv2. The improvement is mainly for perceptual quality and very subtle for intelligibility . C. Separation Results and Analysis W e show the results for multi-channel 2-speech separation in T able III, with the simulated noisy separation dataset mentioned in Sec. IV -B. From row B1-B5 in T able III, we can see that α = 0 (row B2) shows the best refinement performance, which improves the FaSNet-T A C baseline by about 0.08 in eSTOI, 0.23 in wide- band PESQ, 0.3 in narrow-band PESQ, 1.3 dB in SI-SDR, more than 15 percent in WER, and about 0.9 in UTMOSv2, for the 8-channel case. The default configuration in row B3 also shows remarkable results for all metrics, showing Uni-ArrayDPS’ s ability to adapt to source separation in noisy en vironments. For USES2’ s separation results from row C1 to C5, the default Uni-ArrayDPS (row C3) impro ves the USES2 baseline by 0.03 in eSTOI, more than 0.2 in wide-band PESQ, more than 6 percent in WER, and about 0.3 in UTMOSv2 for the 8-channel case. Similar improvement is also shown for the 4-channel case and other parameter configurations. For the strongest baseline in simulated datasets, SpatialNet can also be greatly improv ed by Uni-ArrayDPS for noisy source separation. In ro w D3, the def ault Uni-ArrayDPS can improv e SpatialNet by more than 0.01 in eSTOI, about 0.2 11 T ABLE III: Uni-ArrayDPS ev aluation for multi-channel speech separation and enhancement on the simulated adhoc microphone array dataset. row Methods ξ α 4-channel 8-channel STOI eSTOI PESQ(NB/WB) SI-SDR WER(%) DNSMOS UTMOSv2 STOI eSTOI PESQ(NB/WB) SI-SDR WER(%) DNSMOS UTMOSv2 A0 Noisy - - 0.568 0.299 1.29 / 1.09 -10.1 95.8 1.47 1.66 0.568 0.299 1.29 / 1.09 -10.1 95.8 1.47 1.66 B1 FaSNet-T A C [23] - - 0.755 0.540 2.06 / 1.35 1.63 75.0 2.19 1.26 0.780 0.577 2.15 / 1.40 2.60 69.1 2.29 1.35 B2 Refined FaSNet-T A C 0.4 0 0.786 0.607 2.31 / 1.52 2.71 63.1 2.54 2.10 0.820 0.657 2.45 / 1.63 3.90 53.9 2.59 2.23 B3 Refined FaSNet-T A C 0.4 0.5 0.781 0.587 2.27 / 1.48 2.37 63.4 2.39 2.68 0.808 0.630 2.39 / 1.57 3.40 55.4 2.43 1.81 B4 Refined FaSNet-T A C 0.2 0.5 0.775 0.576 2.24 / 1.47 2.21 66.5 2.39 1.67 0.801 0.618 2.39 / 1.57 3.40 58.5 2.44 1.80 B5 Refined FaSNet-T A C 0.6 0.5 0.784 0.594 2.28 / 1.49 2.43 62.3 2.38 1.68 0.812 0.637 2.40 / 1.59 3.50 53.7 2.43 1.79 C1 USES2 [25] - - 0.880 0.754 2.81 / 2.00 4.25 42.5 2.75 2.50 0.892 0.775 2.91 / 2.09 4.20 37.7 2.75 2.62 C2 Refined USES2 0.4 0 0.889 0.776 2.88 / 2.10 5.10 37.9 2.90 2.90 0.907 0.806 3.00 / 2.25 4.90 32.4 2.90 2.96 C3 Refined USES2 0.4 0.5 0.894 0.779 2.96 / 2.19 4.92 35.9 2.85 2.80 0.908 0.805 3.06 / 2.32 4.70 31.1 2.86 2.89 C4 Refined USES2 0.2 0.5 0.890 0.774 2.94 / 2.17 4.80 38.1 2.85 2.79 0.905 0.800 3.05 / 2.30 4.70 32.0 2.86 2.88 C5 Refined USES2 0.6 0.5 0.895 0.782 2.96 / 2.20 4.90 36.0 2.84 2.79 0.909 0.808 3.07 / 2.33 4.70 30.4 2.85 2.88 D1 SpatialNet [26] - - 0.933 0.848 3.19 / 2.53 12.20 26.3 2.87 2.97 0.952 0.887 3.39 / 2.80 13.80 19.8 2.89 3.09 D2 Refined SpatialNet 0.4 0 0.929 0.846 3.15 / 2.49 12.10 26.2 2.93 3.06 0.947 0.879 3.32 / 2.74 13.50 20.4 2.93 3.10 D3 Refined SpatialNet 0.4 0.5 0.938 0.861 3.28 / 2.70 12.70 23.1 2.94 3.11 0.955 0.894 3.48 / 2.98 14.30 17.8 2.95 3.18 D4 Refined SpatialNet 0.2 0.5 0.937 0.858 3.28 / 2.70 12.60 23.8 2.95 3.11 0.954 0.892 3.47 / 2.97 14.10 18.2 2.96 3.18 D5 Refined SpatialNet 0.6 0.5 0.938 0.861 3.28 / 2.69 12.80 23.3 2.93 3.10 0.956 0.896 3.48 / 2.98 14.40 17.4 2.94 3.17 in wide-band PESQ, more than 3 percent in WER, and 0.1 in UTMOSv2 for the 4-channel setting. Overall, extensiv e results have shown that Uni-ArrayDPS can refine any strong and competitive discriminati ve model, for both multi-channel speech enhancement and separation. The improvement can be observed for both intelligibility and perceptual metrics. W e also sho w ablations on dif ferent parameters and ho w the y would affect the algorithm. V I . C O N C L U S I O N W e introduced Uni-ArrayDPS, a training-free, generati ve, and array-agnostic refinement framew ork that le verages a pre- trained speech dif fusion model to improve the outputs of exist- ing discriminativ e multi-channel enhancement and separation systems. Starting from a discriminati ve estimate, we estimate a noise spatial cov ariance matrix and use that to guide an ArrayDPS sampling procedure that enforces multi-channel con- sistency while steering the generativ e prior toward clean speech. Across a range of backbones (including SO T A time-domain and STFT -domain baselines) and array configurations (e.g., 4- and 8-channel setups), ArrayDPS-Refine consistently improves both perceptual quality and intelligibility , sho wing con vincing results in both intrusive metrics (SI-SDNR, PESQ, STOI, WER), and non-instrusive metrics (DNSMOS, UTMOSv2). These results indicate that Uni-ArrayDPS refinement can serve as a practical plug-and-play module for multi-microphone speech processing without any constraint of the discriminati ve model, array-geometry , and number of sources. Ho wev er , there are a few limitations of Uni-ArrayDPS. First, Uni-ArrayDPS is based on diffusion posterior sampling, which is computationally expensi ve and unsuitable for real-time processing. Second, we assume static speakers in this paper , while moving sources are common in real-world scenarios. W e leave these limitations to future research. R E F E R E N C E S [1] J. H. McDermott, “The cocktail party problem, ” Current Biology , vol. 19, no. 22, pp. R1024–R1027, 2009. [2] E. C. Cherry , “Some experiments on the recognition of speech, with one and with two ears, ” The Journal of the acoustical society of America , vol. 25, no. 5, pp. 975–979, 1953. [3] C. Zheng, H. Zhang, W . Liu, X. Luo, A. Li, X. Li, and B. C. Moore, “Sixty years of frequency-domain monaural speech enhancement: From traditional to deep learning methods, ” T rends in Hearing , vol. 27, p. 23312165231209913, 2023. [4] S. Araki, N. Ito, R. Haeb-Umbach, G. Wichern, Z.-Q. W ang, and Y . Mit- sufuji, “30+ years of source separation research: Achievements and future challenges, ” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2025, pp. 1–5. [5] D. W ang and J. Chen, “Supervised speech separation based on deep learning: An overview , ” IEEE/A CM Tr ansactions on Audio, Speech, and Language Processing , vol. 26, no. 10, pp. 1702–1726, 2018. [6] A. R. A vila, M. J. Alam, D. O’Shaughnessy , and T . Falk, “Inv estigating speech enhancement and perceptual quality for speech emotion recognition, ” in INTERSPEECH , 2018, pp. 3663–3667. [7] T . Ochiai, K. Iwamoto, M. Delcroix, R. Ikeshita, H. Sato, S. Araki, and S. Katagiri, “Rethinking processing distortions: Disentangling the impact of speech enhancement errors on speech recognition performance, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , vol. 32, pp. 3589–3602, 2024. [8] V . T ourbabin, P . Guiraud, S. Hafezi, P . A. Naylor, A. H. Moore, J. Donley , and T . Lunner, “The SPEAR challenge-revie w of results, ” 2023. [9] R. Mira, B. Xu, J. Donley , A. Kumar , S. Petridis, V . K. Ithapu, and M. Pantic, “LA-V ocE: Low-snr audio-visual speech enhancement using neural vocoders, ” in ICASSP , 2023, pp. 1–5. [10] J. Richter, S. W elker, J.-M. Lemercier , B. Lay , and T . Gerkmann, “Speech enhancement and dereverberation with diffusion-based generati ve models, ” IEEE/A CM T ransactions on A udio, Speech, and Langua ge Pr ocessing , vol. 31, pp. 2351–2364, 2023. [11] S. Lutati, E. Nachmani, and L. W olf, “Separate and diffuse: Using a pretrained diffusion model for better source separation, ” in The T welfth International Conference on Learning Representations , 2024. [12] Y .-J. Lu, Z.-Q. W ang, S. W atanabe, A. Richard, C. Y u, and Y . Tsao, “Conditional diffusion probabilistic model for speech enhancement, ” in ICASSP , 2022, pp. 7402–7406. [13] M. Y ang, C. Zhang, Y . Xu, Z. Xu, H. W ang, B. Raj, and D. Y u, “uSee: Unified speech enhancement and editing with conditional diffusion models, ” in ICASSP . IEEE, 2024, pp. 7125–7129. [14] S. Lee, S. Cheong, S. Han, and J. W . Shin, “Flowse: Flow matching- based speech enhancement, ” in ICASSP 2025-2025 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2025, pp. 1–5. [15] R. Scheibler, Y . Ji, S.-W . Chung, J. Byun, S. Choe, and M.-S. Choi, “Diffusion-based generative speech source separation, ” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2023, pp. 1–5. [16] R. Scheibler , J. R. Hershey , A. Doucet, and H. Li, “Source separation by flow matching, ” arXiv preprint , 2025. [17] J.-M. Lemercier, J. Richter, S. W elker , and T . Gerkmann, “StoRM: A diffusion-based stochastic regeneration model for speech enhancement and dereverberation, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , vol. 31, pp. 2724–2737, 2023. [18] R. Sawata, N. Murata, Y . T akida, T . Uesaka, T . Shibuya, S. T akahashi, and Y . Mitsufuji, “Diffiner: A versatile diffusion-based generativ e refiner for speech enhancement, ” in INTERSPEECH , 2023, pp. 3824–3828. 12 [19] B. Kawar , M. Elad, S. Ermon, and J. Song, “Denoising diffusion restoration models, ” Advances in neural information pr ocessing systems , vol. 35, pp. 23 593–23 606, 2022. [20] S. Gannot, E. V incent, S. Markovich-Golan, and A. Ozerov , “ A consolidated perspectiv e on multimicrophone speech enhancement and source separation, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , vol. 25, no. 4, pp. 692–730, 2017. [21] A. Pandey , B. Xu, A. Kumar , J. Donley , P . Calamia, and D. W ang, “TP ARN: Triple-path attenti ve recurrent network for time-domain multichannel speech enhancement, ” in ICASSP , 2022, pp. 6497–6501. [22] ——, “T ime-domain ad-hoc array speech enhancement using a triple-path network, ” in INTERSPEECH , 2022, pp. 729–733. [23] Y . Luo, Z. Chen, N. Mesgarani, and T . Y oshioka, “End-to-end microphone permutation and number in variant multi-channel speech separation, ” in ICASSP , 2020, pp. 6394–6398. [24] W . Zhang, K. Saijo, Z.-Q. W ang, S. W atanabe, and Y . Qian, “T oward univ ersal speech enhancement for diverse input conditions, ” in ASR U , 2023, pp. 1–6. [25] W . Zhang, J.-w . Jung, and Y . Qian, “Improving design of input condition in variant speech enhancement, ” in ICASSP , 2024, pp. 10 696–10 700. [26] C. Quan and X. Li, “Spatialnet: Extensively learning spatial information for multichannel joint speech separation, denoising and dereverberation, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , vol. 32, pp. 1310–1323, 2024. [27] Z.-Q. W ang, S. Cornell, S. Choi, Y . Lee, B.-Y . Kim, and S. W atanabe, “Tf-gridnet: Integrating full- and sub-band modeling for speech separation, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 31, pp. 3221–3236, 2023. [28] A. Pandey , B. Xu, A. Kumar , J. Donley , P . Calamia, and D. W ang, “Multichannel speech enhancement without beamforming, ” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2022, pp. 6502–6506. [29] S. Dowerah, R. Serizel, D. Jouvet, M. Mohammadamini, and D. Matrouf, “Joint optimization of diffusion probabilistic-based multichannel speech enhancement with far-field speaker verification, ” in Spoken Language T echnology W orkshop , 2023, pp. 428–435. [30] S. Dowerah, A. Kulkarni, R. Serizel, and D. Jouvet, “Self-supervised learning with diffusion-based multichannel speech enhancement for speaker verification under noisy conditions, ” in Interspeech 2023 , 2023, pp. 3849–3853. [31] F . Chen, W . Lin, C. Sun, and Q. Guo, “A T wo-Stage Beamforming and Diffusion-Based Refiner System for 3D Speech Enhancement, ” Circuits Systems and Signal Processing , vol. 43, no. 7, pp. 4369–4389, Jul. 2024. [32] Z. Xu, X. Fan, Z.-Q. W ang, X. Jiang, and R. R. Choudhury , “ ArrayDPS: Unsupervised blind speech separation with a diffusion prior, ” in ICML , 2025. [33] Z. Xu, A. Pandey , J. Azcarreta, Z. Ni, S. Parekh, and B. Xu, “ArrayDPS- Refine: Generative refinement of discriminativ e multi-channel speech enhancement, ” in Pr oc. IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2026, to appear . [34] H. Chung, J. Kim, M. T . Mccann, M. L. Klasky , and J. C. Y e, “Diffusion posterior sampling for general noisy in verse problems, ” in ICLR , 2023. [35] Y . Wu, Z. Xu, J. Chen, Z.-Q. W ang, and R. R. Choudhury , “Unsupervised multi-channel speech dereverberation via diffusion, ” , 2025. [36] J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models, ” in Advances in Neural Information Processing Systems , vol. 33, 2020, pp. 6840–6851. [37] Y . Song, J. Sohl-Dickstein, D. P . Kingma, A. K umar , S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations, ” in ICLR , 2021. [38] T . Karras, M. Aittala, T . Aila, and S. Laine, “Elucidating the design space of diffusion-based generativ e models, ” in Proc. NeurIPS , 2022. [39] A. Q. Nichol and P . Dhariwal, “Impro ved denoising dif fusion probabilistic models, ” in ICML . PMLR, 2021, pp. 8162–8171. [40] Z. Kong, W . Ping, J. Huang, K. Zhao, and B. Catanzaro, “Diffwa ve: A versatile diffusion model for audio synthesis, ” arXiv preprint arXiv:2009.09761 , 2020. [41] J. Song, A. V ahdat, M. Mardani, and J. Kautz, “Pseudoin verse- guided diffusion models for in verse problems, ” in International Confer ence on Learning Repr esentations , 2023. [Online]. A vailable: https://openrevie w .net/forum?id=9 gsMA8MRKQ [42] A. Iashchenko, P . Andreev , I. Shchekotov , N. Babaev , and D. V etrov , “Undiff: Unsupervised voice restoration with unconditional diffusion model, ” arXiv preprint , 2023. [43] E. Moliner , J. Lehtinen, and V . V ¨ alim ¨ aki, “Solving audio inverse problems with a dif fusion model, ” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2023, pp. 1–5. [44] E. Thuillier , J.-M. Lemercier, E. Moliner, T . Gerkmann, and V . V ¨ alim ¨ aki, “Hrtf estimation using a score-based prior , ” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2025, pp. 1–5. [45] J.-M. Lemercier, E. Moliner , S. W elker, V . V ¨ alim ¨ aki, and T . Gerkmann, “Unsupervised blind joint dereverberation and room acoustics estimation with diffusion models, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2408.07472 [46] M. ˇ Svento, E. Moliner, L. Juvela, A. Wright, and V . V ¨ alim ¨ aki, “Estimation and restoration of unknown nonlinear distortion using diffusion, ” arXiv pr eprint arXiv:2501.05959 , 2025. [47] E. Moliner, M. ˇ Svento, A. Wright, L. Juvela, P . Rajmic, and V . V ¨ alim ¨ aki, “Unsupervised estimation of nonlinear audio ef fects: Comparing diffusion-based and adversarial approaches, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2504.04751 [48] E. Moliner, F . Elvander , and V . V ¨ alim ¨ aki, “Blind audio bandwidth exten- sion: A diffusion-based zero-shot approach, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 32, pp. 5092–5105, 2024. [49] H. Chung, J. Kim, S. Kim, and J. C. Y e, “Parallel diffusion models of operator and image for blind inv erse problems, ” in Proceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , 2023, pp. 6059–6069. [50] S. Basu, C. Amballa, Z. Xu, J. V . Sampedro, S. Nelakuditi, and R. R. Choudhury , “Contrastiv e diffusion guidance for spatial in verse problems, ” arXiv preprint arXiv:2509.26489 , 2025. [51] Z.-Q. W ang, G. W ichern, and J. L. Roux, “Conv olutiv e prediction for monaural speech dereverberation and noisy-reverberant speaker separation, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 29, pp. 3476–3490, 2021. [52] G. Zhu, Y . W en, M.-A. Carbonneau, and Z. Duan, “Edmsound: Spectrogram based diffusion models for efficient and high-quality audio synthesis, ” 2023. [Online]. A vailable: https://arxiv .org/abs/2311.08667 [53] Z.-Q. W ang and S. W atanabe, “UNSSOR: Unsupervised neural speech separation by leveraging ov er-determined training mixtures, ” in Thirty-seventh Confer ence on Neural Information Pr ocessing Systems , 2023. [Online]. A vailable: https://openrevie w .net/forum?id=T5h69frFF7 [54] M. Hirano, K. Shimada, Y . Koyama, S. T akahashi, and Y . Mitsufuji, “Diffusion-based signal refiner for speech separation, ” arXiv preprint arXiv:2305.05857 , 2023. [55] C. K. A. Reddy , V . Gopal, R. Cutler , E. Beyrami, R. Cheng, H. Dubey , S. Matusevych, R. Aichner , A. Aazami, S. Braun, P . Rana, S. Srinivasan, and J. Gehrke, “The INTERSPEECH 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results, ” arXiv:2005.13981 , 2020. [56] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” in International Conference on Learning Representations (ICLR) , 2015. [Online]. A vailable: https://arxiv .org/abs/1412.6980 [57] J. B. Allen and D. A. Berkley , “Image method for efficiently simulating small-room acoustics, ” The Journal of the Acoustical Society of America , vol. 65, no. 4, pp. 943–950, 1979. [58] R. Scheibler , E. Bezzam, and I. Dokmani ´ c, “Pyroomacoustics: A python package for audio room simulation and array processing algorithms, ” in ICASSP , 2018, pp. 351–355. [59] A. Pandey and D. W ang, “Dense cnn with self-attention for time-domain speech enhancement, ” IEEE/ACM Tr ansactions on Audio, Speech, and Language Processing , vol. 29, pp. 1270–1279, 2021. [60] B. Y ang, C. Quan, Y . W ang, P . W ang, Y . Y ang, Y . Fang, N. Shao, H. Bu, X. Xu, and X. Li, “Realman: A real-recorded and annotated microphone array dataset for dynamic speech enhancement and localization, ” Advances in Neur al Information Pr ocessing Systems , vol. 37, pp. 105 997–106 019, 2024. [61] C. H. T aal, R. C. Hendriks, R. Heusdens, and J. Jensen, “ A short-time objectiv e intelligibility measure for time-frequency weighted noisy speech, ” in ICASSP , 2010, pp. 4214–4217. [62] J. Jensen and C. H. T aal, “ An algorithm for predicting the intelligibility of speech masked by modulated noise maskers, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 24, no. 11, pp. 2009–2022, 2016. [63] A. Radford, J. W . Kim, T . Xu, G. Brockman, C. McLeav ey , and I. Sutske ver , “Robust speech recognition via large-scale weak supervision, ” in ICML , 2023, pp. 28 492–28 518. 13 [64] A. Rix, J. Beerends, M. Hollier, and A. Hekstra, “Perceptual ev aluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs, ” in ICASSP , vol. 2, 2001, pp. 749–752. [65] C. K. A. Reddy , V . Gopal, and R. Cutler, “DNSMOS: A non-intrusiv e perceptual objective speech quality metric to evaluate noise suppressors, ” in ICASSP , 2021, pp. 6493–6497. [66] K. Baba, W . Nakata, Y . Saito, and H. Saruwatari, “The T05 system for the V oiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech, ” in Spoken Language T echnology W orkshop , 2024. [67] J. L. Roux, S. Wisdom, H. Erdogan, and J. R. Hershey , “SDR – half-baked or well done?” ICASSP , pp. 626–630, 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment