비전‑언어 모델과 인간의 지각 이미지 품질 평가 비교
본 연구는 6개의 최신 비전‑언어 모델(VLM)이 인간의 심리물리학적 평가와 얼마나 일치하는지를 세 가지 이미지 품질 속성(대조, 색채 풍부도, 전체 선호도)에서 정량적으로 벤치마크한다. 모델별 일관성, 상호 일치도, 인간과의 정합성을 분석한 결과, 색채 풍부도에서는 일부 모델이 ρ = 0.93까지 인간과 높은 상관을 보였으나 대조 평가에서는 일관성이 떨어졌다. 또한, 모델 내부 일관성이 높다고 해서 인간과의 정합성이 높은 것은 아니며, 자극 …
저자: Imran Mehmood, Imad Ali Shah, Ming Ronnier Luo
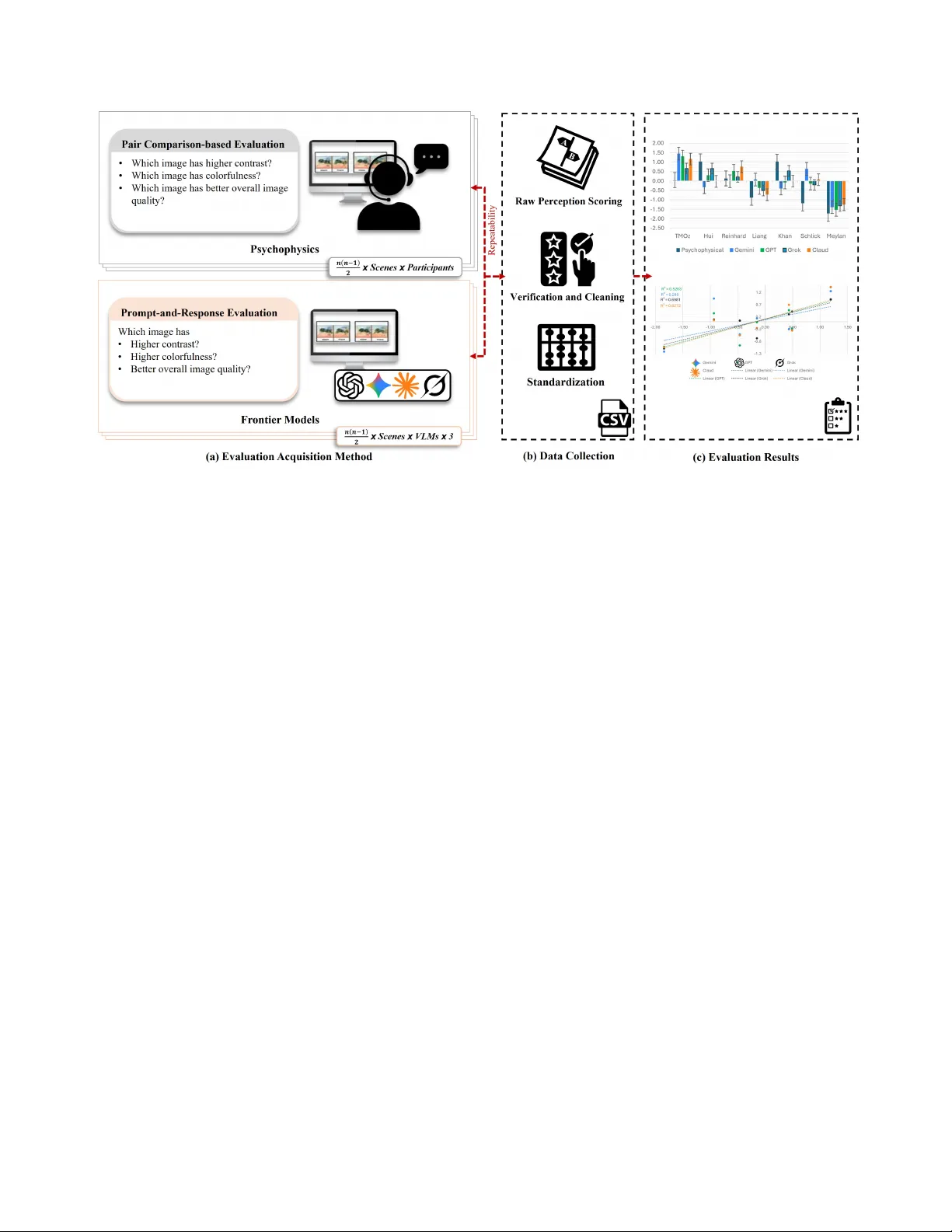
이 논문은 인간의 심리물리학적 이미지 품질 평가와 최신 비전‑언어 모델(VLM)의 판단을 직접 비교함으로써, VLM이 인간 수준의 지각 판단을 대체하거나 보조할 수 있는지를 탐구한다. 연구는 세 가지 이미지 품질 속성—대조(contrast), 색채 풍부도(colorfulness), 전체 선호도(overall preference)—에 초점을 맞추고, 6개의 VLM(Anthropic Claude Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT‑5.2, xAI Grok‑4.1, InternVL‑3.5‑38B, Alibaba Qwen3‑VL‑32B‑Instruct)을 벤치마크한다.
**데이터와 실험 설계**
실험에 사용된 데이터는 10개의 고동적 범위(HDR) 이미지에 7가지 톤 매핑 연산자(TMO)를 적용해 만든 70개의 이미지이며, 각 이미지 쌍에 대해 인간 피험자 20명이 대조, 색채 풍부도, 전체 선호도 세 축으로 273개의 쌍대 비교를 수행했다. 인간 실험은 엄격한 디스플레이 보정, 조명 조건, 시야거리 등을 통제했으며, 결과는 Thurstone’s law를 이용해 z‑score로 정규화하였다.
VLM 평가에서는 동일한 쌍대 비교 프로토콜을 프롬프트 기반으로 구현했다. 프롬프트는 “Which image has higher Contrast (choose A or B) …”와 같은 강제 선택 형식을 사용했으며, 각 이미지 쌍을 3회씩 입력해 모델의 응답 일관성을 측정했다. 모델은 API 혹은 로컬 실행을 통해 이미지 쌍을 직접 받아들였으며, 온도 파라미터는 기본값 1로 유지해 자연스러운 변동성을 보존하였다.
**분석 항목**
1. **내부 일관성(Intra‑model variability)**: 각 모델이 동일 이미지 쌍에 대해 3번 반복했을 때 선택이 얼마나 일관되는지를 변동률(VR%)로 측정했다. Claude는 색채 풍부도(0.95 %)와 전체 선호도(1.27 %)에서 가장 낮은 변동을 보이며, InternVL은 대조(17.78 %)와 색채 풍부도(14.92 %)에서 가장 높은 변동을 나타냈다. 전반적으로 대부분 모델은 10 % 이하의 변동을 보였으며, 이는 인간 실험에서 관찰되는 불확실성 패턴과 유사했다.
2. **모델 간 일치도(Cross‑model variability)**: 모델 쌍별 불일치 비율을 계산해 속성별 상호 일관성을 평가했다. 대조에서는 Claude‑GPT(25.87 %)가 가장 큰 차이를 보였고, 색채 풍부도에서는 Claude‑Qwen(15.08 %)이 가장 낮은 불일치를 보였다. 전체 선호도에서는 GPT‑Gemini(39.21 %)가 비교적 높은 불일치를 보였지만, 전반적으로 색채 풍부도와 전체 선호도는 대조에 비해 모델 간 일관성이 더 높았다. 이는 대조가 저수준 밝기·명암 차이를 민감하게 판단해야 하는 복잡한 과제임을 시사한다.
3. **인간‑VLM 정합도(Alignment with human psychophysics)**: 인간 순위와 모델 순위 사이의 Spearman 상관계수(ρ)를 계산했다. 색채 풍부도에서는 Claude(ρ = 0.93), Qwen(ρ = 0.93), InternVL(ρ = 0.92) 등 세 모델이 인간과 거의 일치했으며, 대조에서는 GPT(ρ = 0.75)와 Gemini(ρ = 0.79)가 비교적 높은 정합도를 보였다. 전체 선호도에서는 GPT(ρ = 0.86)와 Claude(ρ = 0.64)가 인간과 어느 정도 일치했지만, 대부분 모델은 0.5 이하에 머물렀다.
특히, 내부 일관성이 높은 Claude는 색채 풍부도에서는 인간과 높은 정합을 보였지만, 대조에서는 낮은 정합을 나타냈다. 이는 모델이 특정 시각 속성에 특화된 내부 표현을 가지고 있음을 의미한다. 또한, 인간‑VLM 일치도는 자극 간 차이가 명확히 드러나는 경우(예: 색채가 크게 변한 이미지)에서 상승했으며, 미세한 차이를 구분해야 하는 경우에는 급격히 감소했다. 이는 VLM이 인간과 유사한 ‘감각적 구분 한계’를 공유한다는 중요한 통찰을 제공한다.
**실용적 시사점**
본 연구는 VLM을 이미지 품질 자동 평가에 활용할 경우, 속성별 강점을 고려한 모델 선택이 필요함을 강조한다. 색채 풍부도와 같은 전반적 색상 특성 평가에서는 Claude, Qwen, InternVL이 신뢰할 수 있는 대체 수단이 될 수 있다. 반면, 대조와 같은 저수준 밝기·명암 판단에서는 GPT나 Gemini이 더 적합하다. 또한, VLM의 응답 변동성을 활용해 인간 실험에서 발생할 수 있는 불확실성을 사전에 탐지하고, 실험 설계 단계에서 자극 선택을 최적화하는 데 활용할 가능성도 제시한다.
결론적으로, 비전‑언어 모델은 특정 이미지 품질 속성에 대해 인간과 높은 수준의 일치를 보일 수 있지만, 속성마다 성능 차이가 크며, 모델 내부 일관성과 인간 정합성은 반드시 일치하지 않는다. 향후 연구에서는 속성별 특화 학습, 멀티‑모달 피드백 루프, 그리고 인간‑VLM 혼합 평가 프레임워크를 통해 보다 견고하고 일반화 가능한 IQA 시스템을 구축하는 것이 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기