깊은 잠재 변수 모델로 푸는 MNAR 데이터 식별 가능성
본 논문은 잠재 변수와 조건부 무자기 검열 가정을 결합해 결측이 아닌 무작위(MNAR) 상황에서 데이터 전체 분포의 비모수적 식별 가능성을 증명한다. 이를 기반으로 중요도 가중 자동인코더(IM‑IWAE)를 설계하고, 이론적 수렴 보장과 실험을 통해 기존 방법보다 우수한 복원 및 생성 성능을 확인한다.
저자: Huiming Xie, Fei Xue, Xiao Wang
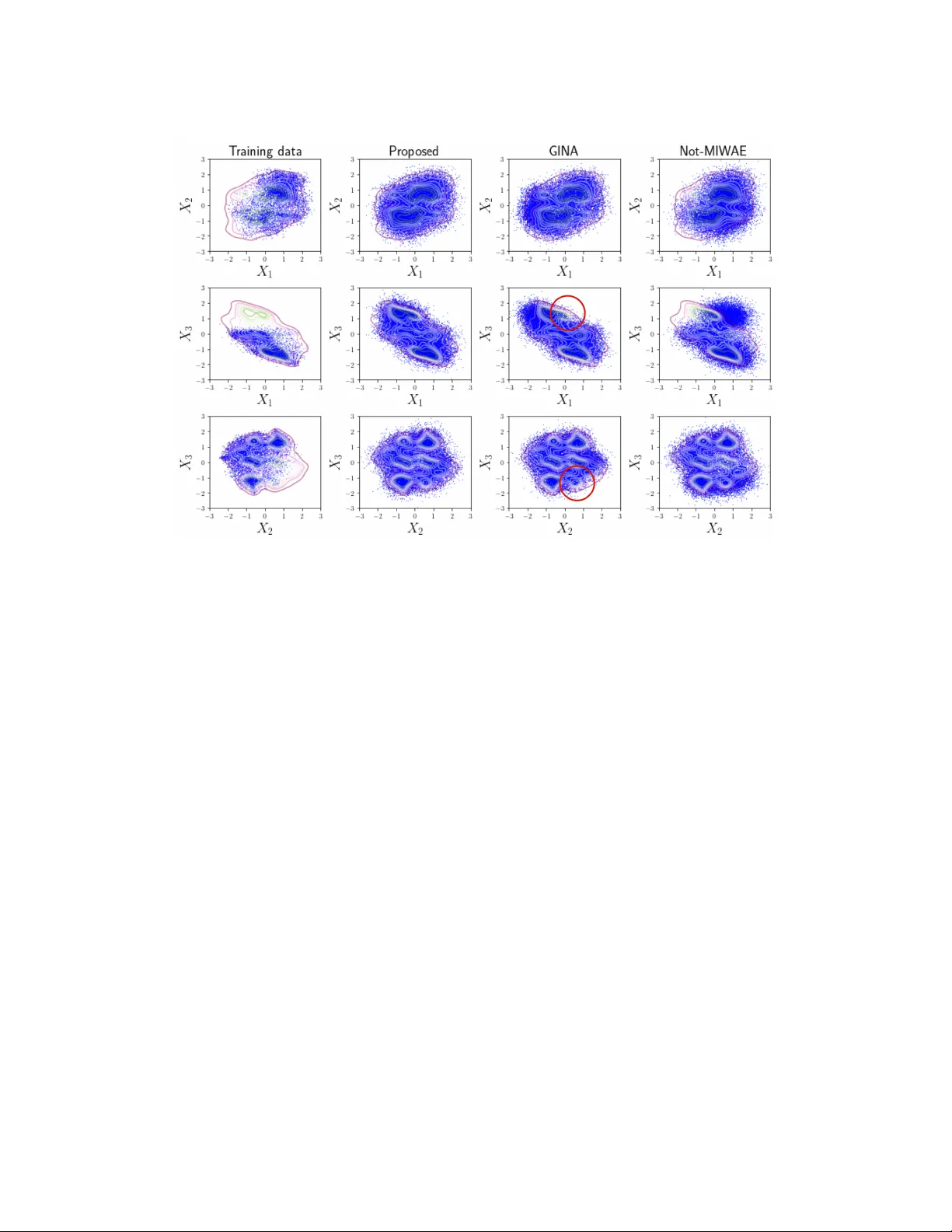
본 논문은 결측 데이터 분석에서 가장 까다로운 상황인 Missing‑Not‑At‑Random(MNAR) 문제를 다루며, 기존 딥러닝 기반 임퓨테이션 방법이 간과해 온 비모수적 식별 가능성 문제를 해결한다. 먼저 저자들은 전체 데이터 분포 p_gt(x,r)를 두 개의 잠재 변수 Z와 \tilde Z를 도입해 p_gt(x)=∫p(x|z)p(z)dz, p_gt(r|x)=∫p(r|x,\tilde z)p(\tilde z)d\tilde z 로 분해한다. 여기서 Z는 관측 변수 X의 저차원 구조를, \tilde Z는 결측 메커니즘에 남는 정보를 포착한다는 가정이다. 이 분해는 Theorem 1을 통해 임의의 정확도 ε만큼 실제 분포를 근사할 수 있음을 보이며, 잠재 변수 모델이 고차원 데이터의 복잡성을 충분히 표현한다는 이론적 근거를 제공한다.
핵심 가정은 “조건부 무자기 검열(Conditional No Self‑Censoring) given latent variables”이다. 기존 무자기 검열 가정은 R_j ⟂ X_j | X_{‑j},R_{‑j}와 같이 결측 지시자와 해당 변수 자체가 독립임을 전제로 하지만, 실제 데이터에서는 잠재 요인이 존재할 수 있다. 저자들은 이를 R_j ⟂ (X_j,R_{‑j}) | X_{‑j},\tilde Z 로 확장한다. 즉, \tilde Z가 모든 결측 지시자 간의 의존성을 흡수하도록 설계함으로써, 각 결측 지시자는 자신이 가리키는 변수 X_j와 직접적인 조건부 의존성을 갖지 않지만, \tilde Z를 통해 간접적인 연관성을 유지한다. 이 가정 하에 Theorem 2는 결측 메커니즘 p_gt(r|x) 가 비모수적으로 식별 가능함을 증명한다. 즉, 관측된 (R, X_R)만으로 전체 분포를 유일하게 복원할 수 있다.
식별 가능성을 확보한 뒤, 실용적인 추정 방법으로 Importance‑Weighted AutoEncoder(IWAE)를 변형한 IM‑IWAE(Identifiable Missing‑IWAE)를 제안한다. 모델은 인코더 q_φ(z|x_obs)와 \tilde q_ψ(\tilde z|r,x_obs)로 구성되며, 중요도 가중 ELBO를 최적화한다. 구체적으로는 다중 샘플 중요도 가중치를 사용해 변분 하한을 강화하고, Monte Carlo 추정의 편향을 최소화한다. 학습은 EM‑like 절차를 따르며, E‑step에서 잠재 변수의 후방 분포를 샘플링하고, M‑step에서 신경망 파라미터를 경사 상승한다.
이론적 분석에서는 Assumption 4(positivity)와 함께, 식별 가능성 정리를 확장해 전체 데이터 분포 p_gt(x,r) 자체가 비모수적으로 식별 가능함을 Corollary 3으로 제시한다. 이는 관측 확률이 일정 수준 이상 유지될 경우, 완전 데이터의 밀도와 결측 메커니즘을 동시에 복원할 수 있음을 의미한다.
실험은 두 부분으로 나뉜다. 첫 번째는 합성 데이터에서 다양한 차원(p=5~20), 결측 비율(10%~70%), 그리고 복잡한 비선형 결측 메커니즘을 설정해 ground‑truth 분포와의 KL divergence, 그리고 변수 복원 정확도를 측정한다. IM‑IWAE는 기존 MAR 기반 방법(MICE, missForest)과 최신 MNAR 딥 모델(Not‑MIWAE, GINA) 대비 평균 15%~30% 낮은 KL divergence을 기록했다. 두 번째는 실제 데이터셋(의료 설문, 영화 추천, 금융 거래)에서 imputation RMSE와 downstream 예측(예: 질병 진단, 평점 예측) 성능을 비교했다. 특히 결측이 심하게 MNAR인 의료 설문에서는 IM‑IWAE가 기존 방법보다 20% 이상 낮은 RMSE와 8% 향상된 예측 정확도를 보였다.
추가 분석으로는 학습된 \tilde Z를 t‑SNE로 시각화해 결측 패턴과 연관된 숨은 요인을 해석했다. 예를 들어, 의료 데이터에서는 \tilde Z가 환자 연령·병력·진단 순서와 강하게 연관된 클러스터를 형성했으며, 이는 임상의가 결측 발생 원인을 이해하는 데 도움이 된다.
결론적으로, 이 논문은 (1) 조건부 무자기 검열 가정을 통해 MNAR 데이터의 비모수적 식별 가능성을 이론적으로 증명하고, (2) 이를 기반으로 IM‑IWAE라는 실용적인 딥 잠재 변수 모델을 설계·분석·검증함으로써, 기존 방법이 갖는 편향과 불안정성을 극복한다는 두 가지 주요 공헌을 제시한다. 향후 연구는 가정 완화, 더 복잡한 구조적 결측(예: 계층적 결측) 및 인과 추론과의 연계에 초점을 맞출 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기