멜로디 유지와 가사 자유 편집을 동시에 YingMusic Singer
YingMusic‑Singer는 세 가지 입력(음색 참조, 멜로디 제공 클립, 수정된 가사)만으로 수동 정렬 없이 멜로디를 보존하면서 가사를 자유롭게 바꿀 수 있는 완전 diffusion 기반 노래 음성 합성 모델이다. 커리큘럼 학습과 Group Relative Policy Optimization(GRPO)을 도입해 음성 인식 오류와 멜로디 일치 사이의 트레이드오프를 완화했으며, Vevo2 대비 멜로디 보존, 가사 정확도, 주관적 자연스러움 모…
저자: Chunbo Hao, Junjie Zheng, Guobin Ma
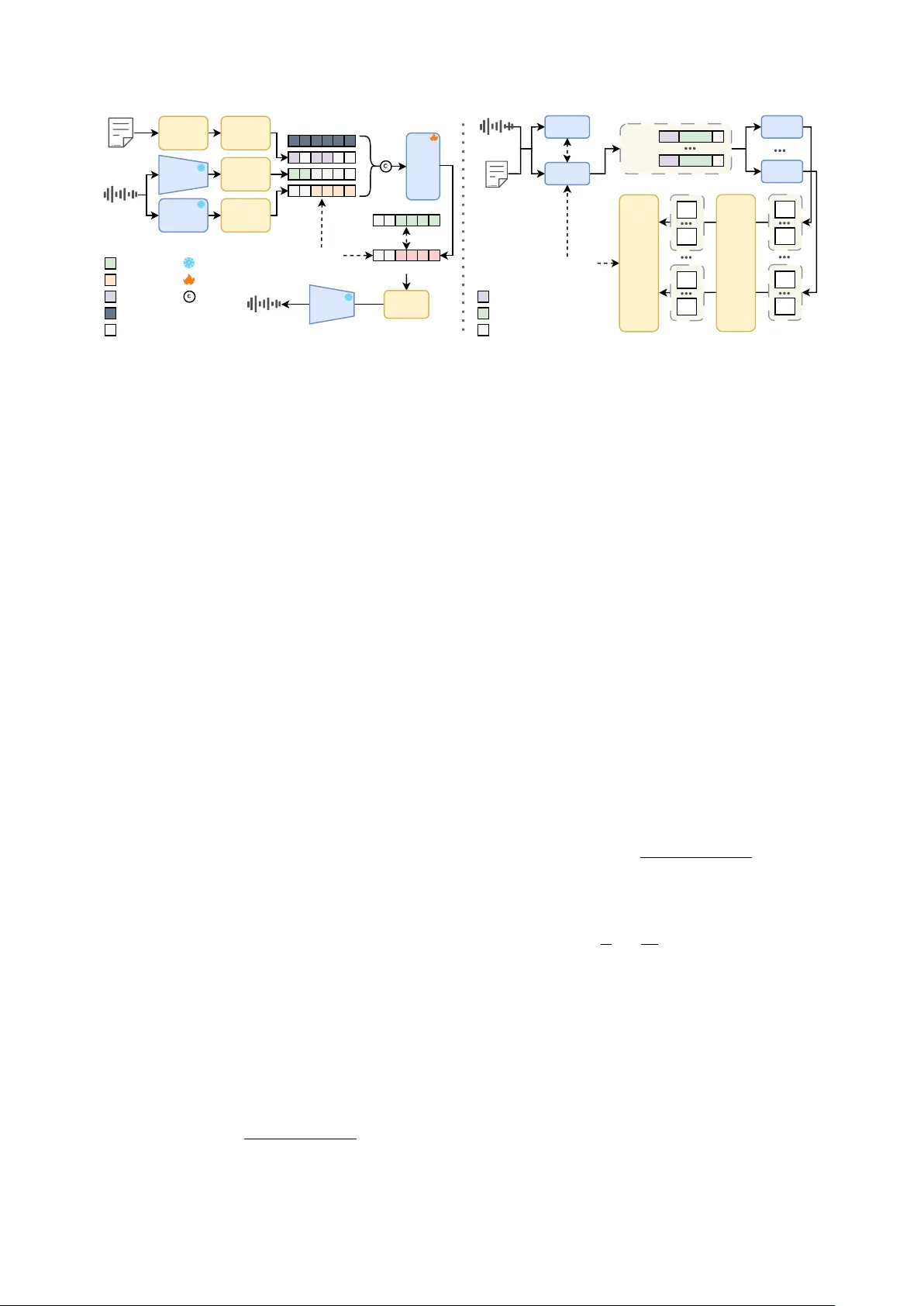
본 논문은 ‘노래 음성 편집(노래 가사 수정 후 멜로디 유지)’이라는 실용적이면서도 기술적으로 어려운 문제를 해결하기 위해 YingMusic‑Singer라는 완전 diffusion 기반 모델을 제안한다. 기존 방법은 크게 두 갈래로 나뉜다. 첫 번째는 인컨텍스트 학습으로 주변 컨텍스트를 이용해 마스크된 구간을 재생성하는 방식인데, 이는 지역적인 편집에만 국한되고 멜로디 제어가 제한적이다. 두 번째는 상용 SVS 툴(예: Synthesizer V, ACE Studio)처럼 사용자가 직접 가사와 멜로디를 정렬해야 하는 방식으로, 높은 제어성을 제공하지만 정렬 작업이 번거롭고 다국어·번역 작업에서 비용이 크게 증가한다. 이러한 한계를 극복하고자 저자들은 세 가지 입력(음색 참조, 멜로디 제공 클립, 수정된 가사)만으로 정렬 없이 바로 합성을 수행하는 파이프라인을 설계했다.
모델 아키텍처는 크게 네 부분으로 구성된다. 첫 번째는 Stable Audio 2 기반의 VAE로, 44.1 kHz 스테레오 파형을 2048배 다운샘플링해 잠재 공간(z∈ℝ^{T'×D})에 매핑하고, 디코더가 고품질 오디오를 복원한다. 두 번째는 사전 학습된 MIDI 추출 모델의 인코더를 활용한 멜로디 추출기(M)로, 입력 클립에서 멜로디 특성(h∈ℝ^{L×D_m})을 추출하고 시간 보간을 통해 VAE 잠재 프레임 레이트에 맞춘다. 세 번째는 중국어·영어 모두를 지원하는 IPA 토크나이저로, 가사를 음소 시퀀스로 변환하고 문장 수준 정렬을 적용해 프롬프트와 타깃 영역을 구분한다. 마지막으로 DiT 기반 조건부 흐름 모델(CFM)을 사용해 노이즈가 섞인 잠재(z_t)와 조건(c=
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기