YingMusic-Singer: Controllable Singing Voice Synthesis with Flexible Lyric Manipulation and Annotation-free Melody Guidance
Regenerating singing voices with altered lyrics while preserving melody consistency remains challenging, as existing methods either offer limited controllability or require laborious manual alignment. We propose YingMusic-Singer, a fully diffusion-ba…
Authors: Chunbo Hao, Junjie Zheng, Guobin Ma
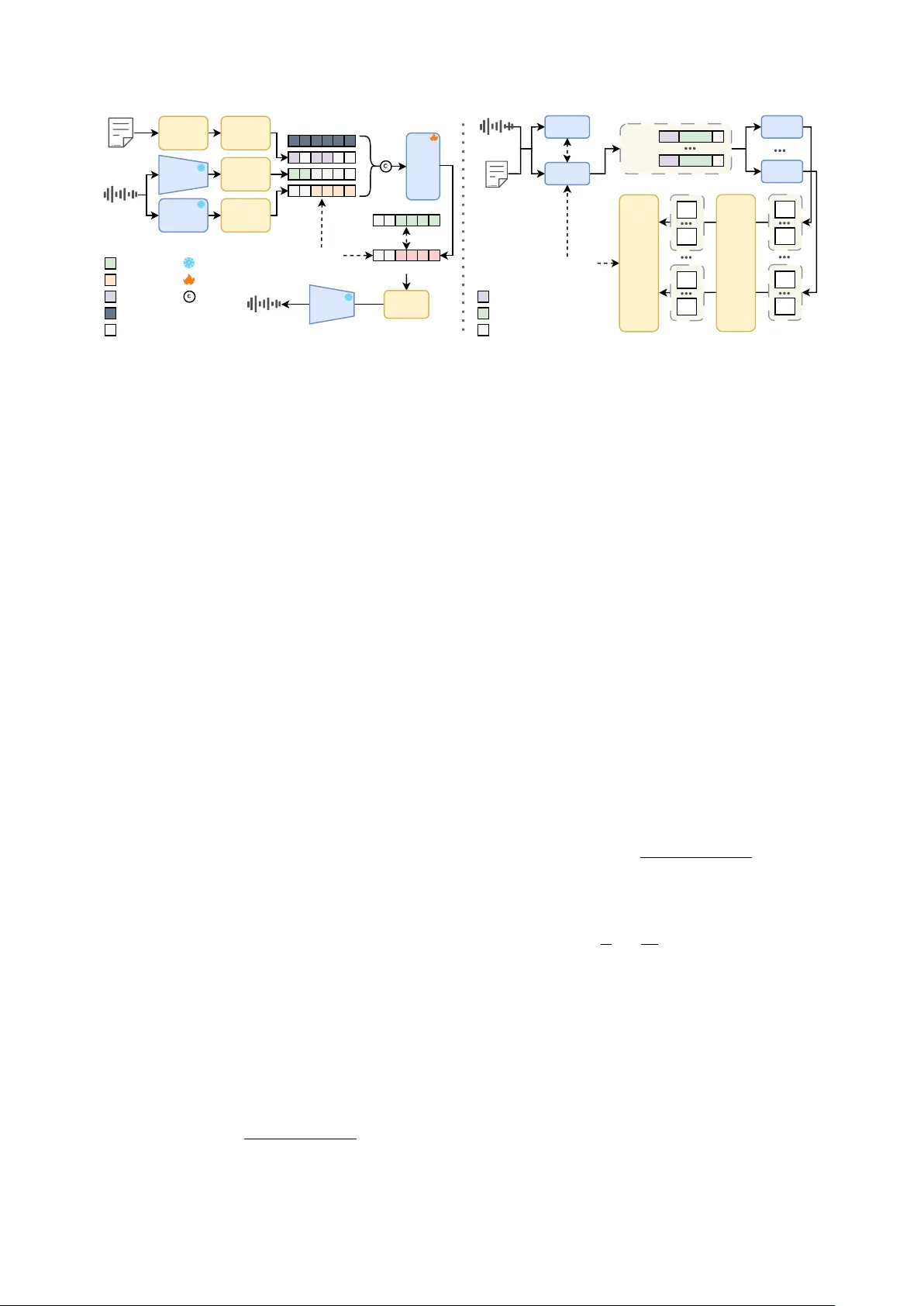
Y ingMusic-Singer: Contr ollable Singing V oice Synthesis with Flexible L yric Manipulation and Annotation-fr ee Melody Guidance Chunbo Hao ID 1 , 2 , J unjie Zheng ID 2 , Guobin Ma ID 1 , Y uepeng Jiang 1 , Huakang Chen 1 , W enjie T ian 1 , Gongyu Chen ID 2 , Zihao Chen ID 2 , Lei Xie 1 , ∗∗ 1 Audio, Speech and Language Processing Group (ASLP@NPU) School of Computer Science, Northwestern Polytechnical Uni versity , China 2 AI Lab, GiantNetwork, China cbhao@mail.nwpu.edu.cn, zhengjunjie@ztgame.com, lxie@nwpu.edu.cn Abstract Regenerating singing voices with altered lyrics while preserv- ing melody consistency remains challenging, as existing meth- ods either offer limited controllability or require laborious manual alignment. W e propose Y ingMusic-Singer, a fully diffusion-based model enabling melody-controllable singing voice synthesis with flexible lyric manipulation. The model takes three inputs: an optional timbre reference, a melody- providing singing clip, and modified lyrics, without manual alignment. T rained with curriculum learning and Group Rela- tiv e Policy Optimization, Y ingMusic-Singer achiev es stronger melody preservation and lyric adherence than V e vo2, the most comparable baseline supporting melody control with- out manual alignment. W e also introduce L yricEditBench, the first benchmark for melody-preserving lyric modification ev aluation. The code, weights, benchmark, and demos are publicly av ailable at https://github.com/ASLP- lab/ YingMusic- Singer . Index T erms : singing voice synthesis, lyric editing, reinforce- ment learning, diffusion model 1. Intr oduction Singing V oice Synthesis (SVS) aims to generate human-like singing voices from musical scores, lyrics, and timbre refer- ences. Modern systems [1, 2, 3, 4, 5, 6] achiev e high-fidelity synthesis, yet most rely on precisely annotated paired data as- sociating each phoneme with an exact pitch contour and du- ration. While such fine-grained control is indispensable for professional music production, preparing these annotations cre- ates a prohibitiv e barrier for an increasingly important use case, singing voice editing , which regenerates an existing singing voice with modified lyrics while preserving the original melodic and rhythmic structure. This capability is highly desirable for song adaptation, personalized cov er generation, rapid prototyp- ing of vocal arrangements, and multilingual song localization. Existing editing paradigms fall into two categories. The first adopts an in-context learning strate gy that masks the region to be edited and regenerates it conditioned on the surround- ing context and target lyrics [7, 8]. Although con venient, this approach is restricted to local segments and provides limited melody control. The second category , widely adopted in prac- tice, relies on commercial SVS models such as Synthesizer V 1 and ACE Studio 2 , where users manually align modified lyrics ** indicates the corresponding author . 1 https://dreamtonics.com/synthesizerv 2 https://acestudio.ai with MIDI notes and durations before re-synthesizing the audio. This pipeline offers strong controllability but demands manual effort, and the complexity increases for tasks such as cross- lingual translation. In summary , existing approaches either de- pend on the surrounding context to recover melody or require manual alignment of word-le vel timestamps with melody infor - mation, limiting their flexibility and scalability . Se veral recent efforts address these challenges. V ev o2 [9] achieves melody- controllable generation, yet suffers from reduced intelligibility and poor melody adherence. SoulX-Singer [10] supports exist- ing singing as melody input but still requires manual alignment of word-level timestamps, lea ving the core burden unresolved. While these recent efforts narrow the gap, they either achie ve suboptimal performance or still need manual alignment. T o address these challenges, we propose Y ingMusic-Singer , a fully dif fusion-based SVS model. First, Y ingMusic-Singer introduces a streamlined editing paradigm that synthesizes singing voices from only three inputs, namely an optional tim- bre reference clip, a singing clip providing the tar get melody , and the corresponding modified lyrics, without the need for manual alignment or precise annotation. Second, to miti- gate limited phoneme generalization caused by the small scale and challenging vocal techniques in singing data, and to ad- dress the inherent trade-off between faithful lyric reproduc- tion and melody adherence, we employ a curriculum training strategy combined with Group Relati ve Policy Optimization (GRPO) [11], enabling strong performance on both dimensions simultaneously . Third, we construct LyricEditBench based on GTSinger [12], the first benchmark for lyric modification ev al- uation under matched melody conditions, cov ering six common editing scenarios with balanced sampling for fair and compre- hensiv e comparison. Experiments sho w that Y ingMusic-Singer outperforms V evo2 [9], currently a comparable alignment-free alternativ e, in both melody preserv ation and lyric adherence. W e will release model weights, inference code, and L yricEd- itBench to facilitate further research and advance the practical adoption of singing voice editing. 2. Methodology 2.1. Architectur e Overview As sho wn in Figure 1, Y ingMusic-Singer generates singing voices at 44.1 kHz from three inputs: an optional timbre ref- erence, a melody-providing singing clip, and corresponding modified lyrics. It comprises: (1) a V ariational Autoencoder (V AE) follo wing Stable Audio 2 [13], whose encoder E down- samples a stereo 44.1 kHz singing wa veform x ∈ R T × 2 by DiT Blocks Sing W aveform L yric V AE Encoder CKA Loss × N Generated Sing MSE Loss V AE Latent Melody Latent L yric IP A Random Noise P AD Training Frozen V AE Decoder Concat T arget Latent Predicted Flow ODE Solver Sentence Alignment IP A T okenizer Melody Extractor Interpolation & Perturbation Group 1 Group G Reward Model 1 Reward Model 2 Clipped Loss SingEdit Ref Model R 1 1 R 1 G Rewards R M 1 R M G A 1 1 A 1 G A M 1 A M G Advantages Group Compute W eighted A verage Generated Sing Pad Prompt Sing Sing W aveform T arget L yric SingEdit Sample KL Loss Random Mask Figure 1: Over all ar chitectur e of Y ingMusic-Singer . Left: the training pipeline consisting of a V ariational Autoencoder , a Melody Extractor , an IP A T okenizer , and DiT -based conditional flow matching. Right: the GRPO training pipeline. a factor of 2048 into z = E ( x ) ∈ R T ′ × D , and whose de- coder D reconstructs high-fidelity audio ˆ x = D ( z ) at infer - ence; (2) a Melody Extractor built upon the encoder of a pre- trained MIDI e xtraction model, whose intermediate represen- tations naturally capture disentangled melody information. It produces h = M ( M ) ∈ R L × D m , which is then temporally in- terpolated to ˜ h ∈ R T ′ × D m to match the V AE latent frame rate; (3) an IP A T okenizer that conv erts both Chinese and English lyrics into a unified discrete phoneme sequence. T o ensure the model correctly distinguishes between prompt and generation regions, av oiding phoneme omission or repetition at boundaries, we adopt sentence-lev el alignment following DiffRhythm [14]. Each lyric sentence is con verted into an IP A subsequence and placed at its corresponding onset frame within a padded frame- lev el sequence of length T ′ . The aligned sequence is passed through a learnable embedding layer to yield e ∈ R T ′ × D e . During inference, prompt lyrics are placed at the beginning of the sequence and target lyrics at the start of the masked region, requiring no timestamp annotation from the user; and (4) a DiT - based CFM backbone following F5-TTS [15]. During training, a proportion γ of V AE latent frames is randomly masked as the synthesis tar get, with the unmasked portion serving as timbre context. Let z ctx denote the un- masked V AE latent (zero-filled in masked regions). The con- dition c = [ ˜ h ; e ; z ctx ] is concatenated with the noisy latent z t = (1 − t ) z 0 + t z 1 along the channel dimension and fed into the CFM, which learns a velocity field via: L MSE = E t, z 0 , z 1 , c ∥ v θ ( z t , t, c ) − ( z 1 − z 0 ) ∥ 2 . (1) 2.2. Curriculum T raining T o mitigate limited phoneme generalization caused by the small scale and challenging vocal techniques in singing data, Y ingMusic-Singer first undergoes TTS Pretr aining without melody conditioning. The subsequent Singing V oice Super- vised F ine-T uning (SFT) stage has two phases. Phase 1 enables sentence-lev el alignment on singing data, allowing the model to adapt to the singing domain. Phase 2 activ ates melody con- ditioning and introduces a Centered Kernel Alignment (CKA) loss to enforce melody adherence. Gi ven the predicted v θ and melody ˜ h , CKA measures their alignment via Gram matrices K = v θ v ⊤ θ and L = ˜ h ˜ h ⊤ : L CKA = 1 − ∥ K ⊤ L ∥ 2 F ∥ K ⊤ K ∥ F ∥ L ⊤ L ∥ F , (2) and the total phase 2 loss is L SFT = L MSE + λ L CKA . 2.3. Group Relative Policy Optimization While curriculum training achiev es high performance, SFT Phase 2 simultaneously degrades PER, exposing a persistent trade-off. L MSE targets holistic latent reconstruction and can- not isolate specific deficiencies for tar geted optimization, while adjusting λ in L CKA only shifts the balance without resolv- ing the trade-off itself. Moreover , ine vitable noise in large- scale singing data, such as backing vocals and quality artifacts, caps model performance at the dataset ceiling. T o o vercome these limitations, reinforcement learning (RL) becomes essen- tial. PPO requires a v alue netw ork that is e xpensive to train. Offline methods such as DPO suffer from distribution shift, as pre-collected preference data becomes stale when the policy improv es. GRPO [11] operates online and estimates baselines from within-group reward statistics, eliminating the v alue net- work while remaining ef ficient and stable. Follo wing recent efforts [16, 17, 18], we conv ert the deter- ministic ODE trajectory into an SDE but restrict stochastic steps to a bounded window , ensuring precise advantage attrib ution to exploratory steps. T o prev ent collapse toward a single rew ard dimension, we employ M reward models jointly and compute the advantage for each sample as A i = M X k =1 w k R i k − mean( { R j k } ) std( { R j k } ) , (3) and the final GRPO loss is L GRPO ( θ ) = 1 G G X i =1 1 | S | X t ∈ S ( −L clip + β D KL ) , (4) where L clip is the clipped surrogate objective over the current- to-old policy likelihood ratio, D KL regularizes the current pol- icy toward the reference, G is the group size, S the set of SDE sampling steps, and β the KL regularization strength. 2.4. L yricEditBench W e build L yricEditBench from GTSinger [12] by removing all Paired Speech Group content, deduplicating audio via MD5 hashing, and excluding clips exceeding 15 seconds. DeepSeek V3.2 [19] then generates modified lyrics for each of the six T able 1: T ask types for lyric modification in LyricEditBenc h. Abbr . T ask T ype Description PSub Partial Substitution Substitute part of the words FSub Full Substitution Completely rewrite the song Del Deletion Delete some words Ins Insertion Insert some words T rans T ranslation CN ↔ EN translation Mix Code-Mixing Mixed-language lyrics modification types in T able 1. Given original lyrics and modifi- cation instructions, the LLM produces revised v ersions, with non-compliant outputs discarded, yielding 11,535 v alid sam- ples. Samples are classified by singer gender (male/female) and language (Chinese/English) into four categories, then orga- nized by modification type. For each combination, we select 30 samples per singing technique (cov ering the six techniques in GTSinger) and 120 for the technique-free category , resulting in 300 per modification type per category and 7,200 test instances in total. For each instance, a timbre prompt of no more than 15 seconds is randomly drawn from the remaining audio pool, so each L yricEditBench instance comprises a melody reference clip, a timbre prompt, and the corresponding modified lyrics. 3. Experimental Setup Dataset. The Chinese and English subsets of Emilia [20] are used for TTS pretraining. F or Singing V oice SFT , internally licensed music tracks are processed by SongF ormer [21] to seg- ment structural boundaries and label function categories, dis- carding non-vocal segments. V ocal stems are then isolated us- ing Mel-band RoFormer [22]. W e retain clips between 2 and 30 seconds, splitting longer ones at sentence boundaries, ulti- mately obtaining 33,562.6 hours of singing data. The GRPO dataset is constructed by filtering SFT data with three criteria: ASR transcript verification, retaining only clips with a word er- ror rate below 5%, speaker diarization via pyannote [23, 24], keeping only single-speaker clips, and a DNSMOS P808 qual- ity score [25, 26] threshold of 3.5. This yields approximately 20,240 curated clips with balanced Chinese and English con- tent. The test set in the proposed L yricEditBench is strictly ex- cluded from training. Evaluation Metrics. W e ev aluate models with four ob- jectiv e and two subjectiv e metrics. For objectiv e ev aluation, Phoneme Err or Rate (PER) measures phoneme-lev el intelligi- bility , as singing exhibits lo wer semantic density , fewer contex- tual cues, and greater pronunciation variation than speech. Both Chinese and English clips are transcribed by singing-trained Qwen3-ASR-1.7B [27] and con verted to phoneme sequences with tone markers removed. Speaker Similarity (SIM) follows F5-TTS [15], e xtracting speaker embeddings with a W avLM- large-based verification model and computing cosine similarity . F0 P earson Corr elation (F0-CORR) measures melody adher- ence via frame-wise Pearson correlation between F0 contours of generated and reference clips using RMVPE [28]. V ocal Scor e (VS) adopts V ocalV erse2 [29] as a learned metric aligned with human perceptual preferences. For subjective ev aluation, 120 samples uniformly sampled across task types and languages are rated by 30 listeners on two dimensions: Naturalness Mean Opinion Score (N-MOS) for overall perceptual quality and nat- uralness, and Melody Mean Opinion Score (M-MOS) for faith- fulness to the reference melody , both on a 5-point scale. Implementation Details. W e adopt the V AE from Stable Audio 2 [13] ( D = 64 ), the encoder of SOME 3 as Melody Extractor ( D m = 128 , temporal dropout 0.1), and a DiT back- bone following F5-TTS [15] (22 layers, 16 heads, hidden dim 1024, D e = 512 ). The full system has ∼ 727.3M parame- ters (453.6M CFM, 156.1M V AE, 117.6M Melody Extractor), trained on 8 × A800 80GB GPUs with DDP and bf16. Across all stages, 70%–100% of latent frames are randomly masked. TTS pretraining runs for 1M steps (batch duration 1.268h, lr 1e-4). Singing V oice SFT Phase 1 disables melody condition- ing for 240K steps; Phase 2 enables it for 170K steps ( λ decayed from 0.3 to 0.01 ov er the first 2K steps; batch duration 1.69h, lr 2.5e-5). F or GRPO, G =8 candidates are scored by M =4 equally weighted re ward models (SDE noise a =0 . 8 , windo w W with w min =1 , w s =8 , ϵ u =0 . 01 , ϵ l =0 . 002 , β =1 ), optimized for 1.2K steps (batch size 6, lr 7e-6) without CFG. Inference uses 32 ODE steps with CFG scale 3. 4. Experimental Results 4.1. Main Results W e compare against V ev o2 [9], a token-based autore gressive model with disentangled timbre and melody control, where the timbre and melody references share the same clip for singing voice editing, or use separate clips for melody control. V evo2 is the most direct baseline, as other systems operate under funda- mentally dif ferent paradigms: in-conte xt learning approaches require manually aligned edit boundaries and are restricted to local segments, while SoulX-Singer relies on precise character- lev el timestamps that are either impractical to obtain or would grant an unrealistic advantage if sourced from curated datasets. As sho wn in T able 2, Y ingMusic-Singer consistently out- performs V e vo2 across all six modification types under both Melody Control and Sing Edit settings in PER, F0-CORR, and VS, demonstrating strong adherence to both the reference melody and modified lyrics. The intelligibility gap is most pronounced on Trans and Mix tasks, indicating that recon- structing a substantially dif ferent phoneme sequence while pre- serving melody is inherently challenging. Note that PER on Mix tasks may be further inflated by ASR hallucinations on code-switched utterances. V e vo2’ s incomplete melody disen- tanglement tends to reduce intelligibility and introduce halluci- nations, whereas Y ingMusic-Singer’ s unified IP A tokenization and GRPO-based lyric adherence optimization maintain robust- ness even under these extreme conditions. F0-CORR further distinguishes the two systems: benefiting from CKA alignment and GRPO, Y ingMusic-Singer maintains consistently high cor- relation across all tasks and languages, whereas V ev o2 fluctu- ates considerably , suggesting less robust melody control. For SIM, V evo2 benefits from its multi-stage architecture, where an autoregressiv e LLM handles melody and content generation while a dedicated CFM focuses on timbre reconstruction, ef- fectiv ely easing speaker modeling. Y ingMusic-Singer instead adopts a single-stage CFM that jointly models all f actors, prior- itizing architectural simplicity for practical deployment. How- ev er, V ev o2 achiev es higher SIM but simultaneously exhibits degraded PER and F0-CORR. In practice, faithfully rendering modified lyrics while preserving the original melodic structure remains the primary concern in lyric editing. As shown in T a- ble 3, Y ingMusic-Singer consistently achiev es higher N-MOS and M-MOS than V e vo2 across both tasks and languages. The strong subjective scores also indicate that GRPO optimization does not overfit to the reward models but generalizes to human 3 https://github.com/openvpi/SOME T able 2: Comparison with Baseline Model on LyricEditBench acr oss T ask T ypes in T able 1 and Languages. Metrics (M): P: PER, S: SIM, F: F0-CORR, V : VS are detailed in Section 3. Best results ar e Bold . T ask Model M Chinese English PSub FSub Del Ins T rans Mix PSub FSub Del Ins T rans Mix Melody Control V e vo2 [9] P ↓ 0.1378 0.1462 0.1545 0.1872 0.4409 0.4757 0.3352 0.3481 0.3812 0.3135 0.8019 0.5132 S ↑ 0.6462 0.6550 0.6457 0.6551 0.6115 0.6490 0.6357 0.6161 0.6277 0.6359 0.6237 0.6325 F ↑ 0.8471 0.8188 0.8345 0.8552 0.7678 0.8526 0.8794 0.8409 0.8924 0.8888 0.8776 0.8927 V ↑ 1.3578 1.3784 1.3491 1.1346 1.3061 1.4208 1.0340 1.1217 1.0476 0.9610 1.0281 1.0925 Ours P ↓ 0.0192 0.0197 0.0458 0.0208 0.0881 0.1563 0.0685 0.0692 0.1053 0.0716 0.0413 0.2668 S ↑ 0.6543 0.6561 0.6489 0.6552 0.5791 0.6395 0.6078 0.5914 0.6001 0.5889 0.5982 0.6076 F ↑ 0.9364 0.9428 0.9351 0.9381 0.9378 0.9352 0.9355 0.9279 0.9309 0.9315 0.9290 0.9389 V ↑ 2.0779 2.1419 2.1219 1.9887 1.9372 2.1002 1.5054 1.5418 1.6081 1.4036 1.5769 1.5060 Sing Edit V e vo2 [9] P ↓ 0.1290 0.1303 0.1596 0.1810 0.4111 0.4659 0.3414 0.3538 0.3531 0.2944 0.7680 0.4951 S ↑ 0.7875 0.7729 0.8269 0.8324 0.7252 0.8015 0.7971 0.7729 0.8183 0.8378 0.7563 0.8346 F ↑ 0.8858 0.8805 0.8969 0.9115 0.8456 0.9023 0.9258 0.9278 0.9365 0.9415 0.9137 0.9465 V ↑ 1.4860 1.5100 1.5094 1.2935 1.3535 1.4377 1.0910 1.1110 1.1682 1.1156 1.1178 1.1453 Ours P ↓ 0.0214 0.0186 0.0946 0.0426 0.1009 0.1903 0.0906 0.0782 0.1700 0.1070 0.0538 0.2946 S ↑ 0.7622 0.7392 0.7874 0.8028 0.6539 0.7564 0.7398 0.7105 0.7764 0.7714 0.6918 0.7708 F ↑ 0.9615 0.9587 0.9628 0.9642 0.9542 0.9607 0.9610 0.9563 0.9675 0.9660 0.9498 0.9668 V ↑ 1.9761 2.0345 1.8837 1.7689 1.9371 1.9283 1.4448 1.4086 1.3820 1.2553 1.4788 1.3464 T able 3: Subjective evaluation on L yricEditBench. N-MOS and M-MOS denote naturalness and melody adher ence, r espec- tively . T ask Model ZH EN N ↑ M ↑ N ↑ M ↑ Melody Control V e vo2 [9] 4.25 ± 0.06 4.28 ± 0.05 4.31 ± 0.05 4.31 ± 0.04 Ours 4.31 ± 0.04 4.44 ± 0.04 4.36 ± 0.05 4.51 ± 0.03 Sing Edit V e vo2 [9] 4.48 ± 0.05 4.41 ± 0.05 4.44 ± 0.04 4.50 ± 0.04 Ours 4.52 ± 0.04 4.55 ± 0.04 4.55 ± 0.04 4.58 ± 0.03 perception. V e vo2 receiv es lower ratings ov erall with notably higher variance, and listeners report perceptible artifacts such as unf aithful lyric rendering and melodic misalignment in its outputs, suggesting less robust generation quality . Beyond model comparison, the breadth of ev aluation across six editing types, tw o languages, and both objectiv e and subjec- tiv e metrics further validates L yricEditBench as a comprehen- siv e benchmark for melody-preserving lyric editing, supporting future research on song adaptation, cover generation, and cross- lingual vocal arrangement. 4.2. Ablation Study As sho wn in T able 4, the curriculum learning pipeline intro- duces clearly separable improvements at each stage. TTS Pre- train establishes articulatory priors but lacks singing capability (F0-CORR near zero), with PER degrading significantly when a singing clip serves as the ICL prompt, indicating poor domain adaptation. SFT Phase 1 substantially improv es all metrics, achieving the lowest PER as the model adapts to the singing domain while freely generating melody from the ICL prompt, bypassing the demanding task of explicit melody alignment. F0-CORR under Sing Edit improves slightly , showing partial melody capture from context alone, yet explicit guidance re- mains necessary for faithful reproduction. SFT Phase 2 acti- vates the Melody Extractor and raises F0-CORR above 0.92, though PER increases, reflecting the difficulty of jointly main- taining melody fidelity and lyric faithfulness. GRPO resolves this trade-off by recovering PER while further improving F0- T able 4: Ablation Study on L yricEditBench. Best r esults ar e bold , second best underlined. Lg V ariant Melody Control Sing Edit P ↓ S ↑ F ↑ V ↑ P ↓ S ↑ F ↑ V ↑ ZH TTS Pretrain 0.41 0.57 0.01 0.50 0.37 0.59 0.06 0.49 SFT Phase1 0.05 0.68 0.03 1.55 0.05 0.73 0.31 1.53 SFT Phase2 0.08 0.63 0.92 1.57 0.11 0.75 0.95 1.62 -w/o CKA 0.08 0.64 0.91 1.57 0.12 0.75 0.93 1.61 -w/o Dist 0.45 0.63 0.94 1.42 0.46 0.79 0.95 1.55 Full Model 0.06 0.64 0.94 2.06 0.08 0.75 0.96 1.92 EN TTS Pretrain 0.46 0.54 0.01 0.49 0.43 0.56 0.00 0.50 SFT Phase1 0.10 0.65 0.03 1.07 0.11 0.73 0.40 1.13 SFT Phase2 0.14 0.60 0.92 1.17 0.19 0.75 0.96 1.21 -w/o CKA 0.14 0.60 0.90 1.19 0.20 0.75 0.94 1.18 -w/o Dist 0.48 0.58 0.95 1.00 0.49 0.78 0.96 0.98 Full Model 0.10 0.60 0.93 1.52 0.13 0.74 0.96 1.39 CORR and VS with SIM unchanged, confirming that reward- based optimization jointly enhances all dimensions. In SFT Phase 2, incorporating CKA further improves melody adherence, as reflected in F0-CORR gains. For the per - turbation ablation (w/o Dist), we remove the temporal dropout applied to the melody latent ˜ h . This causes sev ere intelligibility degradation, as the unperturbed latent retains residual semantic information that the model exploits to bypass genuine lyric gen- eration. T emporal dropout eliminates this leakage, forcing re- liance on the abstract melodic contour and preserving prosodic structure while allowing free generation of modified lyrics. 5. Conclusion W e present Y ingMusic-Singer, a melody-controllable singing voice editing model that synthesizes from a timbre reference, a melody-providing singing clip, and modified lyrics without manual alignment. Through curriculum training and GRPO- based reinforcement learning, Y ingMusic-Singer achie ves su- perior melody preservation and lyric adherence on L yricEdit- Bench, the first comprehensi ve benchmark we introduce for this task, demonstrating strong potential for practical end-to- end singing voice editing. 6. Generativ e AI Use Disclosure Generativ e AI tools are used solely for linguistic refinement and play no role in methodology , e xperimentation, interpretation, or the production of scientific results. The authors bear full intel- lectual responsibility for all content in this manuscript. 7. Refer ences [1] J. Liu, C. Li, Y . Ren, F . Chen, and Z. Zhao, “Diffsinger: Singing voice synthesis via shallow diffusion mechanism, ” in AAAI . AAAI Press, 2022, pp. 11 020–11 028. [2] J. He, J. Liu, Z. Y e, R. Huang, C. Cui, H. Liu, and Z. Zhao, “Rmssinger: Realistic-music-score based singing voice synthe- sis, ” in ACL (Findings) , ser . Findings of A CL, vol. ACL 2023. Association for Computational Linguistics, 2023, pp. 236–248. [3] Y . Zhang, R. Huang, R. Li, J. He, Y . Xia, F . Chen, X. Duan, B. Huai, and Z. Zhao, “Stylesinger: Style transfer for out-of- domain singing voice synthesis, ” in AAAI . AAAI Press, 2024, pp. 19 597–19 605. [4] F . W ang, B. Bai, Y . Deng, J. Xue, Y . Gao, and Y . Li, “Expres- siv esinger: Synthesizing expressive singing voice as an instru- ment, ” in ISCSLP . IEEE, 2024, pp. 304–308. [5] Y . Y u, J. Shi, Y . W u, Y . T ang, and S. W atanabe, “V isinger2+: End-to-end singing v oice synthesis augmented by self-supervised learning representation, ” in SLT . IEEE, 2024, pp. 719–726. [6] Y . Zhang, W . Guo, C. Pan, D. Y ao, Z. Zhu, Z. Jiang, Y . W ang, T . Jin, and Z. Zhao, “Tcsinger 2: Customizable multilingual zero- shot singing voice synthesis, ” in ACL (F indings) , ser . Findings of A CL, vol. ACL 2025. Association for Computational Linguis- tics, 2025, pp. 13 280–13 294. [7] S. Lei, Y . Zhou, B. T ang, M. W . Y . Lam, F . Liu, H. Liu, J. W u, S. Kang, Z. Wu, and H. Meng, “Songcreator: Lyrics-based uni- versal song generation, ” in NeurIPS , 2024. [8] C. Y ang, S. W ang, H. Chen, J. Y u, W . T an, R. Gu, Y . Xu, Y . Zhou, H. Zhu, and H. Li, “Songeditor: Adapting zero-shot song gener- ation language model as a multi-task editor, ” in AAAI . AAAI Press, 2025, pp. 25 597–25 605. [9] X. Zhang, J. Zhang, Y . W ang, C. W ang, Y . Chen, D. Jia, Z. Chen, and Z. W u, “V ev o2: A unified and controllable frame- work for speech and singing v oice generation, ” CoRR , vol. abs/2508.16332, 2025. [10] J. Qian, H. Meng, T . Zheng, P . Zhu, H. Lin, Y . Dai, H. Xie, W . Cao, R. Shang, J. W u, H. Liu, H. W en, J. Zhao, Z. Jiang, Y . Chen, S. Yin, M. T ao, J. W ei, L. Xie, and X. W ang, “Soulx- singer: T owards high-quality zero-shot singing voice synthesis, ” CoRR , vol. abs/2602.07803, 2026. [11] D. Guo, D. Y ang, H. Zhang, J. Song et al. , “Deepseek-r1 incen- tivizes reasoning in llms through reinforcement learning, ” Nat. , vol. 645, no. 8081, pp. 633–638, 2025. [12] Y . Zhang, C. Pan, W . Guo, R. Li, Z. Zhu, J. W ang, W . Xu, J. Lu, Z. Hong, C. W ang, L. Zhang, J. He, Z. Jiang, Y . Chen, C. Y ang, J. Zhou, X. Cheng, and Z. Zhao, “Gtsinger: A global multi- technique singing corpus with realistic music scores for all singing tasks, ” in NeurIPS , 2024. [13] Z. Evans, J. D. Parker , C. Carr , Z. Zuko wski, J. T aylor, and J. Pons, “Long-form music generation with latent diffusion, ” in ISMIR , 2024, pp. 429–437. [14] Z. Ning, H. Chen, Y . Jiang, C. Hao, G. Ma, S. W ang, J. Y ao, and L. Xie, “Diffrhythm: Blazingly fast and embarrassingly sim- ple end-to-end full-length song generation with latent diffusion, ” CoRR , vol. abs/2503.01183, 2025. [15] Y . Chen, Z. Niu, Z. Ma, K. Deng, C. W ang, J. Zhao, K. Y u, and X. Chen, “F5-TTS: A fairytaler that fakes fluent and faith- ful speech with flow matching, ” in A CL (1) . Association for Computational Linguistics, 2025, pp. 6255–6271. [16] J. Liu, G. Liu, J. Liang, Y . Li, J. Liu, X. W ang, P . W an, D. Zhang, and W . Ouyang, “Flow-grpo: Training flow matching models via online RL, ” CoRR , vol. abs/2505.05470, 2025. [17] J. Li, Y . Cui, T . Huang, Y . Ma, C. Fan, M. Y ang, and Z. Zhong, “Mixgrpo: Unlocking flow-based GRPO efficiency with mixed ODE-SDE, ” CoRR , vol. abs/2507.21802, 2025. [18] H. W ang, B. Tian, Y . Jiang, Z. Pan, S. Zhao, B. Ma, D. Chen, and X. Li, “Flowse-grpo: Training flo w matching speech enhancement via online reinforcement learning, ” CoRR , vol. abs/2601.16483, 2026. [19] DeepSeek-AI, “Deepseek-v3.2: Pushing the frontier of open large language models, ” CoRR , vol. abs/2512.02556, 2025. [20] H. He, Z. Shang, C. W ang, X. Li, Y . Gu, H. Hua, L. Liu, C. Y ang, J. Li, P . Shi, Y . W ang, K. Chen, P . Zhang, and Z. W u, “Emilia: An extensi ve, multilingual, and diverse speech dataset for large-scale speech generation, ” in SLT . IEEE, 2024, pp. 885–890. [21] C. Hao, R. Y uan, J. Y ao, Q. Deng, X. Bai, W . Xue, and L. Xie, “Songformer: Scaling music structure analysis with heteroge- neous supervision, ” CoRR , vol. abs/2510.02797, 2025. [22] J. W ang, W . T . Lu, and M. W on, “Mel-band roformer for music source separation, ” CoRR , vol. abs/2310.01809, 2023. [23] A. Plaquet and H. Bredin, “Powerset multi-class cross entropy loss for neural speaker diarization, ” in INTERSPEECH . ISCA, 2023, pp. 3222–3226. [24] H. Bredin, “pyannote.audio 2.1 speaker diarization pipeline: prin- ciple, benchmark, and recipe, ” in INTERSPEECH . ISCA, 2023, pp. 1983–1987. [25] C. K. A. Reddy , V . Gopal, and R. Cutler, “Dnsmos: A non- intrusiv e perceptual objective speech quality metric to ev aluate noise suppressors, ” in ICASSP . IEEE, 2021, pp. 6493–6497. [26] ——, “Dnsmos P .835: A non-intrusi ve perceptual objective speech quality metric to ev aluate noise suppressors, ” in ICASSP . IEEE, 2022, pp. 886–890. [27] X. Shi, X. W ang, Z. Guo, Y . W ang, P . Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Y ang, J. Xu, J. Zhou, and J. Lin, “Qwen3-asr technical report, ” CoRR , vol. abs/2601.21337, 2026. [28] H. W ei, X. Cao, T . Dan, and Y . Chen, “RMVPE: A robust model for vocal pitch estimation in polyphonic music, ” in INTER- SPEECH . ISCA, 2023, pp. 5421–5425. [29] Z. W ang, R. Y uan, Z. Geng, H. Li, X. Qu, X. Li, S. Chen, H. Fu, R. B. Dannenberg, and K. Zhang, “Singing timbre popularity as- sessment based on multimodal large foundation model, ” in ACM Multimedia . ACM, 2025, pp. 12 227–12 236.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment