Identifiable Deep Latent Variable Models for MNAR Data
Missing data is a ubiquitous challenge in data analysis, often leading to biased and inaccurate results. Traditional imputation methods usually assume that the missingness mechanism is missing-at-random (MAR), where the missingness is independent of …
Authors: Huiming Xie, Fei Xue, Xiao Wang
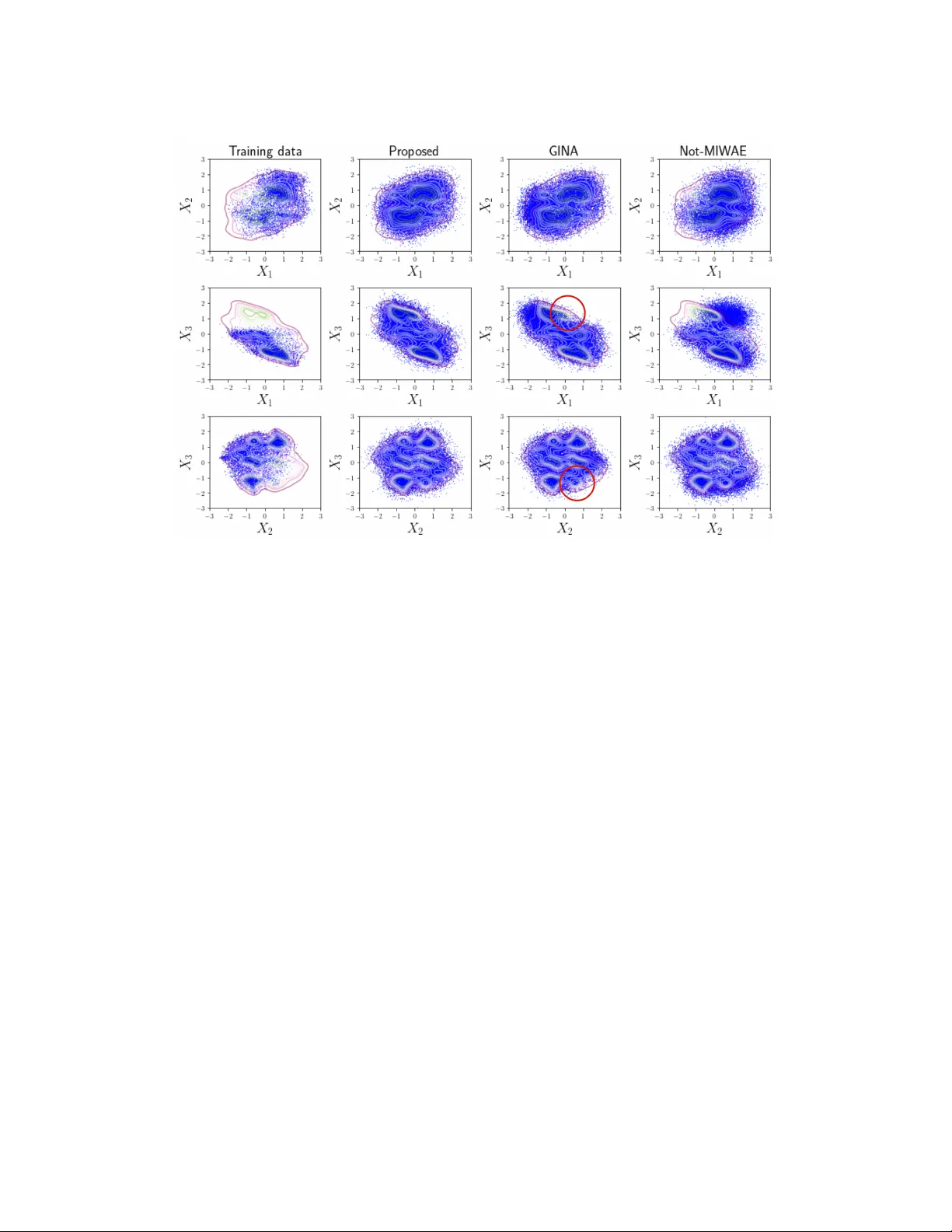
Identifiable Deep La tent V ariable Models for MNAR D a t a Iden tifiable Deep Laten t V ariable Models for MNAR Data Huiming Xie xie339@purdue.edu Dep artment of Statistics Pur due University West L afayette, IN 47907, USA F ei Xue feixue@purdue.edu Dep artment of Statistics Pur due University West L afayette, IN 47907, USA Xiao W ang w angxia o@purdue.edu Dep artment of Statistics Pur due University West L afayette, IN 47907, USA Editor: Abstract Missing data is a ubiquitous challenge in data analysis, often leading to biased and inaccu- rate results. T raditional imputation metho ds usually assume that the missingness mech- anism is missing-at-random (MAR), where the missingness is independent of the missing v alues themselv es. This assumption is frequen tly violated in real-w orld scenarios, prompted b y recent adv ances in imputation methods using deep learning to address this c hallenge. Ho w ev er, these methods neglect the crucial issue of nonparametric iden tifiability in missing- not-at-random (MNAR) data, whic h can lead to biased and unreliable results. This pap er seeks to bridge this gap by prop osing a nov el framework based on deep latent v ariable mo dels for MNAR data. Building on the assumption of conditional no self-censoring given laten t v ariables, w e establish the identifiabilit y of the data distribution. This crucial the- oretical result guarantees the feasibility of our approach. T o effec tiv ely estimate unknown parameters, we develop an efficient algorithm utilizing imp ortance-weigh ted auto enco ders. W e demonstrate, both theoretically and empirically , that our estimation process accurately reco v ers the ground-truth join t distribution under sp e cific regularit y conditions. Extensiv e sim ulation studies and real-world data exp eriments show case the adv an tages of our pro- p osed method compared to v arious classical and state-of-the-art approac hes to missing data imputation. Keyw ords: Auto enco ders, generativ e mo dels, imputation, missing-not-at-random, v ari- ational inference 1 Introduction The issue of missing data p oses a p erv asive c hallenge across diverse applications, often necessitating data imputation due to the prev alence of mo dels designed exclusively for com- plete data. Methods for addressing missing data hav e b een studied extensively in ignorable missing situations where missingness dep ends only on the fully observ ed v ariables of the data, known as missing-at-random (MAR), or is indep endent of any data v ariable, kno wn 1 Xie, Xue, W ang as missing-completely-at-random (MCAR) (Robins et al., 1994). On the basis of suc h ig- norabilit y assumptions, man y in teresting imputation methods hav e b een developed to make use of most mo dels designed for complete data. F or example, missF orest (Stekhov en and B ¨ uhlmann, 2012) based on random forests is one of the p opular metho ds for single impu- tation, while MICE (V an Buuren and Gro oth uis-Oudsho orn, 2011), short for multiv ariate imputation b y c hained equations, is a typical metho d for multiple imputation (Little and Rubin, 2019). Supp orted by increased computing p o w er, recen t adv ances hav e witnessed the developmen t of sophisticated imputation metho ds, particularly deep generative mo dels, based on these ignorabilit y assumptions (Y o on et al., 2018; Ma et al., 2018; Li et al., 2019; Mattei and F rellsen, 2019). While con venien t for mo deling, these ignorability assumptions often do not align with the realit y of real-w orld applications, spanning domains such as surv eys, recommendation systems, and the medical field. F or instance, in surveys, a question asso ciated with so cial stigma could result in nonresponse (Marra et al., 2017; Malinsky et al., 2021). Certain med- ical records could be incomplete either b ecause the information is unnecessary or b ecause acquiring it is c hallenging due to the patien ts’ health conditions (Shpitser, 2016; Jak obsen et al., 2017). In situations where absence of data is potentially influenced b y c haracter- istics of missing v ariables, kno wn as missing-not-at-random (MNAR), mo deling b ecomes significan tly more complex (Robins, 1997). There has b een a relativ ely limited b o dy of w ork addressing MNAR settings within the con text of scalable missing v alue imputation. The scenario is explored more often in the application of recommender systems using probabilistic models (Hern´ andez-Lobato et al., 2014; Ling et al., 2012; Liang et al., 2016b). Other p ersp ectives include causal approac hes with an explicit mo del of exp osure for MNAR (Liang et al., 2016a; W ang et al., 2018; W ang and Blei, 2019), and inv erse probability weigh ting metho ds (Ma and Chen, 2019; Schnabel et al., 2016; W ang et al., 2019). More recently , deep generative mo dels, esp ecially deep latent v ariable mo dels (DL VMs) ha v e b een studied under MNAR assumptions. F or example, not-MIW AE (Ipsen et al., 2020), short for the not-missing-at-random imp ortance-weigh ted auto enco der, is a p ow erful mo del that incorporates prior kno wledge of the missingness mec hanism in to density estimation. Nonetheless, these mo dels often ov erlook the critical issue of nonparametric iden tifiability in MNAR data, as discussed in the seminal work by Robins (1997). Some initial efforts in DL VMs to address iden tification issues, suc h as the deep generativ e imputation mo del (GINA) (Ma and Zhang, 2021), require the presence of auxiliary v ariables, which ma y not alw ays b e av ailable. Consequen tly , these mo dels tend to learn multiple non-unique complete data distributions that match the observed data (Robins, 1997). Ov erlo oking this fundamen tal asp ect of MNAR data in mo deling can introduce bias and inconsistency , p oten tially impairing inference and do wnstream tasks. On the other hand, n umerous theoretical studies hav e delved into the identifi cation of MNAR data using nonparametric or semiparametric inference tec hniques. They of- ten impose constraints on the missingness mechanism to uniquely iden tify a functional or parameter of interest. Examples include the group p ermutation missing process (Robins, 1997), sequen tial iden tification (Sadinle and Reiter, 2018), discrete c hoice models (Tc hetgen et al., 2018), nearest iden tified pattern restriction (Linero, 2017), conditions in graphical mo dels (F a y, 1986; Ma et al., 2003; Mohan and Pearl, 2021; Nabi et al., 2020), the no 2 Identifiable Deep La tent V ariable Models for MNAR Da t a self-censoring mo del (Malinsky et al., 2021; Shpitser, 2016; Sadinle and Reiter, 2017), and the self-censoring mo del with completeness assumptions (Li et al., 2022). Ho wev er, these metho ds generally imp ose a sp ecific parametric mo del on the ground-truth distributions, whic h migh t b e missp ecified. In this pap er, w e prop ose an identifiable missing-not-at-r andom imp ortanc e-weighte d auto enc o der (IM-IW AE) metho d to estimate the true distribution of all the v ariables and impute missing v alues for MNAR data. The prop osed metho d is built up on a new con- ditional no self-censoring assumption given latent v ariables for missingness mechanisms, whic h assumes that the missing indicator of a random v ariable is conditionally indep enden t of this v ariable and other missing indicators giv en all other v ariables and laten t factors. Our con tributions are outlined as follows: • W e establish the nonparametric identifiabilit y of the true data distribution under our prop osed conditional no self-censoring assumption for MNAR data. Bey ond pro vid- ing identifiabilit y , this assumption clarifies how no self-censoring can b e formulated within latent v ariable mo dels, offering a foundation for subsequen t metho dological dev elopmen ts. • W e prop ose IM-IW AE, a w orking parametric model based on deep neural net works, whic h can asymptotically approximate the full-data distribution without requiring parametric assumptions on the true data distribution. The mo del can b e used to impute missing v alues and generate syn thetic data from the underlying distribu- tion, where the parameters are estimated through an algorithm based on imp ortance w eigh ted v ariational inference. T o our kno wledge, this is the first approac h that jointly addresses nonparametric identifiabilit y of MNAR data and practical mo deling through deep laten t v ariable metho ds. • Through extensive n umerical studies, w e demonstrate the ability of our metho d to pro- vide iden tifiable estimates and v alid imputations and generations under correct mo del assumptions, as well as its robustness to practical violations of the no self-censoring assumption in MNAR data. This empirical ev aluation, conducted across simulations and real-world datasets, sho ws adv antages ov er classical imputation metho ds and existing deep learning imputation metho ds in handling MNAR data. Repro ducible Python code is a v ailable at https://github.com/hxstat/IM- IWAE . The remainder of the pap er is organized as follo ws. Section 2 introduces the ground- truth mo del for the full-data distribution. Section 3 pro vides iden tification assumptions on the missingness mec hanism in the ground-truth model. In Section 4, w e propose a deep laten t v ariable approac h for learning the ground-truth data distribution in the presence of MNAR data. In Section 5, w e establish the theoretical prop erties of the proposed metho d. Sections 6 and 7 provide n umerical studies through sim ulations and real data analysis, resp ectiv ely . The paper ends with the conclusion of Section 8. 2 Ground-truth mo del of full-data distribution In this section, w e presen t the ground-truth mo del for the distribution of all v ariables and missing indicators. W e b egin b y in troducing the notation. W e use capital letters to denote 3 Xie, Xue, W ang random v ariables or v ectors, and lo w ercases for their v alues. Consider a random vector X = ( X 1 , · · · , X p ) T ∈ X , where X is a d -dimensional manifold embedded in R p for d ≤ p . Let R = ( R 1 , · · · , R p ) T ∈ { 0 , 1 } p b e a v ector of missingness indicators of X , where 1 corresp onds to “observed”, and 0 corresp onds to “missing”. Let ( r (1) , x (1) ) , · · · , ( r ( n ) , x ( n ) ) denote n indep endently and iden tically distributed (i.i.d.) samples of the pair ( R, X ). With a sligh t abuse of notation, we write R = r as a shorthand for ( R 1 , .., R p ) = ( r 1 , · · · , r p ). Let X ( r ) b e a sub v ector of observ ed elements in X when R = r . The observ ed data consist of i.i.d. realizations of the vector ( R , X ( R ) ). F or conv enience, w e define another indicator M = 1 − R as the opp osite of R , that is, M j = 1 represents X j missing and 0 represents X j observ ed. F or simplicit y and clarit y , we call the joint distribution of ( X , R ) the ful l-data distri- bution . Let p g t ( x, r ) = p g t ( x ) p g t ( r | x ) denote the gr ound-truth ful l-data distribution , where p g t ( x ) is the gr ound-truth c omplete data distribution of X , and p g t ( r | x ) is the gr ound-truth c onditional distribution of R given X , known as the missingness me chanism . When data are high-dimensional, latent v ariable mo dels (L VMs) are p ow erful to ols for c haracterizing and discov ering low-dimensional structures in data (Kingma and W elling, 2013; Chen et al., 2016). F rom this inspiration, w e adopt an L VM for the data distribution p g t ( x ) by assuming that X are generated from a laten t v ariable Z ∈ R q 1 through the conditional distribution p X | Z ( x | z ) so that p g t ( x ) = R p X | Z ( x | z ) p Z ( z ) dz . Analogously , for the missingness mechanism p g t ( r | x ), w e adopt another laten t v ariable ˜ Z ∈ R q 2 to capture the information in R that could not be explained b y X alone and assume that R is generated through p R | X, ˜ Z ( r | x, ˜ z ). F or this reason, it is natural to ha v e the follo wing assumptions: Assumption 1. The gr ound-truth data distribution c an b e de c omp ose d as p g t ( x ) = Z p X | Z ( x | z ) p Z ( z ) dz . (1) Assumption 2. Assume ˜ Z is indep endent of X and Z , and the gr ound-truth missingness me chanism c an b e de c omp ose d as p g t ( r | x ) = Z p R | X, ˜ Z ( r | x, ˜ z ) p ˜ Z ( ˜ z ) d ˜ z . (2) The abov e tw o assumptions lead to the decomp osition of the full-data distribution: p g t ( x, r ) = Z Z p X | Z ( x | z ) p R | X, ˜ Z ( r | x, ˜ z ) p Z ( z ) p ˜ Z ( ˜ z ) dz d ˜ z . (3) A t this point, we present a theoretical justification for adopting this decomp osition approac h for modeling the full-data distribution in general missing data problems. Theorem 1. Supp ose that X is a Riemannian manifold diffe omorphic to R d , and that µ g t is a pr ob ability me asur e on X which has a nowher e vanishing density function p g t ( x ) with r esp e ct to the volume me asur e. (a) If d < p , then for any ϵ > 0 , r ∈ { 0 , 1 } p , and a me asur able set A ⊂ R p satisfy- ing µ g t ( ∂ A ∩ X ) = 0 , wher e ∂ A is the b oundary of A , ther e exist latent variables 4 Identifiable Deep La tent V ariable Models for MNAR Da t a Z ∼ N (0 , I q 1 ) with q 1 ≥ d, ˜ Z ∼ N (0 , I q 2 ) with q 2 ≥ 1 , a multivariate normal density p X | Z ( x | z ) , and a multivariate Bernoul li distribution p R | X, ˜ Z ( r | x, ˜ z ) such that Z x ∈ A Z Z p X | Z ( x | z ) p R | X, ˜ Z ( r | x, ˜ z ) p Z ( z ) p ˜ Z ( ˜ z ) dz d ˜ z dx − Z X ∩ A p g t ( r | x ) µ g t ( dx ) < ϵ. (4) (b) If d = p , then for any ϵ > 0 , r ∈ { 0 , 1 } p , and x ∈ X , ther e ar e latent variables and distributions as ab ove satisfying Z Z p X | Z ( x | z ) p R | X, ˜ Z ( r | x, ˜ z ) p Z ( z ) p ˜ Z ( ˜ z ) dz d ˜ z − p g t ( r | x ) p g t ( x ) < ϵ. (5) T ec hnical terms not withstanding, Theorem 1 shows that in the missing data problem, the true full-data distribution can alw a ys b e approximated arbitrarily w ell by an analyti- cally tractable distribution in the form of R R p X | Z ( x | z ) p R | X, ˜ Z ( r | x, ˜ z ) p Z ( z ) p ˜ Z ( ˜ z ) dz d ˜ z . This implies that mo deling the full-data distribution of ( X , R ) using the decomp osition in (3) ei- ther accurately represen ts the true data generation process or appro ximates the distribution with high fidelity , thereb y justifying its application. R emark. W e emphasize that Theorem 1 should be regarded as a motiv ating result for our laten t v ariable formulation rather than as a central theoretical contribution. It primarily serv es to illustrate the representational capacity of laten t v ariable mo dels, not to pro vide a fully general or exhaustiv e theoretical statement. While the theorem is presen ted under a diffeomorphism assumption for analytical simplicit y , recen t results such as Dahal et al. (2022) and W ang et al. (2025) demonstrate that mappings from simple base distributions to arbitrary target distributions can exist without this assumption, suggesting p ossible extensions b ey ond the presen t theoretical scop e. Nevertheless, these generalizations fall b ey ond the present scop e but ma y offer promising directions for future theoretical w ork. Henceforth, w e will refer to (3) as the ground-truth mo del on which w e build our method throughout the pap er. 3 Conditional no self-censoring giv en laten t v ariables Without an y assumption on the missingness mec hanism, the identification of the join t dis- tribution of ( X , R ) is unachiev able when data are MNAR. T o solve this identifiabilit y issue, w e mak e the follo wing assumption ab out the missingness mechanism. Assumption 3 (Conditional no self-censoring given latent v ariables) . We assume that R j ⊥ ⊥ ( X j , R − j ) X − j , ˜ Z for j = 1 , ..., p, (6) wher e A − j = ( A 1 , ..., A j − 1 , A j +1 , ..., A p ) denotes a subve ctor of A with the j th entry r emove d. Assumption 3 incorp orates t w o parts: conditional indep endence among missingness in- dicators in R and conditional indep endence b etw een each missingness indicator R j and its corresp onding data v ariable X j . In fact, conditional indep endence assumption among miss- ingness indicators given X and ˜ Z is natural under the laten t v ariable mo del for R and the 5 Xie, Xue, W ang Figure 1: Left: An example arc hitecture of conditional no self-censoring giv en laten t v ari- ables for 3 v ariables. Right: An example arc hitecture of the traditional no self- censoring independence mo del for 3 v ariables. indep endence betw een X and ˜ Z , as X and ˜ Z are supp osed to capture all the dep endence among missingness indicators. Besides that, our Assumption 3 requires that the conditional indep endence related to R j still holds ev en if we exclude X j from the giv en v ariables. This and the second part (conditional indep endence b et w een eac h missingness indicator and its corresp onding data v ariable) are where “no self-censoring” inv olved. F rom a practical standp oint, there are man y real-w orld situations in whic h a no self- censoring mec hanism is plausible. F or instance, in the clinical ev aluation of Alzheimer’s disease, the decision to p erform an in v asiv e lumbar puncture dep ends on prior examination results, physician judgment, and patient preference, rather than on the unobserv ed v alues of the cerebrospinal fluid (CSF) biomarkers themselv es (Lo et al., 2012). More generally , c hoices ab out whether to conduct additional diagnostic tests are t ypically informed b y a v ailable clinical evidence, not b y the unseen outcomes of the tests (Djulb egovic et al., 2015). Suc h scenarios illustrate a no self-censoring mechanism, where missingness is independent of the v ariable itself once other relev ant v ariables are taken into account. An example arc hitecture of our conditional no self-censoring mo del giv en latent v ariables is illustrated on the left panel of Figure 1 with p = 3, where eac h missingness indicator R j is generated from X − j along with ˜ Z for j = 1 , 2 , 3. Note that giv en X − j and ˜ Z , Assumption 3 excludes the conditional dep endency b etw een X j and its own missingness R j , but does not exclude the marginal dependencies b etw een them. Compared to existing no self-censoring assumptions R j ⊥ ⊥ X j | X − j , R − j and R j ⊥ ⊥ ( X j , R − j ) | X − j (Sadinle and Reiter, 2017; Shpitser, 2016; Malinsky et al., 2021; Mohan et al., 2013; Mohan and P earl, 2021), Assumption 3 accoun ts for laten t v ariables and requiremen ts from latent v ariable models. F or a b e tter comparison b et w een these assumptions, w e pro vide an example arc hitecture of the R j ⊥ ⊥ X j | X − j , R − j assumption on the right panel of Figure 1. An example of the R j ⊥ ⊥ ( X j , R − j ) | X − j assumption can b e ac hieved if w e eliminate the dep endence of missingness indicators R on the latent v ariables ˜ Z in the left panel of Figure 1. Under our prop osed conditional no self-censoring assumption, w e establish the iden tifi- abilit y of the ground-truth missingness mechanism in the follo wing theorem. Theorem 2 (Iden tifiabilit y of missingness mechanism) . The gr ound-truth missingness me ch- anism p g t ( r | x ) is nonp ar ametric al ly identifiable under Assumptions 2 and 3. 6 Identifiable Deep La tent V ariable Models for MNAR Da t a Nonparametric identifiabilit y essen tially requires that there is a one-to-one mapping b e- t w een the full-data distribution and the observed data distribution, so that the distribution of in terest is a function of observ ed data only and not a function of unobserved data at all (Sadinle and Reiter, 2018; Malinsky et al., 2021). F or the identification of the full-data dis- tribution, an additional mild assumption on the probability of observing all data v ariables is required. Assumption 4 (P ositivit y) . Supp ose that p g t ( R = 1 | X ) > c (7) with pr ob ability 1 for some c onstant c > 0 . Cor ol lary 3 . Under Assumptions 2 – 4, the full-data distribution with ground truth p g t ( x, r ) is nonparametrically identifiable. This result further implies that the ground-truth data distribution p g t ( x ) of X is also nonparametrically identifiable. The identifiabilit y not only serves as a desirable prop ert y itself, but also la ys the foundation for the subsequen t theoretical results of our prop osed metho d on recov ery of the full-data distribution. 4 Metho d 4.1 The working model In this subsection, we prop ose to approximate the true full-data distribution p g t ( x, r ) using a parametric working mo del. The prop osed w orking mo del is p θ,ψ ( x, r ) = p θ ( x ) p ψ ( r | x ) , where p θ ( x ) = Z p Y j =1 p θ ( x j | z ) p ( z ) dz = Z p θ ( x ( r ) | z ) p θ ( x ( m ) | z ) p ( z ) dz (8) and p ψ ( r | x ) = Z p Y j =1 p ψ ( r j | x − j , ˜ z ) p ( ˜ z ) d ˜ z . (9) Here x ( r ) and x ( m ) represen t v ectors consisting of observ ed and missing elements in x , resp ectiv ely , p θ and p ψ are known distributions up to unknown parameters θ ∈ Ω θ and ψ ∈ Ω ψ , resp ectively , and p ( z ) and p ( ˜ z ) are densit y functions of latent v ariables Z and ˜ Z , resp ectiv ely , where Ω θ and Ω ψ are parameter spaces. W e will pro vide specific forms for the known distributions p θ and p ψ in Section 4.3. In this working mo del, we let latent v ariables Z ∼ N (0 , I κ 1 ) and ˜ Z ∼ N (0 , I κ 2 ), where the dimensions κ 1 and κ 2 of the Z and ˜ Z are not required to b e the same as those ( q 1 and q 2 ) in the ground-truth mo del since that information is lacking in practice. Note that conditional indep endence among X giv en laten t v ariable Z is used in Equation (8), which enables us to separate observ ed and missing elements in x given Z . In fact, it do es not exclude the correlations among X themselves. The conditional no self-censoring 7 Xie, Xue, W ang in Assumption 3 is preserved in Equation (9) of the w orking mo del. W e will demonstrate in Section 5.2 that the factorization in Equations (8) and (9) do es not preven t the prop osed mo del from recov ering the ground-truth full data distribution. W e prop ose to estimate the parameters ( θ, ψ ) through maximizing the log-likelihoo d of observ ed data under the w orking mo del: log p θ,ψ ( x ( r ) , r ) = log Z Z Z p θ ( x ( r ) | z ) p θ ( x ( m ) | z ) p Y j =1 p ψ ( r j | x − j , ˜ z ) p ( z ) p ( ˜ z ) dz d ˜ z dx ( m ) . (10) Ho w ev er, the in tegral ov er missing and laten t v ariables mak es the maximization in tractable. W e will provide an efficient approximation to the log-likelihoo d in the following subsection. 4.2 V ariational inference In this subsection, we introduce a v ariational inference metho d to solv e the intractabil- it y issue of the integral in Equation (10). Sp ecifically , we prop ose v ariational distribu- tions q ϕ ( z | x ( r ) , r ) and q λ ( ˜ z | x ( r ) , r ) as approximations to the posteriors p θ,ψ ( z | x ( r ) , r ) and p θ,ψ ( ˜ z | x ( r ) , r ) in the working mo del, resp ectiv ely , where ϕ ∈ Ω ϕ and λ ∈ Ω λ are unkno wn parameters with parameter spaces Ω ϕ and Ω λ . W e incorp orate the v ariational distributions through rewriting the log-likelihoo d log p θ,ψ ( x ( r ) , r ) of the observed data as log p θ,ψ ( x ( r ) , r ) = log E q ϕ ( z | x ( r ) ,r ) q λ ( ˜ z | x ( r ) ,r ) p θ ( x ( m ) | z ) p θ ( x ( r ) | z ) p ψ ( r | x ( r ) , x ( m ) , ˜ z ) p ( z ) p ( ˜ z ) q ϕ ( z | x ( r ) , r ) q λ ( ˜ z | x ( r ) , r ) . The evidence low er b ound (ELBO) (Kingma and W elling, 2013) for this log-likelihoo d is L 1 ( θ , ψ , ϕ, λ ; x ( r ) , r ) = E q ϕ ( z | x ( r ) ,r ) q λ ( ˜ z | x ( r ) ,r ) p θ ( x ( m ) | z ) log p θ ( x ( r ) | z ) p ψ ( r | x ( r ) , x ( m ) , ˜ z ) p ( z ) p ( ˜ z ) q ϕ ( z | x ( r ) , r ) q λ ( ˜ z | x ( r ) , r ) . F or simplicity , w e denote the fraction inside the logarithm as w = p θ ( x ( r ) | z ) p ψ ( r | x ( r ) , x ( m ) , ˜ z ) p ( z ) p ( ˜ z ) q ϕ ( z | x ( r ) , r ) q λ ( ˜ z | x ( r ) , r ) . (11) Similar to the approach prop osed in Ipsen et al. (2020) inspired by the imp ortance- w eigh ted v ariational inference in Burda et al. (2015), w e improv e the abov e ELBO through replacing the fraction inside the logarithm in the ELBO with a Mon te Carlo estimate of it. Th us our prop osed ob jective function is L K ( θ , ψ , ϕ, λ ; x ( r ) , r ) = E Q K k =1 q ϕ ( z k | x ( r ) ,r ) q λ ( ˜ z k | x ( r ) ,r ) p θ ( x ( m ) ,k | z k ) " log 1 K K X k =1 w k # , (12) where w k = p θ ( x ( r ) | z k ) p ψ ( r | x ( r ) , x ( m ) ,k , ˜ z k ) p ( z k ) p ( ˜ z k ) q ϕ ( z k | x ( r ) , r ) q λ ( ˜ z k | x ( r ) , r ) , X ( m ) ,k , Z k and ˜ Z k follo w the same distributions as X ( m ) , Z and ˜ Z , resp ectively , for 1 ≤ k ≤ K. Note that when K = 1, the low er b ound (12) coincides with ELBO. In Section 5.1, 8 Identifiable Deep La tent V ariable Models for MNAR Da t a w e will sho w that L K is a tigh ter lo w er b ound for the log-likelihoo d than L 1 for K > 1. The low er bounds of the log-likelihoo d based on v ariational distributions approximate the log-lik eliho o d in the working mo del while circum v enting the issue of intractabilit y . Despite our common foundation with the mo del of not-MIW AE by Ipsen et al. (2020) built on imp ortance w eigh ted v ariational inference and missingness mechanisms, we note a main difference of the proposed ob jectiv e function: w e ha ve an additional latent v ariable ˜ Z for R , and hence an additional q λ ( ˜ z | x ( r ) , r ) as appro ximations to the posterior p θ,ψ ( ˜ z | x ( r ) , r ), and prior p ( ˜ z ), along with the conditional indep endence of R j and X j giv en ˜ Z . These are critical for incorp orating correlations among the missingness indicators and iden tifiabilit y . Since the exp ectation in L K is unachiev able from samples, we define the p er-sample estimator of L K , ˆ L K = log 1 K K X k =1 w k , and use ˆ L K as our ob jective in practice. W e estimate the v ariational parameters ( ϕ, λ ) and the generativ e parameters ( θ , ψ ) through maximizing ˆ L K . W e note that this working parametric deep latent v ariable mo del architecture explicitly incorp orates the prop osed no self-censoring condition (Assumption 3) through Equation (9), whic h directly constrains the log-likelihoo d, its low er b ound, and the empirical low er b ound that defines the ob jective function. Consequently , the condition required for iden tifiabilit y is enforced during learning, guiding the mo del to generalize to the shap e of the complete-data distribution. 4.3 Implementation In this subsection, we pro vide implementation details of the prop osed metho d based on the sto chastic gradient descent algorithm. As in the arc hitectures of V AEs, w e refer to the inference mo dels q ϕ ( z | x ( r ) , r ) and q λ ( ˜ z | x ( r ) , r ) as pr ob abilistic enc o ders , and p θ ( x | z ) and p ψ ( r | x, ˜ z ) as pr ob abilistic de c o ders , for whic h we ha ve the following conv entions. The enco ders are set to take the form of multiv ariate Gaussian such that q ϕ ( z | x ( r ) , r ) = N ( µ z , Σ z ) and q λ ( ˜ z | x ( r ) , r ) = N ( µ ˜ z , Σ ˜ z ) , where µ z = f µ z ( x ( r ) , r ; ϕ ) and Σ z = S z S T z with S z = f S z ( x ( r ) , r ; ϕ ), and µ ˜ z = f µ ˜ z ( x ( r ) , r ; λ ) and Σ ˜ z = S ˜ z S T ˜ z with S ˜ z = f S ˜ z ( x ( r ) , r ; λ ). F or the deco ders, a Gaussian decoder is adopted for the data: p θ ( x | z ) = N ( µ x , Σ x ) , with deco der moments µ x = f µ x ( z ; θ ) and Σ x = γ I for a tunable scalar γ > 0 . F or the bi- nary missingness indicators, a Bernoulli deco der is used for eac h dimension 1 ≤ j ≤ p : p ψ ( r j | x, ˜ z ) = Bernoulli( π j ) , where π j = f r j ( x, ˜ z ; ψ ). Here f µ z , f S z , f µ ˜ z , f S ˜ z , f µ x and f r j sp ecify parameterized functional forms that can be arbitrarily complex, and we use deep neural net works to approximate these functions. F or the missing part of the input to neural net w orks, we resort to an initial zero im- putation following the common practice in Nazabal et al. (2020); Ipsen et al. (2020); Ma and Zhang (2021). In the generative missingness mo del p ψ ( r | x, ˜ z ), we use a mixture of the observ ed part of the data x ( r ) and the generated data for the original missing part ˆ x ( m ) from the generativ e mo del p θ ( x | z ). P arameters { θ , ψ , ϕ, λ } are estimated by sto chastic gra- dien t descen t, with reparameterization tric ks (Kingma and W elling, 2013) for laten t random 9 Xie, Xue, W ang Algorithm 1 The proposed IM-IW AE Input: Missingness indicators r (1) , · · · , r ( n ) , observed data x (1) ( r (1) ) , · · · , x ( n ) ( r ( n ) ) , batch size b , learning rate α , num b er of importance samples K , deco der v ariance γ , maximum n um ber of iterations l max , deterministic neural net w orks: enco ders f µ z , f S z , f µ ˜ z , f S ˜ z , deco ders f µ x , f r j for 1 ≤ j ≤ p Output: ϕ, λ, θ , ψ ϕ [0] , λ [0] , θ [0] , ψ [0] ← random initialization for l ← 1 to l max do Select a batc h { ( x (1) ( r (1) ) , r (1) ) , · · · , ( x ( b ) ( r ( b ) ) , r ( b ) ) } from the data at random Let ˜ x ( i ) ( m ( i ) ) = 0 for 1 ≤ i ≤ b , and ˜ X = { ˜ x (1) , · · · , ˜ x ( b ) } for eac h ˜ x ( i ) ∈ ˜ X do Generate noise ϵ 1 , · · · , ϵ K i.i.d ∼ N (0 , I κ 1 + κ 2 ) ( µ T z , µ T ˜ z ) T ← f T µ z ( ˜ x ( i ) ; ϕ [ l − 1] ) , f T µ ˜ z ( ˜ x ( i ) ; λ [ l − 1] ) T , with µ z ∈ R κ 1 , µ ˜ z ∈ R κ 2 , ( σ T z , σ T ˜ z ) T ← f T S z ( ˜ x ( i ) ; ϕ [ l − 1] ) , f T S ˜ z ( ˜ x ( i ) ; λ [ l − 1] ) T , with σ z ∈ R κ 1 , σ ˜ z ∈ R κ 2 for k ← 1 to K do ( z T k , ˜ z T k ) T ← ( µ T z , µ T ˜ z ) T + ( σ T z , σ T ˜ z ) T ⊙ ϵ k , where ⊙ denotes Hadamard pro duct µ x ← f µ x z k ; θ [ l − 1] , ˆ x ( i ) k ← N ( µ x , γ I ) for j ← 1 to p do ˆ r ( i ) j,k ← f r j ( ¯ x ( i ) k ) − j , ˜ z k ; ψ [ l − 1] , where ¯ x ( i ) k = ˜ x ( i ) + ˆ x ( i ) k ⊙ (1 − r ( i ) ) end for end for L ( i ) K = log 1 K P K k =1 w ( i ) k , where w ( i ) k = p θ [ l − 1] ( ˆ x ( i ) ( r ( i ) ) | z k ) p ψ [ l − 1] ( ˆ r ( i ) k | ¯ x ( i ) k , ˜ z k ) p ( z k ) p ( ˜ z k ) q ϕ [ l − 1] ( z k | x ( i ) ( r ( i ) ) ,r ( i ) ) q λ [ l − 1] ( ˜ z k | x ( i ) ( r ( i ) ) ,r ( i ) ) end for ( ϕ [ l ] , λ [ l ] , θ [ l ] , ψ [ l ] ) T ← ( ϕ [ l − 1] , λ [ l − 1] , θ [ l − 1] , ψ [ l − 1] ) T − α · ∇ P b i =1 L ( i ) K ( ϕ [ l − 1] , λ [ l − 1] , θ [ l − 1] , ψ [ l − 1] ) if conv ergence then break end if end for v ariables and missing data so that Monte Carlo estimates of expectations with resp ect to q ϕ ( z | x ( r ) ,r ) q λ ( ˜ z | x ( r ) , r ) p θ ( x ( m ) | z ) are differentiable. W e summarize the algorithm for the implemen tation of the prop osed method in Algorithm 1. 4.4 Data imputation W e prop ose to impute missing v alues through min x impute E x ( m ) [ L ( x ( m ) , x impute ) | x ( r ) , r ], where L is a criterion function. When L corresp onds to the squared error, the proposed imputation will be the conditional mean E [ x ( m ) | x ( r ) , r ] = Z Z Z x ( m ) p ψ ( r | x ( r ) , x ( m ) , ˜ z ) p θ ( x ( r ) | z ) p ( z ) p ( ˜ z ) q ϕ ( z | x ( r ) , r ) q λ ( ˜ z | x ( r ) , r ) dz d ˜ z dx ( m ) . (13) After obtaining the estimated parameters ( ˆ ϕ, ˆ λ, ˆ θ , ˆ ψ ) through Algorithm 1, we use the self- normalized imp ortance sampling (Mattei and F rellsen, 2019; Ipsen et al., 2020), with the 10 Identifiable Deep La tent V ariable Models for MNAR Da t a prop osal q ˆ ϕ ( z | x ( r ) , r ) q ˆ λ ( ˜ z | x ( r ) , r ) p ˆ θ ( x ( m ) | z ) to obtain an estimate ˆ x ( m ) = E [ x ( m ) | x ( r ) , r ] ≈ B X b =1 α b x ( m ) ,b , with α b = w b w 1 + ... + w B , where for 1 ≤ b ≤ B , w b = p ˆ θ ( x ( r ) | z b ) p ˆ ψ ( r | x ( r ) , x ( m ) ,b , ˜ z b ) p ( z b ) p ( ˜ z b ) q ˆ ϕ ( z b | x ( r ) , r ) q ˆ λ ( ˜ z b | x ( r ) , r ) , and { ( z b , ˜ z b , x ( m ) ,b ) } B b =1 are B i.i.d. samples from q ˆ ϕ ( z | x ( r ) , r ) q ˆ λ ( ˜ z | x ( r ) , r ) p ˆ θ ( x ( m ) | z ). In addition to missing data imputation, the prop osed mo del can generate syn thetic data from the laten t v ariables through the learned distribution of the data. This is an imp ortant adv antage of generativ e mo dels in the presence of missing data, since the generated data can be used to gain more insigh t into the distribution itself in addition to predicting missing v alues using the observed data, whic h w e will illustrate in Section 6. 4.5 On the choice of laten t dimensions In real-w orld data scenarios, where the true laten t dimensions q 1 , q 2 are unkno wn, the laten t dimensions in the learning metho d, κ 1 , κ 2 , must be empirically set to c hosen v alues. W e ha v e observ ed that v arying the latent dimension for the missingness mec hanism, κ 2 , do es not significantly impact p erformance, with κ 2 = 1 generally p erforming as w ell as higher v alues (See App endix C for more details). This aligns with our theoretical results and the pro of in A.1.1: a single contin uous laten t dimension for the missingness mechanism suffices to appro ximate the join t distribution of binary v ariables. Additional dimensions add no b enefit, as they can b e ignored in recov ering the join t distribution. In con trast, for κ 1 , the dimension of the latent v ariable corresp onding to the contin uous data, setting its v alue just ab o v e the intrinsic dimensionality generally improv es p erformance compared with smaller v alues, as it allows the laten t space to represent the data distribution more faithfully under practical net work capacity (W ang et al., 2025). F or κ 1 , w e propose the follo wing cross-v alidation selection pro cedure. One challenge in applying cross-v alidation to real-w orld data with missing v alues is that not all data p oin ts are av ailable. T o address this, w e prop ose the following approac h: for eac h training and v alidation dataset, b oth con taining missing v alues, w e train the mo del on the training data and mask some observed v alues in the v alidation data completely at random. W e then use the trained model to impute the missing v alues in the v alidation set (including both the originally missing and synthetically masked v alues) and calculate the imputation errors solely on the synthetically masked entries. Recognizing that these synthetically mask ed missing v alues are ignorable, we impute them using a different estimate, E [ x ( m ) | x ( r ) ], which does not depend on the v alues of the missingness indicators as in (13). The v alue of κ 1 that minimizes the imputation errors on a v erage across the v alidation sets is selected. See Figure 5 in Section 7 for an example of c ho osing the latent dimensions in the real data. 11 Xie, Xue, W ang 5 Theory In this section, we establish asymptotic prop erties of the prop osed ob jective function L K , as well as the capacity of the prop osed metho d to recov er ground-truth distributions. All pro ofs are p ostp oned to the supplementary material. 5.1 Conv ergence of low er b ounds In this subsection, w e inv estigate theoretical limits on the appro ximation of the ob jective function to the log-likelihoo d of the observed data under the working mo del, along with the bias and v ariance of the ob jective function when we consider it as an estimator of the log-lik eliho o d. Theorem 4. F or al l K ≥ 1 , the lower b ounds satisfy L K +1 ( θ , ψ , ϕ, λ ; x ( r ) , r ) ≥ L K ( θ , ψ , ϕ, λ ; x ( r ) , r ) , and log p θ,ψ ( x ( r ) , r ) ≥ L K ( θ , ψ , ϕ, λ ; x ( r ) , r ) ∀ ϕ ∈ Ω ϕ , λ ∈ Ω λ . Mor e over, if w in Equation (11) is b ounde d, we have log p θ,ψ ( x ( r ) , r ) = lim K →∞ L K ( θ , ψ , ϕ, λ ; x ( r ) , r ) ∀ ϕ ∈ Ω ϕ , λ ∈ Ω λ . Theorem 4 demonstrates the con v ergence of the lo w er b ound (the p opulation-version ob- jectiv e function L K ) of the proposed IM-IW AE method to the log-lik elihoo d. A distinction of our bound from the one for not-MIW AE is that we in tegrate ov er t w o laten t spaces for not only the data but also the missingness mec hanism (Ipsen et al., 2020). Suc h a difference do es not fundamentally alter the property of the bound in terms of the appro ximation to the log-lik eliho o d. In the following, we provide the bias and v ariance of the empirical-version ob jective function ˆ L K when w e treat it as an estimate of the log-likelihoo d log p θ,ψ ( x ( r ) , r ). Prop osition 5 (Bias and v ariance of ˆ L K ) . Supp ose that the distribution of w define d in Equation (11) is supp orte d on the p ositive r e al line with finite moments of every or der. As K → ∞ , we have the fol lowing asymptotic r esults for ˆ L K as an estimator of log p θ,ψ ( x ( r ) , r ) : Bias ( ˆ L K ) = − 1 K µ 2 2 µ 2 + 1 K 2 µ 3 3 µ 3 − 3 µ 2 2 4 µ 4 + o ( K − 2 ) , and V ar ( ˆ L K ) = 1 K µ 2 µ 2 − 1 K 2 µ 3 µ 3 − 5 µ 2 2 2 µ 4 + o ( K − 2 ) , wher e µ i : = E [( w − E [ w ]) i ] and µ : = E P [ w ] . F or eac h ( θ , ψ ), Prop osition 5 sho ws that b oth the bias and the v ariance of the estimator ˆ L K decrease at a rate of O (1 /K ). Note that the leading terms inv olv es µ 2 /µ 2 , which is the v ariance of the distribution of w divided by the squared mean, also known as the squared c o efficient of variation . Hence, for large K , the bias and the v ariance of ˆ L K are small when the coefficient of v ariation is lo w. This leads to the following conv ergence of ˆ L K . 12 Identifiable Deep La tent V ariable Models for MNAR Da t a Cor ol lary 6 (Conv ergence of ˆ L K ) . F or all ϵ > 0, lim K →∞ P ( | ˆ L K − log p θ,ψ ( x ( r ) , r ) | ≥ ϵ ) = 0 5.2 Recov ery of the ground-truth full-data distribution In this subsection, we establish the theoretical framework at the p opulation lev el for reco v- ering the ground-truth full-data distribution using the prop osed w orking model, to w ards whic h a crucial step is to demonstrate that the prop osed mo del can accurately approximate the ground-truth distribution of missingness indicators. Lemma 7. When we c onsider a Bernoul li distribution with me an f r j ( x − j , ˜ z ; ψ ) as the de c o der p ψ ( r j | x − j , ˜ z ) of the missingness me chanism for j = 1 , . . . , p , ther e exist f r j ’s with p ar ameter ψ ∗ that r e c over the gr ound truth such that p ψ ∗ ( r | x ) = p g t ( r | x ) . Lemma 7 theoretically justifies the capacity of the prop osed model to recov er the ground- truth missingness mec hanism by means of a factorization among the missingness indicators giv en the data X and the latent v ariable ˜ Z . Based on the result for the capacity with resp ect to the deco der in Lemma 7, we can show that the underlying true join t distribution of X ( R ) and R can b e w ell approximated by our laten t v ariable mo dels, as stated in the follo wing theorem. Theorem 8. Consider the pr op ose d IM-IW AE metho d with the obje ctive function in Equa- tion (12). Supp ose the gr ound-truth density p g t ( x ) is nonzer o everywher e on R p . Assume that w is b ounde d. Then for any chosen latent dimension κ 1 and κ 2 for the metho d with κ 1 ≥ p and κ 2 ≥ 1 , ther e is a se quenc e of de c o ders and enc o ders with p ar ameters { θ ∗ t , ψ ∗ t , ϕ ∗ t , λ ∗ t } such that lim t →∞ lim K →∞ L K ( θ ∗ t , ψ ∗ t , ϕ ∗ t , λ ∗ t ; x ( r ) , r ) = log p g t ( x ( r ) , r ) . W e note that Theorem 8, our central result on recov ering data distributions with the w orking models, holds independently of the manifold assumption in Theorem 1, as Theorem 1 only serves to motiv ate the use of laten t v ariable models. Theorem 8 suggests that, giv en a sufficien tly large K , we can appro ximate the ground-truth join t distribution of the observ ed data and the missingness indicators through the parameterized ob jectiv e function, regardless of conditions on the missingness mec hanism. Theorem 2 (identification) and Theorem 8 (reco v ery of the true distribution p g t ( x ( r ) , r )) together ensure the reco v ery of the true full- data distribution p g t ( x, r ) including the missing part, whic h is the target of our metho d, as the identification sp ecifies a one-to-one mapping b etw een the joint distribution p g t ( x ( r ) , r ) of the observed part and the full-data distribution p g t ( x, r ). 6 Simulations In this section, we pro vide a series of simulation studies to ev aluate our approach. Our ev aluation encompasses v arious asp ects, including data imputation, data generation, and 13 Xie, Xue, W ang estimation for a parameter of interest. T o b enchmark the effectiveness of our prop osed metho ds, w e compare them with tw o contemporary deep generative mo dels for MNAR data, GINA (Ma and Zhang, 2021) and not-MIW AE (Ipsen et al., 2020). F urthermore, w e include tw o classical imputation metho ds, MICE (V an Buuren and Groothuis-Oudshoorn, 2011) and missF orest (Stekho v en and B ¨ uhlmann, 2012), which are based on the commonly used MAR assumptions, as our baseline references. W e adopt the same neural net w ork structures and hyperparameter settings for m etho ds based on generative mo dels. 6.1 Imputation and generation W e first fo cus on 3-dimensional missing data scenarios with no self-censoring, and then consider more complex cases later in this subsection. Generation of complete data. The data generation pro cess b egins with latent v ariables Z 1 , Z 2 , Z 3 i.i.d ∼ N (0 , 1) . Subsequen tly , w e generate each data v ariable as X j = f θ j ( Z 1 , Z 2 , Z 3 ) + ϵ j , for j = 1 , 2 , 3, where f θ j represen ts a nonlinear mapping with one hidden lay er coupled with the tanh function and randomly generated co efficien ts, and θ j denotes distinct parameter sets for f θ j . And ϵ 1 , ϵ 2 , ϵ 3 i.i.d ∼ N (0 , 0 . 01) serve as noise v ariables. F or the missingness mec hanism, w e simulate missingness under t wo different strategies. Sim ulation of missingness with latent v ariables. F or the first strategy , we adopt the sc heme R j ∼ Bernoulli h ψ j ( X − j , ˜ Z ) , 1 ≤ j ≤ 3 , in v olving a latent v ariable ˜ Z ∼ N (0 , 1) and a mapping function h ψ j for whic h w e experiment with both linear and nonlinear structures, where the co efficien ts are randomly c hosen, and the tanh function is used for the nonlinear case. Note that in this scenario, all v ariables X 1 , X 2 , X 3 could be missing and that auxiliary v ariables are unav ailable. Sim ulation of missingness without laten t v ariables. W e also examine a more general case, where we sim ulate missingness according to the no self-censoring condition without resorting to a laten t v ariable. W e establish a dep endency of the missingness indicators on the other data v ariables while preserving the correlation b etw een these indicators, as in the righ t panel of Figure 1. This is achiev ed using an indep endent noise v ariable according to the noise-outsourcing lemma in probability theory (Kallenberg and Kallenberg, 1997; Austin, 2015). Sp ecifically , when generating missingness, for each dimension j ∈ { 1 , 2 , 3 } of the missingness indicators, w e sample from a uniform distribution U ∼ U (0 , 1) and apply a transformation g ψ j ( X − j ) with randomized parameter ψ j , where g ψ j is a linear function or a nonlinear function with tanh activ ations. W e let R j = 1 if U > g ψ j ( X − j ), and R j = 0 otherwise. In eac h missingness strategy , we simulate a total of 20 , 000 random samples in each replication, with a total of 50 replications conducted. The simulated missing rates are con trolled to fall within the range of 30% to 40% by adding a constant to the logits of Bernoulli distribution for the missingness mechanism. Samples in which all v ariables are missing are excluded from the training set. Results. W e ev aluate the p erformance of eac h method under eac h setting via the imputation ro ot mean squared error (RMSE) which is pro vided in T able 1. In the first setting where 14 Identifiable Deep La tent V ariable Models for MNAR Da t a T able 1: Imputation RMSE of simulated missing data with no self-censoring Metho d With laten t v ariables Without laten t v ariables linear nonlinear linear nonlinear Prop osed 0.7081 (0.1146) 0.7145 (0.1325) 0.7386 (0.1687) 0.7188 (0.1186) GINA 0.8682 (0.2309) 0.8676 (0.1324) 0.9957(0.3484) 0.8650(0.1062) Not-MIW AE 0.9311(0.6139) 0.7570(0.1619) 0.8877(0.3558) 0.7423(0.1230) MICE 1.2544(0.3144) 1.0498(0.2255) 1.1998(0.2794) 1.0772 (0.2370) MissF orest 0.9718(0.2198) 0.9507(0.1400) 0.9998(0.1694) 0.9506(0.1208) laten t v ariables are used for the missingness mechanism, there is no mo del missp ecification for our metho d. As shown on the left side of T able 1, the proposed method significantly outp erforms GINA which also incorporates latent v ariables for the missingness indicators y et with a modeling of self-censoring. Not-MIW AE sho ws a less stable performance in terms of both mean and standard deviation. This instabilit y is lik ely due to its inability to accoun t for the correlation among missingness indicators and the exclusion of self-censoring. It is notew orth y that neither of GINA and not-MIW AE guaran tees mo del identifiabilit y under this MNAR scenario, which may hav e con tributed to their inferior p erformance in our exp erimen ts. The three deep generative mo dels designed for MNAR data clearly outp erform the classical metho ds (MICE and MissF orest) based on MAR assumptions in terms of lo w er imputation RMSE. In the setting where missingness is generated without laten t v ariables, as shown on the righ t side of T able 1, our imputation errors increase sligh tly compared to the previous case probably due to the model misspecification of the missingness mechanism. Ho w ev er, our metho d still outperforms other methods o verall. In contrast, GINA exhibits deteriorated imputation p erformance similar to the baseline metho ds for MAR data, and increased v ari- ance, in the linear case, which could b e possibly due to its nonidentifiabilit y issue that our mo del has successfully addressed. These results demonstrate adv an tages of our proposed metho d ov er existing metho ds and certain robustness in terms of missing v alue imputation in differen t scenarios of no self-censoring. Visualization. W e plot the generated data distributions of the three deep generative mo dels in Figure 2, and compare them with the original complete data and the training data with missing v alues. W e examine the data in all 2-dimensional combinations of the 3-dimensional data. The contour lines in Figure 2 represent the densit y of the true data distribution, where pink represen ts lo w er v alues, white ones represen t middle v alues, and green ones represen t higher v alues. The blue dots in Figure 2 represen t samples in the training data or from the imputation based on deep generativ e mo dels. Due to MNAR, samples in the training data are a biased representation of the true data distribution. Although all three generative models ha v e made a clear effort to reco v er the original distribution by including a missingness mo del, not-MIW AE pro duced a substantial bias. The p erformances of the prop osed mo del and GINA do not app ear to differ m uc h, but a closer examination of the areas in the red circles in Figure 2 rev eals that GINA tends to miss some of the modes in the data distribution, while the prop osed mo del captured those more closely . In addition, calculations of the maxim um mean discrepancy (MMD) against the true data distribution o v er 50 replications show that the prop osed mo del has a mean 15 Xie, Xue, W ang Figure 2: Visualization of generated data from the deep generativ e models under the setting with laten t v ariables and a linear transformation g ψ j . 0 . 0086 with a standard deviation 0 . 0074, while GINA has a higher mean of 0 . 0098 with a larger standard deviation 0 . 0102, again demonstrating the sup erior learning and generative p erformance of our mo del in this scenario. Higher dimensions The lo w-dimensional sim ulation enabled us to closely examine the p er- formance of the metho d, both n umerically and visually , in comparison with other methods across different scenarios. Applying similar settings to higher dimensions provides v aluable insigh ts in to the model’s p erformance in more challenging situations. F or higher dimensions, we generated X from laten t v ariables, experimenting with data dimensions of p = 30 , 50 , 100 while k eeping the latent dimension fixed at 10. All other parameters and settings w ere consistent with the previous 3-dimensional exp eriments, with no latent v ariable used for generating missingness and with the mapping function h b eing linear. The missing rates w ere controlled to b e around 50%. In these higher-dimensional sim ulations, w e considered different settings with blo ck-wise missingness, where v ariables within the same group are either missing together or observed together. See Figure 3 for an illustration of a dataset with 3 groups. Specifically , we v aried the sizes of the groups. The term “no self-censoring” in the con text of block-wise missingness refers to the scenario where the missingness of the v ariables in a group do es not depend on an y of the v ariables within that group. The imputation results are presented in T able 2. Due to the prohibitive computational time of the MissF orest metho d, w e excluded it from these higher-dimensional sim ulations. Ho w ev er, w e retained MICE as a baseline for comparison, giv en its ignorabilit y assumption in contrast to other metho ds. 16 Identifiable Deep La tent V ariable Models for MNAR Da t a Figure 3: An illustration of blo ck-wise missingness with 4 groups for n sub jects. Each group is a set of v ariables either missing together or observ ed together. Each ro w represen ts a sub ject, that is, a sample of X . Here white areas represent blo c ks of missing v alues. Different colors represent different missing patterns. Note that sub jects are arranged in an order suc h that they ha v e the same missing pattern. F or the sak e of brevity , we presen t only a subset of the missing patterns, omitting the others. (Note that the group sizes are not required to b e the same, where the group size means the num b er of v ariables within a group.The block- wise missingness with 4 groups corresp ond to the case with p = 100 and g s = 25, the last column in T able 2 for the exp eriments.) The prop osed metho d demonstrated a clear adv antage in these scenarios. The impro v e- men t of the prop osed metho d b ecame more pronounced as the group size increased. It is notable that with the increasing group sizes (and consequently the decreasing n um b er of groups) for a giv en n umber of v ariables, the issue of noniden tifiabilit y is magnified in the other imputation metho ds assuming MNAR. Under these conditions, GINA and Not- MIW AE sho w ed significan tly deteriorating p erformances, whereas the prop osed method exhibited relativ e stabilit y . The imputation p erformance of MICE remained fairly stable, but its ov erall imputation RMSE was noticeably w orse compared to the prop osed metho d. 6.2 Mean estimation for mixture of Gaussian distributions In this subsection, we ev aluate our metho d from an alternative p ersp ective, fo cusing on the estimation of a mean parameter. This allo ws us to put our model in the con text of con v en tional statistical techniques (such as parameter estimation), as one of our goals is to harness the strengths of these traditional metho ds, bac k ed b y w ell-established theory. 17 Xie, Xue, W ang T able 2: Imputation RMSE of sim ulated data with higher dimensions and 10 latent v ari- ables, where p is the n um b er of v ariables in X and g s is the group size of the v ariables, i.e., the num b er of v ariables within a group. Metho d p = 30 p = 50 p = 100 g s = 2 g s = 3 g s = 5 g s = 2 g s = 5 g s = 10 g s = 5 g s = 10 g s = 25 Prop osed 0.61(0.02) 0.64(0.02) 0.74(0.16) 0.47(0.01) 0.55(0.02) 0.70(0.17) 0.34(0.01) 0.38(0.02) 0.50(0.18) GINA 0.70(0.04) 0.86(0.15) 1.37(0.31) 0.50(0.02) 0.88(0.15) 1.15(0.27) 0.42(0.06) 0.60(0.09) 0.90(0.30) Not-MIW AE 0.65(0.06) 0.99(0.25) 1.79(0.31) 0.47(0.02) 1.19(0.16) 1.50(0.20) 0.46(0.08) 0.74(0.13) 1.00(0.24) MICE 0.83(0.03) 0.83(0.03) 0.82(0.03) 0.74(0.03) 0.75(0.02) 0.77(0.02) 0.60(0.01) 0.69(0.02) 0.90(0.01) Figure 4: Estimation of E ( X 3 ) in the Gaussian mixtures. The dotted line represen ts the true v alue of E ( X 3 ). W e follo w the data generation framework in Malinsky et al. (2021), whic h inv olves a 3- dimensional mixture of Gaussian distributions with missingness in tro duced in to the data via a conditional Gaussian graph mo del that complies with the no self-censoring assumption. The missingness patterns R = r are sampled from a multinomial distribution, while the data follo w distinct Gaussian distributions based on v arying missingness patterns, i.e. X | R = r ∼ N ( µ 0 ( r ) , Σ 0 ). By adjusting certain in teraction terms or mean parameters to zero, the no self-censoring condition can b e satisfied in this parametric data generation pro cess (Højsgaard et al., 2012, p.119–120). The parameter v alues for the simulation study are detailed in the supplementary material. In this setting, all v ariables X = ( X 1 , X 2 , X 3 ) could potentially b e missing. Our aim is to estimate the mean of a sp ecific v ariable, that is, X 3 . W e p erformed 100 replications with sample size 20000 and provided boxplots of estimated mean v alues of all replications and metho ds in Figure 4 to illustrate the results, where green b oxes represent estimates based on observed v alues and imputed v alues, and red b oxes represen t estimates based on generated v alues only . 18 Identifiable Deep La tent V ariable Models for MNAR Da t a In particular, the estimates derived from our proposed metho d, whether based on im- puted v alues or generated data, exhibit a substantial con vergence with respect to the actual v alue represen ted b y the dotted line in Figure 4. This signifies a successful recov ery of the distribution, in con trast to the estimates obtained from other metho ds, which demon- strate biases. Our p erformance in mean estimation is also comp etitive in terms of accuracy with the semiparametric inference method prop osed b y Malinsky et al. (2021) for the same problem. F urthermore, the estimates generated by our approac h displa y a limited range of v ariation, similar to the results of t wo w ell-established classical imputation metho ds operat- ing under the inherently identifiable MAR assumption. W e susp ect that the large v ariation of the other deep generativ e mo dels is due to their lac k of identifiabilit y . 7 Real data analysis 7.1 UCI data with syn thetic missingness T o assess the efficacy of our method in more realistic data distributions, w e p erform a se- ries of exp eriments fo cusing on missing v alue imputation utilizing datasets from the widely recognized UCI mac hine learning rep ository (Asuncion and Newman, 2007). These experi- men ts encompass six differen t datasets, including banknote authen tication, red wine qualit y , white wine qualit y , concrete compressive strength, y east, and wa v eform database genera- tor. These datasets do not contain inherent missing v alues. W e in troduce synthetic MNAR missingness to ev aluate the p erformance of imputation. Since w e know the truth, this al- lo ws us to compare our prop osed method with other baseline tec hniques and state-of-the-art metho ds. W e use the imputation RMSE to ev aluate eac h metho d. Considering the fact that real-w orld missing data with MNAR mechanisms could b e differen t from no self-censoring, we conduct exp eriments using sim ulated MNAR mec ha- nism which is differen t from no self-censoring for the in v estigation of robustness. In this setting, each missing indicator could p otentially dep end on all v ariables in the data. This generation of missingness closely resembles the one in our exp eriments of linear no self- censoring without latent v ariables on synthetic data in Section 6.1, with the exception that the self-censoring asp ect is also included in the missingness mechanisms. Sp ecifically , w e sample U ∼ U (0 , 1) and apply a linear transformation g ψ j ( X ) on X , for each dimension j of missingness indicators R , with randomized parameters ψ j . W e let R j = 1 if U > g ψ j ( X ), and R j = 0 otherwise. Figure 5: Selection of laten t dimensions for UCI datasets with MNAR missingness. The curv es represent the a v erage imputation RMSE across eac h v alidation set during 5-fold cross-v alidation, where the entries to b e imputed are MCAR in the v alida- tion sets. 19 Xie, Xue, W ang The missing rates in our exp eriments range from 30% to 50%, and no v ariables are designed to alw ays be observed. It is notew orth y that, unlike in simulations where latent dimensions are kno wn, the laten t dimensions in real-w orld data are not as clear. Conse- quen tly , we select the laten t dimensions for eac h dataset in the presence of missingness using cross-v alidation, as described in Section 4.5. The process of selecting the data latent di- mensions inv olves imputing the man ually MCAR missing entries in the v alidation sets after training the mo del on the training sets. Figure 5 illustrates the av erage imputation RMSE on 5-fold cross-v alidated missing data with differen t laten t dimensions for eac h dataset. The optimal latent dimensions w ere determined using the elbow metho d, identif ying the p oint where the rate of impro v emen t for imputation sharply decreases. T able 3: Imputation RMSE on UCI Data with MNAR. The default missingness mo del in the generative models is linear; (nl) denotes a nonlinear missingness mo del and (s) represen ts self-censoring. Metho d banknote concrete y east red wine white wine w a v eform Prop osed 0.713(0.118) 0.745(0.070) 0.966(0.134) 0.762(0.059) 0.827(0.054) 0.722(0.011) Prop osed(nl) 0.715(0.129) 0.748(0.064) 0.965(0.132) 0.787(0.055) 0.840(0.056) 0.730(0.013) GINA 0.843(0.106) 0.884(0.055) 1.062(0.120) 0.877(0.051) 0.921(0.049) 0.786(0.007) GINA(nl) 0.880(0.119) 0.926(0.056) 1.110(0.083) 0.915(0.051) 0.970(0.041) 0.799(0.010) Not-MIW AE 0.772(0.209) 0.825(0.077) 1.115(0.271) 0.853(0.079) 0.870(0.059) 0.736(0.011) Not-MIW AE(nl) 0.915(0.150) 0.841(0.068) 1.029(0.087) 0.879(0.055) 0.901(0.041) 0.770(0.015) Not-MIW AE(s) 1.693(0.672) 1.619(0.539) 2.225(0.710) 2.222(0.626) 2.493(0.685) 1.889(0.642) MICE 1.045(0.155) 1.054(0.061) 3.030(1.585) 1.050(0.051) 1.078(0.050) 0.991(0.032) MissF orest 0.940(0.155) 1.020(0.071) 1.534(0.289) 1.013(0.071) 1.053(0.067) 0.891(0.022) W e conduct 50 replications for sim ulating missingness, and explore the influence of linear and non-linear structures on deep generativ e mo dels in this setting. The results in T able 3 sho w that our method outperforms b oth other deep generativ e mo dels and classical imputation baselines, ev en when other deep generativ e models emplo y a missingness mo del that matches the missingness generation in this setting, which is lik ely due to their noniden tifiabilit y. This could also b e attributed to the fact that the assumption of no self-censoring only excludes one v ariable for each dimension in the missingness mec hanism, whic h contributes to its strong p erformance. The goo d p erformance ma y also rely on the prop osed metho d’s robustness to self-censoring, as mentioned in the supplementary material, whic h may result from the correlations betw een data v ariables. In con trast, Not- MIW AE(s) p erform po orly in this case, as the model only considers self-censoring and ignores all other parts in the missingness mechanism, which deviates from the true mo del b y a large amoun t. F urthermore, from the comparisons of linear and nonlinear missingness mo dels for the generativ e models, it is eviden t that the model complexit y has little influence on the prop osed metho d, which pro duces the b est p erformance using either missingness mo del, while using the nonlinear mo del for GINA and Not-MIW AE yield more apparen t v ariation in p erformance. These experiments illustrate that our approac h could pro ve b eneficial in situations where the data is b elieved to exhibit MNAR patterns, but the exact missingness mechanisms are uncertain or not well-defined. Additionally , the finding that there is minimal discrepancy b et w een the results obtained with linear and nonlinear c hoices for the missingness model 20 Identifiable Deep La tent V ariable Models for MNAR Da t a T able 4: Estimated join t distribution of HAAR T contin uation during pregnancy (H), low CD4 + coun t (C), and preterm deliv ery (P) in HIV-infected women in Botswana. P , C, H 1, 1, 1 1, 1, 0 1, 0, 0 1, 0, 1 0, 1, 1 0, 1, 0 0, 0, 0 0, 0, 1 Prop osed 0.0188 0.0616 0.5030 0.1582 0.0112 0.0380 0.1604 0.0487 AIPW 0.0122 0.0268 0.5206 0.1722 0.0091 0.0542 0.1618 0.0430 MICE 0.0164 0.0355 0.5156 0.1705 0.0140 0.0483 0.1641 0.0357 CC 0.0137 0.0342 0.3320 0.0979 0.0333 0.1802 0.2380 0.0705 in our method demonstrates that it could effectiv ely learn the distribution, ev en when emplo ying an ov erparameterized nonlinear structure, aligning with our theoretical findings regarding iden tification. 7.2 HIV p ositive mothers in Botsw ana A w ell-kno wn dataset for the study of MNAR data is the data of HIV positive mothers in Botsw ana. In this dataset, the goal is to estimate the asso ciation b etw een highly active an tiretro viral therapy (HAAR T) during pregnancy and preterm delivery . The complete data consists of 33 , 148 obstetric records from 6 cites in Botswana (Chen et al., 2012). W e follow the practice of Tc hetgen et al. (2018); Sun et al. (2018); Shpitser (2016); Malinsky et al. (2021) b y fo cusing on HIV-p ositive w omen ( n = 9711) and 3 binary v ariables: HAAR T exp osure during pregnancy (68 . 9% missing), an indicator of low CD4 + coun t (less than 200 µL ), and preterm delivery (6 . 7% missing). T here is a small portion of complete cases (10 . 5%). The missingness mechanism is suspected to b e MNAR (Shpitser, 2016; Malinsky et al., 2021). W e learn the distribution of the data using our metho d with the Bernoulli distribution for the data generativ e mo del. As the first step in estimating the relationship of in terest, w e obtained the joint distribution using our generativ e mo del, and compared the results with other estimation metho ds including complete case analysis (CC), MICE, and estimation using the augmented in v erse probabilit y weigh ted (AIPW) b y Malinsky et al. (2021) whic h assumes a no self-censoring mo del. W e can see from the join t distribution in T able 4 that certain probabilities are similar for the prop osed metho d, AIPW and MICE, which all ha v e substan tial differences from those for the complete case analysis. Based on the estimated join t distribution by the prop osed metho d, we estimate the o dds ratios b etw een HAAR T and preterm deliv ery at differen t lev els of CD4 + coun t: 1 . 03 (0 . 53 , 2 . 94) for lo w CD4 + coun t and 1 . 04 (0 . 73 , 1 . 53) for mo derate or high CD4 + coun t, resp ectiv ely . Without conditioning on CD4 + , the o dds ratio is computed as 1 . 04 (0 . 76 , 1 . 48). W e also estimate the effect of lo w CD4 + on the result of delivery and obtain the o dds ratio as 0 . 52 (0 . 36 , 0 . 81). The n um b ers in parentheses represen t the 95% confidence in terv als and are computed by b o otstrap (p ercentile) o v er 1000 subsamples. The metho d of AIPW found a significantly p ositive relationship conditional on low CD4 + . Our metho d do es not find a significant result that app ears similar to the result of Shpitser (2016) with an estima- tion based on the pseudo-likelihoo d approach using a no self-censoring model. It has been susp ected that the data is sufficien tly noisy to find insignificant results (Shpitser, 2016). 21 Xie, Xue, W ang Figure 6: Bar graphs o v er rating v alues for the Y aho o! R3 dataset. The first t wo are from the MNAR training set and the MCAR test set. The last three show the data v alues of the imputed test set using differen t methods. 7.3 Y aho o! R3 m usic ratings In this subsection, w e apply our method to the Y aho o! R3 dataset (Marlin and Zemel, 2009; W ang et al., 2018). This dataset is primarily designed for the analysis of user-song ratings, with a sp ecific focus on ev aluating MNAR imputation techniques. Within this dataset, w e ha v e a training set that consists of more than 300,000 self-selected ratings on a scale from 1 to 5 provided b y 15,400 users for a selection of 1,000 songs, which has an en try-wise missing rate of around 98 . 0%. In addition, there is an MCAR test set, which comprises ratings from 5,400 users across a set of 10 songs c hosen at random. W e train our model on the training set and subsequently ev aluate the imputation p erformance on the test set. W e ac kno wledge that this dataset likely in v olv es self-censoring. Our aim here is not to assume otherwise, but to demonstrate the robustness and practical effectiveness of our metho d on a complex real-w orld dataset. W e compare the prop osed metho d with GINA (Ma and Zhang, 2021) and not-MIW AE (Ipsen et al., 2020), which are also designed for MNAR but did not address the issue of iden tifiabilit y without resorting to auxiliary v ariables. W e mo del the missingness mec hanism as a linear function in all methods, allowing eac h R j to depend on all dimensions of X in the baselines. W e did not include classical methods such as MICE or missF orest due to their prohibitiv ely long training time. W e visualize the imputation results in the five categorical bar graphs, together with the training and test data. First, we can notice that the training data hav e a v ery different distribution from the test data, where the latter is known to b e a relativ ely unbiased represen tation of the true data distribution, while the training data are MNAR and thus biased. More importantly , w e find that all the generative mo dels learn a data distribution closer to the test data than to the training data, where the proposed model pro duces the most pronounced difference b et w een ratings 1 and 2 among all the metho ds, relativ ely closest to the distribution of the un biased test data. Since results of deep generativ e metho ds dep end on c hoices of seeds, we re-run each deep generative metho d for 50 times using different seeds, yielding the results of mean and standard deviation of imputation RMSE for the different metho ds: 1 . 1807(0 . 0073), 1 . 1870(0 . 0089), 1 . 1818(0 . 0062) for the prop osed mo del, GINA and not-MIW AE, resp ec- tiv ely . Consisten t with the bar graphs, our prop osed metho d shows sligh tly b etter p erfor- mance than the alternatives, though the differences are not substan tial. This is exp ected, 22 Identifiable Deep La tent V ariable Models for MNAR Da t a since in high-dimensional settings correlations across man y v ariables may dilute the impact of self-censoring, making the no self-censoring assumption relativ ely mild. 8 Conclusion In this pap er, w e prop ose a new deep laten t v ariable model for MNAR data under a con- ditional no self-censoring assumption. W e hav e established theoretical iden tifiability under mild conditions. This theoretical foundation forms the basis for the no vel practical algo- rithm IM-IW AE using importance-weigh ted auto enco ders for data generation and imputa- tion of MNAR data, with the theoretical justification of its abilit y to reco v er ground-truth data distributions. Our comprehensive exp eriments, which include sim ulation studies and real-w orld applications, effectiv ely highlight the adv an tages and robustness of the prop osed metho d. The experiments hav e also demonstrated that our metho d could b e potentially useful when data is susp ected to be MNAR but the specific missingness mec hanisms are agnostic or unclear. Some future directions include but not limited to extending identifiable deep latent v ariable mo dels for MNAR data to more general top ological spaces, enhancing the imputa- tion p erformance of the prop osed method in data with extremely high missing rates, and in v estigating other reasonable and practical identification conditions for MNAR data to incorp orate them into deep generative mo dels. App endix A. Pro ofs of Theoretical Results A.1 Proof of Theorem 1 Pro of W e fo cus on the missingness mechanism first, i.e., the conditional distribution of R giv en X . A.1.1 The appr o xima tion of the missingness mechanism Without loss of generalit y , let ˜ Z ∼ N (0 , 1), i.e. q 2 = 1. (In the case of q 2 > 1, it is trivial to sho w that the last q 2 − 1 dimensions can be ignored in the conditional distribution of R giv en ˜ Z and X .) Then w e ha ve dH ( ˜ z ) = p ( ˜ z ) d ˜ z = N ( ˜ z | 0 , 1) d ˜ z . No w, denote the ground-truth missingness mechanism as P g t ( R = r | x ) = p r , with P r ∈{ 0 , 1 } p p r = 1. With a little abuse of notation, w e write below r < r ′ b y treating r , r ′ as binary num b ers. F or example, if r = (0 , 0 , 1) and r ′ = (0 , 1 , 0), then write r < r ′ . By using indicator functions 1 ( · ), w e define a set of deterministic functions f ( x, u ) = ( f (1) ( x, u ) , · · · , f ( p ) ( x, u )) for x ∈ R p and u ∈ [0 , 1] as f (1) ( x, u ) = 1 { X r ′ < (1 , 0 ... 0) p r ′ < u ≤ 1 } r 1 1 { 0 ≤ u ≤ X r ′ < (1 , 0 ... 0) p r ′ } 1 − r 1 , 23 Xie, Xue, W ang f (2) ( x, u ) = 1 { X r ′ < (0 , 1 , 0 ... 0) p r ′ < u ≤ X r ′ < (1 , 0 , 0 ... 0) p r ′ or X r ′ < (1 , 1 , 0 ... 0) p r ′ < u ≤ 1 } r 2 1 { 0 ≤ u ≤ X r ′ < (0 , 1 , 0 ... 0) p r ′ or X r ′ < (1 , 0 , 0 ... 0) p r ′ < u X r ′ < (1 , 1 , 0 ... 0) p r ′ } 1 − r 2 , · · · f ( p ) ( x, u ) = 1 { X r ′ < (0 ,..., 0 , 1) p r ′ < u ≤ X r ′ < (0 ,..., 0 , 1 , 0) p r ′ or · · · or X r ′ < (1 ,..., 1) p r ′ < u ≤ 1 } r p 1 { 0 ≤ u ≤ X r ′ < (0 ,..., 0 , 1) p r ′ or X r ′ < (1 ,..., 1 , 0) p r ′ < u X r ′ < (1 ,..., 1) p r ′ } 1 − r p . Then w e hav e that P g t ( R = r | x ) = Z 1 0 p Y j =1 Bernoulli( f ( j ) ( x, u )) du = Z 1 0 p Y j =1 Bernoulli( f ( j ) ( x, H ( ˜ z )) dH ( ˜ z ) = Z R p Y j =1 Bernoulli( f ( j ) ( x, H ( ˜ z )) p ( ˜ z ) d ˜ z (14) Hence, there exists a decomposition of the missingness mechanism in the form of P g t ( R = r | x ) = Z R P g t ( R = r | x, ˜ z ) p ( ˜ z ) d ˜ z , where P g t ( R = r | x, ˜ z ) = p Y j =1 Bernoulli( f ( j ) ( x, H ( ˜ z ))) . F or the part of the data v ariables X , w e separate the pro of into t w o cases d < p and d = p , where d is the dimension of the manifold X for the data v ariable X . A.1.2 The appr o xima tion for the d a t a distribution when d < p W e first examine the v ariable Z for the data X . F or clarit y , let p x g t ( · ) denote the ground-truth manifold density of X (instead of simply p g t ( · )). W e aim to construct a bijection b et w een X and R d whic h transforms the ground-truth measure µ g t to a Gaussian distribution, b efore whic h one step is needed that bijects b etw een X and R d using a diffeomorphism φ ( · ), so it transforms the ground-truth probabilit y distribution p x g t ( x ) to another distribution p u g t ( u ), where u ∈ R d . The relationship b et w een the tw o distributions is p u g t ( u ) du = p x g t ( x ) µ V ( dx ) | x = φ − 1 ( u ) = µ g t ( dx ) , where µ V ( dx ) is the volume measure with respect to X . 24 Identifiable Deep La tent V ariable Models for MNAR Da t a Define the function F : R d 7→ [0 , 1] d as F ( u ) = [ F 1 ( u 1 ) , F 2 ( u 2 ; u 1 ) , · · · , F d ( u d ; u d − 1 )] , with F j ( u j ; u 1: j − 1 ) = Z u j u ′ j = −∞ p u g t ( u ′ j | u 1: j − 1 ) du ′ j . By this definition, we hav e dF ( u ) = p u g t ( u ) du. Because φ is a diffeomorphism, b oth φ and φ − 1 are differentiable. Thus dx/du is nonzero ev erywhere on the manifold. Considering p x g t ( x ) is also nonzero everywhere, p u g t ( u ) is nonzero ev erywhere. Since p u g t ( u ) is nonzero everywhere, F ( · ) is inv ertible. W.l.o.g., let Z ∼ N (0 , I q 1 ) and q 1 = d . (In the case of q 1 > d , it is trivial to sho w that the last q 1 − d dimensions can b e ignored in the conditional distribution of X giv en Z .) W e define another differen tiable and in v ertible function G : R d 7→ [0 , 1] d as G ( z ) = [ G 1 ( z 1 ) , G 2 ( z 2 ) , · · · , G d ( z d )] T , with G j ( z j ) = Z z j z ′ j = −∞ N ( z j | 0 , 1) dz ′ j . Then dG ( z ) = p ( z ) dz = N ( z | 0 , I ) dz . No w, consider a random v ariable Y ∈ R p with a parameter β > 0 for its density: p ( y ; β ) = Z R d p ( y | z ; β ) p ( z ) dz . Let p ( y | z ; β ) = N ( y | φ − 1 ◦ F − 1 ◦ G ( z ) , 1 β I ) so that p ( y ; β ) = Z R d N ( y | φ − 1 ◦ F − 1 ◦ G ( z ) , 1 β I ) dG ( z ) = Z [0 , 1] d N ( y | φ − 1 ◦ F − 1 ( ξ ) , 1 β I ) dξ = Z R d N ( y | φ − 1 ( u ) , 1 β I ) p u g t ( u ) du = Z y ′ ∈X N ( y | y ′ , 1 β I ) µ g t ( dy ′ ) (15) Consider a measurable set A ∈ R p . Let p R | X, ˜ Z ( r | y , ˜ z ) = p Y j =1 Bernoulli( f ( j ) ( y , H ( ˜ z )) 25 Xie, Xue, W ang as in (14). Also, b y (14), we hav e lim β →∞ Z y ∈ A Z Z p ( y | z ; β ) p ( z ) p R | X, ˜ Z ( r | y , ˜ z ) p ( ˜ z ) dz d ˜ z dy = lim β →∞ Z y ∈ A p ( y | β ) p g t ( r | y ) dy . (16) F urthermore, lim β →∞ Z y ∈ A p ( y | β ) p g t ( r | y ) dy = lim β →∞ Z y ∈ A Z y ′ ∈X N ( y | y ′ , 1 β I ) µ g t ( dy ′ ) p g t ( r | y ) dy = lim β →∞ Z y ′ ∈X Z y ∈ A N ( y | y ′ , 1 β I ) p g t ( r | y ) dy µ g t ( dy ′ ) = Z y ′ ∈X lim β →∞ Z y ∈ A N ( y | y ′ , 1 β I ) p g t ( r | y ) dy µ g t ( dy ′ ) . (17) The second equalit y follo ws by F ubini’s theorem. The third equalit y follows b y the b ounded con v ergence theorem. W e no w note that the term inside the first in tegration. Now, note that lim β →∞ Z y ∈ A N ( y | y ′ , 1 β I ) p g t ( r | y ) dy = ( p g t ( r | y ) if y ′ ∈ A − ∂ A, 0 if y ′ ∈ A c − ∂ A. W e separate the manifold X in to three parts: X ∩ ( A − ∂ A ), X ∩ ( A c − ∂ A ) and X ∩ ∂ A . Then (17) can b e separated in to three parts corresp ondingly . The first t w o parts can be deriv ed as Z X ∩ ( A − ∂ A ) lim β →∞ Z y ∈ A N ( y | y ′ , 1 β I ) p g t ( r | y ) dy µ g t ( dy ′ ) = Z X ∩ ( A − ∂ A ) p g t ( r | y ) µ g t ( dy ′ ) , Z X ∩ ( A c − ∂ A ) lim β →∞ Z y ∈ A N ( y | y ′ , 1 β I ) p g t ( r | y ) dy µ g t ( dy ′ ) = Z X ∩ ( A − ∂ A ) 0 µ g t ( dy ′ ) = 0 . F or the third part, given the assumption that µ g t ( ∂ A ) = 0, w e hav e 0 ≤ Z X ∩ ∂ A lim β →∞ Z y ∈ A N ( y | y ′ , 1 β I ) p g t ( r | y ) dy µ g t ( dy ′ ) ≤ Z X ∩ ∂ A 1 µ g t ( dy ′ ) = µ g t ( X ∩ ∂ A ) = 0 . Therefore, w e hav e Z X ∩ ∂ A lim β →∞ Z y ∈ A N ( y | y ′ , 1 β I ) p g t ( r | y ) dy µ g t ( dy ′ ) = 0 and so lim β →∞ Z y ∈ A p ( y | β ) p g t ( r | y ) dy = Z X lim β →∞ Z y ∈ A N ( y | y ′ , 1 β I ) p g t ( r | y ) dy µ g t ( dy ′ ) = Z X ∩ ( A − ∂ A ) p g t ( r | y ) µ g t ( dy ′ ) + 0 + 0 = Z X ∩ A p g t ( r | y ) µ g t ( dy ′ ) . Com bining this and (16), w e hav e the result as desired. 26 Identifiable Deep La tent V ariable Models for MNAR Da t a A.1.3 The appr o xima tion for the d a t a distribution when d = p T ak e φ in the case of d = p to b e the iden tit y function (so that we can actually omit the diffeomorphism step when constructing a bijection b etw een X and R d .) In the case of d = p , p x g t ( x ) ≜ µ g t ( dx ) /dx represen ts the ground-truth probabilit y density with resp ect to the standard Leb esgue measure in Euclidean space. Define the function F : R p 7→ [0 , 1] p as F ( x ) = [ F 1 ( x 1 ) , F 2 ( x 2 ; x 1 ) , · · · , F p ( x p ; x p − 1 )] , F j ( x j ; x 1: j − 1 ) = Z x j x ′ j = −∞ p x g t ( x ′ j | x 1: j − 1 ) dx ′ j . By this definition, we hav e dF ( x ) = p x g t ( x ) dx. Since p x g t ( x ) is nonzero ev erywhere, F ( · ) is in v ertible. W.l.o.g., let Z ∼ N (0 , I q 1 ) and q 1 = p . (In the case of q 1 > p , it is trivial to sho w that the last q 1 − p dimensions can b e ignored in the conditional distribution of X given Z .) W e define another differentiable and inv ertible function G : R p 7→ [0 , 1] p as G ( z ) = [ G 1 ( z 1 ) , G 2 ( z 2 ) , · · · , G p ( z p )] T , G j ( z j ) = Z z j z ′ j = −∞ N ( z j | 0 , 1) dz ′ j . Then dG ( z ) = p ( z ) dz = N ( z | 0 , I ) dz . No w, consider a random v ariable Y ∈ R p with a parameter β > 0 for its density: p ( y ; β ) = Z R p p ( y | z ; β ) p ( z ) dz . Let p ( y | z ; β ) = N ( y | F − 1 ◦ G ( z ) , 1 β I ) so that p ( y ; β ) = Z R p N ( y | F − 1 ◦ G ( z ) , 1 β I ) dG ( z ) = Z [0 , 1] p N ( y | F − 1 ( ξ ) , 1 β I ) dξ , where ξ = G ( z ). Let y ′ = F − 1 ( ξ ) such that dξ = dF ( y ′ ) = p x g t ( y ′ ) dy ′ . Plugging this expression in to p ( y ; β ) w e hav e p ( y ; β ) = Z R p N ( y | y ′ , 1 β I ) p x g t ( y ′ ) dy ′ . As β → ∞ , N ( y | y ′ , 1 β I ) becomes a Dirac-delta function, resulting in lim β →∞ p ( y ; β ) = Z R p δ ( y ′ − y ) p x g t ( y ′ ) dy ′ = p x g t ( y ) . 27 Xie, Xue, W ang Putting the results for p g t ( x ) and p g t ( r | x ) together, we ha ve the result for the case d = p in the theorem. A.2 Proof of Theorem 2 Pro of Under Assumption 3, p g t ( r | x ) = Z p g t ( r | x, ˜ z ) p ( ˜ z ) d ˜ z = Z p Y j =1 p g t ( r j | x − j , ˜ z ) p ( ˜ z ) d ˜ z = Z p Y j =1 p g t ( r j | x − j , R − j = 1 , ˜ z ) p ( ˜ z ) d ˜ z . Th us, p g t ( r | x ) is only a function of observed data. A.3 Proof of Corollary 3 Pro of Using the o dds ratio parametrization (Y un Chen, 2007; Chen, 2010) with o dds ratio function OR( r , x ) ≡ OR( r, x ; r 0 = 1 , x 0 = 0 ) = p g t ( r | x ) p g t ( R = 1 | x ) p g t ( R = 1 | X = 0 ) p g t ( r | X = 0 ) . Then the full-data distribution (Li et al., 2022) can b e written as p g t ( x, r ) = O R ( r, x ) p g t ( x | R = 1 ) p g t ( r | X = 0 ) P r ′ E [ O R ( r ′ , y ) | R = 1 ] p g t ( r ′ | X = 0 ) , whic h is also a function of observed data only . A.4 Proof of Theorem 4 Pro of W e need to sho w log p θ,ψ ( x ( r ) , r ) ≥ L k , L k ≥ L m for k ≥ m ≥ 1; w e also need to sho w log p θ,ψ ( x ( r ) , r ) = lim k →∞ L k assuming w is bounded, with L k ( θ , ψ , ϕ, λ ) = E log 1 k k X l =1 w k , where w l = p θ ( x ( r ) | z l ) p ψ ( r | x ( r ) , x ( m ) ,l , ˜ z l ) p ( z l ) p ( ˜ z l ) q ϕ ( z l | x ( r ) , r ) q λ ( ˜ z l | x ( r ) , r ) , 28 Identifiable Deep La tent V ariable Models for MNAR Da t a for 1 ≤ l ≤ k . W e hav e L k ( θ , ψ , ϕ, λ ) = E log 1 k k X l =1 w l ≤ log E 1 k k X l =1 w l = log p θ,ψ ( x ( r ) , r ) . F or k ≥ m , denoting h l = ( z l , ˜ z l , x ( m ) ,l ) for 1 ≤ l ≤ k L k = E h 1 , ··· ,h k log 1 k k X l =1 w l = E h 1 , ··· ,h k log E I = { l 1 ,...,l m } 1 m m X j =1 w l j ≥ E h 1 , ··· ,h k E I = { l 1 ,...,l m } log 1 m m X j =1 w l j = E h 1 , ··· ,h m log 1 m m X l =1 w l = L m . Consider the random v ariable M k = 1 k P k l =1 w l . If w is b ounded. then it follo ws from SLLN that M k con v erges to E q ( h | x ( r ) ,r ) [ w ] = p θ,ψ ( x ( r ) , r ) almost surely . Hence L k = E [log M k ] con v erges to log p θ,ψ ( x ( r ) , r ) as k → ∞ . A.5 Proof of Proposition 5 Pro of First, define the random v ariable Y K : = 1 K P K k =1 w k , whic h corresponds to the sample mean of w 1 , · · · , w K . W e ha v e ˆ L K = log Y K = log( E [ w ] + ( Y K − E [ w ])) = log E [ w ] − ∞ X i =1 ( − 1) i i E [ w ] i ( Y K − E [ w ]) i , and so E [ ˆ L K ] = E [log Y K ] = log E [ w ] − ∞ X i =1 ( − 1) i i E [ w ] i E [( Y K − E [ w ]) i ] . (18) Denote γ i : = E [( Y K − E [ Y K ]) i ], the i -th cen tral moments of Y K for i ≥ 2, and µ i : = E [( w − E [ w ]) i ], the i -th cen tral momen ts of P for i ≥ 2. Denote γ = E [ Y K ] and µ = E [ w ], the first non-cen tral momen ts. Since Y K is a sample mean, we can use existing results that relate γ i to µ i . In Angelov a (2012), Theorem 1 giv es the relations: γ = µ, γ 2 = µ 2 K , γ 3 = µ 3 K 2 , γ 4 = 3 K 2 µ 2 2 + 1 K 3 ( µ 4 − 3 µ 2 2 ) , γ 5 = 10 K 3 µ 3 µ 2 + 1 K 4 ( µ 5 − 10 µ 3 µ 2 ) , where the first t w o ar e w ell- kno wn relations of means and v ariances of b et w een samples and p opulations. Expanding (18) to the fifth order using the ab o v e relations gives E [ ˆ L K ] = log E [ w ] − 1 2 µ 2 µ 2 K + 1 3 µ 3 µ 3 K 2 − 1 4 µ 4 3 K 2 µ 2 2 + 1 K 3 ( µ 4 − 3 µ 2 2 ) + 1 5 µ 5 10 K 3 µ 3 µ 2 + 1 K 4 ( µ 5 − 10 µ 3 µ 2 ) + o ( K − 3 ) . (19) The result for bias follows b y regrouping the terms by order of K and then subtracting log p θ,ψ ( x ( r ) , r ) = log E [ w ] from (19). 29 Xie, Xue, W ang By using the definition of the v ariance and the series expansion of the logarithm function, w e ha ve V ar(log Y K ) = E [(log Y K − E [log Y K ]) 2 ] = E log µ − ∞ X i =1 ( − 1) i iµ i ( Y K − µ ) i − log µ + ∞ X i =1 ( − 1) i iµ i E [( Y K − µ ) i ] ! 2 = E ∞ X i =1 ( − 1) i iµ i ( E [( Y K − µ ) i ] − ( Y K − µ ) i ) ! 2 . By expanding the ab ov e equation to the third order w e hav e the follo wing: V ar(log Y K ) ≈ γ 2 µ 2 − 1 µ 3 ( γ 3 − γ 1 γ 2 ) + 2 3 µ 4 ( γ 4 − γ 1 γ 3 ) + 1 4 µ 4 ( γ 4 − γ 2 2 ) − 1 3 µ 5 ( γ 5 − γ 2 γ 3 ) + 1 9 µ 6 ( γ 6 − γ 2 3 ) . By substituting the sample momen ts γ i of Y K with the cen tral momen ts µ i of distribution P using their relations, w e get V ar(log Y K ) = 1 K µ 2 µ 2 − 1 K 2 µ 3 µ 3 − 5 µ 2 2 2 µ 4 + o ( K − 2 ) . A.6 Proof of Corollary 6 Pro of P ( | ˆ L K − log p θ,ψ ( x ( r ) , r ) | ≥ ϵ ) = P ( | ˆ L K − E [ ˆ L K ] + E [ ˆ L K ] log p θ,ψ ( x ( r ) , r ) | ≥ ϵ ) ≤ P ( | ˆ L K − E [ ˆ L K ] | + | E [ ˆ L K ] log p θ,ψ ( x ( r ) , r ) | ≥ ϵ ) ≤ P ( | ˆ L K − E [ ˆ L K ] | ≥ ϵ 2 ) + P ( | E [ ˆ L K ] log p θ,ψ ( x ( r ) , r ) | ≥ ϵ 2 ) , where the second term is deterministic and is either 0 or 1, and it will alwa ys b e zero for K large enough according to Prop osition 1. Applying Chebyshev’s inequality to the first term and setting τ = ϵ 2 √ V ar( ˆ L K ) , w e hav e P ( | ˆ L K − E [ ˆ L K ] | ≥ ϵ 2 ) = P ( | ˆ L K − E [ ˆ L K ] | ≥ τ q V ar( ˆ L K )) ≤ 1 τ 2 = 4 q V ar( ˆ L K ) ϵ 2 = O (1 /K ) . F or K → ∞ and an y ϵ > 0, this term has a limit of 0. And w e ha ve the conv ergence in probabilit y , and hence consistency . 30 Identifiable Deep La tent V ariable Models for MNAR Da t a A.7 Proof of Lemma 7 Pro of Without loss of generalit y , w e assume the dimension of ˜ z to b e κ 2 = 1 in the pro of. (In the case of κ 2 > 1, it is trivial to show that the last κ 2 − 1 dimensions can b e ignored in the conditional distribution of R given ˜ Z and X .) Define a differentiable and in v ertible function G : R → [0 , 1] as G ( ˜ z ) = Z ˜ z ˜ z ′ = −∞ N ( ˜ z | 0 , 1) d ˜ z ′ . Then dG ( ˜ z ) = p ( ˜ z ) d ˜ z = N ( ˜ z | 0 , 1) d ˜ z . F or r j ∈ { 0 , 1 } for 1 ≤ j ≤ p , w e hav e P ψ ( R 1 = r 1 , · · · , R p = r p | x ) = Z R p Y j =1 P ψ ( R j = r j | x, ˜ z ) p ( ˜ z ) d ˜ z = Z R p Y j =1 P ψ ( R j = r j | x, G ( ˜ z )) dG ( ˜ z ) = Z 1 0 p Y j =1 P ψ ( R j = r j | x, u ) du = Z 1 0 p Y j =1 Bernoulli( f ( j ) ψ ( x, u )) du, where f ψ ( x, u ) = ( f (1) ψ ( x, u ) , · · · , f ( p ) ψ ( x, u )) is the deterministic deco der for the missingness mec hanism. Now, denote the ground-truth join t densit y as P g t ( R = r | x ) = p r , with X r ∈{ 0 , 1 } p p r = 1 . With a little abuse of notation, w e write b elow r < r ′ b y treating r , r ′ as binary num bers. F or example, if r = (0 , 0 , 1) and r ′ = (0 , 1 , 0), then write r < r ′ . By using indicator functions 1 ( · ), w e can write the ground-truth distribution of the missingness mec hanism as P g t ( R = r | x ) = Z [0 , 1] 1 { X r ′ < (1 , 0 ... 0) p r ′ < u ≤ 1 } r 1 1 { 0 ≤ u ≤ X r ′ < (1 , 0 ... 0) p r ′ } 1 − r 1 1 { X r ′ < (0 , 1 , 0 ... 0) p r ′ < u ≤ X r ′ < (1 , 0 , 0 ... 0) p r ′ or X r ′ < (1 , 1 , 0 ... 0) p r ′ < u ≤ 1 } r 2 1 { 0 ≤ u ≤ X r ′ < (0 , 1 , 0 ... 0) p r ′ or X r ′ < (1 , 0 , 0 ... 0) p r ′ < u X r ′ < (1 , 1 , 0 ... 0) p r ′ } 1 − r 2 · · · 1 { X r ′ < (0 ,..., 0 , 1) p r ′ < u ≤ X r ′ < (0 ,..., 0 , 1 , 0) p r ′ or · · · or X r ′ < (1 ,..., 1) p r ′ < u ≤ 1 } r p 1 { 0 ≤ u ≤ X r ′ < (0 ,..., 0 , 1) p r ′ or X r ′ < (1 ,..., 1 , 0) p r ′ < u X r ′ < (1 ,..., 1) p r ′ } 1 − r p du. 31 Xie, Xue, W ang Hence, w e can see that by setting f (1) ψ ∗ ( x, u ) = 1 { X r ′ < (1 , 0 ... 0) p r ′ < u ≤ 1 } r 1 1 { 0 ≤ u ≤ X r ′ < (1 , 0 ... 0) p r ′ } 1 − r 1 , f (2) ψ ∗ ( x, u ) = 1 { X r ′ < (0 , 1 , 0 ... 0) p r ′ < u ≤ X r ′ < (1 , 0 , 0 ... 0) p r ′ or X r ′ < (1 , 1 , 0 ... 0) p r ′ < u ≤ 1 } r 2 1 { 0 ≤ u ≤ X r ′ < (0 , 1 , 0 ... 0) p r ′ or X r ′ < (1 , 0 , 0 ... 0) p r ′ < u X r ′ < (1 , 1 , 0 ... 0) p r ′ } 1 − r 2 , · · · f ( p ) ψ ∗ ( x, u ) = 1 { X r ′ < (0 ,..., 0 , 1) p r ′ < u ≤ X r ′ < (0 ,..., 0 , 1 , 0) p r ′ or · · · or X r ′ < (1 ,..., 1) p r ′ < u ≤ 1 } r p 1 { 0 ≤ u ≤ X r ′ < (0 ,..., 0 , 1) p r ′ or X r ′ < (1 ,..., 1 , 0) p r ′ < u X r ′ < (1 ,..., 1) p r ′ } 1 − r p , the decoder f ψ ∗ ( x, u ) can recov er the ground-truth distribution of missingness mec hanism, i.e., P g t ( R = r | x ) = Z 1 0 p Y j =1 Bernoulli( f ( j ) ψ ∗ ( x, u )) du. A.8 Proof of Theorem 8 Pro of F or V AE (the sp ecial case of K = 1 for IW AE) for complete data, Dai and Wipf (2019) sho wed that there is a sequence of decoders such that lim t →∞ p θ ∗ t ( x ) = p g t ( x ) , under certain conditions. W e first show that suc h a result on complete data is applicable to the observed data when there is missingness in the data. Denote the dimension of the observ ed data as p ( r ) for 1 ≤ p ( r ) ≤ p , with p ( r ) b eing the n um ber of 1’s in r . Define the function F : R p ( r ) 7→ [0 , 1] p ( r ) as F ( x ( r ) ) = [ F 1 ( x ( r ) , 1 ) , F 2 ( x ( r ) , 2 ; x ( r ) , 1 ) , · · · , F p ( r ) ( x ( r ) ,p ( r ) ; x ( r ) ,p ( r ) − 1 )] , where for 1 ≤ j ≤ p ( r ) , F j is defined as F j ( x ( r ) ,j ; x ( r ) , 1: j − 1 ) = Z x ( r ) ,j x ′ ( r ) ,j = −∞ p g t ( x ′ ( r ) ,j | x ( r ) , 1: j − 1 ) dx ′ ( r ) ,j , 32 Identifiable Deep La tent V ariable Models for MNAR Da t a where x ( r ) ,j denotes the j th observ ed dimension in x ( r ) . By this definition, w e hav e dF ( x ( r ) ) = p g t ( x ( r ) ) dx ( r ) . Since p g t ( x ), and hence p g t ( x ( r ) ), is assumed to be nonzero ev erywhere, F ( · ) is in v ertible. Similarly , w e define another differentiable and inv ertible function G : R p ( r ) 7→ [0 , 1] p ( r ) for the part of the latent v ariable corresp onding to the observed part of the data x ( r ) , which w e denote as z ( r ) : G ( z ( r ) ) = [ G 1 ( z ( r ) , 1 ) , G 2 ( z ( r ) , 2 ) , · · · , G p ( r ) ( z ( r ) ,p ( r ) )] T , with G j ( z ( r ) ,j ) = Z z ( r ) ,j z ′ ( r ) ,j = −∞ N ( z ( r ) ,j | 0 , 1) dz ′ ( r ) ,j . Then dG ( z ( r ) ) = p ( z ( r ) ) dz ( r ) = N ( z ( r ) | 0 , I ) dz ( r ) . Let the deco der b e f µ x ( z ( r ) ; θ ∗ t ) = F − 1 ◦ G ( z ( r ) ) , with γ ∗ t = 1 t . Then w e hav e that p θ ∗ t ( x ( r ) ) = Z R p ( r ) p θ ∗ t ( x ( r ) | z ( r ) ) p ( z ( r ) ) dz ( r ) = Z R p ( r ) N ( x ( r ) | F − 1 ◦ G ( z ( r ) ) , γ ∗ t I ) dG ( z ( r ) ) . Let ξ = G ( z ( r ) ) suc h that p θ ∗ t ( x ( r ) ) = Z [0 , 1] p ( r ) N ( x ( r ) | F − 1 ( ξ ) , γ ∗ t I ) dξ , and let x ′ ( r ) = F − 1 ( ξ ) suc h that dξ = dF ( x ′ ( r ) ) = p g t ( x ′ ( r ) ) dx ′ ( r ) . Plugging this expression in to the previous p θ ∗ t ( x ( r ) ) w e get p θ ∗ t ( x ( r ) ) = Z R p ( r ) N ( x ( r ) | x ′ ( r ) , γ ∗ t I ) p g t ( x ′ ( r ) ) dx ′ ( r ) . As t → ∞ , γ ∗ t b ecomes infinitely small and N ( x ( r ) | x ′ ( r ) , γ ∗ t I ) becomes a Dirac-delta function, resulting in lim t →∞ p θ ∗ t ( x ( r ) ) = Z X ( r ) δ ( x ′ ( r ) − x ( r ) ) p g t ( x ′ ( r ) ) dx ′ ( r ) = p g t ( x ( r ) ) . where X ( r ) denotes the part of the data space corresponding to the observ ed dimensions of the data. 33 Xie, Xue, W ang Com bining this result with Lemma 7 that there exists a deco der with parameter ψ ∗ that recov ers the ground truth p ψ ∗ ( r | x ( r ) ) = p g t ( r | x ( r ) ), we hav e that there is a sequence of deco ders for the observed joint distribution suc h that lim t →∞ p θ ∗ t ,ψ ∗ t ( x ( r ) , r ) = p g t ( x ( r ) , r ) . By con tinuit y , w e ha ve lim t →∞ log p θ ∗ t ,ψ ∗ t ( x ( r ) , r ) = log p g t ( x ( r ) , r ) . According to Theorem 4, if w is bounded, then lim K →∞ L K ( θ ∗ t , ψ ∗ t , ϕ ∗ t , λ ∗ t ) = log p θ ∗ t ,ψ ∗ t ( x ( r ) , r ) , ∀ ϕ ∗ t ∈ Ω ϕ , λ ∗ t ∈ Ω λ . So w e hav e lim t →∞ lim K →∞ L K ( θ ∗ t , ψ ∗ t , ϕ ∗ t , λ ∗ t ) = log p g t ( x ( r ) , r ) . App endix B. Parameter Settings for Sim ulation Study W e follo w ed the parameter settings in Malinsky et al. (2021) for the sim ulation study for mean estimation. F or K = 3 missing v ariables, missingness patterns (1 , 0 , 0), (0 , 1 , 0), (1 , 1 , 0), (0 , 0 , 1), (1 , 0 , 1), (0 , 1 , 1), (1 , 1 , 1), and (0 , 0 , 0) w ere sampled with probabilities 0 . 169, 0 . 153, 0 . 136, 0 . 119, 0 . 102, 0 . 085, 0 . 169, and 0 . 068 resp ectively (rounded to the 3 rd decimal place). Set the mean parameter vector for each missingness pattern R = r is µ 0 ( r ) = Σ 0 h ( r ) where h (1 , 0 , 0) = (1 . 4 , 1 . 6 , 0 . 9) ′ h (0 , 1 , 0) = (1 . 9 , 1 . 1 , 1 . 4) ′ h (1 , 1 , 0) = (1 . 9 , 1 . 6 , 0 . 2) ′ h (0 , 0 , 1) = (0 . 5 , 1 . 9 , 2 . 1) ′ h (1 , 0 , 1) = (0 . 5 , 2 . 4 , 0 . 9) ′ h (0 , 1 , 1) = (1 . 0 , 1 . 9 , 1 . 4) ′ h (1 , 1 , 1) = (1 . 0 , 2 . 4 , 0 . 2) ′ h (0 , 0 , 0) = (1 . 4 , 1 . 1 , 2 . 1) ′ . and the v ariance-cov ariance matrix as Σ 0 = 4 . 4 1 . 3 − 2 . 8 1 . 3 3 . 2 1 . 3 − 2 . 8 1 . 3 3 . 5 , It is straigh tforw ard to verify that under these parameter settings, the assumption of no self-censoring is met in the generated data. 34 Identifiable Deep La tent V ariable Models for MNAR Da t a Figure 7: Imputation RMSE with different latent dimensions for the missingness mecha- nism, dim( ˜ Z ) in UCI datasets with simulated no self-censoring missingness. Eac h column is a different dataset, and eac h ro w represen ts the true laten t dimension for the missingness mec hanism in the sim ulation in the corresp onding dataset. The y-axis sho ws the imputation RMSE on the synthetically missing en tries. The x-axis shows the latent dimension for the missingness mec hanism used in the learning model. App endix C. More Details on the Choice of the Laten t Dimension κ 2 W e exp erimen ted with the choice of laten t dimensions for the missingness mechanism using the UCI datasets. W e sim ulated missingness on the original complete UCI data according to no self-censoring with the latent q 2 dimensions chosen from 0 , ⌊ p/ 2 ⌋ and p , where p is the data dimension of eac h dataset. In each of these sim ulation settings, (fixing the latent dimensions for the data, whic h ha v e b een kno wn for the complete datasets through cross- v alidation using the generative mo dels,) we exp erimented with different laten t dimensions for the missingness mec hanism, κ 2 in the learning mo del. See Figure 7. There does not app ear to b e significan t difference among different choices of κ 2 in the learning model in each case, and choosing the dimension κ 2 to b e 1 w orks sufficien tly w ell in the learning model from these exp erimen ts, no matter what the true laten t dimensions are. This empirical result is consistent with the theoretical conclusion in Lemma 7. App endix D. Additional Exp erimen tal Results D.1 Maxim um Mean Discrepancy (MMD) for syn thetic data exp eriments W e presen t more n umerical results on the comparison of generated data in the syn thetic data experiments with the condition of no self-censoring in Section 5.1 in terms of maxim um mean discrepancy (MMD). As shown in T able 5 b elo w, the prop osed method sho ws a clear adv an tage o v er the other state-of-the-art metho ds in terms of mean of MMD when 35 Xie, Xue, W ang comparing the generated data distribution with the ground-truth complete-data distribution p g t ( x ). T able 5: Mean(SD) for maximum mean discrepancy (MMD) of simulated 3D no self- censoring missing data using differen t imputation metho ds, for b oth linear and nonlinear censoring with corresp onding generativ e mo del arc hitectures. Metho d Using laten t v ariables No laten t v ariables linear nonlinear linear nonlinear Prop osed 0.0086 (0.0074) 0.0062 (0.0071) 0.0126 (0.0203) 0.0053 (0.0039) GINA 0.0098 (0.0102) 0.0073 (0.0069) 0.0143 (0.0131) 0.0061 (0.0039) Not-MIW AE 0.0167 (0.0192) 0.0085 (0.0083) 0.0145 (0.0155) 0.0059 (0.0038) D.2 Experiments with no self-censoring in UCI data F or the real-w orld data from UCI machine learning repository , we ev aluated the imputation p erformance in scenarios where the missingness mec hanism aligns with the no self-censoring assumption, but without using laten t v ariables for the missingness mec hanism. T o empha- size the role of the MNAR mechanism, we primarily fo cused on linear transformations for generating the missingness indicators from the data. W e simulated the missingness according to no self-censoring without latent v ariables as describ ed in the synthetic exp eriments in Section 5.1. The results, as presented in T able 6, consisten tly indicated that our metho d outp er- formed alternativ e approac hes in the missingness mec hanism of no self-censoring, even though the simulation of missingness did not rely on laten t v ariables. T able 6: Mean(SD) for imputation RMSE on UCI Data with no self-censoring. By de- fault, the missingness mec hanisms in deep generativ e mo dels are general linear structures, while (nl) indicates that a nonlinear structure is used instead, and (s) means self-censoring structure which particularly applies to not-MIW AE. Metho d banknote concrete y east red wine white wine wa v eform Prop osed 0.62(0.09) 0.65(0.05) 0.91(0.08) 0.71(0.03) 0.75(0.02) 0.69(0.01) Prop osed(nl) 0.62(0.08) 0.67(0.05) 0.95(0.10) 0.73(0.04) 0.77(0.03) 0.70(0.01) GINA 0.82(0.12) 0.85(0.04) 1.06(0.05) 0.87(0.04) 0.91(0.02) 0.78(0.01) GINA(nl) 0.85(0.12) 0.90(0.05) 1.11(0.05) 0.91(0.04) 0.96(0.03) 0.79(0.01) Not-MIW AE 0.76(0.15) 0.81(0.10) 1.16(0.18) 0.85(0.07) 0.88(0.08) 0.73(0.01) Not-MIW AE(nl) 0.92(0.11) 0.85(0.08) 1.06(0.06) 0.86(0.04) 0.90(0.04) 0.77(0.02) Not-MIW AE(s) 1.82(0.78) 1.74(0.55) 2.44(0.67) 2.27(0.63) 2.37(0.4) 1.94(0.58) MICE 1.00(0.13) 1.01(0.05) 4.79(2.17) 1.01(0.05) 1.02(0.03) 0.94(0.02) MissF orest 0.87(0.15) 0.94(0.08) 1.46(0.29) 0.96(0.06) 0.97(0.07) 0.83(0.01) 36 Identifiable Deep La tent V ariable Models for MNAR Da t a D.3 Experiments with self-censoring in UCI data Despite its mild and flexible nature as a condition for nonparametric iden tification in MNAR data, it is imp ortant to ackno wledge that the no self-censoring mo del assumption ma y not alw a ys hold in real MNAR data scenarios. T o assess the robustness and adaptabilit y of our mo del in the presence of model missp ecification, we conducted a comparative analysis b y con trasting the results of differen t metho ds under the opp osite of no self-censoring within the MNAR regime — the self-censoring mo del. In the self-censoring mo del, we follo wed the metho dology outlined in Ipsen et al. (2020). Here, w e retained the v alues for half of the features, while for the other half, their v alues w ere set to b e missing if they exceeded the av erage v alue of that resp ectiv e feature. Among all MNAR mec hanisms, this particular setting stands out as one of the most c hallenging scenarios for a method based on the no self-censoring model, as it sp ecifically encompasses the self-censoring asp ect that our model inheren tly lac ks. In the results presen ted in T able 7, it is observ ed that not-MIW AE with a linear self- censoring mo del for missingness consisten tly outp erforms other mo dels. This aligns with exp ectations since it is the only mo del that matches the self-censoring assumption. Ho w ev er, when the self-censoring missingness mo del is replaced b y a general linear one, as seen in b oth not-MIW AE and GINA, there is a noticeable decline in performance, despite the linear self-censoring being a special case of the linear mo del. Remark ably , our prop osed model, which do es not incorp orate any mo deling of self- censoring, achiev es relatively acceptable results even in the presence of mo del missp eci- fication, particularly when using a nonlinear no self-censoring missingness mo del. This observ ation implies that the correlation b etw een data v ariables could make the no self- censoring mo del a practical assumption, even in scenarios where self-censoring might be a factor to consider. T able 7: Mean(SD) for imputation RMSE on UCI Data with self-censoring. The best tw o results are highligh ted. By default, the missingness mec hanisms in deep generativ e mo dels are general linear structures, while (nl) indicates that a nonlinear structure is used instead, and (s) means a self-censoring structure whic h particularly applies to not-MIW AE. The results sho w a certain degree of robustness of the prop osed metho d in the case of model missp ecification. Metho d banknote concrete y east red wine white wine wa v eform Prop osed 1.38(0.08) 1.77(0.10) 1.65(0.05) 1.52(0.03) 1.59(0.02) 1.45(0.02) Prop osed(nl) 1.21(0.04) 1.67(0.03) 1.65(0.05) 1.44(0.02) 1.57(0.02) 1.43(0.01) GINA 2.66(1.46) 2.37(1.32) 1.52(0.05) 1.88(0.56) 1.74(0.26) 1.55(0.10) Not-MIW AE 1.73(0.61) 1.99(0.67) 1.51(0.11) 1.79(0.65) 1.63(0.01) 1.52(0.04) Not-MIW AE(s) 1.04(0.16) 1.21(0.10) 1.27(0.12) 1.15(0.01) 1.20(0.03) 0.94(0.02) MICE 1.41(0.00) 1.87(0.00) 1.76(0.00) 1.68(0.00) 1.41(0.00) 1.42(0.00) MissF orest 1.28(0.01) 1.81(0.02) 1.72(0.01) 1.62(0.02) 1.63(0.01) 1.51(0.00) 37 Xie, Xue, W ang App endix E. Implementation Details in Exp eriments W e consider the implemen tation for both linear missingness models and nonlinear missing- ness mo dels, that is, whether p ψ ( r | x ) is a linear or nonlinear function of x . F or learning a linear missingness mo del, there are no hidden lay ers from input X and ˜ Z to the output R . W e can remo v e the connection betw een X j and R j for all 1 ≤ j ≤ p from the fully connected neural net w ork structure to arrive at a structure of no self-censoring. T o mo del a nonlinear relationship, at least one hidden lay er is added with a nonlinear transformation such as RELU or tanh . There is no direct wa y of removing edges from suc h a net w ork to obtain a no self-censoring effect. One brute-force w ay to implemen t this nonlinear self-censoring mo del is to use a whole set of unique edges for each missingness indicator R j for 1 ≤ j ≤ p and iterate through the dimensions. Instead, w e prop ose to use a shortcut b y remasking eac h corresp onding data v ariable X j with zero for each missingness indicator R j , while still sharing all the w eigh t parameters for eac h dimension j for 1 ≤ j ≤ p . This is inspired b y the practice of initial zero imputation prior to training used for DL VMs for missing data, which deactiv ates the propagation of the loss on the asso ciated weigh t parameters (Nazabal et al., 2020). The n um ber of parameters of the mo del can be kept down in this regime, and ev en smaller than a general missingness mechanism mo del without considering no self-censoring. F or all exp erimen ts, T ensorFlow probability (Dillon et al., 2017) and the Adam optimizer (Kingma and Ba, 2014) w ere emplo y ed, with the learning rate set at 0.001. No regularization tec hniques w ere applied. F or MICE and missF orest, we utilize the implementation in the Python pac k age sklearn directly . In the follo wing, we use D for the dimension of the laten t space for the data, and H for the n um ber of neurons in the hidden lay er. A 1-dimensional laten t space w as emplo y ed for the missingness indicators. In the inference netw ork, w e mainly utilized a structure of p - H - H -( D + 1), which maps the data (with missing data filled with zero) in to distributional parameters for the tw o latent spaces. The decoder p θ ( x | z ) follo w ed a structure of D - H - H - p . In the linear implemen tation of the missingness mo del, there was no hidden la y er, while in the nonlinear one, we included one hidden lay er. All neural net w orks incorporated tanh activ ations, except for the output la y er where no activ ation function was used. The generativ e mo dels adopted the ob jectives with K = 20 imp ortance samples. The observ ational noise γ for the data v ariables w as set as a learnable parameter in the mo del. All metho ds were trained with a batch size of 16 for 10k epo chs. Imputation RMSE w as estimated using 10k imp ortance samples. F or data generation, w e generated from the latent v ariables one sample for each data dimension in each iteration. Sim ulation W e used latent dimension H = 128 with D = 3 for low-dimensional data, and D = 10 for high-dimensional data in the sim ulation. In the mixture of Gaussians, we simplified the net w ork structures to ha ve one hidden la yer for both the enco der and deco der for the data, p - H -( D + 1) and D - H - p resp ectiv ely , and the maxim um num b er of ep o chs w ere set to b e 20k. UCI data W e used laten t dimension D = p − 1 for UCI data, where the data were stan- dardized to hav e a mean of 0 and unit v ariance b efore introducing missing v alues. And the data are randomly shuffled at the beginning of eac h iteration of the exp eriment. HIV data As the data is binary , one can not differentiate b et w een the zero v alues and the initial zero imputation, w e input both the data and missingness indicators to the encoder 38 Identifiable Deep La tent V ariable Models for MNAR Da t a and employ ed an enco der structure similar to the one in the synthetic experiment for a mixture of Gaussians. Additionally , a Bernoulli decoder instead of a Gaussian deco der w as used for the data. Y ahoo! data Prior to training, all user ratings are normalized to fall within the range of 0 to 1 (this normalization will b e rev ersed during ev aluation). Gaussian likelihoo d with a v ariance of γ = 0 . 02 is emplo y ed for all the generativ e mo dels. A 20-dimensional laten t space for the data is utilized, and the decoder follo ws a structure of 20-10- p . The inference netw ork adopts the point net structure prop osed b y Ma et al. (2018), employing a 20-dimensional feature mapping h parameterized b y a single-lay er neural netw ork and 20-dimensional ID v ectors for each v ariable. The symmetric operator is defined as the summation op erator. The missing mo del is parameterized b y a linear neural net w ork. All metho ds underw ent training for 100 ep o chs with a batc h size of 100. Imputation RMSE was estimated using 10 imp ortance samples. References Jordank a A Angelov a. On moments of sample mean and v ariance. Int. J. Pur e Appl. Math , 79(1):67–85, 2012. Arth ur Asuncion and Da vid Newman. UCI mac hine learning rep ository , 2007. Tim Austin. Exc hangeable random measures. In Annales de l’IHP Pr ob abilit ´ es et statis- tiques , v olume 51, pages 842–861, 2015. Y uri Burda, Roger Grosse, and Ruslan Salakhutdino v. Importance w eighted auto enco ders. arXiv pr eprint arXiv:1509.00519 , 2015. Hua Y un Chen. Compatibility of conditionally sp ecified mo dels. Statistics & pr ob ability letters , 80(7-8):670–677, 2010. Jennifer Y Chen, Heather J Ribaudo, Sa jini Souda, Natasha P arekh, Anthon y Ogwu, Shahin Lo c kman, Kathleen Po wis, Scott Dryden-Peterson, T racy Creek, William Jimbo, et al. Highly activ e an tiretro viral therapy and adv erse birth outcomes among HIV-infected w omen in b otswana. The Journal of infe ctious dise ases , 206(11):1695–1705, 2012. Xi Chen, Y an Duan, Rein Houtho oft, John Sch ulman, Ily a Sutskev er, and Pieter Abb eel. Infogan: Interpretable represen tation learning by information maximizing generativ e ad- v ersarial nets. A dvanc es in neur al information pr o c essing systems , 29, 2016. Bira j Dahal, Alexander Havrilla, Minsh uo Chen, T uo Zhao, and W enjing Liao. On deep gen- erativ e mo dels for appro ximation and estimation of distributions on manifolds. A dvanc es in Neur al Information Pr o c essing Systems , 35:10615–10628, 2022. Bin Dai and David Wipf. Diagnosing and enhancing V AE models. arXiv pr eprint arXiv:1903.05789 , 2019. Josh ua V Dillon, Ian Langmore, Dustin T ran, Eugene Brevdo, Sriniv as V asudev an, Dav e Mo ore, Brian Patton, Alex Alemi, Matt Hoffman, and Rif A Saurous. T ensorflo w distri- butions. arXiv pr eprint arXiv:1711.10604 , 2017. 39 Xie, Xue, W ang Benjamin Djulb egovic, Jef v an den Ende, Robert M Hamm, Thomas Mayrhofer, Iztok Hozo, Stephen G P auk er, and In ternational Threshold W orking Group (ITW G). When is rational to order a diagnostic test, or prescrib e treatmen t: the threshold mo del as an explanation of practice v ariation. Eur op e an journal of clinic al investigation , 45(5): 485–493, 2015. Rob ert E F ay . Causal mo dels for patterns of nonresp onse. Journal of the Americ an Statis- tic al Asso ciation , 81(394):354–365, 1986. Jos ´ e Miguel Hern´ andez-Lobato, Neil Houlsb y , and Zoubin Ghahramani. Probabilistic matrix factorization with non-random missing data. In International Confer enc e on Machine L e arning , pages 1512–1520. PMLR, 2014. Søren Højsgaard, Da vid Edw ards, and Steffen Lauritzen. Gr aphic al mo dels with R . Springer Science & Business Media, 2012. Niels Bruun Ipsen, Pierre-Alexandre Mattei, and Jes F rellsen. not-MIW AE: Deep generativ e mo delling with missing not at random data. arXiv pr eprint arXiv:2006.12871 , 2020. Jan us Christian Jak obsen, Christian Gluud, Jørn W etterslev, and P er Wink el. When and ho w should multiple imputation b e used for handling missing data in randomised clinical trials–a practical guide with flow c harts. BMC me dic al r ese ar ch metho dolo gy , 17(1):1–10, 2017. Ola v Kallen berg and Olav Kallenberg. F oundations of mo dern pr ob ability , v olume 2. Springer, 1997. Diederik P Kingma and Jimmy Ba. Adam: A metho d for sto c hastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. Diederik P Kingma and Max W elling. Auto-enco ding v ariational ba y es. arXiv pr eprint arXiv:1312.6114 , 2013. Stev en Cheng-Xian Li, Bo Jiang, and Benjamin Marlin. MisGAN: Learning from incomplete data with generative adversarial netw orks. arXiv pr eprint arXiv:1902.09599 , 2019. Yilin Li, W ang Miao, Ily a Shpitser, and Eric J Tchetgen Tc hetgen. A self-censoring mo del for multiv ariate nonignorable nonmonotone missing data. arXiv pr eprint arXiv:2207.08535 , 2022. Da w en Liang, Laurent Charlin, and David M Blei. Causal inference for recommendation. In Causation: F oundation to Applic ation, Workshop at UAI. A UAI , 2016a. Da w en Liang, Lauren t Charlin, James McInerney , and Da vid M Blei. Mo deling user expo- sure in recommendation. In Pr o c e e dings of the 25th international c onfer enc e on World Wide Web , pages 951–961, 2016b. An tonio R Linero. Bay esian nonparametric analysis of longitudinal studies in the presence of informativ e missingness. Biometrika , 104(2):327–341, 2017. 40 Identifiable Deep La tent V ariable Models for MNAR Da t a Guang Ling, Haiqin Y ang, Mic hael R Lyu, and Irwin King. Resp onse a ware mo del-based collab orativ e filtering. arXiv pr eprint arXiv:1210.4869 , 2012. Ro deric k JA Little and Donald B Rubin. Statistic al analysis with missing data , volume 793. John Wiley & Sons, 2019. Ra ymond Y Lo, William J Jagust, Paul Aisen, Clifford R Jac k Jr, Arthur W T oga, Laurel Bec k ett, An thon y Gamst, Holly Soares, Rob ert C. Green, T om Mon tine, et al. Predicting missing biomarker data in a longitudinal study of alzheimer disease. Neur olo gy , 78(18): 1376–1382, 2012. Chao Ma and Cheng Zhang. Iden tifiable generative mo dels for missing not at random data imputation. A dvanc es in Neur al Information Pr o c essing Systems , 34:27645–27658, 2021. Chao Ma, Sebastian Tschiatsc hek, Konstan tina P alla, Jos´ e Miguel Hern´ andez-Lobato, Se- bastian No w ozin, and Cheng Zhang. Eddi: Efficient dynamic discov ery of high-v alue information with partial V AE. arXiv pr eprint arXiv:1809.11142 , 2018. W ei Ma and George H Chen. Missing not at random in m atrix completion: The effectiv eness of estimating missingness probabilities under a lo w nuclear norm assumption. A dvanc es in neur al information pr o c essing systems , 32, 2019. W en-Qing Ma, Zhi Geng, and Y ong-Hua Hu. Iden tification of graphical mo dels for nonig- norable nonresp onse of binary outcomes in longitudinal studies. Journal of multivariate analysis , 87(1):24–45, 2003. Daniel Malinsky , Ilya Shpitser, and Eric J Tc hetgen Tc hetgen. Semiparametric inference for nonmonotone missing-not-at-random data: the no self-censoring model. Journal of the Americ an Statistic al Asso ciation , pages 1–9, 2021. Benjamin M Marlin and Richard S Zemel. Collab orativ e prediction and ranking with non- random missing data. In Pr o c e e dings of the thir d ACM c onfer enc e on R e c ommender systems , pages 5–12, 2009. Giampiero Marra, Rosalba Radice, Till B¨ arnighausen, Simon N W oo d, and Mark E McGo v- ern. A sim ultaneous equation approac h to estimating HIV prev alence with nonignorable missing resp onses. Journal of the Americ an Statistic al Asso ciation , 112(518):484–496, 2017. Pierre-Alexandre Mattei and Jes F rellsen. MIW AE: Deep generativ e modelling and impu- tation of incomplete data sets. In International c onfer enc e on machine le arning , pages 4413–4423. PMLR, 2019. Karthik a Mohan and Judea P earl. Graphical mo dels for pro cessing missing data. Journal of the A meric an Statistic al Asso ciation , 116(534):1023–1037, 2021. Karthik a Mohan, Judea Pearl, and Jin Tian. Graphical mo dels for inference with missing data. A dvanc es in neur al information pr o c essing systems , 26, 2013. 41 Xie, Xue, W ang Razieh Nabi, Rohit Bhattac hary a, and Ily a Shpitser. F ull la w identification in graphical mo dels of missing data: Completeness results. In International Confer enc e on Machine L e arning , pages 7153–7163. PMLR, 2020. Alfredo Nazabal, Pablo M Olmos, Zoubin Ghahramani, and Isab el V alera. Handling incom- plete heterogeneous data using V AEs. Pattern R e c o gnition , 107:107501, 2020. James M Robins. Non-resp onse mo dels for the analysis of non-monotone non-ignorable missing data. Statistics in me dicine , 16(1):21–37, 1997. James M Robins, Andrea Rotnitzky , and Lue Ping Zhao. Estimation of regression co effi- cien ts when some regressors are not alw a ys observ ed. Journal of the A meric an statistic al Asso ciation , 89(427):846–866, 1994. Mauricio Sadinle and Jerome P Reiter. Itemwise conditionally indep endent nonresponse mo delling for incomplete multiv ariate data. Biometrika , 104(1):207–220, 2017. Mauricio Sadinle and Jerome P Reiter. Sequential identification of nonignorable missing data mec hanisms. Statistic a Sinic a , 28(4):1741–1759, 2018. T obias Schnabel, Adith Sw aminathan, Ashudeep Singh, Navin Chandak, and Thorsten Joac hims. Recommendations as treatments: Debiasing learning and ev aluation. In inter- national c onfer enc e on machine le arning , pages 1670–1679. PMLR, 2016. Ily a Shpitser. Consistent estimation of functions of data missing non-monotonically and not at random. A dvanc es in Neur al Information Pr o c essing Systems , 29, 2016. Daniel J Stekho ven and Peter B ¨ uhlmann. MissF orest—non-parametric missing v alue im- putation for mixed-type data. Bioinformatics , 28(1):112–118, 2012. BaoLuo Sun, Lan Liu, W ang Miao, Kathleen Wirth, James Robins, and Eric J Tc hetgen Tc hetgen. Semiparametric estimation with data missing not at random using an instru- men tal v ariable. Statistic a Sinic a , 28(4):1965, 2018. Eric J Tc hetgen Tc hetgen, Lin b o W ang, and BaoLuo Sun. Discrete c hoice mo dels for nonmonotone nonignorable missing data: Identification and inference. Statistic a Sinic a , 28(4):2069, 2018. Stef V an Buuren and Karin Groothuis-Oudshoorn. MICE: Multiv ariate imputation b y c hained equations in R. Journal of statistic al softwar e , 45:1–67, 2011. Kevin W ang, Hongqian Niu, Yixin W ang, and Didong Li. Deep generative mo dels: Com- plexit y , dimensionality , and approximation. arXiv pr eprint arXiv:2504.00820 , 2025. Xiao jie W ang, Rui Zhang, Y u Sun, and Jianzhong Qi. Doubly robust joint learning for recommendation on data missing not at random. In International Confer enc e on Machine L e arning , pages 6638–6647. PMLR, 2019. Yixin W ang and Da vid M Blei. The blessings of multiple causes. Journal of the A meric an Statistic al Asso ciation , 114(528):1574–1596, 2019. 42 Identifiable Deep La tent V ariable Models for MNAR Da t a Yixin W ang, Da wen Liang, Lauren t Charlin, and David M Blei. The deconfounded recommender: A causal inference approach to recommendation. arXiv pr eprint arXiv:1808.06581 , 2018. Jinsung Y oon, James Jordon, and Mihaela Sc haar. GAIN: Missing data imputation using generativ e adv ersarial nets. In International c onfer enc e on machine le arning , pages 5689– 5698. PMLR, 2018. Hua Y un Chen. A semiparametric o dds ratio model for measuring asso ciation. Biometrics , 63(2):413–421, 2007. 43
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment